缓存(1):三级缓存
三级缓存是指什么
我们常说的三级缓存如下:
- CPU三级缓存
- Spring三级缓存
- 应用架构(JVM、分布式缓存、db)三级缓存
CPU
基本概念
CPU 的访问速度每 18 个月就会翻 倍,相当于每年增⻓ 60% 左右,内存的速度当然也会不断增⻓,但是增⻓的速度远小于 CPU,平均每年 只增⻓ 7% 左右。于是,CPU 与内存的访问性能的差距不断拉大。
为了弥补 CPU 与内存两者之间的性能差异,就在 CPU 内部引入了 CPU Cache,也称高速缓存。
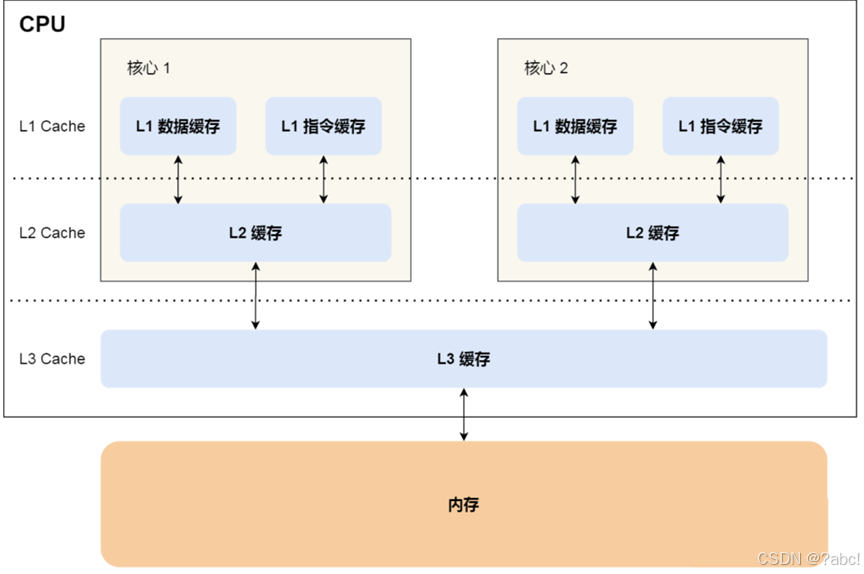
CPU Cache 通常分为大小不等的三级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache。其中L3是多个核心共享的。
离 CPU 核心越近,缓存的读写速度就越快
但 CPU 的空间很狭小,离 CPU 越近缓存大小受到的限制也越大。
所以,综合硬件布局、性能等因素,CPU 缓存通常分为大小不等的三级缓存。
三级缓存要比一、二级缓存大许多倍,这是因为当下的 CPU 都是多核心的,
每个核心都有自己的一、二级缓存,- 但
三级缓存却是一颗 CPU 上所有核心共享的 缓存一致性:在多核CPU时代,CPU有“缓存一致性”原则,也就是说每个处理器(核)都会通过嗅探在总线上传播的数据来检查自己的缓存值是不是过期了。如果过期了,则失效。- 比如声明volitate,当变量被修改,则会立即要求写入系统内存。
程序执行数据流向
顺序如下
- 先将内存中的数据加载到共享的 L3 Cache 中,
- 再加载到每个核心独有的 L2 Cache,
- 最后 进入到最快的 L1 Cache,之后才会被 CPU 读取。
- 之间的层级关系,如下图。
Spring三级缓存
概述
三级缓存就是在Bean生成流程中保存Bean对象三种形态的三个Map集合
]
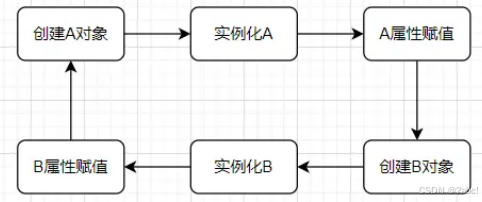
这个三级缓存就是为了解决循环依赖
当创建相互依赖的对象时,会形成死循环,例如下图无缓存中的情况。
- 而Spring通过增加缓存,
将未完全创建好的A提前暴露在缓存中,当相互依赖的对象B对属性A赋值时,可以直接从缓存中获取A,而不需要再创建A。如下所示
哪三个缓存
Spring三级缓存机制包括以下三个缓存:
singletonObjects:一级缓存,缓存中的bean是已经创建完成的,该bean经历过实例化->属性填充->初始化以及各种的后置处理。因此,一旦需要获取bean时,会优先寻找一级缓存earlySingletonObjects:二级缓存,该缓存跟一级缓存的区别在于,该缓存所获取到的bean是提前曝光出来的,是还没创建完成的。