最新字节跳动运维云原生面经分享
继续分享最新的go面经。
今天分享的是组织内部的朋友在字节的go运维工程师岗位的云原生方向的面经,涉及Prometheus、Kubernetes、CI/CD、网络代理、MySQL主从、Redis哨兵、系统调优及基础命令行工具等知识点,问题我都整理在下面了

面经详解
Prometheus 的信息采集原理?
回答思路:
- 数据模型:Prometheus 采用时间序列数据模型,每个数据点由以下部分组成:
- 度量名称(Metric Name):标识数据的类型(如
http_requests_total)。 - 标签(Labels):键值对形式的元数据,用于唯一标识数据的来源和维度(如
job="api-server", instance="192.168.1.100:9090")。 - 时间戳(Timestamp):记录数据采集的时间。
- 数值(Value):具体指标值(如 CPU 使用率 75%)。
- 度量名称(Metric Name):标识数据的类型(如
- 数据采集:
- 拉取模式(Pull Model):Prometheus 定期主动从目标(Targets)拉取指标数据,默认周期为 1 分钟。
- 推送模式(Push Model):通过中间件(如 Pushgateway)将数据推送到 Prometheus,适用于短生命周期任务(如批处理作业)。
- Service Discovery:支持自动发现目标节点(如 Kubernetes 服务、Consul 注册中心),减少手动配置。
- 存储与查询:
- 数据存储为时间序列,按度量名称和标签分组,支持高效查询。
- PromQL:提供丰富的查询语言,支持聚合运算(如
avg(),sum())、范围查询([5m])、条件判断(如> 90)等。
- 优势与局限性:
- 优势:高可用、分布式、灵活的标签系统。
- 局限性:拉取模式可能因网络问题漏数据,存储成本较高。
Prometheus 采集K8S是哪个接口?
回答思路:
- Kubernetes API Server:
- Prometheus 通过 Kubernetes API 监控集群资源状态(如 Pod、Deployment、Node 等),需配置
kubernetes_sd_config进行服务发现。 - 示例配置:
- Prometheus 通过 Kubernetes API 监控集群资源状态(如 Pod、Deployment、Node 等),需配置
scrape_configs: - job_name: 'kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints relabel_configs: - action: keep regex: default source_labels: [__meta_kubernetes_namespace]
- Metrics Server:
- 提供 Pod、Node 的资源使用指标(如 CPU/内存使用率),需通过
kube-state-metrics或cAdvisor采集。 - 示例:
- 提供 Pod、Node 的资源使用指标(如 CPU/内存使用率),需通过
curl http://localhost:8080/api/v1/nodes/{node-name}/metrics
- 自定义接口:
- 应用需暴露
/metrics端点,格式符合 Prometheus 文本格式(如通过prometheus-client-go库实现)。
- 应用需暴露
- 注意事项:
- 需配置 RBAC 权限,确保 Prometheus 有权限访问 K8S API。
- 使用
kube-prometheus-stackHelm Chart 可一键部署完整监控链。
Prometheus 的告警是怎么配置的?
回答思路:
- 告警规则(Alert Rules):
- 在
prometheus.yml或独立的.rules文件中定义规则,例如:
- 在
groups: - name: example rules: - alert: HighCPUUsage expr: instance:node_cpu_usage:rate1m > 0.8 for: 5m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} CPU usage is high"
expr:PromQL 表达式,定义触发条件。for:告警持续时间(避免短暂波动触发)。labels和annotations:补充告警元数据和描述。- Alertmanager 配置:
- 路由(Routes):根据标签(如
severity)将告警分发到不同接收者。
- 路由(Routes):根据标签(如
route: group_by: ['alertname'] group_wait: 30s group_interval: 5m receiver: 'team-alerts' routes: - match_re: severity: critical receiver: 'oncall-team'
- 抑制(Inhibit):高优先级告警(如
InstanceDown)可抑制低优先级告警(如HighCPUUsage)。 - 接收器(Receivers):支持多种通知方式(如 Slack、PagerDuty、Email)。
- 实践建议:
- 避免“告警疲劳”:合理设置阈值和
for参数。 - 验证告警:通过
fire-and-forget模式测试配置。
- 避免“告警疲劳”:合理设置阈值和
Prometheus 的告警是基于哪个组件配置的?
回答思路:
- 核心组件:Alertmanager
- 功能:
- 接收 Prometheus 发送的告警事件。
- 根据配置路由规则将告警分发给接收者(如团队 Slack 频道)。
