Mysql进阶篇1_存储引擎、索引、SQL性能分析指令
文章目录
- 1.存储引擎
- InnoDB
- MyISAM
- Memory
- 存储引擎选择和对比
- 2.索引
- 索引结构
- 索引分类
- 索引语法
- 索引使用(建议看完第3节后观看)!!!
- mysql如何使用索引查询数据(个人理解)
- 3.SQL性能分析
- SQL执行频率
- 慢查询日志
- profile
- explain
Mysql结构图-mysql执行sql的过程
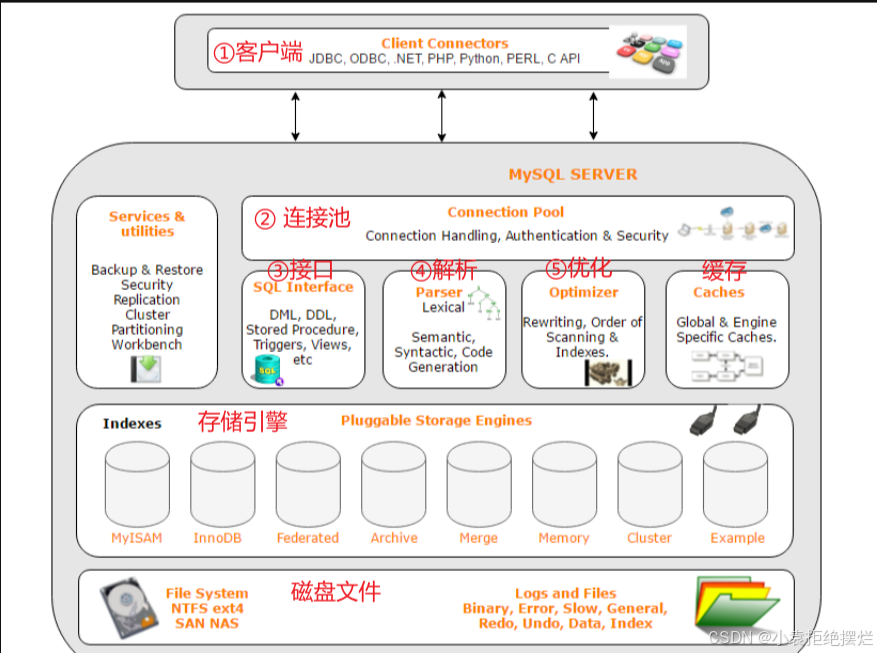
1.存储引擎
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。
存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
我们可以在创建表的时候,来指定选择的存储引擎,如果没有指定将自动选择默认的存储引擎,默认为InnoDB。
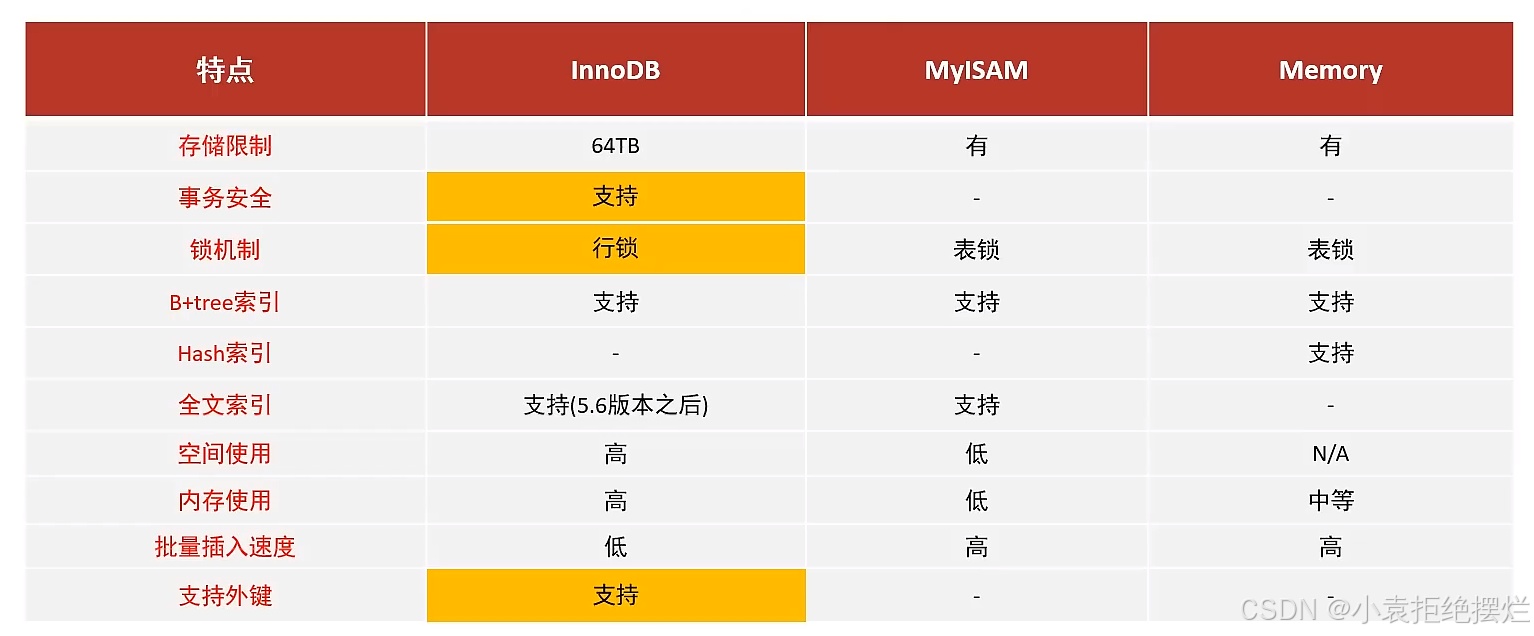
我们常用的存储引擎有两种1.MyISAM 2.InnoDB
InnoDB
在 MySQL 5.5 之后,InnoDB是默认的 MySQL 存储引擎。
特点
- 事务支持:支持 ACID 事务,适合需要高并发和数据一致性的应用。
- 行级锁:支持行级锁,减少锁冲突,提高并发性能。
- 外键约束:支持外键FOREIGN KEY约束,保证数据的完整性。(一般不用这个约束,都是逻辑约束)
- 崩溃恢复:具有崩溃恢复能力,数据安全性高。
文件
xxx.ibd:xxx是表名,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构、数据和索引。
参数innodb_file_per_table:决定是多张表对应一个.ibd文件,还是一张表对应一个.idb文件
show variables like 'innodb_file_per_table';

