强化学习--2.数学
强化学习--数学
- 1、概率统计知识
- 1.1 随机变量与观测值
- 1.2 概率密度函数(PDF)
- 1.3 期望
- 1.4 随机抽样
- 2、数据期望E
- 3、正态分布
- 4、条件概率
- 1. **与多个条件相关**(依赖所有前置条件)
- 2. **仅与上一个条件相关**(马尔可夫性质)
- 5、马尔可夫
- 1、马尔可夫链
- 2、n 阶马尔可夫链
- 3、马尔可夫奖励过程/决策过程
- 4、隐马尔可夫
- 隐马尔可夫模型(HMM)
- 三个基本问题
- 前向算法、后向算法、Viterbi算法
- 6、KL散度(相对熵)
- 1、相对熵(KL散度)
- 2、交叉熵
- 7、贝尔曼方程
- **1. 定义问题**
- **2. 贝尔曼方程的推导**
- **状态值函数的贝尔曼方程**
- **动作值函数的贝尔曼方程**
- **3. 贝尔曼最优方程**
- **4. 关键思想**
- **总结**
- 8、强化学习知识点
1、概率统计知识
强化学习数学基础详解与示例
参考:https://blog.csdn.net/CltCj/article/details/119445005
1.1 随机变量与观测值
定义
随机变量是描述随机事件结果的变量,其取值具有不确定性;观测值则是随机事件实际发生后记录的具体结果。
示例:
假设抛一枚硬币,定义随机变量 X X X 表示抛硬币结果:正面记为 X = 1 X=1 X=1,反面记为 X = 0 X=0 X=0。抛硬币前, X X X 的取值是未知的,但概率分布已知( P ( X = 1 ) = 0.5 P(X=1)=0.5 P(X=1)=0.5, P ( X = 0 ) = 0.5 P(X=0)=0.5 P(X=0)=0.5)。若连续抛4次硬币,得到观测值序列 x 1 = 1 , x 2 = 0 , x 3 = 1 , x 4 = 1 x_1=1, x_2=0, x_3=1, x_4=1 x1=1,x2=0,x3=1,x4=1,这些具体数值即为观测值。
1.2 概率密度函数(PDF)
定义
概率密度函数描述随机变量在某一取值附近的相对可能性。
• 连续型分布:如高斯分布 N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2),其概率密度函数为:
p ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 p(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}} p(x)=2πσ1e−2σ2(x−μ)2
该函数表明随机变量在均值 μ \mu μ 附近取值的概率较高。
• 离散型分布:例如随机变量 X X X 的取值为 {1, 3, 7},对应的概率密度函数为:
P ( X = 1 ) = 0.2 , P ( X = 3 ) = 0.5 , P ( X = 7 ) = 0.3 P(X=1)=0.2, \quad P(X=3)=0.5, \quad P(X=7)=0.3 P(X=1)=0.2,P(X=3)=0.5,P(X=7)=0.3
所有可能取值的概率之和为1。
1.3 期望
定义
期望是随机变量所有可能取值的概率加权平均,反映其长期平均结果。
• 连续型期望:
E [ f ( X ) ] = ∫ − ∞ ∞ f ( x ) p ( x ) d x \mathbb{E}[f(X)] = \int_{-\infty}^{\infty} f(x) p(x) \, dx E[f(X)]=∫−∞∞f(x)p(x)dx
例如,高斯分布 X ∼ N ( 0 , 1 ) X \sim \mathcal{N}(0, 1) X∼N(0,1) 的期望为 μ = 0 \mu=0 μ=0 。
• 离散型期望:
E [ f ( X ) ] = ∑ x ∈ X f ( x ) P ( X = x ) \mathbb{E}[f(X)] = \sum_{x \in \mathcal{X}} f(x) P(X=x) E[f(X)]=x∈X∑f(x)P(X=x)
以离散分布 P ( X = 1 ) = 0.2 , P ( X = 3 ) = 0.5 , P ( X = 7 ) = 0.3 P(X=1)=0.2, P(X=3)=0.5, P(X=7)=0.3 P(X=1)=0.2,P(X=3)=0.5,P(X=7)=0.3 为例,其期望为:
E [ X ] = 1 × 0.2 + 3 × 0.5 + 7 × 0.3 = 3.8 \mathbb{E}[X] = 1 \times 0.2 + 3 \times 0.5 + 7 \times 0.3 = 3.8 E[X]=1×0.2+3×0.5+7×0.3=3.8
。
1.4 随机抽样
定义
随机抽样是从概率分布中生成观测值的过程,用于近似理论分布。
示例:
假设一个箱子中有红球(20%)、绿球(50%)、蓝球(30%),每次随机抽取一个球并记录颜色。重复多次后,观测值的分布会趋近理论概率。通过Python代码实现:
import numpy as np
samples = np.random.choice(['R', 'G', 'B'], size=100, p=[0.2, 0.5, 0.3])
结果可能为 ['G', 'B', 'R', 'G', ...],其中红球占比接近20%,绿球50%,蓝球30%。
强化学习中的关联应用
- 策略函数中的动作选择:策略 π ( a ∣ s ) \pi(a|s) π(a∣s) 可视为动作空间的概率密度函数,例如在状态 s s s 下,动作 a 1 a_1 a1 的概率为0.7, a 2 a_2 a2 为0.3,通过随机抽样决定实际动作。
- 状态转移的随机性:环境的状态转移概率 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a) 类似条件概率密度函数,例如智能体执行动作后,环境可能以80%概率转移到状态 s 1 s_1 s1,20%概率到 s 2 s_2 s2 。
- 蒙特卡洛方法:通过随机抽样轨迹估计状态价值函数,例如多次模拟游戏过程,计算平均回报以近似期望值。
2、数据期望E
https://zhuanlan.zhihu.com/p/481760712
离散型随机变量的一切可能的取值与对应的概率乘积之和称为该离散型随机变量的数学期望 [2](若该求和绝对收敛),记为E(x)




