语音合成之六端到端TTS模型的演进
端到端TTS模型的演进
- 引言
- Tacotron:奠基之作
- FastSpeech:解决效率瓶颈
- VITS:实现高保真和富有表现力的语音
- SparkTTS:利用LLM实现高效可控的TTS
- Cosyvoice:一种可扩展的多语种TTS方法
- 端到端TTS模型的演进与未来方向
引言
传统的TTS系统通常由多个独立阶段组成,例如文本分析前端、声学模型和音频合成模块 。构建这些组件往往需要大量的领域专业知识,并且各个模块之间的复杂依赖关系可能导致系统脆弱性增加 。这种复杂性以及对专业知识的依赖促使研究人员转向端到端TTS模型的开发 。
近年来,深度学习技术的飞速发展极大地推动了TTS领域的发展 。深度神经网络强大的建模能力使得端到端TTS系统能够直接从配对的文本和音频数据中学习复杂的映射关系,无需人工设计特征或复杂的中间步骤 。端到端模型通过简化TTS流程,降低了系统的复杂性以及对领域专业知识的需求 。
在追求高质量语音合成的同时,如何有效地训练模型并提高其推理效率,成为了端到端TTS系统发展过程中需要重点关注的问题。高质量的语音合成通常需要更复杂的模型和大量的训练数据,这可能会牺牲训练和推理的效率。反之,为了提高效率而采用的模型可能在语音的自然度和表现力方面有所妥协。因此,如何在生成质量和训练效率之间取得平衡,是端到端TTS模型研究的关键挑战。
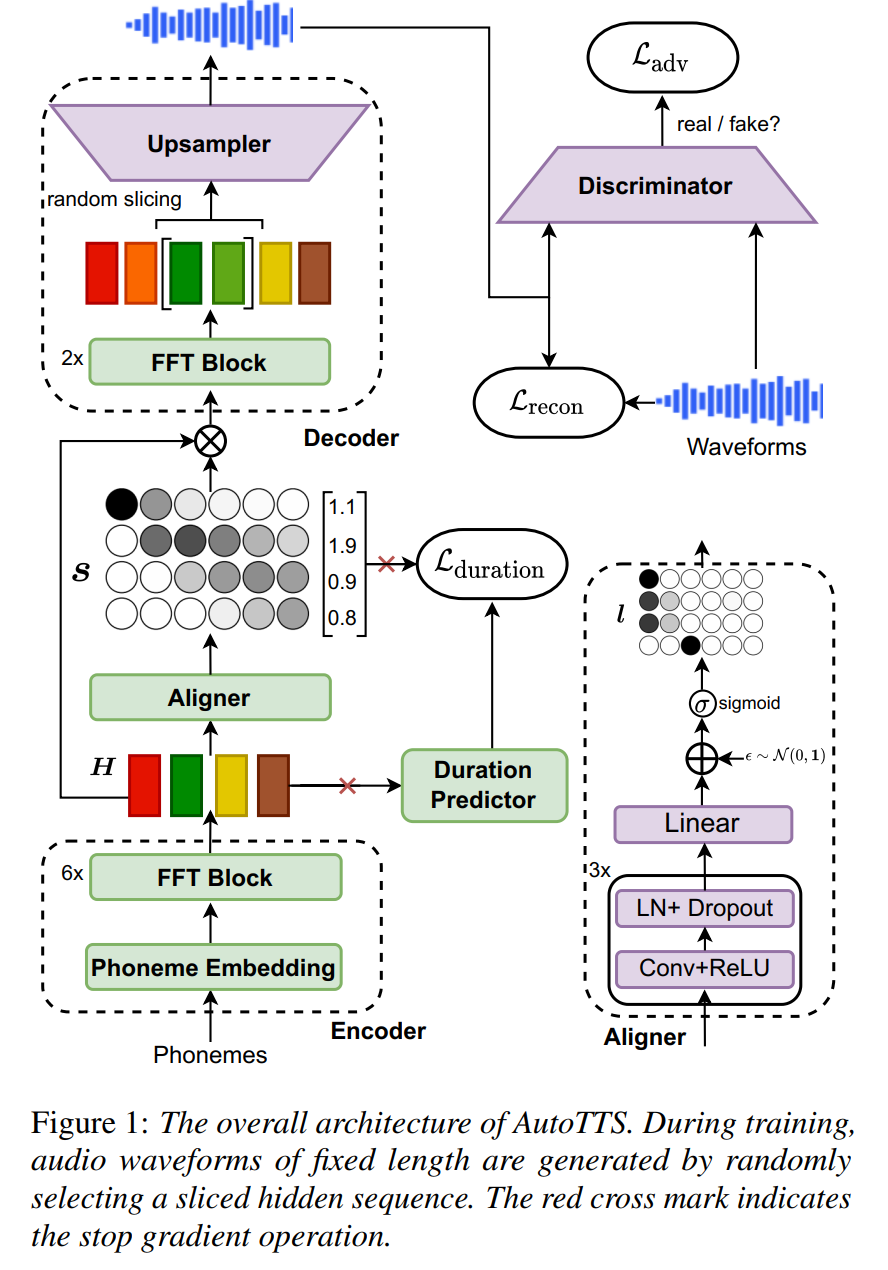
Tacotron:奠基之作
Tacotron模型作为端到端TTS领域的开创性工作,为后续研究奠定了基础。最初的Tacotron(通常称为Tacotron 1)采用了编码器-解码器结构,并引入了注意力机制 。编码器部分负责将输入的字符序列转化为一系列隐藏表示 。注意力机制是Tacotron模型的一项关键创新,它使得解码器在生成每个音频帧时,能够自动地聚焦于输入文本序列的相关部分,从而学习文本特征与相应音频帧之间的对齐关系 。
解码器则基于编码器的输出和注意力机制提供的上下文信息,逐帧生成频谱图 。为了从生成的频谱图中合成最终的语音波形,Tacotron 1采用了Griffin-Lim算法 。Tacotron 1的后处理网络中使用了CBHG模块(卷积滤波器组、高速公路网络、双向GRU循环神经网络),该模块的设计灵感来源于机器翻译领域,能够有效地从序列中提取鲁棒的特征表示 。CBHG模块通过卷积滤波器捕获局部和上下文信息,并通过高速公路网络和双向GRU进一步提取高层序列特征。
Tacotron 2作为Tacotron 1的改进版本,在架构上进行了一些重要的调整 。Tacotron 2将编码器和解码器中的CBHG模块和门控循环单元(GRU)替换为更简单的卷积层和长短期记忆网络(LSTM) 。这种简化旨在减少模型的复杂性和参数数量,同时保持或提升性能。此外,Tacotron 2的目标输出从线性频谱图改为梅尔频谱图 。
梅尔频谱图在感知上更贴近人类听觉系统。为了生成更高质量的音频波形,Tacotron 2集成了WaveNet声码器(或者后来的WaveGlow) 。与Griffin-Lim算法相比,神经声码器能够合成更自然、更高保真度的语音。Tacotron 2还采用了位置敏感注意力机制,该机制在计算注意力权重时考虑了先前时间步的注意力对齐信息,从而提高了文本和语音之间的对齐质量 。与Tacotron 1不同,Tacotron 2不再使用“缩减因子”,即解码器的每一步对应生成一个频谱帧 。
Tacotron模型的主要特点在于其端到端的学习方式,能够直接从文本输入生成语音输出 。Tacotron模型能够学习到自然的韵律和语调 。在性能方面,Tacotron 1在美国英语上取得了3.82的平均意见得分(MOS) ,而Tacotron 2则达到了接近人类录音的语音质量 。
