卷积神经网络迁移学习:原理与实践指南
引言
在深度学习领域,卷积神经网络(CNN)已经在计算机视觉任务中取得了巨大成功。然而,从头开始训练一个高性能的CNN模型需要大量标注数据和计算资源。迁移学习(Transfer Learning)技术为我们提供了一种高效解决方案,它能够将预训练模型的知识迁移到新任务中,显著减少训练时间和数据需求。本文将全面介绍CNN迁移学习的原理、优势及实践方法。
1、内容
迁移学习是指利用已经训练好的模型,在新的任务上进行微调。迁移学习可以加快模型训练速度,提高模型性能,并且在数据稀缺的情况下也能很好地工作
2、步骤
1、选择预训练的模型和适当的层:通常,我们会选择在大规模图像数据集(如ImageNet)上预训练的模型,如VGG、ResNet等。然后,根据新数据集的特点,选择需要微调的模型层。对于低级特征的任务(如边缘检测),最好使用浅层模型的层,而对于高级特征的任务(如分类),则应选择更深层次的模型。
2、冻结预训练模型的参数:保持预训练模型的权重不变,只训练新增加的层或者微调一些层,避免因为在数据集中过拟合导致预训练模型过度拟合。
3、在新数据集上训练新增加的层:在冻结预训练模型的参数情况下,训练新增加的层。这样,可以使新模型适应新的任务,从而获得更高的性能。
4、微调预训练模型的层:在新层上进行训练后,可以解冻一些已经训练过的层,并且将它们作为微调的目标。这样做可以提高模型在新数据集上的性能。
5、评估和测试:在训练完成之后,使用测试集对模型进行评估。如果模型的性能仍然不够好,可以尝试调整超参数或者更改微调层。
Resnet网络:
原理:
卷积神经网络都是通过卷积层和池化层的叠加组成的。 在实际的试验中发现,随着卷积层和池化层的叠加,学习效果不会逐渐变好,反而出现2个问题:
1、梯度消失和梯度爆炸
梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
2、退化问题
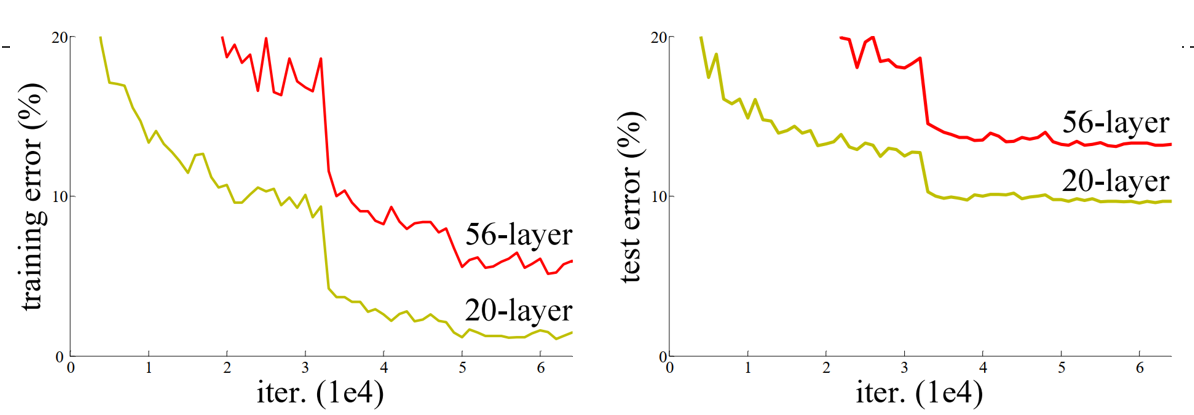
为了解决梯度消失或梯度爆炸问题,论文提出通过数据的预处理以及在网络中使用 BN(Batch Normalization)层来解决。
为了解决深层网络中的退化问题,可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为 残差网络 (ResNets)。
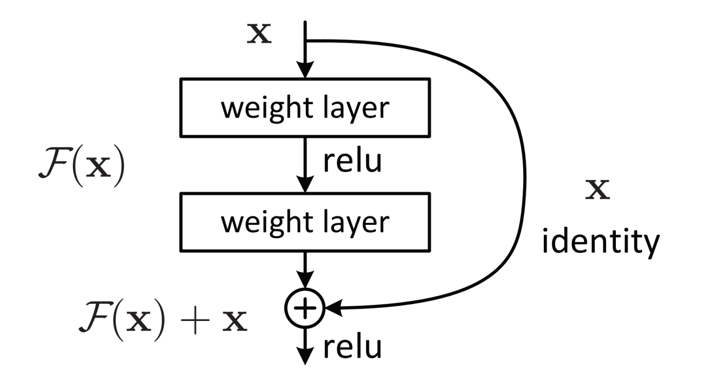
1、18层resnet结构:
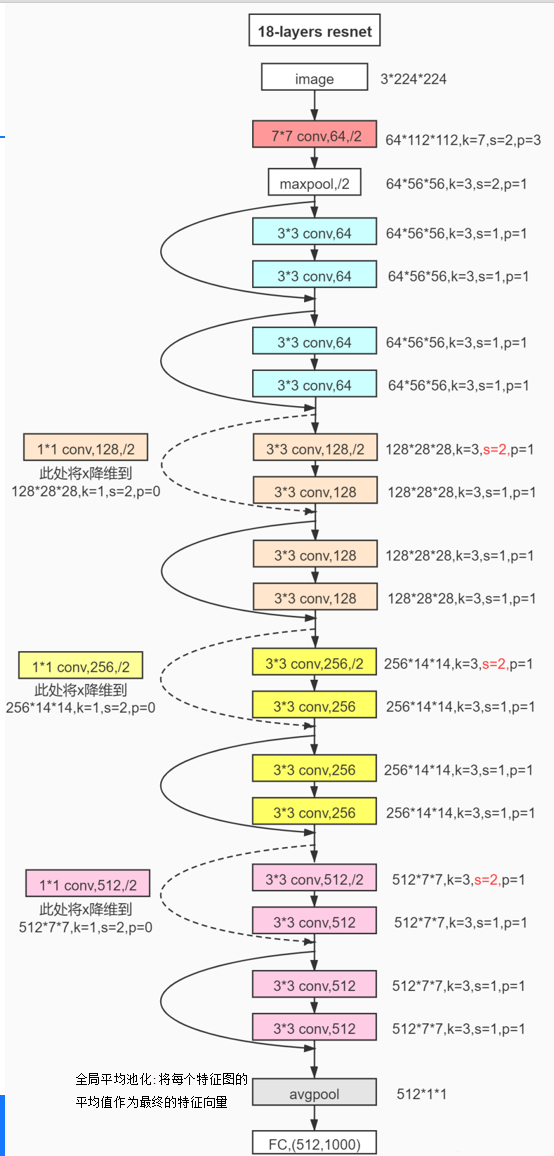
2、BN(Batch Normalization)
实例
1、导入相关的库
import torch
from torch.utils.data import DataLoader,Dataset #数据包管理工具,打包数据,
from torchvision import transforms
from torch import nn
import torchvision.models as models
from PIL import Image
import numpy as np2、调取模型并冻结参数
#不再需要自己来搭建模型了。预训练的文件也加载进去了。
# 将resnet18模型迁移到食物分类项目中.#残差网络是固定的网络结构,不需要你自己来类定义了。
resnet_model=models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
#weights=models.ResNet18_Weights.DEFAULT表示使用在 ImageNet 数据集上预先训练好的权重
for param in resnet_model.parameters():print(param)param.requires_grad=False #冻结
