豆瓣图书数据采集与可视化分析(三)- 豆瓣图书数据统计分析
文章目录
- 前言
- 一、数据读取与保存
- 1. 读取清洗后数据
- 2. 保存数据到CSV文件
- 3. 保存数据到MySQL数据库
- 二、不同分类统计分析
- 1. 不同分类的图书数量统计分析
- 2. 不同分类的平均评分统计分析
- 3. 不同分类的平均评价人数统计分析
- 4. 不同分类的平均价格统计分析
- 5. 分类综合分析
- 三、不同年份统计分析
- 1. 不同年份出版的图书数量统计分析
- 2. 不同年份出版的图书平均评分分析
- 3. 不同年份出版的图书平均评价人数分析
- 4. 不同年份出版的图书平均价格分析
- 5. 年份综合分析
- 四、不同作者统计分析
- 1. 不同作者的图书数量统计分析
- 2. 不同作者的平均评分分析
- 3. 不同作者的平均评价人数分析
- 4. 不同作者的平均价格分析
- 5. 作者综合分析
- 五、不同出版社分析
- 1. 不同出版社的图书数量统计分析
- 2. 不同出版社的平均评分分析
- 3. 不同出版社的平均评价人数分析
- 4. 不同出版社的平均价格分析
- 5. 出版社综合分析
- 六、其他分析
- 1. 图书评分分布分析
- 2. 图书价格分布分析
- 3. 译者翻译的图书数量统计分析(前15)
- 4. 评价人数多的图书分析(前15)
- 5. 评分最高的图书分析(前15)
- 6. 评价人数最多且评分高的图书分析(前15)
- 七、完整代码
前言
本项目旨在通过对豆瓣图书数据集的详细分析,挖掘其中隐藏的规律和趋势,为图书出版行业、读者以及相关研究人员提供有价值的参考。从数据读取与保存这一基础环节出发,构建了完善的数据处理流程,确保能够高效地获取和存储清洗后的高质量数据,为后续分析筑牢根基。在数据分析阶段,从多个维度展开深入探究。在不同分类统计分析中,详细剖析了各类图书在数量、平均评分、平均评价人数以及平均价格等方面的表现,有助于出版方精准把握市场需求,读者快速定位感兴趣的图书类别。针对不同年份的统计分析,能够清晰洞察图书出版趋势随时间的演变,了解不同年份图书在质量、受欢迎程度和价格上的变化规律。而对不同作者和出版社的分析,则为评估创作者和出版机构的影响力提供了量化依据。此外,其他分析板块涵盖了图书评分分布、价格分布、热门图书筛选等多个视角,进一步丰富了对图书市场的认知。
一、数据读取与保存
1. 读取清洗后数据
def load_data(csv_file_path):try:data = pd.read_csv(csv_file_path)return dataexcept FileNotFoundError:print("未找到指定的 CSV 文件,请检查文件路径和文件名。")except Exception as e:print(f"加载数据时出现错误: {e}")
清洗后的部分数据如下图所示:
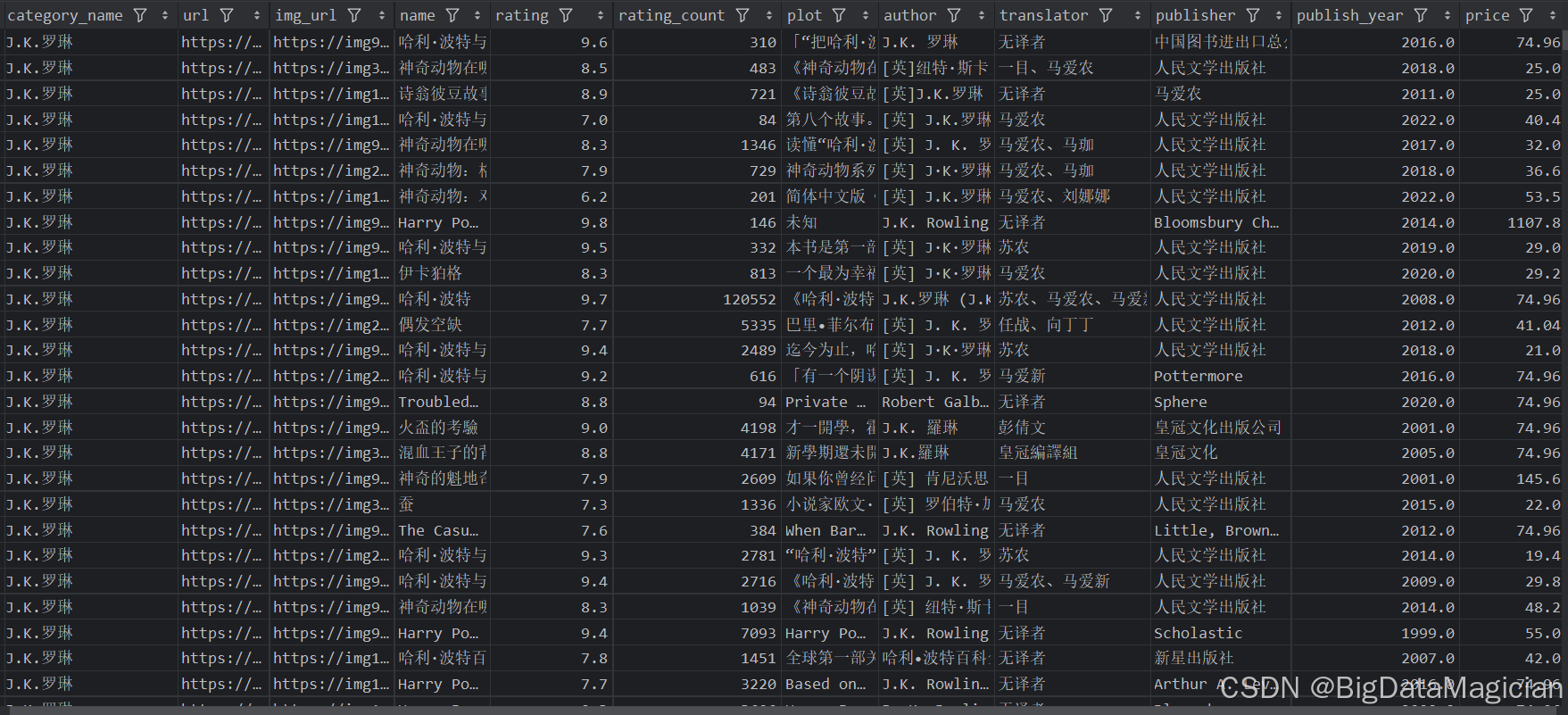
2. 保存数据到CSV文件
def save_to_csv(data, csv_file_path):# 使用 pathlib 处理文件路径path = Path(csv_file_path)# 检查文件所在目录是否存在,如果不存在则创建path.parent.mkdir(parents=True, exist_ok=True)data.to_csv(csv_file_path, index=False, encoding='utf-8-sig', mode='w', header=True)print(f'清洗后的数据已保存到 {csv_file_path} 文件')
3. 保存数据到MySQL数据库
def save_to_mysql(data, table_name):engine = create_engine(f'mysql+mysqlconnector://root:zxcvbq@127.0.0.1:3306/douban')data.to_sql(table_name, con=engine, index=False, if_exists='replace')print(f'清洗后的数据已保存到 {table_name} 表')
二、不同分类统计分析
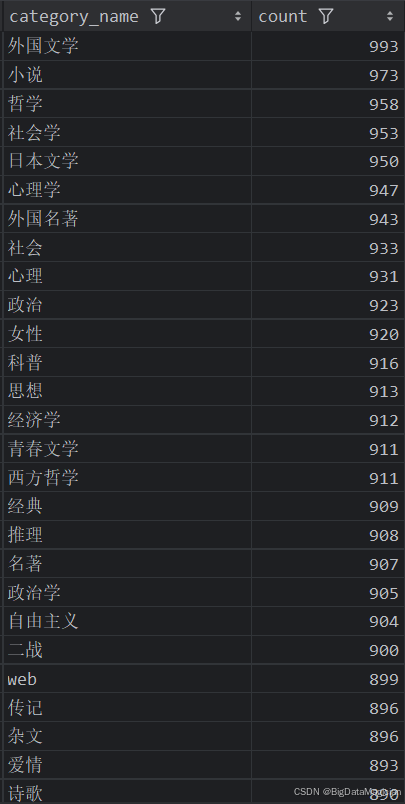
1. 不同分类的图书数量统计分析
def category_count_analysis(data):# 统计每个分类的图书数量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']save_to_csv(category_counts, './结果输出层/数据分析结果数据/分类图书数量统计分析.csv')save_to_mysql(category_counts, '分类图书数量统计分析')
分析结果如下图所示:
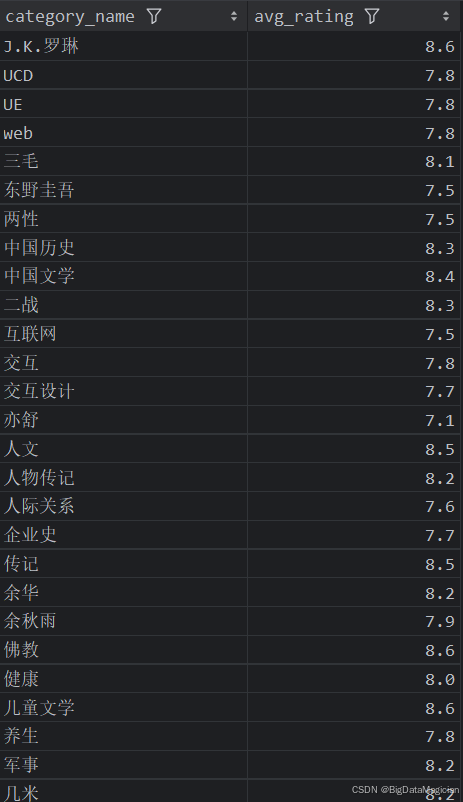
2. 不同分类的平均评分统计分析
def category_rating_analysis(data):# 计算每个分类的平均评分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']save_to_csv(category_ratings, './结果输出层/数据分析结果数据/每个分类的平均评分统计分析.csv')save_to_mysql(category_ratings, '每个分类的平均评分统计分析')
分析结果如下图所示:
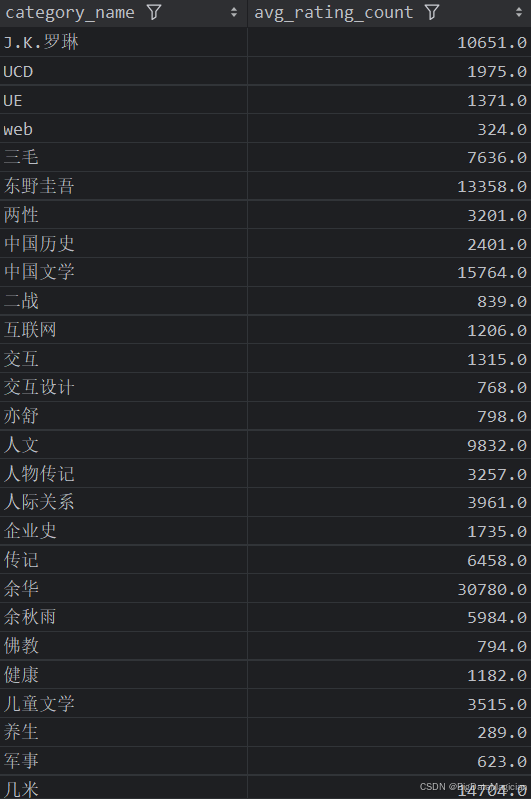
3. 不同分类的平均评价人数统计分析
def category_rating_count_analysis(data):# 计算每个分类的平均评价人数category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']save_to_csv(category_rating_counts, './结果输出层/数据分析结果数据/每个分类的平均评价人数统计分析.csv')save_to_mysql(category_rating_counts, '每个分类的平均评价人数统计分析')
分析结果如下图所示:
4. 不同分类的平均价格统计分析
def category_price_analysis(data):# 计算每个分类的平均价格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']save_to_csv(category_prices, './结果输出层/数据分析结果数据/每个分类的平均价格统计分析.csv')save_to_mysql(category_prices, '每个分类的平均价格统计分析')
分析结果如下图所示:
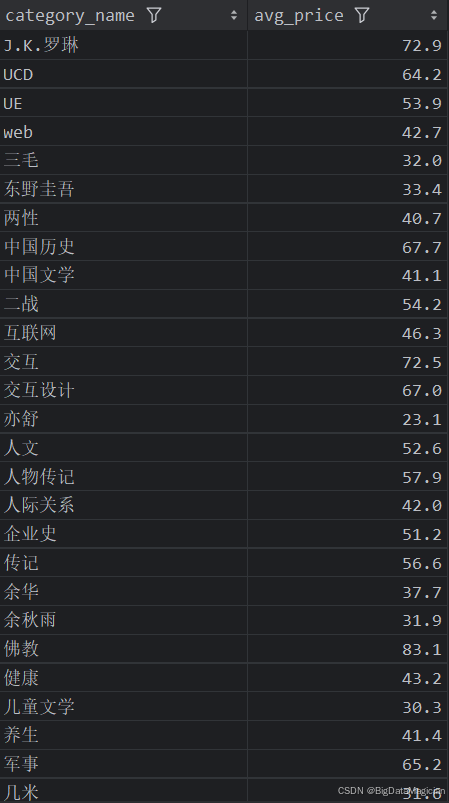
5. 分类综合分析
def category_analysis(data):# 统计每个分类的图书数量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']# 计算每个分类的平均评分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']# 计算每个分类的平均评价人数category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']# 计算每个分类的平均价格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']# 合并四个结果merged_result = pd.merge(category_counts, category_ratings, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_rating_counts, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_prices, on='category_name', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/每种分类的图书数量和平均评分和平均评价人数和平均价格统计分析.csv')save_to_mysql(merged_result, '每种分类的图书数量和平均评分和平均评价人数和平均价格统计分析')
分析结果如下图所示:
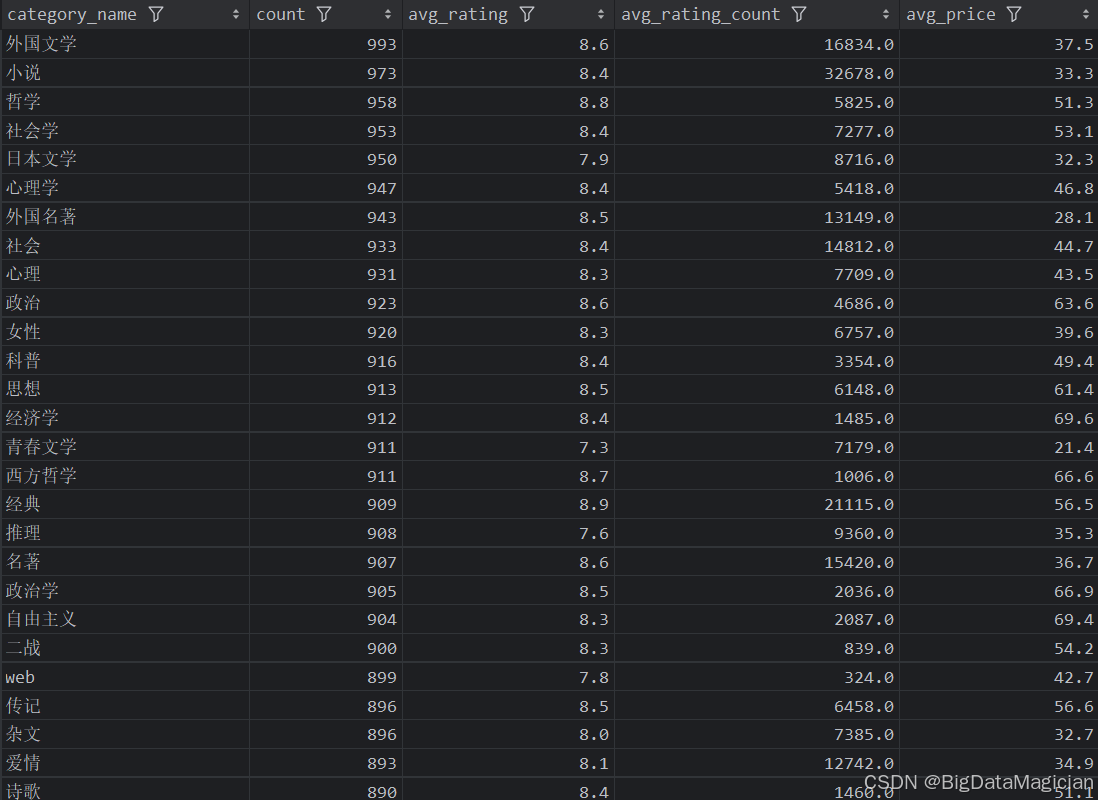
三、不同年份统计分析
1. 不同年份出版的图书数量统计分析
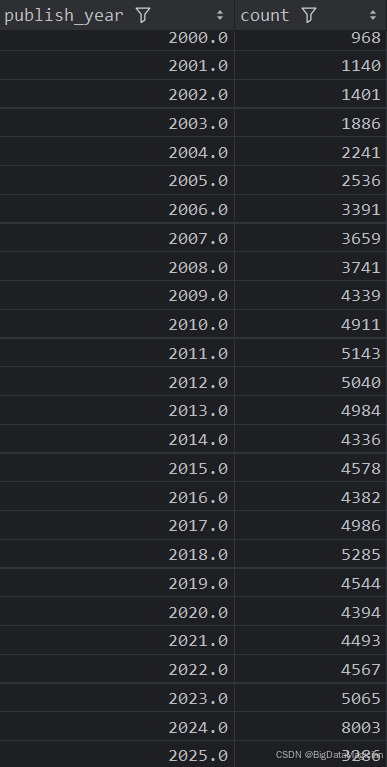
def year_count_analysis(data):# 统计每年出版的图书数量year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()# 按照年份升序排序year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']save_to_csv(year_counts, './结果输出层/数据分析结果数据/每年出版的图书数量统计分析.csv')save_to_mysql(year_counts, '每年出版的图书数量统计分析')
分析结果如下图所示:
2. 不同年份出版的图书平均评分分析
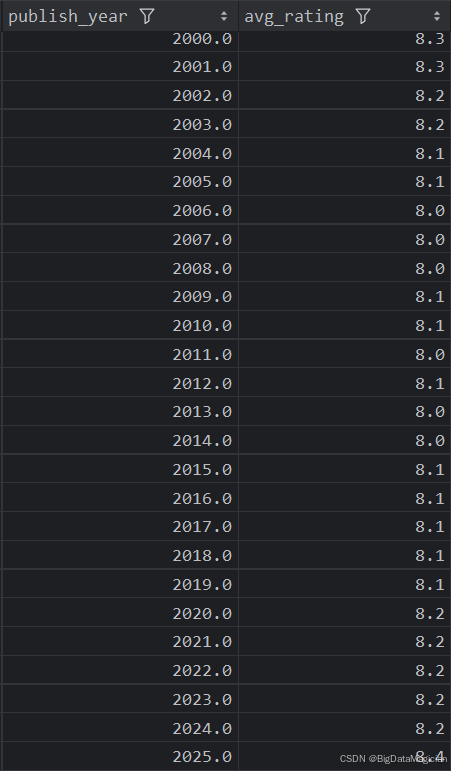
def year_rating_analysis(data):year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']save_to_csv(year_ratings, './结果输出层/数据分析结果数据/每年出版的图书平均评分分析.csv')save_to_mysql(year_ratings, '每年出版的图书平均评分分析')
分析结果如下图所示:
3. 不同年份出版的图书平均评价人数分析
def year_rating_count_analysis(data):year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']save_to_csv(year_rating_counts, './结果输出层/数据分析结果数据/每年出版图书平均评价人数分析.csv')save_to_mysql(year_rating_counts, '每年出版图书平均评价人数分析')
分析结果如下图所示:
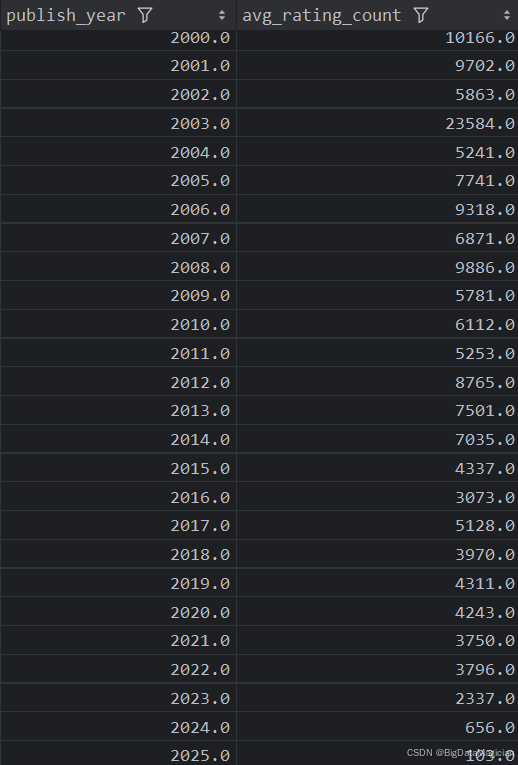
4. 不同年份出版的图书平均价格分析
def year_price_analysis(data):year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')year_prices.columns = ['publish_year', 'avg_price']save_to_csv(year_prices, './结果输出层/数据分析结果数据/每年出版图书平均价格分析.csv')save_to_mysql(year_prices, '每年出版图书平均价格分析')
