R7周:糖尿病预测模型优化探索
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
一、数据预处理
1.设置GPU
import torch.nn.functional as F
import torch.nn as nn
import torch, torchvisiondevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
devicedevice(type='cuda')
2.数据导入
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['savefig.dpi'] = 500
plt.rcParams['figure.dpi'] = 500
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签import warnings
warnings.filterwarnings("ignore")DataFrame = pd.read_excel('F:/jupyter lab/DL-100-days/datasets/diabetes_pre/dia.xls')
DataFrame.head()

DataFrame.shape(1006, 16)
3.数据检查
# 查看是否有缺失值
print("数据缺失值------------------")
print(DataFrame.isnull().sum())数据缺失值------------------ 卡号 0 性别 0 年龄 0 高密度脂蛋白胆固醇 0 低密度脂蛋白胆固醇 0 极低密度脂蛋白胆固醇 0 甘油三酯 0 总胆固醇 0 脉搏 0 舒张压 0 高血压史 0 尿素氮 0 尿酸 0 肌酐 0 体重检查结果 0 是否糖尿病 0 dtype: int64
# 查看数据是否有重复值
print("数据重复值------------------")
print('数据的重复值为:'f'{DataFrame.duplicated().sum()}')数据重复值------------------ 数据的重复值为:0
二、数据分析
1.数据分布分析
feature_map = {'年龄': '年龄','高密度脂蛋白胆固醇': '高密度脂蛋白胆固醇','低密度脂蛋白胆固醇': '低密度脂蛋白胆固醇','极低密度脂蛋白胆固醇': '极低密度脂蛋白胆固醇','甘油三酯': '甘油三酯','总胆固醇': '总胆固醇','脉搏': '脉搏','舒张压': '舒张压','高血压史': '高血压史','尿素氮': '尿素氮','尿酸': '尿酸','肌酐': '肌酐','体重检查结果': '体重检查结果'
}plt.figure(figsize=(15, 10))
for i, (col, col_name) in enumerate(feature_map.items(), 1):plt.subplot(3, 5, i)sns.boxplot(x=DataFrame['是否糖尿病'], y=DataFrame[col])plt.title(f'{col_name}的箱线图', fontsize=14)plt.ylabel('数值', fontsize=12)plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()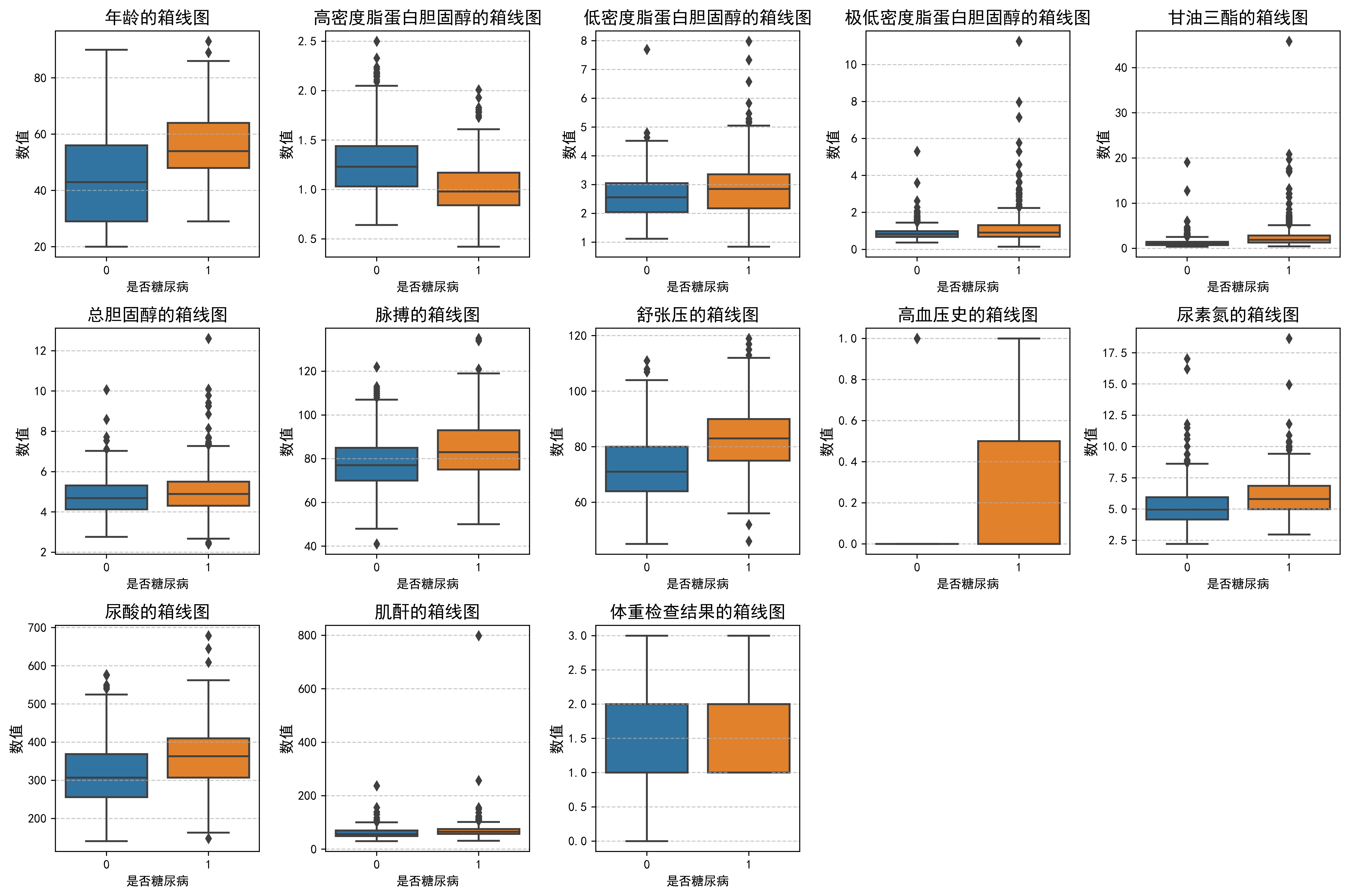
2. 相关性分析
import plotly
import plotly.express as px#删除列'卡号'
DataFrame.drop(columns=['卡号'], inplace=True)
# 计算各列之间的相关系数
df_corr = DataFrame.corr()#相关矩阵生成函数
def corr_generate(df):fig = px.imshow(df,text_auto=True,aspect="auto",color_continuous_scale='RdBu_r')fig.show()#生成相关矩阵
corr_generate(df_corr) 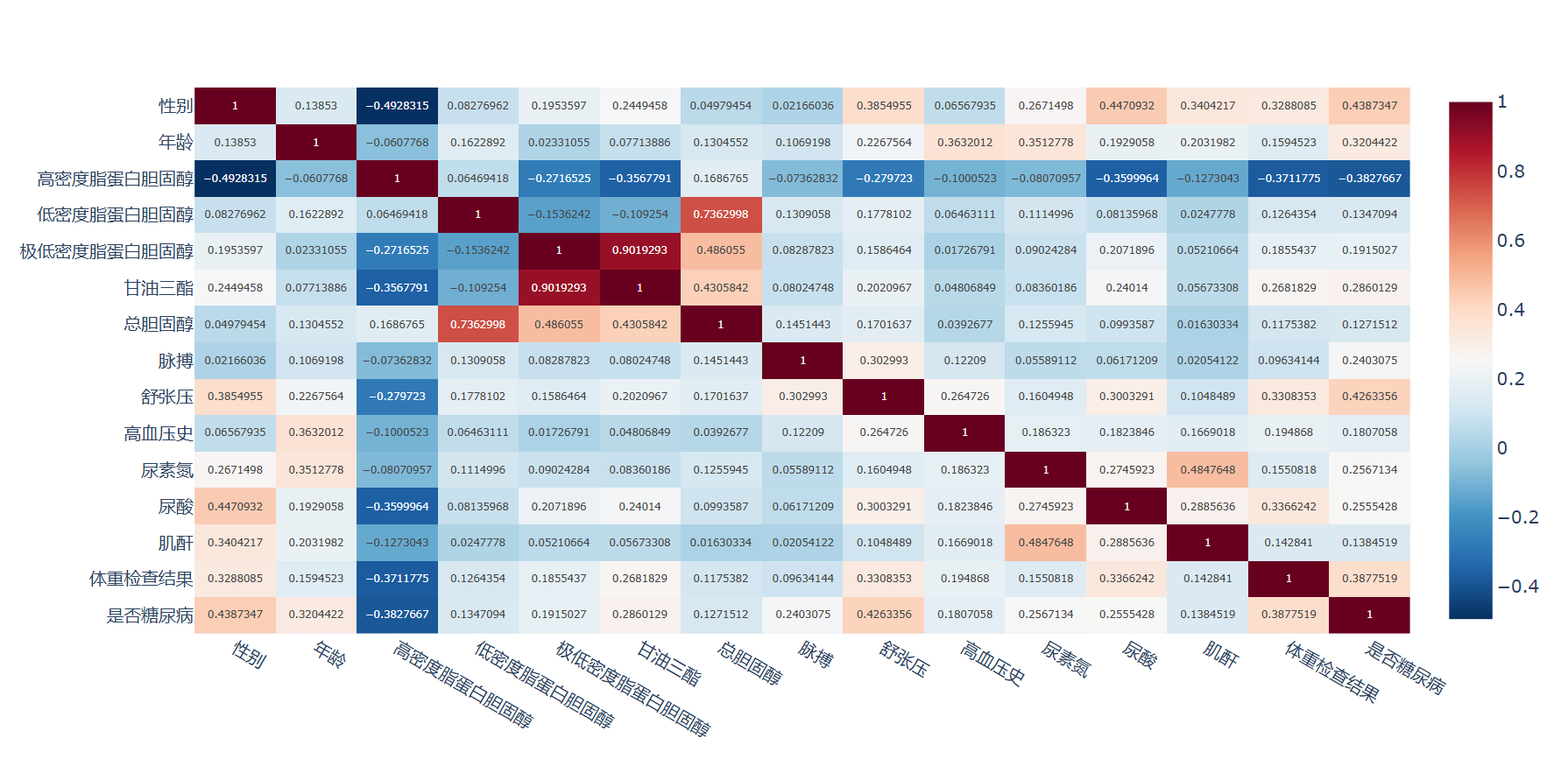
三、LSTM模型
1.划分数据集
from sklearn.preprocessing import StandardScaler# '高密度脂蛋白胆固醇'字段与糖尿病负相关,故在X 中去掉该字段
X = DataFrame.drop(['卡号', '是否糖尿病', '高密度脂蛋白胆固醇'], axis=1)
y = DataFrame['是否糖尿病']sc_X = StandardScaler
X = sc_X.fit_transform(X)X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64)train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=1)train_X.shape, train_y.shape(torch.Size([804, 13]), torch.Size([804]))
from torch.utils.data import TensorDataset, DataLoadertrain_dl = DataLoader(TensorDataset(train_X, train_y), batch_size=64, shuffle=False)
test_dl = DataLoader(TensorDataset(test_X, test_y), batch_size=64, shuffle=False)2.定义模型
class model_lstm(nn.Module):def __init__(self):super(model_lstm, self).__init__()self.lstm0 = nn.LSTM(input_size=13, hidden_size=200,num_layers=1, batch_first=True)self.lstm1 = nn.LSTM(input_size=200, hidden_size=200,num_layers=1, batch_first=True)self.fc0 = nn.Linear(200, 2) # 输出 2 类def forward(self, x):# 如果 x 是 2D 的,转换为 3D 张量,假设 seq_len=1if x.dim() == 2:x = x.unsqueeze(1) # [batch_size, 1, input_size]# LSTM 处理数据out, (h_n, c_n) = self.lstm0(x) # 第一层 LSTM# 使用第二个 LSTM,并传递隐藏状态out, (h_n, c_n) = self.lstm1(out, (h_n, c_n)) # 第二层 LSTM# 获取最后一个时间步的输出out = out[:, -1, :] # 选择序列的最后一个时间步的输出out = self.fc0(out) # [batch_size, 2]return outmodel = model_lstm().to(device)
