大模型如何作为reranker?
大模型如何作为reranker?
作者:爱工作的小小酥
原文地址:https://zhuanlan.zhihu.com/p/31805674335
只为了感动自己而去做一些事情纯属浪费时间。 ————爱工作的小小酥
引言
用于检索的模型中,我们最熟悉的就是单塔和双塔了,双塔经常用于召回阶段,单塔用于排序阶段。并且,其往往都是Encoder 结构的模型,例如BERT。
进入大模型时代后,模型结构大多只以deocder构成。当大模型在各个领域任务上表现出出色的能力,其在检索任务中是否也能超越以前的模型呢?
在之前的文章「爱工作的小小酥:大模型时代如何得到更好的embedding表征?」中,我们介绍了LLM如何用于编码embedding,以用于召回阶段。
我们这次再来看一下生成式模型——大模型如何用于排序阶段。
在检索任务的排序阶段,我们为了query和document的特征可以深度交互,要把query和document进行拼接输入模型,最后得到匹配分数。那么,对于以decoder结构为主的大模型来说,主要有以下需要解决的问题点:
-
如何得到分数值?
-
采用什么样的训练损失训练模型?
如何得到分数值?
LLM作为一种生成模型,需要一步步解码token得到所有结果。而对于reranker模型来说,不需要生成token,而只需要一个相似度值。在现有的研究中,主要分为3种情况:使用固定的token的特征的logits、直接让模型输出顺序「不再需要输出分数」、使用query中的词对应的logits。
使用固定的token
生成式模型,一步解码后得到的是在所有词表上的分布,我们往往通过选择在这个词表上最大的词作为此步解码token。因此,在这个过程中,我们可以得到当前步词表上所有token的logits,其实选择其中任何一个都可以用于计算分数,只是通过设置不同的prompt,可能有些token会更有意义一些。
(1)模型生成Yes,No。
当构造的prompt中,让模型输出Yes或者No时,此时选择Yes token对应的概率作为分数就会更有意义。

相对应的,也可以设置为True或者False,当然也要在prompt中做出相应更改。具体计算分数的时候有的会直接在所有词表上进行softmax,有的直接使用yes token的logits,有的只在Yes和No之间进行softmax「感觉这个更合理一些」。
具体使用方法参考论文:The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
(2)模型第一个输出token中的特殊token
如果设置的prompt中没有明确输出指令,常常会指定「特殊的token」作为计算分数的特征,例如<extra_id_10>或者。此时,一般使用一个linear层直接将logits转化为分数「对应下面的Dense」。
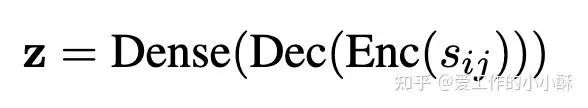
具体参考论文:
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Fine-Tuning LLaMA for Multi-Stage Text Retrieval
直接输出顺序
问答作为目前大模型最直观的使用方式,我们其实也可以直接让大模型排序,而不是输出分数后,最后再排序。例如,使用如下的prompt,就可以实现对document排序。

这种方法会有一个问题,模型接受的长度有限,而候选文档的个数一般都很多。目前现有的方法是采用「滑动窗口」的方式进行排序,有点类似冒泡排序。

参考论文:
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
RankVicuna: Zero-Shot Listwise Document Reranking with Open-Source Large Language Models
Zero-Shot Listwise Document Reranking with a Large Language Model
使用query的logits平均计算
还有一种用的人比较少的计算分数的方式,不按照常规构建rerank模型数据方式,而是只使用document,计算其生成label query的概率,这个作为query和document匹配的概率。
例如,使用下面的prompt,让模型生成对应的query。

