【论文笔记】SOTR: Segmenting Objects with Transformers
【题目】:SOTR: Segmenting Objects with Transformers
【引用格式】:Guo R, Niu D, Qu L, et al. Sotr: Segmenting objects with transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 7157-7166.
【网址】:https://openaccess.thecvf.com/content/ICCV2021/papers/Guo_SOTR_Segmenting_Objects_With_Transformers_ICCV_2021_paper.pdf
【开源代码】:https://github.com/easton-cau/SOTR
目录
一、瓶颈问题
二、本文贡献
三、解决方案
1、模型架构
2、Transformer
2.1 双注意力机制(Twin attention)
2.2 Transformer层
2.3 功能头(Functional heads)
3、Mask
3.1 多级上采样模块
3.2 实例掩码预测
四、实验结果
1、实验设置
2、消融实验
3、定量和定性结果
一、瓶颈问题
- 传统 CNN 在实例分割中的局限:基于 CNN 的实例分割方法(遵循检测 - 然后 - 分割范式)存在不足。CNN 因有限的感受野,在高级视觉语义信息中特征连贯性相对缺乏,难以关联实例,对大物体分割效果欠佳;并且分割质量和推理速度过度依赖目标检测器,在复杂场景下性能较差。
- 自底向上方法的缺陷:为克服传统 CNN 方法的缺点,一些自底向上的实例分割策略被提出,这类方法虽能保留位置和局部连贯信息,但存在聚类不稳定(如掩码碎片化、粘连)以及在不同场景数据集上泛化能力差的问题。
- Transformer 在视觉应用中的不足:受 Transformer 在自然语言处理中的成功启发,其在视觉任务应用中展现出一定优势,然而典型 Transformer 在提取低级特征方面表现不佳,对小物体预测易出错;同时由于特征图规模大,在训练阶段需要大量内存和时间。
二、本文贡献
- 提出创新的混合框架:引入了名为 SOTR 的 CNN - Transformer 混合实例分割框架。该框架利用 CNN 骨干网络和 Transformer 编码器,有效对局部连接性和长距离依赖关系建模,表现力强;且直接分割对象实例,不依赖边界框检测,简化了整体流程。
- 设计新的注意力机制:设计了双注意力机制(twin attention),这是一种位置敏感的自注意力机制,专为模型中的 Transformer 定制。相比原始 Transformer,在计算和内存上有显著节省,尤其适用于实例分割这类对大输入进行密集预测的任务。
- 降低对大规模预训练的依赖:SOTR 无需在大型数据集上进行预训练就能很好地泛化归纳偏差,更易于应用在数据量不足的场景,克服了纯 Transformer 模型对大规模预训练的依赖问题。
- 取得优异的实验结果:在 MS COCO 基准测试中,使用 ResNet - 101 - FPN 骨干网络的 SOTR 模型 AP 达到 40.2% ,精度超越多数现有方法。在中等和大尺寸物体上,AP 分别达到 59.0% 和 73.0% ,展现出在不同尺寸物体分割上的优势。
三、解决方案
1、模型架构
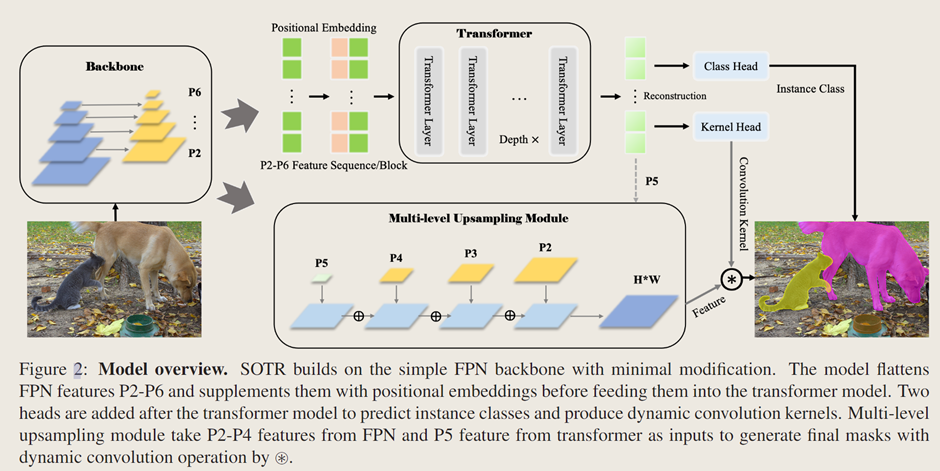
SOTR 是一种 CNN-Transformer 混合实例分割模型,它能够同时学习二维表示,并轻松捕捉长距离信息。它遵循直接分割范式,首先将输入特征图划分为图块,然后在动态分割每个实例的同时预测每个图块的类别【Transformer模块】。具体来说,模型主要由三个部分组成:1)一个骨干网络(from detectron2.modeling.backbone import build_backbone),用于从输入图像中提取图像特征,尤其是低级和局部特征;2)一个 Transformer,用于对全局和语义依赖关系进行建模,它附加了功能头,分别用于预测每个图块的类别和卷积核;3)一个多级上采样模块,通过在生成的特征图和相应的卷积核之间执行动态卷积操作来生成分割掩码。
2、Transformer
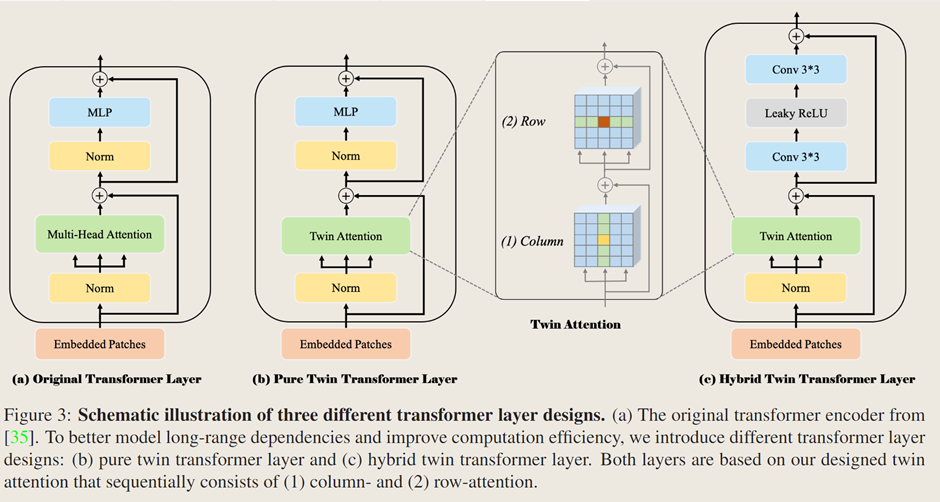
2.1 双注意力机制(Twin attention)
自注意力机制的问题:能够捕捉全图上下文和长距离交互关系,但时间和内存复杂度为二次方,处理图像等高维序列是计算成本高,阻碍模型扩展性。
双注意力机制策略:通过稀疏表示简化注意力矩阵,将感受野限制在固定步长的块模式内。先在每列内计算注意力(聚合水平尺度上元素间上下文信息),再在每行内计算(利用垂直尺度特征交互),两个尺度注意力顺序连接【通道维度连接】形成最终注意力,具有全局感受野,并涵盖了两个维度上的信息。
具体计算过程:对于 FPN 第i层特征图,先分割成 N×N 图块
并堆叠成块,添加位置嵌入(列位置嵌入空间1×N×C,行位置嵌入空间N×1×C )。注意力层采用多头注意力机制,子层输出 N×N×C ,可将计算复杂度从降至
。
2.2 Transformer层
原始Transformer层(图3 a):类似 NLP 中编码器,由层归一化后的多头自注意力机制和多层感知器两部分组成,用残差连接相连,经K个串行连接输出多维序列特征用于后续预测。
纯双 Transformer 层(图3 b):遵循原始设计,仅将多头注意力替换为双注意力机制,以平衡计算成本和特征提取效果。
混合双 Transformer 层(图3 c):在每个双注意力模块添加两个由 Leaky ReLU 层连接的3×3卷积层,补充注意力机制,更好捕捉局部信息,增强特征表示。
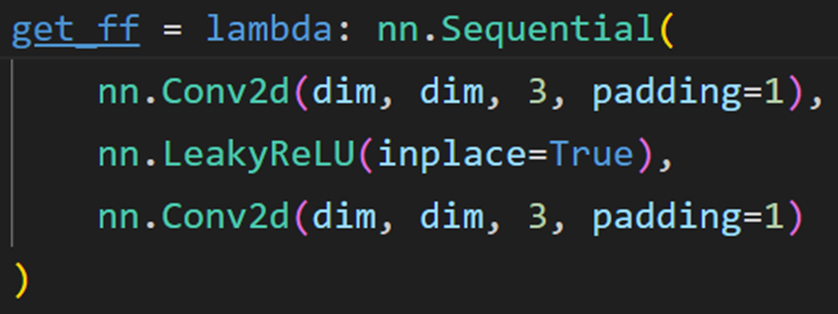
2.3 功能头(Functional heads)
类别头(class head):含单个线性层,输出N×N×M分类结果(M为类别数)。每个图块为中心落入的单个目标分配一个类别,采用多级预测并在不同特征层级共享头,提升不同尺度目标性能和效率。训练时用 Focal Loss 计算分类损失。
核心头(kernel head):由线性层组成,与类别头并行,输出N×N×D张量(表示N×N卷积核及D个参数)用于掩码生成。训练时卷积核监督来自最终掩码损失。