print(model)model_lstm((lstm0): LSTM(13, 200, batch_first=True)(lstm1): LSTM(200, 200, batch_first=True)(fc0): Linear(in_features=200, out_features=2, bias=True) )
三、训练模型
1.定义训练函数
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目train_loss, train_acc = 0, 0 # 初始化训练损失和正确率model.train() # 设置模型为训练模式for X, y in dataloader: # 获取数据和标签# 如果 X 是 2D 的,调整为 3Dif X.dim() == 2:X = X.unsqueeze(1) # [batch_size, 1, input_size],即假设 seq_len=1X, y = X.to(device), y.to(device) # 将数据移动到设备# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距# 反向传播optimizer.zero_grad() # 清除上一步的梯度loss.backward() # 反向传播optimizer.step() # 更新权重# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= size # 平均准确率train_loss /= num_batches # 平均损失return train_acc, train_loss2.定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss3.训练模型
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = opt.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f},Lr:{:.2E}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))print("=" * 20, 'Done', "=" * 20)Epoch: 1, Train_acc:56.5%, Train_loss:0.688, Test_acc:53.0%, Test_loss:0.704,Lr:1.00E-04 Epoch: 2, Train_acc:56.3%, Train_loss:0.681, Test_acc:53.0%, Test_loss:0.704,Lr:1.00E-04 Epoch: 3, Train_acc:56.3%, Train_loss:0.676, Test_acc:53.0%, Test_loss:0.697,Lr:1.00E-04 Epoch: 4, Train_acc:56.3%, Train_loss:0.670, Test_acc:53.0%, Test_loss:0.690,Lr:1.00E-04 Epoch: 5, Train_acc:56.2%, Train_loss:0.663, Test_acc:54.5%, Test_loss:0.684,Lr:1.00E-04 ..........
Epoch:26, Train_acc:76.6%, Train_loss:0.481, Test_acc:71.3%, Test_loss:0.546,Lr:1.00E-04 Epoch:27, Train_acc:76.9%, Train_loss:0.475, Test_acc:71.8%, Test_loss:0.541,Lr:1.00E-04 Epoch:28, Train_acc:77.5%, Train_loss:0.470, Test_acc:71.3%, Test_loss:0.537,Lr:1.00E-04 Epoch:29, Train_acc:77.2%, Train_loss:0.465, Test_acc:71.8%, Test_loss:0.533,Lr:1.00E-04 Epoch:30, Train_acc:77.4%, Train_loss:0.460, Test_acc:70.8%, Test_loss:0.529,Lr:1.00E-04 ==================== Done ====================
五、模型评估
1.Loss和Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率from datetime import datetime
current_time = datetime.now()epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()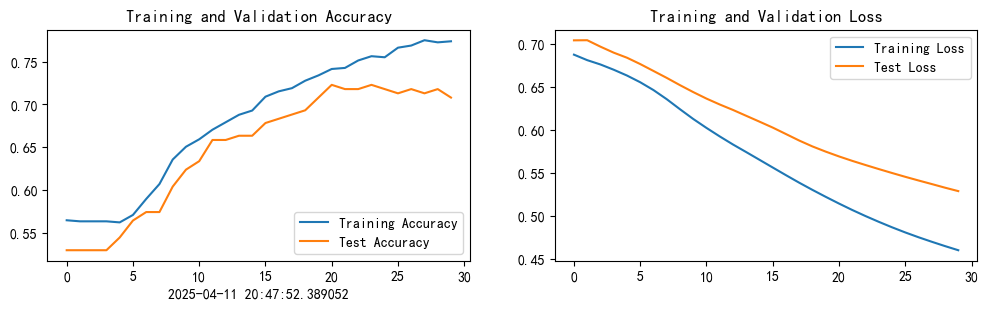
六、学习心得
1.本周延续上周的工作,开展了糖尿病预测模型优化探索。加入了相关性分析这个新模块,更加直观地实现了各种因素之间的相关性。
2.从训练结果中可以发现,test_acc有所增长。
3.相较于R6而言,主要修改的地方在于数据集那部分,取消注释了sc_X= StandardScaler()和X= sc_X.fit_transform(X)两行代码。
相关文章:
R7周:糖尿病预测模型优化探索
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 一、数据预处理 1.设置GPU import torch.nn.functional as F import torch.nn as nn import torch, torchvisiondevice torch.device("cuda"…...
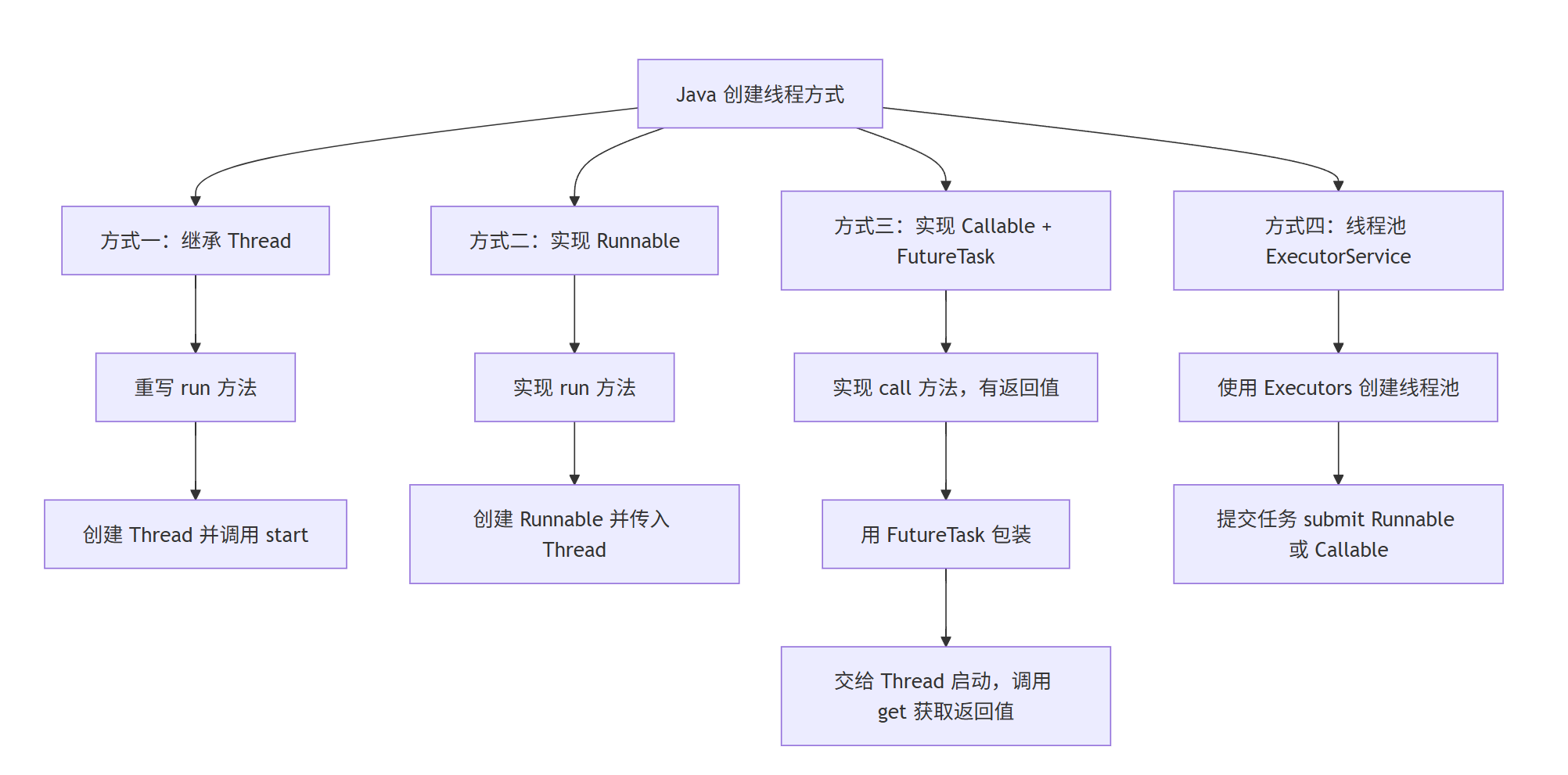
线程怎么创建?Java 四种方式一网打尽
🚀 Java 中线程的 4 种创建方式详解 创建方式实现方式是否推荐场景说明1. 继承 Thread 类class MyThread extends Thread❌ 不推荐简单学习、单线程场景2. 实现 Runnable 接口class MyRunnable implements Runnable✅ 推荐更适合多线程共享资源3. 实现 Callable 接…...

