【MongoDB篇】MongoDB的聚合框架!

目录
- 引言
- 第一节:什么是聚合框架? 🤔
- 第二节:管道的“发动机”们——常用聚合阶段详解!⚙️
- 第三节:聚合表达式——管道中的“计算器”和“转换器” 🧮✏️
- 第四节:性能优化与考量——让聚合管道跑得更快!🏃♀️💨
- 第五节:总结聚合操作!🎉📊
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
看之前可以先了解一下MongoDB是什么:【MongoDB篇】万字带你初识MongoDB!
引言
各位大佬们,好久不见!✨🧙♀️
通过之前的文章我们已经掌握了对单个文档的 CRUD 操作,这就像是你会使用基础的工具来处理一份文件。但是,如果你想对大量文档进行复杂的处理,比如统计某个年龄段的用户数量、计算商品的平均价格、找出每个城市有多少男性用户等等,简单的 find() 查询就显得力不从心了!
这时候,就轮到 MongoDB 的“瑞士军刀”——聚合框架 (Aggregation Framework) 出场了!它就像一个数据处理的工厂流水线,可以对你的数据进行一系列复杂的转换、筛选、分组和计算,最终得出你想要的“成品”!🏭➡️📦📊
第一节:什么是聚合框架? 🤔
聚合框架是 MongoDB 提供的一个强大的、灵活的数据处理工具。它基于数据处理管道 (Data Processing Pipeline) 的概念。
你可以把聚合管道想象成一个由多个阶段 (Stage) 串联组成的流水线。集合中的文档作为“原料”,从管道的入口进入,经过第一个阶段的处理,输出的结果再作为第二个阶段的输入,依此类推,直到通过最后一个阶段,最终得到处理后的结果!
管道阶段 (Pipeline Stage) 是聚合框架的核心。每个阶段都执行特定的数据处理任务,比如:
- 筛选文档 (过滤掉不符合条件的) 🔍
- 重塑文档结构 (添加/删除/重命名字段,计算新字段) 🔨
- 对文档进行分组 (按某个字段分组) 🧑🤝🧑
- 对分组进行计算 (求和、平均值、计数等) 📊
- 对结果进行排序、限制数量 ⬆️⬇️✂️
- 展开数组 💥
- 关联其他集合 (类似 JOIN) 🤝
通过将这些阶段按照特定的顺序组合起来,你可以实现各种复杂的数据处理和分析任务!👍
核心方法:aggregate()
使用聚合框架,主要通过 db.collection.aggregate([pipeline], options) 方法。
[pipeline]: 一个数组,数组中的每个元素就是一个管道阶段。阶段按照数组的顺序依次执行。这是聚合管道的“蓝图”! blueprintsoptions: 可选参数,用于配置聚合的行为,比如:allowDiskUse: <boolean>:如果设置为true,当聚合操作内存不足时,允许将数据临时写入磁盘。处理大量数据时非常有用,但可能降低性能。默认通常为false。💾cursor: <document>:指定返回结果游标的初始配置。readConcern: <string>:指定读取数据的隔离级别。writeConcern: <document>:如果聚合管道的最后一个阶段是$out或$merge,可以指定写入安全级别。
use mydatabase;// 一个简单的聚合管道示例:计算所有用户的平均年龄
db.users.aggregate([{$group: { // 第一个阶段: 分组_id: null, // 按 null 分组,表示对所有文档进行一次分组avgAge: { $avg: "$age" } // 计算 age 字段的平均值}}
]);
上面的例子虽然简单,但它展示了聚合管道的基本结构:一个包含阶段的数组。
第二节:管道的“发动机”们——常用聚合阶段详解!⚙️
理解并熟练使用各种管道阶段,是掌握聚合框架的关键!哥来详细讲解一些最常用、最重要的阶段!
假设我们有一个 orders 集合,文档结构大致如下:
{"_id": ObjectId(...),"order_id": "A123","customer_id": "C001","order_date": ISODate("2023-01-15T10:00:00Z"),"items": [{ "product_id": "P001", "name": "Laptop", "price": 800, "quantity": 1 },{ "product_id": "P002", "name": "Mouse", "price": 20, "quantity": 2 }],"total_amount": 840,"status": "completed"
}
以及一个 products 集合:
{"_id": ObjectId(...),"product_id": "P001","name": "Laptop","category": "Electronics","price": 800
}
我们将使用这些集合来举例说明不同阶段的功能。
-
$match- 筛选文档 (过滤) 🔍📄作用:根据指定的条件过滤输入文档,只将符合条件的文档传递给管道的下一个阶段。
位置:通常放在管道的开头,因为它可以减少后续阶段需要处理的文档数量,大大提高效率!利用索引!🚀
语法:{ $match: { <query document> } },query document的语法跟find()方法的查询条件一样!// 找出所有状态为 "completed" 的订单 db.orders.aggregate([{ $match: { status: "completed" } } ]);// 找出所有总金额大于 1000 的订单 db.orders.aggregate([{ $match: { total_amount: { $gt: 1000 } } } ]);// 组合条件:找出状态为 "completed" 且总金额大于 500 的订单 db.orders.aggregate([{ $match: { status: "completed", total_amount: { $gt: 500 } } } ]); -
$project- 重塑文档 (选择、计算字段) 🔨📄➡️📄作用:重塑每个文档的结构,可以包含、排除、重命名字段,添加新字段(基于现有字段进行计算),或创建嵌套文档。
语法:{ $project: { <specification document> } },规范文档使用1或0控制字段包含/排除,或者使用表达式定义新字段。// 只保留 order_id 和 total_amount 字段 (并排除 _id,因为 _id 默认包含) db.orders.aggregate([{$project: {_id: 0, // 排除 _id 字段orderId: "$order_id", // 重命名 order_id 为 orderIdamount: "$total_amount"}} ]);// 添加一个新字段:订单年限 db.orders.aggregate([{$project: {order_id: 1,orderYear: { $year: "$order_date" } // 使用日期表达式 $year 提取年份}} ]);// 计算每个订单的商品总数量 db.orders.aggregate([{$project: {order_id: 1,totalItems: { $sum: "$items.quantity" } // 使用数组表达式 $sum 计算 items 数组中所有 quantity 的总和}} ]);$project是进行数据转换和结构调整的神器!你可以使用各种聚合表达式在$project中进行计算和操作。 -
$group- 分组与聚合计算 🧑🤝🧑📊作用:根据指定的分组键 (
_id) 对文档进行分组,然后对每个分组应用一个或多个累加器表达式 (Accumulator Expressions) 来计算聚合值。
语法:{ $group: { _id: <expression>, <field1>: { <accumulator1> }, ... } }_id: 分组键。可以是一个字段名 ("$field"), 多个字段的组合文档 ({ field1: "$field1", ... }), 或 null (对所有文档进行一次分组)。<field>: { <accumulator> }:定义分组后新增的字段及其计算方式。<accumulator>是累加器表达式。
常用累加器表达式:
$sum: 计算总和。可以是数值字段,或1来计数。$avg: 计算平均值。$min: 找到最小值。$max: 找到最大值。$count: 计数分组中的文档数量 (MongoDB 3.4+)。$first: 获取分组中的第一个文档的某个字段值 (取决于分组前的顺序)。$last: 获取分组中的最后一个文档的某个字段值 (取决于分组前的顺序)。$push: 将分组中文档的某个字段值添加到结果文档的一个数组中。$addToSet: 将分组中文档的某个字段值添加到结果文档的一个数组中,并确保唯一性。
// 统计每个客户的订单数量 db.orders.aggregate([{$group: {_id: "$customer_id", // 按 customer_id 分组orderCount: { $sum: 1 } // 每个文档加 1,然后求和,就是订单数量}} ]);// 统计每个客户的总消费金额 db.orders.aggregate([{$group: {_id: "$customer_id",totalSpend: { $sum: "$total_amount" } // 对每个分组的 total_amount 求和}} ]);// 统计不同状态的订单数量和总金额 db.orders.aggregate([{$group: {_id: "$status", // 按 status 分组count: { $sum: 1 },total: { $sum: "$total_amount" }}} ]);// 统计每个订单的商品名称列表 (使用 $push) // 注意:这里需要先展开 items 数组才能访问每个 item 的 name db.orders.aggregate([{ $unwind: "$items" }, // 先展开 items 数组{$group: {_id: "$order_id", // 按 order_id 分组productNames: { $push: "$items.name" } // 将每个 item 的 name 收集到一个数组中}} ]);$group是聚合框架中最常用的阶段之一,用于实现各种统计和分组分析! -
$sort- 排序 ⬆️⬇️作用:对管道中的文档进行排序,就像
find().sort()一样。
位置:放在$group之后通常用于对分组结果排序。放在$limit或$skip之前通常用于配合分页。
语法:{ $sort: { <field1>: 1/-1, ... } }// 找出订单金额最高的 5 个客户 (先按总金额降序,然后限制 5 个) db.orders.aggregate([{$group: {_id: "$customer_id",totalSpend: { $sum: "$total_amount" }}},{ $sort: { totalSpend: -1 } }, // 按总金额降序排序{ $limit: 5 } // 限制前 5 个 ]); -
$limit- 限制数量 ✂️作用:限制通过管道的文档数量。
位置:通常放在$sort之后用于分页或获取 Top N。
语法:{ $limit: <number> }// 获取最近的 10 个订单 (假设文档按插入顺序排列或者前面有 $sort) db.orders.aggregate([{ $sort: { order_date: -1 } }, // 按日期降序{ $limit: 10 } // 限制前 10 个 ]); -
$skip- 跳过 🏃♂️作用:跳过指定数量的文档。
位置:通常与$sort和$limit结合用于分页。
语法:{ $skip: <number> }// 分页:获取订单的第二页,每页 10 条 (假设已排序) db.orders.aggregate([{ $sort: { order_date: -1 } },{ $skip: 10 }, // 跳过第一页 (10 条){ $limit: 10 } // 获取第二页 (10 条) ]); -
$unwind- 展开数组 💥作用:将输入文档中的一个数组字段“展开”。对于输入文档中的数组字段,
$unwind阶段会为数组中的每个元素输出一个新文档。新文档与原文档相同,只是数组字段的值被替换为数组中的一个元素。
用处:当你需要对数组中的每个元素独立进行处理或分析时,$unwind是 필수 (必须的)!
语法:{ $unwind: "$<array field name>" }// 展开 orders 集合的 items 数组 db.orders.aggregate([{ $unwind: "$items" } // 将每个 order 的 items 数组展开// 展开后,一个有 2 个 items 的订单会变成 2 个文档,每个文档的 items 字段分别是数组中的一个元素 ]);// 展开 items 数组后,计算每种产品的总销售数量 db.orders.aggregate([{ $unwind: "$items" }, // 展开 items 数组{$group: { // 按 products_id 分组_id: "$items.product_id",totalSold: { $sum: "$items.quantity" } // 计算每个产品的总销售数量}} ]);$unwind是处理包含数组字段的文档的利器! -
$lookup- 关联查询 (Left Outer Join) 🤝作用:对集合执行左外连接 (Left Outer Join)。它允许你将来自另一个集合的文档合并到当前管道中的文档中,实现类似关系型数据库 JOIN 的功能!
语法:{$lookup: {from: "<collection to join>", // 要连接的另一个集合localField: "<field from input documents>", // 当前集合中用于连接的字段foreignField: "<field from the documents of the 'from' collection>", // 'from' 集合中用于连接的字段as: "<output array field name>" // 输出的新数组字段名,匹配到的文档会放入这个数组} }// 将订单文档与产品文档进行关联,获取每个订单中产品的详细信息 db.orders.aggregate([{ $unwind: "$items" }, // 先展开 items 数组,以便按 product_id 关联{$lookup: {from: "products", // 连接 products 集合localField: "items.product_id", // orders (当前) 集合中用于连接的字段foreignField: "product_id", // products (from) 集合中用于连接的字段as: "productInfo" // 将匹配到的产品信息放入 productInfo 数组}},// $lookup 返回的是一个数组,通常需要 $unwind 展开,如果确定只有一个匹配项的话{ $unwind: "$productInfo" },{$project: { // 重塑输出文档结构_id: 0,order_id: 1,item_name: "$items.name",item_quantity: "$items.quantity",product_category: "$productInfo.category", // 从关联到的 productInfo 中获取 categoryproduct_price: "$productInfo.price" // 从关联到的 productInfo 中获取 price}} ]);$lookup是实现集合之间关联查询的关键阶段! -
$out- 输出到新集合 📤📁作用:将聚合管道的最终结果写入一个新的集合。如果目标集合已存在,会覆盖整个集合!谨慎使用! 💣
位置:必须是管道的最后一个阶段。
语法:{ $out: "<output collection name>" }// 将每个客户的总消费金额计算出来,并写入一个新集合 customer_total_spend db.orders.aggregate([{$group: {_id: "$customer_id",totalSpend: { $sum: "$total_amount" }}},{ $out: "customer_total_spend" } // 将结果输出到 customer_total_spend 集合 ]);$out适合用于创建“物化视图”,比如定期生成报表数据供查询使用。 -
