Spark缓存
生活中缓存容量受成本和体积限制(比如 CPU 缓存只有几 MB 到几十 MB),但会通过算法(如 “最近最少使用” 原则)智能决定存什么,确保存的是 “最可能被用到的数据”。
1. 为什么需要缓存?
-
惰性执行机制:Spark 的转换操作(如
map,filter,join)是惰性的,只有在触发行动操作(如count,collect)时才会真正执行。如果多次使用同一个 RDD/DataFrame,每次行动操作都会重新计算整个血缘(Lineage),导致性能浪费。 -
缓存的作用:将重复使用的数据持久化到内存或磁盘,避免重复计算。
2. 如何缓存数据?
Spark 提供两种方法缓存数据:
-
persist(storageLevel):指定存储级别(如内存、磁盘等)。 -
cache():等价于persist(StorageLevel.MEMORY_ONLY),默认将数据存储在内存中。
3.RDD缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存多个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的行动算子时,该RDD将会被缓存在计算节点的内存中,并供以后重用。
不用缓存的例子
代码展示:
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Cache {
def main(args: Array[String]): Unit = {
// 配置Spark
val conf = new SparkConf().setAppName("CacheExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// conf.set("spark.local.dir", "_cache")
sc.setLogLevel("WARN")
// 创建一个包含大量随机数的 RDD
val largeRDD = sc.parallelize(1 to 1000*1000*10).map(_ => scala.util.Random.nextInt(1000))
// 定义一个复杂的转换函数
def complexTransformation(num: Int): Int = {
var result = num
for (_ <- 1 to 1000) {
result = result * 2 % 1000
}
result
}
// 不使用 cache 的情况
val nonCachedRDD = largeRDD.map(complexTransformation)
// 第一次触发行动算子,计算并统计时间
val startTime1 = System.currentTimeMillis()
val result1 = nonCachedRDD.collect()
val endTime1 = System.currentTimeMillis()
println(s"不使用 cache 第一次计算耗时: ${endTime1 - startTime1} 毫秒")
// 第二次触发行动算子,计算并统计时间
val startTime2 = System.currentTimeMillis()
val result2 = nonCachedRDD.collect()
val endTime2 = System.currentTimeMillis()
println(s"不使用 cache 第二次计算耗时: ${endTime2 - startTime2} 毫秒")
sc.stop()
}
}
核心代码说明:
1.map算子是转换算子,并不会导致真正的计算
2.第一次调用collect和第二调用collect花的时间基本一致。这就是没有缓存的效果。
带缓存的例子:
代码展示:
// 使用 cache 的情况
val cachedRDD = largeRDD.map(complexTransformation).cache()
// 第一次触发行动算子,计算并统计时间
val startTime3 = System.currentTimeMillis()
val result3 = cachedRDD.collect()
val endTime3 = System.currentTimeMillis()
println(s"使用 cache 第一次计算耗时: ${endTime3 - startTime3} 毫秒")
// 第二次触发行动算子,计算并统计时间
val startTime4 = System.currentTimeMillis()
val result4 = cachedRDD.collect()
val endTime4 = System.currentTimeMillis()
println(s"使用 cache 第二次计算耗时: ${endTime4 - startTime4} 毫秒")
println(s"spark.local.dir 的值: ${conf.get("spark.local.dir")}")
sc.stop()
核心代码说明:
第一次调用collect时,程序需要对RDD中的每个元素执行fibonacci函数进行计算,这涉及到递归运算,比较耗时。
第二次调用collect时,因为之前已经调用了cache方法,并且结果已被缓存,所以不需要再次执行计算,直接从缓存中读取数据。通过对比两次计算的耗时,可以明显发现第二次计算耗时会远小于第一次(在数据量较大或计算复杂时效果更显著),这就体现了cache方法缓存计算结果、避免重复计算、提升后续操作速度的作用 。
相关文章:

Spark缓存
生活中缓存容量受成本和体积限制(比如 CPU 缓存只有几 MB 到几十 MB),但会通过算法(如 “最近最少使用” 原则)智能决定存什么,确保存的是 “最可能被用到的数据”。 1. 为什么需要缓存? 惰性执…...
计算机视觉与深度学习 | 基于Transformer的低照度图像增强技术
基于Transformer的低照度图像增强技术通过结合Transformer的全局建模能力和传统图像增强理论(如Retinex),在保留颜色信息、抑制噪声和平衡亮度方面展现出显著优势。以下是其核心原理、关键公式及典型代码实现: 一、原理分析 1. 全局依赖建模与局部特征融合 Transformer的核…...
学习设计模式《八》——原型模式
一、基础概念 原型模式的本质是【克隆生成对象】; 原型模式的定义:用原型实例指定创建对象的种类,并通过拷贝这些原型创建新的对象 。 原型模式的功能: 1、通过克隆来创建新的对象实例; 2、为克隆出来的新对象实例复制…...

疗愈服务预约小程序源码介绍
基于ThinkPHP、FastAdmin和UniApp开发的疗愈服务预约小程序源码,这款小程序在功能设计和用户体验上都表现出色,为疗愈行业提供了一种全新的服务模式。 该小程序源码采用了ThinkPHP作为后端框架,保证了系统的稳定性和高效性。同时,…...

如何通过外网访问内网?对比5个简单的局域网让互联网连接方案
在实际应用中,常常需要从外网访问内网资源,如远程办公访问公司内部服务器、在家访问家庭网络中的设备等。又或者在本地内网搭建的项目应用需要提供互联网服务。以下介绍几种常见的外网访问内网、内网提供公网连接实现方法参考。 一、公网IP路由器端口映…...

Linux 服务器静态 IP 配置初始化指南
✅ 第一步:确认网络管理方式 运行以下命令判断系统使用的网络管理服务: # 检查 NetworkManager 是否活跃 systemctl is-active NetworkManager# 检查 network(旧服务)是否活跃 systemctl is-active network或者检查配置路径&…...

【随笔】Google学术:but your computer or network may be sending automated queries.
文章目录 一、问题复述二、问题原因三、解决 前提:你的xxx是自己做的,你自己可以管理,而不是用的那些劣质✈场。 一、问题复述 🟢如下图所示:可以打开谷歌学术,但是一搜索就是这个界面。 二、问题原因 …...

长事务:数据库中的“隐形炸弹“——金仓数据库运维避坑指南
引言:凌晨三点的告警 "张工!生产库又告警了!"凌晨三点的电话铃声总是格外刺耳。运维团队发现数据库频繁进入单用户模式,排查发现某核心表的年龄值(Age)已突破20亿大关。经过一夜奋战,…...
ubuntu nobel + qt5.15.2 设置qss语法识别正确
问题展示 解决步骤 首选项里面的高亮怎么编辑选择都没用。如果已经有generic-highlighter和css.xml,直接修改css.xml文件最直接! 在generic-highlighter目录下找到css.xml文件,位置是:/opt/Qt/Tools/QtCreator/share/qtcreator/…...