尽管Tacotron模型取得了显著的成功,但也存在一些局限性。由于解码器的自回归特性,Tacotron模型的推理速度相对较慢 。训练注意力机制也具有一定的挑战性,可能导致对齐失败,进而出现跳词或重复词等问题 。此外,Tacotron模型在处理复杂词汇和领域外文本时可能会遇到困难 。原始的Tacotron模型对语音参数(如语速或情感)的控制能力有限 。最后,Tacotron模型依赖于一个单独的声码器(WaveNet或WaveGlow),这增加了计算成本 。
FastSpeech:解决效率瓶颈
为了解决Tacotron模型推理速度慢的问题,FastSpeech模型被提出。FastSpeech采用了完全前馈的Transformer网络结构,能够并行生成梅尔频谱图,从而显著提高了推理速度 。
FastSpeech的编码器和解码器都由若干个前馈Transformer(FFT)模块堆叠而成 。每个FFT模块包含一个自注意力机制和一个一维卷积网络 。与Tacotron模型不同,FastSpeech去除了文本和语音之间的注意力机制,取而代之的是一个基于时长预测器的长度调节器 。时长预测器用于预测每个音素的持续时间,长度调节器则根据预测的时长将音素的隐藏序列扩展到与梅尔频谱图序列的长度相匹配,从而实现并行生成 。
FastSpeech相对于Tacotron模型在速度和鲁棒性方面都有显著的提升。在梅尔频谱图生成速度方面,FastSpeech比自回归的Transformer TTS模型快了高达270倍,端到端的语音合成速度也提升了38倍 。
由于采用了显式的时长建模,FastSpeech几乎消除了跳词和重复词的问题,提高了合成的鲁棒性 。在语音质量方面,FastSpeech能够达到与Tacotron相当甚至更好的水平 。此外,通过长度调节器,FastSpeech还能够灵活地控制语速和韵律 。
FastSpeech的训练流程依赖于一个自回归的教师模型(例如Tacotron 2)来预测音素时长并进行知识蒸馏 。首先,训练一个教师模型,然后从教师模型的注意力对齐中提取音素的持续时间,并使用教师模型生成的梅尔频谱图作为目标来训练FastSpeech模型及其时长预测器 。知识蒸馏有助于简化非自回归FastSpeech模型的学习任务 。
FastSpeech 2作为FastSpeech的改进版本,进一步提升了性能 。FastSpeech 2不再依赖教师模型的输出,而是直接使用真实的梅尔频谱图作为训练目标 。这简化了训练流程,并避免了因使用教师模型而可能导致的信息损失。
此外,FastSpeech 2引入了音高和能量预测器,从而能够更好地建模语音的韵律特征,生成更具表现力的语音 。FastSpeech 2还采用了通过强制对齐获得的更准确的音素时长信息,进一步提高了合成语音的质量 。与FastSpeech相比,FastSpeech 2的训练速度也更快 。
VITS:实现高保真和富有表现力的语音
VITS模型是一种端到端的TTS模型,它结合了变分自编码器(VAE)、归一化流和对抗学习等先进技术,旨在生成高保真且富有表现力的语音 。
VITS模型由后验编码器、解码器和条件先验组成 。VAE的结构使得模型能够学习到以文本为条件的语音的潜在表示。VITS模型中包含一个基于Transformer的文本编码器和多个耦合层的流式模块,用于预测频谱图 。归一化流技术允许模型生成复杂的频谱图分布。VITS模型使用HiFi-GAN声码器来生成高保真度的语音波形 。HiFi-GAN是一种先进的神经声码器,以其生成自然逼真的音频而闻名。
为了生成具有不同节奏的语音,VITS模型还包含一个随机时长预测器 。与确定性时长预测不同,随机时长预测能够反映人类语音的自然变化。VITS模型采用单调对齐搜索(Monotonic Alignment Search, MAS)来学习文本到音频的对齐,而无需外部对齐标注 。MAS允许模型直接从数据中学习对齐关系,简化了训练过程。
VITS模型通过端到端的方式联合训练所有组件(编码器、解码器、声码器) 。这种联合训练能够更好地优化整个系统。VITS模型对潜在变量的不确定性进行建模 ,这有助于捕捉语音中固有的变化性。对抗训练过程 通过使用判别器来区分真实语音和生成语音,从而提高输出的真实感。