分析结果如下图所示:
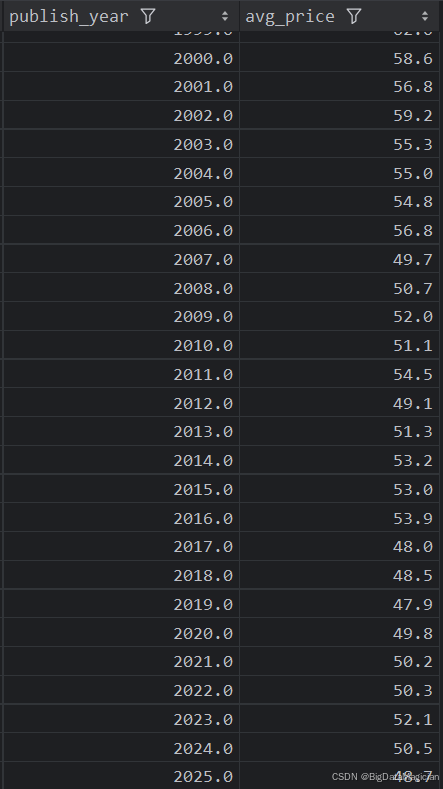
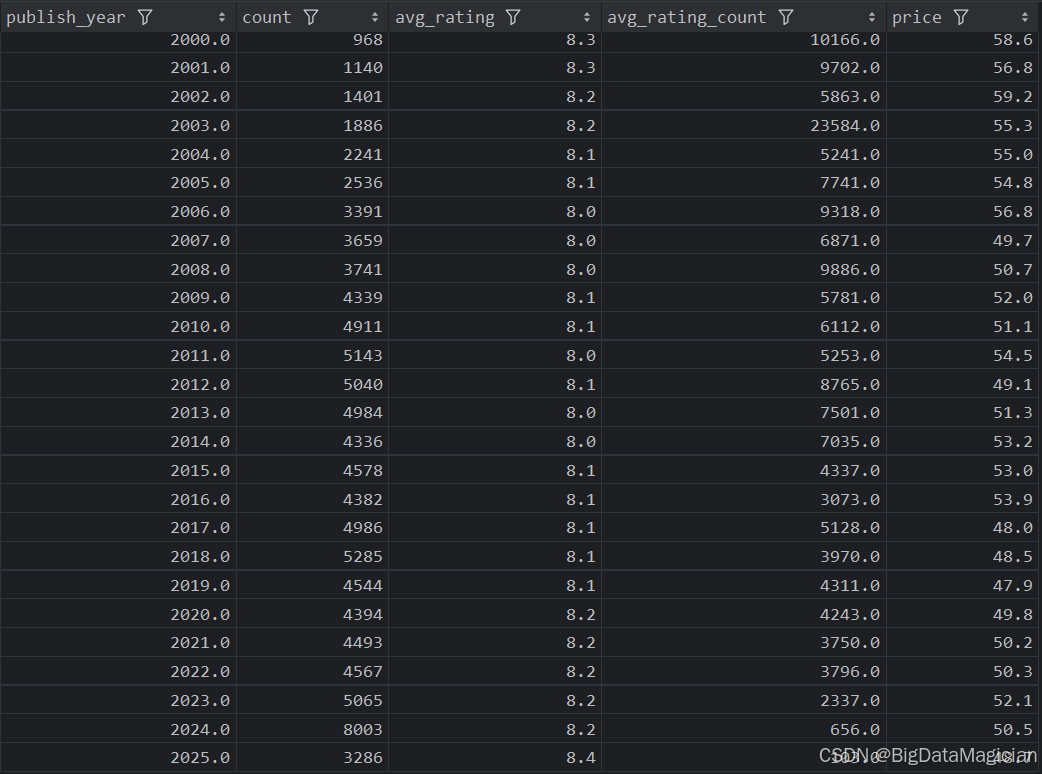
5. 年份综合分析
def year_analysis(data):# 每年出版的图书数量统计分析year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']# 每年出版的图书平均评分分析year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']# 每年出版的图书平均评价人数分析year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']# 每年出版的图书平均价格分析year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')# 合并四个结果merged_result = pd.merge(year_counts, year_ratings, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_rating_counts, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_prices, on='publish_year', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/每年出版图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '每年出版图书数量和平均评分和平均价格和平均评价人数分析')
分析结果如下图所示:
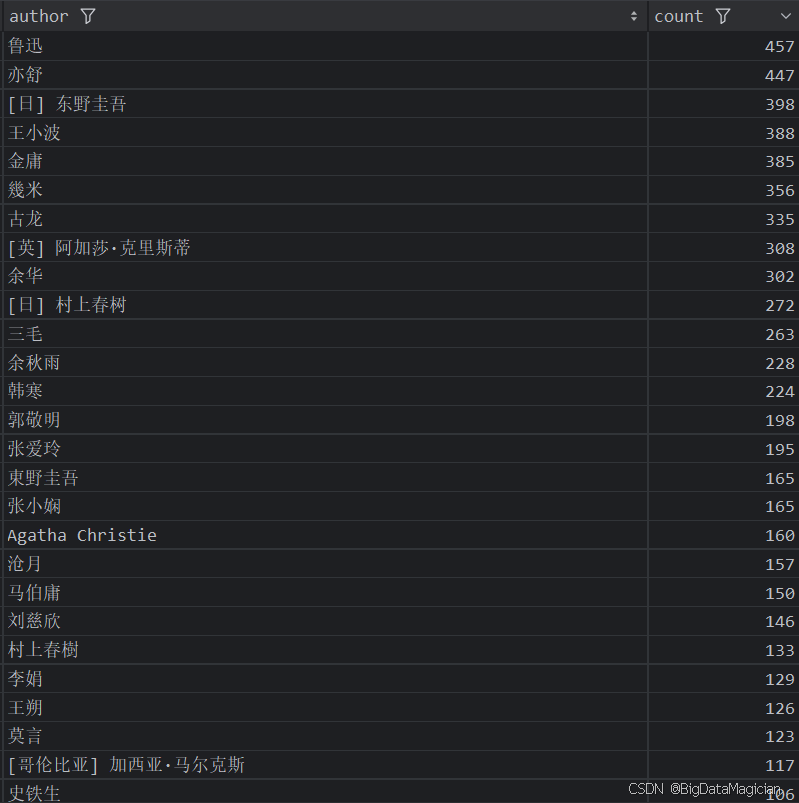
四、不同作者统计分析
1. 不同作者的图书数量统计分析
def author_count_analysis(data):# 统计每个作者的图书数量author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']save_to_csv(author_counts, './结果输出层/数据分析结果数据/作者图书数量统计分析.csv')save_to_mysql(author_counts, '作者图书数量统计分析')
分析结果如下图所示:
2. 不同作者的平均评分分析
def author_rating_analysis(data):# 计算每个作者的平均评分author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']save_to_csv(author_ratings, './结果输出层/数据分析结果数据/作者平均评分分析.csv')save_to_mysql(author_ratings, '作者平均评分分析')
分析结果如下图所示:
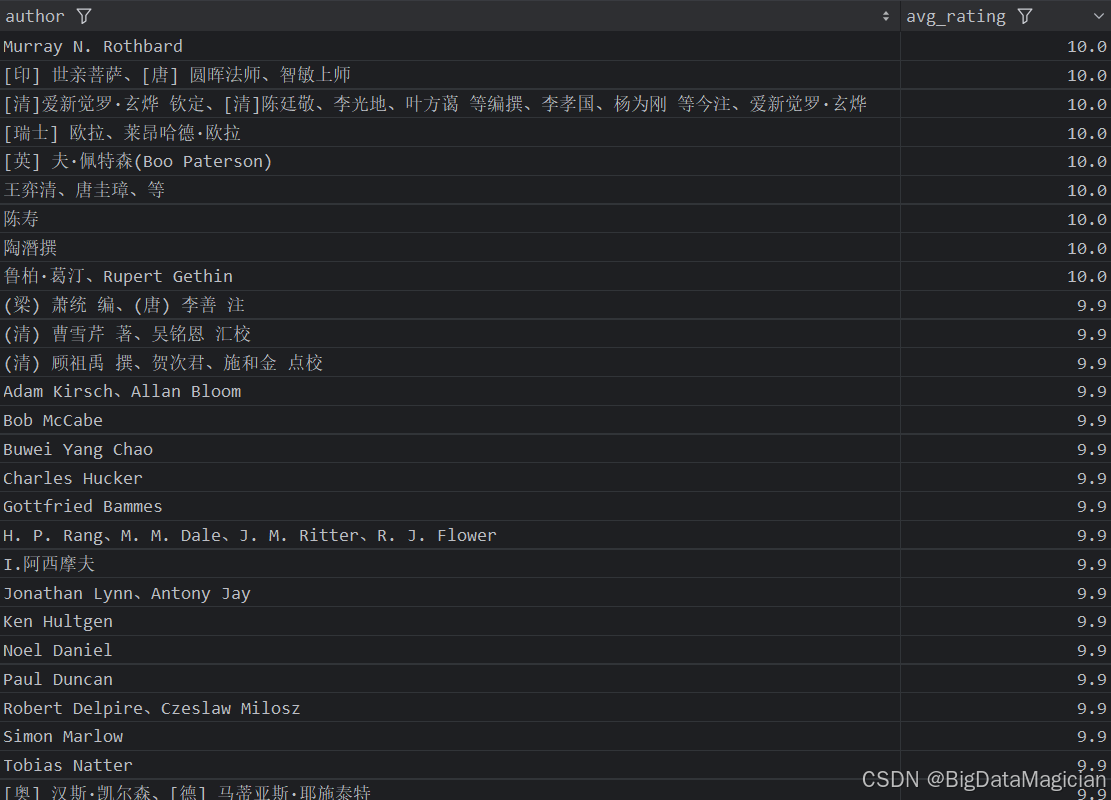
3. 不同作者的平均评价人数分析
def author_rating_count_analysis(data):# 计算每个作者的平均评价人数author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']save_to_csv(author_rating_counts, './结果输出层/数据分析结果数据/作者平均评价人数分析.csv')save_to_mysql(author_rating_counts, '作者平均评价人数分析')
分析结果如下图所示:
4. 不同作者的平均价格分析
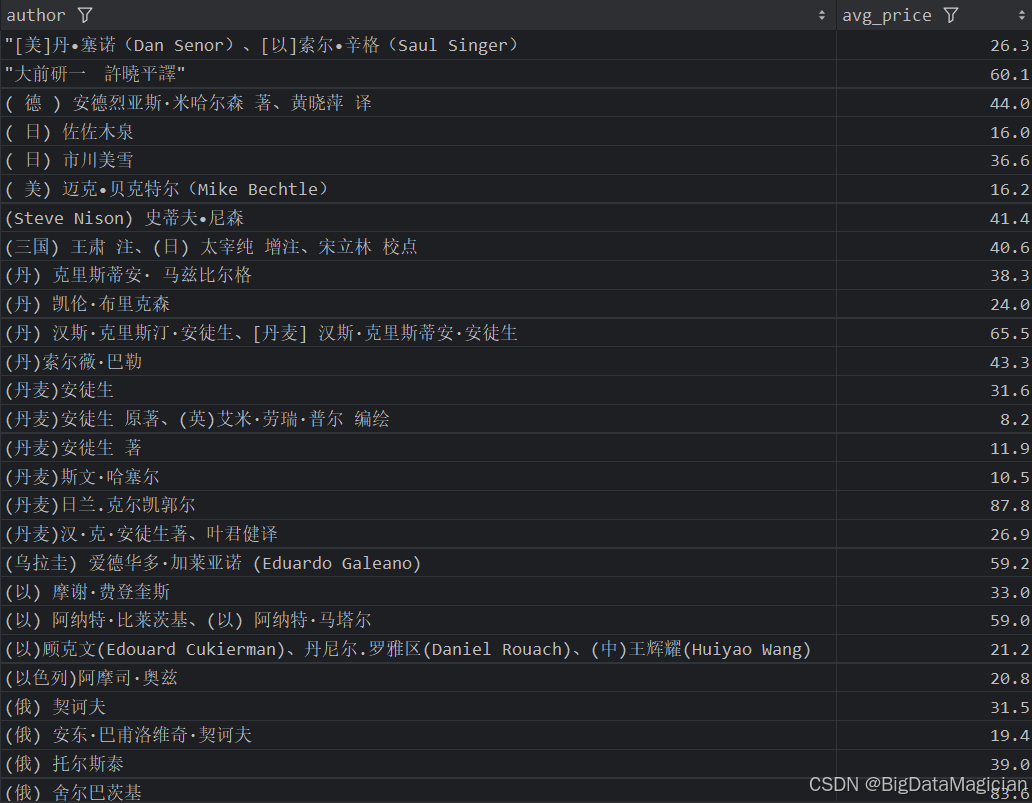
def author_price_analysis(data):# 计算每个作者的平均价格author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']save_to_csv(author_prices, './结果输出层/数据分析结果数据/作者平均价格分析.csv')save_to_mysql(author_prices, '作者平均价格分析')
分析结果如下图所示:
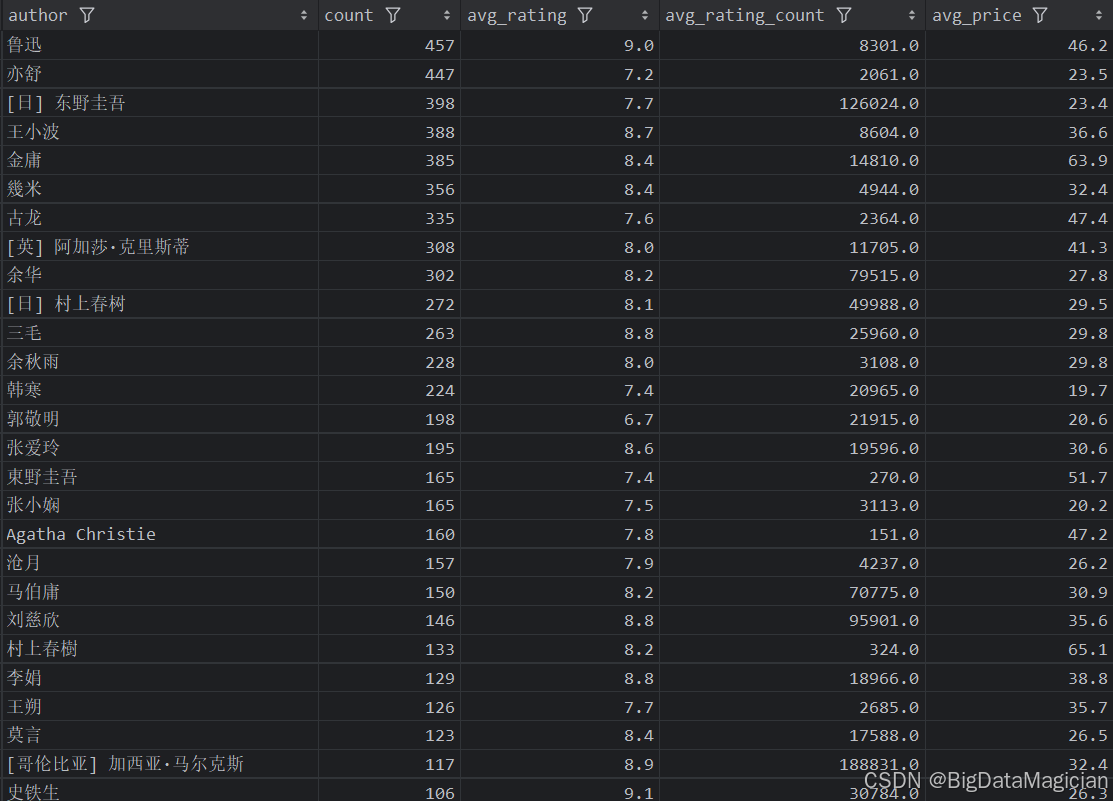
5. 作者综合分析
def author_analysis(data):# 每个作者的图书数量统计分析author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']# 每个作者的平均评分分析author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']# 每个作者的平均评价人数分析author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']# 每个作者的平均价格分析author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']# 合并四个结果merged_result = pd.merge(author_counts, author_ratings, on='author', how='outer')merged_result = pd.merge(merged_result, author_rating_counts, on='author', how='outer')merged_result = pd.merge(merged_result, author_prices, on='author', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/作者图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '作者图书数量和平均评分和平均价格和平均评价人数分析')
分析结果如下图所示:
五、不同出版社分析
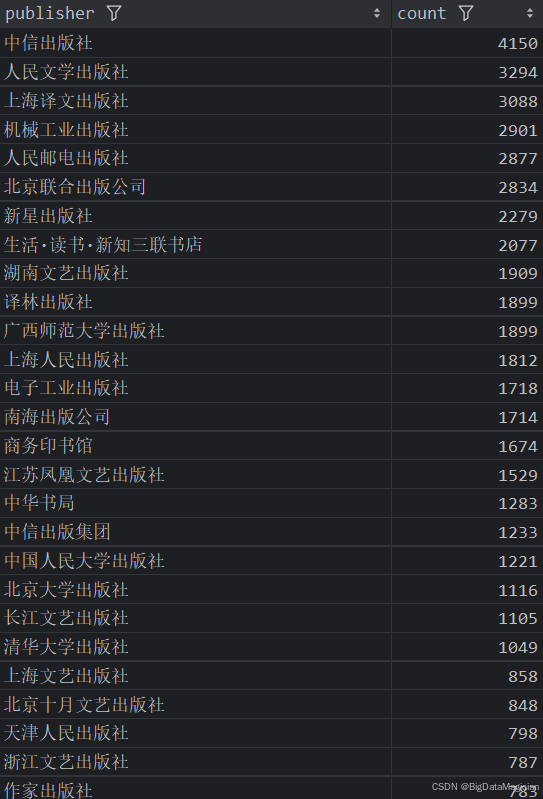
1. 不同出版社的图书数量统计分析
def publish_count_analysis(data):# 统计每个出版社的图书数量publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']save_to_csv(publish_counts, './结果输出层/数据分析结果数据/出版社图书数量统计分析.csv')save_to_mysql(publish_counts, '出版社图书数量统计分析')
分析结果如下图所示:
2. 不同出版社的平均评分分析
def publish_rating_analysis(data):# 计算每个出版社的平均评分publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']save_to_csv(publish_ratings, './结果输出层/数据分析结果数据/出版社平均评分分析.csv')save_to_mysql(publish_ratings, '出版社平均评分分析')
分析结果如下图所示:
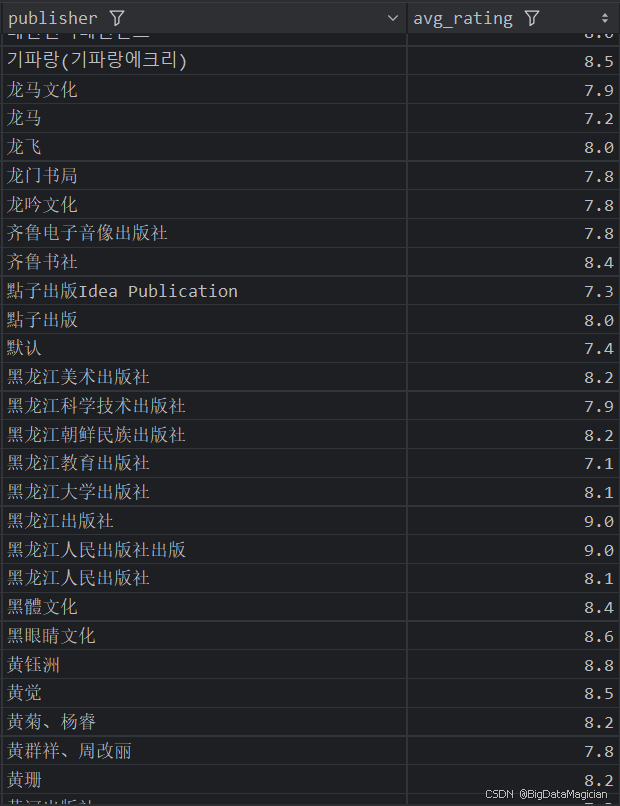
3. 不同出版社的平均评价人数分析
def publish_rating_count_analysis(data):# 计算每个出版社的平均评价人数publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']save_to_csv(publish_rating_counts, './结果输出层/数据分析结果数据/出版社平均评价人数分析.csv')save_to_mysql(publish_rating_counts, '出版社平均评价人数分析')
分析结果如下图所示:
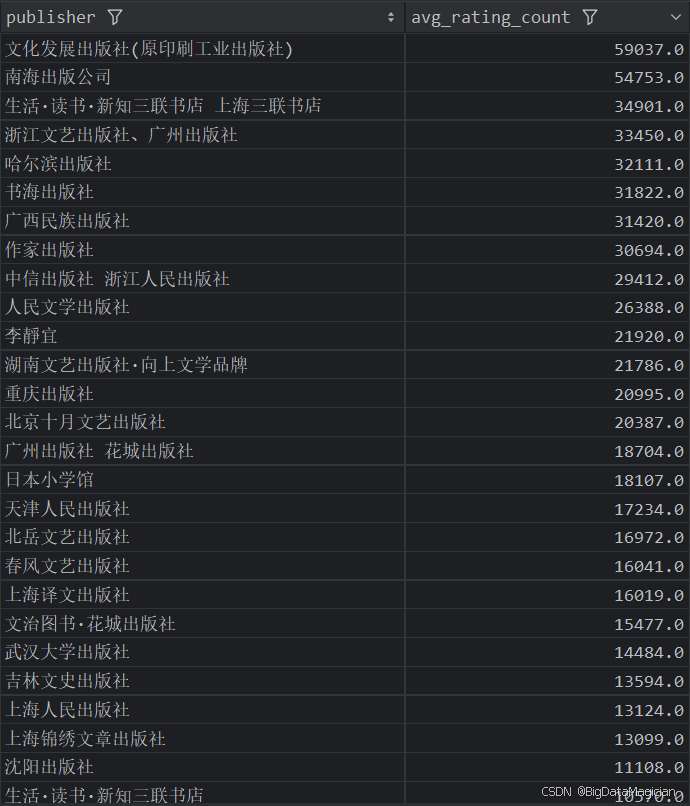
4. 不同出版社的平均价格分析
def publish_price_analysis(data):# 计算每个出版社的平均价格publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']save_to_csv(publish_prices, './结果输出层/数据分析结果数据/出版社平均价格分析.csv')save_to_mysql(publish_prices, '出版社平均价格分析')
分析结果如下图所示:
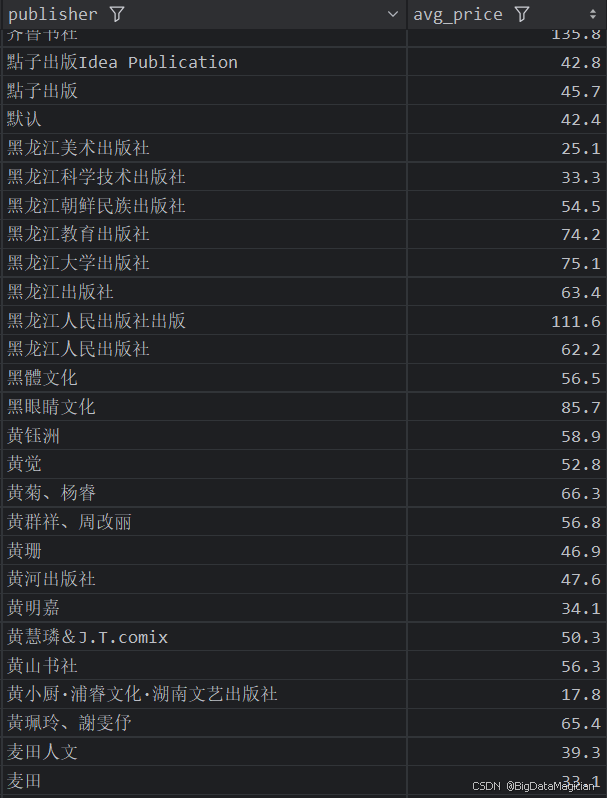
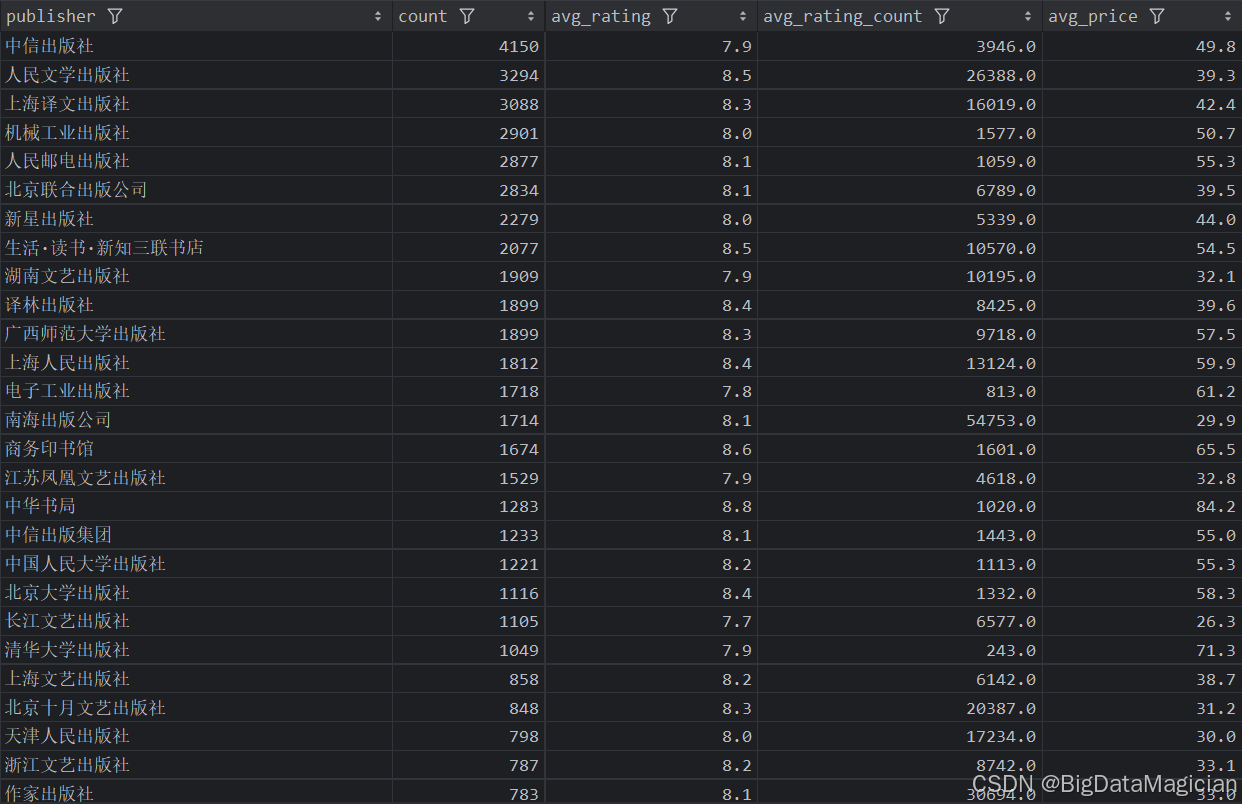
5. 出版社综合分析
def publish_analysis(data):# 每个出版社的图书数量统计分析publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']# 每个出版社的平均评分分析publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']# 每个出版社的平均评价人数分析publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']# 每个出版社的平均价格分析publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']# 合并四个结果merged_result = pd.merge(publish_counts, publish_ratings, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_rating_counts, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_prices, on='publisher', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/出版社图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '出版社图书数量和平均评分和平均价格和平均评价人数分析')
分析结果如下图所示:
六、其他分析
1. 图书评分分布分析
def rating_analysis(data):# 定义评分区间bins = [0, 2, 4, 6, 8, 10]labels = ['0-2', '2-4', '4-6', '6-8', '8-10']# 使用 pd.cut 函数将评分进行分组data['rating_group'] = pd.cut(data['rating'], bins=bins, labels=labels, right=False)# 统计每个评分区间的图书数量rating_counts = data['rating_group'].value_counts()rating_counts = rating_counts.reset_index()rating_counts.columns = ['rating_range', 'count']save_to_csv(rating_counts, './结果输出层/数据分析结果数据/评分分布统计分析.csv')save_to_mysql(rating_counts, '评分分布统计分析')
