The Action Replay Process
Preface
A commonly used inequality
− x > ln ( 1 − x ) , 0 < x < 1 -x > \ln(1 - x), \quad 0 < x < 1 −x>ln(1−x),0<x<1
Proof: Let f ( x ) = ln ( 1 − x ) + x f(x) = \ln(1 - x) + x f(x)=ln(1−x)+x, for 0 < x < 1 0 < x < 1 0<x<1. Then f ( 0 ) = 0 f(0) = 0 f(0)=0.
f ′ ( x ) = − 1 1 − x + 1 = x x − 1 < 0 f'(x) = \frac{-1}{1 - x} + 1 = \frac{x}{x - 1} < 0 f′(x)=1−x−1+1=x−1x<0
Hence, − x > ln ( 1 − x ) , 0 < x < 1 -x > \ln(1 - x), \quad 0 < x < 1 −x>ln(1−x),0<x<1. Q.E.D.
Fundamental Theorem
If a n > − 1 a_n > -1 an>−1, then
∏ n = 1 ∞ ( 1 + a n ) = 0 ⇔ ∑ n = 1 ∞ ln ( 1 + a n ) = − ∞ \prod_{n=1}^\infty (1 + a_n) = 0 \Leftrightarrow \sum_{n=1}^\infty \ln(1 + a_n) = -\infty n=1∏∞(1+an)=0⇔n=1∑∞ln(1+an)=−∞
Proof: Let P k = ∏ n = 1 k ( 1 + a n ) P_k = \prod_{n=1}^k (1 + a_n) Pk=∏n=1k(1+an), then
ln P k = ln ( ∏ n = 1 k ( 1 + a n ) ) = ∑ n = 1 k ln ( 1 + a n ) \ln P_k = \ln\left(\prod_{n=1}^k (1 + a_n)\right) = \sum_{n=1}^k \ln(1 + a_n) lnPk=ln(n=1∏k(1+an))=n=1∑kln(1+an)
Thus,
∑ n = 1 ∞ ln ( 1 + a n ) = − ∞ ⇔ lim k → ∞ ∑ n = 1 k ln ( 1 + a n ) = − ∞ ⇔ lim k → ∞ ln P k = − ∞ ⇔ lim k → ∞ P k = 0 \sum_{n=1}^\infty \ln(1 + a_n) = -\infty \Leftrightarrow \lim_{k \to \infty} \sum_{n=1}^k \ln(1 + a_n) = -\infty \Leftrightarrow \lim_{k \to \infty} \ln P_k = -\infty \Leftrightarrow \lim_{k \to \infty} P_k = 0 n=1∑∞ln(1+an)=−∞⇔k→∞limn=1∑kln(1+an)=−∞⇔k→∞limlnPk=−∞⇔k→∞limPk=0
Q.E.D.
Corollary
If 0 ≤ b n < 1 0 \le b_n < 1 0≤bn<1 and ∑ n = 1 ∞ b n = + ∞ \sum_{n=1}^\infty b_n = +\infty ∑n=1∞bn=+∞, then
∏ n = 1 ∞ ( 1 − b n ) = 0 \prod_{n=1}^\infty (1 - b_n) = 0 n=1∏∞(1−bn)=0
Proof: Consider the subsequence { b n k } \{b_{n_k}\} {bnk} consisting of non-zero b n b_n bn. Since − b n k > − 1 -b_{n_k} > -1 −bnk>−1, and applying the fundamental theorem, we have:
∏ n = 1 ∞ ( 1 − b n ) = ∏ k = 1 ∞ ( 1 − b n k ) = 0 ⇔ ∑ k = 1 ∞ ln ( 1 − b n k ) = − ∞ \prod_{n=1}^\infty (1 - b_n) = \prod_{k=1}^\infty (1 - b_{n_k}) = 0 \Leftrightarrow \sum_{k=1}^\infty \ln(1 - b_{n_k}) = -\infty n=1∏∞(1−bn)=k=1∏∞(1−bnk)=0⇔k=1∑∞ln(1−bnk)=−∞
We now show ∑ k = 1 ∞ ln ( 1 − b n k ) = − ∞ \sum_{k=1}^\infty \ln(1 - b_{n_k}) = -\infty ∑k=1∞ln(1−bnk)=−∞.
Given 0 < 1 − b n k < 1 0 < 1 - b_{n_k} < 1 0<1−bnk<1, we have ln ( 1 − b n k ) < 0 \ln(1 - b_{n_k}) < 0 ln(1−bnk)<0, and ∑ k = 1 ∞ b n k = + ∞ \sum_{k=1}^\infty b_{n_k} = +\infty ∑k=1∞bnk=+∞. It’s not immediately obvious, so we proceed by contradiction:
Assume ∑ k = 1 ∞ ln ( 1 − b n k ) ≠ − ∞ \sum_{k=1}^\infty \ln(1 - b_{n_k}) \ne -\infty ∑k=1∞ln(1−bnk)=−∞. Since each term is negative, this implies convergence, i.e.,
∑ k = 1 ∞ ln ( 1 − b n k ) > − ∞ \sum_{k=1}^\infty \ln(1 - b_{n_k}) > -\infty k=1∑∞ln(1−bnk)>−∞
But ∑ k = 1 ∞ ( − b n k ) = − ∞ ≥ ∑ k = 1 ∞ ln ( 1 − b n k ) > − ∞ \sum_{k=1}^\infty (-b_{n_k}) = -\infty \ge \sum_{k=1}^\infty \ln(1 - b_{n_k}) > -\infty ∑k=1∞(−bnk)=−∞≥∑k=1∞ln(1−bnk)>−∞, a contradiction.
Therefore, ∑ k = 1 ∞ ln ( 1 − b n k ) = − ∞ \sum_{k=1}^\infty \ln(1 - b_{n_k}) = -\infty ∑k=1∞ln(1−bnk)=−∞, and so
∏ n = 1 ∞ ( 1 − b n ) = 0 \prod_{n=1}^\infty (1 - b_n) = 0 n=1∏∞(1−bn)=0
Q.E.D.
The Essence of Mathematical Truth: Induction
Observe a linear-looking relation, fantasize wildly, then coldly examine whether it is truly valid.
Given X 1 X_1 X1 and the recursive formula:
X n + 1 = X n + β n ( ξ n − X n ) = ( 1 − β n ) X n + β n ξ n X_{n+1} = X_n + \beta_n(\xi_n - X_n) = (1 - \beta_n)X_n + \beta_n \xi_n Xn+1=Xn+βn(ξn−Xn)=(1−βn)Xn+βnξn
Show that
X n + 1 = ∑ j = 1 n ξ j β j ∏ i = j n − 1 ( 1 − β i + 1 ) + X 1 ∏ i = 1 n ( 1 − β i ) X_{n+1} = \sum_{j=1}^{n} \xi_j \beta_j \prod_{i=j}^{n-1} (1 - \beta_{i+1}) + X_1 \prod_{i=1}^n (1 - \beta_i) Xn+1=j=1∑nξjβji=j∏n−1(1−βi+1)+X1i=1∏n(1−βi)
Proof:
-
Base case: n = 1 n = 1 n=1
X 2 = ( 1 − β 1 ) X 1 + β 1 ξ 1 = ξ 1 β 1 + X 1 ( 1 − β 1 ) X_2 = (1 - \beta_1)X_1 + \beta_1 \xi_1 = \xi_1 \beta_1 + X_1 (1 - \beta_1) X2=(1−β1)X1+β1ξ1=ξ1β1+X1(1−β1)
holds.
-
Inductive step: assume true for n n n, prove for n + 1 n+1 n+1:
X n + 2 = ( 1 − β n + 1 ) X n + 1 + β n + 1 ξ n + 1 X_{n+2} = (1 - \beta_{n+1})X_{n+1} + \beta_{n+1} \xi_{n+1} Xn+2=(1−βn+1)Xn+1+βn+1ξn+1
Plug in inductive hypothesis:
= ( 1 − β n + 1 ) [ ∑ j = 1 n ξ j β j ∏ i = j n − 1 ( 1 − β i + 1 ) + X 1 ∏ i = 1 n ( 1 − β i ) ] + β n + 1 ξ n + 1 = (1 - \beta_{n+1})\left[\sum_{j=1}^{n} \xi_j \beta_j \prod_{i=j}^{n-1} (1 - \beta_{i+1}) + X_1 \prod_{i=1}^n (1 - \beta_i)\right] + \beta_{n+1} \xi_{n+1} =(1−βn+1)[j=1∑nξjβji=j∏n−1(1−βi+1)+X1i=1∏n(1−βi)]+βn+1ξn+1
= ∑ j = 1 n + 1 ξ j β j ∏ i = j n ( 1 − β i + 1 ) + X 1 ∏ i = 1 n + 1 ( 1 − β i ) = \sum_{j=1}^{n+1} \xi_j \beta_j \prod_{i=j}^{n} (1 - \beta_{i+1}) + X_1 \prod_{i=1}^{n+1} (1 - \beta_i) =j=1∑n+1ξjβji=j∏n(1−βi+1)+X1i=1∏n+1(1−βi)
-
By induction, the formula holds for all positive integers n n n. Q.E.D.
