embedding_model模型通没有自带有归一化层该怎么处理?
embedding_model 是什么:
嵌入式模型(Embedding)是一种广泛应用于自然语言处理(NLP)和计算机视觉(CV)等领域的机器学习模型,它可以将高维度的数据转化为低维度的嵌入空间(embedding space),并保留原始数据的特征和语义信息,从而提高模型的效率和准确性。本文将对嵌入式模型进行详细的介绍,包括其背景、原理、应用和常见类型等方面。
Embedding常用于将文本数据映射为固定长度的实数向量,从而使计算机能够更好地处理和理解这些数据。每个单词或句子都可以用一个包含其语义信息的实数向量来表示。
为什么使用embedding_model :
它能够将高维度的数据转化为低维度的嵌入空间,并保留原始数据的特征和语义信息,从而提高模型的效率和准确性。
能使用 SentenceTransformer 调用的模型
我们现在 魔塔社区查看到的 embedding_model类型模型:
通常情况embedding_model模型的核心目录如下:
text2vec-base-chinese-sentence/
├── 0_Transformer/
├── 1_Pooling/
├── 2_Normalize/
├── config.json
├── config_sentence_transformers.json
├── modules.json
└── pytorch_model.bin
我们这里以 text2vec-base-chinese 模型为例:
一种是huggingFace 格式模型

