C++ - 仿 RabbitMQ 实现消息队列(1)(环境搭建)
C++ - 仿 RabbitMQ 实现消息队列(1)(环境搭建)
- 什么是消息队列
- 核心特点
- 核心组件
- 工作原理
- 常见消息队列实现
- 应用场景
- 优缺点
- 项目配置
- 开发环境
- 技术选型
- 更换软件源
- 安装一些工具
- 安装epel 软件源
- 安装 lrzsz 传输工具
- 安装git
- 安装 cmake
- 安装 SQLite3
- 安装GTest
- 安装高版本 gcc/g++编译器
- 1. 确认可用的 GCC 工具集版本
- 2. 安装默认的 GCC 工具集
- 3. 正确的启用方式
- 4. 永久启用(可选)
- 安装Protobuf
- 1. 解压源码包
- 2. 进入源码目录
- 3. 生成配置脚本
- 4. 配置编译选项
- 5. 编译源码
- 6. 安装到系统
- 7. 更新动态库缓存
- 完整流程总结
- 验证安装
- 安装 Muduo
我们今天来开一个新的项目仿 RabbitMQ 实现消息队列,这个项目更加接近公司的开发流程,开发和测试各个方面都会涉及到。不过在这之前,我们先来了解一下什么是消息队列,消息队列是用来干嘛的。
什么是消息队列
消息队列(Message Queue)是一种用于在分布式系统或应用程序之间传递消息的通信机制,它通过一个中间存储结构(队列)来管理消息的传递,允许发送方和接收方以异步的方式交互。消息队列的核心作用是解耦生产者和消费者,提升系统的可扩展性、可靠性和性能。
核心特点
-
解耦性
生产者(发送方)和消费者(接收方)无需直接通信,也无需知道彼此的存在。双方通过消息队列进行交互,降低了系统间的耦合度。 -
异步通信
生产者将消息发送到队列后,无需等待消费者立即处理,可以继续执行其他任务。消费者可以按自己的节奏处理消息,提高系统响应速度。 -
削峰填谷
在流量高峰时,消息队列可以缓冲大量请求,避免系统过载。消费者可以逐步处理队列中的消息,平稳系统负载。 -
可靠性
消息队列通常提供持久化存储,即使消费者崩溃或网络中断,消息也不会丢失,确保数据不丢失。
核心组件
-
生产者(Producer)
负责生成消息并将其发送到消息队列中。 -
消息队列(Message Queue)
中间存储结构,用于临时存储消息,支持消息的持久化、排序和分发。 -
消费者(Consumer)
从消息队列中获取消息并进行处理。
工作原理
- 生产者发送消息:生产者将消息发送到指定的队列中。
- 消息存储:消息队列将消息持久化存储,等待消费者处理。
- 消费者拉取或推送消息:消费者从队列中获取消息(拉取模式)或通过订阅机制接收消息(推送模式)。
- 消息处理:消费者处理消息,并可能返回处理结果。
- 消息确认(可选):消费者处理完成后,向消息队列发送确认信号,队列可以删除或标记消息为已处理。
常见消息队列实现
-
RabbitMQ
- 基于AMQP协议的开源消息代理,支持多种消息模式(如发布/订阅、路由、主题)。
- 适合需要灵活路由和复杂消息模式的场景。
-
Kafka
- 高吞吐量的分布式消息系统,常用于大数据和实时流处理。
- 支持持久化日志、分区和副本,适合大规模数据处理。
-
ActiveMQ
- 基于JMS规范的开源消息代理,支持多种协议(如AMQP、STOMP、MQTT)。
- 适合企业级应用和集成场景。
-
Redis Stream
- Redis 5.0引入的流数据结构,支持简单的消息队列功能。
- 适合轻量级、低延迟的场景。
-
Amazon SQS/Azure Service Bus
- 云服务提供商提供的托管消息队列服务,适合云原生应用。
应用场景
-
异步任务处理
例如:用户注册后发送欢迎邮件、订单处理后更新库存。 -
应用解耦
例如:电商系统中,订单服务、支付服务和物流服务通过消息队列解耦。 -
流量削峰
例如:秒杀活动中,将用户请求暂存到消息队列,后台服务逐步处理。 -
日志处理
例如:将应用日志发送到消息队列,由日志收集服务统一处理。 -
事件驱动架构
例如:微服务架构中,服务之间通过事件消息进行通信。
优缺点
优点:
- 解耦生产者和消费者,降低系统复杂度。
- 支持异步通信,提高系统响应速度。
- 提供削峰填谷能力,增强系统稳定性。
- 支持消息持久化,确保数据不丢失。
缺点:
- 引入了额外的组件,增加了系统复杂度。
- 消息顺序和重复消费等问题需要额外处理。
- 消息队列本身可能成为性能瓶颈(需合理设计)。
我们这次的项目围绕着RabbitMQ 模拟实现一个简单的消息队列
项目配置
开发环境
| 组件 | 版本/工具 |
|---|---|
| 操作系统 | CentOS9 / Ubuntu-22.04 |
| 代码编辑器 | VSCode / Vim |
| 编译调试工具 | g++ / gdb |
| 构建工具 | Makefile |
技术选型
| 类别 | 选择 |
|---|---|
| 开发主语言 | C++ |
| 序列化框架 | Protobuf 二进制序列化 |
| 网络通信方案 | 自定义应用层协议 + muduo库(推荐,适用于TCP长连接及高并发场景) 或者自定义应用层协议 + 原生socket(复杂度较高) |
| 数据库 | SQLite3 |
| 单元测试框架 | Gtest |
更换软件源
首先,我们得要首先把软件源换成国内的,如果使用系统本身的软件源,就要访问国外的网站,速度会非常慢。
我们换成清华大学的镜像源:
https://mirrors.tuna.tsinghua.edu.cn/
执行以下的代码:
sudo tee /etc/yum.repos.d/CentOS-Stream.repo << 'EOF'
[baseos]
name=CentOS Stream 9 - BaseOS (Tsinghua)
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos-stream/9-stream/BaseOS/x86_64/os/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial[appstream]
name=CentOS Stream 9 - AppStream (Tsinghua)
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos-stream/9-stream/AppStream/x86_64/os/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial[extras]
name=CentOS Stream 9 - Extras (Tsinghua)
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos-stream/SIGs/9-stream/extras/x86_64/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial
EOF
这段代码是在配置 CentOS Stream 9 的 YUM 软件仓库(repository),具体作用如下:
- 使用
sudo tee命令将后面的内容写入/etc/yum.repos.d/CentOS-Stream.repo文件(需要管理员权限) << 'EOF'表示将后续内容作为标准输入,直到遇到EOF结束标记- 文件内容配置了三个软件源仓库:
[baseos]:基础操作系统软件包[appstream]:应用程序包[extras]:额外软件包
每个仓库配置包含:
name:仓库描述名称(标明是清华镜像源)baseurl:指定软件包的下载地址(使用清华大学开源镜像站)gpgcheck=1:启用 GPG 签名验证gpgkey:指定 GPG 密钥位置用于验证软件包
这样配置后,当你使用 yum 或 dnf 命令安装软件时,系统会从清华大学的镜像站点下载 CentOS Stream 9 的软件包,速度会比官方源更快(特别是在中国境内)。
注意:这段代码会覆盖同名的现有仓库配置文件,如果之前有其他配置会被替换。
大家注意一下三个部分的baseurl,如果路径不对,是会失败的,这里给大家指明一下路径:
baseos的baseurl:
https://mirrors.tuna.tsinghua.edu.cn/centos-stream/9-stream/BaseOS/x86_64/
appstream的baseurl:
https://mirrors.tuna.tsinghua.edu.cn/centos-stream/9-stream/AppStream/x86_64/os/
extras的baseurl:
https://mirrors.tuna.tsinghua.edu.cn/centos-stream/SIGs/9-stream/extras/x86_64/
安装一些工具
安装epel 软件源
sudo dnf install epel-release
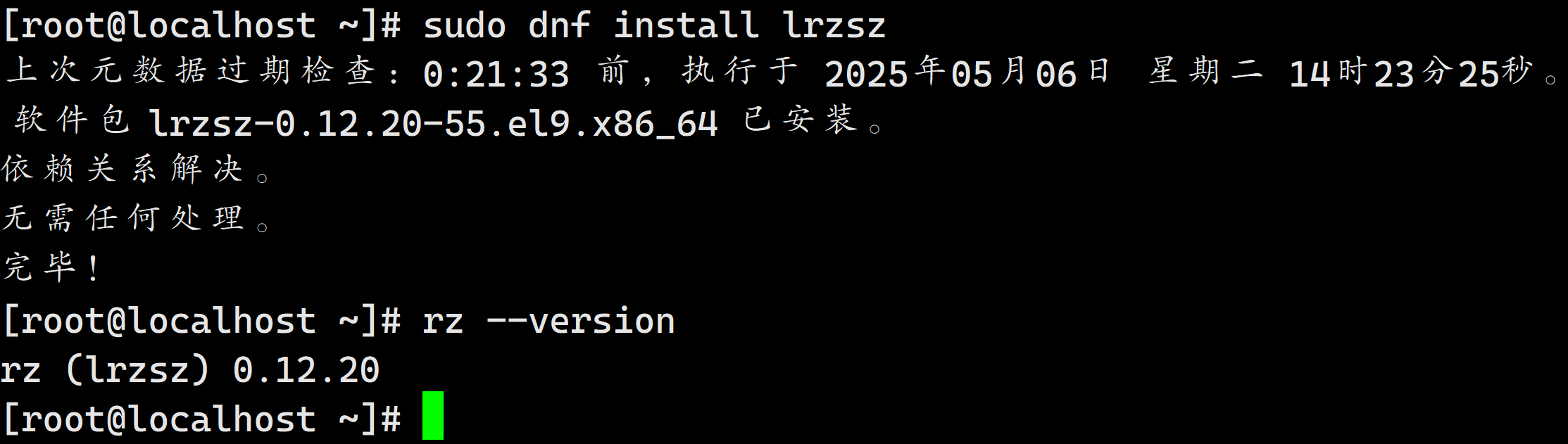
安装 lrzsz 传输工具
sudo dnf install lrzsz
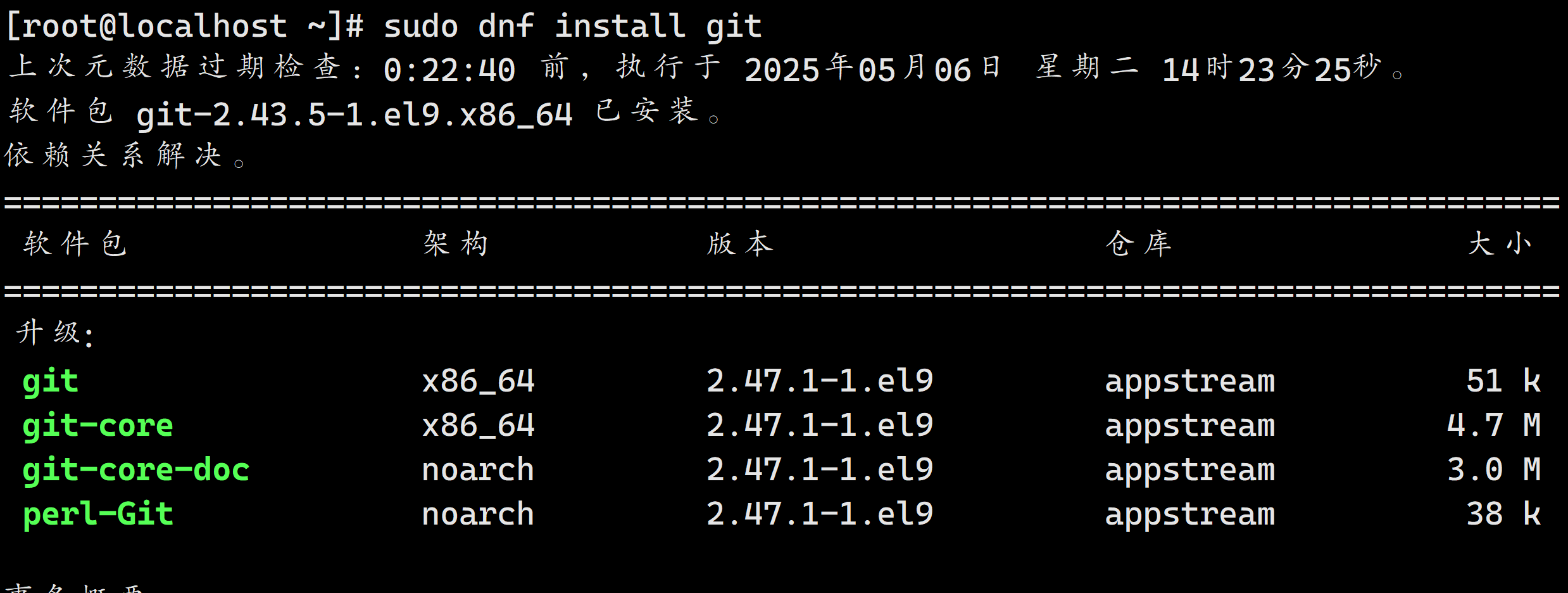
安装git
sudo dnf install git

