星火燎原:大数据时代的Spark技术革命在数字化浪潮席卷全球的今天,海量数据如同奔涌不息的洪流,传统的数据处理方式已难以满足实时、高效的需求。
星火燎原:大数据时代的Spark技术革命
在数字化浪潮席卷全球的今天,海量数据如同奔涌不息的洪流,传统的数据处理方式已难以满足实时、高效的需求。Apache Spark作为大数据领域的璀璨明星,凭借其卓越的性能和强大的功能,为数据处理带来了一场革命性的变革,成为众多企业和开发者处理大数据的首选工具。
一、Spark的诞生与发展
Spark诞生于美国加州大学伯克利分校的AMP实验室。当时,MapReduce在大数据处理领域占据主导地位,但它在迭代计算和交互式查询方面存在明显的性能瓶颈。为了突破这些限制,Matei Zaharia等研究人员开发了Spark,旨在提供一个更快、更通用的大数据处理框架。2013年,Spark加入Apache孵化器,并迅速发展成为Apache顶级项目。随着时间的推移,Spark不断完善和扩展,逐渐形成了一个涵盖数据处理全流程的生态系统,包括Spark SQL、Spark Streaming、MLlib(机器学习库)和GraphX(图计算库)等组件 ,广泛应用于数据科学、商业智能、实时分析等多个领域。
二、Spark的核心优势
(一)内存计算,极速处理
Spark最大的亮点之一在于其内存计算能力。与MapReduce将中间结果写入磁盘不同,Spark将数据缓存到内存中,大大减少了磁盘I/O操作。这使得Spark在处理迭代算法(如机器学习中的梯度下降算法)和交互式查询时,性能相较于MapReduce有了显著提升,速度可达到MapReduce的10到100倍。例如,在推荐系统中,利用Spark进行用户行为分析和推荐模型训练,能够快速处理海量的用户点击数据和商品信息,实现实时的个性化推荐,提升用户体验和商业价值。
(二)统一的生态系统,一站式解决方案
Spark提供了统一的编程模型和API,涵盖了数据提取、转换、分析、机器学习和图计算等多个环节。开发者可以使用Scala、Java、Python或R等编程语言,在同一个Spark应用程序中轻松实现不同类型的任务。例如,通过Spark SQL可以方便地进行结构化数据的查询和分析;利用Spark Streaming能够对实时数据流进行处理,实现实时监控和预警;MLlib则为机器学习任务提供了丰富的算法库,降低了机器学习应用的开发门槛。这种一站式的解决方案,极大地提高了数据处理的效率和灵活性,避免了在不同工具之间切换带来的复杂性和性能损耗。
(三)高容错性与扩展性
Spark采用了弹性分布式数据集(Resilient Distributed Dataset,RDD)这一核心抽象概念。RDD是一个容错的、可并行操作的分布式数据集合,它通过记录数据的转换操作(即血统关系),在出现故障时能够快速恢复数据,保证计算的连续性。同时,Spark支持在集群中动态添加或移除节点,轻松应对数据量和计算任务的增长。无论是小型企业处理TB级数据,还是大型互联网公司处理PB级甚至EB级数据,Spark都能凭借其强大的扩展性,提供稳定、高效的计算能力。
三、Spark的典型应用场景
(一)实时数据分析
在金融领域,股票交易数据、银行转账记录等实时数据流不断产生。Spark Streaming可以实时接收这些数据,结合Spark SQL进行实时分析,快速检测异常交易行为,如欺诈交易、洗钱等,及时采取措施防范风险。在电商行业,Spark能够实时分析用户的购物行为,如浏览商品、添加购物车、下单等操作,实时调整商品推荐策略,提高用户的购买转化率。
(二)机器学习与数据挖掘
Spark的MLlib提供了丰富的机器学习算法,包括分类、回归、聚类、协同过滤等。在医疗领域,利用Spark和MLlib可以对大量的病历数据、基因数据进行分析,建立疾病预测模型,帮助医生提前发现疾病风险,制定个性化的治疗方案。在广告推荐领域,通过对用户的兴趣偏好、历史行为数据进行聚类和协同过滤分析,为用户精准推送广告,提高广告投放效果和用户点击率。
(三)图计算
GraphX是Spark用于图计算的组件,能够高效处理大规模图数据。在社交网络中,GraphX可以分析用户之间的关系网络,挖掘潜在的社交圈子,推荐好友;在交通领域,利用GraphX对城市交通网络进行建模和分析,优化交通流量,规划最佳路线。例如,滴滴出行等打车平台可以利用GraphX分析车辆和乘客的位置关系、道路拥堵情况等,实现智能派单,提高运营效率。
四、Spark的未来展望
随着大数据、人工智能和云计算技术的不断融合发展,Spark也在持续进化。未来,Spark有望在以下几个方面取得更大的突破:
1. 与人工智能的深度融合:进一步优化MLlib,支持更复杂的深度学习框架和算法,推动人工智能技术在大数据处理中的广泛应用,实现更智能的数据分析和决策。
2. 云原生架构的完善:随着云计算的普及,Spark将更好地适应云原生环境,提高在公有云、私有云和混合云场景下的部署和运行效率,降低企业的运维成本。
3. 实时计算性能的提升:在实时计算领域,Spark将不断优化流处理性能,降低延迟,提高吞吐量,满足金融、物联网等对实时性要求极高的行业需求。
Apache Spark以其强大的性能、丰富的功能和广阔的应用前景,在大数据领域占据着举足轻重的地位。从诞生之初的创新突破,到如今的广泛应用,Spark持续推动着大数据技术的发展。在未来,Spark必将继续引领大数据处理的潮流,为数字化时代的数据驱动决策和创新发展提供强大的动力,如同星火一般,照亮大数据世界的每一个角落,实现燎原之势。
相关文章:

星火燎原:大数据时代的Spark技术革命在数字化浪潮席卷全球的今天,海量数据如同奔涌不息的洪流,传统的数据处理方式已难以满足实时、高效的需求。
星火燎原:大数据时代的Spark技术革命 在数字化浪潮席卷全球的今天,海量数据如同奔涌不息的洪流,传统的数据处理方式已难以满足实时、高效的需求。Apache Spark作为大数据领域的璀璨明星,凭借其卓越的性能和强大的功能,…...
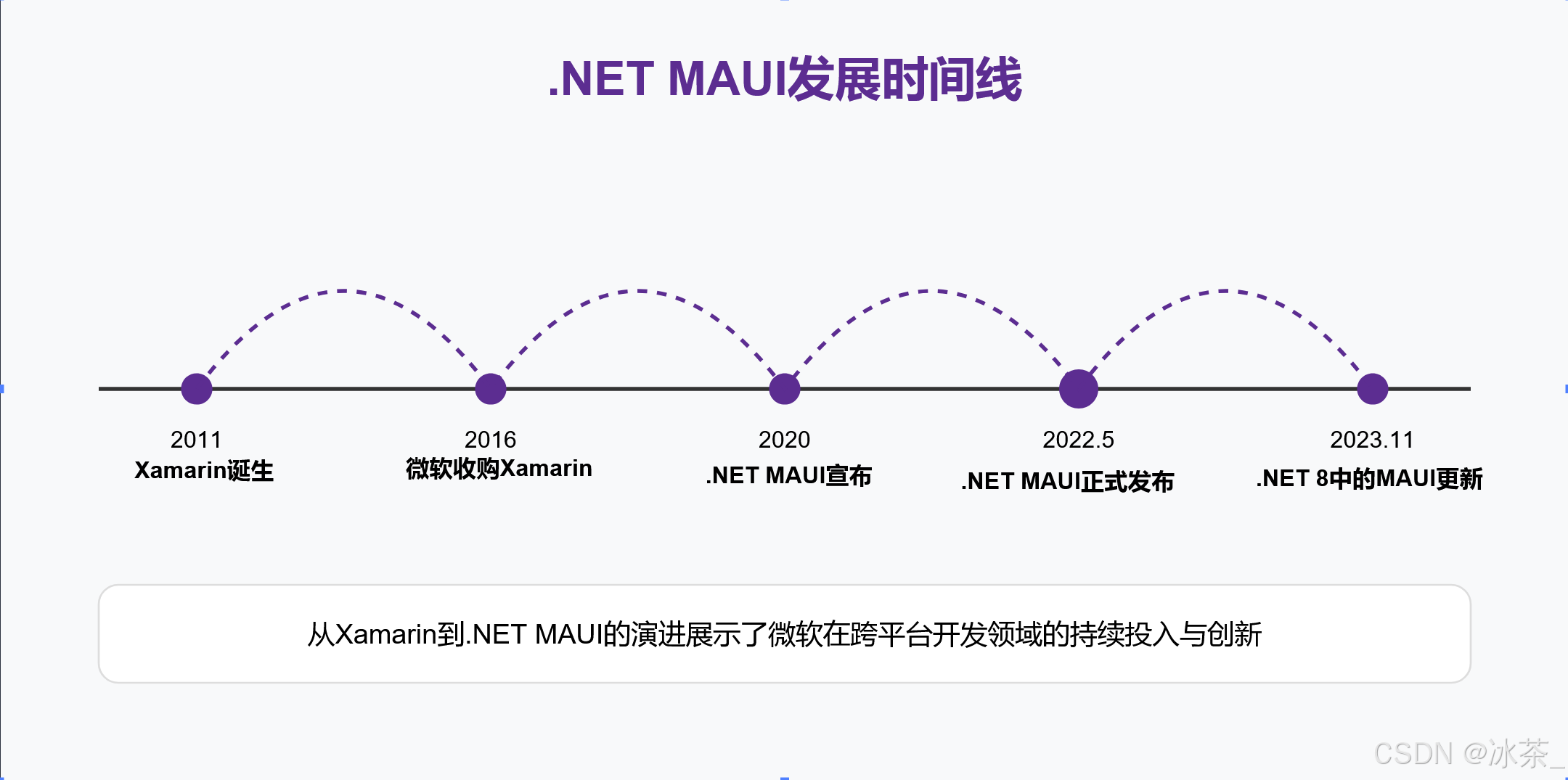
.NET MAUI 发展历程:从 Xamarin 到现代跨平台应用开发框架
文章目录 引言Xamarin 起源:MAUI 的前身Xamarin 的创立(2011年)Xamarin Studio 与 Visual Studio 集成(2013年)Xamarin.Forms 的诞生(2014年)微软收购Xamarin(2016年) .N…...

