Transformer-LSTM混合模型在时序回归中的完整流程研究
Transformer-LSTM混合模型在时序回归中的完整流程研究
引言与背景
深度学习中的长期依赖建模一直是时序预测的核心问题。长短期记忆网络(LSTM)作为一种循环神经网络,因其特殊的门控结构能够有效捕捉序列的历史信息,并在时序预测中表现出色;然而LSTM的序列计算方式限制了其并行处理能力和对全局上下文信息的感知。相比之下,Transformer模型通过自注意力机制可以并行处理数据并捕捉全局依赖,对复杂时序数据(例如季节性、周期性强的数据)具有天然优势。因此,将两者结合可以兼顾短期局部模式和长期全局关联:LSTM负责提取连续时序中的细节信息,Transformer补充全局依赖权重,从而提高预测精度和泛化性能。
此类混合模型适用于多种时序回归场景,例如金融市场(股票、指数预测)、能耗预测、工业过程监控等。已有研究表明,在复杂工程系统如地下钻井进度预测、可再生能源管理等领域,LSTM-Transformer混合模型往往比单一模型具有更高精度和实时性。例如,Cao等人的研究指出,将LSTM的记忆单元与Transformer的自注意力机制相结合,可以在多个任务上获得明显提升。基于这些背景,本研究将详细介绍Transformer-LSTM混合模型在时序回归任务中的从头到尾的完整流程,包括数据处理、模型设计、训练优化、评估、部署等环节。
数据准备
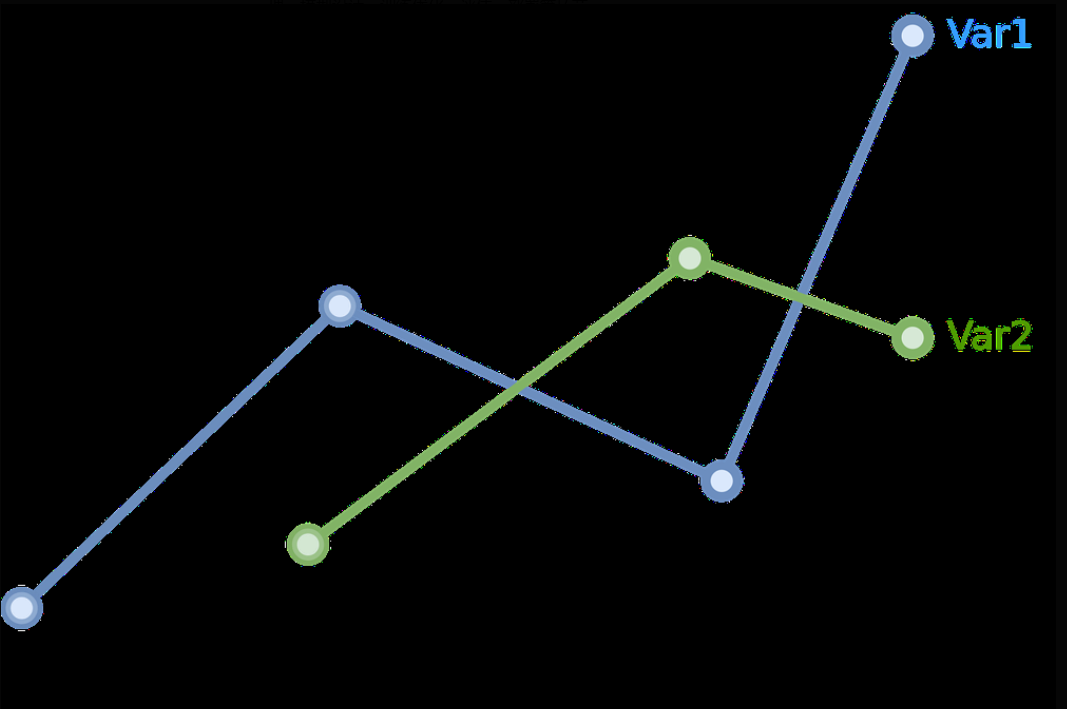
对时序回归任务而言,数据准备是至关重要的一步。合成数据常用于验证模型框架的有效性,例如生成带有趋势和周期的正弦波序列或随机漫步序列进行实验;真实数据则需要进行清洗与预处理,包括去除缺失值、异常值处理,以及归一化或标准化等操作,使数据尺度一致。通常采用滑动窗口的方法将时序数据转为监督学习格式:设定一个固定长度的窗口,将窗口内的历史$W$步数据作为输入特征,用于预测接下来$H$步或1步的目标值。例如,图1示例了两个变量的多变量时序数据:使用过去若干时刻的两个特征(Var1、Var2)同时作为模型输入,预测未来值。下图即为示例,其中蓝色线为Var1随时间的变化,绿色线为Var2的变化,两者同时输入模型进行联合预测。
图1. 示例多变量时序数据(蓝色Var1、绿色Var2)随着时间的变化。多特征时序常常需要对每个时间步的多维观测进行组合,作为模型输入。
在具体实现中,滑动窗口的数据集构造可以使用numpy或TensorFlow等工具实现。下面给出一个示例代码,演示如何生成合成时序并构建滑动窗口数据集:
import numpy as np
import tensorflow as tf# 生成合成时序数据(两个特征)
t = np.arange(0, 1000, 0.5)
series1 = np.sin(0.02 * t) + 0.5 * np.random.randn(len(t)) # 特征1:正弦 + 噪声
series2 = np.cos(0.01 * t) + 0.5 * np.random.randn(len(t)) # 特征2:余弦 + 噪声
data = np.stack([series1, series2], axis=1) # 形状 (len(t), 2)# 数据归一化(保持尺度一致)
data_mean = data.mean(axis=0)
data_std = data.std(axis=0)
data = (data - data_mean) / data_std# 滑动窗口参数
input_width = 20 # 输入窗口长度
label_width = 1 # 预测步长
shift = 1 # 步幅为1,即下一个时刻# 使用 tf.keras.utils.timeseries_dataset_from_array 构造数据集
dataset = tf.keras.utils.timeseries_dataset_from_array(data=data,targets=data[:, 0], # 假设预测第一个特征(可根据任务不同选择)sequence_length=input_width,sequence_stride=1,sampling_rate=1,batch_size=32,shuffle=True
)
# 划分训练/验证集
total_samples = len(data) - input_width - label_width + 1
train_size = int(total_samples * 0.8)
train_dataset = dataset.take(train_size // 32)
val_dataset = dataset.skip(train_size // 32)
上述代码中,我们生成了两个特征的合成时序数据,并使用timeseries_dataset_from_array将其转换为滑动窗口数据集,每个样本由过去input_width步的数据(形状为(batch, input_width, 2))映射到下一步第1个特征的值。对真实数据,同样需要根据时间戳做排序,然后进行类似的窗口划分。此外,可选地加入时间特征(如小时、星期等周期信息)或进行差分处理等特征工程,以提高模型对周期性和趋势的敏感度。
模型结构详解
本研究所用的混合模型结构主要由两部分组成:LSTM层用于捕捉短期序列依赖,Transformer编码器(自注意力层)用于建模全局依赖。在该设计中,输入首先经由若干层LSTM编码为时序特征表示,然后送入Transformer模块进行全局上下文编码,最后通过全连接层输出回归结果。LSTM层的记忆单元能够保留历史信息,而Transformer的自注意力机制可以对序列中不同位置进行加权,互补了LSTM对长序列建模的局限。这种串联结构有效结合了两者的优势,例如LSTM擅长捕捉序列模式,Transformer擅长抓取宏观信息,有利于提高预测的准确性。
