月之暗面开源 Kimi-Audio-7B-Instruct,同时支持语音识别和语音生成
我们向您介绍在音频理解、生成和对话方面表现出色的开源音频基础模型–Kimi-Audio。该资源库托管了 Kimi-Audio-7B-Instruct 的模型检查点。

Kimi-Audio 被设计为通用的音频基础模型,能够在单一的统一框架内处理各种音频处理任务。主要功能包括:
- 通用功能:可处理各种任务,如语音识别 (ASR)、音频问题解答 (AQA)、音频字幕 (AAC)、语音情感识别 (SER)、声音事件/场景分类 (SEC/ASC)、文本到语音 (TTS)、语音转换 (VC) 和端到端语音对话。
- 最先进的性能:在众多音频基准测试中取得了 SOTA 级结果(参见我们的技术报告)。
- 大规模预训练:在超过 1300 万小时的各种音频数据(语音、音乐、声音)和文本数据上进行预训练。
- 新颖的架构:采用混合音频输入(连续声音+离散语义标记)和 LLM 内核,并行头用于文本和音频标记生成。
- 高效推理:采用基于流匹配的分块流式解码器,可生成低延迟音频。
https://github.com/MoonshotAI/Kimi-Audio
架构概述
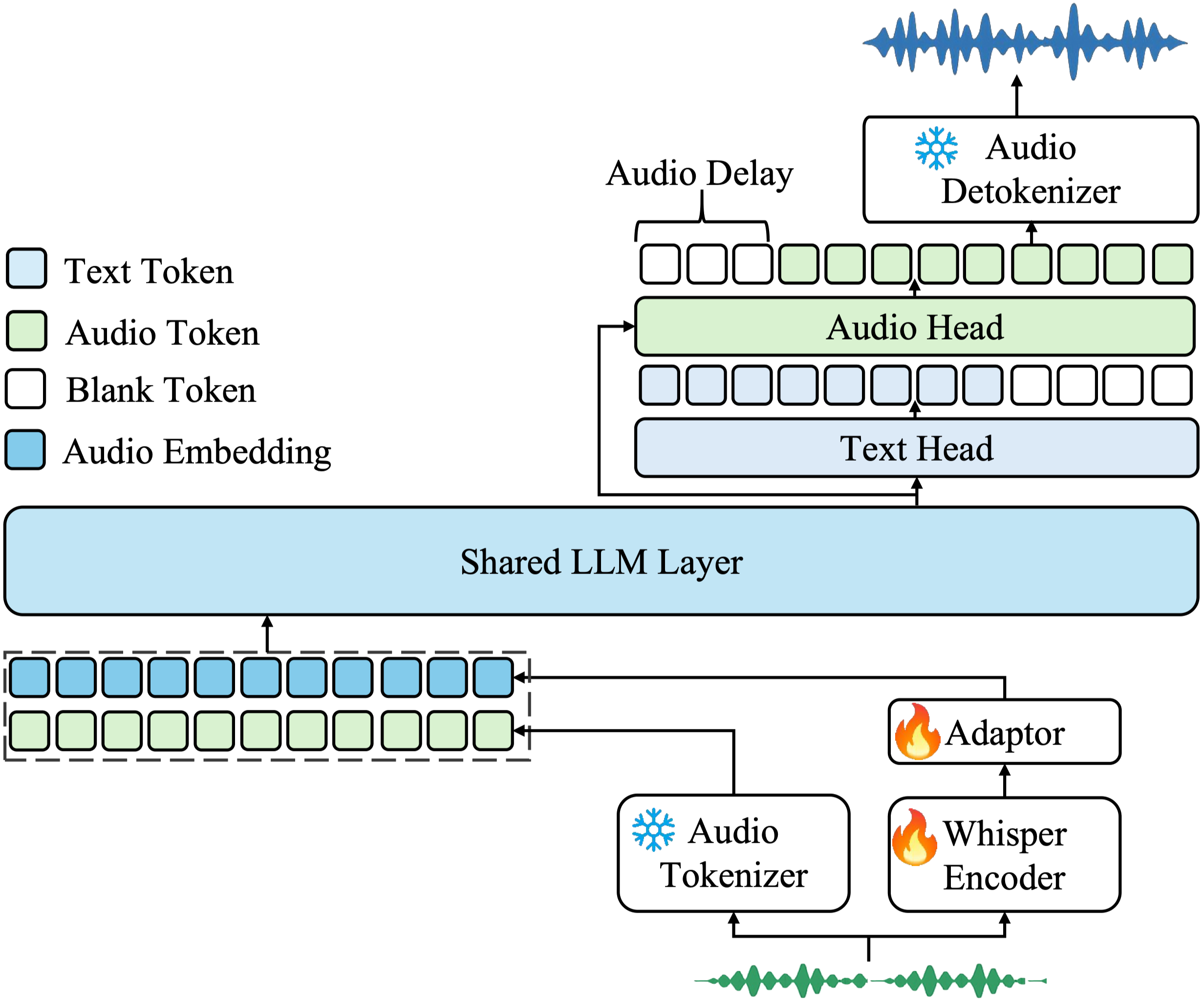
Kimi-Audio consists of three main components:
- Audio Tokenizer: 将输入音频转换为:
使用向量量化的离散语义标记(12.5Hz)。
从 Whisper 编码器获得的连续声学特征(降采样至 12.5Hz)。 - Audio LLM: 基于转换器的模型(从 Qwen 2.5 7B 等预先训练好的文本 LLM 初始化),具有处理多模态输入的共享层,然后是并行头,用于自回归生成文本标记和离散音频语义标记。
- Audio Detokenizer: 使用流匹配模型和声码器(BigVGAN)将预测的离散语义音频标记转换成高保真波形,支持采用前瞻机制的分块流,以降低延迟。
评估
Kimi-Audio在广泛的音频基准测试中实现了最先进的(SOTA)性能。
以下是总体表现:
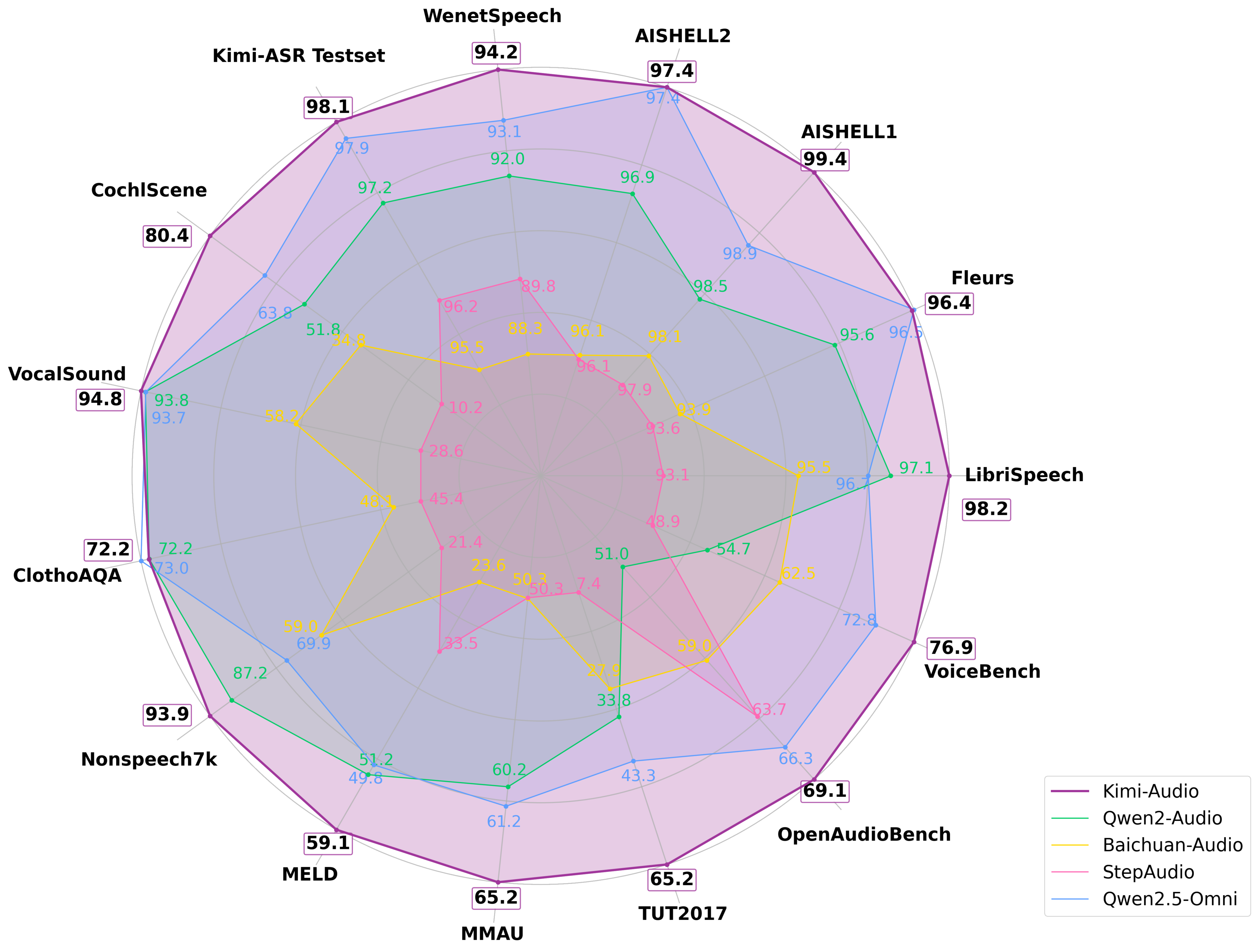
Automatic Speech Recognition (ASR)
| Datasets | Model | Performance (WER↓) |
|---|---|---|
| LibriSpeech test-clean | test-other | Qwen2-Audio-base | 1.74 | 4.04 |
| Baichuan-base | 3.02 | 6.04 | |
| Step-Audio-chat | 3.19 | 10.67 | |
| Qwen2.5-Omni | 2.37 | 4.21 | |
| Kimi-Audio | 1.28 | 2.42 | |
| Fleurs zh | en | Qwen2-Audio-base | 3.63 | 5.20 |
| Baichuan-base | 4.15 | 8.07 | |
| Step-Audio-chat | 4.26 | 8.56 | |
| Qwen2.5-Omni | 2.92 | 4.17 | |
| Kimi-Audio | 2.69 | 4.44 | |
| AISHELL-1 | Qwen2-Audio-base | 1.52 |
| Baichuan-base | 1.93 | |
| Step-Audio-chat | 2.14 | |
| Qwen2.5-Omni | 1.13 | |
| Kimi-Audio | 0.60 | |
| AISHELL-2 ios | Qwen2-Audio-base | 3.08 |
| Baichuan-base | 3.87 | |
| Step-Audio-chat | 3.89 | |
| Qwen2.5-Omni | 2.56 | |
| Kimi-Audio | 2.56 | |
| WenetSpeech test-meeting | test-net | Qwen2-Audio-base | 8.40 | 7.64 |
| Baichuan-base | 13.28 | 10.13 | |
| Step-Audio-chat | 10.83 | 9.47 | |
| Qwen2.5-Omni | 7.71 | 6.04 | |
| Kimi-Audio | 6.28 | 5.37 | |
| Kimi-ASR Internal Testset subset1 | subset2 | Qwen2-Audio-base | 2.31 | 3.24 |
| Baichuan-base | 3.41 | 5.60 | |
| Step-Audio-chat | 2.82 | 4.74 | |
| Qwen2.5-Omni | 1.53 | 2.68 | |
| Kimi-Audio | 1.42 | 2.44 |
Audio Understanding
| Datasets | Model | Performance↑ |
|---|---|---|
