C++ 部署的性能优化方法
一、使用结构体提前存放常用变量
在编写前后处理函数时,通常会多次用到一些变量,比如模型输入 tensor 的 shape,count 等等,若在每个处理函数中都重复计算一次,会增加部署时的计算量。对于这种情况,可以考虑使用结构体,并定义一个初始化函数。先计算好需要的值,之后需要用到该变量的时候直接引用(&)传递即可。
// 定义结构体
struct ModelInfo {hbDNNPackedHandle_t packed_handle;hbDNNHandle_t model_handle;const char * model_path;const char ** model_name_list;int model_count;int input_count;int output_count;
};
// 函数声明
int init_model(ModelInfo &model_info);
int other_function(ModelInfo &model_info, ...);
//主函数
int main(){// 初始化ModelInfo prefill_model = {0};prefill_model.model_path = drobotics_model_path_prefill.c_str();init_model(prefill_model);// 在其他函数中使用引用传递相关参数other_function(prefill_model, ...);return 0;
}
// 初始化函数的完整定义
int init_model(ModelInfo &model_info) {hbDNNInitializeFromFiles(&model_info.packed_handle, &model_info.model_path, 1);HB_CHECK_SUCCESS(hbDNNGetModelNameList(&model_info.model_name_list, &model_info.model_count, model_info.packed_handle),"hbDNNGetModelNameList failed");HB_CHECK_SUCCESS(hbDNNGetModelHandle(&model_info.model_handle, model_info.packed_handle, model_info.model_name_list[0]),"hbDNNGetModelHandle failed");HB_CHECK_SUCCESS(hbDNNGetInputCount(&model_info.input_count, model_info.model_handle), "hbDNNGetInputCount failed");HB_CHECK_SUCCESS(hbDNNGetOutputCount(&model_info.output_count, model_info.model_handle), "hbDNNGetOutputCount failed");return 0;
}
// 其他函数参数中使用引用传递
int other_function(ModelInfo &model_info, ...){...
}
二、函数使用引用代替值传递
考虑到 C++的特性,函数的参数建议使用引用 (&) 来代替值传递,有这几个显著优点:
- 只将原对象的引用传递给函数,避免不必要的拷贝,降低计算耗时
- 因为不会复制数据,所以引用相比值传递可以避免内存的重复开销,降低内存占用
但需要注意,引用会允许函数修改原始数据,因此若不希望原始数据被修改,请不要使用引用方法。
三、量化/反量化融合
3.1 在前后处理的循环中融合
在前后处理中通常会遍历数据,而量化/反量化也会遍历数据,因此可以考虑合并计算,以减少数据遍历耗时。这是最常见的量化/反量化融合思路,可以直接参考 ai benchmark 中的大量源码示例。
3.2 将数据存进 tensor 时融合
如果在前处理中没找到融合的机会,那么也可以在数据复制进 input tensor 的时候做量化计算。
int64_t kv_count = 0;
int8_t* input_ptr = reinterpret_cast<int8_t*>(model_info.input_tensors[i].sysMem.virAddr);
for (int n = 0; n < total_count; n++) {input_ptr[n] = quantize_int8(kv_decode[kv_count++], cur_scale, cur_zero_point);
}
3.3 填充初始值时,提前计算量化后的值
有时我们想给模型准备特定的输入,比如生成一个全 0 数组,再为数组的特定区域填充某个固定的浮点值。在这种情况下,如果先生成完整的浮点数组,再遍历整个数组做量化,会产生不必要的遍历耗时,常见的优化思路是先提前计算好填充值量化后的结果,填充的时候直接填入定点值,这样就可以避免多余的量化耗时。
std::vector<int16_t> prepare_decode_attention_mask(ModelInfo &model_info,DecodeInfo &decode_info, PrefillInfo &prefill_info, int decode_infer_num){// 初始化全 0 数组std::vector<int16_t> decode_attention_mask_int(decode_info.kv_cache_len, 0);// 提前计算填充值量化后的结果hbDNNQuantiScale scale = model_info.input_tensors[1].properties.scale;auto cur_scale = scale.scaleData[0];auto cur_zero_point = scale.zeroPointData[0];int16_t pad_value_int = quantize_s16(-2048.0, cur_scale, cur_zero_point);// 将量化后的填充值填充到数组中特定区域for(int i = 0; i < decode_info.kv_cache_len - prefill_info.tokens_len- decode_infer_num -1; i++){decode_attention_mask_int[i] = pad_value_int;}// 返回相当于已经量化了的数组return decode_attention_mask_int;
}
3.4 根据后处理的实际作用,跳过反量化
在某些情况下,比如后处理只做 argmax 时,完全没有必要做反量化,直接使用整型数据做 argmax 即可。需要用户根据后处理的具体原理来判断是否使用这种优化方法。
// 直接对模型输出的 int16_t 数据做 argmax 计算
int logits_argmax(std::vector<hbDNNTensor> &output_tensor) {auto data_tensor = reinterpret_cast<int16_t *>(output_tensor[0].sysMem.virAddr);int maxIndex = -1;int maxValue = -32768;for (int i = 0; i < 151936; ++i) {if (data_tensor[i] > maxValue) {maxValue = data_tensor[i];maxIndex = i;}}return maxIndex;
}
四、循环推理同个模型时,输出数据直接存进输入 tensor
