tokenizer的用法
下面介绍下基于 Hugging Face Transformers 库中 tokenizer(分词器)的主要用法和常用方法,帮助你了解如何在各种场景下处理文本。这里以 AutoTokenizer 为例,但大多数模型对应的 tokenizer 用法大同小异。
─────────────────────────────
- 加载 Tokenizer
• 自动加载(AutoTokenizer)
使用 AutoTokenizer 可以根据模型名称或本地路径快速加载对应的分词器:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(“模型名称或者本地路径”)
例如:
tokenizer = AutoTokenizer.from_pretrained(“bert-base-uncased”)
或加载本地模型目录:
tokenizer = AutoTokenizer.from_pretrained(“/home/zhangchenlong.8/resources/qwen2.53b”)
• 指定参数
加载时可以传入一些参数,如是否返回 fast 版本(更高效的C++实现),是否下载缓存等。
tokenizer = AutoTokenizer.from_pretrained(“模型名称”, use_fast=True)
─────────────────────────────
2. 基本编码方法(encode / call)
• 单条文本编码为 token id 列表
token_ids = tokenizer.encode(“Hello world”, add_special_tokens=True)
注意:add_special_tokens 参数控制是否在结果中加入模型所需的特殊 token(例如 [CLS], [SEP])
• 编码多条文本(Batch Encoding)
encoded = tokenizer([“Hello world”, “How are you?”], padding=True, truncation=True, return_tensors=“pt”)
返回结果通常是一个字典,包含 input_ids, attention_mask 等(当 return_tensors 指定返回 tensor 时)
如果只需要 id 列表,可以不指定返回 tensor:
encoded = tokenizer([“Hello world”, “How are you?”], padding=True, truncation=True)
• call 方法
由于 tokenizer 类实现了 call 方法,因此直接传入文本也可以:
result = tokenizer(“Hello world”, add_special_tokens=True)
最终返回字典形式:{“input_ids”: […], “attention_mask”: […]},有时还会包含其他信息比如 “token_type_ids”、“offset_mapping”(用于对齐)等。
─────────────────────────────
3. 编码参数详解
在调用 encode、batch_encode_plus 或 call 方法时,可以传入的常用参数有:
• add_special_tokens: 是否在编码时加入特殊标记,如 [CLS] 或 [SEP]
• padding: 是否对输出进行补齐(填充)。例如 padding=True 会补齐到当前 batch 内最大长度;可以传入 “max_length” 强制到固定长度。
• truncation: 是否截断超过指定最大长度的文本。
• max_length: 最大长度
• return_tensors: 指定返回类型,如 “pt”(PyTorch tensor)、“tf” 或 “np”(NumPy 数组)
• return_attention_mask: 是否返回 attention mask 信息
• return_token_type_ids: 是否返回 token type ids
• verbose: 控制消息显示
• add_prefix_space: 一些基于字节对编码(BPE)的 tokenizer 可能需要(如 GPT-2)
─────────────────────────────
4. 解码(decode)
转换 token id 序列回文本:
text = tokenizer.decode(token_ids, skip_special_tokens=True)
参数 skip_special_tokens=True 可以过滤掉 [CLS]、[SEP] 等特殊 token,使输出更纯净。
如果需要对一批 token 序列进行解码,可以使用 decode 方法配合循环,或使用 batch_decode 方法:
texts = tokenizer.batch_decode(list_of_token_ids, skip_special_tokens=True)
将 prefix_tokens 转换为 tokens
prefix_tokens_str = tokenizer.convert_ids_to_tokens(prefix_tokens)
─────────────────────────────
5. 高阶功能
• 获取词汇表
可以通过 tokenizer.vocab 访问词典(部分 tokenizer 不支持此属性);或使用 tokenizer.get_vocab() 方法:
vocab = tokenizer.get_vocab()
返回字典形式:{token: id, …}
• 分词(Tokenization)
有时只需要知道文本被划分成哪些 token(通常是字符串),用 tokenizer.tokenize():
tokens = tokenizer.tokenize(“Hello world”)
有的是基于 subword 或 SentencePiece 实现,返回结果可能包含 ## 或前置空格,取决于模型设计。
• 映射与偏移信息
有时需要知道每个 token 在原字符文本中的位置,可传入参数 return_offsets_mapping:
encoded = tokenizer(“Hello world”, return_offsets_mapping=True)
encoded[“offset_mapping”] 即是每个 token 对应的 (start, end) 位置信息。
• 处理特殊场景
– 对于长文本自动截断和溢出(overflow tokens),可以用参数 return_overflowing_tokens=True
– 对于分词后需要中英文对齐信息,也可以查看 tokenizer 的高级用法和文档说明。
─────────────────────────────
6. Tokenizer 的用途
• 数据预处理
在模型训练前,将原始文本转换为模型所需的 token id 序列。
• 后处理(解码)
将模型输出的 id 序列转换回可读文本。
• 调试和分析
通过 tokenization 可以检查是不是特殊字符没有正确处理,或测试不同 tokenizer 对同一文本的分词效果。
• 自定义处理
可以基于现有 tokenizer 进行修改,如添加自定义的 token(tokenizer.add_tokens([“新词”])),从而扩展词汇表,此时可调用 tokenizer.resize_token_embeddings(model) 更新模型嵌入层。
─────────────────────────────
7. 注意事项
• 模型预训练时通常使用了特定的 tokenizer,使用时最好保证加载相同版本,确保 token id 对应关系一致。
• 有的 tokenizer 有 fast 版本(基于 Rust 的 tokenizers 库实现),具备更高效率和更多功能,如 offset mapping、动态 padding 等。
• 部分 tokenizer 对空格、标点等处理与我们直觉可能不同(比如 GPT-2 在 token 开头会有空格提示),需要熟悉模本的使用说明。
• 当用于多语言或特殊场景时,有时需要调整 tokenizer 的参数(例如 normalization、pre-tokenization、post-processing)。
─────────────────────────────
总结
以上即介绍了 Hugging Face 中 tokenizer 的加载、编码、解码、参数设置以及进阶功能。具体应用时建议参阅官方文档(https://huggingface.co/transformers/main_classes/tokenizer.html),结合你使用的模型的特点,来调试和完善你的文本处理流程。
相关文章:

tokenizer的用法
下面介绍下基于 Hugging Face Transformers 库中 tokenizer(分词器)的主要用法和常用方法,帮助你了解如何在各种场景下处理文本。这里以 AutoTokenizer 为例,但大多数模型对应的 tokenizer 用法大同小异。 ───────────…...
)
kotlin和MVVM的结合使用总结(二)
MVVM 架构详解 核心组件:ViewModel 和 LiveData 在 Android 中,MVVM 架构主要借助 ViewModel 和 LiveData 来实现。ViewModel 负责处理业务逻辑,而 LiveData 则用于实现数据的响应式更新。 ViewModel 的源码分析 ViewModel 的核心逻辑在 …...

Git 入门知识详解
文章目录 一、Git 是什么1、Git 简介2、Git 的诞生3、集中式 vs 分布式3.1 集中式版本控制系统3.2 分布式版本控制系统 二、GitHub 与 Git 安装1、GitHub2、Git 安装 一、Git 是什么 1、Git 简介 Git 是目前世界上最先进的分布式版本控制系统。版本控制系统能帮助我们更好地管…...

React.memo 和 useMemo
现象 React 中,通常父组件的某个state发生改变,会引起父组件的重新渲染(和其他state的重新计算),从而会导致子组件的重新渲染(和其他非相关属性的重新计算) 问题一:如何避免因为某个…...

EDI 如何与 ERP,CRM,WMS等系统集成
在数字化浪潮下,与制造供应链相关产业正加速向智能化供应链转型。传统人工处理订单、库存和物流的方式已难以满足下单客户对响应速度和数据准确性的严苛要求。EDI技术作为企业间数据交换的核心枢纽,其与ERP、CRM、WMS等业务系统的深度集成,成…...

面试踩过的坑
1、 “”和equals 的区别 “”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。equals是Object的方法,比较的是所指向的对象的地址值,一般情况下,重…...

