李沐动手深度学习(pycharm中运行笔记)——09.softmax回归+图像分类数据集+从零实现+简洁实现
09.softmax回归+图像分类数据集+从零实现+简洁实现(与课程对应)
目录
一、softmax回归
1、回归 vs 分类
2、经典分类数据集:
3、从回归到分类——均方损失
4、从回归到多类分类——无校验比例
5、从回归到多类分类——校验比例
6、softmax和交叉熵损失
7、总结
二、损失函数
1、均方损失函数 L2 loss
2、绝对值损失函数L1 loss
3、Huber‘s 鲁棒损失
三、图片分类数据集
四、从零实现
五、简洁实现
一、softmax回归
1、回归 vs 分类
回归估计一个连续值:例如房子卖的价格
- 单连续数值输出
- 自然区间R
- 跟真实值的区别作为损失

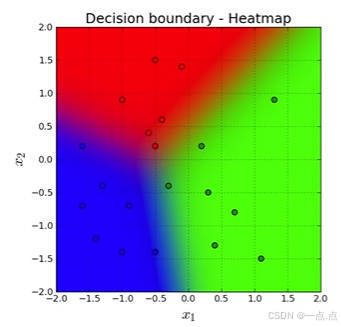
分类预测一个离散类别:例如一个图片里面是猫还是狗
- 通常多个输出
- 输出 i 是预测为第 i 类的置信度。
2、经典分类数据集:
MNIST 数据集 :一个非常经典的数据集,用于识别手写数字 0 到 9,是一个十类分类问题。

ImageNet 数据集 :深度学习中特别经典的数据集,有 100 万张图片,每一张图片是一个自然物体,属于 1000 类自然物体之一,其中包含大概 100 种不同的狗 ,该问题为 1000 类的分类问题。

3、从回归到分类——均方损失
- 类别编码 :
- 编码原因 :类别常为字符串,不是数值,需进行编码处理。
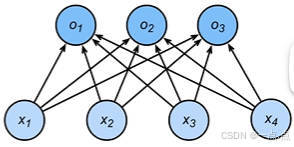
- 编码方式 :若有 n 个类别,采用一位有效编码。标号是长为 n 的向量 Y1、Y2 … YN ,若真实类别是第 i 个,则 Yi 等于 1,其他元素全部为 0 。
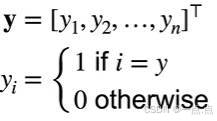
- 模型训练与预测 :
- 训练方法 :编码后可用回归问题的均方损失进行训练,无需改动。
- 预测方式 :训练出模型后,做预测时选取使置信度值最大化的 i,即通过 argmax o i 得到预测标号 yhat 。
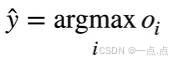
4、从回归到多类分类——无校验比例
- Softmax 回归的问题及目标:
- 关注置信度 :在分类中,更关心对正确类别的置信度要足够大,而非实际值。
- 目标函数改进 :希望正确类别 y 的置信度 oy 远大于其他非正确类的 oi,数学表示为 oy - oi 大于某阈值 Delta,以此拉开正确类与其他类的距离(最大值作为预测、需要更置信的识别正确类)。
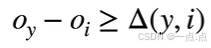
5、从回归到多类分类——校验比例
- 输出处理的想法:
- 输出值区间调整 :将输出值放到合适区间能让后续处理更简单,比如希望输出是概率。
- 引入 Softmax 操作 :对输出向量 o 应用 Softmax 操作得到 y hat 向量,其元素非负且和为 1,满足概率属性。
- Softmax 具体计算 :y hat 的第 i 个元素等于 o 的第 i 个元素做指数后,除以所有 o 元素做指数的和,这样 y hat 就可作为概率。
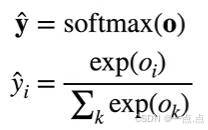
6、softmax和交叉熵损失
- 交叉熵基本概念:
- 衡量概率区别:使用交叉熵(cross entropy)衡量两个概率的区别,将其作为损失来比较预测概率和真实概率。
- 离散概率公式:假设有两个离散概率 p 和 q,有 n 个元素,交叉熵公式为对每个元素 i,负的 pi 乘以 log qi 然后求和。
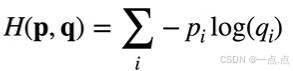
- 在分类问题中的损失计算:
- 损失公式:对于真实标号 y 和预测标号 y hat,损失 l (y, y hat) 等于对所有 i 类别求和,负的 yi 乘以 log yi hat 。
- 简化计算:由于 y 中只有一个元素为 1 其余为 0,求和可简化为负的对真实类别 y 的预测值 y hat 求 log 。

- 与梯度的关系:
- 梯度计算:损失的梯度是真实概率和预测概率的区别,如损失对 DOI 求导等于 Softmax 的第二个元素减去真实类别 y。
- 梯度下降作用:梯度下降时不断减去真实和预测概率的区别,使预测的 Softmax 值和真实的 y 更相近 。

