第十二章 Python语言-大数据分析PySpark(终)
目录
一. PySpark前言介绍
二.基础准备
三.数据输入
四.数据计算
1.数据计算-map方法
2.数据计算-flatMap算子
3.数据计算-reduceByKey方法
4.数据计算-filter方法
5.数据计算-distinct方法
6.数据计算-sortBy方法
五.数据输出
1.输出Python对象
(1)collect算子
(2)reduce算子
(3)take算子
(4)count算子
2.输出到文件中
六.分布式集群运行(作者谈感受)
此章节主要讲解PySpark技术其中内容分为:前言介绍、基础准备、数据输入、数据计算、数据输出、分布式集群运行。
基础准备主要是:“安装PySpark”和PySpark执行环境入口对象,理解PySpark的编程模型。
分布式集群运行这一章,作者并未学到liunx还有专门的大数据因此无法演示。
一. PySpark前言介绍
Spark的定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎

简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据

学习PySpark技术的目的:由于Python应用场景和就业方向是十分丰富的,其中,最为亮点的方向为:“大数据开发”和“人工智能”

总结:
1.什么是Spark、什么是PySpark
- Spark是Apache基金会旗下的顶级开源项目,用于对海量数据进行大规模分布式计算。
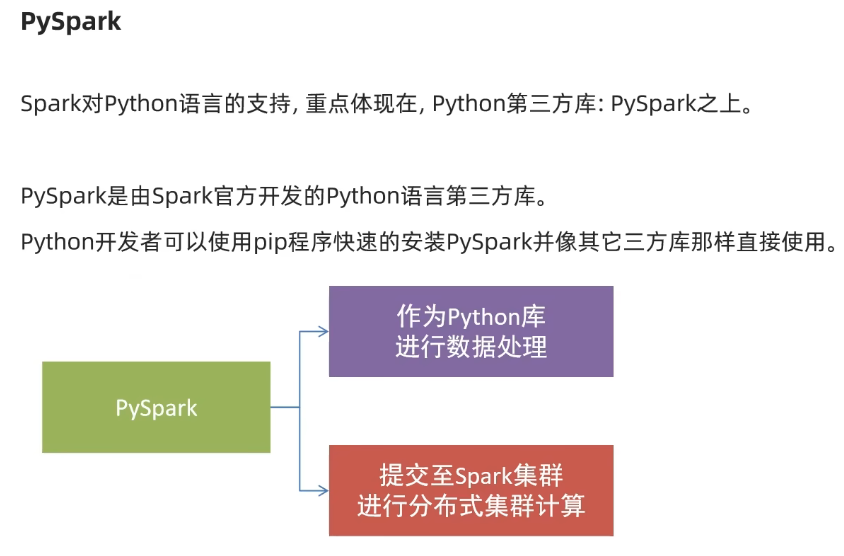
- PySpark是Spark的Python实现,是Spark为Python开发者提供的编程入口,用于以Python代码完成Spark任务的开发
- PySpark不仅可以作为Python第三方库使用,也可以将程序提交的Spark集群环境中,调度大规模集群进行执行。
二.基础准备
PySpark库的安装
同其它的Python第三方库一样,PySpark同样可以使用pip程序进行安装。
在”CMD”命令提示符程序内,输入:
pip install pyspark
或使用国内代理镜像网站(清华大学源)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
构建PySpark执行环境入口对象
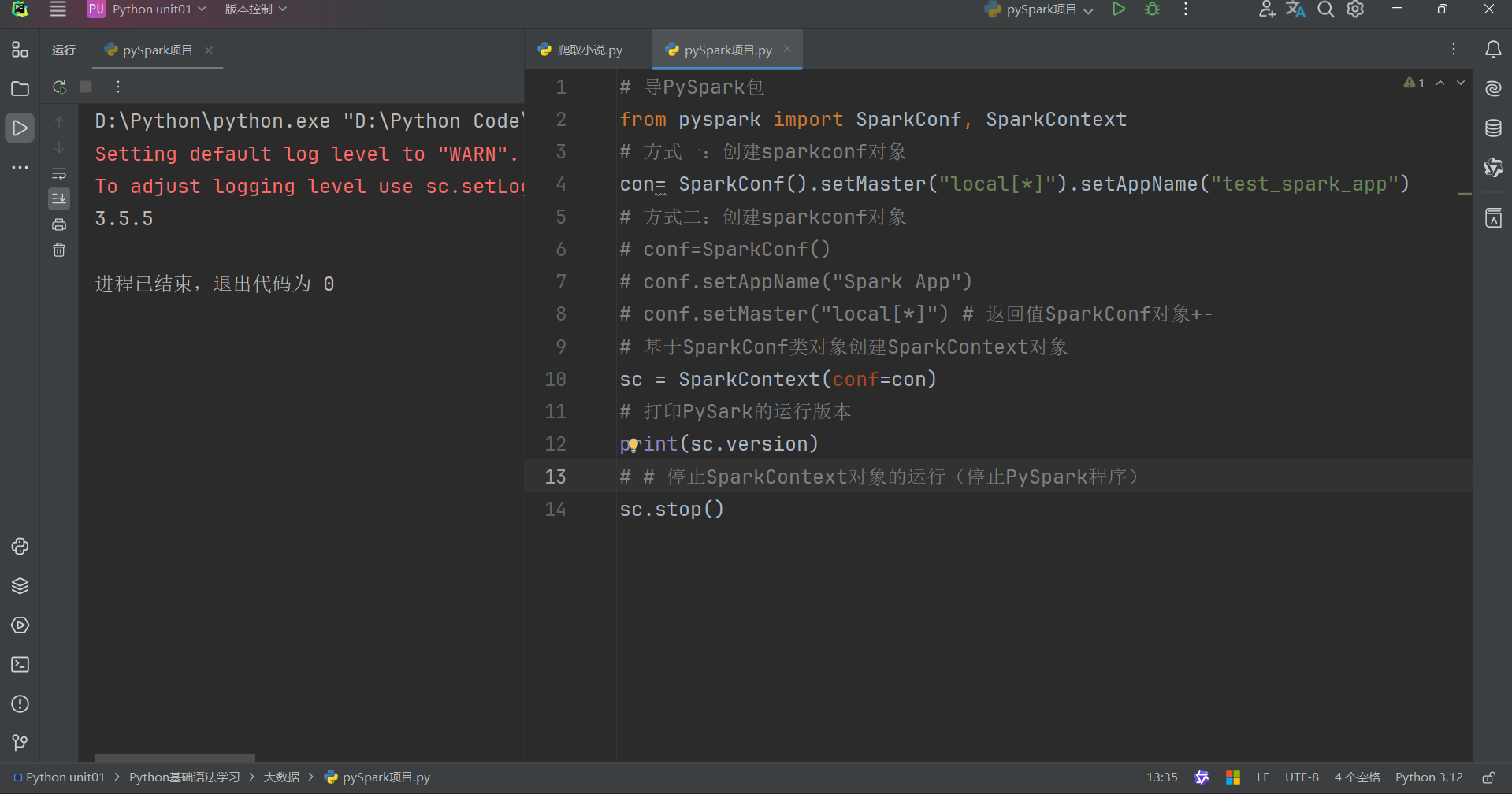
想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象。
PySpark的执行环境入口对象是:类SparkContext 的类对象

以下是示例代码如下:
注:
若输出结果是cmd �����ڲ����ⲿ���Ҳ���ǿ����еij��� ���������ļ���
Java gateway process exited before sending its port number
则需要你去环境变量添加JDK和在path中添加“C:\Windows\System32”即可,作者亲测有效。后面可能还需要hadoop的配置,可自行b站,作者也是找半天配半天,甚至这个问题也是靠了我们CSDN大佬的各种解决方法得出来,我只能说CSDN是国内最好用的平台。
PySpark的编程模型
SparkContext类对象,是PySpark编程中一切功能的入口。
PySpark的编程,主要分为如下三大步骤:

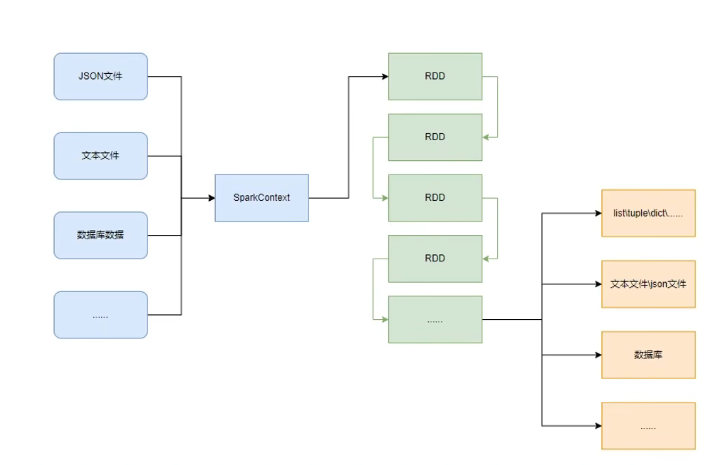
- 通过SparkContext对象,完成数据输入
- 输入数据后得到RDD对象,对RDD对象进行迭代计算
- 最终通过RDD对象的成员方法,完成数据输出工作
总结:
1.如何安装PySpark库
pip install pyspark
2.为什么要构建SparkContext对象作为执行入口
PySpark的功能都是从SparkContext对象作为开始
3.PySpark的编程模型是?
数据输入:通过5parkContext完成数据读取
数据计算:读取到的数据转换为RDD对象,调用RDD的成员方法完成
计算
数据输出:调用RDD的数据输出相关成员方法,将结果输出到list、元组、字典、文本文件、数据库等
三.数据输入
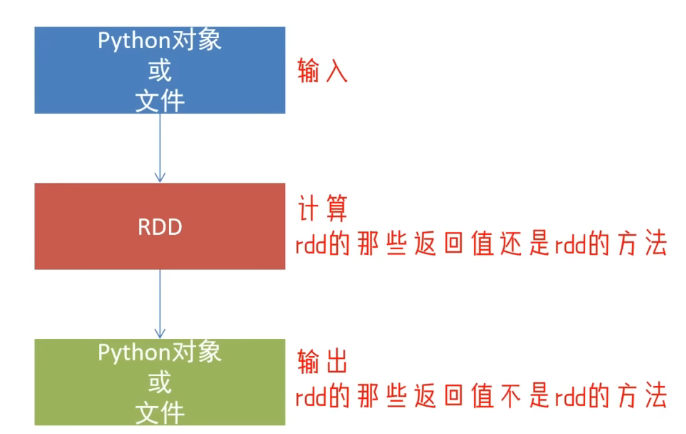
RDD对象
如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(ResilientDistributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
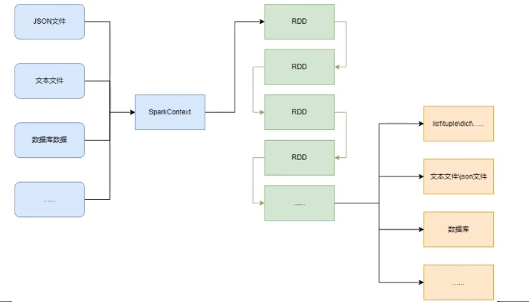
PySpark支持通过SparkContext对象的parallelize成员方法,将:
- list
- tuple
- set
- dict
- str
转换为PySpark的RDD对象

注意:
- 字符串会被拆分出1个个的字符,存入RDD对象
- 字典仅有key会被存入RDD对象
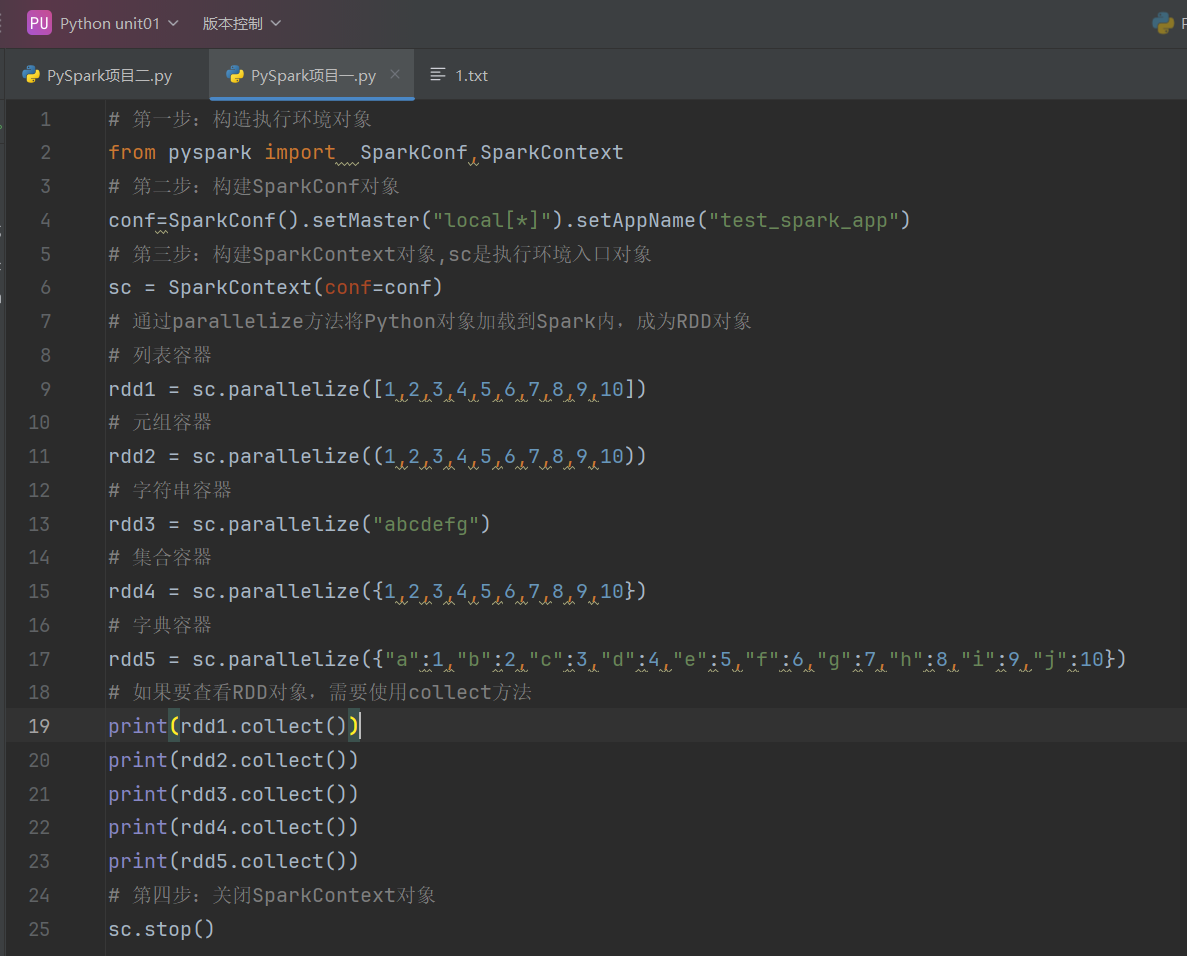
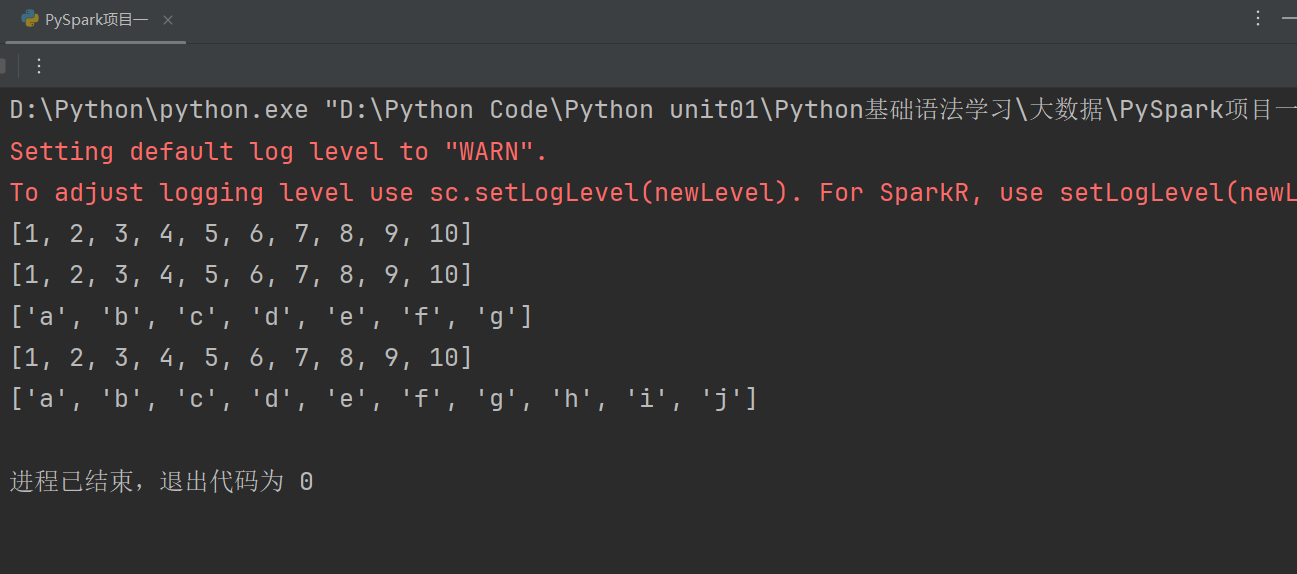
代码示例如下:
读取文件转RDD对象
PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象。