也就是说获取到的bean只能确保已经进行了实例化,但是属性填充跟初始化还没有做完,因此该bean还没创建完成,时半成品,仅仅能作为指针提前曝光,被其他bean所引用singletonFactories:三级缓存,在bean实例化完之后,属性填充以及初始化之前,如果允许提前曝光,spring会将实例化后的bean提前曝光,也就是把该bean转换成beanFactory并加入到三级缓存。在需要引用提前曝光对象时再通过singletonFactory.getObject()获取。
// 一级缓存Map 存放完整的Bean(流程跑完的)
private final Map<String, Object> singletonObjects = new ConcurrentHashMap(256);// 二级缓存Map 存放不完整的Bean(只实例化完,还没属性赋值、初始化)
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap(16);// 三级缓存Map 存放一个Bean的lambda表达式(也是刚实例化完)
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
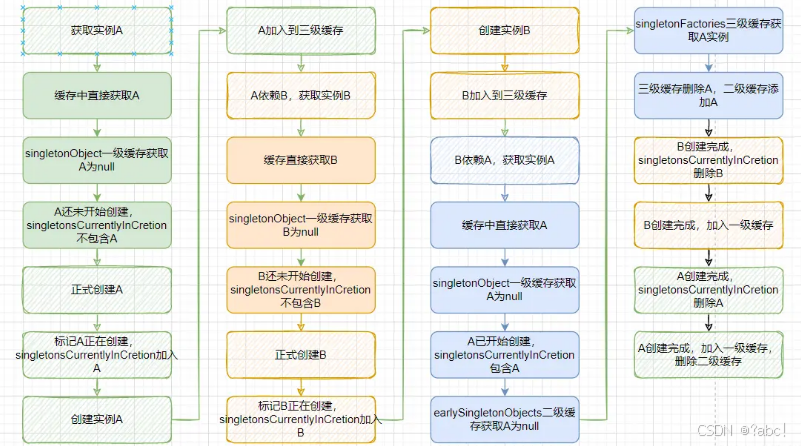
发现两个Bean循环依赖时
当Spring发现两个或更多个bean之间存在循环依赖关系时
- 它会
先将其中一个beanA创建的过程中尚未完成的实例放入earlySingletonObjects缓存中, - 然后
将创建该beanA的工厂对象放入singletonFactories缓存中。 - 接着,
Spring会暂停当前bean的创建过程,去创建它所依赖的bean。 - 当
依赖的bean创建完成后,Spring会将其放入singletonObjects缓存中,并使用它来完成当前bean的创建过程。 - 在创建当前bean的过程中,如果发现它还依赖其他的bean,Spring会重复上述过程,直到所有bean的创建过程都完成为止。
注意:当使用构造函数注入方式时,循环依赖是无法解决的。- 因为在创建bean时,必须先创建它所依赖的bean实例,而构造函数注入方式需要在创建bean实例时就将依赖的bean实例传入构造函数中。
- 如果依赖的bean实例尚未创建完成,就无法将其传入构造函数中,从而导致循环依赖无法解决。
- 此时,
可以考虑使用setter注入方式来解决循环依赖问题。
当A和B相互依赖时,若先创建实例A,则整个调用过程如下:
简化图如下
应用架构三级缓存
概述
应用架构三级缓存的时候,一般说JVM级别的、分布式缓存级别的、数据库级别的
JVM级别:一般常见本地缓存框架有Guava Cache和Caffeine Cache分布式缓存级别:一般用的Redis。数据库级别:mysql等数据库
众所周知 MySQL 数据库会将数据存储在硬盘以防止掉电丢失,但是受制于硬盘的物理设计,即便是目前性能最好的企业级 SSD 硬盘,也比内存的这种高速设备 IO 层面差一个数量级