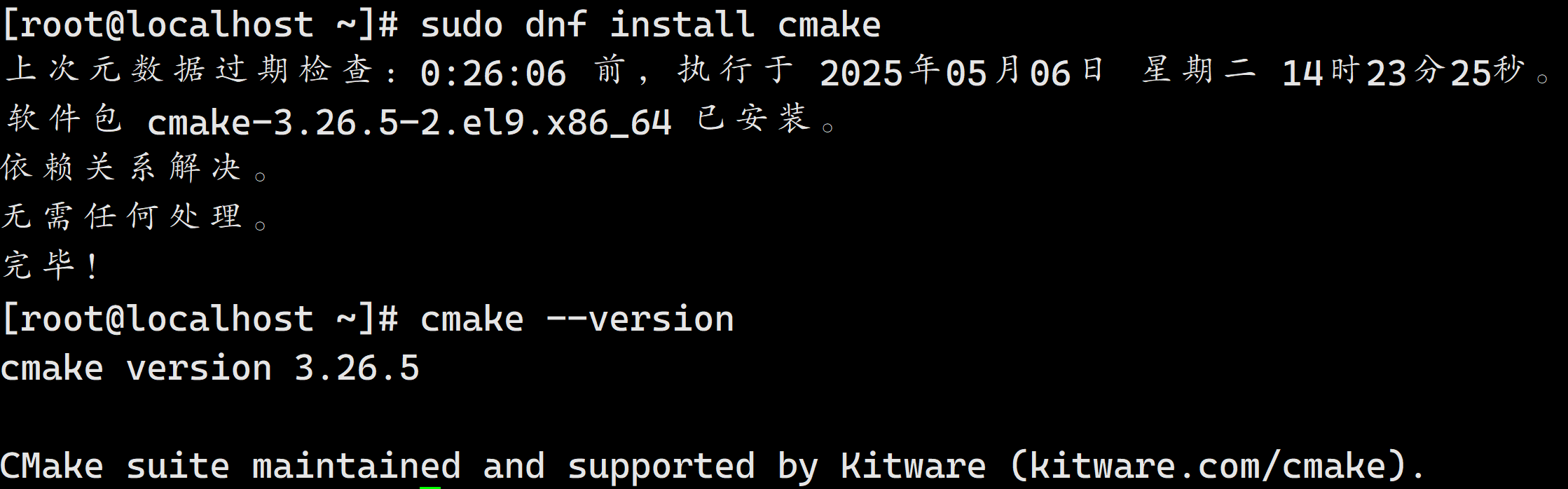
安装 cmake
sudo dnf install cmake
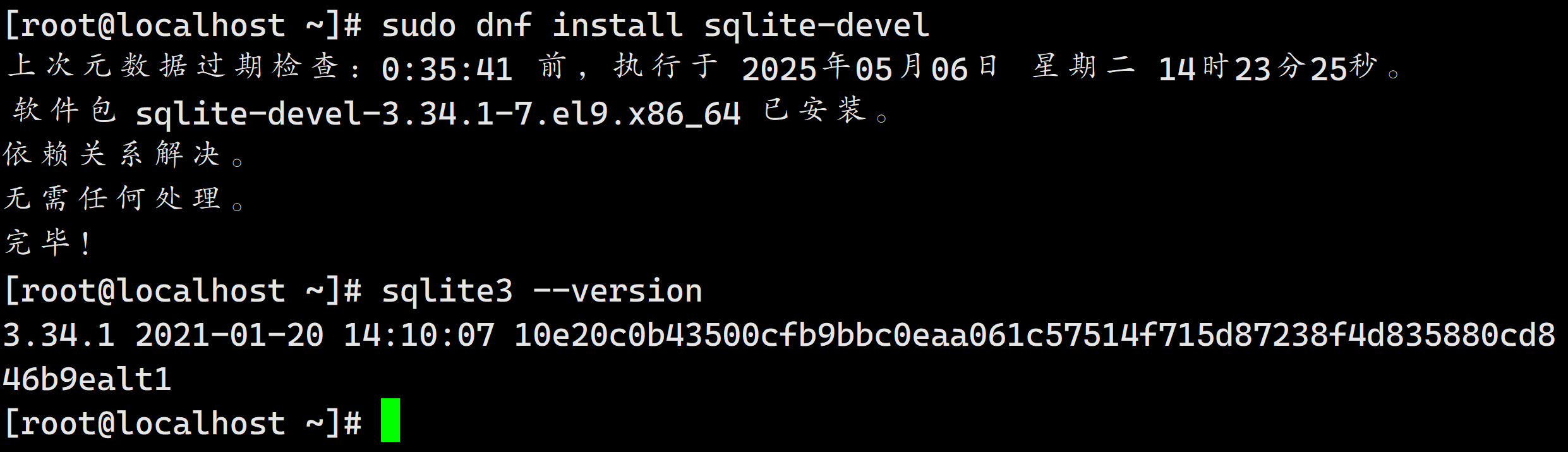
安装 SQLite3
sudo dnf install sqlite-devel
安装GTest
sudo dnf install gtest gtest-devel
ls /usr/include/gtest/gtest.h

