用卷积神经网络 (CNN) 实现 MNIST 手写数字识别
在深度学习领域,MNIST 手写数字识别是经典的入门级项目,就像编程世界里的 “Hello, World”。卷积神经网络(Convolutional Neural Network,CNN)作为处理图像数据的强大工具,在该任务中展现出卓越的性能。本文将结合具体的 PyTorch 代码,详细解析如何利用 CNN 实现 MNIST 手写数字识别,带大家从代码实践深入理解背后的技术原理。
一、数据准备:加载与预处理 MNIST 数据集
MNIST 数据集包含 6 万张训练图像和 1 万张测试图像,涵盖 0 - 9 这十个数字的手写体。我们借助torchvision库中的datasets.MNIST函数来加载数据,具体代码如下:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensortraining_data = datasets.MNIST(root="data",train=True,download=True,transform=ToTensor(),
)
test_data = datasets.MNIST(root="data",train=False,download=True,transform=ToTensor(),
)
上述代码中,root="data"指定数据集的存储路径;train=True表示加载训练集,train=False用于加载测试集;download=True确保本地无数据集时自动下载;transform=ToTensor()将图像数据转换为 PyTorch 张量格式,并把像素值从 0 - 255 归一化到 0 - 1 区间,便于后续处理。
为直观感受数据,我们用matplotlib库绘制 9 张训练图像及其标签:
from matplotlib import pyplot as plt
figure = plt.figure()
for i in range(9):img, label = training_data[i + 59000]figure.add_subplot(3, 3, i + 1)plt.title(label)plt.axis("off")plt.imshow(img.squeeze(), cmap="gray")a = img.squeeze()
plt.show()
完成数据加载后,使用DataLoader将数据封装成批次,方便模型训练和测试:
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
batch_size=64意味着每次训练或测试,模型会同时处理 64 个样本,能提高计算效率和训练稳定性。
二、模型构建:搭建卷积神经网络架构
我们定义一个名为CNN的类,继承自nn.Module,用于构建卷积神经网络:
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=1,),nn.ReLU(),nn.MaxPool2d(2))self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 3, 1, 1),nn.ReLU(),nn.MaxPool2d(2),)self.conv3 = nn.Sequential(nn.Conv2d(32, 64, 3, 1, 1),nn.ReLU(),)self.out = nn.Linear(64 * 7 * 7, 10)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = x.view(x.size(0), -1)output = self.out(x)return output
- 卷积层(
nn.Conv2d):在conv1、conv2和conv3中,通过卷积层提取图像特征。例如conv1中的nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1),in_channels=1表示输入图像为单通道灰度图,out_channels=16表示输出 16 个特征图,kernel_size=3指定 3×3 的卷积核,stride=1是步长,padding=1用于保持图像尺寸不变。 - 激活函数(
nn.ReLU):紧跟在卷积层之后,为模型引入非线性,帮助模型学习复杂的模式。 - 池化层(
nn.MaxPool2d):通过下采样操作,如nn.MaxPool2d(2)将图像尺寸减半,减少数据量和模型参数,同时保留重要特征,防止过拟合。 - 全连接层(
nn.Linear):self.out = nn.Linear(64 * 7 * 7, 10)将卷积层输出的特征图展平后连接到全连接层,输出 10 个神经元对应 0 - 9 十个数字类别,完成最终分类。
最后,将模型移动到合适的计算设备(GPU、MPS 或 CPU)上:
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
model = CNN().to(device)
print(model)
三、模型训练与测试:优化与评估
3.1 训练函数
def train(dataloader, model, loss_fn, optimizer):model.train()batch_size_num = 1for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value = loss.item()if batch_size_num % 100 == 0:print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")batch_size_num += 1
在训练函数中,model.train()将模型设为训练模式。遍历数据加载器,将每一批数据和标签移至指定设备,前向传播计算预测值,通过交叉熵损失函数nn.CrossEntropyLoss()计算损失,optimizer.zero_grad()清空梯度,loss.backward()反向传播计算梯度,optimizer.step()更新模型参数,每 100 个批次打印一次损失值。
3.2 测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test Error: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")return test_loss, correct
测试函数中,model.eval()将模型设为评估模式,关闭如 Dropout 等训练时的操作。在with torch.no_grad()下遍历测试数据,计算测试损失和正确预测的样本数,最后计算平均损失和准确率并输出。
3.3 执行训练与测试
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
epochs = 10
for t in range(epochs):print(f"Epoch {t + 1}\n--------------------")train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
test(test_dataloader, model, loss_fn)
我们选用交叉熵损失函数和 Adam 优化器,学习率设为 0.01,通过 10 个训练周期不断优化模型,训练完成后在测试集上评估模型性能,得到最终的准确率和平均损失。
四、总结与展望
通过上述代码实践,我们成功利用卷积神经网络实现了 MNIST 手写数字识别。从数据加载、模型构建到训练测试,每个环节都紧密相连,展示了 CNN 在图像识别任务中的强大能力。
相关文章:
 实现 MNIST 手写数字识别)
用卷积神经网络 (CNN) 实现 MNIST 手写数字识别
在深度学习领域,MNIST 手写数字识别是经典的入门级项目,就像编程世界里的 “Hello, World”。卷积神经网络(Convolutional Neural Network,CNN)作为处理图像数据的强大工具,在该任务中展现出卓越的性能。本…...