多模态大语言模型arxiv论文略读(四十)
The Wolf Within: Covert Injection of Malice into MLLM Societies via an MLLM Operative ➡️ 论文标题:The Wolf Within: Covert Injection of Malice into MLLM Societies via an MLLM Operative ➡️ 论文作者:Zhen Tan, Chengshuai Zhao, Raha M…...

【蓝桥杯选拔赛真题104】Scratch回文数 第十五届蓝桥杯scratch图形化编程 少儿编程创意编程选拔赛真题解析
目录 scratch回文数 一、题目要求 1、准备工作 2、功能实现 二、案例分析 1、角色分析 2、背景分析 3、前期准备 三、解题思路 四、程序编写 五、考点分析 六、推荐资料 1、scratch资料 2、python资料 3、C++资料 scratch回文数 第十五届青少年蓝桥杯scratch编…...
OpenWrt 与 Docker:打造轻量级容器化应用平台技术分享
文章目录 前言一、OpenWrt 与 Docker 的集成前提1.1 硬件与内核要求1.2 软件依赖 二、Docker 环境部署与验证2.1 基础服务配置2.2 存储驱动适配 三、容器化应用部署实践3.1 资源限制策略3.2 Docker Compose 适配 四、性能优化与监控4.1 容器资源监控4.2 镜像精简策略 五、典型问…...