#模型所有参数(即权重和偏差)的requires_grad属性设置为False,从而冻结所有模型参数,详细说明:
-
models.resnet18()加载ResNet18架构 -
weights=models.ResNet18_Weights.DEFAULT指定使用官方预训练权重 -
遍历所有参数并冻结
3、对网络模型进行微调
in_features=resnet_model.fc.in_features #获取模型原输入的特征个数
resnet_model.fc=nn.Linear(in_features,20) #创建一个全连接层4、保存需要训练的参数
params_to_update=[] #保存需要训练的参数,仅仅包含全连接层的参数
for param in resnet_model.parameters():if param.requires_grad==True:params_to_update.append(param)5、数据预处理
data_transforms={
'train':
transforms.Compose([transforms.Resize([300, 300]),transforms.RandomRotation(45), # 随机旋转,-45到45度之间随机选transforms.CenterCrop(224), # 从中心开始裁剪[256,256]transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转# transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),transforms.RandomGrayscale(p=0.1), # 概率转换成灰度率,3通道就是R=G=Btransforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'valid':
transforms.Compose([transforms.Resize([224,224]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
数据预处理包括:
-
训练集使用多种数据增强(随机旋转、水平翻转等)
-
验证集只进行简单的resize和归一化
-
归一化参数使用ImageNet的均值和标准差
6、自定义数据集的类
class food_dataset(Dataset):def __init__(self,file_path,transform=None):self.file_path=file_pathself.imgs=[]self.labels=[]self.transform=transformwith open(self.file_path) as f:samples=[x.strip().split(' ') for x in f.readlines()]for img_path,label in samples:self.imgs.append(img_path)self.labels.append(label)def __len__(self):return len(self.imgs)def __getitem__(self, idx):image=Image.open(self.imgs[idx])if self.transform:image=self.transform(image)label = self.labels[idx]label = torch.from_numpy(np.array(label,dtype=np.int64))return image,label这个自定义Dataset类:
-
从文本文件读取图像路径和标签
-
实现