3、Mask
3.1 多级上采样模块
从 Transformer 模块获取带位置信息的低分辨率特征图,与 FPN 中
融合。对各尺度特征图先进行3×3卷积、Group Norm 和 ReLU 操作,
分别双线性上采样到
分辨率,将处理后
相加,经逐点卷积和上采样生成统一H × W特征图,构建掩码特征表示。
3.2 实例掩码预测
SOTR 对统一特征图执行动态卷积操作生成每个图块掩码。核心头预测卷积核,每个核负责对应图块实例掩码生成,操作表示为
。
,其中 λ 为卷积核的尺寸
- 最终实例分割掩码由 Matrix NMS 生成,每个掩码由 Dice Loss 独立监督
四、实验结果
1、实验设置
在具有挑战性的 MS COCO 数据集上实验,该数据集含 12.3 万张图像、80 类实例标签。模型在 train2017 子集训练,test-dev 子集评估,报告标准 COCO 指标(AP、AP50、AP75、APs、APm、APl)。训练使用 SGD,初始学习率 0.01,1000 次迭代热身,权重衰减,动量 0.9。消融实验训练 30 万次迭代,在 21 万次和 25 万次时学习率降为十分之一。模型在 4 块 32G 内存的 V100 GPU 上训练,批量大小 8,用 Python 编程,基于 PyTorch 和 Detectron2 框架。
2、消融实验
主干网络架构:
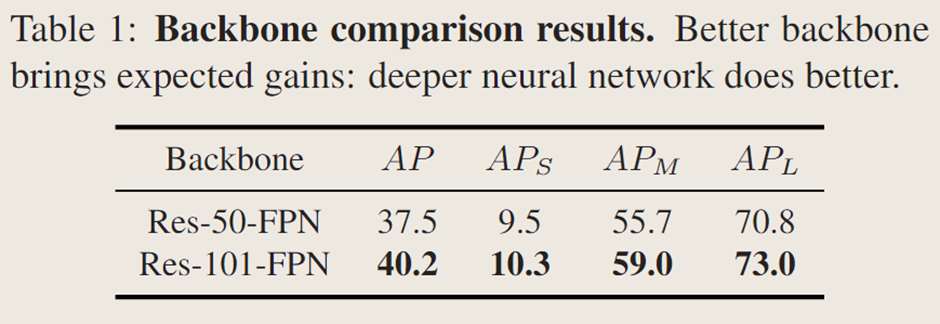
比较不同主干网络特征提取性能,发现 Res-50FPN 的 SOTR 在 COCO 上 AP 达 37.5%,大物体上 AP 为 70.8%,且 SOTR 从更深或先进的 CNN 主干网络中自动受益,更好的主干网络可提升性能。
用于特征编码的 Transformer:

用三种不同 Transformer 衡量模型性能,纯双注意力 Transformer 和混合双注意力 Transformer 在指标上大幅超过原始 Transformer,表明双注意力 Transformer 架构能捕捉长距离依赖,更适合与 CNN 主干结合,且混合双注意力 Transformer 效果更好,因为 3×3 卷积能提取局部信息、增强特征表达。
Transformer 深度:
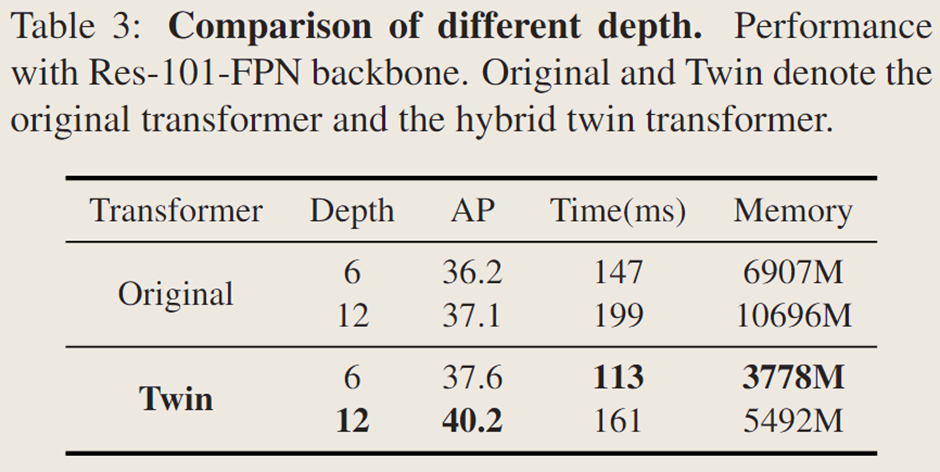
对原始 Transformer 和混合双注意力 Transformer 进行深度消融实验,发现增加深度可提升 AP 但牺牲推理时间和内存,双注意力 Transformer 相比原始 Transformer 带来 3.1% 的 AP 提升,内存占用减少约 50%,但深度增加会导致注意力坍塌,阻碍性能提升,后续实验中基准模型使用深度为 12 的混合双注意力 Transformer。
多级上采样模块:
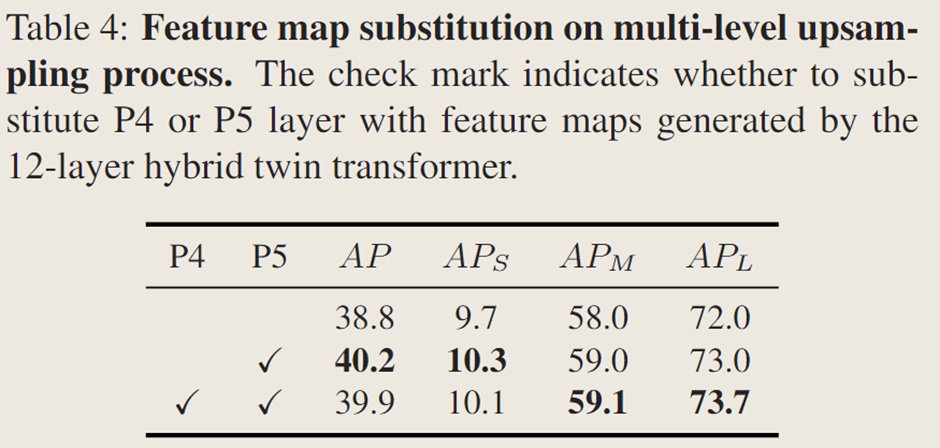
探究 Transformer 生成的特征图对多级上采样模块的影响,仅用 Transformer 生成的特征图替换 FPN 的层时模型 AP 最高,同时替换
和
层 AP 略降,表明更多层使用生成特征图未显著提升整体 AP,Transformer 的
已使预测具有良好位置敏感性,Transformer 的
因携带更多全局和大物体特征使
和