一种是带有 -sentence 后缀的模型;
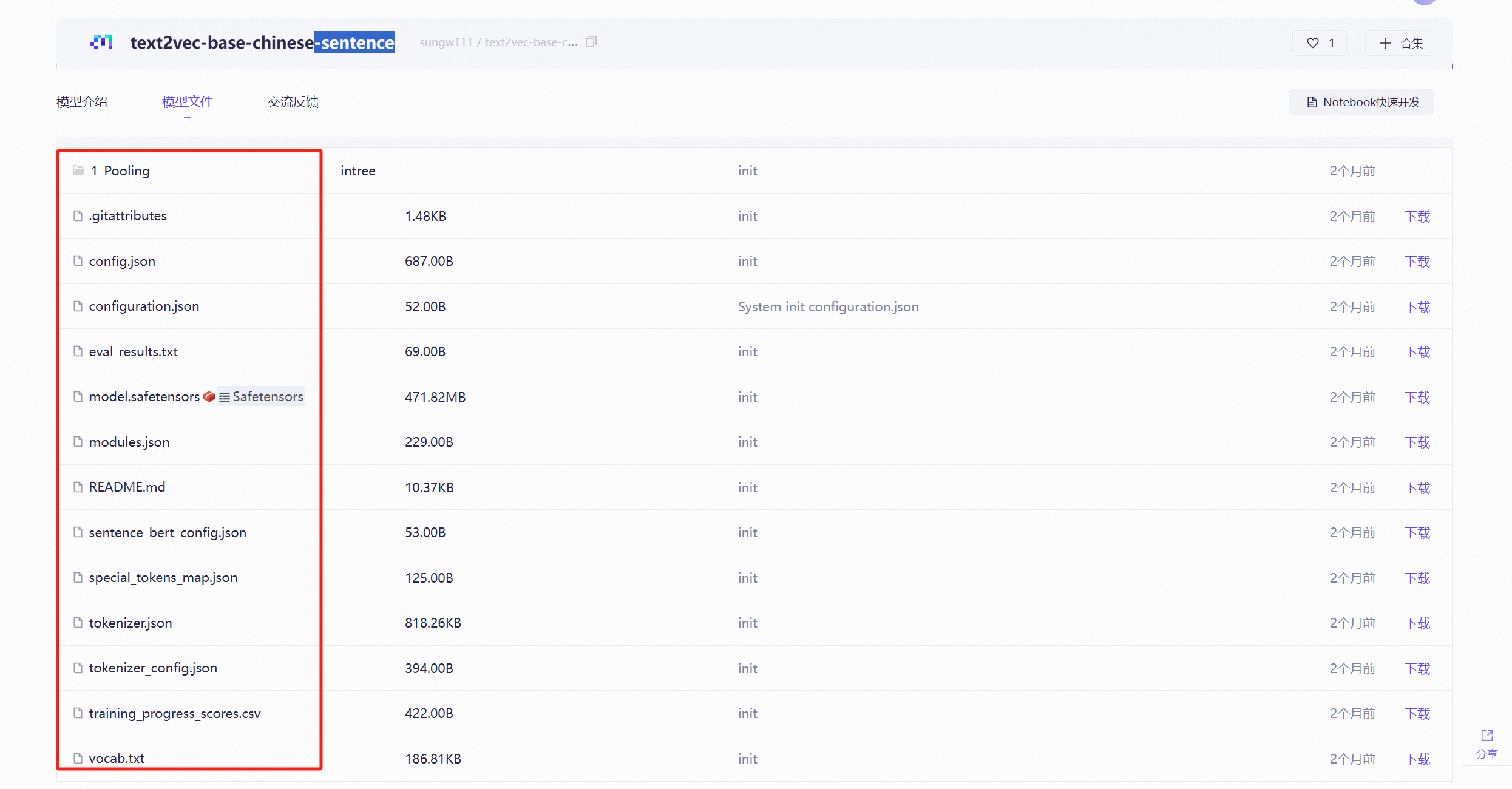
可以看出这个两种格式的模型所包含的文件都是不同的;带有-sentence 后缀的模型中有1_Pooling文件
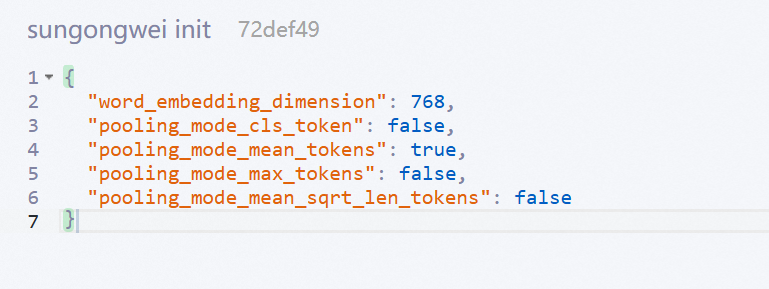
这文件中定义了模型的调用方式;当我们使用 SentenceTransformer 调用 huggingFace 格式模型是后报错所无法找到模型;需要指定的模型为sentence 格式的模型;
这里说的带-sentence 后缀是我这里使用 text2vec-base-chinese模型时举例使用的, 有的模型上传时文件名后缀也没有添加sentence后缀, 主要区分方式是看模型文件中是否有 1_Pooling 文件;有九八说明是sentence 格式的模型,可以使用 SentenceTransformer 调用;
embedding_model模型不带有归一化层怎么处理
embedding_model通常情况是自带有归一化层的。一般可以通过Normalize目录或者modules.json来
判断是否准确包含归一化层。如果未包含归一化层,则需要手动转换添加:
import numpy as np
from sentence_transformers import SentenceTransformer,modelsmodel_path = r"D:ai_model\text2vec-
base-chinese-sentence"
bert = models.Transformer(model_path)
pooling = models.Pooling(bert.get_word_embedding_dimension(),
pooling_mode='mean')# 添加缺失的归一化层
normalize = models.Normalize()# 组合完整模型
full_model = SentenceTransformer(modules=[bert, pooling, normalize])
print(full_model)
save_path=r"D:ai_model\text2vec-base-chinese-sentence"
full_model.save(save_path)# 加载修复后的模型
model =SentenceTransformer(r"D:ai_model\text2vec-base-chinese-sentence")# 验证向量归一化
text = "测试文本"
vec = model.encode(text)
print("修正后模长:", np.linalg.norm(vec)) # 应输出≈1.0
转换后的modules.json如下
[{"idx": 0,"name": "0","path": "","type": "sentence_transformers.models.Transformer"},{"idx": 1,"name": "1","path": "1_Pooling","type": "sentence_transformers.models.Pooling"},{"idx": 2,"name": "2","path": "2_Normalize","type": "sentence_transformers.models.Normalize"}
]相关文章:
embedding_model模型通没有自带有归一化层该怎么处理?
embedding_model 是什么: 嵌入式模型(Embedding)是一种广泛应用于自然语言处理(NLP)和计算机视觉(CV)等领域的机器学习模型,它可以将高维度的数据转化为低维度的嵌入空间࿰…...