__len__和__getitem__方法,供DataLoader使用 -
应用指定的transform处理图像
7、数据加载器准备
# 创建训练集和测试集实例
training_data = food_dataset(file_path='trainda.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path='testda.txt', transform=data_transforms['valid'])# 创建数据加载器
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
数据加载器提供:
-
批量加载功能(batch_size=64)
-
训练数据随机打乱(shuffle=True)
-
多线程数据预读取
8、训练和测试流程
def train(dataloader,model,loss_fn,optimizer):model.train() #告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w。在训练过程中,w会被修改的
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train()和 model.eval()。
#一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval()for X,y in dataloader: #其中batch为每一个数据的编号X,y=X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPUpred=model.forward(X) #.forward可以被省略,父类中已经对次功能进行了设置。自动初始化loss=loss_fn(pred,y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值woptimizer.step() #根据梯度更新网络w参数best_acc=0
def test(dataloader, model, loss_fn):global best_accsize = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= size9、循环训练
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(params_to_update, lr=0.001) # Adam优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # 学习率调度# 训练10个epoch
epoch = 10
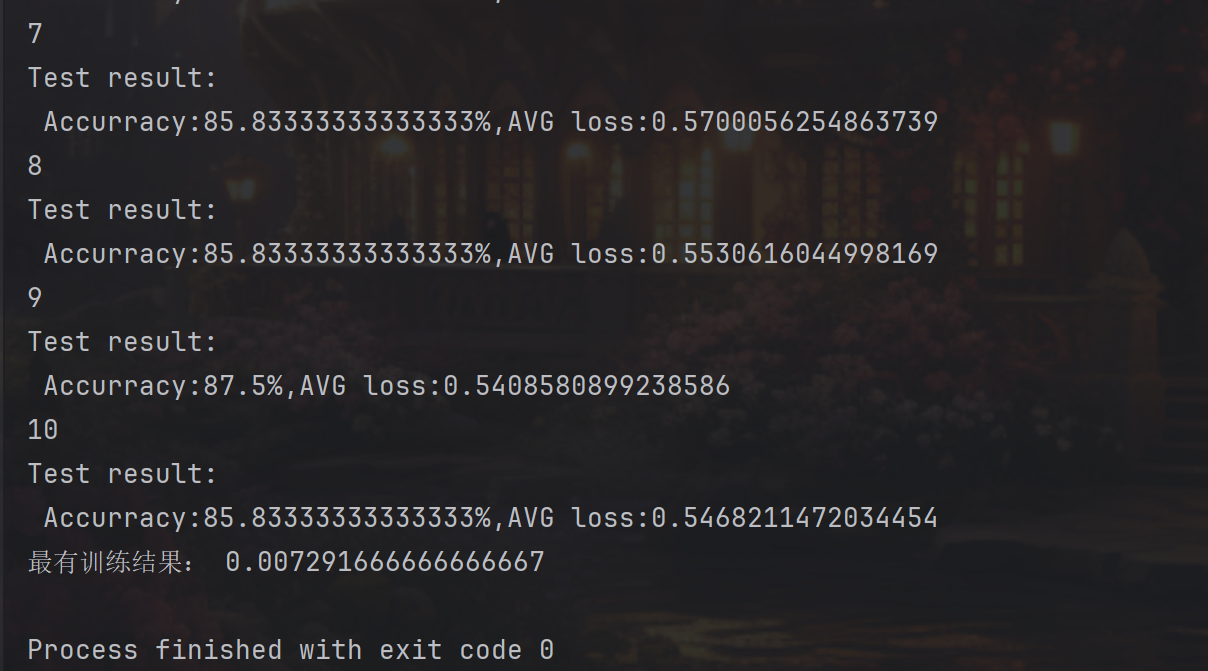
for i in range(epoch):print(f"Epoch {i + 1}")train(train_dataloader, model, loss_fn, optimizer) # 训练scheduler.step() # 更新学习率test(test_dataloader, model, loss_fn) # 测试print('Best accuracy:', best_acc) # 打印最佳准确率主循环流程:
-
定义损失函数和优化器
-
设置学习率调度器(每5个epoch学习率减半)
-
进行10轮训练和测试
-
打印最终最佳准确率
结果展示:
相关文章:
卷积神经网络迁移学习:原理与实践指南
引言 在深度学习领域,卷积神经网络(CNN)已经在计算机视觉任务中取得了巨大成功。然而,从头开始训练一个高性能的CNN模型需要大量标注数据和计算资源。迁移学习(Transfer Learning)技术为我们提供了一种高效解决方案,它能够将预训练模型的知识…...