| MMAU music | sound | speech | Qwen2-Audio-base | 58.98 | 69.07 | 52.55 |
| Baichuan-chat | 49.10 | 59.46 | 42.47 | |
| GLM-4-Voice | 38.92 | 43.54 | 32.43 | |
| Step-Audio-chat | 49.40 | 53.75 | 47.75 | |
| Qwen2.5-Omni | 62.16 | 67.57 | 53.92 | |
| Kimi-Audio | 61.68 | 73.27 | 60.66 | |
| ClothoAQA test | dev | Qwen2-Audio-base | 71.73 | 72.63 |
| Baichuan-chat | 48.02 | 48.16 | |
| Step-Audio-chat | 45.84 | 44.98 | |
| Qwen2.5-Omni | 72.86 | 73.12 | |
| Kimi-Audio | 71.24 | 73.18 | |
| VocalSound | Qwen2-Audio-base | 93.82 |
| Baichuan-base | 58.17 | |
| Step-Audio-chat | 28.58 | |
| Qwen2.5-Omni | 93.73 | |
| Kimi-Audio | 94.85 | |
| Nonspeech7k | Qwen2-Audio-base | 87.17 |
| Baichuan-chat | 59.03 | |
| Step-Audio-chat | 21.38 | |
| Qwen2.5-Omni | 69.89 | |
| Kimi-Audio | 93.93 | |
| MELD | Qwen2-Audio-base | 51.23 |
| Baichuan-chat | 23.59 | |
| Step-Audio-chat | 33.54 | |
| Qwen2.5-Omni | 49.83 | |
| Kimi-Audio | 59.13 | |
| TUT2017 | Qwen2-Audio-base | 33.83 |
| Baichuan-base | 27.9 | |
| Step-Audio-chat | 7.41 | |
| Qwen2.5-Omni | 43.27 | |
| Kimi-Audio | 65.25 | |
| CochlScene test | dev | Qwen2-Audio-base | 52.69 | 50.96 |
| Baichuan-base | 34.93 | 34.56 | |
| Step-Audio-chat | 10.06 | 10.42 | |
| Qwen2.5-Omni | 63.82 | 63.82 | |
| Kimi-Audio | 79.84 | 80.99 |
Audio-to-Text Chat
| Datasets | Model | Performance↑ |
|---|---|---|
| OpenAudioBench AlpacaEval | Llama Questions | Reasoning QA | TriviaQA | Web Questions | Qwen2-Audio-chat | 57.19 | 69.67 | 42.77 | 40.30 | 45.20 |
| Baichuan-chat | 59.65 | 74.33 | 46.73 | 55.40 | 58.70 | |
| GLM-4-Voice | 57.89 | 76.00 | 47.43 | 51.80 | 55.40 | |
| StepAudio-chat | 56.53 | 72.33 | 60.00 | 56.80 | 73.00 | |
| Qwen2.5-Omni | 72.76 | 75.33 | 63.76 | 57.06 | 62.80 | |
| Kimi-Audio | 75.73 | 79.33 | 58.02 | 62.10 | 70.20 | |
| VoiceBench AlpacaEval | CommonEval | SD-QA | MMSU | Qwen2-Audio-chat | 3.69 | 3.40 | 35.35 | 35.43 |
| Baichuan-chat | 4.00 | 3.39 | 49.64 | 48.80 | |
| GLM-4-Voice | 4.06 | 3.48 | 43.31 | 40.11 | |
| StepAudio-chat | 3.99 | 2.99 | 46.84 | 28.72 | |
| Qwen2.5-Omni | 4.33 | 3.84 | 57.41 | 56.38 | |
| Kimi-Audio | 4.46 | 3.97 | 63.12 | 62.17 | |
| VoiceBench OpenBookQA | IFEval | AdvBench | Avg | Qwen2-Audio-chat | 49.01 | 22.57 | 98.85 | 54.72 |
| Baichuan-chat | 63.30 | 41.32 | 86.73 | 62.51 | |
