【随笔】地理探测器原理与运用
文章目录
- 一、作者与下载
- 1.1 软件作者
- 1.2 软件下载
- 二、原理简述
- 2.1 空间分异性与地理探测器的提出
- 2.2 地理探测器的数学模型
- 2.21 分异及因子探测
- 2.22 交互作用探测
- 2.23 风险区与生态探测
- 三、使用:excel
一、作者与下载
1.1 软件作者
作者:

DOI: 10.11821/dlxb201701010
文献:地理探测器:原理与展望。直接看这个文献也可以。
1.2 软件下载
主页:http://www.geodetector.cn/Download.html
分别是excel宏、R包、QGIS和ArcGIS Pro工具箱。
excel的都带有示例数据,不过第三个和第一个的数据是相同的(可能是网站文件设置错误,截至我发文日期)。
二、原理简述
2.1 空间分异性与地理探测器的提出
空间分异性的科学意义:
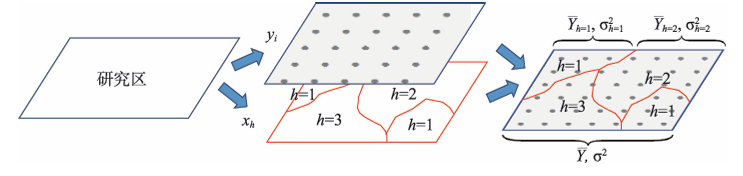
空间分异性(空间分层异质性)表现为地理现象在子区域内的方差小于总区域方差,例如气候带、土地利用分区等。地理探测器通过量化这一分异性,为揭示其驱动因子提供了统计学工具。
地理探测器的核心优势:
- 无需线性假设:适用于非线性关系分析。
- 物理含义明确:通过方差分解直接量化因子解释力。
- 多类型数据兼容:支持类型量(如分类地图)和离散化数值量的分析。
基本逻辑:
- 分异性检验:若子区域方差和( S S W SSW SSW)小于总方差( S S T SST SST),则存在空间分异。
- 因子关联性:若两变量空间分布一致,则存在统计关联。
2.2 地理探测器的数学模型
2.21 分异及因子探测
q统计量用于度量因子解释力:
q = 1 − ∑ h = 1 L N h σ h 2 N σ 2 = 1 − S S W S S T q = 1 - \frac{\sum_{h=1}^{L} N_h \sigma_h^2}{N\sigma^2} = 1 - \frac{SSW}{SST} q=1−Nσ2∑h=1LNhσh2=1−SSTSSW
式中:
- L L L为分层数, N h N_h Nh和 N N N为子区域与全区域样本数。
- σ h 2 \sigma_h^2 σh2和 σ 2 \sigma^2 σ2为子区域与总体方差。
显著性检验通过非中心F分布实现:
F = N − L L − 1 ⋅ q 1 − q ∼ F ( L − 1 , N − L ; λ ) F = \frac{N-L}{L-1} \cdot \frac{q}{1-q} \sim F(L-1, N-L; \lambda) F=L−1N−L⋅1−qq∼F(L−1,N−L;λ)
其中非中心参数 λ \lambda λ为:
λ = 1 σ 2 [ ∑ h = 1 L Y ˉ h 2 − 1 N ( ∑ h = 1 L N h Y ˉ h ) 2 ] \lambda = \frac{1}{\sigma^2} \left[ \sum_{h=1}^{L} \bar{Y}_h^2 - \frac{1}{N} \left( \sum_{h=1}^{L} N_h \bar{Y}_h \right)^2 \right] λ=σ21 h=1∑LYˉh2−N1(h=1∑LNhYˉh)2
某个因子的q值越大,他对因变量的解释力就越强。显著性检验的p值,就不用说了吧,比如小于0.01,就代表xxx.
2.22 交互作用探测
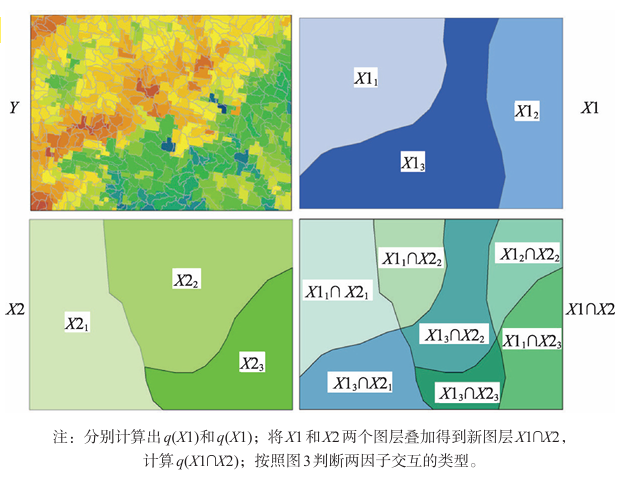
通过比较单因子与多因子叠加的 q q q值,判断交互作用类型:
- 非线性增强: q ( X 1 ∩ X 2 ) > q ( X 1 ) + q ( X 2 ) q(X_1 \cap X_2) > q(X_1) + q(X_2) q(X1∩X2)>q(X1)+q(X2)
- 双因子增强: q ( X 1 ∩ X 2 ) > max ( q ( X 1 ) , q ( X 2 ) ) q(X_1 \cap X_2) > \max(q(X_1), q(X_2)) q(X1∩X2)>max(q(X1),q(X2))
- 单因子主导: max ( q ( X 1 ) , q ( X 2 ) ) < q ( X 1 ∩ X 2 ) < q ( X 1 ) + q ( X 2 ) \max(q(X_1), q(X_2)) < q(X_1 \cap X_2) < q(X_1) + q(X_2) max(q(X1),q(X2))<q(X1∩X2)<q(X1)+q(X2)
- 独立作用: q ( X 1 ∩ X 2 ) = q ( X 1 ) + q ( X 2 ) q(X_1 \cap X_2) = q(X_1) + q(X_2) q(X1∩X2)=q(X1)+q(X2)
- 非线性减弱: q ( X 1 ∩ X 2 ) < min ( q ( X 1 ) , q ( X 2 ) ) q(X_1 \cap X_2) < \min(q(X_1), q(X_2)) q(X1∩X2)<min(q(X1),q(X2))

