Oracle--SQL性能优化与提升策略
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除

一、导致性能问题的内在原因
系统性能问题的底层原因主要有三个方面:
- CPU占用率过高导致资源争用和等待
- 内存使用率过高导致内存不足并需要使用磁盘虚拟内存
- I/O占用率过高导致磁盘访问需要等待。
性能影响的优先级从高到低依次是CPU-->内存-->I/O。在PL/SQL性能优化中,重点是减少I/O瓶颈,即尽量减少对磁盘I/O的访问
根据上述分析,PL/SQL优化的核心思想可以总结为以下几点:
- 避免使用过多复杂的SQL脚本,以减少系统的解析过程
- 避免进行无用的计算,例如避免出现死循环等低效代码
- 避免浪费内存空间,例如避免执行不必要的SQL脚本,以免导致内存不足
- 充分利用内存中的计算和访问速度快的优势
- 尽可能减少磁盘的访问数据量
- 尽可能减少磁盘的访问次数,这是PL/SQL优化中的重要原则
二、如何进行SQL优化
1、选择最有效率的表名顺序
Oracle的解析器从右到左处理FROM子句中的表名,因此最后写的表(基础表 driving table)最先处理。在多表查询时,建议将记录最少的表作为基础表,以减少连接操作的数据量。Oracle会通过排序和合并方式连接表:先扫描并排序基础表,再扫描其他表并与基础表匹配。这种处理顺序对查询性能至关重要,建议按照此规则编写SQL语句。目前主要使用基于成本的优化器(CBO),它会自动评估最佳执行计划,但遵循上述规则有助于提升SQL效率。
--例如:员工表emp有16384条记录,而部门表dept有1条记录,选择dept作为基础表 select count(*) from emp,dept; --选择dept作为基础表耗时0.96sselect count(*) from dept,emp; --选择emp作为基础表耗时26.09s2、WHERE子句中的连接顺序
ORACLE 采用自下而上的顺序解析 WHERE 子句,根据这个原理,表之间的连接必须写在其他 WHERE 条件之前
--低效:select dept.deptno,emp.jobfrom emp.deptwhere emp.job='MANAGER' AND emp.deptno=dept.deptno;--优化后:select dept.deptno,emp.jobfrom emp.deptwhere emp.deptno=dept.deptno AND emp.job='MANAGER';3、SELECT子句中避免使用'*'
在SELECT子句中使用动态SQL列引用“*”虽然方便,但效率低下。Oracle解析时会通过查询数据字典将“”转换为所有列名,这增加了额外的开销和时间成本。因此,建议在SELECT子句中尽量避免使用“”,而是明确列出所需的列名,以提高查询效率。
4、用EXITS 替代 IN
使用EXISTS替换IN效果有时不明显,但在基础表查询需联接另一表时,EXISTS通常提高效率,因EXISTS找到匹配即停止搜索
--低效select *from table_name1where column1 in(select column1 from table_name2where column2=str_column2and column3='xxxx');--优化后:select *from table_name1where exists(select 1 from table_name2where column1=table_name2.column1and column2=str_column2and column3='xxxx');5、用 NOT EXISTS 替代 NOT IN
Oracle 10g前 NOT IN 效率低,10g 虽改进但仍存在问题。建议用 NOT EXISTS 替代 NOT IN ,因 NOT IN 对子查询表全表遍历且需内部排序合并,效率低。改写为 NOT EXISTS 可提升效率
--低效:select * from table_name1where column1 NOT IN(select column1 from table_name2where column3='xxxx');--优化后:select *from table_name1where not exists(select 1 from table_name2where column1=table_name2.column1and column3='xxxx');6、用表连接替换 EXISTS
在子查询的表和主表查询是多对一的情况,一般采用表连接的方式比 EXISTS 更有效率
--低效:select table name1.*from table name1where exists (select 1 from table_name2where column1 =table name1.column1and column2='xxxx'and column3='xxxxxx');--优化后:SELECT table_name1.*FROM table namel,table name2 Wheretable_name1.column1=table_name2.column1and table_name2.column2='xxxx'and column3='xxxx';7、减少对表的查询
该问题是我们编程中出现过的问题,请大家一定注意,并且该类问题优化可以带来较大性能的提升
--低效:cursor cur_table_lj1 isselect column1from table1where column1 = str_column1 and column2='1111';cursor cur_table1_lj2 isselect column1from table1where column1 =str_column1 and column2='2222';for rec_lj1 in cur_table1 loop业务逻辑1处理end loop;for rec_lj2 in cur_table2 loop业务逻辑2处理end loop;--优化后:cursor cur_tablel_lj1 isselect column1,column2from table1where column1 =str_columnl and column2 in ('11111','22222');for rec_ljl in cur_tablel lj1 loopif rec_lj1.column2='11111' then业务逻辑1处理.…..end if;if rec lj1.column2='22222' then业务逻辑2处理....end if,end loop;高效的做法使用同样的条件(或者说是索引)只访问一次磁盘,低效的做法访问了2次磁盘,这样速度差 别将近2倍。
8、避免循环(游标)里面嵌查询
游标中不能有游标或update、delete等语句,只能有select语句,但在实际编程中难以完全避免,需尽量减少。优化方法是将游标循环中的查询语句提前到游标查询中一次性查询出来,减少磁盘访问次数,提升效率。如果无法避免游标中使用查询语句,要确保查询语句使用索引,提高查询速度。
9、尽量用 union all 替换 all
Union 会去掉重复的记录,会有排序的动作,会浪费时间。因此在没有重复记录的情况下或可以允许有重,复记录的话,要尽量采用 uoion all 来关联
10、group by 优化
Group by需要查询后分组,速度慢影响性能,如果查询数据量大,并且分组复杂,这样的査询语句在性能上是有问题的。采用 group by的也一定要进行优化
--低效:select table1.column1,table2.column2table2.column3,sum(column5),table1.column4from table1,table2where table1.column1=table2.column1and table1.column4='xxxxxx'group py table1.column1,table2.column2table2.column3,table2.column4--优化后:select table1.column1,table2.column2,table2.column3,gzze,table1.column4from(select column1,sum(column5) gzzefrom table1 group by column1) table1,table2where table1.column1=table2.column1and column4='xxxx';11、尽量避免用 order by
