Python----神经网络(基于AlexNet的猫狗分类项目)
一、基于AlexNet的猫狗分类
1.1、项目背景
猫和狗是我们生活中最常见的宠物,它们的图像数据大量存在于互联网上。对此进行分类不仅可以帮助开发自动化宠物识别应用,也可以应用于更广泛的计算机视觉领域。例如,训练良好的模型可以支持流浪动物的识别和归类、动物行为监测、虚拟宠物应用等方面。通过本项目,我们希望展现深度学习在实际应用中的有效性,以及其对社会的正面影响。
1.2、项目目的
在本项目中,我们的目标是构建一个深度学习模型,能够有效地识别和分类猫和狗的图像。通过使用卷积神经网络(CNN),尤其是著名的AlexNet架构,我们希望实现高精度的图像分类。完成该项目后,用户能够方便地将图像上传至应用程序,并获得该图像是猫还是狗的预测结果。
1.3、网络描述
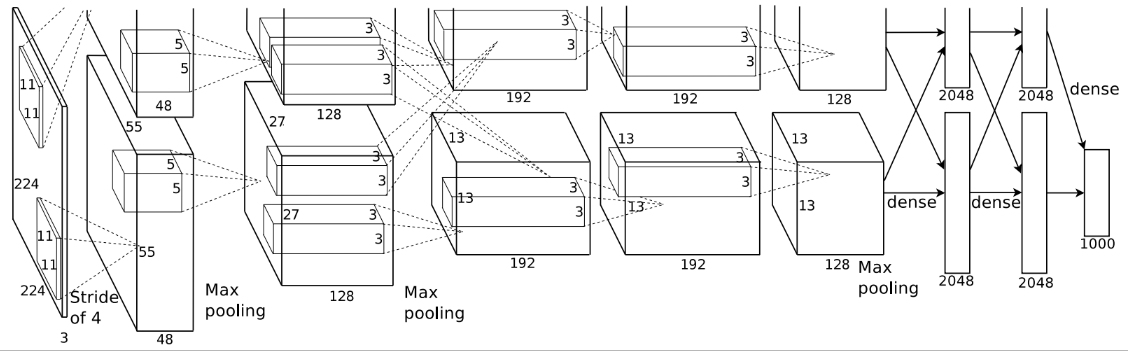
AlexNet 是由Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在2012年提出的深度学习模型。它在ImageNet大规模视觉识别挑战赛中取得了显著的成功,显著提高了图像分类的准确率。该模型采用了多个卷积层、ReLU激活函数、全连接层和Dropout正则化方法,以有效防止过拟合。AlexNet的成功不仅证明了深度学习在计算机视觉领域的潜力,还推动了后续更多深度学习模型的研究和应用。
1.4、数据集

