Python爬虫中time.sleep()与动态加载的配合使用

一、动态加载网页的挑战
动态加载网页是指网页的内容并非一次性加载完成,而是通过JavaScript等技术在用户交互或页面加载过程中逐步加载。这种设计虽然提升了用户体验,但对于爬虫来说,却增加了抓取的难度。传统的爬虫方法,如简单的HTTP请求,往往只能获取到网页的初始HTML结构,而无法获取到动态加载的内容。
例如,许多电商网站的商品详情页、社交媒体平台的用户动态等,都是通过动态加载实现的。如果直接使用<font style="color:rgba(0, 0, 0, 0.9);">requests</font>库发送请求,可能会发现返回的HTML中并没有我们需要的数据,因为这些数据是通过JavaScript在页面加载后动态生成的。
二、<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>的作用与局限性
在Python中,<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>是一个常用的函数,它可以暂停程序的执行一段时间。在爬虫开发中,<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>常被用来模拟用户浏览网页的行为,避免爬虫过于频繁地发送请求,从而降低被网站封禁的风险。
然而,<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>在处理动态加载网页时存在一定的局限性。它只能简单地暂停程序,而无法感知网页的加载状态。如果设置的暂停时间过短,可能会导致网页尚未加载完成,爬虫就尝试解析数据,从而获取不到有效信息;如果设置的暂停时间过长,又会降低爬虫的效率。
三、结合<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>与动态加载的策略
为了克服<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>的局限性,我们需要结合动态加载的特点,采用更加灵活的策略。
(一)分析动态加载的机制
在动手编写爬虫之前,首先要对目标网页的动态加载机制进行深入分析。通过浏览器的开发者工具(如Chrome DevTools),可以观察到网页在加载过程中发出的网络请求,以及返回的数据格式。这些信息是编写爬虫的关键依据。
例如,某些网页可能在初始加载时获取基本的HTML结构,然后通过异步请求(AJAX)获取动态内容。我们需要找到这些异步请求的URL、请求参数以及返回的数据格式,以便在爬虫中模拟这些请求。
(二)使用<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>合理控制爬虫速度
在确定了动态加载的机制后,可以使用<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>来合理控制爬虫的请求频率。一般来说,建议将暂停时间设置在1到3秒之间,具体时间可以根据目标网站的响应速度和反爬策略进行调整。
import time
import requestsdef fetch_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}response = requests.get(url, headers=headers)if response.status_code == 200:return response.textelse:return Nonedef crawl_dynamic_content():base_url = "https://example.com/dynamic"for i in range(1, 10): # 假设需要抓取10页动态内容page_url = f"{base_url}?page={i}"page_content = fetch_page(page_url)if page_content:# 处理页面内容print(f"Page {i} content fetched successfully.")else:print(f"Failed to fetch page {i}.")time.sleep(2) # 暂停2秒,避免过于频繁的请求crawl_dynamic_content()
(三)动态检测加载状态
除了使用<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>控制请求频率外,还可以通过动态检测网页的加载状态来进一步优化爬虫的性能。例如,可以使用<font style="color:rgba(0, 0, 0, 0.9);">Selenium</font>库来模拟浏览器行为,实时检测网页是否加载完成。
<font style="color:rgba(0, 0, 0, 0.9);">Selenium</font>是一个强大的自动化测试工具,它可以通过模拟用户操作(如点击、滚动等)来加载动态内容,并获取完整的网页HTML。与<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>相比,<font style="color:rgba(0, 0, 0, 0.9);">Selenium</font>可以更加智能地判断网页的加载状态。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdef crawl_dynamic_content_with_selenium():driver = webdriver.Chrome()driver.get("https://example.com/dynamic")try:# 等待页面加载完成,直到某个特定元素出现element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "dynamic-content")))# 获取加载完成后的页面HTMLpage_content = driver.page_sourceprint("Dynamic content fetched successfully.")# 处理页面内容finally:driver.quit()crawl_dynamic_content_with_selenium()
在上述代码中,<font style="color:rgba(0, 0, 0, 0.9);">WebDriverWait</font>和<font style="color:rgba(0, 0, 0, 0.9);">expected_conditions</font>用于动态检测网页的加载状态。当指定的元素(如<font style="color:rgba(0, 0, 0, 0.9);">dynamic-content</font>)出现时,说明网页已经加载完成,此时可以获取页面的HTML内容进行解析。
四、实际案例分析
为了更好地理解<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>与动态加载的配合使用,我们以一个实际案例为例:抓取某电商网站的商品评论数据。
假设该电商网站的商品评论是通过动态加载实现的,每次加载10条评论,用户可以通过点击“更多评论”按钮来加载更多评论。以下是实现代码:
import time
import requests
from bs4 import BeautifulSoup# 代理信息
proxyHost = "www.16yun.cn"
proxyPort = "5445"
proxyUser = "16QMSOML"
proxyPass = "280651"# 构造代理服务器的URL
proxyUrl = f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"proxies = {"http": proxyUrl,"https": proxyUrl