on时,一张表对应一个.ibd文件
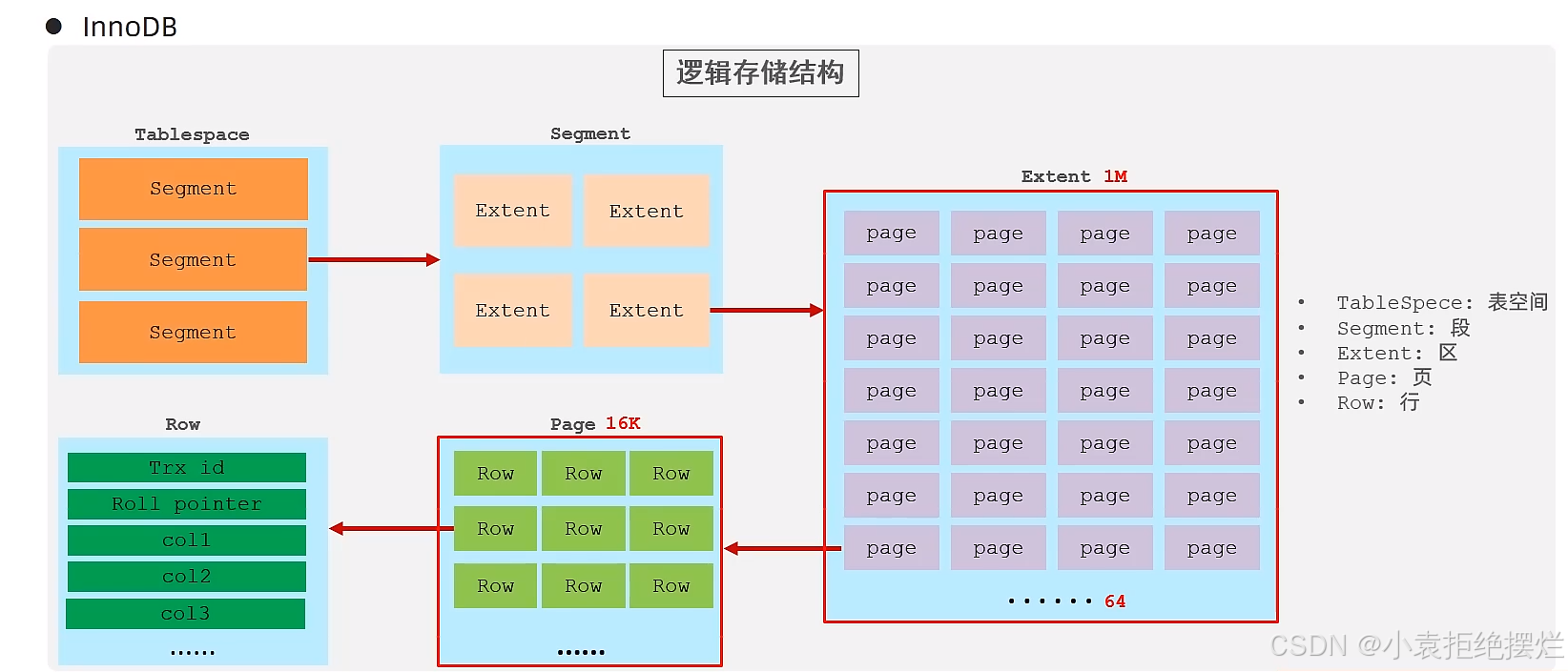
- 表空间 : InnoDB存储引擎逻辑结构的最高层,ibd文件其实就是表空间文件,在表空间中可以包含多个Segment段。
- 段 : 常见的段有数据段、索引段、回滚段等。InnoDB中对于段的管理,都是引擎自身完成,不需要人为对其控制,一个段中包含多个区。
- 区 : 区是表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一个区中一共有64个连续的页。
- 页 : 页是组成区的最小单元,页也是InnoDB 存储引擎磁盘管理的最小单元,
即每次读取到内存的时候是读取一页的数据,每个页的大小默认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。 - 行 : InnoDB 存储引擎是面向行的,也就是说数据是按行进行存放的,在每一行中除了定义表时所指定的字段以外,还包含两个隐藏字段(MVCC会讲解)。
MyISAM
MyISAM是MySQL早期的默认存储引擎
特点
- 表级锁:只支持表级锁,适合读多写少的场景。
- 全文索引:支持全文索引,适合文本搜索。
- 不支持事务:不适合需要事务支持的应用。
文件
xxx.sdi:存储表结构信息
xxx.MYD: 存储数据
xxx.MYI: 存储索引
Memory
Memory:数据存储在内存中,速度快,但重启后数据丢失,只能将这些表作为临时表或缓存使用。
默认使用Hash索引
存储引擎选择和对比
- InnoDB: 是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
- MyISAM : 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
2.索引
索引(index)是帮助 MySQL 高效获取数据的数据结构。
数据库系统除了维护数据之外,还维护着索引。索引指向着数据。
索引结构
概述
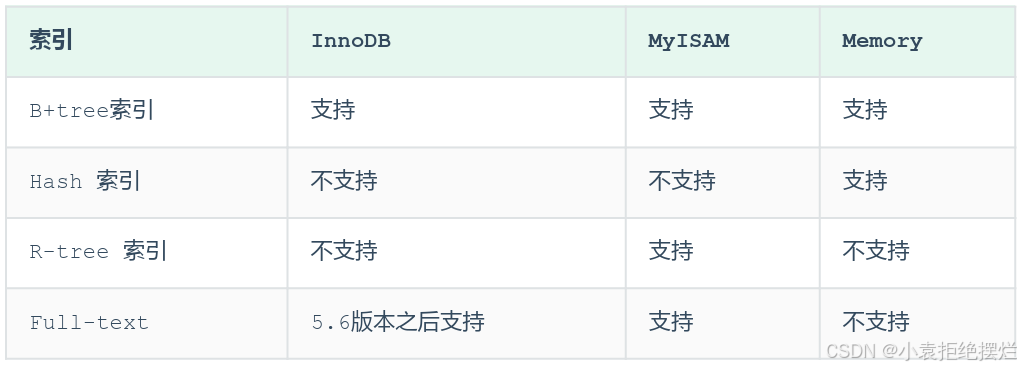
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种
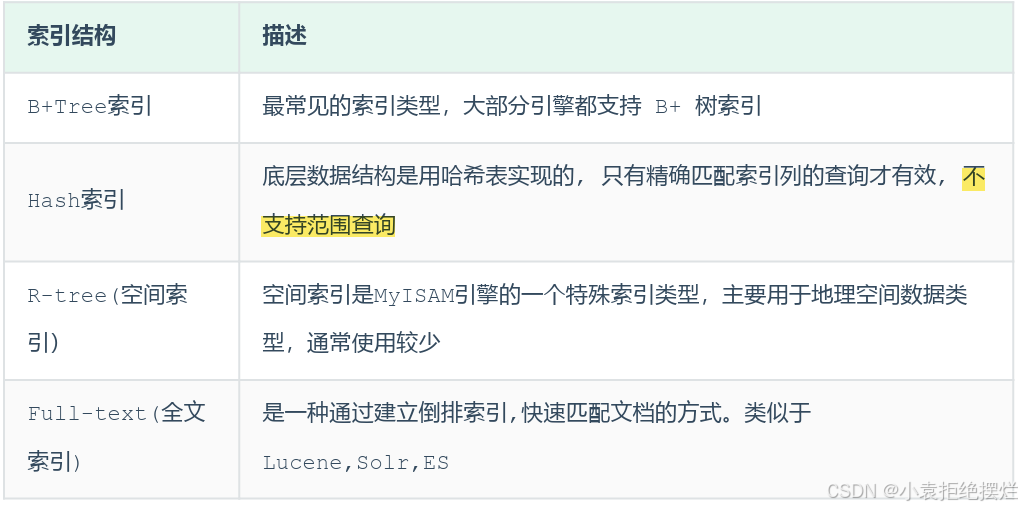
不同的存储引擎对于索引结构的支持情况。
为什么要使用B+树而不是B树或者二叉树
二叉树
如果选择二叉树作为索引结构,会存在以下缺点:
- 顺序插入时,会形成一个链表,查询性能大大降低。
- 大数据量情况下,层级较深,检索速度慢。
如果选择红黑树作为索引结构,但在大数据量情况下,层级较深,检索速度慢。
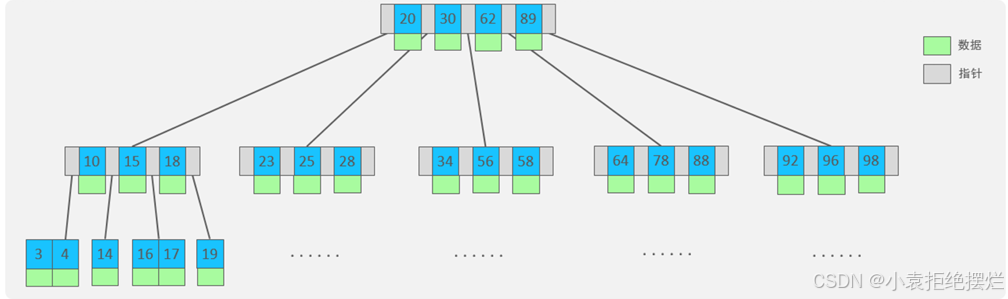
B-Tree
B树:是一个多叉的平衡搜索树。
度数(节点的子节点个数)为5的B树,B树的每个节点最多存储4个Key,5个指针。