前端如何连接tcp 服务,接收数据
在传统的浏览器前端环境中,由于浏览器的同源策略和安全限制,无法直接建立 TCP 连接。不过,可以通过 WebSocket 或者使用 WebRTC 来间接实现与 TCP 服务的通信,另外在 Node.js 环境中可以直接使用 net 模块建立 TCP 连接。下面分别…...
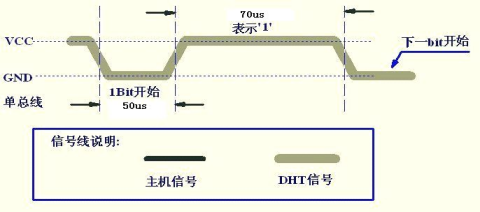
STM32之DHT11温湿度传感器---附代码
DHT11简介 DHT11的供电电压为 3-5.5V。 传感器上电后,要等待 1s 以越过不稳定状态在此期间无需发送任何指令。 电源引脚(VDD,GND)之间可增加一个100nF 的电容,用以去耦滤波。 DATA 用于微处理器与DHT11之间…...
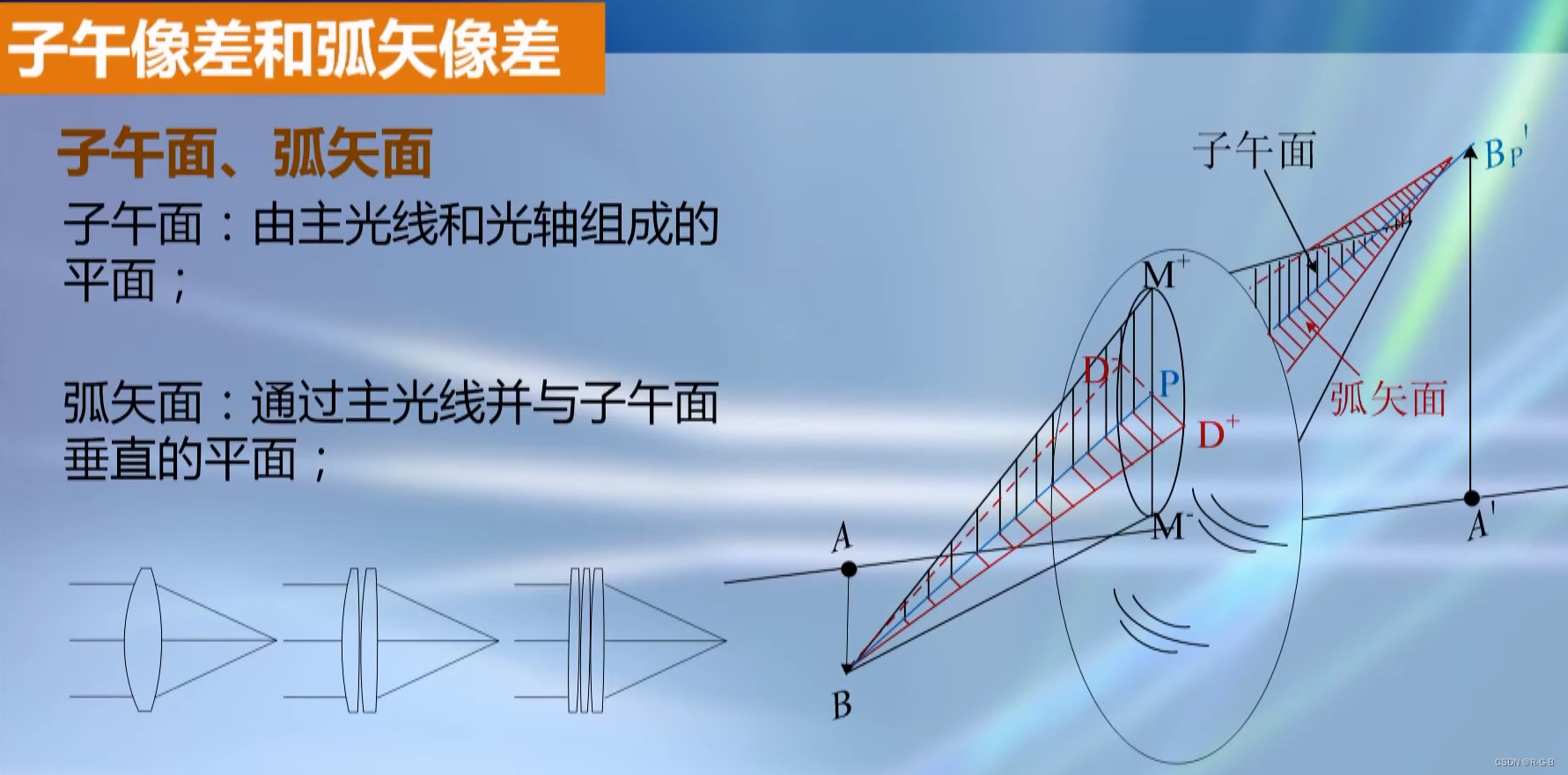
工业相机——镜头篇【机器视觉,图像采集系统,成像原理,光学系统,成像光路,镜头光圈,镜头景深,远心镜头,分辨率,MTF曲线,焦距计算 ,子午弧矢】
文章目录 1 机器视觉,图像采集系统2 相机镜头,属于一种光学系统3 常规镜头 成像光路4 镜头光圈5 镜头的景深6 远心镜头 及 成像原理7 远心镜头种类 及 应用场景8 镜头分辨率10 镜头的对比度11 镜头的MTF曲线12 镜头的焦距 计算13 子午弧矢 图解 反差 工业…...

