《淘宝 API 数据湖构建:实时商品详情入湖 + Apache Kafka 流式处理指南》
随着电商行业的蓬勃发展,淘宝作为头部电商平台,积累了海量的商品数据。构建淘宝 API 数据湖,将实时商品详情数据纳入其中,并借助 Apache Kafka 进行流式处理,能够为企业提供强大的数据支撑,助力精准营销、市场分析等业务决策。本文将详细介绍如何构建淘宝 API 数据湖,实现实时商品详情数据入湖,并利用 Apache Kafka 进行流式处理,同时提供相关代码示例。
一、数据湖与 Apache Kafka 概述
1.1 数据湖
数据湖是一个集中式存储库,用于存储结构化、半结构化和非结构化数据。与传统数据仓库不同,数据湖在数据存储阶段不强制要求数据的预定义模式,允许在数据分析阶段再进行模式定义和数据处理,具有极高的灵活性和扩展性,能够满足企业多样化的数据处理需求。
1.2 Apache Kafka
Apache Kafka 是一个分布式流处理平台,具有高吞吐量、可扩展性、容错性等特点。它以主题(Topic)的形式组织数据,生产者(Producer)将数据发送到指定的主题,消费者(Consumer)从主题中读取数据。Kafka 的流式处理能力使其非常适合处理实时数据,在数据采集、传输和处理等环节发挥着重要作用。
二、淘宝 API 数据湖构建准备
2.1 申请淘宝 API 权限
在开始构建数据湖之前,需要在淘宝注册并申请相应的 API 权限。申请成功后,获取 ApiKey 和 ApiSecret,用于后续 API 调用的身份验证。
2.2 搭建数据湖存储环境
数据湖的存储可以选择多种方式,如 Hadoop 分布式文件系统(HDFS)、云存储(如 AWS S3、阿里云 OSS)等。以 HDFS 为例,需要安装配置 Hadoop 集群,确保能够正常存储和访问数据。如果选择云存储,需根据对应云服务提供商的文档进行配置和权限设置。
2.3 安装配置 Apache Kafka
- 下载安装包:从 Apache Kafka 官方网站下载适合系统的 Kafka 安装包。
- 解压安装:将下载的安装包解压到指定目录,例如/opt/kafka。
- 配置 Kafka:编辑config/server.properties文件,配置 Kafka 的相关参数,如broker.id(唯一标识 Broker)、listeners(监听地址和端口)、log.dirs(日志存储目录)等。
- 启动 Zookeeper 和 Kafka:Kafka 依赖 Zookeeper 进行集群管理和协调,先启动 Zookeeper,再启动 Kafka Broker。
# 启动Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties# 新终端启动Kafka Broker
bin/kafka-server-start.sh config/server.properties三、实时商品详情数据入湖
3.1 编写淘宝 API 数据采集代码
使用编程语言(如 Python)编写代码调用淘宝 API 获取商品详情数据。这里使用requests库发送 HTTP 请求,并使用json库处理返回的 JSON 数据。以下是一个简单的示例:
import requests
import jsonapp_key = "YOUR_APP_KEY"
app_secret = "YOUR_APP_SECRET"
api_url = "https://api.taobao.com/router/rest"def get_product_detail(product_id):params = {"method": "taobao.item.get","app_key": app_key,"num_iid": product_id,"format": "json","v": "2.0",# 这里省略签名计算,实际使用需按淘宝API文档添加签名}response = requests.get(api_url, params=params)if response.status_code == 200:data = json.loads(response.text)return dataelse:print(f"请求失败,状态码: {response.status_code}")return None
3.2 配置 Kafka 生产者
在 Python 中使用kafka-python库配置 Kafka 生产者,将采集到的商品详情数据发送到 Kafka 主题。首先安装kafka-python库:
pip install kafka-python然后编写生产者代码:
from kafka import KafkaProducer
import jsonproducer = KafkaProducer(bootstrap_servers=['localhost:9092'], # 根据实际Kafka配置修改value_serializer=lambda v: json.dumps(v).encode('utf-8')