然后,基于下面的公式,求取所有query token对应的概率。
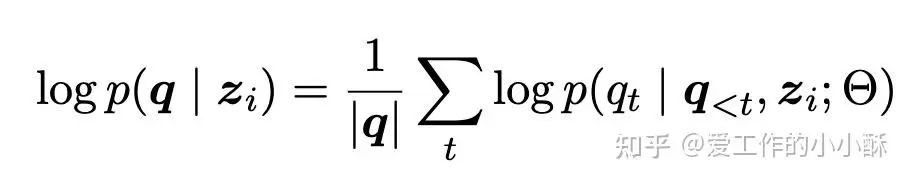
参考论文:Improving Passage Retrieval with Zero-Shot Question Generation
采用什么样的训练损失训练模型?
Pointwise Ranking Loss
Pointwise loss只需要匹配query和一个document之间的相似度关系,在三种损失里面是相对容易数据的一种训练方法,通常情况下,只需要对每个query,选择出困难负样本即可,具体可以参考bge的官方训练代码。
https://github.com/FlagOpen/FlagEmbedding/tree/master
这里将每个query、对应的正样本、对应的负样本作为一个组,每个组内部使用交叉熵损失计算loss。有点类似组内的INfoNCE,没有in batch negative。
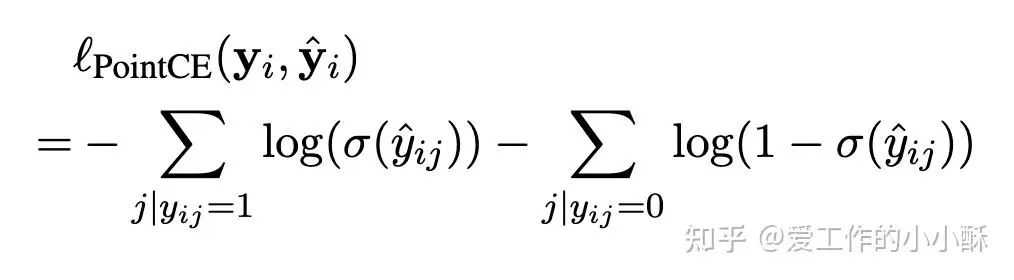
参考论文:
Fine-Tuning LLaMA for Multi-Stage Text Retrieval
The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Pairwise Ranking Loss
Pairwise 训练的样本为三元组,<query, 正样本,负样本>, 模型输出query是否和第一个样本更加匹配。最终需要根据相应的算法将两两顺序转化为最终的顺序。目前最常采用的损失函数为RankNet loss。
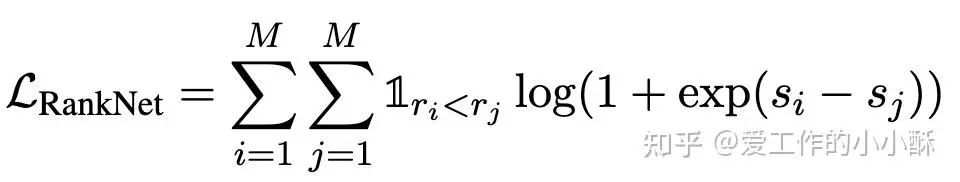