VITS模型的架构结合了GlowTTS的编码器和HiFi-GAN的声码器 。VITS模型具备高质量的语音生成能力 ,在LJ Speech等数据集上取得了与真实录音相当的平均意见得分(MOS) ,并且能够生成富有表现力的、具有不同节奏和语调的语音 。
SparkTTS:利用LLM实现高效可控的TTS
SparkTTS模型是一种利用大型语言模型(LLM)进行高效且可控的TTS的新型系统 。SparkTTS采用了单流编解码器架构(BiCodec) ,该架构将语音分解为语义标记(低比特率,包含语言内容)和全局标记(固定长度,包含说话人属性) 。这种分离使得对语音的不同方面进行更有效的表示和操作成为可能。
SparkTTS集成了Qwen2.5等大型语言模型作为其骨干网络 ,并通过微调使LLM具备TTS能力 。该模型采用了链式思考(Chain-of-Thought, CoT)生成方法来实现属性控制 ,提供了一个用于粗粒度(性别、风格)和细粒度(音高、语速)属性的分层控制系统 。SparkTTS能够直接从LLM预测的代码中重建音频,无需单独的声学特征生成模型 ,从而简化了架构并提高了效率。
SparkTTS采用低比特率的语义标记进行高效编码 。其解码器比骨干网络小得多,有助于实现低延迟生成 。该模型还支持Nvidia Triton Inference Serving和TensorRT-LLM,以加速推理 。在性能指标方面,Spark-TTS-0.5B模型的名称暗示了其参数规模约为0.5亿 。在L20 GPU上,当并发数为1时,其推理延迟约为876毫秒,实时因子(Real-Time Factor, RTF)为0.1362 ,表明其推理速度相对较快。
SparkTTS具备零样本语音克隆和跨语言合成能力 ,即使没有特定说话人的训练数据,也能复制其声音 ,并支持中文和英文,能够进行跨语言的语音克隆 。这是SparkTTS的一个关键优势,表明其能够很好地泛化到未见过的声音和语言。
Cosyvoice:一种可扩展的多语种TTS方法
Cosyvoice模型是一种基于监督语义标记的多语种零样本TTS合成器 。与现有的无监督标记相比,使用监督标记旨在提高语音克隆的内容一致性和说话人相似度。
Cosyvoice由一个用于文本到标记生成的LLM和一个用于标记到语音合成的条件流匹配模型组成 。Cosyvoice还融入了x-vector来将语音建模分离为语义、说话人和韵律三个部分 。它通过分类器自由引导和余弦调度器等技术优化了流匹配过程 。
Cosyvoice在多语种和零样本TTS方面采用了独特的方法,是一个可扩展的多语种文本到语音合成器 ,支持包括中文、英文、日语、韩语以及各种汉语方言(粤语、四川话、上海话、天津话、武汉话等)在内的多种语言 。其关键特性是零样本上下文学习能力,仅需一段简短的参考语音样本即可复制任何声音 ,并且能够进行跨语言和混合语言的零样本语音克隆 。
与其他端到端TTS模型相比,Cosyvoice在内容一致性方面表现相当,并在说话人相似度方面表现更优 。与Cosy系列模型(指早期版本或相关模型)相比,Cosyvoice在韵律和情感方面表现显著更好 。Cosyvoice 2旨在以低延迟在流式模式下实现接近人类水平的自然度 。
在性能指标方面,Cosyvoice 2报告的MOS评分为5.53,与商业化的大型语音合成模型相当 。它在Seed-TTS评估集的硬测试集上实现了最低的字错误率 。在流式模式下,首次合成数据包的延迟低至150毫秒 。
为了更清晰地理解不同端到端TTS模型之间的差异,下表对Tacotron、FastSpeech、VITS、SparkTTS和Cosyvoice等模型在架构、关键特性、优化目标、优势、局限性以及典型应用场景等方面进行了比较。
表 1: 端到端TTS模型比较
| 模型 | 架构 | 关键特性 | 优化目标 | 优势 | 局限性 | 典型应用场景 |
|---|---|---|---|---|---|---|