优化01-统计信息
Oracle 的统计信息是数据库优化器生成高效执行计划的核心依据。它记录了数据库对象(如表、索引、列等)的元数据信息,帮助优化器评估查询成本并选择最优执行路径。以下是关于 Oracle 统计信息的详细介绍: 一、统计信息的分类 表统…...
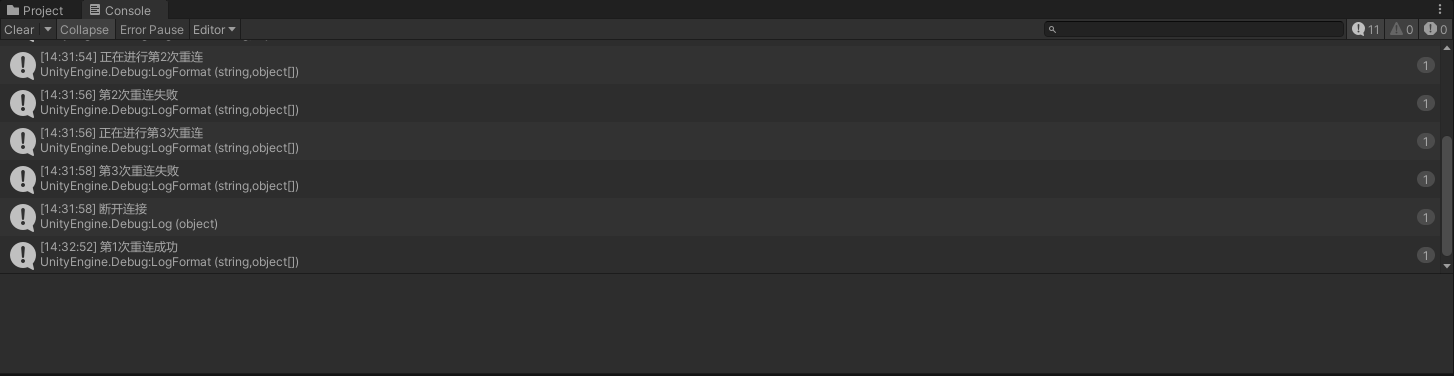
Unity-Socket通信实例详解
今天我们来讲解socket通信。 首先我们需要知道什么是socket通信: Socket本质上就是一个个进程之间网络通信的基础,每一个Socket由IP端口组成,熟悉计网的同学应该知道IP主要是应用于IP协议而端口主要应用于TCP协议,这也证明了Sock…...
MATLAB仿真定点数转浮点数(对比VIVADO定点转浮点)
MATLAB仿真定点数转浮点数 定点数可设置位宽,小数位宽;浮点数是单精度浮点数 对比VIVADO定点转浮点 目录 前言 一、定点数 二、浮点数 三、定点数转浮点数 四、函数代码 总结 前言 在FPGA上实现算法时,相比MATLAB实现往往需要更长的开发…...
