【机器学习-线性回归-5】多元线性回归:概念、原理与实现详解
线性回归是机器学习中最基础且广泛应用的算法之一,而多元线性回归则是其重要扩展。本文将全面介绍多元线性回归的核心概念、数学原理及多种实现方式,帮助读者深入理解这一强大的预测工具。
1. 多元线性回归概述
1.1 什么是多元线性回归
多元线性回归(Multiple Linear Regression)是简单线性回归的扩展,用于建模**多个自变量(特征)与一个因变量(目标)**之间的线性关系。与简单线性回归(y = ax + b)不同,多元线性回归的模型可以表示为:
y = β₀ + β₁x₁ + β₂x₂ + … + βₚxₚ + ε
其中:
- y:因变量(目标变量)
- x₁, x₂,…, xₚ:自变量(特征)
- β₀:截距项
- β₁, β₂,…, βₚ:各自变量的系数
- ε:误差项
1.2 应用场景
多元线性回归广泛应用于各个领域:
- 经济学:预测GDP增长基于多个经济指标
- 金融:评估股票价格与多种因素的关系
- 市场营销:分析广告投入在不同渠道的效果
- 医学:预测疾病风险基于多种生理指标
2. 数学原理与假设
2.1 模型假设
多元线性回归的有效性依赖于以下关键假设:
- 线性关系:自变量与因变量存在线性关系
- 无多重共线性:自变量之间不应高度相关
- 同方差性:误差项的方差应保持恒定
- 正态性:误差项应近似正态分布
- 无自相关:误差项之间不应相关
- 无测量误差:自变量应准确测量
2.2 参数估计:最小二乘法
多元线性回归通常采用**普通最小二乘法(OLS)**估计参数,目标是使残差平方和(RSS)最小化:
RSS = Σ(yᵢ - ŷᵢ)² = Σ(yᵢ - (β₀ + β₁x₁ + … + βₚxₚ))²
矩阵形式的解为:
β = (Xᵀ X)⁻¹ Xᵀ y
其中:
- X:设计矩阵(包含所有特征)
- y:目标向量
- β:系数向量
2.3 模型评估指标
评估多元线性回归模型的常用指标:
- R² (决定系数):解释变量对目标变量的解释程度
- 范围:[0,1],越接近1模型越好
- 公式:R² = 1 - RSS/TSS
- 调整R²:考虑特征数量的R²修正
- 公式:Adj-R² = 1 - [(1-R²)(n-1)/(n-p-1)]
- 均方误差(MSE):预测值与真实值的平均平方差
- MSE = RSS/n
- 均方根误差(RMSE):MSE的平方根,与目标变量同单位
3. 多元线性回归的实现
3.1 Python实现方式
3.1.1 使用NumPy手动实现
import numpy as npclass MultipleLinearRegression:def __init__(self):self.coefficients = Noneself.intercept = Nonedef fit(self, X, y):# 添加截距项X = np.insert(X, 0, 1, axis=1)# 计算系数 (X'X)^-1 X'yX_transpose = np.transpose(X)X_transpose_X = np.dot(X_transpose, X)X_transpose_X_inv = np.linalg.inv(X_transpose_X)X_transpose_y = np.dot(X_transpose, y)coefficients = np.dot(X_transpose_X_inv, X_transpose_y)self.intercept = coefficients[0]self.coefficients = coefficients[1:]def predict(self, X):return self.intercept + np.dot(X, self.coefficients)
3.1.2 使用scikit-learn实现
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler# 示例数据准备
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)# 数据标准化(可选)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 创建并训练模型
model = LinearRegression()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"MSE: {mse:.2f}, R2: {r2:.2f}")
3.2 特征工程与模型优化
3.2.1 特征选择
- 前向选择:从零特征开始,逐步添加最有统计意义的特征
- 后向消除:从全特征开始,逐步移除最无统计意义的特征
- 正则化方法:使用Lasso(L1)或Ridge(L2)回归自动进行特征选择
3.2.2 处理多重共线性
-