| Tacotron | 编码器-解码器(RNN/LSTM,v1中含CBHG),注意力机制 | 梅尔/线性频谱图,WaveNet/WaveGlow声码器 | 高质量语音合成 | 自然的韵律和语调,端到端学习 | 推理速度慢,注意力机制可能失效 | 语音助手 |
| FastSpeech | 前馈Transformer | 长度调节器,时长预测器 | 快速推理,鲁棒性,可控性 | 并行生成,推理速度快,几乎消除跳词和重复词 | 训练依赖教师模型 | 实时应用 |
| VITS | VAE,归一化流,对抗学习 | HiFi-GAN声码器,随机时长预测器,MAS对齐 | 高保真度,富有表现力的语音 | 音质高,表现力强,端到端训练 | 模型复杂 | 研究,高质量应用 |
| SparkTTS | 单流BiCodec,LLM骨干 | CoT控制,解耦语音标记 | 高效编码,快速推理,可控性 | 零样本语音克隆,跨语言合成 | 新兴模型,仍在发展 | 可定制语音生成 |
| Cosyvoice | 监督语义标记,LLM,流匹配 | x-vector,条件流匹配 | 多语种,零样本语音克隆,流式合成 | 多语种支持,零样本语音克隆,流式推理 | 依赖高质量数据 | 多语种应用 |
从架构设计上看,Tacotron系列采用了循环神经网络(RNN/LSTM)和注意力机制,而FastSpeech则转向了完全前馈的Transformer结构。VITS模型则是一种混合架构,结合了VAE、归一化流和对抗学习。SparkTTS和Cosyvoice则更侧重于利用大型语言模型,并在标记化和生成流程上有所创新。
在优化目标方面,FastSpeech和SparkTTS主要关注推理速度和效率,而VITS和Cosyvoice则更侧重于提高语音的质量和表现力。Tacotron 2则试图在质量和效率之间取得平衡。性能指标方面,MOS评分常用于衡量语音的自然度,而实时因子和延迟则反映了模型的推理速度。鲁棒性和模型大小也是重要的评估指标。每个模型都有其独特的优势和局限性,因此在实际应用中选择合适的模型需要根据具体的使用场景和需求进行权衡。
端到端TTS模型的演进与未来方向
端到端TTS模型的发展历程可以追溯到2017年提出的Tacotron模型 。Tacotron作为首个成功的端到端TTS模型,为后续研究奠定了基础。2019年,FastSpeech的出现解决了自回归模型推理速度慢的瓶颈 。2021年,VITS通过引入先进的生成技术,将语音质量推向了新的高度 。近年来,基于大型语言模型的TTS模型,如2025年提出的SparkTTS ,以及侧重于可扩展性和多语种能力的Cosyvoice(2024年) ,相继涌现。
未来,端到端TTS模型的研究可能会朝着以下几个方向发展:进一步提高推理速度和效率,以满足更多实时应用的需求 ;增强合成语音的自然度和表现力,包括更好地控制情感和语速 ;开发更鲁棒的模型,能够处理嘈杂环境和不同的说话条件 ;在低资源语言TTS和跨语言语音克隆方面取得更多进展 ;探索新的架构和训练技术,例如扩散模型和更高级的LLM应用 ;以及提高TTS系统的可控性和个性化程度 。
相关文章:
语音合成之六端到端TTS模型的演进
端到端TTS模型的演进 引言Tacotron:奠基之作FastSpeech:解决效率瓶颈VITS:实现高保真和富有表现力的语音SparkTTS:利用LLM实现高效可控的TTSCosyvoice:一种可扩展的多语种TTS方法端到端TTS模型的演进与未来方向 引言 …...
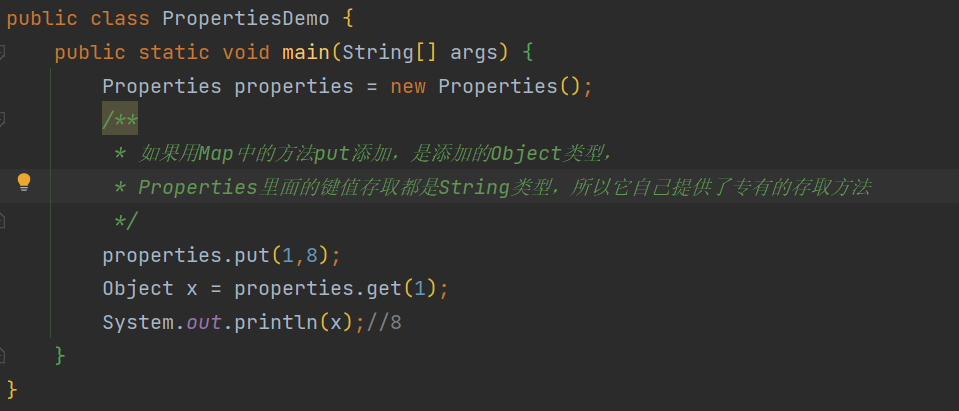
Properties配置文件
Properties(是一个特殊的Map)默认键值都是String类型 备注:Properties能调用Map中的所有方法,但由于放入Properties中的key-value都是String类型,Properties中提供了特殊的存值和取值的方法,所以尽量不要用Map中的方法,如下 Properties的作用 A、将内存中的数据写入到…...

