CV和NLP领域常见模型列表
图像分类(Image Classification)
| 模型名 | 特点 | 备注 |
|---|---|---|
| ConvNeXt V2 | 卷积改进,媲美 Transformer | 强于 ResNet、EfficientNet |
| Vision Transformer (ViT) | 全 Transformer 架构 | 开创图像 transformer 浪潮 |
| Swin Transformer V2 | 局部注意力 + 金字塔结构 | 更强的多尺度能力 |
| CoaT / CMT / EfficientFormer | 卷积+注意力结合 | 提高效率,兼顾性能 |
目标检测(Object Detection)
| 模型名 | 类型 | 特点 |
|---|---|---|
| YOLOv8 | 单阶段 | 快速轻量,工业实用 |
| RT-DETR | Transformer | 实时 DETR,端到端快 |
| DINO | Transformer | DETR 系列最强,效果极佳 |
| Sparse R-CNN | Region-based | 不用 anchor,更精炼 |
| Deformable DETR | Transformer + 可变卷积 | 提高收敛速度 |
实例分割(Instance Segmentation)
| 模型名 | 基础架构 | 特点 |
|---|---|---|
| Mask R-CNN | Faster R-CNN + mask head | 经久不衰的经典方案 |
| SOLOv2 / YOLACT | 单阶段 | 实时分割方案 |
| Mask2Former | Transformer + 全任务统一 | 分割任务通吃(语义/实例/全景) |
语义分割(Semantic Segmentation)
| 模型名 | 特点 | 数据集 |
|---|---|---|
| SegFormer | 高效的 transformer 分割 | Cityscapes, ADE20K |
| HRNet | 高分辨率保持 | 多尺度信息并行 |
| DeepLabv3+ | 空洞卷积 | 曾是标准方法 |
| Mask2Former | 通用分割架构 | 适配所有分割类型 |
视频理解(Video Understanding)
| 模型名 | 任务 | 特点 |
|---|---|---|
| VideoMAE | 视频分类 | 自监督预训练,表现强 |
| TimeSFormer | Transformer | 分离时空 attention |
| SlowFast | 动作识别 | 快慢路径建模动作变化 |
多模态视觉(Vision + Language)
| 模型名 | 类型 | 特点 |
|---|---|---|
| BLIP / BLIP-2 | 图文生成/理解 | 支持图像描述、VQA、跨模态检索 |
| OFA | One-For-All | 统一多模态任务 |
| GIT | 图文 Transformer | 图像 → 文本,轻量高效 |
| MiniGPT-4 / LLaVA | 类 GPT-4V | 图文对话,基于视觉 encoder + LLM |
自动驾驶/3D 检测(3D Detection / Perception)
| 模型名 | 特点 | 数据集 |
|---|---|---|
| BEVFormer | bird’s-eye-view Transformer | NuScenes, Waymo |
| PointRCNN | 基于点云的 R-CNN | KITTI |
| PV-RCNN | 高效的两阶段点云检测 | 3D 识别 SOTA 多次 |
| CenterPoint | anchor-free + center-based | 快速稳定 |
视觉基础模型(视觉大模型,VLM)
| 模型名 | 类型 | 特点 |
|---|---|---|
| CLIP | 图文对齐 | 开创多模态预训练 |
| DINOv2 | 视觉表示学习 | 强大的通用视觉表征 |
| SAM (Segment Anything) | 万能分割器 | Promptable 分割范式 |
| SEEM | Everything Model | 多模态提示泛化分割 |
| Florence / BEiT-3 | 微软大模型 | 文本图像联合建模 |
文本分类 / 情感分析(Text Classification / Sentiment Analysis)
| 模型 | 特点 | 常用数据集 |
|---|---|---|
| RoBERTa | BERT 的优化版,泛化更强 | SST-2, AGNews |
| DeBERTa V3 | 解耦注意力,表现顶级 | GLUE, IMDb |
| ERNIE 3.0 | 知识增强预训练 | 中文任务强 |
| ELECTRA | GAN 式训练,高效收敛 | - |
文本生成(Text Generation)
| 模型 | 特点 | 应用方向 |
|---|---|---|
| GPT-4 | 多模态,推理能力强 | 通用文本生成 |
| LLaMA 2 | 开源强模型,适合微调 | Chat、创作等 |
| GLM-4 | 中英文表现均衡,开放模型 | 中英生成、对话 |
| T5 / FLAN-T5 | 任务统一建模 | 可调教生成模型 |
阅读理解 / 问答(Reading Comprehension / QA)
| 模型 | 特点 | 数据集 |
|---|---|---|
| UnifiedQA | 多任务问答统一架构 | SQuAD, HotpotQA |
| Macaw | 开放域 QA | 可解答常识、多步问题 |
| GPT 系列 + Retrieval | 检索增强生成 | RAG, WebQA 等 |
| ChatGPT (GPT-3.5/4) | 多轮推理能力 | 多任务泛化强 |
语言建模 / 通用 LLM
| 模型 | 说明 |
|---|---|
| GPT-4 / ChatGPT | 多任务通用模型,表现全面 |
| Claude 3 | 强推理与安全性兼顾 |
| Gemini | Google 的多模态旗舰 |
| LLaMA 2 | 高性价比开源 LLM |
| GLM 系列 | 中文支持强,开源友好 |
| Mistral / Mixtral | 小模型高性能,MoE 架构代表 |
文本摘要(Summarization)
| 模型 | 特点 | 任务类型 |
|---|---|---|
| PEGASUS | 预训练专为摘要设计 | abstractive summarization |
| BART / mBART | 编码解码 + 噪声建模 | 多语言支持强 |
| T5 / FLAN-T5 | 任务统一建模 | 任意格式摘要 |
| ChatGPT / GPT-4 | 长文摘要能力优秀 | 长文+结构保持 |
信息抽取(NER / RE / Event Extraction)
| 模型 | 特点 |
|---|---|
| BERT-MRC / UIE(统一信息抽取) | 提示式信息抽取(统一问答框架) |
| LayoutLMv3 | 文档抽取 + 视觉增强 |
| DyGIE++ | 实体 + 关系 + 事件联合抽取 |
| ChatGLM + Prompt | 用于小样本 Prompt NER |
机器翻译(Machine Translation)
| 模型 | 特点 | 来源 |
|---|---|---|
| mBART / mT5 | 多语言预训练 | Facebook / Google |
| NLLB-200 | 支持 200 多种语言 | Meta |
| DeepL + GPT-4 | 实用最强组合 | 商业翻译+润色 |
| ChatGPT | 润色式翻译优于通用 NMT |
推理任务(自然语言推理 NLI / 多跳问答 / 多步推理)
| 模型 | 特点 | 数据集 |
|---|---|---|
| DeBERTa / RoBERTa | NLI 经典强者 | MNLI |
| GPT-4 | 多步链式推理能力强 | Chain-of-Thought |
| ReAct / CoT Prompting | 结合工具和思考的推理范式 | HotpotQA, OpenBookQA |