**方差膨胀因子(VIF)**检测:
from statsmodels.stats.outliers_influence import variance_inflation_factorvif_data = pd.DataFrame() vif_data["feature"] = X.columns vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(len(X.columns))] print(vif_data)VIF > 5-10表示存在多重共线性问题
-
解决方案:
- 删除高相关特征
- 使用主成分分析(PCA)
- 应用正则化回归
3.2.3 正则化方法
-
岭回归(Ridge Regression):
from sklearn.linear_model import Ridge ridge = Ridge(alpha=1.0) ridge.fit(X_train, y_train) -
Lasso回归:
from sklearn.linear_model import Lasso lasso = Lasso(alpha=0.1) lasso.fit(X_train, y_train) -
弹性网络(ElasticNet):
from sklearn.linear_model import ElasticNet elastic = ElasticNet(alpha=0.1, l1_ratio=0.5) elastic.fit(X_train, y_train)
4. 高级主题与注意事项
4.1 非线性关系的处理
当自变量与因变量存在非线性关系时,可以考虑:
- 添加多项式特征
- 使用样条回归
- 进行变量转换(如对数变换)
4.2 离群值检测与处理
离群值会显著影响回归结果,处理方法包括:
- 可视化检测(箱线图、散点图)
- 统计方法(Z-score、IQR)
- 稳健回归方法(RANSAC、Huber回归)
4.3 交互作用项
考虑特征间的交互作用:
from sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures(degree=2, interaction_only=True, include_bias=False)
X_interaction = poly.fit_transform(X)
5. 实战案例:房价预测
以下是一个完整的多元线性回归应用示例:
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt# 加载数据
data = fetch_california_housing()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['Target'] = data.target# 数据探索
print(df.describe())
df.hist(figsize=(12, 10))
plt.tight_layout()
plt.show()# 特征选择
X = df.drop('Target', axis=1)
y = df['Target']# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 创建并训练模型
model = LinearRegression()
model.fit(X_train, y_train)# 模型评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)print(f"RMSE: {rmse:.4f}")
print(f"R2 Score: {r2:.4f}")# 特征重要性
importance = pd.DataFrame({'Feature': data.feature_names,'Coefficient': model.coef_
}).sort_values('Coefficient', key=abs, ascending=False)print("\n特征重要性:")
print(importance)# 残差分析
residuals = y_test - y_pred
plt.figure(figsize=(10, 6))
plt.scatter(y_pred, residuals, alpha=0.5)
plt.axhline(y=0, color='r', linestyle='--')
plt.xlabel('Predicted Values')
plt.ylabel('Residuals')
plt.title('Residual Plot')
plt.show()
6. 总结与最佳实践
多元线性回归虽然简单,但功能强大。以下是一些最佳实践:
- 数据预处理:标准化/归一化、处理缺失值
- 特征工程:选择相关特征、处理非线性关系
- 模型诊断:检查假设、分析残差
- 正则化:当特征多或存在共线性时使用
- 交叉验证:避免过拟合,确保模型泛化能力
多元线性回归作为机器学习的基础算法,理解其原理和实现对于掌握更复杂的模型至关重要。通过本文的介绍,希望读者能够熟练应用多元线性回归解决实际问题。
相关文章:

【机器学习-线性回归-5】多元线性回归:概念、原理与实现详解
线性回归是机器学习中最基础且广泛应用的算法之一,而多元线性回归则是其重要扩展。本文将全面介绍多元线性回归的核心概念、数学原理及多种实现方式,帮助读者深入理解这一强大的预测工具。 1. 多元线性回归概述 1.1 什么是多元线性回归 多元线性回归(…...
)
【软件设计师:数据结构】1.数据结构基础(一)
一 线性表 1.线性表定义 线性表是n个元素的有限序列,通常记为(a1,a2,…,an)。 特点: 存在惟一的表头和表尾。除了表头外,表中的每一个元素均只有惟一的直接前驱。除了表尾外,表中的每一个元素均只有惟一的直接后继。2.线性表的存储结构 (1)顺序存储 是用一组地址连续…...

简单面试提问
Nosql非关系型数据库: Mongodb:开源、json形式储存、c编写 Redis:key-value形式储存,储存在内存,c编写 关系型数据库: sqlite;:轻量型、0配置、磁盘存储、支持多种语言 mysql:开源…...

探秘数据中台:五大核心平台的功能全景解析
数据中台作为企业数据资产的 “智慧中枢”,通过整合数据处理全流程的核心功能,实现数据价值的深度挖掘与高效应用。以下从五大核心平台出发,全面拆解数据中台的功能架构与应用价值。 一、数据可视化平台:让数据 “开口说话” 1.…...

leetcode 3342. 到达最后一个房间的最少时间 II 中等
有一个地窖,地窖中有 n x m 个房间,它们呈网格状排布。 给你一个大小为 n x m 的二维数组 moveTime ,其中 moveTime[i][j] 表示在这个时刻 以后 你才可以 开始 往这个房间 移动 。你在时刻 t 0 时从房间 (0, 0) 出发,每次可以移…...
redis----通用命令
文章目录 前言一、运行redis二、help [command]三、通用命令 前言 提示:这里可以添加本文要记录的大概内容: 学习一些通用命令 以下操作在windows中演示 提示:以下是本篇文章正文内容,下面案例可供参考 一、运行redis 我们先c…...

PostgreSQL 查看索引碎片的方法
PostgreSQL 查看索引碎片的方法 在 PostgreSQL 中,索引碎片(Index Fragmentation)是指索引由于频繁的插入、更新和删除操作导致物理存储不连续,从而影响查询性能的情况。以下是几种查看索引碎片的方法: 一 使用 pgstattuple 扩展 1.1 安装…...

pip 常用命令及配置
一、python -m pip install 和 pip install 的区别 在讲解 pip 的命令之前,我们有必要了解一下 python -m pip install 和 pip install 的区别,以便于我们在不同的场景使用不同的方式。 python -m pip install 命令使用 python 可执行文件将 pip 模块作…...
IntelliJ IDEA 保姆级使用教程
文章目录 一、创建项目二、创建模块三、创建包四、创建类五、编写代码六、运行代码注意 七、IDEA 常见设置1、主题2、字体3、背景色 八、IDEA 常用快捷键九、IDEA 常见操作9.1、类操作9.1.1、删除类文件9.1.2、修改类名称注意 9.2、模块操作9.2.1、修改模块名快速查看 9.2.2、导…...
Comfyui 与 SDwebui
ComfyUI和SD WebUI是基于Stable Diffusion模型的两种不同用户界面工具,它们在功能、用户体验和适用场景上各有优劣。 1. 功能与灵活性 ComfyUI:ComfyUI以其节点式工作流设计为核心,强调用户自定义和灵活性。用户可以通过连接不同的模块&…...