}def fetch_comments(product_id, page):url = f"https://example.com/product/{product_id}/comments?page={page}"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}try:response = requests.get(url, headers=headers, proxies=proxies)if response.status_code == 200:return response.textelse:print(f"Failed to fetch comments. Status code: {response.status_code}")return Noneexcept requests.exceptions.RequestException as e:print(f"Request error: {e}")return Nonedef parse_comments(html):soup = BeautifulSoup(html, 'html.parser')comments = []for item in soup.find_all('div', class_='comment-item'):comment = {'user': item.find('span', class_='user').text,'content': item.find('p', class_='comment-content').text,'date': item.find('span', class_='comment-date').text}comments.append(comment)return commentsdef crawl_product_comments(product_id):page = 1while True:html = fetch_comments(product_id, page)if not html:print("Failed to fetch comments.")breakcomments = parse_comments(html)if not comments:print("No more comments.")breakfor comment in comments:print(comment)page += 1time.sleep(2) # 暂停2秒,避免过于频繁的请求crawl_product_comments("123456")
在上述代码中,<font style="color:rgba(0, 0, 0, 0.9);">fetch_comments</font>函数用于发送请求获取评论数据,<font style="color:rgba(0, 0, 0, 0.9);">parse_comments</font>函数用于解析HTML并提取评论信息。通过循环调用<font style="color:rgba(0, 0, 0, 0.9);">fetch_comments</font>函数,可以逐页抓取评论数据。同时,使用<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>在每次请求之间暂停2秒,以避免被网站封禁。
五、优化与注意事项
在实际应用中,为了提高爬虫的效率和稳定性,还需要注意以下几点:
(一)合理设置请求头
在发送请求时,合理的请求头可以模拟正常用户的浏览器行为,降低被网站封禁的风险。除了常见的<font style="color:rgba(0, 0, 0, 0.9);">User-Agent</font>外,还可以根据目标网站的要求设置<font style="color:rgba(0, 0, 0, 0.9);">Referer</font>、<font style="color:rgba(0, 0, 0, 0.9);">Accept</font>等头部信息。
(二)使用代理IP
对于一些反爬措施较强的网站,频繁的请求可能会导致IP被封禁。使用代理IP可以有效解决这一问题。可以通过购买代理IP服务或使用免费的代理IP池来获取多个IP地址,并在爬虫中动态切换。
(三)异常处理
在爬虫运行过程中,可能会遇到各种异常情况,如网络请求失败、解析错误等。通过合理的异常处理机制,可以确保爬虫在遇到问题时能够自动恢复或记录错误信息,从而提高爬虫的稳定性。
import time
import requests
from bs4 import BeautifulSoupdef fetch_comments(product_id, page):url = f"https://example.com/product/{product_id}/comments?page={page}"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}try:response = requests.get(url, headers=headers)if response.status_code == 200:return response.textelse:print(f"Failed to fetch comments. Status code: {response.status_code}")return Noneexcept requests.exceptions.RequestException as e:print(f"Request error: {e}")return Nonedef parse_comments(html):try:soup = BeautifulSoup(html, 'html.parser')comments = []for item in soup.find_all('div', class_='comment-item'):comment = {'user': item.find('span', class_='user').text,'content': item.find('p', class_='comment-content').text,'date': item.find('span', class_='comment-date').text}comments.append(comment)return commentsexcept Exception as e:print(f"Parse error: {e}")return []def crawl_product_comments(product_id):page = 1while True:html = fetch_comments(product_id, page)if not html:print("Failed to fetch comments.")breakcomments = parse_comments(html)if not comments:print("No more comments.")breakfor comment in comments:print(comment)page += 1time.sleep(2) # 暂停2秒,避免过于频繁的请求crawl_product_comments("123456")
在上述代码中,通过<font style="color:rgba(0, 0, 0, 0.9);">try-except</font>语句对请求和解析过程中的异常进行了捕获和处理,确保爬虫在遇到问题时能够正常运行。
六、总结
Python爬虫在处理动态加载网页时,<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>是一个简单而有效的工具,但它也有其局限性。通过结合动态加载的机制,合理使用<font style="color:rgba(0, 0, 0, 0.9);">time.sleep()</font>并配合其他技术(如<font style="color:rgba(0, 0, 0, 0.9);">Selenium</font>),可以实现高效、稳定的数据抓取。在实际开发中,还需要注意合理设置请求头、使用代理IP以及进行异常处理,以提高爬虫的性能和稳定性。
相关文章:
Python爬虫中time.sleep()与动态加载的配合使用
一、动态加载网页的挑战 动态加载网页是指网页的内容并非一次性加载完成,而是通过JavaScript等技术在用户交互或页面加载过程中逐步加载。这种设计虽然提升了用户体验,但对于爬虫来说,却增加了抓取的难度。传统的爬虫方法,如简单…...