在TensorFlow/Keras中,可以使用tf.keras.layers.LSTM和tf.keras.layers.MultiHeadAttention来实现上述混合结构。下面给出一个示例模型结构的代码片段:
from tensorflow.keras import layers, Modelinput_width = 20 # 输入窗口长度
n_features = 2 # 特征数量
inputs = layers.Input(shape=(input_width, n_features))# LSTM编码层
x = layers.LSTM(64, return_sequences=True)(inputs) # 输出序列用于自注意力
# 可选添加dropout防止过拟合
x = layers.Dropout(0.2)(x)# Transformer自注意力模块(单层示例)
# 1. 多头自注意力
attn_output = layers.MultiHeadAttention(num_heads=4, key_dim=16)(x, x)
# 2. 残差连接与Layer Norm
x = layers.Add()([x, attn_output])
x = layers.LayerNormalization()(x)
# 3. 前馈网络
ff = layers.Dense(64, activation='relu')(x)
ff = layers.Dense(x.shape[-1])(ff)
x = layers.Add()([x, ff])
x = layers.LayerNormalization()(x)# 聚合输出(取最后一个时间步)并回归输出
x = layers.Flatten()(x)
outputs = layers.Dense(1)(x) # 回归预测值
model = Model(inputs, outputs)
model.summary()
在这个示例中,先构建了一个LSTM层(return_sequences=True),输出为与输入长度相同的序列,以便后续进行自注意力计算。然后通过多头注意力层(MultiHeadAttention)实现Transformer编码,添加了残差连接和LayerNormalization保持稳定。最后将序列输出展平,接全连接层预测目标值。该结构图如图2所示:
图2. LSTM-Transformer混合模型结构示意图(输入序列->LSTM编码->Transformer编码->全连接输出)。
模型结构还可以有多种变体,例如将Transformer模块置于LSTM之前,或并行设计多个分支后融合输出,也可在后续加入额外的LSTM或卷积层强化特征提取。但无论结构如何变化,核心思想都是让LSTM和Transformer协同工作,补充彼此的长短期依赖建模能力。
训练与调优
训练阶段首先需要设置损失函数和优化器。对于回归任务,常用均方误差(MSE)作为损失函数,优化器可选用Adam或AdamW等高级优化算法。Adam优化器通过对梯度一阶、二阶矩估计自适应调整学习率,通常能带来稳定快速的收敛。例如,编译模型时可写:
model.compile(loss='mse', optimizer='adam', metrics=['mae'])
超参数设置方面,主要包括学习率、批量大小、LSTM单元数、Transformer头数、注意力维度、层数等。参考经验,常见的超参数有:嵌入(隐藏)维度、注意力头数、Transformer层数、学习率、批量大小等。例如,可以先尝试学习率$10^{-3}$、批量大小32、LSTM隐藏层64、注意力头数4、Transformer深度12层。然后根据验证效果调整:过大的学习率可能使训练不稳定,过小则收敛缓慢;批量大小受显存限制,一般32128之间为佳。
正则化与早停也是重要手段。可在LSTM和全连接层之间加Dropout层来减少过拟合;例如在上述代码中已经加入了Dropout(0.2)。另外,可以使用tf.keras.callbacks.EarlyStopping监控验证集损失,当损失在若干轮内不再下降时提前终止训练,以避免过拟合。可选的学习率调度策略包括ReduceLROnPlateau(当验证性能停滞时衰减学习率)或Transformer常用的学习率预热(warmup)后衰减策略。
示例训练代码,其中包含超参数、早停等设置:
from tensorflow.keras.callbacks import EarlyStopping# 假设已有 train_dataset, val_dataset
early_stop = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
history = model.fit(train_dataset,validation_data=val_dataset,epochs=50,callbacks=[early_stop]
)
通过fit训练,模型将自动在训练集和验证集上更新权重,并保存训练过程中的损失值曲线用于后续分析。以示例代码为基准,可以视实际情况改变超参数,并通过多次实验观察模型性能变化,采用网格搜索、随机搜索等方法调优。
性能评估
训练结束后,通过多种指标和可视化来评估模型性能。常用的回归指标包括平均绝对误差(MAE)和均方根误差(RMSE),它们分别衡量预测值与真实值偏差的平均大小和均方根大小。通常,指标值越低代表预测越准确。我们可以使用scikit-learn等库来计算这些指标:
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error# 假设 test_X, test_y 为测试集输入输出
y_pred = model.predict(test_X)
mae = mean_absolute_error(test_y, y_pred)
rmse = np.sqrt(mean_squared_error(test_y, y_pred))
print(f"测试集 MAE: {mae:.4f}, RMSE: {rmse:.4f}")
除了数值指标,还应绘制训练过程中的损失曲线和预测结果对比图。训练曲线(损失随迭代变化)可以反映是否出现了过拟合或欠拟合;预测对比图(将模型输出与真实序列叠加或做散点图)则直观展示预测精度。图3中展示了模型在测试集上的预测趋势示例,我们可以将预测值与真实值一起绘制,观察二者吻合程度。
图3. 模型预测效果示例图(图中显示某时序数据的真实值与预测值变化曲线)。
在实际评估中,还应与基线模型做对比,例如纯LSTM模型、传统ARIMA模型或其它简单方法,比较MAE/RMSE等指标差异。如果混合模型显著优于基线,则说明Transformer的引入有效改善了预测效果。已有研究表明,与单一网络相比,LSTM-Transformer组合通常能取得更好的效果。最后,可以对预测误差进行误差分析:检查哪些时刻误差较大,是异常值引起还是模型欠拟合等,为后续改进提供参考。
部署实践
训练完成后,需要将模型用于生产环境的预测服务中。首先将训练好的模型导出:对于Keras模型,可使用model.save将其保存为TensorFlow SavedModel格式,以便于TensorFlow Serving部署。例如:
# 导出模型用于部署
model.save('saved_model/my_model', save_format='tf')
上面代码会在saved_model/my_model/目录生成SavedModel所需的assets/, variables/, saved_model.pb等文件。此后,可以选择两种常见的服务方式:
- TensorFlow Serving:使用官方的TFS服务器,将导出的模型加载为REST或gRPC接口服务。可以通过Docker快速部署,并通过HTTP请求实现高并发预测。例如执行命令
tensorflow_model_server --model_base_path=saved_model --rest_api_port=8501即可启动服务,随后客户端可发送POST请求获取预测结果。 - 自定义REST API:使用Flask、FastAPI等Python框架封装模型推理接口。示例代码如下:
from flask import Flask, request, jsonify
import tensorflow as tfapp = Flask(__name__)
# 加载SavedModel
loaded_model = tf.keras.models.load_model('saved_model/my_model')@app.route('/predict', methods=['POST'])
def predict():data = request.json['input_data'] # 假设客户端以JSON格式发送输入数据# 转换为numpy数组并进行预测x = np.array(data)pred = loaded_model.predict(x)return jsonify(pred.tolist())if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
部署后需要进行推理效率测试:衡量模型在目标硬件上的响应时间和吞吐量。这可以通过测试固定大小的输入批次预测耗时来完成(可用time.time()或timeit测量),或者使用加载监控(如TFS自带的监控端点)评估并发性能。对于延迟敏感的场景,还可考虑模型量化或TensorRT优化来加速推理。
总结与扩展建议
本研究详细梳理了Transformer-LSTM混合模型在时序回归任务中的从数据准备到部署的全流程。此类混合模型充分结合了LSTM的记忆能力和Transformer的全局建模能力,已在多个领域展现出优越性能。总结如下:
- 优势:混合结构能同时捕捉局部和全局时序特征,提高了复杂数据上的预测精度;Transformer的并行化计算也加快了训练速度。
- 改进方向:可尝试更深的网络(多层LSTM/Transformer)、不同的融合方式(如并行分支)、更丰富的输入特征(如外部时间标签、统计量),或结合卷积层处理局部模式等。
- 迁移性:由于时序模式在金融、气象、医疗、工业等领域普遍存在,此模型结构具有较好的迁移潜力。在具体应用时可根据领域特点调整模型架构和超参数。
- 未来研究:可以探索在线学习和增量更新(使模型随新数据持续优化)、注意力机制改进(如引入稀疏注意力、层次化注意力)、结合图神经网络处理时空关系等方向,不断提升模型的适用性和性能。
总之,Transformer-LSTM混合模型为时序回归提供了一种高效而灵活的方案,本文的完整流程与经验分享可为相关场景的建模与实践提供参考和借鉴。
具体代码流程
- 合成与真实数据生成及滑窗处理
- 数据归一化与训练/验证集切分
- 混合模型定义:串联 LSTM 与 Transformer 编码器
- 训练策略:MSE 损失、Adam 优化、EarlyStopping、学习率调度
- Keras Tuner 自动化超参数搜索
- 性能评估:MAE、RMSE 计算与可视化
- 模型导出与 Flask REST API 部署
以下代码一气呵成,可直接运行并根据实际场景替换数据部分。