Ubuntu Linux系统配置账号无密码sudo
在Linux系统中,配置无密码sudo可以通过修改sudoers文件来实现。以下是具体的配置步骤 一、编辑sudoers文件 输入sudo visudo命令来编辑sudo的配置文件。visudo是一个专门用于编辑sudoers文件的命令,它会在保存前检查语法错误,从而防止可能的…...
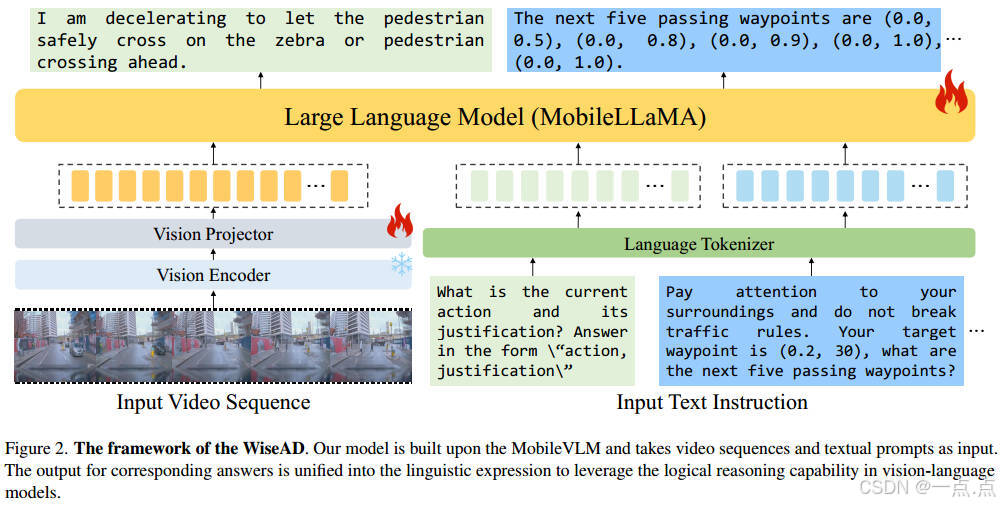
WiseAD:基于视觉-语言模型的知识增强型端到端自动驾驶——论文阅读
《WiseAD: Knowledge Augmented End-to-End Autonomous Driving with Vision-Language Model》2024年12月发表,来自新加坡国立和浙大的论文。 在快速发展的视觉语言模型(VLM)中,一般人类知识和令人印象深刻的逻辑推理能力的出现&a…...

探索SQLMesh中的Jinja宏:提升SQL查询的灵活性与复用性
在数据工程和数据分析领域,SQL是不可或缺的工具。随着项目复杂度的增加,如何高效地管理和复用SQL代码成为了一个重要课题。SQLMesh作为一款强大的工具,不仅支持标准的SQL语法,还引入了Jinja模板引擎的宏功能,极大地提升…...