2. 图书价格分布分析
def price_analysis(data):# 定义价格区间bins = [0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500]labels = ['0-50', '50-100', '100-150', '150-200', '200-250', '250-300', '300-350', '350-400', '400-450', '450-500']# 使用 pd.cut 函数将价格进行分组data['price_group'] = pd.cut(data['price'], bins=bins, labels=labels, right=False)# 统计每个价格区间的图书数量price_counts = data['price_group'].value_counts()price_counts = price_counts.reset_index()price_counts.columns = ['price_range', 'count']save_to_csv(price_counts, './结果输出层/数据分析结果数据/图书价格分布统计分析.csv')save_to_mysql(price_counts, '图书价格分布统计分析')
3. 译者翻译的图书数量统计分析(前15)
def translator_count_analysis(data):# 统计每个译者的图书数量translator_counts = data['translator'].value_counts()translator_counts = translator_counts.reset_index()translator_counts.columns = ['translator', 'count']translator_counts = translator_counts.sort_values(by='count', ascending=False)translator_counts = translator_counts.head(15)save_to_csv(translator_counts, './结果输出层/数据分析结果数据/译者图书数量统计分析.csv')save_to_mysql(translator_counts, '译者图书数量统计分析')
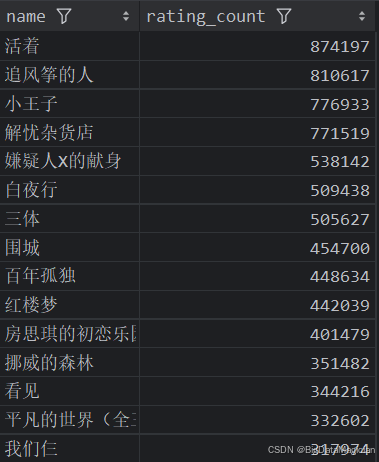
4. 评价人数多的图书分析(前15)
def high_rating_count_books_analysis(data):high_rating_count_books = data[['name', 'rating_count']]high_rating_count_books = high_rating_count_books.sort_values(by='rating_count', ascending=False)high_rating_count_books = high_rating_count_books.drop_duplicates(subset=['name'])high_rating_count_books = high_rating_count_books.head(15)save_to_csv(high_rating_count_books, './结果输出层/数据分析结果数据/评价人数多的图书分析.csv')save_to_mysql(high_rating_count_books, '评价人数多的图书分析')
分析结果如下图所示:
5. 评分最高的图书分析(前15)
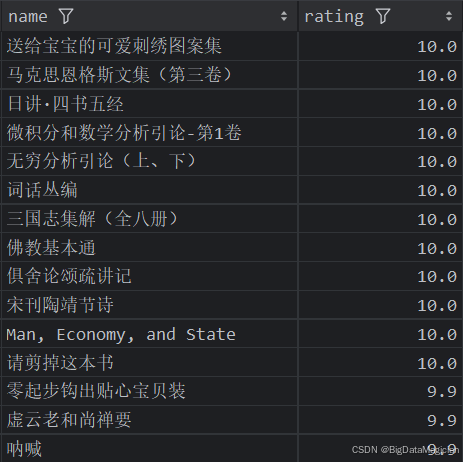
def high_rating_books_analysis(data):high_rating_books = data[['name', 'rating']]high_rating_books = high_rating_books.sort_values(by='rating', ascending=False)high_rating_books = high_rating_books.drop_duplicates(subset=['name'])high_rating_books = high_rating_books.head(15)save_to_csv(high_rating_books, './结果输出层/数据分析结果数据/评分最高的图书分析.csv')save_to_mysql(high_rating_books, '评分最高的图书分析')
分析结果如下图所示:
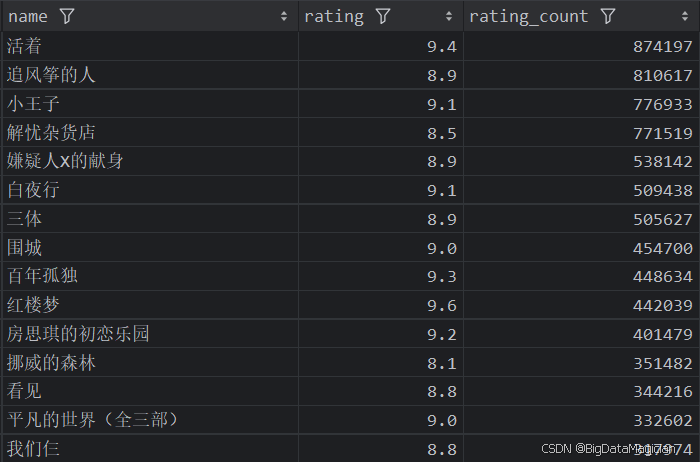
6. 评价人数最多且评分高的图书分析(前15)
def high_rating_and_rating_count_books_analysis(data):high_rating_and_rating_count_books = data[['name', 'rating', 'rating_count']]high_rating_and_rating_count_books = high_rating_and_rating_count_books.sort_values(by=['rating_count', 'rating'], ascending=False)high_rating_and_rating_count_books = high_rating_and_rating_count_books.drop_duplicates(subset=['name'])high_rating_and_rating_count_books = high_rating_and_rating_count_books.head(15)save_to_csv(high_rating_and_rating_count_books, './结果输出层/数据分析结果数据/评分高且评价人数最多的图书分析.csv')save_to_mysql(high_rating_and_rating_count_books, '评分高且评价人数最多的图书分析')
分析结果如下图所示:
七、完整代码
from pathlib import Pathimport pandas as pd
from matplotlib import pyplot as plt
from sqlalchemy import create_engine# 设置支持中文的字体,这里以黑体为例
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题def load_data(csv_file_path):try:data = pd.read_csv(csv_file_path)return dataexcept FileNotFoundError:print("未找到指定的 CSV 文件,请检查文件路径和文件名。")except Exception as e:print(f"加载数据时出现错误: {e}")# 保存分析后的数据为csv文件
def save_to_csv(data, csv_file_path):# 使用 pathlib 处理文件路径path = Path(csv_file_path)# 检查文件所在目录是否存在,如果不存在则创建path.parent.mkdir(parents=True, exist_ok=True)data.to_csv(csv_file_path, index=False, encoding='utf-8-sig', mode='w', header=True)print(f'清洗后的数据已保存到 {csv_file_path} 文件')# 保存分析后的数据到MySQL数据库
def save_to_mysql(data, table_name):engine = create_engine(f'mysql+mysqlconnector://root:zxcvbq@127.0.0.1:3306/douban')data.to_sql(table_name, con=engine, index=False, if_exists='replace')print(f'清洗后的数据已保存到 {table_name} 表')# 每种分类图书数量统计分析
def category_count_analysis(data):# 统计每个分类的图书数量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']save_to_csv(category_counts, './结果输出层/数据分析结果数据/分类图书数量统计分析.csv')save_to_mysql(category_counts, '分类图书数量统计分析')# 每种分类的平均评分统计分析
def category_rating_analysis(data):# 计算每个分类的平均评分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']save_to_csv(category_ratings, './结果输出层/数据分析结果数据/每个分类的平均评分统计分析.csv')save_to_mysql(category_ratings, '每个分类的平均评分统计分析')# 每种分类的平均评价人数统计分析
def category_rating_count_analysis(data):# 计算每个分类的平均评价人数category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']save_to_csv(category_rating_counts, './结果输出层/数据分析结果数据/每个分类的平均评价人数统计分析.csv')save_to_mysql(category_rating_counts, '每个分类的平均评价人数统计分析')# 每种分类的平均价格统计分析
def category_price_analysis(data):# 计算每个分类的平均价格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']save_to_csv(category_prices, './结果输出层/数据分析结果数据/每个分类的平均价格统计分析.csv')save_to_mysql(category_prices, '每个分类的平均价格统计分析')# 每种分类的图书数量、平均评分、平均价格和平均评价人数统计分析