环境依赖安装
pip install tensorflow keras-tuner scikit-learn matplotlib flask
1. 数据生成与预处理
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split# 1.1 合成时序数据
np.random.seed(42)
t = np.arange(0, 1000, 0.5)
series1 = np.sin(0.02 * t) + 0.5 * np.random.randn(len(t))
series2 = np.cos(0.01 * t) + 0.5 * np.random.randn(len(t))
data = np.stack([series1, series2], axis=1) # (2000, 2)# 1.2 归一化
scaler_X = MinMaxScaler(); scaler_y = MinMaxScaler()
data_norm = scaler_X.fit_transform(data) # :contentReference[oaicite:0]{index=0}
target = series1.reshape(-1, 1)
target_norm = scaler_y.fit_transform(target) # :contentReference[oaicite:1]{index=1}# 1.3 滑动窗口转换
input_width = 20
ds = tf.keras.utils.timeseries_dataset_from_array(data=data_norm,targets=target_norm,sequence_length=input_width,sequence_stride=1,batch_size=32,shuffle=True
) # :contentReference[oaicite:2]{index=2}# 1.4 划分训练/验证集
total = len(data_norm) - input_width + 1
train_size = int(total * 0.8)
train_ds = ds.take(train_size // 32)
val_ds = ds.skip(train_size // 32)
2. 模型构建
from tensorflow.keras import layers, Modeldef build_transformer_lstm(input_shape, lstm_units=64, heads=4, dim=32, num_layers=2, dropout=0.2):inputs = layers.Input(shape=input_shape)# 2.1 LSTM 编码x = layers.LSTM(lstm_units, return_sequences=True)(inputs) # :contentReference[oaicite:3]{index=3}x = layers.Dropout(dropout)(x)# 2.2 Transformer 编码器堆叠for _ in range(num_layers):attn = layers.MultiHeadAttention(num_heads=heads, key_dim=dim)(x, x) # :contentReference[oaicite:4]{index=4}x = layers.Add()([x, attn])x = layers.LayerNormalization()(x) # :contentReference[oaicite:5]{index=5}# 前馈ffn = layers.Dense(lstm_units, activation='relu')(x)ffn = layers.Dense(x.shape[-1])(ffn)x = layers.Add()([x, ffn])x = layers.LayerNormalization()(x)# 2.3 回归输出x = layers.GlobalAveragePooling1D()(x)x = layers.Dense(64, activation='relu')(x)x = layers.Dropout(dropout)(x)outputs = layers.Dense(1)(x)return Model(inputs, outputs)input_shape = (input_width, data.shape[-1])
model = build_transformer_lstm(input_shape)
model.compile(optimizer='adam', loss='mse', metrics=['mae']) # :contentReference[oaicite:6]{index=6}
model.summary()
3. 训练策略与超参数调优
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
import keras_tuner as kt# 3.1 回调
early_stop = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True) # :contentReference[oaicite:7]{index=7}
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=3) # :contentReference[oaicite:8]{index=8}# 3.2 Keras Tuner 自动调参