在某些情况下,我们希望 C++程序能重复推理同一个模型,并且模型上一帧的输出可以作为下一帧的输入。如果按照常规手段,我们可能会将输出 tensor 的内容保存到特定数组,再把这个数组拷贝到输入 tensor,这样一来一回就产生了两次数据拷贝的耗时,也占用了更多内存。实际上,我们可以将模型的输出 tensor 地址直接指向输入 tensor,这样模型第一帧的推理结果会直接写在输入 tensor 上,推理第二帧的时候就可以直接利用这份数据,不需要再单独准备输入,可以节省大量耗时。
如果想使用该方法,需要模型输入输出对应节点的 shape/stride 等信息完全相同。此外,如果模型删除了量化/反量化算子,并且对应的 scale 完全相同,那么重复利用的这部分 tensor 是不需要 flush 的(因为不涉及 CPU 操作),还可进一步节约耗时。
这里举个例子详细说明一下。
假设我们有一个模型,这个模型有 59 个输入节点(0-58),57 个输出节点(0-56),量化/反量化算子均已删除,且输入输出最后 56 个节点对应的 scale/shape/stride 等信息均相同。在第一帧推理完成后,输出节点 1-56 的值需要传递给输入节点的 3-58,那么我们在分配模型输入输出 tensor 的时候,输出 tensor 只需要为 1 分配即可,在分配输入 tensor 时,3-58 的 tensor 可以同时 push_back 给输出 tensor。具体来说,可以这样写:
int prepare_tensor(std::vector<hbDNNTensor> & input_tensor, std::vector<hbDNNTensor> & output_tensor,hbDNNHandle_t dnn_handle) {int input_count = 0;int output_count = 0;hbDNNGetInputCount(&input_count, dnn_handle);hbDNNGetOutputCount(&output_count, dnn_handle);for (int i = 0; i < 1; i++) {hbDNNTensor output;HB_CHECK_SUCCESS(hbDNNGetOutputTensorProperties(&output.properties, dnn_handle, i),"hbDNNGetOutputTensorProperties failed");int output_memSize = output.properties.alignedByteSize;HB_CHECK_SUCCESS(hbUCPMallocCached(&output.sysMem, output_memSize, 0), "hbUCPMallocCached failed");output_tensor.push_back(output);}for (int i = 0; i < input_count; i++) {hbDNNTensor input;HB_CHECK_SUCCESS(hbDNNGetInputTensorProperties(&input.properties, dnn_handle, i),"hbDNNGetInputTensorProperties failed");int input_memSize = input.properties.alignedByteSize;HB_CHECK_SUCCESS(hbUCPMallocCached(&input.sysMem, input_memSize, 0), "hbUCPMallocCached failed");input_tensor.push_back(input);if(i > 2){output_tensor.push_back(input);}}return 0;
}
在模型推理时,重复利用的这部分 tensor 不需要再 flush,因此只需要给 output_tensor 的 0,以及 input_tensor 的 0/1/2 进行 flush 操作即可(这几个 tensor 和 CPU 产生了交互)。
while(1){hbUCPTaskHandle_t task_handle_decode{nullptr};hbDNNTensor *output_decode = decode_model.output_tensors.data();HB_CHECK_SUCCESS(hbDNNInferV2(&task_handle_decode, output_decode,decode_model.input_tensors.data(), decode_model.model_handle), "hbDNNInferV2 failed");hbUCPSchedParam ctrl_param_decode;HB_UCP_INITIALIZE_SCHED_PARAM(&ctrl_param_decode);ctrl_param_decode.backend = HB_UCP_BPU_CORE_ANY;HB_CHECK_SUCCESS(hbUCPSubmitTask(task_handle_decode, &ctrl_param_decode), "hbUCPSubmitTask failed");HB_CHECK_SUCCESS(hbUCPWaitTaskDone(task_handle_decode, 0), "hbUCPWaitTaskDone failed");// 只刷新一部分输出内存(output_tensor 0)hbUCPMemFlush(&decode_model.output_tensors[0].sysMem, HB_SYS_MEM_CACHE_INVALIDATE);HB_CHECK_SUCCESS(hbUCPReleaseTask(task_handle_decode), "hbUCPReleaseTask failed");// 后处理(只针对 output_tensor 0)decode_argmax_id = logits_argmax(decode_model.output_tensors);// 准备下一帧推理的 input_tensor 0/1/2 输入数据prepare_input_tensor(...);// 只刷新一部分输入内存(input_tensor 0/1/2)for (int i = 0; i < 3; i++) {hbUCPMemFlush(&decode_model.input_tensors[i].sysMem, HB_SYS_MEM_CACHE_CLEAN);}
}
此外,如果使用了这种优化方法,那么在模型推理结束释放内存时,要避免同一块内存的重复释放。对于该案例,input_tensor 全部释放完毕后,output_tensor 只需要释放 output_tensor 0。
for (int i = 0; i < decode_model.input_count; i++) {HB_CHECK_SUCCESS(hbUCPFree(&(decode_model.input_tensors[i].sysMem)), "hbUCPFree decode_model.input_tensors failed");
}
for (int i = 0; i < 1; i++) {HB_CHECK_SUCCESS(hbUCPFree(&(decode_model.output_tensors[i].sysMem)), "hbUCPFree decode_model.output_tensors failed");
}
五、多线程后处理
对于 yolo v5 这种有三个输出头的模型,可以考虑使用三个线程同时对三个输出头做后处理,以显著提升性能。
相关文章:

C++ 部署的性能优化方法
一、使用结构体提前存放常用变量 在编写前后处理函数时,通常会多次用到一些变量,比如模型输入 tensor 的 shape,count 等等,若在每个处理函数中都重复计算一次,会增加部署时的计算量。对于这种情况,可以考…...
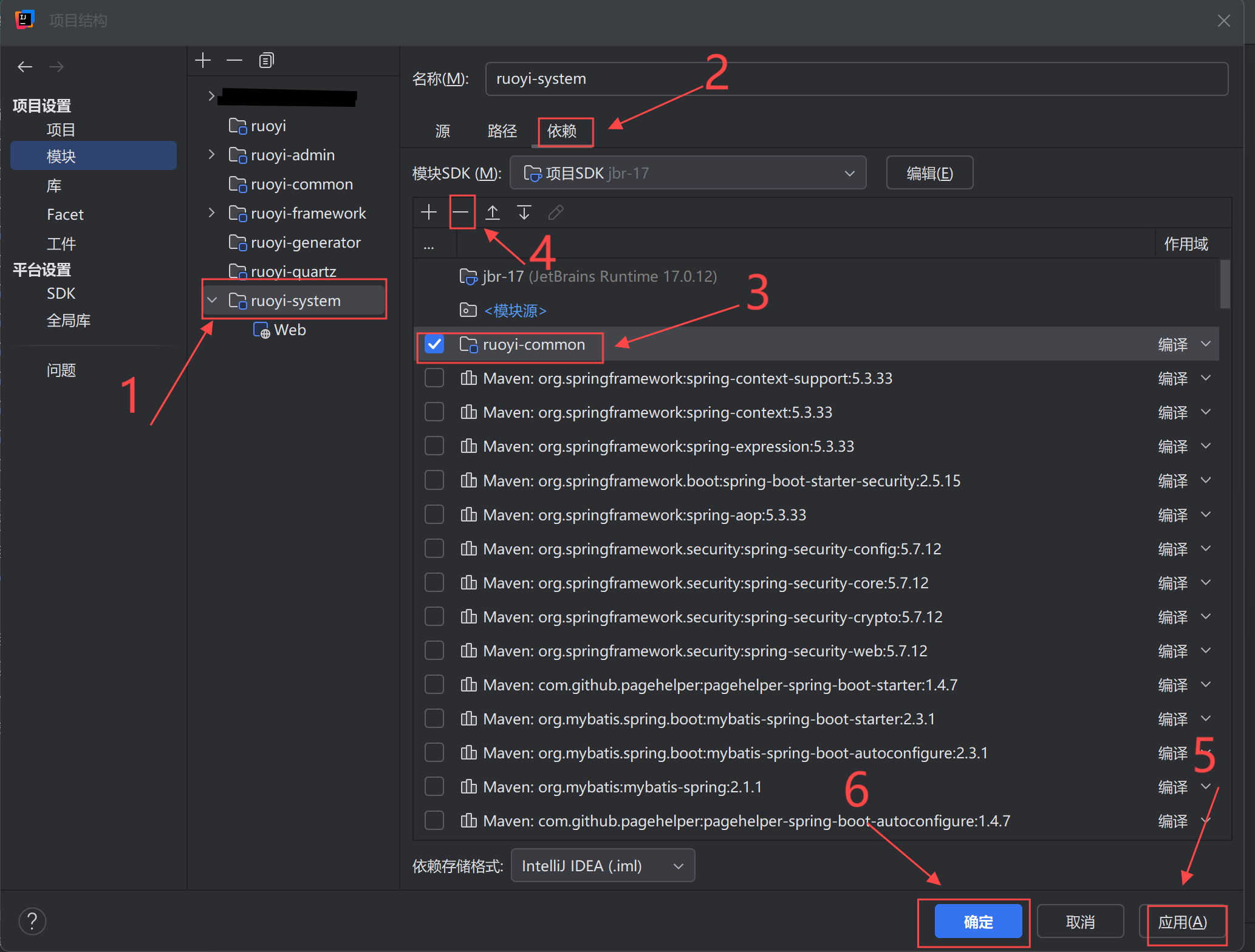
关于IDEA的循环依赖问题
bug描述:(java: 模块循环不支持注解处理。请确保将循环 [...] 中的所有模块排除在注解处理之外) 解决方法:...

