聊聊Spring AI Alibaba的SentenceSplitter
序
本文主要研究一下Spring AI Alibaba的SentenceSplitter
SentenceSplitter
spring-ai-alibaba-core/src/main/java/com/alibaba/cloud/ai/transformer/splitter/SentenceSplitter.java
public class SentenceSplitter extends TextSplitter {private final EncodingRegistry registry = Encodings.newLazyEncodingRegistry();private final Encoding encoding = registry.getEncoding(EncodingType.CL100K_BASE);private static final int DEFAULT_CHUNK_SIZE = 1024;private final SentenceModel sentenceModel;private final int chunkSize;public SentenceSplitter() {this(DEFAULT_CHUNK_SIZE);}public SentenceSplitter(int chunkSize) {this.chunkSize = chunkSize;this.sentenceModel = getSentenceModel();}@Overrideprotected List<String> splitText(String text) {SentenceDetectorME sentenceDetector = new SentenceDetectorME(sentenceModel);String[] texts = sentenceDetector.sentDetect(text);if (texts == null || texts.length == 0) {return Collections.emptyList();}List<String> chunks = new ArrayList<>();StringBuilder chunk = new StringBuilder();for (int i = 0; i < texts.length; i++) {int currentChunkSize = getEncodedTokens(chunk.toString()).size();int textTokenSize = getEncodedTokens(texts[i]).size();if (currentChunkSize + textTokenSize > chunkSize) {chunks.add(chunk.toString());chunk = new StringBuilder(texts[i]);}else {chunk.append(texts[i]);}if (i == texts.length - 1) {chunks.add(chunk.toString());}}return chunks;}private SentenceModel getSentenceModel() {try (InputStream is = getClass().getResourceAsStream("/opennlp/opennlp-en-ud-ewt-sentence-1.2-2.5.0.bin")) {if (is == null) {throw new RuntimeException("sentence model is invalid");}return new SentenceModel(is);}catch (IOException e) {throw new RuntimeException(e);}}private List<Integer> getEncodedTokens(String text) {Assert.notNull(text, "Text must not be null");return this.encoding.encode(text).boxed();}}
SentenceSplitter继承了TextSplitter,其构造器会通过getSentenceModel()来加载
/opennlp/opennlp-en-ud-ewt-sentence-1.2-2.5.0.bin这个SentenceModel;splitText方法创建SentenceDetectorME,使用其sentDetect来拆分句子,再根据chunkSize进一步合并或拆分
示例
spring-ai-alibaba-core/src/test/java/com/alibaba/cloud/ai/transformer/splitter/SentenceSplitterTests.java
class SentenceSplitterTests {private SentenceSplitter splitter;private static final int CUSTOM_CHUNK_SIZE = 100;@BeforeEachvoid setUp() {// Initialize with default chunk sizesplitter = new SentenceSplitter();}/*** Test default constructor. Verifies that splitter can be created with default chunk* size.*/@Testvoid testDefaultConstructor() {SentenceSplitter defaultSplitter = new SentenceSplitter();assertThat(defaultSplitter).isNotNull();}/*** Test constructor with custom chunk size. Verifies that splitter can be created with* specified chunk size.*/@Testvoid testCustomChunkSizeConstructor() {SentenceSplitter customSplitter = new SentenceSplitter(CUSTOM_CHUNK_SIZE);assertThat(customSplitter).isNotNull();}/*** Test splitting simple sentences. Verifies basic sentence splitting functionality.*/@Testvoid testSplitSimpleSentences() {String text = "This is a test. This is another test. And this is a third test.";Document doc = new Document(text);List<Document> documents = splitter.apply(Collections.singletonList(doc));assertThat(documents).isNotNull();assertThat(documents).hasSize(1);assertThat(documents.get(0).getText()).contains("This is a test", "This is another test","And this is a third test");}/*** Test splitting empty text. Verifies handling of empty input.*/@Testvoid testSplitEmptyText() {Document doc = new Document("");List<Document> documents = splitter.apply(Collections.singletonList(doc));assertThat(documents).isEmpty();}/*** Test splitting text with special characters. Verifies handling of text with various* punctuation and special characters.