3、正态分布
https://baike.baidu.com/item/%E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83/829892
正态分布(Normal distribution),又称为常态分布或高斯分布,通常记作X~N(μ ,σ2)。其中, μ是正态分布的数学期望(均值), σ2是正态分布的方差。μ = 0,σ = 1的正态分布被称为标准正态分布 [1]。


4、条件概率
https://baike.baidu.com/item/%E6%9D%A1%E4%BB%B6%E6%A6%82%E7%8E%87/4475278
- 条件概率
条件概率是指事件A在事件B发生的条件下发生的概率。条件概率表示为:P(A|B),读作“A在B发生的条件下发生的概率”。若只有两个事件A,B,那么,。 - 联合概率
表示两个事件共同发生的概率。A与B的联合概率表示为 P(AB) 或者P(A,B),或者P(A∩B)。 [2] - 边缘概率
是某个事件发生的概率,而与其它事件无关。边缘概率是这样得到的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率)。这称为边缘化(marginalization)。A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
条件概率,多条件Xn,与多个条件相关和只与上一个条件相关:
当事件序列 X 1 , X 2 , … , X n X_1, X_2, \dots, X_n X1,X2,…,Xn 的条件概率依赖关系不同时,联合概率的计算方式也会不同。
1. 与多个条件相关(依赖所有前置条件)
• 定义:每个事件 X i X_i Xi 的条件概率依赖于之前所有事件 X 1 , X 2 , … , X i − 1 X_1, X_2, \dots, X_{i-1} X1,X2,…,Xi−1 的发生。
• 链式法则:
联合概率可分解为一系列条件概率的乘积,公式为:
P ( X 1 , X 2 , … , X n ) = P ( X 1 ) ⋅ P ( X 2 ∣ X 1 ) ⋅ P ( X 3 ∣ X 1 , X 2 ) ⋅ ⋯ ⋅ P ( X n ∣ X 1 , … , X n − 1 ) P(X_1, X_2, \dots, X_n) = P(X_1) \cdot P(X_2|X_1) \cdot P(X_3|X_1,X_2) \cdot \dots \cdot P(X_n|X_1,\dots,X_{n-1}) P(X1,X2,…,Xn)=P(X1)⋅P(X2∣X1)⋅P(X3∣X1,X2)⋅⋯⋅P(Xn∣X1,…,Xn−1)
- 概率计算:在这种情况下,计算事件 A 发生的概率 P(A|B,C,D) 可以用联合概率除以边缘概率的方法,即 P(A|B,C,D) = P(A,B,C,D)/P(B,C,D),其中 P(B,C,D) > 0。联合概率 P(A,B,C,D) 表示事件 A、B、C、D 同时发生的概率,边缘概率 P(B,C,D) 表示事件 B、C、D 同时发生的概率。
2. 仅与上一个条件相关(马尔可夫性质)
• 定义:每个事件 X i X_i Xi 的条件概率仅依赖于前一个事件 X i − 1 X_{i-1} Xi−1,即 P ( X i ∣ X 1 , … , X i − 1 ) = P ( X i ∣ X i − 1 ) P(X_i|X_1,\dots,X_{i-1}) = P(X_i|X_{i-1}) P(Xi∣X1,…,Xi−1)=P(Xi∣Xi−1)。
• 简化形式:
联合概率可简化为:
P ( X 1 , X 2 , … , X n ) = P ( X 1 ) ⋅ P ( X 2 ∣ X 1 ) ⋅ P ( X 3 ∣ X 2 ) ⋅ ⋯ ⋅ P ( X n ∣ X n − 1 ) P(X_1, X_2, \dots, X_n) = P(X_1) \cdot P(X_2|X_1) \cdot P(X_3|X_2) \cdot \dots \cdot P(X_n|X_{n-1}) P(X1,X2,…,Xn)=P(X1)⋅P(X2∣X1)⋅P(X3∣X2)⋅⋯⋅P(Xn∣Xn−1)
这种形式常见于时序模型(如马尔可夫链),例如网页 6 提到的股票价格预测中,当前价格可能仅依赖前一时段的价格。
- 概率计算:在这种情况下,条件概率可以简化为 P(A|B),而不必考虑更前面的条件。例如,在一个二阶马尔可夫链中,事件 A 发生的概率只与前两个事件有关,即 P(A|B,C),但与更早的事件无关。不过,对于一阶马尔可夫链,就只考虑前一个事件,即 P(A|B)。
5、马尔可夫
https://zhuanlan.zhihu.com/p/489239366
https://zhuanlan.zhihu.com/p/448575579
1、马尔可夫链
俄国数学家 Andrey Andreyevich Markov 研究并提出一个用数学方法就能解释自然变化的一般规律模型,被命名为马尔科夫链(Markov Chain)。马尔科夫链为状态空间中经过从一个状态到另一个状态的转换的随机过程,该过程要求具备“无记忆性 ”,即下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性 ”称作马尔可夫性质。
状态转移矩阵的稳定性:
状态转移矩阵有一个非常重要的特性,经过一定有限次数序列的转换,最终一定可以得到一个稳定的概率分布 ,且与初始状态概率分布无关。
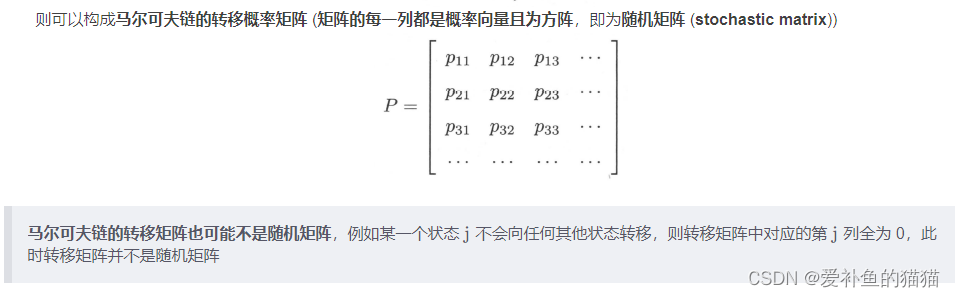
马尔科夫链(Markov Chain)-随机餐厅
https://zhuanlan.zhihu.com/p/489239366