学习Cesium Entities
🌐 Cesium中的Entities系统趣味学习 📊 Entities系统架构流程图 #mermaid-svg-Lkue5O3gYOkEVSbD {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Lkue5O3gYOkEVSbD .error-icon{fill:#552222;}#mermaid-svg-Lku…...

如何减少锁竞争并细化锁粒度以提高 Rust 多线程程序的性能?
在并发编程中,锁(Lock)是一种常用的同步机制,用于保护共享数据免受多个线程同时访问造成的竞态条件(Race Condition)。然而,不合理的锁使用会导致严重的性能瓶颈,特别是在高并发场景…...

Logback官方文档翻译章节目录
Logback官方文档翻译章节目录 第一章 Logback简介 第二章 Logback的架构(一) Logback的架构(二) Logback的架构(三) 持续更新中…...

AtCoder Beginner Contest 404 A-E 题解
还是ABC好打~比ARC好打多了( 题解部分 A - Not Found 给定你一个长度最大25的字符串,任意输出一个未出现过的小写字母 签到题,map或者数组下标查询一下就好 #include<bits/stdc.h>using namespace std;#define int long long #def…...
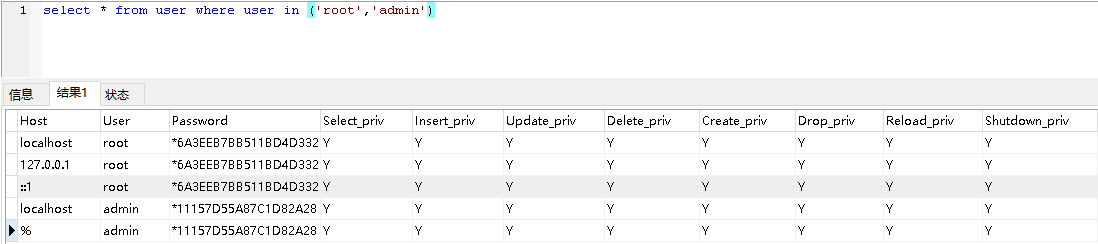
【mysql】常用命令