7、总结
- Softmax回归是一个多类分类模型
- 使用Softmax操作子得到每个类的预测置信度
- 使用交叉熵来衡量预测和标号的区别
二、损失函数
损失函数用于衡量预测值和真实值间的区别,在机器学习里是重要概念。简单介绍三个常用的损失函数。
1、均方损失函数 L2 loss
- 定义 :均方损失又叫 L2 loss,定义为真实值 y 减去预测值 y',做平方再除以 2,这样求导数时 2 和 1/2 抵消变为 1。
- 特性可视化 :用三条曲线可视化其特性,蓝色曲线表示 y = 0 时变换预测值 y' 的函数,是二次函数且为偶函数;橙色线表示损失函数的梯度,是穿过原点的一次函数。
- 参数更新 :梯度决定参数更新方式,预测值 y' 与真实值 y 距离远时梯度大,参数更新多;靠近时梯度绝对值变小,参数更新幅度变小。

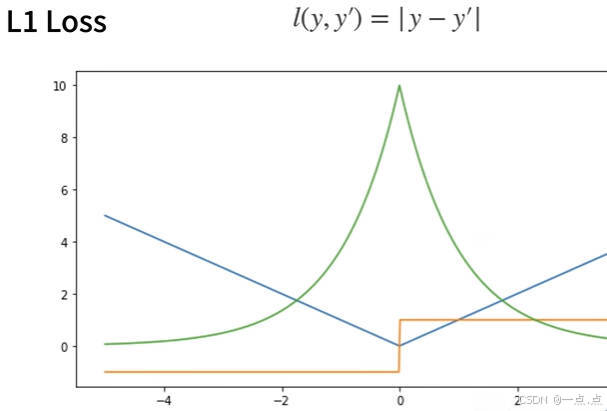
2、绝对值损失函数L1 loss
- L1 损失函数定义:
- 公式形式:L1 损失函数定义为预测值减去真实值的绝对值,反过来也一样,即 | 预测值 - 真实值 |。
- 函数曲线情况:
- 曲线呈现:蓝色线是损失函数曲线,当 y = 0 时的样子;绿色线是似然函数曲线,在原点处有一个很尖的点。
- L1 损失函数导数:
- 大于 0 时导数:当 y' 大于 0 时,导数为常数 1。
- 小于 0 时导数:当 y' 小于 0 时,导数为常数 -1。
- 特殊点情况:由于绝对值函数在 0 点处不可导,其 subgradients(次梯度)可以在 -1 和 1 之间 。
- L1 损失函数特性:
- 距离远时特点:当预测值跟真实值隔得比较远时,不管距离多远,梯度永远是常数,这带来稳定性好处,权重更新不会特别大。
- 距离近时劣势:在零点处不可导,且在零点处有从 -1 到 1 之间的剧烈变化,这种不平滑性导致在预测值和真实值靠得比较近,即优化末期时可能变得不稳定 。
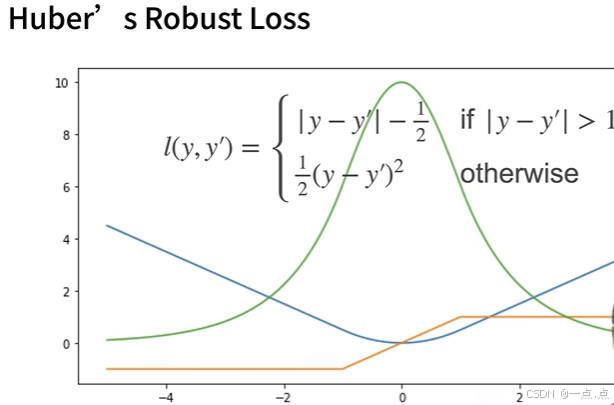
3、Huber‘s 鲁棒损失
- Harbor 鲁棒损失函数定义:
- 差值较大情况:当预测值和真实值差的绝对值大于 1 时,损失函数是绝对值误差(y 减去 y 一撇的绝对值)并减去 LNG,使曲线能连起来。
- 差值较近情况:当预测值和真实值差的绝对值小于等于 1 时,损失函数是平方误差。
- Harbor 鲁棒损失函数曲线特点:
- 蓝色曲线:在正 1 负 1 之间是平滑二次函数曲线,之外是另一条曲线。
- 绿色线(Sech 函数):类似高斯分布,在原点处不像绝对值误差那样尖锐。
- Harbor 鲁棒损失函数导数特点:
- 差值较大时:当 y 撇大于 1 或者小于 -1 时,导数是常数。
- 差值较小时:当 y 撇在 -1 到 1 之间时,导数是渐变过程。
- 导数好处:预测值和真实值差得远时,梯度用均匀力度往回拉;靠近时,梯度绝对值变小,保证优化平滑,避免数值问题。
三、图片分类数据集
MNIST数据集是图像分类中广泛使用的数据集之一,但作为基准数据集过于简单,使用类似但更复杂的Fashion-MNIST数据集。
1、导入库
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l2、 通过框架中的内置函数,将Fashion-MNIST数据集下载并读取到内存中
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式;并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor() # 预处理,用于将图片转为tensor
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True) # 在torchvision.datasets找到FashionMNIST数据集,参数:root="../data"下载目录, train=True下载训练数据集, transform=trans图片转为pytorch的tensor, download=True下载
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)
print("len(mnist_train):", len(mnist_train), "\nlen(mnist_test):", len(mnist_test))
print("mnist_train[0][0].shape,训练集中第一张图片的形状:", mnist_train[0][0].shape, "\nmnist_train[0][1],训练集中第一张图片的标签:", mnist_train[0][1]) # mnist_train[0][0]是图片、mnist_train[0][1]是标签
3、 两个可视化数据集的函数,来画一下数据集
def get_fashion_mnist_labels(labels):"""返回Fashion-MNIST数据集的文本标签"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):"""绘制图像列表"""figsize = (num_cols * scale, num_rows * scale)_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize) # 使用subplots创建子图axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):ax.imshow(img.numpy()) # 图片张量else:ax.imshow(img) # PIL图片ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])return axesX, y = next(iter(data.DataLoader(mnist_train, batch_size=18))) # 加载批量图片
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y)) # 显示图片并添加标签
d2l.plt.show() # 图片在线展示4、 读取一小批量数据,大小batch_size
batch_size = 256
def get_dataloader_workers():"""使用4个进程来读取的数据"""return 0 # 写几就是几个进程train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers())
timer = d2l.Timer()
for X, y in train_iter:continue
print(f'{timer.stop():.2f} sec')5、 整合所有组件
# 4、整合所有组件
def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers()))
# 测试整和组件功能
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:print(X.shape, X.dtype, y.shape, y.dtype)break完整代码:
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l# 1、通过框架中的内置函数,将Fashion-MNIST数据集下载并读取到内存中
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式;并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor() # 预处理,用于将图片转为tensor
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True) # 在torchvision.datasets找到FashionMNIST数据集,参数:root="../data"下载目录, train=True下载训练数据集, transform=trans图片转为pytorch的tensor, download=True下载
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)
print("len(mnist_train):", len(mnist_train), "\nlen(mnist_test):", len(mnist_test))
print("mnist_train[0][0].shape,训练集中第一张图片的形状:", mnist_train[0][0].shape, "\nmnist_train[0][1],训练集中第一张图片的标签:", mnist_train[0][1]) # mnist_train[0][0]是图片、mnist_train[0][1]是标签# 2、两个可视化数据集的函数,来画一下数据集
def get_fashion_mnist_labels(labels):"""返回Fashion-MNIST数据集的文本标签"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):"""绘制图像列表"""figsize = (num_cols * scale, num_rows * scale)_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize) # 使用subplots创建子图axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):ax.imshow(img.numpy()) # 图片张量else:ax.imshow(img) # PIL图片ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])return axesX, y = next(iter(data.DataLoader(mnist_train, batch_size=18))) # 加载批量图片
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y)) # 显示图片并添加标签
# d2l.plt.show() # 图片在线展示# 3、读取一小批量数据,大小batch_size
batch_size = 256
def get_dataloader_workers():"""使用4个进程来读取的数据"""return 0 # 写几就是几个进程train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers())