论文阅读:2024 ACL ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 Artprompt: Ascii art-based jailbreak attacks against aligned llms https://www.doubao.com/chat/3846685176618754 https://arxiv.org/pdf/2402.11753 https://github…...
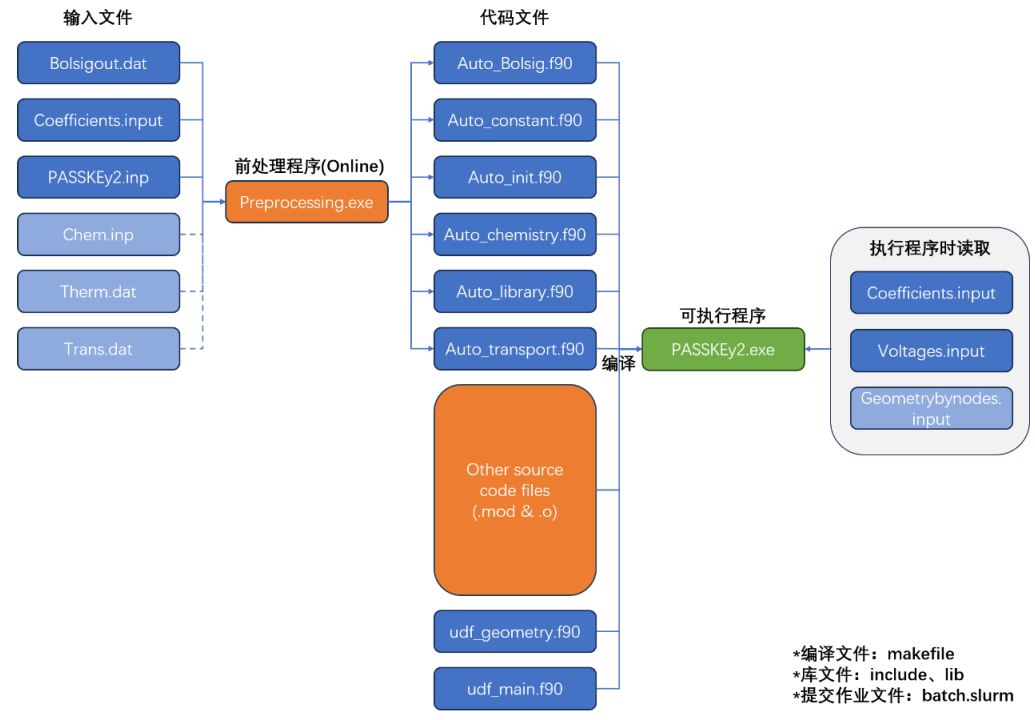
多物理场耦合低温等离子体装置求解器PASSKEy2
文章目录 PASSKEy2简介PASSKEY2计算流程PASSKEy2 中求解的物理方程电路模型等离子体模型燃烧模型 PASSKEy2的使用 PASSKEy2简介 PASSKEy2 是在 PASSKEy1 的基础上重新编写的等离子体数值模拟程序。 相较于 PASSKEy1, PASSKEy2 在具备解决低温等离子体模拟问题的能力…...
视频噪点多,如何去除画面噪点?
你是否遇到过这样的困扰?辛辛苦苦拍摄的视频,导出后却满屏 “雪花”,夜景变 “噪点盛宴”,低光环境秒变 “马赛克现场”? 无论是日常拍摄的vlog、珍贵的家庭录像,还是专业制作的影视作品,噪点问…...

09前端项目----分页功能
分页功能 分页器的优点实现分页功能自定义分页器先实现静态分页器调试分页器动态数据/交互 Element UI组件 分页器的优点 电商平台同时展示的数据很多,所以采用分页功能实现分页功能 Element UI已经有封装好的组件,但是也要掌握原理,以及自定…...

第十二届蓝桥杯 2021 C/C++组 直线
目录 题目: 题目描述: 题目链接: 思路: 核心思路: 两点确定一条直线: 思路详解: 代码: 第一种方式代码详解: 第二种方式代码详解: 题目:…...

《Piper》皮克斯技术解析:RIS系统与云渲染如何创造奥斯卡级动画短片
本文由专业专栏作家 Mike Seymour 撰写,内容包含非常有价值的行业资讯。 译者注 《Piper》是皮克斯动画工作室的一部技术突破性的短片,讲述了一只小鸟在海滩上寻找食物并面对自然挑战的故事。它不仅凭借其精美的视觉效果和细腻的情感表达赢得了2017年奥…...
Java在excel中导出动态曲线图DEMO
1、环境 JDK8 POI 5.2.3 Springboot2.7 2、DEMO pom <dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.3</version></dependency><dependency><groupId>commons…...