一 系统mysql用户密码查询 1、在工程目录如/usr/local/httpd/下的*.php中查找类似有db.inf的文件 以php为例。 2、在代码文件中确认有数据库连接的的功能实现 例如: $dbconf parse_ini_file(/usr/local/httpd/conf/db.inf); $link mysql_connect($dbconf[d…...
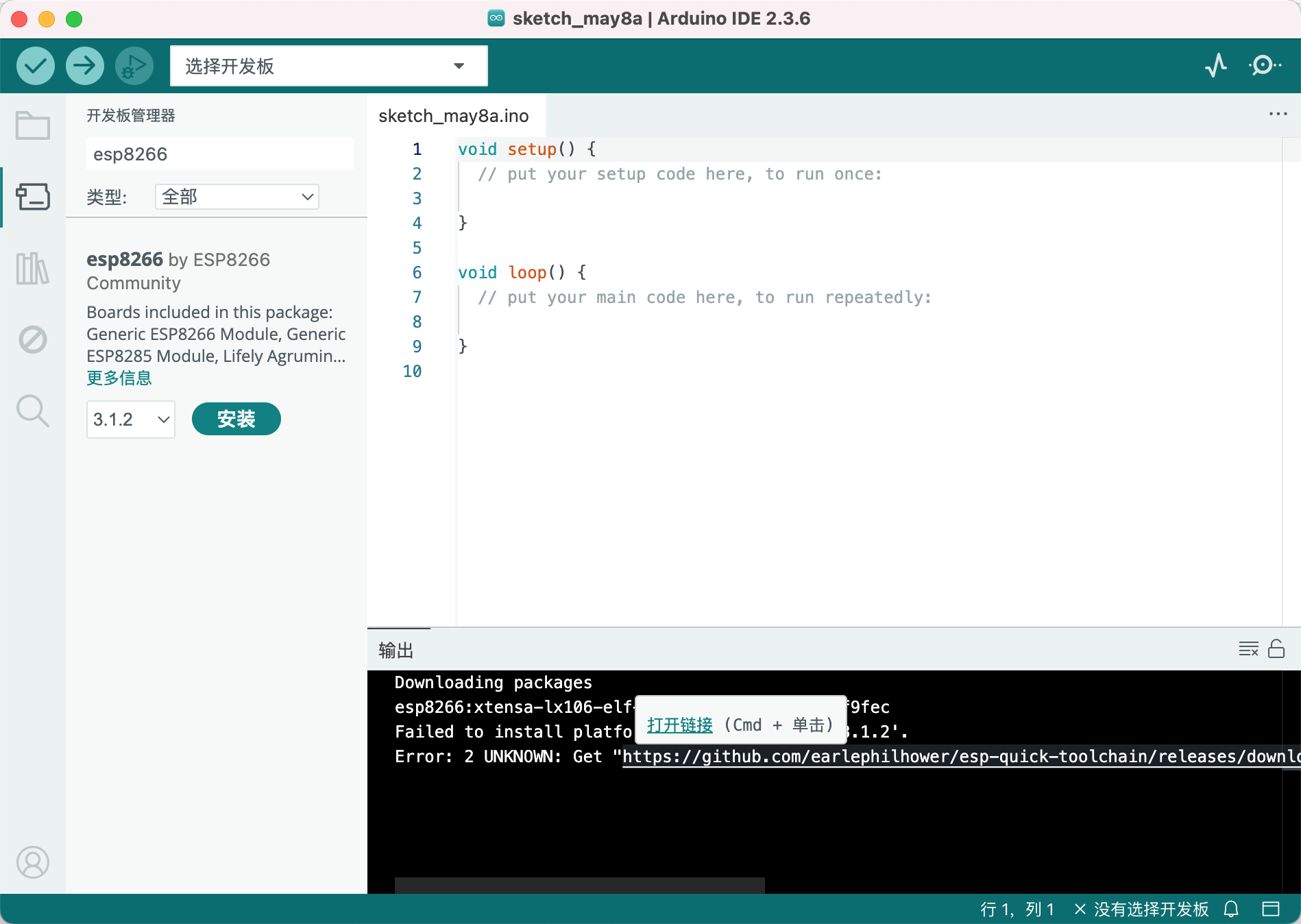
macOS Arduino IDE离线安装ESP8266支持包
其实吧,本来用platformio也是可以的,不过有时候用Arduino IDE可能更快一些,因为以前一直是Arduino.app和Arduino IDE.app共存了一段时间,后来下决心删掉Arduino.app并升级到最新的Arduino IDE.app。删除了旧的支持板级支持包之后就…...
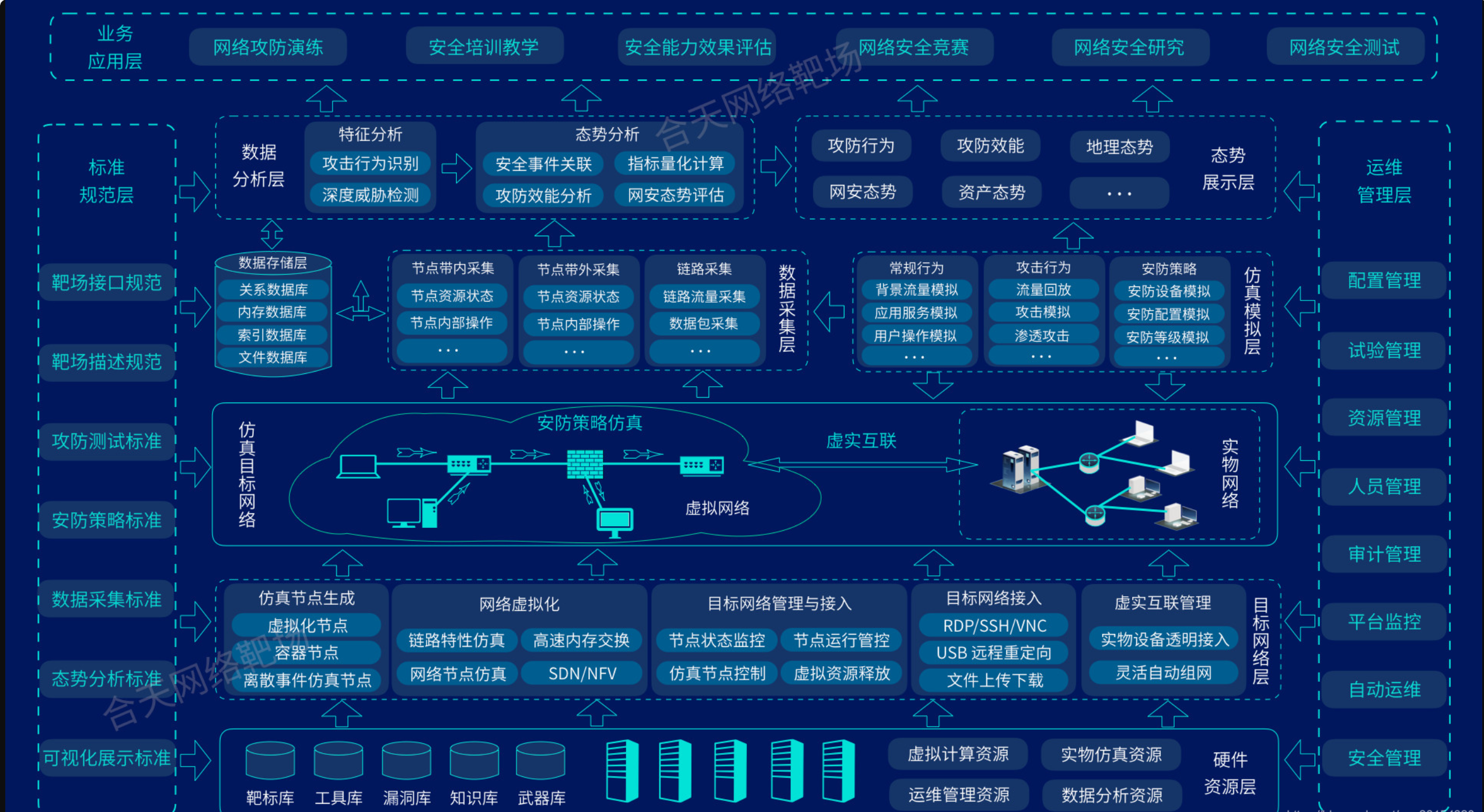
网络靶场基础知识
一、网络靶场的核心概念 网络靶场(Cyber Range)是一种基于虚拟化和仿真技术的网络安全训练与测试平台,通过模拟真实网络环境和业务场景,为攻防演练、漏洞验证、安全测试和人才培养提供安全可控的实验空间。其核心目标是通过“虚实…...

基于Partial Cross Entropy的弱监督语义分割实战指南
一、问题背景:弱监督学习的挑战 在计算机视觉领域,语义分割任务面临最大的挑战之一是**标注成本**。以Cityscapes数据集为例,单张图像的像素级标注需要约90分钟人工操作。这催生了弱监督学习(Weakly Supervised Learning)的研究方向,其中partial cross entropy loss(部…...