使用 ORDER BY 会因查询后排序而拖慢速度,尤其数据量大时。尽管有时无法避免使用 ORDER BY ,但需注意排序列表应符合索引,这样能显著提升速度。
12、用where 子句替换Having 子句
避免使用HAVING子句,因为它会在检索完所有记录后才对结果集进行过滤,这个过程需要排序、总计等操作。如果能通过WHERE子句限制记录数量,就能减少这方面的开销。
--低效:select column1,count(1) from table1group by column1having column1 in ('1','2');--优化后:select column1,count(1) from table1where column1 in ('1','2')group by column1;HAVING 中的条件一般用于对一些集合函数的比较,如 COUNT() 等等。除此而外,一般的条件应该写在 WHERE 子句中
13、使用表的别名(alias)
在SQL语句中连接多个表时,使用表的别名并将其前缀于每个列名,可减少解析时间及因列名歧义引发的语法错误。
14、COMMIT 使用
- 提交频率过高会浪费时间,尽管单次提交时间短。
- 提交可释放资源,在大量数据更新时需及时提交。
--cur_table1 有5000万数据n_count :=0For arec in cur_table1 loopInsert into table ...n_count := n_count + 1;If n_count = = 100000 then --10万一提交commit;n_count := 0End if;End loop;Commit;15、减少多表关联
- 表关联越多,查询速度越慢,建议表关联不超过3个(子查询也算表关联)。
- 大数据量表关联会影响索引效率,可采用建立临时表的方法来提高速度。
三、索引使用优化
1、避免在索引列上使用函数或运算
在实际编程中要注意:在索引列上使用函数或运算,查询条件不会使用索引。
--不使用索引select * from table1where column1='xxx'and to_char(column2,'yyyymm')='200801';或者select * from table1where column1='xxx'and column2+1=sysdate;--使用索引select * from table1where column1='xxx'and column2=to_date('200801','yyyymm');或者select * from table1where column1='xxx'and column2=sysdate -1;2、避免改变索引列的类型
索引列的条件如果类型不匹配,则不能使用索引。
3、避免在索引列上使用NOT
避免在索引列上使用 NOT , NOT 不会使查询条件使用索引。对于 != 这样的判断也不能使用索引,因为索引只能告诉你什么存在于表中,而不能告诉你什么不存在于表中。
--低效:select * from table1 where not column1='10';--优化后:select * from table1 where column1 in ('20','30');4、用>=替代>
虽然效果不是特别明显,但建议采用这种方式
--低效:select * from table1 where column1 > '10';--优化后:select * from table1 where column >= '20';特别说明:两者的区别在于,前者 DBMS 首先定位到 column1=10的记录并且向前扫描到第一个column1 大于 10 的记录,而后者 DBMS 将直接跳到第一个 column1 等于 20 的记录
5、避免在索引列上使用 IS NULL和IS NOT NULL
在Oracle中,索引列使用 IS NULL 或 IS NOT NULL 时不会利用索引,因为空值不存储于索引列。这会导致Oracle停用索引
--低效:select * from table1 where column1 is not null;--优化后:select * from table1 where column1 in ('10','20','30');6、带通配符(%)的like语句
%在常量前面索引就不会使用。
--不使用索引:select * from table1 where column1 like '%210104';select * from table1 where column1 like '%210104%';--使用索引:select * from table1 where column1 like '210104%';7、总是使用索引的第一个列
如果索引是建立在多个列上,只有在它的第一个列被 where 子句引用时,优化器才会选择使用该索引。
--如:table1的复合索引(column1,column2,column3)--低效(不会使用索引):select * from table1 where column2='110' and column3='200801';--优化后(会使用索引):select * from table1 where column1 = '10001000';如果不使用索引第一列基本上不会使用索引,使用索引要按照索引的顺序使用,另外使用复合索引的列越多,查询的速度就越快
8、 关于索引建立
索引可大幅提升查询速度,但也占用空间。过多索引会影响 INSERT 、 DELETE 和 UPDATE 操作的速度,因这些操作会改变索引顺序,需Oracle调整,导致性能下降。因此,要合理创建有效索引,编程时符合索引规则,而非让索引适应编程。
示例:在某项目数据转换中,采用游标循环插入2000万条数据耗时4小时,因目标表索引过多。解决方法是先删除索引再执行转换脚本,不到1小时完成,重建所有索引仅需半小时。
四、对于千万级的大表应该怎么优化
1、制定优化方案
针对Oracle数据库千万级大表的读、写、计算优化,可采取以下措施:
优化读:
- 建立合适索引,使用索引覆盖查询避免全表扫描。
- 使用分区表,将大表拆分,查询时只需扫描部分数据。
- 增加内存,扩大数据库缓存区,减少磁盘I/O操作。
- 优化SQL语句,避免子查询、减少连接操作。
优化写:
- 使用并行写入,将数据写入多个表或节点。
- 采用批量写入,减少写入操作次数。
- 减少索引数量,避免过多索引影响写入性能。
- 避免使用触发器,减少额外的I/O操作。
优化计算:
- 使用分布式计算,分散计算任务到多个节点。
- 采用并行计算,将任务划分成多个子任务并行执行。
- 使用合适的数据结构,减少计算时间。
- 优化SQL语句,减少计算操作的数据量。
2、优化方案总结
总结优化方案的几种方法:
- 建立合适的索引:索引可提升查询速度,但过多或不合适的索引会影响数据库性能,需根据实际情况合理建立。
- 分区表:将大表分成多个小表,提高查询速度和维护效率。
- 优化SQL语句:减少数据库的I/O操作,提高查询效率。可采用优化查询语句、查询条件,避免使用子查询等方式。
- 增加内存:扩大数据库缓存区和内存,减少磁盘I/O操作,提高查询效率。
- 优化磁盘I/O:使用RAID技术、SSD硬盘等方式提升磁盘I/O速度,增强数据库性能。
学习永无止境,让我们共同进步!!
相关文章:
Oracle--SQL性能优化与提升策略
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 一、导致性能问题的内在原因 系统性能问题的底层原因主要有三个方面: CPU占用率过高导致资源争用和等待内存使用率过高导致内存不足并需…...