配置linux自启java程序
配置linux自启java程序 1、切换root用户,并进入自启配置目录 sudo su - cd /etc/systemd/system2、编写启动文件 例如:class-server.service vi class-server.service脚本内容 [Unit] DescriptionClassServer Java Application Afternetwork.target…...
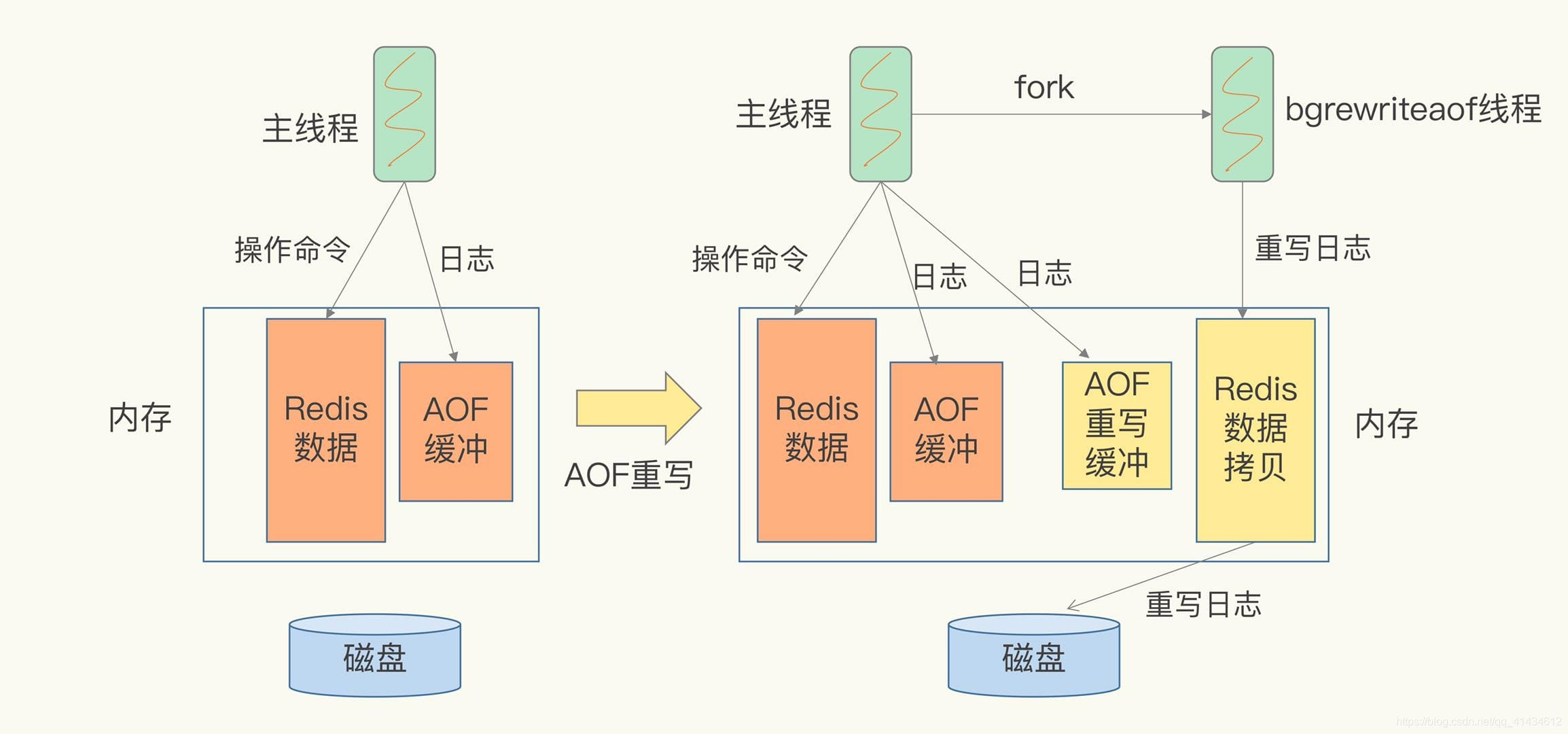
对Redis组件的深入探讨
目录 1、磁盘和内存 1.1、概念 1.2、区别 1.3、联系 2、redis基本特性 2.1、数据结构 2.2、性能 2.3、事件驱动架构 2.4、原子性 3、redis模型 3.1、单线程 3.2、事件驱动模型 3.3、epoll多路复用 4、数据持久化 4.1、RDB快照 4.2、AOF(Append Only…...

Uni-app 组件使用
在前端开发领域,能够高效地创建跨平台应用是开发者们一直追求的目标。Uni-app 凭借其 “一次开发,多端部署” 的特性,成为了众多开发者的首选框架。而组件作为 Uni-app 开发的基础单元,合理运用组件能够极大地提升开发效率和代码的…...