timer = d2l.Timer()
for X, y in train_iter:continue
print(f'{timer.stop():.2f} sec')'''
# 4、整合所有组件
def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers()))
# 测试整和组件功能
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:print(X.shape, X.dtype, y.shape, y.dtype)break
'''四、从零实现
1、导入库
import torch
from IPython import display
from d2l import torch as d2l2、数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 每次读取256张图片,返回训练集、测试集的迭代器:train_iter, test_iter# 将展平每个图像1x28x28=784,将它们视为长度为784的向量(因为对于softmax回归来讲,输入需要是一个向量)。因为我们的数据集有10个类别,所以网络输出维度为10
num_inputs = 784
num_outputs = 103、参数初始化
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True) # 均值为0,方差为0.01初始化W权重
b = torch.zeros(num_outputs, requires_grad=True) # 全0初始化4、实现softmax
# 实现softmax
def softmax(X):X_exp = torch.exp(X) # 对每一个元素做指数运算partition = X_exp.sum(1, keepdim=True) # 按照维度为1来求和,对每一行求和;按行求和并保持维度不变,还是2维矩阵return X_exp / partition # 这里应用了广播机制,# 实现softmax回归模型
def net(X):return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b) # 对X reshape使其能够与W做内积
5、实现交叉熵损失函数
# 实现交叉熵损失函数
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])6、 将预测类别与真实y元素进行比较
def accuracy(y_hat, y):"""计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1) # argmax返回每行最大值的索引cmp = y_hat.type(y.dtype) == y # cmp为01向量,表示y_hat和y相同索引的个数return float(cmp.type(y.dtype).sum()) # 返回cmp中所有相同索引的和
7、 评估任意模型net的精度
# 我们可以评估任意模型net的精度
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # eval()停用dropout和batchnormmetric = Accumulator(2) # 创建两个元素的列表with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel()) # 累加获得预测正确的个数和总个数return metric[0] / metric[1]# Accumulator实例中创建了2个变量, 分别用于存储正确预测的数量和预测的总数量
class Accumulator:"""在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)] # 对数据累加def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
8、Softmax回归的训练
# Softmax回归的训练
def train_epoch_ch3(net, train_iter, loss, updater):"""训练模型一个迭代周期(定义见第3章)"""if isinstance(net, torch.nn.Module): # 判断是否自己实现函数net.train()metric = Accumulator(3)for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.sum().backward()updater.step()else:l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())return metric[0] / metric[2], metric[1] / metric[2]# 定义一个在动画中绘制数据的实用程序类
class Animator:"""在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()display.display(self.fig)display.clear_output(wait=True)# 训练函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):"""训练模型(定义见第3章)"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metricsassert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc# 小批量随机梯度下降来优化模型的损失函数
lr = 0.1
def updater(batch_size):return d2l.sgd([W, b], lr, batch_size)# 训练模型10个迭代周期
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater) # 调用前面的函数
d2l.plt.show()9、对图像进行分类预测
# 对图像进行分类预测
def predict_ch3(net, test_iter, n=6):"""预测标签(定义见第3章)"""for X, y in test_iter:breaktrues = d2l.get_fashion_mnist_labels(y)preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true +'\n' + pred for true, pred in zip(trues, preds)]d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])predict_ch3(net, test_iter)
d2l.plt.show()完整代码:
import torch
from IPython import display
from d2l import torch as d2l# softmax回归的从零开始实现
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 每次读取256张图片,返回训练集、测试集的迭代器:train_iter, test_iter# 将展平每个图像1x28x28=784,将它们视为长度为784的向量(因为对于softmax回归来讲,输入需要是一个向量)。因为我们的数据集有10个类别,所以网络输出维度为10
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True) # 均值为0,方差为0.01初始化W权重
b = torch.zeros(num_outputs, requires_grad=True) # 全0初始化# 实现softmax
def softmax(X):X_exp = torch.exp(X) # 对每一个元素做指数运算partition = X_exp.sum(1, keepdim=True) # 按照维度为1来求和,对每一行求和;按行求和并保持维度不变,还是2维矩阵return X_exp / partition # 这里应用了广播机制,# 实现softmax回归模型
def net(X):return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b) # 对X reshape使其能够与W做内积# 实现交叉熵损失函数
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])# 将预测类别与真实y元素进行比较
def accuracy(y_hat, y):"""计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1) # argmax返回每行最大值的索引cmp = y_hat.type(y.dtype) == y # cmp为01向量,表示y_hat和y相同索引的个数return float(cmp.type(y.dtype).sum()) # 返回cmp中所有相同索引的和# 我们可以评估在任意模型net的精度
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # eval()停用dropout和batchnormmetric = Accumulator(2) # 创建两个元素的列表with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel()) # 累加获得预测正确的个数和总个数return metric[0] / metric[1]# Accumulator实例中创建了2个变量, 分别用于存储正确预测的数量和预测的总数量
class Accumulator:"""在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)] # 对数据累加def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]# Softmax回归的训练