代码演示如下:
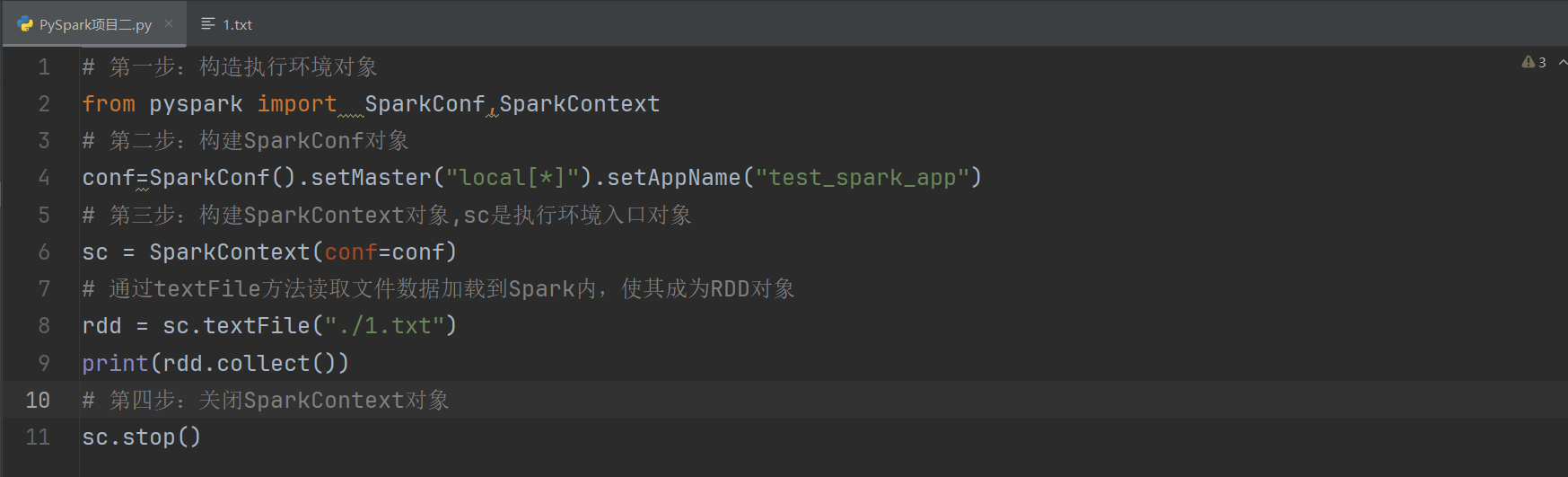

总结:
1.RDD对象是什么?为什么要使用它?
RDD对象称之为分布式弹性数据集,是PySpark中数据计算的载体,它可以:
- 提供数据存储
- 提供数据计算的各类方法
- 数据计算的方法,返回值依旧是RDD(RDD选代计算)
后续对数据进行各类计算,都是基于RDD对象进行
2.如何输入数据到Spark(即得到RDD对象)
- 通过SparkContext的parallelize成员方法,将Python数据容器转换为RDD对象
- 通过SparkContext的textFile成员方法,读取文本文件得到RDD对象
四.数据计算
此小节分为:map方法、flatMap方法、reduceByKey方法、filter方法、distinct方法、sortBy方法。
1.数据计算-map方法
PySpark的数据计算,都是基于RDD对象来进行的,那么如何进行呢?
自然是依赖,RDD对象内置丰富的:成员方法(算子)
map算子
功能: map算子,是将RDD的数据 一条条处理( 处理的逻辑 基于map算子中接收的处理函数),返回新的RDD
语法:

示例代码演示如下:
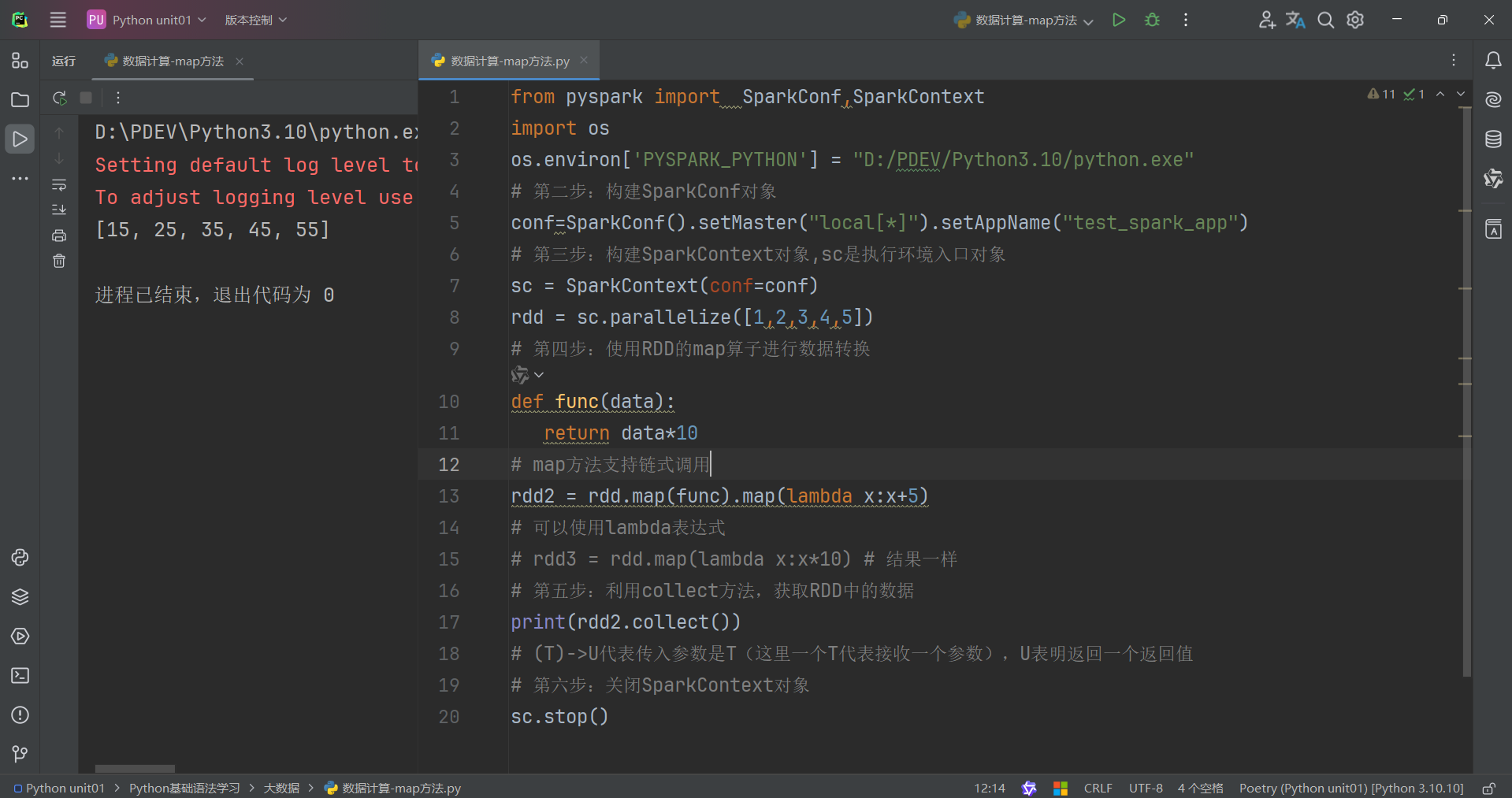
map方法会根据你序列的数据进行一个一个计算,并且返回新的rdd。
因此它也支持链式调用。
注:
这里使用map方法有两个注意地方,作者花大量时间解决这个。一个就是看看自己的Python解释器一定要是3.10及以下的3.11及最新不能使用,作者已经测试过了。如果你报错,就一定要将Python解释器装一个3.10然后再换上3.10。这是第一个地方。
第二个地方一定要在前面加上import OS导入OS包。并且要在最前面加上:os.environ['PYSPARK_PYTHON'] = "D:/PDEV/Python3.10/python.exe"
这个路径一定要根据你电脑Python解释器上面填写,根据自己电脑配置解释器的位置进行调配。以上是最主要会导致你程序报错的原因。
总结:
1.map算子(成员方法)
- 接受一个处理函数,可用lambda表达式快速编写
- 对RDD内的元素逐个处理,并返回一个新的RDD
2.链式调用
- 对于返回值是新RDD的算子,可以通过链式调用的方
- 式多次调用算子
2.数据计算-flatMap算子
flatMap算子的功能: 对rdd执行map操作,然后进行解除嵌套操作
解除嵌套:

代码如下:

代码演示如下:
未使用flatMap方法代码如下:
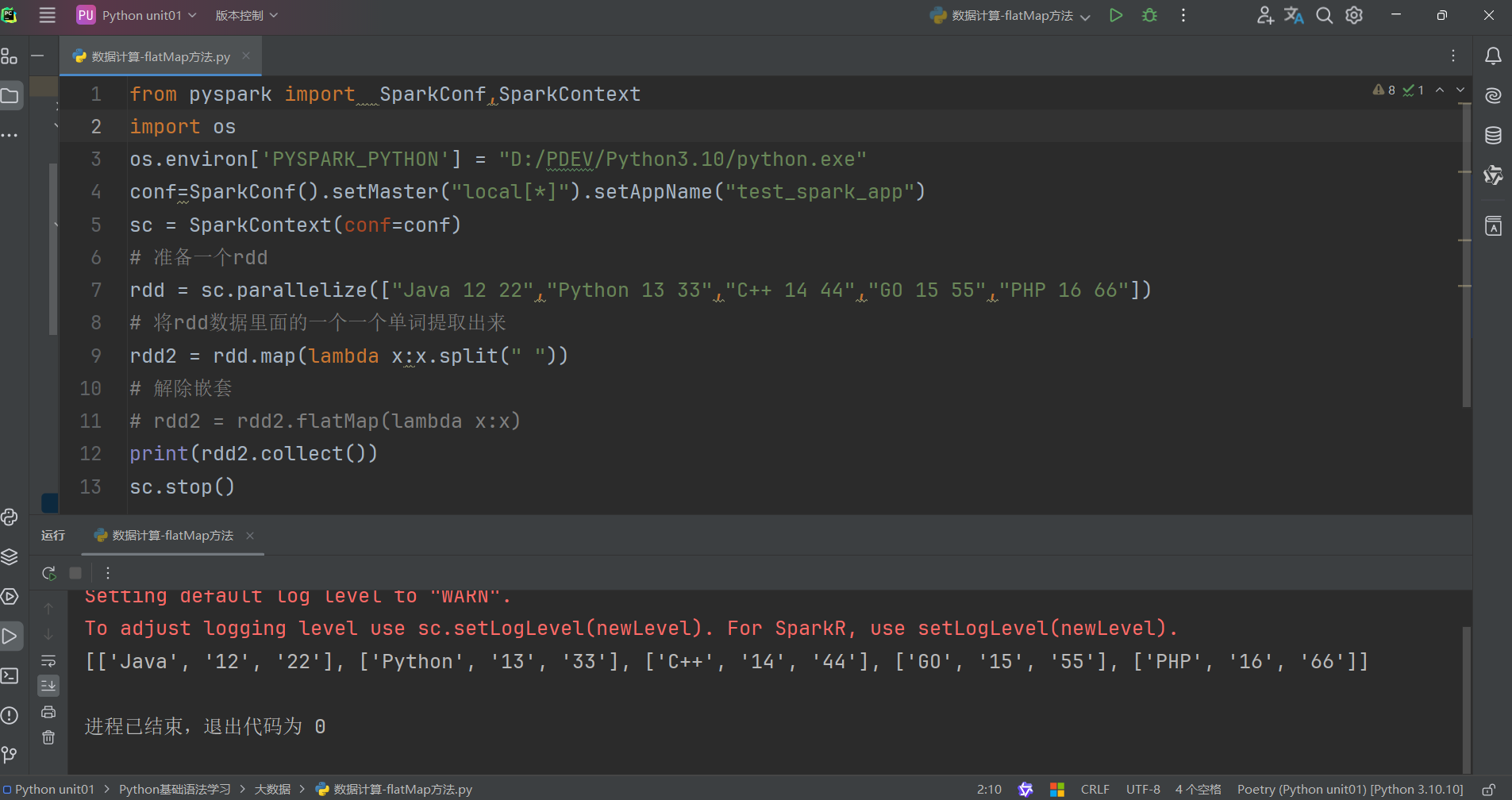
使用flatMap方法解除嵌套代码如下:
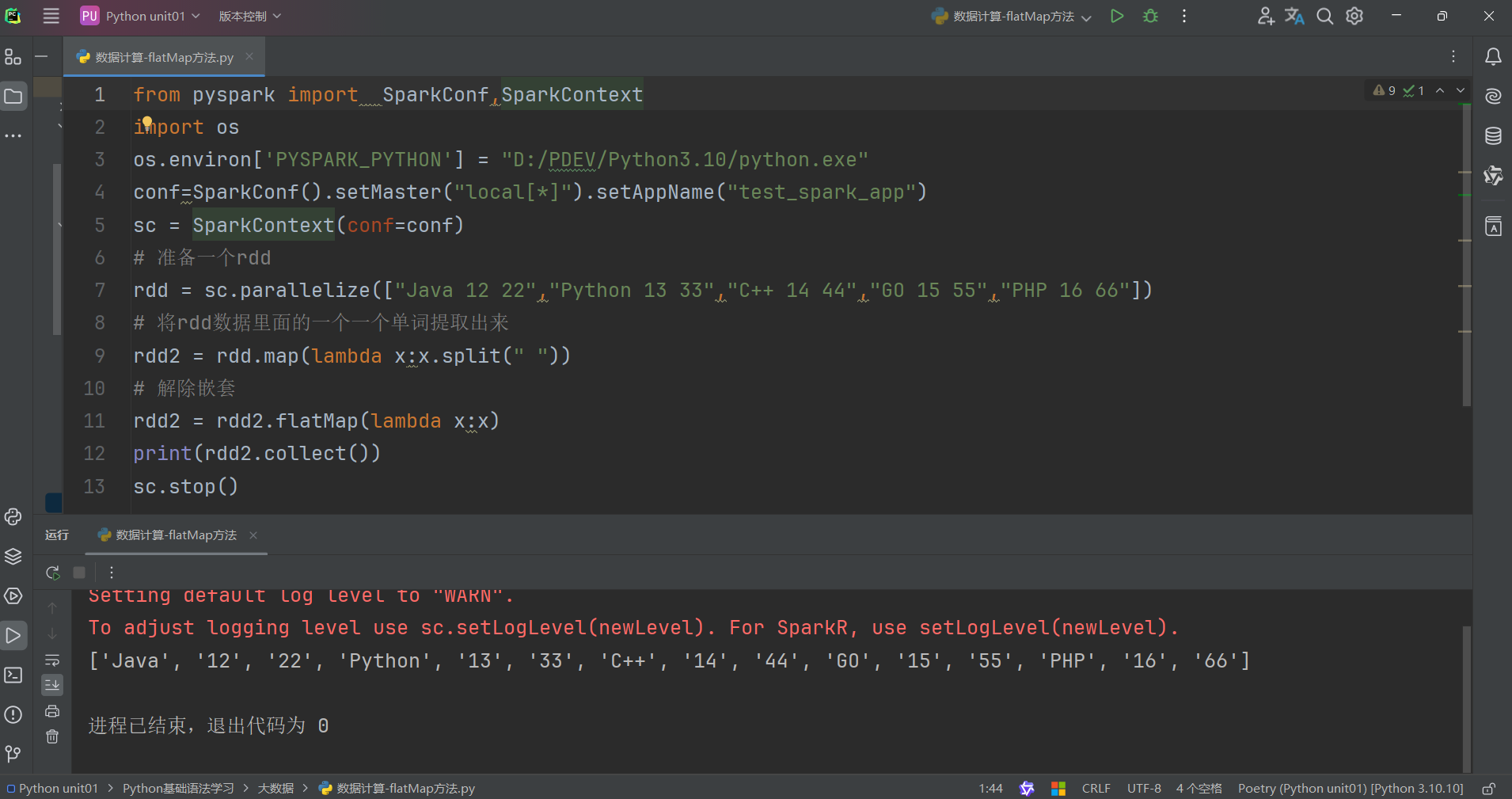
总结:
1.flatMap算子
- 计算逻辑和map一样
- 可以比map多出,解除一层嵌套的功能
3.数据计算-reduceByKey方法
reduceByKey算子的功能:针对KV型 RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作。
注:KV型指的是存储数据是二元元组就称为KV型。
用法:



注:
rdd中存放的是二元元组,元组元素有2个,第一个元素可以视作字典的键,第二个是键入的值。通过reduceByKey方法可以根据键来整合数据的运算操作,这就是聚合。
reduceByKey中接收的函数,只负责聚合,不理会分组。
分组是自动 by key 来分组的。
二元元组,几元元组指的是元组内部的元素个数有几个就称作几元元组。
reduceBeKey中的聚合逻辑是:
比如,有[1,2,3,4,5],然后聚合函数是:lambda a,b:a+b
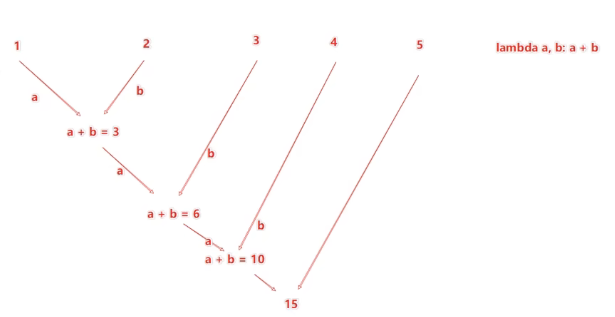
代码演示如下:
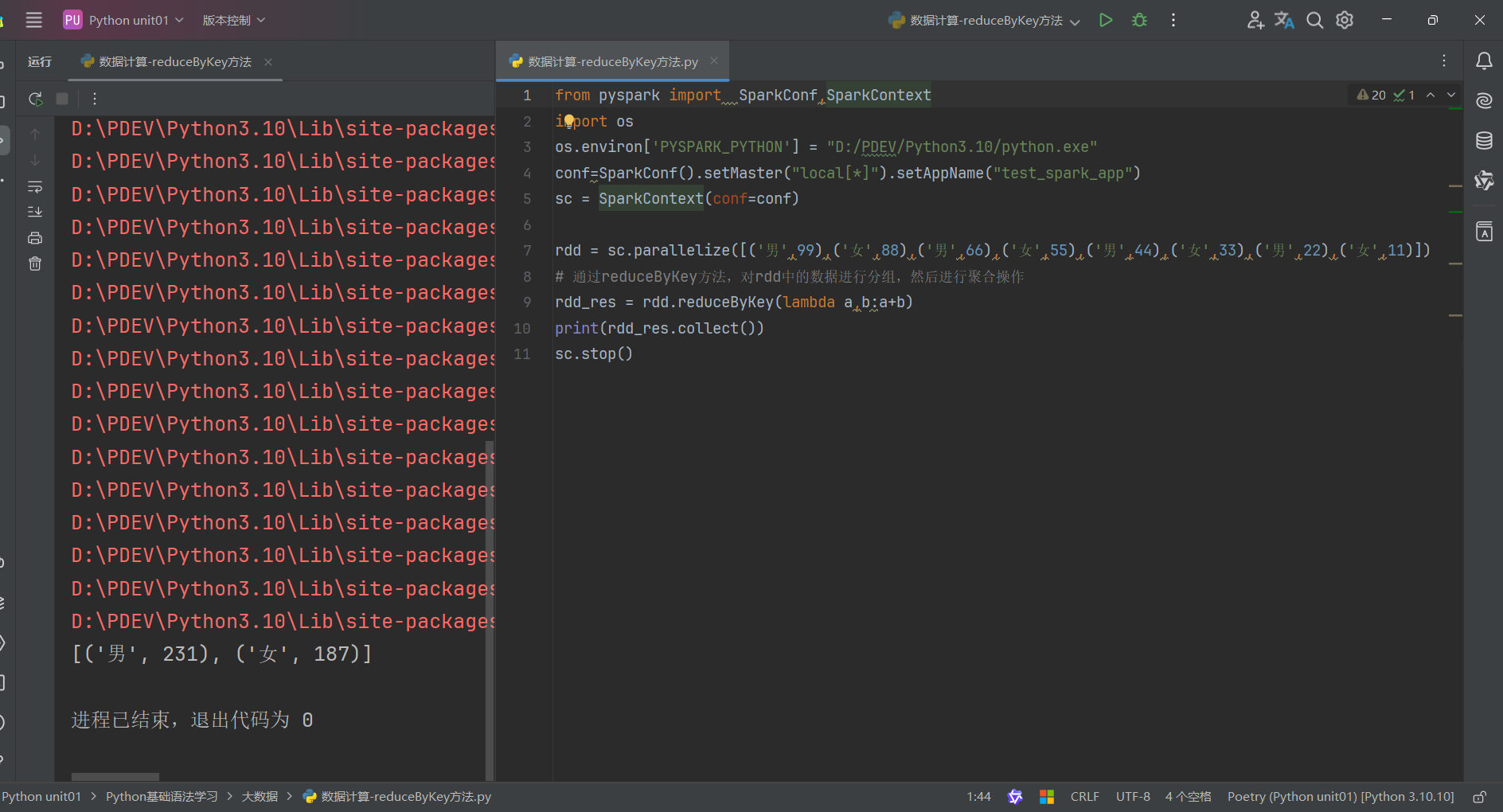
总结:
1.reduceByKey算子
接受一个处理函数,对数据进行两两计算
4.数据计算-filter方法
Filter方法的功能:过滤想要的数据进行保留
语法:
![]()
返回的是True的数据被保留,False的数据被丢弃。
代码如下:

代码演示如下:

总结:
1.filter算子
- 接受一个个处理函数,可用lambda快速编写
- 函数对RDD数据逐个处理,得到True的保留至返回值的RDD中
5.数据计算-distinct方法
distinct算子
功能:对RDD数据进行去重,返回新RDD
语法: ![]()
代码演示如下:
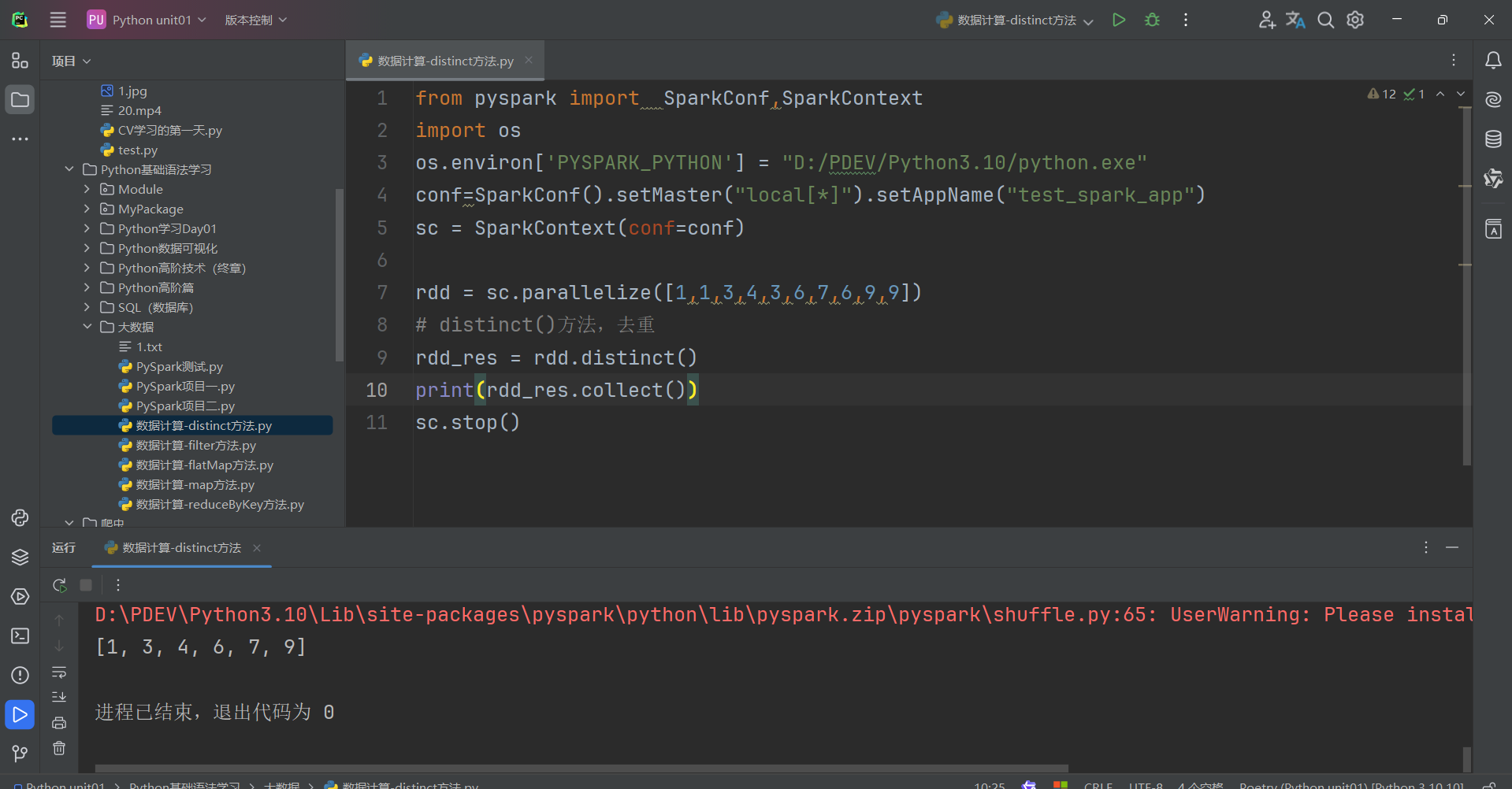
总结:
1.distinct算子
- 完成对RDD内数据的去重操作
6.数据计算-sortBy方法
sortBy算子功能:对RDD数据进行排序,基于你指定的排序依据。
语法:

代码演示如下:
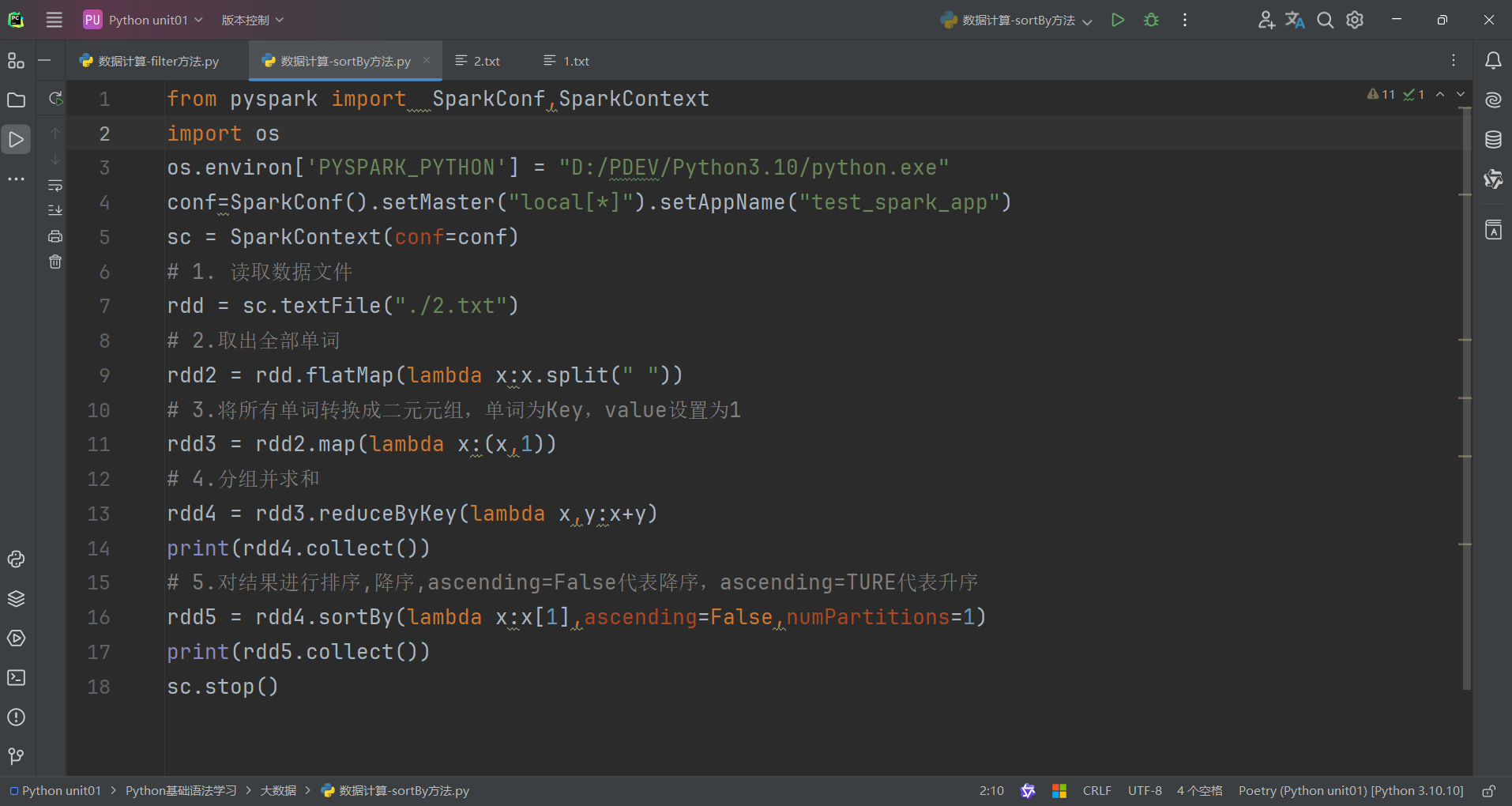
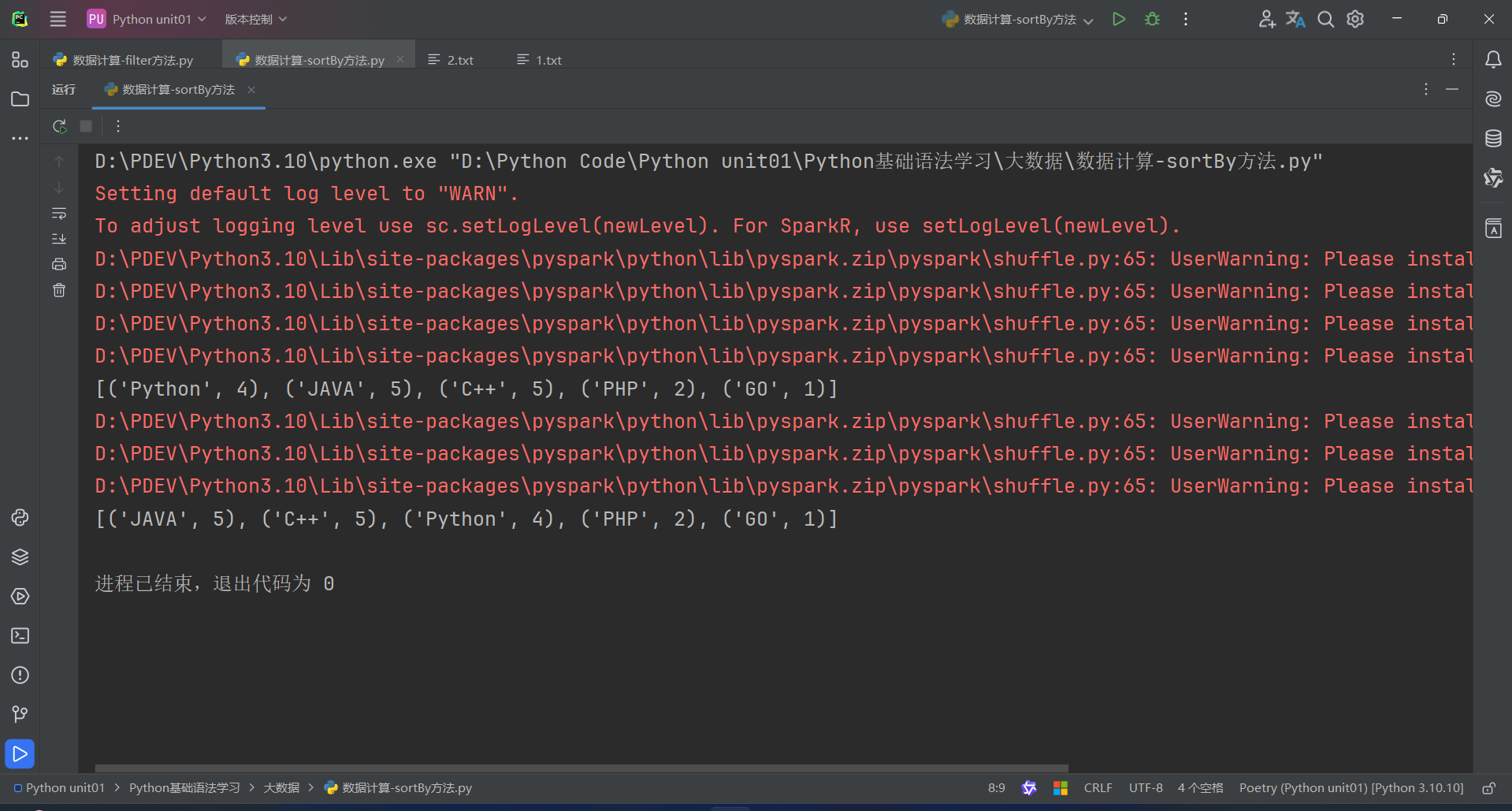
1.sortBy算子
- 接收一个处理函数,可用lambda快速编写
- 函数表示用来决定排序的依据
- 可以控制升序或降序
- 全局排序需要设置分区数为1
五.数据输出
此小节分为:输出为Python对象和输出到文件中。
1.输出Python对象
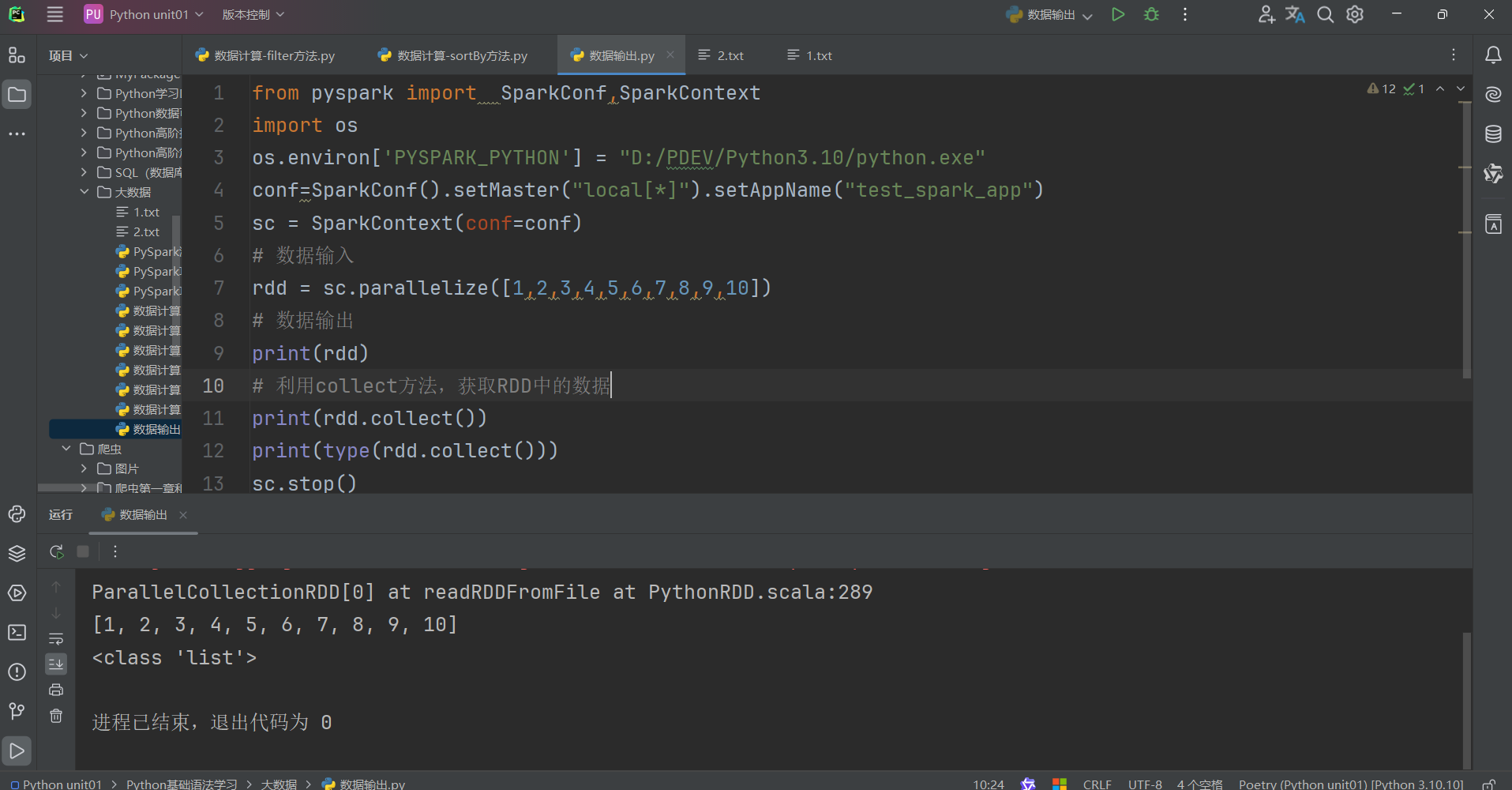
数据输出
数据输入:
- sc.parallelize
- sc.textFile
数据计算:
- rdd.map
- rdd.flatMap
- rdd.reduceByKey
- ………
(1)collect算子
collect算子的功能:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象。
用法:
![]()
返回值是一个List
(2)reduce算子
reduce算子功能: 对RDD数据集按照你传入的逻辑进行聚合
语法:

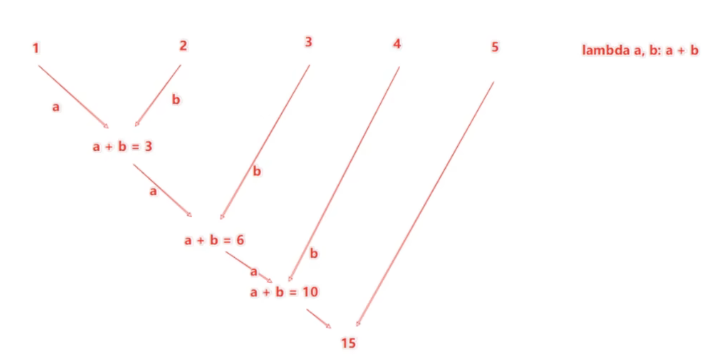

返回值等同于计算函数的返回值
代码演示如下:
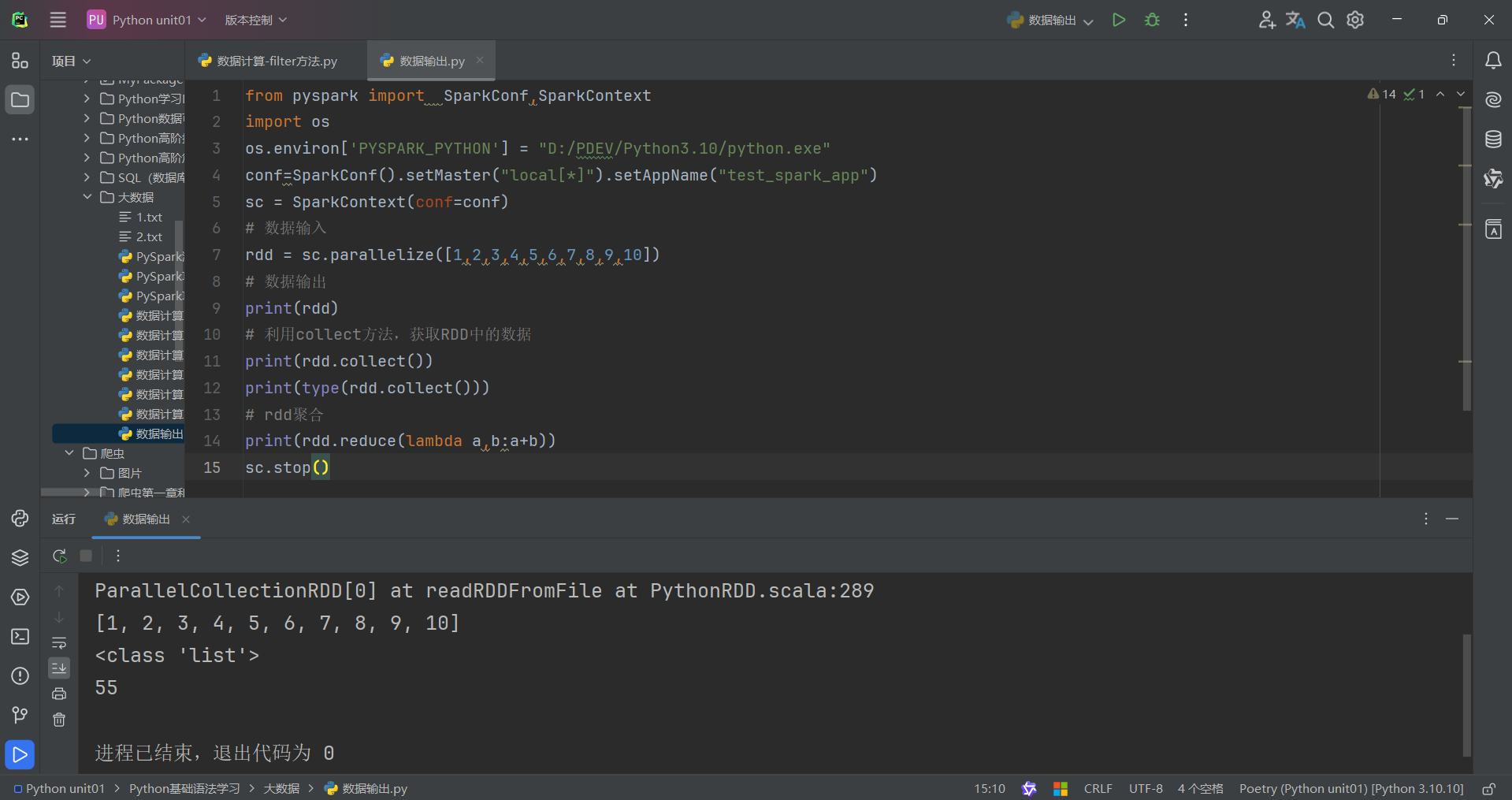
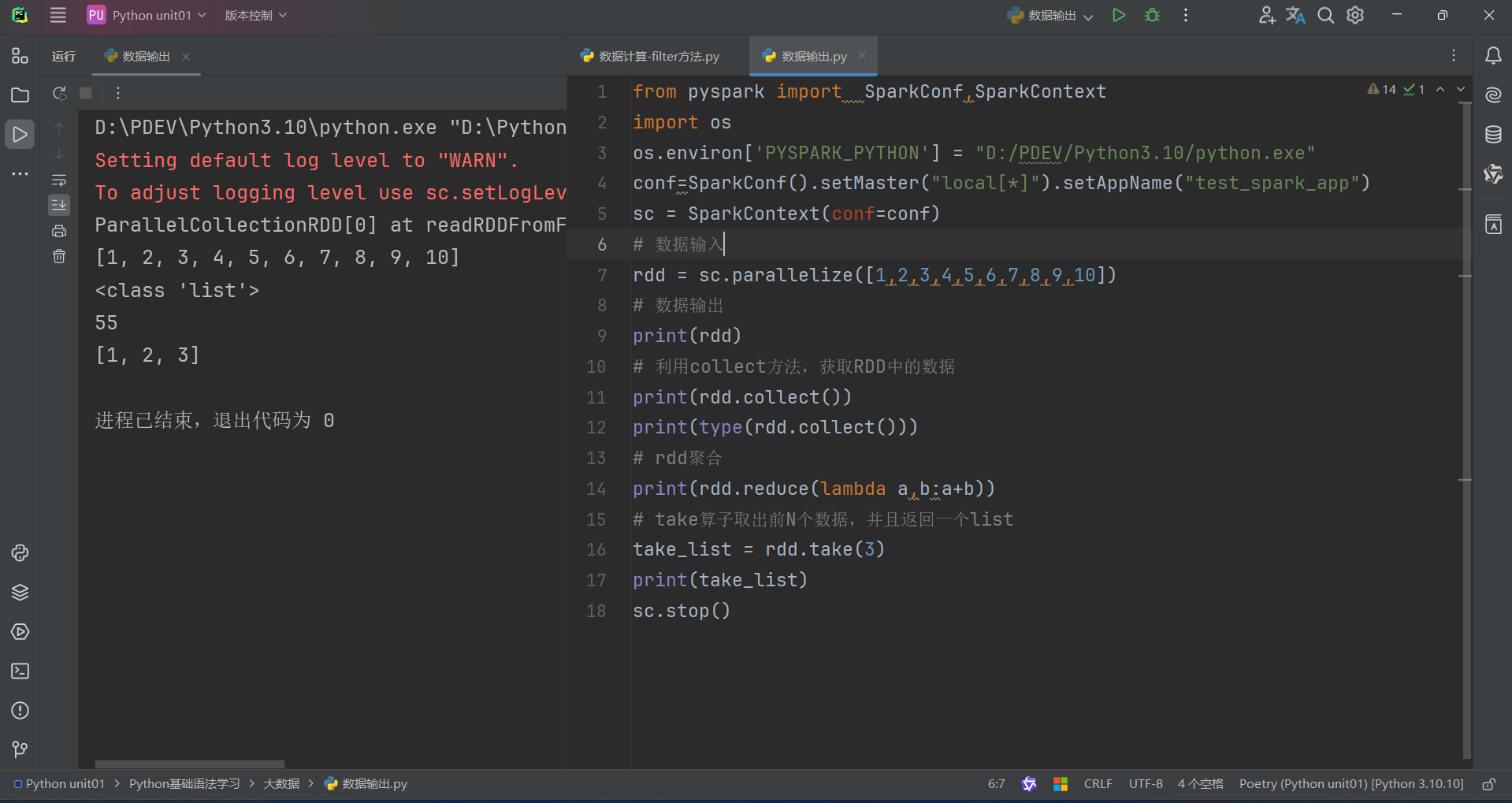
(3)take算子
take算子的功能:取RDD的前N个元素,组成list返回给你
用法:

代码如下:
(4)count算子
count算子的功能:计算RDD有多少条数据,返回值是一个数字
用法:

代码演示如下:
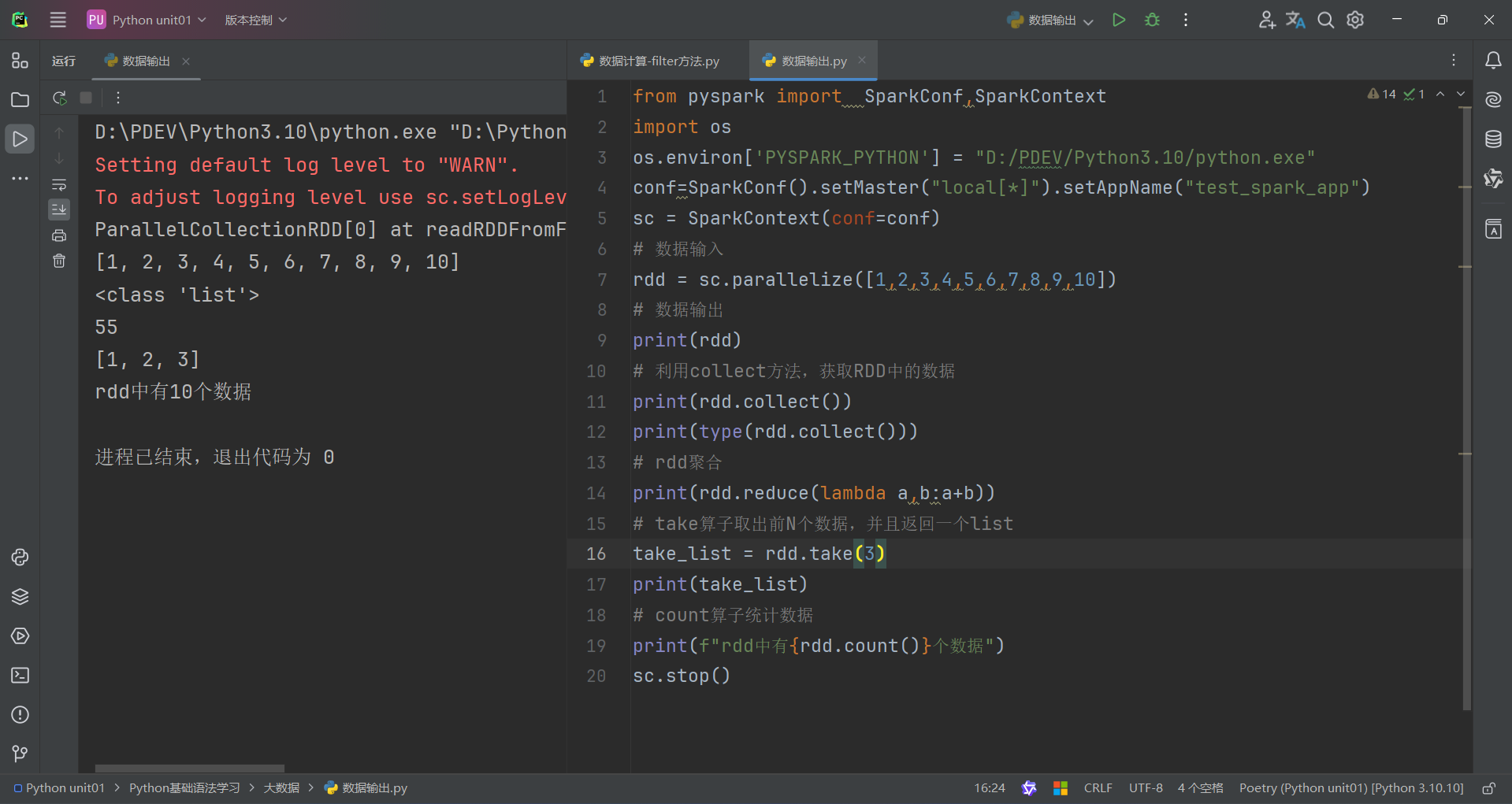
总结:
1.Spark的编程流程就是:
- 将数据加载为RDD(数据输入)
- 对RDD进行计算(数据计算)
- 将RDD转换为Python对象(数据输出)
2.数据输出的方法
- collect:将RDD内容转换为list
- reduce:对RDD内容进行自定义聚合
- take:取出RDD的前N个元素组成list
- count:统计RDD元素个数
数据输出可用的方法是很多的,本小节简单的介绍了4个
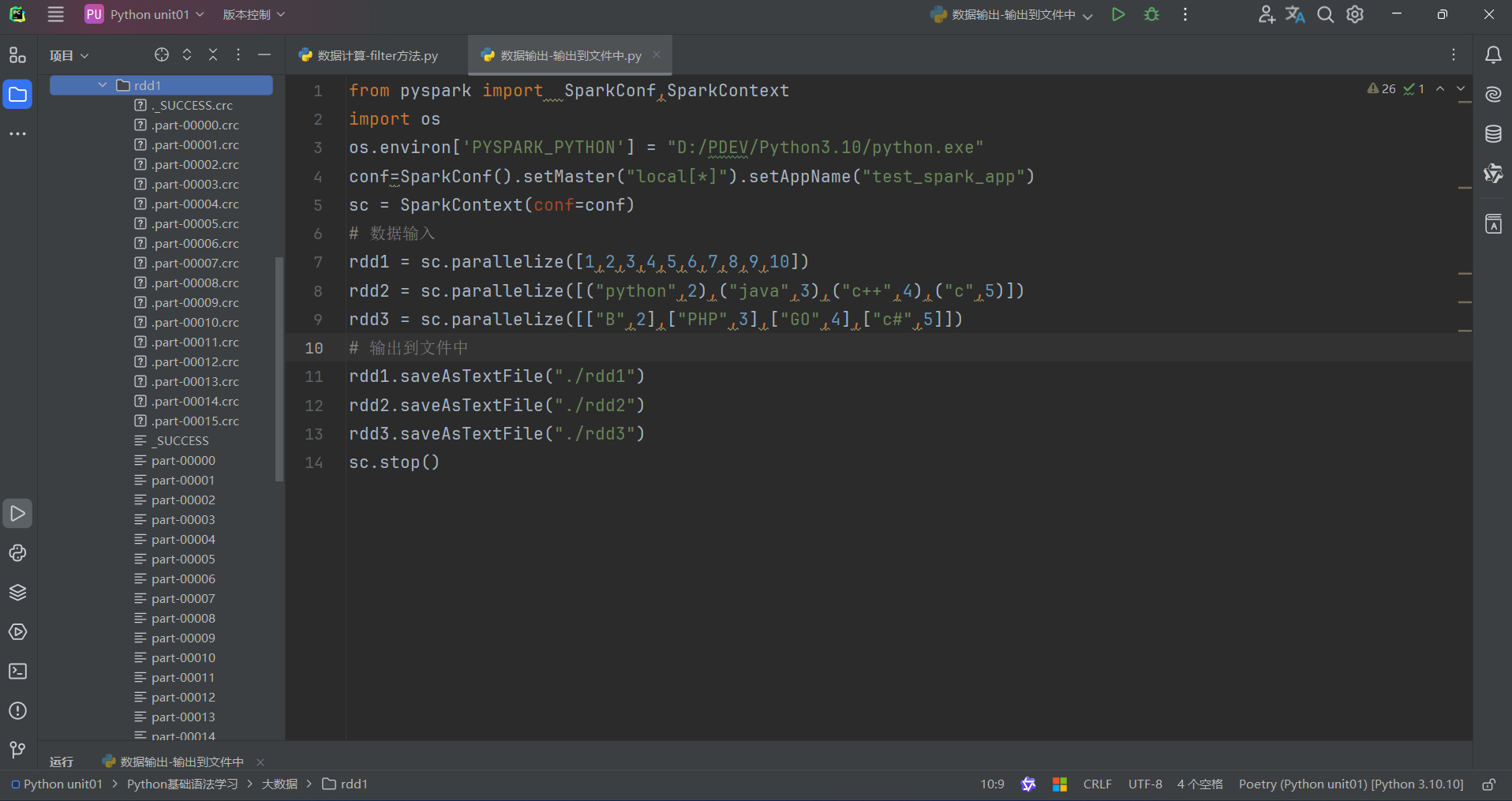
2.输出到文件中
(1)saveAsTextFile算子
saveAsTextFile算子的功能: 将RDD的数据写入文本文件中
支持 本地写出,hdfs等文件系统
代码:

注:
这里需要配置hadoop,作者也是花了大量时间去配置这个东西,它操作太繁琐,首先你需要有JAVA的JDK并且最好是JDK8,最新版本可能导致不兼容,然后由于我使用的Windows系统还需要去改动一些项目文件中的代码,这里作者只能说都是泪。由于作者是计科专业不是大数据专业,校内也未给我们开设过Python的课程,这些配置纯由作者一点一滴配置完成,吃过苦头,受过折磨得出的经验。
注意事项
调用保存文件的算子,需要配置Hadoop依赖
下载Hadoop安装包
- http://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
解压到电脑任意位置
在Python代码中使用os模块配置:os.environ['HADOOP_HOME”]='HADOOP解压文件夹路径
下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe
下载hadoop.dll,并放入:C:/Windows/System32 文件夹内
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll
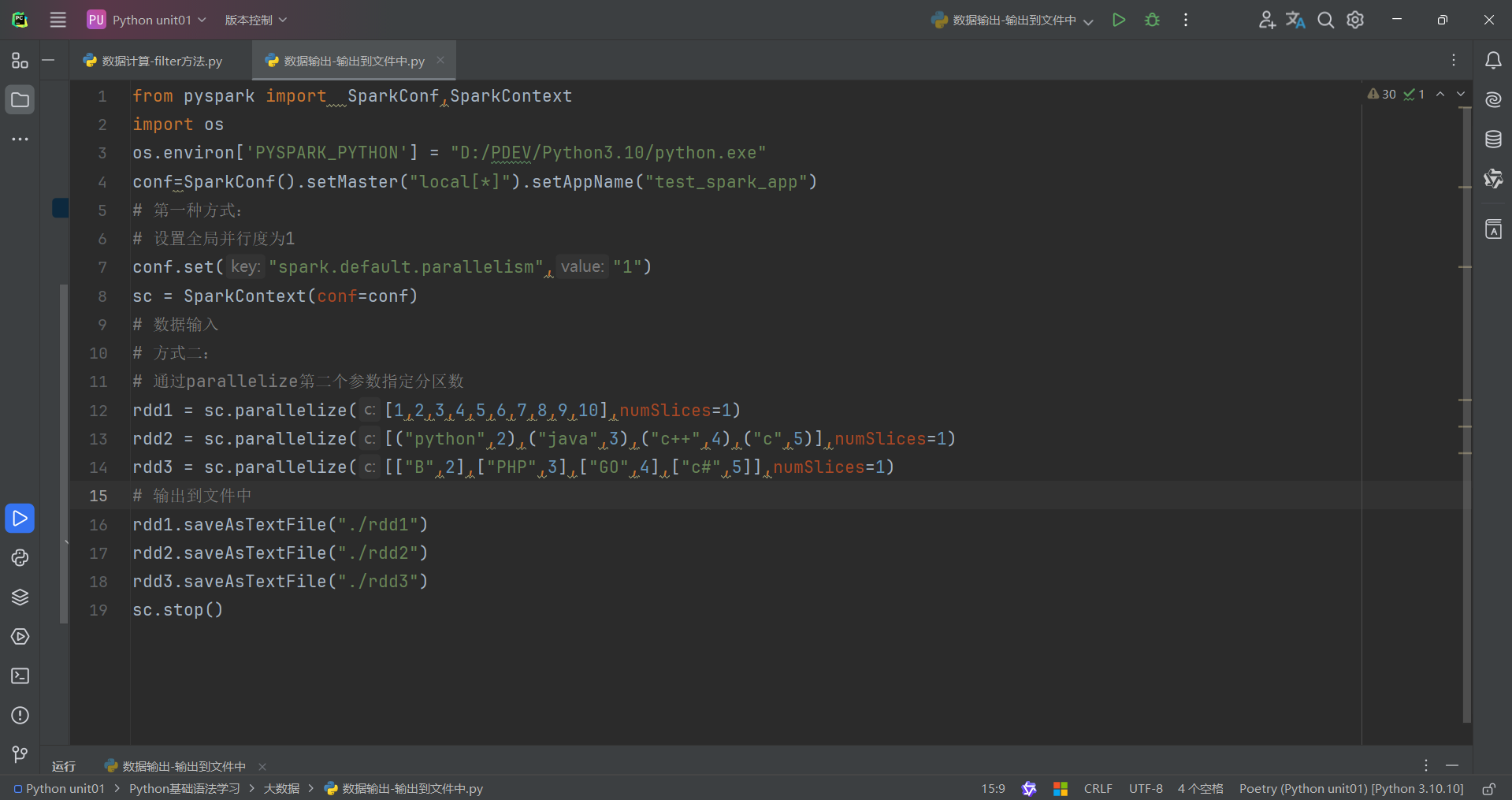
回归正题,由于作者电脑是CPU是15核,所以生成15个分区,这15个分区存储的数据有一些有,有一些没有。因此我们想要修改RDD分区为1有如下方式:

代码演示如下:
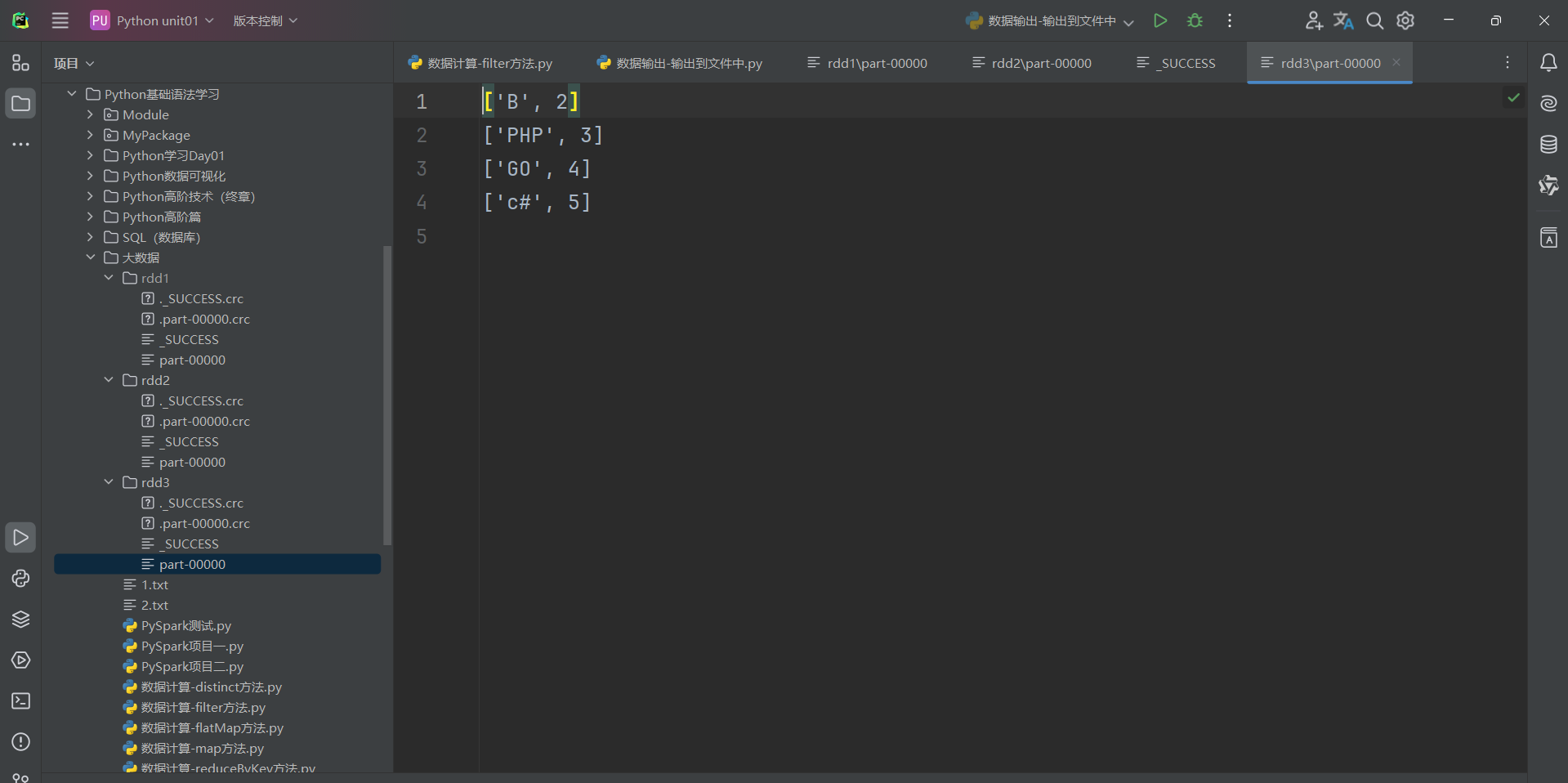
总结:
1.RDD输出到文件的方法
- rdd.saveAsTextFile(路径)
- 输出的结果是一个文件夹
- 有几个分区就输出多少个结果文件
2.如何修改RDD分区
SparkConf对象设置conf.set("spark.default.parallelism","1")
创建RDD的时候,sc.parallelize方法传入numSlices参数为1
六.分布式集群运行(作者谈感受)
分布式集群需要Linux系统,作者还没学,不过作者已经配置好了分布式集群,后续若用到我会在此补充。未来作者还是会去学习Linux系统。希望我未来在企业能用到这个吧。尽力了这一节作者没法演示了,作者才大一新生,还是一个双非排名靠后的本科,通过自身学习一步一步学,无导师指导甚至前辈指导都没有,作者都是一个人钻研,一钻研可能就是几天甚至半个月,这个环境配置作者一直没有放弃一直在整配置,用过AI去寻求帮助,但是AI都不太行,我认为AI对比于人来说,可能人优势还是非常大,人的优势就是能过灵活随机应变并且拥有真正解决问题的能力,AI是一贯的套路,甚至它们给的方法不一定对于实际问题有合理解决的方法,所以我认为AI很代替真正能够善于解决问题的人,它们现在只是一个辅助工具,未来AI是什么样的我不清楚,但是我知道的是人的潜力是AI永远代替不了的,我通过不断钻研学习,尽管今天的技术也许我这辈子用不到,但是我对于计算机的热爱,还是比较浓厚的我愿意花很大的时间在这个上面,我学了很多的东西尽管很杂乱,也许因为杂乱我可能很快忘了它们但是我知道这个印象永远在我脑海,因为我花了很多的时间在某一关卡,一卡可能是一天甚至一周乃至一个月,但是我没放弃过去思考这些问题,我认为只要是问题总会有突破口,计算机需要你花很多的时间,我听过很多说计算机如今行业不行了,但是我不在意因为热爱一件事情不一定要去思考它未来怎么样,只要一直走下去迟早这个技术会在你手里发光发热,而不是因为自己懒惰和自己不想去找到属于自己的兴趣爱好以及道路而放弃,可以不热爱学习,但是一定要热爱自己有兴趣的事情。
注:
这一节作者没法演示,只能讲我这学过来的感受从C语言的一点不会到Python、JAVA、C++这些语言我都学过了。未来我更新的东西会很多也很杂乱,不知道未来在企业能否用到,甚至高薪,但是走一步看一步吧。未来我还会继续更新我的学习,大学四年是一个学习积累非常好的一个机会。
相关文章:
第十二章 Python语言-大数据分析PySpark(终)
目录 一. PySpark前言介绍 二.基础准备 三.数据输入 四.数据计算 1.数据计算-map方法 2.数据计算-flatMap算子 3.数据计算-reduceByKey方法 4.数据计算-filter方法 5.数据计算-distinct方法 6.数据计算-sortBy方法 五.数据输出 1.输出Python对象 (1&am…...

【RedisLockRegistry】分布式锁
RedisLockRegistry分布式锁 介绍 RedisLockRegistry是Spring框架提供的一种分布式锁机制,它基于Redis来实现对共享资源的保护,防止多个进程同时对同一资源进行修改,从而避免数据不一致或其他问题 基本原理 RedisLockRegistry通过Redi…...

leetcode-排序
排序 面试题 01.01. 判定字符是否唯一 题目 实现一个算法,确定一个字符串 s 的所有字符是否全都不同。 示例 1: 输入: s "leetcode" 输出: false 示例 2: 输入: s "abc" 输出: true限制: 0 < len(s) &…...
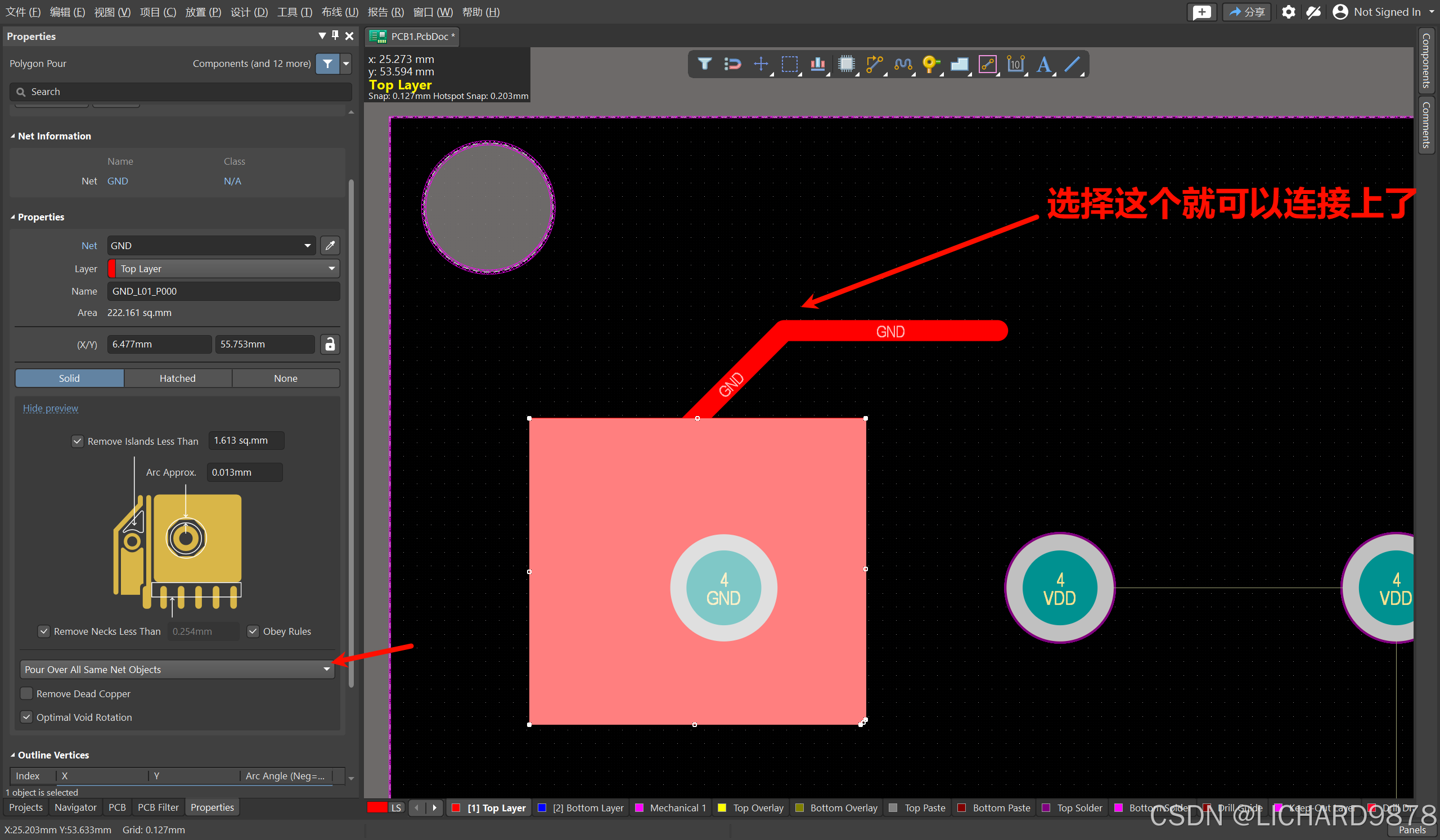
AD相同网络的铜皮和导线连接不上
出现这样的情况是不是很烦恼,明明是相同的网络连接不上????? 直接修改铜皮属性(选择所有相同这个选项) 这样就可以连接上了...
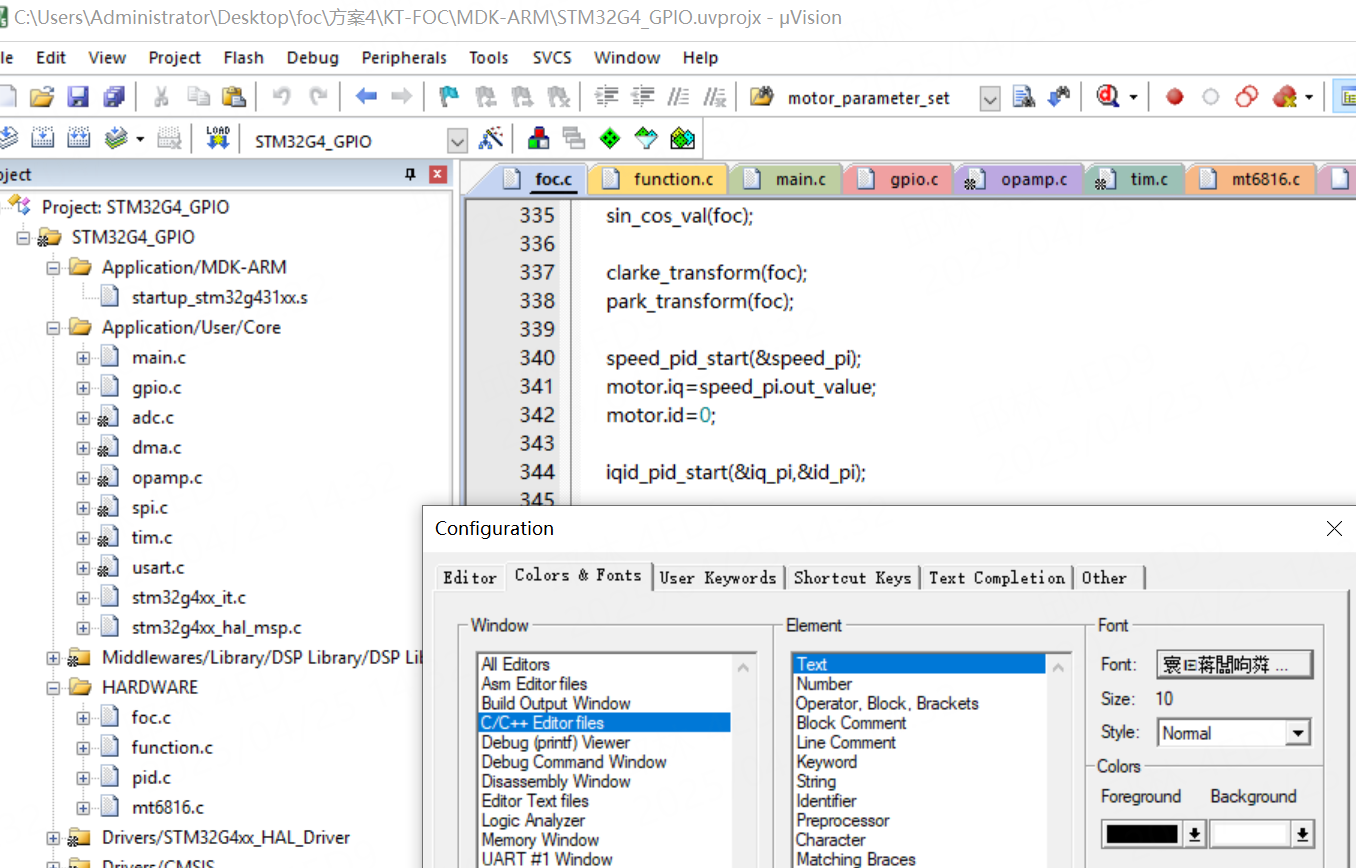
keil修改字体无效,修改字体为“微软雅黑”方法
在网上下载了微软雅黑字体,微软雅黑参考下载链接 结果在Edit->Configuration中找不到这个字体 这个时候可以在keil的安装目录中找到UV4/global.prop文件 用记事本打开它进行编辑,把字体名字改成微软雅黑 重新打开keil就发现字体成功修改了。 这个…...
【网络编程】从零开始彻底了解网络编程(三)
本篇博客给大家带来的是网络编程的知识点. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 要开心要快乐顺便进步 TCP流…...