Centos虚拟机远程连接缓慢
文章目录 Centos虚拟机远程连接缓慢1. 问题:SSH远程连接卡顿现象2. 原因:SSH服务端DNS检测机制3. 解决方案:禁用DNS检测与性能调优3.1 核心修复步骤3.2 辅助优化措施 4. 扩展认识:SSH协议的核心机制4.1 SSH工作原理4.2 关键配置文…...

Spark与Hadoop之间的联系和对比
(一)Spark概述 Apache Spark 是一个快速、通用、可扩展的大数据处理分析引擎。它最初由加州大学伯克利分校 AMPLab 开发,后成为 Apache 软件基金会的顶级项目。Spark 以其内存计算的特性而闻名,能够在内存中对数据进行快速处理&am…...
——STL之删除算法)
C++学习笔记(三十九)——STL之删除算法
STL 算法分类: 类别常见算法作用排序sort、stable_sort、partial_sort、nth_element等排序搜索find、find_if、count、count_if、binary_search等查找元素修改copy、replace、replace_if、swap、fill等修改容器内容删除remove、remove_if、unique等删除元素归约for…...

C++——Lambda表达式
在C中,Lambda表达式是一种匿名函数对象,它允许你在代码中直接定义一个函数,而不需要提前声明一个单独的函数。Lambda表达式是从C11标准开始引入的,它极大地增强了C语言的灵活性和表达能力,尤其在处理函数对象、回调函数…...
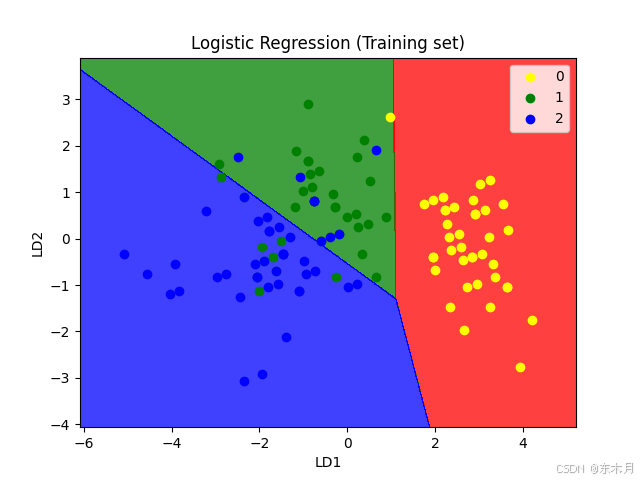
基于线性LDA算法对鸢尾花数据集进行分类
基于线性LDA算法对鸢尾花数据集进行分类 1、效果 2、流程 1、加载数据集 2、划分训练集、测试集 3、创建模型 4、训练模型 5、使用LDA算法 6、画图3、示例代码 # 基于线性LDA算法对鸢尾花数据集进行分类# 基于线性LDA算法对鸢尾花数据集进行分类 import numpy as np import …...