这里的叠加,不是把各个因子相加,而是相交,简单来说就是分类增加了。看下图就明白了:
2.23 风险区与生态探测
-
风险区差异检验(t检验):
t Y ˉ h = 1 − Y ˉ h = 2 = Y ˉ h = 1 − Y ˉ h = 2 Var ( Y ˉ h = 1 ) n h = 1 + Var ( Y ˉ h = 2 ) n h = 2 t_{\bar{Y}_{h=1} - \bar{Y}_{h=2}} = \frac{\bar{Y}_{h=1} - \bar{Y}_{h=2}}{\sqrt{\frac{\text{Var}(\bar{Y}_{h=1})}{n_{h=1}} + \frac{\text{Var}(\bar{Y}_{h=2})}{n_{h=2}}}} tYˉh=1−Yˉh=2=nh=1Var(Yˉh=1)+nh=2Var(Yˉh=2)Yˉh=1−Yˉh=2
自由度 d f df df为:
d f = ( Var ( Y ˉ h = 1 ) n h = 1 + Var ( Y ˉ h = 2 ) n h = 2 ) 2 1 n h = 1 − 1 ( Var ( Y ˉ h = 1 ) n h = 1 ) 2 + 1 n h = 2 − 1 ( Var ( Y ˉ h = 2 ) n h = 2 ) 2 df = \frac{\left( \frac{\text{Var}(\bar{Y}_{h=1})}{n_{h=1}} + \frac{\text{Var}(\bar{Y}_{h=2})}{n_{h=2}} \right)^2}{\frac{1}{n_{h=1}-1} \left( \frac{\text{Var}(\bar{Y}_{h=1})}{n_{h=1}} \right)^2 + \frac{1}{n_{h=2}-1} \left( \frac{\text{Var}(\bar{Y}_{h=2})}{n_{h=2}} \right)^2} df=nh=1−11(nh=1Var(Yˉh=1))2+nh=2−11(nh=2Var(Yˉh=2))2(nh=1Var(Yˉh=1)+nh=2Var(Yˉh=2))2 -
生态探测(F检验):
F = N X 1 ( N X 2 − 1 ) S S W X 1 N X 2 ( N X 1 − 1 ) S S W X 2 F = \frac{N_{X1}(N_{X2}-1)SSW_{X1}}{N_{X2}(N_{X1}-1)SSW_{X2}} F=NX2(NX1−1)SSWX2NX1(NX2−1)SSWX1
其中 S S W X 1 SSW_{X1} SSWX1和 S S W X 2 SSW_{X2} SSWX2为两因子分层后的层内方差和。
三、使用:excel
以excel版本为例,R语言和GIS版本的也是类似的,R语言看它的help有函数说明的。
直接打开excel版本的xlsm文件,你可能无法使用,因为这是带宏的表格,系统会阻止运行。
在xlsm文件上右键–>属性:在最下面的位置会有一个解除阻止运行之类的选项(名字忘了),设置一下即可。图中我已经解除限制了,没有显示。
🟢打开表格:里面的数据可以删除换成自己的。自变量需要设置为分类变量。比如一个自变量是全国各个城市的GDP,你可以使用各自算法将数据分为几类,比如使用分位数,分为高中低三类,再编码为1、2、3这种。这个不会的话问AI即可。
接着读取数据到GUI界面,设置自变量、因变量,运行。
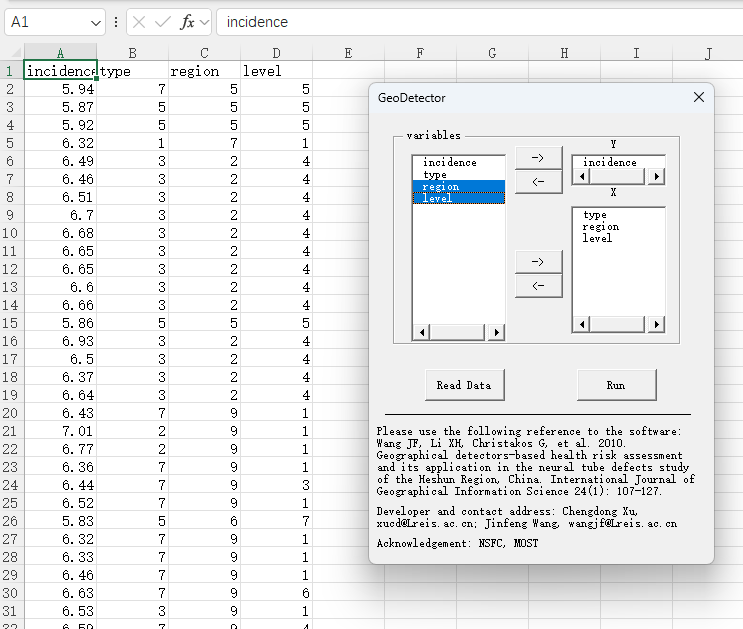
运行后会生成几个sheet:一般只使用交互效应和因子探测的表格,环境和风险的不常用。