NVIDIA --- 端到端自动驾驶
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、传统驾驶模型二、NVIDIA的端到端驾驶模型1.基本模型2.自查讯向量3.通用框架 总结 前言 端到端自动驾驶指的是系统接收来自摄像头雷达和激光雷达的原始传感…...

关于在Springboot中设置时间格式问题
目录 1-设置全局时间格式1.Date类型的时间2.JDK8时间3.使Date类和JDK8时间类统统格式化时间 2-关于DateTimeFormat注解 1-设置全局时间格式 1.Date类型的时间 对于老项目来说,springboot中许多类使用的是Date类型的时间,没有用到LocalDateTime等JDK8时…...
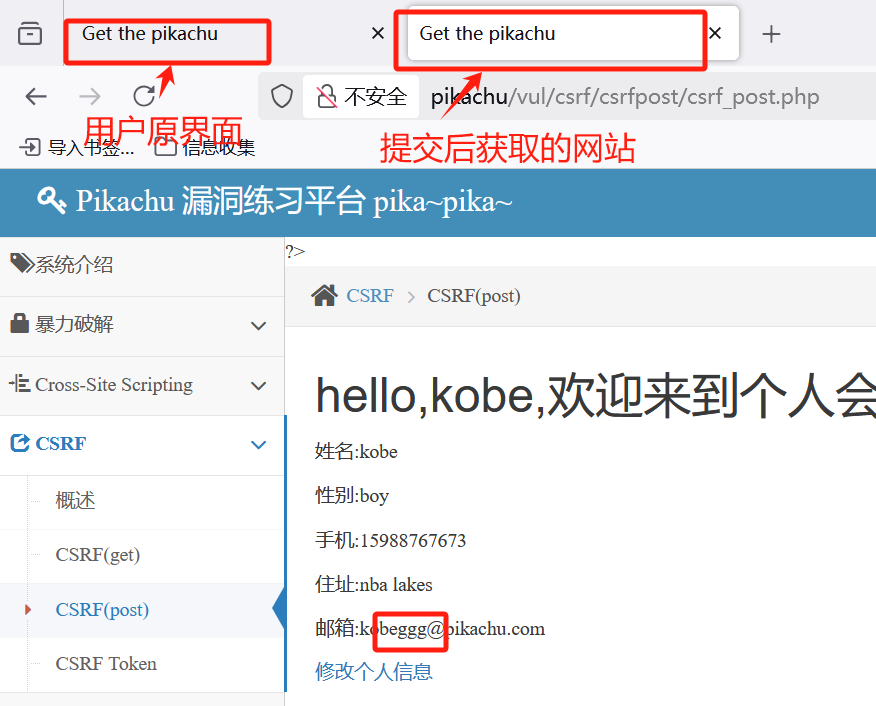
CSRF请求伪造
该漏洞主要是关乎于用户,告诫用户不可乱点击链接,提升自我防范,才能不落入Hacker布置的陷阱! 1. cookie与session 简单理解一下两者作用 1.1. 🍪 Cookie:就像超市的会员卡 存储位置:你钱包里…...
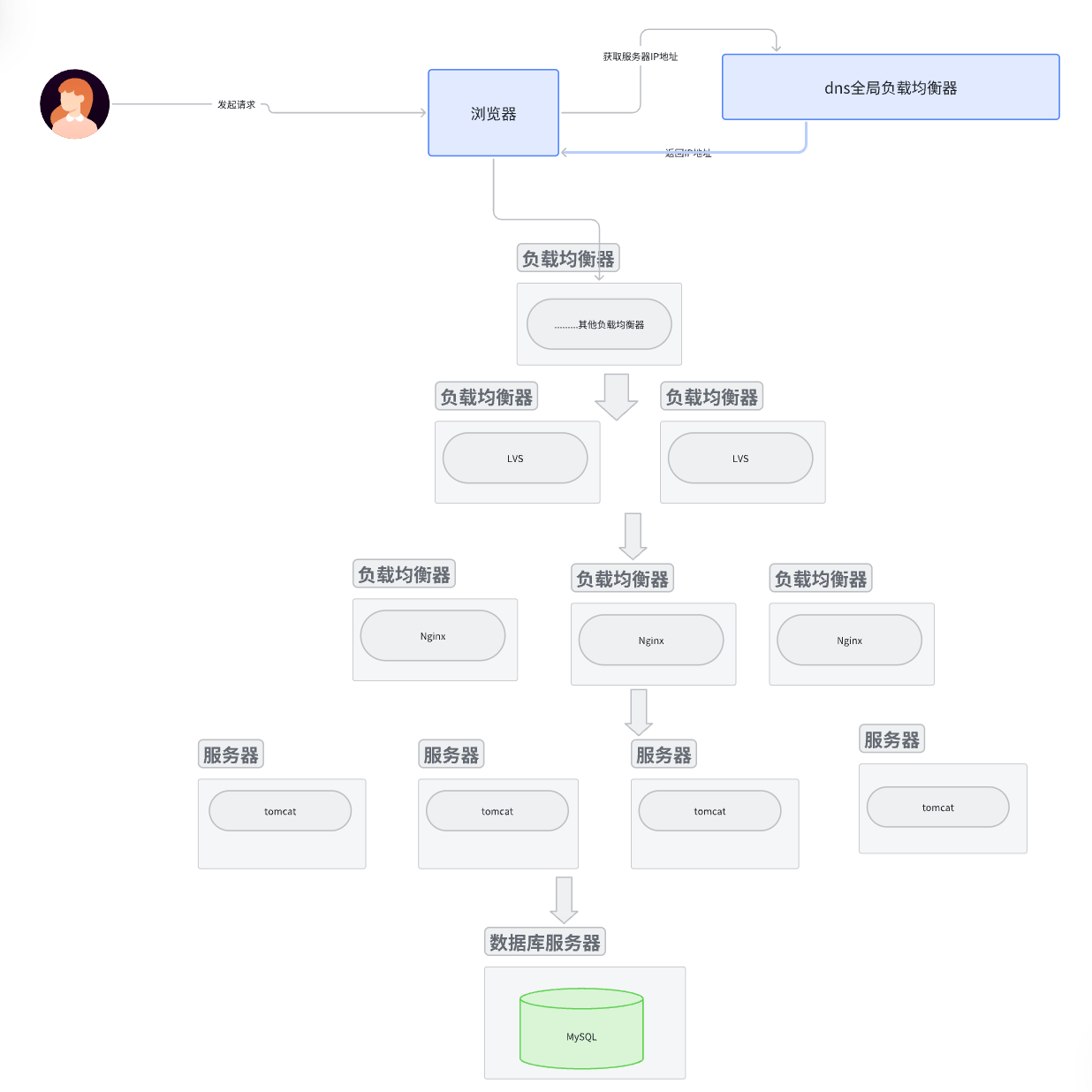
(一)单机架构、应用数据分离架构、应用服务集群架构
文章目录 明确为什么要学习架构的演进单机架构什么是单机架构单机架构的模型单机架构的优缺点优点缺点 单机架构的技术案例 应用数据分离架构什么是应用数据分离架构架构模型应用数据分离架构的优缺点优点缺点 技术案例 应用服务集群架构什么是应用服务集群架构架构模型应用服务…...

Python数据分析案例72——基于股吧评论数据的情感分析和主题建模(LDA)
背景 好久没更新了,最近忙其他去了。最近股市波动太大,看了不少新闻的评论。抽空写了个股吧评论数据的LDA建模和情感分析,简单写到博客上来更新一下。 数据来源 上证指数(000001)股吧_上证指数怎么样_分析讨论社区— 数据来源上述网站的东…...

Git分支管理方案
成都众望智慧有限公司Git分支管理方案 采用 轻量级Git Flow 敏捷版本控制策略,在保证稳定性的同时提升开发效率。以下是优化后的方案: 1. 精简分支模型(相比6-8人团队减少分支层级) 分支类型作用生命周期devops生产环境代码&am…...
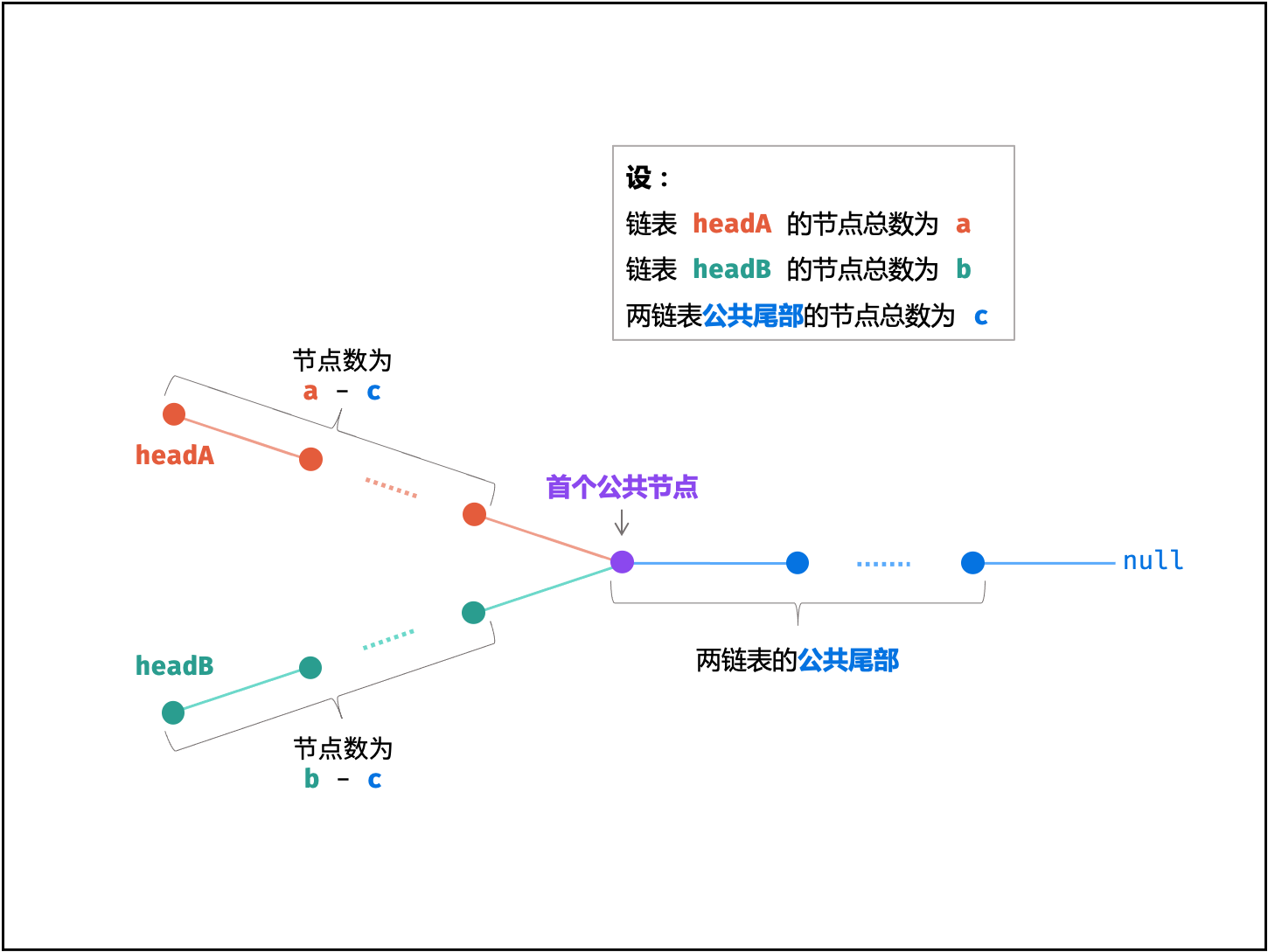
力扣-160.相交链表
题目描述 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中不存在环。 注意,函数返…...