基于STM32、HAL库的MCP3421A0T模数转换器ADC驱动程序设计
一、简介: MCP3421A0T是Microchip公司生产的一款18位Δ-Σ模数转换器(ADC),具有以下特点: 18位分辨率 单通道差分输入 可编程增益放大器(PGA):1, 2, 4, 8 可选的转换速率(3.75/15/60/240SPS) 内部基准电压(2.048V 0.05%) IC…...

八大排序——冒泡排序/归并排序
八大排序——冒泡排序/归并排序 一、冒泡排序 1.1 冒泡排序 1.2 冒泡排序优化 二、归并排序 1.1 归并排序(递归) 1.2 递归排序(非递归) 一、冒泡排序 1.1 冒泡排序 比较相邻的元素。如果第一个比第二个大,就交换…...

银发科技:AI健康小屋如何破解老龄化困局
随着全球人口老龄化程度的不断加深,如何保障老年人的健康、提升他们的生活质量,成为了社会各界关注的焦点。 在这场应对老龄化挑战的战役中,智绅科技顺势而生,七彩喜智慧养老系统构筑居家养老安全网。 而AI健康小屋作为一项创新…...

Python实例题:使用Pvthon3编写系列实用脚本
目录 Python实例题 题目 1. 文件重命名脚本 csv_data_statistics.py file_rename.py web_crawler.py 2. CSV 文件数据统计脚本 3. 简单的网页爬虫脚本 运行思路 文件重命名脚本 CSV 文件数据统计脚本 简单的网页爬虫脚本 注意事项 Python实例题 题目 使用Pvthon…...
命令行指引的尝试
效果 步骤 首先初始化一个空的项目,然后安装一些依赖 npm init -y npm install inquirer execa chalk ora至于这些依赖是干嘛的,如下图所示: 然后再 package.json 中补充一个 bin 然后再根目录下新建一个 index.js , 其中的内容如下 #!/…...

Sharding-JDBC 系列专题 - 第九篇:高可用性与集群管理
Sharding-JDBC 系列专题 - 第九篇:高可用性与集群管理 本系列专题旨在帮助开发者全面掌握 Sharding-JDBC,一个轻量级的分布式数据库中间件。本篇作为系列的第九篇文章,将重点探讨 高可用性(High Availability, HA) 和 集群管理,包括数据库高可用方案、Sharding-JDBC 的故…...

【Dify系列教程重置精品版】第1课 相关概念介绍
文章目录 一、Dify是什么二、Dify有什么用三、如何玩转Dify?从螺丝刀到机甲战士的进阶指南官方网站:https://dify.ai github地址:https://github.com/langgenius/dify 一、Dify是什么 Dify(Define + Implement + For You)。这是一款开源的大…...
leetcode0106. 从中序与后序遍历序列构造二叉树-medium
1 题目:从中序与后序遍历序列构造二叉树 官方标定难度:中 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入…...