🟢 数据说明:
他需要你提供一个“表格”形式的数据,比如ArcGIS的属性表。
数据量不要太大了:
- 第一是数据量大,你电脑内存可能不足,比如一个像元一个值,几十米分辨率,你的研究区可能就会有几十亿个像元,存为csv需要几十GB,运行的时候内存通常不足;
- 第二是运行时间太久,这个不用多说;
- 第三是使用excel的情况下,excel就支持几百万行数据。实际上几万行数据,这个程序就会溢出的。
- 第四十结果q值会非常小,因为这个计算出来的方差会非常小,那个比值接近1,q就接近0了。
建议的数据示例:每个城市的数据(因变量+自变量),这样就只有几百或者几十行数据。
另外一点是,自变量的分类(离散化)可能会影响结果:因为这个地理探测器的原理可以看作是,找到一条或者几条分界线,使得自变量和因变量都是用这一组分界线,能将数据很好的区分(当然这个比喻并不是是否准确)。这个分界线其实就相当于你对自变量的分类。
参考文献:
王劲峰, 徐成东. 地理探测器:原理与展望[J]. 地理学报, 2017, 72(1): 116-134 https://doi.org/10.11821/dlxb201701010
Jinfeng WANG, Chengdong XU. Geodetector: Principle and prospective[J]. Acta Geographica Sinica, 2017, 72(1): 116-134 https://doi.org/10.11821/dlxb201701010
相关文章:
【随笔】地理探测器原理与运用
文章目录 一、作者与下载1.1 软件作者1.2 软件下载 二、原理简述2.1 空间分异性与地理探测器的提出2.2 地理探测器的数学模型2.21 分异及因子探测2.22 交互作用探测2.23 风险区与生态探测 三、使用:excel 一、作者与下载 1.1 软件作者 作者: DOI: 10.…...

【人工智能】Python中的深度学习模型部署:从训练到生产环境
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 随着深度学习在各个领域的应用日益增多,如何将训练好的深度学习模型高效地部署到生产环境中,成为了开发者和数据科学家的重要课题。本文将…...