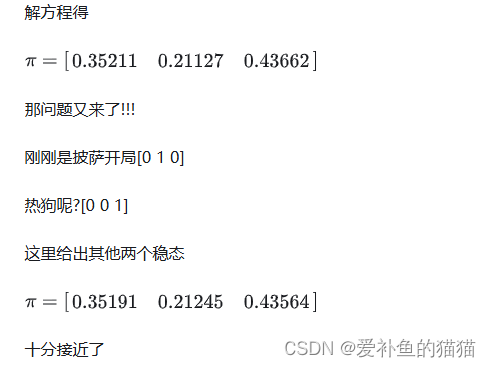
2、n 阶马尔可夫链
http://www.mselab.cn/media/files/B03.%E9%A9%AC%E5%B0%94%E5%8F%AF%E5%A4%AB%E6%A8%A1%E5%9E%8B.pdf
马尔科夫过程是指过程中的状态的转移依赖于之前的状态,当影响转移状态的数目是n时,这个过程被称为 n阶马尔科夫模型.

N-Gram最简单有效,所以应用的也最广泛。它基于独立输入假设:第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。
应用:
让机器“听懂”人类的语言,两个马尔科夫模型就解决了:
声学模型:利用HMM建模(隐马尔可夫模型),HMM是指这一马尔可夫模型的内部状态外界不可见,外界只能看到各个时刻的输出值。对语音识别系统,输出值通常就是从各个帧计算而得的声学特征。
语言模型:N-Gram最简单有效,所以应用的也最广泛。它基于独立输入假设:第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。

3、马尔可夫奖励过程/决策过程
https://www.cnblogs.com/jsfantasy/p/jsfantasy.html
https://blog.csdn.net/qq_33302004/article/details/115027798
马尔科夫过程又叫做马尔科夫链(Markov Chain),它是一个无记忆的随机过程,可以用一个元组<S, P>表示。(上节回顾)。



马尔科夫奖励过程: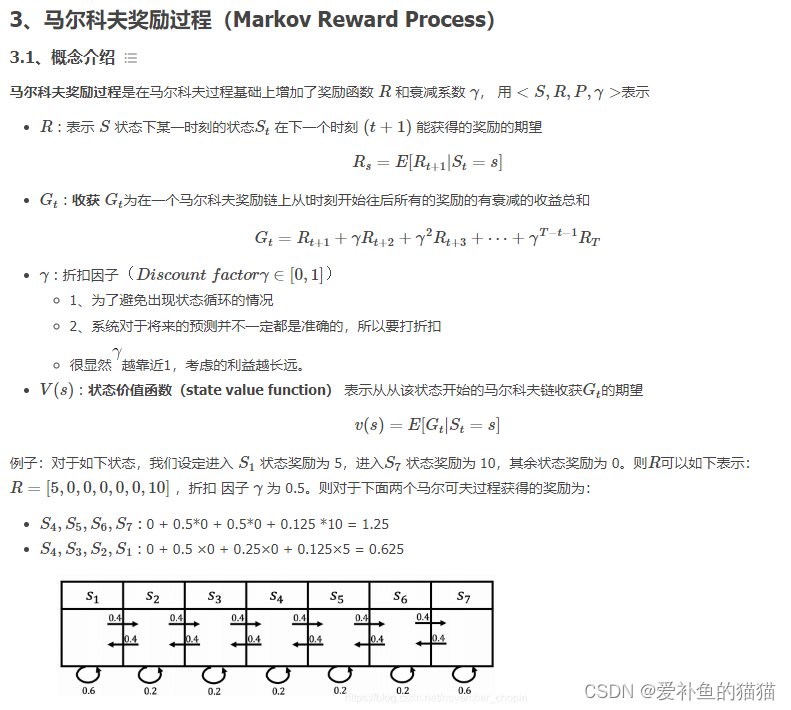
通过贝尔曼方程,可以看到价值函数有两部分组成,一个是当前获得的奖励的期望,另一个是下一时刻的状态期望,即下一时刻 可能的状态能获得奖励期望与对应状态转移概率乘积的和,最后在加上折扣。

马尔科夫决策过程(Markov Decision Process),马尔科夫决策过程是在马尔科夫奖励过程的基础上加了 Decision 过程,相当于多了一个动作集合。最优价值函数
解决强化学习问题意味着要寻找一个最优的策略让个体在与环境交互过程中获得始终比其它策略都要多的收获,这个最优策略我们可以用 π 表示。一旦找到这个最优策略π ,那么我们就解决了这个强化学习问题。一般来说,比较难去找到一个最优策略,但是可以通过比较若干不同策略的优劣来确定一个较好的策略,也就是局部最优解。