第5.5章:ModelScope-Agent:支持多种API无缝集成的开源框架
5.5.1 ModelScope-Agent概述 ModelScope-Agent,由阿里巴巴旗下ModelScope社区开发,是一个开源的、模块化的框架,旨在帮助开发者基于大型语言模型快速构建功能强大、灵活性高的智能代理。它的核心优势在于支持与多种API和外部系统的无缝集成&…...
Spring Boot默认缓存管理
Spring框架支持透明地向应用程序添加缓存,以及对缓存进行管理,其管理缓存的核心是将缓存应用于操作数据的方法,从而减少操作数据的执行次数,同时不会对程序本身造成任何干扰。Spring Boot继承了Spring框架的缓存管理功能ÿ…...
XYNU2024信安杯-REVERSE(复现)
前言 记录记录 1.Can_you_find_me? 签到题,秒了 2.ea_re 快速定位 int __cdecl main_0(int argc, const char **argv, const char **envp) {int v4; // [esp0h] [ebp-1A0h]const char **v5; // [esp4h] [ebp-19Ch]const char **v6; // [esp8h] [ebp-198h]char v7;…...
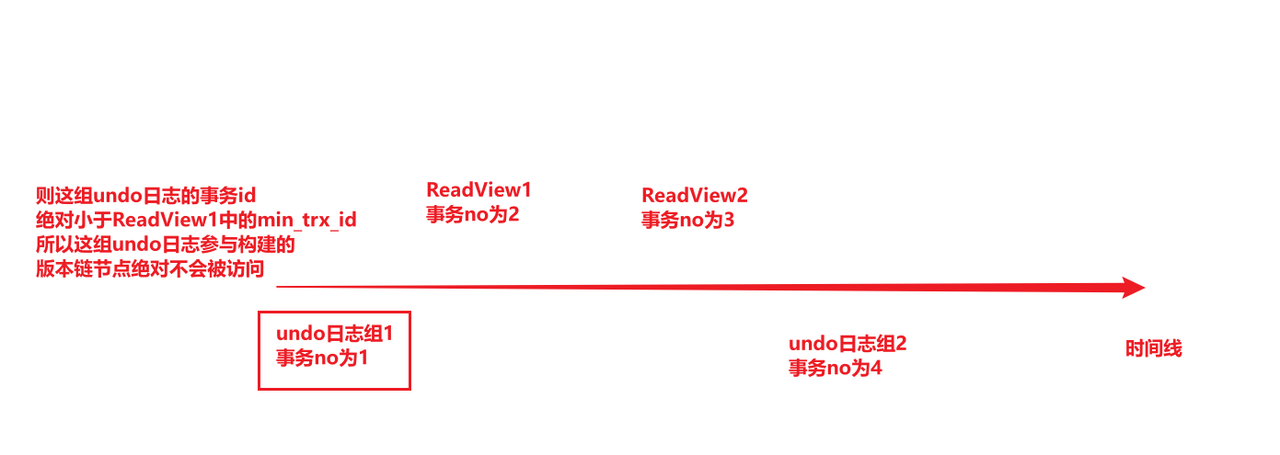
MySQL的MVCC【学习笔记】
MVCC 事务的隔离级别分为四种,其中Read Committed和Repeatable Read隔离级别,部分实现就是通过MVCC(Multi-Version Concurrency Control,多版本并发控制) 版本链 版本链是通过undo日志实现的, 事务每次修改…...

罗德FSP13 FSP40频谱分析仪频率13.6GHz
罗德FSP13 FSP40频谱分析仪频率13.6GHz 附加的功能: 分辨率带宽:1 Hz 至 10 MHz 显示的平均噪音水平:-155 dBm (1 Hz) 相位噪声:10 kHz 时 -113 dB (1 Hz) 附加滤波器:100 Hz 至 5 MHz 的通道滤波器和 RRC 滤波器、…...

腾讯PC客户端面经
1.有关虚函数调用问题 空指针可以在特定的情况下去调用非虚函数,因为非虚函数在编译阶段就可以确定地址,调用的时候this指针传的是nullptr没有问题,不需要依赖对象的创建。 空指针不可以去调用虚函数,因为虚函数的调用需要虚表&…...
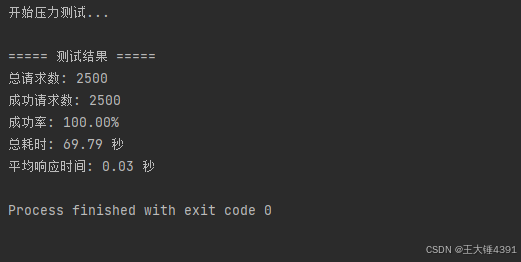
达梦数据库压力测试报错超出全局hash join空间,适当增加HJ_BUF_GLOBAL_SIZE解决
1.名词解释:达梦数据库中的HJ_BUF_GLOBAL_SIZE是所有哈希连接操作可用的最大哈希缓冲区大小,单位为兆字节(MB) 2.达梦压测报错: 3.找到达梦数据库安装文件 4.压力测试脚本 import http.client import multiprocessi…...