Rule.resource作用说明
1. 说明 作用 Rule.resource 用于定义哪些文件需要被当前规则处理。它是对传统 test、include、exclude 的更底层封装,支持更灵活的匹配方式。 与 test/include/exclude 的关系 test: /.js$/ 等价于resource: { test: /.js$/ } include: path.resolve(__dirname, ‘…...
来提高线程的复用率,减少线程创建和销毁的开销)
C++如何设计线程池(thread pool)来提高线程的复用率,减少线程创建和销毁的开销
线程池的基本概念与多线程编程中的角色 线程池,顾名思义,是一种管理和复用线程的资源池。它的核心思想在于预先创建一定数量的线程,并将这些线程保持在空闲状态,等待任务的分配。一旦有任务需要执行,线程池会从池中取出…...

从零开始使用SSH链接目标主机(包括Github添加SSH验证,主机连接远程机SSH验证)
添加ssh密钥(当前机生成和远程机承认) 以下是从头开始生成自定义名称的SSH密钥的完整步骤(以GitHub为例,适用于任何SSH服务): 1. 生成自定义名称的SSH密钥对 # 生成密钥对(-t 指定算法,-f 指定路径和名称…...
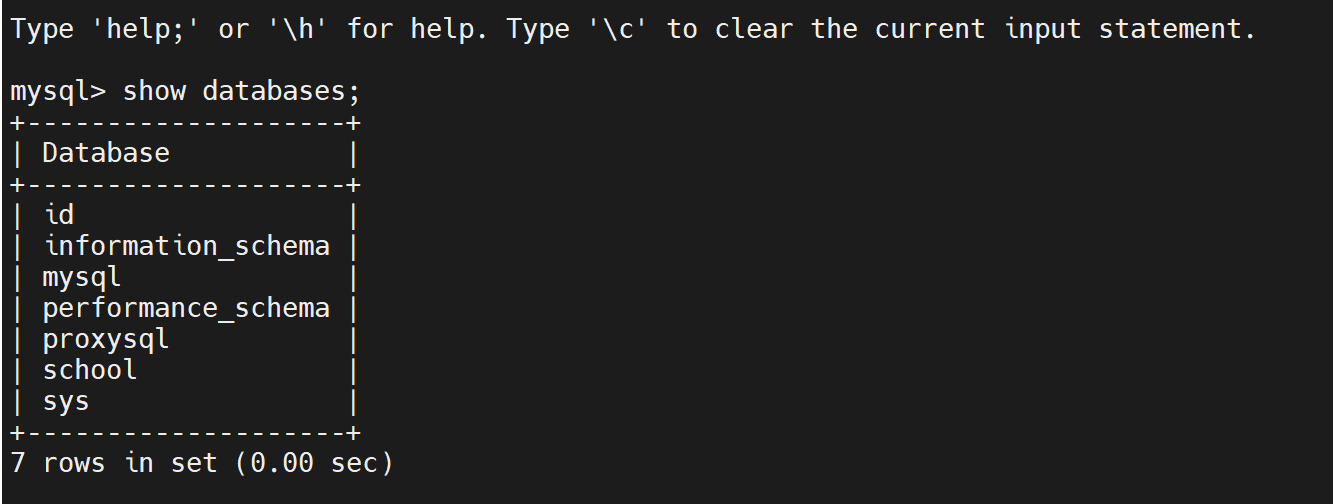
Maxscale实现Mysql的读写分离
介绍: Maxscale是mariadb开发的一个MySQL数据中间件,配置简单,能够实现读写分离,并且能根据主从状态实现写库的自动切换,对多个服务器实现负载均衡。 实验环境: 基于gtid的主从同步的基础上进行配置 中…...

以运营为核心的智能劳动力管理系统,破解连锁零售、制造业排班难题
在连锁零售、制造业、物流等劳动力密集型行业中,排班与考勤管理不仅是人力资源管理的核心环节,更是直接影响企业运营效率、成本控制与合规风险的关键场景。尤其在当前经济环境下,企业面临用工成本攀升、政策合规趋严、业务波动频繁等多重挑战…...
)
c++_csp-j算法 (5)
动态规划 介绍 动态规划(Dynamic Programming)是一种常用的解决优化问题的算法设计技术,常用于解决具有重叠子问题和最优子结构性质的问题。动态规划算法通过将问题划分为子问题,解决子问题并将子问题的解保存起来,最终构建出原问题的解。在本节中,我们将详细介绍动态规…...

sql server tempdb库的字符集和用户库字符集不一样
执行2个表用not in 关联,但是提示这个错误 消息 468,级别 16,状态 9,第 74 行 无法解决 equal to 运算中 "Latin1_General_CI_AS" 和 "Chinese_PRC_CI_AS" 之间的排序规则冲突。 对比2个表字段字符集都是&…...
Spring Boot 启动生命周期详解
Spring Boot 启动生命周期详解 1. 启动阶段划分 Spring Boot 启动过程分为 4个核心阶段,每个阶段涉及不同的核心类和执行逻辑: 阶段 1:预初始化(Pre-initialization) 目标:准备启动器和环境配置关键类&am…...