多语言 NLP(Multilingual NLP)
| 模型 | 特点 |
|---|---|
| mBERT / XLM-R | 多语言预训练的经典 |
| mT5 / mBART50 | 多语言翻译 + NLU 支持 |
| NLLB-200 | 特别适合低资源语言 |
视觉定位概览
过去几年,视觉定位领域从基于 DETR 的模块化检测-定位框架发展到大规模多模态预训练,再到结合大型语言模型的多粒度生成式方法。早期代表作 MDETR(2021)首次将检测与定位端到端统一;随后 GLIP(2021)通过语言——图像对齐预训练在 COCO 上取得 60.8 AP 的 SOTA 成绩;GLIPv2(2022)进一步拓展到实例分割与多任务跨模态理解。2023 年,Grounding DINO 在零样本检测与定位上刷新记录;2024 年底的 OneRef 与 HiVG 引入了生成式和层次化多模态策略;最新的Ferret(ICLR 2024)将定位能力嵌入到多模态 LLM,实现任意形状的开放词汇定位;甚至 3D 视觉定位领域也涌现出 SeeGround(2024 12)等零样本框架。
从基于 DETR 的端到端方法(如 MDETR)➔区域–短语对齐预训练(如 GLIP/GLIPv2)➔零样本&开放词汇定位(GroundingDINO 及其 Pro 版本)➔生成式&统一框架(OneRef、Generative VLM)➔多模态大模型(Ferret、Kosmos-2)的融合应⽤。
1. 基于 DETR 的端到端定位模型
- MDETR (2021):首个将目标检测与自然语言定位统一在 DETR 框架下,通过多模态编码器-解码器端到端训练,实现对 RefCOCO 系列基准的领先表现。
- LightMDETR (2024):轻量化版本,P@1 在 RefCOCO(85.92%)与 RefCOCOg(80.97%)上略超原始 MDETR,验证了“低成本”端到端方法的可行性
- Position-guided Text Prompt:在预训练阶段通过“分块+填空”机制强化图文位置对齐,有效提升下游定位精度。
- RefFormer(NIPS 2024):通过“查询适配(Referential Query)”模块,将 CLIP 作为背靠骨干,生成初始查询以减轻多模态解码难度,在五个视觉定位基准上超越此前 SOTA。
2. 区域—短语对齐预训练
- GLIP (CVPR 2022):Grounded Language-Image Pre-training 模型,统一目标检测与短语定位预训练,实现 60.8 AP on COCO val,并展现强zero-shot、few-shot 能力。
- GLIPv2 (2022):在 GLIP 基础上,增加实例分割与多任务理解,统一 Localization 与 Vision–Language Pre-training,使单一模型同时达到检测、分割与定位的 SOTA 水平。
- CLIP-VG (TMM 2023):利用 CLIP 生成伪语言标签并自适应课程学习,在 RefCOCO/+/g 上的全/弱监督与无监督场景均刷新了当时记录。
3. 零样本与开放词汇定位
- GroundingDINO (ECCV 2024):将 DINO 检测器与 grounded pre-training 结合,实现开放词汇检测与定位的零样本 SOTA,在 COCO、LVIS 及 ODinW 等基准上表现优异。
- GroundingDINO 1.6 Pro (2025 Q1):对 1.5 版本进一步优化,尤其是在 LVIS “rare” 类的零样本迁移上取得更大提升。
- Florence-2-large-ft:在 Papers With Code Leaderboard 上,Florence-2-large-ft 在 RefCOCO+、RefCOCO、RefCOCOg 多个拆分上均居榜首。
4. 生成式统一与层次化多模态策略
- OneRef (NeurIPS 2024):通过生成式定位机制,实现端到端从文本到检测框的“一步到位” Referring Expression Comprehension,通过 Mask Referring Modeling(MRefM)在 RefCOCOg/Flickr30K 上刷新记录。
- Learning Visual Grounding from Generative VLM (Jul 2024):利用大规模生成式 VLM 自动构建 1M+ 对应表达的 Grounding 数据集,零样本迁移到 RefCOCO 系列便大幅超越人标方
- HiVG (ACM MM 2024):采用层次化多模态细粒度特征融合,进一步提升复杂表达式下的定位准确率。
5. 大型多模态语言模型融合
- Ferret (ICLR 2024):将混合离散坐标与连续特征的区域表示融合到 MLLM 中,支持任意形状、开放词汇的精细化视觉定位。
- Kosmos-2 (2023):通过 Markdown 链接式表达
[text span](bounding boxes),基于大规模 GrIT 语义-视觉对齐数据集训练,将定位能力内嵌到通用多模态 LLM,实现多任务跨模态理解与定位。 - BLIP-2 (2023):利用冻结的图像与语言模型,通过轻量级查询器桥接两者,实现低成本预训练并在包括定位在内的多项视觉-语言任务上刷新 SOTA。
6. 3D 场景定位
- SeeGround (2024 12):零样本 3D 视觉定位框架,将 2D 预训练 VLM 扩展至 3D 场景,通过多视角渲染与空间描述融合,超越弱监督和部分监督 SOTA。
视觉定位的 SOTA 模型已覆盖从端到端 DETR、区域–短语预训练、零样本开放词汇、生成式一体化,到多模态大模型等全栈技术路线。选型应根据下游需求(精度 vs. 效率、零/少样本、生成能力、LLM 集成)进行权衡。
| 模型名称 | 参数量 (B) | RefCOCO (val / testA / testB) | RefCOCO+ (val / testA / testB) | RefCOCOg (val / test) |
|---|---|---|---|---|
| KOSMOS-2 | 1.6 | 52.32 / 57.42 / 47.26 | 45.48 / 50.73 / 42.24 | 60.57 / 61.65 |
| MDETR-R101 | – | 86.75 / 89.58 / 81.41 | 79.52 / 84.09 / 70.62 | 81.64 / 80.89 |
| NExT-Chat | 7 | 85.50 / 90.00 / 77.90 | 77.20 / 84.50 / 68.00 | 80.10 / 79.80 |
| MDETR-ENB3 | – | 87.51 / 90.40 / 82.67 | 81.13 / 85.52 / 72.96 | 83.35 / 83.31 |
| Shikra | 7 | 87.01 / 90.61 / 80.24 | 81.60 / 87.36 / 72.12 | 82.27 / 82.19 |
| Ferret | 7 | 87.49 / 91.35 / 82.45 | 80.78 / 87.38 / 73.14 | 83.93 / 84.76 |
| GroundingGPT | 7 | 88.02 / 91.55 / 82.47 | 81.61 / 87.18 / 73.18 | 81.67 / 81.99 |
| PixelLLM | 4 | 89.80 / 92.20 / 86.40 | 83.20 / 87.00 / 78.90 | 84.60 / 86.00 |
| SimVG-DB-Base | 0.18 | 91.47 / 93.65 / 87.94 | 84.83 / 88.85 / 79.12 | 86.30 / 87.26 |
| COMM-7B | 7 | 91.73 / 94.06 / 88.85 | 87.21 / 91.74 / 81.39 | 87.32 / 88.33 |
| SimVG-DB-Large | 0.61 | 92.87 / 94.35 / 89.46 | 87.28 / 91.64 / 82.41 | 87.99 / 89.15 |
相关文章:

CV和NLP领域常见模型列表
图像分类(Image Classification) 模型名特点备注ConvNeXt V2卷积改进,媲美 Transformer强于 ResNet、EfficientNetVision Transformer (ViT)全 Transformer 架构开创图像 transformer 浪潮Swin Transformer V2局部注意力 金字塔结构更强的多…...
Git简介与入门
Git的发明 Git由著名的Linux创始人linus于2005年发明(所以git的界面、使用方式与Linux挺像的,即命令行方式) 经过发展,现在广泛应用于代码管理与团队协作。 Git特性 Git是分布式版本控制系统 分布式 每个开发者拥有完整仓库&…...
Linux 网络基础三 (数据链路层协议:以太网协议、ARP 协议)
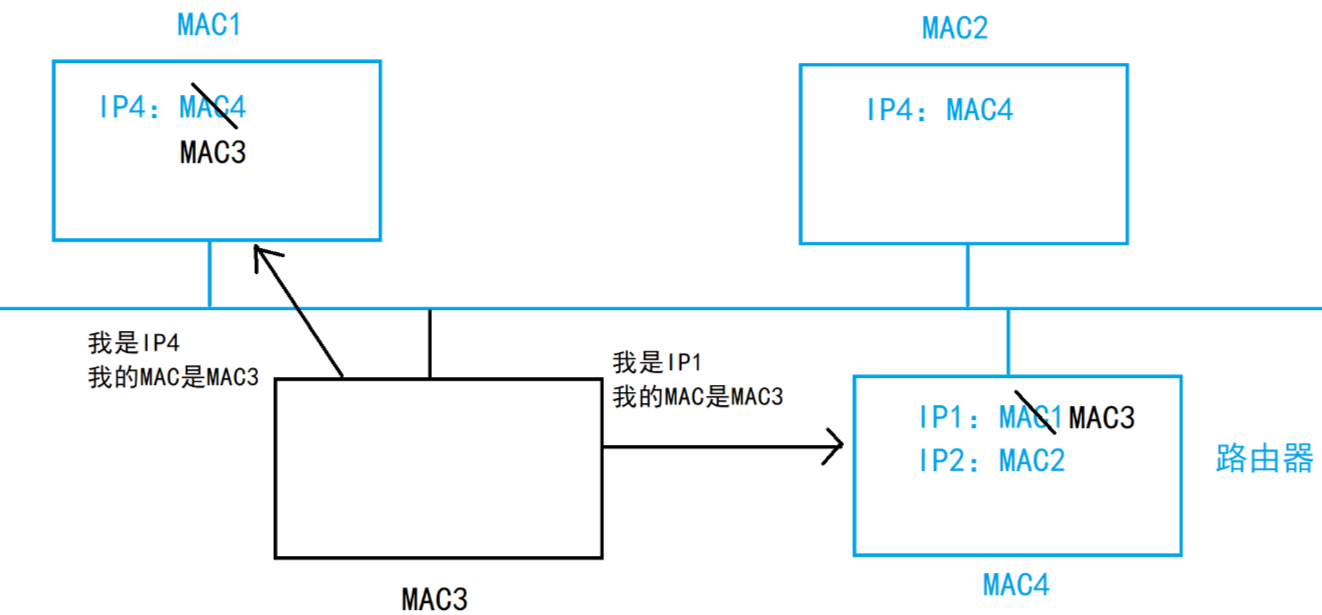
一、以太网 两个不同局域网的主机传递数据并不是直接传递的,而是通过路由器 “一跳一跳” 的传递过去。 跨网络传输的本质:由无数个局域网(子网)转发的结果。 所以,要理解数据跨网络转发原理就要先理解一个局域网中数…...