$merge- 合并到现有集合 ➡️📁作用:将聚合管道的最终结果合并到现有的集合。比
$out更灵活,可以指定如何处理匹配到的文档。
位置:必须是管道的最后一个阶段。
语法:{$merge: {into: "<collection to merge into>", // 要合并到的目标集合on: "<field(s)>", // 用于匹配文档的字段或字段数组whenMatched: "<action>", // 当找到匹配文档时采取的行动 ('replace', 'merge', 'fail', 'pipeline')whenNotMatched: "<action>" // 当没有找到匹配文档时采取的行动 ('insert', 'discard', 'fail')} }// 将计算出的客户总消费金额合并到现有的 customers 集合中 db.orders.aggregate([{$group: {_id: "$customer_id",totalSpend: { $sum: "$total_amount" }}},{$merge: {into: "customers", // 合并到 customers 集合on: "_id", // 以 _id 字段进行匹配 (假设 customers 的 _id 是 customer_id)whenMatched: "merge", // 找到匹配项时,合并字段whenNotMatched: "insert" // 没有找到匹配项时,插入新文档}} ]);$merge在需要更新或同步数据时非常有用!
第三节:聚合表达式——管道中的“计算器”和“转换器” 🧮✏️
很多聚合阶段(比如 $project, $group, $match 的 $expr)都需要使用聚合表达式 (Aggregation Expressions) 来进行计算、转换或引用字段值。表达式非常强大,支持各种运算符和函数。
- 引用字段:使用
"$fieldName"语法来引用当前文档中的字段值。 - 字面量:直接使用数值、字符串、布尔值、日期等常量。
- 系统变量:使用
"$开头的系统变量,比如$$ROOT(当前文档的根),$$CURRENT(当前处理的字段值)。
常见的表达式类别:
- 算术表达式:
$add,$subtract,$multiply,$divide,$mod等。 - 字符串表达式:
$concat,$substr,$toUpper,$toLower,$split等。 - 日期表达式:
$year,$month,$dayOfMonth,$hour,$minute,$second,$dayOfWeek,$dateToString等。 - 逻辑表达式:
$and,$or,$not,$eq,$ne,$gt,$lt,$cond(条件判断) 等。 - 数组表达式:
$size(数组长度),$arrayElemAt(获取数组元素),$filter(过滤数组元素),$map(转换数组元素) 等。 - 集合表达式:
$setEquals,$setIntersection,$setUnion,$setDifference,$setIsSubset等 (用于比较数组集合)。 - 条件表达式:
$cond(if-then-else),$ifNull(如果为 null 则使用默认值),$switch(多条件分支)。
表达式示例:
db.orders.aggregate([{$project: {_id: 0,order_id: 1,// 计算折扣价格 (假设 total_amount 是原价)discountedPrice: { $multiply: ["$total_amount", 0.9] },// 判断订单是否是今年创建的isThisYear: { $eq: [{ $year: "$order_date" }, { $year: new Date() }] },// 使用 $cond 根据状态显示不同消息message: {$cond: {if: { $eq: ["$status", "completed"] },then: "订单已完成",else: "订单处理中"}},// 将 items 数组的每个元素的 quantity 乘以 10updatedItems: {$map: {input: "$items",as: "item",in: {product_id: "$$item.product_id",name: "$$item.name",price: "$$item.price",quantity: { $multiply: ["$$item.quantity", 10] }}}}}}
]);
聚合表达式非常丰富,掌握它们能够让你在聚合管道中进行各种复杂的数据计算和转换!去查阅官方文档,探索更多强大的表达式吧!💪
第四节:性能优化与考量——让聚合管道跑得更快!🏃♀️💨
聚合框架功能强大,但也可能非常消耗资源。优化聚合管道的性能至关重要!
$match阶段前移:将$match阶段放在管道的越前面越好!这样可以尽早减少进入后续阶段的文档数量,显著提高效率。- 利用索引:聚合管道最开始的
$match阶段和紧随其后的$sort阶段可以利用索引来提高性能。确保你为这些阶段使用的字段创建了合适的索引。但是,管道后面的阶段通常无法利用索引,它们操作的是内存中的文档。 $project只保留必要的字段:在$project阶段,只包含你后续需要的字段。减少文档的体积可以提高管道的处理速度,特别是当数据需要溢出到磁盘时。- 避免在
$sort之前使用会改变文档结构或数量的阶段:比如在$sort之前使用$project重命名了排序字段,或者使用了$unwind改变了文档数量,都会影响$sort阶段能否利用索引。 - 内存限制:如前所述,聚合阶段有内存限制。对于大型聚合,使用
allowDiskUse: true选项,但要意识到这会影响性能。优化管道以减少内存使用是更好的方法。 - 使用
.explain()分析聚合管道:这是分析聚合性能的最重要工具!在你的aggregate()调用后面加上.explain(),查看每个阶段的执行情况、是否使用了索引、处理了多少文档等等。通过分析执行计划,找出性能瓶颈并进行优化!📊🔬 - 考虑创建物化视图:对于需要频繁查询的复杂聚合结果,可以考虑使用
$out或$merge将结果写入一个单独的集合(物化视图),然后直接查询这个物化视图,而不是每次都重新执行复杂的聚合管道。
第五节:总结聚合操作!🎉📊
太棒了!我们一起探索了 MongoDB 强大的聚合框架!我们了解了它作为数据处理流水线的概念,学习了 aggregate() 方法以及 $match, $project, $group, $sort, $limit, $skip, $unwind, $lookup, $out, $merge 等核心管道阶段的功能和用法!我们也了解了聚合表达式以及如何进行聚合性能优化。
核心要点回顾:
- 聚合框架是用于复杂数据处理和分析的管道。
- 管道由多个阶段组成,按顺序处理文档。
aggregate()方法用于执行聚合管道。- 常用阶段包括筛选 (
$match), 重塑 ($project), 分组 ($group), 排序 ($sort), 限制 ($limit), 跳过 ($skip), 展开数组 ($unwind), 关联 ($lookup), 输出 ($out), 合并 ($merge)。 - 聚合表达式用于阶段内的计算和转换。
- 性能优化关注阶段顺序、索引利用、内存使用、使用
.explain()。
聚合框架是 MongoDB 的一大亮点,也是进行数据分析和报表生成不可或缺的工具!掌握了聚合框架,你的数据处理能力将达到一个新的高度!💪
继续加油!用聚合框架玩转你的数据吧!🚀
了解数据库操作请看:【MongoDB篇】MongoDB的数据库操作!
了解集合操作请看:【MongoDB篇】MongoDB的集合操作!
了解文档操作请看:【MongoDB篇】MongoDB的文档操作!
了解索引操作请看:【MongoDB篇】MongoDB的索引操作!
相关文章:
【MongoDB篇】MongoDB的聚合框架!
目录 引言第一节:什么是聚合框架? 🤔第二节:管道的“发动机”们——常用聚合阶段详解!⚙️第三节:聚合表达式——管道中的“计算器”和“转换器” 🧮✏️第四节:性能优化与考量——让…...