def category_analysis(data):# 统计每个分类的图书数量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']# 计算每个分类的平均评分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']# 计算每个分类的平均评价人数category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']# 计算每个分类的平均价格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']# 合并四个结果merged_result = pd.merge(category_counts, category_ratings, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_rating_counts, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_prices, on='category_name', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/每种分类的图书数量和平均评分和平均评价人数和平均价格统计分析.csv')save_to_mysql(merged_result, '每种分类的图书数量和平均评分和平均评价人数和平均价格统计分析')# 每年出版的图书数量统计分析
def year_count_analysis(data):# 统计每年出版的图书数量year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()# 按照年份升序排序year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']save_to_csv(year_counts, './结果输出层/数据分析结果数据/每年出版的图书数量统计分析.csv')save_to_mysql(year_counts, '每年出版的图书数量统计分析')# 每年出版的图书平均评分分析
def year_rating_analysis(data):year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']save_to_csv(year_ratings, './结果输出层/数据分析结果数据/每年出版的图书平均评分分析.csv')save_to_mysql(year_ratings, '每年出版的图书平均评分分析')# 每年出版图书平均评价人数分析
def year_rating_count_analysis(data):year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']save_to_csv(year_rating_counts, './结果输出层/数据分析结果数据/每年出版图书平均评价人数分析.csv')save_to_mysql(year_rating_counts, '每年出版图书平均评价人数分析')# 每年出版图书平均价格分析
def year_price_analysis(data):year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')year_prices.columns = ['publish_year', 'avg_price']save_to_csv(year_prices, './结果输出层/数据分析结果数据/每年出版图书平均价格分析.csv')save_to_mysql(year_prices, '每年出版图书平均价格分析')# 每年出版图书数量、平均评分、平均价格和平均评价人数分析
def year_analysis(data):# 每年出版的图书数量统计分析year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']# 每年出版的图书平均评分分析year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']# 每年出版的图书平均评价人数分析year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']# 每年出版的图书平均价格分析year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')# 合并四个结果merged_result = pd.merge(year_counts, year_ratings, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_rating_counts, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_prices, on='publish_year', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/每年出版图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '每年出版图书数量和平均评分和平均价格和平均评价人数分析')# 每个作者的图书数量统计分析
def author_count_analysis(data):# 统计每个作者的图书数量author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']save_to_csv(author_counts, './结果输出层/数据分析结果数据/作者图书数量统计分析.csv')save_to_mysql(author_counts, '作者图书数量统计分析')# 每个作者的平均评分分析
def author_rating_analysis(data):# 计算每个作者的平均评分author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']save_to_csv(author_ratings, './结果输出层/数据分析结果数据/作者平均评分分析.csv')save_to_mysql(author_ratings, '作者平均评分分析')# 每个作者的平均评价人数分析
def author_rating_count_analysis(data):# 计算每个作者的平均评价人数author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']save_to_csv(author_rating_counts, './结果输出层/数据分析结果数据/作者平均评价人数分析.csv')save_to_mysql(author_rating_counts, '作者平均评价人数分析')# 每个作者的平均价格分析
def author_price_analysis(data):# 计算每个作者的平均价格author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']save_to_csv(author_prices, './结果输出层/数据分析结果数据/作者平均价格分析.csv')save_to_mysql(author_prices, '作者平均价格分析')# 每个作者的图书数量、平均评分、平均价格和平均评价人数分析
def author_analysis(data):# 每个作者的图书数量统计分析author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']# 每个作者的平均评分分析author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']# 每个作者的平均评价人数分析author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']# 每个作者的平均价格分析author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']# 合并四个结果merged_result = pd.merge(author_counts, author_ratings, on='author', how='outer')merged_result = pd.merge(merged_result, author_rating_counts, on='author', how='outer')merged_result = pd.merge(merged_result, author_prices, on='author', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/作者图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '作者图书数量和平均评分和平均价格和平均评价人数分析')# 每个出版社的图书数量统计分析
def publish_count_analysis(data):# 统计每个出版社的图书数量publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']save_to_csv(publish_counts, './结果输出层/数据分析结果数据/出版社图书数量统计分析.csv')save_to_mysql(publish_counts, '出版社图书数量统计分析')# 每个出版社的平均评分分析
def publish_rating_analysis(data):# 计算每个出版社的平均评分publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']save_to_csv(publish_ratings, './结果输出层/数据分析结果数据/出版社平均评分分析.csv')save_to_mysql(publish_ratings, '出版社平均评分分析')# 每个出版社的平均评价人数分析
def publish_rating_count_analysis(data):# 计算每个出版社的平均评价人数publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']save_to_csv(publish_rating_counts, './结果输出层/数据分析结果数据/出版社平均评价人数分析.csv')save_to_mysql(publish_rating_counts, '出版社平均评价人数分析')# 每个出版社的平均价格分析
def publish_price_analysis(data):# 计算每个出版社的平均价格publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']save_to_csv(publish_prices, './结果输出层/数据分析结果数据/出版社平均价格分析.csv')save_to_mysql(publish_prices, '出版社平均价格分析')# 每个出版社的图书数量、平均评分、平均价格和平均评价人数分析