如何在Spring Boot中配置自定义端口运行应用程序
Spring Boot 应用程序默认在端口 8080 上运行嵌入式 Web 服务器(如 Tomcat、Jetty 或 Undertow)。然而,在开发、测试或生产环境中,开发者可能需要将应用程序配置为在自定义端口上运行,例如避免端口冲突、适配微服务架构…...
六个能够白嫖学习资料的网站
一、咖喱君的资源库 地址:https://flowus.cn/galijun/share/de0f6d2f-df17-4075-86ed-ebead0394a77 这是一个学习资料/学习网站分享平台,包含了英语、法语、德语、韩语、日语、泰语等几十种外国语言的学习资料及平台,这个网站的优势就是外语…...

破界出海:HR SaaS平台的全球化实践与组织效能跃升
全球化浪潮下的HR SaaS破局实践 在全球化与数字化双重浪潮的推动下,中国企业出海已从战略选择演变为生存刚需。然而,跨文化管理冲突、多国法律合规风险、复杂薪酬体系与人才发展需求,构成了企业国际化的四大核心挑战。据艾瑞咨询数据&#x…...
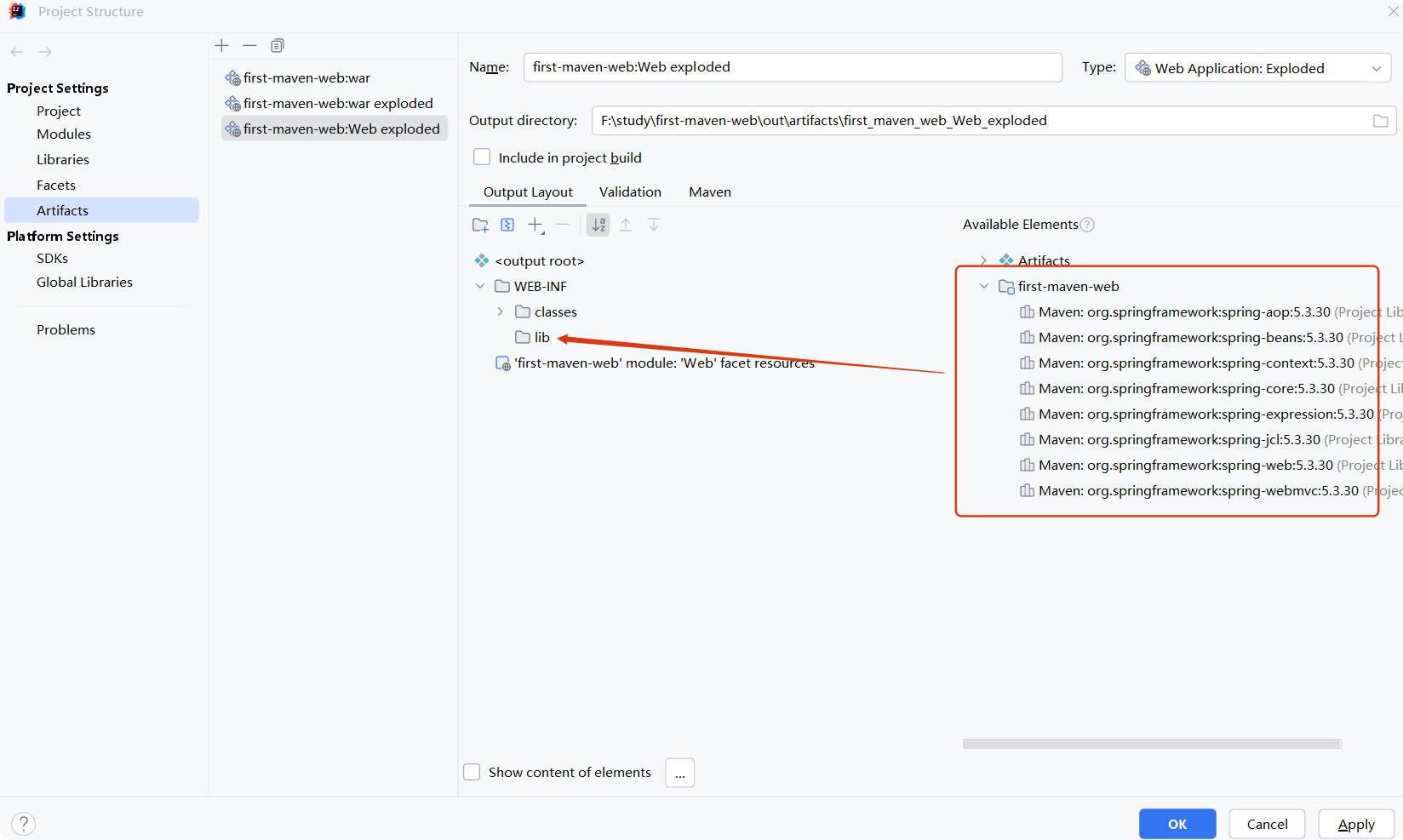
IntelliJ IDEA 中配置 Spring MVC 环境的详细步骤
以下是在 IntelliJ IDEA 中配置 Spring MVC 环境的详细步骤: 步骤 1:创建 Maven Web 项目 新建项目 File -> New -> Project → 选择 Maven → 勾选 Create from archetype → 选择 maven-archetype-webapp。输入 GroupId(如 com.examp…...
