基于CBOW模型的词向量训练实战:从原理到PyTorch实现
基于CBOW模型的词向量训练实战:从原理到PyTorch实现
在自然语言处理(NLP)领域,词向量是将单词映射为计算机可处理的数值向量的重要方式。通过词向量,单词之间的语义关系能够以数学形式表达,为后续的文本分析、机器翻译、情感分析等任务奠定基础。本文将结合连续词袋模型(CBOW),详细介绍如何使用PyTorch训练词向量,并通过具体代码实现和分析训练过程。
一、CBOW模型原理简介
CBOW(Continuous Bag-of-Words)模型是一种用于生成词向量的神经网络模型,它基于上下文预测目标词。其核心思想是:给定一个目标词的上下文单词,通过模型预测该目标词。在训练过程中,模型会不断调整参数,使得预测结果尽可能接近真实的目标词,最终训练得到的词向量能够捕捉单词之间的语义关系。
例如,在句子 “People create programs to direct processes” 中,如果目标词是 “programs”,CBOW模型会利用其上下文单词 “People”、“create”、“to”、“direct” 来预测 “programs”。通过大量类似样本的训练,模型能够学习到单词之间的语义关联,从而生成有效的词向量。
二、代码实现与详细解析
下面我会逐行解释你提供的代码,此代码借助 PyTorch 实现了一个连续词袋模型(CBOW)来学习词向量。
1. 导入必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from tqdm import tqdm, trange # 显示进度条
import numpy as np
torch:PyTorch 深度学习框架的核心库。torch.nn:用于构建神经网络的模块。torch.nn.functional:提供了许多常用的函数,像激活函数等。torch.optim:包含各种优化算法。tqdm和trange:用于在训练过程中显示进度条。numpy:用于处理数值计算和数组操作。
2. 定义上下文窗口大小和原始文本
CONTEXT_SIZE = 2
raw_text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules called a program.
People create programs to direct processes.
In effect,we conjure the spirits of the computer with our spells.""".split()
CONTEXT_SIZE:上下文窗口的大小,意味着在预测目标词时,会考虑其前后各CONTEXT_SIZE个单词。raw_text:原始文本,将其按空格分割成单词列表。
3. 构建词汇表和索引映射
vocab = set(raw_text) # 集合,词库,里面的内容独一无二(将文本中所有单词去重后得到的词汇表)
vocab_size = len(vocab) # 词汇表的大小word_to_idx = {word: i for i, word in enumerate(vocab)} # 单词到索引的映射字典
idx_to_word = {i: word for i, word in enumerate(vocab)} # 索引到单词的映射字典
vocab:把原始文本中的所有单词去重后得到的词汇表。vocab_size:词汇表的大小。word_to_idx:将单词映射为对应的索引。idx_to_word:将索引映射为对应的单词。
4. 构建训练数据集
data = [] # 获取上下文词,将上下文词作为输入,目标词作为输出,构建训练数据集(用于存储训练数据,每个元素是一个元组,包含上下文词列表和目标词)
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE):context = ([raw_text[i - (2 - j)] for j in range(CONTEXT_SIZE)]+ [raw_text[i + j + 1] for j in range(CONTEXT_SIZE)]) # 获取上下文词target = raw_text[i] # 获取目标词data.append((context, target)) # 将上下文词和目标词保存到 data 中
data:用于存储训练数据,每个元素是一个元组,包含上下文词列表和目标词。- 通过循环遍历原始文本,提取每个目标词及其上下文词,然后将它们添加到
data中。
5. 定义将上下文词转换为张量的函数
def make_context_vector(context, word_to_ix): # 将上下词转换为 one - hotidxs = [word_to_ix[w] for w in context]return torch.tensor(idxs, dtype=torch.long)
make_context_vector:把上下文词列表转换为对应的索引张量。
6. 打印第一个上下文词的索引张量
print(make_context_vector(data[0][0], word_to_idx))
- 打印第一个训练样本的上下文词对应的索引张量。
7. 定义 CBOW 模型