16.QT-Qt窗口-菜单栏|创建菜单栏|添加菜单|创建菜单项|添加分割线|添加快捷键|子菜单|图标|内存泄漏(C++)
Qt窗⼝是通过QMainWindow类来实现的。 QMainWindow是⼀个为⽤⼾提供主窗⼝程序的类,继承⾃QWidget类,并且提供了⼀个预定义的布局。QMainWindow包含⼀个菜单栏(menu bar)、多个⼯具栏(tool bars)、多个浮动窗⼝(铆接部…...
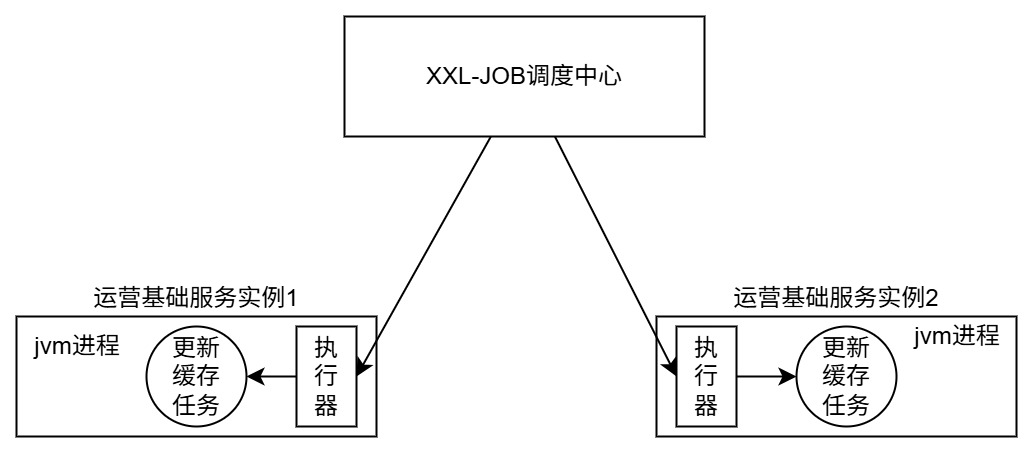
[特殊字符] 分布式定时任务调度实战:XXL-JOB工作原理与路由策略详解
在微服务架构中,定时任务往往面临多实例重复执行、任务冲突等挑战。为了解决这一问题,企业级调度框架 XXL-JOB 提供了强大的任务统一调度与执行机制,特别适合在分布式系统中使用。 本文将从 XXL-JOB 的核心架构入手,详细讲解其调…...

