从零开始学习人工智能(Python高级教程)Day6-Python3 正则表达式
一、Python3 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
在 Python 中,使用 re 模块来处理正则表达式。
re 模块提供了一组函数,允许你在字符串中进行模式匹配、搜索和替换操作。
re 模块使 Python 语言拥有完整的正则表达式功能。
本章节主要介绍 Python 中常用的正则表达式处理函数,如果你对正则表达式不了解,可以查看我们的 正则表达式 - 教程。
1.re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 None。
函数语法:
re.match(pattern, string, flags=0)
import re
#re.match()函数用于查找字符串的开头是否匹配正则表达式,如果字符串开头匹配正则表达式,则返回一个Match对象,否则返回None。
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
# 首先尝试在 'www.runoob.com' 的起始位置匹配 'www'。
# 由于匹配成功,re.match() 返回一个 Match 对象。然后,.span() 方法被调用,返回一个元组 (0, 3),
# 表示 'www' 在原字符串中的位置是从索引 0 开始到索引 3 结束(不包括索引 3 的字符)print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配,返回None匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
我们可以使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
line = "Cats are smarter than dogs"
matchObj = re.match(r'(.*) are (.*?) .*', line, re.M | re.I)
# re.match(pattern, string, flags=0): 这是 Python 正则表达式模块 re 中的一个函数,用于在字符串的起始位置匹配正则表达式。
# 如果匹配成功,则返回一个 Match 对象;如果匹配失败,则返回 None。# pattern: 在这里是一个字符串 r'(.*) are (.*?) .*',它是一个正则表达式模式。
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
# 这里的 r 表示原始字符串,即不处理其中的转义字符,直接将其作为正则表达式的内容来处理。# string: 这里是 line,即要进行匹配操作的字符串。
# 在这个例子中,line 的值是 "Cats are smarter than dogs"。# flags: 这里使用了 re.M 和 re.I 两个标志。re.M 表示多行模式,这种模式下,
# ^ 和 $ 表示每一行的开始和结束,而不是整个字符串的开始和结束。
# re.I 表示忽略大小写模式,使匹配过程不区分大小写。
# re.M | re.I 使用了按位或操作符 | 来合并这两个标志,表示在匹配时同时使用多行模式和忽略大小写模式。#group()方法用于获得匹配的字符串。
#group(1)方法用于获得第一个分组匹配的字符串。
#group(2)方法用于获得第二个分组匹配的字符串。
#groups()方法用于获得所有分组匹配的字符串。
if matchObj:print("matchObj.group() : ", matchObj.group())print("matchObj.group(1) : ", matchObj.group(1))print("matchObj.group(2) : ", matchObj.group(2))print("matchObj.groups() : ", matchObj.groups())
else:print("No match!!")2. re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配,用法与match类似。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
import reprint(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
#输出:(0, 3)print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配(与match有区别)
#输出:(11, 14) 匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
3.re.match 与 re.search的区别
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
4.检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
phone = "2004-959-559 # 这是一个电话号码"# 删除字符串中的 Python注释
num = re.sub(r'#.*$', "", phone)
# 匹配字符串中的井号(#)字符。
# .* 匹配井号后面的所有字符,直到遇到换行符(非贪婪模式)。
# $ 匹配字符串的结尾。
print("电话号码 : ", num) # 输出:2004-959-559# 移除非数组字符
num = re.sub(r'\D', "", phone)
# \D 是一个正则表达式元字符,它匹配任何不是数字的字符。
# D 是 d 的反义词,d 匹配数字(等价于 [0-9]),而 D 匹配非数字(等价于 [^0-9])。
print("电话号码 : ", num) # 输出:20049595594.1 repl 参数是一个函数
# repl为替换函数,参数为匹配到的内容,返回值为替换后的内容。
# 将匹配的数字乘以 2
def double(matched):value = int(matched.group('value'))return str(value * 2)s = 'A23G4HFD567'print(re.search(r'(?P<value>\d+)', s).group(1)) # 输出:23
