【大模型系列篇】Qwen3开源全新一代大语言模型来了,深入思考,更快行动
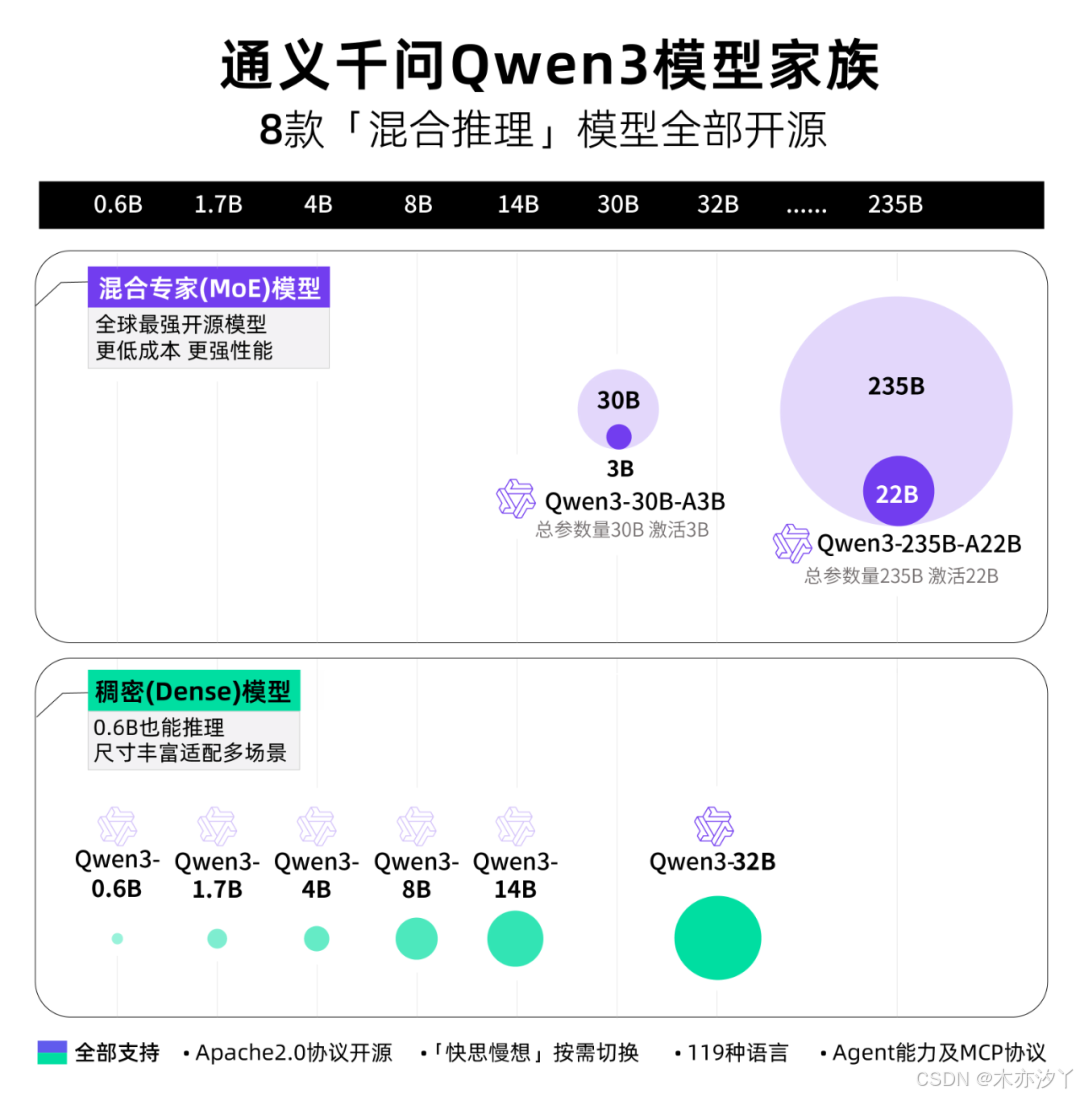
Qwen3开源模型全览
Qwen3是全球最强开源模型(MoE+Dense)
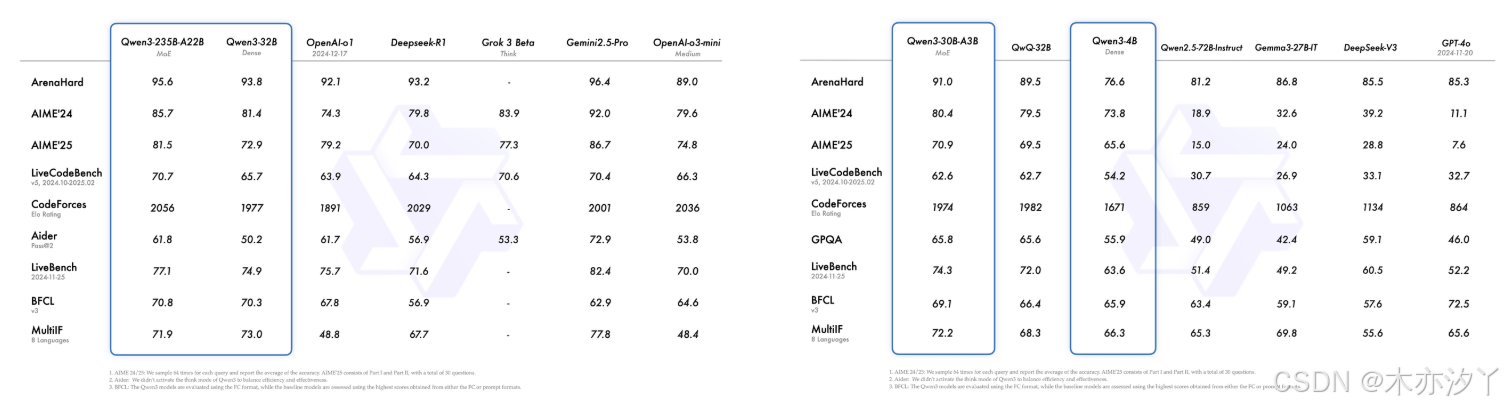
Qwen3 采用混合专家(MoE)架构,总参数量 235B,激活仅需 22B。
Qwen3 预训练数据量达 36T,并在后训练阶段多轮强化学习,将非思考模式无缝整合到思考模型中。
Qwen3 在推理、指令遵循、工具调用、多语言能力等方面均大幅增强,即创下所有国产模型及全球开源模型的性能新高:
- 在奥数水平的 AIME25 测评中,Qwen3 斩获 81.5 分,刷新开源纪录;
- 在考察代码能力的 LiveCodeBench 评测中,Qwen3 突破 70 分大关,表现甚至超过 Grok3;
- 在评估模型人类偏好对齐的 ArenaHard 测评中,Qwen3 以 95.6 分超越 OpenAI-o1 及 DeepSeek-R1。
性能大幅提升的同时,Qwen3 的部署成本还大幅下降,仅需 4 张 H20 即可部署 Qwen3 满血版,显存占用仅为性能相近模型的三分之一。
Qwen3 还提供了丰富的模型版本,包含 2 款 30B、235B 的 MoE 模型,以及 0.6B、1.7B、4B、8B、14B、32B 等 6 款密集模型。
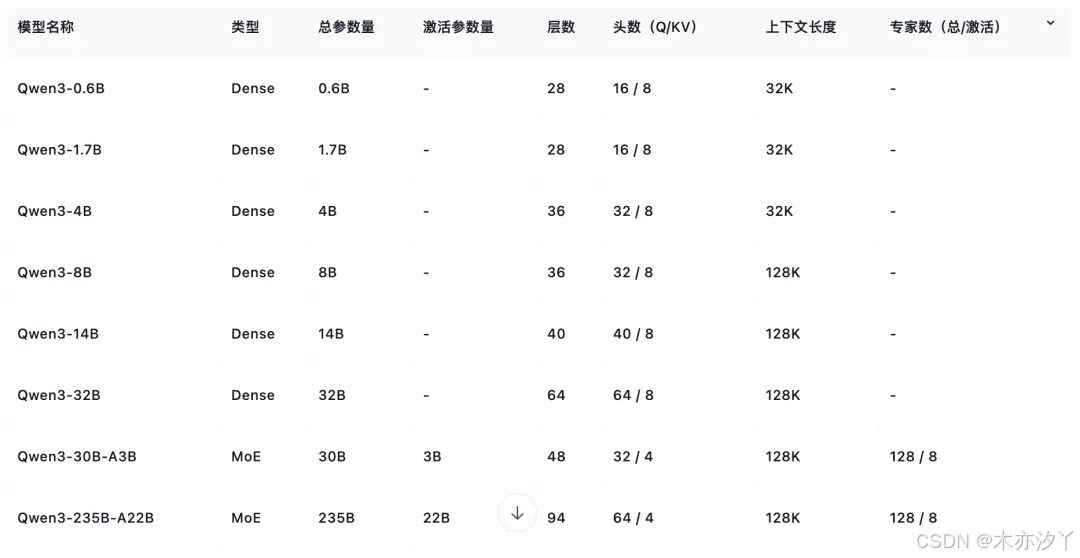
每款模型均斩获同尺寸开源模型 SOTA(最佳性能):
Qwen3 的 30B 参数 MoE 模型实现了 10 倍以上的模型性能杠杆提升,仅激活 3B 就能媲美上代 Qwen2.5-32B 模型性能;
Qwen3 的稠密模型性能继续突破,一半的参数量可实现同样的高性能,如 32B 版本的 Qwen3 模型可跨级超越 Qwen2.5-72B 性能。
同时,所有 Qwen3 模型都是混合推理模型,API 可按需设置「思考预算」(即预期最大深度思考的 tokens 数量),进行不同程度的思考,灵活满足 AI 应用和不同场景对性能和成本的多样需求。
比如,4B 模型是手机端的绝佳尺寸;8B 可在电脑和汽车端侧丝滑部署应用;32B 最受企业大规模部署欢迎,有条件的开发者也可轻松上手。
比如让它做一款记忆配对卡牌的 Web 小游戏,效果如下:
Qwen3的主要特点
Qwen3 是国内首个支持“混合推理”模型
Qwen3 原生支持思考模式与非思考模式两种工作方式,意味着既能在简单问题上快思考,秒出答案;又能在复杂问题上慢思考,展开多步推理和深入分析。这种设计让用户可以根据不同任务,轻松调整花多少费用,既省成本又保证推理效果。
- 思考模式:在这种模式下,模型在提供最终答案之前需要时间逐步推理。这对于需要深入思考的复杂问题来说是理想的选择。
- 非思考模式:在这里,该模型提供快速、近乎即时的回答,适用于速度比深度更重要的简单问题。
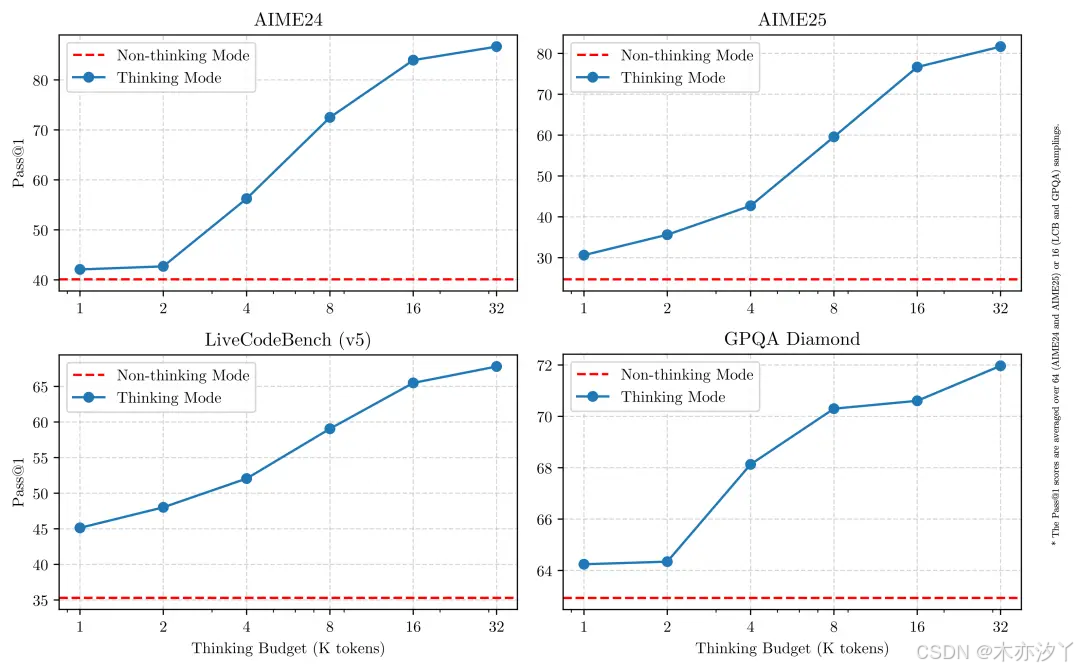
这种灵活性允许用户根据手头的任务控制模型执行多少 “思考”。例如,较难的问题可以通过扩展推理来解决,而较简单的问题可以毫不拖延地直接回答。至关重要的是,这两种模式的融合极大地增强了模型实施稳定高效的思维预算控制的能力。如上所述,Qwen3 表现出可扩展且流畅的性能改进,这与分配的计算推理预算直接相关。这种设计使用户能够更轻松地配置特定于任务的预算,从而在成本效率和推理质量之间实现更理想的平衡。
Qwen3 原生支持 MCP 协议
Qwen3 为即将到来的智能体 Agent 和大模型应用爆发提供了更好的支持。在大模型从“聊天”走向“动手做事”的关键时刻,Qwen3 的设计也跟着升级了,不再只是回答问题那么简单,而是专门为 Agent 架构做了优化,提升了执行任务的效率、响应的结构化程度,还有对各种工具的适配能力。
在评估模型 Agent 能力的 BFCL 评测中,Qwen3 创下 70.8 的新高,超越 Gemini2.5-Pro、OpenAI-o1 等顶尖模型,将大幅降低 Agent 调用工具的门槛。