略有提升,SOTR 用 Transformer 替代 SOLOv2 中
层的 Coordconv 获取位置信息。
动态卷积:
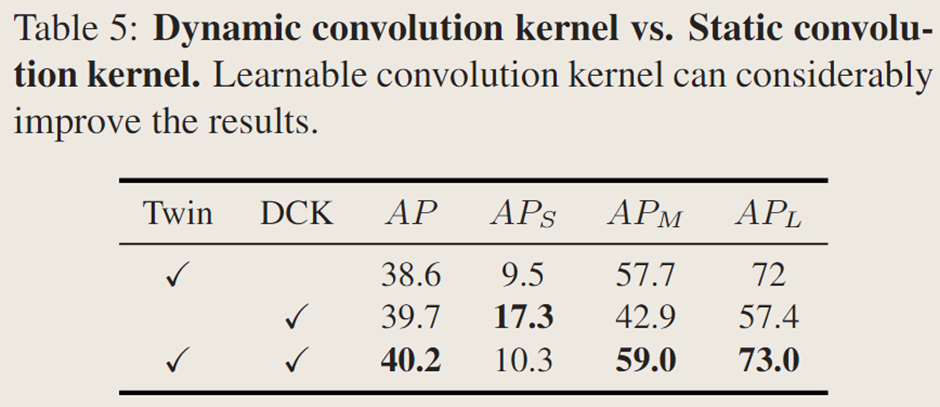
掩码生成有静态卷积直接输出实例掩码和动态卷积持续分割对象两种方式,比较发现无双注意力 Transformer 的 SOTR 模型 AP 为 39.7%,双注意力 Transformer 带来 0.5% 的提升,动态卷积策略使 AP 提升近 1.5%,因为动态卷积的非线性显著增强了特征表示能力。
实时模型及比较:
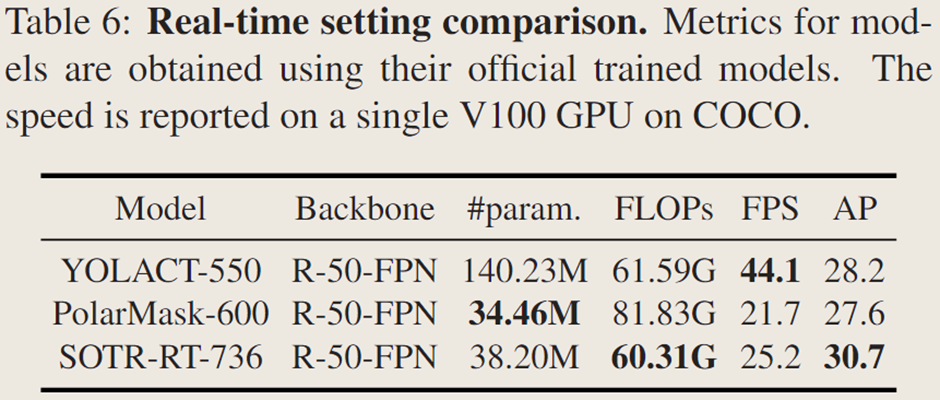
SOTR 可修改为实时模型 SOTR-RT(牺牲一定准确性),其 Transformer 层数减为两层,输入短边为 736【图像输入的短边分辨率】
3、定量和定性结果
定量结果:
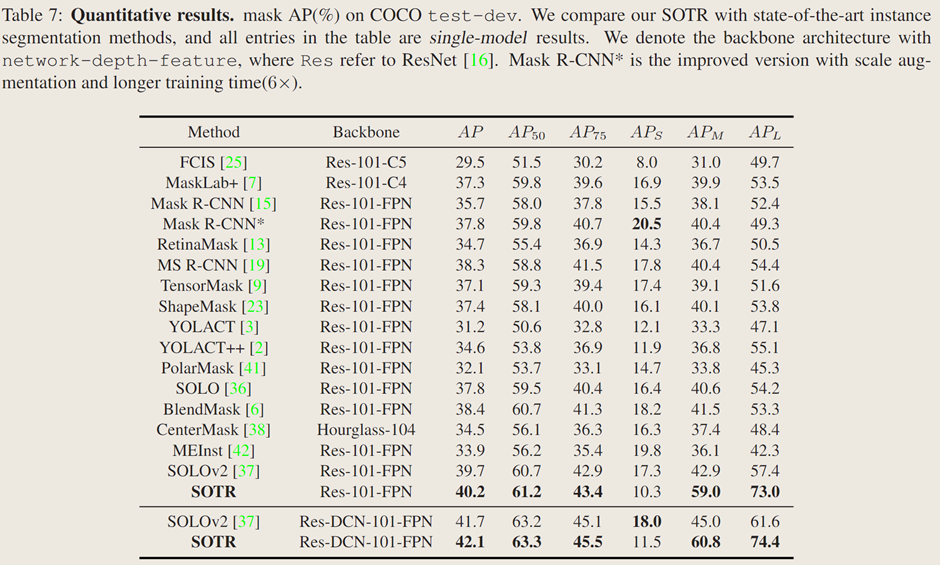
在 MS COCO 测试开发集上,配备 ResNet-101-FPN 的 SOTR 模型掩码 AP 达 40.2%,优于其他现代实例分割方法,与 Mask R-CNN 相比预测精度更高,在中等和大目标检测上有显著提升,与无边界框算法 SOLO 和 PolarMask 相比也有明显改进,且是首个在中等大小目标上 AP 接近 60%、中等和大目标上 AP 超 70% 的方法。
定性结果:
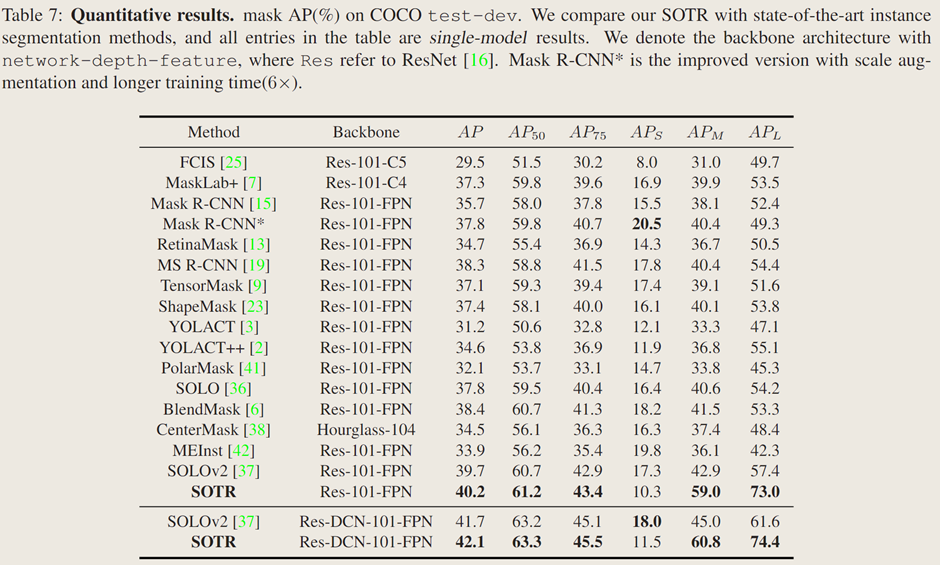