tkinter的文件对话框:filedialog
诸神缄默不语-个人技术博文与视频目录 文章目录 一、前言二、tkinter.filedialog模块详解2.1 模块导入方式2.2 通用参数说明 三、五大核心函数实战3.1 选择单个文件 - askopenfilename()3.2 多文件选择 - askopenfilenames()3.3 保存文件对话框 - asksaveasfilename()3.4 选择目…...
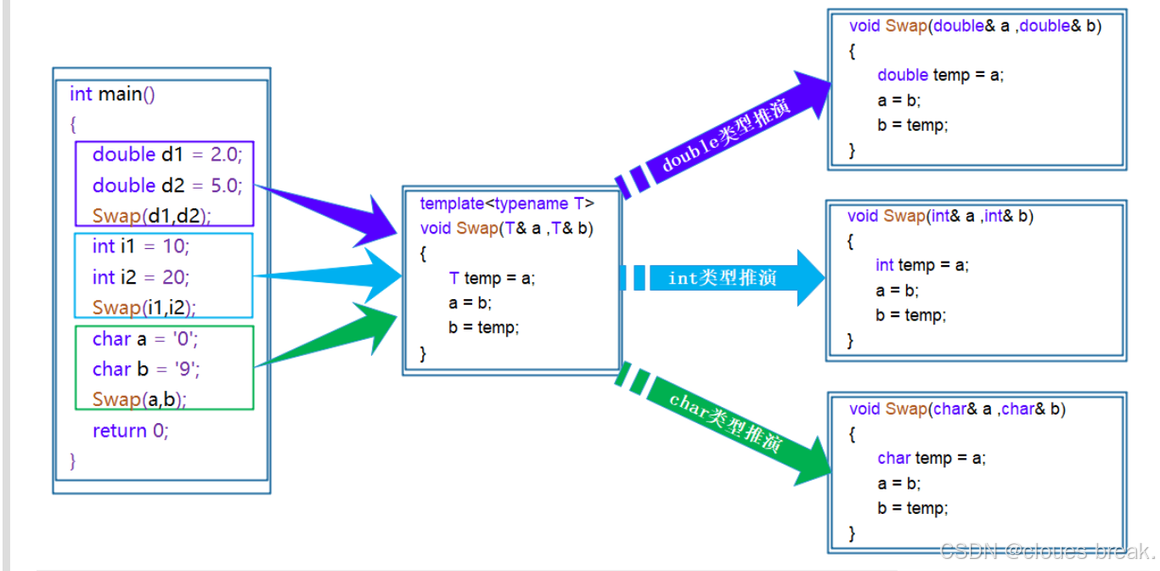
C++初阶----模板初阶
引言 什么是模板 模板是泛型编程的基础,泛型编程是以一种独立于任何特定类型的方式编写代码。 模板也是创建泛型类或者函数的蓝图。 如:库容器,迭代器和算法,都是泛型编程的例子 1. 泛型编程 首先,我们应该了解什么是…...

网络流量分析 | 流量分析基础
流量分析是网络安全领域的一个子领域,其主要重点是调查网络数据,以发现问题和异常情况。本文将涵盖网络安全和流量分析的基础知识。 网络安全与网络中的数据 网络安全的两个最关键概念就是:认证(Authentication)和授…...

幻读是什么项目中是怎么保证不会出现幻读
幻读(Phantom Read)是数据库并发控制中的一种现象,指的是在事务处理中,一个事务在读取某个数据范围时,另一个事务插入、删除或者修改了该数据范围,导致第一个事务再次读取数据时,看到的数据发生…...

C语言实现对哈希表的操作:创建哈希表与扩容哈希表
一. 简介 前面文章简单了解了哈希表 这种数据结构,文章如下: 什么是哈希表-CSDN博客 本文来学习一下哈希表,具体学习一下C语言实现对哈希表的简单实现。 二. C语言实现对哈希表的操作 1. 哈希表 哈希表(Hash Tableÿ…...