特点:
-
例如:5阶的B树,每一个节点最多存储4个key,对应5个指针
-
在B树中,非叶子节点和叶子节点都会存放数据。
B+Tree
B+Tree是B-Tree的变种,我们以一颗最大度数(max-degree)为4(4阶)的b+tree为例,来看一下其结构示意图:
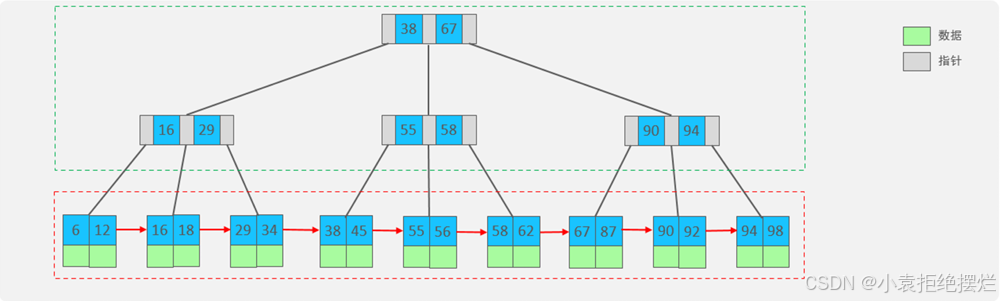
我们可以看到,两部分: -
蓝色框起来的部分,是索引部分,仅仅起到索引数据的作用,不存储数据。
-
绿色框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据。
B+Tree 与 B-Tree相比,主要有以下三点区别:
- 所有的数据都会出现在叶子节点。
- 叶子节点形成一个单向链表。
- 非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的
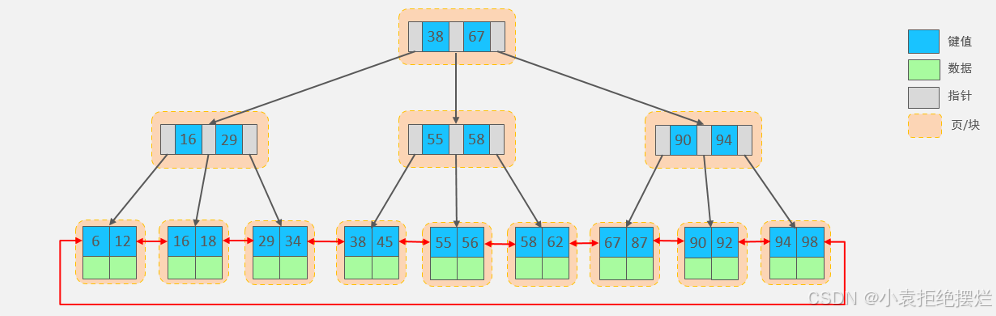
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。
单向链表变双向链表
Hash
MySQL中除了支持B+Tree索引,还支持一种索引类型—Hash索引。
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中
如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决
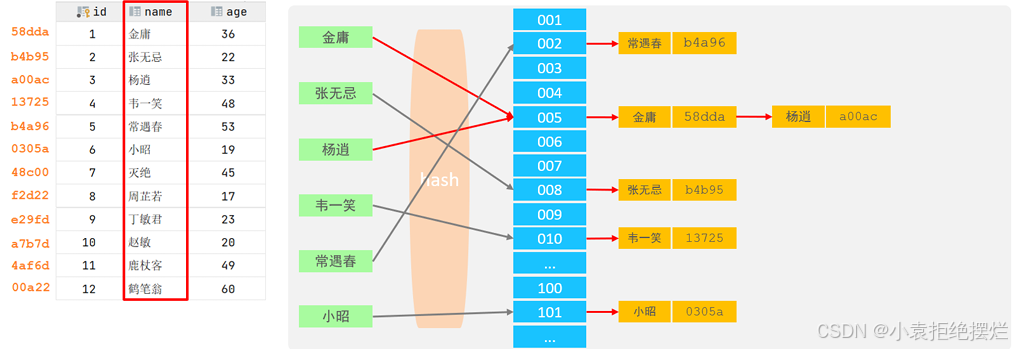
特点:
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,…)
- 无法利用索引完成排序操作
- 查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
在MySQL中,支持hash索引的是Memory存储引擎。 而InnoDB中具有自适应hash功能,hash索引是InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
面试题:
为什么InnoDB存储引擎选择使用B+tree索引结构
1.相对于二叉树,层级更少,搜索效率高
2.对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低。(且难以进行范围查询,查找数据的时间稳定性不足)
3.相对Hash索引,B+tree支持范围匹配及排序操作
索引分类
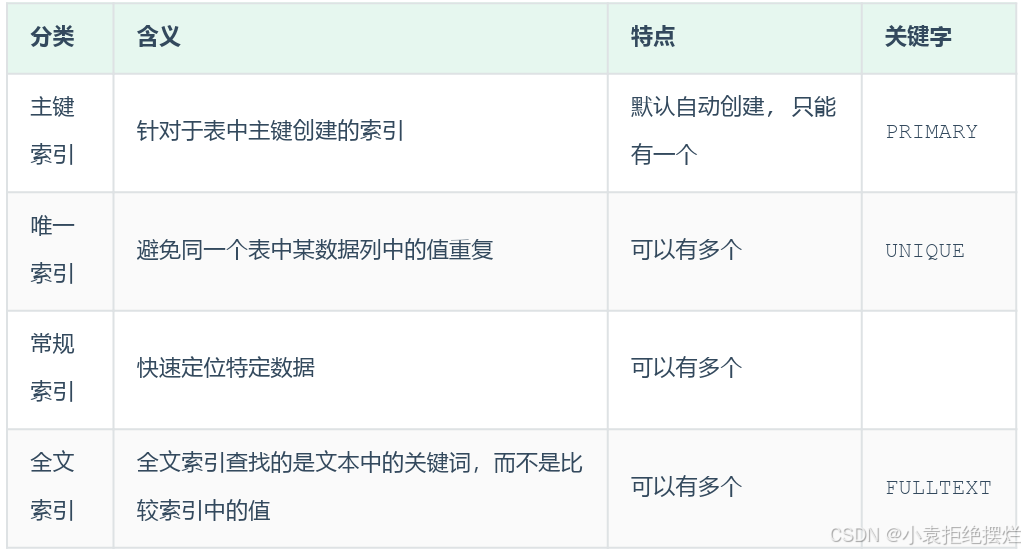
索引分类
在MySQL数据库,将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引。
聚集索引&二级索引
注:聚簇索引只能存在一个,且必须要有

聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
聚集索引和二级索引的具体结构如下:
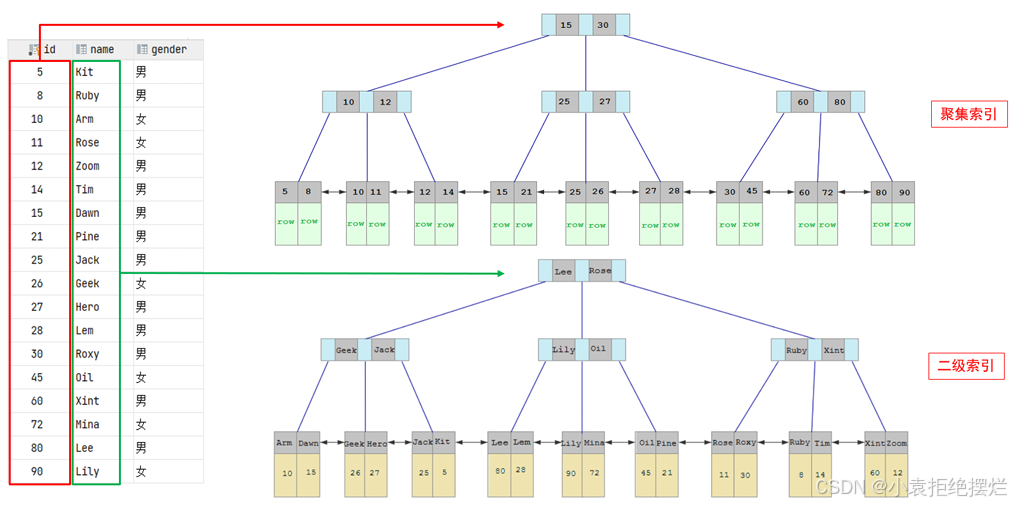
- 聚集索引的叶子节点下挂的是这一行的数据 。
- 二级索引的叶子节点下挂的是该字段值对应的主键值。
回表查询: 先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询
所以直接查聚集索引必用二级索引要快,少了回表查询这个步骤
索引语法
1.创建索引
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name ( index_col_name,... );
2.查看索引
SHOW INDEX FROM table_name;
3.删除索引
DROP INDEX index_name ON table_name;
索引使用(建议看完第3节后观看)!!!
最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)。
注意:
注意 : 最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段 (即第一个字段) 必须存在,与我们编写SQL时,条件编写的先后顺序无关。
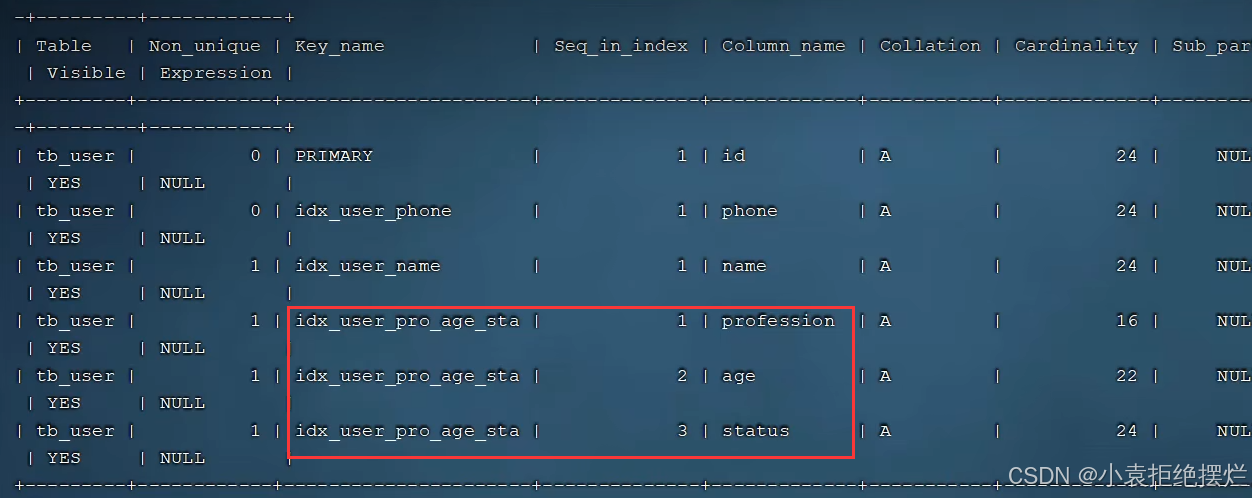
举例:比如这三个是联合索引,profession是最左字段,age和status紧跟其后
如果select * from tb_user where profession= xxx and age = xx and status = xx(三个都用)
或者select * from tb_user where profession= xxx and age = xx(用profession和age)
都会使用到联合索引
如果where中无profession这个字段,就不会走索引,不满足最左前缀法则
如果where 只用了profession 和 status(少了中间的age),也会用索引,但是 只会用profession的索引
那么索引不连续会造成什么后果呢?
查询效率的降低,以下是查询索引不连续的查询流程,逐行过滤降低了查询筛选效率
可以看下这篇文章,可以加深对于最左前缀法则的理解,简单来说后一个字段依靠前一个字段的排序来进行排序的,没有用前面的字段索引就没法用有后面的字段索引
MySQL联合索引底层数据结构是怎样的
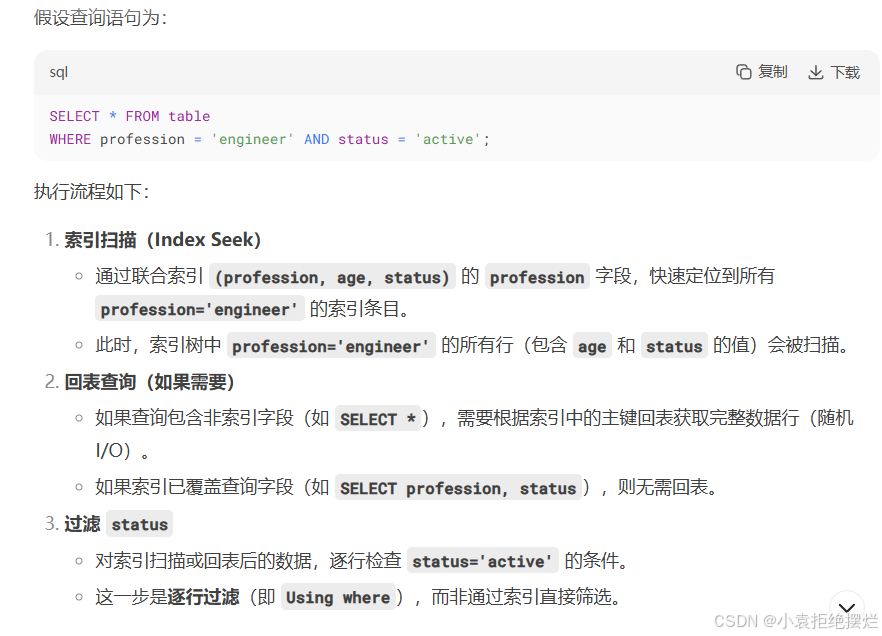
范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
在业务允许的情况下,尽可能的使用类似于>=或 <= 这类的范围查询,而避免使用 > 或 <
索引失效情况
索引列计算
不要在索引列上进行运算操作, 索引将失效。
explain select * from tb_user where substring(phone,10,2) = '15'; # phone索引失效
字符串不加引号
字符串类型字段使用时,不加引号,索引将失效。(规范书写)
select * from tb_user where phone = '123456';
和
select * from tb_user where phone = 123456;
都可以查到,但是下面那个不会用到索引,我猜测应该是底层用了某种计算转换(相当于索引列计算呗)
模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
即在like模糊查询中,在关键字后面加%,索引可以生效。而如果在关键字前面加了%,
索引将会失效
select * from tb_user where name like '小%'; 索引正常起作用
select * from tb_user where name like '%小%'; 索引失效
or连接条件
用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
当or连接的条件,左右两侧字段都有索引时,索引才会生效。
数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引。
下面的explain的type有具体说明
SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
use index:建议MySQL使用哪一个索引完成此次查询(仅仅是建议,mysql内部还会再次进行评估)
比如现在我的profession有两个索引,一个是联合索引idx_user_sta,一个是单列索引idx_user_pro
explain select * from tb_user use index(idx_user_pro) where profession = '软件工程';
ignore index : 忽略指定的索引,不用哪个索引。
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工程';
force index : 强制使用索引,必须用哪个索引。
explain select * from tb_user force index(idx_user_pro) where profession = '软件工程';
覆盖索引