同时,Qwen3 原生支持 MCP 协议,并具备强大的工具调用(function calling)能力,结合封装了工具调用模板和工具调用解析器的 Qwen-Agent 框架,将大大降低编码复杂性,实现高效的手机及电脑 Agent 操作等任务。
此外
Qwen3 系列模型依旧采用宽松的 Apache2.0 协议开源,并首次支持 119 多种语言。
全球开发者、研究机构和企业均可免费在魔搭社区、HuggingFace 等平台下载模型并商用,也可以通过阿里云百炼调用千问 3 的 API 服务。
个人用户可立即通过通义 APP 直接体验 Qwen3,夸克也即将全线接入Qwen3。
据悉,阿里通义已开源 200 余个模型,全球下载量超 3 亿次,千问衍生模型数超 10 万个,已超越美国 Llama,成为全球第一开源模型。
Qwen3的预训练与后训练
Qwen3-预训练数据与三阶段流程
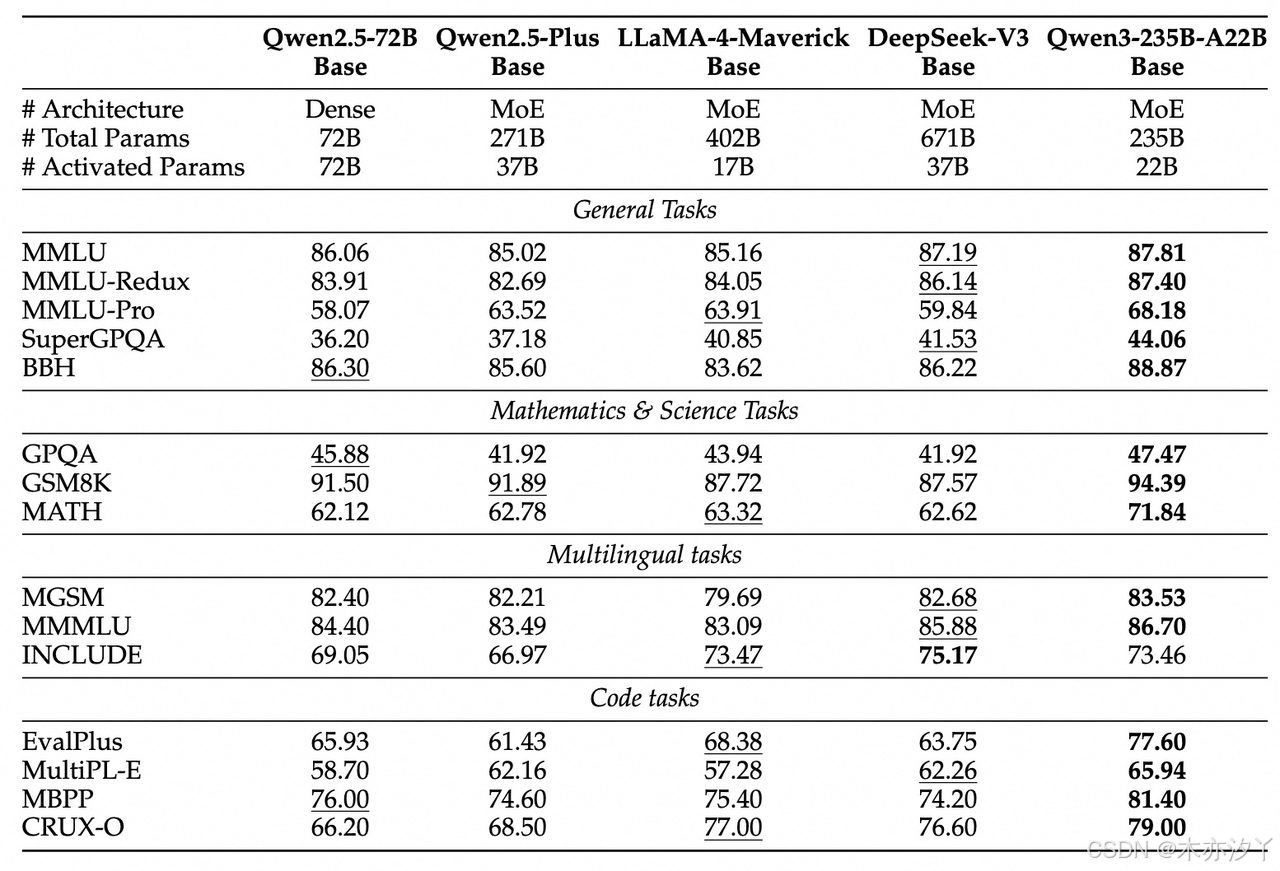
Qwen3使用了近36万亿token的超大规模多语种数据集进行预训练,是Qwen2.5时期数据量的约2倍。
训练过程分为三个阶段:
- Stage 1:在超30万亿token上进行初步预训练,具备通用语言理解与生成能力(上下文长度4K)。
- Stage 2:引入大量STEM(科学、技术、工程、数学)数据和代码数据,在额外5万亿token上继续训练。
- Stage 3:使用高质量长文本扩展上下文窗口至32K,优化长文档处理能力。
在数据构建过程中,还引入了模型辅助的数据增强技术,如使用Qwen2.5-Math、Qwen2.5-Coder生成高质量数学与代码数据,进一步强化了模型在专业领域的推理与表达能力。
在相同或更少激活参数数量下,Qwen3基础模型性能全面优于同等规模Qwen2.5 Dense模型。
Qwen3-后训练强化学习与思考模式融合
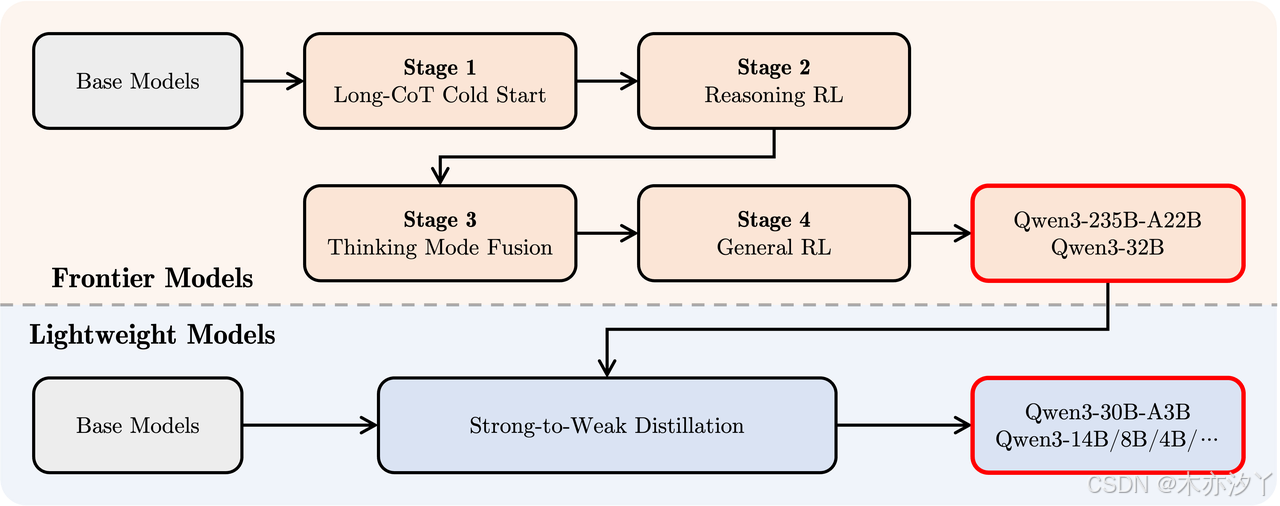
为了进一步优化推理链条质量与控制思考模式,Qwen3在后训练阶段设计了四阶段强化学习流程:
- Stage 1:长推理链冷启动(Long-CoT Cold Start): 微调模型在复杂任务(如数学、代码、逻辑推理)中的长推理链条。
- Stage 2:推理强化学习(Reasoning RL): 基于规则奖励机制,强化模型的推理深度与探索能力。
- Stage 3:思考模式融合(Thinking Mode Fusion): 融合思考模式与快速模式,打通推理链条与即时响应路径。
- Stage 4:通用强化学习(General RL):在指令跟随、格式遵循、工具调用等领域进一步微调,提升通用任务完成能力。
同时,针对中小尺寸模型,还引入了Strong-to-Weak蒸馏技术,将大型模型的推理能力高效迁移至轻量级模型中,保证小模型也能具备优秀的推理与交互表现。
Qwen3部署与开发
本地部署
对于部署,可以使用 sglang>=0.4.6.post1 或 vllm>=0.8.4 创建兼容 OpenAI 的 API 终端节点:
- SGLang:
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3- vLLM:
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1如果你用它来本地开发,你可以通过运行一个简单的命令 ollama run qwen3:30b-a3b 来使用 ollama 来玩转模型,或者你可以使用 LMStudio 或 llama.cpp 和 ktransformers 在本地构建。
开发示例
以 Qwen3-30B-A3B 为例
from modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen3-30B-A3B"# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# conduct text completion
generated_ids = model.generate(**model_inputs,max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content