class CBOW(nn.Module): # 神经网络def __init__(self, vocab_size, embedding_dim):super(CBOW, self).__init__()self.embeddings = nn.Embedding(vocab_size, embedding_dim)self.proj = nn.Linear(embedding_dim, 128)self.output = nn.Linear(128, vocab_size)def forward(self, inputs):embeds = sum(self.embeddings(inputs)).view(1, -1)out = F.relu(self.proj(embeds)) # nn.relu() 激活层out = self.output(out)nll_prob = F.log_softmax(out, dim=1)return nll_prob
CBOW:继承自nn.Module,定义了 CBOW 模型的结构。__init__:初始化模型的层,包含一个嵌入层、一个线性层和另一个线性层。forward:定义了前向传播过程,将输入的上下文词索引转换为嵌入向量,求和后经过线性层和激活函数,最后输出对数概率。
8. 选择设备并创建模型实例
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device") # 字符串的格式化
model = CBOW(vocab_size, 10).to(device)
device:检查当前设备是否支持 GPU(CUDA 或 MPS),若支持则使用 GPU,否则使用 CPU。model:创建 CBOW 模型的实例,并将其移动到指定设备上。
9. 定义优化器、损失函数和损失列表
optimizer = optim.Adam(model.parameters(), lr=0.001) # 创建一个优化器,
losses = [] # 存储损失的集合
loss_function = nn.NLLLoss()
optimizer:使用 Adam 优化器来更新模型的参数。losses:用于存储每个 epoch 的损失值。loss_function:使用负对数似然损失函数。
10. 训练模型
model.train()for epoch in tqdm(range(200)):total_loss = 0for context, target in data:context_vector = make_context_vector(context, word_to_idx).to(device)target = torch.tensor([word_to_idx[target]]).to(device)# 开始向前传播train_predict = model(context_vector)loss = loss_function(train_predict, target)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()losses.append(total_loss)print(losses)
model.train():将模型设置为训练模式。- 通过循环进行 200 个 epoch 的训练,每个 epoch 遍历所有训练数据。
- 将上下文词和目标词转换为张量并移动到指定设备上。
- 进行前向传播得到预测结果。
- 计算损失。
- 进行反向传播并更新模型参数。
- 累加每个 epoch 的损失值。
11. 进行预测
context = ['People', 'create', 'to', 'direct']
context_vector = make_context_vector(context, word_to_idx).to(device)model.eval() # 进入到测试模式
predict = model(context_vector)
max_idx = predict.argmax(1) # dim = 1 表示每一行中的最大值对应的索引号, dim = 0 表示每一列中的最大值对应的索引号print("CBOW embedding weight =", model.embeddings.weight) # GPU
W = model.embeddings.weight.cpu().detach().numpy()
print(W)
- 选择一个上下文词列表进行预测。
model.eval():将模型设置为评估模式。- 进行预测并获取预测结果中概率最大的索引。
- 打印嵌入层的权重,并将其转换为 NumPy 数组。
12. 构建词向量字典
word_2_vec = {}
for word in word_to_idx.keys():word_2_vec[word] = W[word_to_idx[word], :]
print('jiesu')
word_2_vec:将每个单词映射到其对应的词向量。
13. 保存和加载词向量
np.savez('word2vec实现.npz', file_1 = W)
data = np.load('word2vec实现.npz')
print(data.files)
np.savez:将词向量保存为.npz文件。np.load:加载保存的.npz文件,并打印文件中的数组名称。
综上所述,这段代码实现了一个简单的 CBOW 模型来学习词向量,并将学习到的词向量保存到文件中。 。运行结果