- 聚合相似告警,减少重复通知(如
group_by)。 - 抑制冗余告警(如主节点宕机时抑制其下所有服务的告警)。
- 配置文件示例:
- 功能:
global: resolve_timeout: 5m route: receiver: 'team-email' group_wait: 30s receivers: - name: 'team-email' email_configs: - to: 'team@example.com'
- Prometheus 集成:
- 在
prometheus.yml中指定 Alertmanager 地址:
- 在
alerting: alertmanagers: - static_configs: - targets: ['alertmanager:9093']
- 扩展能力:
- 支持与 Grafana、PagerDuty 等工具集成,实现更复杂的告警管理。
CI 流水线发现问题是怎么排查解决的?
回答思路:
- 分层排查法:
- 环境层:
- 检查流水线运行的环境(如 Docker 镜像、依赖版本、网络配置)。
- 使用
docker inspect或kubectl describe pod查看容器状态。
- 日志层:
- 定位到失败步骤的日志,关注错误代码、堆栈信息。
- 使用日志聚合工具(如 ELK、Splunk)快速筛选关键信息。
- 代码层:
- 复现问题:本地复现流水线环境,逐步调试代码。
- 单元测试:针对可疑代码添加测试用例。
- 配置层:
- 检查流水线 YAML 文件中的参数、路径、工具版本。
- 确认敏感信息(如 API 密钥)是否正确注入。
- 环境层:
- 工具辅助:
- GitLab CI/CD:通过
echo命令输出中间变量,或使用debug模式。 - Jenkins:使用 Blue Ocean 插件可视化流水线状态。
- GitLab CI/CD:通过
- 预防措施:
- 增加流水线前置检查(如依赖库版本校验)。
- 实施变更管理流程,减少环境漂移。
访问服务出现 502 是什么问题?
回答思路:
- 常见原因及排查步骤:
- 反向代理问题:
- Nginx 配置错误:检查
proxy_pass是否指向正确的后端服务地址。 - 超时设置:调整
proxy_read_timeout或proxy_connect_timeout。
- Nginx 配置错误:检查
- 后端服务问题:
- 服务未启动:检查进程状态(
ps aux | grep service_name)。 - 负载过高:监控 CPU/内存使用率,优化代码或扩容。
- 服务未启动:检查进程状态(
- 网络问题:
- 防火墙/安全组:确认后端服务端口是否开放。
- DNS 解析:使用
dig或nslookup验证域名解析。
- 健康检查失败:
- 如果使用负载均衡(如 Kubernetes Ingress),检查健康检查配置是否合理。
- 反向代理问题:
- 示例排查流程:
- 访问日志:检查 Nginx 的
error.log中的502错误详情。 - 模拟请求:直接访问后端服务(如
curl http://backend:8080)。 - 查看后端日志:检查服务端日志(如
tail -f /var/log/app.log)。
- 访问日志:检查 Nginx 的
- 解决方案:
- 重启服务或代理。
- 调整超时参数或负载均衡策略。
- 优化后端服务性能(如增加缓存、分页查询)。
K8S service 的服务类型有几种?
回答思路:
- ClusterIP:
- 默认类型,仅在集群内部通过虚拟 IP(VIP)访问。
- 适用场景:后端服务间通信(如数据库、API 服务)。
- NodePort:
- 在每个 Node 的 IP 上开放一个端口(默认
30000-32767),外部可通过NodeIP:NodePort访问。 - 适用场景:开发/测试环境暴露服务,或需要快速访问。
- 在每个 Node 的 IP 上开放一个端口(默认
- LoadBalancer:
- 在云平台(如 AWS、GCP)创建云负载均衡器,流量自动转发到 Service。
- 适用场景:生产环境的高可用服务暴露。
- ExternalName:
- 通过 CNAME 将 Service 映射到外部域名(如
api.example.com),常用于跨集群访问。
- 通过 CNAME 将 Service 映射到外部域名(如
- 高级场景:
- 头信息修改:通过
externalTrafficPolicy: Local控制流量来源。 - Ingress 控制器:结合 Ingress 资源实现基于路径或域名的路由(如 Nginx Ingress)。
- 头信息修改:通过
- 选择建议:
- 生产环境优先使用 LoadBalancer 或 Ingress。
- 避免在生产环境使用 NodePort,因其端口冲突风险较高。
给文件的每一个前面增加head?
回答思路:
- Vim 编辑器:
- 打开文件:
vim filename。 - 进入命令模式,输入
:%s/^/head /g(替换每一行开头)。 - 或使用可视模式:
ggVG:Ihead(全局插入)。
- 打开文件:
- sed 命令:
sed -i 's/^/head /' filename # 或批量处理多行: sed -i '1i\head' filename # 在文件开头插入(非每行)
- awk 命令:
awk '{print "head " $0}' filename > newfile
- 注意事项:
-i参数会直接修改原文件,建议先备份。- 若需保留原文件,可重定向输出:
awk ... > newfile。
awk 提取数值为8的第二列的数量,分隔符为 | ,怎么提取?
回答思路:
- 基础命令:
awk -F '|' '$2 == 8 {count++} END {print count}' filename
-F '|':设置分隔符为|。$2 == 8:筛选第二列值为 8 的行。count++:计数器自增。- 扩展场景:
- 统计范围:
$2 > 5 && $2 < 10统计第二列在 5~10 之间的行数。 - 多条件匹配:
- 统计范围:
awk -F '|' '$2 == 8 && $3 ~ /error/ {count++} END {print count}'
- 输出详细信息:
awk -F '|' '$2 == 8 {print $0}' filename > result.txt
- 性能优化:
- 处理大文件时,可结合
time命令或parallel加速。
- 处理大文件时,可结合
nginx 的负载均衡怎么配置?
回答思路:
- 基础配置步骤:
- 定义 upstream 组:
upstream backend { server backend1.example.com weight=3; server backend2.example.com; # 权重默认1 server backup.example.com backup; # 备用节点 }
- 配置 server 和 location:
server { listen 80; server_name example.com; location / { proxy_pass http://backend; proxy_next_upstream error timeout invalid_header http_500; # 失败重试策略 } }
- 负载均衡算法:
round_robin(默认):轮询。ip_hash:根据客户端 IP 分配,保持会话。least_conn:最少连接数。
- 健康检查:
- 主动健康检查(需 Nginx Plus):
upstream backend { zone backend 64k; server backend1.example.com; health_check; }
- 被动健康检查:通过
proxy_next_upstream规则剔除故障节点。 - 高级配置:
- 超时设置:
proxy_connect_timeout 5s;。 - 会话保持:结合
ip_hash或 Cookie。
- 超时设置:
- 验证与测试:
- 使用
curl -I http://example.com检查响应头的X-Forwarded-For。 - 模拟节点故障,观察流量切换是否正常。
- 使用
MySQL 主从架构和 redis哨兵 前端是用什么连接的服务,读取数据库中的数据,对数据进行一个应用的?
回答思路:
- MySQL 主从架构:
- 连接方式:
- 前端应用通过主节点写入数据,通过从节点读取(读写分离)。
- 使用连接池(如 HikariCP)管理数据库连接。
- 注意事项:
- 从库延迟可能导致读写不一致,需通过
read_only参数控制从库写入。 - 使用中间件(如 MyCat)实现自动路由。
- 从库延迟可能导致读写不一致,需通过
- 连接方式:
- Redis 哨兵模式:
- 连接方式:
- 客户端连接哨兵集群(如通过 JedisSentinelPool),哨兵自动发现主节点。
- 高可用机制:
- 哨兵监控主节点,主节点故障时自动选举新主节点。
- 客户端通过哨兵获取最新主节点地址。
- 连接方式:
- 应用层设计:
- MySQL:业务逻辑中区分读写操作(如
@Transactional注解控制)。 - Redis:使用连接池自动处理主从切换,避免手动干预。
- MySQL:业务逻辑中区分读写操作(如
linux 系统调优是怎么进行调优的,对应简历中的性能是怎么调优的?
回答思路:
- 性能监控工具:
- 资源监控:
top/htop:实时查看 CPU、内存、进程状态。vmstat:监控内存、swap、IO 等。iostat:分析磁盘 IO 性能。
- 网络监控:
netstat,tcpdump,iftop。
- 资源监控:
- 调优方向:
- CPU:
- 优化线程调度(如
nice调整优先级)。 - 调整内核参数(如
vm.swappiness控制 swap 使用)。
- 优化线程调度(如
- 内存:
- 增加
vm.max_map_count(如 Elasticsearch 需要)。 - 使用
oom_score_adj防止关键进程被 OOM Killer 终止。
- 增加
- IO:
- 调整
read_ahead缓冲区大小。 - 使用
noatime挂载选项减少磁盘写入。
- 调整
- 网络:
- 调整
net.core.somaxconn扩大连接队列。 - 启用
TCP BBR拥塞控制算法。
- 调整
- CPU:
- 实践案例:
- 场景:数据库服务器 CPU 使用率持续 90%。
- 步骤:
- 通过
perf top定位热点函数。 - 优化 SQL 查询(添加索引、减少全表扫描)。
- 调整 MySQL 配置(如
innodb_buffer_pool_size)。
- 通过
- 验证:对比调优前后的
sar数据,确保性能提升。
- 自动化监控:
- 结合 Prometheus + Grafana 实时监控关键指标,设置告警阈值。
欢迎关注 ❤
我们搞了一个免费的面试真题共享群,互通有无,一起刷题进步。
没准能让你能刷到自己意向公司的最新面试题呢。
感兴趣的朋友们可以私信我,备注:面试群。
相关文章:
最新字节跳动运维云原生面经分享
继续分享最新的go面经。 今天分享的是组织内部的朋友在字节的go运维工程师岗位的云原生方向的面经,涉及Prometheus、Kubernetes、CI/CD、网络代理、MySQL主从、Redis哨兵、系统调优及基础命令行工具等知识点,问题我都整理在下面了 面经详解 Prometheus …...