*/@Testvoid testSplitTextWithSpecialCharacters() {String text = "Hello, world! How are you? I'm doing great... This is a test; with various punctuation.";Document doc = new Document(text);List<Document> documents = splitter.apply(Collections.singletonList(doc));assertThat(documents).isNotNull();assertThat(documents).hasSize(1);assertThat(documents.get(0).getText()).contains("Hello, world", "How are you", "I'm doing great","This is a test");}/*** Test splitting long text. Verifies handling of text that exceeds default chunk* size.*/@Testvoid testSplitLongText() {// Generate a very long text that will exceed the default chunk size (1024// tokens)StringBuilder longText = new StringBuilder();String longSentence = "This is a very long sentence with many words that will contribute to the total token count and eventually force the text to be split into multiple chunks because it exceeds the default chunk size limit of 1024 tokens. ";// Repeat the sentence enough times to ensure we exceed the chunk sizefor (int i = 0; i < 50; i++) {longText.append(longSentence);}Document doc = new Document(longText.toString());List<Document> documents = splitter.apply(Collections.singletonList(doc));// Verify that the text was split into multiple documentsassertThat(documents).isNotNull();assertThat(documents).hasSizeGreaterThan(1);// Verify that each document contains part of the original textdocuments.forEach(document -> assertThat(document.getText()).contains("This is a very long sentence"));}/*** Test splitting text with multiple line breaks. Verifies handling of text with* various types of line breaks.*/@Testvoid testSplitTextWithLineBreaks() {String text = "First sentence.\nSecond sentence.\r\nThird sentence.\rFourth sentence.";Document doc = new Document(text);List<Document> documents = splitter.apply(Collections.singletonList(doc));assertThat(documents).isNotNull();assertThat(documents.get(0).getText()).contains("First sentence", "Second sentence", "Third sentence","Fourth sentence");}/*** Test splitting text with single character sentences. Verifies handling of very* short sentences.*/@Testvoid testSplitSingleCharacterSentences() {String text = "A. B. C. D.";Document doc = new Document(text);List<Document> documents = splitter.apply(Collections.singletonList(doc));assertThat(documents).isNotNull();assertThat(documents).hasSize(1);assertThat(documents.get(0).getText()).contains("A", "B", "C", "D");}/*** Test splitting multiple documents. Verifies handling of multiple input documents.*/@Testvoid testSplitMultipleDocuments() {List<Document> inputDocs = new ArrayList<>();inputDocs.add(new Document("First document. With multiple sentences."));inputDocs.add(new Document("Second document. Also with multiple sentences."));List<Document> documents = splitter.apply(inputDocs);assertThat(documents).isNotNull();assertThat(documents).hasSizeGreaterThan(1);}}
小结
Spring AI Alibaba提供了SentenceSplitter,它使用了opennlp的SentenceDetectorME进行拆分,其构造器会加载/opennlp/opennlp-en-ud-ewt-sentence-1.2-2.5.0.bin这个SentenceModel。
doc
- 1.0.0-M6.1/get-started
相关文章:

聊聊Spring AI Alibaba的SentenceSplitter
序 本文主要研究一下Spring AI Alibaba的SentenceSplitter SentenceSplitter spring-ai-alibaba-core/src/main/java/com/alibaba/cloud/ai/transformer/splitter/SentenceSplitter.java public class SentenceSplitter extends TextSplitter {private final EncodingRegis…...

前端-什么是结构语言、样式语言、脚本语言?
目录 1. 结构语言(HTML / WXML)——房子的骨架 2. 样式语言(CSS / WXSS)——房子的装修 3. 脚本语言(JavaScript)——房子的智能控制系统 总结对比表: 1. 结构语言(HTML / WXML&a…...
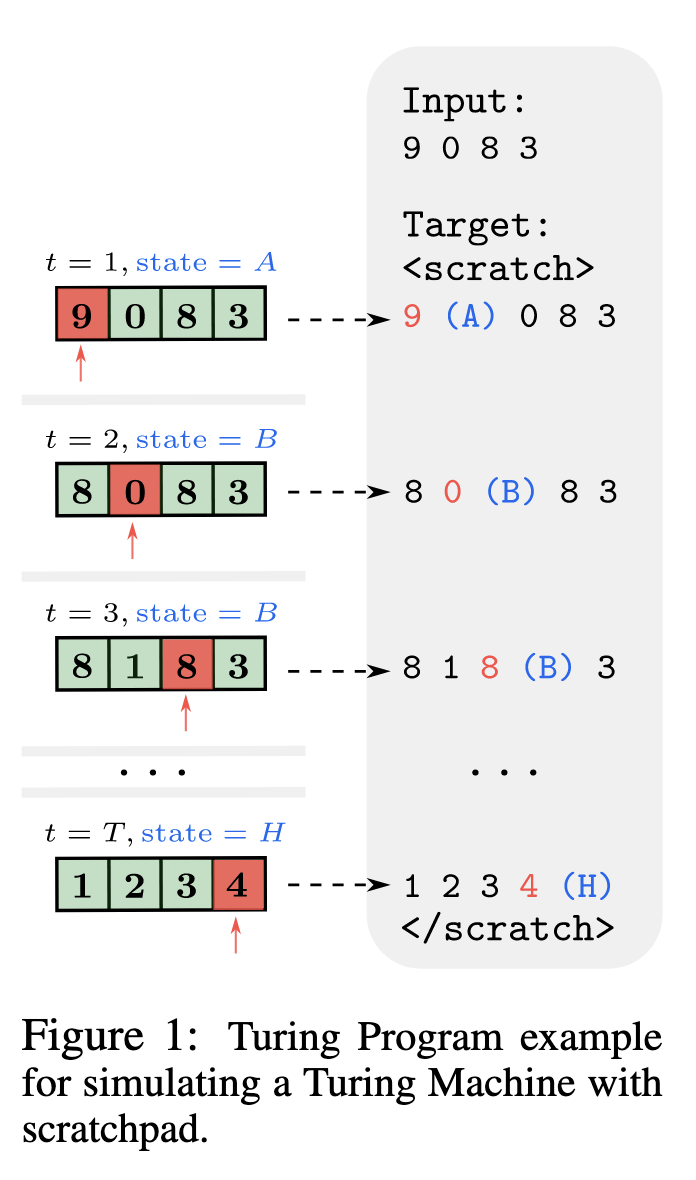
LLM论文笔记 28: Universal length generalization with Turing Programs
Arxiv日期:2024.10.4机构:Harvard University 关键词 图灵机 CoT 长度泛化 核心结论 Turing Programs 的提出 提出 Turing Programs,一种基于图灵机计算步骤的通用 CoT 策略。通过将算法任务分解为逐步的“磁带更新”(类似图灵…...