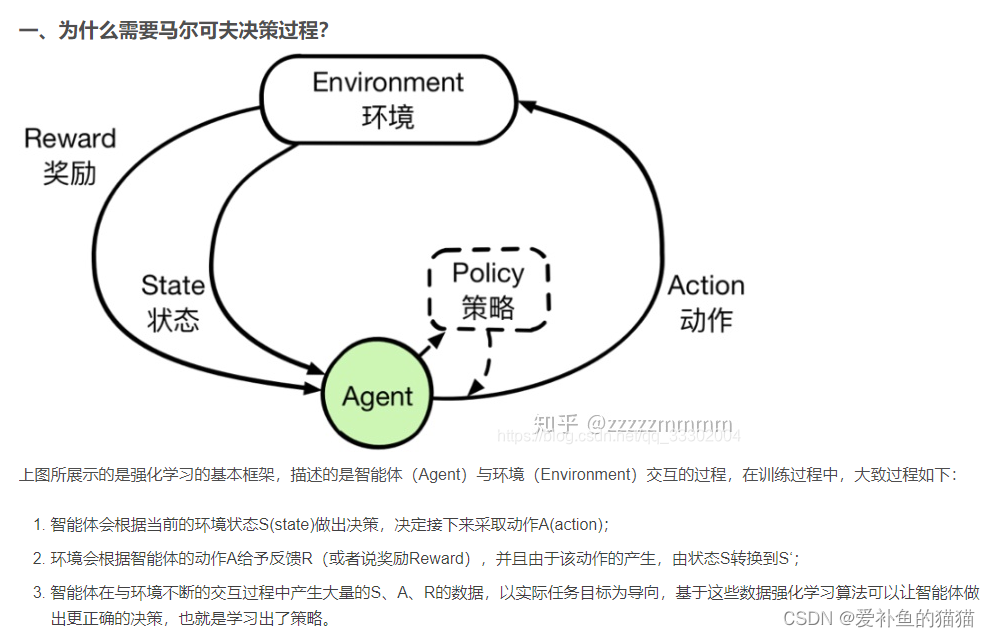
4、隐马尔可夫
https://zhuanlan.zhihu.com/p/35651762
https://zhuanlan.zhihu.com/p/151011287
https://zhuanlan.zhihu.com/p/547259609
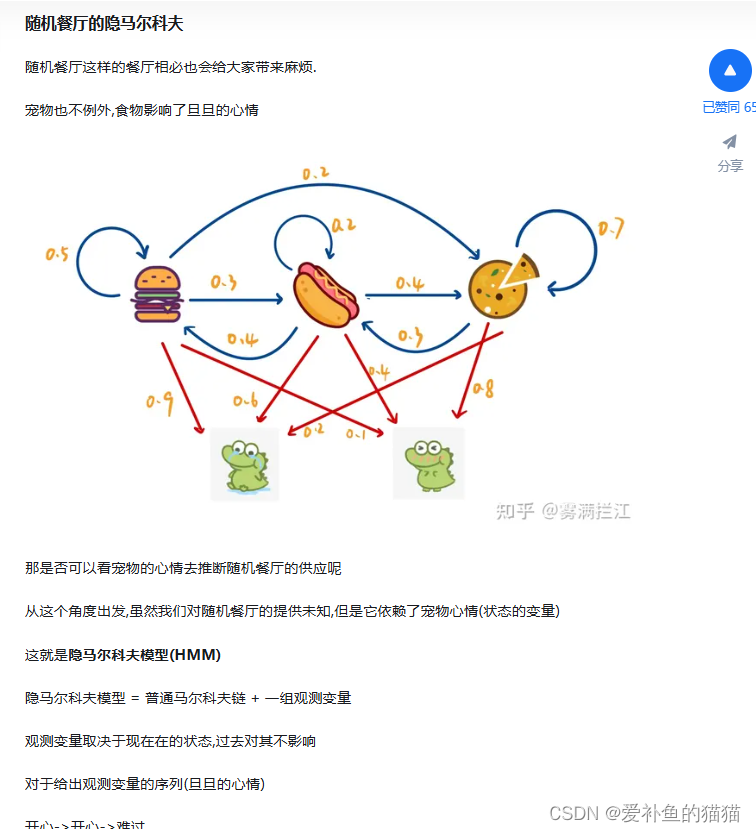
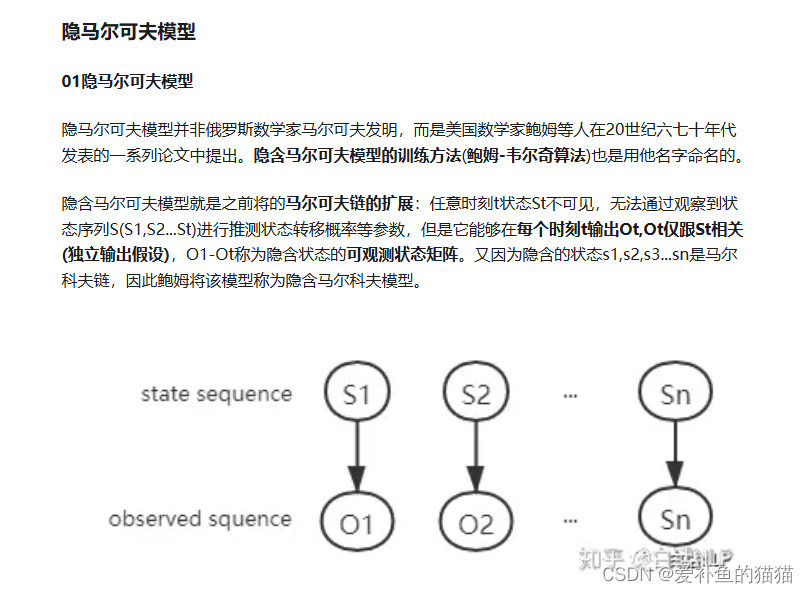
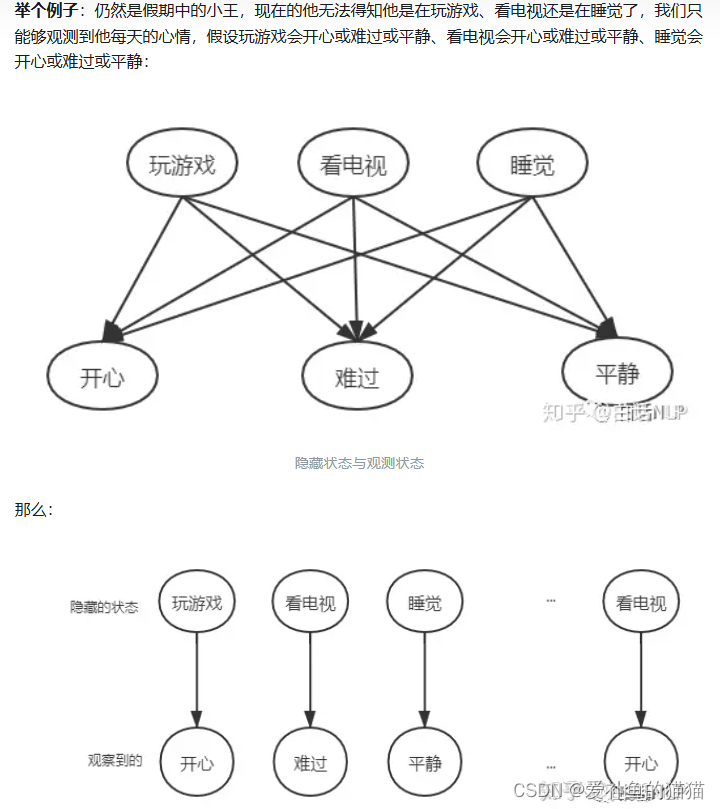
隐马尔可夫模型(HMM)
隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言应用领域。经过长期发展,尤其在语音识别中成功应用,使它成为一种通用的统计工具。