def publish_analysis(data):# 每个出版社的图书数量统计分析publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']# 每个出版社的平均评分分析publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']# 每个出版社的平均评价人数分析publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']# 每个出版社的平均价格分析publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']# 合并四个结果merged_result = pd.merge(publish_counts, publish_ratings, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_rating_counts, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_prices, on='publisher', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/出版社图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '出版社图书数量和平均评分和平均价格和平均评价人数分析')# 评分分布分析
def rating_analysis(data):# 定义评分区间bins = [0, 2, 4, 6, 8, 10]labels = ['0-2', '2-4', '4-6', '6-8', '8-10']# 使用 pd.cut 函数将评分进行分组data['rating_group'] = pd.cut(data['rating'], bins=bins, labels=labels, right=False)# 统计每个评分区间的图书数量rating_counts = data['rating_group'].value_counts()rating_counts = rating_counts.reset_index()rating_counts.columns = ['rating_range', 'count']save_to_csv(rating_counts, './结果输出层/数据分析结果数据/评分分布统计分析.csv')save_to_mysql(rating_counts, '评分分布统计分析')# 图书价格分布分析
def price_analysis(data):# 定义价格区间bins = [0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500]labels = ['0-50', '50-100', '100-150', '150-200', '200-250', '250-300', '300-350', '350-400', '400-450', '450-500']# 使用 pd.cut 函数将价格进行分组data['price_group'] = pd.cut(data['price'], bins=bins, labels=labels, right=False)# 统计每个价格区间的图书数量price_counts = data['price_group'].value_counts()price_counts = price_counts.reset_index()price_counts.columns = ['price_range', 'count']save_to_csv(price_counts, './结果输出层/数据分析结果数据/图书价格分布统计分析.csv')save_to_mysql(price_counts, '图书价格分布统计分析')# 译者翻译的图书数量统计分析(前15)
def translator_count_analysis(data):# 统计每个译者的图书数量translator_counts = data['translator'].value_counts()translator_counts = translator_counts.reset_index()translator_counts.columns = ['translator', 'count']translator_counts = translator_counts.sort_values(by='count', ascending=False)translator_counts = translator_counts.head(15)save_to_csv(translator_counts, './结果输出层/数据分析结果数据/译者图书数量统计分析.csv')save_to_mysql(translator_counts, '译者图书数量统计分析')# 价格、评分、评分人数和出版年份相关性分析
def correlation_analysis(data):# 计算价格、评分、评分人数和出版年份之间的相关性correlation = data[['price', 'rating', 'rating_count', 'publish_year']].corr()correlation = correlation.reset_index()# 保存统计结果到 CSV 文件save_to_csv(correlation, './结果输出层/数据分析结果数据/价格、评分、评分人数和出版年份相关性分析.csv')save_to_mysql(correlation, '价格、评分、评分人数和出版年份相关性分析')# 评价人数多的图书分析(前15)
def high_rating_count_books_analysis(data):high_rating_count_books = data[['name', 'rating_count']]high_rating_count_books = high_rating_count_books.sort_values(by='rating_count', ascending=False)high_rating_count_books = high_rating_count_books.drop_duplicates(subset=['name'])high_rating_count_books = high_rating_count_books.head(15)save_to_csv(high_rating_count_books, './结果输出层/数据分析结果数据/评价人数多的图书分析.csv')save_to_mysql(high_rating_count_books, '评价人数多的图书分析')# 评分最高的图书分析(前15)
def high_rating_books_analysis(data):high_rating_books = data[['name', 'rating']]high_rating_books = high_rating_books.sort_values(by='rating', ascending=False)high_rating_books = high_rating_books.drop_duplicates(subset=['name'])high_rating_books = high_rating_books.head(15)save_to_csv(high_rating_books, './结果输出层/数据分析结果数据/评分最高的图书分析.csv')save_to_mysql(high_rating_books, '评分最高的图书分析')# 评分高且评价人数最多的图书(前15)
def high_rating_and_rating_count_books_analysis(data):high_rating_and_rating_count_books = data[['name', 'rating', 'rating_count']]high_rating_and_rating_count_books = high_rating_and_rating_count_books.sort_values(by=['rating_count', 'rating'], ascending=False)high_rating_and_rating_count_books = high_rating_and_rating_count_books.drop_duplicates(subset=['name'])high_rating_and_rating_count_books = high_rating_and_rating_count_books.head(15)save_to_csv(high_rating_and_rating_count_books, './结果输出层/数据分析结果数据/评分高且评价人数最多的图书分析.csv')save_to_mysql(high_rating_and_rating_count_books, '评分高且评价人数最多的图书分析')if __name__ == '__main__':# 加载数据data = load_data('./中间处理层/清洗后的豆瓣图书数据集.csv')category_count_analysis(data)category_rating_analysis(data)category_rating_count_analysis(data)category_price_analysis(data)category_analysis(data)year_count_analysis(data)year_rating_analysis(data)year_rating_count_analysis(data)year_price_analysis(data)year_analysis(data)author_count_analysis(data)author_rating_analysis(data)author_rating_count_analysis(data)author_price_analysis(data)author_analysis(data)publish_count_analysis(data)publish_rating_analysis(data)publish_rating_count_analysis(data)publish_price_analysis(data)publish_analysis(data)rating_analysis(data)price_analysis(data)translator_count_analysis(data)correlation_analysis(data)high_rating_count_books_analysis(data)high_rating_books_analysis(data)high_rating_and_rating_count_books_analysis(data)
相关文章:
豆瓣图书数据采集与可视化分析(三)- 豆瓣图书数据统计分析
文章目录 前言一、数据读取与保存1. 读取清洗后数据2. 保存数据到CSV文件3. 保存数据到MySQL数据库 二、不同分类统计分析1. 不同分类的图书数量统计分析2. 不同分类的平均评分统计分析3. 不同分类的平均评价人数统计分析4. 不同分类的平均价格统计分析5. 分类综合分析 三、不同…...