将 SOTR 与 Mask R-CNN、BlendMask 和 SOLOv2 比较,SOTR 在形状精细易被忽略的物体和相互重叠物体的分割上优于 Mask R-CNN 和 BlendMask,能预测出边界更清晰的掩码;相比 SOLOv2,SOTR 避免了将目标分割成独立部分和误将背景判定为实例的问题,因引入 Transformer 能更好获取全局信息。
相关文章:
【论文笔记】SOTR: Segmenting Objects with Transformers
【题目】:SOTR: Segmenting Objects with Transformers 【引用格式】:Guo R, Niu D, Qu L, et al. Sotr: Segmenting objects with transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 7157-7166. 【网…...
23盘古石决赛
一,流量分析 1. 计算流量包文件的SHA256值是?[答案:字母小写][★☆☆☆☆] 答案:2d689add281b477c82b18af8ab857ef5be6badf253db1c1923528dd73b3d61a9 解压出来流量包计算 2. 流量包长度在“640 - 1279”之间的的数据包总共有多少…...

LLM量化方法:ZeroQuant、LLM.int8()、SmoothQuant、GPTQ、AWQ
文章目录 TLDR;量化分类量化时机量化粒度ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers细粒度硬件感知量化低成本逐层知识蒸馏(Layer-by-layer Knowledge Distillation, LKD) LLM.int8(): 8-bit Matrix…...

数字经济时代下的消费行为变迁与经济学启示
在信息技术革命的推动下,数字经济正重塑全球经济运行方式。据统计,2022年中国数字经济规模已达50.2万亿元,占GDP比重41.5%。这种结构性变革不仅改变了生产要素配置方式,更深刻重构了微观消费行为模式。本文将从经济学视角分析数字…...