【算法基础】选择排序算法 - JAVA
一、算法基础 1.1 什么是选择排序 选择排序是一种简单直观的排序算法,它的工作原理是:首先在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小…...

电商平台的流量秘密:代理IP在用户行为分析中的角色
在电商江湖中,流量是氧气,用户行为数据是DNA。当你在电商平台点击商品、加入购物车时,背后有一套精密的系统正在分析你的每个动作。而在这套系统的运作中,代理IP正扮演着"隐形推手"的角色——它既是数据采集的"隐身…...

批量清洗与修改 YOLO 标签:删除与替换指定类别
在使用 YOLO 格式的数据进行训练或部署前,常常需要对标签文件进行清洗或修改。本文整理了两种常见场景的 Python 脚本:删除指定类别 和 修改某类为其他类,并支持自动打印检测到该类别的文件名,帮助你快速定位问题数据。 …...
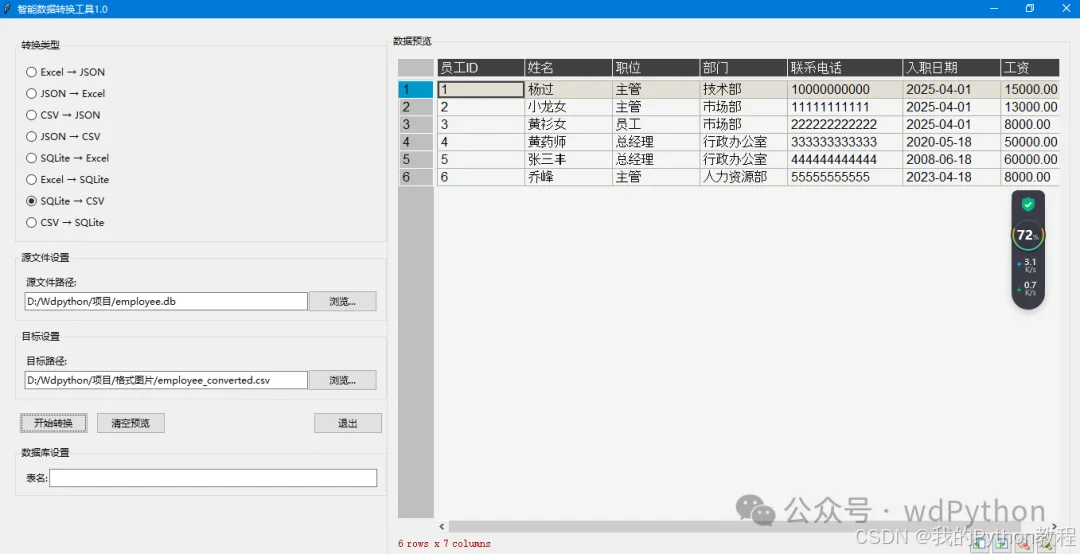
Python项目源码57:数据格式转换工具1.0(csv+json+excel+sqlite3)
1.智能路径处理:自动识别并修正文件扩展名,根据转换类型自动建议目标路径,实时路径格式验证,自动补全缺失的文件扩展名。 2.增强型预览功能:使用pandastable库实现表格预览,第三方模块自己安装一下&#x…...