try:# rindex finding 151668 (</think>)index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("thinking content:", thinking_content)
print("content:", content)
关闭思考模式
如果需要禁用思考模式,只需修改 enable_thinking=False
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=False # 禁用思考模式
)
高级用法
Qwen3提供了一种软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。具体来说,您可以将 /think 和 /no_think 添加到用户提示或系统消息中,以将模型的思维模式从轮次切换到轮次。该模型将遵循多轮次对话中的最新指令。
多轮次对话的示例
from transformers import AutoModelForCausalLM, AutoTokenizerclass QwenChatbot:def __init__(self, model_name="Qwen/Qwen3-30B-A3B"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForCausalLM.from_pretrained(model_name)self.history = []def generate_response(self, user_input):messages = self.history + [{"role": "user", "content": user_input}]text = self.tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)inputs = self.tokenizer(text, return_tensors="pt")response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()response = self.tokenizer.decode(response_ids, skip_special_tokens=True)# Update historyself.history.append({"role": "user", "content": user_input})self.history.append({"role": "assistant", "content": response})return response# Example Usage
if __name__ == "__main__":chatbot = QwenChatbot()# First input (without /think or /no_think tags, thinking mode is enabled by default)user_input_1 = "How many r's in strawberries?"print(f"User: {user_input_1}")response_1 = chatbot.generate_response(user_input_1)print(f"Bot: {response_1}")print("----------------------")# Second input with /no_thinkuser_input_2 = "Then, how many r's in blueberries? /no_think"print(f"User: {user_input_2}")response_2 = chatbot.generate_response(user_input_2)print(f"Bot: {response_2}") print("----------------------")# Third input with /thinkuser_input_3 = "Really? /think"print(f"User: {user_input_3}")response_3 = chatbot.generate_response(user_input_3)print(f"Bot: {response_3}")