Oracle--SQL性能优化与提升策略
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 一、导致性能问题的内在原因 系统性能问题的底层原因主要有三个方面: CPU占用率过高导致资源争用和等待内存使用率过高导致内存不足并需…...

如何在Spring Boot中配置自定义端口运行应用程序
Spring Boot 应用程序默认在端口 8080 上运行嵌入式 Web 服务器(如 Tomcat、Jetty 或 Undertow)。然而,在开发、测试或生产环境中,开发者可能需要将应用程序配置为在自定义端口上运行,例如避免端口冲突、适配微服务架构…...
六个能够白嫖学习资料的网站
一、咖喱君的资源库 地址:https://flowus.cn/galijun/share/de0f6d2f-df17-4075-86ed-ebead0394a77 这是一个学习资料/学习网站分享平台,包含了英语、法语、德语、韩语、日语、泰语等几十种外国语言的学习资料及平台,这个网站的优势就是外语…...

破界出海:HR SaaS平台的全球化实践与组织效能跃升
全球化浪潮下的HR SaaS破局实践 在全球化与数字化双重浪潮的推动下,中国企业出海已从战略选择演变为生存刚需。然而,跨文化管理冲突、多国法律合规风险、复杂薪酬体系与人才发展需求,构成了企业国际化的四大核心挑战。据艾瑞咨询数据&#x…...
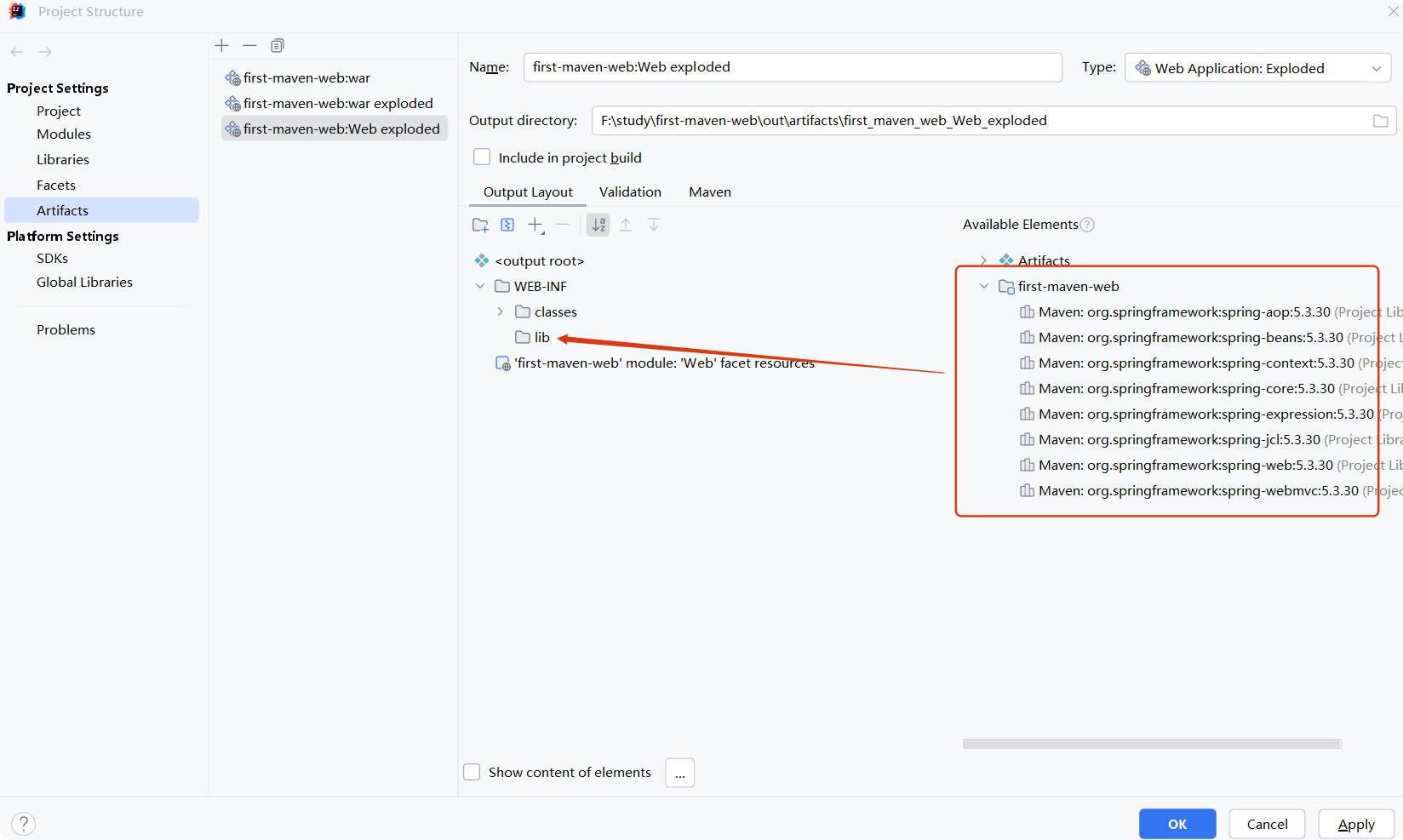
IntelliJ IDEA 中配置 Spring MVC 环境的详细步骤