1.5、构建随机数种子
import os
from random import random
import numpy as np
import torchdef setup_seed(seed):np.random.seed(seed) # 设置 Numpy 随机种子random.seed(seed) # 设置 Python 内置随机种子os.environ['PYTHONHASHSEED'] = str(seed) # 设置 Python 哈希种子torch.manual_seed(seed) # 设置 PyTorch 随机种子if torch.cuda.is_available():torch.cuda.manual_seed(seed) # 设置 CUDA 随机种子torch.cuda.manual_seed_all(seed)torch.backends.cudnn.benchmark = False # 关闭 cudnn 加速torch.backends.cudnn.deterministic = True # 设置 cudnn 为确定性算法1.6、 CUDA检测
import torch
# 检查是否有可用的 GPU,如果有则使用 GPU,否则使用 CPU
if torch.cuda.is_available():device = torch.device("cuda") # 使用 GPUprint("CUDA is available. Using GPU.")
else:device = torch.device("cpu") # 使用 CPUprint("CUDA is not available. Using CPU.")1.7、读取数据
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"test": transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
}train_dataset = datasets.ImageFolder("./dataset/train", transform=transform["train"])
test_dataset = datasets.ImageFolder("./dataset/test", transform=transform["test"])train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)1.8、显示图像
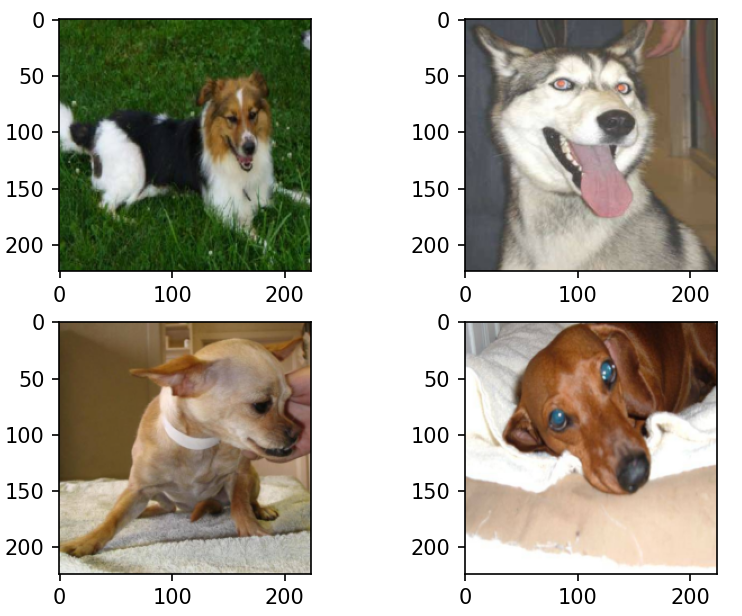
import matplotlib.pyplot as plt
import numpy as np
# 打印图片
examples = enumerate(test_dataloader)
batch_idx, (imgs, labels) = next(examples)
for i in range(4):mean = np.array([0.5, 0.5, 0.5])std = np.array([0.5, 0.5, 0.5])image = imgs[i].numpy() * std[:, None, None] + mean[:, None, None]# 将图片转成numpy数组,主要是转换通道和宽高位置image = np.transpose(image, (1, 2, 0))plt.subplot(2, 2, i+1)plt.imshow(image)plt.title(f"Truth: {labels[i]}")
plt.show()1.9、构建网络
import torch
from torch import nnclass AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 96, 11, 4, 2),nn.ReLU(inplace=True),nn.MaxPool2d(3, 2),nn.Conv2d(96, 256, 5, 1, 2),nn.ReLU(inplace=True),nn.MaxPool2d(3, 2),nn.Conv2d(256, 384, 3, 1, 1),nn.ReLU(inplace=True),nn.Conv2d(384, 384, 3, 1, 1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, 3, 1, 1),nn.ReLU(inplace=True),nn.MaxPool2d(3, 2),)self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(256 * 6 * 6, 4096),nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)x = self.classifier(x)return x1.10、损失函数和优化器
cri = torch.nn.CrossEntropyLoss()
optomizer = torch.optim.Adam(model.parameters(), lr=0.0001)1.11、训练模型
epoches = 100
for epoch in range(epoches):model.train()total_loss = 0for i, (images, labels) in enumerate(train_dataloader):# 数据放在设备上images = images.to(device)labels = labels.to(device)# 前向传播outputs = model(images)loss = cri(outputs, labels)# 反向传播optomizer.zero_grad()loss.backward()optomizer.step()total_loss += lossprint(f"Epoch [{epoch + 1}/{epoches}], Iter [{i}/{len(train_dataloader)}], Loss {loss:.4f}")avg_loss = total_loss / len(train_dataloader)print(f"Epoch [{epoch + 1}/{epoches}], Loss {avg_loss:.4f}")if (epoch+1) % 10 == 0:torch.save(model.state_dict(), f"./model/model_{epoch}.pth")1.12、 验证模型
print("开始验证/评估模型:")
model.load_state_dict(torch.load("./model_best.pth",weights_only=True))
model.eval()
total = 0
correct = 0
predicted_labels = []
true_labels = []
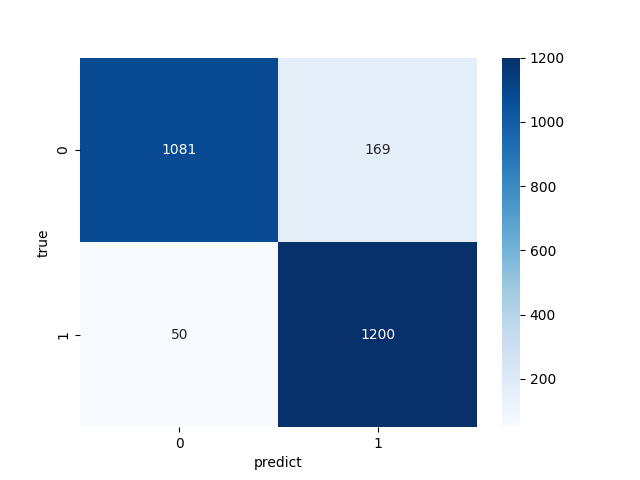