C#高级语法--接口
先引用一些通俗一点的话语说明 1. 接口就像“插座标准”(解耦) 🧩 场景: 你家的手机充电器(USB-C、Lightning)必须插进匹配的插座才能充电。问题:如果每个手机品牌插座都不一样,你换手机就得换充电器,太麻烦了!💡 接口的作用: 定义一个通用的充电口标准(比如U…...

5.6 Microsoft Semantic Kernel:专注于将LLM集成到现有应用中的框架
5.6.1 Semantic Kernel概述 Microsoft Semantic Kernel(以下简称SK)是一个开源的软件开发工具包(SDK),旨在帮助开发者将大型语言模型(LLM)无缝集成到现有的应用程序中。它支持C#、Python和Java…...
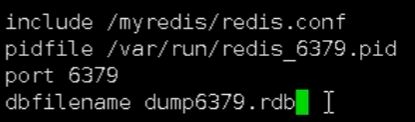
【尚硅谷Redis6】自用学习笔记
Redis介绍 Redis是单线程 多路IO复用技术(类似黄牛买票) 默认有16个库,用select进行切换 默认端口号为6379 Memcached:多线程 锁(数据类型单一,不支持持久化) 五大常用数据类型 Redis key …...
Vue里面elementUi-aside 和el-main不垂直排列
先说解决方法 main.js少导包 import element-ui/lib/theme-chalk/index.css; //加入此行即可 问题复现 排查了一个小时终于找出来问题了,建议导包去看官方的文档,作者就是因为看了别人的导包流程导致的问题 导包官网地址Element UI导包快速入门...