Now, let’s relax for a while — it’s movie time.
1. Definition of Action Replay Process
Given an n n n-step finite MDP with a possibly varying learning rate α \alpha α, in step i i i, the agent is in state x i x_i xi, takes action a i a_i ai, receives random reward r i r_i ri, and transitions to a new state y i y_i yi.
Action Replay Process (ARP) is a re-examination of state x x x and action a a a within a given MDP.
Suppose we focus on state x x x and action a a a, and consider an MDP consisting of n n n steps.
We add a step 0 in which the agent immediately terminates and receives reward Q 0 ( x , a ) Q_0(x,a) Q0(x,a).
During steps 1 to n n n, due to MDP randomness, the agent may take action a a a in state x x x at time steps 1 ≤ n i 1 , n i 2 , . . . , n i ∗ ≤ n 1 \le n^{i_1}, n^{i_2}, ..., n^{i_*} \le n 1≤ni1,ni2,...,ni∗≤n.
If action a a a is never taken at x x x in this episode, the only opportunity for it is at step 0.
When i ∗ ≥ 1 i_* \ge 1 i∗≥1, to determine ARP’s next reward and state, we sample an index n i e n^{i_e} nie as follows:
n i e = { n i ∗ , with probability α n i ∗ n i ∗ − 1 , with probability ( 1 − α n i ∗ ) α n i ∗ − 1 ⋮ 0 , with probability ∏ i = 1 i ∗ ( 1 − α n i ) n^{i_e} = \begin{cases} n^{i_*}, & \text{with probability } \alpha_{n^{i_*}} \\ n^{i_{*-1}}, & \text{with probability } (1 - \alpha_{n^{i_*}})\alpha_{n^{i_{*-1}}} \\ \vdots \\ 0, & \text{with probability } \prod_{i=1}^{i_*}(1 - \alpha_{n^i}) \end{cases} nie=⎩ ⎨ ⎧ni∗,ni∗−1,⋮0,with probability αni∗with probability (1−αni∗)αni∗−1with probability ∏i=1i∗(1−αni)
Then, after one ARP step, the state < x , n > <x, n> <x,n> transitions to < y n i e , n i e − 1 > <y_{n^{i_e}}, n^{i_e} - 1> <ynie,nie−1>, and the reward is r n i e r_{n^{i_e}} rnie.
Clearly, n i e − 1 < n n^{i_e} - 1 < n nie−1<n, so ARP terminates with probability 1. Thus, ARP is a finite process almost surely.
To summarize, the core transition formula is:
< x , n > → a < y n i e , n i e − 1 > , reward r n i e <x,n> \overset{a}{\rightarrow} <y_{n^{i_e}}, n^{i_e} - 1>, \quad \text{reward } r_{n^{i_e}} <x,n>→a<ynie,nie−1>,reward rnie
2. Properties of the Action Replay Process
We now examine ARP’s properties, particularly in comparison to MDPs. Given an MDP rule and a (non-terminating) instance, we can construct an ARP accordingly.
Property 1
∀ n , x , a , Q A R P ∗ ( < x , n > , a ) = Q n ( x , a ) \forall n, x, a,\quad Q^*_{ARP}(<x, n>, a) = Q_n(x, a) ∀n,x,a,QARP∗(<x,n>,a)=Qn(x,a)
Proof:
Using mathematical induction on n n n:
-
Base case n = 1 n=1 n=1:
-
If the MDP did not take a a a at x x x in step 1, ARP gives reward Q 0 ( x , a ) = 0 = Q 1 ( x , a ) Q_0(x,a) = 0 = Q_1(x,a) Q0(x,a)=0=Q1(x,a)
-
If ( x , a ) = ( x 1 , a 1 ) (x,a) = (x_1, a_1) (x,a)=(x1,a1), then:
Q A R P ∗ ( < x , 1 > , a ) = α 1 r 1 + ( 1 − α 1 ) Q 0 ( x , a ) = α 1 r 1 = Q 1 ( x , a ) Q^*_{ARP}(<x,1>, a) = \alpha_1 r_1 + (1 - \alpha_1) Q_0(x,a) = \alpha_1 r_1 = Q_1(x,a) QARP∗(<x,1>,a)=α1r1+(1−α1)Q0(x,a)=α1r1=Q1(x,a)
-
-
Inductive step: Assume Q A R P ∗ ( < x , k − 1 > , a ) = Q k − 1 ( x , a ) Q^*_{ARP}(<x, k-1>, a) = Q_{k-1}(x,a) QARP∗(<x,k−1>,a)=Qk−1(x,a), show for k k k:
-
If ( x , a ) ≠ ( x k , a k ) (x,a) \ne (x_k, a_k) (x,a)=(xk,ak), then:
Q k ( x , a ) = Q k − 1 ( x , a ) = Q A R P ∗ ( < x , k > , a ) Q_k(x,a) = Q_{k-1}(x,a) = Q^*_{ARP}(<x, k>, a) Qk(x,a)=Qk−1(x,a)=QARP∗(<x,k>,a)
-
If ( x , a ) = ( x k , a k ) (x,a) = (x_k, a_k) (x,a)=(xk,ak), then:
Q A R P ∗ ( < x , k > , a ) = α k [ r k + γ max a Q k − 1 ( y k , a ) ] + ( 1 − α k ) Q k − 1 ( x , a ) = Q k ( x , a ) Q^*_{ARP}(<x,k>, a) = \alpha_k [r_k + \gamma \max_a Q_{k-1}(y_k,a)] + (1 - \alpha_k) Q_{k-1}(x,a) = Q_k(x,a) QARP∗(<x,k>,a)=αk[rk+γamaxQk−1(yk,a)]+(1−αk)Qk−1(x,a)=Qk(x,a)
-
-
Therefore, Q A R P ∗ ( < x , n > , a ) = Q n ( x , a ) Q^*_{ARP}(<x,n>, a) = Q_n(x,a) QARP∗(<x,n>,a)=Qn(x,a). Q.E.D.
Property 2 In the ARP ${<x_i,n_i>}$, for all l , s , ϵ > 0 l, s, \epsilon > 0 l,s,ϵ>0, there exists h > l h > l h>l such that for all n 1 > h n_1 > h n1>h,
P ( n s + 1 < l ) < ϵ P(n_{s+1} < l) < \epsilon P(ns+1<l)<ϵ
Proof:
Let us first consider the final step, that is, the case where n i e < n i l n^{i_e} < n^{i_l} nie<nil or even lower.
Given in the ARP, starting from < x , h > <x, h> <x,h>, after taking action a a a, the probability of reaching a level lower than l l l in one step is:
∑ j = 0 i l − 1 [ α n j ∏ k = j + 1 i h ( 1 − α n k ) ] = ∑ j = 0 i l − 1 [ α n j ∏ k = j + 1 i l − 1 ( 1 − α n k ) ] [ ∏ i = i l i h ( 1 − α n i ) ] = [ ∏ i = i l i h ( 1 − α n i ) ] ∑ j = 0 i l − 1 [ α n j ∏ k = j + 1 i l − 1 ( 1 − α n k ) ] \sum_{j=0}^{i_l - 1} \left[ \alpha_{n^j} \prod_{k=j+1}^{i_h} (1 - \alpha_{n^k}) \right] = \sum_{j=0}^{i_l - 1} \left[ \alpha_{n^j} \prod_{k=j+1}^{i_l - 1} (1 - \alpha_{n^k}) \right] \left[ \prod_{i=i_l}^{i_h} (1 - \alpha_{n^i}) \right] = \left[ \prod_{i=i_l}^{i_h} (1 - \alpha_{n^i}) \right] \sum_{j=0}^{i_l - 1} \left[ \alpha_{n^j} \prod_{k=j+1}^{i_l - 1} (1 - \alpha_{n^k}) \right] j=0∑il−1 αnjk=j+1∏ih(1−αnk) =j=0∑il−1 αnjk=j+1∏il−1(1−αnk) [i=il∏ih(1−αni)]=[i=il∏ih(1−αni)]j=0∑il−1 αnjk=j+1∏il−1(1−αnk)