| GLM-4-Voice | 52.97 | 24.91 | 88.08 | 57.17 | |
| StepAudio-chat | 31.87 | 29.19 | 65.77 | 48.86 | |
| Qwen2.5-Omni | 79.12 | 53.88 | 99.62 | 72.83 | |
| Kimi-Audio | 83.52 | 61.10 | 100.00 | 76.93 |
Speech Conversation
| Model | Ability | |||||
|---|---|---|---|---|---|---|
| Speed Control | Accent Control | Emotion Control | Empathy | Style Control | Avg | |
| GPT-4o | 4.21 | 3.65 | 4.05 | 3.87 | 4.54 | 4.06 |
| Step-Audio-chat | 3.25 | 2.87 | 3.33 | 3.05 | 4.14 | 3.33 |
| GLM-4-Voice | 3.83 | 3.51 | 3.77 | 3.07 | 4.04 | 3.65 |
| GPT-4o-mini | 3.15 | 2.71 | 4.24 | 3.16 | 4.01 | 3.45 |
| Kimi-Audio | 4.30 | 3.45 | 4.27 | 3.39 | 4.09 | 3.90 |
快速上手
部署环境
git clone https://github.com/MoonshotAI/Kimi-Audio
cd Kimi-Audio
git submodule update --init --recursive
pip install -r requirements.txt
推理代码
import soundfile as sf
# Assuming the KimiAudio class is available after installation
from kimia_infer.api.kimia import KimiAudio
import torch # Ensure torch is imported if needed for device placement# --- 1. Load Model ---
# Load the model from Hugging Face Hub
# Make sure you are logged in (`huggingface-cli login`) if the repo is private.
model_id = "moonshotai/Kimi-Audio-7B-Instruct" # Or "Kimi/Kimi-Audio-7B"
device = "cuda" if torch.cuda.is_available() else "cpu" # Example device placement
# Note: The KimiAudio class might handle model loading differently.
# You might need to pass the model_id directly or download checkpoints manually
# and provide the local path as shown in the original readme_kimia.md.
# Please refer to the main Kimi-Audio repository for precise loading instructions.
# Example assuming KimiAudio takes the HF ID or a local path:
try:model = KimiAudio(model_path=model_id, load_detokenizer=True) # May need device argumentmodel.to(device) # Example device placement
except Exception as e:print(f"Automatic loading from HF Hub might require specific setup.")print(f"Refer to Kimi-Audio docs. Trying local path example (update path!). Error: {e}")# Fallback example:# model_path = "/path/to/your/downloaded/kimia-hf-ckpt" # IMPORTANT: Update this path if loading locally# model = KimiAudio(model_path=model_path, load_detokenizer=True)# model.to(device) # Example device placement# --- 2. Define Sampling Parameters ---