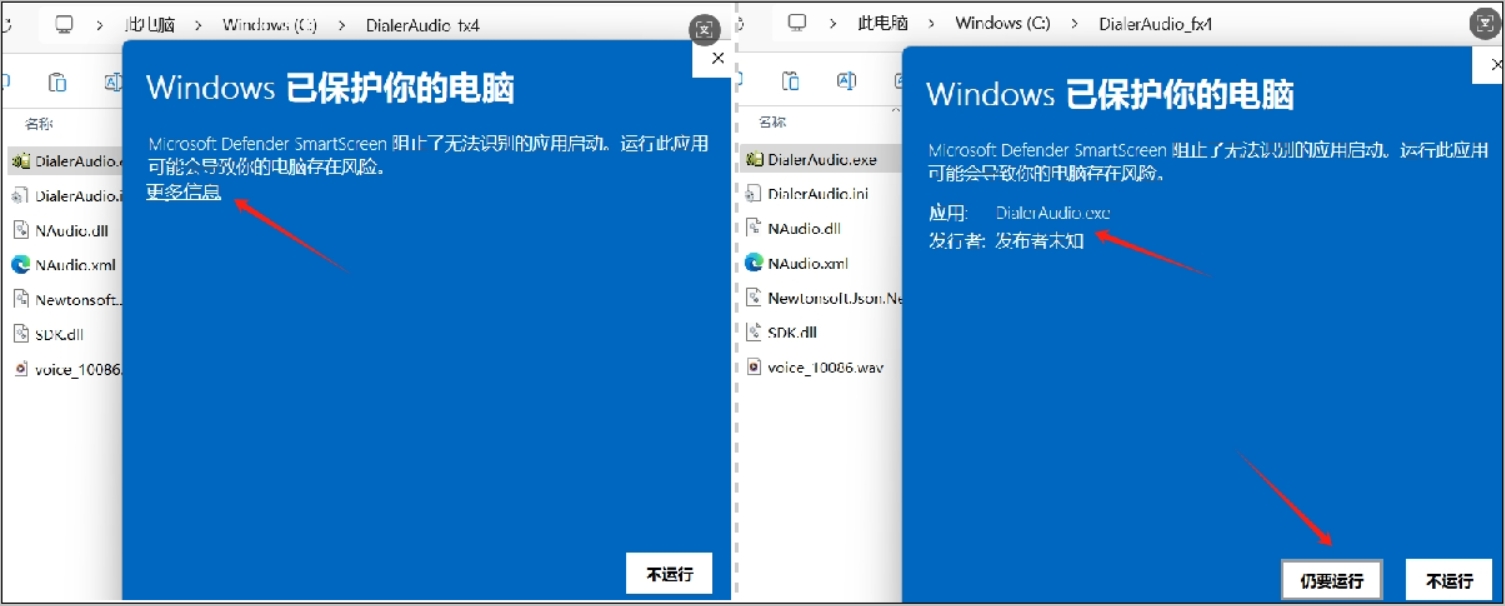
手机打电话时电脑坐席同时收听对方说话并插入IVR预录声音片段
手机打电话时电脑坐席同时收听对方说话并插入IVR预录声音片段 --本地AI电话机器人 前言 书接上一篇,《手机打电话通话时如何向对方播放录制的IVR引导词声音》中介绍了【蓝牙电话SDK示例App】可以实现手机app在电话通话过程中插播预先录制的开场白等语音片段的功能。…...
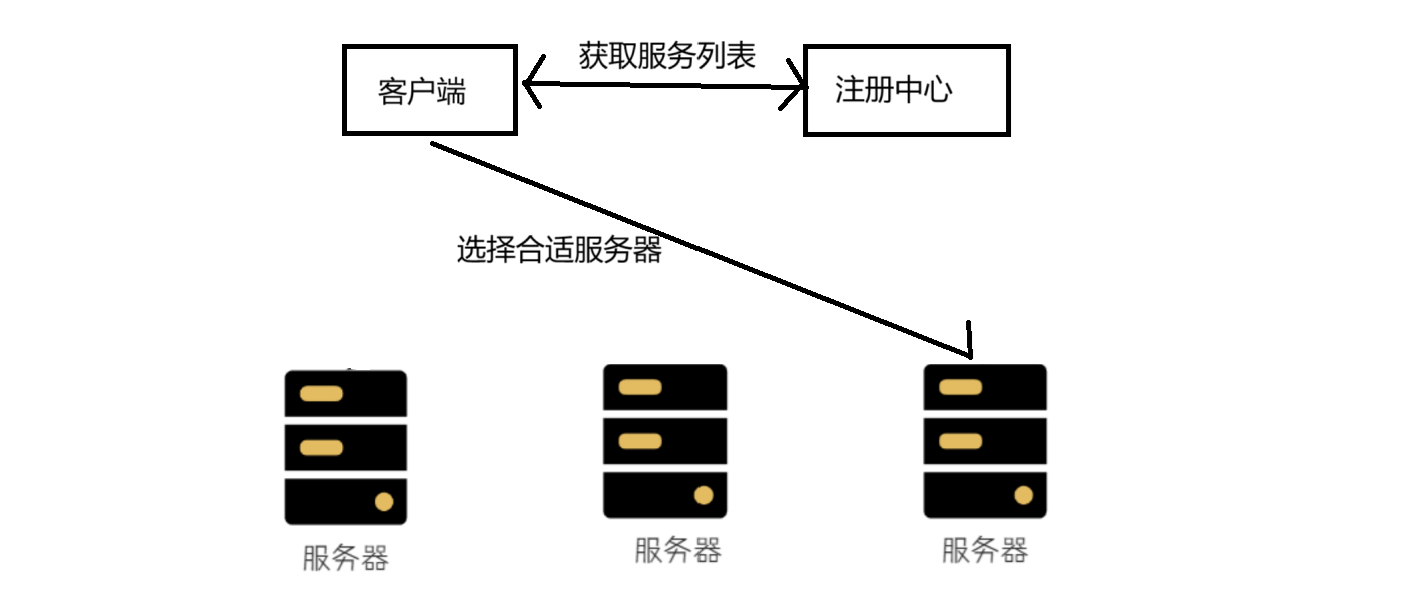
SpringCloud——负载均衡
一.负载均衡 1.问题提出 上一篇文章写了服务注册和服务发现的相关内容。这里再提出一个新问题,如果我给一个服务开了多个端口,这几个端口都可以访问服务。 例如,在上一篇文章的基础上,我又新开了9091和9092端口,现在…...
Python Transformers 库介绍
Hugging Face 的 Transformers 库是一个用于自然语言处理(NLP)的强大 Python 库,它提供了对各种预训练模型的访问和使用接口。该库具有以下特点和功能: 主要特点 丰富的预训练模型:Transformers 库包含了大量的预训练模型,如 BERT、GPT - 2、RoBERTa、XLNet 等。这些模型…...