三个基本问题
https://blog.csdn.net/qq_52785580/article/details/135746941
https://zhuanlan.zhihu.com/p/151011287
https://zhuanlan.zhihu.com/p/88362664

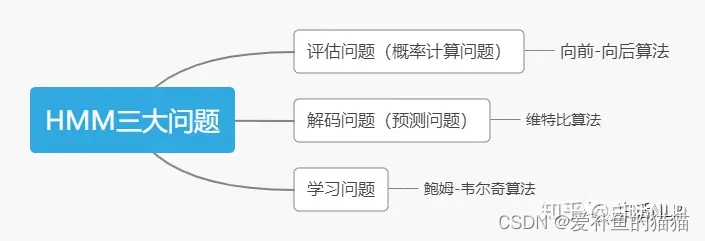

前向算法、后向算法、Viterbi算法
https://zhuanlan.zhihu.com/p/35651762
https://zhuanlan.zhihu.com/p/547259609
https://zhuanlan.zhihu.com/p/29938926






6、KL散度(相对熵)
https://blog.csdn.net/Rocky6688/article/details/103470437
https://zhuanlan.zhihu.com/p/74075915
信息量、熵、相对熵(KL散度)、交叉熵、JS散度、推土机理论、Wasserstein距离、WGAN中对JS散度,KL散度和推土机距离的描述
1、相对熵(KL散度)
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异。
在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布,那么KL散度就可以计算两个分布的差异,也就是Loss损失值。
从KL散度公式中可以看到Q的分布越接近P(Q分布越拟合P),那么散度值越小,即损失值越小。
因为对数函数是凸函数,所以KL散度的值为非负数。
有时会将KL散度称为KL距离,但它并不满足距离的性质:
KL散度不是对称的;
KL散度不满足三角不等式。

2、交叉熵

7、贝尔曼方程
贝尔曼方程,又叫动态规划方程,是以Richard Bellman命名的,表示动态规划问题中相邻状态关系的方程。某些决策问题可以按照时间或空间分成多个阶段,每个阶段做出决策从而使整个过程取得效果最优的多阶段决策问题,可以用动态规划方法求解。某一阶段最优决策的问题,通过贝尔曼方程转化为下一阶段最优决策的子问题,从而初始状态的最优决策可以由终状态的最优决策(一般易解)问题逐步迭代求解。存在某种形式的贝尔曼方程,是动态规划方法能得到最优解的必要条件。绝大多数可以用最优控制理论解决的问题,都可以通过构造合适的贝尔曼方程来求解。
贝尔曼方程是强化学习中描述状态值函数(或动作值函数)递归关系的核心方程,其推导基于马尔科夫决策过程(MDP)和全期望公式。以下是关键步骤和逻辑:
1. 定义问题
- 状态值函数 V π ( s ) V^\pi(s) Vπ(s):在策略 π \pi π 下,从状态 s s s 开始的期望累积回报:
V π ( s ) = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] V^\pi(s) = \mathbb{E}_\pi\left[ \sum_{k=0}^\infty \gamma^k R_{t+k+1} \mid S_t = s \right] Vπ(s)=Eπ[k=0∑∞γkRt+k+1∣St=s]
其中 γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1] 是折扣因子, R t + k + 1 R_{t+k+1} Rt+k+1 是未来奖励。 - 动作值函数 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a):在状态 s s s 执行动作 a a a 后,遵循策略 π \pi π 的期望累积回报:
Q π ( s , a ) = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] Q^\pi(s,a) = \mathbb{E}_\pi\left[ \sum_{k=0}^\infty \gamma^k R_{t+k+1} \mid S_t = s, A_t = a \right] Qπ(s,a)=Eπ[k=0∑∞γkRt+k+1∣St=s,At=a]