def tuner_model(hp):hp_lstm = hp.Int('lstm_units', 32, 128, step=32)hp_heads = hp.Int('heads', 2, 8, step=2)hp_layers = hp.Int('layers', 1, 3)hp_lr = hp.Float('lr', 1e-4, 1e-2, sampling='log')m = build_transformer_lstm(input_shape, lstm_units=hp_lstm, heads=hp_heads,num_layers=hp_layers)m.compile(optimizer=tf.keras.optimizers.Adam(hp_lr),loss='mse', metrics=['mae']) # :contentReference[oaicite:9]{index=9}return mtuner = kt.Hyperband(tuner_model,objective='val_loss',max_epochs=20,factor=3,directory='tuner_dir',project_name='ts_transformer_lstm'
)
tuner.search(train_ds, validation_data=val_ds, callbacks=[early_stop, reduce_lr])
best_hp = tuner.get_best_hyperparameters(1)[0]
print(best_hp.values)
4. 最终训练与评估
# 4.1 根据最佳超参构建模型
opt_model = build_transformer_lstm(input_shape,lstm_units=best_hp.get('lstm_units'),heads=best_hp.get('heads'),num_layers=best_hp.get('layers')
)
opt_model.compile(optimizer=tf.keras.optimizers.Adam(best_hp.get('lr')),loss='mse', metrics=['mae']
)# 4.2 训练
history = opt_model.fit(train_ds,validation_data=val_ds,epochs=50,callbacks=[early_stop, reduce_lr]
)# 4.3 性能评估
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error, mean_squared_error# 预测
X_test, y_test = next(iter(val_ds))
y_pred = opt_model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"MAE: {mae:.4f}, RMSE: {rmse:.4f}") # :contentReference[oaicite:10]{index=10}# 4.4 可视化
plt.figure(figsize=(10,4))
plt.plot(y_test[:100], label='True')
plt.plot(y_pred[:100], label='Pred')
plt.legend(); plt.title('Prediction vs True (first 100 samples)')
plt.show()
5. 模型导出与部署
# 5.1 保存模型
opt_model.save('saved_model/ts_transformer_lstm')# 5.2 Flask REST API 示例
from flask import Flask, request, jsonify
import tensorflow as tfapp = Flask(__name__)
m = tf.keras.models.load_model('saved_model/ts_transformer_lstm')@app.route('/predict', methods=['POST'])
def predict():data = np.array(request.json['instances'])preds = m.predict(data).flatten().tolist()return jsonify({'predictions': preds})if __name__=='__main__':app.run(host='0.0.0.0', port=5000)
通过上面给出的完整代码,即可在本地复现Transformer‑LSTM 混合模型的全流程,从数据处理到部署,涵盖早停、学习率调整及自动超参搜索,帮助你在时序回归场景中获得更优性能。
相关文章:
Transformer-LSTM混合模型在时序回归中的完整流程研究
Transformer-LSTM混合模型在时序回归中的完整流程研究 引言与背景 深度学习中的长期依赖建模一直是时序预测的核心问题。长短期记忆网络(LSTM)作为一种循环神经网络,因其特殊的门控结构能够有效捕捉序列的历史信息,并在时序预测…...
UE5 渲染思路笔记(角色)
参考示例 首先是怎么做到辉光只有部分有而整体没有的 使用的是Bloom内的阈值,控制光的溢光量 Threshold(阈值):这个参数决定了图像中哪些像素会参与泛光计算。只有那些亮度超过阈值的像素才会触发泛光效果。阈值越低,更多的像素会…...