这种损失函数构造样本就会更加复杂一些,需要得到query和所有候选的顺序。有的会直接使用更大的模型得到顺序,例如chatgpt。有的直接随机采样负样本,忽略负样本之间的顺序,只保证正样本在负样本前面即可。
最后,可以采用以下累积分数的方式得到每个document的得分:
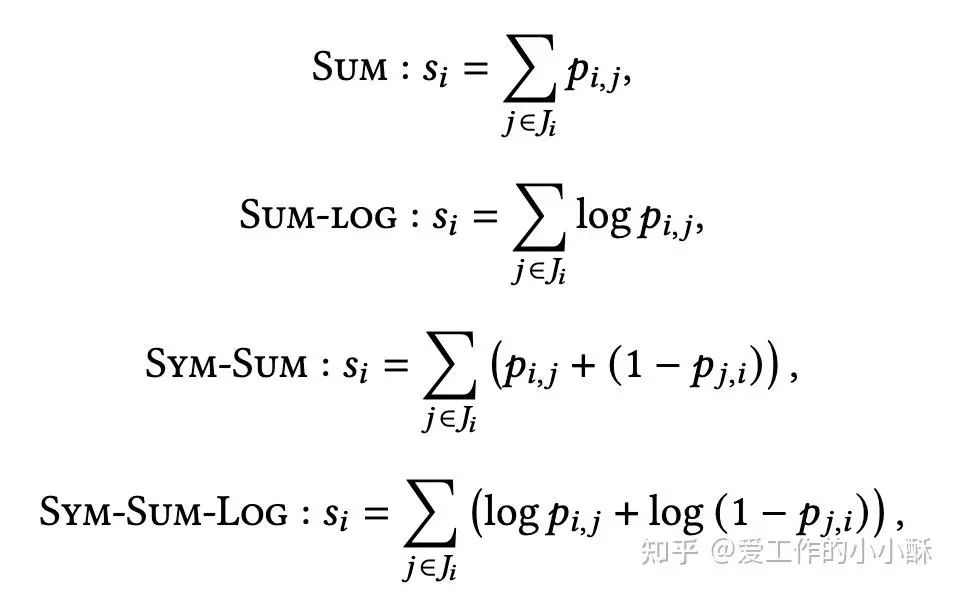
参考论文:
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Listwise Ranking Loss
Listwise loss是对整个序列顺序计算损失,因此,这个损失函数要求知道数据的真实顺序。构造数据的方法类似上述的Pairwise Ranking Loss。
目前经常采用的损失函数包括ListNet softmax 版本和PolyLoss。
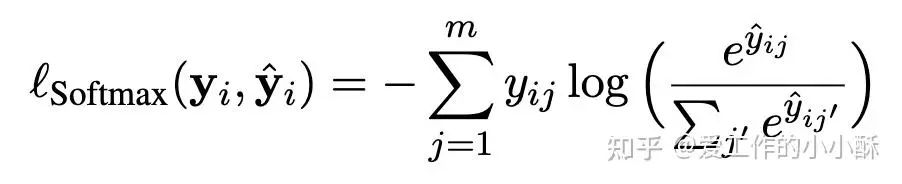
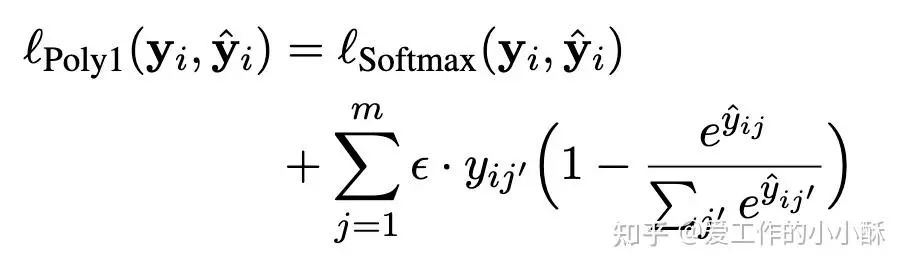
在RankT5论文中,验证listwise的损失效果最好,但目前看使用这个损失的模型也比较少,可能比较难构造数据。
参考论文:RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
总结
生成式模型不像之前的BERT,其多出了一个decoder结构,如何借助decoder本身的能力得到一个更加有意义的相似度分数成为关键,在现有的方法中主要通过更改prompt或者直接增大特殊token实现。除此之外,还可以直接利用大模型本身的能力,使其对候选文档直接排序。而在训练方式和,和之前的小模型相差不大,都是选用Pointwise Ranking Loss、Pairwise Ranking Loss或者Listwise Ranking Loss。