print(re.search(r'(?P<value>\d+)', s).groups()) # 输出:('23',)for match in re.finditer(r'(?P<value>\d+)', s):print(match.group(1)) # 输出:23 4 567print(re.sub('(?P<value>\d+)', double, s)) # 输出:A46G8HFD1134
# (?P<value>\d+): 这是一个命名捕获组,
# 用于从匹配的子串中提取特定部分。(?P<name>...) 是Python中命名捕获组的语法,
# 其中name是你为该捕获组指定的名称,在这里名称为 value。
# \d+: 这个模式用于匹配一个或多个数字。
# \d 是一个正则表达式元字符,表示匹配任何数字字符(等价于 [0-9]),后面的 + 表示匹配前面的元素一次或多次。4.2 compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags])
参数:
- 1.pattern : 一个字符串形式的正则表达式
- 2.flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
-
- re.IGNORECASE 或 re.I - 使匹配对大小写不敏感
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.MULTILINE 或 re.M - 多行模式,改变 ^ 和 $ 的行为,使它们匹配字符串的每一行的开头和结尾。
- re.DOTALL 或 re.S - 使 . 匹配包括换行符在内的任意字符。
- re.ASCII - 使 \w, \W, \b, \B, \d, \D, \s, \S 仅匹配 ASCII 字符。
- re.VERBOSE 或 re.X - 忽略空格和注释,可以更清晰地组织复杂的正则表达式。
这些标志可以单独使用,也可以通过按位或'|'组合使用。例如,re.IGNORECASE | re.MULTILINE 表示同时启用忽略大小写和多行模式。
# compile 函数
pattern = re.compile(r'\d+') # 编译正则表达式: \d+
# r'\d+' 是一个正则表达式模式。
# r 表示原始字符串(raw string),即不处理其中的转义字符
# \d 是正则表达式中的一个元字符,表示匹配任何数字字符(等价于 [0-9])。
# + 是一个量词,表示匹配前面的元素一次或多次。因此,\d+ 用于匹配一个或多个连续的数字。# 使用 compile 函数编译的正则表达式可以重复使用,提高效率。
print(pattern.match('one123one')) #输出:None
print(pattern.match('one123four',3,6))
#输出:<re.Match object; span=(3, 6), match='123'>
在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …])方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用group()或group(0);start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;span([group])方法返回(start(group), end(group))。
# compile 函数
pattern = re.compile(r'\d+') # 编译正则表达式: \d+
# r'\d+' 是一个正则表达式模式。
# r 表示原始字符串(raw string),即不处理其中的转义字符
# \d 是正则表达式中的一个元字符,表示匹配任何数字字符(等价于 [0-9])。
# + 是一个量词,表示匹配前面的元素一次或多次。因此,\d+ 用于匹配一个或多个连续的数字。# 使用 compile 函数编译的正则表达式可以重复使用,提高效率。
print(pattern.match('one123one')) #输出:None
m=pattern.match('one123four',3,6)
print(m)
#输出:<re.Match object; span=(3, 6), match='123'>print(m.group()) # 输出:123
print(m.group(0)) # 输出:123
print(m.start()) # 输出:3
print(m.end()) # 输出:6
print(m.span()) # 输出:(3, 6)4.3 findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法格式为:
re.findall(pattern, string, flags=0)
或
pattern.findall(string[, pos[, endpos]])
参数:
- pattern 匹配模式。
- string 待匹配的字符串。
- pos 可选参数,指定字符串的起始位置,默认为 0。
- endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
#findall
s = 'hello 123 world, hello 456 python'
pattern = re.compile(r'\d+')
print(pattern.findall(s)) # 输出:['123', '456']
print(pattern.findall(s,10,25)) # 输出:['4']# 多个匹配模式,返回元组列表:
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
# 模式 (\w+)=(\d+) 会匹配所有的单词字符后跟一个等号,然后是数字字符。
print(result) # 输出:[('width', '20'), ('height', '10')]5.re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
#finditer
it = re.finditer(r"\d+", "12a32bc43jf3")
for match in it:print(match.group())# 输出:12 32 43 36.re.split
plit 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| maxsplit | 分割次数,maxsplit=1 分割一次,默认为 0,不限制次数。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
print(re.split(r'\W+', 'runoob,runoob,runoob.') )