洛谷 P1179【NOIP 2010 普及组】数字统计 —— 逐位计算
题面:P1179 [NOIP 2010 普及组] 数字统计 - 洛谷 一:题目解释: 需要求一区间内数字 2 的出现次数。注意22则记为 2 次,其它没别的... 二:思路、 思想可以考虑动态规划需要计算在每一位上数字 2 的出现次数,然后将这些…...
面试常问系列(一)-神经网络参数初始化-之自注意力机制为什么除以根号d而不是2*根号d或者3*根号d
首先先罗列几个参考文章,大家之后可以去看看,加深理解: 面试常问系列(一)-神经网络参数初始化面试常问系列(一)-神经网络参数初始化之自注意力机制_注意力机制的参数初始化怎么做-CSDN博客面试常问系列(一)-神经网络参数初始化-之-softmax-C…...
C++使用PoDoFo库处理PDF文件
📚 PoDoFo 简介 PoDoFo 是一个用 C 编写的自由开源库,专用于 读取、写入和操作 PDF 文件。它适用于需要程序化处理 PDF 文件的应用程序,比如批量生成、修改、合并、提取元数据、绘图等。 🌟 核心特点 特性说明📄 P…...

【Unity】Unity中修改网格的大小和倾斜网格
一、问题 unity中的网格(Grid)或者地面Plane组件,在使用时,都是正方形的网格,而且建立该网格后,在不改变Scale情况下,没发使其整体变大,而且也没法改变每个网格的大小,而…...