相关文章:
大模型如何作为reranker?
大模型如何作为reranker? 作者:爱工作的小小酥 原文地址:https://zhuanlan.zhihu.com/p/31805674335 只为了感动自己而去做一些事情纯属浪费时间。 ————爱工作的小小酥 引言 用于检索的模型中,我们最熟悉的就是单塔和双塔了&…...
发放优惠券
文章目录 概要整体架构流程技术细节小结 概要 发放优惠券 处于暂停状态,或者待发放状态的优惠券,在优惠券列表中才会出现发放按钮,可以被发放: 需求分析以及接口设计 需要我们选择发放方式,使用期限。 发放方式分…...

Java大师成长计划之第3天:Java中的异常处理机制
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在 Java 编程中,异常处理…...
试完5个AI海报工具后,我投了秒出设计一票!
随着AI技术的不断发展,越来越多的AI生成工具进入了设计领域,海报生成工具成为了其中的重要一员。今天,我们将为大家介绍三款热门的AI海报生成工具,并进行对比分析,帮助大家选择最适合的工具。 1. 秒出设计:…...

SD2351核心板:重构AI视觉产业价值链的“超级节点”
在AI视觉技术狂飙突进的当下,一个吊诡的现象正在浮现:一方面,学术界不断刷新着ImageNet等基准测试的精度纪录;另一方面,产业界却深陷“算法有、场景无,技术强、落地难”的怪圈。明远智睿SD2351核心板的问世…...

PH热榜 | 2025-04-25
1. LambdaTest Accessibility Testing Suite 标语:轻松点击,确保网站的包容性和合规性。 介绍:LambdaTest 的可访问性测试工具可以自动识别你的网站和网络应用中是否符合 WCAG(网页内容无障碍指南)标准。你可以设置定…...
模方ModelFun是什么?如何安装?
摘要:本文主要介绍模方ModelFun的软件简介、特性、安装环境配置、插件及软件安装。 1.软件简介 模方是一款实景三维模型的场景修饰与单体化建模工具,是建模的后处理软件,包括网格模型编辑和单体化建模两大模块。 场景修饰模块可以对 OBJ、OSG…...

[AI Workflow] 基于多语种知识库的 Dify Workflow 构建与优化实践
在实际应用中,基于用户提供的资料快速构建高质量的知识库,并以此背景精准回答专业问题,是提升人工智能系统实用性的重要方向。然而,在跨语种环境下(如中、日、英混合资料与提问),传统的知识检索和回答生成流程往往面临匹配不准确、信息检索不全面的问题。 本文将介绍一种…...

运维案例:让服务器稳定运行,守护业务不掉线!
在数字经济高速发展的今天,作为全球领先的智能手机制造商,面临着日均数千台服务器运维管理的挑战。随着海外市场拓展与产品线迭代加速,该企业的IT基础设施规模持续扩大,传统人工运维模式已无法满足效率与安全需求。如何在海量补丁…...

Pycharm(十六)面向对象进阶
一、继承 概述: 实际开发中,我们发现很多类中的步分内容是相似的,或者相同的,每次写很麻烦,针对这种情况, 我们可以把这些相似(相同的)部分抽取出来,单独地放到1个类中&…...

Nginx 反向代理,啥是“反向代理“啊,为啥叫“反向“代理?而不叫“正向”代理?它能干哈?
Nginx 反向代理的理解与配置 User 我打包了我的前端vue项目,上传到服务器,在宝塔面板安装了nginx服务,配置了文件 nginx.txt .运行了项目。 我想清楚,什么是nginx反向代理?是nginx作为一个中介?中间件来集…...
)
文章记单词 | 第45篇(六级)
一,单词释义 cross [krɒs] 动词(v.),穿越;穿过;横过;渡过;交叉;相交;使交叉;使交叠 名词(n.),十字形记号&am…...

WebGL图形编程实战【4】:光影交织 × 逐片元光照与渲染技巧
现实世界中的物体被光线照射时,会反射一部分光。只有当反射光线进人你的眼睛时,你才能够看到物体并辩认出它的颜色。 光源类型 平行光(Directional Light):光线是相互平行的,平行光具有方向。平行光可以看…...