)
配置Jupyter Notebook环境及Token认证(Linux服务器)
配置Jupyter Notebook环境及Token认证(Linux服务器) 背景 在Ubuntu 18.04.6 LTS服务器(IP: 39.105.167.2)上,基于虚拟环境pytorch_env,通过Mac终端(SSH)配置Jupyter Notebook环境&…...
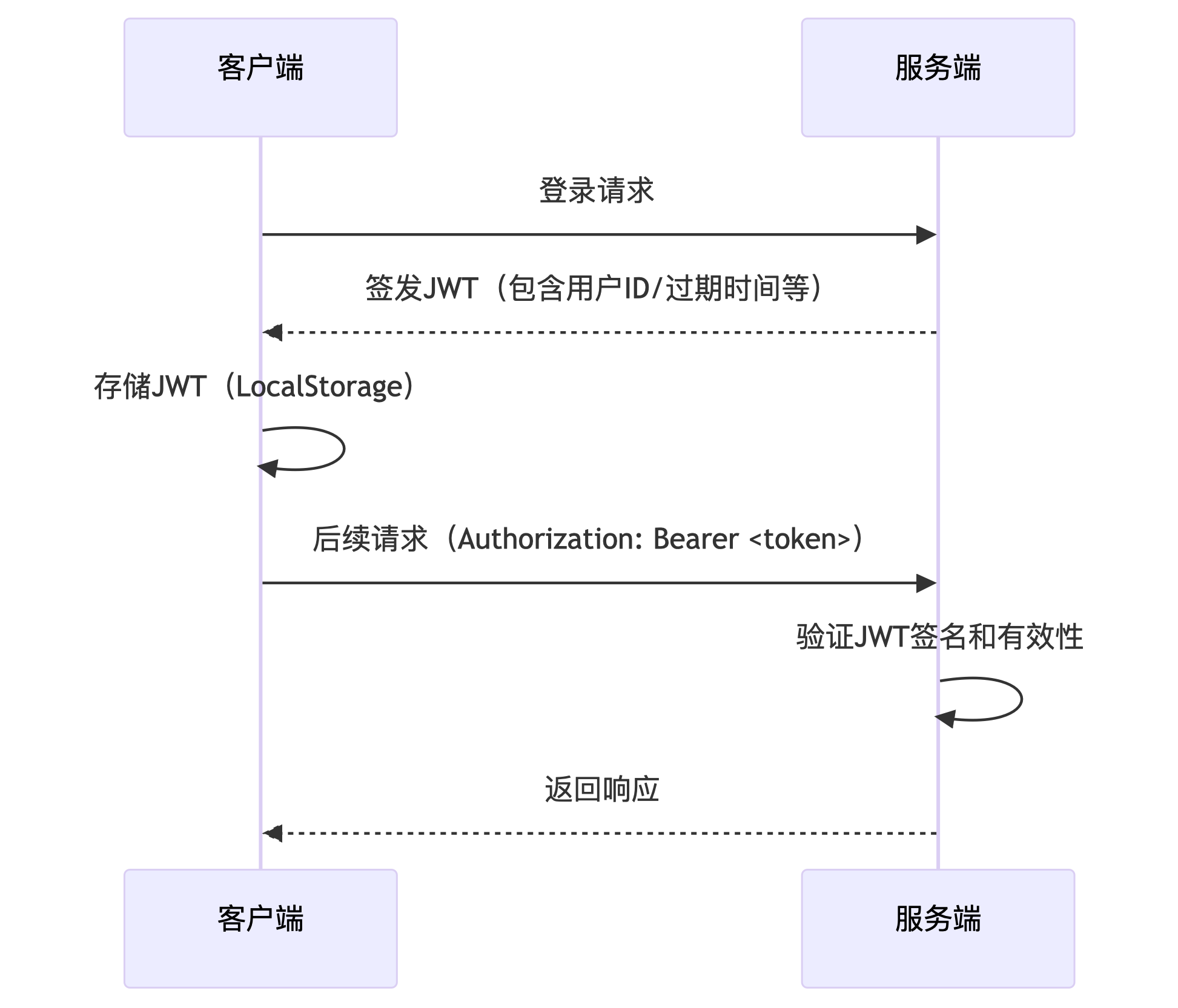
【计算机网络】Cookie、Session、Token之间有什么区别?
大家在日常使用浏览器时可能会遇到:是否清理Cookie?这个问题。 那么什么是Cookie呢?与此相关的还有Session、Token这些。这两个又是什么呢? 本文将对这三个进行讲解区分,如果对小伙伴有帮助的话,也请点赞、…...