)def send_product_data_to_kafka(product_data):topic = "taobao_product_details" # 自定义主题名称producer.send(topic, value=product_data)producer.flush()
3.3 整合数据采集与发送
将数据采集和发送到 Kafka 的代码整合起来,实现实时商品详情数据的采集和发送:
product_id = "123456789" # 替换为实际商品ID
product_data = get_product_detail(product_id)
if product_data:send_product_data_to_kafka(product_data)
四、Apache Kafka 流式处理
4.1 配置 Kafka 消费者
在 Python 中使用kafka-python库配置 Kafka 消费者,从指定主题读取商品详情数据。代码如下:
from kafka import KafkaConsumer
import jsonconsumer = KafkaConsumer("taobao_product_details", # 与生产者主题一致bootstrap_servers=['localhost:9092'],auto_offset_reset='earliest',group_id='taobao_data_processing_group',value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
4.2 数据处理逻辑
在消费者获取到数据后,进行数据处理,例如提取关键信息、数据清洗、格式转换等。以下是一个简单的数据处理示例,提取商品的标题、价格和销量:
for message in consumer:product_data = message.valueitem = product_data.get('item', {})title = item.get('title', '')price = item.get('price', '')volume = item.get('volume', '')print(f"商品标题: {title}, 价格: {price}, 销量: {volume}")
4.3 数据入湖
将处理后的数据存储到数据湖的存储系统中。如果使用 HDFS,可以使用hdfs库进行文件操作;如果使用云存储,需使用对应云服务的 SDK。以 HDFS 为例,安装hdfs库:
pip install hdfs然后编写数据入湖代码:
from hdfs import InsecureClientclient = InsecureClient('http://localhost:9870', user='your_username') # 根据实际HDFS配置修改def save_data_to_hdfs(data, file_path):with client.write(file_path, encoding='utf-8', overwrite=True) as writer:writer.write(json.dumps(data))在数据处理逻辑中调用save_data_to_hdfs函数,将处理后的数据保存到 HDFS 指定路径:
for message in consumer:product_data = message.valueitem = product_data.get('item', {})title = item.get('title', '')price = item.get('price', '')volume = item.get('volume', '')processed_data = {"title": title,"price": price,"volume": volume}file_path = "/taobao_data_lake/products/{}.json".format(item.get('num_iid', 'unknown'))save_data_to_hdfs(processed_data, file_path)
五、总结
通过以上步骤,我们成功构建了淘宝 API 数据湖,实现了实时商品详情数据入湖,并利用 Apache Kafka 进行流式处理。从淘宝 API 数据采集、Kafka 生产者发送数据,到 Kafka 消费者进行数据处理和入湖存储,整个流程形成了一个完整的数据处理链路。在实际应用中,还可以根据业务需求进一步扩展和优化数据处理逻辑,如增加数据的实时分析、数据可视化等功能。随着大数据技术的不断发展,这种基于数据湖和流式处理的架构将为企业挖掘数据价值提供更强大的支持。
相关文章:

《淘宝 API 数据湖构建:实时商品详情入湖 + Apache Kafka 流式处理指南》
随着电商行业的蓬勃发展,淘宝作为头部电商平台,积累了海量的商品数据。构建淘宝 API 数据湖,将实时商品详情数据纳入其中,并借助 Apache Kafka 进行流式处理,能够为企业提供强大的数据支撑,助力精准营销、市…...

基于ArduinoIDE的任意型号单片机 + GPS北斗BDS卫星定位
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言1.1 器件选择1.2 接线方案 二、驱动实现2.1 核心代码解析(arduino/ESP32-S3) 三、坐标解析代码四、典型问题排查总结 前言 北斗卫星导航…...

代码随想录算法训练营第60期第二十二天打卡
大家好!我们今天来到了一个全新的章节,回溯算法,那究竟什么是回溯算法,我们应该如何理解回溯算法,以及回溯算法可以解决的题目,我们今天就来一探究竟。 第一部分 回溯算法理论基础 其实我可以告诉大家的是…...
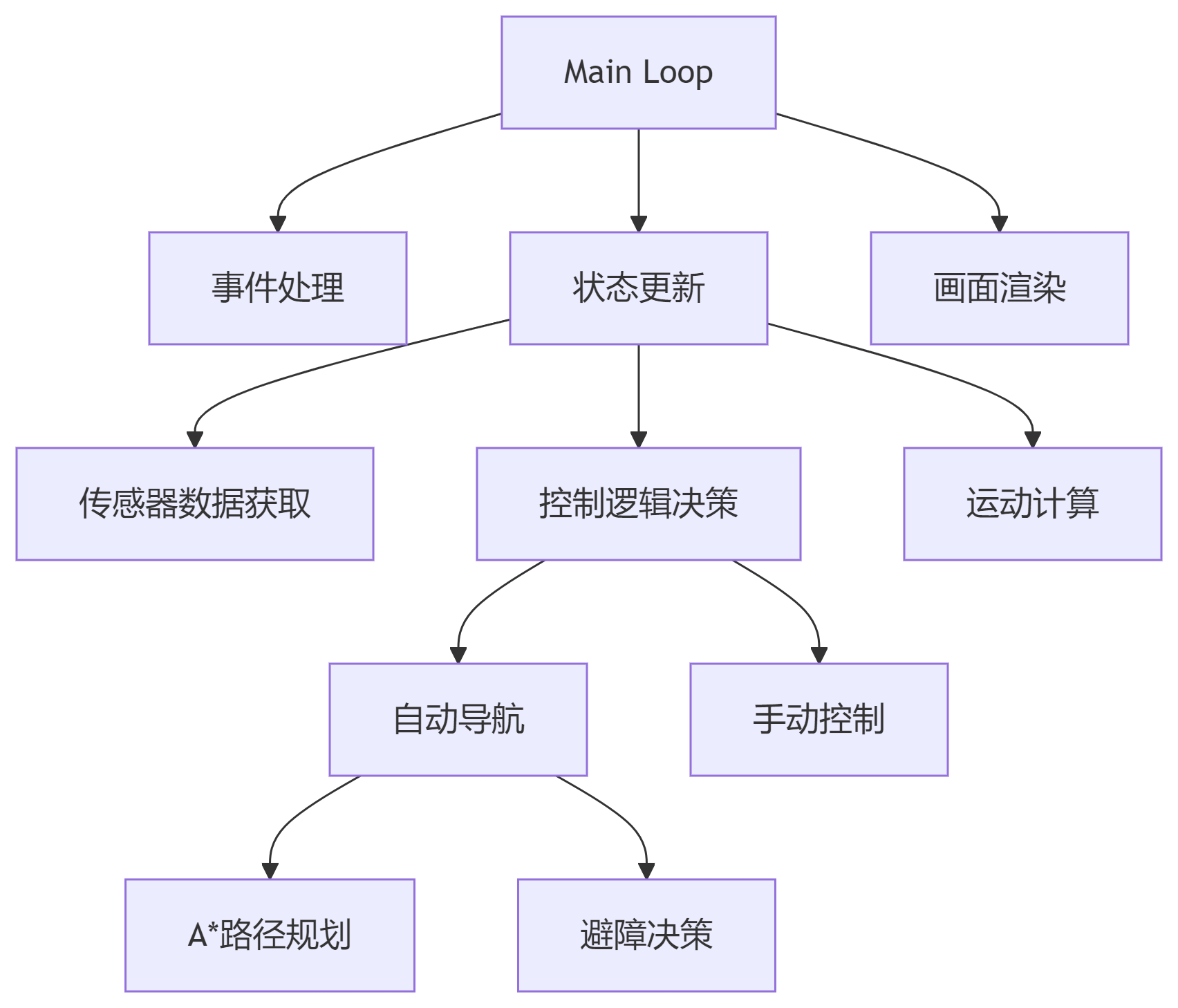
自主机器人模拟系统
一、系统概述 本代码实现了一个基于Pygame的2D自主机器人模拟系统,具备以下核心功能: 双模式控制:支持手动控制(WASD键)和自动导航模式(鼠标左键设定目标) 智能路径规划:采用改进型…...