#输出:['runoob', 'runoob', 'runoob', '']
# \W 是一个正则表达式元字符,表示匹配任何非单词字符(等价于 [^a-zA-Z0-9_])
# re.split() 会查找字符串中所有符合 \W+ 模式的子串,并以这些子串为分隔符将原字符串分割成多个部分。
# 在字符串 'runoob, runoob, runoob.' 中,\W+ 匹配到的是逗号 ,和句号 .。
# 因此,该字符串会被分割成 ['runoob', 'runoob', 'runoob', ''] 这四个部分。
# 注意最后一个空字符串 '' 的存在,这是因为字符串末尾有一个句号 .,它被当作分隔符,导致在它之后还产生了一个空字符串。print( re.split('\W+', ' runoob, runoob, runoob.', 1) ) #限制分割次数为1
# 输出:['', 'runoob, runoob, runoob.']print(re.split(r'(\W+)', 'runoob, runoob, runoob.'))
# 输出:['runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
# r'(\W+)' 是一个正则表达式模式。
# r 表示原始字符串,这样在字符串中使用转义字符时,避免 Python 字符串的转义处理。
# 在这个模式中,\W 是一个正则表达式元字符,它匹配任何非单词字符(等价于 [^a-zA-Z0-9_])。
# + 是一个量词,表示匹配前面的元素一次或多次。因此,\W+ 用于匹配一个或多个连续的非单词字符。
# 括号 () 用于捕获匹配的子串,并将其包含在分割结果中。7.正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。
re.MatchObject
group() 返回被 RE 匹配的字符串。
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
8.正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。
以下标志可以单独使用,也可以通过按位或(|)组合使用。例如,re.IGNORECASE | re.MULTILINE 表示同时启用忽略大小写和多行模式。
| 修饰符 | 描述 | 实例 |
|---|---|---|
| re.IGNORECASE 或 re.I | 使匹配对大小写不敏感 | import re
pattern = re.compile(r'apple', flags=re.IGNORECASE)
result = pattern.match('Apple')
print(result.group()) # 输出: 'Apple' |
| re.MULTILINE 或 re.M | 多行匹配,影响 ^ 和 $,使它们匹配字符串的每一行的开头和结尾。 | import re pattern = re.compile(r'^\d+', flags=re.MULTILINE) text = '123\n456\n789' result = pattern.findall(text) print(result) # 输出: ['123', '456', '789'] |
| re.DOTALL 或 re.S: | 使 . 匹配包括换行符在内的任意字符。 | import re
pattern = re.compile(r'a.b', flags=re.DOTALL)
result = pattern.match('a\nb')
print(result.group()) # 输出: 'a\nb' |
| re.ASCII | 使 \w, \W, \b, \B, \d, \D, \s, \S 仅匹配 ASCII 字符。 | import re
pattern = re.compile(r'\w+', flags=re.ASCII)
result = pattern.match('Hello123')
print(result.group()) # 输出: 'Hello123' |
| re.VERBOSE 或 re.X | 忽略空格和注释,可以更清晰地组织复杂的正则表达式。 | import re
pattern = re.compile(r'''\d+ # 匹配数字[a-z]+ # 匹配小写字母
''', flags=re.VERBOSE)
result = pattern.match('123abc')
print(result.group()) # 输出: '123abc' |
9.正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式。
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 \\t )匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来匹配所包含的任意一个字符,例如 [amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i(大小写), m(多行), 或 x(忽略空格和注释) 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
10.正则表达式实例
字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
特殊字符类
| 实例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
参考:Python3 正则表达式 | 菜鸟教程![]() https://www.runoob.com/python3/python3-reg-expressions.html
https://www.runoob.com/python3/python3-reg-expressions.html
相关文章:
从零开始学习人工智能(Python高级教程)Day6-Python3 正则表达式
一、Python3 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 在 Python 中,使用 re 模块来处理正则表达式。 re 模块提供了一组函数,允许你在字符串中进行模式匹配、搜索和替换操作。 r…...
Qt开发:项目视图(Item Views)的介绍和使用
文章目录 一、清单视图(List View)1.1 基本概念1.2 使用示例(文字列表)1.3 图标文字(图标模式)1.4 常用设置1.5 完整示例 二、树视图(Tree View)2.1 基本概念2.2 常用类简介2.3 快速…...