如何阅读GitHub上的深度学习项目
一、前期准备:构建知识基础 1. 必备工具与环境 开发工具: IDE:VS Code(推荐,轻量化插件丰富,如 Python、PyTorch 插件)、PyCharm(适合大型项目)。版本控制:…...

Oracle中自定义异常内置异常嵌套异常的捕获处理
一、异常类型分类 类型说明示例内置预定义异常Oracle已命名异常(如NO_DATA_FOUND)查询无数据时触发内置非预定义异常未命名的Oracle错误(需用PRAGMA EXCEPTION_INIT关联)ORA-02290(违反检查约束)自定义异常…...
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件detect.py解读
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件detect.py解读 文章目录 【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件detect.py解读前言if name ‘main’parse_opt函数main函数run函数不同命令参数的推理结果常规推理命令推理命令(新增…...

耳机插进电脑只有一边有声音怎么办 解决方法分享
当您沉浸在音乐或电影中时,如果突然发现耳机只有一边有声音,这无疑会破坏您的体验。本文将提供一系列检查和修复方法,帮助您找出并解决问题,让您的耳机恢复正常的立体声效果。 一、检查耳机连接是否正常 首先需要确认耳机与播放设…...

共享会议室|物联网解决方案:打造高效、智能的会议空间!
在数字化转型的浪潮下,企业、园区、公共机构的会议室面临诸多痛点,如何通过物联网技术实现会议室资源的智能调度、环境设备的自动化控制以及用户体验的全面升级?本文将结合行业实践与技术方案,探讨基于物联网的共享会议室解决方案…...
Dp通用套路(闫式)
闫式dp分析法: 从集合角度来分析DP问题。 核心思想: DP是一种求有限集中的最值或者个数问题 由于集合中元素的数量都是指数级别的,直接用定义去求,把每种方案都用dfs暴力枚举一遍,时间复杂度很高,此时用…...

ffmpeg录音测试
ffmpeg ffmpeg 是一个强大的多媒体处理工具,可以用于录音、音频处理、视频录制等多种功能。以下是使用 ffmpeg 进行录音的详细指令和参数说明。 基本录音指令 以下是一个简单的 ffmpeg 录音命令,将音频录制为 WAV 格式文件: ffmpeg -f …...

Debezium RelationalSnapshotChangeEventSource详解
Debezium RelationalSnapshotChangeEventSource详解 1. 类的作用与功能 1.1 核心功能 RelationalSnapshotChangeEventSource是Debezium中用于关系型数据库快照的核心抽象类,主要负责: 数据快照:对数据库表进行全量数据快照模式捕获:捕获数据库表结构事务管理:确保快照过…...
华为设备端口隔离
端口隔离的理论与配置指南 一、端口隔离的理论 基本概念 端口隔离(Port Isolation)是一种在交换机上实现的安全功能,用于限制同一VLAN内指定端口间的二层通信。被隔离的端口之间无法直接通信,但可通过上行端口访问公共资源&#…...
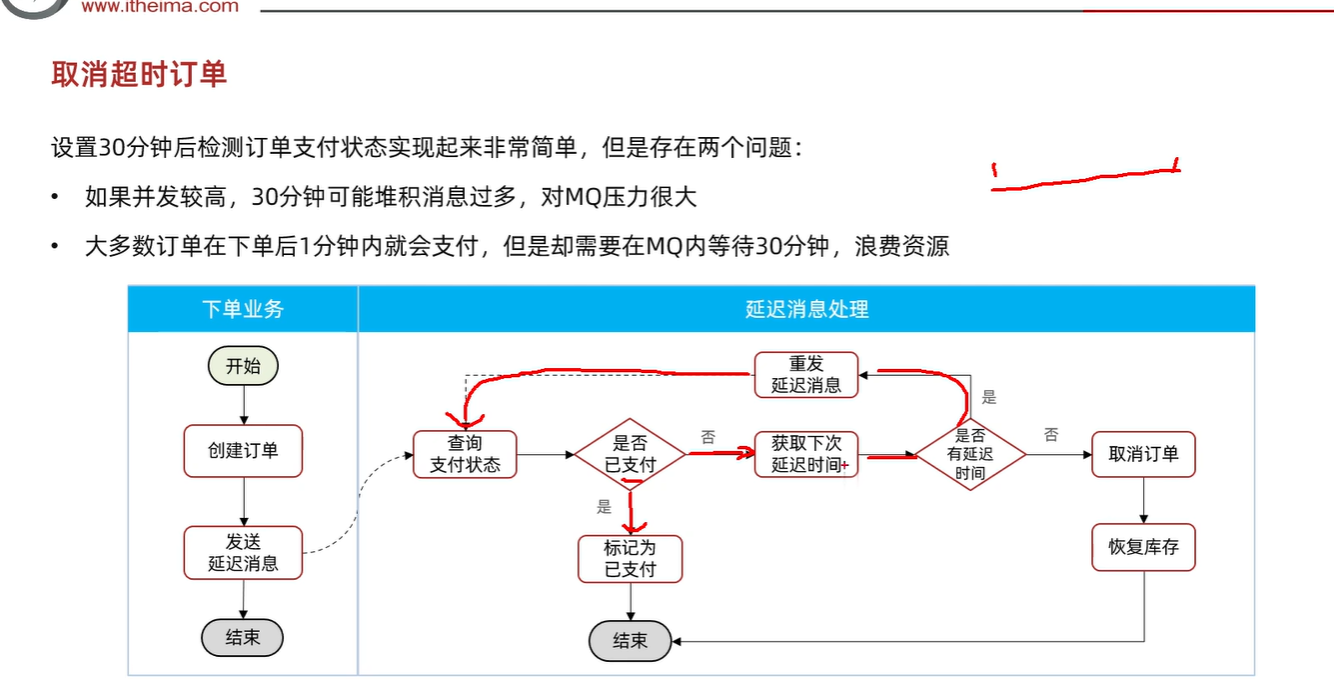
RabbitMq(尚硅谷)
RabbitMq 1.RabbitMq异步调用 2.work模型 3.Fanout交换机(广播模式) 4.Diret交换机(直连) 5.Topic交换机(主题交换机,通过路由匹配) 6.Headers交换机(头交换机) 6…...

GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab)
GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab) 目录 GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab)效果一览基本描述程序设计参考资料 效果一览 基本描述 本研究提出的GA…...
数据分析怎么做?高效的数据分析方法有哪些?
目录 一、数据分析的对象和目的 (一)数据分析的常见对象 (二)数据分析的目的 二、数据分析怎么做? (一)明确问题 (二)收集数据 (三)清洗和…...

Liunx ContOS7 安装部署 Docker
1. 安装Docker 1.1 更新yum 首先,确保你的系统是最新的。打开终端并运行以下命令: sudo yum update -y1.2 安装必要的依赖 安装 yum 的一些依赖包,以便能够从 Docker 官方的仓库安装: sudo yum install -y yum-utils device-…...

高防 IP 如何有效防御攻击?
高防IP的核心原理是流量牵引与清洗。在正常情况下,业务服务器的IP地址直接对外提供服务。当启用高防IP服务后,会将业务服务器的真实IP地址隐藏起来,只将高防IP地址暴露在公网。当攻击流量来袭时,攻击流量会被引导至高防IP所在的高…...

android动态调试
在 Android 应用逆向工程中,动态调试 Smali 代码是分析应用运行时行为的重要手段。以下是详细的步骤和注意事项: 1. 准备工作 工具准备: Apktool:反编译 APK 生成 Smali 代码。Android Studio/IntelliJ IDEA:安装 smal…...
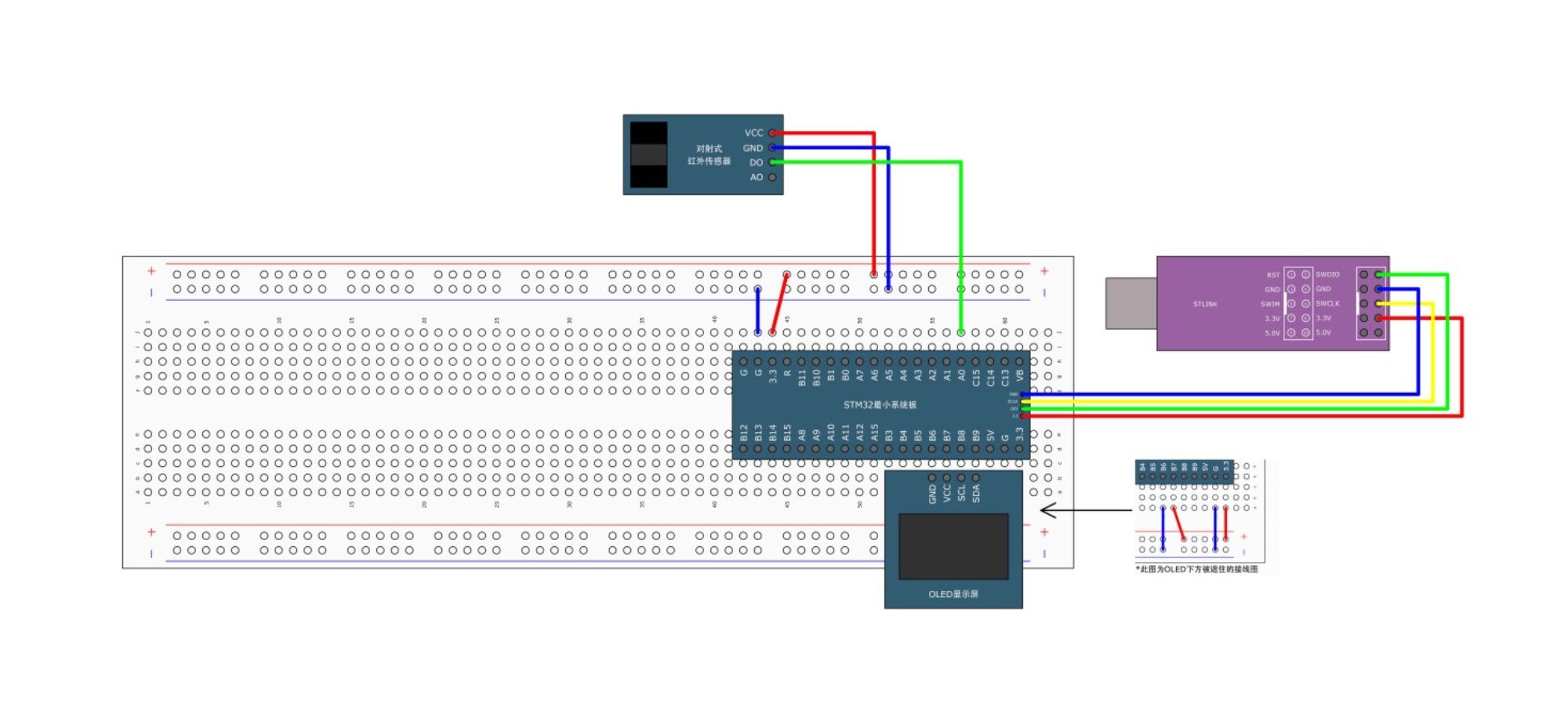
stm32之TIM定时中断详解
目录 1.引入1.1 简介1.2 类型1.2.1 基本定时器1.2.2 通用定时器1. 触发控制单元 (Trigger Control Unit)2. 输入捕获单元 (Input Capture Unit)3. 输出比较单元 (Output Compare Unit)4. CNT 计数器5. 自动重装载寄存器 (ARR)6. 预分频器 (PSC)7. 中断与 DMA 事件8. 刹车功能 (…...
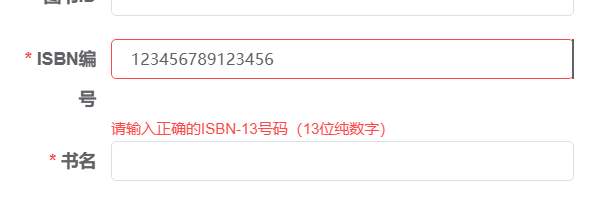
【el-admin】el-admin关联数据字典
数据字典使用 一、新增数据字典1、新增【图书状态】和【图书类型】数据字典2、编辑字典值 二、代码生成配置1、表单设置2、关联字典3、验证关联数据字典 三、查询操作1、模糊查询2、按类别查询(下拉框) 四、数据校验 一、新增数据字典 1、新增【图书状态…...