如何在idea中写spark程序
在 IntelliJ IDEA 中编写 Spark 程序,可按以下步骤进行: 1. 创建新项目 打开 IntelliJ IDEA,选择File -> New -> Project。在左侧面板选择Maven或者Gradle(这里以 Maven 为例),确保Project SDK选择…...
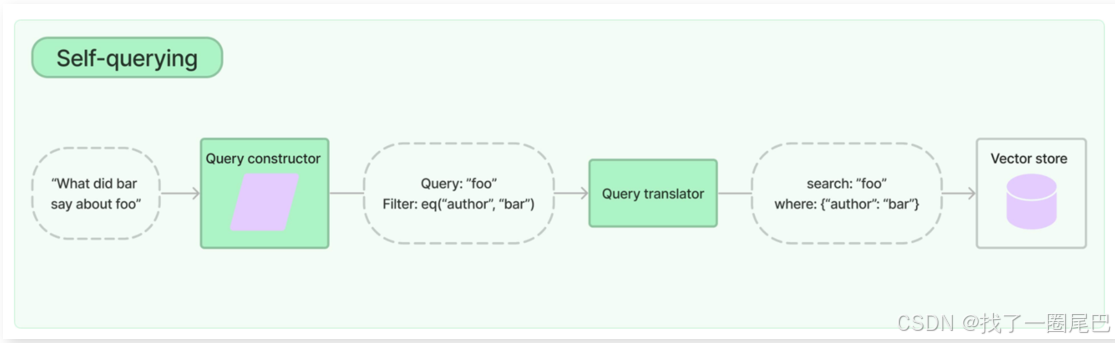
RAG工程-基于LangChain 实现 Advanced RAG(预检索优化)
Advanced RAG 概述 Advanced RAG 被誉为 RAG 的第二范式,它是在 Naive RAG 基础上发展起来的检索增强生成架构,旨在解决 Naive RAG 存在的一些问题,如召回率低、组装 prompt 时的冗余和重复以及灵活性不足等。它重点聚焦在检索增强࿰…...