sampling_params = {"audio_temperature": 0.8,"audio_top_k": 10,"text_temperature": 0.0,"text_top_k": 5,"audio_repetition_penalty": 1.0,"audio_repetition_window_size": 64,"text_repetition_penalty": 1.0,"text_repetition_window_size": 16,
}# --- 3. Example 1: Audio-to-Text (ASR) ---
# TODO: Provide actual example audio files or URLs accessible to users
# E.g., download sample files first or use URLs
# wget https://path/to/your/asr_example.wav -O asr_example.wav
# wget https://path/to/your/qa_example.wav -O qa_example.wav
asr_audio_path = "./test_audios/asr_example.wav" # IMPORTANT: Make sure this file exists
qa_audio_path = "./test_audios/qa_example.wav" # IMPORTANT: Make sure this file existsmessages_asr = [{"role": "user", "message_type": "text", "content": "Please transcribe the following audio:"},{"role": "user", "message_type": "audio", "content": asr_audio_path}
]# Generate only text output
# Note: Ensure the model object and generate method accept device placement if needed
_, text_output = model.generate(messages_asr, **sampling_params, output_type="text")
print(">>> ASR Output Text: ", text_output)
# Expected output: "这并不是告别,这是一个篇章的结束,也是新篇章的开始。" (Example)# --- 4. Example 2: Audio-to-Audio/Text Conversation ---
messages_conversation = [{"role": "user", "message_type": "audio", "content": qa_audio_path}
]# Generate both audio and text output
wav_output, text_output = model.generate(messages_conversation, **sampling_params, output_type="both")# Save the generated audio
output_audio_path = "output_audio.wav"
# Ensure wav_output is on CPU and flattened before saving
sf.write(output_audio_path, wav_output.detach().cpu().view(-1).numpy(), 24000) # Assuming 24kHz output
print(f">>> Conversational Output Audio saved to: {output_audio_path}")
print(">>> Conversational Output Text: ", text_output)
# Expected output: "A." (Example)print("Kimi-Audio inference examples complete.")相关文章:
月之暗面开源 Kimi-Audio-7B-Instruct,同时支持语音识别和语音生成
我们向您介绍在音频理解、生成和对话方面表现出色的开源音频基础模型–Kimi-Audio。该资源库托管了 Kimi-Audio-7B-Instruct 的模型检查点。 Kimi-Audio 被设计为通用的音频基础模型,能够在单一的统一框架内处理各种音频处理任务。主要功能包括: 通用功…...
IDEA配置将Servlet真正布署到Tomcat
刚开始只能IDEA运行完Servlet web application 并保持IDEA运行才能通过浏览器访问到我的Servlet,跟想象中的不一样,不应该是IDEA运行完项目以后只要打开Tomcat就能访问吗?事实时运行完项目只要关掉IDEA就不能再访问到应用了,而且T…...