安装高版本 gcc/g++编译器
在 CentOS Stream 9 中,gcc-toolset-11 可能不再直接提供,或者它的包名称/仓库配置发生了变化。以下是解决方案:
1. 确认可用的 GCC 工具集版本
运行以下命令查看当前可用的 GCC 相关包:
dnf search gcc-toolset
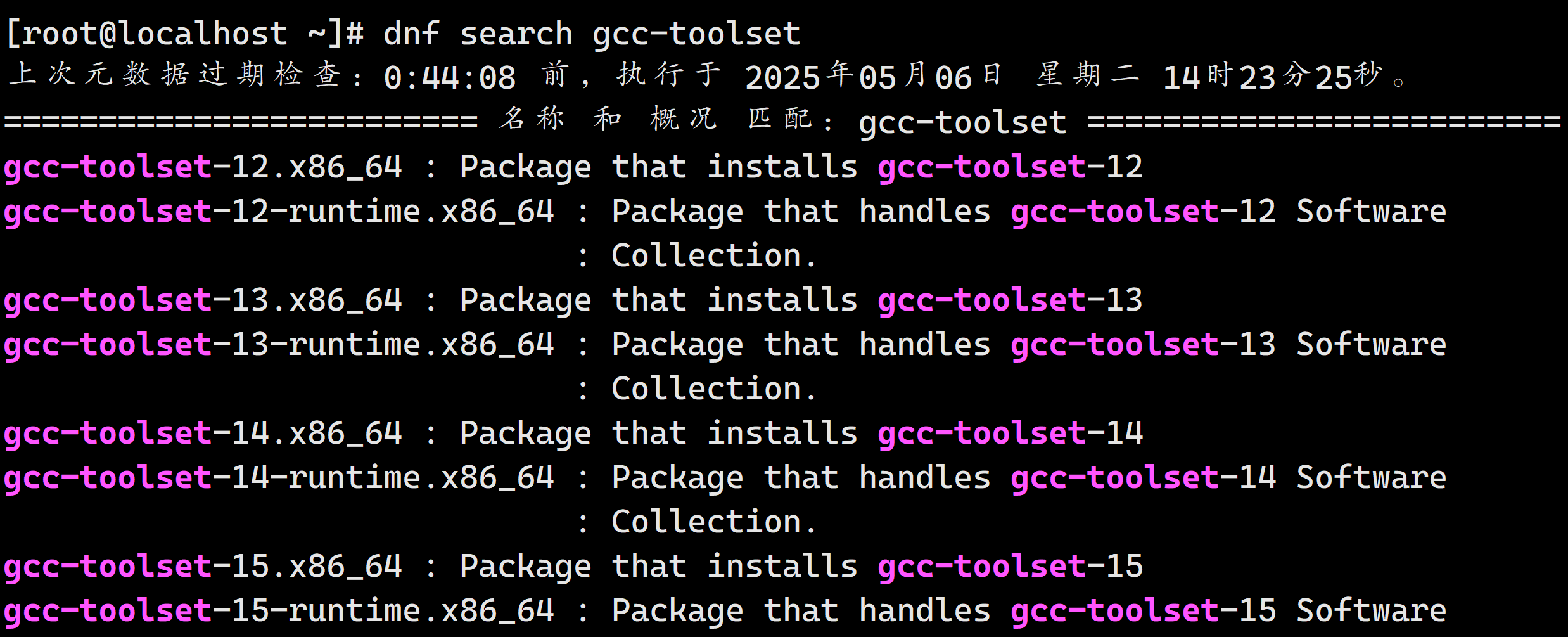
我们这里选择12版本
2. 安装默认的 GCC 工具集
CentOS Stream 9 可能默认提供 GCC Toolset 12 或更高版本:
sudo dnf install gcc-toolset-12
3. 正确的启用方式
在 CentOS Stream 9 中,gcc-toolset-12 不再通过 module load 启用,而是通过 直接加载环境变量:
source /opt/rh/gcc-toolset-12/enable
然后验证 GCC 版本:
gcc --version
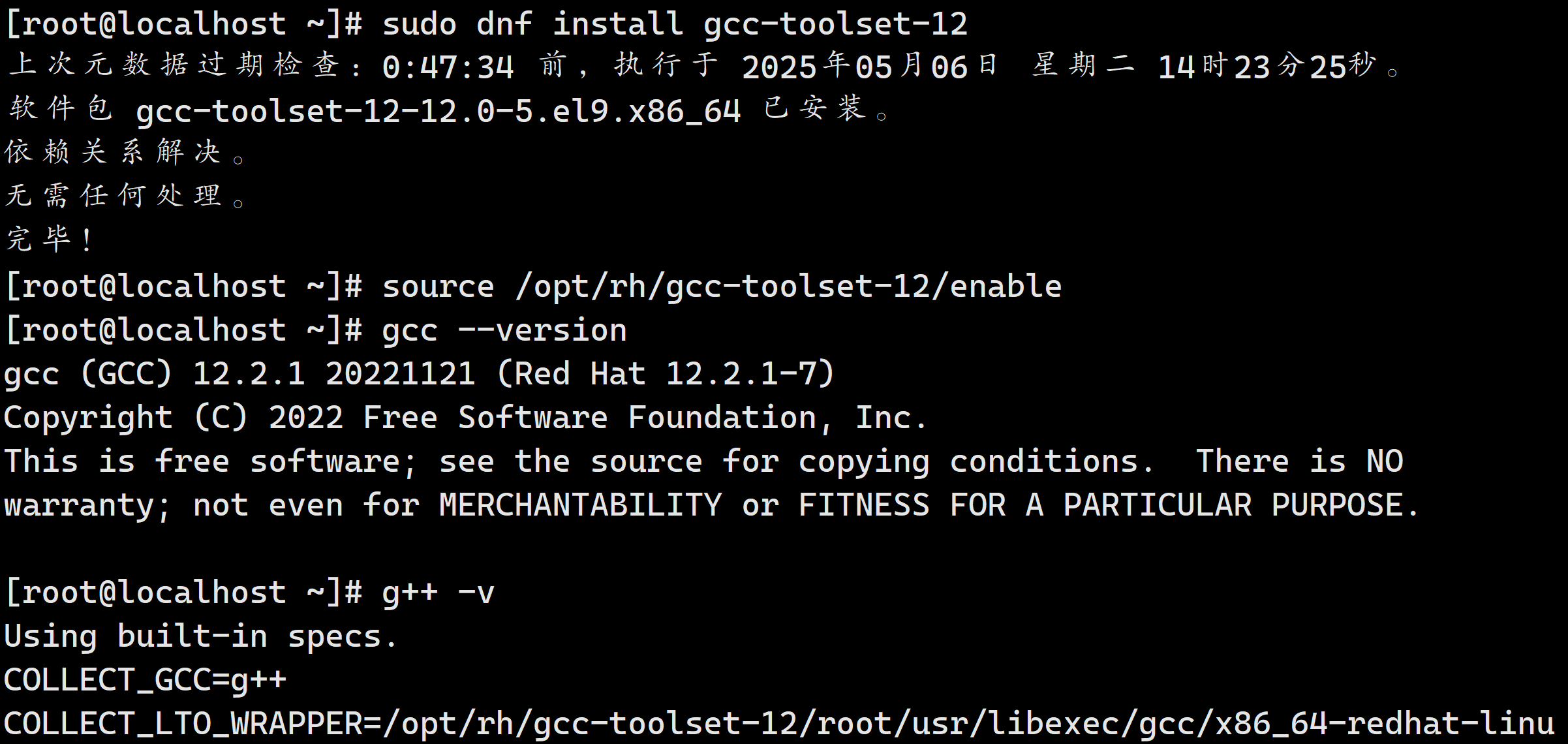
4. 永久启用(可选)
如果希望每次登录自动启用,可以将以下内容添加到 ~/.bashrc:
echo 'source /opt/rh/gcc-toolset-12/enable' >> ~/.bashrc
source ~/.bashrc
安装Protobuf
这里建议大家先在windows上下好了传到Linux上:
下载链接(如果有VPN,可以开一个,下得快):
https://github.com/protocolbuffers/protobuf/releases/download/v3.2
0.2/protobuf-all-3.20.2.tar.gz
然后执行以下代码:
tar -xzf protobuf-all-21.12.tar.gz
cd protobuf-21.12
./autogen.sh
./configure
make -j$(nproc)
sudo make install
sudo ldconfig
这段代码是用于从源码编译并安装 Protocol Buffers (Protobuf) 的完整流程。Protobuf 是 Google 开发的一种高效的数据序列化格式,广泛用于网络通信和数据存储。以下是每一步的详细解释:
1. 解压源码包
tar -xzf protobuf-all-21.12.tar.gz
- 作用:解压名为
protobuf-all-21.12.tar.gz的压缩包。 - 参数说明:
-x:解压文件。-z:使用gzip解压(针对.tar.gz文件)。-f:指定文件名。
- 结果:生成
protobuf-21.12目录,包含 Protobuf 的源码。
2. 进入源码目录
cd protobuf-21.12
- 作用:切换到解压后的 Protobuf 源码目录,准备进行编译。
3. 生成配置脚本
./autogen.sh
- 作用:运行
autogen.sh脚本,生成configure文件(如果源码包未提供预生成的configure文件)。 - 适用场景:
某些开源项目(如 Protobuf)使用autotools构建系统,需要先运行autogen.sh生成configure脚本。
4. 配置编译选项
./configure
- 作用:运行
configure脚本,检测系统环境(如编译器、库路径等),并生成Makefile。 - 关键行为:
- 检查系统是否安装了必要的依赖(如
g++、make、libtool等)。 - 生成针对当前系统的编译配置(如优化选项、安装路径等)。
- 检查系统是否安装了必要的依赖(如
- 自定义选项:
可以通过参数指定安装路径(如./configure --prefix=/usr/local/protobuf)。
5. 编译源码
make -j$(nproc)
- 作用:使用
make编译 Protobuf 源码。 - 参数说明:
-j$(nproc):启用多线程编译,$(nproc)自动获取 CPU 核心数,加速编译过程。
- 结果:生成可执行文件和库(如
protoc编译器、libprotobuf.so等)。
6. 安装到系统
sudo make install
- 作用:将编译好的 Protobuf 文件安装到系统目录(如
/usr/local/bin、/usr/local/lib)。 - 权限要求:需要
sudo权限,因为安装到系统目录需要管理员权限。 - 安装内容:
- 可执行文件(如
protoc)安装到/usr/local/bin。 - 库文件(如
libprotobuf.*)安装到/usr/local/lib。 - 头文件安装到
/usr/local/include。
- 可执行文件(如
7. 更新动态库缓存
sudo ldconfig
- 作用:更新系统的动态库缓存,使新安装的 Protobuf 库(
libprotobuf.so)能被系统识别。 - 必要性:
如果不运行ldconfig,程序在运行时可能找不到新安装的库,导致报错(如libprotobuf.so: cannot open shared object file)。
完整流程总结
- 解压源码:
tar -xzf protobuf-all-21.12.tar.gz - 进入目录:
cd protobuf-21.12 - 生成配置脚本:
./autogen.sh - 配置环境:
./configure - 编译代码:
make -j$(nproc) - 安装到系统:
sudo make install - 更新库缓存:
sudo ldconfig
验证安装
安装完成后,可以通过以下命令验证 Protobuf 是否安装成功:
protoc --version # 检查 protoc 版本
如果输出版本号(如 libprotoc 3.21.12),则安装成功。
安装 Muduo
先获取一下zip包:
wget https://gitee.com/hansionz/mq/raw/master/resource/muduo-master.zip
unzip muduo-master.zip
cd muduo-master
Muduo 需要以下依赖:
sudo dnf install -y gcc-c++ cmake make \boost-devel openssl-devel protobuf-devel \zlib-devel curl-devel
然后进行编译
# 进入 Muduo 源码目录
cd muduo-master# 使用 CMake 构建
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=Release .. # 推荐 Release 模式
make -j$(nproc) # 并行编译
最后进行安装:
sudo make install