关于常量指针和指向常量的指针
关于指针,对于常量指针和指向常量的指针也是傻傻分不清。看到定义时,不知道是指针不能变,还是指针指向的内容不能变量。 先看形式: const char * A; char * const B; 这两种有什么区别?傻傻分不清。 A这种定义&am…...

《Masked Autoencoders Are Scalable Vision Learners》---CV版的BERT
目录 一、与之前阅读文章的关系? 二、标题:带掩码的自auto编码器是一个可拓展的视觉学习器 三、摘要 四、核心图 五、结果图 六、不同mask比例对比图 七、“Introduction” (He 等, 2021, p. 1) 引言 八、“Related Work” (He 等, 2021, p. 3)相…...

高压直流输电MATLAB/simulink仿真模型+说明文档
1.模型简介 本仿真模型基于MATLAB/Simulink(版本MATLAB 2018Ra)软件。建议采用matlab2018 Ra及以上版本打开。(若需要其他版本可联系代为转换) 使用一个传输功率为1000MW(500 kV,2 kA)直流互连…...
locust压力测试
安装 pip install locust验证是否安装成功 locust -V使用 网上的教程基本上是前几年的,locust已经更新了好几个版本,有点过时了,在此做一个总结 启动 默认是使用浏览器进行设置的 # 使用浏览器 locust -f .\main.py其他参数 Usage: locust […...

python 线程池顺序执行
在Python中,线程池(ThreadPoolExecutor)默认是并发执行任务的,但若需要实现任务的顺序执行(按提交顺序执行或按结果顺序处理),可以通过以下方案实现: 方案一:强制单线程&…...

第十二届蓝桥杯 2021 C/C++组 空间
目录 题目: 题目描述: 题目链接: 思路: 思路详解: 代码: 代码详解: 题目: 题目描述: 题目链接: 空间 - 蓝桥云课 思路: 思路详解&#…...

以太网的mac帧格式
一.以太网的mac帧 帧的要求 1.长度 2.物理层...

前端如何使用Mock模拟数据实现前后端并行开发,提升项目整体效率
1. 安装 Mock.js npm install mockjs --save-dev # 或使用 CDN <script src"https://cdn.bootcdn.net/ajax/libs/Mock.js/1.0.0/mock-min.js"></script>2. 创建 Mock 数据文件 在项目中新建 mock 目录,创建 mock.js 文件: // m…...

【hadoop】HBase shell 操作
1.创建course表 hbase(main):002:0> create course,cf 2.查看HBase所有表 hbase(main):003:0> list 3.查看course表结构 hbase(main):004:0> describe course 4.向course表插入数据 hbase(main):005:0> put course,001,cf:cname,hbase hbase(main):006:0> …...