java面试题及答案2020,java最新面试题(四十四)
java面试题及答案2020 二面-2020/3/18 1、自我介绍项目比赛 2、java集合框架全部介绍。。从list set queue到map 3、hashmap底层扩容线程安全问题 4、如果-一个对象要作为hashmap的key需要做什么 5、Threadlocal类以及 内存泄漏 6、线程同步方式,具体每一个怎么做的 7、jvm类加…...

Spring Boot 中处理 JSON 数值溢出问题:从报错到优雅解决
一、问题背景:为什么我的接口突然报错了? 假设你正在开发一个 Spring Boot 接口,接收类似这样的 JSON 请求: {"size": 111111111111111111111 }然后突然收到用户的反馈:请求报错啦! 查看日志&a…...

oracle 锁的添加方式和死锁的解决
DML锁添加方式 DML 锁可由一个用户进程以显式的方式加锁,也可通过某些 SQL 语句隐含方式实现。 DML 锁有三种加锁方式:共享锁方式、独占锁方式、共享更新。 共享锁,独占锁用于 TM 锁,共享锁用于 TX 锁。 1)共享方式的表级锁 共享方…...
基于Hadoop的音乐推荐系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 本毕业生数据分析与可视化系统采用B/S架构,数据库是MySQL,网站的搭建与开发采用了先进的Java语言、爬虫技术进行编写,使用了Spring Boot框架。该系统从两个对象:由管理员和用户来对系统进行设计构建。主要功能包括ÿ…...
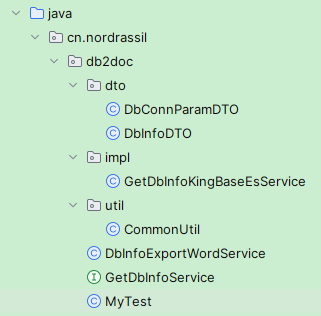
Java查询数据库表信息导出Word
参考: POI生成Word多级标题格式_poi设置word标题-CSDN博客 1.概述 使用jdbc查询数据库把表信息导出为word文档, 导出为word时需要下载word模板文件。 已实现数据库: KingbaseES, 实现代码: 点击跳转 2.效果图 2.1.生成word内容 所有数据库合并 数据库不合并 2.2.生成文件…...

DAY9:Oracle数据库安全管理深度解析
引言 在当今数据泄露事件频发的时代,数据库安全管理已成为DBA和开发者的必修课。本文将深入探讨Oracle数据库安全管理的四大核心领域:用户权限管理、数据库审计、透明数据加密(TDE)和虚拟私有数据库(VPD)&…...

RK3588平台用v4l工具调试USB摄像头实践(亮度,饱和度,对比度,色相等)
目录 前言:v4l-utils简介 一:查找当前的摄像头设备 二:查看当前摄像头支持的v4l2-ctl调试参数 三根据提示设置对应参数,在提示范围内设置 四:常用调试命令 五:应用内执行命令方法 前言:v4l-utils简介 v4l-utils工具是由Linu…...

Dart Flutter数据类型详解 int double String bool list Map
目录 字符串的几种方式 bool值的判断 List的定义方式 Map的定义方式 Dart判断数据类型 (is 关键词来判断类型) Dart的数据类型详解 int double String bool list Map 常用数据类型: Numbers(数值): int double Strings(字符串) String Booleans(布尔…...