2. 贝尔曼方程的推导
状态值函数的贝尔曼方程
- 分解回报:将累积回报拆分为即时奖励和未来奖励:
V π ( s ) = E π [ R t + 1 + γ ∑ k = 1 ∞ γ k − 1 R t + k + 1 ∣ S t = s ] V^\pi(s) = \mathbb{E}_\pi\left[ R_{t+1} + \gamma \sum_{k=1}^\infty \gamma^{k-1} R_{t+k+1} \mid S_t = s \right] Vπ(s)=Eπ[Rt+1+γk=1∑∞γk−1Rt+k+1∣St=s] - 利用马尔科夫性质:下一状态 s ′ s' s′ 的转移概率仅依赖当前状态 s s s 和动作 a a a,即 P ( s ′ ∣ s , a ) P(s' \mid s, a) P(s′∣s,a),且策略 π ( a ∣ s ) \pi(a \mid s) π(a∣s) 决定动作选择。
- 全期望公式展开:
V π ( s ) = ∑ a π ( a ∣ s ) [ R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V π ( s ′ ) ] V^\pi(s) = \sum_{a} \pi(a \mid s) \left[ R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) V^\pi(s') \right] Vπ(s)=a∑π(a∣s)[R(s,a)+γs′∑P(s′∣s,a)Vπ(s′)]
其中 R ( s , a ) = E [ R t + 1 ∣ S t = s , A t = a ] R(s,a) = \mathbb{E}[R_{t+1} \mid S_t=s, A_t=a] R(s,a)=E[Rt+1∣St=s,At=a] 是即时奖励期望 。
动作值函数的贝尔曼方程
- 类似地,对 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a) 进行分解:
Q π ( s , a ) = R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) ∑ a ′ π ( a ′ ∣ s ′ ) Q π ( s ′ , a ′ ) Q^\pi(s,a) = R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) \sum_{a'} \pi(a' \mid s') Q^\pi(s',a') Qπ(s,a)=R(s,a)+γs′∑P(s′∣s,a)a′∑π(a′∣s′)Qπ(s′,a′)
即当前动作 a a a 的价值等于即时奖励加上未来动作价值的期望 。
3. 贝尔曼最优方程
若策略 π \pi π 是最优策略 π ∗ \pi^* π∗,则值函数满足贝尔曼最优方程:
V ∗ ( s ) = max a [ R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V ∗ ( s ′ ) ] V^*(s) = \max_a \left[ R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) V^*(s') \right] V∗(s)=amax[R(s,a)+γs′∑P(s′∣s,a)V∗(s′)]
Q ∗ ( s , a ) = R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) max a ′ Q ∗ ( s ′ , a ′ ) Q^*(s,a) = R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) \max_{a'} Q^*(s',a') Q∗(s,a)=R(s,a)+γs′∑P(s′∣s,a)a′maxQ∗(s′,a′)
最优方程通过最大化未来价值,体现了“贪心”策略的选择 。
4. 关键思想
- 递归关系:当前状态的价值由即时奖励和未来状态的价值共同决定,形成递归结构 。
- 动态规划基础:贝尔曼方程是动态规划求解最优策略的核心,通过迭代更新值函数逼近最优解 。
- 折扣因子 γ \gamma γ:控制未来奖励的重要性, γ = 0 \gamma=0 γ=0 时仅关注即时奖励, γ = 1 \gamma=1 γ=1 时完全考虑长期回报 。
总结
贝尔曼方程通过将复杂的时间序列问题转化为递归形式,为强化学习提供了数学基础。其推导依赖于MDP的马尔科夫性、全期望公式和最优性原理 。
8、强化学习知识点
强化学习知识点链接
相关文章:
强化学习--2.数学
强化学习--数学 1、概率统计知识1.1 随机变量与观测值1.2 概率密度函数(PDF)1.3 期望1.4 随机抽样 2、数据期望E3、正态分布4、条件概率1. **与多个条件相关**(依赖所有前置条件)2. **仅与上一个条件相关**(马尔可夫性…...

边缘计算:开启智能新时代的“秘密武器”
大家好,我是沛哥儿,我们又见面了。今天我们来简单说下什么是边缘计算,它怎么工作的,有哪些优势。有哪些具体的应用场景。 文章目录 1、边缘计算是什么?2、边缘计算如何工作?3、边缘计算有哪些优势ÿ…...
# 如何使用 PyQt5 创建一个简单的警报器控制界面
如何使用 PyQt5 创建一个简单的警报器控制界面 引言 在现代自动化和监控系统中,警报器扮演着至关重要的角色。它们可以提醒我们注意潜在的危险或紧急情况。在这篇文章中,我将向您展示如何使用Python的PyQt5库创建一个简单的警报器控制界面。这个界面将…...
MySQL报错解决过程
我在调试datagrip的时候,显示拒绝连接,开始的时候,我以为只是服务没有开启,结果到后来在网上搜索各种解决办法无果后,就选择卸载,卸载之后安装新的MySQL 以下就是我的解决过程。 如果只是在使用外置软件&…...
【AI入门】CherryStudio入门5:创建知识库,对接Obsidian 笔记
前言 来吧,继续CherryStudio的实践,前边给Cherry Studio添加知识库,对接思源笔记,但美中不足,思源笔记得导出再导入知识库,本文看一下obsidian笔记,笔记内容直接被知识库使用,免去导…...
Redis 8.0正式发布,再次开源为哪般?
Redis 8.0 已经于 2025 年 5 月 1 日正式发布,除了一些新功能和性能改进之外,一个非常重要的改变就是新增了开源的 AGPLv3 协议支持,再次回归开源社区。 为什么说再次呢?这个需要从 2024 年 3 月份 Redis 7.4 说起,因为…...
【Redis】Redis常用命令
4.Redis常见命令 4.1 Redis数据结构介绍 Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样: 命令太多,不需要死记,学会查询就好了~ Redis为了方便我们学习,将操作不同数据类型…...
NGINX)
负载均衡算法解析(一)NGINX
文章目录 1. 核心数据结构:算法的基石1.1 负载均衡节点结构:定义服务器实体1.2 关键概念阐述:权重 (Weight) 2. NGINX加权轮询算法旨在解决的具体问题深度分析2.1 应对后端服务器间的负载不均衡问题2.2 后端服务健康状态的动态感知与自适应调…...

计算机网络——HTTP/IP 协议通俗入门详解
HTTP/IP 协议通俗入门详解 一、什么是 HTTP 协议?1. 基本定义2. HTTP 是怎么工作的? 二、HTTP 协议的特点三、HTTPS 是什么?它和 HTTP 有啥区别?1. HTTPS 概述2. HTTP vs HTTPS 四、HTTP 的通信过程步骤详解: 五、常见…...

ChromeDriverManager的具体用法
ChromeDriverManager 是 webdriver_manager 库的一部分,它用于自动管理 ChromeDriver 的下载和更新。使用 ChromeDriverManager 可以避免手动下载 ChromeDriver 并匹配系统中安装的 Chrome 浏览器版本。以下是 ChromeDriverManager 的基本用法: 步骤 1…...