VS Code搭建C/C++开发环境
文章目录 一、VScode 是什么?二、VScode的下载和安装1、下载2、安装 三、环境介绍1、安装中文插件 四、VScode配置 C/C开发环境1、下载MinGW-w64 编译器套件2、配置MingGW643、验证4、安装C/C插件 五、在VSCode上编写C语言代码并编译成功1、打开文件夹2、新建C语言文件&#x…...

6.ArkUI Row的介绍和使用
ArkUI Row 组件介绍与使用指南 什么是 Row 组件? Row 是 ArkUI 中的基础布局容器组件,用于水平(横向)排列子组件。它与 Column 组件相对应,是构建用户界面最常用的布局方式之一,类似于其他UI框架中的水平…...
mysql 在 dbeaver中下载驱动失败处理
直接上解决方法 1. 在mysql官网下载驱动 2. 引入dbeaver中即可 3. 最后再双击即可...

Java 安全:如何防止 SQL 注入与 XSS 攻击?
Java 安全:如何防止 SQL 注入与 XSS 攻击? 在 Java 开发领域,安全问题至关重要,而 SQL 注入和 XSS 攻击是两种常见的安全威胁。本文将深入探讨如何有效防止这两种攻击,通过详细代码实例为您呈现解决方案。 一、SQL 注…...

fastbev mmdetection3D 角度和方向损失
角度/方向损失 sin(a−b)sinacosb−cosasinb config参数 dir_offset0.7854, # pi/4 dir_limit_offset0, box编解码 # Copyright (c) OpenMMLab. All rights reserved. import torchfrom mmdet.core.bbox import BaseBBoxCoder from mmdet.core.bbox.builder import BBOX_COD…...
)
力扣-hot100(滑动窗口最大值)
239. 滑动窗口最大值 困难 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums […...
一种专用车辆智能配电模块的设计解析:技术革新与未来展望
关键词:智能配电模块、STM32、CAN总线、电子开关、新能源汽车 引言:传统配电系统的痛点与智能化转型 传统配电系统依赖继电器和保险丝,存在体积大、寿命短、智能化低等缺陷(如图1)。而新能源汽车和无人驾驶技术对配电…...
《深入浅出ProtoBuf:从环境搭建到高效数据序列化》
ProtoBuf详解 1、初识ProtoBuf2、安装ProtoBuf2.1、ProtoBuf在Windows下的安装2.2、ProtoBuf在Linux下的安装 3、快速上手——通讯录V1.03.1、步骤1:创建.proto文件3.2、步骤2:编译contacts.proto文件,生成C文件3.3、步骤3:序列化…...