理解 Elasticsearch 的评分机制和 Explain API
作者:来自 Elastic Kofi Bartlett 深入了解 Elasticsearch 的评分机制并探索 Explain API。 想获得 Elastic 认证吗?查看下一期 Elasticsearch Engineer 培训的时间! Elasticsearch 拥有大量新功能,帮助你为你的使用场景构建最佳…...

NGINX `ngx_http_charset_module` 字符集声明与编码转换
一、模块定位与功能 ngx_http_charset_module 主要提供两大能力: 响应头声明:在 Content-Type 头部自动添加 ; charsetXXX,告知客户端所用字符集。单向编码转换:在 NGINX 层将一种单字节编码(如 koi8-r、windows-125…...
视频编解码学习三之显示器
整理自:显示器_百度百科,触摸屏_百度百科,百度安全验证 分为阴极射线管显示器(CRT),等离子显示器PDP,液晶显示器LCD 液晶显示器的组成。一般来说,液晶显示器由以下几个部分组成: […...

Python中的re库详细用法与代码解析
目录 1. 前言 2. 正则表达式的基本概念 2.1 什么是正则表达式? 2.2 常用元字符 3. re库的适应场景 3.1 验证用户输入 3.2 从文本中提取信息 3.3 文本替换与格式化 3.4 分割复杂字符串 3.5 数据清洗与预处理 4. re库的核心功能详解 4.1 re.match()&#…...

K8s网络从0到1
K8s网络从0到1 前言 K8s是一个强大的平台,但它的网络比较复杂,涉及很多概念,例如Pod网络,Service网络,Cluster IPs,NodePort,LoadBalancer和Ingress等等。为了帮助大家理解,模仿TC…...
13.Excel:分列
一 分列的作用 将一个单元格中的内容拆分到两个或多个单元格当中。 二 如何使用 1.常规分列使用 注意:分列功能一次只能拆分一列。 长度一致或者数据间有分隔符。 补充:快速选择一列。 CTRL shift 向下箭头。 补充:中英文逗号不同。 可以先通…...

第十六届蓝桥杯大赛软件赛C/C++大学B组部分题解
第十六届蓝桥杯大赛软件赛C/C大学B组题解 试题A: 移动距离 问题描述 小明初始在二维平面的原点,他想前往坐标(233,666)。在移动过程中,他只能采用以下两种移动方式,并且这两种移动方式可以交替、不限次数地使用: 水平向右移动…...

计算机网络应用层(5)-- P2P文件分发视频流和内容分发网
💓个人主页:mooridy 💓专栏地址:《计算机网络:自顶向下方法》 大纲式阅读笔记_mooridy的博客-CSDN博客 💓本博客内容为《计算机网络:自顶向下方法》第二章应用层第五、六节知识梳理 关注我&…...

Gin优雅关闭 graceful-shutdown
文章目录 优雅关闭示例 - Close 方法项目结构使用方法代码如下代码说明如果去掉代码中的数字1,会发生什么 优雅关闭示例项目结构使用方法使用上下文通知不使用上下文通知 代码 notify-without-context-server.go代码说明 代码 notify-with-context-server.go代码说明…...
)
Android 查看 Logcat (可纯手机方式 无需电脑)
安装 Logcat Reader Github Google Play 如果有电脑 使用其ADB方式可执行如下命令 后续无需安装Termux # 使用 ADB 授予 android.permission.READ_LOGS 权限给 Logcat Reader adb shell "pm grant com.dp.logcatapp android.permission.READ_LOGS && am force-…...