DeepSeek Copilot idea插件推荐
🌌 DeepSeek Copilot for IntelliJ IDEA 让 AI 成为你的编程副驾驶,极速生成单元测试 & 代码注释驱动开发! 🚀 简介 DeepSeek Copilot 是一款为 IntelliJ IDEA 打造的 AI 编程助手插件,它能够智能分析你的代码逻辑…...

贪心算法应用:最小反馈顶点集问题详解
贪心算法应用:最小反馈顶点集问题详解 1. 问题定义与背景 1.1 反馈顶点集定义 反馈顶点集(Feedback Vertex Set, FVS)是指在一个有向图中,删除该集合中的所有顶点后,图中将不再存在任何有向环。换句话说,反馈顶点集是破坏图中所…...

游戏引擎学习第259天:OpenGL和软件渲染器清理
回顾并为今天的内容做好铺垫 今天,我们将对游戏的分析器进行升级。在之前的修复中,我们解决了分析器的一些敏感问题,例如它无法跨代码重新加载进行分析,以及一些复杂的小问题。现在,我们的分析器看起来已经很稳定了。…...

一篇文章看懂时间同步服务
Linux 系统时间与时区管理 一、时间与时钟类型 时钟类型说明管理工具系统时钟由 Linux 内核维护的软件时钟,基于时区配置显示时间timedatectl硬件时钟 (RTC)主板上的物理时钟,通常以 UTC 或本地时间存储,用于系统启动时初始化时间hwclock …...
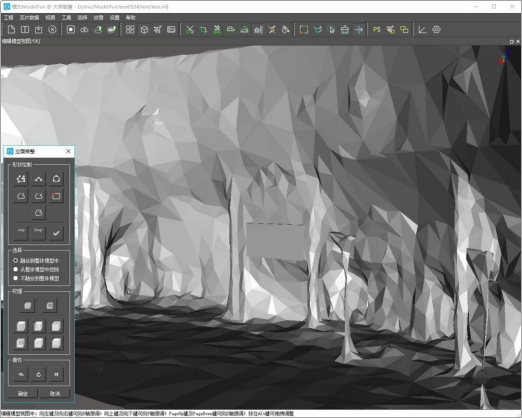
12.模方ModelFun工具-立面修整
摘要:本文主要介绍模方ModelFun修模工具——立面修整的操作方法。 点击工具栏即可找到立面修整工具,点击可打开并使用该工具,如下图: 图 工具菜单栏 (1)截面绘制: 快速绘制竖直矩形࿱…...

git命令常见用法【持续更新中……】
一、已有本地代码,在gitee创建了空仓库后想将代码与该仓库相连 在本地项目目录下初始化Git # 1. 初始化本地仓库 git init# 2. 添加所有文件到暂存区 git add .# 3. 提交第一个版本 git commit -m "Initial commit: 项目初始化"将本地仓库关联到Gitee 根…...
Docker 渡渡鸟镜像同步站 使用教程
Docker 渡渡鸟镜像同步站 使用教程 🚀 介绍 Docker.aityp.com(渡渡鸟镜像同步站)是一个专注于为国内开发者提供 Docker 镜像加速和同步服务的平台。它通过同步官方镜像源(如 Docker Hub、GCR、GHCR 等),为…...

Python TensorFlow库【深度学习框架】全面讲解与案例
一、TensorFlow 基础知识 1. 核心概念 张量 (Tensor): 多维数组,是 TensorFlow 的基本数据单位(标量、向量、矩阵等)。计算图 (Graph): 早期版本中的静态图机制(TF2.x 默认启用动态图)。会话 (Session): 在 TF1.x 中用于执行计算图(TF2.x 中已弃用)。2. 基本操作 impo…...

火影bug,未保证短时间数据一致性,拿这个例子讲一下Redis
本文只拿这个游戏的bug来举例Redis,如果有不妥的地方,联系我进行删除 描述:今天在高速上打火影(有隧道,有时候会卡),发现了个bug,我点了两次-1000的忍玉(大概用了1千七百…...

Power Query 是 Excel 和 Power BI 中强大的数据获取、转换和加载工具
Power Query 链接是什么 Power Query 是 Excel 和 Power BI 中强大的数据获取、转换和加载工具。Power Query 链接指的是在 Excel 或 Power BI 里通过 Power Query 建立的与外部数据源的连接。这些数据源可以是各种类型,像文本文件(CSV、TXT)…...

探索元生代:ComfyUI 工作流与计算机视觉的奇妙邂逅
目录 一、引言 二、蓝耘元生代和 ComfyUI 工作流初印象 (一)蓝耘元生代平台简介 (二)ComfyUI 工作流创建是啥玩意儿 三、计算机视觉是个啥 (一)计算机视觉的基本概念 (二)计算…...
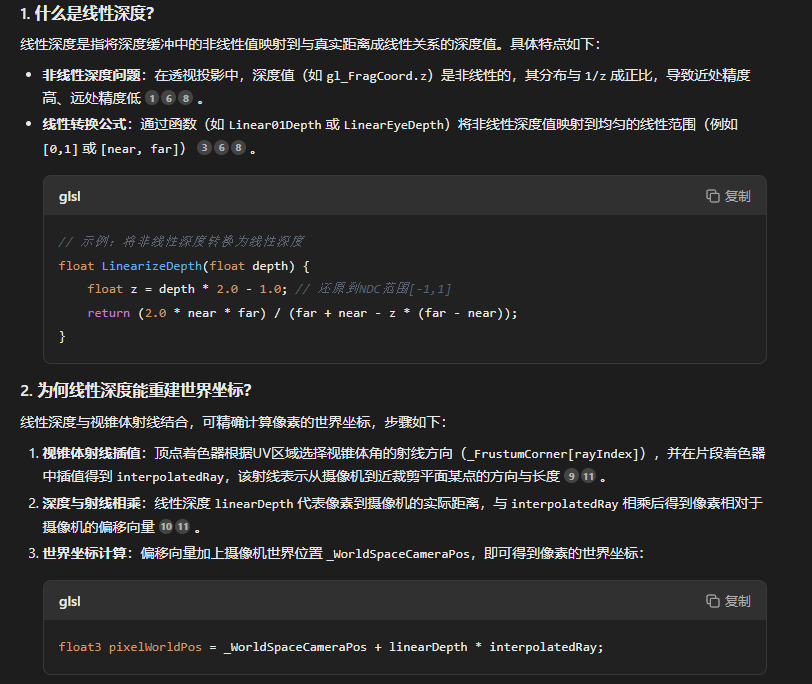
Unity-Shader详解-其五
关于Unity的Shader部分的基础知识其实已经讲解得差不多了,今天我们来一些实例分享: 溶解 效果如下: 代码如下: Shader "Chapter8/chapter8_1" {Properties{// 定义属性[NoScaleOffset]_Albedo("Albedo", 2…...