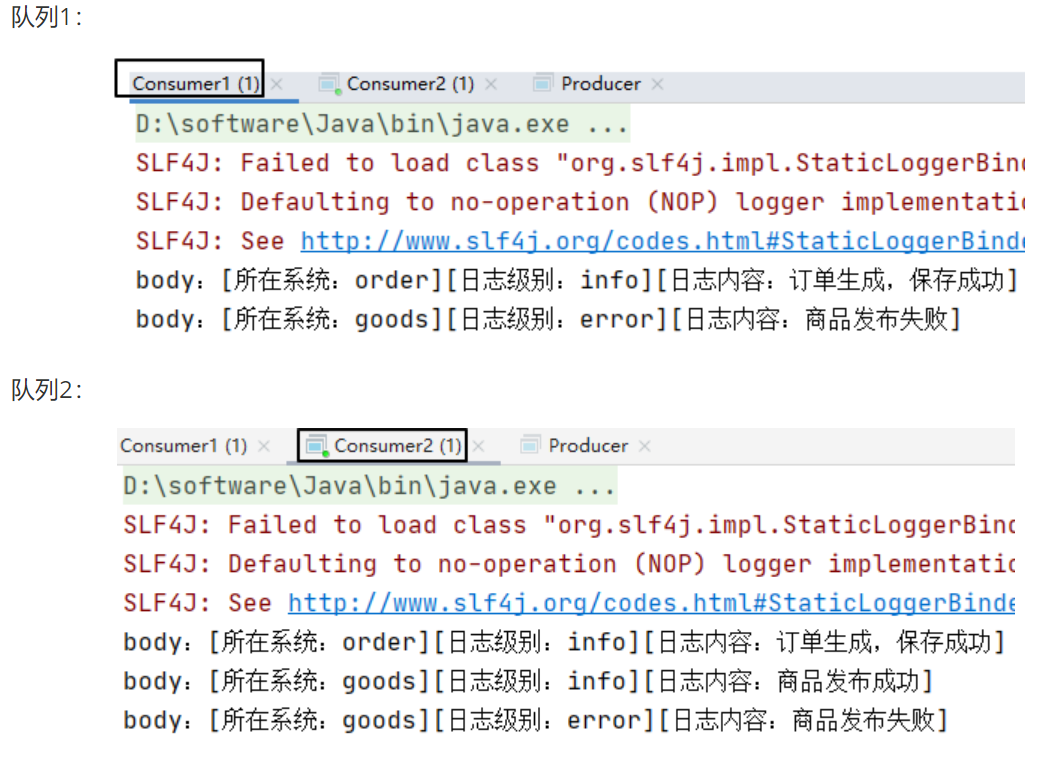
然后进入到bin目录我们可以来测试一下:
执行:
./protobuf_server 9091