AI日报 · 2025年5月07日|谷歌发布 Gemini 2.5 Pro 预览版 (I/O 版本),大幅提升编码与视频理解能力
1、谷歌发布 Gemini 2.5 Pro 预览版 (I/O 版本),大幅提升编码与视频理解能力 谷歌于5月6日提前发布 Gemini 2.5 Pro 预览版 (I/O 版本),为开发者带来更强编码能力,尤其优化了前端与UI开发、代码转换及智能体工作流构建,并在WebDe…...

指定Docker镜像源,使用阿里云加速异常解决
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo异常贴图 yum-config-manager:找不到命令 因为系统默认没有安装这个命令,这个命令在yum-utils 包里,可以通过命令yum -y install yum-util…...

VITA STANDARDS LIST,VITA 标准清单下载
VITA STANDARDS LIST,VITA 标准清单下载 DesignationTitleAbstractStatusVMEbus Handbook, 4th EditionA users guide to the VME, VME64 and VME64x bus specifications - features over 70 product photos and over 160 circuit diagrams, tables and graphs. The…...
Python从入门到高手8.3节-元组的常用操作方法
目录 11.3.1 元组的常用操作方法 11.3.2 元组的查找 11.3.3 祈祷明天不再打雷下雨 11.3.1 元组的常用操作方法 元组类型是一种抽象数据类型,抽象数据类型定义了数据类型的操作方法,在本节的内容中,着重介绍元组类型的操作方法。 元组是…...

Linux系统安装PaddleDetection
一、安装cuda 1. 查看设备 先输入nvidia-smi,查看设备支持的最大cuda版本,选择官网中支持的cuda版本 https://www.paddlepaddle.org.cn/install/quick?docurl/documentation/docs/zh/install/conda/linux-conda.html 2. 下载CUDA并安装 使用快捷键…...
【漫话机器学习系列】239.训练错误率(Training Error Rate)
机器学习基础概念 | 训练错误率(Training Error Rate)详解 在机器学习模型训练过程中,评估模型性能是至关重要的一个环节。其中,训练错误率(Training Error Rate) 是最基础也最重要的性能指标之一。 本文将…...

Vue3路由模式为history,使用nginx部署上线是空白的问题
一、问题 将vue使用打包后 npm run build将dist文件的内容,放入nginx的html中,并在nginx.conf中,设置端口 启动nginx,打开发现网页内容为空白 二、解决问题 1.配置vue-route const router createRouter({history: createWe…...
:AI的安全可靠 - 电商数据智能的红线与指南)
Python 数据智能实战 (13):AI的安全可靠 - 电商数据智能的红线与指南
写在前面 —— 技术向善,行稳致远:在智能时代,坚守数据伦理,构建可信赖的 AI 应用 通过前面的篇章,我们已经深入探索了如何利用 Python 和大语言模型 (LLM) 挖掘电商数据的巨大潜力,从智能用户分群到语义推荐,再到个性化内容生成和模型效果评估。我们手中的工具越来越…...
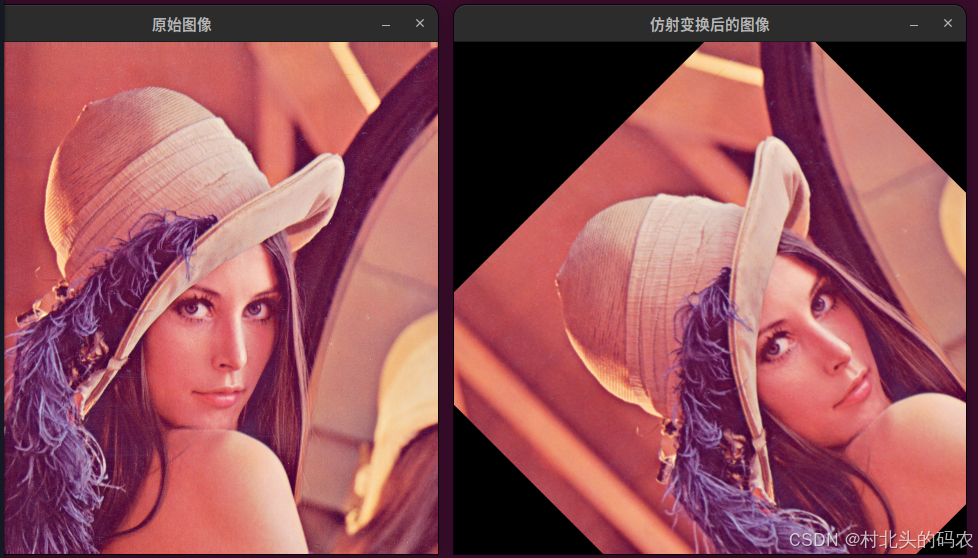
OpenCV 图形API(80)图像与通道拼接函数-----仿射变换函数warpAffine()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 对图像应用仿射变换。 函数 warpAffine 使用指定的矩阵对源图像进行变换: dst ( x , y ) src ( M 11 x M 12 y M 13 , M 21 x M…...