SpringCloud服务拆分:Nacos服务注册中心 + LoadBalancer服务负载均衡使用
SpringCloud中Nacos服务注册中心 LoadBalancer服务负载均衡使用 前言Nacos工作流程nacos安装docker安装window安装 运行nacos微服务集成nacos高级特性1.服务集群配置方法效果图模拟服务实例宕机 2.权重配置3.环境隔离 如何启动集群节点本地启动多个节点方法 LoadBalancer集成L…...

Spring AI 集成 DeepSeek V3 模型开发指南
Spring AI 集成 DeepSeek V3 模型开发指南 前言 在人工智能飞速发展的当下,大语言模型不断推陈出新,DeepSeek AI 推出的开源 DeepSeek V3 模型凭借其卓越的推理和问题解决能力备受瞩目。与此同时,Spring AI 作为一个强大的框架,…...
Apache Doris 使用指南:从入门到生产实践
目录 一、Doris 核心概念 1.1 架构组成 1.2 数据模型 二、Doris 部署方式 2.1 单机部署(测试环境) 2.2 集群部署(生产环境) 三、数据操作指南 3.1 数据库与表管理 3.2 数据导入方式 3.2.1 批量导入 3.2.2 实时导入 3.…...

26届秋招收割offer指南
26届暑期实习已经陆续启动,这也意味着对于26届的同学们来说,“找工作”已经提上了日程。为了帮助大家更好地准备暑期实习和秋招,本期主要从时间线、学习路线、核心知识点及投递几方面给大家介绍,希望能为大家提供一些实用的建议和…...
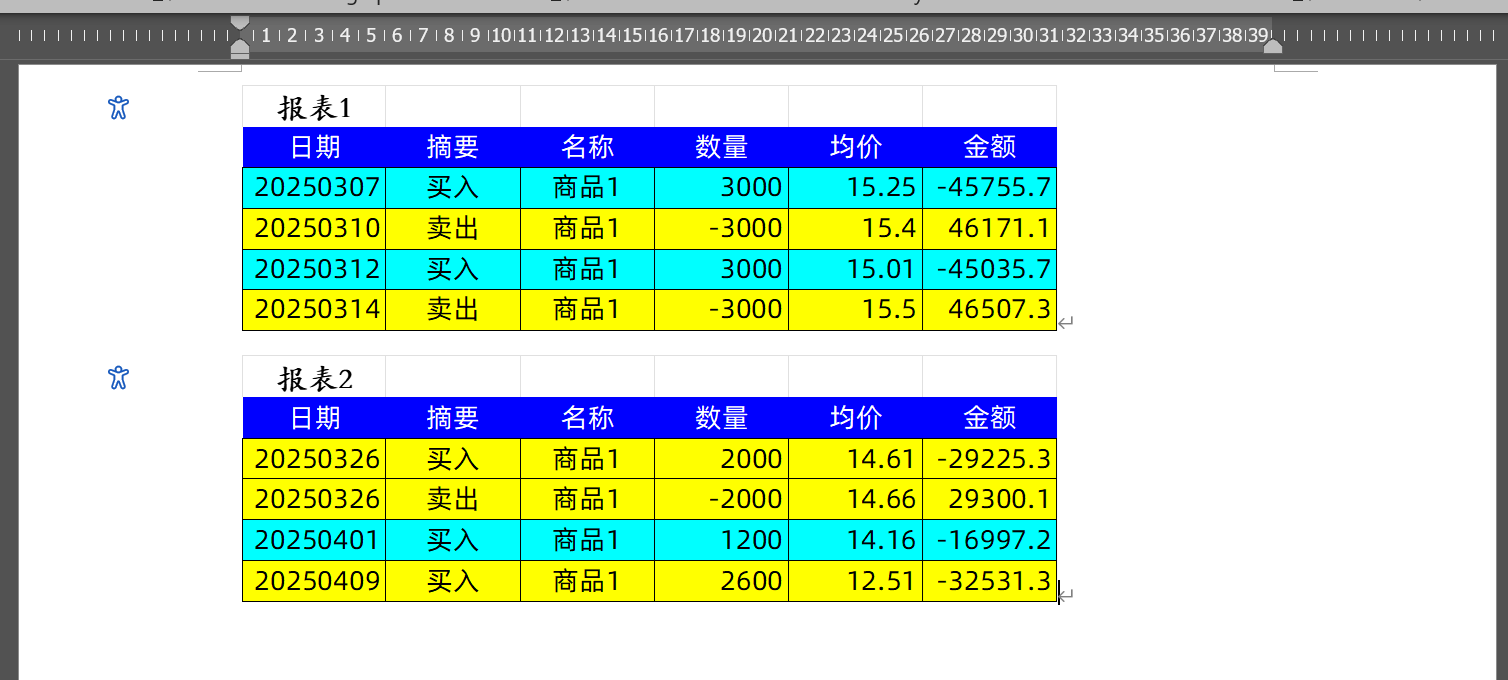
拷贝多个Excel单元格区域为图片并粘贴到Word
Excel工作表Sheet1中有两个报表,相应单元格区域分别定义名称为Report1和Report2,如下图所示。 现在需要将图片拷贝图片粘贴到新建的Word文档中。 示例代码如下。 Sub Demo()Dim oWordApp As ObjectDim ws As Worksheet: Set ws ThisWorkbook.Sheets(&…...