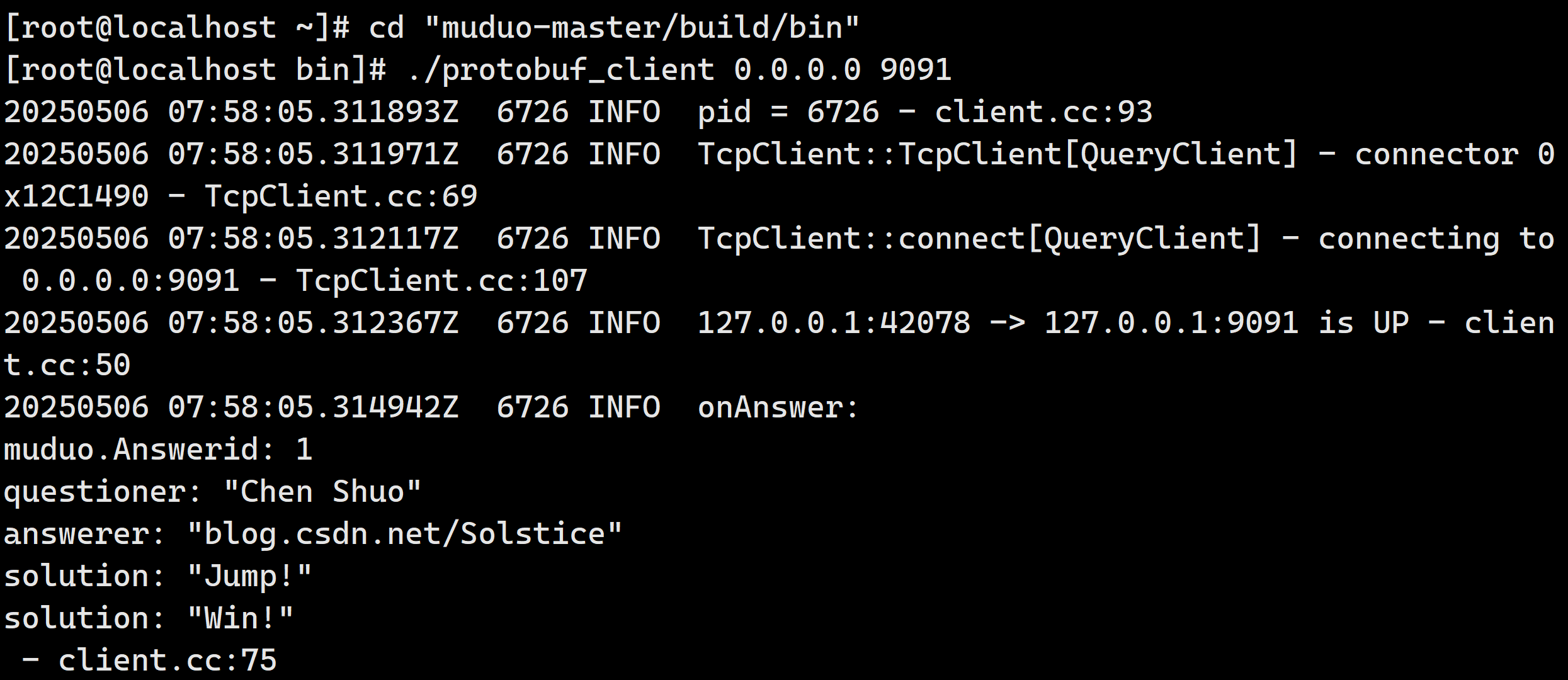
然后复制SSH渠道,执行:
./protobuf_client 0.0.0.0 9091
相关文章:
C++ - 仿 RabbitMQ 实现消息队列(1)(环境搭建)
C - 仿 RabbitMQ 实现消息队列(1)(环境搭建) 什么是消息队列核心特点核心组件工作原理常见消息队列实现应用场景优缺点 项目配置开发环境技术选型 更换软件源安装一些工具安装epel 软件源安装 lrzsz 传输工具安装git安装 cmake安装…...
微服务的高可用性)
66、微服务保姆教程(九)微服务的高可用性
微服务的高可用性与扩展 服务的高可用性 集群搭建与负载均衡。服务的故障容错与自愈。分布式事务与一致性 分布式事务的挑战与解决方案。使用 RocketMQ 实现分布式事务。微服务的监控与可观测性 metrics 和日志的收集与分析。sentinel 的监控功能。容器化与云原生 将微服务部署…...
RK3568-OpenHarmony(1) : OpenHarmony 5.1的编译
概述: 本文主要描述了,如何在ubuntu-20.04操作系统上,编译RK3568平台的OpenHarmony 5.1版本。 搭建编译环境 a. 安装软件包 sudo apt-get install git-lfs ruby genext2fs build-essential git curl libncurses5-dev libncursesw5-dev openjdk-11-jd…...
eFish-SBC-RK3576工控板外部RTC测试操作指南
备注: 1)测试时一定要接电池,否则外部RTC断电后无法工作导致测试失败; 2)如果连接了网络,系统会自动同步NTP时钟,所以需要关闭自动同步时钟。 关闭自动同步NTP时钟方法: 先查看是…...

vue3的深入组件-组件 v-model
组件 v-model 基本用法 v-model 可以在组件上使用以实现双向绑定。 从 Vue 3.4 开始,推荐的实现方式是使用 defineModel() 宏: <script setup> const model defineModel()function update() {model.value } </script><template>…...

【MySQL】数据库、数据表的基本操作
个人主页:Guiat 归属专栏:MySQL 文章目录 1. MySQL基础命令1.1 连接MySQL1.2 基本命令概览 2. 数据库操作2.1 创建数据库2.2 查看数据库2.3 选择数据库2.4 修改数据库2.5 删除数据库2.6 数据库备份与恢复 3. 表操作基础3.1 创建表3.2 查看表信息3.3 创建…...
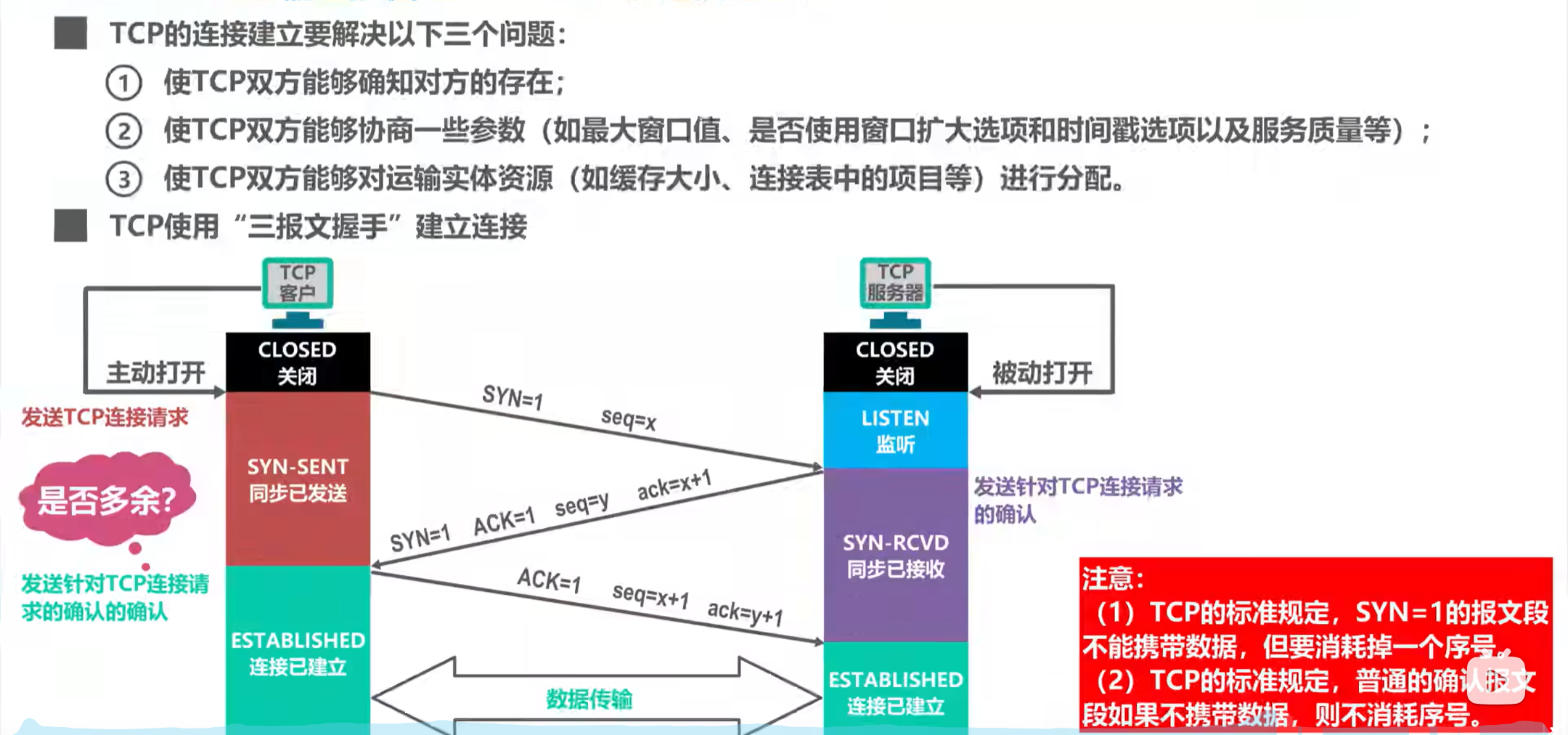
TCP的连接管理
三次握手 什么是三次握手? 1. 第一次握手(客户端 → 服务器) 客户端发送一个 SYN 报文,请求建立连接。 报文中包含一个初始序列号 SEQ x。 表示:我想和你建立连接,我的序列号是 x。 2. 第二次握手&a…...