如何使用 Redis 缓存验证码
目录 🧠 Redis 缓存验证码的工作原理 🧰 实现流程 1. 安装 Redis 和 Python 客户端 2. 生成并缓存验证码 示例代码:生成并存储验证码 3. 发送验证码(以短信为例) 4. 校验验证码 示例代码:校验验证码…...

深度学习---框架流程
核心六步 一、数据准备 二、模型构建 三、模型训练 四、模型验证 五、模型优化 六、模型推理 一、数据准备:深度学习的基石 数据是模型的“燃料”,其质量直接决定模型上限。核心步骤包括: 1. 数据收集与标注 来源:公开数据集…...
业绩回暖、股价承压,三只松鼠赴港上市能否重构价值锚点?
在营收重返百亿俱乐部后,三只松鼠再度向资本市场发起冲击。 4月25日,这家坚果零食巨头正式向港交所递交上市申请书,若成功登陆港股,将成为国内首个实现“AH”双上市的零食品牌。 其赴港背后的支撑力,显然来自近期披露…...

JAVA-StringBuilder使用方法
JAVA-StringBuilder使用方法 常用方法 append(Object obj) 追加内容到末尾 sb.append(" World"); insert(int offset, Object obj) 在指定位置插入内容 sb.insert(5, “Java”); delete(int start, int end) 删除指定范围的字符 sb.delete(0, 5); replace(int start…...

【Python】Matplotlib:立体永生花绘制
本文代码部分实现参考自CSDN博客:https://blog.csdn.net/ak_bingbing/article/details/135852038 一、引言 Matplotlib作为Python生态中最著名的可视化库,其三维绘图功能可以创造出令人惊叹的数学艺术。本文将通过一个独特的参数方程,结合极…...
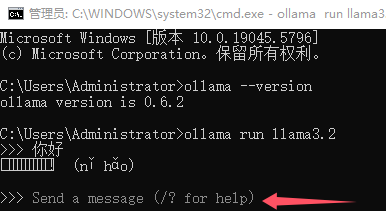
Unity AI-使用Ollama本地大语言模型运行框架运行本地Deepseek等模型实现聊天对话(一)
一、Ollama介绍 官方网页:Ollama官方网址 中文文档参考:Ollama中文文档 相关教程:Ollama教程 Ollama 是一个开源的工具,旨在简化大型语言模型(LLM)在本地计算机上的运行和管理。它允许用户无需复杂的配置…...

terraform使用vault动态管多理云账号AK/SK
为了使用 Terraform 和 HashiCorp Vault 动态管理多个云账号的 Access Key (AK) 和 Secret Key (SK),可以按照以下步骤实现安全、自动化的凭证管理: 一、架构概述 核心组件: Vault:存储或动态生成云账号的 AK/SK,提供…...
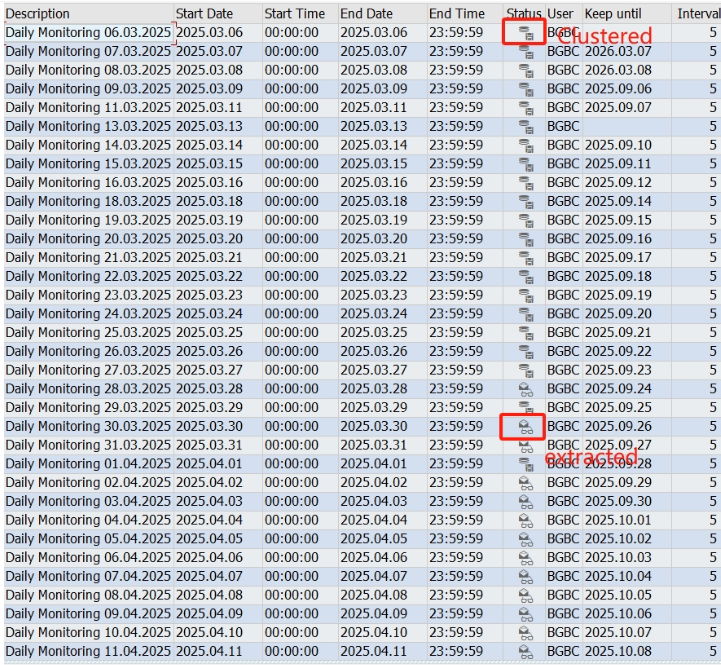
SAP /SDF/SMON配置错误会导致HANA OOM以及Disk Full的情况
一般来说,为了保障每日信息收集,每个企业都会配置/SDF/SMON的监控。这样在出现性能问题时,可以通过收集到的snapshot进行分析检查。如果/SDF/SMON在配置时选取了过多的记录项,或者选择了过低的时间间隔[Interval in seconds],那显…...