But note that:
∑ j = 0 i l − 1 [ α n j ∏ k = j + 1 i l − 1 ( 1 − α n k ) ] = 1 \sum_{j=0}^{i_l - 1} \left[ \alpha_{n^j} \prod_{k=j+1}^{i_l - 1} (1 - \alpha_{n^k}) \right] = 1 j=0∑il−1 αnjk=j+1∏il−1(1−αnk) =1
Therefore,
∑ j = 0 i l − 1 [ α n j ∏ k = j + 1 i h ( 1 − α n k ) ] = ∏ i = i l i h ( 1 − α n i ) < e − ∑ i = i l i h α n i \sum_{j=0}^{i_l - 1} \left[ \alpha_{n^j} \prod_{k=j+1}^{i_h} (1 - \alpha_{n^k}) \right] = \prod_{i=i_l}^{i_h} (1 - \alpha_{n^i}) < e^{-\sum_{i=i_l}^{i_h} \alpha_{n^i}} j=0∑il−1 αnjk=j+1∏ih(1−αnk) =i=il∏ih(1−αni)<e−∑i=ilihαni
As long as every subsequence of { α n } \{\alpha_n\} {αn} diverges, then as h → ∞ h \to \infty h→∞:
∑ j = 0 i l − 1 [ α n j ∏ k = j + 1 i h ( 1 − α n k ) ] = ∏ i = i l i h ( 1 − α n i ) < e − ∑ i = i l i h α n i → 0 \sum_{j=0}^{i_l - 1} \left[ \alpha_{n^j} \prod_{k=j+1}^{i_h} (1 - \alpha_{n^k}) \right] = \prod_{i=i_l}^{i_h} (1 - \alpha_{n^i}) < e^{-\sum_{i=i_l}^{i_h} \alpha_{n^i}} \to 0 j=0∑il−1 αnjk=j+1∏ih(1−αnk) =i=il∏ih(1−αni)<e−∑i=ilihαni→0
Moreover, since the MDP is finite, we have:
∀ l j ∈ N ∗ , ∀ η j > 0 , ∃ M j > 0 , ∀ n j > M j , ∀ X j , a j , \forall l_j \in \mathbb{N}^*, \forall \eta_j > 0, \exists M_j > 0, \forall n_j > M_j, \forall X_j, a_j, ∀lj∈N∗,∀ηj>0,∃Mj>0,∀nj>Mj,∀Xj,aj,
starting from < X j , n j > <X_j, n_j> <Xj,nj>, after taking action a j a_j aj,
P ( n j + 1 ≥ l j ) = 1 − η j P(n_{j+1} \ge l_j) = 1 - \eta_j P(nj+1≥lj)=1−ηj
Using the index j j j, we recursively apply this conclusion from step s s s back to step 1. Then, the probability of reaching at least l = l s l = l_s l=ls is at least:
∏ j = 1 s ( 1 − η j ) = 1 − ϵ \prod_{j=1}^{s} (1 - \eta_j) = 1 - \epsilon j=1∏s(1−ηj)=1−ϵ
where n j + 1 ≥ l j n_{j+1} \ge l_j nj+1≥lj, and < X j + 1 , n j + 1 > <X_{j+1}, n_{j+1}> <Xj+1,nj+1> is reached from < x j , n j > <x_j, n_j> <xj,nj> after executing a j a_j aj. Q.E.D.
Now, define:
P x y ( n ) [ a ] = ∑ m = 1 n − 1 P < x , n > , < y , m > A R P [ a ] P_{xy}^{(n)}[a] = \sum_{m=1}^{n-1} P_{<x,n>,<y,m>}^{ARP}[a] Pxy(n)[a]=m=1∑n−1P<x,n>,<y,m>ARP[a]
Lemma:
Let ξ n {\xi_n} ξn be a sequence of bounded random variables with expectation E \mathfrak{E} E, and let 0 ≤ β n < 1 0 \le \beta_n < 1 0≤βn<1 satisfy ∑ i = 1 ∞ β i = + ∞ \sum_{i=1}^{\infty} \beta_i = +\infty ∑i=1∞βi=+∞ and ∑ i = 1 ∞ β i 2 < + ∞ \sum_{i=1}^{\infty} \beta_i^2 < +\infty ∑i=1∞βi2<+∞.
Define the sequence X n + 1 = X n + β n ( ξ n − X n ) X_{n+1} = X_n + \beta_n(\xi_n - X_n) Xn+1=Xn+βn(ξn−Xn). Then:
P ( lim n → ∞ X n = E ) = 1 P\left( \lim_{n \to \infty} X_n = \mathfrak{E} \right) = 1 P(n→∞limXn=E)=1
My attempt:
X n + 1 = X n + β n ( ξ n − X n ) = ( 1 − β n ) X n + β n ξ n X_{n+1} = X_n + \beta_n(\xi_n - X_n) = (1 - \beta_n) X_n + \beta_n \xi_n Xn+1=Xn+βn(ξn−Xn)=(1−βn)Xn+βnξn
By induction, we obtain:
X n + 1 = ∑ j = 1 n ξ j β j ∏ i = j n − 1 ( 1 − β i + 1 ) + X 1 ∏ i = 1 n ( 1 − β i ) X_{n+1} = \sum_{j=1}^{n} \xi_j \beta_j \prod_{i=j}^{n-1} (1 - \beta_{i+1}) + X_1 \prod_{i=1}^{n} (1 - \beta_i) Xn+1=j=1∑nξjβji=j∏n−1(1−βi+1)+X1i=1∏n(1−βi)
From a corollary of a fundamental theorem:
∏ i = 1 ∞ ( 1 − β i ) = 0 \prod_{i=1}^{\infty} (1 - \beta_i) = 0 i=1∏∞(1−βi)=0
Hence:
lim n → ∞ X n = lim n → ∞ ∑ j = 1 n ξ j β j ∏ i = j + 1 n ( 1 − β i ) = lim n → ∞ ∑ j = 1 n ξ j β j ∏ i = j + 1 n ( 1 − β i ) 1 − 0 \lim_{n \to \infty} X_n = \lim_{n \to \infty} \sum_{j=1}^{n} \xi_j \beta_j \prod_{i=j+1}^{n} (1 - \beta_i) = \frac{ \lim_{n \to \infty} \sum_{j=1}^{n} \xi_j \beta_j \prod_{i=j+1}^{n} (1 - \beta_i) }{1 - 0} n→∞limXn=n→∞limj=1∑nξjβji=j+1∏n(1−βi)=1−0limn→∞∑j=1nξjβj∏i=j+1n(1−βi)
= lim n → ∞ ∑ j = 1 n ξ j β j ∏ i = j + 1 n ( 1 − β i ) 1 − ∏ i = 1 ∞ ( 1 − β i ) = lim n → ∞ ∑ j = 1 n ξ j β j ∏ i = j + 1 n ( 1 − β i ) 1 − ∏ i = 1 n ( 1 − β i ) = \frac{ \lim_{n \to \infty} \sum_{j=1}^{n} \xi_j \beta_j \prod_{i=j+1}^{n} (1 - \beta_i) }{1 - \prod_{i=1}^{\infty} (1 - \beta_i)} = \lim_{n \to \infty} \sum_{j=1}^{n} \xi_j \frac{ \beta_j \prod_{i=j+1}^{n} (1 - \beta_i) }{1 - \prod_{i=1}^{n} (1 - \beta_i)} =1−∏i=1∞(1−βi)limn→∞∑j=1nξjβj∏i=j+1n(1−βi)=n→∞limj=1∑nξj1−∏i=1n(1−βi)βj∏i=j+1n(1−βi)
Property 3
P { lim n → ∞ P x y ( n ) [ a ] = P x y [ a ] } = 1 , P [ lim n → ∞ R x ( n ) ( a ) = R x ( a ) ] = 1 P\left\{ \lim_{n \to \infty} P_{xy}^{(n)}[a] = P_{xy}[a] \right\} = 1, \quad P\left[ \lim_{n \to \infty} \mathfrak{R}_{x}^{(n)}(a) = \mathfrak{R}_{x}(a) \right] = 1 P{n→∞limPxy(n)[a]=Pxy[a]}=1,P[n→∞limRx(n)(a)=Rx(a)]=1
相关文章:

The Action Replay Process
Preface A commonly used inequality − x > ln ( 1 − x ) , 0 < x < 1 -x > \ln(1 - x), \quad 0 < x < 1 −x>ln(1−x),0<x<1 Proof: Let f ( x ) ln ( 1 − x ) x f(x) \ln(1 - x) x f(x)ln(1−x)x, for 0 < x < 1 0 < …...
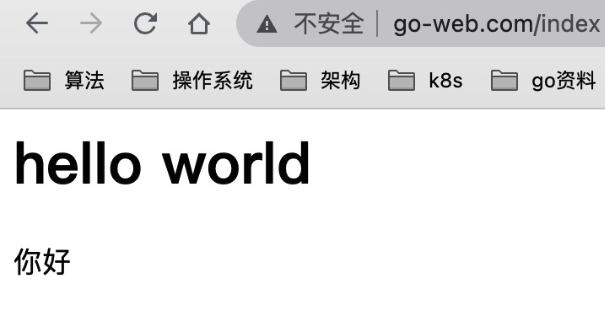
k8s之ingress解释以及k8s创建业务的流程定义
matchLabels ingress Ingress 是反向代理规则,用来规定 HTTP/S 请求应该被转发到哪个 Service 上,比如根据请求中不同的 Host 和 url 路径让请求落到不同的 Service 上。 Ingress Controller 就是一个反向代理程序,它负责解析 Ingress 的反向…...