with torch.no_grad():for images, labels in test_dataloader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()predicted_labels.extend(predicted.cpu().numpy())true_labels.extend(labels.cpu().numpy())print(f"ACC {correct / total * 100}%")# 生成混淆矩阵
conf = confusion_matrix(true_labels, predicted_labels)
# 可视化
sns.heatmap(conf, annot=True, fmt="d", cmap="Blues")
plt.xlabel("predict")
plt.ylabel("true")
plt.show()
1.13、完整代码
import os
import random
import numpy as np
import torch
from torch import nn # 导入神经网络模块
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 设置随机种子以保证结果的可重复性
def setup_seed(seed):np.random.seed(seed) # 设置 Numpy 随机种子,用于控制 Numpy 相关的随机操作random.seed(seed) # 设置 Python 内置随机种子,用于控制 Python 内置的随机操作os.environ['PYTHONHASHSEED'] = str(seed) # 设置 Python 哈希种子,用于控制哈希操作的随机性,保证实验的可复现性torch.manual_seed(seed) # 设置 PyTorch 的 CPU 随机种子,用于控制 PyTorch 中 CPU 相关的随机操作if torch.cuda.is_available(): # 检查是否有可用的 CUDA (GPU)torch.cuda.manual_seed(seed) # 设置当前 GPU 的随机种子torch.cuda.manual_seed_all(seed) # 设置所有 GPU 的随机种子(如果有多个 GPU)torch.backends.cudnn.benchmark = False # 关闭 cuDNN 的 benchmark 模式。benchmark 模式会自动寻找适合当前配置的高效算法,但可能牺牲可重复性torch.backends.cudnn.deterministic = True # 设置 cuDNN 使用确定性算法,保证在相同的输入和权重下,输出是相同的,进一步提高可重复性# 设置随机种子
setup_seed(0)
# 检查是否有可用的 GPU,如果有则使用 GPU,否则使用 CPU
if torch.cuda.is_available():device = torch.device("cuda") # 将设备设置为 CUDA (GPU)print("CUDA is available. Using GPU.")
else:device = torch.device("cpu") # 将设备设置为 CPUprint("CUDA is not available. Using CPU.")# 定义数据预处理的转换
transform = {"train": transforms.Compose([ # 训练集的数据预处理transforms.RandomResizedCrop(224), # 随机裁剪图片到 224x224 的大小,并进行缩放transforms.ToTensor(), # 将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,并将像素值缩放到 [0, 1]transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像的每个通道进行标准化,使其均值为 0.5,标准差为 0.5]),"test": transforms.Compose([ # 测试集的数据预处理transforms.Resize((224, 224)), # 将图片缩放至 224x224 的大小transforms.ToTensor(), # 将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,并将像素值缩放到 [0, 1]transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像的每个通道进行标准化,使其均值为 0.5,标准差为 0.5]),
}# 加载训练数据集,"./dataset/train" 是训练集图片所在的文件夹,transform 指定了数据预处理方式
train_dataset = datasets.ImageFolder("./dataset/train", transform=transform["train"])
# 加载测试数据集,"./dataset/test" 是测试集图片所在的文件夹,transform 指定了数据预处理方式
test_dataset = datasets.ImageFolder("./dataset/test", transform=transform["test"])# 创建训练数据的数据加载器,batch_size 定义了每个批次的大小,shuffle=True 表示在每个 epoch 开始时打乱数据
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 创建测试数据的数据加载器,batch_size 定义了每个批次的大小,shuffle=False 表示不打乱数据
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)# 定义 AlexNet 模型结构
class AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()# 特征提取层self.features = nn.Sequential(nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2), # 卷积层1:输入通道3,输出通道96,卷积核11x11,步长4,填充2nn.ReLU(inplace=True), # ReLU 激活函数,inplace=True 表示直接修改输入nn.MaxPool2d(kernel_size=3, stride=2), # 最大池化层1:池化窗口3x3,步长2nn.Conv2d(96, 256, kernel_size=5, padding=2), # 卷积层2:输入通道96,输出通道256,卷积核5x5,填充2nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # 最大池化层2:池化窗口3x3,步长2nn.Conv2d(256, 384, kernel_size=3, padding=1), # 