三、总结
通过上述代码的实现和分析,我们成功地使用CBOW模型在PyTorch框架下完成了词向量的训练。从数据准备、模型定义,到训练和测试,再到词向量的保存,每一个步骤都紧密相连,共同构建了一个完整的词向量训练流程。
CBOW模型通过上下文预测目标词的方式,能够有效地学习到单词之间的语义关系,生成的词向量可以应用于各种自然语言处理任务。在实际应用中,我们还可以通过调整模型的超参数(如词向量维度、上下文窗口大小、训练轮数等),以及使用更大规模的数据集,进一步优化词向量的质量和模型的性能。希望本文的内容能够帮助读者更好地理解CBOW模型和词向量训练的原理与实践。
相关文章:
基于CBOW模型的词向量训练实战:从原理到PyTorch实现
基于CBOW模型的词向量训练实战:从原理到PyTorch实现 在自然语言处理(NLP)领域,词向量是将单词映射为计算机可处理的数值向量的重要方式。通过词向量,单词之间的语义关系能够以数学形式表达,为后续的文本分…...
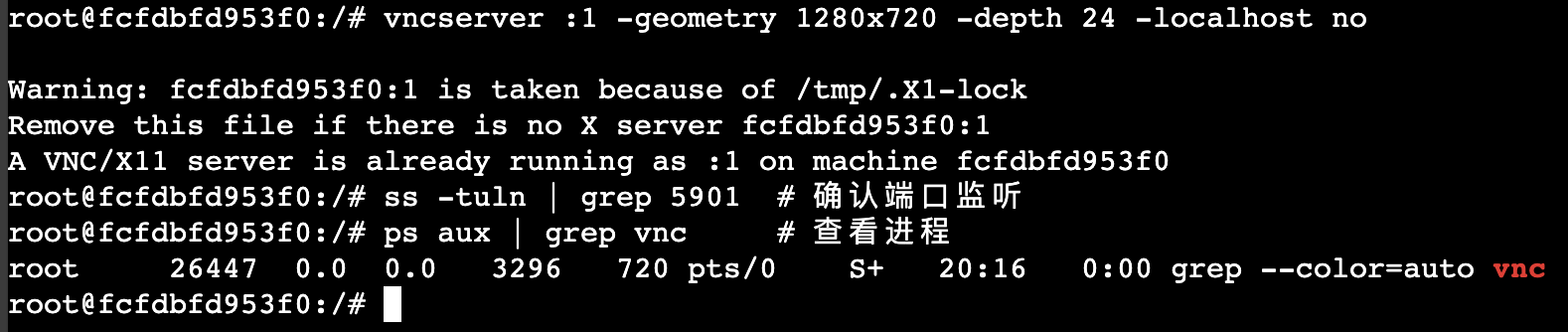
mac连接lniux服务器教学笔记
从你的检查结果看,容器内已经安装了 XFCE 桌面环境(xfce.desktop 和 xubuntu.desktop 的存在说明桌面环境已存在)。以下是针对 Docker 容器环境的远程桌面配置方案: 一、容器内快速配置远程桌面(XFCE VNC)…...