运维打铁:服务器分类及PHP入门
文章目录 C/S架构和B/S架构C/S架构B/S架构 服务器分类服务器类型服务器软件 使用 WampServer 搭建 HTTP服务集成环境的分类WampServer 的安装测试访问配置网站根目录 静态网站和动态网站PHP的常见语法第一段 php 代码注释变量数据类型运算符函数的定义类和对象内容输出循环语句…...

js原型污染 + xss劫持base -- no-code b01lersctf 2025
题目信息:Found this new web framework the other day—you don’t need to write any code, just JSON. 我们先来搞清楚究竟发生了什么 当我们访问 /index /*** 处理 /:page 路径的 GET 请求* param {Object} req - 请求对象* param {Object} reply - 响应对象* returns {Pro…...

力扣92.反转指定范围内的链表、25.k个一组反转链表
92.反转指定范围内的链表 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val val; }* ListNode(int val, ListNode next) { this.val val; this.next next;…...
Python - 爬虫;Scrapy框架(一)
框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。 Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scra…...

The 2024 ICPC Kunming Invitational Contest G. Be Positive
https://codeforces.com/gym/105386/problem/G 题目: 结论: 从0开始每四个相邻数的异或值为0 代码: #include<bits/stdc.h> using namespace std; #define int long long void solve() {int n;cin >> n;if(n1||n%40){cout &…...