蓝桥杯 20. 压缩变换
压缩变换 原题目链接 题目描述 小明最近在研究压缩算法。他知道,压缩时如果能够使数值很小,就能通过熵编码得到较高的压缩比。然而,要使数值变小是一个挑战。 最近,小明需要压缩一些正整数序列,这些序列的特点是&a…...

数据湖DataLake和传统数据仓库Datawarehouse的主要区别是什么?优缺点是什么?
数据湖和传统数据仓库的主要区别 以下是数据湖和传统数据仓库的主要区别,以表格形式展示: 特性数据湖传统数据仓库数据类型支持结构化、半结构化及非结构化数据主要处理结构化数据架构设计扁平化架构,所有数据存储在一个大的“池”中多层架…...

YOLO改进实战:添加SOCA注意力机制提升目标检测性能
## 目录 1. **注意力机制简介** 2. **SOCA模块的核心原理** 3. **YOLOv5添加SOCA的完整步骤** 4. **实验效果与性能对比** 5. **SOCA的改进优势与创新性** --- ### 一、注意力机制简介 注意力机制(Attention Mechanism)模仿人类视觉的选择性关注特性,通过动态…...

Python爬虫实战:获取网yi新闻网财经信息并做数据分析,以供选股做参考
一、引言 在财经领域,股市信息对投资者意义重大。网yi新闻作为知名新闻资讯平台,其股市板块蕴含丰富的最新股市热点信息。然而,依靠传统人工方式从海量网页数据中获取并分析这些信息,效率低下且难以全面覆盖。因此,利用爬虫技术自动化抓取相关信息,并结合数据分析和机器…...
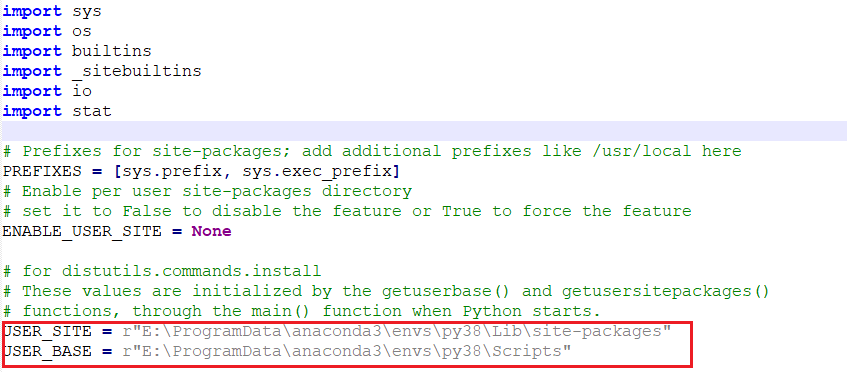
解决conda虚拟环境安装包却依旧安装到base环境下
最近跑项目装包装到几度崩溃,包一直没有安装到正确位置,为此写下这篇文章记录一下,也希望能帮到有需要的人。(此文章开发环境为anaconda和window) 方法一 先conda deactivate,看到(base)消失…...
在AIoT芯片中的应用)
IPOF方法学应用案例:动态电压频率调整(DVFS)在AIoT芯片中的应用
案例:动态电压频率调整(DVFS)在AIoT芯片中的应用 一、背景知识 继上一篇IPOF(Input-Process-Output-Feedback)方法学简介, 这一篇我们给出一个IPOF在集成电路芯片领域的一个应用场景。 动态电压频率调整&…...

Vue 3新手入门指南,从安装到基础语法
作为一名前端新手,你可能听说过Vue.js的简单与强大,但面对框架的安装和一堆新概念,可能会觉得无从下手。别担心!这篇文章将带你从零开始,完成Vue3的安装,并通过简单示例掌握核心语法。无论你是完全零基础&a…...