Kafka消息队列之 【消费者分组】 详解
消费者分组(Consumer Group)是 Kafka 提供的一种强大的消息消费机制,它允许多个消费者协同工作,共同消费一个或多个主题的消息,从而实现高吞吐量、可扩展性和容错性。 基本概念 消费者分组:一组消费者实例的集合,这些消费者实例共同订阅一个或多个主题,并通过分组来协调…...
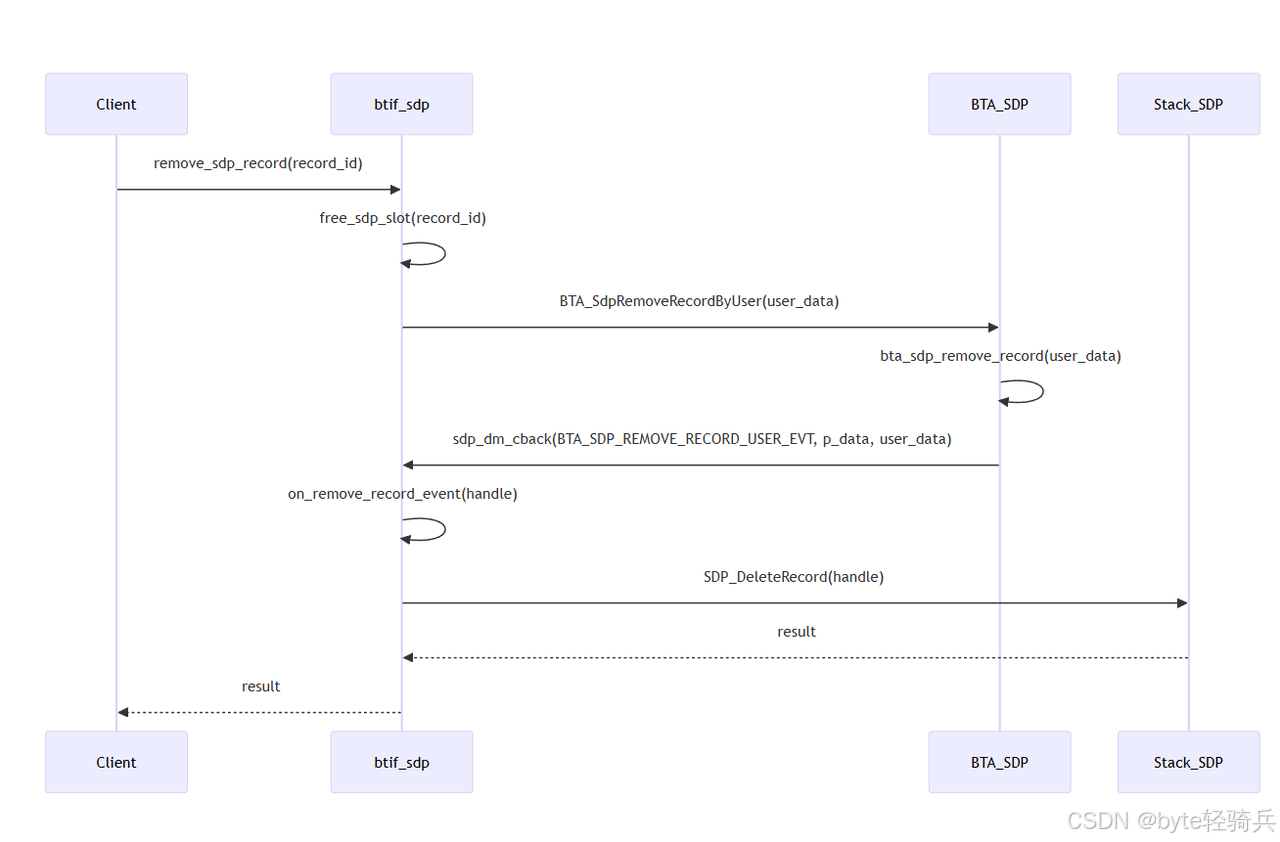
【Bluedroid】蓝牙 SDP(服务发现协议)模块代码解析与流程梳理
本文深入剖析Bluedroid蓝牙协议栈中 SDP(服务发现协议)服务记录的全生命周期管理流程,涵盖初始化、记录创建、服务搜索、记录删除等核心环节。通过解析代码逻辑与数据结构,揭示各模块间的协作机制,包括线程安全设计、回…...

中国自动驾驶研发解决方案,第一!
4月28日,IDC《中国汽车云市场(2024下半年)跟踪》报告发布,2024下半年中国汽车云市场整体规模达到65.1亿元人民币,同比增长27.4%。IDC认为,自动驾驶技术深化与生成式AI的发展将为汽车云打开新的成长天花板,推动云计算在…...
Kubernetes(k8s)学习笔记(四)--入门基本操作
本文通过kubernetes部署tomcat集群,来学习和掌握kubernetes的一些入门基本操作 前提条件 1.各个节点处于Ready状态; 2.配置好docker镜像库(否则会出现ImagePullBackOff等一些问题); 3.网络配置正常(否则即使应用发布没问题,浏…...