LainChain技术解析:基于RAG架构的下一代语言模型增强框架
摘要 随着大语言模型(LLM)在自然语言处理领域的突破性进展,如何突破其知识时效性限制、提升事实准确性成为关键挑战。LainChain通过整合检索增强生成(RAG)技术,构建起动态知识接入框架,为LLM提供实时外部知识支持。本文从技术原理、架构设计、应用场景三个维度,深入解…...
:虚拟列表-VirtualList)
组件是怎样写的(1):虚拟列表-VirtualList
本篇文章是《组件是怎样写的》系列文章的第一篇,该系列文章主要说一下各组件实现的具体逻辑,组件种类取自 element-plus 和 antd 组件库。 每个组件都会有 vue 和 react 两种实现方式,可以点击 https://hhk-png.github.io/components-show/ …...
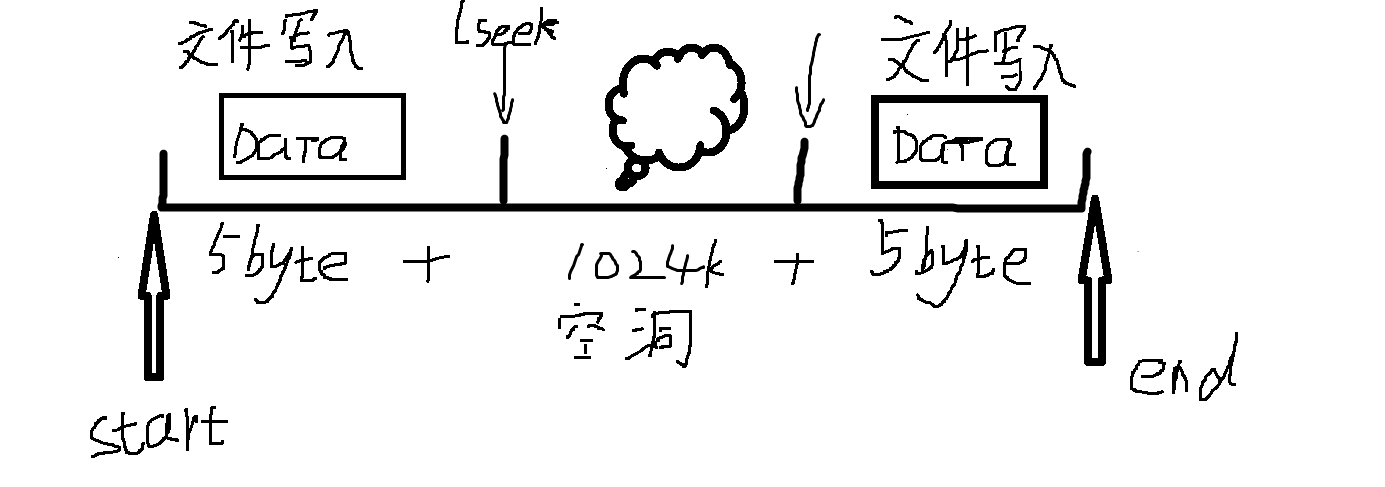
在Linux中,使用read函数去读取写入文件空洞部分时,读取出来的内容是什么?为什么这样操作,以及应用场景?
使用 read 函数读取文件空洞(hole)部分时,读取到的内容会被系统填充为 \0(即零字节)。文件空洞是稀疏文件中未实际分配磁盘空间的区域,但逻辑上表现为连续的零字节。 1.在指定空洞部分后,写入数…...
Qt6笔记-对Qt6中对CMakeLists.txt的解析
首先,新建Qt Console Application项目。 下面对CMakeLists.txt进行次理解。新建好后,Qt Creator会生成CMakeLists.txt,具体内容如下: cmake_minimum_required(VERSION 3.16)project(EasyCppMain LANGUAGES CXX)set(CMAKE_AUTOUIC…...

CIFAR10图像分类学习笔记(三)---数据加载load_cifar10
新创建一个load_cifar10源文件 需要导入的包 import glob from torchvision import transforms from torch.utils.data import DataLoader ,Dataset import os #读取工具 from PIL import Image import numpy as np 01同样定义10个类别的标签名数组 label_name ["airpl…...

计算机视觉cv入门之答题卡自动批阅
前边我们已经讲解了使用cv2进行图像预处理与边缘检测等方面的知识,这里我们以答题卡自动批阅这一案例来实操一下。 大致思路 答题卡自动批阅的大致流程可以分为这五步:图像预处理-寻找考试信息区域与涂卡区域-考生信息区域OCR识别-涂卡区域填涂答案判断…...

Java学习手册:JSON 数据格式基础知识
1. JSON 简介 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于阅读和编写,也易于机器解析和生成。它最初来源于 JavaScript,但如今已被许多语言所采用,包括 Java、Python、C 等。JSON 以…...