基于QT的仿QQ音乐播放器
一、项目介绍 该项目是基于QT开发的⾳乐播放软件,界面友好,功能丰富,主要功能如下: 窗口hand部分: 点击最小化按钮,窗口最小化 点击最大化按钮,窗口最大化 点击关闭按钮,程序退出 …...
腾讯研究院:《工业大模型应用报告》(文末附下载方式)
腾讯研究院发布的《工业大模型应用报告》是一份系统探讨大模型技术在工业领域落地实践的研究成果。该报告基于腾讯在人工智能、云计算及产业互联网的实践经验,结合国内外典型案例,深入分析了工业大模型的行业价值、关键技术、应用场景及未来趋势。报告指…...
)
C语言-指针(一)
目录 指针 内存 概念 指针变量 取地址操作符(&) 操作符“ * ” 指针变量的大小 注意 指针类型的意义 作用 void * 指针 const修饰指针变量 const放在*前 const放在*后 双重const修饰 指针的运算 1.指针 - 整数 2.指针 - 指针 3.指…...

【DeepMLF】具有可学习标记的多模态语言模型,用于情感分析中的深度融合
这是一篇我完全看不懂的论文,写的好晦涩,适合唬人,所以在方法部分我以大白话为主 abstract 在多模态情感分析(MSA)中,多模态融合已经得到了广泛的研究,但融合深度和多模态容量分配的作用还没有得到充分的研究。在这项工作中,我们将融合深度、可扩展性和专用多模容量作…...
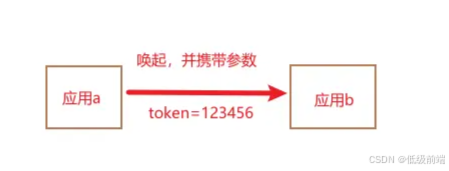
uniapp如何获取安卓原生的Intent对象
通过第三方app唤起,并且获取第三方app唤起时携带的参数 因为应用a唤起应用b时,应用b第一时间就要拿到参数token,所以需要将获取参数的方法写在APP.vue中的onLaunch钩子里,如果其他地方要用可以选择vuex或者采用本地缓存。 uniapp中plus.run…...
implement the “pixel-wise difference“