删除新安装IBM Guardium Data Protection 12.1的baltimorecybertrustroot证书
登录web console,会显示 baltimorecybertrustroot证书过期警告。 采用下面的命令删除过期证书就可消除警告。 collector02.cpd.com> delete certificate keystore Select an alias from the list below to delete the corresponding certificate. Alias List:…...

【蓝桥杯】画展布置
画展布置 题目描述 画展策展人小蓝和助理小桥为即将举办的画展准备了 N N N 幅画作,其艺术价值分别为 A 1 , A 2 , … , A N A_1, A_2, \dots , A_N A1,A2,…,AN。他们需要从这 N N N 幅画中挑选 M M M 幅,并按照一定顺序布置在展厅的 M M …...

请求参数、路径参数、查询参数、Spring MVC/FeignClient请求相关注解梳理
目录 1 请求分类1.1 URL参数--查询参数1.2 URL参数--路径参数 2 请求相关注解2.1 RequestParam--查询参数2.2 PathVariable--路径参数2.3 RequestBody2.4 Param & RequestLine2.5 SpringMVC请求参数注解用在FeignClient里 使用SpringMVC处理http请求或使用FeignClient进行请…...

MySQL 详解之复制与集群:构建高可用与可扩展数据库架构
随着业务的发展,单一的数据库实例往往难以满足需求: 性能瓶颈: 读写请求量不断增加,单个服务器的 CPU、内存、磁盘、网络资源达到上限,尤其是读请求远大于写请求的场景。高可用性: 单个服务器一旦发生故障(硬件故障、操作系统问题、机房断电等),数据库服务将完全中断,…...
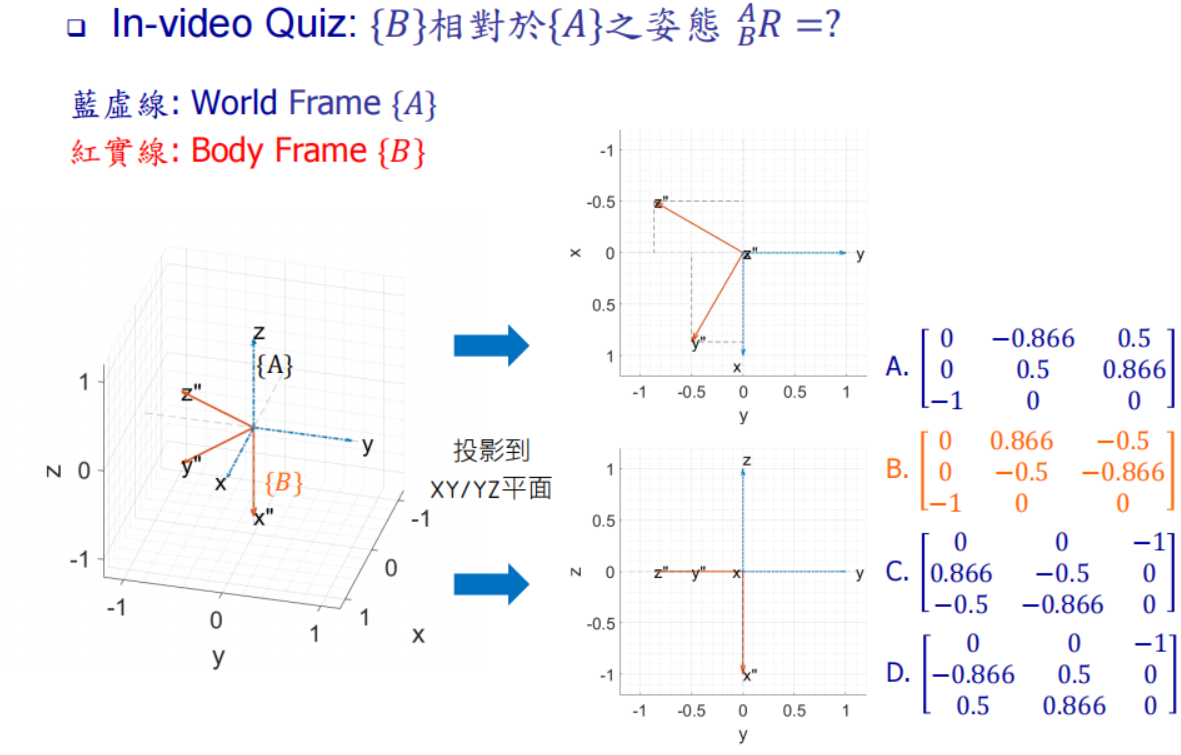
刚体运动 (位置向量 - 旋转矩阵) 笔记 1.1~1.3 (台大机器人学-林沛群)