卷积层3:输入通道256,输出通道384,卷积核3x3,填充1nn.ReLU(inplace=True),nn.Conv2d(384, 384, kernel_size=3, padding=1), # 卷积层4:输入通道384,输出通道384,卷积核3x3,填充1nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1), # 卷积层5:输入通道384,输出通道256,卷积核3x3,填充1nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # 最大池化层3:池化窗口3x3,步长2)# 分类器self.classifier = nn.Sequential(nn.Dropout(p=0.5), # Dropout 层1:以 50% 的概率随机将一部分神经元的输出置为 0,防止过拟合nn.Linear(256 * 6 * 6, 4096), # 全连接层1:输入特征数 256 * 6 * 6,输出特征数 4096nn.ReLU(inplace=True),nn.Dropout(p=0.5), # Dropout 层2nn.Linear(4096, 4096), # 全连接层2:输入特征数 4096,输出特征数 4096nn.ReLU(inplace=True),nn.Linear(4096, num_classes), # 全连接层3:输出层,输出特征数等于类别数)def forward(self, x):x = self.features(x) # 通过特征提取层x = torch.flatten(x, 1) # 将多维特征图展平成一维向量,方便输入到全连接层x = self.classifier(x) # 通过分类器return x# 实例化 AlexNet 模型,num_classes=2 表示分类的类别数为 2,并将模型移动到指定的设备 (GPU 或 CPU) 上
model = AlexNet(num_classes=2).to(device)
# 定义损失函数为交叉熵损失,常用于多分类任务
cri = torch.nn.CrossEntropyLoss()
# 定义优化器为 Adam 优化器,model.parameters() 指定了需要优化的模型参数,lr=0.0001 是学习率
optomizer = torch.optim.Adam(model.parameters(), lr=0.0001)# 定义训练的 epoch 数
epoches = 100
# 开始训练循环
for epoch in range(epoches):most_acc = 0 # 初始化最佳的测试集准确率model.train() # 将模型设置为训练模式,启用 dropout 和 batch normalizationtotal_loss = 0 # 初始化每个 epoch 的总损失# 遍历训练数据加载器中的每个批次for i, (images, labels) in enumerate(train_dataloader):# 将图像和标签移动到指定的设备 (GPU 或 CPU) 上images = images.to(device)labels = labels.to(device)# 前向传播:将图像输入模型,得到模型的输出outputs = model(images)# 计算损失:将模型的输出和真实的标签输入损失函数,得到损失值loss = cri(outputs, labels)# 反向传播之前将优化器的梯度清零optomizer.zero_grad()# 反向传播:计算损失相对于模型参数的梯度loss.backward()# 更新模型参数:根据计算得到的梯度和优化器的规则更新模型参数optomizer.step()# 累加每个批次的损失值total_loss += loss# 打印训练过程中的信息,包括当前的 epoch、迭代次数和当前的损失值print(f"Epoch [{epoch + 1}/{epoches}], Iter [{i}/{len(train_dataloader)}], Loss {loss:.4f}")# 计算一个 epoch 的平均训练损失avg_loss = total_loss / len(train_dataloader)# 打印每个 epoch 的平均训练损失print(f"Train Data: Epoch [{epoch + 1}/{epoches}], Loss {avg_loss:.4f}")# 进入模型评估模式,禁用 dropout 和 batch normalizationmodel.eval()total, correct, test_loss, total_loss = 0, 0, 0, 0 # 初始化测试过程中的总样本数、正确样本数、批次损失和总损失# 在评估模式下,不计算梯度with torch.no_grad():# 遍历测试数据加载器中的每个批次for images, labels in test_dataloader:# 将图像和标签移动到指定的设备 (GPU 或 CPU) 上images = images.to(device)labels = labels.to(device)# 前向传播:将图像输入模型,得到模型的输出outputs = model(images)# 计算测试集的损失test_loss = cri(outputs, labels)# 累加每个批次的测试损失total_loss += test_loss# 获取模型输出中每个样本的最大值和对应的索引(即预测的类别)_, predicted = torch.max(outputs.data, 1)# 累加测试集的总样本数total += labels.size(0)# 累加预测正确的样本数correct += (predicted == labels).sum().item()# 计算平均测试损失avg_test_loss = total_loss / len(test_dataloader)# 计算测试集的准确率acc = correct / total# 打印每个 epoch 的测试损失和准确率print(f"Test Data: Epoch [{epoch+1}/{epoches}], Loss {avg_test_loss:.4f}, Accuracy {acc * 100}%")# 如果当前的测试准确率是最高的,则保存当前模型的权重if acc > most_acc:torch.save(model.state_dict(), f"./model/model_best.pth")most_acc = acc# 每隔 10 个 epoch 保存一次模型的权重if (epoch+1) % 10 == 0:torch.save(model.state_dict(), f"./model/model_{epoch+1}.pth")相关文章:
Python----神经网络(基于AlexNet的猫狗分类项目)
一、基于AlexNet的猫狗分类 1.1、项目背景 猫和狗是我们生活中最常见的宠物,它们的图像数据大量存在于互联网上。对此进行分类不仅可以帮助开发自动化宠物识别应用,也可以应用于更广泛的计算机视觉领域。例如,训练良好的模型可以支持流浪动物…...