k8s pod request/limit 值不带单位会发生什么?
在 Kubernetes 中,Pod 的 resources.requests 和 limits 字段必须显式指定单位。 一、未正确设置requests和limits字段的单位会产生影响? 1. 资源分配严重不足 例如,以下配置存在严重错误: resources:requests:memory: 512 # …...
)
Ruby 字符串(String)
Ruby 字符串(String) 引言 在编程语言中,字符串是表示文本数据的一种基本数据类型。在Ruby中,字符串处理是日常编程中非常常见的一项任务。本文将详细介绍Ruby中的字符串(String)类型,包括其创…...
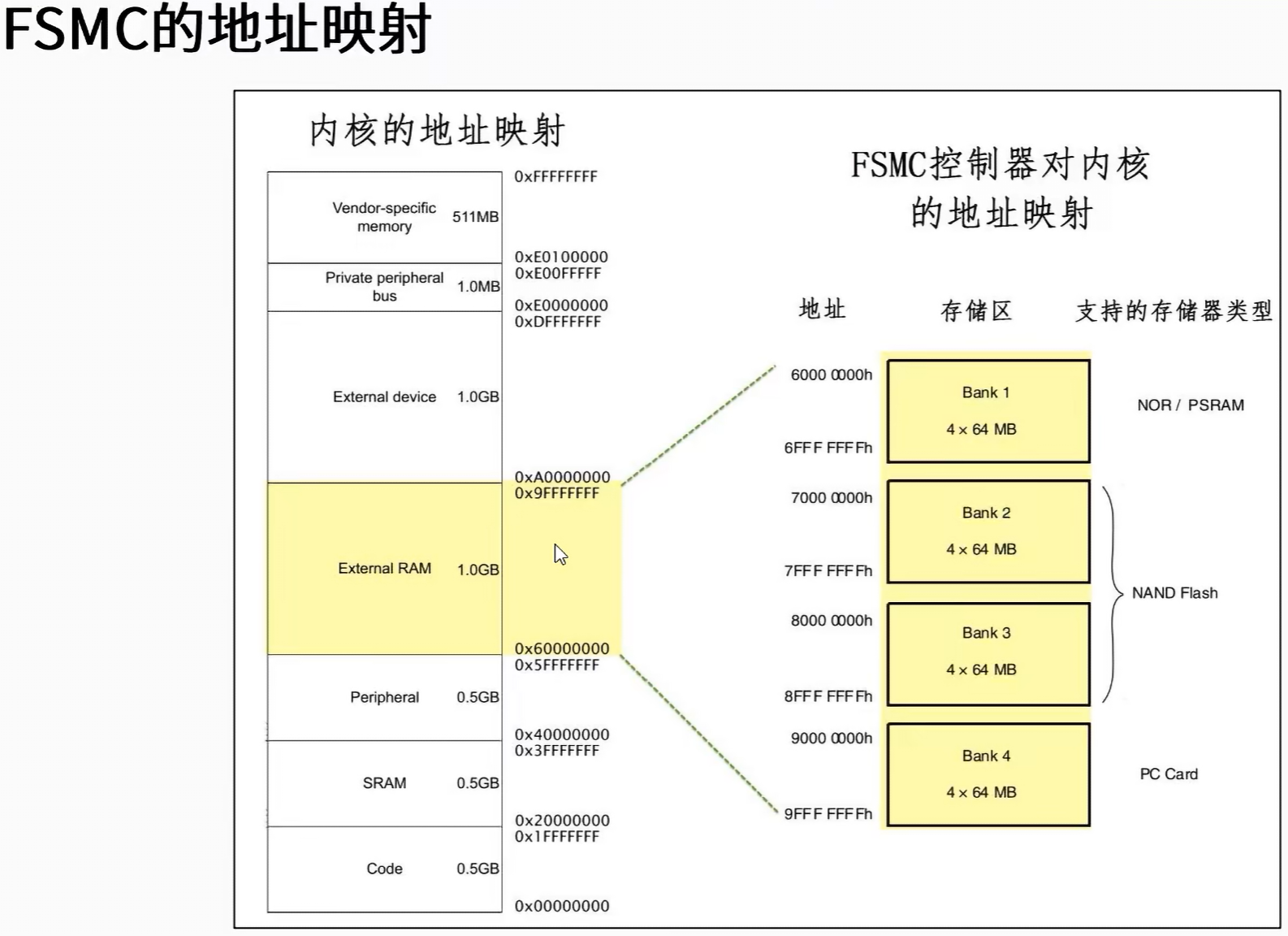
嵌入式学习笔记 - STM32 SRAM控制器FSMC
一 SRAM控制器内部结构图: 以下以512K SRAM芯片为例 二 SRAM地址矩阵/寻址方式: SRAM的地址寻址方式通过行地址与列地址交互的方式存储数据 三 STM32 地址映射 从STM32的地址映射中可以看出,FSMC控制器支持扩展4块外部存储器区域࿰…...