典型的 “读多写少” 的场景,需要在设计上进行数据的读写分离,数据写入时直接落盘处理,
而占比超过 90% 的数据读取操作时则从以 Redis 为代表的内存 NoSQL 数据库提取数据,利用内存的高吞吐瞬间完成数据提取,这里 Redis 的作用就是我们常说的缓存。
二级缓存架构
二级缓存架构
1级为本地缓存,或者进程内的缓存(如 Ehcache) ——速度快,进程内可用2级为集中式缓存(如 Redis)——可同时为多节点提供服务
Java 的应用端多级缓存
在 Java 的应用端也要设计多级缓存,我们将进程内缓存与分布式缓存服务结合,有效分摊应用压力。
- 在
Java 应用层面,只有 本地缓存(EhCache、Caffeine Cache) 的缓存不存在时,再去 Redis 分布式缓存获取, - 如果 Redis 也没有此数据再去数据库查询,
数据查询成功后对 Redis 与 本地缓存 同时进行双写更新。 - 这样 Java 应用下一次再查询相同数据时便直接从本地缓存提取,不再产生新的网络通信,应用查询性能得到显著提高。
为了保证缓存一致性,利用 通知(MQ、发布订阅模式等) 向其他服务实例以及 Redis 缓存服务发起变更通知。
相关文章:
缓存(1):三级缓存
三级缓存是指什么 我们常说的三级缓存如下: CPU三级缓存Spring三级缓存应用架构(JVM、分布式缓存、db)三级缓存 CPU 基本概念 CPU 的访问速度每 18 个月就会翻 倍,相当于每年增⻓ 60% 左右,内存的速度当然也会不断…...
Cursor —— AI编辑器 使用详解
Cursor - The AI Code Editor 一、Cursor 是什么? Cursor 是一款优秀的AI代码编辑器,它内置了 Deepseek-R1、GPT-4、Claude等 AI 模型。 简单说,就是:Cursor VS Code 编辑器 AI 大模型 Cursor 功能特性(代码补全、…...
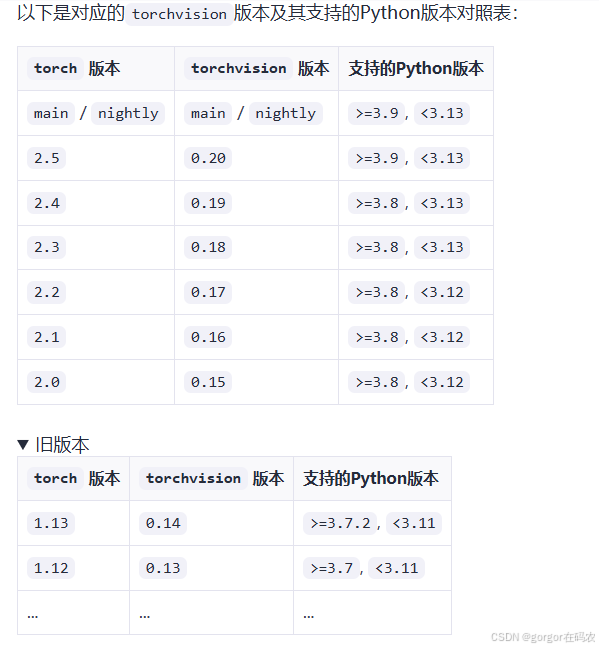
Pytorch-CUDA版本环境配置
Pytorch-CUDA版本环境配置 电脑如果是Windows平台下的Nvidia GPU的用户,需配置Pytorch的CUDA版本,分为三步: 1. 安装或更新NVIDA显卡驱动 官方驱动下载地址: https://www.nvidia.cn/Download/index.aspx?langcn 2. 安装CUDA Too…...
)
一个完整的神经网络训练流程详解(附 PyTorch 示例)
🧠 一个完整的神经网络训练流程详解(附 PyTorch 示例) 📌 第一部分:神经网络训练流程概览(总) 在深度学习中,构建和训练一个神经网络模型并不是简单的“输入数据、得到结果”这么简…...