c语言中float和double 类型的区别
在 C 语言里,float和double都用于表示浮点数,不过二者在多个方面存在差异,下面为你详细介绍: 1. 存储空间大小 在 C 语言中,数据类型所占用的存储空间大小通常与编译器和系统架构有关,但一般来说…...
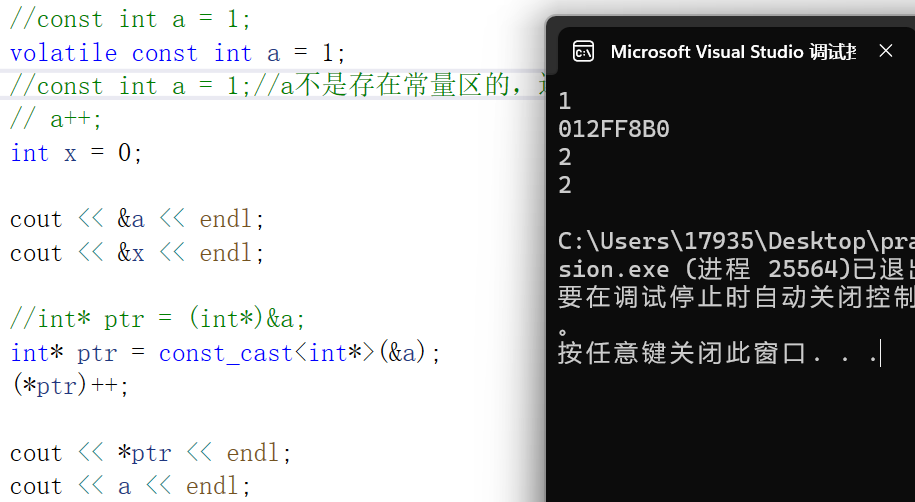
【C++】特殊类的设计、单例模式以及Cpp类型转换
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章: C 智能指针使用,以及shared_ptr编写 下篇文章ÿ…...
050_基于springboot的音乐网站
一、系统架构 前端:vue | element-ui | html | jquery | css | ajax 后端:springboot | mybatis 环境:jdk1.8 | mysql | maven | nodejs | idea 二、代码及数据 三、功能介绍 01. web端-注册 02. web端-登录 03. web…...

全局变量Msg.sender
msg.sender 在 Solidity 中,有一些全局变量可以被所有函数调用。 其中一个就是 msg.sender,它指的是当前调用者(或智能合约)的 address。 注意:在 Solidity 中,功能执行始终需要从外部调用者开始。 一个合…...
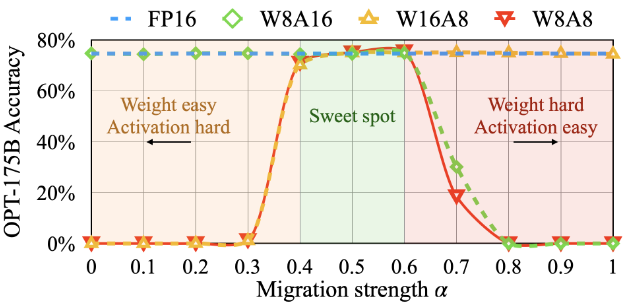
【论文阅读】平滑量化:对大型语言模型进行准确高效的训练后量化
论文题目:SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models 论文地址:[2211.10438] SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models 代码地址:http…...
【资料推荐】LVDS Owner’s Manual
一份年代有些久远的技术资料,但是内容全面且经典! 本用户手册提供了很多有用的信息,首先简要概述了三种最常见的高速接口技术:LVDS(包括B-LVDS和M-LVDS)、CML和LVPECL,并对其相应的特性进行了分…...
ARM Cortex-M (STM32)如何调试HardFault
目录 步骤 1: 实现一个有效的 HardFault 处理程序 步骤 2: 复现 HardFault 并使用调试器分析 步骤 3: 解读故障信息 步骤 4: 定位并修复源代码 HardFault 是 ARM Cortex-M 处理器中的一种异常。当处理器遇到无法处理的错误,或者配置为处理特定类型错误ÿ…...
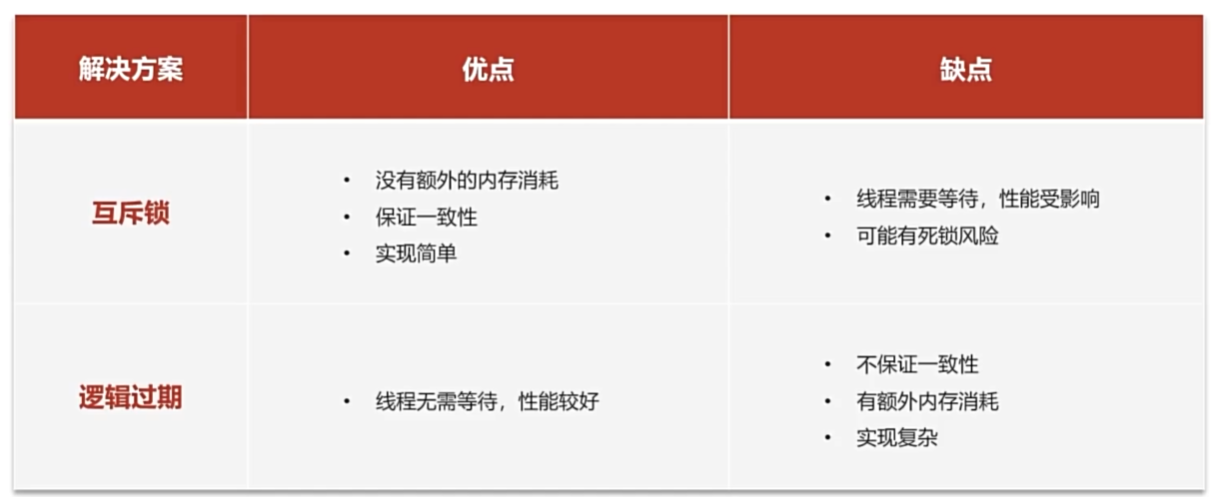
黑马 redis面试篇笔记
redis主从 version: "3.2"services:r1:image: rediscontainer_name: r1network_mode: "host"entrypoint: ["redis-server", "--port", "7001"]r2:image: rediscontainer_name: r2network_mode: "host"entrypoint:…...

Docker端口映射与容器间DNS发现:打通服务通信的任督二脉
Docker端口映射与容器间DNS发现:打通服务通信的任督二脉 一、端口映射深度解析1.1 端口映射核心机制映射规则语法: 1.2 高级映射技巧批量端口映射:查看端口绑定状态: 二、容器间服务发现机制2.1 自定义网络DNS体系DNS解析特性&…...

DBdriver使用taos数据库
首先创建连接 连接后比如数据库里有三个库 选择其中的hypon 选中localhost,右键sql编辑器,打开sql控制台 就插入了一条数据...
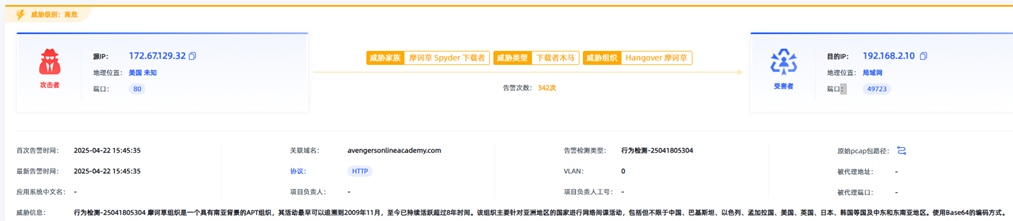
观成科技:摩诃草组织Spyder下载器流量特征分析
一、概述 自2023年以来,摩诃草组织频繁使用Spyder下载器下载远控木马,例如Remcos。观成安全研究团队对近几年的Spyder样本进行了深入研究,发现不同版本的样本在数据加密、流量模式等方面存在差异。基于此,我们对多个版本样本的通…...
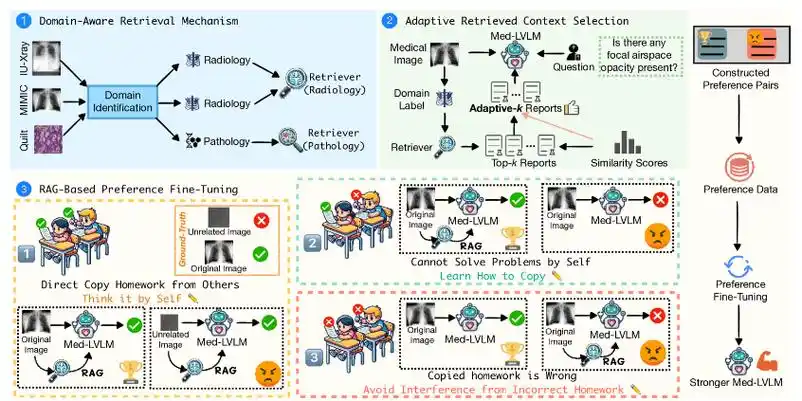
AIGC实战之如何构建出更好的大模型RAG系统
一、RAG 系统核心架构解析 1. 检索模块深度优化 1.1 混合检索技术实现 技术原理:结合稀疏检索(BM25)与密集检索(DPR),通过动态权重分配提升检索精度。例如,在医疗领域,BM25 负责精…...

C++入门小馆: 深入了解STLlist
嘿,各位技术潮人!好久不见甚是想念。生活就像一场奇妙冒险,而编程就是那把超酷的万能钥匙。此刻,阳光洒在键盘上,灵感在指尖跳跃,让我们抛开一切束缚,给平淡日子加点料,注入满满的pa…...

【Git】Fork和并请求
当你在 GitHub 或其他代码托管平台上 Fork 了一个项目后,你可以基于你的 Fork 进行开发,并通过 Pull Request(PR) 的方式将你的更改提交给原始项目(也称为上游仓库)。以下是完整的流程和步骤: 1…...

小白学习java第15天:JDBC
1.数据库驱动 想一下我们之前是怎么操作数据库,是不是使用SQL语句对其mysql数据库管理系统,然后管理系统在进行数据库(硬盘文件里面的)进行操作。那么我现在想使用应用程序对其数据库进行操作,应该怎么办呢࿱…...
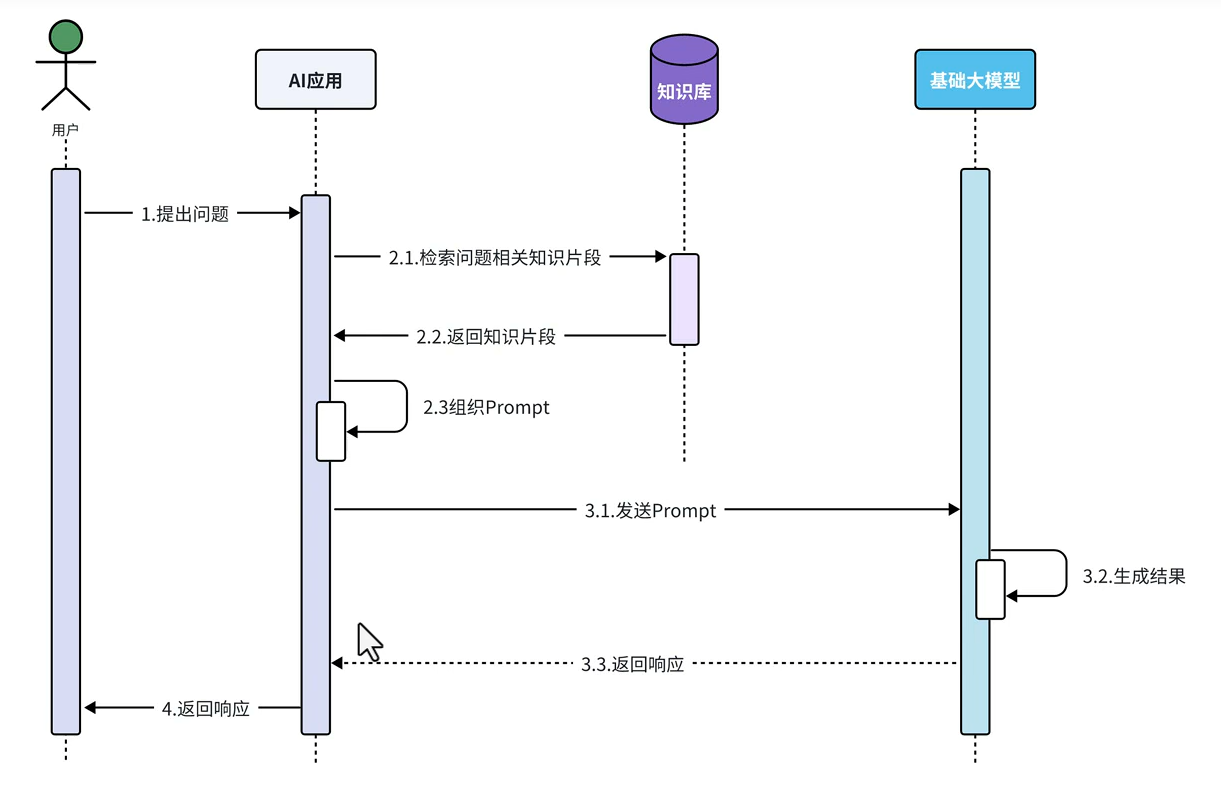
大模型应用开发(PAFR)
Prompt问答 特征:利用大模型推理能力完成应用的核心功能 应用场景: 文本摘要分析 舆情分析 坐席检查 AI对话 AgentFunction Calling 特征:将应用端业务能力与AI大模型推理能力结合,简化复杂业务功能开发 应用场景: 旅行指南 数据…...

Go 剥离 HTML 标签的三把「瑞士军刀」——从正则到 Bluemonday
1 为什么要「剥皮」? 安全:去掉潜在的 <script onload…> 等恶意标签,防止存储型 XSS。可读性:日志、消息队列、搜索索引里往往只需要纯文本。一致性:不同富文本编辑器生成的 HTML 五花八门,统一成「…...