聊透多线程编程-线程互斥与同步-13. C# Mutex类实现线程互斥
目录 一、什么是临界区? 二、Mutex类简介 三、Mutex的基本用法 解释: 四、Mutex的工作原理 五、使用示例1-保护共享资源 解释: 六、使用示例2-跨进程同步 示例场景 1. 进程A - 主进程 2. 进程B - 第二个进程 输出结果 ProcessA …...
)
Sql刷题日志(day5)
面试: 1、从数据分析角度,推荐模块怎么用指标衡量? 推荐模块主要目的是将用户进行转化,所以其主指标是推荐的转化率推荐模块的指标一般都通过埋点去收集用户的行为并完成相应的计算而形成相应的指标数据,而这里的驱动…...

【Test】单例模式❗
文章目录 1. 单例模式2. 单例模式简单示例3. 懒汉模式4. 饿汉模式5. 懒汉式和饿汉式的区别 1. 单例模式 🐧定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点。 单例模式是一种常用的软件设计模式,在它的核心结构中只包…...

c++进阶——类与继承
文章目录 继承继承的基本概念继承的基本定义继承方式继承的一些注意事项 继承类模板 基类和派生类之间的转换继承中的作用域派生类的默认成员函数默认构造函数拷贝构造赋值重载析构函数默认成员函数总结 不能被继承的类继承和友元继承与静态成员多继承及其菱形继承问题继承模型…...