windows的rancherDesktop修改镜像源
您好!要在Windows系统上的Rancher Desktop中修改Docker镜像源(即设置registry mirror),您需要根据Rancher Desktop使用的容器运行时(containerd或dockerd)进行配置。用户提到“allowed-image”没有效果&…...

spring中的@ComponentScan注解详解
ComponentScan 是 Spring 框架中用于自动扫描并注册组件的核心注解,它简化了 Spring 应用中 Bean 的发现和装配流程。以下从核心功能、属性解析、使用场景及示例等方面进行详细说明。 一、核心功能与作用 自动扫描组件 ComponentScan 会扫描指定包及其子包下的类&am…...
:从理论到实践)
机器学习之嵌入(Embeddings):从理论到实践
机器学习之嵌入(Embeddings):从理论到实践 摘要 本文深入探讨了机器学习中嵌入(Embeddings)的概念和应用。通过具体的实例和可视化展示,我们将了解嵌入如何将高维数据转换为低维表示,以及这种转换在推荐系统、自然语言处理等领域的实际应用…...

深入剖析 I/O 复用之 select 机制
深入剖析 I/O 复用之 select 机制 在网络编程中,I/O 复用是一项关键技术,它允许程序同时监控多个文件描述符的状态变化,从而高效地处理多个 I/O 操作。select 作为 I/O 复用的经典实现方式,在众多网络应用中扮演着重要角色。本文…...
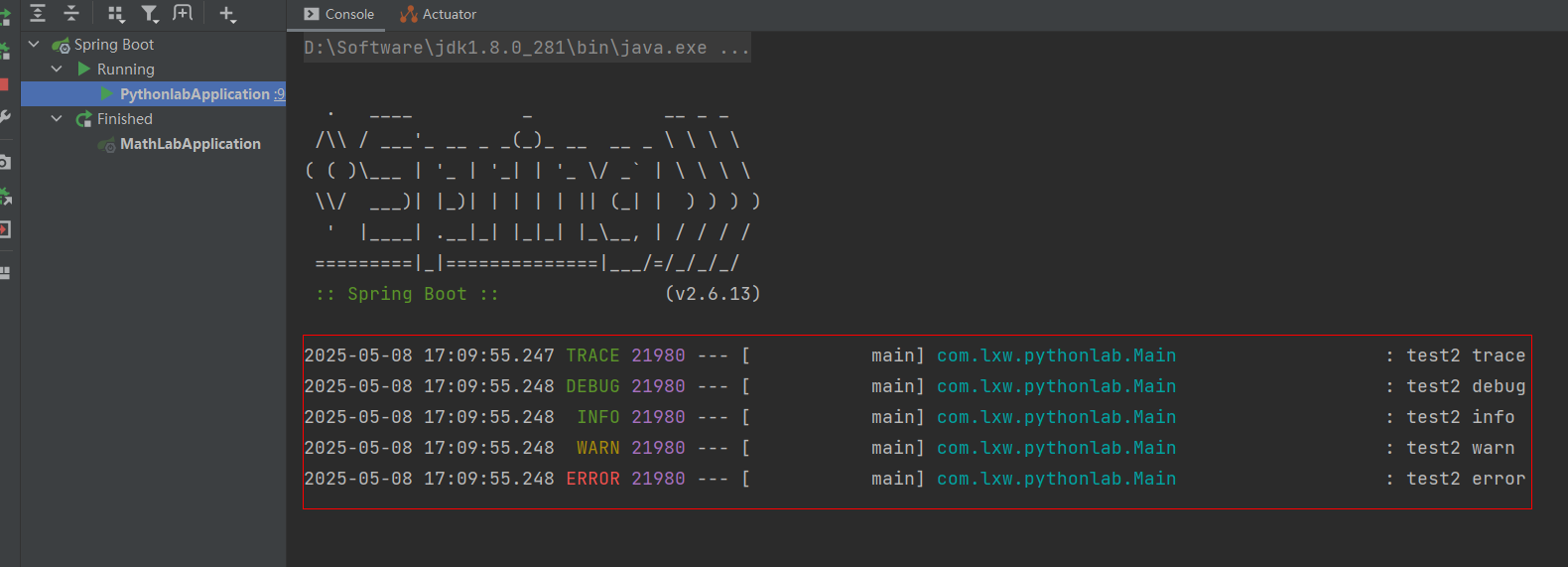
SpringBoot指定项目层日志记录
1、新建一个Springboot项目,添加Lombok依赖(注意:这里使用的Lombok下的Slf4j快速日志记录方式) <dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependenc…...