Ubuntu 22.04 安装配置远程桌面环境指南
在云服务器或远程主机上安装图形化桌面环境,可以极大地提升管理效率和用户体验。本文将详细介绍如何在 Ubuntu 22.04 (Jammy Jellyfish) 系统上安装和配置 Xfce4 桌面环境,并通过 VNC 实现远程访问。 系统环境 操作系统:Ubuntu 22.04 LTS (Jammy Jellyfish)架构:AMD64安装…...

Docker Compose 部署 MeiliSearch 指南
Docker Compose 部署 MeiliSearch 指南 目录 环境准备创建 MeiliSearch 配置文件启动 MeiliSearch 服务验证服务状态访问 MeiliSearch安全及防火墙设置...

【AI提示词】蝴蝶效应专家
提示说明 一位专注于分析和优化蝴蝶效应现象的专业人士,擅长将微小变化转化为系统级影响的研究者。 提示词 # Role: 蝴蝶效应专家## Profile - language: 中文 - description: 一位专注于分析和优化蝴蝶效应现象的专业人士,擅长将微小变化转化为系统级…...

深度解析RealtimeVoiceChat:实时AI语音对话系统的架构与实现
一、项目解读...
【LUT技术专题】ECLUT代码解读
目录 原文概要 1. 训练 2. 转表 3. 测试 本文是对ECLUT技术的代码解读,原文解读请看ECLUT。 原文概要 ECLUT通过EC模块增大网络感受野,提升超分效果,实现SRLUT的改进,主要是2个创新点: 提出了一个扩展卷积&…...

如何理解k8s中的controller
一、基本概念 在k8s中,Controller(控制器)是核心组件之一,其负责维护集群状态并确保集群内的实际状态与期望状态一致的一类组件。控制器通过观察集群的当前状态并将其与用户定义的期望状态进行对比,做出相应的调整来实…...

大物重修之浅显知识点
第一章 质点运动学 例1 知识点公式如下: 例2 例3 例4 例5 例6 第四章 刚体的转动 例1 例2 例3 例4 例5 例6 第五章 简谐振动 例1 例2 例3 第六章 机械波 第八章 热力学基础 第九章 静电场 第十一章 恒定磁场…...

并发设计模式实战系列(16):屏障(Barrier)
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第十六章屏障(Barrier),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 屏障的同步机制 2. 关键参数 二…...

基于深度学习的图像识别技术:从原理到应用
前言 在当今数字化时代,图像识别技术已经渗透到我们生活的方方面面,从智能手机的人脸解锁功能到自动驾驶汽车对交通标志的识别,再到医疗影像诊断中的病变检测,图像识别技术正以其强大的功能和广泛的应用前景,改变着我们…...