MYSQL 常用字符串函数 和 时间函数详解
一、字符串函数 1、CONCAT(str1, str2, …) 拼接多个字符串。 SELECT CONCAT(Hello, , World); -- 输出 Hello World2、SUBSTRING(str, start, length) 或 SUBSTR() 截取字符串。 SELECT SUBSTRING(MySQL, 3, 2); -- 输出 SQ3、LENGTH(str) 与 CHAR_LENGTH…...
)
通过API接口在自己的独立站系统上架商品信息。(实战案例)
以下是一个通过API接口在独立站系统上架商品信息的实战案例,以某跨境电商独立站集成亚马逊产品数据为例,详细说明技术实现流程和关键代码逻辑: 案例背景 某跨境电商独立站需要从亚马逊平台同步商品数据(标题、价格、库存、图片、…...
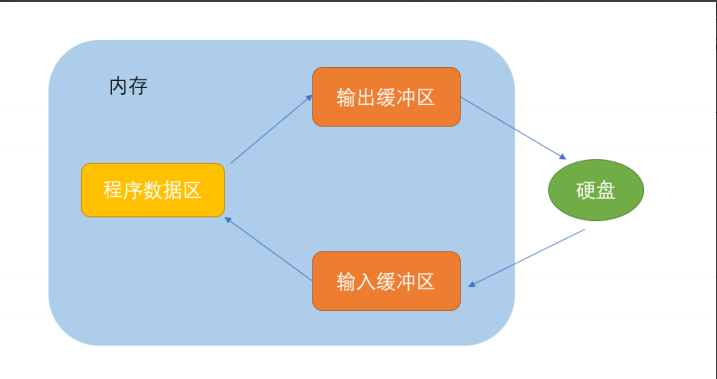
C语言文件操作完全手册:读写·定位·实战
1.什么是文件 1.1文件的概念 文件(File)是计算机中用于持久化存储数据的基本单位。它可以存储文本、图片、音频、程序代码等各种信息,并在程序运行结束后仍然保留数据。 1.2文件名 一个文件要有一个唯一的文件标识,以便用户识别…...

多模态大语言模型arxiv论文略读(三十七)
A Spectrum Evaluation Benchmark for Medical Multi-Modal Large Language Models ➡️ 论文标题:A Spectrum Evaluation Benchmark for Medical Multi-Modal Large Language Models ➡️ 论文作者:Jie Liu, Wenxuan Wang, Yihang Su, Jingyuan Huan, …...

IDEA创建Gradle项目然后删除报错解决方法
根据错误信息,你的项目目录中缺少Gradle构建必需的核心文件(如settings.gradle/build.gradle),且IDEA可能残留了Gradle的配置。以下是具体解决方案: 一、问题根源分析 残留Gradle配置 你通过IDEA先创建了Gradle子模块…...

SpringBoot 学习
什么是 SpringBoot SpringBoot 是基于 Spring 生态的开源框架,旨在简化 Spring 应用的初始化搭建和开发配置。它通过约定大于配置的理念,提供快速构建生产级应用的解决方案,显著降低开发者对 XML 配置和依赖管理的负担。 特点: …...

MoE架构解析:如何用“分治”思想打造高效大模型?
在人工智能领域,模型规模的扩大似乎永无止境。从GPT-3的1750亿参数到传闻中的GPT-4万亿级规模,每一次突破都伴随着惊人的算力消耗。但当我们为这些成就欢呼时,一个根本性问题愈发尖锐:如何在提升模型能力的同时控制计算成本&#…...

云服务器和独立服务器的区别在哪
在当今数字化的时代,服务器成为了支撑各种业务和应用的重要基石。而在服务器的领域中,云服务器和独立服务器是两个备受关注的选项。那么,它们到底有何区别呢? 首先,让我们来聊聊成本。云服务器通常采用按需付费的模式…...