【Python爬虫详解】第四篇:使用解析库提取网页数据——BeautifuSoup
在前一篇文章中,我们学习了如何编写第一个爬虫程序,成功获取了网页的HTML内容。然而,原始HTML通常包含大量我们不需要的信息,真正有价值的数据往往隐藏在HTML的标签和属性中。这一篇,我们将学习如何使用Python的解析库…...
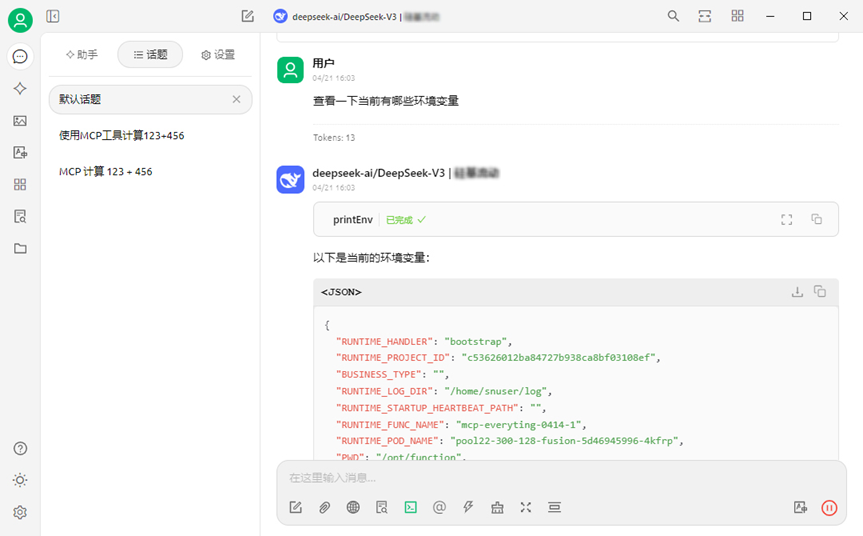
《重塑AI应用架构》系列: Serverless与MCP融合创新,构建AI应用全新智能中枢
在人工智能飞速发展的今天,数据孤岛和工具碎片化问题一直是阻碍AI应用高效发展的两大难题。由于缺乏统一的标准,AI应用难以无缝地获取和充分利用数据价值。 为了解决这些问题,2024年AI领域提出了MCP(Model Context Protocol模型上…...

深度图可视化
import cv2# 1.读取一张深度图 depth_img cv2.imread("Dataset_depth/images/train/1112_0-rgb.png", cv2.IMREAD_UNCHANGED) print(depth_img.shape) cv2.imshow("depth", depth_img) # (960, 1280) print(depth_img)# 读取一张rgb的图片做对比 input_p…...

【调优】log日志海量数据分表后查询速度调优
原始实现 使用pagehelper实现分页 // 提取开始时间的年份和月份,拼装成表名List<String> timeBetween getTimeBetween(condition);List<String> fullTableName getFullTableName(Constants.LOG_TABLE_NAME, timeBetween);PageHelperUtil.startPage(c…...

hive默认的建表格式
在 Hive 中创建表时,默认的建表语法格式如下: CREATE TABLE table_name (column1_type,column2_type,... ) ROW FORMAT DELIMITED FIELDS TERMINATED BY , STORED AS TEXTFILE;在这个语法中: CREATE TABLE table_name:指定要创建…...