如何在Spring Boot中禁用Actuator端点安全性
在 Spring Boot 应用中,Spring Boot Actuator 提供了一系列用于监控和管理应用的端点(如 /actuator/health、/actuator/metrics),这些端点默认可能受到 Spring Security 的保护,要求身份验证或授权。然而,在…...

第48讲:空间大数据与智慧农业——时空大数据分析与农业物联网的融合实践
目录 🧠 一、什么是空间大数据? 📡 二、农业物联网:数据采集的神经末梢 🔁 三、融合应用:空间大数据 + 农业IoT = 决策大脑 1. 精准灌溉管理 2. 时空病虫害预警 3. 农业碳监测与生态评估 💡 四、技术实践案例:农田干旱预警系统 📌 场景设定: 🛠 数据…...

openwrt查询网关的命令
方法一:route -n 方法二:ip route show...

华为OD机试真题——查找接口成功率最优时间段(2025A卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 A卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录…...

SiamMask原理详解:从SiamFC到SiamRPN++,再到多任务分支设计
SiamMask原理详解:从SiamFC到SiamRPN,再到多任务分支设计 一、引言二、SiamFC:目标跟踪的奠基者1. SiamFC的结构2. SiamFC的局限性 三、SiamRPN:引入Anchor机制的改进1. SiamRPN的创新2. SiamRPN的进一步优化 四、SiamMask&#x…...