Java实现加密(七)国密SM2算法的签名和验签(附商用密码检测相关国家标准/国密标准下载)
目录 一、国密标准中,关于SM2签名验签的定义二、SM2签名和验签的实现原理1. 前置知识2. 签名生成过程3. 验签过程4. 数学正确性证明5. 安全性与注意事项 三、带userId、不带userId的区别1. 核心区别2.算法区别(1) 哈希计算过程(2) 签名验签流程 四、Java代码实现1. …...

【华为HCIP | 华为数通工程师】821—多选解析—第十七页
多选835、IS-IS协议所使用的NSAP地址主要由哪几个部分构成? A、AREA ID B、SEL C、DSCp D、SYSTEM ID 解析:NSAP地址:网络服务访问点(Network Service Access Point)是 OSI 协议中用于定位资源的地址。NSAP 的地址结构如图所示,它由 IDP(Initial Domain …...

函数的定义与使用(python)
lst[:]是传入lst的拷贝。改变它对原始lst没有任何影响。 *list一个*的元素在函数体内会被当成一个元组。 以下是对图中 Python 代码的详细解释: 代码总体功能 这段代码定义了一个生成器函数 getItem ,用于依次返回多个列表中的元素。然后通过循环遍历…...
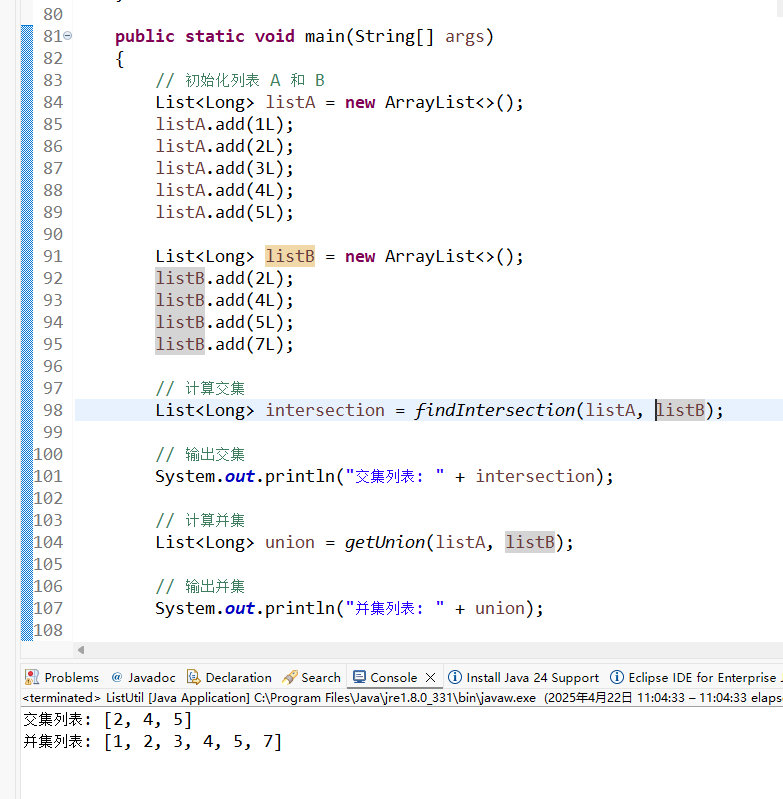
List findIntersection getUnion
List findIntersection & getUnion 求两个列表的交集和并集 package zwf;import java.util.ArrayList; import java.util.LinkedHashSet; import java.util.List;/*** 列表工具类* * author ZengWenFeng* date 2025.04.22* mobile 13805029595* email 117791303qq.com*/ p…...
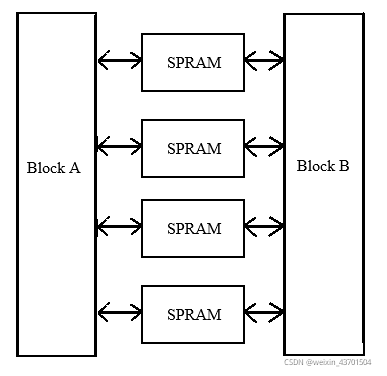
乒乓操作(Ping-Pong)
乒乓操作 “ 乒乓操作” 是一个常常应用于数据流控制的设计思想, 典型的乒乓操作方法如下图 所示: T1周期,输入数据流1缓存到数据缓冲模块1中,如上图棕色;T2周期,输入数据流2缓存到数据缓冲模块2中&…...
微信小程序文章管理系统开发实现
概述 在内容为王的互联网时代,高效的文章管理系统成为各类平台的刚需。幽络源平台今日分享一款基于SSM框架开发的微信小程序文章管理系统完整解决方案,该系统实现了多角色内容管理、智能分类、互动交流等功能。 主要内容 一、用户端功能模块 多角…...