def train_epoch_ch3(net, train_iter, loss, updater):"""训练模型一个迭代周期(定义见第3章)"""if isinstance(net, torch.nn.Module): # 判断是否自己实现函数net.train()metric = Accumulator(3)for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.sum().backward()updater.step()else:l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())return metric[0] / metric[2], metric[1] / metric[2]# 定义一个在动画中绘制数据的实用程序类
class Animator:"""在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()display.display(self.fig)display.clear_output(wait=True)# 训练函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):"""训练模型(定义见第3章)"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metricsassert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc# 小批量随机梯度下降来优化模型的损失函数
lr = 0.1
def updater(batch_size):return d2l.sgd([W, b], lr, batch_size)# 训练模型10个迭代周期
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater) # 调用前面的函数
d2l.plt.show()# 对图像进行分类预测
def predict_ch3(net, test_iter, n=6):"""预测标签(定义见第3章)"""for X, y in test_iter:breaktrues = d2l.get_fashion_mnist_labels(y)preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true +'\n' + pred for true, pred in zip(trues, preds)]d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])predict_ch3(net, test_iter)
d2l.plt.show()
五、简洁实现
1、导入库
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
from torch import nn
2、 人造数据集,使用线性模型参数 w = [2, -3.4]T、b = 4.2;得到features, labels
# 1、人造数据集,使用线性模型参数 w = [2, -3.4]T、b = 4.2;得到features, labels
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)def load_array(data_arrays, batch_size, is_train=True):"""构造一个Pytorch数据迭代"""dataset = data.TensorDataset(*data_arrays) # 得到数据集,*表示接受任意多个参数并将其放在一个元组中,拆包return data.DataLoader(dataset, batch_size, shuffle=is_train) # 加载数据集,shuffle表示是否随机打乱batch_size = 10
data_iter = load_array(data_arrays=(features, labels), batch_size=batch_size) # 把features, labels做成一个list传入到data.TensorDataset,得到数据集datasetprint(next(iter(data_iter)))3、 模型定义;'nn'是神经网络的缩写
# 2、模型定义;'nn'是神经网络的缩写
# (1)使用框架的预定义好的层
net = nn.Sequential(nn.Linear(2, 1)) # 指定输入维度为2,输出维度为1# (2)初始化模型参数
net[0].weight.data.normal_(0, 0.01) # 就是对w初始化化为均值为0,方差为0.01的正态分布
net[0].bias.data.fill_(0) # 就是对b初始化为04、 计算均方误差使用的是MSELoss类,也称为 平方范数
# 3、计算均方误差使用的是MSELoss类,也称为 平方范数
loss = nn.MSELoss()5、 实例化SGD实例,优化器
# 4、实例化SGD实例,优化器
trainer = torch.optim.SGD(net.parameters(), lr=0.03) # 传入参数、学习率6、 训练过程
# 5、训练过程
# (1)超参数设置
num_epochs = 3 # 整个数据扫三遍
# (2)训练的实现大同小异,一般就是两层for循环:第一层是每一次对数据扫一遍;第二层是对于每一次拿出一个批量大小的X、y
for epoch in range(num_epochs):for X, y in data_iter:l = loss(net(X), y) # 把 X 放到模型里面做预测(net本身自己带了模型参数,所以不需要w、b再传入了);把 预测的y 与 真实的y 做损失;得到的损失就是 一个批量大小的向量trainer.zero_grad() # 优化器梯度清0l.backward() # 求梯度,此处不用求sum,因为已经自动求完sum了trainer.step() # 调用step()函数,进行一次模型参数的更新# 对数据扫完一边之后,评价一下进度,此时是不需要梯度的,l = loss(net(features), labels)print(f"epoch {epoch + 1}, loss {l:f}") # 打印评估的结果完整代码:
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
from torch import nn# 线性回归的简洁实现(使用深度学习框架提供的计算);包括数据流水线、模型、损失函数和小批量随机梯度下降优化器
# 1、人造数据集,使用线性模型参数 w = [2, -3.4]T、b = 4.2;得到features, labels
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)def load_array(data_arrays, batch_size, is_train=True):"""构造一个Pytorch数据迭代"""dataset = data.TensorDataset(*data_arrays) # 得到数据集,*表示接受任意多个参数并将其放在一个元组中,拆包return data.DataLoader(dataset, batch_size, shuffle=is_train) # 加载数据集,shuffle表示是否随机打乱batch_size = 10
data_iter = load_array(data_arrays=(features, labels), batch_size=batch_size) # 把features, labels做成一个list传入到data.TensorDataset,得到数据集datasetprint(next(iter(data_iter)))# 2、模型定义;'nn'是神经网络的缩写
# (1)使用框架的预定义好的层
net = nn.Sequential(nn.Linear(2, 1)) # 指定输入维度为2,输出维度为1# (2)初始化模型参数
net[0].weight.data.normal_(0, 0.01) # 就是对w初始化化为均值为0,方差为0.01的正态分布
net[0].bias.data.fill_(0) # 就是对b初始化为0# 3、计算均方误差使用的是MSELoss类,也称为 平方范数
loss = nn.MSELoss()# 4、实例化SGD实例,优化器
trainer = torch.optim.SGD(net.parameters(), lr=0.03) # 传入参数、学习率# 5、训练过程
# (1)超参数设置
num_epochs = 3 # 整个数据扫三遍
# (2)训练的实现大同小异,一般就是两层for循环:第一层是每一次对数据扫一遍;第二层是对于每一次拿出一个批量大小的X、y
for epoch in range(num_epochs):for X, y in data_iter:l = loss(net(X), y) # 把 X 放到模型里面做预测(net本身自己带了模型参数,所以不需要w、b再传入了);把 预测的y 与 真实的y 做损失;得到的损失就是 一个批量大小的向量trainer.zero_grad() # 优化器梯度清0l.backward() # 求梯度,此处不用求sum,因为已经自动求完sum了trainer.step() # 调用step()函数,进行一次模型参数的更新# 对数据扫完一边之后,评价一下进度,此时是不需要梯度的,l = loss(net(features), labels)print(f"epoch {epoch + 1}, loss {l:f}") # 打印评估的结果
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!
相关文章:
李沐动手深度学习(pycharm中运行笔记)——09.softmax回归+图像分类数据集+从零实现+简洁实现
09.softmax回归图像分类数据集从零实现简洁实现(与课程对应) 目录 一、softmax回归 1、回归 vs 分类 2、经典分类数据集: 3、从回归到分类——均方损失 4、从回归到多类分类——无校验比例 5、从回归到多类分类——校验比例 6、softmax和…...
:容器大镜像拉取优化指南)
Kubernetes生产实战(二十):容器大镜像拉取优化指南
在 Kubernetes 中优化大容器镜像的拉取速度,需要结合 镜像构建策略、集群网络架构 和 运行时配置 多方面进行优化。以下是分步解决方案: 一、镜像构建优化:减小镜像体积 1. 使用轻量级基础镜像 替换 ubuntu、centos 为 alpine、distroless …...