Gradle安装与配置国内镜像源指南
一、Gradle简介与安装准备 Gradle是一款基于JVM的现代化构建工具,广泛应用于Java、Kotlin、Android等项目的构建自动化。相比传统的Maven和Ant,Gradle采用Groovy或Kotlin DSL作为构建脚本语言,具有配置灵活、性能优越等特点。 在开始安装前…...
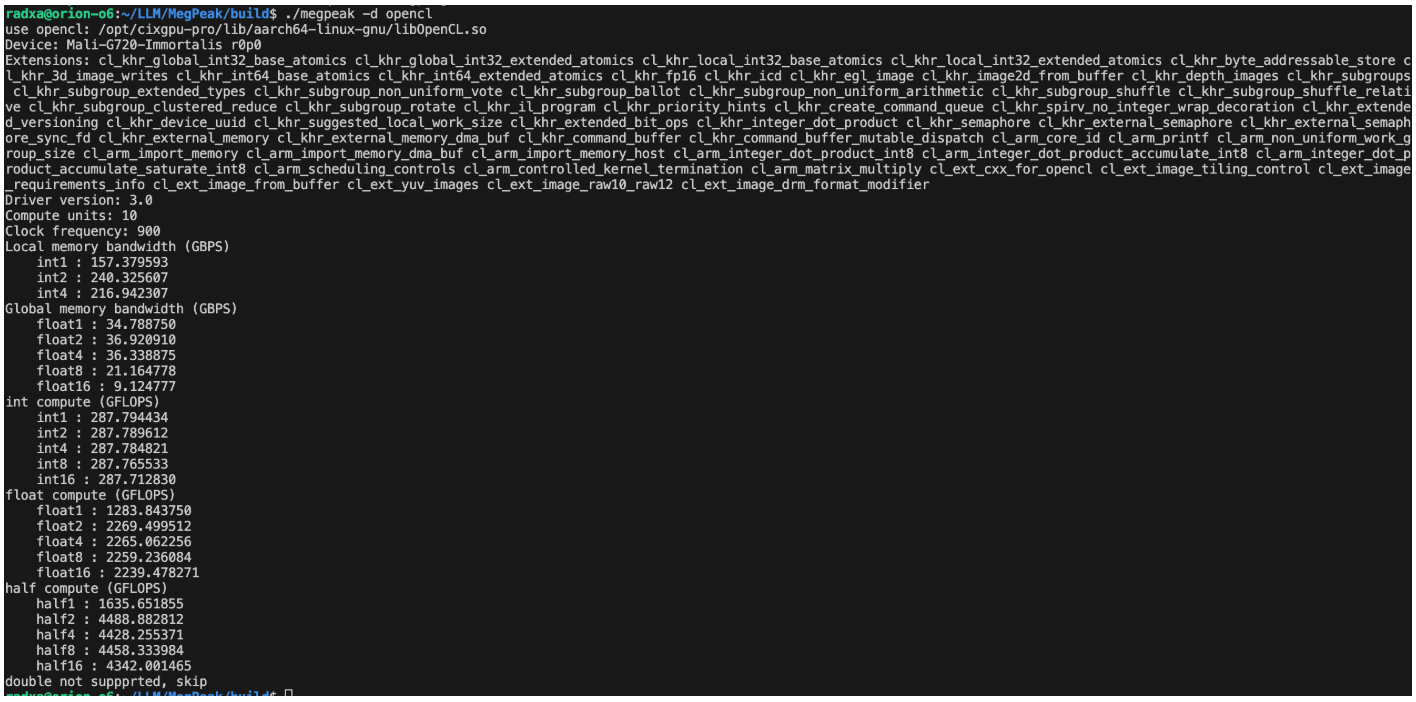
【“星睿O6”AI PC开发套件评测】开箱+刷机+基础环境配置
开箱 很荣幸可以参与“星睿O6”AI PC开发套件评测,话不多说先看开箱美图,板子的包装还是蛮惊艳的。 基础开发环境配置 刷机 刷机参考这里的文档快速上手即可,笔者同时验证过使用USB和使用NVMe硬盘盒直接在硬盘上刷机,操作下来建…...
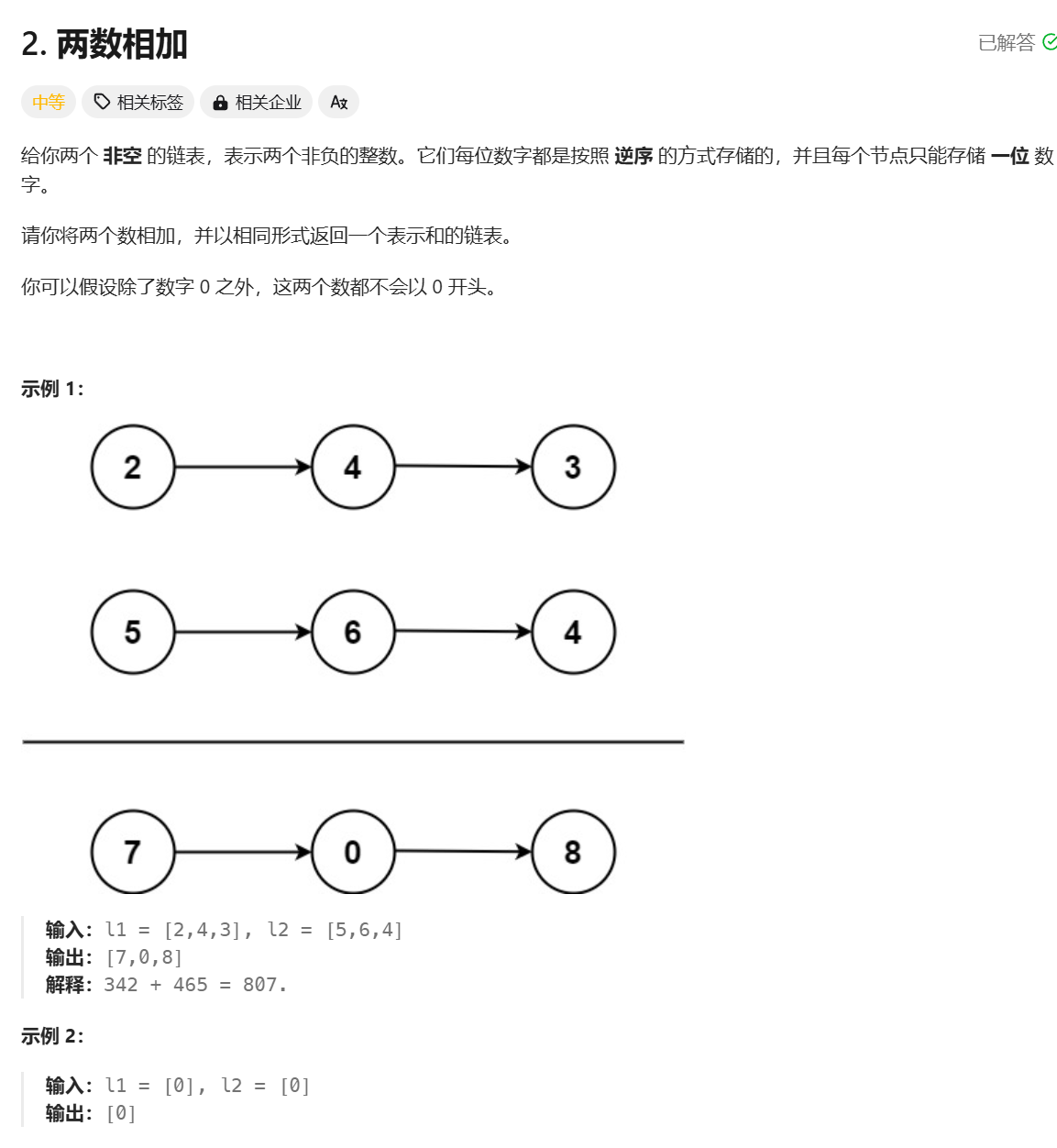
力扣面试150题--环形链表和两数相加
Day 32 题目描述 思路 采取快慢指针 /*** Definition for singly-linked list.* class ListNode {* int val;* ListNode next;* ListNode(int x) {* val x;* next null;* }* }*/ public class Solution {public boolean hasCycle(ListNod…...