【Deepseek基础篇】--v3基本架构
目录 MOE参数 1.基本架构 1.1. Multi-Head Latent Attention多头潜在注意力 1.2.无辅助损失负载均衡的 DeepSeekMoE 2.多标记预测 2.1. MTP 模块 论文地址:https://arxiv.org/pdf/2412.19437 DeepSeek-V3 是一款采用 Mixture-of-Experts(MoE&…...

从爬楼梯到算法世界:动态规划与斐波那契的奇妙邂逅
从爬楼梯到算法世界:动态规划与斐波那契的奇妙邂逅 在算法学习的旅程中,总有一些经典问题让人印象深刻。“爬楼梯问题”就是其中之一,看似简单的题目,却蕴藏了动态规划与斐波那契数列的深刻联系。今天,我就以这个问题…...

centos7使用yum快速安装最新版本Jenkins-2.462.3
Jenkins支持多种安装方式:yum安装、war包安装、Docker安装等。 官方下载地址:https://www.jenkins.io/zh/download 本次实验使用yum方式安装Jenkins LTS长期支持版,版本为 2.462.3。 一、Jenkins基础环境的安装与配置 1.1:基本…...
【vue】【element-plus】 el-date-picker使用cell-class-name进行标记,type=year不生效解决方法
typedete,自定义cell-class-name打标记效果如下: 相关代码: <el-date-pickerv-model"date":clearable"false":editable"false":cell-class-name"cellClassName"type"date"format&quo…...
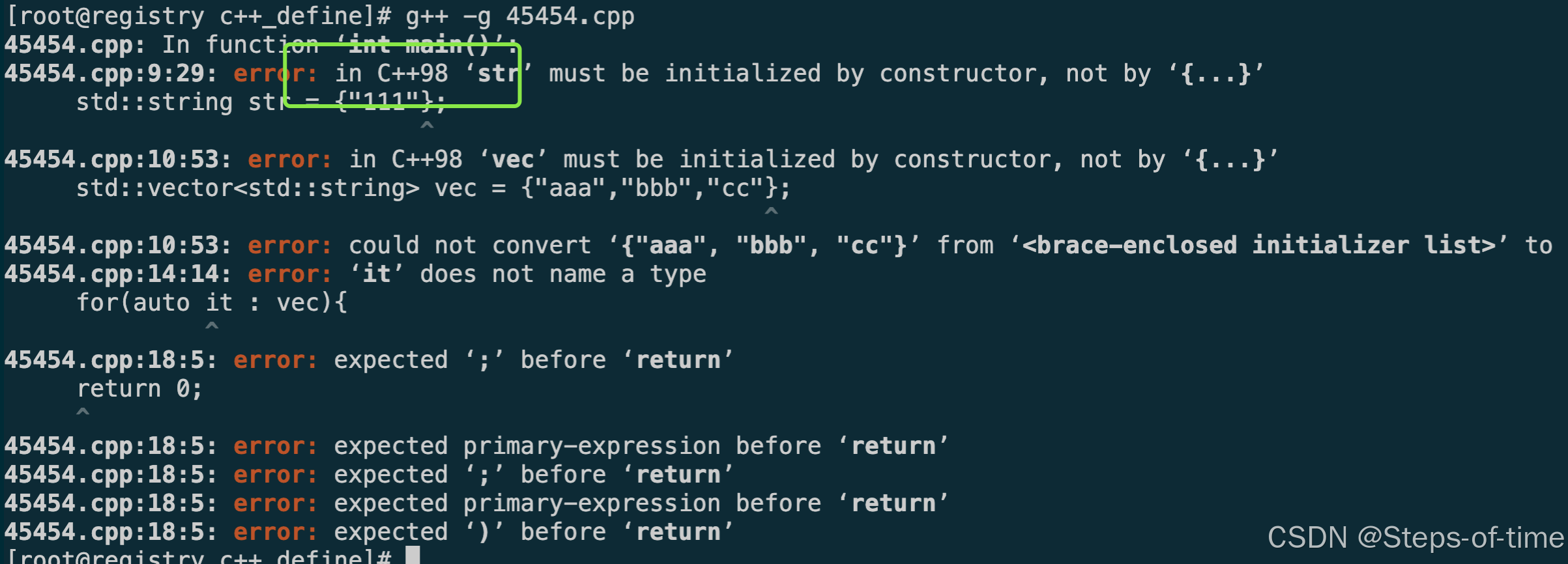
c++11新特性随笔
1.统一初始化特性 c98中不支持花括号进行初始化,编译时会报错,在11当中初始化可以通过{}括号进行统一初始化。 c98编译报错 c11: #include <iostream> #include <set> #include <string> #include <vector>int main() {std:…...