LVGL对象的盒子模型和样式
文章目录 🧱 LVGL 对象盒子模型结构🔍 组成部分说明🎮 示例代码📌 总结一句话 🧱 一、样式的本质:lv_style_t 对象🎨 二、样式应用的方式🧩 三、样式属性分类(核心&#…...
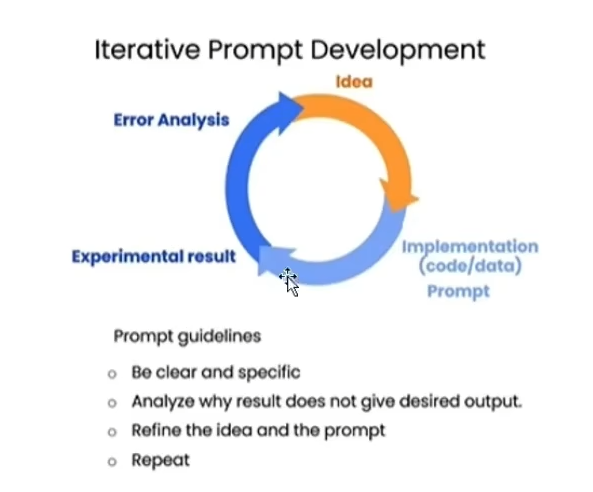
从0开始学习大模型--Day05--理解prompt工程
提示词工程原理 N-gram:通过统计,计算N个词共同出现的概率,从而预测下一个词是什么。 深度学习模型:有多层神经网络组成,可以自动从数据中学习特征,让模型通过不断地自我学习不断成长,直到模型…...