string的基本使用
string的模拟实现 string的基本用法string的遍历(三种方式):关于auto(自动推导):范围for: 迭代器普通迭代器(可读可改)const迭代器(可读不可改) string细小知识点string的常见接口引…...
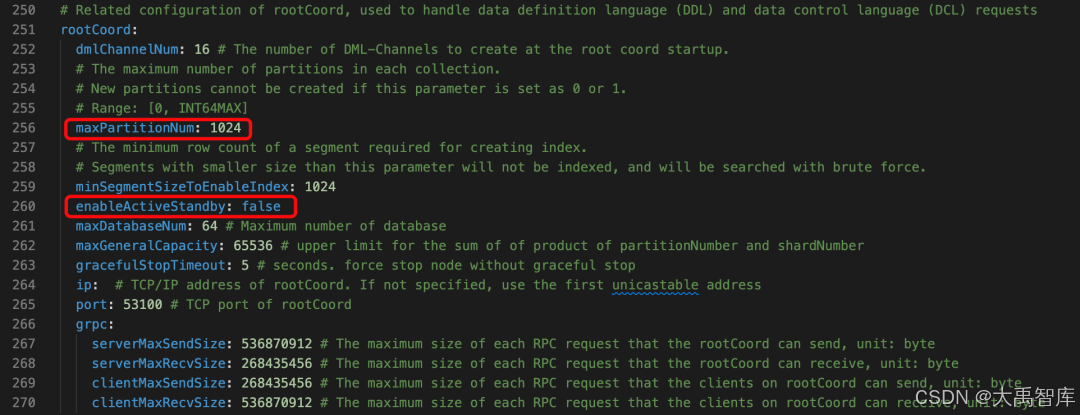
深入解析Mlivus Cloud核心架构:rootcoord组件的最佳实践与调优指南
作为大禹智库的向量数据库高级研究员,同时也是《向量数据库指南》的作者,我在过去30年的向量数据库和AI应用实战中见证了这项技术的演进与革新。今天,我将以专业视角为您深入剖析Mlivus Cloud的核心组件之一——rootcoord,这个组件在系统架构中扮演着至关重要的角色。如果您…...