第19章:Multi-Agent多智能体系统介绍
第19章:Multi-Agent多智能体系统介绍 欢迎来到多智能体系统 (Multi-Agent System, MAS) 的世界!在之前的章节中,我们深入探讨了单个 AI Agent 的构建,特别是结合了记忆、上下文和规划能力的 MCP 框架。然而,现实世界中的许多复杂问题往往需要多个智能体协同工作才能有效解…...
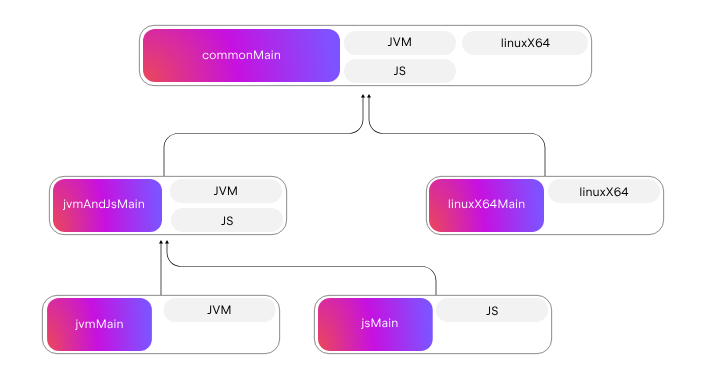
Kotlin Multiplatform--02:项目结构进阶
Kotlin Multiplatform--02:项目结构进阶 引言正文 引言 在上一章中,我们对 Kotlin Multiplatform 项目有了基本的了解,已经可以进行开发了。但我们只是使用了系统默认的项目结构。本章介绍了如何进行更复杂的项目结构管理。 正文 在上一章中&…...
)
Spring Cloud Gateway配置双向SSL认证(完整指南)
本文将详细介绍如何为Spring Cloud Gateway配置双向SSL认证,包括证书生成、配置和使用。 目录结构 /my-gateway-project ├── /certs │ ├── ca.crt # 根证书 │ ├── ca.key # 根私钥 │ ├── gateway.crt # 网关证书 │ ├── …...

Windows同步技术-使用命名对象
在 Windows 系统下使用命名对象(如互斥体、事件、信号量、文件映射等内核对象)时,需注意以下关键要点: 命名规则 唯一性:名称需全局唯一,避免与其他应用或系统对象冲突,建议使用 GUID 或应用专…...

代码随想录算法训练营第五十八天 | 1.拓扑排序精讲 2.dijkstra(朴素版)精讲 卡码网117.网站构建 卡码网47.参加科学大会
1.拓扑排序精讲 题目链接:117. 软件构建 文章讲解:代码随想录 思路: 把有向无环图进行线性排序的算法都可以叫做拓扑排序。 实现拓扑排序的算法有两种:卡恩算法(BFS)和DFS,以下BFS的实现思…...
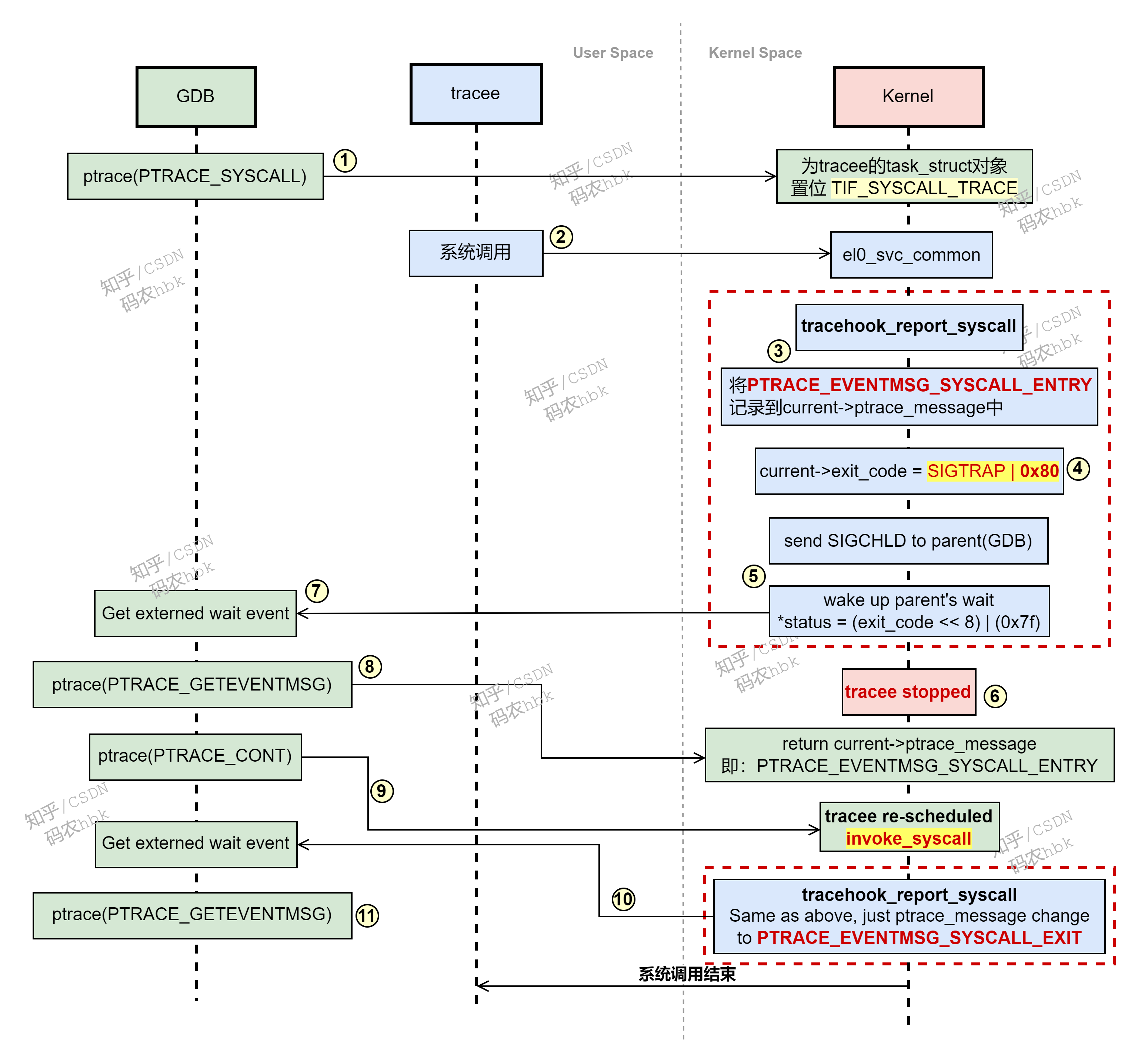
linux ptrace 图文详解(七) gdb、strace跟踪系统调用
目录 一、gdb/strace 跟踪程序系统调用 二、实现原理 三、代码实现 四、总结 (代码:linux 6.3.1,架构:arm64) One look is worth a thousand words. —— Tess Flanders 相关链接: linux ptrace 图…...