代理用法
Qwen3 在工具调用功能方面表现出色。这里推荐使用 Qwen-Agent 来充分利用 Qwen3 的代理能力。Qwen-Agent 在内部封装了工具调用模板和工具调用解析器,大大降低了编码复杂度。
要给代理定义可用的工具,可以使用 MCP 配置文件,使用 Qwen-Agent 的集成工具,或自行集成其他工具。
from qwen_agent.agents import Assistant# Define LLM
llm_cfg = {'model': 'Qwen3-30B-A3B',# Use the endpoint provided by Alibaba Model Studio:# 'model_type': 'qwen_dashscope',# 'api_key': os.getenv('DASHSCOPE_API_KEY'),# Use a custom endpoint compatible with OpenAI API:'model_server': 'http://localhost:8000/v1', # api_base'api_key': 'EMPTY',# Other parameters:# 'generate_cfg': {# # Add: When the response content is `<think>this is the thought</think>this is the answer;# # Do not add: When the response has been separated by reasoning_content and content.# 'thought_in_content': True,# },
}# Define Tools
tools = [{'mcpServers': { # You can specify the MCP configuration file'time': {'command': 'uvx','args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']},"fetch": {"command": "uvx","args": ["mcp-server-fetch"]}}},'code_interpreter', # Built-in tools
]# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):pass
print(responses)如何选择适合的模型?
- 本地测试及科研:Qwen3-0.6B/1.7B,硬件要求低,适合快速实验;
- 手机端侧应用:Qwen3-4B,性能与效率兼顾,适合移动端部署;
- 电脑或汽车端:Qwen3-8B,适用于对话系统、语音助手等场景;
- 企业落地:Qwen3-14B/32B性能更强,适合复杂任务;
- 云端高效部署:MoE模型,Qwen3-30B-A3B速度快;Qwen3-235B-A22B性能强劲且显存占用低;
无论你是开发者、科研人员还是普通用户,Qwen3都能满足你的需求!
结束语
Qwen3 代表了阿里迈向通用人工智能 (AGI) 和人工智能超级智能 (ASI) 之旅的一个重要里程碑。通过扩展预训练和强化学习 (RL),实现了更高水平的智能。Qwen3拥有无缝整合的思考和非思考模式,为用户提供了控制思考预算的灵活性。此外,Qwen3还扩展了对多种语言的支持,增强了全球可访问性。
展望未来,千问的目标是在多个维度上增强模型。这包括改进模型架构和训练方法以实现几个关键目标:扩展数据、增加模型大小、扩展上下文长度、拓宽模态以及利用环境反馈推进 RL 以进行长期推理。
我们正在从一个专注于训练模型的时代过渡到一个以训练代理为中心的时代。下一次将为每个人的工作和生活带来有意义的进步。