docker 代理配置冲突问题
问题描述 执行 systemctl show --property=Environment docker 命令看到有如下代理配置 sudo systemctl show --property=Environment docker Environment=HTTP_PROXY=http://127.0.0.1:65001 HTTPS_PROXY=http://127.0.0.1:65001 NO_PROXY=127.0.0.1,docker.io,ghcr.io,uhub…...

Nginx 配置参数全解版:Nginx 反向代理与负载均衡;Nginx 配置规范与 Header 透传实践指南;Nginx 配置参数详解
Nginx 配置参数全解版:Nginx 反向代理与负载均衡;Nginx 配置规范与 Header 透传实践指南;Nginx 配置参数详解 Nginx 反向代理与负载均衡配置,Header 透传到后端应用(参数全解版)一、Nginx 反向代理与负载均…...
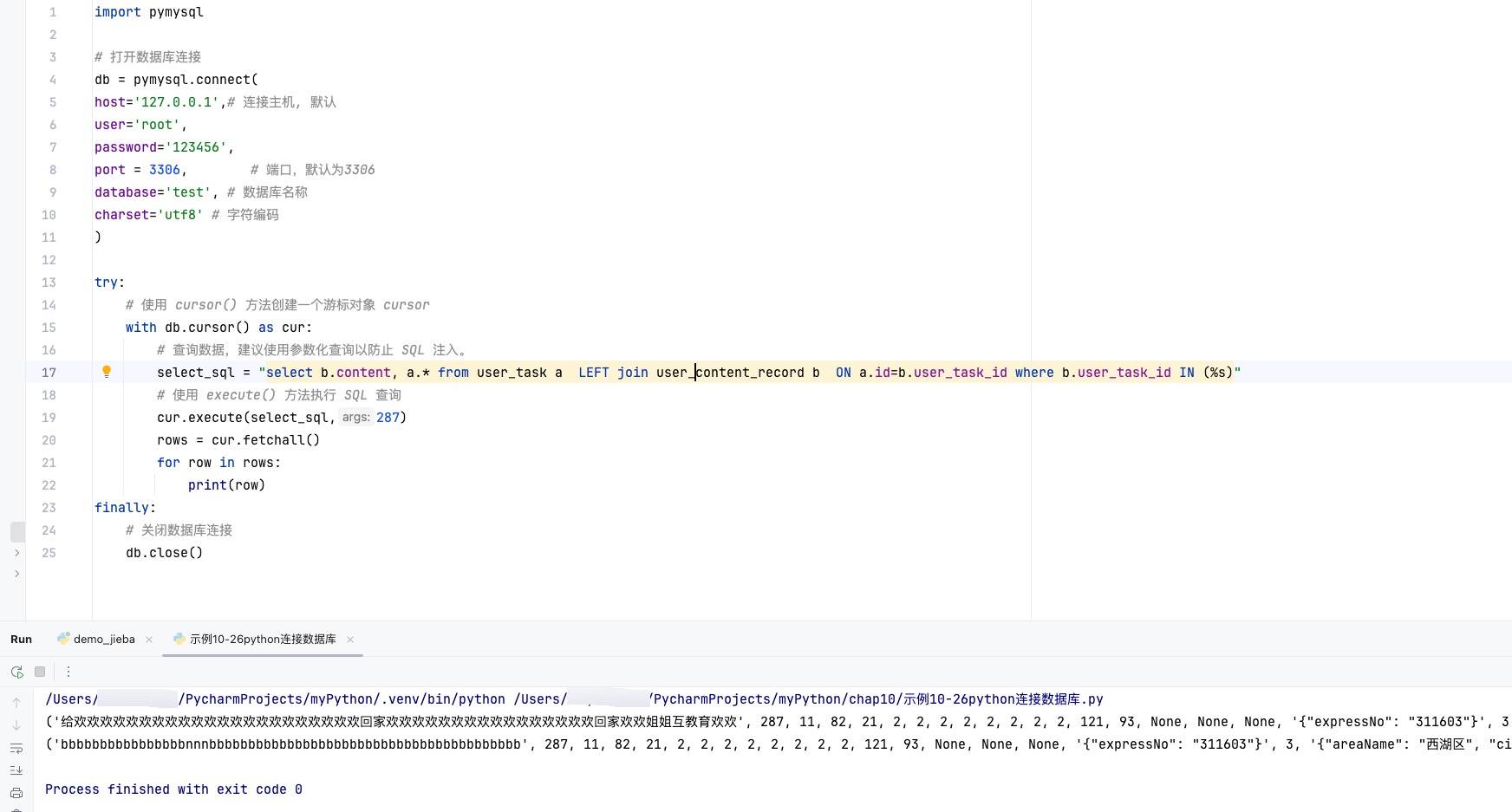
Python常用的第三方模块之【pymysql库】操作数据库
pymysql是在Python3.x版本中用于连接MySQL服务器的一个实现库,Python2中则是使用musqldb。 PyMySQL 是一个纯 Python 实现的 MySQL 客户端库,它允许我们直接在 Python 中执行 SQL 语句并与 MySQL 数据库进行交互。下面我们将详细介绍如何使用 PyMySQL 进…...