DAMA第10章深度解析:参考数据与主数据管理的核心要义与实践指南
引言 在数字化转型的浪潮中,数据已成为企业的核心资产。然而,数据孤岛、冗余和不一致问题严重制约了数据价值的释放。DAMA(数据管理协会)提出的参考数据(Reference Data)与主数据(Master Data&…...
初识Linux · 传输层协议TCP · 下
目录 前言: 滑动窗口和流量控制机制 流量控制 滑动窗口 1.滑动窗口如何移动 2.滑动窗口的大小如何变化的 3.如果发生了丢包如何解决(快重传) 拥塞控制 延迟应答 面向字节流 RST PSH URG 什么是 PSH? 什么是 URG&…...
:集群安全加固全攻略)
Kubernetes生产实战(十六):集群安全加固全攻略
Kubernetes集群安全加固全攻略:生产环境必备的12个关键策略 在容器化时代,Kubernetes已成为企业应用部署的核心基础设施。但根据CNCF 2023年云原生安全报告显示,75%的安全事件源于K8s配置错误。本文将基于生产环境实践,系统讲解集…...
什么是分布式光伏系统?屋顶分布式光伏如何并网?
政策窗口倒计时!分布式光伏如何破局而立? 2025年,中国分布式光伏行业迎来关键转折: ▸ "430"落幕——抢装潮收官,但考验才刚开始; ▸ "531"生死线——新增项目全面市场化交易启动&…...

YOLO 从入门到精通学习指南
一、引言 在计算机视觉领域,目标检测是一项至关重要的任务,其应用场景广泛,涵盖安防监控、自动驾驶、智能交通等众多领域。YOLO(You Only Look Once)作为目标检测领域的经典算法系列,以其高效、快速的特点受到了广泛的关注和应用。本学习指南将带领你从 YOLO 的基础概念…...
)
嵌入式硬件篇---麦克纳姆轮(简单运动实现)
文章目录 前言1. 麦克纳姆轮的基本布局X型布局O型布局 2. 运动模式实现原理(1) 前进/后退前进后退 (2) 左右平移向左平移向右平移 (3) 原地旋转顺时针旋转(右旋)逆时针旋转(左旋) (4) 斜向移动左上45移动 (5) 180旋转 3. 数学原理…...

完整进行一次共线性分析
(随便找个基因家族) 1.数据收集 使用水稻、拟南芥、玉米三种作物进行示例 可以直接去ensemble去找最标准的基因组fasta文件和gff文件。 2.预处理数据 这里对于fasta和gff数据看情况要不要过滤掉线粒体叶绿体的基因,数据差异非常大&#…...
RabbitMQ--基础篇
RabbitMQ 简介:RabbitMQ 是一种开源的消息队列中间件,你可以把它想象成一个高效的“邮局”。它专门负责在不同应用程序之间传递消息,让系统各部分能松耦合地协作 优势: 异步处理:比如用户注册后,主程序将发…...

Quorum协议原理与应用详解
一、Quorum 协议核心原理 基本定义 Quorum 是一种基于 读写投票机制 的分布式一致性协议,通过权衡一致性(C)与可用性(A)实现数据冗余和最终一致性。其核心规则为: W(写成功副本数) …...
vue搭建+element引入
vue搭建element 在使用Vue.js开发项目时,经常会选择使用Element UI作为UI框架,因为它提供了丰富的组件和良好的设计,可以大大提高开发效率。以下是如何在Vue项目中集成Element UI的步骤: 1. 创建Vue项目 如果你还没有创建Vue项…...
食物数据分析系统vue+flask
食物数据分析系统 项目概述 食物数据分析系统是一个集食物营养成分查询、对比分析和数据可视化于一体的Web应用。系统采用前后端分离架构,为用户提供食物营养信息检索、食物对比和营养分析等功能,帮助用户了解食物的营养成分,做出更健康的饮…...
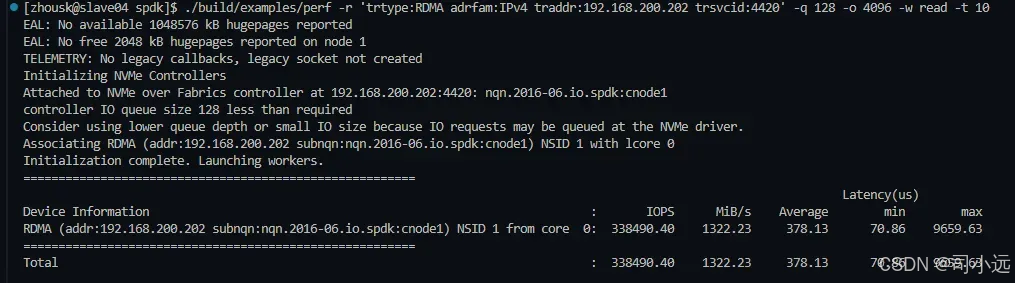
SPDK NVMe of RDMA 部署
使用SPDK NVMe of RDMA 实现多NVMe设备共享 一、编译、安装spdk 1.1、下载 1.1.1 下载spdk源码 首先,我们需要从GitHub上克隆SPDK的源码仓库。打开终端,输入以下命令: git clone -b v22.01 https://github.com/spdk/spdk.git cd spdk1.1.2…...

《C++中插入位的函数实现及示例说明》
《C中插入位的函数实现及示例说明》 这个函数 insertBits 的作用是将整数 M 插入到整数 N 的指定位置区间 [i, j] 中。具体来说,函数会先清除 N 中从第 i 位到第 j 位的所有位,然后将 M 左移 i 位后与清除后的 N 相加,从而将 M 插入到 N 的指…...
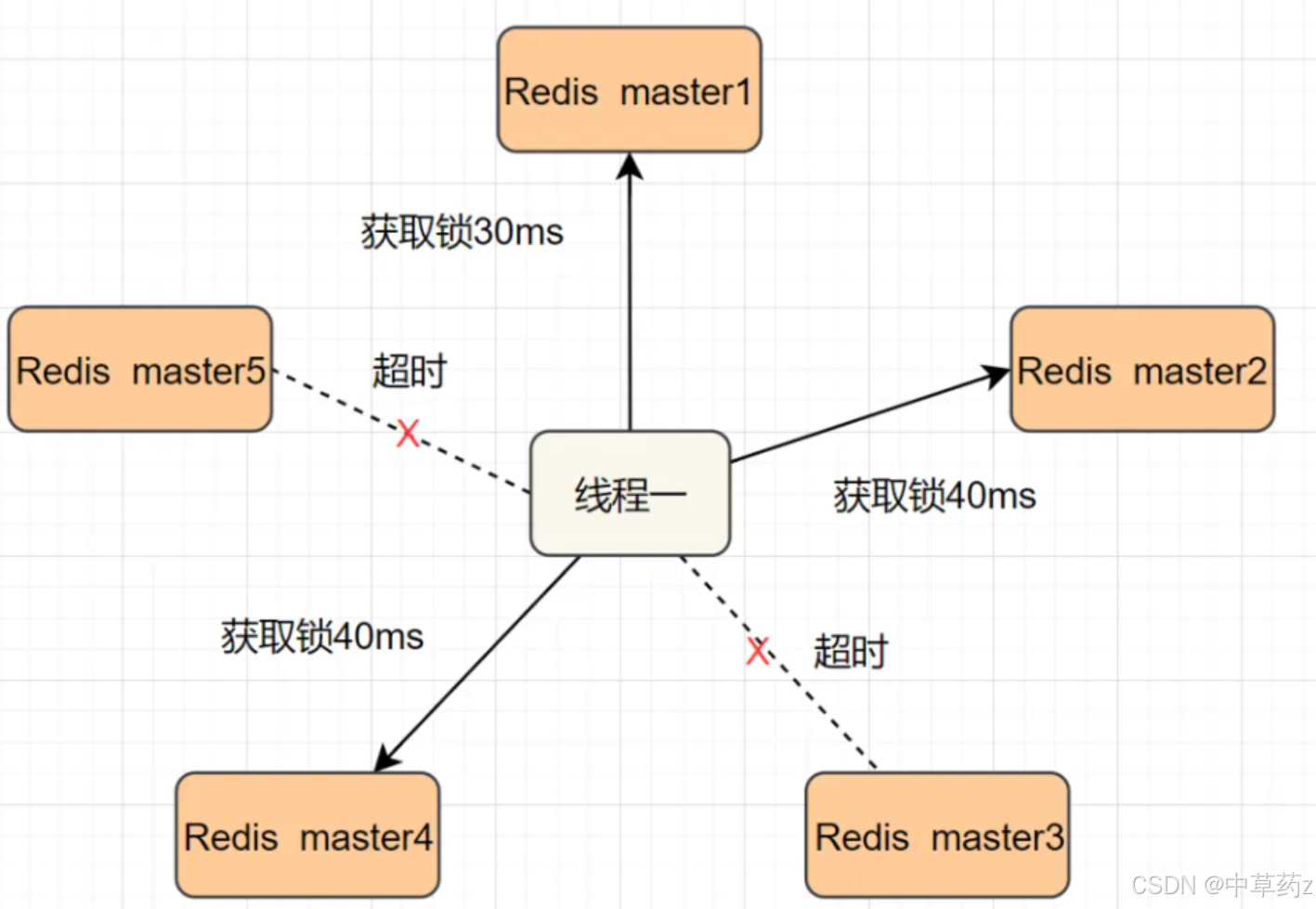
【Redis】缓存和分布式锁
🔥个人主页: 中草药 🔥专栏:【中间件】企业级中间件剖析 一、缓存(Cache) 概述 Redis最主要的应用场景便是作为缓存。缓存(Cache)是一种用于存储数据副本的技术或组件,…...