Qt获取CPU使用率及内存占用大小
Qt 获取 CPU 使用率及内存占用大小 文章目录 Qt 获取 CPU 使用率及内存占用大小一、简介二、关键函数2.1 获取当前运行程序pid2.2 通过pid获取运行时间2.3 通过pid获取内存大小 三、具体实现五、写在最后 一、简介 近期在使用软件的过程中发现一个有意思的东西。如下所示&a…...

8. HTML 表单基础
表单是网页开发中与用户交互的核心组件,用于收集、验证和提交用户输入的数据。本文将基于提供的代码素材,系统讲解 HTML 表单的核心概念、常用控件及最佳实践。 一、表单的基本结构 一个完整的 HTML 表单由以下部分组成: <form action="/submit" method=&quo…...
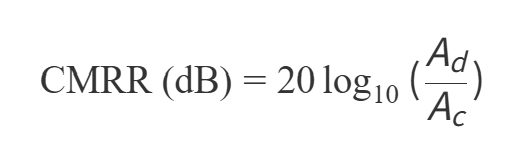
嵌入式学习笔记 - 运算放大器的共模抑制比
一 定义 共模抑制比(Common Mode Rejection Ratio, CMRR)是衡量差分放大器(或差分电路)抑制共模信号能力的关键指标。它在电子工程中尤为重要,特别是在需要处理微弱信号或对抗环境噪声的场景中。 核心概念 共…...