【Python数据分析】Pandas模块之pd.concat 函数
💭 写在前面:合并多个数据框,收集各种数据,并将其合并为一个数据框进行分析。本章我们介绍 Pandas 库中数据框合并的函数 —— concat。 0x00 引入:数据框的合并操作 合并多个数据框:收集各种数据,并将其合并为一个数据框进行分析。 下面介绍一些常用的 Pandas 库中数…...

矫平机深度解析:操作实务、行业标准与智能化升级
一、精细操作指南:不同材料的矫平参数设定 1. 常见金属矫平参数参考表 材料类型 厚度范围(mm) 辊缝初始值(mm) 矫平速度(m/min) 压力系数(k值) 低碳钢(…...

【高频考点精讲】CSS accent-color属性:如何快速自定义表单控件的颜色?
用CSS accent-color属性3分钟搞定表单控件换肤,原来这么简单! 前几天有个学员问我,checkbox和radio这些表单控件默认样式太丑了,有没有什么办法能快速改颜色?" 我一看这问题就乐了——这不正是CSS accent-color属性的拿手好戏吗?今天咱们就来好好聊聊这个被低估的C…...
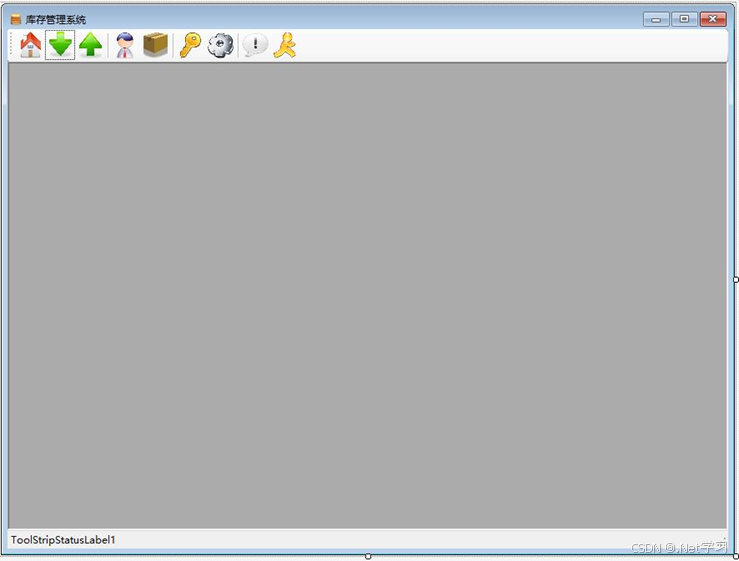
C# 综合示例 库存管理系统7 主界面(FormMain)
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 图99A-22 主界面窗口设计 主界面是多文档界面容器,需要将窗体属性IsMdiContainer设置为True。关于多文档界面编程请参看教程第7.12节《多文档界面》。 主界面并不提…...

vue项目中axios统一或单独控制接口请求时间
先说统一 这里将请求时间统一控制在12秒 // 使用由库提供的配置的默认值来创建实例 // 此时超时配置的默认值是 0 const axiosInstance axios.create()// 覆写库的超时默认值 // 现在,在超时前,所有请求时间统一控制在10秒 axiosInstance.defaults.ti…...
 A-D)
Codeforces Round 1020 (Div. 3) A-D
A. Dr. TC https://codeforces.com/contest/2106/problem/A 题目大意: 对输入字符串每个位置字符依次翻转(1->0 , 0->1) 比如: 101 001 翻转位置1 111 2 100 3 题解: 观察数学特征:ansn…...

系统思考:看清问题背后的结构
组织的挑战,往往不是因为不努力,而是“看不清” 结束了为期两天系统思考课程的第一天,被学员的全情投入深深打动。我们用系统结构图,一步步揭示那些表面看起来“习以为常”的问题: 什么原因跨部门协作总是磕磕绊绊&am…...

netlist
在电子设计自动化(EDA)中,网表(Netlist) 是描述电路设计连接关系的核心数据结构,本质上是电路元件(如逻辑门、晶体管、模块)及其互连关系的 文本化或结构化表示。它是从抽象设计&…...

如何实现Android屏幕和音频采集并启动RTSP服务?
技术背景 在移动直播和视频监控领域,实现高效的屏幕和音频采集并提供流媒体服务是关键技术之一。本文将详细介绍如何基于大牛直播SDK实现Android屏幕和麦克风/扬声器采集,并启动轻量级RTSP服务以对外提供拉流的RTSP URL。在Android平台上,轻…...