excel表数据导入数据库
前两天,有个两DB之间的数据导出导入的需求。对方提供的是excel表,我这边是mysql数据库,excel表第一行是字段名,之后的行是记录的值。 其实没有多复杂,我先将exel转成csv,结果mysql导入csv,第一行…...

SMT贴片钢网精密设计与制造要点解析
内容概要 SMT贴片钢网作为电子组装工艺的核心载体,其设计与制造质量直接影响焊膏印刷精度及产品良率。本文系统梳理了钢网全生命周期中的15项关键技术指标,从材料选择、结构设计到工艺控制构建完整技术框架。核心要点涵盖激光切割精度的微米级调控、开口…...

第三节:条件语句与循环:控制程序流程
📌 第三节:条件语句与循环:控制程序流程 目标:熟练运用条件判断、循环结构,实现动态逻辑与重复操作,掌握常见算法的底层实现。 一、条件语句:让程序“聪明”起来 1. if-else 基础语法 作用&am…...

荣耀A8互动娱乐组件部署实录(第1部分:服务端环境搭建)
作者:一位被“只支持安卓”的前端劝退过三次的技术人 前言 这一套组件我拆包已经不止一遍了,老实讲,不支持 iOS 是遗憾,但对于研究 UI 动态加载、资源分离结构和整体架构来说,A8 的这套服务还算完整,服务器…...

流式渲染 Streaming SSR
以下是关于流式渲染(Streaming SSR)的基本知识点总结: 一、流式渲染核心概念 1. 与传统SSR对比 维度传统SSR流式SSR响应方式完整HTML生成后一次性返回分块逐步返回HTML内容首字节时间较慢(需等待所有数据处理完成)极快(立即发送初始HTML结构)内存压力高(需缓存完整页面…...

基于Python Flask的深度学习电影评论情感分析可视化系统(2.0升级版,附源码)
博主介绍:✌IT徐师兄、7年大厂程序员经历。全网粉丝15W、csdn博客专家、掘金/华为云//InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇dz…...

如何减少极狐GitLab 容器镜像库存储?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 减少容器镜像库存储 (BASIC ALL) 未清理的容器镜像库会随着时间的推移而变大。添加大量镜像或标签时: 获取可用标…...
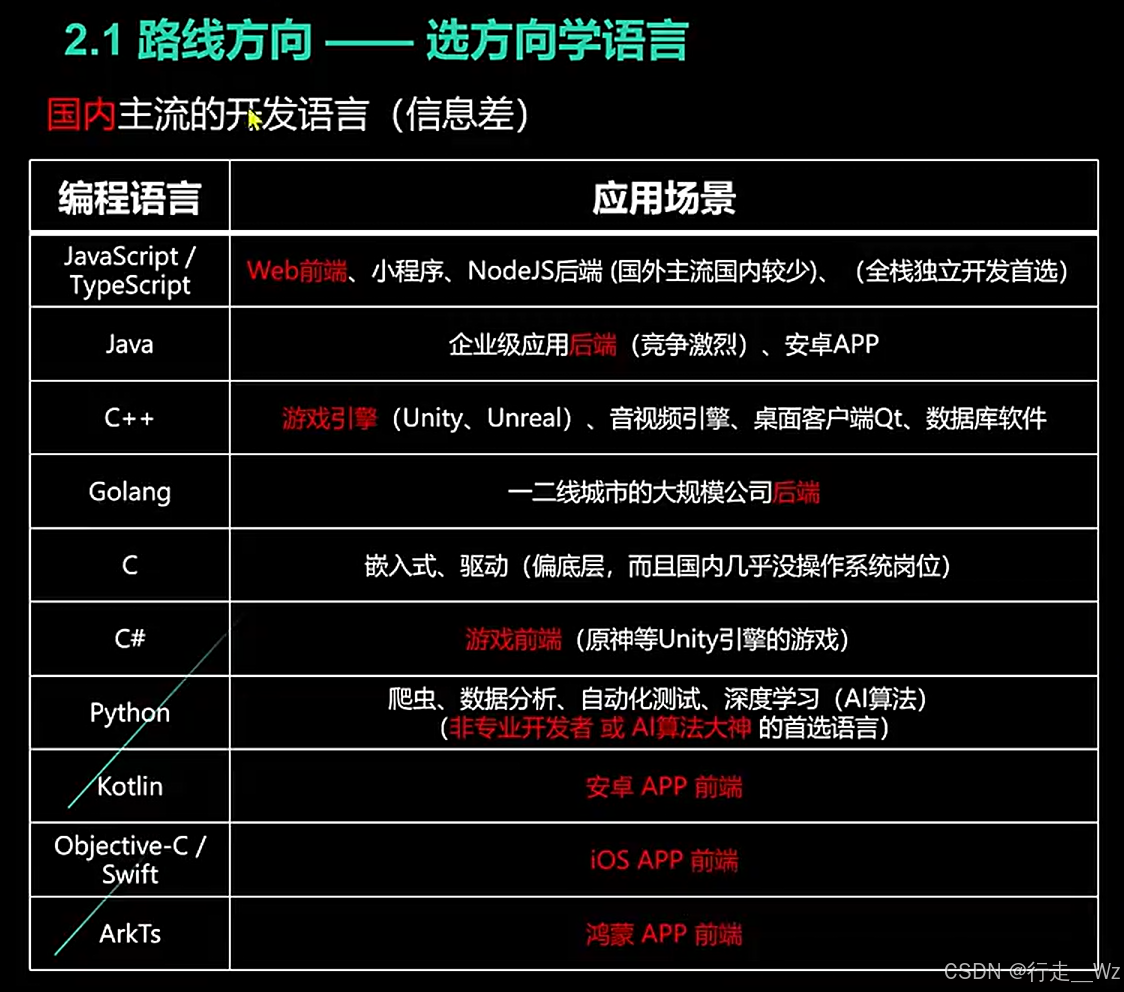
计算机学习路线与编程语言选择(信息差)
——授人以鱼不如授人以渔 计算机学习公式:1/3科班思维 1/3路线选择 1/3工程能力 好工作随便找(来自B站小毛毛熊) 本文主要是路线选择!!!下面开始吧。 面向岗位学习!到招聘网站看看有哪些…...

【redis】redis 手动切换主从
场景一: 测试需要,需要手动切换主从 在redis节点: $ redis-cli -h xx.xx.xx.xx -p XX -a XX shutdown 不要直接关闭redis进程,使用 shutdown ,能在进程关闭前持久化内存中的数据 待主从切换完毕后࿱…...

基于设备指纹识别的反爬虫技术:给设备办 “身份证”
传统的封禁 IP、验证码等反爬虫手段已逐渐失效,基于设备指纹识别的反爬虫技术应运而生,成为守护数据安全的新防线。它如同给每个设备办一张独一无二的 “身份证”,精准区分正常用户与爬虫工具。 一、基础参数采集:构建设备指纹的…...