Linux字符设备驱动开发的详细步骤
1. 确定主设备号 手动指定:明确设备号时,使用register_chrdev_region()静态申请(需确保未被占用)。动态分配:通过alloc_chrdev_region()由内核自动分配主设备号(更灵活,推…...

Nginx 二进制部署与 Docker 部署深度对比
一、核心概念解析 1. 二进制部署 通过包管理器(如 apt/yum)或源码编译安装 Nginx,直接运行在宿主机上。其特点包括: 直接性:与操作系统深度绑定,直接使用系统库和内核功能 。定制化:支持通过编译参数(如 --with-http_ssl_module)启用或禁用模块,满足特定性能需求 。…...

C++23 中 constexpr 的重要改动
文章目录 1. constexpr 函数中使用非字面量变量、标号和 goto (P2242R3)示例代码 2. 允许 constexpr 函数中的常量表达式中使用 static 和 thread_local 变量 (P2647R1)示例代码 3. constexpr 函数的返回类型和形参类型不必为字面类型 (P2448R2)示例代码 4. 不存在满足核心常量…...

CMake ctest
CMake学习–ctest全面介绍 1. 环境准备 确保已安装 cmake 和编译工具: sudo apt update sudo apt install cmake build-essential2. 创建示例项目 假设我们要测试一个简单的数学函数 add(),项目结构如下: math_project/ ├── CMakeList…...