【前端】ES6 引入的异步编程解决方案Promise 详解
Promise 详解 1. 基本概念 定义:Promise 是 ES6 引入的异步编程解决方案,表示一个异步操作的最终完成(或失败)及其结果值。核心作用:替代回调函数,解决“回调地狱”问题,提供更清晰的异步流程控…...

常见正则表达式整理与Java使用正则表达式的例子
一、常见正则表达式整理 1. 基础验证类 邮箱地址 ^[a-zA-Z0-9._%-][a-zA-Z0-9.-]\\.[a-zA-Z]{2,}$ (匹配如 userexample.com)手机号 ^1[3-9]\\\\d{9}$ (匹配国内11位手机号,如 13812345678)中文字符 ^[\u4e00-\u9fa5…...
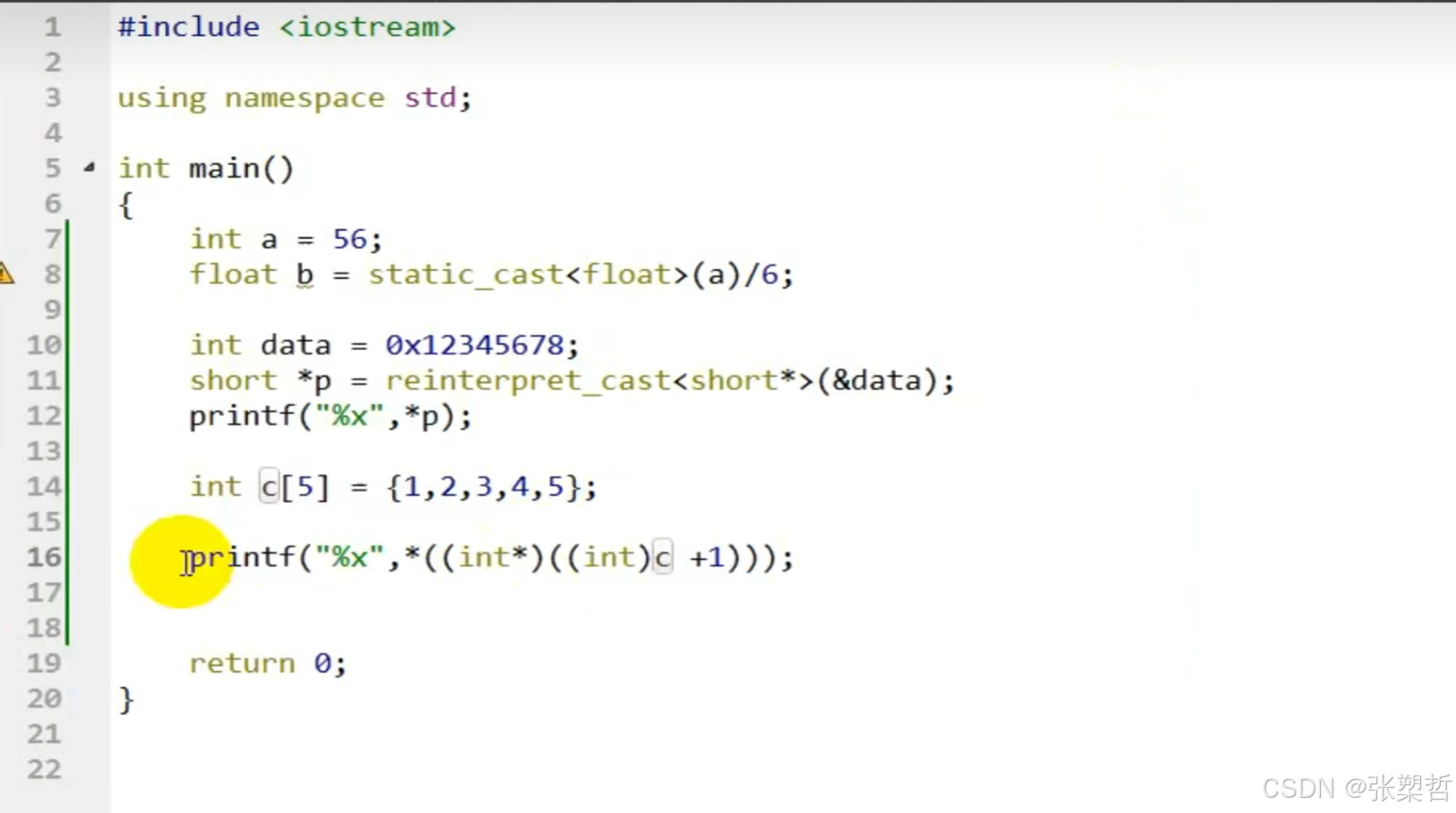
const(C++)
打印出来的结果是 a是12 *p是200 const修饰指针 const修饰引用...
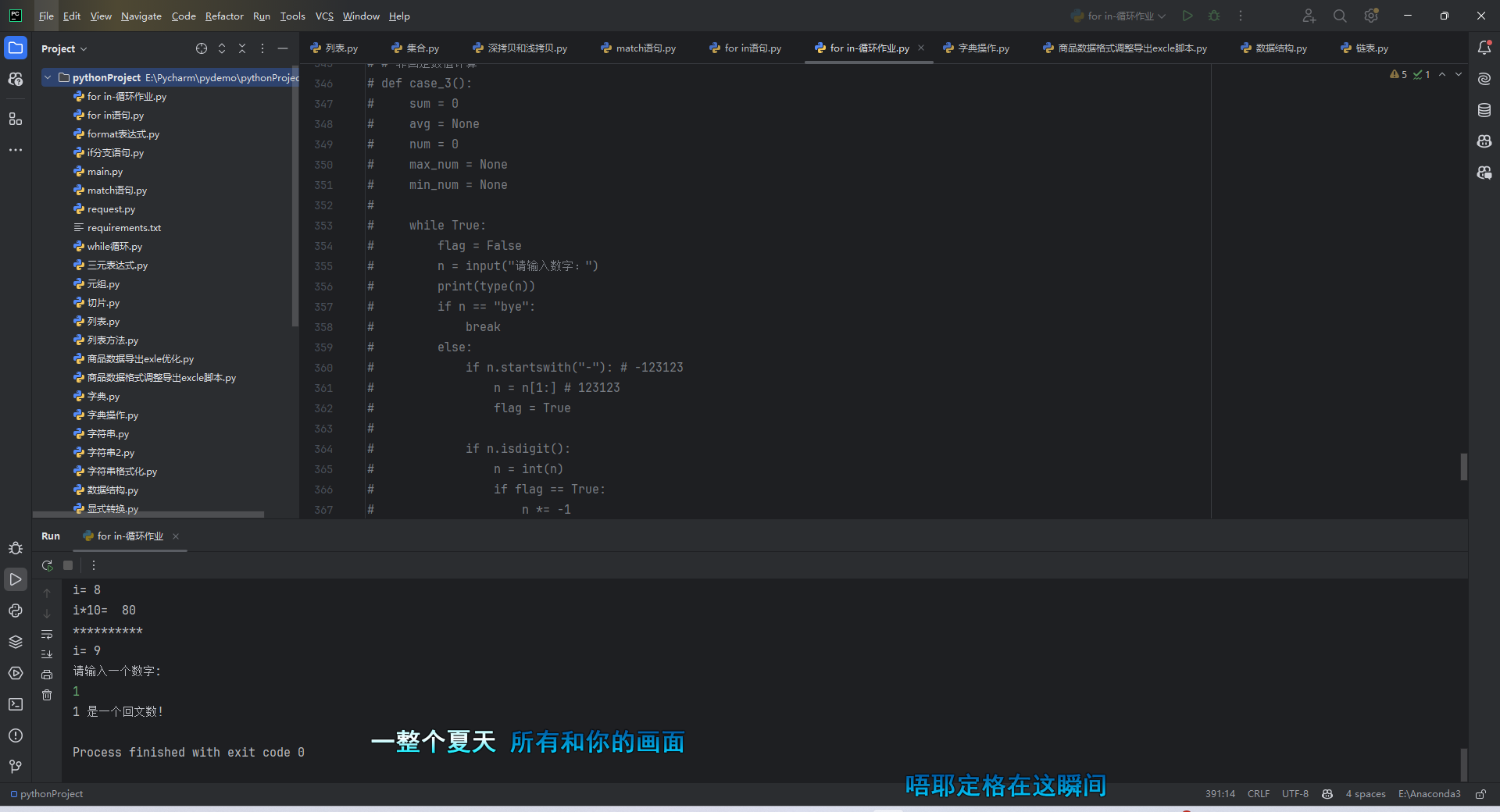
python21-循环小作业