vue3 - keepAlive缓存组件
在Vue 3中,<keep-alive>组件用于缓存动态组件或路由组件的状态,避免重复渲染,提升性能。 我们新建两个组件,在每一个组件里面写一个input,在默认情况下当组件切换的时候,数据会被清空,但…...

阀门产业发展方向报告(石油化工阀门应用技术交流大会)
本文大部分内容来自中国通用机械工业协会副会长张宗列在“2024全国石油化工阀门应用技术交流大会”上发表的报告。 一、国外阀门产业发展 从全球阀门市场分布看,亚洲是最大的工业阀门市场,美洲是全球第二大工业阀门市场,欧洲位列第三。 从国…...
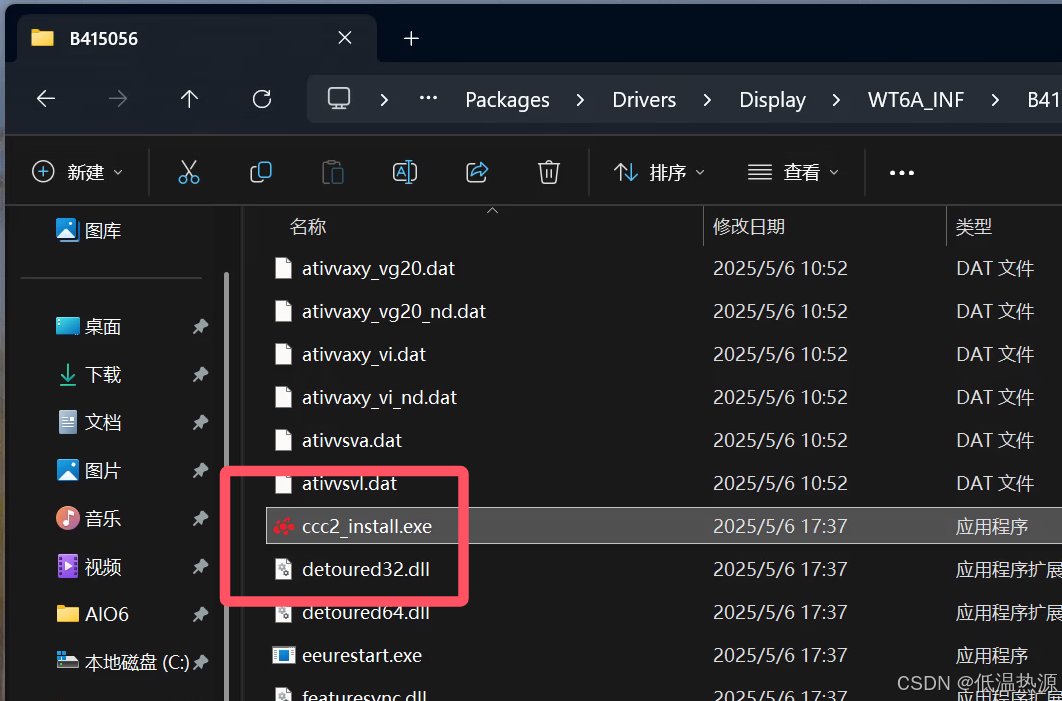
Windows Server 2025 安装AMD显卡驱动
运行显卡驱动安装程序,会提示出问题。但是此时资源已经解压 来到驱动路径 C:\AMD\AMD-Software-Installer\Packages\Drivers\Display\WT6A_INF 打开配置文件,把这两行替换掉 %ATI% ATI.Mfg, NTamd64.10.0...16299, NTamd64.10.0, NTamd64.6.0, NTamd64.…...

用 CodyBuddy 帮我写自动化运维脚本
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴”。 #CodeBuddy首席试玩官 背景 我个人是非常喜欢 Jenkins 自动化部署工具的,之前都是手写 Jenki…...

从单体到微服务:基于 ABP vNext 模块化设计的演进之路
🚀 从单体到微服务:基于 ABP vNext 模块化设计的演进之路 🧩 引言 在需求多变且性能压力日益增大的背景下,传统单体应用在部署、维护和扩展方面存在显著挑战。 ABP vNext 作为基于 ASP.NET Core 的框架,自带模块化设…...
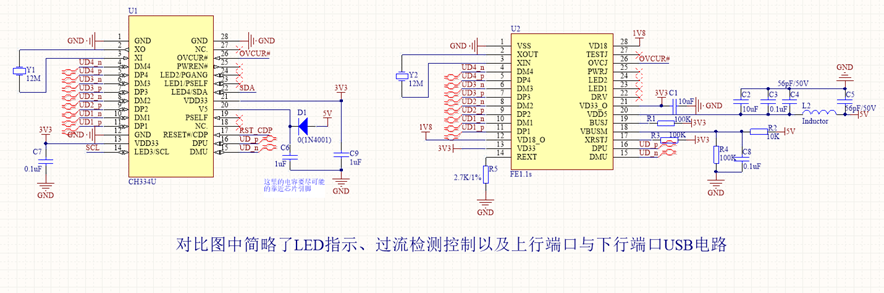
USB集线器芯片革新之战:CH334U如何以工业级性能重新定义HUB控制器
一、当工业智能化遭遇接口瓶颈 在智能制造与边缘计算蓬勃发展的今天,工程师们正面临一个看似微小却至关重要的挑战——如何让USB集线器在极端工况下保持稳定?传统HUB控制器在-20℃以下频繁出现信号失真,产线突然断电导致的静电击穿更是让设备…...