Java高频面试之并发编程-07
hello啊,各位观众姥爷们!!!本baby今天来报道了!哈哈哈哈哈嗝🐶 面试官:线程之间有哪些通信方式? 在 Java 多线程编程中,线程间通信(Inter-Thread Communica…...
的详细解读)
粒子群优化算法(Particle Swarm Optimization, PSO)的详细解读
最近研究基于进化算法的神经网络架构搜索,仔细阅读了TEVC2023年发表的一篇NAS搜索的文章,觉得收益颇多,对比NSGA-2,这里给出PSO的详细解释。【本人目前研究的是多目标进化算法,欢迎交流、留言】 文章题目是࿱…...
.NET代码保护混淆和软件许可系统——Eziriz .NET Reactor 7
.NET代码保护混淆和软件许可系统——Eziriz .NET Reactor 7 1、简介2、功能特点3、知识产权保护功能4、强大的许可系统5、软件开发工具包6、部署方式7、下载 1、简介 .NET Reactor是用于为.NET Framework编写的软件的功能强大的代码保护和软件许可系统,并且支持生成…...
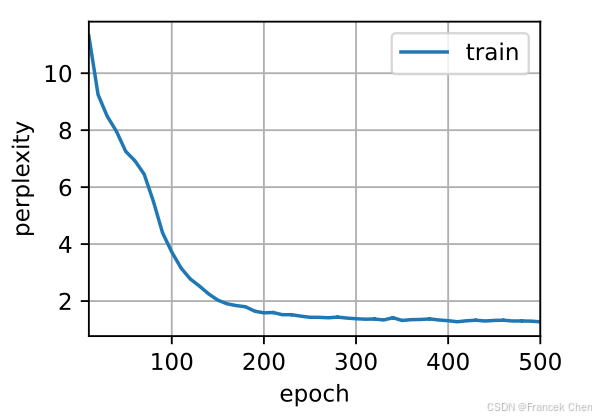
【现代深度学习技术】循环神经网络06:循环神经网络的简洁实现
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

【办公类-89-02】20250424会议记录模版WORD自动添加空格补全下划线
背景需求 4月23日听了一个MJB的征文培训,需要写会议记录 把资料黏贴到模版后,发现每行需要有画满下划线 原来做这套资料,就是手动按空格到一行末,有空格才会出现下划线,也就是要按很多的空格(凑满一行&…...
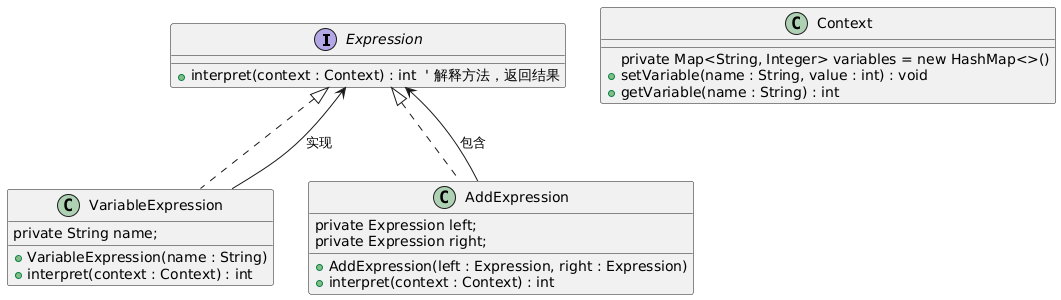
解释器模式:自定义语言解析与执行的设计模式
解释器模式:自定义语言解析与执行的设计模式 一、模式核心:定义语言文法并实现解释器处理句子 在软件开发中,当需要处理特定领域的语言(如数学表达式、正则表达式、自定义配置语言)时,可以通过解释器模式…...

了解互联网
本文来源 : 腾讯元宝 克劳德香农(Claude Shannon) 信息时代之父 克劳德香农(Claude Shannon,1916-2001)是20世纪最具影响力的数学家和工程师之一,被誉为“信息论之父”和“数字…...

Vue和React项目中,统一监听页面错误需要结合框架提供的错误处理机制与JavaScript原生方法
在Vue和React项目中,统一监听页面错误需要结合框架提供的错误处理机制与JavaScript原生方法,以下是具体方案及实现原理: Vue项目统一监听错误 errorCaptured生命周期钩子134 作用:监听所有下级组件的报错,可返回fals…...