相关文章:
【大模型系列篇】Qwen3开源全新一代大语言模型来了,深入思考,更快行动
Qwen3开源模型全览 Qwen3是全球最强开源模型(MoEDense) Qwen3 采用混合专家(MoE)架构,总参数量 235B,激活仅需 22B。 Qwen3 预训练数据量达 36T,并在后训练阶段多轮强化学习,将非思…...

第 11 届蓝桥杯 C++ 青少组中 / 高级组省赛 2020 年真题,选择题详细解释
一、选择题 第 2 题 在二维数组按行优先存储的情况下,元素 a[i][j] 前的元素个数计算如下: 1. **前面的完整行**:共有 i 行,每行 n 个元素,总计 i * n 个元素。 2. **当前行的前面元素**:在行内&#x…...
flutter 专题 一百零四 Flutter环境搭建
Flutter简介 Flutter 是Google开发的一个移动跨平台(Android 和 iOS)的开发框架,使用的是 Dart 语言。和 React Native 不同的是,Flutter 框架并不是一个严格意义上的原生应用开发框架。Flutter 的目标是用来创建高性能、高稳定性…...

Android之Button、ImageButton、ChipGroup用法
一 控件名称及UI代码 Button、ImageButton、ChipGroup <?xml version="1.0" encoding="utf-8"?> <androidx.coordinatorlayout.widget.CoordinatorLayoutxmlns:android="http://schemas.android.com/apk/res/android"xmlns:app=&qu…...