根据在处理图像数据的来源和格式的不同,在具体实现“两幅图像残差比较”的时候,分为两类方法。 类型一:PyTorch 的 Tensor 图像格式 imgs_pil_o [transforms.ToPILImage()(img_o) for img_o in imgs_o] imgs_pil_w [transforms.ToPILImag…...
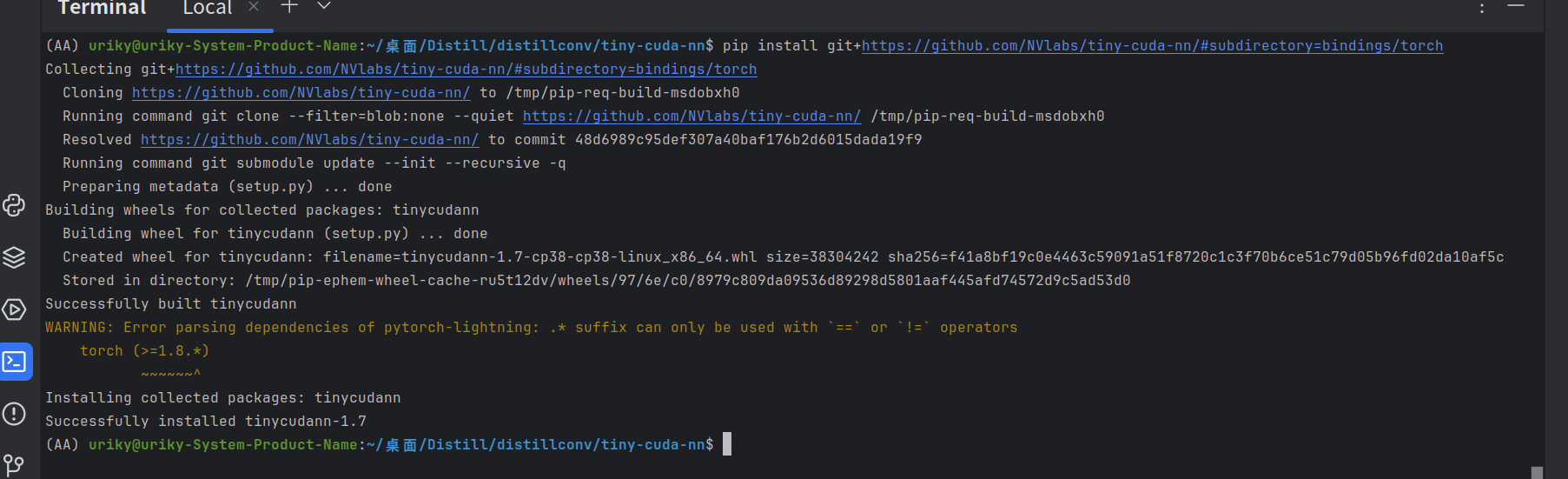
tinycudann安装过程加ubuntu18.04gcc版本的升级(成功版!!!!)
使用的是 Linux,安装以下软件包 sudo apt-get install build-essential git安装 CUDA 并将 CUDA 安装添加到您的 PATH。 例如,如果您有 CUDA 12.6.3,请将以下内容添加到您的/usr/local/~/.bashrcexport PATH"/usr/local/cuda-12.6.3/bi…...
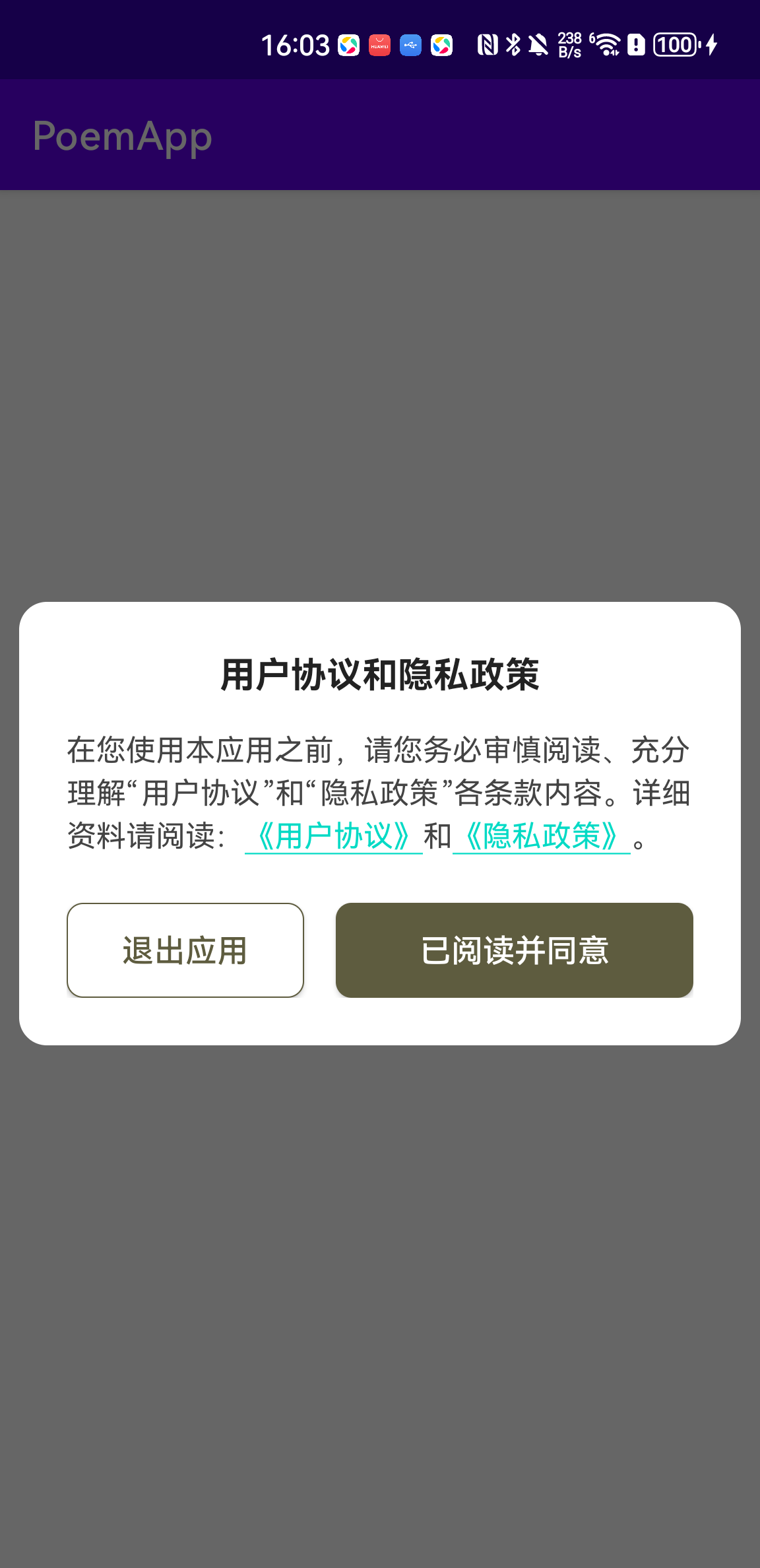
Android 实现一个隐私弹窗
效果图如下: 1. 设置同意、退出、点击用户协议、点击隐私协议的函数参数 2. 《用户协议》、《隐私政策》设置成可点击的,且颜色要区分出来 res/layout/dialog_privacy_policy.xml 文件 <?xml version"1.0" encoding"utf-8"?&…...
)
Oracle无法正常OPEN(三)
在Oracle数据库中,如果几个数据文件丢失,导致数据库无法启动,报错“ORA-01157: cannot identify/lock data file 2 - see DBWR trace file”,如果没有物理备份的情况下,位于丢失数据文件的数据是无法找回的,…...