虚拟滚动;懒加载;高并发组件
虚拟滚动的实现 思路:它只渲染当前可视区域内的元素,而不是整个列表,滚动时计算出应该显示哪些元素 原生JS class VirtualScroll {constructor(container, items, itemHeight, renderItem) {this.container container;this.items items;t…...

复杂地形越野机器人导航新突破!VERTIFORMER:数据高效多任务Transformer助力越野机器人移动导航
作者: Mohammad Nazeri 1 ^{1} 1, Anuj Pokhrel 1 ^{1} 1, Alexandyr Card 1 ^{1} 1, Aniket Datar 1 ^{1} 1, Garrett Warnell 2 , 3 ^{2,3} 2,3, Xuesu Xiao 1 ^{1} 1单位: 1 ^{1} 1乔治梅森大学计算机科学系, 2 ^{2} 2美国陆军研究实验室&…...

Jsp技术入门指南【十】IDEA 开发环境下实现 MySQL 数据在 JSP 页面的可视化展示,实现前后端交互
Jsp技术入门指南【十】IDEA 开发环境下实现 MySQL 数据在 JSP 页面的可视化展示,实现前后端交互 前言一、JDBC 核心接口和类:数据库连接的“工具箱”1. 常用的 2 个“关键类”2. 必须掌握的 5 个“核心接口” 二、创建 JDBC 程序的步骤1. 第一步…...

数据库未正常关闭后,再次启动时只有主进程,数据库日志无输出
瀚高数据库 目录 环境 症状 问题原因 解决方案 环境 系统平台:银河麒麟svs(X86_64) 版本:4.5.8 症状 现象:使用pg_ctl stop停止数据库,未正常关闭;使用pg_ctl stop -m i 强制关闭数据库后&…...
)
【信息系统项目管理师】高分论文:论成本管理与采购管理(信用管理系统)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 论文1、规划成本管理2、成本估算3、成本预算4、成本控制论文 2019年1月,我作为项目经理参与了 XX基金管理有限公司信用管理系统项目。该项目成 本1000万,建设期为1年。通过该项目,XX基金管理有限公司在信用…...
Oracle Recovery Tools修复ORA-00742、ORA-600 ktbair2: illegal inheritance故障
接到客户反馈,一套运行在虚拟化平台中的Oracle数据库,由于机房断电,导致数据库无法启动,最初启动报错 2025-04-22T16:59:48.92222708:00 Completed: alter database mount exclusive alter database open 2025-04-22T16:59:52.60972608:00 Ping without log force is disabled:…...

基于 Netmiko 的网络设备自动化操作
学习目标 掌握 Netmiko 库的核心功能与使用场景。能够通过 Netmiko 连接多厂商设备并执行命令和配置。实现批量设备管理、配置备份与自动化巡检。掌握异常处理、日志记录与性能优化技巧。理解 Netmiko 在自动化运维体系中的角色。 1. Netmiko 简介 1.1 什么是 Netmiko Netmi…...
)
玉米产量遥感估产系统的开发实践(持续迭代与更新)
项目地址:项目首页 - maize_yield_estimation:玉米估产的flaskvue项目 - GitCode 开发中,敬请期待。。。 以下是预先写的提纲,准备慢慢补充 一、项目背景与工程目标 业务需求分析 农业遥感估产的行业痛点(数据分散、模型精度不足…...
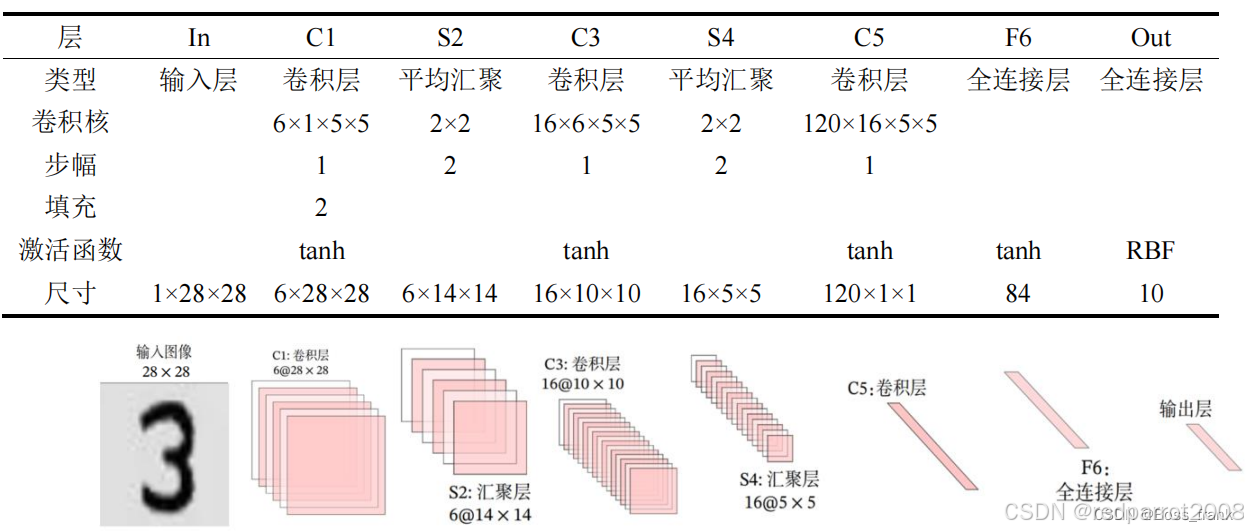
LeNet5 神经网络的参数解析和图片尺寸解析
1.LeNet-5 神经网络 以下是针对 LeNet-5 神经网络的详细参数解析和图片尺寸变化分析,和原始论文设计,通过分步计算说明各层的张量变换过程。 经典的 LeNet-5架构简化版(原始论文输入为 32x32,MNIST 常用 28x28 需调整)…...