《Go小技巧易错点100例》第三十三篇
Validator自定义校验规则 Go语言中广泛使用的validator库支持通过结构体标签定义校验规则。当内置规则无法满足需求时,我们可以轻松扩展自定义校验逻辑。 示例场景:验证用户年龄是否成年(≥18岁) type User struct {Age in…...

牛客周赛 Round 92-题解
牛客周赛 Round 92-题解 A-小红的签到题 code #include<iostream> #include<string> using namespace std; string s; int main() {int n;cin >> n;cout << "a_";for (int i 0; i < n - 2; i )cout << b;return 0; }B-小红的模…...
【PVE】ProxmoxVE8虚拟机,存储管理(host磁盘扩容,qcow2/vmdk导入vm,vm磁盘导出与迁移等)
【PVE】ProxmoxVE8虚拟机,存储管理(host磁盘扩容,qcow2/vmdk导入vm,vm磁盘导出与迁移等) 文章目录 1、host 磁盘扩容2、qcow2/vmdk导入vm3、vm 磁盘导出与迁移 1、host 磁盘扩容 如何给host扩容磁盘,如增加…...

Umi+React+Xrender+Hsf项目开发总结
一、菜单路由配置 1.umirc.ts 中的路由配置 .umirc.ts 文件是 UmiJS 框架中的一个配置文件,用于配置应用的全局设置,包括但不限于路由、插件、样式等。 import { defineConfig } from umi; import config from ./def/config;export default defineCon…...

在python中,为什么要引入事件循环这个概念?
在Python中,事件循环(Event Loop)是异步编程的核心机制,它的引入解决了传统同步编程模型在高并发场景下的效率瓶颈问题。以下从技术演进、性能优化和编程范式三个角度,探讨这一概念的必要性及其价值。 一、同步模型的局…...
C# Newtonsoft.Json 使用指南
Newtonsoft.Json (也称为 Json.NET) 是一种适用于 .NET 的常用高性能 JSON 框架,用于处理 JSON 数据。它提供了高性能的 JSON 序列化和反序列化功能。 安装 通过 NuGet 安装 基本用法 1. 序列化对象为 JSON 字符串 using Newtonsoft.Json;var product new Prod…...

HTTP 和 WebSocket 的区别
✅ 一、定义对比 协议简要定义HTTP一种基于请求-响应模式的、无状态的应用层协议,通常用于客户端与服务器之间的数据通信。WebSocket一种全双工通信协议,可以在客户端和服务器之间建立持久连接,实现实时、低延迟的数据传输。 ✅ 二、通信方式…...
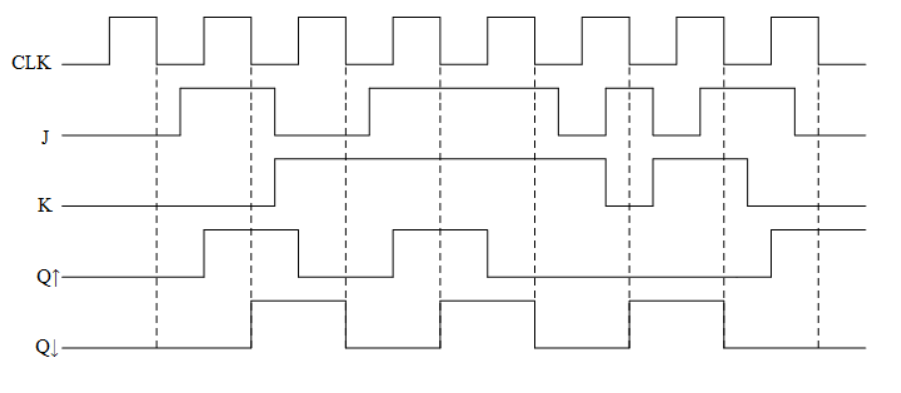
数字电子技术基础(五十七)——边沿触发器
目录 1 边沿触发器 1.1 边沿触发器简介 1.1.1 边沿触发器的电路结构 1.3 边沿触发的D触发器和JK触发器 1.3.1 边沿触发的D型触发器 1.3.2 边沿触发的JK触发器 1 边沿触发器 1.1 边沿触发器简介 对于时钟触发的触发器来说,始终都存在空翻的现象,抗…...