GET请求如何传复杂数组参数
背景 有个历史项目,是GET请求,但是很多请求还是复杂参数,比如:参数是数组,且数组中每一个元素都是复杂的对象,这个时候怎么传参数呢? 看之前请求直接是拼接在url后面 类似&items%5B0%5D.…...
leetcode - 双指针问题
文章目录 前言 题1 移动零: 思路: 参考代码: 题2 复写零: 思考: 参考代码: 题3 快乐数: 思考: 参考代码: 题4 盛最多水的容器: 思考:…...

人工智能之数学基础:二次型
本文重点 二次型作为线性代数领域的重要概念,架起了代数方程与几何分析之间的桥梁。从古典解析几何中的圆锥曲线方程到现代优化理论中的目标函数,二次型以其简洁的数学表达和丰富的结构特性,在数学物理、工程技术和经济金融等领域发挥着不可替代的作用。 二次型的基本概念…...

存储过程补充——流程控制语句详解
文章目录 1. 条件判断语句1.1 分支结构之 IF1.2 分支结构之 CASE 2. 循环语句2.1 循环结构之LOOP2.2 循环结构之WHILE2.3 循环结构之REPEAT 3. 跳转语句3.6 跳转语句之LEAVE语句3.7 跳转语句之ITERATE语句 在数据库管理系统中,存储过程是一种强大的工具,…...
【Unity笔记】实现支持不同渲染管线的天空盒曝光度控制组件(SkyboxExposureController)——参数化控制
写在前面 在Unity中,天空盒(Skybox)不仅承担视觉上的背景作用,更是场景环境光照与氛围塑造的重要组成部分。不同时间、天气、场景转换等,都需要灵活调整天空的亮度。而**曝光度(Exposure)**就是…...
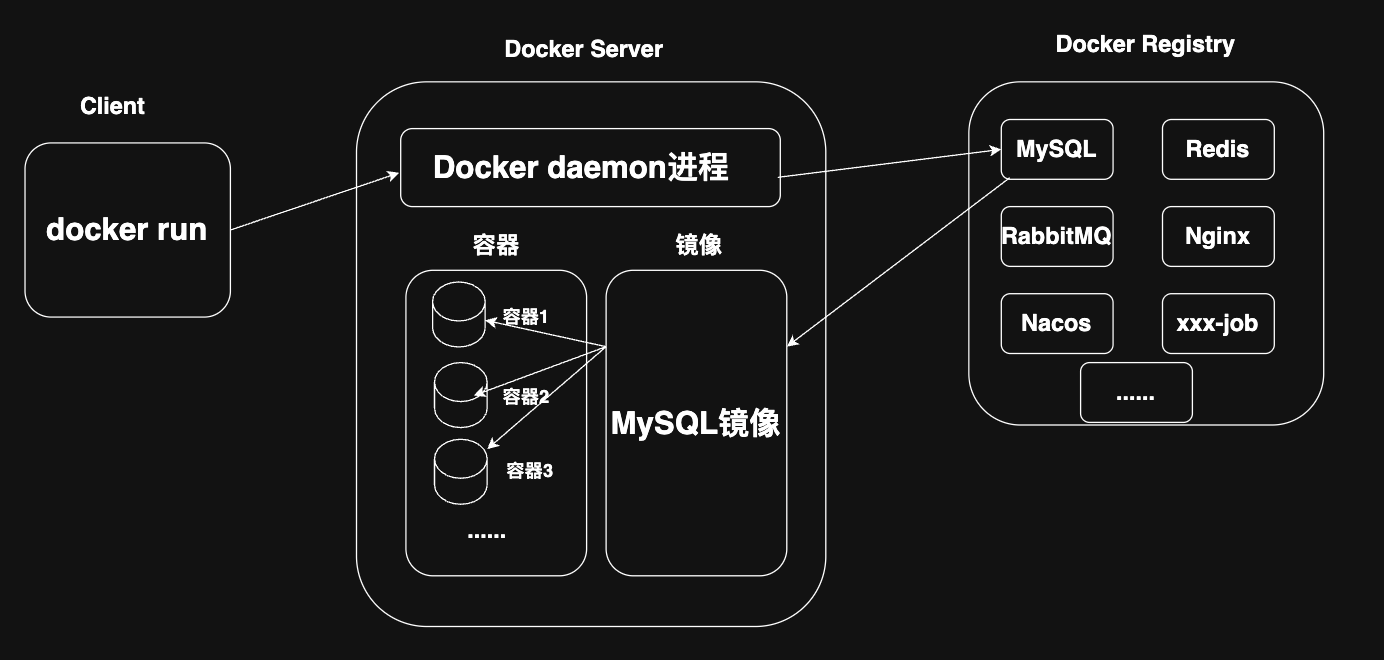
Docker 使用与部署(超详细)
目录 引入 入门使用 部署对比 镜像仓库 命令解释 基础 常见命令 示例 数据卷的使用 数据卷的概念 数据卷的使用 挂载本地目录文件 镜像 结构 Dockerfile 容器网络 部署 DockerCompose 语法 编辑 基础命令 引入 当我们在 Linux 上部署一个集成了很多中间件…...

CSS实现图片垂直居中方法
html <div class"footer border-top-row"><div class"footer-row"><span class"footer-row-col01">制单人:{{ printData[pageIndex - 1].rkMaster.makerName}}<img :src"getPersonSignImgSrc(printData[pa…...

C#实现Socket通信:基于TCP/IP协议的网络编程
TCP/IP网络模型 最上层的是应用层,也就是我们日常可以接触到的,它会给数据添加对应的头部,并传输给传输层,应用层是我们日常会接触到的,比如HTTP,FTP,Telnet,DNS,SMTP。…...

基于C++的IOT网关和平台7:github项目ctGateway设备协议开发指南
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。 源码指引:github源码指引_初级代码游戏的博客-CSDN博客 系…...

大数据实时数仓的数据质量监控解决方案
实时数仓不仅仅是传统数据仓库的升级版,它更强调数据的实时性、流动性和高可用性,通过对海量数据的即时处理和分析,为企业提供近乎实时的洞察力。这种能力在金融、零售、制造、互联网等行业中尤为关键,例如,电商平台可以通过实时数仓监控用户行为,动态调整推荐算法;金融…...

Python+Scrapy跨境电商爬虫实战:从亚马逊/沃尔玛数据采集到反爬攻克(附Pangolin API高效方案)
从零实战到反爬攻克,揭秘跨境数据抓取全流程与Pangolin Scrape API终极方案 在当今数据驱动的跨境电商时代,谁掌握了优质的市场数据,谁就掌握了成功的关键。随着全球电商市场规模持续扩大(据Statista最新报告显示,2025…...