尽量使用覆盖索引,减少select *。
那么什么是覆盖索引呢? 覆盖索引是指查询条件使用了索引,并且需要返回的列,在该索引中已经全部能够找到 。
注:这里的该索引是mysql优化器选择的索引
SELECT * FROM tb_user WHERE id=1 AND name=‘Alice’;
比如该语句,若sql优化器语句选择id索引就不会回表查
选择name就需要回表查询
但mysql一般会选覆盖索引的索引来查询
所以我们需要的是where后面有索引的字段中有一个索引结构中包含查询字段的全部信息即可
一般创建联合索引解决该问题
接下来,我们来看一组SQL的执行计划,看看执行计划的差别,然后再来具体做一个解析。
explain select id, profession from tb_user where profession = '软件工程' and age = 31 and status = '0' ;
explain select id,profession,age, status from tb_user where profession = '软件工程' and age = 31 and status = '0' ;
explain select id,profession,age, status, name from tb_user where profession = '软件工程' and age = 31 and status = '0';
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';
上述这几条SQL的执行结果为:
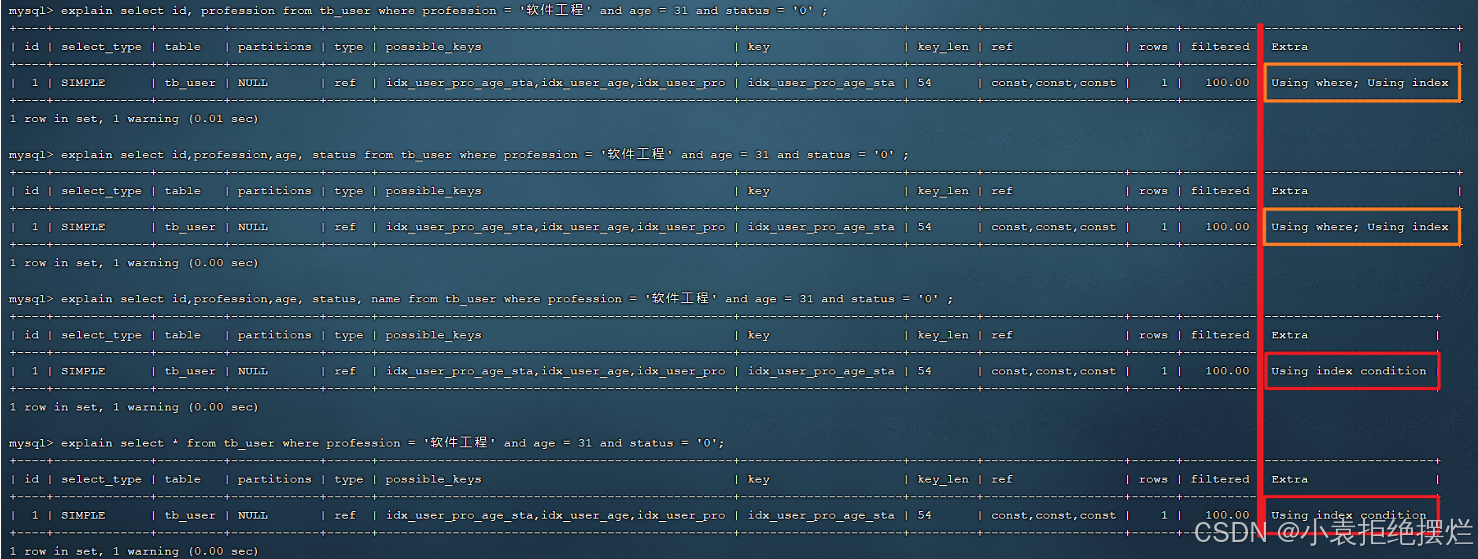
从上述的执行计划我们可以看到,这四条SQL语句的执行计划前面所有的指标都是一样的,看不出来差异。但是此时,我们主要关注的是后面的Extra,前面两天SQL的结果为 Using where; Using Index ; 而后面两条SQL的结果为:Using index condition。
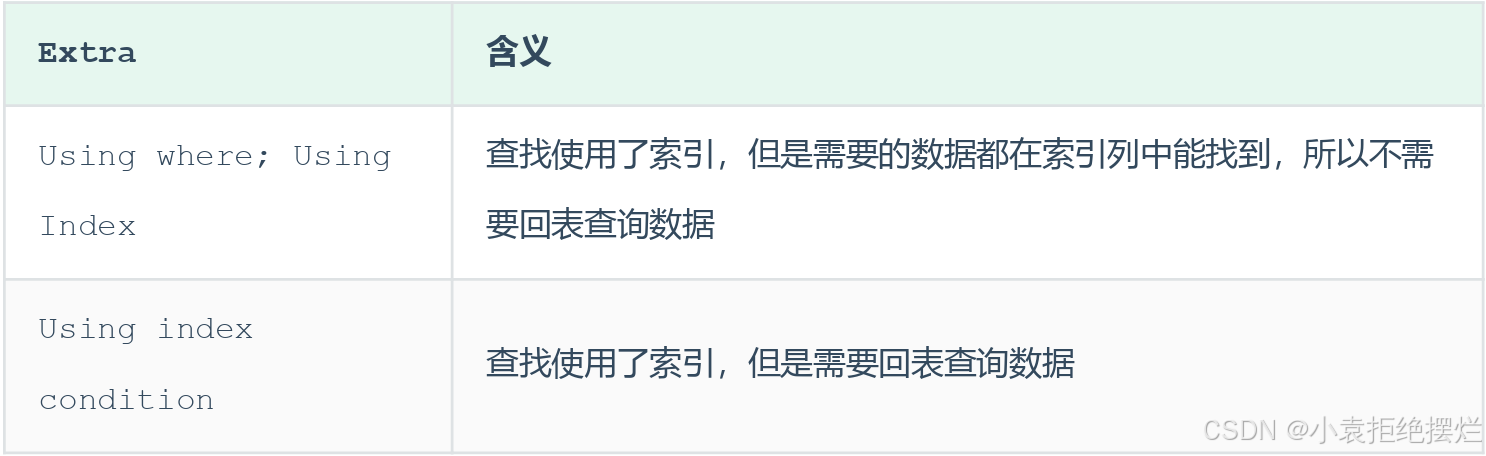
下面我们解释一下回表查询
像前两条sql语句就不会涉及到回表查询
因为索引结构已经包含了所有需要查询的字段-覆盖索引
select * from tb_user where id=2;使用聚簇索引查询可以使用*不用回表(聚簇索引下就是所有数据)
select id,name from tb_user where name=‘Arm’;使用其他索引也可以带上聚簇索引所在的列,也不会回表查询,因为其他索引除了存储本列的值还存储了对应聚簇索引列的值
而第三条sql由于多引用了一个gender,只根据name的索引结构查不出所以要回表查询
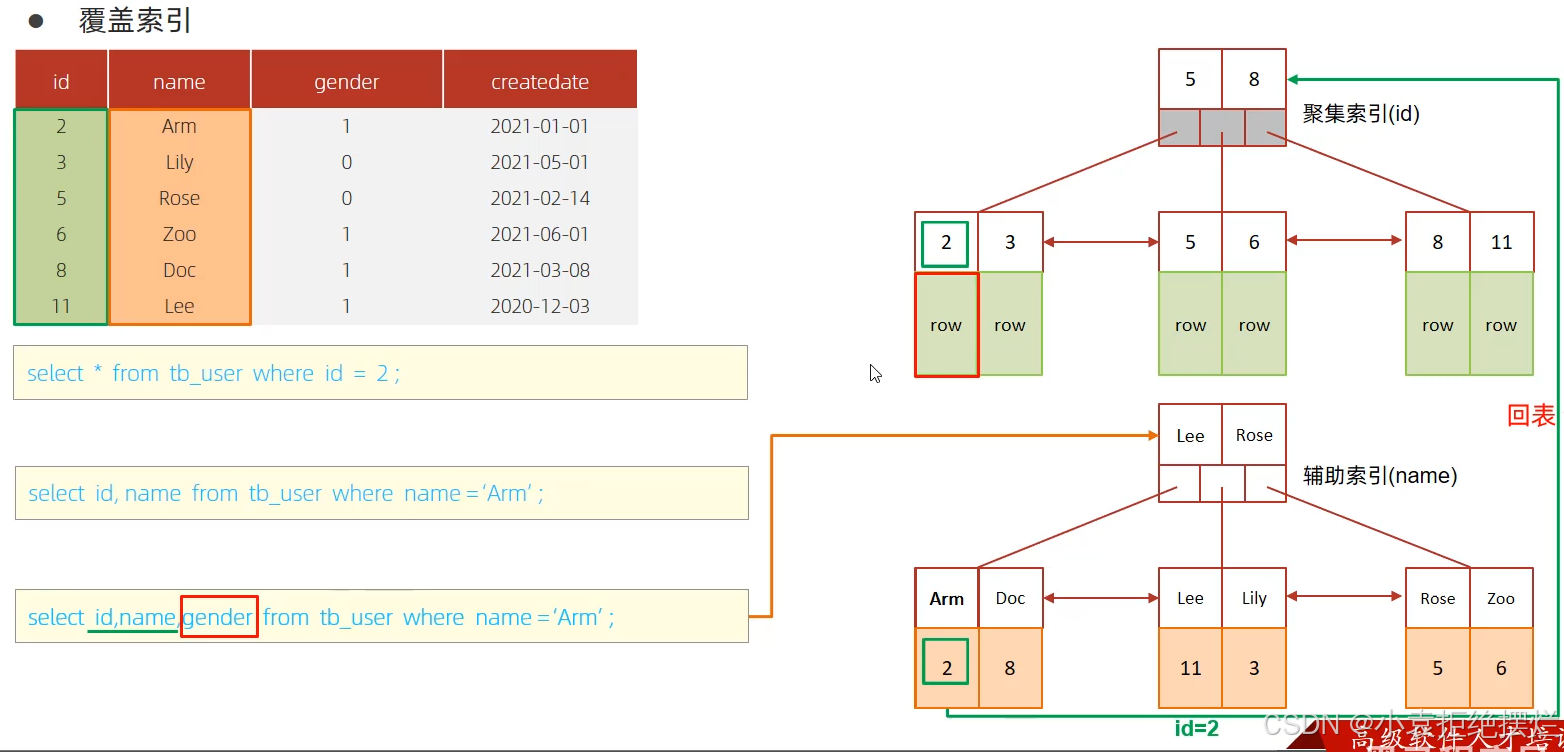
所以为什么要减少使用select * 呢?
因为极易产生回表查询
思考题:
一张表, 有四个字段(id, username, password, status), 由于数据量大, 需要对以下SQL语句进行优化, 该如何进行才是最优方案:
select id,username,password from tb_user where username = ‘itcast’;
答案: 针对于 username, password建立联合索引, sql为: create index idx_user_name_pass on tb_user(username,password);
这样username和password是索引结构既有他们自己的值,也有id的值
可以避免上述的SQL语句,在查询的过程中,出现回表查询。
前缀索引
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
create index idx_xxxx on table_name(column(n));
n代表使用前n个字符创建前缀索引
关于n长度的选择要平衡选择性和索引体积来指定
选择性就是当你的索引每个值但是唯一的,选择性就是1(unique 索引就是1),如果有重复就是distinct/count,选择性越高,查询效率越高,而索引体积就是依靠于n取多少
select count(distinct substring(字符串字段名,1,n))/count(*) from table
来观察,对应的值就是选择性,通过改变n的值获取最佳的n
通过前缀索引回表查询到数据之后还要对比一下(因为索引匹配只是前缀匹配,不确定就整个字符串都匹配,你选择性为1当我没说)
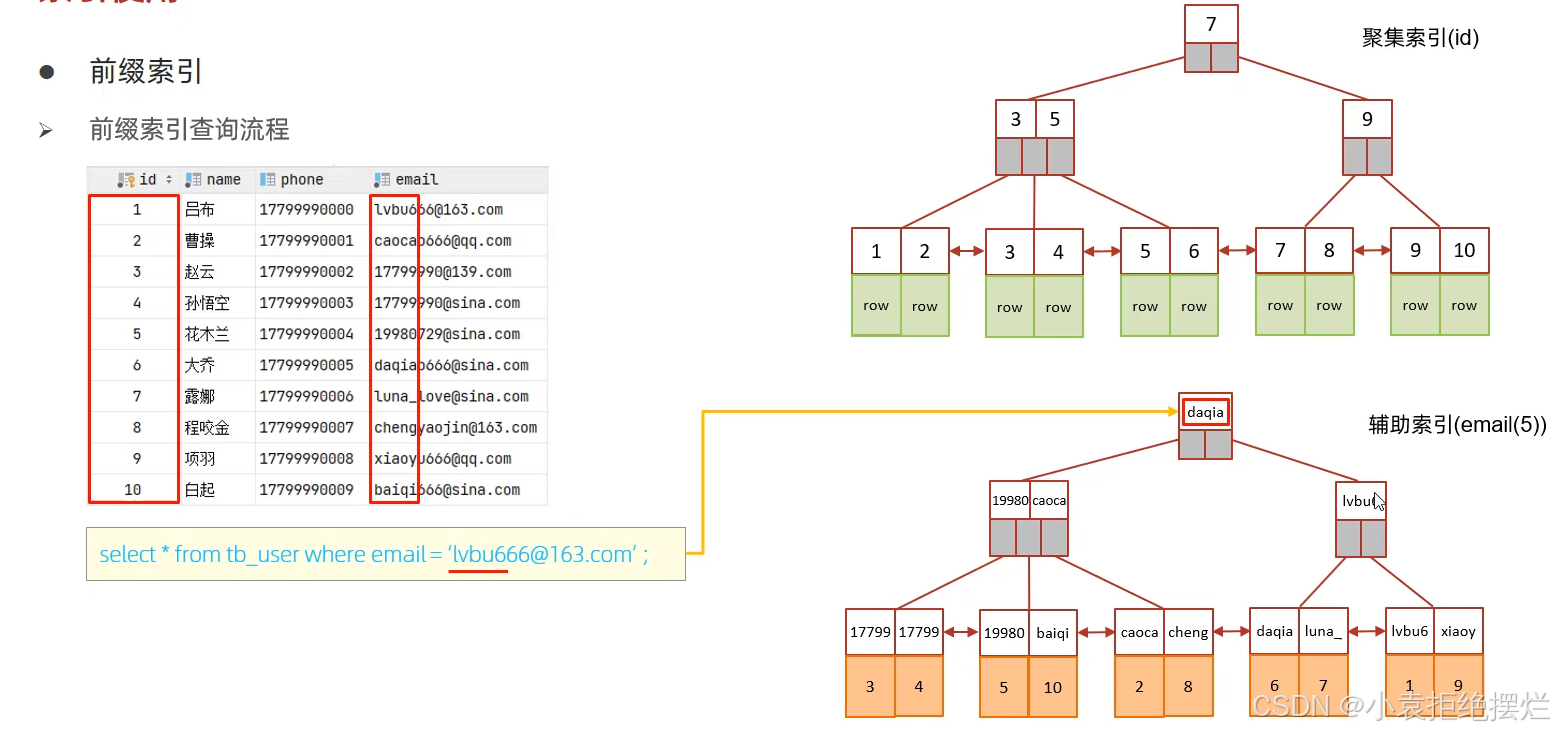
单列索引与联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。联合索引的数据结构,叶子结点会包含所有索引列的值(降低回表查询概率),且也可以通过
最左前缀原则使用联合索引中的列进行查询
可以看下这篇文章
MySQL联合索引底层数据结构是怎样的
索引使用原则
- 针对于数据量较大,且查询比较频繁的表建立索引。
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
mysql如何使用索引查询数据(个人理解)
id为主键索引,name为普通索引
WHERE id=1 AND name=‘Alice’
比如说这条语句,筛选了两个条件,优化器会选择一个最优索引进行查询,一般有主键值都先选主键(主键不会产生回表查询)