SQL 与 Python:日期维度表创建的不同选择
文章目录 一、日期维度表概述日期维度表结构 二、使用 SQL 创建日期维度表2.1 表结构设计2.2 数据插入2.3 SQL 创建方式的优势与局限 三、使用 Python 创建日期维度表3.1 依赖库引入3.2 代码实现3.3 Python 创建方式的优势与局限 四、应用场景与选择建议4.1 应用场景4.2 选择建…...
Transformer-LSTM混合模型在时序回归中的完整流程研究
Transformer-LSTM混合模型在时序回归中的完整流程研究 引言与背景 深度学习中的长期依赖建模一直是时序预测的核心问题。长短期记忆网络(LSTM)作为一种循环神经网络,因其特殊的门控结构能够有效捕捉序列的历史信息,并在时序预测…...
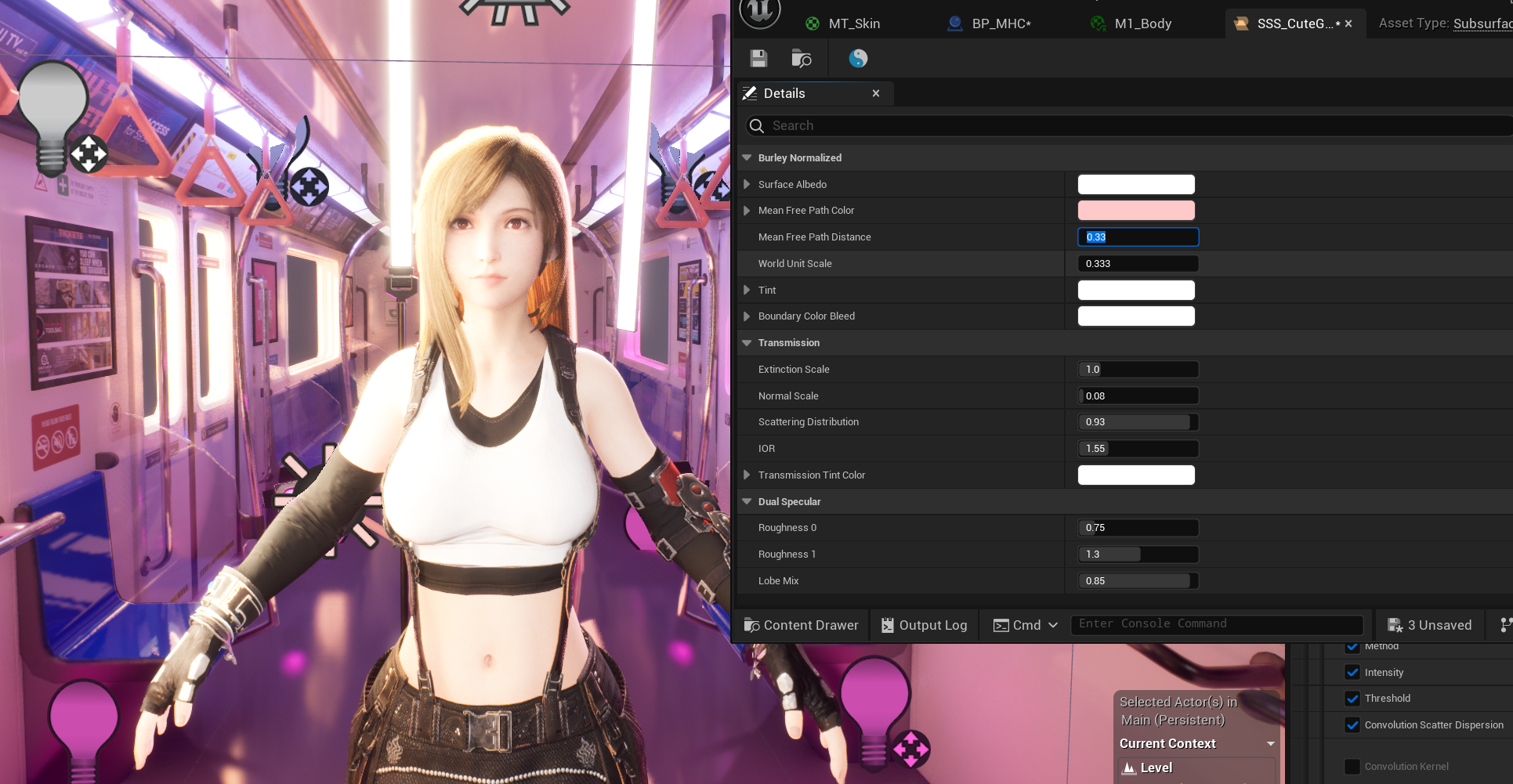
UE5 渲染思路笔记(角色)
参考示例 首先是怎么做到辉光只有部分有而整体没有的 使用的是Bloom内的阈值,控制光的溢光量 Threshold(阈值):这个参数决定了图像中哪些像素会参与泛光计算。只有那些亮度超过阈值的像素才会触发泛光效果。阈值越低,更多的像素会…...

运维打铁:服务器分类及PHP入门
文章目录 C/S架构和B/S架构C/S架构B/S架构 服务器分类服务器类型服务器软件 使用 WampServer 搭建 HTTP服务集成环境的分类WampServer 的安装测试访问配置网站根目录 静态网站和动态网站PHP的常见语法第一段 php 代码注释变量数据类型运算符函数的定义类和对象内容输出循环语句…...

js原型污染 + xss劫持base -- no-code b01lersctf 2025
题目信息:Found this new web framework the other day—you don’t need to write any code, just JSON. 我们先来搞清楚究竟发生了什么 当我们访问 /index /*** 处理 /:page 路径的 GET 请求* param {Object} req - 请求对象* param {Object} reply - 响应对象* returns {Pro…...

力扣92.反转指定范围内的链表、25.k个一组反转链表
92.反转指定范围内的链表 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val val; }* ListNode(int val, ListNode next) { this.val val; this.next next;…...
Python - 爬虫;Scrapy框架(一)
框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。 Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scra…...

The 2024 ICPC Kunming Invitational Contest G. Be Positive
https://codeforces.com/gym/105386/problem/G 题目: 结论: 从0开始每四个相邻数的异或值为0 代码: #include<bits/stdc.h> using namespace std; #define int long long void solve() {int n;cin >> n;if(n1||n%40){cout &…...