“ES7+ React/Redux/React-Native snippets“常用快捷前缀
请注意,这是一个常用的列表,不是扩展提供的所有前缀。最完整和最新的列表请参考扩展的官方文档或在 VS Code 中查看扩展的详情页面。 React (通常用于 .js, .jsx, .ts, .tsx): rfce: React Functional Component with Export Defaultrafce: React Arro…...

keepalived详细笔记
keepalived 是一种基于VRRP(虚拟路由器冗余协议)的高可用解决方案,主要是用于服务器的负载均衡和高可用性的保障,自动将服务切换到备份服务器上,确保业务的连续性。 工作原理: VRRP协议:一组路…...
xLua笔记
Generate Code干了什么 肉眼可见的,在Asset文件夹生成了XLua/Gen文件夹,里面有一些脚本。然后对加了[CSharpCallLua]的变量寻找引用,发现它被XLua/Gen/DelegatesGensBridge引用了。也可以在这里查哪些类型加了[CSharpCallLua]。 public over…...
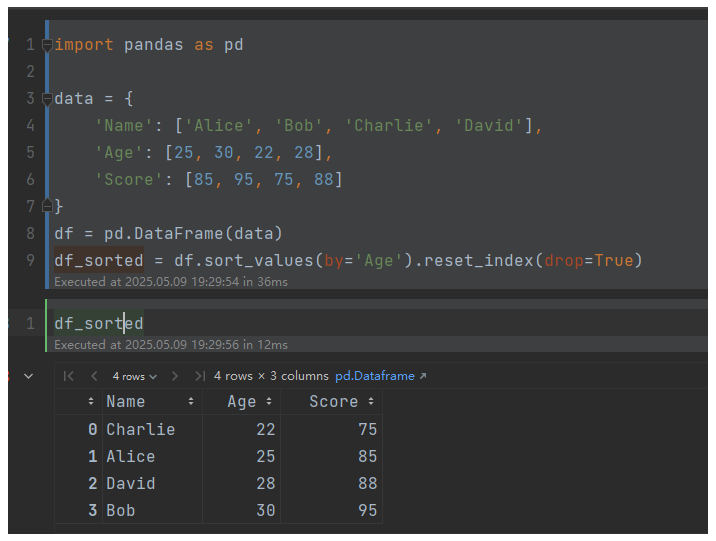
一周学会Pandas2 Python数据处理与分析-Pandas2数据排序操作
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili Pandas 2提供了多种灵活的数据排序方法,主要针对 DataFrame 和 Series 对象。 1. 按值排序:s…...