Java 中常见的数据结构及其常用 API
本文总结了 Java 中常见的数据结构及其常用 API,帮助开发者在写算法时能够快速选择合适的数据结构和操作。通过使用合适的 API,可以有效减少计算复杂度,并提高代码的执行效率。 1. 数组 数组是 Java 中最常用的数据结构之一,Jav…...
五子棋html
<!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8" /> <meta name"viewport" content"widthdevice-width, initial-scale1" /> <title>五子棋游戏</title> <style>bo…...

在Laravel 12中实现基于parent_id的树状数组
在Laravel中实现基于parent_id的树状数组,可以通过预加载所有节点并在内存中递归构建树结构来完成。以下是具体步骤和代码示例: 1. 创建模型及数据库迁移 迁移文件: // 创建节点表 Schema::create(nodes, function (Blueprint $table) {$t…...

JavaWeb:后端web基础(TomcatServletHTTP)
一、今日内容 二、Tomcat 介绍与使用 介绍 基本使用 小结 配置 配置 查找进程 三、Servlet 什么是Servlet 快速入门 需求 步骤 1.新建工程-模块(Maven) 2.修改打包方式-war 3.编写代码 /*** 可以选择继承HttpServlet*/ WebServlet("/hello&q…...

C++负载均衡远程调用学习之负载均衡算法与实现
目录 01 lars 系统架构回顾 02 lars-lbAgentV0.4-route_lb处理report业务流程 03 lars-lbAgentV0.4-负责均衡判断参数配置 04 lars-lbAgentV0.4-负载均衡idle节点的失败率判断 05 lars-lbAgentV0.4-负载均衡overload节点的成功率判断 06 lars-lbAgentV0.4-负载均衡上报提交…...
缓存(1):三级缓存
三级缓存是指什么 我们常说的三级缓存如下: CPU三级缓存Spring三级缓存应用架构(JVM、分布式缓存、db)三级缓存 CPU 基本概念 CPU 的访问速度每 18 个月就会翻 倍,相当于每年增⻓ 60% 左右,内存的速度当然也会不断…...
Cursor —— AI编辑器 使用详解
Cursor - The AI Code Editor 一、Cursor 是什么? Cursor 是一款优秀的AI代码编辑器,它内置了 Deepseek-R1、GPT-4、Claude等 AI 模型。 简单说,就是:Cursor VS Code 编辑器 AI 大模型 Cursor 功能特性(代码补全、…...
Pytorch-CUDA版本环境配置
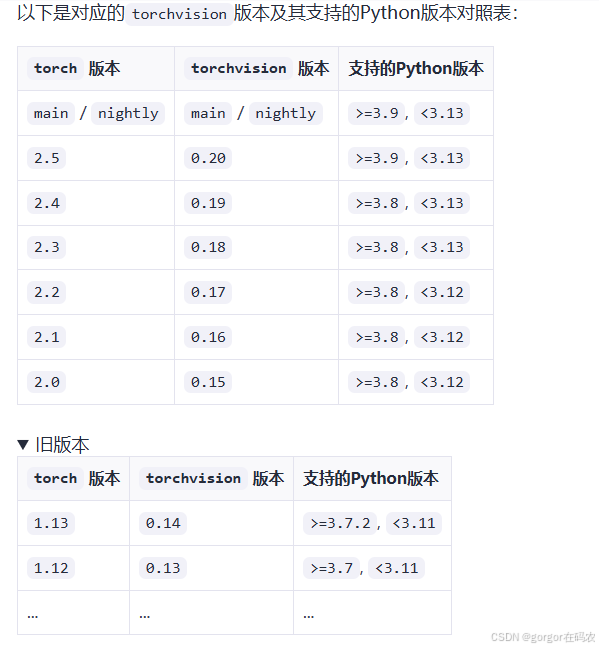
Pytorch-CUDA版本环境配置 电脑如果是Windows平台下的Nvidia GPU的用户,需配置Pytorch的CUDA版本,分为三步: 1. 安装或更新NVIDA显卡驱动 官方驱动下载地址: https://www.nvidia.cn/Download/index.aspx?langcn 2. 安装CUDA Too…...
)
一个完整的神经网络训练流程详解(附 PyTorch 示例)
🧠 一个完整的神经网络训练流程详解(附 PyTorch 示例) 📌 第一部分:神经网络训练流程概览(总) 在深度学习中,构建和训练一个神经网络模型并不是简单的“输入数据、得到结果”这么简…...