【项目篇之统一硬盘操作】仿照RabbitMQ模拟实现消息队列
统一硬盘操作 创建出实例封装交换机的操作封装队列的操作封装绑定的操作封装消息的操作总的完整代码: 我们之前已经使用了数据库去管理交换机,绑定,队列 还使用了数据文件去管理消息 此时我们就搞一个类去把上述两个部分都整合在一起&#…...

【基础复习笔记】计算机视觉
目录 一、计算机视觉基础 1. 卷积神经网络原理 2. 目标检测系列 二、算法与模型实现 1. 在PyTorch/TensorFlow中实现自定义损失函数或网络层的步骤是什么? 2. 如何设计一个轻量级模型用于移动端的人脸识别? 3. 描述使用过的一种注意力机制&#…...
基于 GO 语言的 Ebyte 勒索软件——简要分析
一种新的勒索软件变种,采用Go 语言编写,使用ChaCha20进行加密,并使用ECIES进行安全密钥传输,加密用户数据并修改系统壁纸。其开发者EvilByteCode曾开发过多种攻击性安全工具,现已在 GitHub 上公开 EByte 勒索软件。尽管该勒索软件声称仅用于教育目的,但滥用可能会导致严重…...
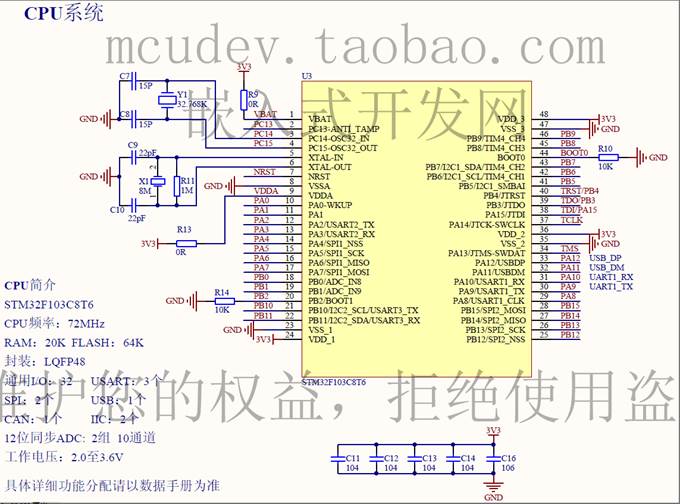
0基础 | STM32 | STM32F103C8T6开发板 | 项目开发
注:本专题系列基于该开发板进行,会分享源代码 F103C8T6核心板链接: https://pan.baidu.com/s/1EJOlrTcProNQQhdTT_ayUQ 提取码:8c1w 图 STM32F103C8T6开发板 1、黑色制版工艺、漂亮、高品质 2、入门级配置STM32芯片(SEM32F103…...