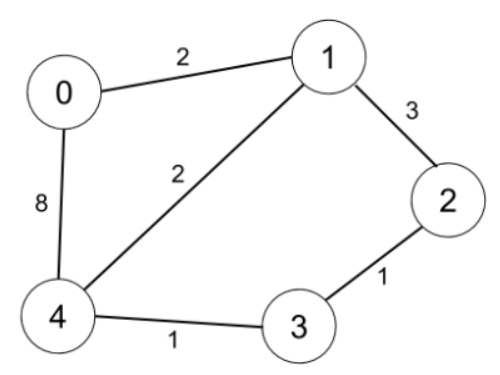
数据结构与算法:图论——最短路径
最短路径 先给出一些leetcode算法题,以后遇见了相关题目再往上增加 最短路径的4个常用算法是Floyd、Bellman-Ford、SPFA、Dijkstra。不同应用场景下,应有选择地使用它们: 图的规模小,用Floyd。若边的权值有负数,需要…...
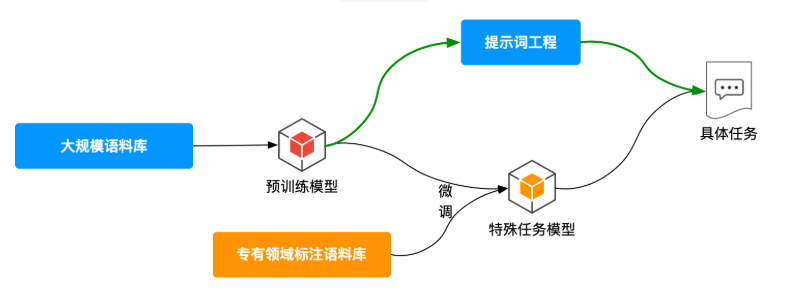
提示词工程:通向AGI时代的人机交互艺术
引言:从基础到精通的提示词学习之旅 欢迎来到 "AGI时代核心技能" 系列课程的第二模块——提示词工程。在这个模块中,我们将系统性地探索如何通过精心设计的提示词,释放大型语言模型的全部潜力,实现高效、精…...

FreeRTOS系统CPU使用率统计
操作系统中CPU使用率是在软件架构设计中必须要考虑的一个重要性能指标。它直接影响到程序的执行时间以及优先级更高的任务能否实时响应的问题。而CPU使用率也不能过低,避免资源浪费。 基本原理 操作系统会统计系统总共运行了多少时间,以及在此期间每个任…...
是更换Window资源管理器的时候了-> Files-community/Files
Files • 主页https://files.community/ 它已经做到了 云盘文件集成、标签页和多种布局、丰富的文件预览…… 您想要的一切现代文件管理器的强大功能, Files 都能做到。 概述 Files 是一个现代文件管理器,可帮助用户组织他们的文件和文件夹。Files 的…...
基于windows安装MySQL8.0.40
基于windows安装MySQL8.0.40 基于windows 安装 MySQL8.0.40,解压文件到D:\mysql-8.0.40-winx64 在D:\mysql-8.0.40-winx64目录下创建my.ini文件,并更新一下内容 [client] #客户端设置,即客户端默认的连接参数 # 设置mysql客户端连接服务…...
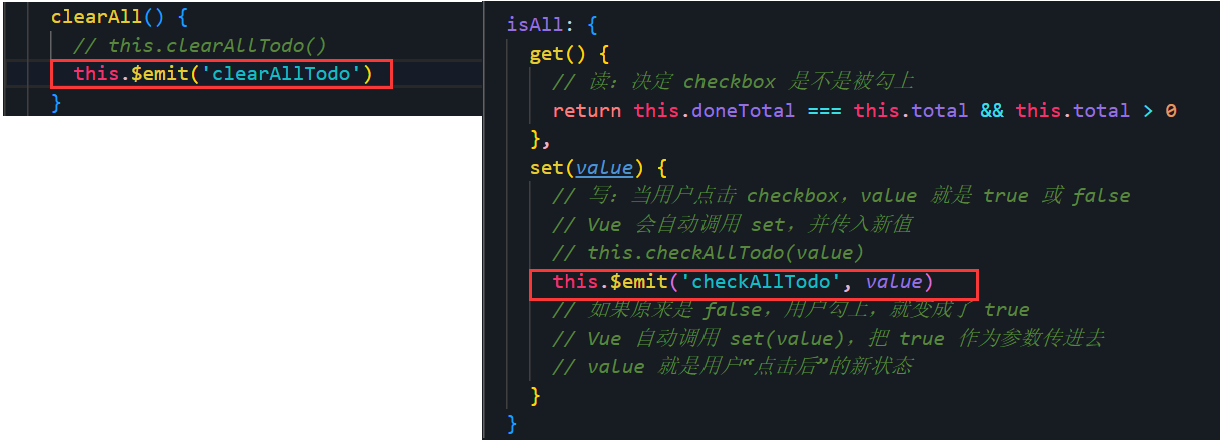
【Vue】组件自定义事件 TodoList 自定义事件数据传输
目录 一、绑定 二、解绑 组件自定义事件总结 TodoList案例对数据传输事件的修改 总结不易~ 本章节对我有很大收获, 希望对你也是!!! 本章节素材已上传Gitee:yihaohhh/我爱Vue - Gitee.com 前面我们学习的clikc、…...