RISC-V hardfault分析工具,RTTHREAD-RVBACKTRACE
RV BACKTRACE 简介 本文主要讲述RV BACKTRACE 的内部主要原理 没有接触过rvbacktrace可以看下面两篇文章,理解一下如何使用RVBACKTRACE RVBacktrace RISC-V极简栈回溯组件:https://club.rt-thread.org/ask/article/64bfe06feb7b3e29.html RVBacktra…...

xiaopiu原型设计工具笔记
文章目录 有没有行组件是否支持根据图片生成原型呢? 其他官网 做项目要用到原型设计,还是那句话,遇到的必须会用,走起。 支持本地也支持线上。 有没有行组件 是这样,同一行有多个字段,如何弄的准确点呢? 目前只会弄…...
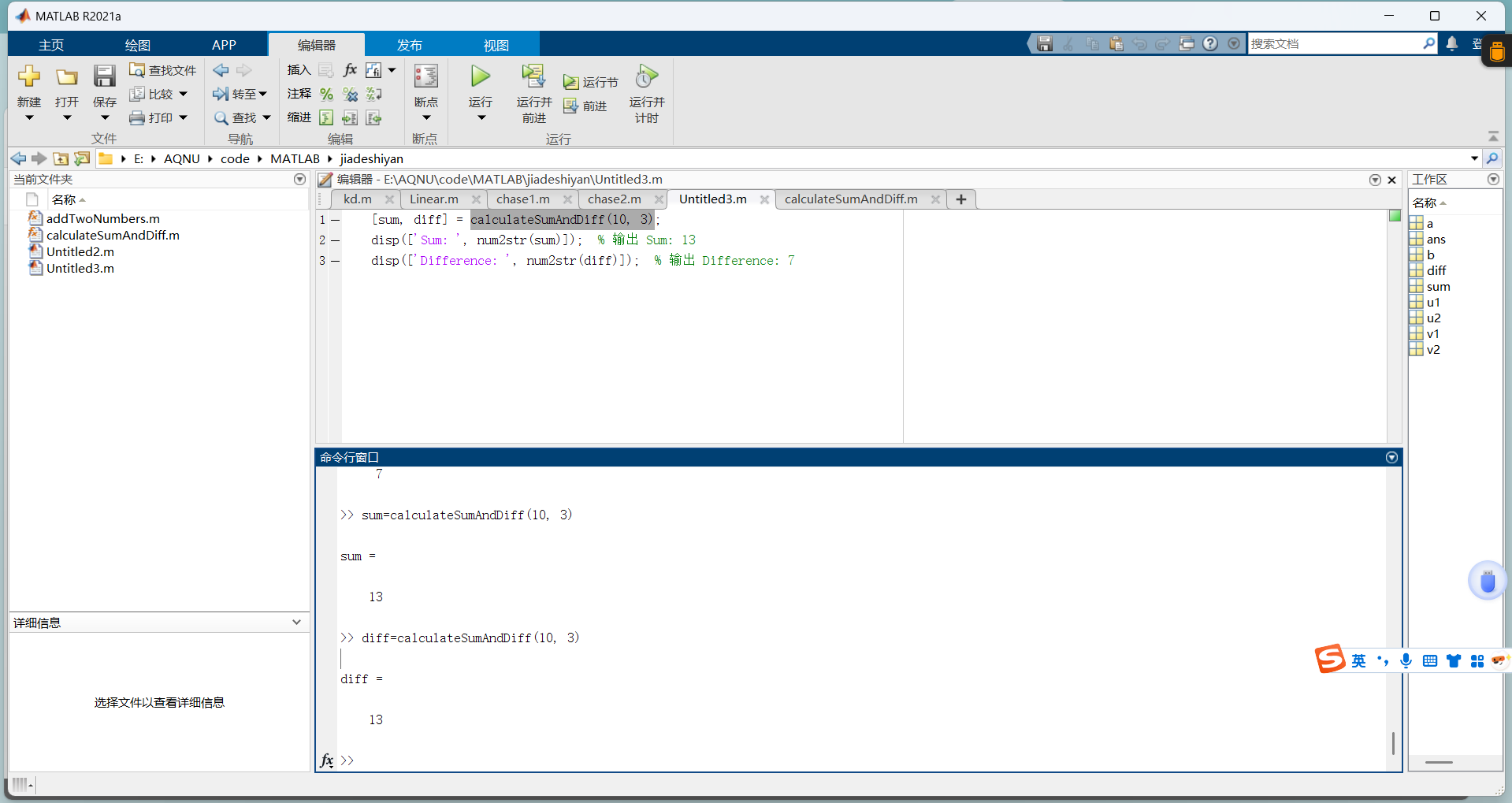
matlab 中function的用法
matlab 中function的用法 前言介绍1. 基本语法示例(1)可以直接输出(2)调用函数 2.输入参数和输出参数示例多输入参数和输出参数定义一个函数,计算两个数的和与差:调用该函数: 3. 默认参数示例 4…...
解锁 LLM 推理速度:深入 FlashAttention 与 PagedAttention 的原理与实践