Axure大屏可视化模板:多领域数据决策的新引擎
在数据驱动决策的时代,Axure大屏可视化模板凭借交互性与可定制性,成为农业、园区管理、智慧城市、企业及医疗领域的创新工具,助力高效数据展示与智能决策。 核心应用场景 1. 农业精细化:实时监控土壤湿度、作物生长曲线&#x…...

大内存生产环境tomcat-jvm配置实践
话不多讲,奉上代码,分享经验,交流提高! 64G物理内存,8核CPU生产环境tomcat-jvm配置如下: JAVA_OPTS-server -XX:MaxMetaspaceSize4G -XX:ReservedCodeCacheSize2G -XX:UseG1GC -Xms48G -Xmx48G -XX:MaxGCPauseMilli…...
)
APP和小程序需要注册域名吗?(国科云)
在移动互联网时代,APP和小程序已成为企业和个人提供服务、展示产品的重要渠道。那么APP和小程序的兴起是否对域名造成了冲击,APP和小程序是否需要注册域名呢? APP是否需要注册域名? 从技术上讲,没有域名的APP仍然可以…...
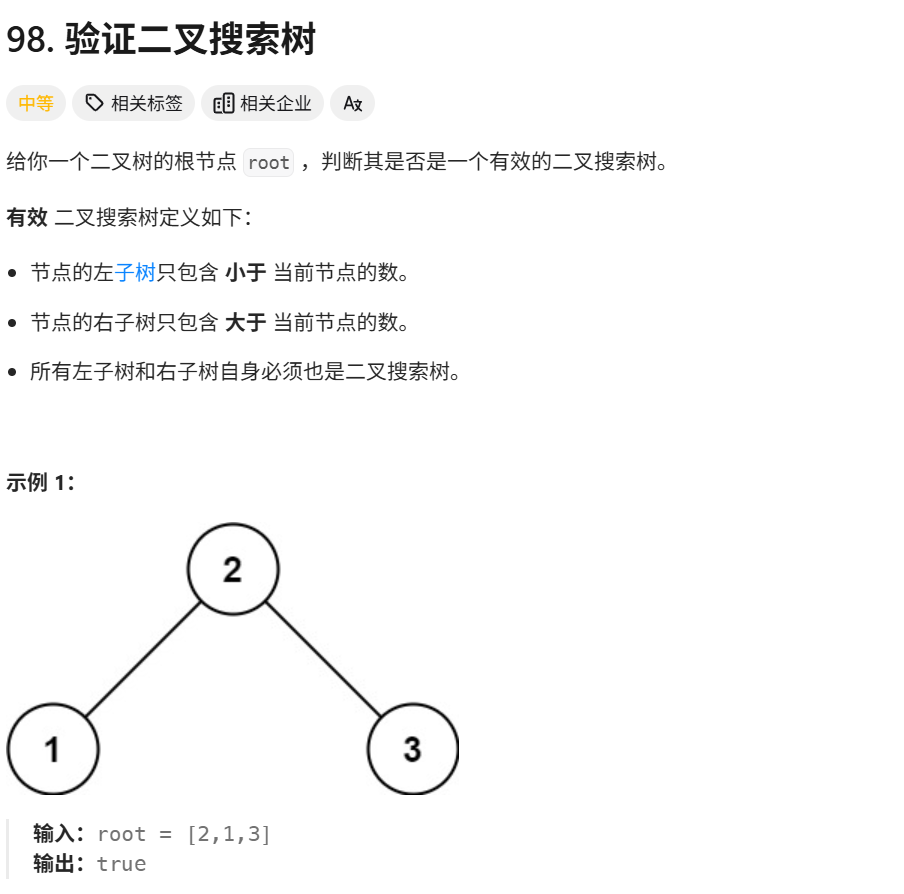
代码随想录算法训练营第60期第十七天打卡
今天我们继续进入二叉树的下一个章节,今天的内容我在写今天的博客前大致看了一下部分题目难度不算大,那我们就进入今天的题目。 第一题对应力扣编号为654的题目最大二叉树 这道题目的坑相当多,我第一次题目没有看明白就是我不知道到底是如何…...
)
小刚说C语言刷题——1565成绩(score)
1.题目描述 牛牛最近学习了 C 入门课程,这门课程的总成绩计算方法是: 总成绩作业成绩 20% 小测成绩 30% 期末考试成绩 50%。 牛牛想知道,这门课程自己最终能得到多少分。 输入 三个非负整数 A、B、C ,分别表示牛牛的作业成…...
SOC估算:开路电压修正的安时积分法
SOC估算:开路电压修正的安时积分法 基本概念 开路电压修正的安时积分法是一种结合了两种SOC估算方法的混合技术: 安时积分法(库仑计数法) - 通过电流积分计算SOC变化 开路电压法 - 通过电池电压与SOC的关系曲线进行校准 方法原…...
)
Spark-SQL(总结)
了解到Spark SQL是Spark用于结构化数据处理的模块,其前身是Shark。Shark基于Hive开发,但对Hive的依赖制约了Spark的发展。掌握了 Spark - SQL 的特点,如易整合、统一数据访问、兼容 Hive 以及支持标准数据连接,可处理多种数据源的…...
——Oracle安装和配置)
Oracle for Linux安装和配置(11)——Oracle安装和配置
11.3. Oracle安装和配置 Linux上Oracle的安装及配置与Windows上差不多,只是安装软件的准备等有所不同,下面只对不同于Windows的部分进行较为详细的讲解,其他类似部分不再赘述。另外,无论选择使用虚机还是物理机,Oracle安装、配置和使用等方面几乎都是完全一样的。 11.3.…...

【防火墙 pfsense】2配置
(1)接口配置和接口 IP 地址分配 ->配置广域网(WAN)和局域网(LAN)接口,分配设备标识符,如 eth0、eth1 等; ->如将WAN 接口将被分配到 eth0,而 LAN 接口将…...
使用 SSE + WebFlux 推送日志信息到前端
为什么使用 SSE 而不使用 WebSocket, 请看 SEE 对比 Websocket 的优缺点。 特性SSEWebSocket通信方向单向(服务器→客户端)双向(全双工)协议基于 HTTP独立协议(需 ws:// 前缀)兼容性现代浏览器(…...

Ollama 常见命令速览:本地大模型管理指南
Ollama 常见命令速览:本地大模型管理指南 一、什么是 Ollama? Ollama 是一个轻量级工具,允许用户在本地快速部署和运行大型语言模型(LLM),如 Llama、DeepSeek、CodeLlama 等。其命令行工具设计简洁&#…...

C++开发之设计模式
设计模式存在的意义 设计模式提供了经过验证的解决方案,帮助开发者在不同的项目中重用这些解决方法,减少重复劳动,提高代码的复用性。设计模式通常遵循面向对象的设计原则,如单一职责原则、开放封闭原则等,能够帮助开…...

AWS Glue ETL设计与调度最佳实践
一、引言 在AWS Glue中设计和调度ETL过程时,需结合其无服务器架构和托管服务特性,采用系统化方法和最佳实践,以提高效率、可靠性和可维护性。本文将从调度策略和设计方法两大维度详细论述,并辅以实际案例说明。 二、调度策略的最…...
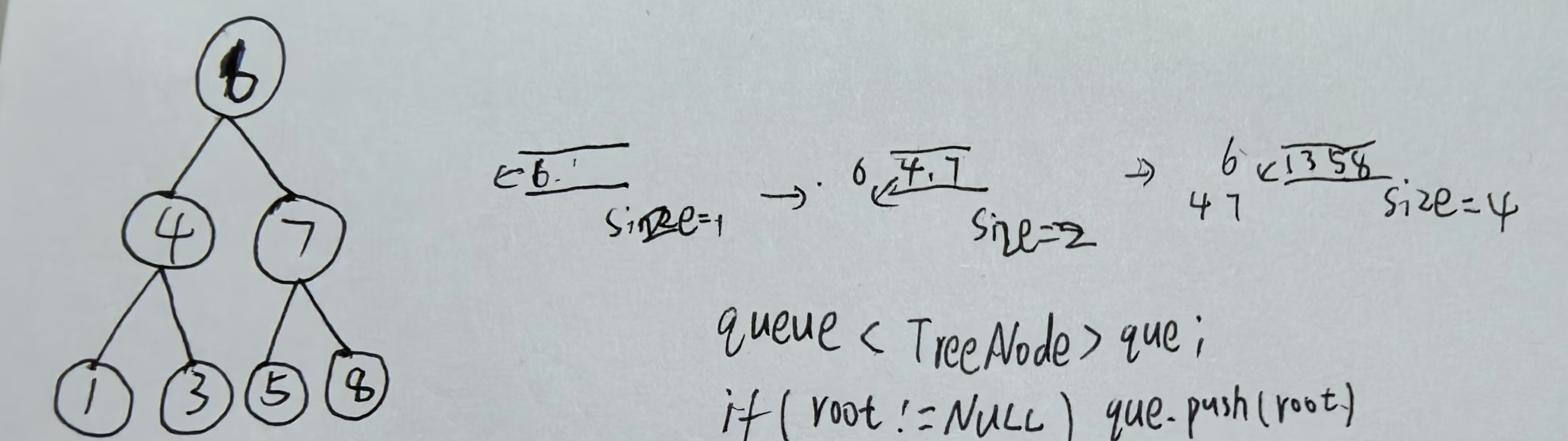
二叉树的遍历(广度优先搜索)
二叉树的第二种遍历方式,层序遍历,本质是运用队列对二叉树进行搜索。 层序遍历是指将二叉树的每一层按顺序遍历,通过队列实现就是先将根节点push入队,统计此时的队列中的元素数量size,将size元素全部pop出去࿰…...

JavaScript 里创建对象
咱们来用有趣的方式探索一下 JavaScript 里创建对象的各种“魔法咒语”! 想象一下,你是一位魔法工匠,想要在你的代码世界里创造各种奇妙的“魔法物品”(也就是对象)。你有好几种不同的配方和工具: 1. 随手捏造(对象字面量 {}) 场景:你想快速做一个独一无二的小玩意儿…...

2025年计算机视觉与智能通信国际会议(ICCVIC 2025)
2025 International Conference on Computer Vision and Intelligent Communication 一、大会信息 会议简称:ICCVIC 2025 大会地点:中国杭州 收录检索:提交Ei Compendex,CPCI,CNKI,Google Scholar等 二、会议简介 2025年计算机视觉与智能通…...