【Java 专题补充】流程控制语句
流程控制语句是用来控制程序中各语句执行顺序的语句,是程序中既基本又非常关键的部分。流程控制语句可以把单个的语句组合成有意义的、能完成一定功能的小逻辑模块。最主要的流程控制方式是结构化程序设计中规定的三种基本流程结构。 1.1 结构化程序设计的三种基本流…...

恶心的win11更新DIY 设置win11更新为100年
打开注册表编辑器:按下Win R键,输入regedit,然后按回车打开注册表编辑器。12导航到指定路径:在注册表编辑器中,依次展开HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings新建DWORD值&…...

【ArcGIS微课1000例】0146:将多个文件夹下的影像移动到一个目标文件夹(以Landscan数据为例)
本文讲述将多个文件夹下的影像移动到一个目标文件夹,便于投影变换、裁剪等操作。 文章目录 一、数据准备二、解压操作三、批量移动四、查看效果五、ArcGIS操作一、数据准备 全球人口数据集Landscan2000-2023如下所示,每年数据位一个压缩包: 二、解压操作 首先将其解压,方…...
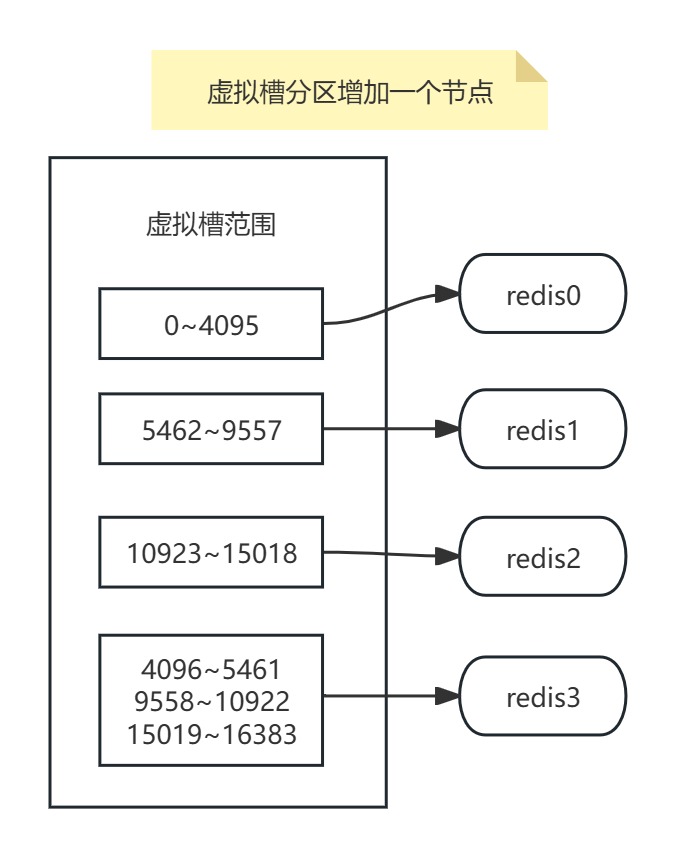
【redis】分片方案
Redis分片(Sharding)是解决单机性能瓶颈的核心技术,其本质是将数据分散存储到多个Redis节点(实例)中,每个实例将只是所有键的一个子集,通过水平扩展提升系统容量和性能。 分片的核心价值 性能提…...
springboot+mysql+element-plus+vue完整实现汽车租赁系统
目录 一、项目介绍 二、项目截图 1.项目结构图 三、系统详细介绍 管理后台 1.登陆页 2.管理后台主页 3.汽车地点管理 4.汽车类别 5.汽车品牌 6.汽车信息 7.用户管理 8.举报管理 9.订单管理 10.轮播图管理 11.交互界面 12.图表管理 汽车租赁商城 1.首页 2.汽…...

Linux第四节:进程控制
一、进程创建 1.1 fork函数 1. fork函数有两个返回值问题 返回的本质就是写入!所以,谁先返回,谁就先写入id,因为进程具有独立性,会发生写时拷贝,父进程和子进程各自指向return语句。 2. fork返回后&#x…...

Qt 编译 sqldrivers之psql
编译postgres pgsql驱动 下载驱动源码修改配置文件编译 下载驱动源码 // 源代码下载 https://download.qt.io/archive/qt/5.15/5.15.2/submodules/驱动目录:qtbase-everywhere-src-5.15.2\src\plugins\sqldrivers 修改配置文件 打开pro文件 右键点击添加库 此处的为debu…...

382_C++_在用户会话结束时,检查是否有其他会话仍然来自同一个客户端 IP 地址,没有连接状态设置为断开,否则为连接
之前出现的问题:重启管理机,工作机上面热备连接状态显示未连接 (此时是有一个工作机连接管理机的),所以正常应该是连接状态解决:根因分析: 重启管理机后,管理机给过来的cookie是空的,导致工作机同时存在两个管理机的session,在其中一个超时后,调用回调函数通知会话断开…...