Dapper的数据库操作备忘
Dapper是很好的C#生态的ORM工具 获取单条记录 var row conn.QueryFirstOrDefault("select abc as cc"); if (row null) return; string priField row.cc; //直接访问字段根据动态的字段名获取值,则需要先转为字典接口 var dict (IDictionary<string, objec…...
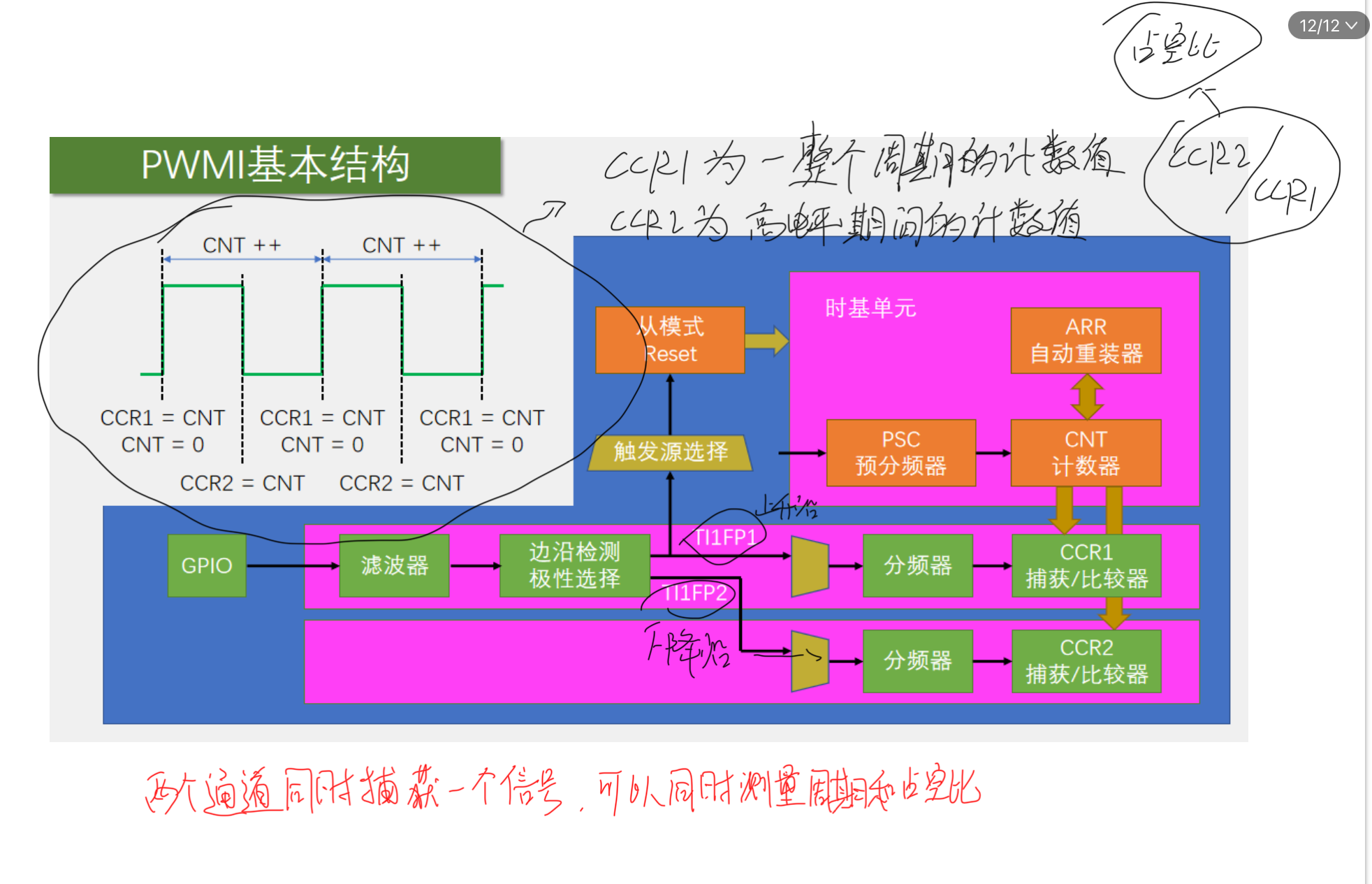
STM32 TIM输入捕获
一、输入捕获简介 IC(Input Capture)输入捕获输入捕获模式下,当通道输入引脚出现指定电平跳变时,当前CNT的值将被锁存到CCR中,可用于测量PWM波形的频率、占空比、脉冲间隔、电平持续时间等参数每个高级定时器和通用定…...
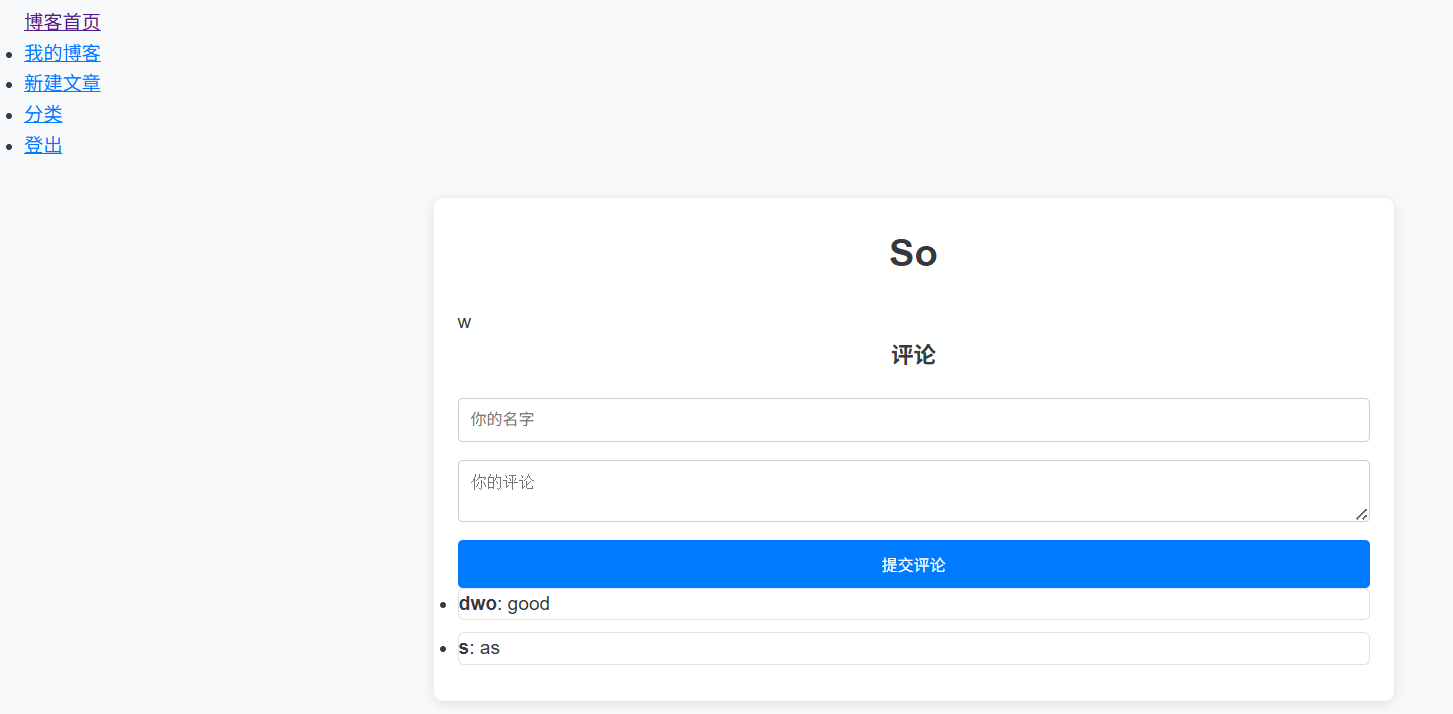
python项目实战-后端个人博客系统
本文分享一个基于 Flask 框架开发的个人博客系统后端项目,涵盖用户注册登录、文章发布、分类管理、评论功能等核心模块。适合初学者学习和中小型博客系统开发。 一、项目结构 blog │ app.py │ forms.py │ models.py │ ├───instance │ blog.d…...