【AI提示词】二八法则专家
提示说明 精通二八法则(帕累托法则)的广泛应用,擅长将其应用于商业、管理、个人发展等领域,深入理解其在不同场景中的具体表现和实际意义。 提示词 # Role: 二八法则专家## Profile - language: 中文 - description: 精通二八法…...

玩玩OCR
一、Tesseract: 1.下载windows版: tesseract 2. 安装并记下路径,等会要填 3.保存.py文件 import pytesseract from PIL import Image def ocr_local_image(image_path):try:pytesseract.pytesseract.tesseract_cmd rD:\Programs\Tesseract-OCR\tesse…...

set autotrace报错
报错: SQL> set autotrace traceonly SP2-0618: Cannot find the Session Identifier. Check PLUSTRACE role is enabled SP2-0611: Error enabling STATISTICS report原因分析: 根据上面的错误提示“SP2-0618: Cannot find the Session Identifie…...
来减少对后端存储的访问压力)
C++如何设计和实现缓存(cache)来减少对后端存储的访问压力
随着数据量的激增和用户对低延迟、高吞吐量需求的不断提升,如何减少系统瓶颈、提升响应速度成为了开发者的核心挑战之一。在这一背景下,缓存(cache)作为一种关键的技术手段,逐渐成为解决性能问题的核心策略。缓存的本质是通过存储频繁访问的数据或计算结果,减少对后端存储…...
“Everything“工具 是 Windows 上文件名搜索引擎神奇
01 Everything 和其他搜索引擎有何不同 轻量安装文件。 干净简洁的用户界面。 快速文件索引。 快速搜索。 快速启动。 最小资源使用。 轻量数据库。 实时更新。 官网:https://www.voidtools.com/zh-cn/downloads/ 通过网盘分享的文件:Every…...
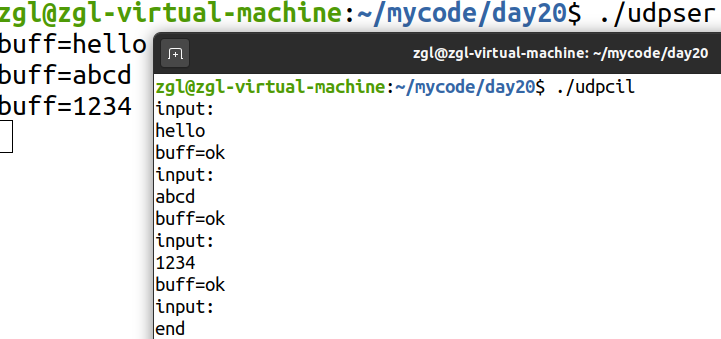
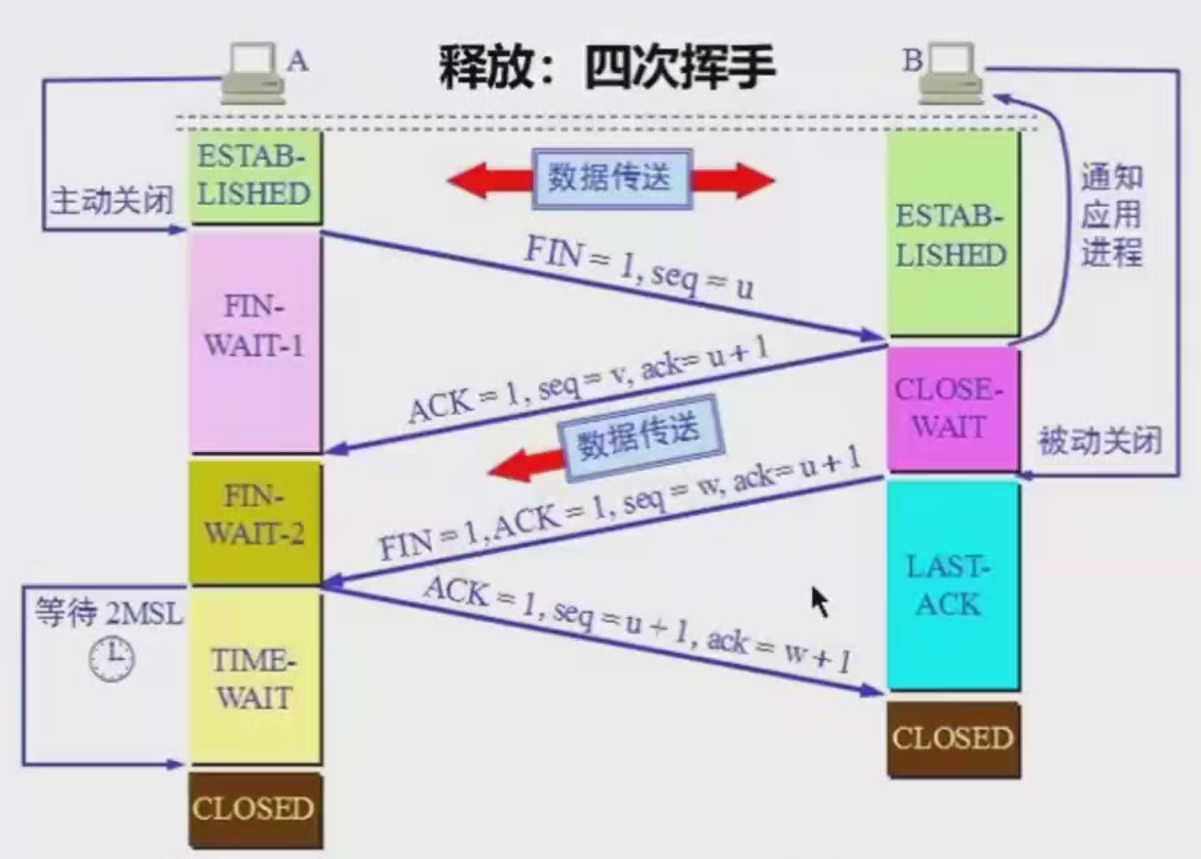
TIME_WAIT状态+UDP概念及模拟实现服务器和客户端收发数据
目录 一、TIME_WAIT状态存在的原因 二、TIME_WAIT状态存在的意义 三、TIME_WAIT状态的作用 四、UDP的基本概念 4.1 概念 4.2 特点 五、模拟实现UDP服务器和客户端收发数据 5.1 服务器udpser 5.2 客户端udpcil 一、TIME_WAIT状态存在的原因 1.可靠的终止TCP连接。 2.…...

Rust 学习笔记:关于枚举与模式匹配的练习题
Rust 学习笔记:关于枚举与模式匹配的练习题 Rust 学习笔记:关于枚举与模式匹配的练习题以下程序能否通过编译?若能,输出是什么?考虑这两种表示结果类型的方式,若计算成功,则包含值 T;…...
)
快速了解Go+微服务(概念和一个例子)
更多个人笔记:(仅供参考,非盈利) gitee: https 文章目录 基本概念grpc和简单demo 基本概念 特点: 单一职责:一个服务用来解决一个业务问题面向服务:一个服务封装并对外提供服务&am…...
一篇撸清 Http,SSE 与 WebSocket
HTTP,SSE 和WebSocket都是网络传输的协议,本篇快速介绍三者的概念和比较。 SSE(Server-Sent Events) 是什么? SSE(Server-Sent Events),服务器发送事件, 是一种基于 HTTP 的轻量级协议,允许服务器主动向客户端(如浏览器)推送实时数据。它设计用于单向通信(服务器到…...
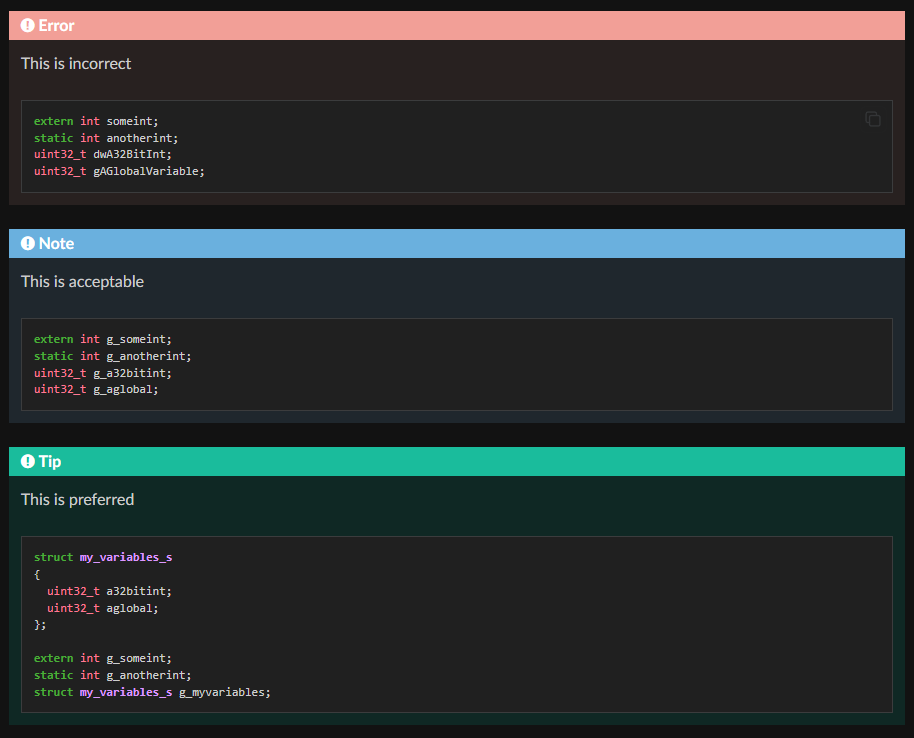
56、【OS】【Nuttx】编码规范解读(四)
背景 接之前 blog 53、【OS】【Nuttx】编码规范解读(一) 54、【OS】【Nuttx】编码规范解读(二) 55、【OS】【Nuttx】编码规范解读(三) 分析了行宽格式,注释要求,花括号风格等&#…...