obj = null; 赋值null之前没有其他引用指向obj对象,那么,当obj=null时,会被垃圾回收机制立即回收吗?
不会立即回收。 具体原因是: 赋值 obj null; 后,对象变成“不可达”,符合垃圾回收条件,但垃圾回收器并不会立刻回收它。垃圾回收是CLR自动控制的非确定性过程,什么时候执行回收取决于系统内存压力、GC策略、分代情况…...

lvm详细笔记
LVM简介 逻辑卷管理器,是Linux 系统中用于管理磁盘储存的关键技术。 LVM 则打破了磁盘分区一旦确定,其大小调整往往较为复杂,且难以灵活应对业务变化这种限制,它允许用户将多个物理分区组合卷组。例如,系统中的多个物…...

250505_HTML
HTML 1. HTML5语法与基础标签1.1 HTML5特性1.1.1 空白折叠现象1.1.2 转义字符 1.2 HTML注释1.3 基础标签1.3.1 div标签1.3.2 标题标签1.3.3 段落标签1.3.4 title1.3.5 meta 1.4 html骨架1.4.1 DTD1.4.2 html标签1.4.3 head与body标签 1.5 div标签详解1.5.1 常见class类名 2. 列…...

【HarmonyOS NEXT+AI】问答05:ArkTS和仓颉编程语言怎么选?
在“HarmonyOS NEXTAI大模型打造智能助手APP(仓颉版)”课程里面,有学员提到了这样一个问题: 鸿蒙的主推开发语言不是ArkTS吗,本课程为什么使用的是仓颉编程语言? 这里就这位同学的问题,统一做下回复,以方便…...

【专家库】Kuntal Chowdhury
昆塔尔乔杜里 Kuntal Chowdhury 是 NVIDIA 的 6G 开发者关系经理和技术布道师。他致力于推动与 NVIDIA 平台和工具的开发者和早期采用者生态系统的联系,以促进 6G 研究社区的蓬勃发展。在此之前,他是 BlueFusion, Inc. 的创始人,这是一家创新…...

【代码优化篇】强缓存和协商缓存
强缓存和协商缓存 一、强缓存与协商缓存的区别二、Vue2 前端实现强缓存(静态资源)三、Spring Boot 后端实现协商缓存(动态接口)四、测试缓存效果五、注意事项 一、强缓存与协商缓存的区别 强缓存:浏览器直接读取本地缓…...
电路中的DGND、GROUND、GROUND_REF的区别,VREF、VCC、VDD、VEE和VSS的区别?
目录 1 DGND、GROUND、GROUND_REF的区别 1.1 DGND(Digital Ground) 1.2 GROUND(Ground) 1.3 GROUND_REF(Ground Reference) 1.4 区别 2 VREF、VCC、VDD、VEE和VSS的区别 2.1 VREF(Refere…...

使用AES-CBC + HMAC-SHA256实现前后端请求安全验证
AES-CBC HMAC-SHA256 加密验证方案,下面是该方案二等 优点 与 缺点 表格,适用于文档、评审或技术选型说明。 ✅ 优点表格:AES-CBC HMAC-SHA256 加密验证方案 类别优点说明🔐 安全性使用 AES-CBC 对称加密使用 AES-128-CBC 是可…...

Excel 数据 可视化 + 自动化!Excel 对比软件
各位Excel小能手们!你们有没有过要对比两个Excel表格数据差异,却看得眼睛都花了的经历?其实啊,现在有专门的Excel文件比较软件能帮咱解决这大难题。这软件就是用来快速找出两个或多个Excel表格数据不同之处,还能把修改…...

开始使用WebStorm
目录 开始使用WebStorm打开、检出或创建项目打开项目从版本控制系统检出项目的步骤创建一个空的WebStorm项目在项目中创建新文件的步骤 熟悉WebStorm用户界面找到你要找的代码查找项目符号的调用按名称查找项目符号搜索文本片段转到符号声明历史记录 补全代码实时检查并修复代码…...
【计算机视觉】Car-Plate-Detection-OpenCV-TesseractOCR:车牌检测与识别
Car-Plate-Detection-OpenCV-TesseractOCR:车牌检测与识别技术深度解析 在计算机视觉领域,车牌检测与识别(License Plate Detection and Recognition, LPDR)是一个极具实用价值的研究方向,广泛应用于智能交通系统、安…...

【MongoDB篇】MongoDB的聚合框架!
目录 引言第一节:什么是聚合框架? 🤔第二节:管道的“发动机”们——常用聚合阶段详解!⚙️第三节:聚合表达式——管道中的“计算器”和“转换器” 🧮✏️第四节:性能优化与考量——让…...