以下是在 IntelliJ IDEA 中配置 Spring MVC 环境的详细步骤: 步骤 1:创建 Maven Web 项目 新建项目 File -> New -> Project → 选择 Maven → 勾选 Create from archetype → 选择 maven-archetype-webapp。输入 GroupId(如 com.examp…...
手机打电话时电脑坐席同时收听对方说话并插入IVR预录声音片段
手机打电话时电脑坐席同时收听对方说话并插入IVR预录声音片段 --本地AI电话机器人 前言 书接上一篇,《手机打电话通话时如何向对方播放录制的IVR引导词声音》中介绍了【蓝牙电话SDK示例App】可以实现手机app在电话通话过程中插播预先录制的开场白等语音片段的功能。…...
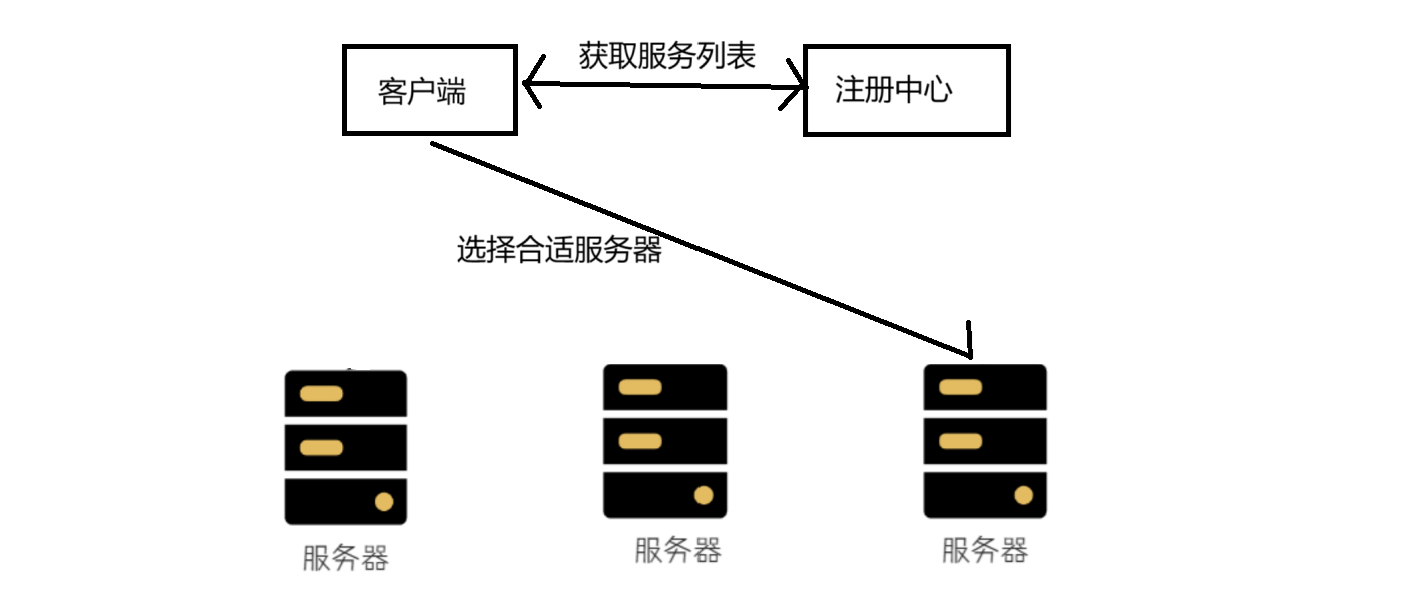
SpringCloud——负载均衡
一.负载均衡 1.问题提出 上一篇文章写了服务注册和服务发现的相关内容。这里再提出一个新问题,如果我给一个服务开了多个端口,这几个端口都可以访问服务。 例如,在上一篇文章的基础上,我又新开了9091和9092端口,现在…...
Python Transformers 库介绍
Hugging Face 的 Transformers 库是一个用于自然语言处理(NLP)的强大 Python 库,它提供了对各种预训练模型的访问和使用接口。该库具有以下特点和功能: 主要特点 丰富的预训练模型:Transformers 库包含了大量的预训练模型,如 BERT、GPT - 2、RoBERTa、XLNet 等。这些模型…...