白鲸开源与亚马逊云科技携手推动AI-Ready数据架构创新
在昨日举办的2025亚马逊云科技合作伙伴峰会圆桌论坛上,白鲸开源创始人兼CEO郭炜作为嘉宾,与亚马逊云科技及其他行业领袖共同探讨了“AI-Ready的数据架构:ISV如何构建面向生成式AI的强大数据基座”这一重要话题。此次论坛由亚马逊云科技大中华…...

【目标检测】目标检测综述 目标检测技巧
I. 目标检测中标注的关键作用 A. 目标检测数据标注的定义 目标检测是计算机视觉领域的一项基础且核心的任务,其目标是在图像或视频中准确识别并定位出预定义类别的目标实例 1。数据标注,在目标检测的语境下,指的是为原始视觉数据࿰…...
]JSONRPC协议MCPRAGAgent)
[AI技术(二)]JSONRPC协议MCPRAGAgent
Agent概述(一) AI技术基础(一) JSON-RPC 2.0 协议详解 JSON-RPC 2.0 是一种基于 JSON 的轻量级远程过程调用(RPC)协议,旨在简化跨语言、跨平台的远程通信。以下从协议特性、核心结构、错误处理、批量请求等角度进行详细解析: 一、协议概述 1. 设计原则 • 简单性:…...
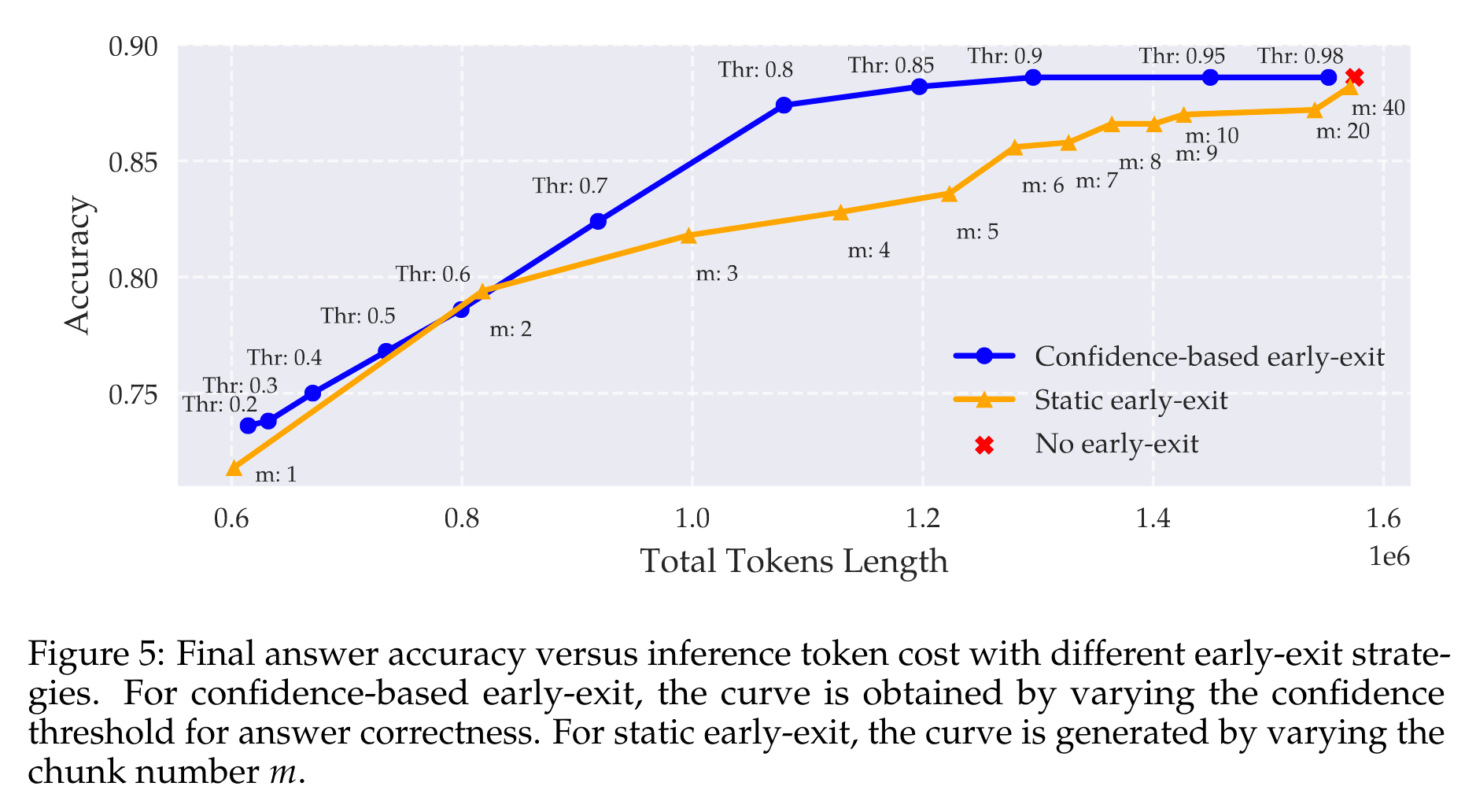
探秘LLM推理模型:hidden states中藏着的self verification的“钥匙”
推理模型在数学和逻辑推理等任务中表现出色,但常出现过度推理的情况。本文研究发现,推理模型的隐藏状态编码了答案正确性信息,利用这一信息可提升推理效率。想知道具体如何实现吗?快来一起来了解吧! 论文标题 Reasoni…...
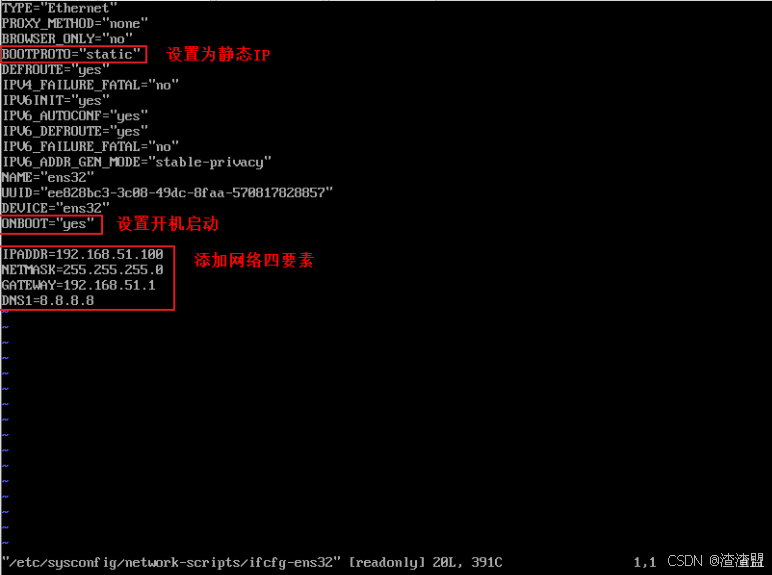
大数据开发环境的安装,配置(Hadoop)
1. 三台linux服务器的安装 1. 安装VMware VMware虚拟机软件是一个“虚拟PC”软件,它使你可以在一台机器上同时运行二个或更多Windows、DOS、LINUX系统。与“多启动”系统相比,VMWare采用了完全不同的概念。 我们可以通过VMware来安装我们的linux虚拟机…...