本地服务验证-仙盟创梦IDE-智能编程,编程自动备份+编程审计
本地服务验证server using System; using System.Net;class Program {static void Main(){HttpListener listener new HttpListener();listener.Prefixes.Add("http://localhost:8080/");listener.Start();Console.WriteLine("服务器已启动,监听中…...
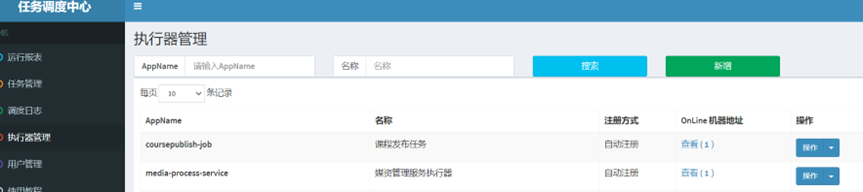
[学成在线]22-自动部署项目
自动部署 实战流程 下边使用jenkins实现CI/CD的流程。 1、将代码使用Git托管 2、在jenkins创建任务,从Git拉取代码。 3、拉取代码后进行自动构建:测试、打包、部署。 首先将代码打成镜像包上传到docker私服。 自动创建容器、启动容器。 4、当有代…...
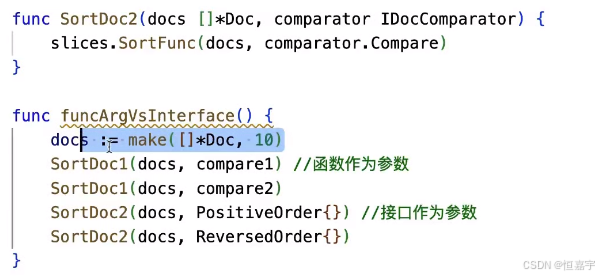
Golang|使用函数作为参数和使用接口的联系
函数作为数据类型的一种,可以成为其他函数的参数。在 Go(Golang) 中,函数作为参数 和 接口(interface),本质上都和抽象、灵活调用有关 —— 都是让代码更灵活、更可扩展的手段。不过它们各有侧重…...