C#学习7_面向对象:类、方法、修饰符
一、类 1class 1)定义类 访问修饰符class 类名{ 字段 构造函数:特殊的方法(用于初始化对象) 属性 方法... } eg: public class Person { // 字段 private string name; private int a…...
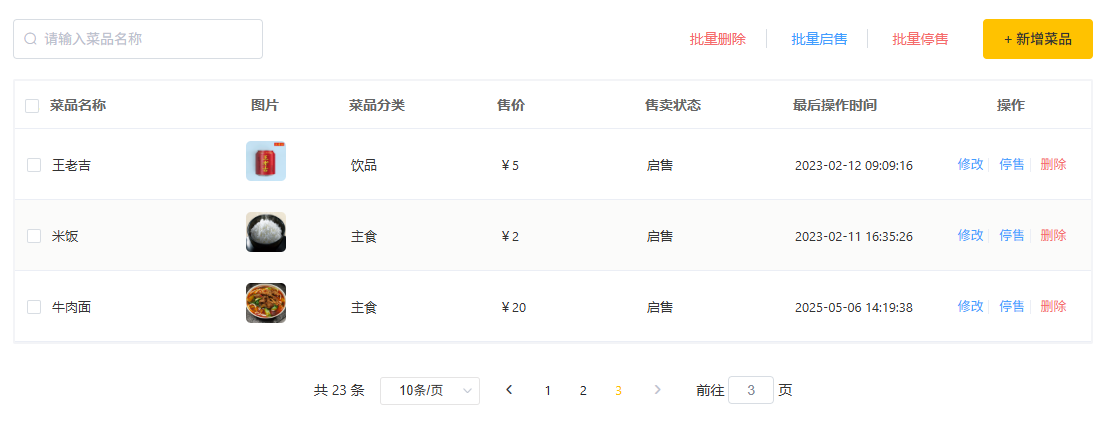
基于 Spring Boot 瑞吉外卖系统开发(十)
基于 Spring Boot 瑞吉外卖系统开发(十) 修改菜品 修改菜品是在原有的菜品信息的上对菜品信息进行更新,对此修改菜品信息之前需要将原有的菜品信息在修改界面进行展示,然后再对菜品信息进行修改。 修改菜品分为回显菜品信息和更…...