目录 1. 理解刚体的“自由度”(Degrees of Freedom, DOF) 1.1 平面运动 (2D) 1.2 空间运动 (3D) 2. 统一描述:引入“体坐标系”(Body Frame) 3. 从“状态”到“运动”:引入微分 3.1 补充:…...
openAICEO山姆奥特曼未来预测雄文之三个观察
《三个观察》 山姆奥特曼 这篇文章主要讲的是关于AGI(人工通用智能)的未来发展及其对社会的影响,用大白话总结如下: 核心观点: AGI是什么? AGI是一种能像人类一样解决各种复杂问题的智能系统,比…...

Java 异常 SSLException: fatal alert: protocol_version 全解析与解决方案
在 Java 网络通信中,SSLException: fatal alert: protocol_version 是典型的 TLS/SSL 协议版本不兼容异常。本文结合 Java 官方规范、TLS 协议标准及实战经验,提供体系化解决方案,帮助开发者快速定位并解决协议版本冲突问题。 一、异常本质&…...

比象AI创作系统,多模态大模型:问答分析+AI绘画+管理后台系统
比象AI创作系统是新一代集智能问答、内容创作与商业运营于一体的综合型AI平台。本系统深度融合GPT-4.0/GPT-4o多模态大模型技术,结合实时联网搜索与智能分析能力,打造了从内容生产到商业变现的完整闭环解决方案。 智能问答中枢 系统搭载行业领先的对话…...

【2025 最新前沿 MCP 教程 03】基础构建模块:工具、资源与提示
文章目录 1. 开始啦2. 工具(模型控制):赋予 AI 行动能力3. 资源(应用控制):为 AI 提供关键上下文4. 提示(用户可控):优化 AI 交互5. 它们如何协同工作 1. 开始啦 欢迎来…...

Docker-高级使用
前言 书接上文Docker-初级安装及使用_用docker安装doccano-CSDN博客,我们讲解了Docker的基本操作,下面我们讲解的是高级使用,请大家做好准备! 大家如果是从初级安装使用过来的话,建议把之前镜像和搭载的容器数据卷里面…...

计算机网络 | Chapter1 计算机网络和因特网
💓个人主页:mooridy-CSDN博客 💓文章专栏:《计算机网络:自定向下方法》 大纲式阅读笔记_mooridy的博客-CSDN博客 🌹关注我,和我一起学习更多计算机网络的知识 🔝🔝 目录 …...