CMU和苹果公司合作研究机器人长序列操作任务,提出ManipGen
我们今天来介绍一项完成Long-horizon任务的一项新的技术:ManipGen。 什么叫Long-horizon?就是任务比较长。说到底,也是任务比较复杂。 那么这个技术就给我们提供了一个非常好的解决这类问题的思路,同时,也取得了不错的…...
大模型(LLMs)强化学习—— PPO
一、大语言模型RLHF中的PPO主要分哪些步骤? 二、举例描述一下 大语言模型的RLHF? 三、大语言模型RLHF 采样篇 什么是 PPO 中 采样过程?介绍一下 PPO 中 采样策略?PPO 中 采样策略中,如何评估“收益”? …...
)
[Python开发] 如何用 VSCode 编写和管理 Python 项目(从 PyCharm 转向)
在 Python 开发领域,PyCharm 一直是广受欢迎的 IDE,但其远程开发功能(如远程 SSH 调试)仅在付费版中提供。为了适应服务器部署需求,很多开发者开始将目光转向更加轻量、灵活且免费扩展能力强的 VSCode。本篇文章将详细介绍,从 PyCharm 转向 VSCode 后,如何高效搭建和管理…...

Maven多模块工程版本管理:flatten-maven-plugin扁平化POM
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...
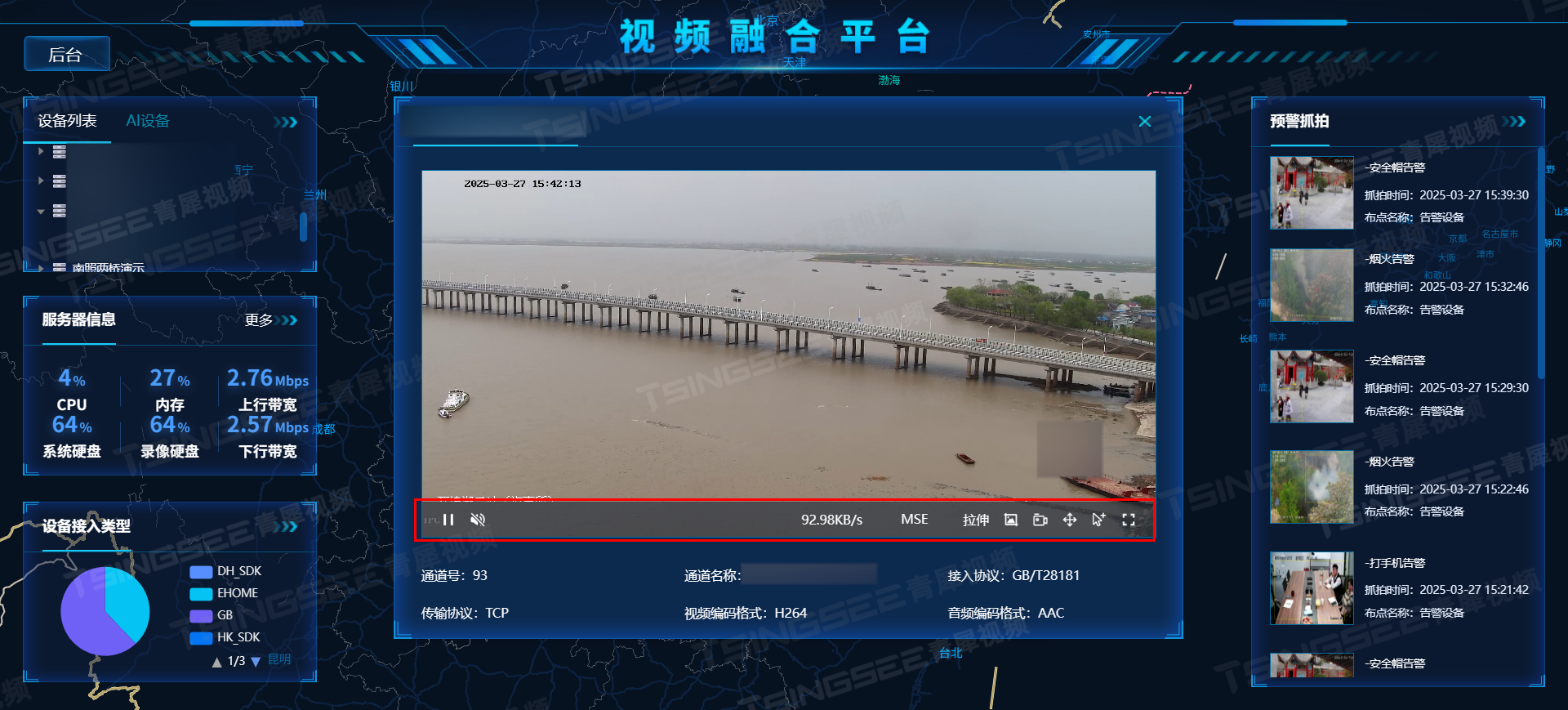
视频汇聚平台EasyCVR赋能高清网络摄像机:打造高性价比视频监控系统
在现代视频监控系统中,高清网络摄像机作为核心设备,其性能和配置直接影响监控效果和整体系统的价值。本文将结合EasyCVR视频监控的功能,探讨如何在满足使用需求的同时,优化监控系统的设计,降低项目成本,并提…...