基于Centos7的DHCP服务器搭建
一、准备实验环境: 克隆两台虚拟机 一台作服务器:DHCP Server 一台作客户端:DHCP Clinet 二、部署服务器 在网络模式为NAT下使用yum下载DHCP 需要管理员用户权限才能下载,下载好后关闭客户端,改NAT模式为仅主机模式…...
LabVIEW超声波液位计检定
在工业生产、运输和存储等环节,液位计的应用十分广泛,其中超声波液位计作为非接触式液位测量设备备受青睐。然而,传统立式水槽式液位计检定装置存在受建筑高度影响、量程范围受限、流程耗时长等问题,无法满足大量程超声波液位计的…...

Ubuntu 24.04 完整Docker安装指南:从零配置到实战命令大全
文章目录 1. 安装 Docker2. 配置 Docker 镜像加速器2.1 配置 Docker 镜像源2.2 重启 Docker 服务 3. Docker 常用命令3.1 Docker 常用命令速查表3.1.1 容器管理3.1.2 镜像管理3.1.3 网络管理3.1.4 数据卷管理3.1.5 容器资源管理3.1.6 Docker Compose(容器编排&#…...
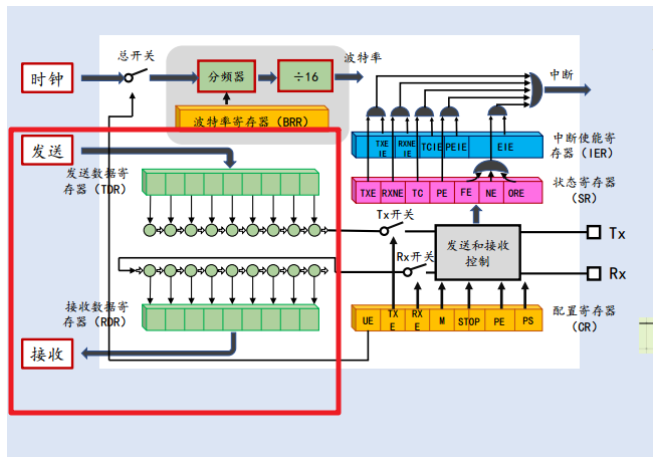