PowerBi中ALLEXCEPT怎么使用?
在 Power BI 的 DAX 中,ALLEXCEPT() 是一个非常重要的函数,用来实现**“在保留部分筛选条件的前提下,移除其他所有筛选器”**,它常用于 同比、占比、累计汇总 等分析中。 ✅ 一、ALLEXCEPT 是什么意思? 函数全称&…...
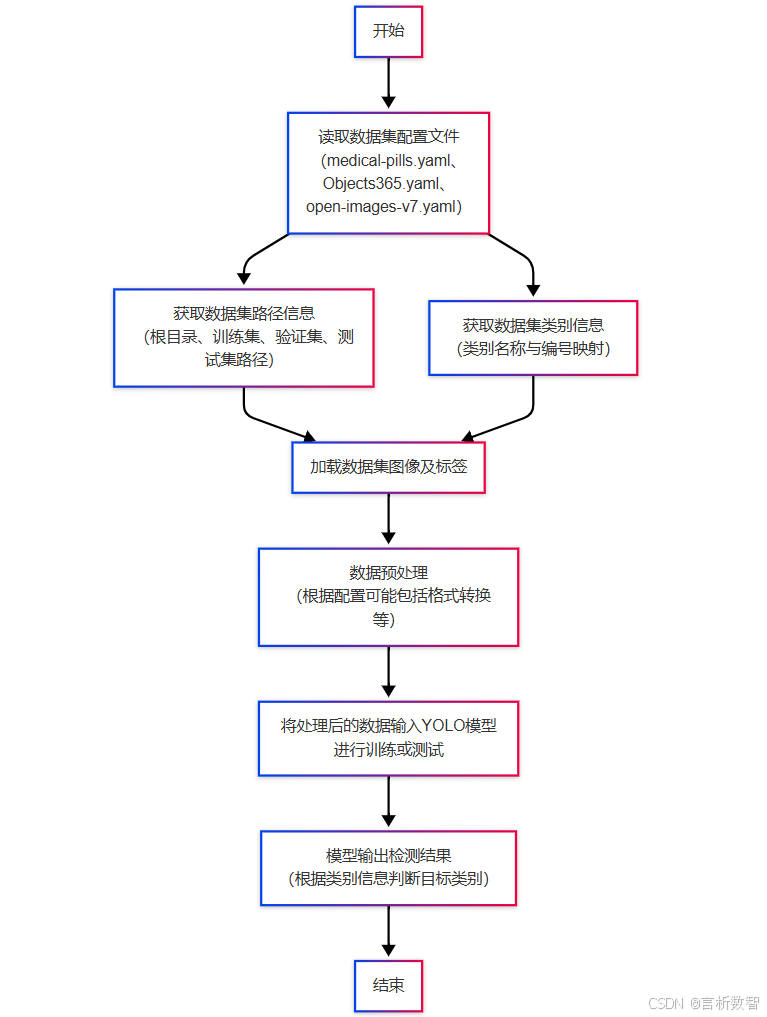
开源项目实战学习之YOLO11:ultralytics-cfg-datasets-Objects365、open-images-v7.yaml文件(六)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 medical - pills.yaml 通常用于配置与医学药丸检测任务相关的参数和信息 Objects365.yaml 用于配置与 Objects365 数据集相关信息的文件。Objects365 数据集包含 365 个不同的物体类别…...

蚂蚁集团“Plan A”重磅登场,开启AI未来
近期,蚂蚁集团面向全球高潜AI人才,正式发布顶级专项招募计划——“Plan A”。作为其“蚂蚁星”校招体系的全新升级模块,Plan A聚焦人工智能领域科研精英,旨在与全球高校AI研究者协同突破AGI前沿,共绘技术未来图谱。 蚂…...
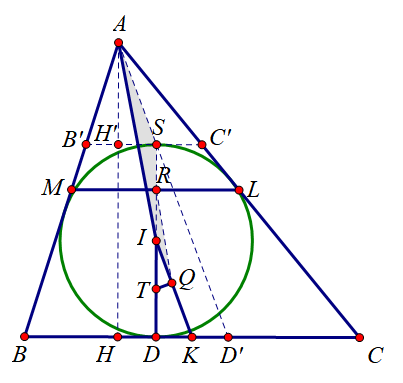
高中数学联赛模拟试题精选第18套几何题
在 △ A B C \triangle ABC △ABC 中, A B < A C AB< AC AB<AC, 点 K K K, L L L, M M M 分别是边 B C BC BC, C A C A CA, A B AB AB 的中点. △ A B C \triangle ABC △ABC 的内切圆圆心为 I I I, 且与边 B C BC BC 相切于点 D D D. 直线 l l l 经过线段…...

Kettle学习
一、Kettle 简介 Kettle(现称为 Pentaho Data Integration)是一款开源ETL工具,支持从多种数据源抽取、转换和加载数据,广泛应用于数据仓库构建、数据迁移和清洗。其核心优势包括: 可视化操作:通过拖拽组件设计数据处理流程(转换和作业)。多数据源支持:数据库(MySQL/…...

Synopsys 逻辑综合的整体架构概览
目录 一、DC Shell 逻辑综合的整体架构概览 ⛓️ 逻辑综合的主要阶段(Pipeline) 二、核心架构模块详解 1. Internal Database(设计对象数据库) 2. Scheduler(调度器) 3. Rewriting Engine(…...

Missashe考研日记-day27
Missashe考研日记-day27 0 写在前面 博主昨晚有事所以没学专业课,白天学了其他科,但是觉得不太好写博客,就合在今天一起写好了。 1 专业课408 学习时间:3h30min学习内容: 今天把内存管理部分剩下的关于分页分段和段…...

Java 富文本转word
前言: 本文的目的是将传入的富文本内容(html标签,图片)并且分页导出为word文档。 所使用的为docx4j 一、依赖导入 <!-- 富文本转word --><dependency><groupId>org.docx4j</groupId><artifactId>docx4j</artifactId&…...