Unity 接入阿里的全模态大模型Qwen2.5-Omni
1 参考 根据B站up主阴沉的怪咖 开源的项目的基础上修改接入 AI二次元老婆开源项目地址(unity-AI-Chat-Toolkit): Github地址:https://github.com/zhangliwei7758/unity-AI-Chat-Toolkit Gitee地址:https://gitee.com/DammonSpace/unity-ai-chat-too…...
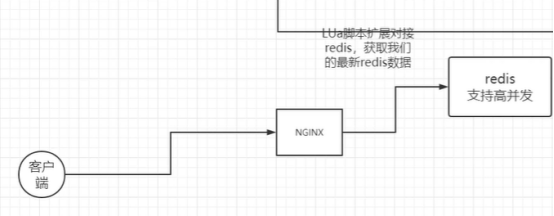
Nginx知识点
Nginx发展历史 Nginx 是由俄罗斯程序员 Igor Sysoev 开发的高性能开源 Web 服务器、反向代理服务器和负载均衡器 ,其历史如下: 起源与早期开发(2002 - 2004 年) 2002 年,当时 Igor Sysoev 在为俄罗斯门户网站 Rambl…...
——DeepSeek系列概览与发展背景)
NLP高频面试题(五十五)——DeepSeek系列概览与发展背景
大型模型浪潮背景 近年来,大型语言模型(Large Language Model, LLM)领域发展迅猛,从GPT-3等超大规模模型的崛起到ChatGPT的横空出世,再到GPT-4的问世,模型参数规模和训练数据量呈指数级增长。以GPT-3为例,参数高达1750亿,在570GB文本数据上训练,显示出模型规模、数据…...
)
详解 Unreal Engine(虚幻引擎)
详解 Unreal Engine(虚幻引擎) Unreal Engine(简称 UE)是由 Epic Games 开发的一款全球领先的实时渲染引擎,自 1998 年随首款游戏《Unreal》问世以来,已发展成为覆盖 游戏开发、影视制作、建筑可视化、汽车…...