C++ 与 Lua 联合编程
在软件开发的广阔天地里,不同编程语言各有所长。C 以其卓越的性能、强大的功能和对硬件的直接操控能力,在系统开发、游戏引擎、服务器等底层领域占据重要地位,但c编写的程序需要编译,这往往是一个耗时操作,特别对于大型…...
详解)
中介者模式(Mediator Pattern)详解
文章目录 1. 中介者模式概述1.1 定义1.2 基本思想2. 中介者模式的结构3. 中介者模式的UML类图4. 中介者模式的工作原理5. Java实现示例5.1 基本实现示例5.2 飞机空中交通控制示例5.3 GUI应用中的中介者模式6. 中介者模式的优缺点6.1 优点6.2 缺点7. 中介者模式的适用场景8. 中介…...
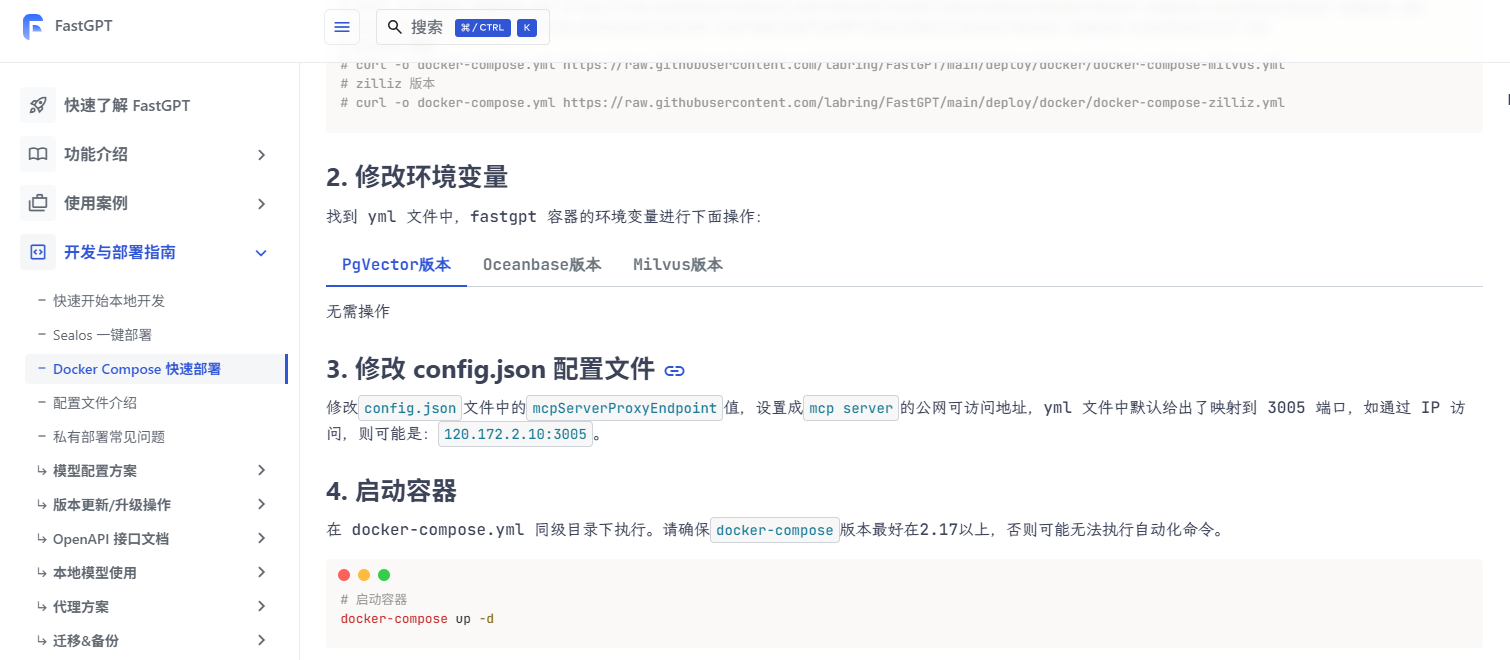