AI催生DLP新战场 | 天空卫士连续6年入选Gartner 全球数据防泄漏(DLP)市场指南
“管理数据外泄风险仍然是企业的重大挑战之一,客户处出于各种因素寻求DLP。最近,一些组织对使用DLP控制机器对敏感信息的访问表现出很大兴趣。 随着生成式人工智能(GenAI)的运用和数据的不断扩散,数据外泄的问题变得更…...
)
23种设计模式-行为型模式之策略模式(Java版本)
Java 策略模式(Strategy Pattern)详解 🧠 什么是策略模式? 策略模式是一种行为型设计模式,它定义了一系列算法,把它们一个个封装起来,并且使它们可以互相替换。策略模式让算法独立于使用它的客…...
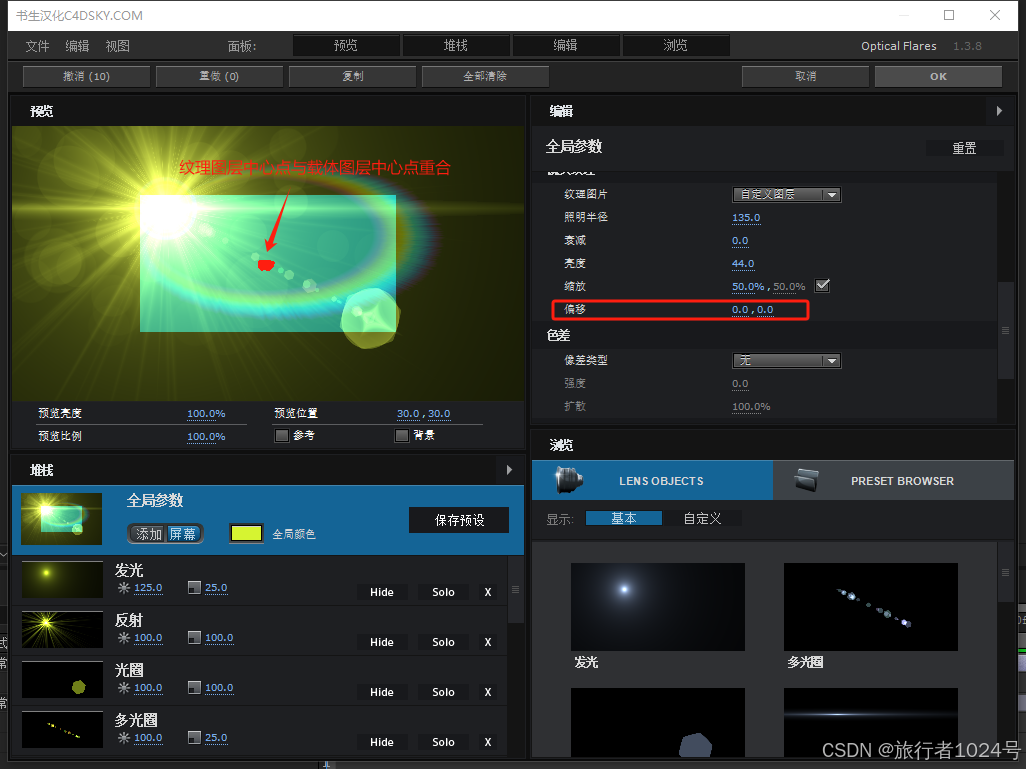
Adobe After Effects的插件--------Optical Flares之Lens Objects参数
Lens Objects,即【镜头对象】。 通用设置 全局参数发光多光圈光圈条纹微光反射钉球闪光圆环箍焦散镜头球缩放✔✔✔✔✔✔✔✔✔✔✔✔✔缩放偏移✔长宽比✔✔✔✔✔✔✔✔✔✔✔✔✔混合模式✔颜色✔全局种子✔亮度✔✔✔✔✔✔✔✔✔✔✔✔拉伸✔✔✔✔✔✔✔✔✔✔✔✔距离…...

使用Matlab工具将RAW文件转化为TXT文件,用于FPGA仿真输入
FPGA实现图像处理算法时,通常需要将图像作为TestBench的数据输入。 使用VHDL编写TestBench时,只能读取二进制TXT文件。 现在提供代码,用于实现RAW图像读取,图像显示,图像转化为二进制数据并存入TXT文件中。 clc; cl…...
【问题】解决docker的方式安装n8n,找不到docker.n8n.io/n8nio/n8n:latest镜像的问题
问题概览 用docker方式安装n8n,遇到错误,安装不了的问题: Unable to find image docker.n8n.io/n8nio/n8n:latest locally docker: Error response from daemon: Get "https://registry-1.docker.io/v2/": net/http: request can…...