SDK游戏盾与高防ip的的区别
SDK游戏盾与高防IP是两种针对不同业务场景设计的网络安全防护方案,二者在技术原理、防护能力、应用场景及用户体验等方面存在显著差异。以下为具体对比分析: 一、技术原理与实现方式 高防IP 原理:通过DNS解析或BGP路由将流量牵引至高防机房…...
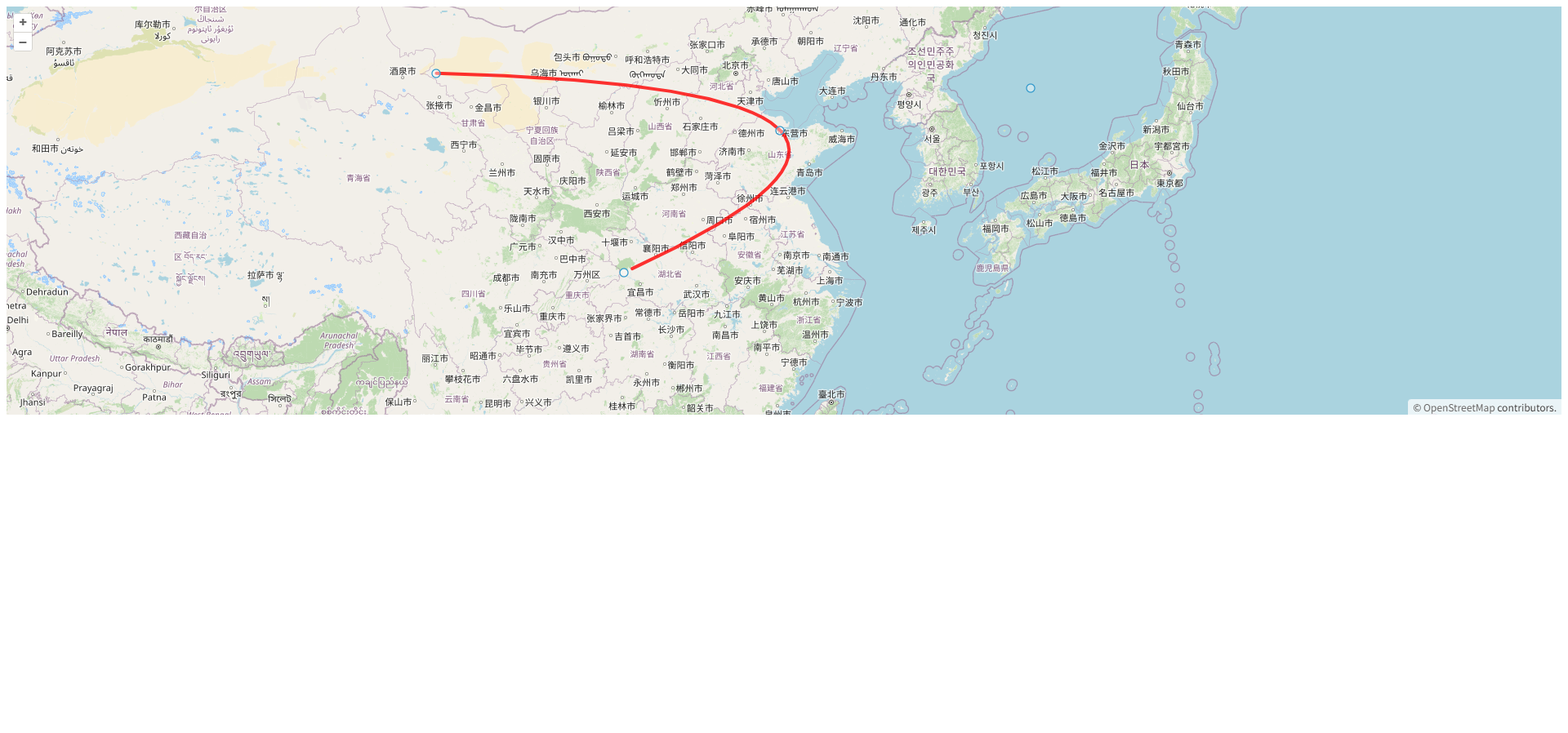
OpenLayers 精确经过三个点的曲线绘制
OpenLayers 精确经过三个点的曲线绘制 根据您的需求,我将提供一个使用 OpenLayers 绘制精确经过三个指定点的曲线解决方案。对于三个点的情况,我们可以使用 二次贝塞尔曲线 或 三次样条插值,确保曲线精确通过所有控制点。 实现方案 下面是…...
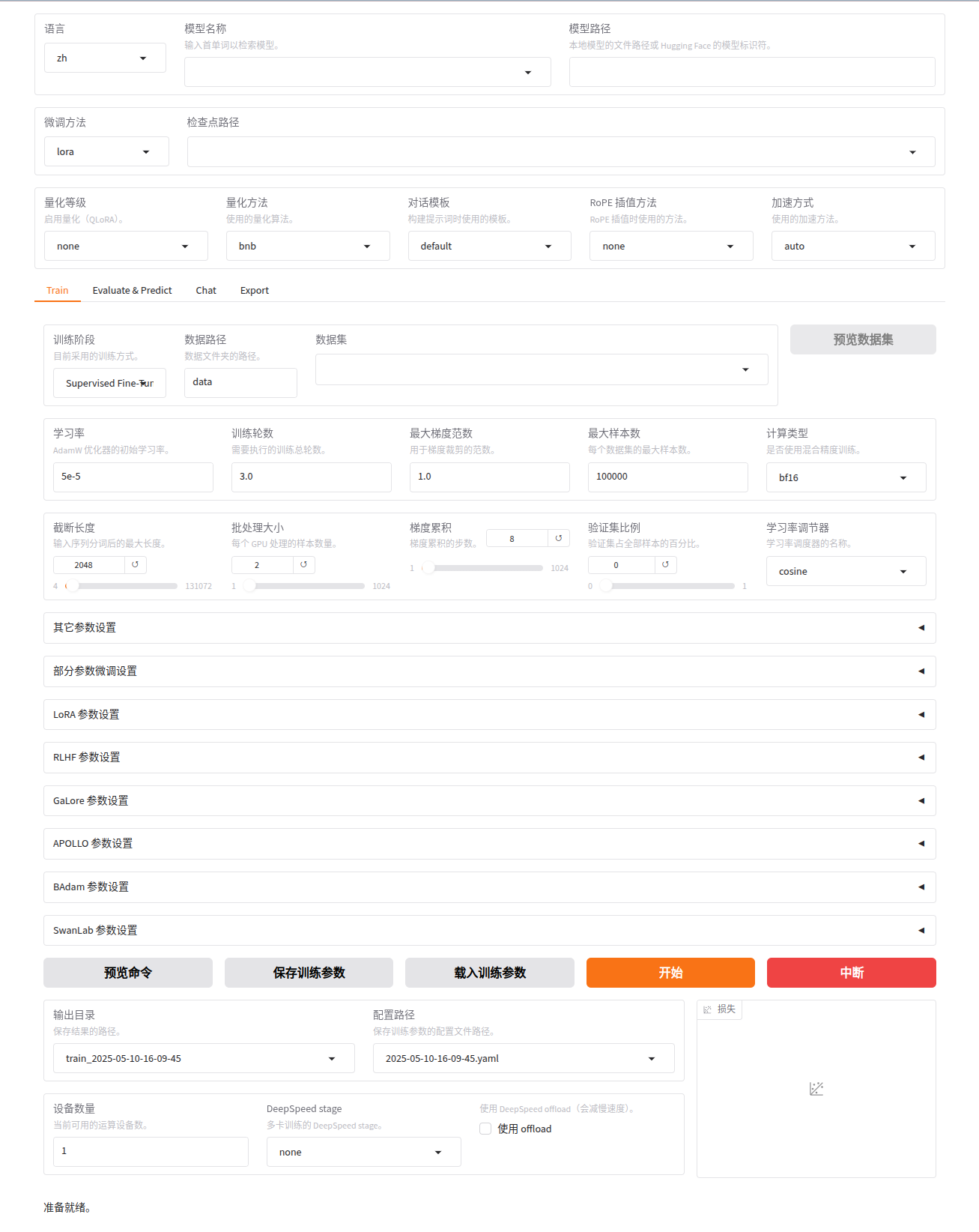
大模型微调指南之 LLaMA-Factory 篇:一键启动LLaMA系列模型高效微调
文章目录 一、简介二、如何安装2.1 安装2.2 校验 三、开始使用3.1 可视化界面3.2 使用命令行3.2.1 模型微调训练3.2.2 模型合并3.2.3 模型推理3.2.4 模型评估 四、高级功能4.1 分布训练4.2 DeepSpeed4.2.1 单机多卡4.2.2 多机多卡 五、日志分析 一、简介 LLaMA-Factory 是一个…...
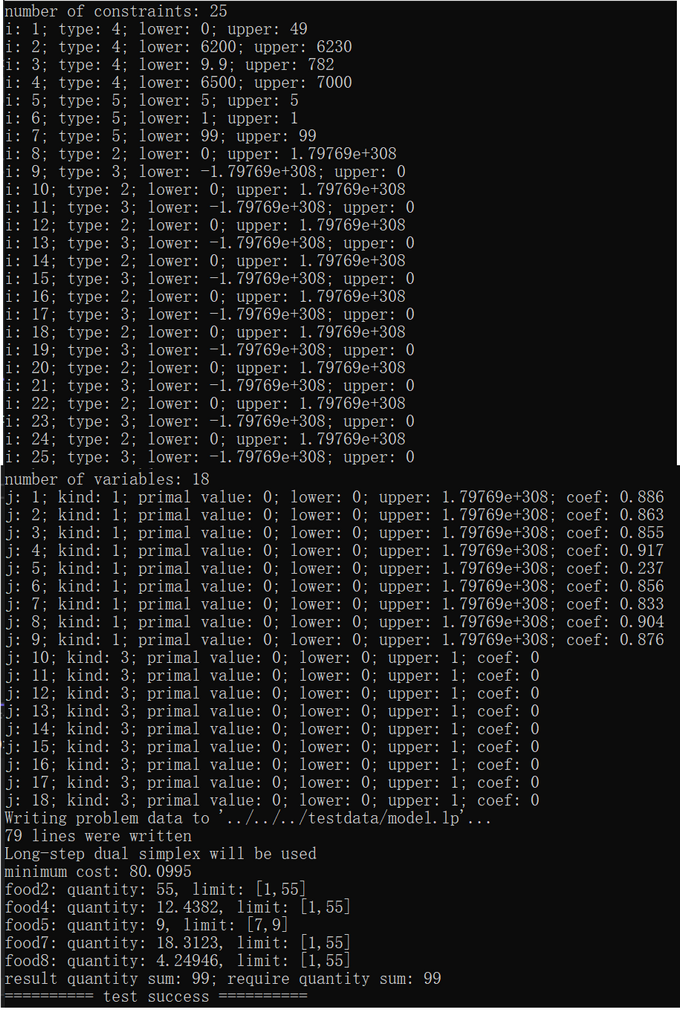
GLPK(GNU线性规划工具包)介绍
GLPK全称为GNU Linear Programming Kit(GNU线性规划工具包),可从 https://sourceforge.net/projects/winglpk/ 下载源码及二进制库,最新版本为4.65。也可从 https://ftp.gnu.org/gnu/glpk/ 下载,仅包含源码,最新版本为5.0。 GLPK是…...
:负载均衡流量分发管理实战指南)
Kubernetes生产实战(十七):负载均衡流量分发管理实战指南
在Kubernetes集群中,负载均衡是保障应用高可用、高性能的核心机制。本文将从生产环境视角,深入解析Kubernetes负载均衡的实现方式、最佳实践及常见问题解决方案。 一、Kubernetes负载均衡的三大核心组件 1)Service资源:集群内流…...