使用 Pandas 进行多格式数据整合:从 Excel、JSON 到 HTML 的处理实战
前言 在数据处理与分析的实际场景中,我们经常需要整合不同格式的数据,例如 Excel 表格、JSON 配置文件、HTML 报表等。本文以一个具体任务(蓝桥杯模拟练习题)为例,详细讲解如何使用 Python 的 Pandas 库结合其他工具&…...

深入解析 Linux 中动静态库的加载机制:从原理到实践
引言 在 Linux 开发中,动静态库是代码复用的核心工具。静态库(.a)和动态库(.so)的加载方式差异显著,直接影响程序的性能、灵活性和维护性。本文将深入剖析两者的加载机制,结合实例演示和底层原…...

VuePress 使用教程:从入门到精通
VuePress 使用教程:从入门到精通 VuePress 是一个以 Vue 驱动的静态网站生成器,它为技术文档和技术博客的编写提供了优雅而高效的解决方案。无论你是个人开发者、团队负责人还是开源项目维护者,VuePress 都能帮助你轻松地创建和管理你的文档…...

Kafka与Spark-Streaming
大数据处理的得力助手:Kafka与Spark-Streaming 在大数据处理的领域中,Kafka和Spark-Streaming都是极为重要的工具。今天,咱们就来深入了解一下它们,看看这些技术是如何让数据处理变得高效又强大的。先来说说Kafka,它是…...

【设计】接口幂等性设计
1. 幂等性定义 接口幂等性: 无论调用次数多少,对系统状态的影响与单次调用相同。 比如用户支付接口因网络延迟重复提交了三次。 导致原因: 用户不可靠(手抖多点)网络不可靠(超时重传)系统不可…...

闲聊人工智能对媒体的影响
技术总是不断地改变信息的传播方式。互联网促进了社交媒体的蓬勃发展。 网络媒体成为主流。大语言模型为代表的人工智能的出现,又会对媒体传播带来怎样的改变呢?媒体的演变反映了社会和技术的演变。 人工智能(AI) 将继续对整个媒体行业产生变革性的影响。…...

卷积神经网络--手写数字识别
本文我们通过搭建卷积神经网络模型,实现手写数字识别。 pytorch中提供了手写数字的数据集 ,我们可以直接从pytorch中下载 MNIST中包含70000张手写数字图像:60000张用于训练,10000张用于测试 图像是灰度的,28x28像素 …...

Pandas 数据导出:如何将 DataFrame 追加到 Excel 的不同工作表
在数据分析和数据处理过程中,将数据导出到 Excel 文件是一个常见的需求。Pandas 提供了强大的功能来实现这一需求,尤其是将数据追加到同一个 Excel 文件的不同工作表(Sheet)中。本文将详细介绍如何使用 Pandas 实现这一功能&#…...
)
Unity中数据和资源加密(异或加密,AES加密,MD5加密)
在项目开发中,始终会涉及到的一个问题,就是信息安全,在调用接口,或者加载的资源,都会涉及安全问题,因此就出现了各种各样的加密方式。 常见的也是目前用的最广的加密方式,分别是:DE…...
SQL Server 2019 安装与配置详细教程
一、写在最前的心里话 和 MySQL 对比,SQL Server 的安装和使用确实要处理很多细节: 需要选择配置项很多有“定义实例”的概念,同一机器可以运行多个数据库服务设置身份验证方式时,需要同时配置 Windows 和 SQL 登录要想 Spring …...

Qt 调试信息重定向到本地文件
1、在Qt软件开发过程中,我们经常使用qDebug()输出一些调试信息在QtCreator终端上。 但若将软件编译、生成、打包为一个完整的可运行的程序并安装在系统中后,系统中没有QtCreator和编译环境,那应用程序出现问题,如何输出信息排查…...
MyBatisPlus文档
一、MyBatis框架回顾 使用springboot整合Mybatis,实现Mybatis框架的搭建 1、创建示例项目 (1)、创建工程 新建工程 创建空工程 创建模块 创建springboot模块 选择SpringBoot版本 (2)、引入依赖 <dependencies><dependency><groupId>org.springframework.…...