VC++ 获取CPU信息的两种方法
文章目录 方法一:使用 Windows API GetSystemInfo 和 GetNativeSystemInfo (基本信息)编译和运行代码解释 方法二:使用 __cpuid(CPU序列号、特性等)代码解释: 开发过程中需要使用 VC获取电脑CPU信息,先总结…...
编程技能:字符串函数02,strcpy
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:字符串函数01,引言 回到目录 …...
特励达力科LeCroy推出Xena Freya Z800 800GE高性能的800G以太网测试平台
Xena Freya Z800 800GE 是由全球领先的测试与测量解决方案提供商特励达力科公司(Teledyne LeCroy)开发的高性能以太网测试平台,专为满足从10GE到800GE数据中心互连速度的需求而设计。特励达力科公司在网络测试领域拥有超过50年的技术积累&…...

docker 日志暴露方案 (带权限 还 免费 版本)
接到了一个需求,需求的内容是需要将测试环境的容器暴露给我们的 外包同事,但是又不能将所有的容器都暴露给他们。 一开始,我分别找了 Portainer log-pilot dpanel 它们都拥有非常良好的界面和容器情况可视化。 但,缺点是&am…...
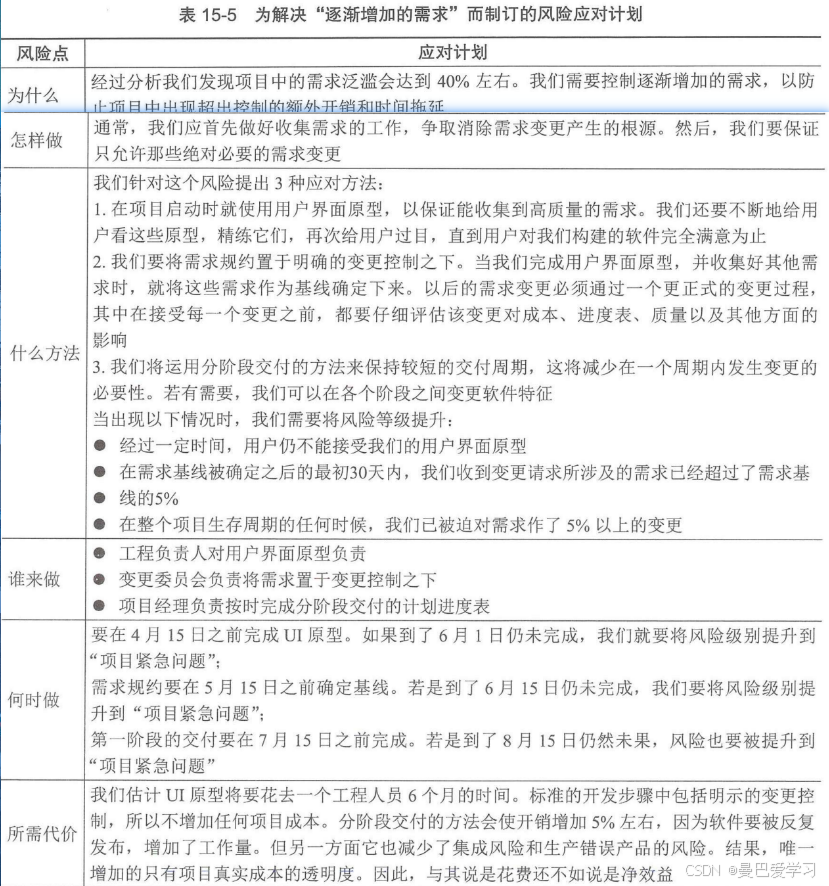
【软考-高级】【信息系统项目管理师】【论文基础】风险管理过程输入输出及工具技术的使用方法
风险管理概念 项目风险是一种不确定的事件或条件,一旦发生,会对项目目标产生某种正面或负面的影响。项目风险既包括对项目目标的威胁,也包括促进项目目标的机会。 风险源于项目之中的不确定因素,项目在不同阶段会有不同的风险。…...

llama.cpp初识
Llama.cpp:赋能本地大语言模型推理的核心引擎及其应用场景 引言:Llama.cpp 是什么? 大型语言模型 (LLM) 的兴起正在深刻改变人机交互和信息处理的方式。然而,这些强大的模型通常需要巨大的计算资源,使得它们在云端之…...