南京大学OpenHarmony技术俱乐部正式揭牌 仓颉编程语言引领生态创新
2025年4月24日,由OpenAtom OpenHarmony(以下简称“OpenHarmony”)项目群技术指导委员会与南京大学软件学院共同举办的“南京大学OpenHarmony技术俱乐部成立大会暨基础软件与生态应用论坛”在南京大学仙林校区召开。 大会聚焦国产自主编程语言…...
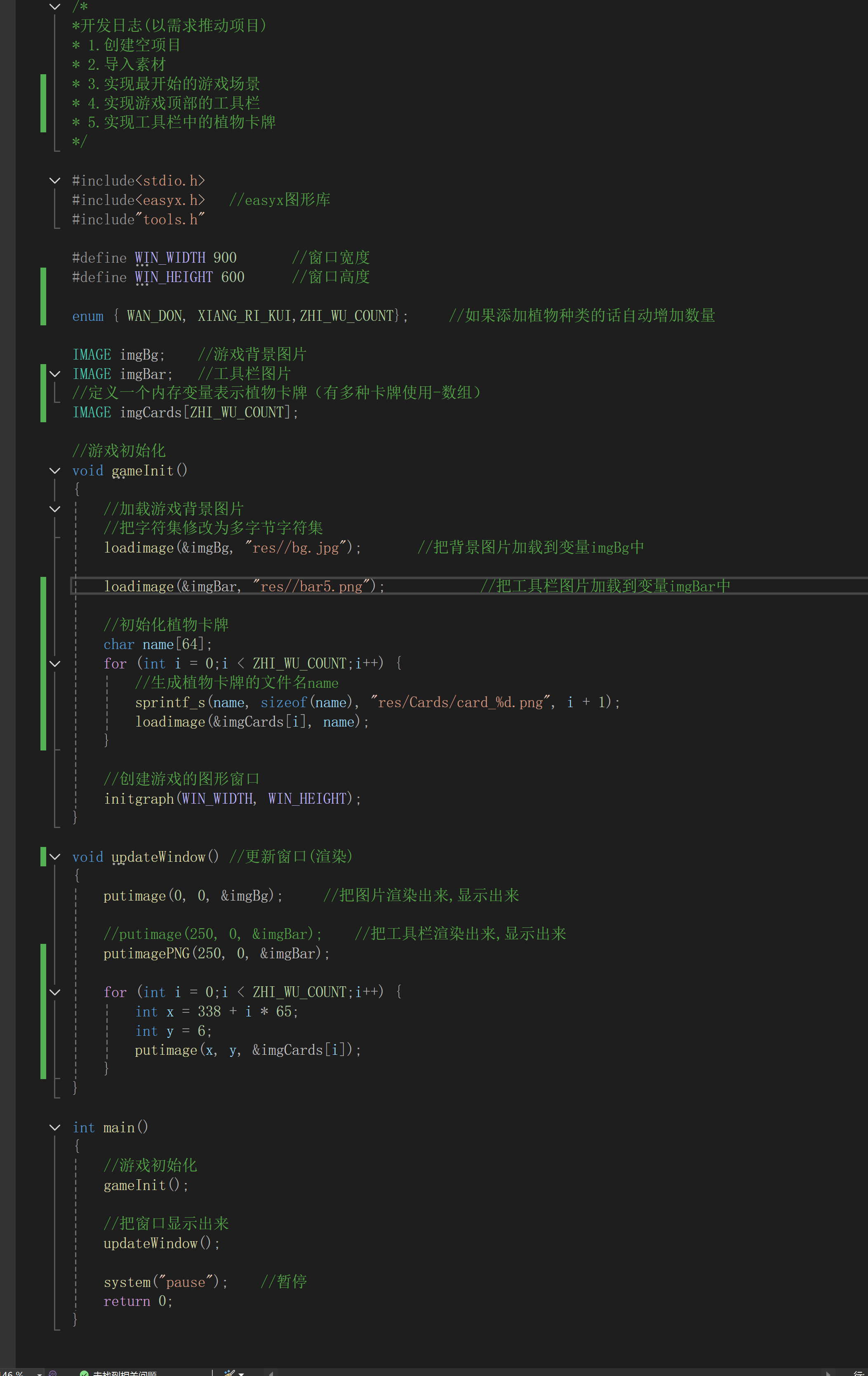
主场景 工具栏 植物卡牌的渲染
前置知识:使用easyx图形库 1.IMAGE内存变量存储的是一张位图(图像),存储了像素数据(颜色,尺寸等) 2.loadimage(&变量名,"加载的文件路径")表示从文件中加载图像到变量中 3. saveimage("文件路径", &变…...

计算机网络:深入分析三层交换机硬件转发表生成过程
三层交换机的MAC地址转发表生成过程结合了二层交换和三层路由的特性,具体可分为以下步骤: 一、二层MAC地址表学习(基础转发层) 初始状态 交换机启动时,MAC地址表为空,处于学习阶段。 数据帧接收与源MAC学习 当主机A发送数据帧到主机B时,交换机会检查数据帧的源MAC地址。…...