[STM32] 4-2 USART与串口通信(2)
文章目录 前言4-2 USART与串口通信(2)数据发送过程双缓冲与连续发送数据发送过程中的问题 数据接收过程TXE标志位(发送数据寄存器空)TC标志位(发送完成标志位)单个数据的发送数据的连续发送 接收过程中遇到的问题问题描述…...
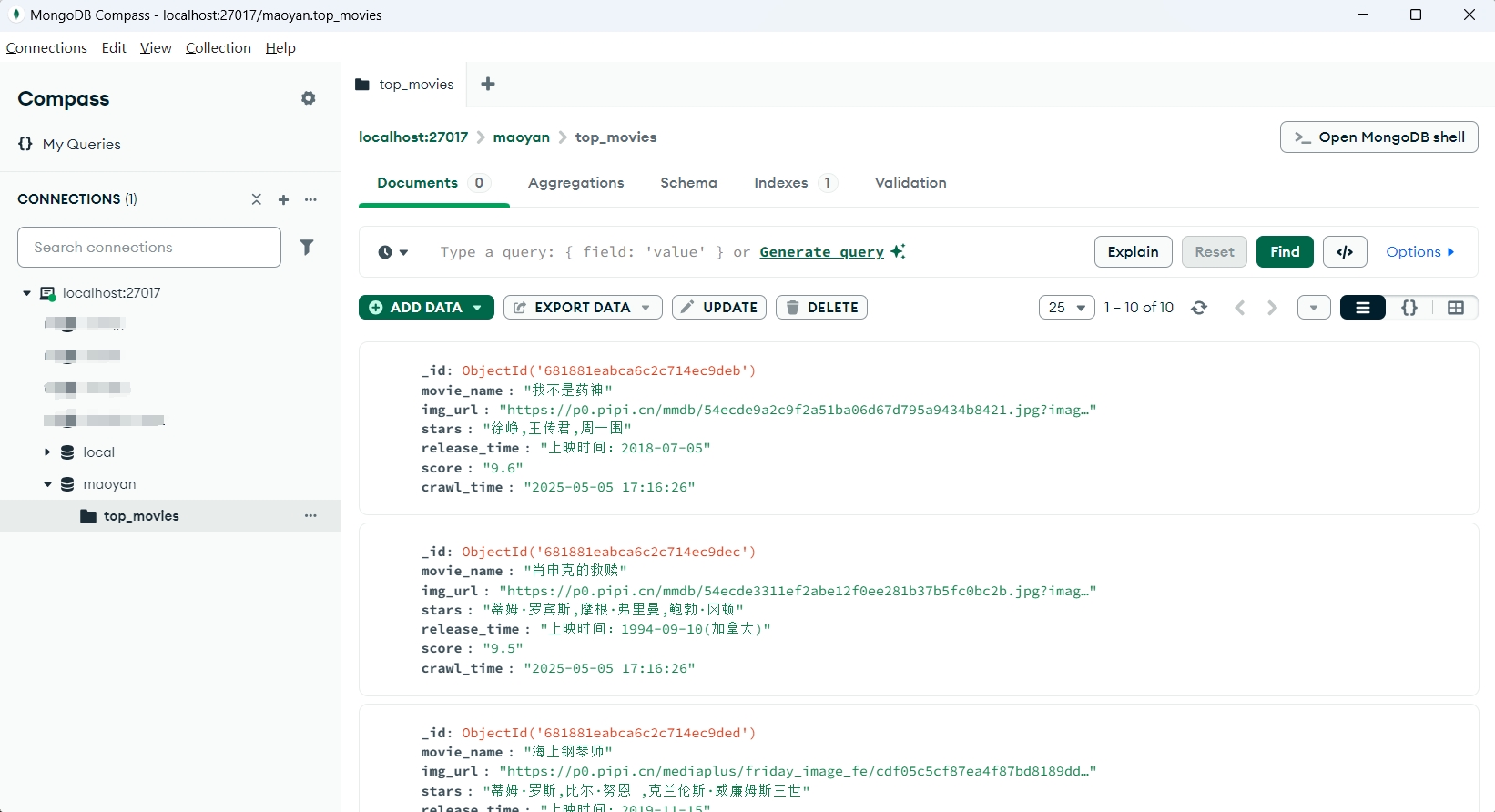
基于Python+MongoDB猫眼电影 Top100 数据爬取与存储
前言:从猫眼电影排行榜页面(TOP100榜 - 猫眼电影 - 一网打尽好电影 )爬取 Top100 电影的电影名称、图片地址、主演、上映时间和评分等关键信息,并将这些信息存储到本地 MongoDB 数据库中,🔗 相关链接Xpath&…...

前端缓存踩坑指南:如何优雅地解决浏览器缓存问题?
浏览器缓存,配置得当,它能让页面飞起来;配置错了,一次小小的上线,就能把你扔进线上 bug 的坑里。你可能遇到过这些情况: 部署上线了,结果用户还在加载旧的 JS;接口数据改了…...
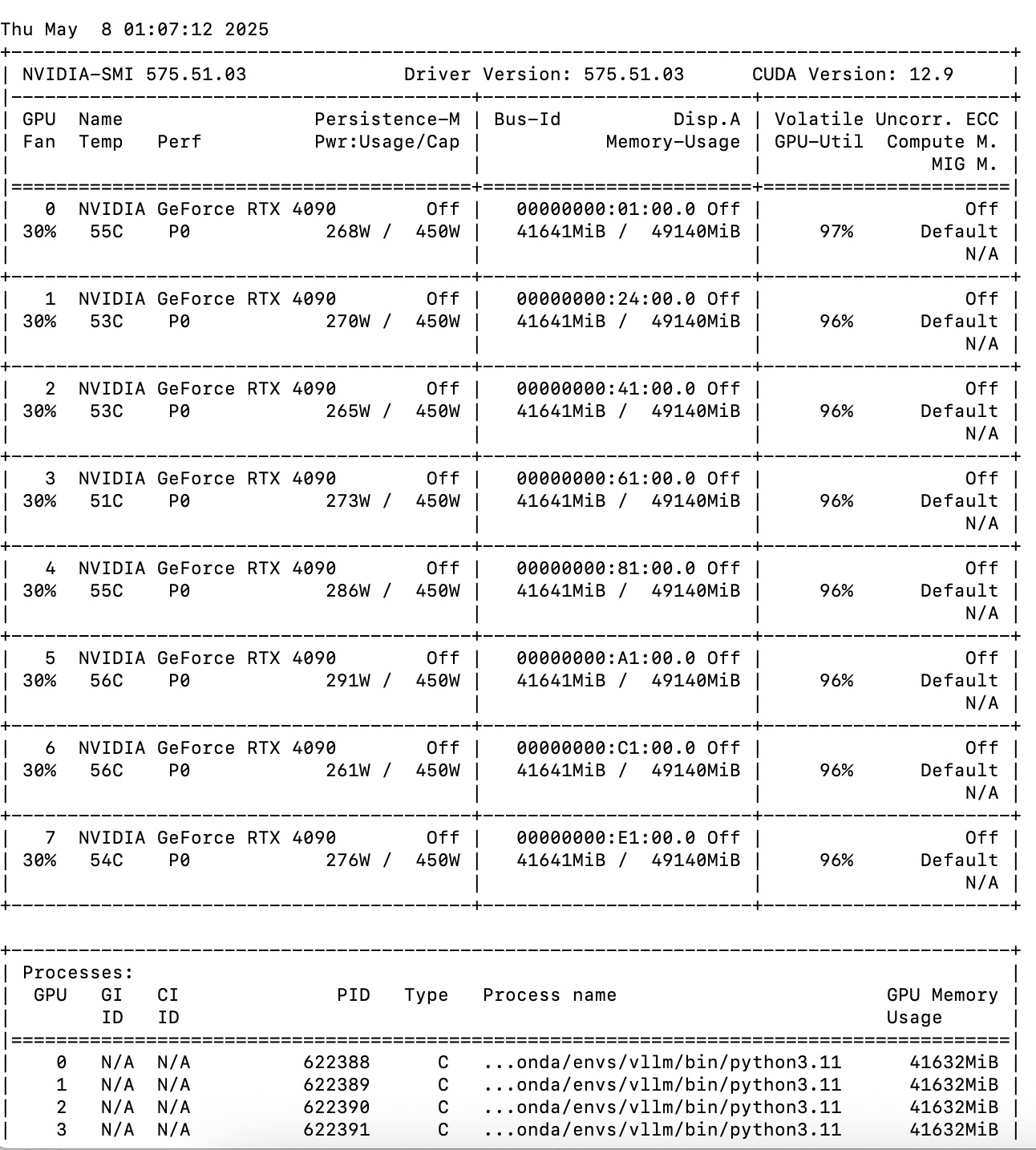
Ubuntu 单机多卡部署脚本: vLLM + DeepSeek 70B