计算机视觉——基于树莓派的YOLO11模型优化与实时目标检测、跟踪及计数的实践
概述 设想一下,你在多地拥有多个仓库,要同时监控每个仓库的实时状况,这对于时间和精力而言,都构成了一项艰巨挑战。从成本和可靠性的层面考量,大规模部署计算设备也并非可行之策。一方面,大量计算设备的购…...
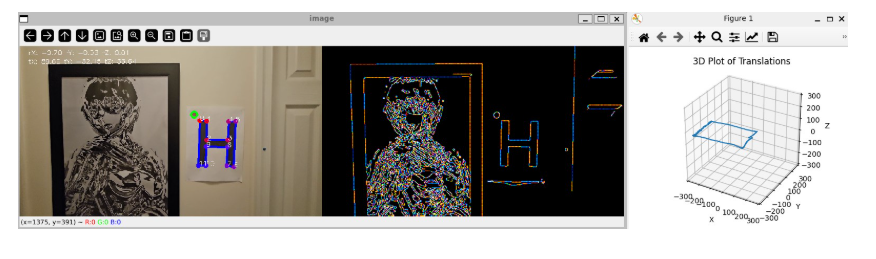
【计算机视觉】OpenCV项目实战:OpenCV_Position 项目深度解析:相机定位技术
OpenCV_Position 项目深度解析:基于 OpenCV 的相机定位技术 一、项目概述二、技术原理(一)单应性矩阵(Homography)(二)算法步骤(三)相机内参矩阵 三、项目实战运行&#…...
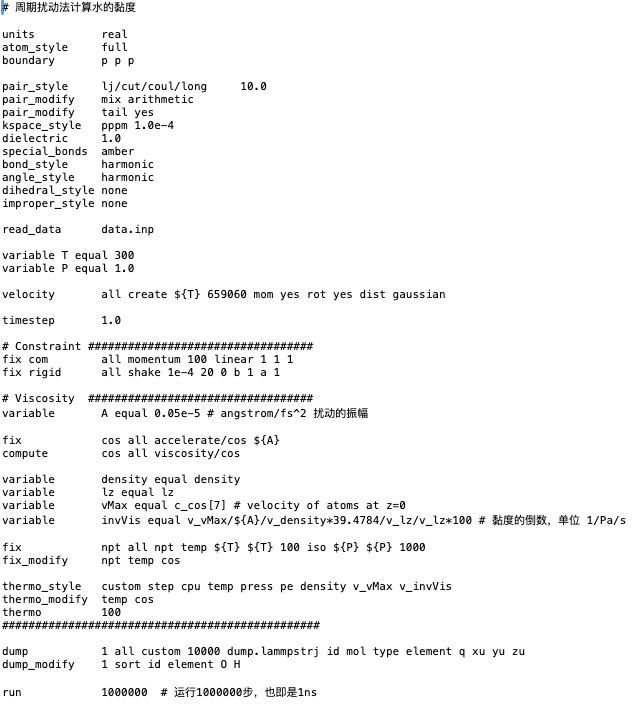
LAMMPS分子动力学基于周期扰动法的黏度计算
关键词:黏度,周期扰动法,SPC/E水分子,分子动力学,lammps 目前分子动力学计算黏度主要有以下方法:(1)基于 Green - Kubo 关系的方法。从微观角度出发,利用压力张量自相关函数积分计算…...
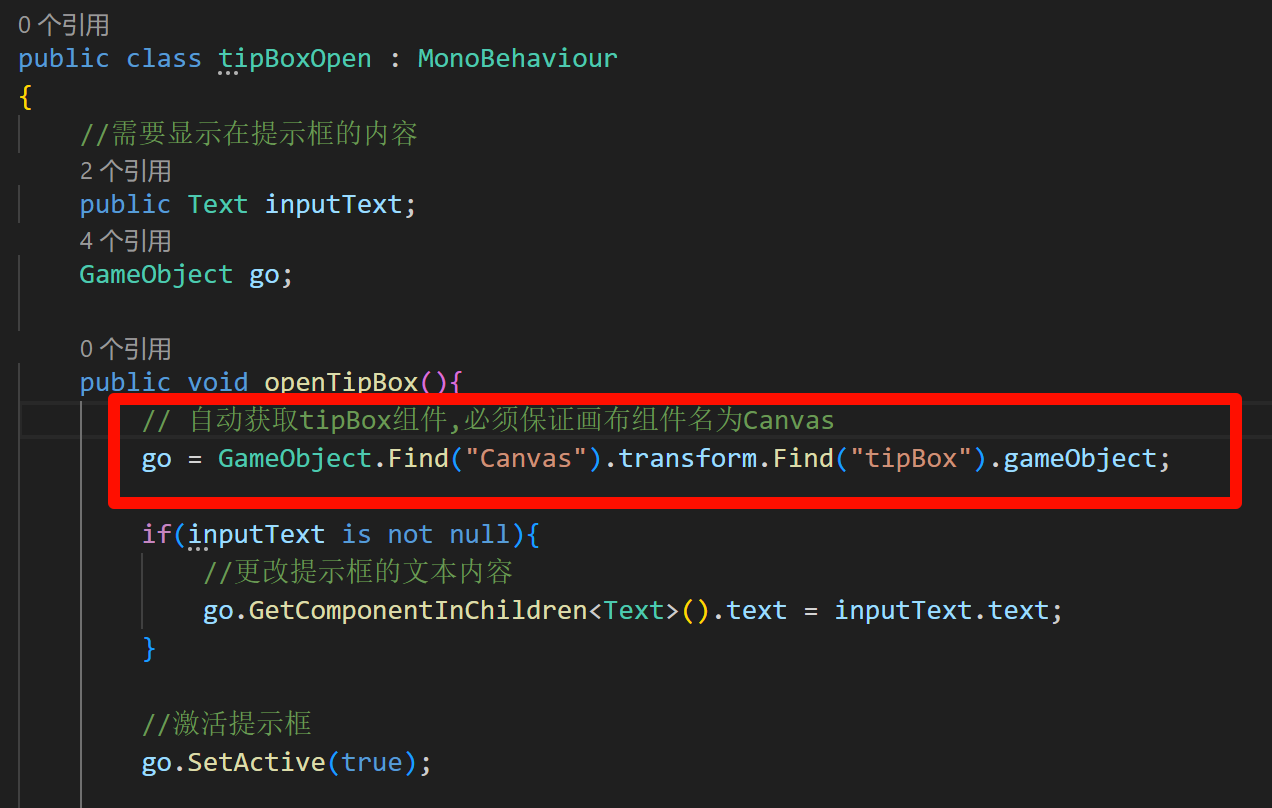
unity通过transform找子物体只能找子级
unity通过transform找子物体只能找子级,孙级以及更低级别都找不到,只能找到自己的下一级 如果要获取孙级以下的物体,最快的方法还是直接public挂载...
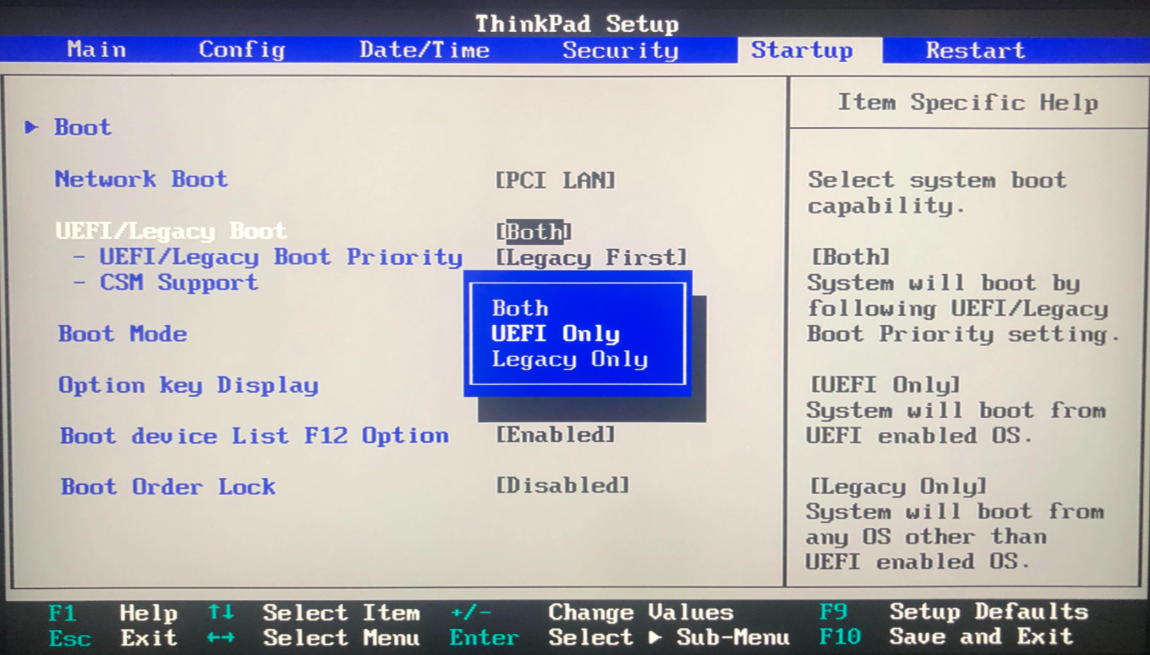
ThinkPad T440P如何从U盘安装Ubuntu24.04系统
首先制作一个安装 U 盘。我使用的工具是 Rufus ,它的官网是 rufus.ie ,去下载最新版就可以了。直接打开这个工具,选择自己从ubuntu官网下载Get Ubuntu | Download | Ubuntu的iso镜像制作U盘安装包即可。 其次安装之前,还要对 Thi…...