多模态大语言模型arxiv论文略读(四十三)
InteraRec: Screenshot Based Recommendations Using Multimodal Large Language Models ➡️ 论文标题:InteraRec: Screenshot Based Recommendations Using Multimodal Large Language Models ➡️ 论文作者:Saketh Reddy Karra, Theja Tulabandhula …...
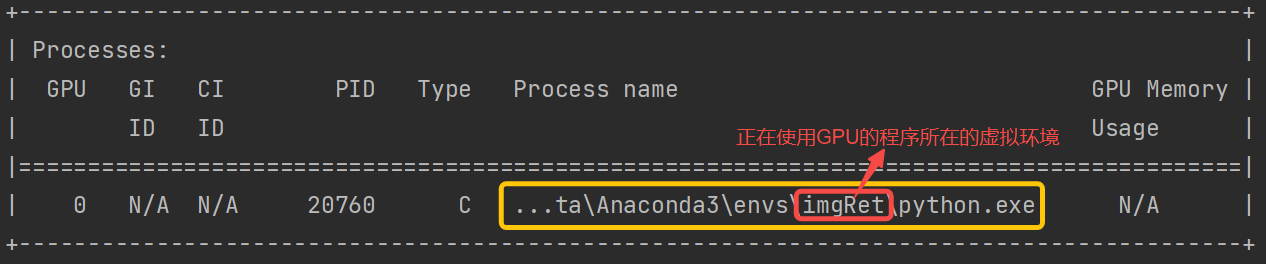
GPU加速-系统CUDA12.5-Windows10
误区注意 查看当前系统可支持的最高版本cuda:nvidia-smi 说明: 此处显示的12.7只是驱动对应的最高版本,不一定是 / 也不一定需要是 当前Python使用的版本。但我们所安装的CUDA版本需要 小于等于它(即≤12.7)因此即使…...
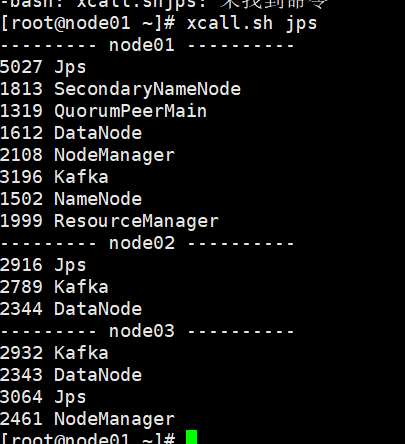
kafka课后总结
Kafka是由LinkedIn开发的分布式发布 - 订阅消息系统,具备高吞吐量、低延迟、可扩展性、持久性、可靠性、容错性和高并发等特性。其主要角色包括Broker、Topic、Partition、Producer、Consumer、Consumer Group、replica、leader、follower和controller。消息系统中存…...
)
排序算法(快排+推排序+归并排序)
一、快排(不稳定O(NlogN)) 分治思想,随机选一个数作为pivot,然后放到数组最后去,比这个元素小的放左边,比这个元素大的放右边。最后再交换左边放完后的下一个元素和pivot,这样就把一个元素排好…...
【股票系统】使用docker本地构建ai-hedge-fund项目,模拟大师炒股进行分析。人工智能的对冲基金的开源项目
股票系统: https://github.com/virattt/ai-hedge-fund 镜像地址: https://gitcode.com/gh_mirrors/ai/ai-hedge-fund 项目地址: https://gitee.com/pythonstock/docker-run-ai-hedge-fund 这是一个基于人工智能的对冲基金的原理验证项目。本项目旨在探讨利用人工智能进行…...

施工安全巡检二维码制作
进入新时代以来,人们对安全的重视程度越来越高。特别在建筑施工行业,安全不仅是关乎着工人的性命,更是承载着工人背后家庭的幸福生活。此时就诞生了安全巡检的工作,而巡检过程中内容庞杂,安全生产检查、隐患排查、施工…...
什么是函数依赖中的 **自反律(Reflexivity)**、**增广律(Augmentation)** 和 **传递律(Transitivity)?
文章目录 1. 自反律(Reflexivity Rule)规则定义实际例子应用意义 2. 增广律(Augmentation Rule)规则定义实际例子应用意义 3. 传递律(Transitivity Rule)规则定义实际例子应用意义 综合应用场景:…...

基于 Google Earth Engine (GEE) 的土地利用变化监测
一、引言 土地利用变化是全球环境变化的重要组成部分,对生态系统、气候和人类社会产生深远影响。利用遥感技术可以快速、准确地获取土地利用信息,监测其变化情况。本文将详细介绍如何使用 GEE 对特定区域的 Landsat 影像进行处理,实现土地利…...

Java基础语法10分钟速成
Java基础语法10分钟速成,记笔记版 JDKhello world变量字符串 类,继承,多态,重载 JDK JDK即Java development key,Java环境依赖包 在jdk中 编译器javac将代码的Java源文件编译为字节码文件(.classÿ…...