全面解析React内存泄漏:原因、解决方案与最佳实践
在开发React应用时,内存泄漏是一个常见但容易被忽视的问题。如果处理不当,它会导致应用性能下降、卡顿甚至崩溃。由于React的组件化特性,许多开发者可能没有意识到某些操作(如事件监听、异步请求、定时器等)在组件卸载…...
)
JavaScript学习教程,从入门到精通,Ajax数据交换格式与跨域处理(26)
Ajax数据交换格式与跨域处理 一、Ajax数据交换格式 1. XML (eXtensible Markup Language) XML是一种标记语言,类似于HTML但更加灵活,允许用户自定义标签。 特点: 可扩展性强结构清晰数据与表现分离文件体积相对较大 示例代码࿱…...
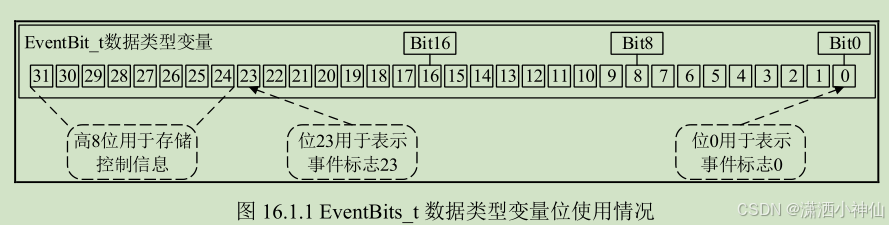
【FreeRTOS】事件标志组
文章目录 1 简介1.1事件标志1.2事件组 2事件标志组API2.1创建动态创建静态创建 2.2 删除事件标志组2.3 等待事件标志位2.4 设置事件标志位在任务中在中断中 2.5 清除事件标志位在任务中在中断中 2.6 获取事件组中的事件标志位在任务中在中断中 2.7 函数xEventGroupSync 3 事件标…...
超级扩音器手机版:随时随地,大声说话
在日常生活中,我们常常会遇到手机音量太小的问题,尤其是在嘈杂的环境中,如KTV、派对或户外活动时,手机自带的音量往往难以满足需求。今天,我们要介绍的 超级扩音器手机版,就是这样一款由上海聚告德业文化发…...
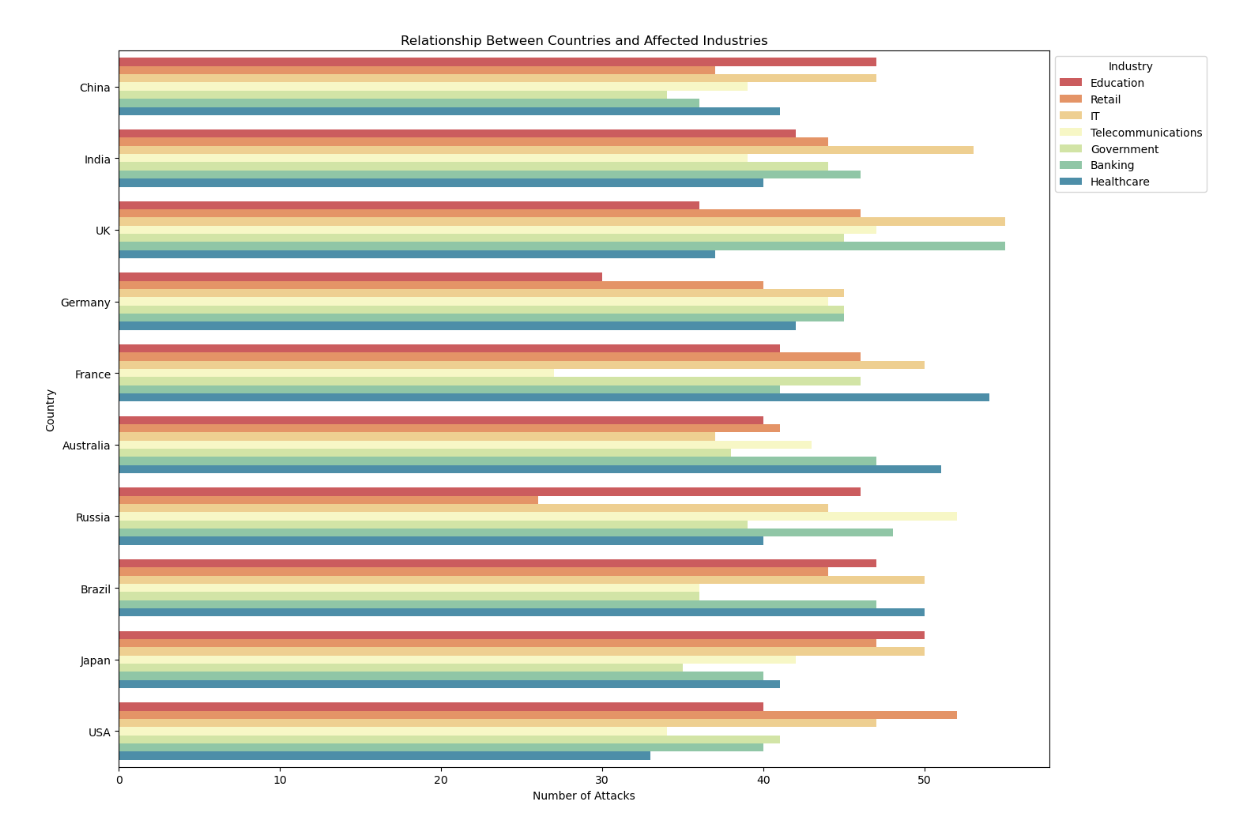
【数据可视化-27】全球网络安全威胁数据可视化分析(2015-2024)
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...
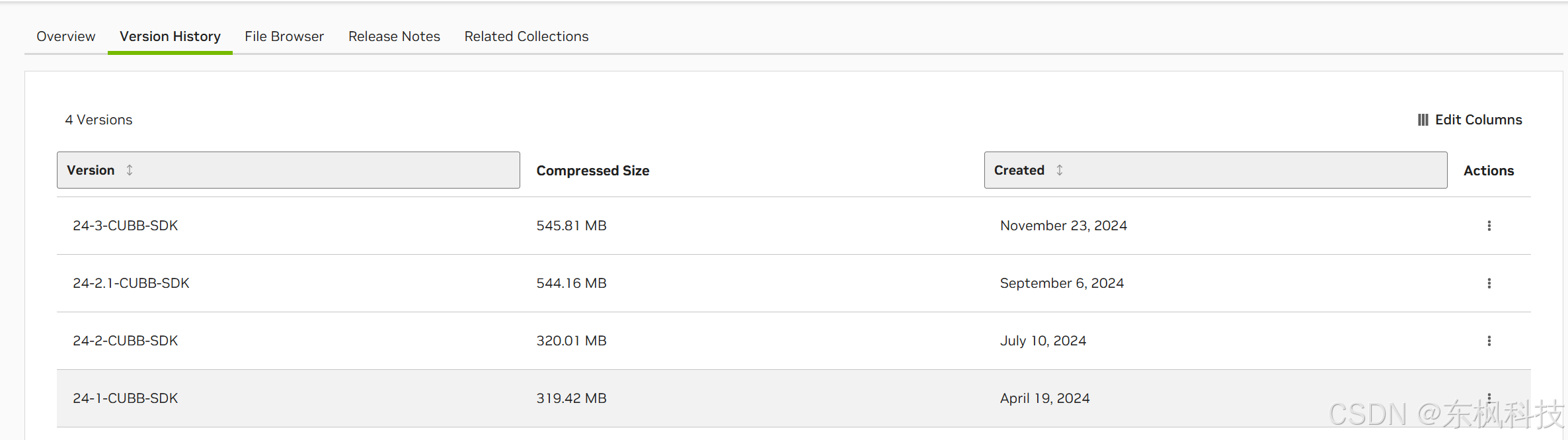
【6G 开发】NV NGC
配置 生成密钥 API Keys 生成您自己的 API 密钥,以便通过 Docker 客户端或通过 NGC CLI 使用 Secrets Manager、NGC Catalog 和 Private Registry 的 NGC 服务 以下个人 API 密钥已成功生成,可供此组织使用。这是唯一一次显示您的密钥。 请妥善保管您的…...