TypeScript 中,属性修饰符
在 TypeScript 中,属性修饰符(Property Modifiers)是用于修饰类的属性或方法的关键字,它们可以改变属性或方法的行为和访问权限。TypeScript 提供了三种主要的属性修饰符:public、private 和 protected。此外ÿ…...
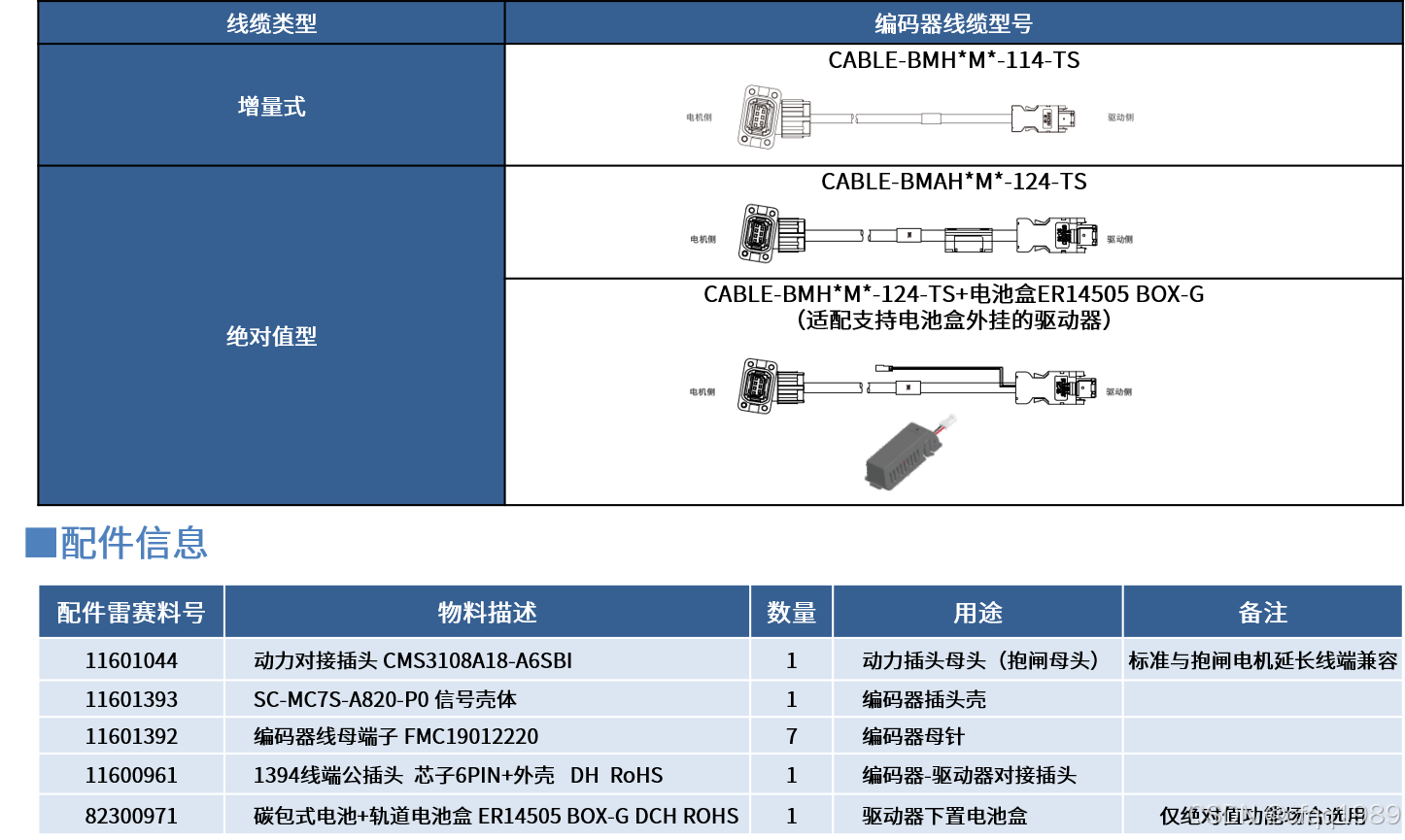
雷赛伺服电机
ACM0经济 编码器17位: ACM1基本 编码器23位磁编, ACM2通用 编码器24位光电, 插头定义:...

基础编程题目集 6-8 简单阶乘计算
本题要求实现一个计算非负整数阶乘的简单函数。 函数接口定义: int Factorial( const int N ); 其中N是用户传入的参数,其值不超过12。如果N是非负整数,则该函数必须返回N的阶乘,否则返回0。 裁判测试程序样例: #in…...

【deepseek教学应用】001:deepseek如何撰写教案并自动实现word排版
本文讲述利用deepseek如何撰写教案并自动实现word高效完美排版。 文章目录 一、访问deepseek官网二、输入教案关键词三、格式转换四、word进一步排版 一、访问deepseek官网 官网:https://www.deepseek.com/ 进入主页后,点击【开始对话】,如…...
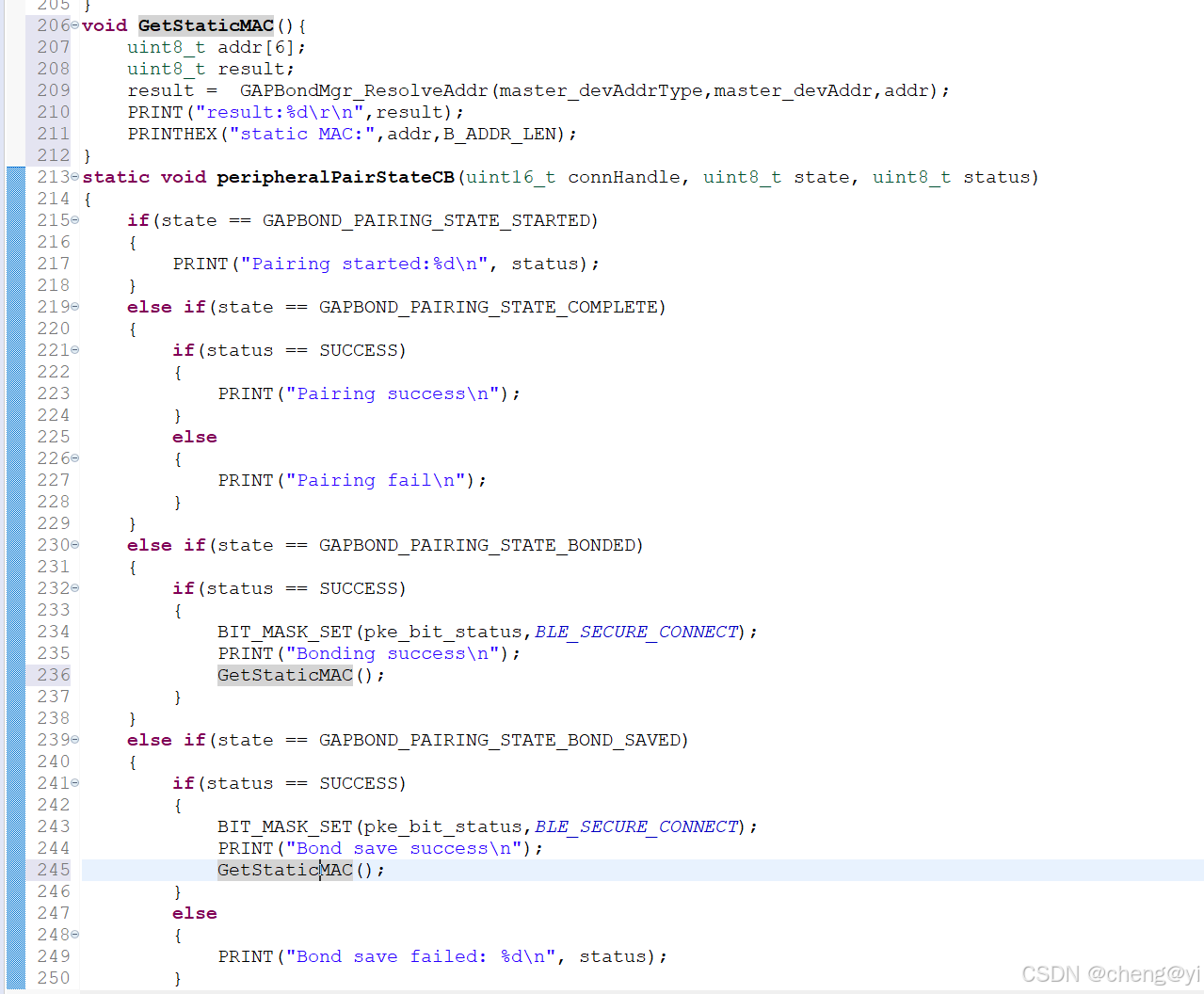
CH32V208GBU6沁恒绑定配对获取静态地址
从事嵌入式单片机的工作算是符合我个人兴趣爱好的,当面对一个新的芯片我即想把芯片尽快搞懂完成项目赚钱,也想着能够把自己遇到的坑和注意事项记录下来,即方便自己后面查阅也可以分享给大家,这是一种冲动,但是这个或许并不是原厂希望的,尽管这样有可能会牺牲一些时间也有哪天原…...