OpenCV 图形API(77)图像与通道拼接函数-----对图像进行几何变换函数remap()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 对图像应用一个通用的几何变换。 函数 remap 使用指定的映射对源图像进行变换: dst ( x , y ) src ( m a p x ( x , y ) , m a p y…...

windows通过wsl安装ubuntu20.04
1 *.bat文件安装hyper-v pushd "%~dp0" dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt for /f %%i in (findstr /i . hyper-v.txt 2^>nul) do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i"…...
Spring AI 入门(持续更新)
介绍 Spring AI 是 Spring 项目中一个面向 AI 应用的模块,旨在通过集成开源框架、提供标准化的工具和便捷的开发体验,加速 AI 应用程序的构建和部署。 依赖 <!-- 基于 WebFlux 的响应式 SSE 传输 --> <dependency><groupId>org.spr…...

QUIC协议优化:HTTP_3环境下的超高速异步抓取方案
摘要 随着 QUIC 和 HTTP/3 的普及,基于 UDP 的连接复用与内置加密带来了远超 HTTP/2 的性能提升,可显著降低连接握手与拥塞恢复的开销。本文以爬取知乎热榜数据为目标,提出一种基于 HTTPX aioquic 的异步抓取方案,并结合代理 IP设…...

uni-app实现完成任务解锁拼图功能
界面如下 代码如下 <template><view class"puzzle-container"><view class"puzzle-title">任务进度 {{completedCount}}/{{totalPieces}}</view><view class"puzzle-grid"><viewv-for"(piece, index) in…...

Vue3 中当组件嵌套层级较深导致 ref 无法直接获取子组件实例时,可以通过 provide/inject + 回调函数的方式实现子组件方法传递到父组件
需求:vue3中使用defineExposeref调用子组件方法报错不是一个function 思路:由于组件嵌套层级太深导致ref失效,通过provide/inject 回调函数来实现多层穿透 1. 父组件提供「方法注册函数」 父组件通过 provide 提供一个用于接收子组件方法…...

关于 js:3. 闭包、作用域、内存模型
一、闭包的本质:函数 其词法作用域环境 闭包(Closure)的本质可以概括为: 闭包是一个函数,以及它定义时捕获的词法作用域中的变量集合。 这意味着:即使外部函数已经返回或作用域结束,只要有内…...

数据链路层(MAC 地址)
目录 一、前言: 二、以太网: 三、MAC 地址的作用: 四、ARP协议: 一、前言: 数据链路层主要负责相邻两个节点之间的数据传输,其中,最常见数据链路层的协议有 以太网(通过光纤 / 网…...
基于DQN的自动驾驶小车绕圈任务
1.任务介绍 任务来源: DQN: Deep Q Learning |自动驾驶入门(?) |算法与实现 任务原始代码: self-driving car 最终效果: 以下所有内容,都是对上面DQN代码的改进&#…...

terraform resource创建了5台阿里云ecs,如要使用terraform删除其中一台主机,如何删除?
在 Terraform 中删除阿里云 5 台 ECS 实例中的某一台,具体操作取决于你创建资源时使用的 多实例管理方式(count 或 for_each)。以下是详细解决方案: 方法一:使用 for_each(推荐) 如果创建时使…...
【Linux】Linux工具(1)
3.Linux工具(1) 文章目录 3.Linux工具(1)Linux 软件包管理器 yum什么是软件包关于 rzsz查看软件包——yum list命令如何安装软件如何卸载软件补充——yum如何找到要安装软件的下载地址 Linux开发工具Linux编辑器-vim使用1.vim的基…...
:词袋法(Bag of Words)原理与实现)
探索大语言模型(LLM):词袋法(Bag of Words)原理与实现
文章目录 引言一、词袋法原理1.1 核心思想1.2 实现步骤 二、数学公式2.1 词频表示2.2 TF-IDF加权(可选) 三、示例表格3.1 构建词汇表3.2 文本向量化(词频) 四、Python代码实现4.1 基础实现(手动计算)4.2 输…...