计算机视觉各类任务评价指标详解
文章目录 计算机视觉各类任务评价指标详解一、图像分类(Image Classification)常用指标1. 准确率(Accuracy)2. Top-k Accuracy3. 精确率(Precision)、召回率(Recall)、F1 分数&#…...

SIEMENS PLC程序解读 -Serialize(序列化)SCATTER_BLK(数据分散)
1、程序数据 第12个字节 PI 2、程序数据 第16个字节 PI 3、程序数据 第76个字节 PO 4、程序代码 2、程序解读 图中代码为 PLC 梯形图,主要包含以下指令及功能: Serialize(序列化): 将 SRC_VARIABLEÿ…...
宁德时代25年时代长安动力电池社招入职测评SHL题库Verify测评语言理解数字推理真题
测试分为语言和数字两部分,测试时间各为17分钟,测试正式开始后不能中断或暂停...

python源码打包为可执行的exe文件
文章目录 简单的方式(PyInstaller)特点步骤安装 PyInstaller打包脚本得到.exe文件 简单的方式(PyInstaller) 特点 支持 Python 3.6打包为单文件(–onefile)或文件夹形式自动处理依赖项 步骤 安装 PyIns…...

数据加密技术:从对称加密到量子密码的原理与实战
数据加密技术:从对称加密到量子密码的原理与实战 在网络安全体系中,数据加密是保护信息机密性、完整性的核心技术。从古代的凯撒密码到现代的量子加密,加密技术始终是攻防博弈的关键战场。本文将深入解析对称加密、非对称加密、哈希函数的核…...

高性能的开源网络入侵检测和防御引擎:Suricata介绍
一、Debian下使用Suricata 相较于Windows,Linux环境对Suricata的支持更加完善,操作也更为便捷。 1. 安装 Suricata 在Debian系统上,你可以通过包管理器 apt 轻松安装 Suricata。 更新软件包列表: sudo apt update安装 Suricata: sudo apt …...

【硬核解析:基于Python与SAE J1939-71协议的重型汽车CAN报文解析工具开发实战】
引言:重型汽车CAN总线的数据价值与挑战 随着汽车电子化程度的提升,控制器局域网(CAN总线)已成为重型汽车的核心通信网络。不同控制单元(ECU)通过CAN总线实时交互海量报文数据,这些数据隐藏着车…...

React类组件与React Hooks写法对比
React 类组件 vs Hooks 写法对比 分类类组件(Class Components)函数组件 Hooks组件定义class Component extends React.Componentconst Component () > {}状态管理this.state this.setState()useState()生命周期componentDidMount, componentDidU…...
Uniapp 自定义 Tabbar 实现教程
Uniapp 自定义 Tabbar 实现教程 1. 简介2. 实现步骤2.1 创建自定义 Tabbar 组件2.2 配置 pages.json2.3 在 App.vue 中引入组件 3. 实现过程中的关键点3.1 路由映射3.2 样式设计3.3 图标处理 4. 常见问题及解决方案4.1 页面跳转问题4.2 样式适配问题4.3 性能优化 5. 扩展功能5.…...