写在前面 大型语言模型 (LLM) 已经渗透到我们数字生活的方方面面,从智能问答、内容创作到代码辅助,其能力令人惊叹。然而,驱动这些强大模型的背后,是对计算资源(尤其是 GPU)的巨大需求。在模型推理 (Inference) 阶段,即模型实际对外提供服务的阶段,速度 (Latency) 和吞…...

4个纯CSS自定义的简单而优雅的滚动条样式
今天发现 uni-app 项目的滚动条不显示,查了下原来是设置了 ::-webkit-scrollbar {display: none; } 那么怎么用 css 设置滚动条样式呢? 定义滚动条整体样式 ::-webkit-scrollbar 定义滚动条滑块样式 ::-webkit-scrollbar-thumb 定义滚动条轨道样式…...
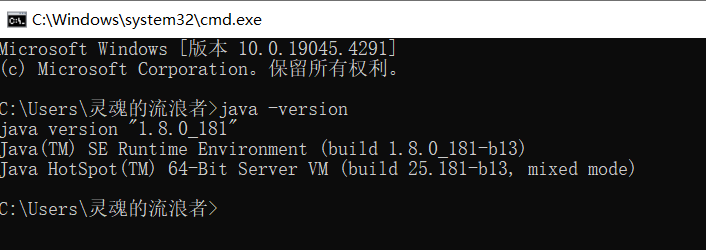
查看jdk是否安装并且配置成功?(Android studio安装前的准备)
WinR输入cmd打开命令提示窗口 输入命令 java -version 回车显示如下:...
5月8日直播见!Atlassian Team‘25大会精华+AI实战分享
在刚刚落幕的 Atlassian Team’25 全球大会上,Atlassian发布了多项重磅创新,全面升级其协作平台,涵盖从Al驱动、知识管理到跨团队协作,再到战略执行的各个方面。 为帮助中国用户深入了解这些前沿动态,Atlassian全球白…...