【C/C++】RPC与线程间通信:高效设计的关键选择
文章目录 RPC与线程间通信:高效设计的关键选择1 RPC 的核心用途2 线程间通信的常规方法3 RPC 用于线程间通信的潜在意义4 主要缺点与限制4.1 缺点列表4.2 展开 5 替代方案6 结论 RPC与线程间通信:高效设计的关键选择 在C或分布式系统设计中,…...

跨线程和跨进程通信还有多种方式对比
📊 常见通信机制对比 通信方式跨线程支持跨进程支持同步/异步性能编程复杂度特点与适用场景SendMessage✅✅(同桌面)同步较高(阻塞)低简单窗口通信、控制PostMessage✅✅(同桌面)异步高低通知、事件触发COM/DCOM✅✅同步/异步中中高系统级服务、进程间服务封装Socket✅…...

RT Thread Studio创建软件和硬件RTC工程
MCU型号:STM32F103RET6 一.配置软件模拟RTC 1.生成一个带串口输出的工程文件,新建RT-Thread项目工程文件。 2.查看电路图中的串口输出管脚,根据STMCubeMx软件可知此串口为USART1,选择芯片型号为STM32F103RET6,控制台…...

Oracle EBS AP发票被预付款核算创建会计科目时间超长
背景 由于客户职能部门的水电、通信和物业等等费用统一管理或对接部门报销费,在报销费的时候,用户把所有费用分摊到各个末级部门,形成AP发票行有上千行, 问题症状 1、用户过账时,请求创建会计科目一直执行20多个小时未完成,只能手工强行取消请求。 2、取消请求以后,从后…...
: 深入解析 lm48100q I2C 音频编解码器驱动模型(基于 i.MX8MP))
驱动开发硬核特训 · Day 30(下篇): 深入解析 lm48100q I2C 音频编解码器驱动模型(基于 i.MX8MP)
作者:嵌入式Jerry 视频教程请关注 B 站:“嵌入式Jerry” 一、背景与目标 在本篇中,我们围绕 TI 的 lm48100q 音频编解码器 展开,深入讲解其作为 I2C 外设如何集成至 Linux 内核音频子系统(ASoC)࿰…...