# 部署脚本:Ubuntu vLLM DeepSeek 70B # 执行前请确保:1. 系统为 Ubuntu 20.04/22.04 2. 拥有NVIDIA显卡(显存≥24G) # 保存两个文件 1 init.sh 初始化 2、test.sh 测试 # init.sh #!/bin/bash # 系统更新与基础依赖sudo apt update && s…...

从软件到硬件:三大主流架构的特点与优劣详解
常见的架构包括软件架构、企业架构、硬件架构等,以下是对这几种常见架构的分析: 一、软件架构 1.分层架构 描述:分层架构是一种经典的软件架构模式,将软件系统按照功能划分为不同的层次,一般包括表现层(…...

STM32printf重定向到串口含armcc和gcc两种方案
STM32串口重定向:MDK与GCC环境下需重写的函数差异 在嵌入式开发中,尤其是使用 STM32系列微控制器 的项目中,调试信息的输出是不可或缺的一部分。为了方便调试,开发者通常会选择将 printf 等标准输出函数通过 UART 串口发送到 PC …...
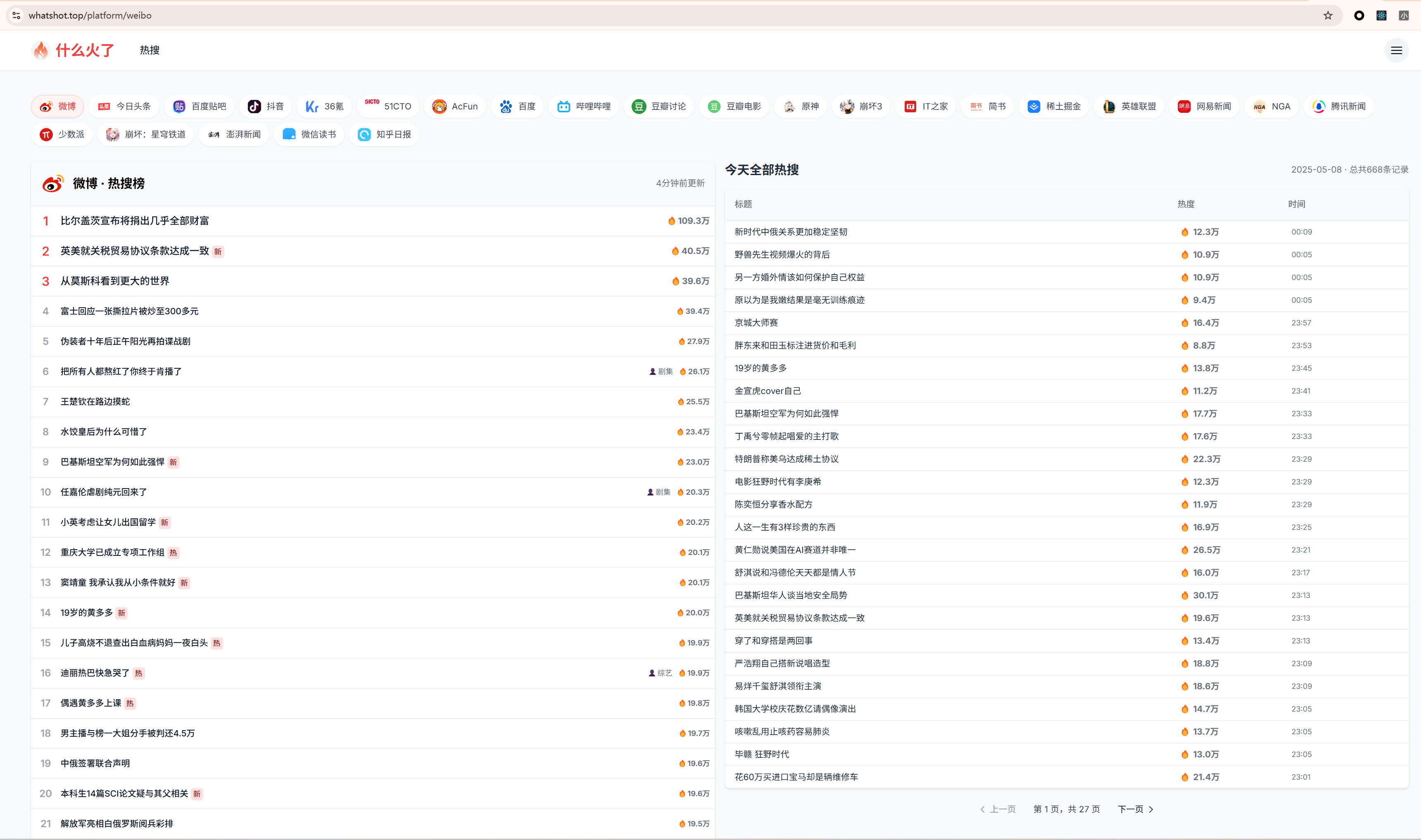