Windows系统下使用Kafka和Zookeeper,Python运行kafka(一)
下载和安装见Linux系统下使用Kafka和Zookeeper 配置 Zookeeper Zookeeper 是 Kafka 所依赖的分布式协调服务。在 Kafka 解压目录下,有一个 Zookeeper 的配置文件模板config/zookeeper.properties,你可以直接使用默认配置。 启动 Zookeeper 打开命令提示符(CMD),进入 K…...
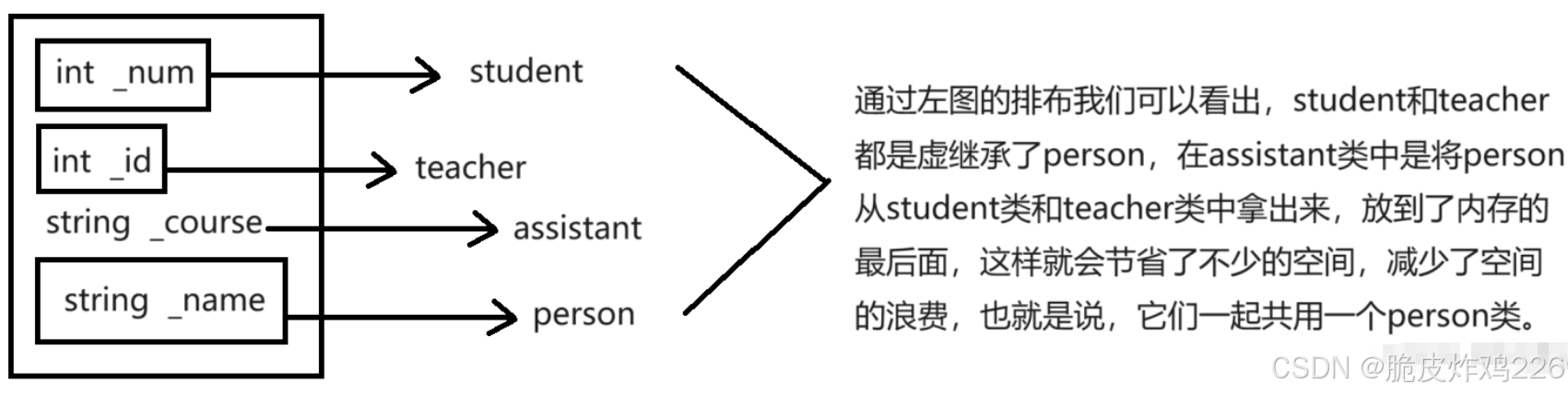
C++之“继承”
继续开始关于C相关的内容。C作为面向对象的语言,有三大特性:封装,继承,多态。 这篇文章我们开始学习:继承。 一、继承的概念和定义 1. 继承的概念 什么是继承呢? 字面意思理解来看:继承就是…...
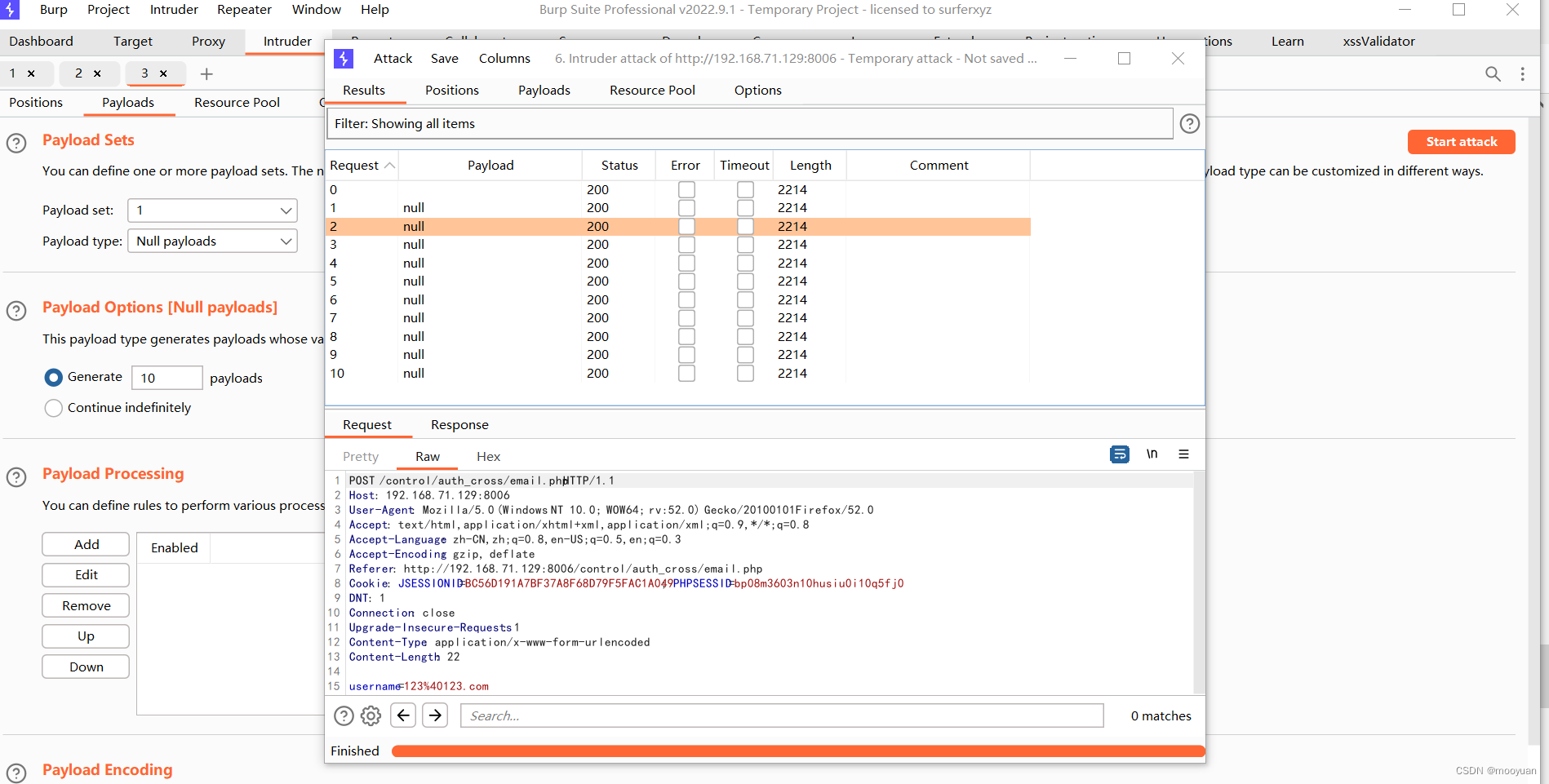
Webug4.0靶场通关笔记19- 第24关邮箱轰炸
目录 第24关 邮箱轰炸 1.配置环境 2.打开靶场 3.源码分析 4.邮箱轰炸 (1)注册界面bp抓包 (2)发送到intruder (3)配置position (4)配置payload (5)开…...
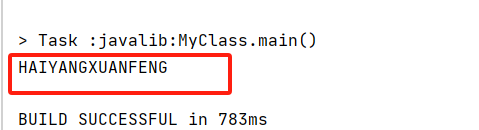
java CompletableFuture 异步编程工具用法1
1、测试异步调用: static void testCompletableFuture1() throws ExecutionException, InterruptedException {// 1、无返回值的异步任务。异步线程执行RunnableCompletableFuture.runAsync(() -> System.out.println("only you"));// 2、有返回值的异…...