vue引入物理引擎matter.js
vue引入物理引擎matter.js 在 Vue 项目中集成 Matter.js 物理引擎的步骤如下: 1. 安装 Matter.js npm install matter-js # 或 yarn add matter-js2. 创建 Vue 组件 <template><div ref="physicsContainer" class="physics-container"><…...
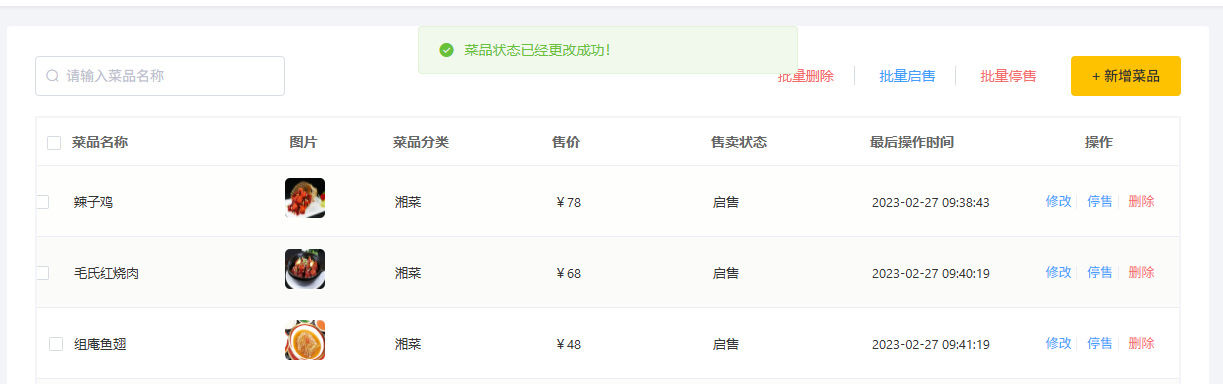
基于 Spring Boot 瑞吉外卖系统开发(十一)
基于 Spring Boot 瑞吉外卖系统开发(十一) 菜品启售和停售 “批量启售”、“批量停售”、操作列的售卖状态绑定单击事件,触发单击事件时,最终携带需要修改售卖状态的菜品id以post请求方式向“/dish/status/{params.status}”发送…...

支持鸿蒙next的uts插件
*本文共四个功能函数,相当于四个插件。作者为了偷懒写成了一个插件,调对应的函数即可。 1、chooseImageHarmony函数:拉起相册选择图片并转为Base64 2、takePhotoAndConvertToBase64函数:拉起相机拍照并转为Base64 3、openBrows…...
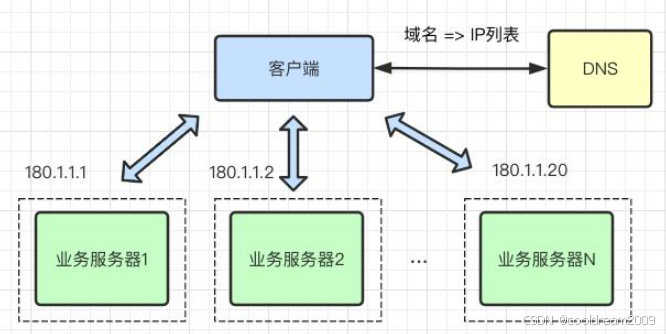
深入理解负载均衡:传输层与应用层的原理与实战
目录 前言1. 传输层(Layer 4)负载均衡1.1 工作层级与核心机制1.2 实现方式详解1.3 优缺点分析1.4 典型实现工具 2. 应用层(Layer 7)负载均衡2.1 工作层级与核心机制2.2 实现方式解析2.3 优缺点分析2.4 常用实现工具 3. Layer 4 与…...
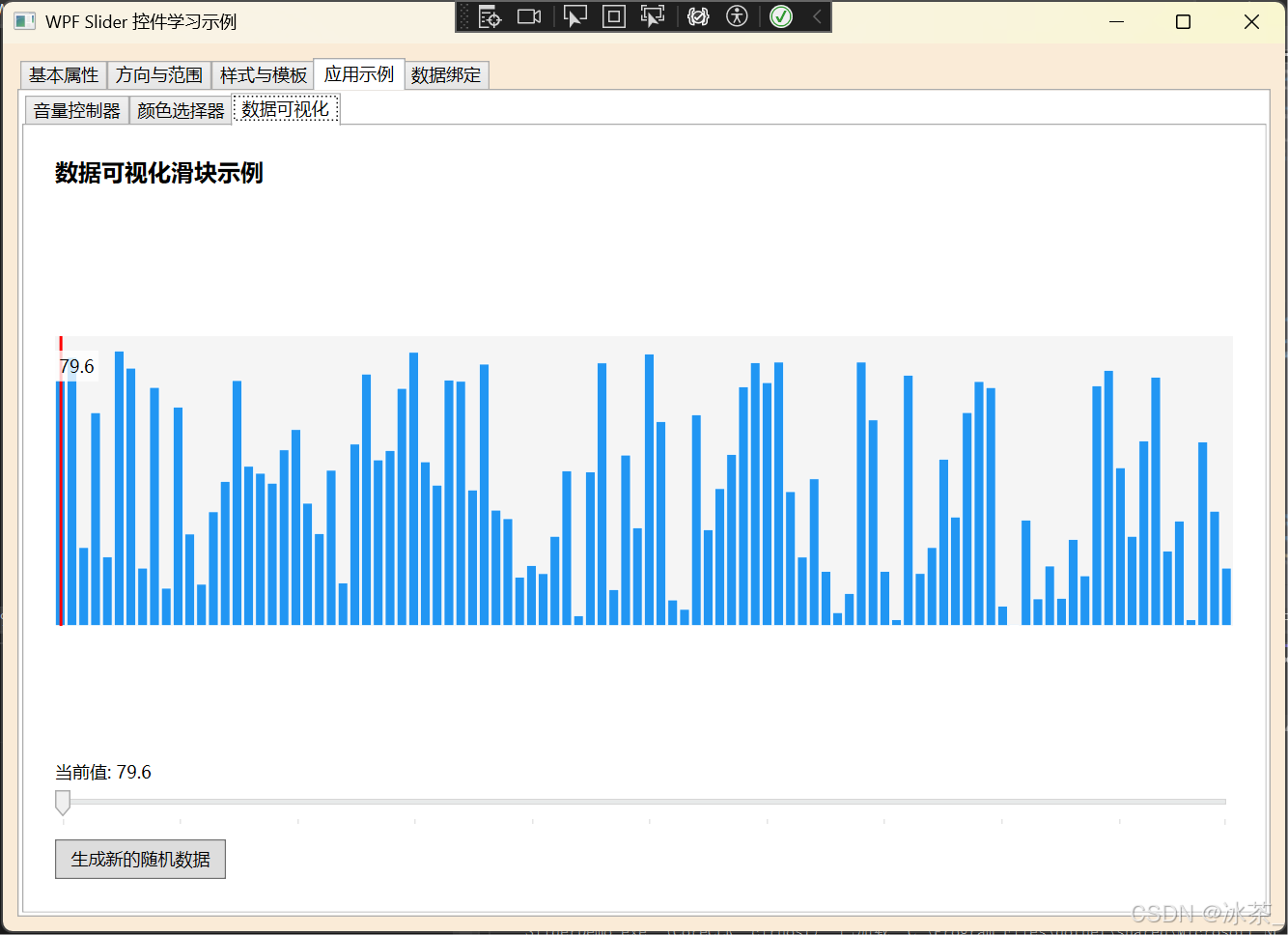
WPF之Slider控件详解
文章目录 1. 概述2. 基本属性2.1 值范围属性2.2 滑动步长属性2.3 刻度显示属性2.4 方向属性2.5 选择范围属性 3. 事件处理3.1 值变化事件3.2 滑块拖动事件 4. 样式和模板自定义4.1 基本样式设置4.2 控件模板自定义 5. 数据绑定5.1 绑定到ViewModel5.2 同步多个控件 6. 实际应用…...