Linux系统(OpenEuler22.03-LTS)部署FastGPT
在 openEuler 22.03 LTS 系统上通过 Docker Compose 安装 FastGPT 的步骤如下: 官方参考文档:https://doc.fastgpt.cn/docs/development/docker/ 1. 安装 Docker 和 Docker Compose 可以参考我之前离线安装Docker的文章:openEuler 22.03 LT…...
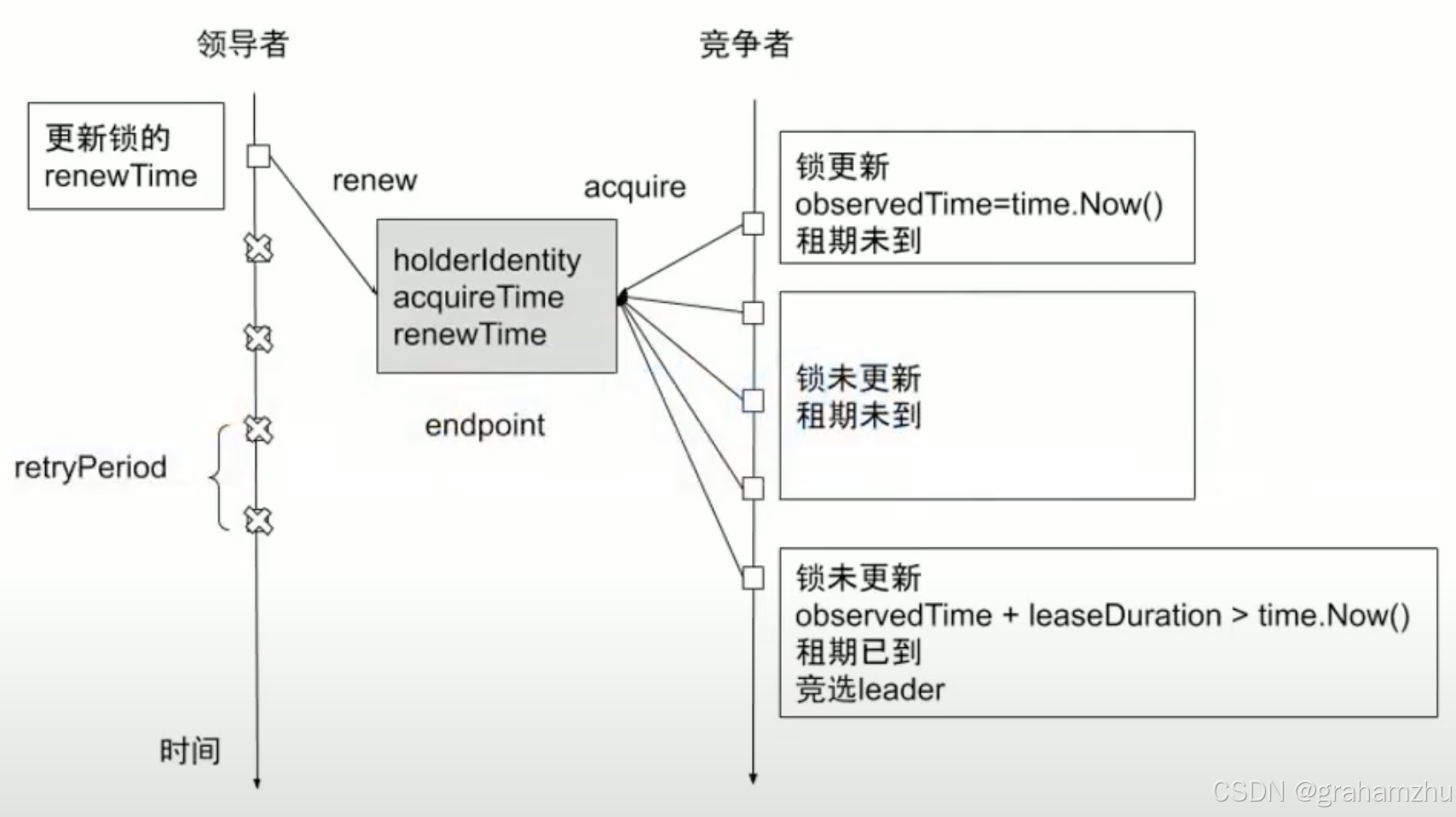
Kubernetes控制平面组件:Controller Manager 之 内置Controller详解
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