Langchain_Agent+数据库
本处使用Agent数据库,可以直接执行SQL语句。可以多次循环查询问题 前文通过chain去联系数据库并进行操作; 通过链的不断内嵌组合,生成SQL在执行SQL再返回。 初始化 import os from operator import itemgetterimport bs4 from langchain.ch…...
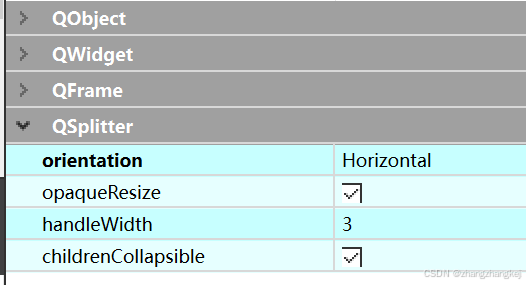
QT6 源(45):分隔条 QSplitter 允许程序的用户修改布局,程序员使用 IDE时,就是分隔条的用户,以及其 QSplitter 源代码
(1) (2)本类的继承关系如下,所以说分隔条属于容器: (3)本类的属性: (4) 这是一份 QSplitter 的举例代码,注意其构造函数时候的传参&am…...

Huffman(哈夫曼)解/压缩算法实现
一、文件压缩 哈夫曼压缩算法需要对输入的文件,逐字节扫描,统计出不同字节出现的数量(频率),根据的得到的频率生成一组叶子节点,这些节点存储着<字节信息>和<频率>,通常需要按频率排序后存储在…...
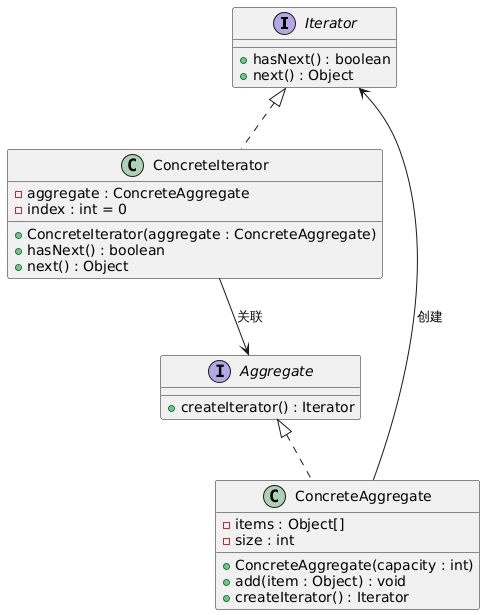
迭代器模式:统一数据遍历方式的设计模式
迭代器模式:统一数据遍历方式的设计模式 一、模式核心:将数据遍历逻辑与数据结构解耦 在软件开发中,不同的数据结构(如数组、链表、集合)有不同的遍历方式。如果客户端直接依赖这些数据结构的内部实现来遍历元素&…...

Oracle_开启归档日志和重做日志
在Oracle中,类似于MySQL的binlog的机制是归档日志(Archive Log)和重做日志(Redo Log) 查询归档日志状态 SELECT log_mode FROM v$database; – 输出示例: – LOG_MODE – ARCHIVELOG (表示已开启) – NO…...

LeetCode每日一题4.23
题目 问题分析 计算每个数字的数位和:对于从 1 到 n 的每个整数,计算其十进制表示下的数位和。 分组:将数位和相等的数字放到同一个组中。 统计每个组的数字数目:统计每个组中有多少个数字。 找到并列最多的组:返回数…...

线性代数-矩阵的秩
矩阵的秩(Rank)是线性代数中的一个重要概念,表示矩阵中线性无关的行(或列)的最大数量。它反映了矩阵所包含的“有效信息”的维度,是矩阵的核心特征之一。 直观理解 行秩与列秩: 行秩࿱…...
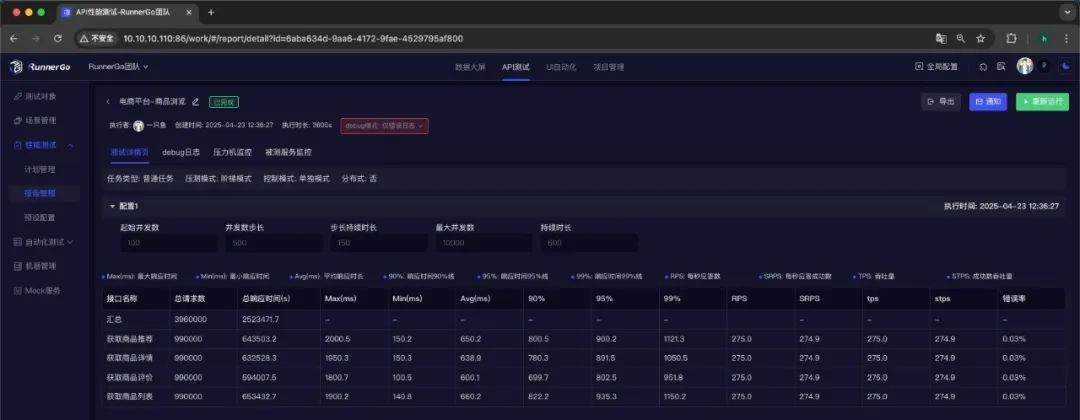
RunnerGo API性能测试实战与高并发调优
API 性能测试通过模拟不同负载场景,量化评估 API 的响应时间、吞吐量、稳定性、可扩展性等性能指标,关注其在正常、高峰甚至极限负载下的表现。这有助于确保 API 稳定高效地运行,为调用者提供优质服务。 接下来,我们借助 RunnerG…...