【网络】TCP/IP协议学习
学TCP/IP最好的方法是阅读lwip源码。 1. 资料 什么是SYN Flood?DoS 和 DDoS 攻击,一个字母之差,到底区别在哪? 2. 技术要点: 技术要点要结合源码,以及向AI提问来理解,否则真的很难理解&…...

系统与网络安全------弹性交换网络(1)
资料整理于网络资料、书本资料、AI,仅供个人学习参考。 Trunk原理与配置 Trunk原理概述 Trunk(虚拟局域网中继技术)是指能让连接在不同交换机上的相同VLAN中的主机互通。 VLAN内通信 实现跨交换的同VLAN通信,通过Trunk链路&am…...
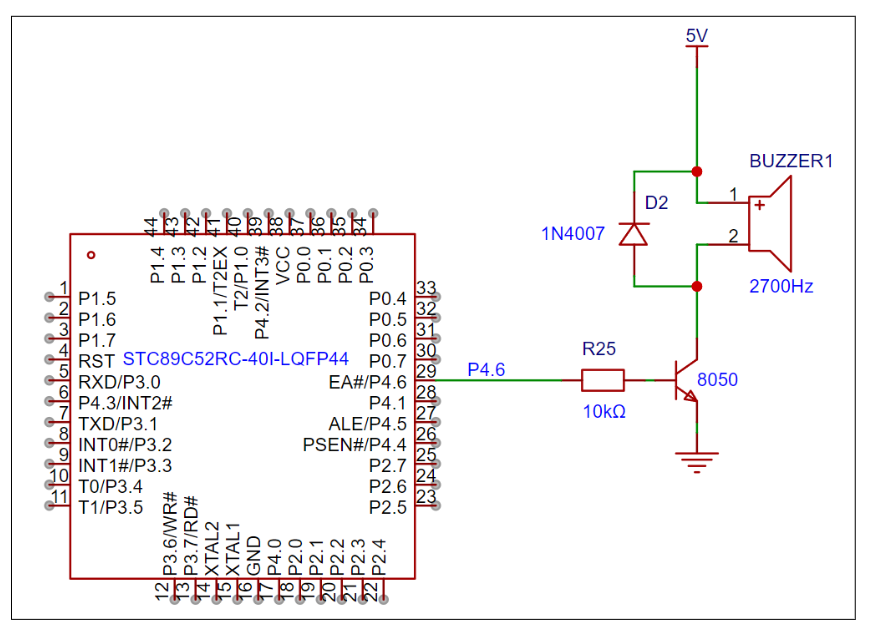
10天学会嵌入式技术之51单片机-day-3
第九章 独立按键 按键的作用相当于一个开关,按下时接通(或断开),松开后断开(或接通)。实物图、原理图、封装 9.2 需求描述 通过 SW1、SW2、SW3、SW4 四个独立按键分别控制 LED1、LED2、LED3、LED4 的亮…...
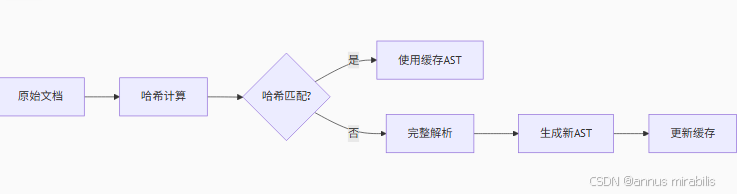
深入解析微软MarkitDown:原理、应用与二次开发指南
一、项目背景与技术定位 微软开源的MarkitDown并非简单的又一个Markdown解析器,而是针对现代文档处理需求设计的工具链核心组件。该项目诞生于微软内部大规模文档系统的开发实践,旨在解决以下技术痛点: 大规模文档处理性能:能够高…...