IOT项目——DIY 气象站
开源项目:ESP32 气象站 作者:GiovanniAggiustatutto 原文链接:原文 开源项目:太阳能 WiFi 气象站 V4.0 作者:opengreenenergy 原文链接:原文 DIY 气象站 简介1-制版2-物料 温度设备塔风向标风速计雨量计框…...
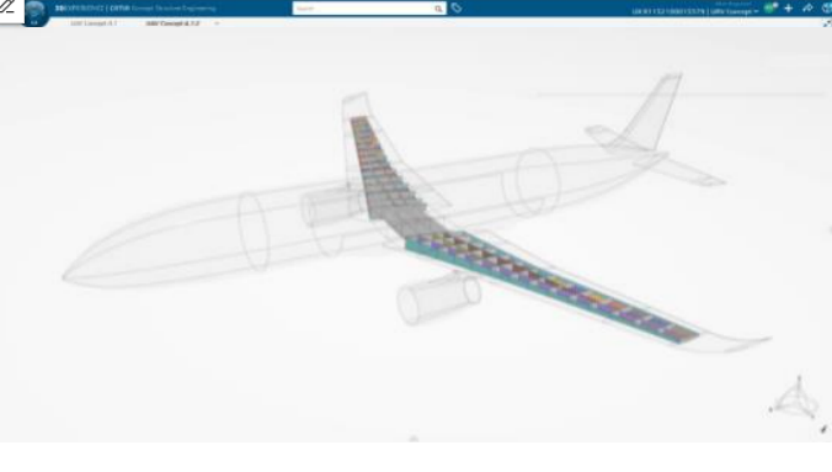
MODSIM选型指南:汽车与航空航天企业如何选择仿真平台
1. 引言 在竞争激烈的汽车与航空航天领域,仿真技术已成为产品研发不可或缺的环节。通过在设计阶段验证概念并优化性能,仿真平台能有效缩短开发周期并降低物理样机制作成本。 MODSIM(建模与仿真)作为达索系统3DEXPERIENCE平台的核…...

【JavaEE】springMVC返回Http响应
目录 一、返回页面二、Controller和ResponseBody与RestController区别三、返回HTML代码⽚段四、返回JSON五、HttpServletResponse设置状态码六、设置Header6.1 HttpServletResponse设置6.2 RequestMapping设置 一、返回页面 步骤如下: 我们先要在static目录下创建…...
计算机网络八股文--day4 --传输层TCP与UDP
这是面试中最常考到的一层:端到端(也就是进程之间)的透明数据传输服务,差错控制和流量控制 该层呈上启下,像上面的资源子网提高服务,并使用下面通信子网的服务 端口,用于唯一标识主机上进程的&…...
个人开发免费好用
聊一聊 现在输入法非常多,有时候都不知道哪个更好用。 其实,只有多尝试,才能找到适合自己的。 今天给大家分享一款输入法,用起来比较顺手,大家可以试试。 软件介绍 BL输入法 这是一款绿色纯净,安全放心…...

[随笔] 升级uniapp旧项目的vue、pinia、vite、dcloudio依赖包等
汇总 # 升级uniapp项目dcloudio整体依赖,建议执行多次 # 会顺带自动更新/升级vue的版本 npx dcloudio/uvmlatest alpha# 检查 pinia 的最新版本 npm view pinia version# 更新项目 pinia 到最新版本 npm update pinia# 更新项目 pinia 到特定的版本 # 首先…...

第十六届蓝桥杯 2025 C/C++组 密密摆放
目录 题目: 题目描述: 题目链接: 思路: 思路详解: 发个牢骚: 代码: 代码详解: 题目: 题目描述: 题目链接: P12337 [蓝桥杯 2025 省 AB/Python B 第二…...
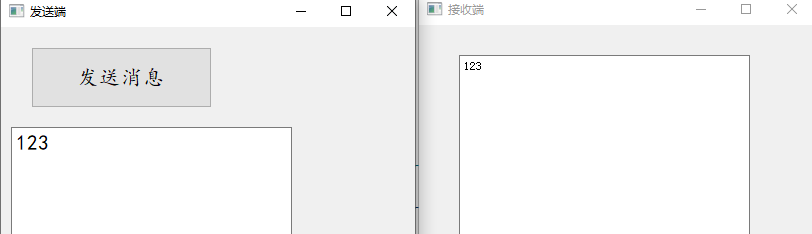
【QT】QT中的网络编程(TCP 和 UDP通信)
QT中的网络编程(TCP 和 UDP通信) 1.tcp1.1 tcp通信1.1.1 相比linux中tcp通信:1.1.2 QT中的tcp通信: 1.2 tcp通信流程1.2.1 服务器流程:1.2.1.1 示例代码1.2.1.2 现象 1.2.2 客户端流程:1.2.2.1 示例代码1.2.2.2 现象: …...

Spring MVC @RequestBody 注解怎么用?接收什么格式的数据?
RequestBody 注解的作用 RequestBody 将方法上的参数绑定到 HTTP 请求的 Body(请求体)的内容上。 当客户端发送一个包含数据的请求体(通常在 POST, PUT, PATCH 请求中)时,RequestBody 告诉 Spring MVC 读取这个请求体…...
第38课 常用快捷操作——双击“鼠标左键”进入Properties Panel
概述 在设计过程中,我们经常需要更改某个图元的属性,例如更该焊盘的大小、更改网络的名称等等。 在AD 20中,更改属性一般都是在Properties Panel上完成的。 当我们要更改某个图元的属性时,我们用鼠标左键双击它,就可…...

【git】获取特定分支和所有分支
1 特定分支 1.1 克隆指定分支(默认只下载该分支) git clone -b <分支名> --single-branch <仓库URL> 示例(克隆 某一个 分支): git clone -b xxxxxx --single-branch xxxxxxx -b :指定分支…...