反爬加密字体替换机制解析
加密字体替换是网站反爬虫的常用技术之一,其核心是通过自定义字体文件对关键数据(如数字、文字)进行动态渲染,使源码中显示的字符与用户实际看到的内容不一致。下面从技术原理、实现类型和破解方法三个方向展开分析,并…...
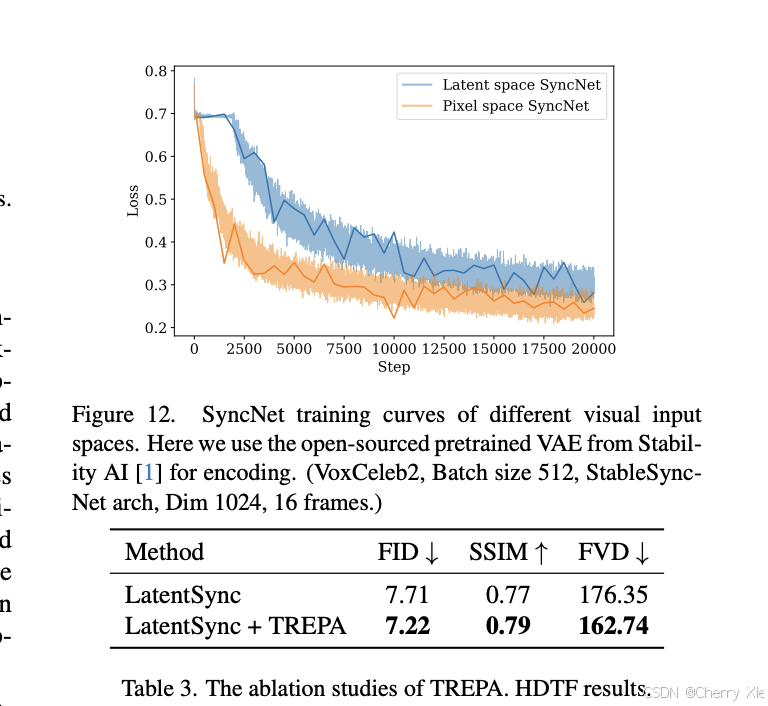
字节跳动开源数字人模型latentsync1.5,性能、质量进一步优化~
项目背景 LatentSync1.5 是由 ByteDance 开发的一款先进的 AI 模型,专门针对视频唇同步(lip synchronization)任务设计,旨在实现音频与视频唇部动作的高质量、自然匹配。随着 AI 技术的快速发展,视频生成和编辑的需求…...

Day12(回溯法)——LeetCode51.N皇后39.组合总和
1 前言 今天刷了三道回溯法和一道每日推荐,三道回溯法也迷迷糊糊的,每日推荐把自己绕进去了,虽然是一道之前做过的题的变种。刷的脑子疼。。。今天挑两道回溯题写一下吧,其中有一道是之前做过的N皇后,今天在详细写一写…...

简历中的专业技能
Java 精通Java 核心,多年一线研发经验,具备良好的编码能力、并熟练应用设计模式精通多进程、Java 高并发编程,阅读过相关 JDK 源码以及Lock锁的底层源码,熟悉 AQS 和 CAS 的核心思想,能够运用其机制优化并发编程精通 …...
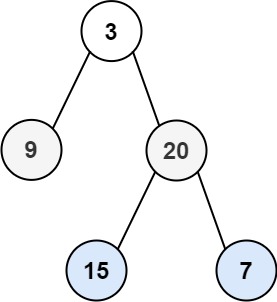
力扣HOT100——102.二叉树层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]] /*** Definition for a bi…...
【Token系列】05 | 位置编码不是位置信息:Transformer如何建立语言顺序感?
文章目录 05 | 位置编码不是位置信息:Transformer如何建立语言顺序感?一、为什么Transformer需要“位置感知”?二、什么是位置编码(Position Encoding, PE)?三、相对 vs 绝对位置编码四、可学习位置编码机制…...

springboot启动的端口如何终止
若要终止 Spring Boot 应用所使用的端口,可依据应用的运行方式,采用不同的解决办法。以下为你详细介绍: 1. 直接停止正在运行的 Spring Boot 应用程序 开发环境(IDE 中运行) IntelliJ IDEA:在 IDE 的运行…...
)
chrony服务器(1)
简介 NTP NTP(Network Time Protocol,网络时间协议)是一种用于同步计算机系统时间的协议是TCP/IP协议族中的一个应用层协议,主要用于在分布式时间服务器和客户端之间进行时钟同步,提供高精准度的时间校正通过分层的时…...