课程:B站大学 记录python学习,直到学会基本的爬虫,使用python搭建接口自动化测试就算学会了,在进阶webui自动化,app自动化 循环语句小作业 for-in作业斐波那契 for 固定数值计算素数字符统计数字序列range 函数 水仙花…...
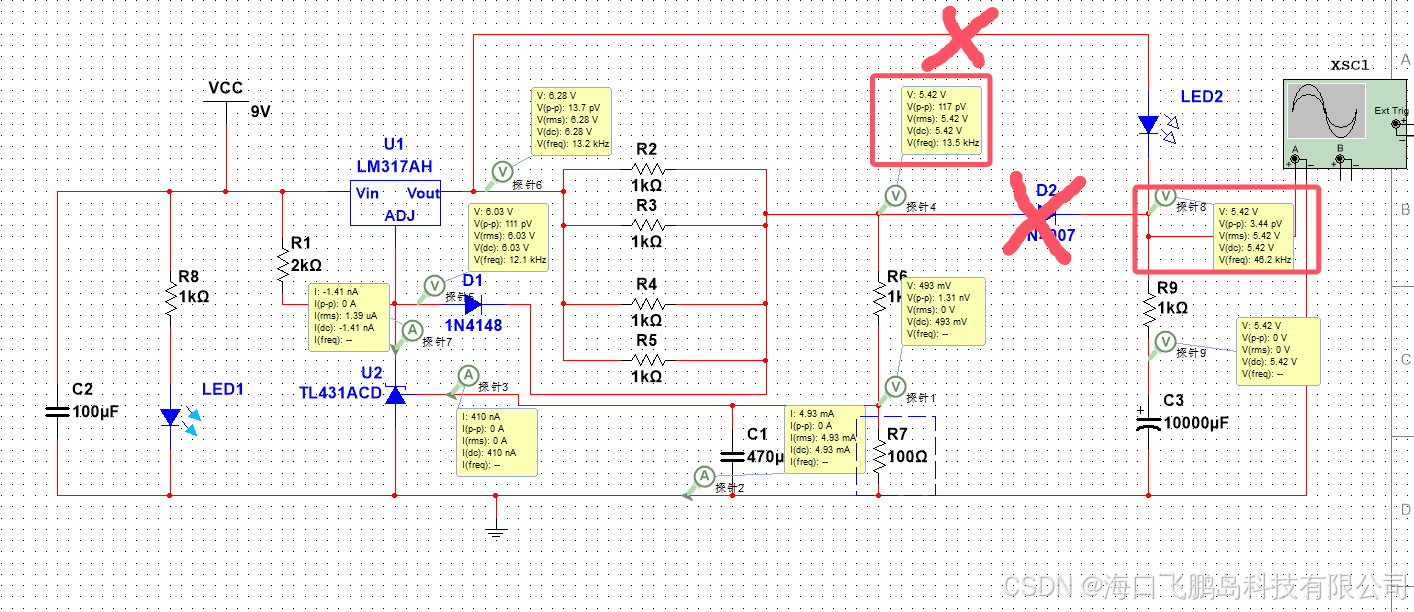
小白电路设计-设计11-恒功率充电电路设计
介绍 作为电子信息工程的我,电路学习是一定要学习的,可惜目前作为EMC测试工程师,无法兼顾太多,索性不如直接将所学的知识进行运用,并且也可以作为契机,进行我本人的个人提升。祝大家与我一起进行提升。1.本…...