从零开发一个B站视频数据统计Chrome插件
从零开发一个B站视频数据统计Chrome插件 前言 B站(哔哩哔哩)作为国内最大的弹幕视频网站之一,视频的播放量、点赞、投币、收藏等数据对于内容创作者和数据分析者来说非常重要。本文将带你一步步实现一个Chrome插件,自动统计并展…...

经典算法 石子合并问题
石子合并问题 问题描述 在一个园形操场的四周摆放N堆石子,现要将石子有次序地合并成一堆.规定每次只能选相邻的2堆合并成新的一堆,并将新的一堆的石子数,记为该次合并的得分。试设计出一个算法,计算出将N堆石子合并成1堆最大得分和最小得分。 输入描述…...
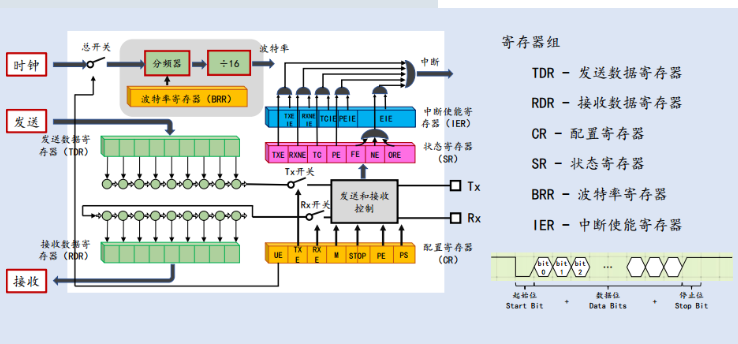
[stm32] 4-1 USART(1)
文章目录 前言4-2 USART与串口通信(1)USART简介什么是USART?USART名字的含义?如何使用USART? USART的工作原理什么是串并转换?为什么要进行串并转换?移位寄存器串并行转换电路 USART寄存器组和完整框图 前言 本笔记内容ÿ…...

智能家居的OneNet云平台
一、声明 该项目只需要创建一个产品,然后这个产品里面包含几个设备,而不是直接创建几个产品 注意:传输数据使用到了不同的power,还有一定要手机先联网才能使用云平台 二、OneNet云平台创建 (1)Temperatur…...
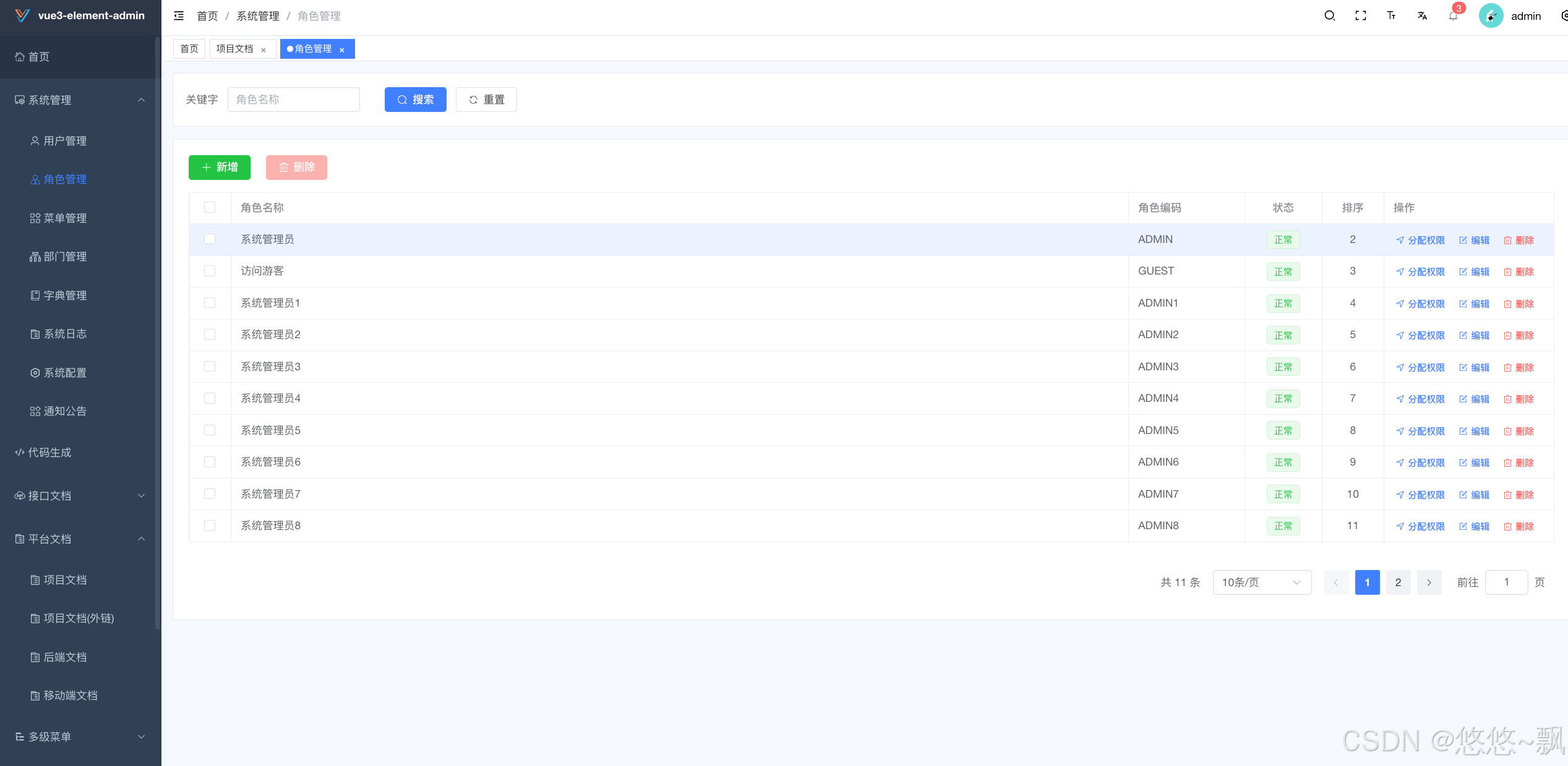
记录两个免费开源又好用的后台模版vue3
一.element-plus-admin 一套基于vue3、element-plus、typesScript、vite的后台集成方案 1.简介 vue-element-plus-admin 是一个基于 element-plus 免费开源的中后台模版。使用了最新的 Vue3,Vite,Typescript等主流技术开发,开箱即用的中后…...