极狐GitLab 如何将项目共享给群组?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 共享项目和群组 (BASIC ALL) 在极狐GitLab 16.10 中,更改为在成员页面的成员选项卡上显示被邀请群组成员…...
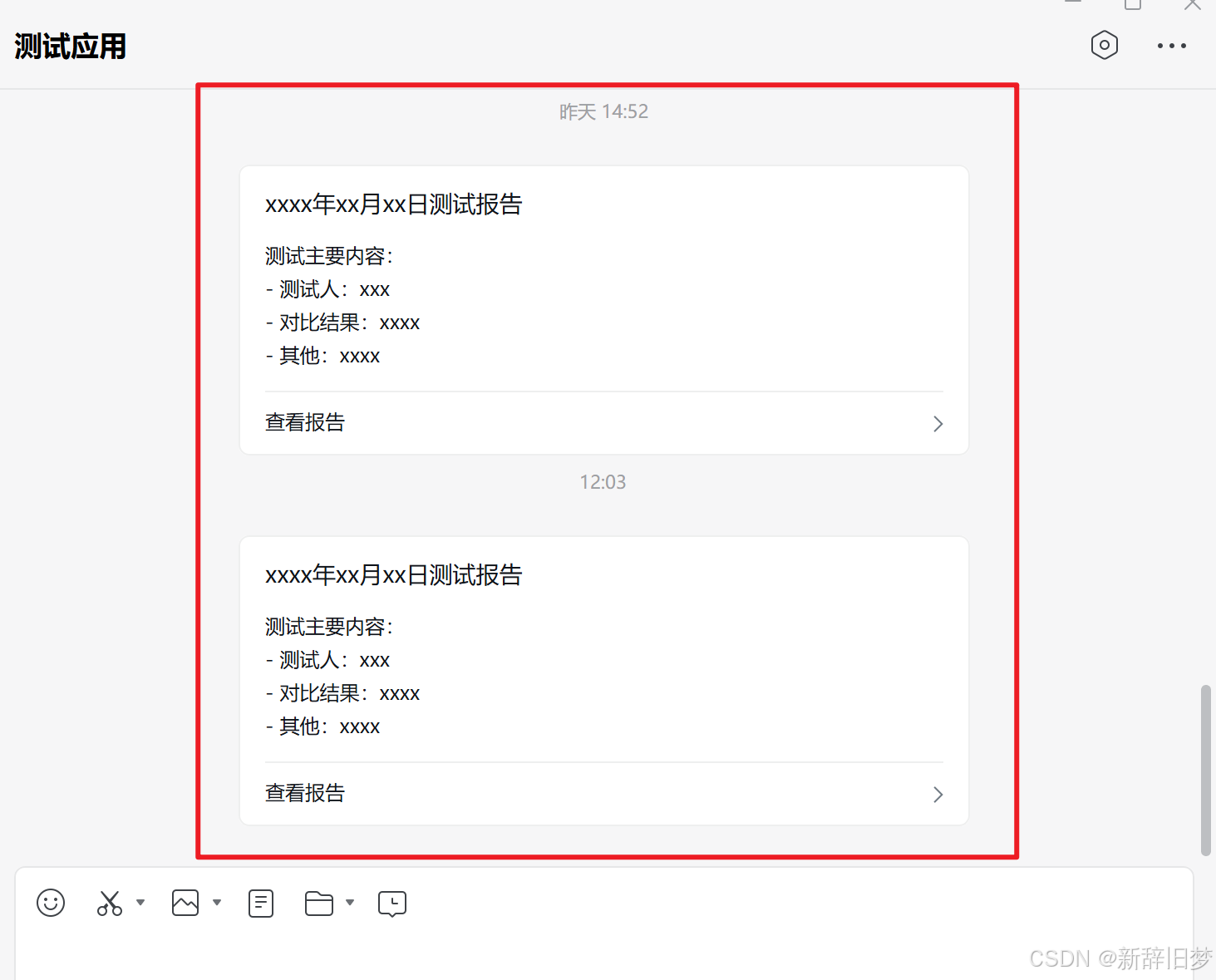
企业微信自建消息推送应用
企业微信自建应用来推送消息 前言 最近有个给特定部门推送消息的需求,所以配置一个应用专门用来推送消息。实现过程大致为:服务器生成每天的报告,通过调用API来发送消息。以前一直都是发邮件,整个邮箱里全是报告文件,…...