经典算法 求解硬币组成问题
求解硬币组成问题 题目描述 实现一个算法求解组成硬币问题。介绍如下: 假设有面值给定的一些硬币,以及给定的总合值,问构成总合值的方法有多少种。 输入描述 第一行包含两个数字 N, M: N 表示硬币面值的种类数M 表示给定的总合…...
数据封装的过程
数据的封装过程 传输层 UDP 直接将数据封装为UDP数据报,添加UDP头部(8B)。 要点: UDP首部简单,无连接不可靠、无重传、无拥塞控制,适用于实时性要求较高的通讯;不需要源端口或不想计算检…...

Docker部署常见应用之Superset
文章目录 使用 Docker 部署使用 Docker Compose 部署参考文章 以下是使用 Docker 部署 Superset 并将存储配置为 MySQL 的详细步骤: 使用 Docker 部署 获取Superset镜像: 使用Docker从官方仓库拉取Superset镜像:docker pull apache/superset:4.0.0创建 …...

LeetCode 216.组合总和 III:回溯算法实现与剪枝优化
目录 问题描述解决思路 回溯法剪枝优化 代码实现复杂度分析示例测试总结与扩展 1. 问题描述 给定两个整数 k 和 n,要求找出所有满足以下条件的组合: 组合包含 k 个不同的数字。组合中数字的和等于 n。组合中的数字范围为 [1, 9],且每个数字…...

住宅 IP 地址:数字时代的真实网络身份载体
在互联网的底层架构中,IP 地址是设备连接网络的 “数字身份证”。而住宅 IP 地址作为其中最贴近真实用户的类型,特指互联网服务提供商(ISP)分配给家庭或个人用户的 IP 地址,具有以下核心特征: 物理关联性 …...

前后端开发---分离 和 不分离开发
前后端分离开发和不分离开发是两种不同的软件开发架构方式,它们的主要区别体现在以下几个方面: 对比维度 前后端分离开发 前后端不分离开发 定义 前端和后端作为两个独立项目开发,通过API接口通信 前端和后端代码混合在一起,…...

[SSM]-Spring介绍
框架是什么 框架 framework 建筑学: 用于承载一个系统必要功能的基础要素的集合计算机: 某特定领域系统的一组约定, 标准, 代码库以及工具的集合 框架vs工具 框架作为项目的骨架合基础结构, 提供了高层次的抽象和可复用性工具作为辅助手段, 帮助开发者完成特定任务并提高工作…...
)
Consumer Group的作用是什么?Rebalance的触发条件有哪些? (实现消费者负载均衡;消费者加入/离开、订阅Topic变化等)
好的,我现在需要回答用户关于Kafka Consumer Group和Rebalance的问题。首先,用户问的是Consumer Group的作用以及Rebalance的触发条件。根据之前的对话历史,用户已经了解了Kafka的基本组件、消息保留策略、顺序性保证等,现在的问题…...
今天的python练习题
目录 一、每日一言 二、练习题 三、效果展示 四、下次题目 五、总结 一、每日一言 晚上8点到的,还是会被感动到,有一位列车员同志在检票期间,叫我到列车员专座位上去坐,我很感激他,温暖人心,所以人间填我…...

Mysql进阶篇1_存储引擎、索引、SQL性能分析指令
文章目录 1.存储引擎InnoDBMyISAMMemory存储引擎选择和对比 2.索引索引结构索引分类索引语法索引使用(建议看完第3节后观看)!!!mysql如何使用索引查询数据(个人理解) 3.SQL性能分析SQL执行频率慢…...

02_MySQl引擎的区别
文章目录 1. InnoDB(默认引擎)2. MyISAM3. Memory4. 其他引擎核心对比总结 MySQL 存储引擎是数据库底层软件组织,不同的存储引擎提供不同的存储机制、索引技巧、锁级别和事务功能。以下是主要存储引擎的区别: 1. InnoDB࿰…...