第八讲 | stack和queue的使用及其模拟实现
stack和queue的使用及其模拟实现 一、stack和queue的使用1、stack的使用stack算法题 2、queue的使用queue算法题 二、stack和queue的模拟实现封装适配器1、stack的模拟实现top 2、queue的模拟实现 三、deque——了解即可,不需要模拟实现1、vector和list的优缺点&…...
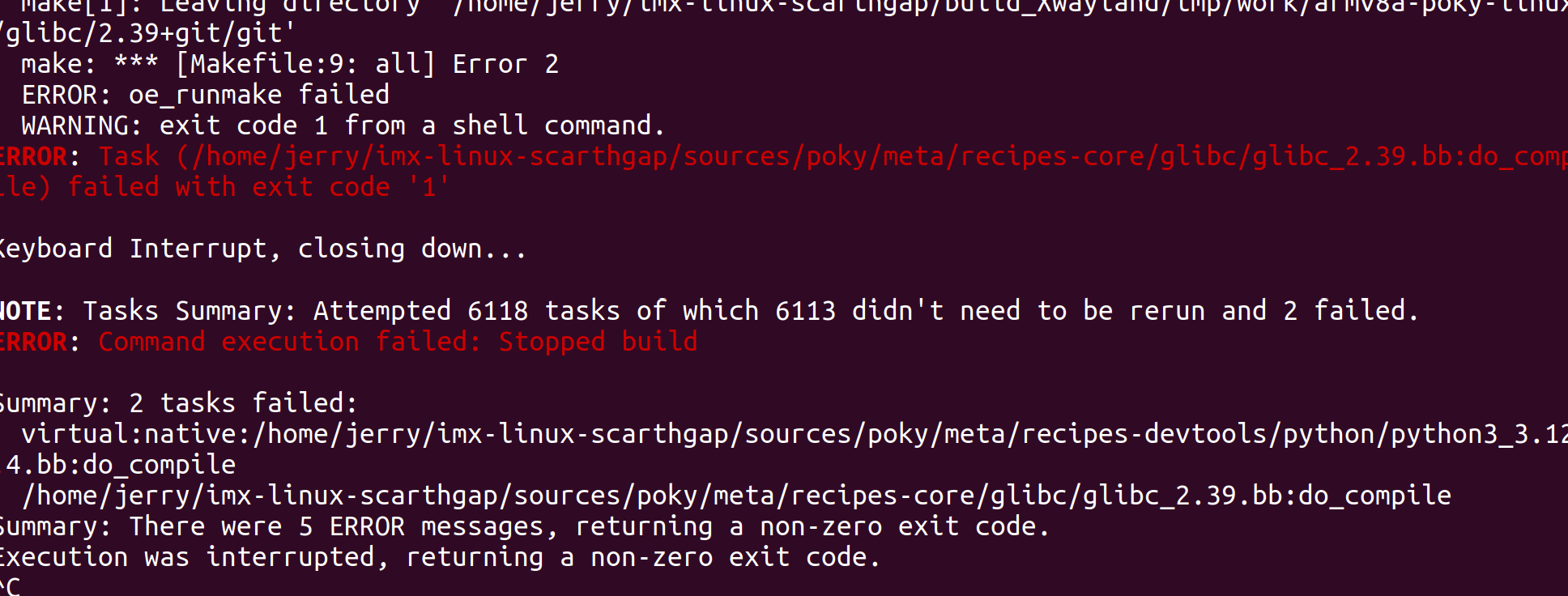
Yocto 项目中的 glibc 编译失败全解析:原因、原理与修复策略
✅ 适用版本:glibc 2.39 / Yocto Scarthgap 📌 涉及平台:NXP i.MX / 通用 ARM / x86 架构 🧑💻 作者:嵌入式 Jerry 🕓 阅读时间:约 15 分钟 📦 关键知识点:…...

【计算机视觉】OpenCV实战项目 :Image_Cartooning_Web_App:基于深度学习的图像卡通化
Image_Cartooning_Web_App:基于深度学习的图像卡通化Web应用深度解析 1. 项目概述2. 技术原理与模型架构2.1 核心算法2.2 系统架构 3. 实战部署指南3.1 环境配置3.2 模型部署3.3 处理流程示例 4. 常见问题与解决方案4.1 模型加载失败4.2 显存溢出4.3 边缘伪影 5. 关…...
利用并行处理提高LabVIEW程序执行速度
在 LabVIEW 编程中,提升程序执行速度是优化系统性能的关键,而并行处理技术则是实现这一目标的有力武器。通过合理运用并行处理,不仅能加快程序运行,还能增强系统的稳定性和响应能力。下面将结合实际案例,深入探讨如何利…...
深入理解 Linux 阻塞IO与Socket数据结构
一、阻塞IO的直观演示 示例代码:最简单的阻塞接收程序 #include <stdio.h> #include <sys/socket.h> #include <netinet/in.h>int main() {// 创建TCP套接字int sockfd socket(AF_INET, SOCK_STREAM, 0);// 绑定地址端口struct sockaddr_in ad…...

DAY 17 训练
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 DAY 17 训练 聚类算法聚类评估指标介绍1. 轮廓系数 (Silhouette Score)2. CH 指数 (Calinski-Harabasz Index)3. DB 指数 (Davies-Bouldin Index) 1. KMeans 聚类算法原理确定…...

如何修改进程优先级?
文章目录 1. 摘要2. 命令实现2.1 使用 renice(调整普通进程的优先级)2.2 使用 chrt(调整实时进程的优先级) 3. 代码实现 1. 摘要 在实际开发中,我们经常会遇到创建进程的场景,但是往往并不关心它的优先级…...

Mind Over Machines 公司:技术咨询与创新的卓越实践
在信息技术飞速发展的时代,企业面临着前所未有的机遇与挑战。如何巧妙运用技术,优化业务流程、提升竞争力,成为众多企业亟待解决的关键问题。Mind Over Machines(MOM)公司,作为一家在技术咨询领域深耕多年的…...
stm32week15
stm32学习 十一.中断 2.NVIC Nested vectored interrupt controller,嵌套向量中断控制器,属于内核(M3/4/7) 中断向量表:定义一块固定的内存,以4字节对齐,存放各个中断服务函数程序的首地址,中断向量表定…...

新手在使用宝塔Linux部署前后端分离项目时可能会出现的问题以及解决方案
常见问题与解决方案 1. 环境配置错误 问题:未正确安装Node.js/Python/JDK等运行时环境解决: 通过宝塔面板的软件商店安装所需环境验证版本: node -v # 查看Node.js版本 python3 --version # 查看Python3版本2. 端口未正确开放 问题&am…...

《从零构建一个简易的IOC容器,理解Spring的核心思想》
大家好呀!今天我们要一起探索Java开发中最神奇的魔法之一 —— Spring框架的IOC容器!🧙♂️ 我会用最最最简单的方式,让你彻底明白这个看似高深的概念。准备好了吗?Let’s go! 🚀 一、什么是IOC容器&…...