搭建基于火灾风险预测与防范的消防安全科普小程序
基于微信小程序的消防安全科普互动平台的设计与实现,是关于微信小程序的,知识课程学习,包括学习后答题。 技术栈主要采用微信小程序云开发,有下面的模块: 1.课程学习模块 2.资讯模块 3.答题模块 4.我的模块 还需…...
RAG技术与应用---0426
大语言模型>3.10 课程中会用到python 工具箱: faiss,modelscope,langchain,langchain_community,PyPDF2 1)大模型应用开发的三种模式 提示词没多少工作量,微调又花费时间费用,RAG是很多公司招聘用来对LLM进行应用…...
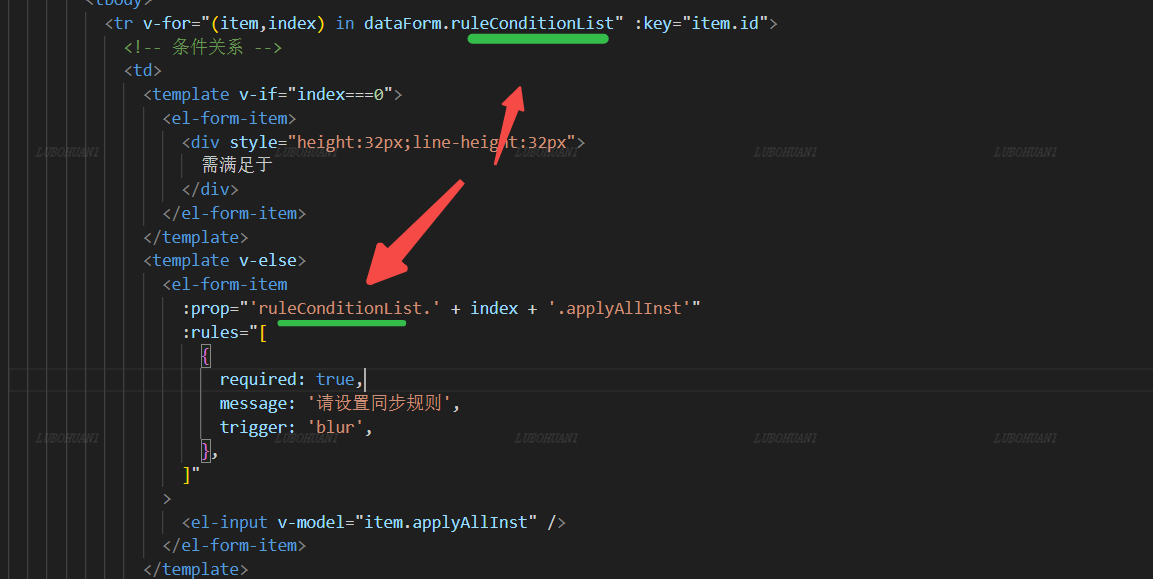
element-ui多个form同时验证,以及动态循环表单注意事项
多个form同时验证: validateForm(refs) {if (!refs) {return false}return new