传感器模块有助于加速嵌入式视觉开发
传感器模块是一种小型成像解决方案,用于轻松将定制的视觉技术集成到机器和设备中,使其具备“视觉”功能。机器人、无人机、物联网、消费电子设备和监控应用的开发人员在设计中使用传感器模块,可以节省开发时间和资源。FRAMOS 推出了一个创新的可互换传感器模块和适配器生态系…...
Spring AI 快速入门:从环境搭建到核心组件集成
Spring AI 快速入门:从环境搭建到核心组件集成 一、前言:Java开发者的AI开发捷径 对于Java生态的开发者来说,将人工智能技术融入企业级应用往往面临技术栈割裂、依赖管理复杂、多模型适配困难等挑战。Spring AI的出现彻底改变了这一局面——…...
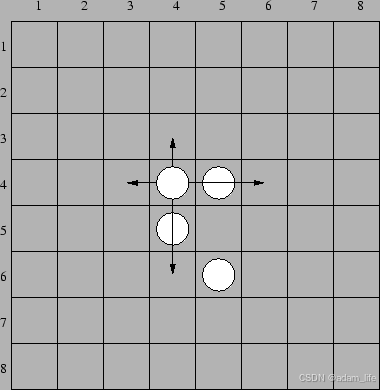
http://noi.openjudge.cn/——2.5基本算法之搜索——200:Solitaire
文章目录 题目宽搜代码总结 题目 总时间限制: 5000ms 单个测试点时间限制: 1000ms 内存限制: 65536kB 描述 Solitaire is a game played on a chessboard 8x8. The rows and columns of the chessboard are numbered from 1 to 8, from the top to the bottom and from left t…...
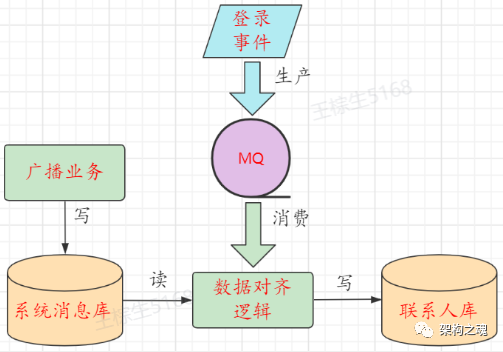
架构师面试(三十六):广播消息
题目 在像 IM、短视频、游戏等实时在线类的业务系统中,一般会有【广播消息】业务,这类业务具有瞬时高流量的特点。 在对【广播消息】业务实现时通常需要同时写 “系统消息库” 和更新用户的 “联系人库” 的操作,用户的联系人表中会有未读数…...

如何开启远程桌面连接外网访问?异地远程控制内网主机
实现远程桌面连接外网访问,能够突破地域限制,随时随地访问远程计算机,满足远程办公、技术支持等多种需求。下面为你详细介绍开启方法。 一、联网条件 确保本地计算机和远程计算机都有稳定的网络连接,有联网能上网。 二、开启远程…...
 的百度新闻定向爬虫:根据输入的关键词在百度新闻上进行搜索,并爬取新闻详情页的内容)
基于 Python(selenium) 的百度新闻定向爬虫:根据输入的关键词在百度新闻上进行搜索,并爬取新闻详情页的内容
该项目能够根据输入的关键词在百度新闻上进行搜索,并爬取新闻详情页的内容。 一、项目准备 1. 开发环境配置 操作系统:支持 Windows、macOS、Linux 等主流操作系统,本文以 Windows 为例进行说明。Python 版本:建议使用 Python 3.8 及以上版本,以确保代码的兼容性和性能。…...