MATLAB技巧——norm和vecnorm两个函数讲解与辨析
在 MATLAB 中,norm 和 vecnorm 是两个用于计算向量或矩阵范数的函数,虽然它们的功能相似,但在使用场景和适用性上存在一些区别。本文将详细解释这两个函数的用途、功能以及如何选择合适的函数。 文章目录 norm函数用法范数类型vecnorm函数用法范数类型选择合适的函数示例对比…...

ubuntu的libc 库被我 sudo apt-get --reinstall install libc6搞没了
我系统的libc 没了 今天为了运行一个开源的yuv 播放器,在运行的时候提醒 Inconsistency detected by ld.so: dl-call-libc-early-init.c: 37: _dl_call_libc_early_init: Assertion sym ! NULL failed!然后听从AI 的建议 当我去执行ls 时,系统提示 就这…...

Ubuntu搭建Conda+Python开发环境
目录 一、环境说明 1、测试环境为ubuntu24.04.1 2、更新系统环境 3、安装wget工具 4、下载miniconda安装脚本 二、安装步骤 1、安装miniconda 2、source conda 3、验证版本 4、配置pip源 三、conda用法 1、常用指令 一、环境说明 1、测试环境为ubuntu24.04.1 2、更…...

智能工厂规划学习——深入解读数字化工厂规划与建设方案
项目总体思路聚焦于通过智能制造和数字化工厂建设,来优化企业战略并提升信息化水平。首先,企业需学习先进国家已经验证的先进经验,并紧跟其正在变革的方向,以确保自身发展的前瞻性和竞争力。 在企业战略层面,企业正从以产品为中心的业务模式,逐步转变为以服务中心…...

【学习笔记】深入理解Java虚拟机学习笔记——第2章 Java内存区域与内存溢出异常
第2章 Java内存区域与内存溢出异常 2.1 概述 略 2.2 运行时数据区域 2.2.1 程序计数器 线程私有,记录执行的字节码位置 2.2.2 Java 虚拟机栈 线程私有,存储一个一个的栈帧,通过栈帧的出入栈来控制方法执行。 -栈帧:对应一个…...
Python全流程开发实战:基于IMAP协议安全下载个人Gmail邮箱内所有PDF附件
在日常办公场景中,面对成百上千封携带PDF附件的邮件,手动逐一下载往往耗时耗力,成为效率瓶颈。如何通过代码实现“一键批量下载”?本文将以**“Gmail全量PDF附件下载工具”**开发为例,完整拆解从需求分析到落地交付的P…...

【验证技能】VIP项目大总结
VIP项目快做一段落了,历时一年半,也该要一个大汇总。 VIP简介 VIP开发流程 VIP难点 进程同步 打拍插入不同bit位宽数据问题。 动态升降lane VIP做的不好的地方和改进想法 各层之间交互 testsuite两端关键 所有层的实现架构不统一 VIP经验 ** 架构…...

Pytest-mark使用详解(跳过、标记、参数 化)
1.前言 在工作中我们经常使用pytest.mark.XXXX进行装饰器修饰,后面的XXX的不同,在pytest中有不同的作 用,其整体使用相对复杂,我们单独将其抽取出来做详细的讲解。 2.pytest.mark.skip()/skipif()跳过用例 import pytest #无条…...