洛谷 P1179【NOIP 2010 普及组】数字统计 —— 逐位计算
题面:P1179 [NOIP 2010 普及组] 数字统计 - 洛谷 一:题目解释: 需要求一区间内数字 2 的出现次数。注意22则记为 2 次,其它没别的... 二:思路、 思想可以考虑动态规划需要计算在每一位上数字 2 的出现次数,然后将这些…...
面试常问系列(一)-神经网络参数初始化-之自注意力机制为什么除以根号d而不是2*根号d或者3*根号d
首先先罗列几个参考文章,大家之后可以去看看,加深理解: 面试常问系列(一)-神经网络参数初始化面试常问系列(一)-神经网络参数初始化之自注意力机制_注意力机制的参数初始化怎么做-CSDN博客面试常问系列(一)-神经网络参数初始化-之-softmax-C…...
C++使用PoDoFo库处理PDF文件
📚 PoDoFo 简介 PoDoFo 是一个用 C 编写的自由开源库,专用于 读取、写入和操作 PDF 文件。它适用于需要程序化处理 PDF 文件的应用程序,比如批量生成、修改、合并、提取元数据、绘图等。 🌟 核心特点 特性说明📄 P…...

【Unity】Unity中修改网格的大小和倾斜网格
一、问题 unity中的网格(Grid)或者地面Plane组件,在使用时,都是正方形的网格,而且建立该网格后,在不改变Scale情况下,没发使其整体变大,而且也没法改变每个网格的大小,而…...