GET请求如何传复杂数组参数
背景 有个历史项目,是GET请求,但是很多请求还是复杂参数,比如:参数是数组,且数组中每一个元素都是复杂的对象,这个时候怎么传参数呢? 看之前请求直接是拼接在url后面 类似&items%5B0%5D.…...
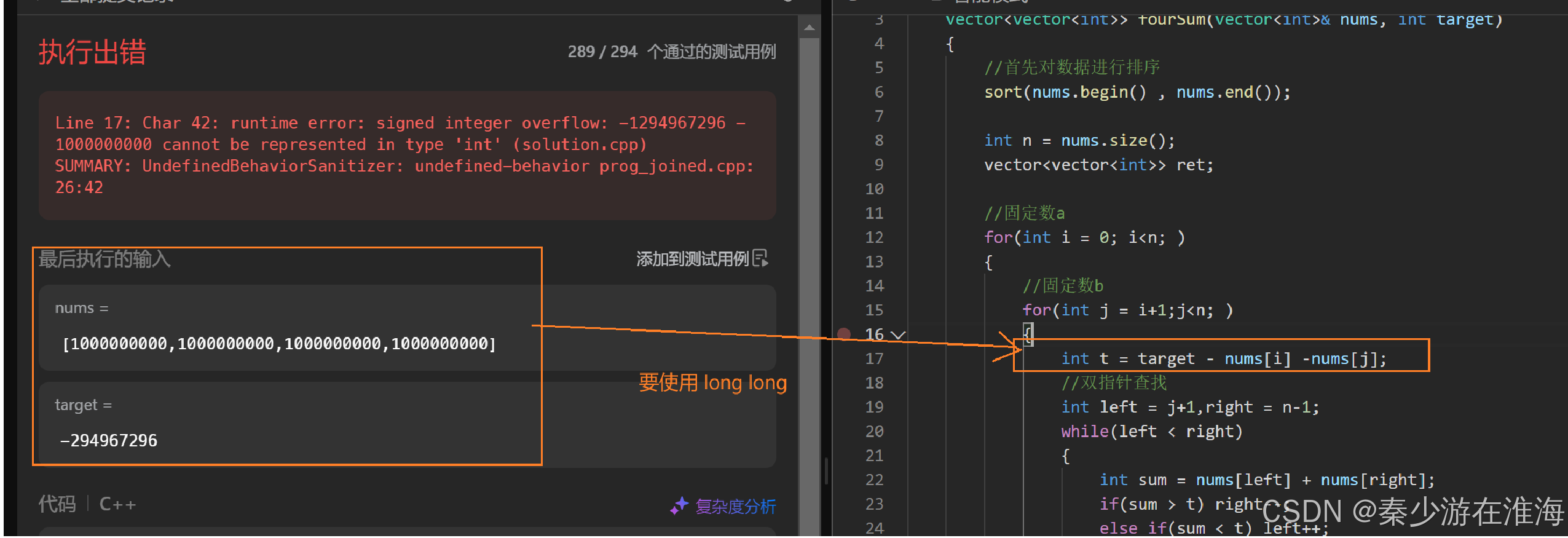
leetcode - 双指针问题
文章目录 前言 题1 移动零: 思路: 参考代码: 题2 复写零: 思考: 参考代码: 题3 快乐数: 思考: 参考代码: 题4 盛最多水的容器: 思考:…...

人工智能之数学基础:二次型
本文重点 二次型作为线性代数领域的重要概念,架起了代数方程与几何分析之间的桥梁。从古典解析几何中的圆锥曲线方程到现代优化理论中的目标函数,二次型以其简洁的数学表达和丰富的结构特性,在数学物理、工程技术和经济金融等领域发挥着不可替代的作用。 二次型的基本概念…...