【浅尝Java】Java简介第一个Java程序(含JDK、JRE与JVM关系、javcdoc的使用)
🍞自我激励:每天努力一点点,技术变化看得见 文章目录 Java语言概述Java是什么Java语言的重要性Java语言发展简史Java语言特性 第一个Java程序main方法示例运行Java程序JDK、JRE、JVM之间的关系注释基本规则注释规范 标识符关键字 Java语言概述…...

游戏打击感实现
视觉表现 1.帧冻结(卡肉) 原理:在攻击命中的瞬间暂停动画播放(通常0.1-0.3s),伯尼真实打击时的反作用力停滞感。实现:通过控制动画播放速度(如Unity的Animator.speed)结…...

项目三 - 任务2:创建笔记本电脑类(一爹多叔)
在本次实战中,我们通过Java的单根继承和多接口实现特性,设计了一个笔记本电脑类。首先创建了Computer抽象类,提供计算的抽象方法,模拟电脑的基本功能。接着定义了NetCard和USB两个接口,分别包含连接网络和USB设备的抽象…...
Electron学习+打包
1. 什么是 Electron? Electron 是⼀个 跨平台桌⾯应⽤ 开发框架,开发者可以使⽤:HTML、CSS、JavaScript 等 Web 技术来构建桌⾯应⽤程序,它的本质是结合了 Chromium 和 Node.js ,现在⼴泛⽤于桌⾯应 ⽤程序开发&a…...

NumPy线性代数功能全解析:矩阵运算与方程求解实用指南
NumPy 是线性代数领域中高效的工具。它可以帮助完成矩阵运算和方程求解。本文将介绍 NumPy 中用于线性代数的常用函数。 矩阵乘法 矩阵乘法会根据两个矩阵生成一个新矩阵。具体做法是将第一个矩阵的每一行与第二个矩阵的每一列相乘,并将乘积相加,得到新…...
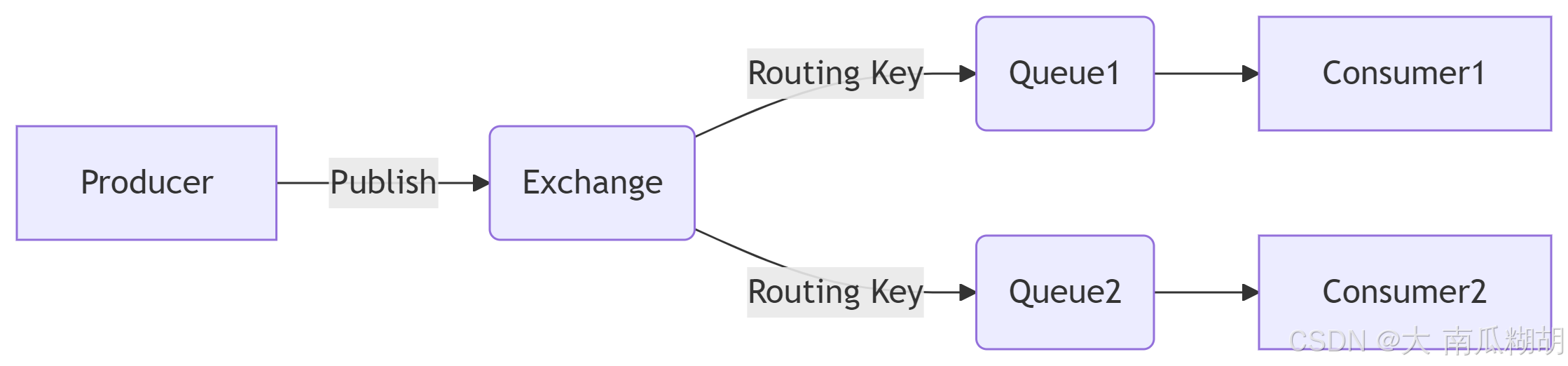
《RabbitMQ 全面解析:从原理到实战的高性能消息队列指南》
一、RabbitMQ 核心原理与架构 1. 核心组件与工作流程 RabbitMQ 基于 AMQP 协议,核心组件包括 生产者(Producer)、交换机(Exchange)、队列(Queue) 和 消费者(Consumer)。…...