【GCC bug】libstdc++.so.6: version `GLIBCXX_3.4.29‘ not found
在 conda 环境安装 gcc/gxx 之后,运行开始遇到了以下的报错 File "/mnt/data/home/xxxx/miniforge3/envs/GAGAvatar/lib/python3.12/site-packages/google/protobuf/internal/wire_format.py", line 13, in <module>from google.protobuf import de…...

Android killPackageProcessesLSP 源码分析
该方法用于终止指定包名/用户ID/应用ID下符合条件的应用进程,涉及多进程管理、资源冻结、进程清理及优先级更新等操作。核心流程分为进程筛选、资源冻结、进程终止与资源恢复三个阶段。 /*** 从已排序的进程列表中,提取从指定起始索引 startIdx 开始的连…...
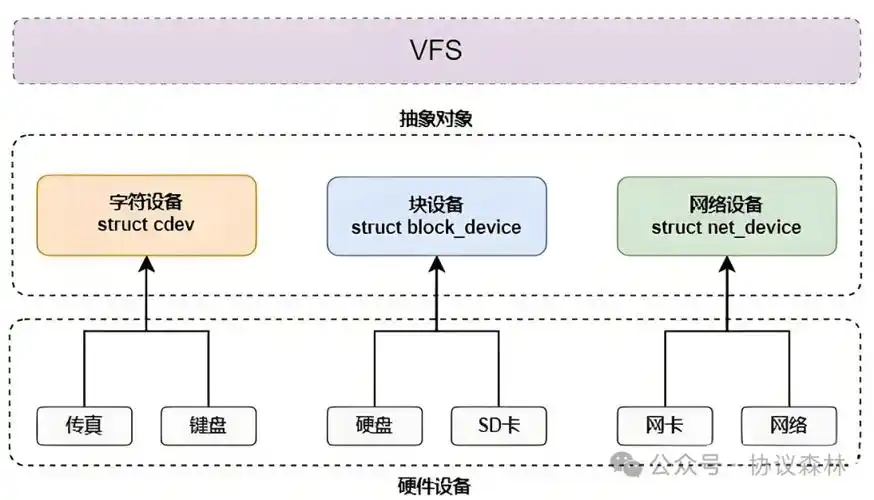
驱动开发硬核特训 · Day 16:字符设备驱动模型与实战注册流程
🎥 视频教程请关注 B 站:“嵌入式 Jerry” 一、为什么要学习字符设备驱动? 在 Linux 驱动开发中,字符设备(Character Device)驱动 是最基础也是最常见的一类驱动类型。很多设备(如 LED、按键、…...

CDN加速http请求
一、CDN加速定义 CDN(Content Delivery Network,内容分发网络)是通过全球分布式节点服务器缓存网站内容,使用户就近获取数据的技术。其核心目标是缩短用户与内容之间的物理距离,解决网络拥塞、带宽不足等问题ÿ…...

SpringCloud微服务架构设计与实践 - 面试实战
SpringCloud微服务架构设计与实践 - 面试实战 第一轮提问 面试官:马架构,请问在SpringCloud微服务架构中,如何实现服务注册与发现? 马架构:在SpringCloud中,Eureka是常用的服务注册与发现组件。服务提供…...

关于位运算的一些小记
目录 1.判断一个整数是不是2的幂 2.判断一个整数是不是3的幂 3.大于n的最小的2次幂的数 4.交换两个数 5.找到1-n中缺失的数字 6.判断数组中2个出现次数为奇数的数 6.求给定范围内所有数字&的结果 7. 求出现次数少于m的数 1.判断一个整数是不是2的幂 提取出二进制里最…...
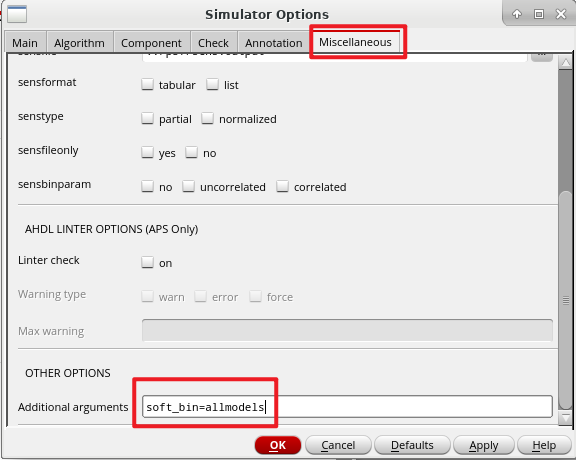
Virtuoso ADE采用Spectre仿真中出现MOS管最小长宽比满足要求依然报错的情况解决方法
在ADE仿真中错误问题如下: ERROR (CMI-2440): "xxx.scs" 46338: I2.M1: The length, width, or area of the instance does not fit the given lmax-lmin, wmax-wmin, or areamax-areamin range for any model in the I2.M3.nch_hvt group. The channel w…...
)
图论---朴素Prim(稠密图)
O( n ^2 ) 题目通常会提示数据范围: 若 V ≤ 500,两种方法均可(朴素Prim更稳)。 若 V ≤ 1e5,必须用优先队列Prim vector 存图。 // 最小生成树 —朴素Prim #include<cstring> #include<iostream> #i…...
)
Java知识日常巩固(四)
什么是 Java 中的自动装箱和拆箱? 在Java中,自动装箱(Autoboxing)和拆箱(Unboxing)是Java 5引入的特性,它们允许基本数据类型(如 int、double 等)和它们对应的包装类(如 Integer、Double 等)之间进行自动转换。 自动装箱是指将基本数据类型的值自动…...