存储过程补充——流程控制语句详解
文章目录 1. 条件判断语句1.1 分支结构之 IF1.2 分支结构之 CASE 2. 循环语句2.1 循环结构之LOOP2.2 循环结构之WHILE2.3 循环结构之REPEAT 3. 跳转语句3.6 跳转语句之LEAVE语句3.7 跳转语句之ITERATE语句 在数据库管理系统中,存储过程是一种强大的工具,…...
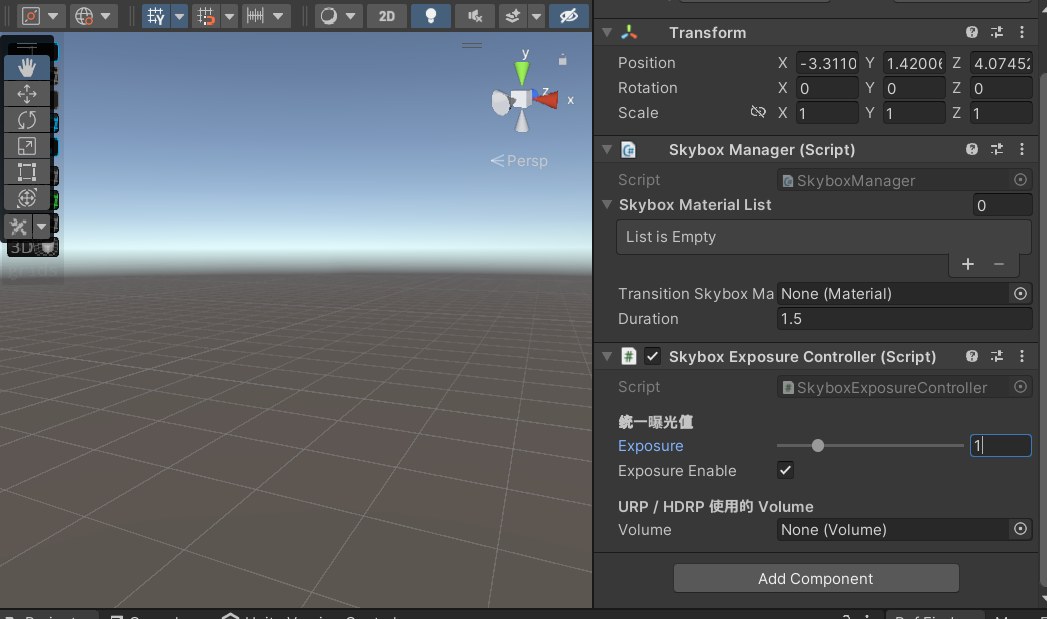
【Unity笔记】实现支持不同渲染管线的天空盒曝光度控制组件(SkyboxExposureController)——参数化控制
写在前面 在Unity中,天空盒(Skybox)不仅承担视觉上的背景作用,更是场景环境光照与氛围塑造的重要组成部分。不同时间、天气、场景转换等,都需要灵活调整天空的亮度。而**曝光度(Exposure)**就是…...
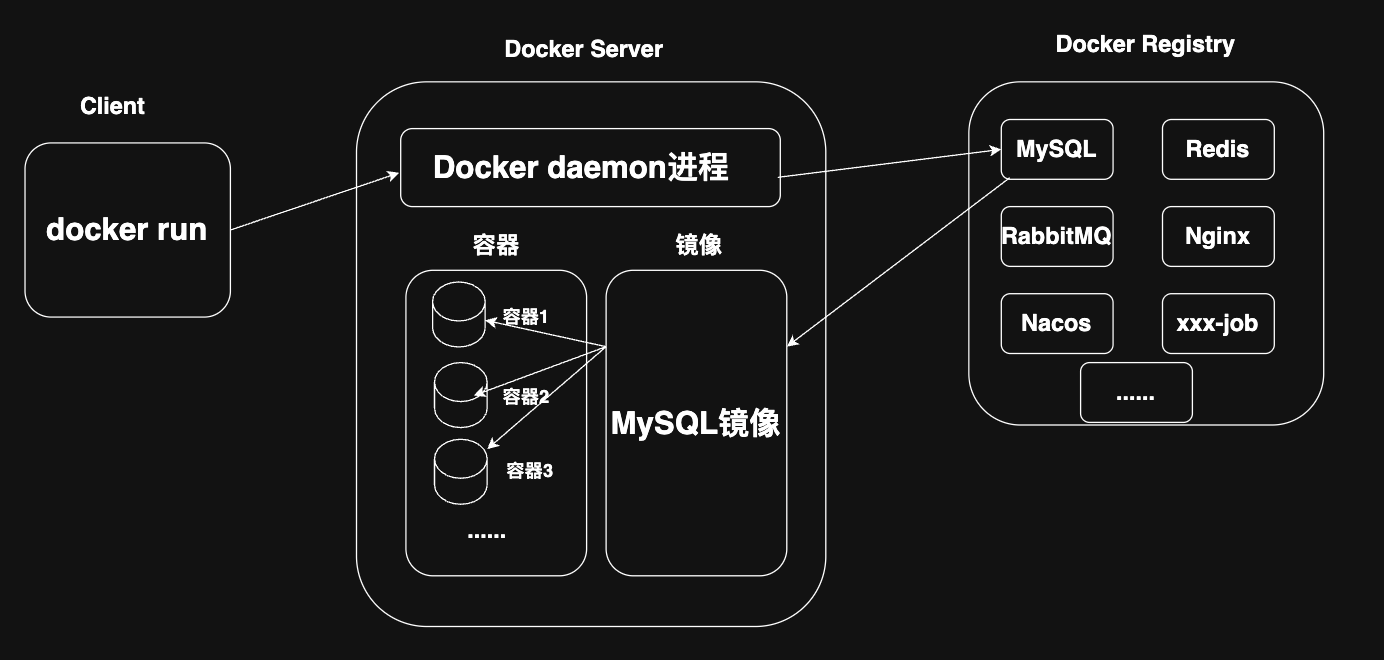
Docker 使用与部署(超详细)
目录 引入 入门使用 部署对比 镜像仓库 命令解释 基础 常见命令 示例 数据卷的使用 数据卷的概念 数据卷的使用 挂载本地目录文件 镜像 结构 Dockerfile 容器网络 部署 DockerCompose 语法 编辑 基础命令 引入 当我们在 Linux 上部署一个集成了很多中间件…...

CSS实现图片垂直居中方法
html <div class"footer border-top-row"><div class"footer-row"><span class"footer-row-col01">制单人:{{ printData[pageIndex - 1].rkMaster.makerName}}<img :src"getPersonSignImgSrc(printData[pa…...

C#实现Socket通信:基于TCP/IP协议的网络编程
TCP/IP网络模型 最上层的是应用层,也就是我们日常可以接触到的,它会给数据添加对应的头部,并传输给传输层,应用层是我们日常会接触到的,比如HTTP,FTP,Telnet,DNS,SMTP。…...

基于C++的IOT网关和平台7:github项目ctGateway设备协议开发指南
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。 源码指引:github源码指引_初级代码游戏的博客-CSDN博客 系…...

大数据实时数仓的数据质量监控解决方案
实时数仓不仅仅是传统数据仓库的升级版,它更强调数据的实时性、流动性和高可用性,通过对海量数据的即时处理和分析,为企业提供近乎实时的洞察力。这种能力在金融、零售、制造、互联网等行业中尤为关键,例如,电商平台可以通过实时数仓监控用户行为,动态调整推荐算法;金融…...

Python+Scrapy跨境电商爬虫实战:从亚马逊/沃尔玛数据采集到反爬攻克(附Pangolin API高效方案)
从零实战到反爬攻克,揭秘跨境数据抓取全流程与Pangolin Scrape API终极方案 在当今数据驱动的跨境电商时代,谁掌握了优质的市场数据,谁就掌握了成功的关键。随着全球电商市场规模持续扩大(据Statista最新报告显示,2025…...