SpringAI框架中的RAG知识库检索与增强生成模型详解
SpringAI框架中的RAG知识库检索与增强生成模型详解 一、RAG简介 RAG(Retrieval-Augmented Generation)可以通过检索知识库,克服大模型训练完成后参数冻结的局限性,携带知识让大模型根据知识进行回答。 二、SpringAI框架支持的R…...
,图解超赞超详细!!!)
【造包工具】【Xcap】精讲Xcap构造分片包(IPv4、ipv6、4G\5G等pcap均可),图解超赞超详细!!!
目录 前言 1. XCap工具概念介绍 2. Xcap环境说明 2.1 新建报文组 2.2 导入数据包 2.3 查看报文组 2.4 复制删除报文组 3. 构造分片包 3.1 造普通/外层分片步骤: 3.2 造内层分片步骤 3.2.1 建立一个新报文 3.2.2 将组装的新报文分片 3.2.3 替换原始包内层部分 3.2…...
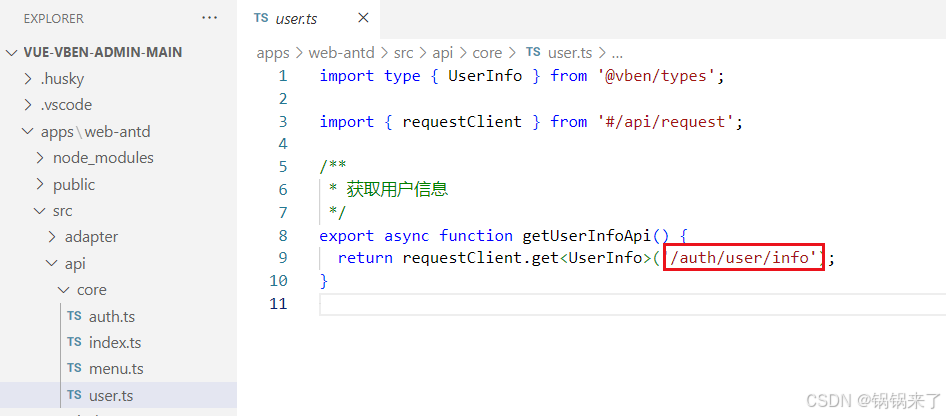
第三节:Vben Admin 最新 v5.0 对接后端登录接口(下)
文章目录 前言一、处理请求头Authorization二、/auth/user/info 接口前端接口后端接口三、/auth/codes 接口1.前端2.后端四、测试接口前言 上一节内容,实现了登录的/auth/login 接口,但是登陆没有完成,还需要完成下面两个接口。才能完成登录。 一、处理请求头Authorizatio…...

爬虫学习————开始
🌿自动化的思想 任何领域的发展原因————“不断追求生产方式的改革,即使得付出与耗费精力越来愈少,而收获最大化”。由此,创造出方法和设备来提升效率。 如新闻的5W原则直接让思考过程规范化、流程化。或者前端框架/后端轮子的…...
Ubuntu18.04搭建samda服务器
一.什么是Samba服务器? Samba服务器是一种基于开源协议实现的网络共享服务软件,主要用于在不同操作系统(如Windows、Linux、Unix)之间实现文件和打印机共享功能。其核心目标是解决跨平台资源共享的兼容性问题,尤其是在…...

K8S扩缩容及滚动更新和回滚
目录: 1、滚动更新1、定义Deployment配置2、应用更新 2、版本回滚1. 使用kubectl rollout undo命令 3、更新暂停与恢复1、暂停更新2、更新镜像(例如,使用kubectl set image命令)3、恢复更新 4、弹性扩缩容1、扩容命令2、缩容命令3…...

一文掌握 LVGL 9 的源码目录结构
文章目录 📂 一文掌握 LVGL 9 的源码目录结构🧭 顶层目录概览📁 1. src/ — LVGL 的核心源码(🔥重点)📁 2. examples/ — API 示例📁 3. demos/ — 综合演示项目📁 4. do…...

2025-05-10-FFmepg库裁切有水印的视频
裁后 代码 import subprocess# 文件路径 input_video_path "bg_video.mp4" output_video_path "output_video_cropped.mp4"# 裁剪视频下方的水印 def crop_video(input_video_path, output_video_path, crop_height):# 获取视频的分辨率def get_video…...

Vue3 路由配置与跳转传参完整指南
目录 一、路由配置 1. 基本路由配置 2. 动态路由配置 3. 可选参数配置 二、路由跳转与传参 1. 声明式导航 (模板中) 2. 编程式导航 (JavaScript中) 三、参数接收 1. 接收动态路由参数 2. 接收查询参数 3. 监听参数变化 四、高级用法 1. 路由元信息 2. 路由守卫控…...
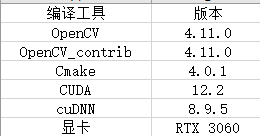
opencv+opencv_contrib+cuda和VS2022编译
本文介绍使用OpenCV和OpenCV_Contrib源码及Cuda进行编译的过程,编译过程中会用到OpenCV、OpenCV_Contrib、CUDA Toolkit、cuDNN、Cmake、VS2022等工具,最终编译OpenCV的Cuda版本。 一、OpenCV下载地址 OpenCV官网下载地址:https://opencv.org/releases…...

《深挖Java中的对象生命周期与垃圾回收机制》
大家好呀!👋 今天我们要聊一个Java中超级重要的话题——对象的生命周期和垃圾回收机制。 一、先来认识Java世界的"居民"——对象 👶 在Java世界里,一切皆对象。就像现实世界中的人一样,每个Java对象也有自…...