【React】Hooks useReducer 详解,让状态管理更可预测、更高效
1.背景 useReducer是React提供的一个高级Hook,没有它我们也可以正常开发,但是useReducer可以使我们的代码具有更好的可读性,可维护性。 useReducer 跟 useState 一样的都是帮我们管理组件的状态的,但是呢与useState不同的是 useReducer 是集…...
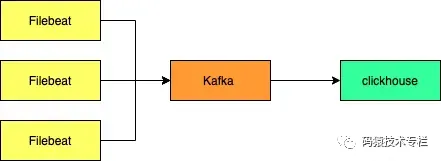
日志之ClickHouse部署及替换ELK中的Elasticsearch
文章目录 1 ELK替换1.1 Elasticsearch vs ClickHouse1.2 环境部署1.2.1 zookeeper 集群部署1.2.2 Kafka 集群部署1.2.3 FileBeat 部署1.2.4 clickhouse 部署1.2.4.1 准备步骤1.2.4.2 添加官方存储库1.2.4.3 部署&启动&连接1.2.4.5 基本配置服务1.2.4.6 测试创建数据库和…...

亚远景-ASPICE vs ISO 21434:汽车软件开发标准的深度对比
ASPICE(Automotive SPICE)和ISO 21434是汽车软件开发领域的两大核心标准,分别聚焦于过程质量与网络安全。以下从核心目标、覆盖范围、实施重点、协同关系及行业价值五个维度进行深度对比分析: 一、核心目标对比 ASPICE࿱…...