PostgreSQL给新用户授权select角色
✅ 切换到你的数据库并以超级用户登录(例如 postgres): admin#localhost: ~$ psql -U postgres -d lily✅ 创建登录的账号机密吗 lily> CREATE USER readonly_user WITH PASSWORD xxxxxxxxxxx; ✅ 确认你授予了这个表的读取权限…...
嵌入式开发学习(阶段二 C语言基础)
C语言:第05天笔记 内容提要 分支结构 条件判断用if语句实现分支结构用switch语句实现分支结构 分支结构 条件判断 条件判断:根据某个条件成立与否,决定是否执行指定的操作。 条件判断的结果是逻辑值,也就是布尔类型值&#…...

【RAG技术全景解读】从原理到工业级应用实践
目录 🌟 前言🏗️ 技术背景与价值🚨 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🔍 一、技术原理剖析📊 核心概念图解💡 核心作用讲解⚙️ 关键技术模块说明🔄 技术选…...

从人体姿态到机械臂轨迹:基于深度学习的Kinova远程操控系统架构解析
在工业自动化、医疗辅助、灾难救援与太空探索等前沿领域,Kinova轻型机械臂凭借7自由度关节设计和出色负载能力脱颖而出。它能精准完成物体抓取、复杂装配和精细操作等任务。然而,实现人类操作者对Kinova机械臂的直观高效远程控制一直是技术难题。传统远程…...

NX949NX952美光科技闪存NX961NX964
NX949NX952美光科技闪存NX961NX964 在半导体存储领域,美光科技始终扮演着技术引领者的角色。其NX系列闪存产品线凭借卓越的性能与创新设计,成为数据中心、人工智能、高端消费电子等场景的核心组件。本文将围绕NX949、NX952、NX961及NX964四款代表性产品…...

【Bootstrap V4系列】学习入门教程之 组件-输入组(Input group)
Bootstrap V4系列 学习入门教程之 组件-输入组(Input group) 输入组(Input group)Basic example一、Wrapping 包装二、Sizing 尺寸三、Multiple addons 多个插件四、Button addons 按钮插件五、Buttons with dropdowns 带下拉按钮…...
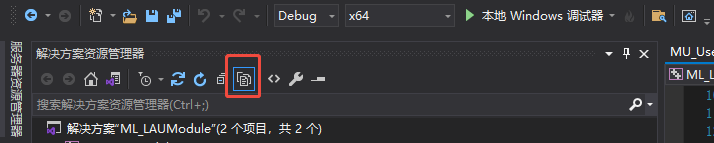
VS “筛选器/文件夹”
每天学习一个VS小技巧: 我在VS创建筛选器的时候,想要想要同步计算机上的文件目录,但是发现并未 同步。 例如我在这儿创建了一个筛选器IoManager 但是在UI这个文件夹里并未创建对应的IoManager文件夹 我右击也没有打开文件所在位置 然后我…...

RAG与语义搜索:让大模型成为测试工程师的智能助手
引言 AI大模型风头正劲,自动生成和理解文本的能力让无数行业焕发新生。测试工程师也不例外——谁不想让AI自动“看懂需求、理解接口、生成用例”?然而,很多人发现:直接丢问题给大模型,答案貌似“懂行”,细…...
)
从 JMS 到 ActiveMQ:API 设计与扩展机制分析(三)
三、ActiveMQ API 设计解析 (一)对 JMS API 的实现与扩展 ActiveMQ 作为 JMS 规范的一种实现,全面且深入地实现了 JMS API,确保了其在 Java 消息服务领域的兼容性和通用性。在核心接口实现方面,ActiveMQ 对 JMS 的 C…...
powerbuilder9.0中文版
经常 用这个版本号写小软件,非常喜欢这个开发软件 . powerbuilder9.0 非常的小巧,快捷,功能强大,使用方便. 我今天用软件 自己汉化了一遍,一些常用的界面都已经翻译成中文。 我自己用的,以后有什么界面需要翻译,再更新一下。 放在这里留个…...

小程序消息订阅的整个实现流程
以下是微信小程序消息订阅的完整实现流程,分为 5个核心步骤 和 3个关键注意事项: 一、消息订阅完整流程 步骤1:配置订阅消息模板 登录微信公众平台进入「功能」→「订阅消息」选择公共模板或申请自定义模板,获取模板IDÿ…...

互联网大厂Java求职面试实战:Spring Boot微服务与数据库优化详解
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通 😁 2. 毕业设计专栏,毕业季咱们不慌忙,几百款毕业设计等你选。 ❤️ 3. Python爬虫专栏…...