sass 变量
基本使用 如果分配给变量的值后面添加了 !default 标志 ,这意味着该变量如果已经赋值,那么它不会被重新赋值,但是,如果它尚未赋值,那么它会被赋予新的给定值。 如果在此之前变量已经赋值,那就不使用默认值…...
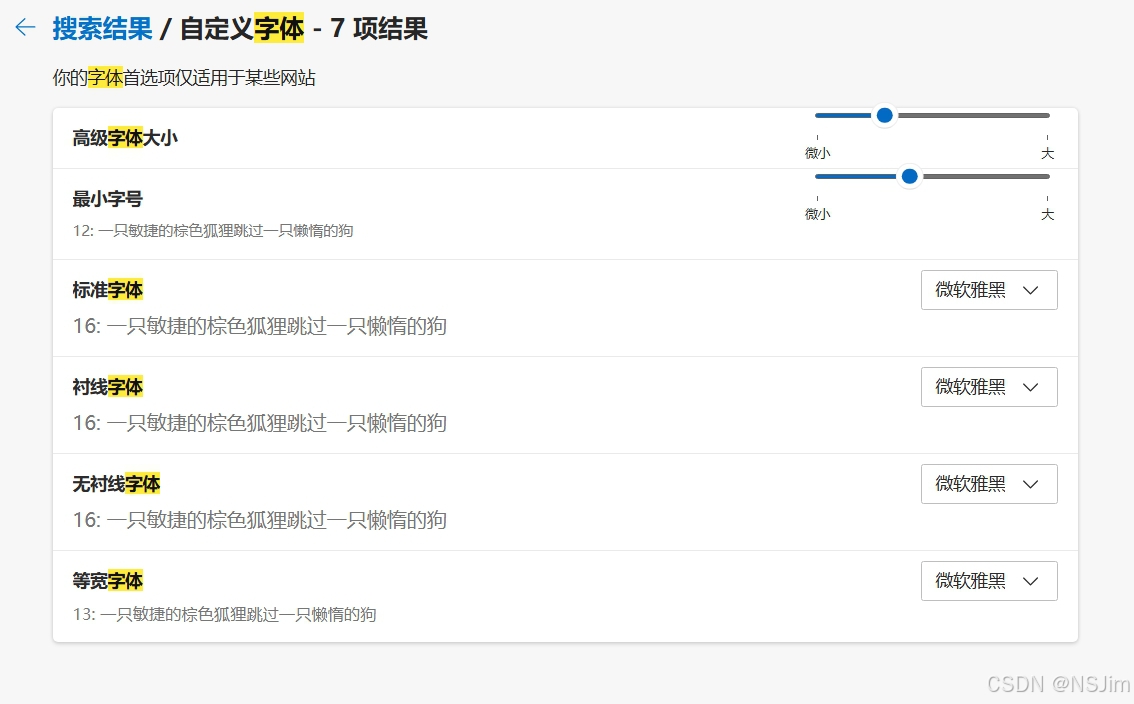
微软Edge浏览器字体设置
前言 时间:2025年4月 自2025年4月起,微软Edge浏览器的默认字体被微软从微软雅黑替换成了Noto Sans,如下图。Noto Sans字体与微软雅黑风格差不多,但在4K以下分辨率的显示器上较微软雅黑更模糊,因此低分辨率的显示器建议…...
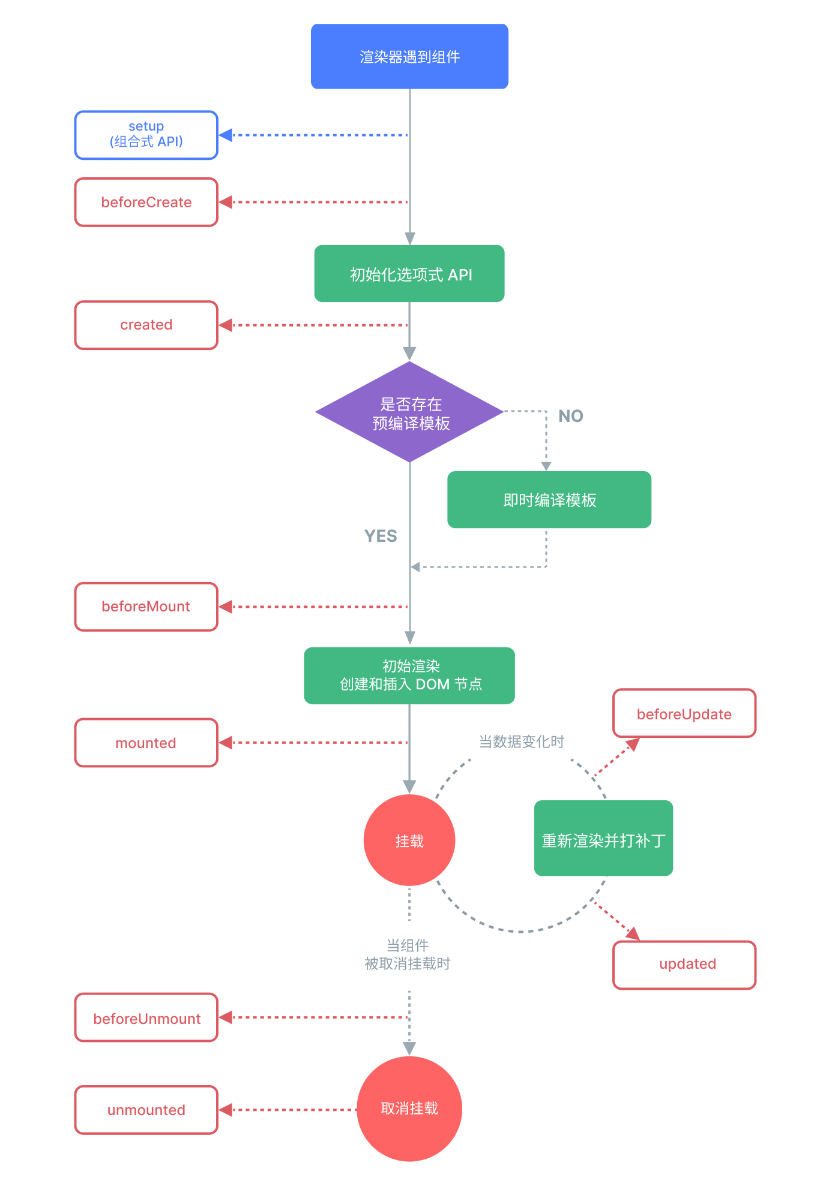
Vue生命周期详细解析
前言 Vue.js作为当前最流行的前端框架之一,其生命周期钩子函数是每个Vue开发者必须掌握的核心概念。本文将全面解析Vue的生命周期,帮助开发者更好地理解Vue实例的创建、更新和销毁过程。 一、Vue生命周期概述 Vue实例从创建到销毁的整个过程被称为Vue…...
基于c#,wpf,ef框架,sql server数据库,音乐播放器
详细视频: 【基于c#,wpf,ef框架,sql server数据库,音乐播放器。-哔哩哔哩】 https://b23.tv/ZqmOKJ5...
前端项目搭建集锦:vite、vue、react、antd、vant、ts、sass、eslint、prettier、浏览器扩展,开箱即用,附带项目搭建教程
前端项目搭建集锦:vite、vue、react、antd、vant、ts、sass、eslint、prettier、浏览器扩展,开箱即用,附带项目搭建教程 前言:一、Vue项目下载快速通道二、React项目下载快速通道三、BrowserPlugins项目下载快速通道四、项目搭建教…...