那么这样只会筛选出来id符合条件的,如果筛选name也符合条件的呢?
先将第一次筛选出来的结果读到内存,再在内存中全部扫描过滤(内存过滤)

3.SQL性能分析
SQL执行频率
MySQL 客户端连接成功后,通过 how [session|global] status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
-- session 是查看当前会话 ;-- global 是查询全局数据 ;SHOW GLOBAL STATUS LIKE 'Com_______';

那么通过查询SQL的执行频次,我们就能够知道当前数据库到底是增删改为主,还是查询为主。 那假如说是以查询为主,我们又该如何定位针对于那些查询语句进行优化呢? 次数我们可以借助于慢查询日志。
慢查询日志
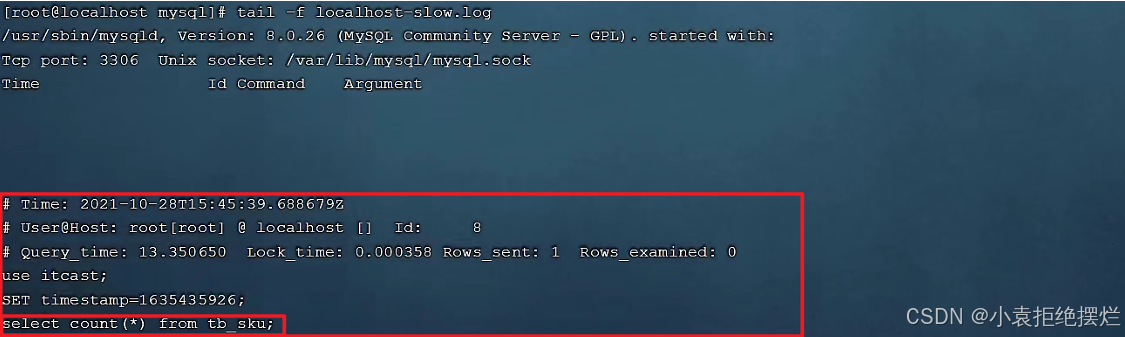
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量 slow_query_log。

如果要开启慢查询日志,需要在MySQL的配置文件(my.ini)中配置如下信息:
# 开启MySQL慢日志查询开关
slow_query_log=1# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
配置完毕之后,重新启动MySQL服务器。
慢查询日志文件生成,文件名为localhost-slow.log
在慢查询日志中,只会记录执行时间超多我们预设时间(2s)的SQL,执行较快的SQL是不会记录的。
那这样,通过慢查询日志,就可以定位出执行效率比较低的SQL,从而有针对性的进行优化。
最下面的就是查询较慢的于语句
profile
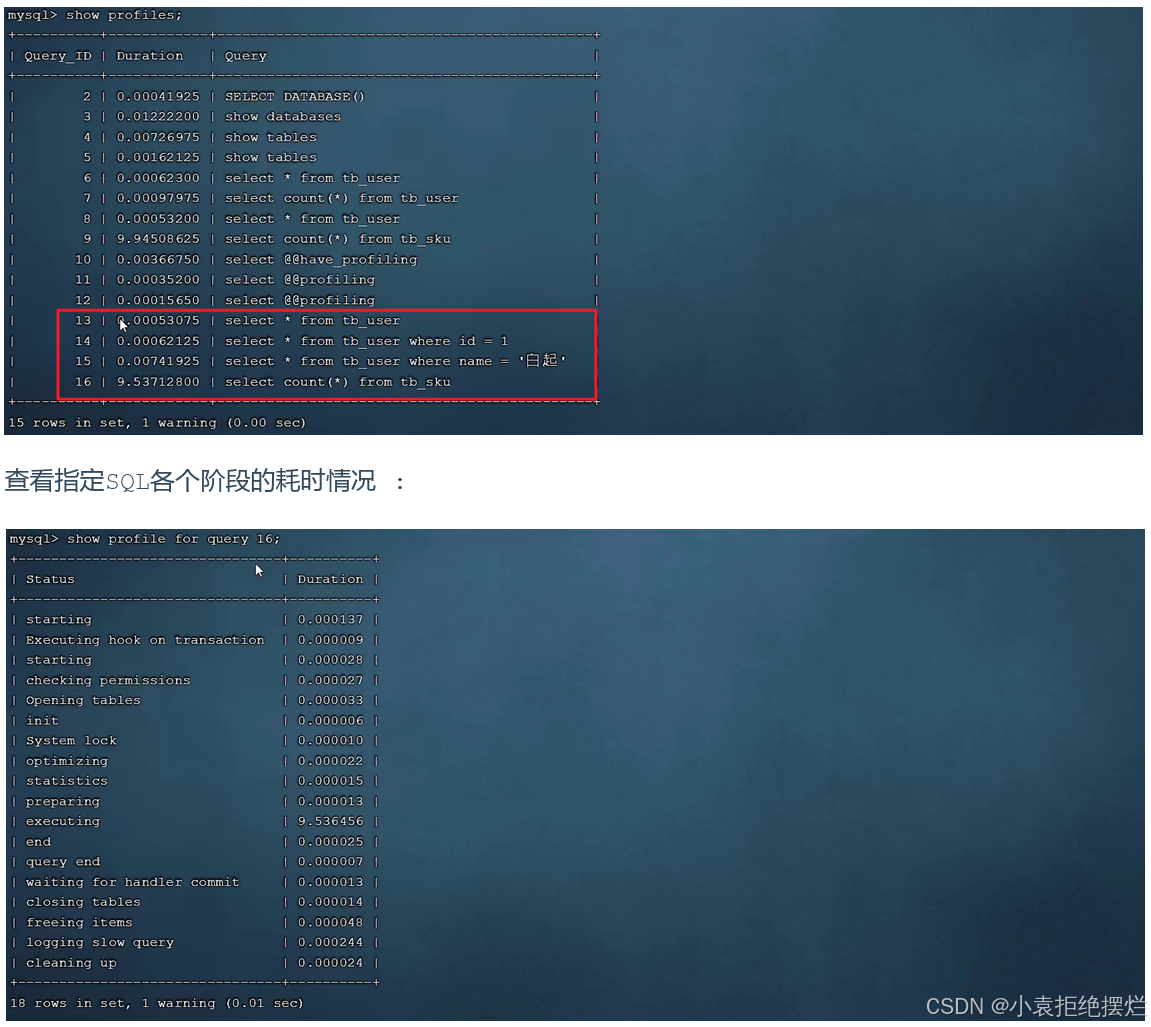
profile详情
show profiles 能够在做SQL优化时帮助我们了解SQL执行时间具体都耗费到哪里去了。
点击后会查询到我们在该回话执行过的sql
然后show profile for query 16(想要查询sql对应的Query_ID)去具体看各个阶段用的时间
自我感觉用处不大,基本上但是exectuing耗时最长,大部分的优化还是直接针对于sql的索引做优化,即用explain查询执行计划
explain
explain 或者 desc 命令获取 MySQL 如何执行 select 语句的信息,包括在 select 语句执行过程中表如何连接和连接的顺序。
-- 直接在select语句之前加上关键字 explain / descEXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 ;

explain 执行计划中各个字段的含义
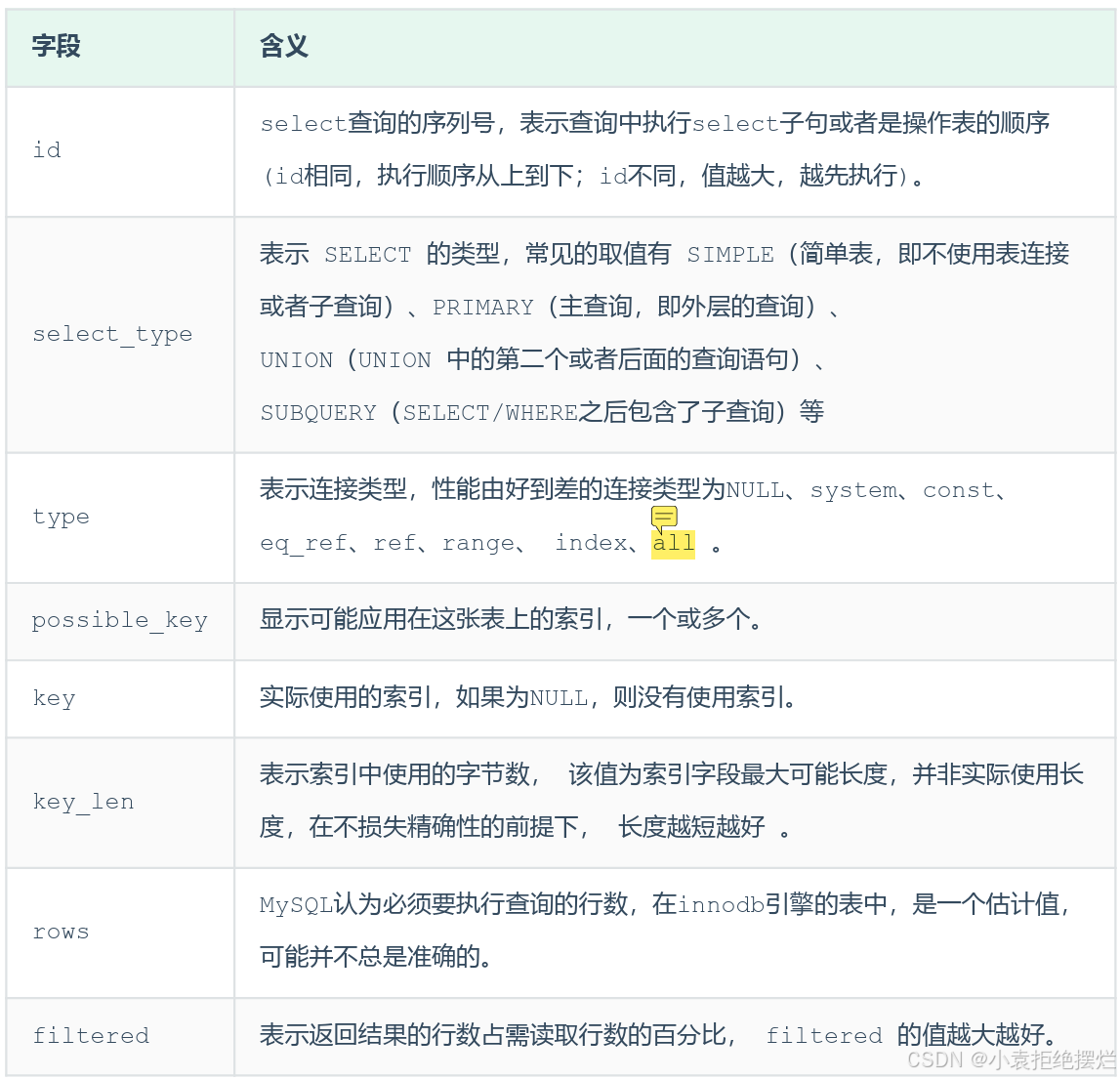
其中type是最重要的字段
解释一下其中可以出现的类型
- NULL 不访问任何表的查询
explain select 'A'
- system 访问一张系统表
- const 使用主键/唯一索引访问
- eq_ref
- ref 使用非唯一索引进行访问时候
- range
- index 用了索引,但是也遍历了整个索引树
- all 全表扫描
注:不一定一定按照上面走
如果表里全是create_user=1的数据
explain SELECT * from category where create_user=1;
其Type为ALL,尽管我再create_user创建了index(普通)
Extra是第二重要的字段,展示是否会回表查询,所以我们查询字段尽量覆盖索引,防止回表查询
rows 用来参考
possible_key、key、key_len也算比较重要的字段
相关文章:

Mysql进阶篇1_存储引擎、索引、SQL性能分析指令
文章目录 1.存储引擎InnoDBMyISAMMemory存储引擎选择和对比 2.索引索引结构索引分类索引语法索引使用(建议看完第3节后观看)!!!mysql如何使用索引查询数据(个人理解) 3.SQL性能分析SQL执行频率慢…...

02_MySQl引擎的区别
文章目录 1. InnoDB(默认引擎)2. MyISAM3. Memory4. 其他引擎核心对比总结 MySQL 存储引擎是数据库底层软件组织,不同的存储引擎提供不同的存储机制、索引技巧、锁级别和事务功能。以下是主要存储引擎的区别: 1. InnoDB࿰…...
协议(消息)生成
目录 协议(消息)生成主要做什么? 知识点二 制作功能前的准备工作 编辑编辑 制作消息生成功能 实现效果 总结 上一篇中配置的XML文件可见: https://mpbeta.csdn.net/mp_blog/creation/editor/147647176 协议(消息)生成主要做什么? //协议生成 主要是…...
-(一))
SEMI E40-0200 STANDARD FOR PROCESSING MANAGEMENT(加工管理标准)-(一)
1 目的 物料(例如晶圆)加工在设备中的自动化管理与控制是实现工厂自动化的关键要素。本标准针对半导体制造环境中与设备内部物料处理相关的通信需求进行了规范。本标准规定了在加工单元接收到的指定材料所应适用的加工方法(例如Etch腔室需要Run哪支Recipe)。它阐述了物料加工的…...

Nginx1.26.2安装包编译安装并配置stream模块
准备nginx安装文件:nginx-1.26.2.tar.gz cd /usr/local wget http://nginx.org/download/nginx-1.26.2.tar.gz tar -zxvf nginx-1.26.2.tar.gz && cd nginx-1.26.2 1.创建安装目录 mkdir nginx 2.解压安装文件nginx-1.26.2.tar.gz tar -zxvf nginx-1.26…...

Linux 系统的指令详解介绍
Linux 系统的指令详解介绍 一、指令的本质与定义1. 什么是指令?2. Linux 指令分类二、指令格式解析1. 基础语法结构2. 语法要素详解(1)选项类型(2)参数类型三、核心指令分类1. 文件操作指令2. 文本处理指令3. 系统管理指令一、指令的本质与定义 1. 什么是指令? 定义:在…...
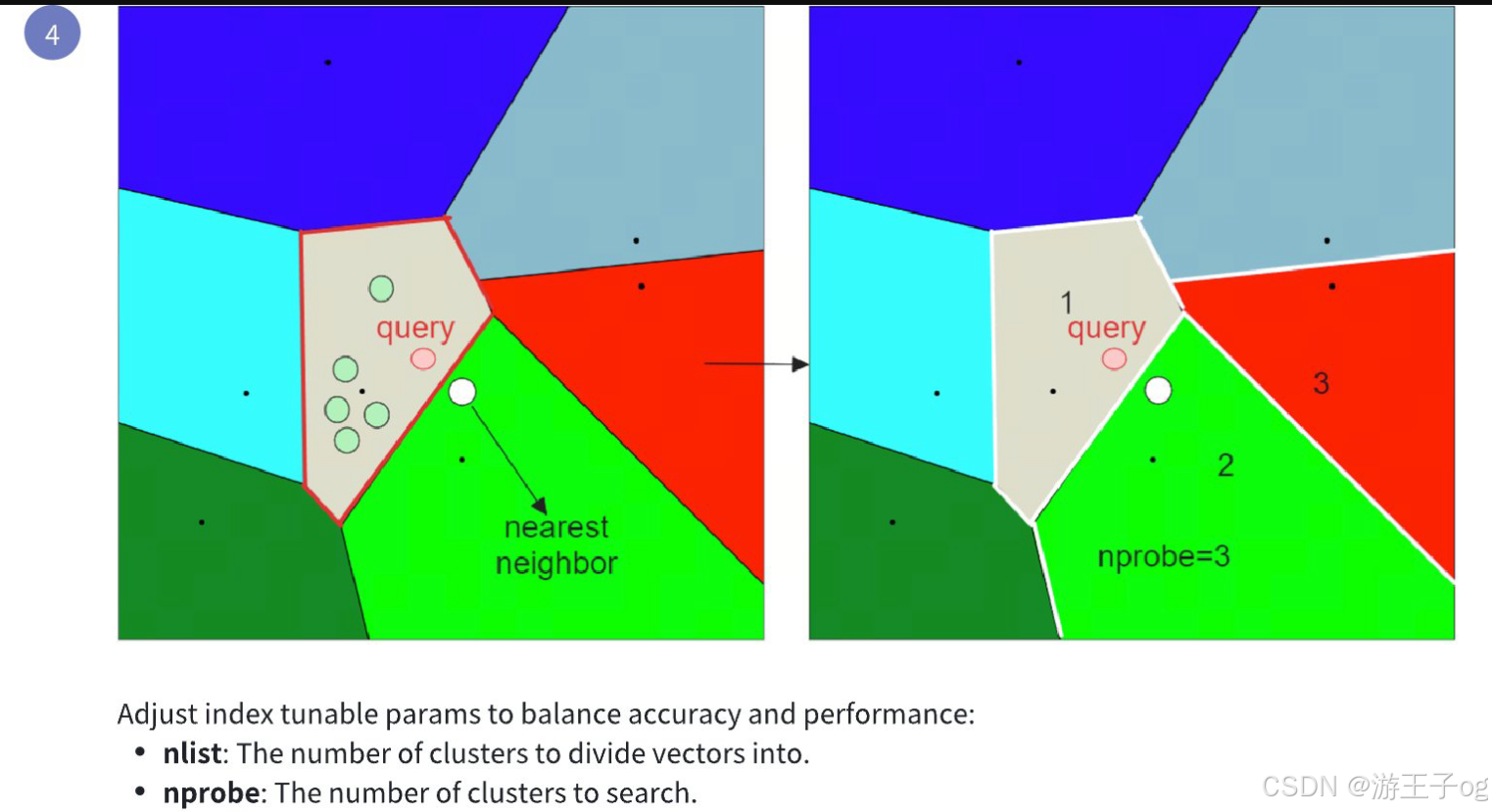
Milvus(17):向量索引、FLAT、IVF_FLAT
1 索引向量字段 利用存储在索引文件中的元数据,Milvus 以专门的结构组织数据,便于在搜索或查询过程中快速检索所需的信息。 Milvus 提供多种索引类型和指标,可对字段值进行排序,以实现高效的相似性搜索。下表列出了不同向量字段类…...
芯片笔记 - 手册参数注释
芯片手册参数注释 基础参数外围设备USB OTG(On-The-Go)以太网存储卡(SD)SDIO 3.0(Secure Digital Input/Output)GPIO(General Purpose Input/Output 通用输入/输出接口)ADC(Analog to Digital C…...

不同大模型对提示词和问题的符号标识
不同大模型对提示词和问题的符号标识 不同大模型对提示词和问题的符号标识存在差异,花括号{}在特定场景下可以使用,但需结合模型特性和上下文。 一、主流模型的符号标识惯例 1. Claude(Anthropic) 推荐符号:XML标签(如<tag>内容</tag>)。 示例:<text…...

RabbitMQ学习(第二天)
文章目录 1、生产者可靠性①、生产者重连②、生产者确认 2、MQ可靠性①、数据持久化②、LazyQueue(惰性队列) 3、消费者可靠性①、消费者确认②、失败重试机制③、保证业务幂等性 总结 之前的学习中,熟悉了java中搭建和操作RabbitMQ发送接收消息,熟悉使用…...
【JS逆向基础】爬虫核心模块:request模块与包的概念
前言:这篇文章主要介绍JS逆向爬虫中最常用的request模块,然后引出一系列的模块的概念,当然Python中其他比较常用的还有很多模块,正是这些模块也可以称之为库的东西构成了Python强大的生态,使其几乎可以实现任何功能。下…...
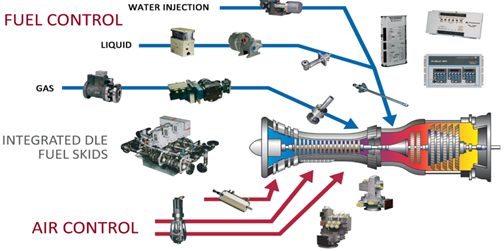
LabVIEW燃气轮机测控系统
在能源需求不断增长以及生态环境保护备受重视的背景下,微型燃气轮机凭借其在经济性、可靠性、维护性及排放性等方面的显著优势,在航空航天、分布式发电等众多领域得到广泛应用。随着计算机技术的快速发展,虚拟仪器应运而生,LabVIE…...