基于C语言的TCP通信测试程序开发指南
一、TCP通信基础原理 1.1 通信流程概述 TCP通信采用客户端-服务器模型,核心流程如下: 服务器端: 创建套接字(Socket) 绑定地址和端口(Bind) 开始监听(Listen) 接受…...

Git 分支指南
什么是 Git 分支? Git 分支是仓库内的独立开发线,你可以把它想象成一个单独的工作空间,在这里你可以进行修改,而不会影响主分支(或 默认分支)。分支允许开发者在不影响项目实际版本的情况下,开…...

教育系统源码如何支持白板直播与刷题功能?功能开发与优化探索
很多行业内同学疑问,如何在教育系统源码中支持白板直播和刷题功能?本篇文章,小编将从功能设计、技术实现到性能优化,带你全面了解这个过程。 一、白板直播功能的核心需求与技术挑战 实时交互与同步性 白板直播的核心是“实时性”。…...

SSM框架整合MyBatis-Plus的步骤和简单用法示例
以下是 SSM框架整合MyBatis-Plus的步骤 和 简单用法示例: 一、SSM整合MyBatis-Plus步骤 1. 添加依赖(Maven) <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.…...

【LeetCode 热题 100】206. 反转链表
📌 难度:简单 📚 标签:链表、双指针、迭代、递归 🔗 题目链接(LeetCode CN) 🧩 一、题目描述 给你单链表的头节点 head,请你反转链表,并返回反转后的链表。 ✅…...

centos8.5.2111 更换阿里云源
使用前提是服务器可以连接互联网 1、备份现有软件配置文件 cd /etc/yum.repos.d/ mkdir backup mv CentOS-* backup/ 2、下载阿里云的软件配置文件 wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo 3、清理并重建…...
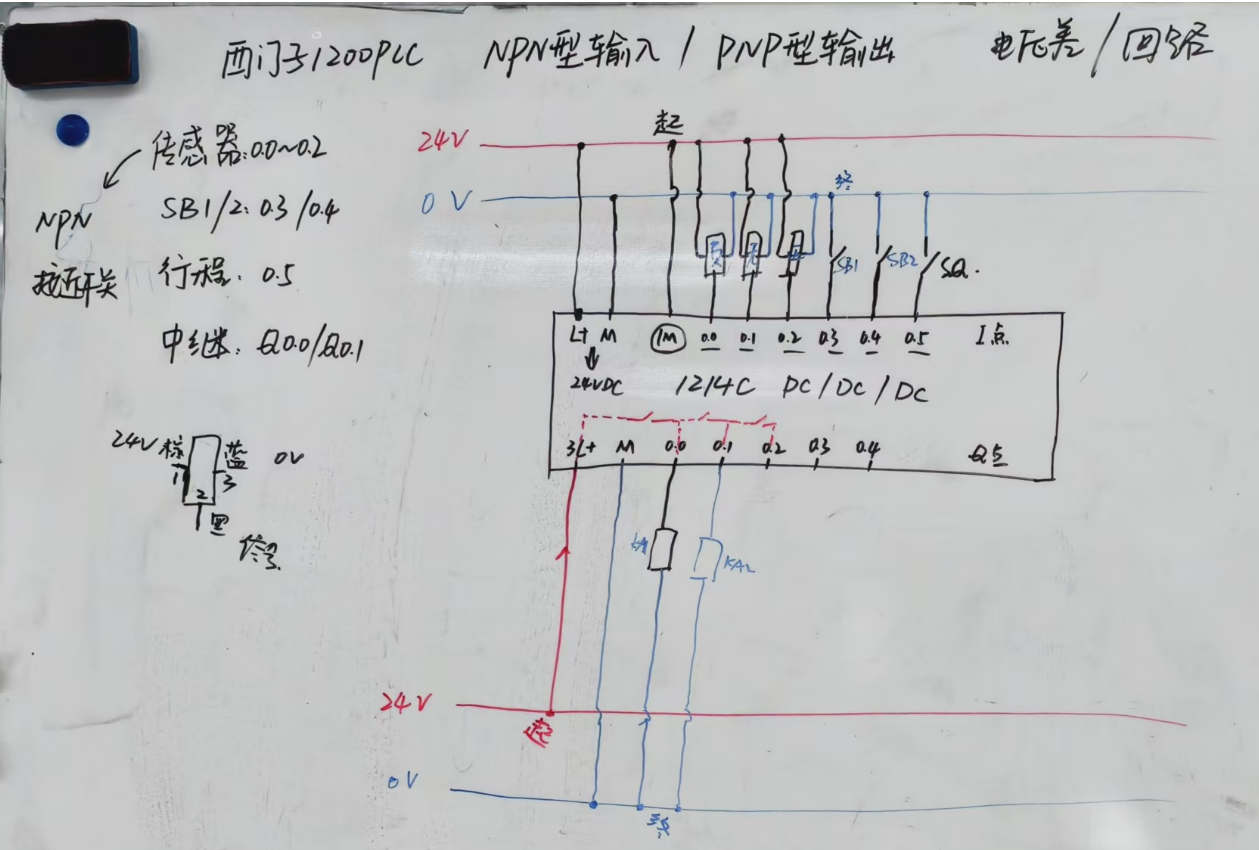
再度深入理解PLC的输入输出接线
本文再次重新梳理: 两线式/三线式传感器的原理及接线、PLC的输入和输出接线,深入其内部原理,按照自己熟悉的方式去理解该知识 在此之前,需要先统一几个基础知识点: 在看任何电路的时候,需要有高低电压差&…...

k8s(11) — 探针和钩子
钩子和探针的区别: 在 Kubernetes(k8s)中,钩子(Hooks)和探针(Probes)是保障应用稳定运行的重要机制,不过它们的用途和工作方式存在差异,以下为你详细介绍&…...
使用jmeter对数据库进行压力测试
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 前言 很多人提到 jmeter时,只会说到jmeter进行接口自动化或接口性能测试,其实jmeter还能对数据库进行自动化操作。个人常用的场景有以下&…...