运维--计划任务
计划任务分为一次性和循环性的计划任务 1.date的用法 date 月日时分年 eg:date 100118222023 date:查看时间和日期、修改时间和日期 获取当前日期:date +%F F:日期 获取当前时间:date +%H:%M:%S H:时 M:分 S:秒 获取周几: date +%w w:周 …...
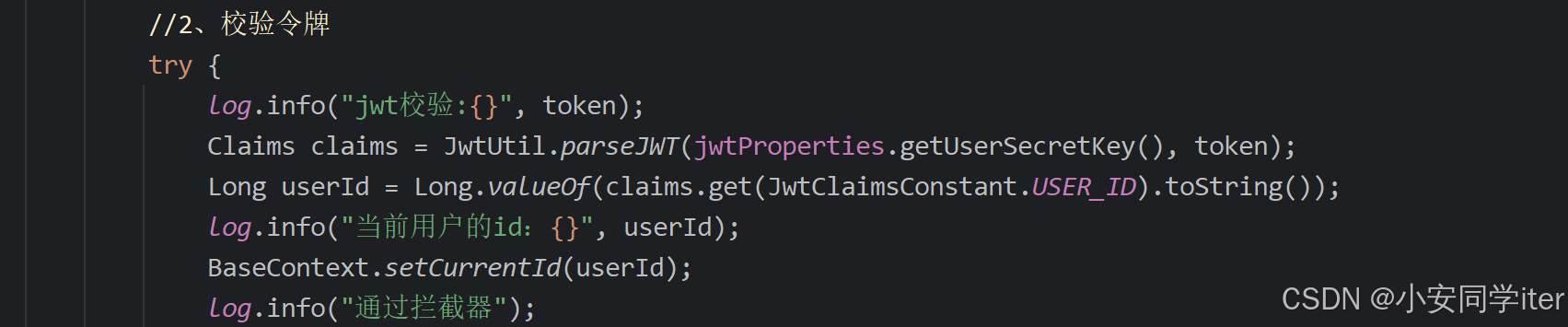
苍穹外卖心得体会
1 登录认证 技术点:JWT令牌技术(JSON Web Token) JWT(JSON Web Token)是一种令牌技术,主要由三部分组成:Header头部、Payload载荷和Signature签名。Header头部存储令牌的类型(如JW…...

Python爬虫实战:获取jd商城最新5060ti 16g显卡销量排行榜商品数据并做分析,为显卡选购做参考
一、引言 1.1 研究目的 本研究旨在利用 Python 爬虫技术,从京东商城获取 “5060ti 16g” 型号显卡的商品数据,并对这些数据进行深入分析。具体目标包括: 实现京东商城的模拟登录,突破登录验证机制,获取登录后的访问权限。高效稳定地爬取按销量排名前 20 的 “5060ti 16g…...

Fedora升级Google Chrome出现GPG check FAILED问题解决办法
https://dl.google.com/linux/linux_signing_key.pub 的 GPG 公钥(0x7FAC5991)已安装 https://dl.google.com/linux/linux_signing_key.pub 的 GPG 公钥(0xD38B4796)已安装 仓库 "google-chrome" 的 GPG 公钥已安装,但是不适用于此软件包。 请检查此仓库的…...
)
信息系统监理师第二版教材模拟题第三组(含解析)
信息系统监理师模拟题第三组(30题) 监理基础理论 信息系统工程监理的性质是( ) A. 服务性、独立性、公正性、科学性 B. 强制性、营利性、行政性、技术性 C. 临时性、从属性、随意性、主观性 D. 单一性、封闭性、被动性、保守性答案:A 解析:监理具有服务性、独立性、公正…...

Zcanpro搭配USBCANFD-200U在新能源汽车研发测试中的应用指南(周立功/致远电子)
——国产工具链的崛起与智能汽车测试新范式 引言:新能源汽车测试的国产化突围 随着新能源汽车智能化、网联化程度的提升,研发测试面临三大核心挑战:多协议融合(CAN FD/LIN/以太网)、高实时性数据交互需求、复杂工况下…...
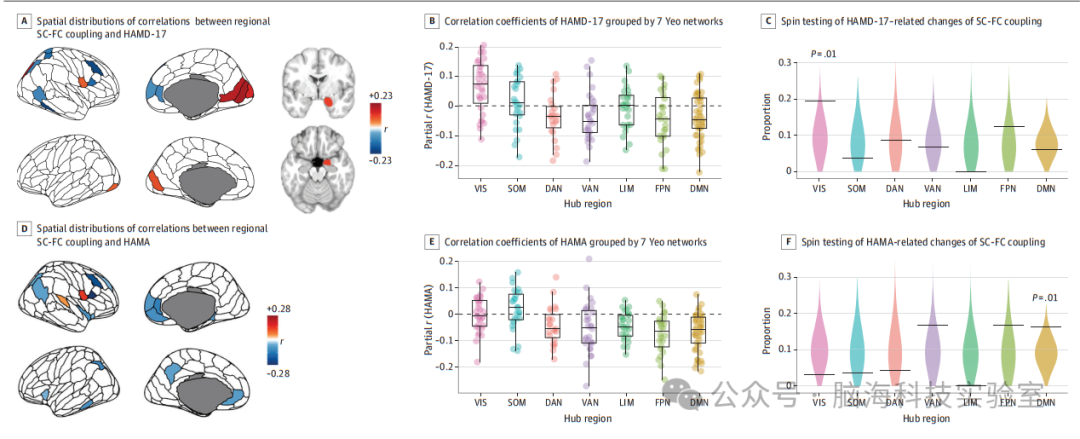
青少年抑郁症患者亚群结构和功能连接耦合的重构
目录 1 研究背景及目的 2 研究方法 2.1 数据来源与参与者 2.1.1 MDD患者: 2.1.2 健康对照组: 2.2 神经影像分析流程 2.2.1 图像采集与预处理: 2.2.2 网络构建: 2.2.3 区域结构-功能耦合(SC-FC耦合)…...