为了摸鱼和吃瓜,我开发了一个网站
平时上班真的比较累,摸鱼和吃瓜还要跳转多个平台的话,就累上加累了。 所以做了一个聚合了全网主流平台热搜的网站。 目前市面上确实有很多这种网站了,所以目前最主要有两点和他们不同: 给热搜列表增加了配图,刷的时候…...
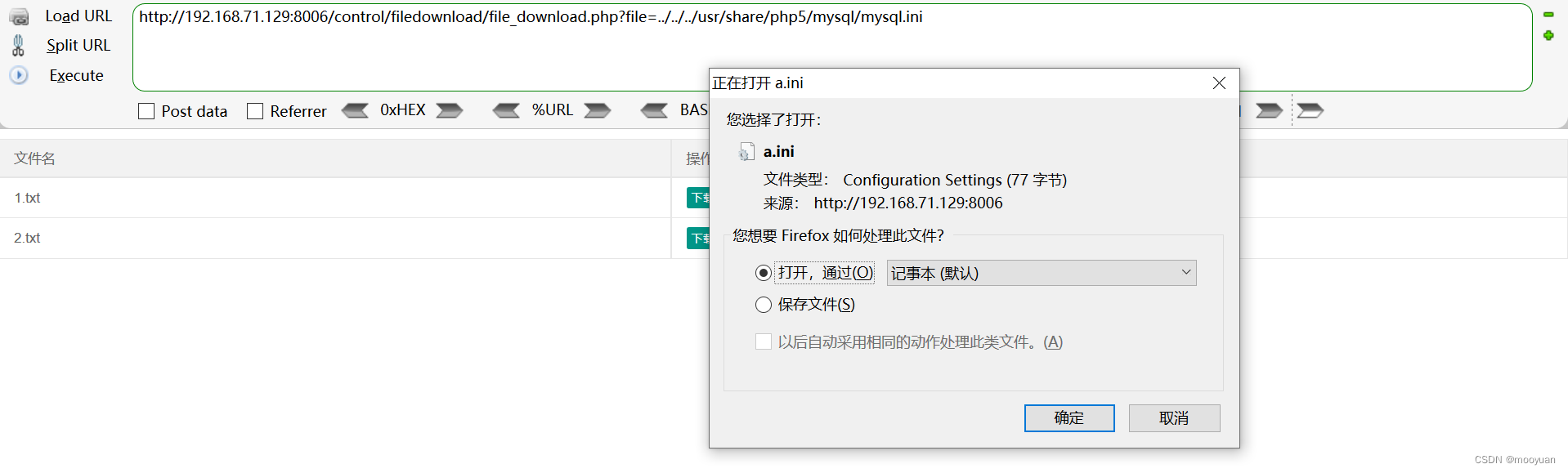
Webug4.0靶场通关笔记11- 第15关任意文件下载与第16关MySQL配置文件下载
目录 一、文件下载 二、第15关 任意文件下载 1.打开靶场 2.源码分析 3.渗透实战 三、第16关 MySQL配置文件下载 1.打开靶场 2.源码分析 3.渗透实战 (1)Windows系统 (2)Linux系统 四、渗透防御 一、文件下载 本文通过…...

【中间件】brpc_基础_remote_task_queue
文章目录 remote task queue1 简介2 核心功能2.1 任务提交与分发2.2 无锁或低锁设计2.3 与 bthread 深度集成2.4 流量控制与背压 3 关键实现机制3.1 数据结构3.2 任务提交接口3.3 任务窃取(Work Stealing)3.4 同步与唤醒 4 性能优化5 典型应用场景6 代码…...