SQL 与 Python:日期维度表创建的不同选择
文章目录 一、日期维度表概述日期维度表结构 二、使用 SQL 创建日期维度表2.1 表结构设计2.2 数据插入2.3 SQL 创建方式的优势与局限 三、使用 Python 创建日期维度表3.1 依赖库引入3.2 代码实现3.3 Python 创建方式的优势与局限 四、应用场景与选择建议4.1 应用场景4.2 选择建…...
Transformer-LSTM混合模型在时序回归中的完整流程研究
Transformer-LSTM混合模型在时序回归中的完整流程研究 引言与背景 深度学习中的长期依赖建模一直是时序预测的核心问题。长短期记忆网络(LSTM)作为一种循环神经网络,因其特殊的门控结构能够有效捕捉序列的历史信息,并在时序预测…...
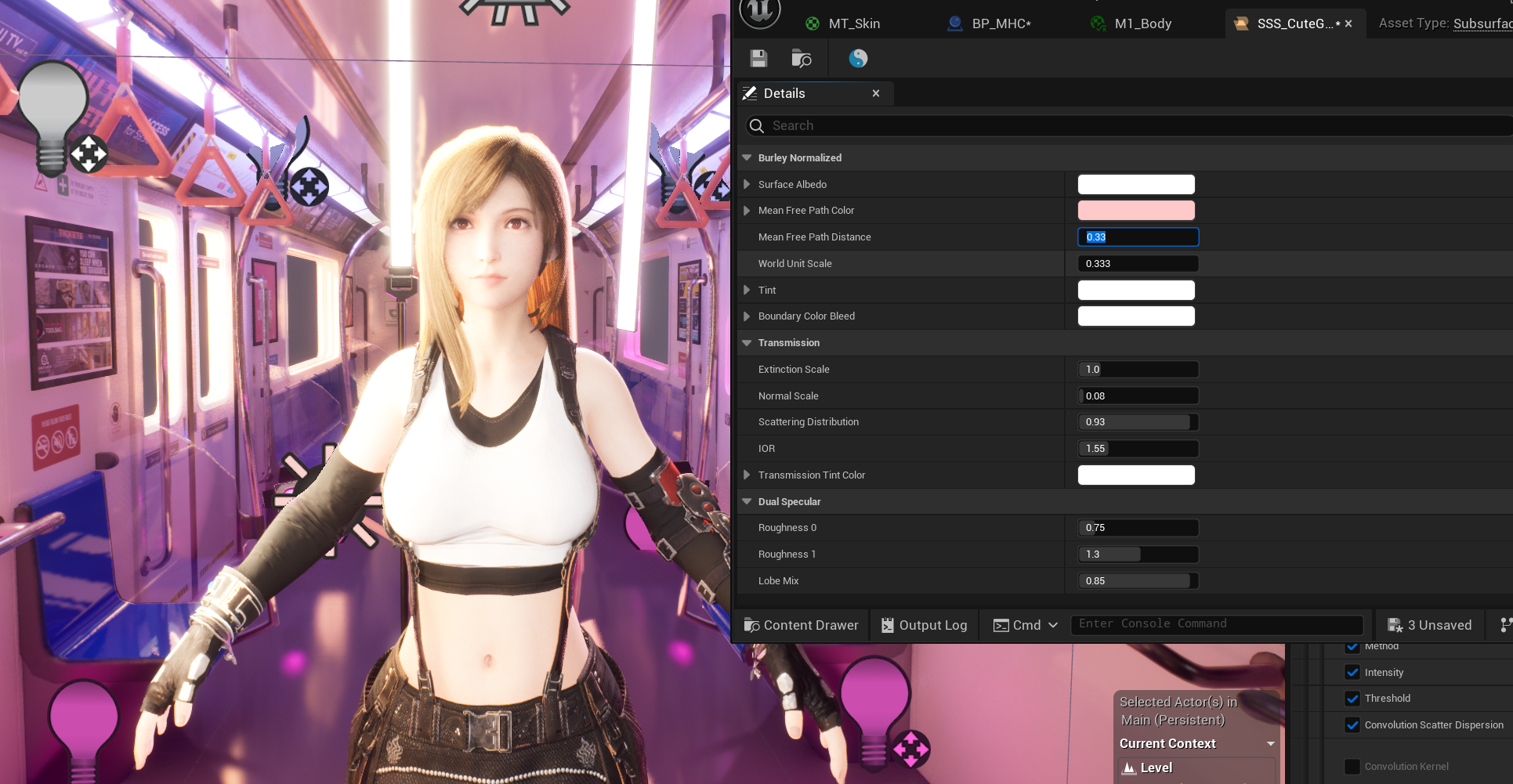
UE5 渲染思路笔记(角色)
参考示例 首先是怎么做到辉光只有部分有而整体没有的 使用的是Bloom内的阈值,控制光的溢光量 Threshold(阈值):这个参数决定了图像中哪些像素会参与泛光计算。只有那些亮度超过阈值的像素才会触发泛光效果。阈值越低,更多的像素会…...

运维打铁:服务器分类及PHP入门
文章目录 C/S架构和B/S架构C/S架构B/S架构 服务器分类服务器类型服务器软件 使用 WampServer 搭建 HTTP服务集成环境的分类WampServer 的安装测试访问配置网站根目录 静态网站和动态网站PHP的常见语法第一段 php 代码注释变量数据类型运算符函数的定义类和对象内容输出循环语句…...

js原型污染 + xss劫持base -- no-code b01lersctf 2025
题目信息:Found this new web framework the other day—you don’t need to write any code, just JSON. 我们先来搞清楚究竟发生了什么 当我们访问 /index /*** 处理 /:page 路径的 GET 请求* param {Object} req - 请求对象* param {Object} reply - 响应对象* returns {Pro…...

力扣92.反转指定范围内的链表、25.k个一组反转链表
92.反转指定范围内的链表 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val val; }* ListNode(int val, ListNode next) { this.val val; this.next next;…...
Python - 爬虫;Scrapy框架(一)
框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。 Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scra…...

The 2024 ICPC Kunming Invitational Contest G. Be Positive
https://codeforces.com/gym/105386/problem/G 题目: 结论: 从0开始每四个相邻数的异或值为0 代码: #include<bits/stdc.h> using namespace std; #define int long long void solve() {int n;cin >> n;if(n1||n%40){cout &…...