简单快速的浮点数转字符串算法,适合单片机环境
目的是在OLED 屏幕上显示浮点数,有几个设计要求: 我已经有一个现成的能显示整数的函数,希望尽量复用;尽量不使用除法;不需要考虑小数四舍五入的问题; 我觉得小数四舍五入其实很多时候没什么用处ÿ…...

c++中构造对象实例的两种方式及其返回值
c中,构造对象实例有两种方式,一种返回对象实例,一种返回该对象实例的指针。如下所示: 一、两种返回值 RedisConn conn1; //得到实例conn1;RedisConn *conn2 new RedisConn();//得到指针conn2;RedisConn conn3 new RedisConn()…...

Python实例题:Python操作excel自动化开发
目录 Python实例题 题目 安装依赖库 示例代码 代码解释 写入 Excel 文件: 读取 Excel 文件: 修改 Excel 文件: 运行思路 注意事项 Python实例题 题目 Python操作excel自动化开发 安装依赖库 pip install openpyxl示例代码 imp…...

【日撸 Java 三百行】Day 7(Java的数组与矩阵元素相加)
目录 Day 7:Java 的数组与矩阵元素相加 一、基本知识 二、矩阵的建立与基本计算 三、代码及测试 拓展:Arrays类详解 小结 Day 7:Java 的数组与矩阵元素相加 Task: 矩阵的赋值.二重循环. 一、基本知识 在学习 Java 中的数组与矩…...

【Python】常用命令提示符
Python常用的命令提示符 一、Python环境基础命令【Windows】 于Windows环境下,针对Python,在CMD(命令提示符)常用的命令以及具体用法,怎么用; 主要包含:运行脚本、包管理、虚拟环境、调试与…...
vite:npm 安装 pdfjs-dist , PDF.js View 预览功能示例
pdfjs-dist 是 Mozilla 的 PDF.js 库的预构建版本,能让你在项目里展示 PDF 文件。下面为你介绍如何用 npm 安装 pdfjs-dist 并应用 pdf.js 和 pdf.worker.js。 为了方便,我将使用 vite 搭建一个原生 js 项目。 1.创建项目 npm create vitelatest pdf-v…...

【开源版】likeshop上门家政系统PHP版全开源+uniapp前端
一.系统介绍 likeshop_上门家政系统,PHP版本更新至2.1.1最新版,全开源,适用于上门家政场景,系统拥有用户端、师傅端、无论运营还是二开都是性价比极高的100%开源家政系统。 二.搭建环境-教程 系统环境:CentOS、 运行…...
(已不推荐使用deprecated,建议使用img、video、audio标签))
html object标签介绍(用于嵌入外部资源通用标签)(已不推荐使用deprecated,建议使用img、video、audio标签)
文章目录 HTML <object> 标签详解基本语法与核心属性关键属性解析1. **data**2. **type**3. **width & height**4. **name** 嵌入不同类型的资源1. **嵌入图像**2. **嵌入音频**3. **嵌入视频**4. **嵌入 PDF** 参数传递与回退内容**参数(<param>&a…...

MySQL 8.0 OCP 英文题库解析(一)
Oracle 为庆祝 MySQL 30 周年,从 2025.04.20 ~ 2025.07.31 之间,所有人均可以免费考取 MySQL OCP 认证。从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证,省1700多RMB&…...

路由器断流排查终极指南:从Ping测试到Wireshark抓包5步定位法
测试路由器是否出现“断流”(网络连接间歇性中断),需通过多维度排查硬件、软件及外部干扰因素。以下是详细步骤指南: 一、基础环境准备 设备连接 有线测试:用网线将电脑直接连接路由器LAN口,排除WiFi干扰。…...

【Python零基础入门系列】第1篇:Python 是什么?怎么装环境?推荐哪些 IDE?
各位网友们,欢迎来到我的 Python 学习专栏! 前两天看到新闻英伟达为 CUDA 添加原生 Python 支持,意味着开发者可直接用 Python 操作 GPU,加速 AI 和高性能计算,降低门槛,让 Python 的应用范围更广、能力更强。 一直想写一系列文章教知友们从零开始学会 Python 编程,目…...

Spring Boot3 实现定时任务 每10分钟执行一次,同时要解决分布式的问题 区分不同场景
在Spring Boot 3中实现分布式定时任务,确保多实例环境下任务仅执行一次,可以采用以下方案: 方案一:Redis分布式锁(推荐) import org.springframework.data.redis.core.StringRedisTemplate; import org.sp…...