结合Splash与Scrapy:高效爬取动态JavaScript网站
在当今的Web开发中,JavaScript的广泛应用使得许多网站的内容无法通过传统的请求-响应模式直接获取。为了解决这个问题,Scrapy开发者经常需要集成像Splash这样的JavaScript渲染引擎。本文将详细介绍Splash JS引擎的工作原理,并探讨如何将其与S…...
用于构建安全AI代理的开源防护系统
大家读完觉得有帮助记得及时关注!!! 大型语言模型(LLMs)已经从简单的聊天机器人演变为能够执行复杂任务的自主代理,例如编辑生产代码、编排工作流程以及基于不受信任的输入(如网页和电子邮件&am…...

算法与数据结构 - 常用图算法总结
在图论中,图算法非常重要,广泛应用于计算机科学、网络分析、社交网络、地理信息系统等领域。下面是一些常用的图算法,按不同功能和应用场景分类: 1. 图的遍历 图遍历算法用于遍历图中的节点和边。主要有两种常见的图遍历方法&am…...
克里金模型+多目标优化+多属性决策!Kriging+NSGAII+熵权TOPSIS!
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 克里金模型多目标优化多属性决策!KrigingNSGAII熵权TOPSIS!!matlab2023b语言运行! 1.克里金模型(Kriging Model)是一种基于空间统计学的插值方法…...
LLM 论文精读(三)Demystifying Long Chain-of-Thought Reasoning in LLMs
这是一篇2025年发表在arxiv中的LLM领域论文,主要描述了长思维链 Long Chain-of-Thought 对LLM的影响,以及其可能的生成机制。通过大量的消融实验证明了以下几点: 与shot CoT 相比,long CoT 的 SFT 可以扩展到更高的性能上限&…...

【Prompt工程—文生图】案例大全
目录 一、人物绘图 二、卡通头像 三、风景图 四、logo设计图 五、动物形象图 六、室内设计图 七、动漫风格 八、二次元图 九、日常场景图 十、古风神化图 十一、游戏场景图 十二、电影大片质感 本文主要介绍了12种不同类型的文生图技巧,通过加入不同的图像…...

本地可执行命令的智能体部署方案
本地可执行命令的智能体部署方案,目标是让大语言模型(LLM)在本地接收自然语言指令,并自动调用系统命令、脚本或应用程序,完成任务自动化。这类系统通常被称为 LLM Agent with Tool Use 或 本地 Agent 实体系统。 &…...

rust程序静态编译的两种方法总结
1. 概述 经过我的探索,总结了两种rust程序静态编译的方法,理论上两种方法都适用于windows、mac os和linux(mac os未验证),实测方法一性能比方法二好,现总结如下,希望能够帮到你. 2.方法一 2.1 添加配置文件 在项目的同级文件夹下新…...
)
验证码(笔记)
为什么要有验证码: 为什么验证码这么让人厌烦,每个网站还要使用它呢?换句话说,这些网站为什么要“故意为难”用户呢? 其实验证码主要是为了区分用户是计算机还是人。假设一个黑客知道了你的账号,根据账号可…...

【Linux系列】目录大小查看
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

2048游戏(含Python源码)
前言 相关参考游戏: 像素飞机大战(含Python源码)-CSDN博客https://blog.csdn.net/weixin_64066303/article/details/147693018?spm1001.2014.3001.5501使用DeepSeek定制Python小游戏——以“俄罗斯方块”为例-CSDN博客https://blog.csdn.n…...

SwiftData 数据持久化解决方案
什么是 SwiftData? SwiftData 是苹果在 WWDC23 上推出的全新数据持久化框架,它构建在 Core Data 之上,但提供了更加 Swift 友好的 API。SwiftData 旨在简化数据模型的创建和管理,让开发者能够以更少的代码实现强大的数据持久化功…...
中间件-RocketMQ
RocketMQ 基本架构消息模型消费者消费消息模式顺序消息机制延迟消息批量消息事务消息消息重试最佳实践 基本架构 nameServer: 维护broker列表信息,客户端连接时只需要连接nameServer。可配置成集群。 broker:broker分为master和slave,master负…...

PostgreSQL 的 pg_current_logfile 函数
PostgreSQL 的 pg_current_logfile 函数 pg_current_logfile() 是 PostgreSQL 9.6 版本引入的一个系统管理函数,用于获取当前正在使用的日志文件路径。 一 基本用法 1 函数定义 pg_current_logfile([text]) → text2 简单查询 -- 获取当前日志文件路径 SELECT …...

Python就业方向有哪些?
Python 作为一门通用、易学且功能强大的编程语言,在多个领域都有广泛的应用,因此就业方向也非常多样化。以下是 Python 主要的就业方向及相关技能要求。 1. Web 开发 岗位:Python Web 开发工程师、后端工程师、全栈工程师技术栈:…...

iptables 访问控制列表使用记录
iptables 是linux操作系统上自带的防火墙程序,功能强大,能够依据策略过滤掉一些恶意访问流量,本次记录一下iptables的常见使用方法,未尽之处,欢迎补充。 一、iptables 下载 我这里使用的是华为openEuler 22.03版本&am…...