【链表扫盲】FROM GPT
链表是一种线性数据结构,由节点(Node)组成,每个节点包含两个部分: 数据域(data): 存储节点值。指针域(next): 存储指向下一个节点的引用。 链表…...

QT | 常用控件
前言 💓 个人主页:普通young man-CSDN博客 ⏩ 文章专栏:C_普通young man的博客-CSDN博客 ⏩ 本人giee: 普通小青年 (pu-tong-young-man) - Gitee.com 若有问题 评论区见📝 🎉欢迎大家点赞👍收藏⭐文章 —…...
-多线程和多进程浅析)
Python学习之路(八)-多线程和多进程浅析
在 Python 中,多线程(Multithreading) 和 多进程(Multiprocessing) 是实现并发编程的两种主要方式。它们各有优劣,适用于不同的场景。 一、基本概念 特性多线程(threading)多进程(multiprocessing)并发模型线程共享内存空间每个进程拥有独立内存空间GIL(全局解释器锁…...

搭建和优化CI/CD流水线
CI/CD(持续集成 / 持续交付)流水线是现代软件开发中的关键实践,它能够自动化软件的构建、测试和部署过程,提高开发效率和软件质量。以下为你介绍搭建和优化 CI/CD 流水线的详细步骤: 搭建 CI/CD 流水线 1. 选择合适的…...

kotlin 01flow-StateFlow 完整教程
一 Android StateFlow 完整教程:从入门到实战 StateFlow 是 Kotlin 协程库中用于状态管理的响应式流,特别适合在 Android 应用开发中管理 UI 状态。本教程将带全面了解 StateFlow 的使用方法。 1. StateFlow 基础概念 1.1 什么是 StateFlow? StateF…...

1.2.1 Linux音频系统发展历程简介
Linux音频系统的发展经历了从最初的简单驱动到今天多层次、模块化音频架构。简要梳理其主要历程: 早期的OSS(Open Sound System) 在90年代及2000年代初,Linux主要使用OSS来支持音频。OSS直接为硬件设备(如声卡&#…...
)
浏览器刷新结束页面事件,调结束事件的接口(vue)
浏览器刷新的时候,正在进行中的事件结束掉,在刷新浏览器的时候做一些操作。 如果是调接口,就不能使用axios封装的接口,需要使用原生的fetch。 找到公共的文件App.vue 使用window.addEventListener(‘beforeunload’, function (e…...

聊聊Spring AI Alibaba的SentenceSplitter
序 本文主要研究一下Spring AI Alibaba的SentenceSplitter SentenceSplitter spring-ai-alibaba-core/src/main/java/com/alibaba/cloud/ai/transformer/splitter/SentenceSplitter.java public class SentenceSplitter extends TextSplitter {private final EncodingRegis…...

前端-什么是结构语言、样式语言、脚本语言?
目录 1. 结构语言(HTML / WXML)——房子的骨架 2. 样式语言(CSS / WXSS)——房子的装修 3. 脚本语言(JavaScript)——房子的智能控制系统 总结对比表: 1. 结构语言(HTML / WXML&a…...
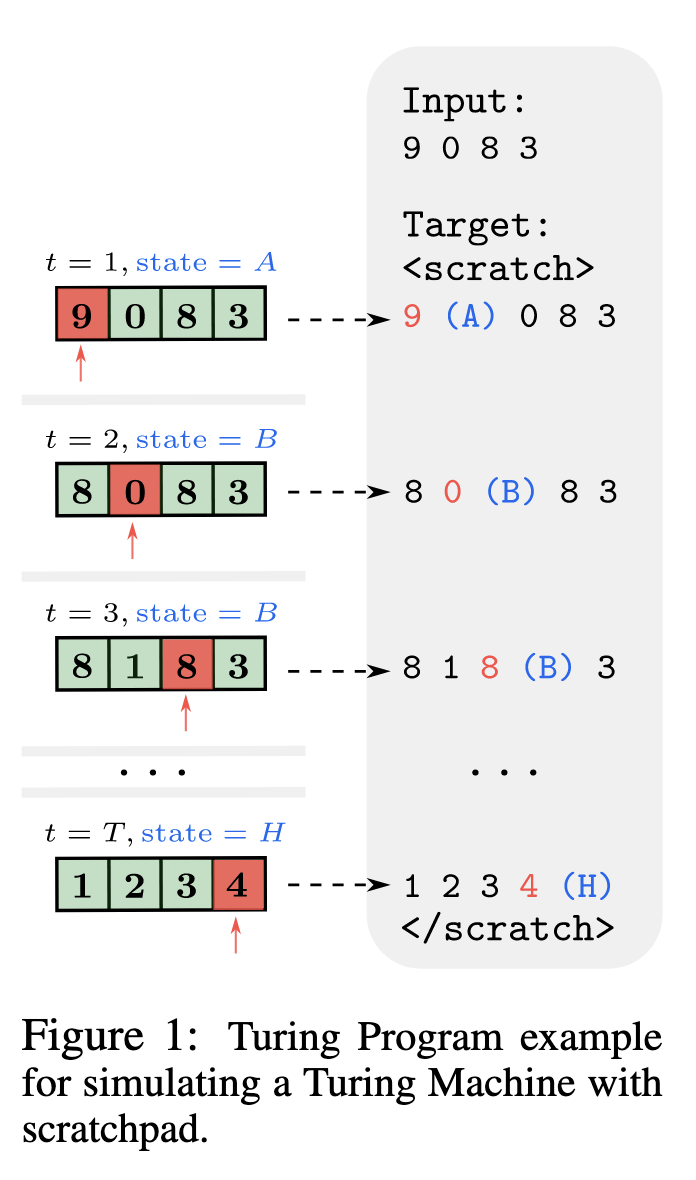
LLM论文笔记 28: Universal length generalization with Turing Programs
Arxiv日期:2024.10.4机构:Harvard University 关键词 图灵机 CoT 长度泛化 核心结论 Turing Programs 的提出 提出 Turing Programs,一种基于图灵机计算步骤的通用 CoT 策略。通过将算法任务分解为逐步的“磁带更新”(类似图灵…...

AI日报 · 2025年5月07日|谷歌发布 Gemini 2.5 Pro 预览版 (I/O 版本),大幅提升编码与视频理解能力
1、谷歌发布 Gemini 2.5 Pro 预览版 (I/O 版本),大幅提升编码与视频理解能力 谷歌于5月6日提前发布 Gemini 2.5 Pro 预览版 (I/O 版本),为开发者带来更强编码能力,尤其优化了前端与UI开发、代码转换及智能体工作流构建,并在WebDe…...

指定Docker镜像源,使用阿里云加速异常解决
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo异常贴图 yum-config-manager:找不到命令 因为系统默认没有安装这个命令,这个命令在yum-utils 包里,可以通过命令yum -y install yum-util…...

VITA STANDARDS LIST,VITA 标准清单下载
VITA STANDARDS LIST,VITA 标准清单下载 DesignationTitleAbstractStatusVMEbus Handbook, 4th EditionA users guide to the VME, VME64 and VME64x bus specifications - features over 70 product photos and over 160 circuit diagrams, tables and graphs. The…...
Python从入门到高手8.3节-元组的常用操作方法
目录 11.3.1 元组的常用操作方法 11.3.2 元组的查找 11.3.3 祈祷明天不再打雷下雨 11.3.1 元组的常用操作方法 元组类型是一种抽象数据类型,抽象数据类型定义了数据类型的操作方法,在本节的内容中,着重介绍元组类型的操作方法。 元组是…...

Linux系统安装PaddleDetection
一、安装cuda 1. 查看设备 先输入nvidia-smi,查看设备支持的最大cuda版本,选择官网中支持的cuda版本 https://www.paddlepaddle.org.cn/install/quick?docurl/documentation/docs/zh/install/conda/linux-conda.html 2. 下载CUDA并安装 使用快捷键…...
【漫话机器学习系列】239.训练错误率(Training Error Rate)
机器学习基础概念 | 训练错误率(Training Error Rate)详解 在机器学习模型训练过程中,评估模型性能是至关重要的一个环节。其中,训练错误率(Training Error Rate) 是最基础也最重要的性能指标之一。 本文将…...

Vue3路由模式为history,使用nginx部署上线是空白的问题
一、问题 将vue使用打包后 npm run build将dist文件的内容,放入nginx的html中,并在nginx.conf中,设置端口 启动nginx,打开发现网页内容为空白 二、解决问题 1.配置vue-route const router createRouter({history: createWe…...
:AI的安全可靠 - 电商数据智能的红线与指南)
Python 数据智能实战 (13):AI的安全可靠 - 电商数据智能的红线与指南
写在前面 —— 技术向善,行稳致远:在智能时代,坚守数据伦理,构建可信赖的 AI 应用 通过前面的篇章,我们已经深入探索了如何利用 Python 和大语言模型 (LLM) 挖掘电商数据的巨大潜力,从智能用户分群到语义推荐,再到个性化内容生成和模型效果评估。我们手中的工具越来越…...