Promise((resolve, reject) > {refs.validate().then((valid) > {resolve(valid)}).catch((val) > {resolve(false)})}) }, async handleConfirm() {Promise.all([this.valid…...
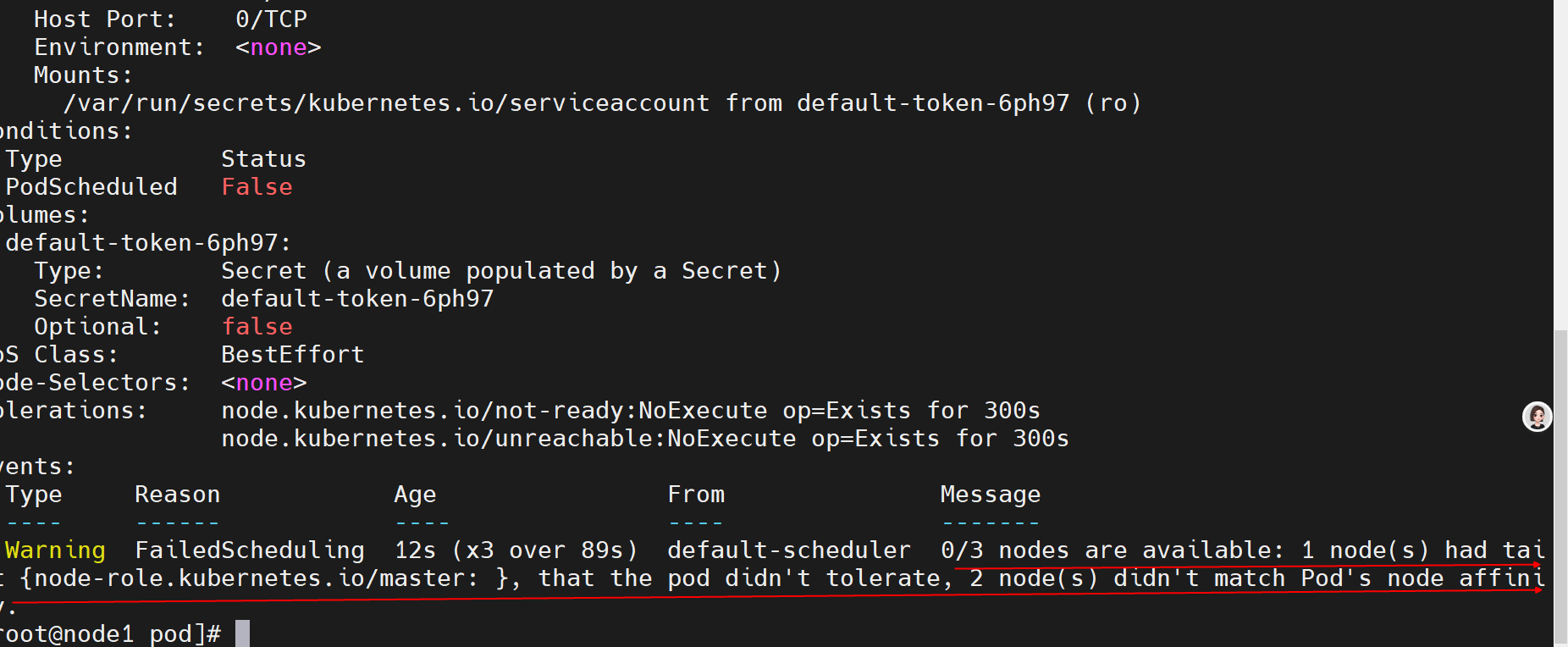
k8s学习记录(四):节点亲和性
一、前言 在上一篇文章里,我们了解了 Pod 中的nodeName和nodeSelector这两个属性,通过它们能够指定 Pod 调度到哪个 Node 上。今天,我们将进一步深入探索 Pod 相关知识。这部分内容不仅信息量较大,理解起来也有一定难度࿰…...
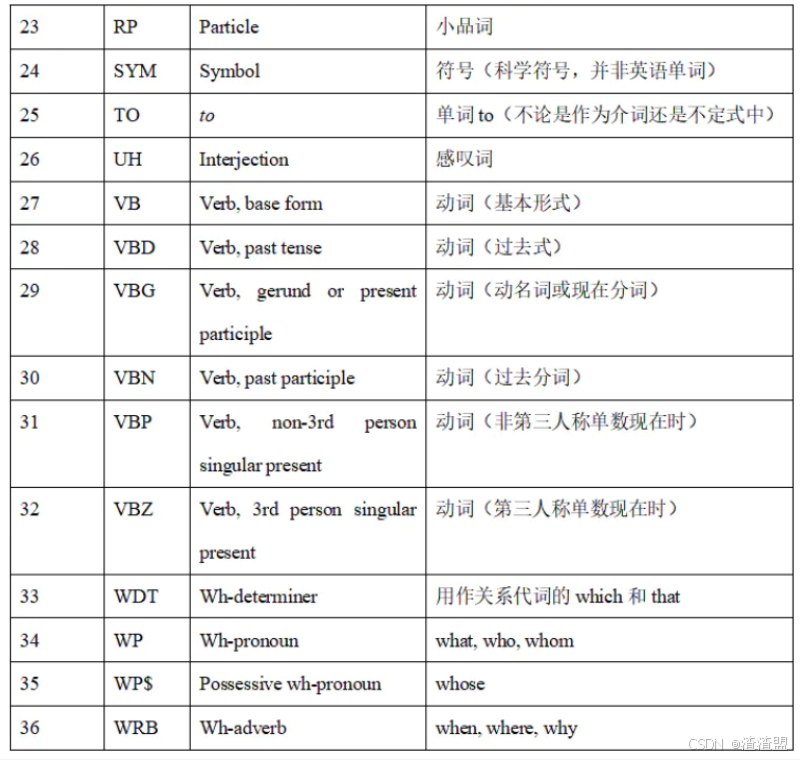
文本预处理(NLTK)
1. 自然语言处理基础概念 1.1 什么是自然语言处理 自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于…...