OpenCV 图形API(77)图像与通道拼接函数-----对图像进行几何变换函数remap()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 对图像应用一个通用的几何变换。 函数 remap 使用指定的映射对源图像进行变换: dst ( x , y ) src ( m a p x ( x , y ) , m a p y…...

windows通过wsl安装ubuntu20.04
1 *.bat文件安装hyper-v pushd "%~dp0" dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt for /f %%i in (findstr /i . hyper-v.txt 2^>nul) do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i"…...
Spring AI 入门(持续更新)
介绍 Spring AI 是 Spring 项目中一个面向 AI 应用的模块,旨在通过集成开源框架、提供标准化的工具和便捷的开发体验,加速 AI 应用程序的构建和部署。 依赖 <!-- 基于 WebFlux 的响应式 SSE 传输 --> <dependency><groupId>org.spr…...

QUIC协议优化:HTTP_3环境下的超高速异步抓取方案
摘要 随着 QUIC 和 HTTP/3 的普及,基于 UDP 的连接复用与内置加密带来了远超 HTTP/2 的性能提升,可显著降低连接握手与拥塞恢复的开销。本文以爬取知乎热榜数据为目标,提出一种基于 HTTPX aioquic 的异步抓取方案,并结合代理 IP设…...

uni-app实现完成任务解锁拼图功能
界面如下 代码如下 <template><view class"puzzle-container"><view class"puzzle-title">任务进度 {{completedCount}}/{{totalPieces}}</view><view class"puzzle-grid"><viewv-for"(piece, index) in…...

Vue3 中当组件嵌套层级较深导致 ref 无法直接获取子组件实例时,可以通过 provide/inject + 回调函数的方式实现子组件方法传递到父组件
需求:vue3中使用defineExposeref调用子组件方法报错不是一个function 思路:由于组件嵌套层级太深导致ref失效,通过provide/inject 回调函数来实现多层穿透 1. 父组件提供「方法注册函数」 父组件通过 provide 提供一个用于接收子组件方法…...

关于 js:3. 闭包、作用域、内存模型
一、闭包的本质:函数 其词法作用域环境 闭包(Closure)的本质可以概括为: 闭包是一个函数,以及它定义时捕获的词法作用域中的变量集合。 这意味着:即使外部函数已经返回或作用域结束,只要有内…...

数据链路层(MAC 地址)
目录 一、前言: 二、以太网: 三、MAC 地址的作用: 四、ARP协议: 一、前言: 数据链路层主要负责相邻两个节点之间的数据传输,其中,最常见数据链路层的协议有 以太网(通过光纤 / 网…...
基于DQN的自动驾驶小车绕圈任务
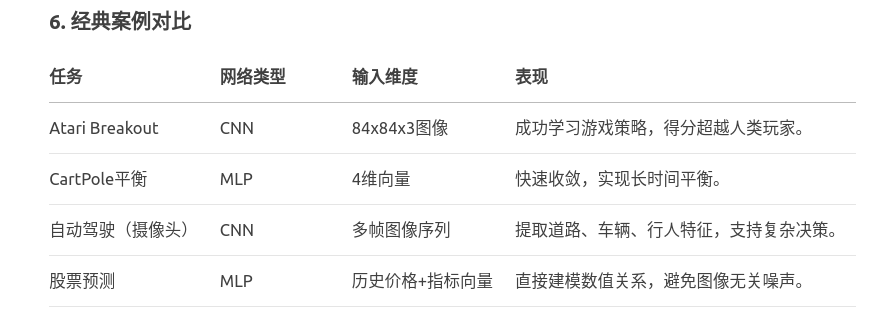
1.任务介绍 任务来源: DQN: Deep Q Learning |自动驾驶入门(?) |算法与实现 任务原始代码: self-driving car 最终效果: 以下所有内容,都是对上面DQN代码的改进&#…...

terraform resource创建了5台阿里云ecs,如要使用terraform删除其中一台主机,如何删除?
在 Terraform 中删除阿里云 5 台 ECS 实例中的某一台,具体操作取决于你创建资源时使用的 多实例管理方式(count 或 for_each)。以下是详细解决方案: 方法一:使用 for_each(推荐) 如果创建时使…...