PCB设计实践(十三)PCB设计中差分线间距与线宽设置的深度解析
一、差分信号的基本原理与物理背景 差分信号技术通过两条等幅反相的传输线实现信号传输,其核心优势体现在电磁场耦合的对称性上。根据麦克斯韦方程组的对称解原理,两条线产生的电磁场在远场区域相互抵消,形成以下特性: 1. 共模噪…...
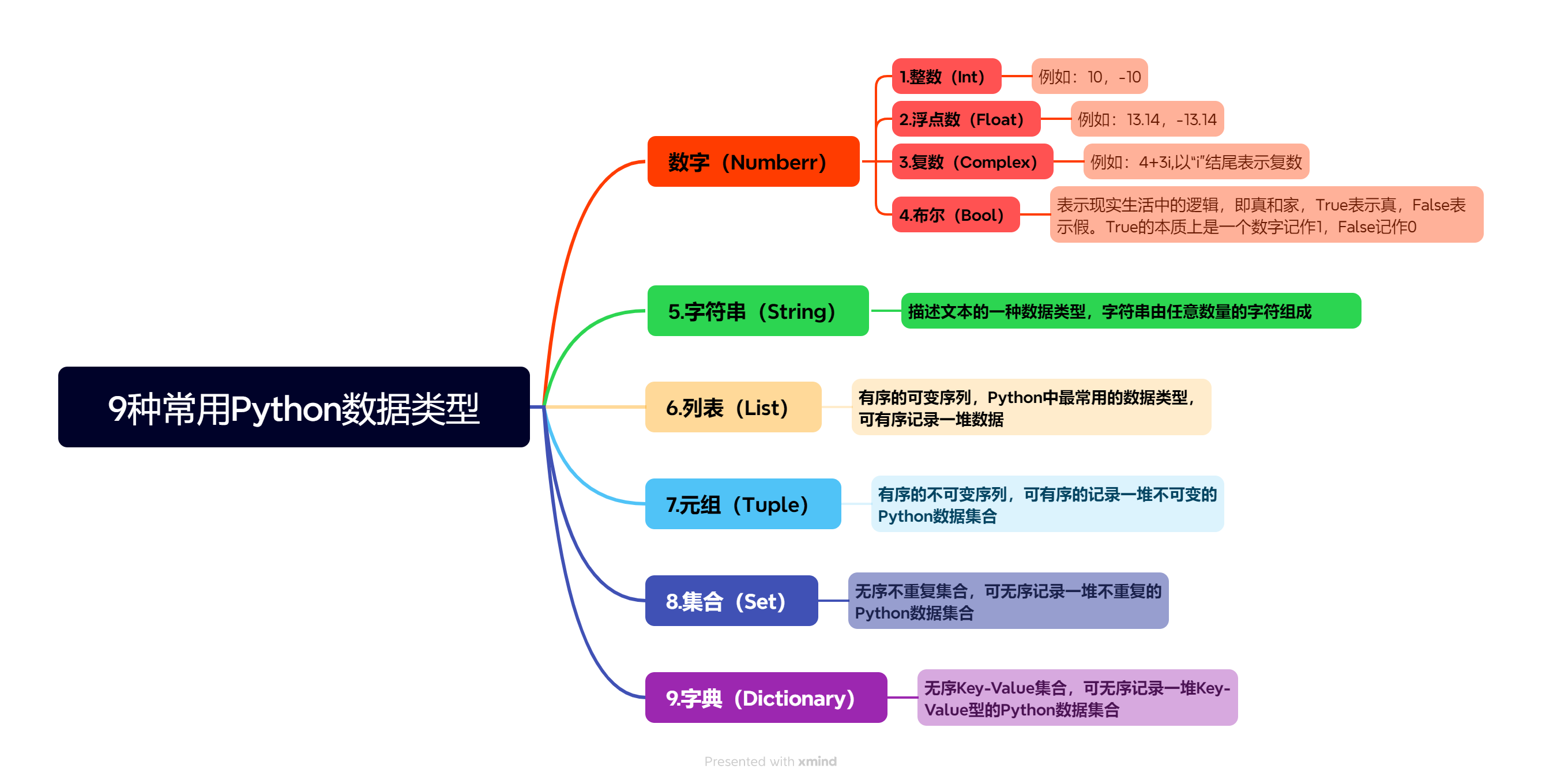
2025python学习笔记
一.Python语言基础入门 第一章 01.初识Python Python的起源: 1989年,为了打发圣诞节假期,Gudio van Rossum吉多范罗苏姆(龟叔)决心开发一个新的解释程序(Python维形)1991年,第一个…...

前端取经路——入门取经:初出师门的九个CSS修行
大家好,我是老十三,一名前端开发工程师。CSS就像前端修行路上的第一道关卡,看似简单,实则暗藏玄机。在今天的文章中,我将带你一起应对九大CSS难题,从Flexbox布局到响应式设计,从选择器优先级到B…...

【Pandas】pandas DataFrame corr
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值DataFrame.all([axis, bool_only, skipna])用于判断 DataFrame 中是否所有元素在指定轴上都为 TrueDataFrame.any(*[, axis, bool_only, skipna])用于判断…...