C++中extern关键字详解:不同情况下的使用方式
在 C 中,extern 关键字主要用于声明变量或函数是在其他文件中定义的,从而可以在当前文件中使用这些变量或函数。下面详细介绍 extern 修饰全局变量、函数等的用法区别以及注意事项。 修饰全局变量 详细介绍 当 extern 用于修饰全局变量时,…...

【QT】深入理解 Qt 中的对象树:机制、用途与最佳实践
深入理解 Qt 中的对象树:机制、用途与最佳实践 在使用 Qt 编程时,你是否注意到很多对象可以设置“父对象”?比如: QPushButton* btn new QPushButton(parentWidget);这不是简单的层级结构,而是 Qt 强大而优雅的 对象…...

如何利用爬虫获得1688商品详情:实战指南
在电商运营和市场分析中,获取1688商品详情数据是一项重要任务。本文将详细介绍如何利用爬虫技术获取1688商品详情,包括准备工作、爬虫实现步骤以及注意事项。 一、准备工作 (一)注册1688开放平台账号 在1688开放平台注册开发者…...
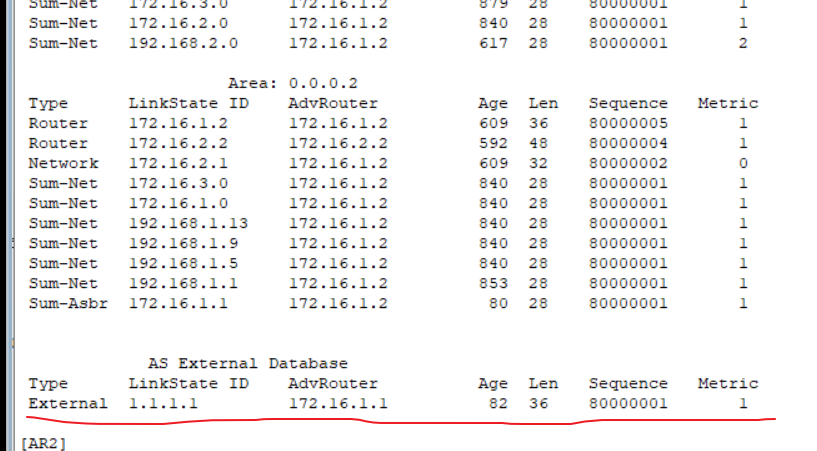
网工实验——OSPF配置
网络拓扑图 配置 1.为每个路由器配置接口(略)(详细见RIP实验) 2.配置OSPF AR1 [AR1]ospf [AR1-ospf-1]area 1 [AR1-ospf-1-area-0.0.0.1]network 172.16.1.1 0.0.0.0 #精确配置网络,也可以像下面那条命令那样配置 …...
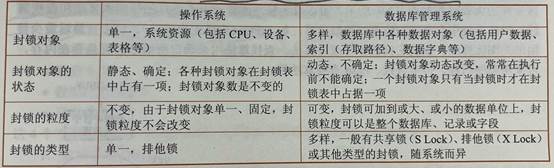
数据库系统概论-基础理论
数据库系统概述: 1、记录:计算机中表示和存储数据的一种格式或方法。 2、数据库(DataBase, DB):数据库是长期储存在计算机内、有组织、可共享的大量数据集合。可为各种用户共享。 3、数据库管理系统(Dat…...
从零开始学习人工智能(Python高级教程)Day6-Python3 正则表达式
一、Python3 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 在 Python 中,使用 re 模块来处理正则表达式。 re 模块提供了一组函数,允许你在字符串中进行模式匹配、搜索和替换操作。 r…...
Qt开发:项目视图(Item Views)的介绍和使用
文章目录 一、清单视图(List View)1.1 基本概念1.2 使用示例(文字列表)1.3 图标文字(图标模式)1.4 常用设置1.5 完整示例 二、树视图(Tree View)2.1 基本概念2.2 常用类简介2.3 快速…...

“ES7+ React/Redux/React-Native snippets“常用快捷前缀
请注意,这是一个常用的列表,不是扩展提供的所有前缀。最完整和最新的列表请参考扩展的官方文档或在 VS Code 中查看扩展的详情页面。 React (通常用于 .js, .jsx, .ts, .tsx): rfce: React Functional Component with Export Defaultrafce: React Arro…...