51单片机快速成长路径
作为在嵌入式领域深耕18年的工程师,分享一条经过工业验证的51单片机快速成长路径,全程干货无注水: 一、突破认知误区(新手必看) 不要纠结于「汇编还是C」:现代开发90%场景用C,掌握指针和内存管…...

使用 NGINX 实现 HTTP Basic 认证ngx_http_auth_basic_module 模块
一、前言 在 Web 应用中,对部分资源进行访问控制是十分常见的需求。除了基于 IP 限制、JWT 验证、子请求校验等方式外,最经典也最简单的一种方式便是 HTTP Basic Authentication。NGINX 提供的 ngx_http_auth_basic_module 模块支持基于用户名和密码的基…...
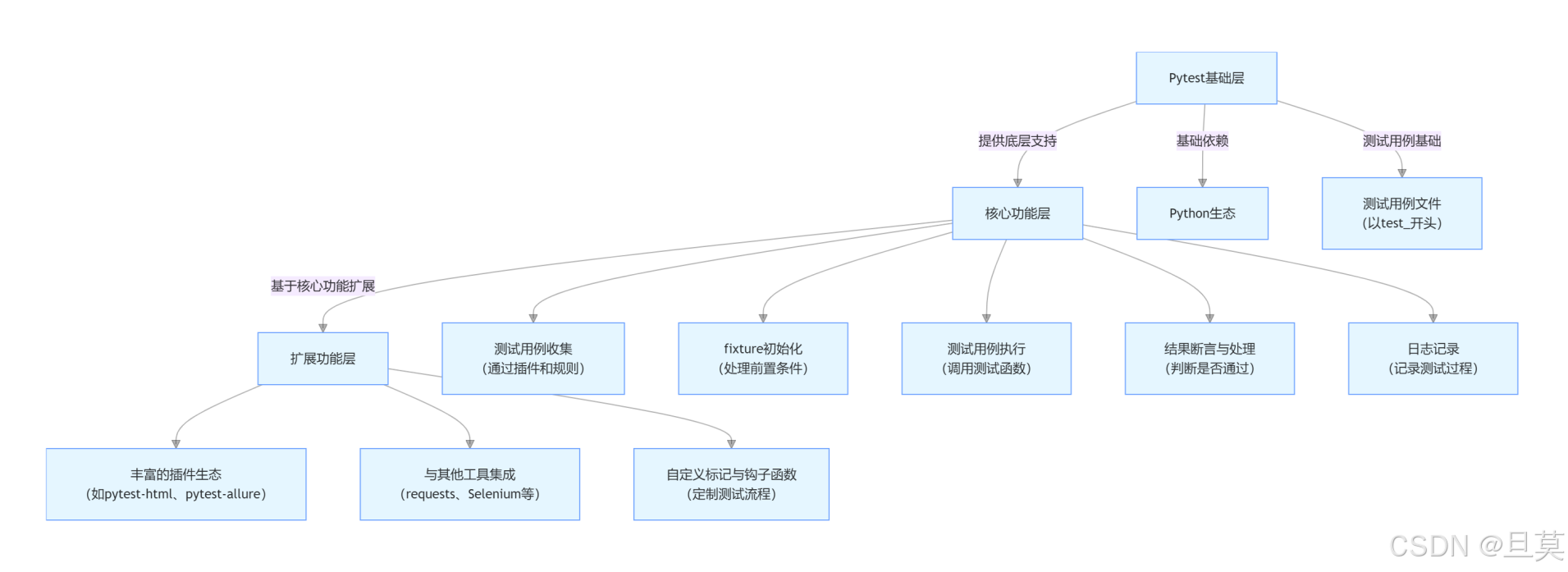
解构与重构:自动化测试框架的进阶认知之旅
目录 一、自动化测试的介绍 (一)自动化测试的起源与发展 (二)自动化测试的定义与目标 (三)自动化测试的适用场景 二、什么是自动化测试框架 (一)自动化测试框架的定义 &#x…...
DockerDesktop替换方案
背景 由于DockerDesktop并非开源软件,如果在公司使用,可能就有一些限制,那是不是除了使用DockerDesktop外,就没其它办法了呢,现在咱们来说说替换方案。 WSL WSL是什么,可自行百度,这里引用WS…...