string的基本使用
string的模拟实现 string的基本用法string的遍历(三种方式):关于auto(自动推导):范围for: 迭代器普通迭代器(可读可改)const迭代器(可读不可改) string细小知识点string的常见接口引…...
深入解析Mlivus Cloud核心架构:rootcoord组件的最佳实践与调优指南
作为大禹智库的向量数据库高级研究员,同时也是《向量数据库指南》的作者,我在过去30年的向量数据库和AI应用实战中见证了这项技术的演进与革新。今天,我将以专业视角为您深入剖析Mlivus Cloud的核心组件之一——rootcoord,这个组件在系统架构中扮演着至关重要的角色。如果您…...

docker 代理配置冲突问题
问题描述 执行 systemctl show --property=Environment docker 命令看到有如下代理配置 sudo systemctl show --property=Environment docker Environment=HTTP_PROXY=http://127.0.0.1:65001 HTTPS_PROXY=http://127.0.0.1:65001 NO_PROXY=127.0.0.1,docker.io,ghcr.io,uhub…...

Nginx 配置参数全解版:Nginx 反向代理与负载均衡;Nginx 配置规范与 Header 透传实践指南;Nginx 配置参数详解
Nginx 配置参数全解版:Nginx 反向代理与负载均衡;Nginx 配置规范与 Header 透传实践指南;Nginx 配置参数详解 Nginx 反向代理与负载均衡配置,Header 透传到后端应用(参数全解版)一、Nginx 反向代理与负载均…...
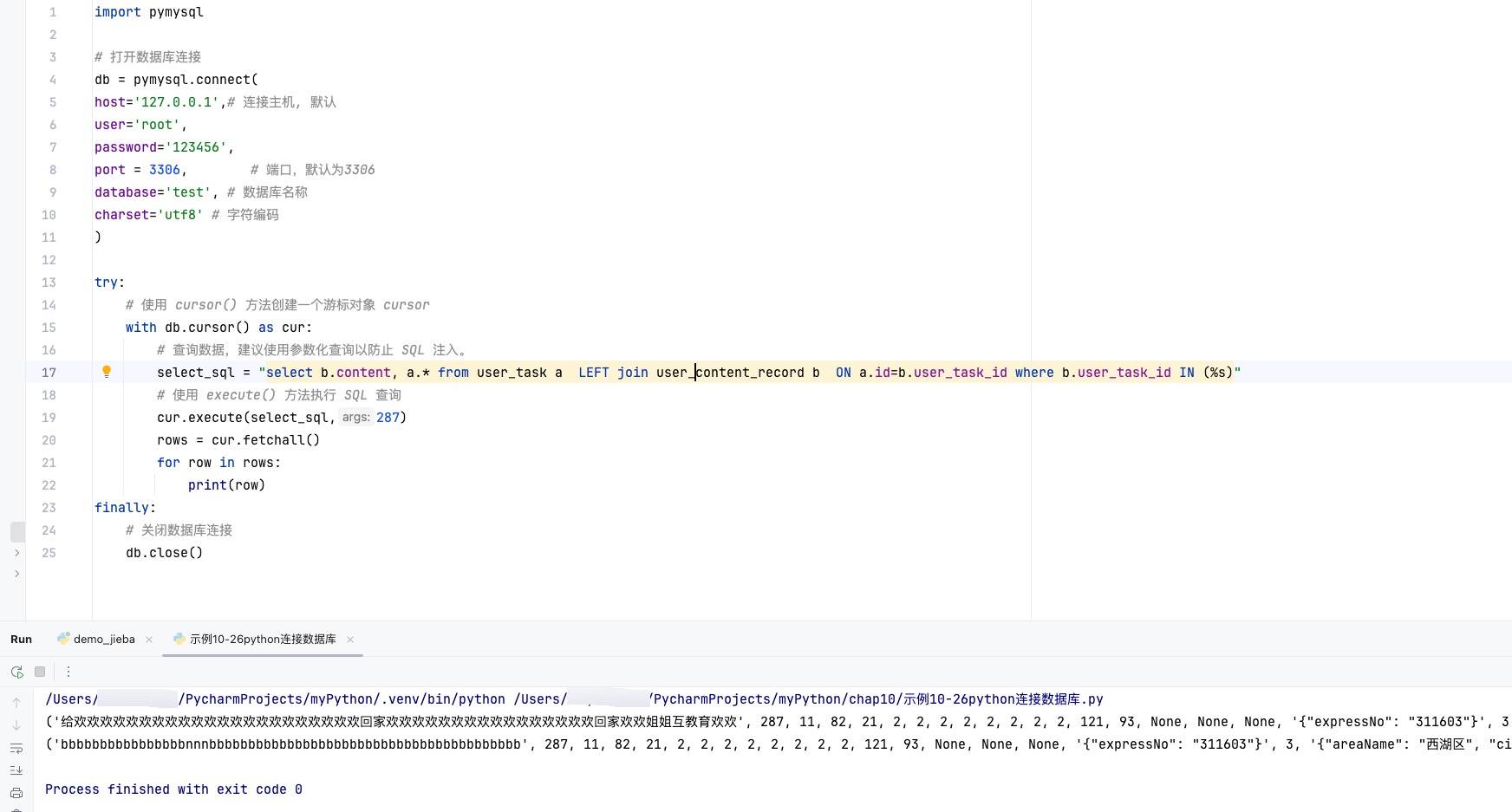
Python常用的第三方模块之【pymysql库】操作数据库
pymysql是在Python3.x版本中用于连接MySQL服务器的一个实现库,Python2中则是使用musqldb。 PyMySQL 是一个纯 Python 实现的 MySQL 客户端库,它允许我们直接在 Python 中执行 SQL 语句并与 MySQL 数据库进行交互。下面我们将详细介绍如何使用 PyMySQL 进…...

【Python数据分析】Pandas模块之pd.concat 函数
💭 写在前面:合并多个数据框,收集各种数据,并将其合并为一个数据框进行分析。本章我们介绍 Pandas 库中数据框合并的函数 —— concat。 0x00 引入:数据框的合并操作 合并多个数据框:收集各种数据,并将其合并为一个数据框进行分析。 下面介绍一些常用的 Pandas 库中数…...