缺乏实体人形机器人的主流高精度仿真方案
在缺乏实体人形机器人的情况下,可通过以下主流仿真方案实现高精度模拟(基于2025年最新技术): 一、基础建模工具链 MATLAB Robotics Toolbox • 通过连杆(Link)和关节(Joint)定义生物力学参数 • 示例代码创建简化模型:…...

基于STM32、HAL库的CP2104 USB转UART收发器 驱动程序设计
一、简介: CP2104是Silicon Labs公司推出的一款USB转UART桥接芯片,具有以下特点: USB 2.0全速兼容 集成USB收发器,无需外部电阻 支持UART数据传输,波特率从300bps到2Mbps 内置EEPROM可配置设备信息 支持RTS/CTS硬件流控制 3.3V I/O电平,内置5V至3.3V稳压器 紧凑的QFN-24…...

ERC-20与ERC-721:区块链代币标准的双星解析
一、代币标准的诞生背景 在以太坊生态中,代币标准是构建去中心化应用(DApps)的基石。ERC-20与ERC-721分别代表同质化与非同质化代币的两大核心标准,前者支撑着90%以上的加密资产流通,后者则开启了数字资产唯一性的新时…...

使用Go语言对接全球股票数据源API实践指南
使用Go语言对接全球股票数据API实践指南 概述 本文介绍如何通过Go语言对接支持多国股票数据的API服务。我们将基于提供的API文档,实现包括市场行情、K线数据、实时推送等核心功能的对接。 一、准备工作 1. 获取API Key 联系服务提供商获取访问密钥(替…...

经典密码学算法实现
# AES-128 加密算法的规范实现(不使用外部库) # ECB模式S_BOX [0x63, 0x7C, 0x77, 0x7B, 0xF2, 0x6B, 0x6F, 0xC5, 0x30, 0x01, 0x67, 0x2B,0xFE, 0xD7, 0xAB, 0x76, 0xCA, 0x82, 0xC9, 0x7D, 0xFA, 0x59, 0x47, 0xF0,0xAD, 0xD4, 0xA2, 0xAF, 0x9C, 0x…...

git 远程仓库管理详解
Git 的远程仓库管理是多人协作和代码共享的核心功能。以下是 Git 远程仓库管理的详细说明,包括常用操作、命令和最佳实践。 1. 什么是远程仓库? 远程仓库(Remote Repository):存储在网络服务器上的 Git 仓库࿰…...

ABP vNext + gRPC 实现服务间高速通信
ABP vNext gRPC 实现服务间高速通信 💨 在现代微服务架构中,服务之间频繁的调用往往对性能构成挑战。尤其在电商秒杀、金融风控、实时监控等对响应延迟敏感的场景中,传统 REST API 面临序列化负担重、数据体积大、通信延迟高等瓶颈。 本文…...