GrassRouter 小草MULE多5G多链路聚合通信路由设备在应急场景的聚合效率测试报告及解决方案
在应急通信场景中,快速、稳定、高效的通信链路是保障救援工作顺利开展的关键。MULE(Multi-Link Unified Link Enhancement)多链路聚合路由通信设备作为一种新型的通信技术解决方案,通过聚合多条通信链路(如4G/5G、卫星…...

筑牢数字防线:商城系统安全的多维守护策略
一、构建网络安全防护屏障 网络安全是商城系统安全的第一道防线。企业应采用先进的防火墙技术,实时监控和过滤进出网络的流量,阻止非法访问和恶意攻击。入侵检测与防御系统(IDS/IPS)也是不可或缺的安全组件,它能够及…...

Linux阻塞与非阻塞I/O:从原理到实践详解
Linux阻塞与非阻塞I/O:从原理到实践详解 1. 阻塞与非阻塞I/O基础概念 1.1 阻塞与非阻塞简介 在Linux系统编程中,I/O操作可以分为两种基本模式:阻塞I/O和非阻塞I/O。这两种模式决定了当设备或资源不可用时,程序的行为方式。 阻…...

【MySQL】MySQL索引与事务
目录 前言 1. 索引 (index) 1.1 概念 1.2 作用 1.3 使用场景 1.4 索引的相关操作 查看索引 创建索引 删除索引 2. 索引背后的数据结构 2.1 B树 2.2 B+树的特点 2.3 B+树的优势 3. 事务 3.1 为什么使用事务 3.2 事…...
华为网路设备学习-19 IGP路由专题-路由策略
一、 二、 注意: 当该节点匹配模式为permit下时,参考if else 当该节点匹配模式为deny下时: 1、该节点中的apply子语句不会执行。 2、如果满足所有判断(if-match)条件时,拒绝该节点并跳出(即不…...

力扣-234.回文链表
题目描述 给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。 class Solution { public:bool isPalindrome(ListNode* head) {//快慢指针找到中间结点p1(偶数个结点…...

Spring Boot 整合 Lock4j + Redisson 实现分布式锁实战
本文基于 Spring Boot 2.7.x MyBatis Plus 3.5.9,演示如何通过 Lock4j 与 Redisson 实现高可靠的分布式锁方案,解决高并发场景下的资源竞争问题。 一、依赖配置关键点 1.1 Maven 依赖(pom.xml) <dependency><groupId&g…...
基于DrissionPage的表情包爬虫实现与解析(含源码)
目录 编辑 一、环境配置与技术选型 1.1 环境要求 1.2 DrissionPage优势 二、爬虫实现代码 三、代码解析 3.1 类结构设计 3.2 目录创建方法 3.3 图片链接获取 3.4 图片下载方法 四、技术升级对比 4.1 代码复杂度对比 4.2 性能测试数据 五、扩展优化建议 5.1 并…...

无限debugger实现原理
1. 直接调用 debugger 关键字 代码示例: debugger; // 手动触发调试器中断特点: 最简单的方式,直接插入 debugger 语句。若未在浏览器开发者工具中禁用断点,每次执行到此代码都会暂停。反制手段:可通过浏览器开发者…...
区间和数量统计 之 前缀和+哈希表
文章目录 1512.好数对的数目2845.统计趣味子数组的数目1371.每个元音包含偶数次的最长子字符串 区间和的数量统计是一类十分典型的问题:记录左边,枚举右边策略前置题目:统计nums[j]nums[i]的对数进阶版本:统计子数组和%modulo k的…...