简单快速的浮点数转字符串算法,适合单片机环境
目的是在OLED 屏幕上显示浮点数,有几个设计要求: 我已经有一个现成的能显示整数的函数,希望尽量复用;尽量不使用除法;不需要考虑小数四舍五入的问题; 我觉得小数四舍五入其实很多时候没什么用处ÿ…...

c++中构造对象实例的两种方式及其返回值
c中,构造对象实例有两种方式,一种返回对象实例,一种返回该对象实例的指针。如下所示: 一、两种返回值 RedisConn conn1; //得到实例conn1;RedisConn *conn2 new RedisConn();//得到指针conn2;RedisConn conn3 new RedisConn()…...

Python实例题:Python操作excel自动化开发
目录 Python实例题 题目 安装依赖库 示例代码 代码解释 写入 Excel 文件: 读取 Excel 文件: 修改 Excel 文件: 运行思路 注意事项 Python实例题 题目 Python操作excel自动化开发 安装依赖库 pip install openpyxl示例代码 imp…...

【日撸 Java 三百行】Day 7(Java的数组与矩阵元素相加)
目录 Day 7:Java 的数组与矩阵元素相加 一、基本知识 二、矩阵的建立与基本计算 三、代码及测试 拓展:Arrays类详解 小结 Day 7:Java 的数组与矩阵元素相加 Task: 矩阵的赋值.二重循环. 一、基本知识 在学习 Java 中的数组与矩…...

【Python】常用命令提示符
Python常用的命令提示符 一、Python环境基础命令【Windows】 于Windows环境下,针对Python,在CMD(命令提示符)常用的命令以及具体用法,怎么用; 主要包含:运行脚本、包管理、虚拟环境、调试与…...
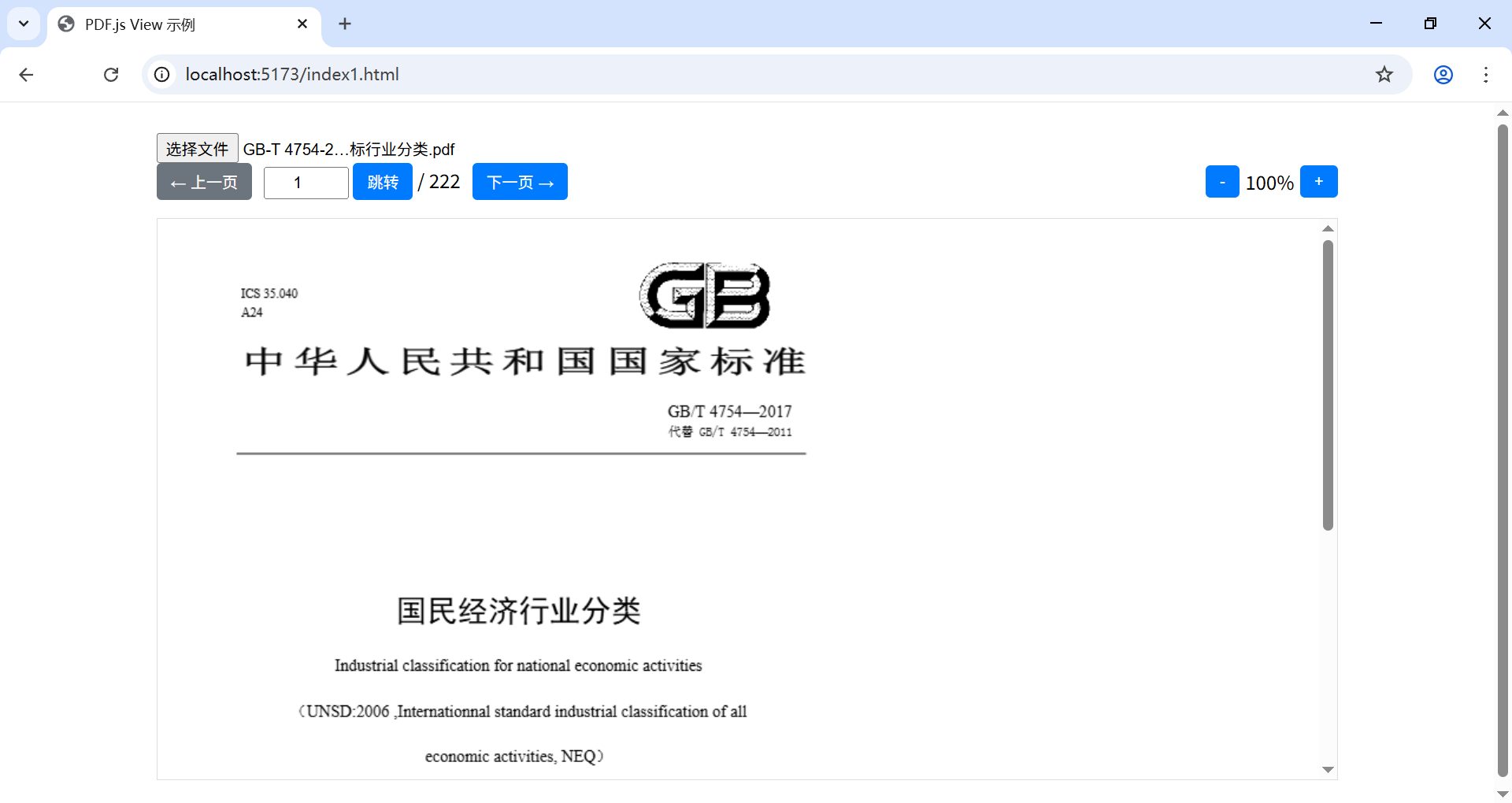
vite:npm 安装 pdfjs-dist , PDF.js View 预览功能示例
pdfjs-dist 是 Mozilla 的 PDF.js 库的预构建版本,能让你在项目里展示 PDF 文件。下面为你介绍如何用 npm 安装 pdfjs-dist 并应用 pdf.js 和 pdf.worker.js。 为了方便,我将使用 vite 搭建一个原生 js 项目。 1.创建项目 npm create vitelatest pdf-v…...