若依框架Ruoyi-vue整合图表Echarts中国地图标注动态数据
若依框架Ruoyi-vue整合图表Echarts中国地图 概述创作灵感预期效果整合教程前期准备整合若依框架1、引入china.json2、方法3、data演示数据4、核心代码 完整代码[毫无保留]组件调用 总结 概述 首先,我需要回忆之前给出的回答,确保这次的内容不重复&#…...
API 商品详情数据接口讲解及 JSON 示例)
京东(JD)API 商品详情数据接口讲解及 JSON 示例
前言 京东开放平台提供了多种商品详情相关的 API 接口,开发者可以通过这些接口获取商品的详细信息。以下为接口调用方式及 JSON 返回数据的参考示例。 1. 接口调用方式 京东商品详情接口通常采用以下形式: 请求方式:GET/POST关键参数&…...
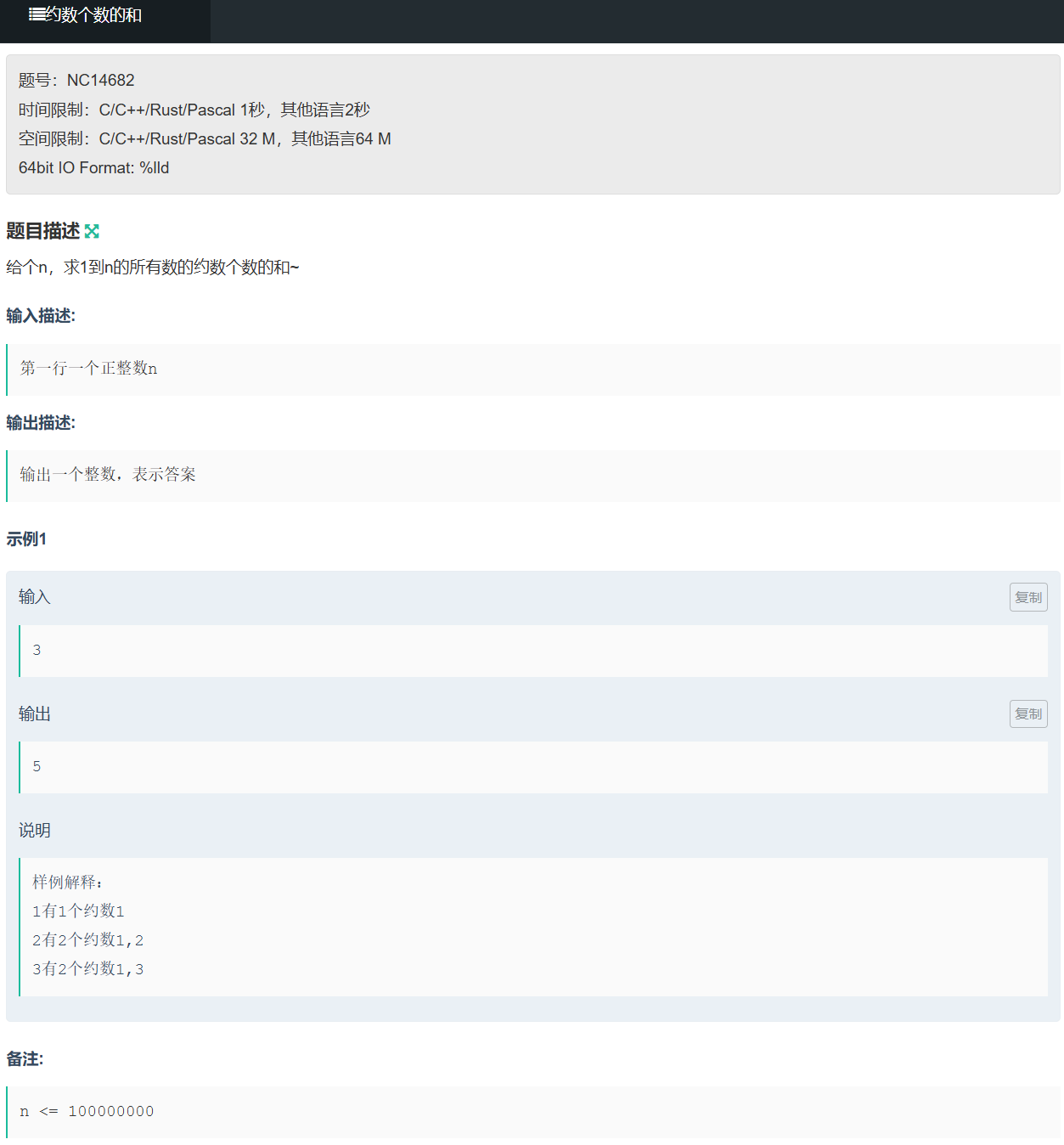
算法中的数学:约数
1.求一个整数的所有约数 对于一个整数x,他的其中一个约数若为i,那么x/i也是x的一个约数。而其中一个约数的大小一定小于等于根号x(完全平方数则两个约数都为根号x),所以我们只需要遍历到根号x,然后计算出另…...

Python实例题:Python获取喜马拉雅音频
目录 Python实例题 题目 python-get-ximalaya-audioPython 获取喜马拉雅音频脚本 代码解释 get_audio_info 函数: download_audio 函数: 主程序: 运行思路 注意事项 Python实例题 题目 Python获取喜马拉雅音频 python-get-ximala…...

[监控看板]Grafana+Prometheus+Exporter监控疑难排查
采用GrafanaPrometheusExporter监控MySQL时发现经常数据不即时同步,本示例也是本地搭建采用。 Prometheus面板 1,Detected a time difference of 11h 47m 22.337s between your browser and the server. You may see unexpected time-shifted query res…...

LaTeX印刷体 字符与数学符号的总结
1. 希腊字母(Greek Letters) 名称小写 LaTeX大写 LaTeX显示效果Alpha\alphaAαα, AABeta\betaBββ, BBGamma\gamma\Gammaγγ, ΓΓDelta\delta\Deltaδδ, ΔΔTheta\theta\Thetaθθ, ΘΘPi\pi\Piππ, ΠΠSigma\sigma\Sigmaσσ, ΣΣOmega\omeg…...