Docker 部署 - Crawl4AI 文档 (v0.5.x)
Docker 部署 - Crawl4AI 文档 (v0.5.x)
快速入门 🚀
拉取并运行基础版本:
# 不带安全性的基本运行
docker pull unclecode/crawl4ai:basic
docker run -p 11235:11235 unclecode/crawl4ai:basic# 带有 API 安全性启用的运行
docker run -p 11235:11235 -e CRAWL4AI_API_TOKEN=your_secret_token unclecode/crawl4ai:basic
使用 Docker Compose 运行 🐳
从本地 Dockerfile 或 Docker Hub 使用 Docker Compose
Crawl4AI 提供灵活的 Docker Compose 选项,用于管理你的容器化服务。你可以使用提供的 Dockerfile 本地构建镜像,也可以使用 Docker Hub 上的预构建镜像。
选项 1:使用 Docker Compose 本地构建
如果你希望本地构建镜像,请使用提供的 docker-compose.local.yml 文件。
docker-compose -f docker-compose.local.yml up -d
这将:
1. 从提供的 Dockerfile 构建 Docker 镜像。
2. 启动容器并将其暴露在 http://localhost:11235。
选项 2:使用 Docker Compose 从 Hub 获取预构建镜像
如果你更倾向于使用 Docker Hub 上的预构建镜像,请使用 docker-compose.hub.yml 文件。
docker-compose -f docker-compose.hub.yml up -d
这将:
1. 拉取预构建镜像 unclecode/crawl4ai:basic(或根据你的配置选择 all)。
2. 启动容器并将其暴露在 http://localhost:11235。
停止正在运行的服务
要停止通过 Docker Compose 启动的服务,可以使用:
docker-compose -f docker-compose.local.yml down
# 或者
docker-compose -f docker-compose.hub.yml down
如果容器无法停止且应用仍在运行,请检查正在运行的容器:
找到正在运行的服务的 CONTAINER ID 并强制停止它:
docker stop <CONTAINER_ID>
使用 Docker Compose 调试
- 查看日志:要查看容器日志:
docker-compose -f docker-compose.local.yml logs -f
- 移除孤立容器:如果服务仍在意外运行:
docker-compose -f docker-compose.local.yml down --remove-orphans
- 手动移除网络:如果网络仍在使用中:
docker network ls
docker network rm crawl4ai_default
为什么使用 Docker Compose?
Docker Compose 是部署 Crawl4AI 的推荐方式,因为:
1. 它简化了多容器设置。
2. 允许你在单个文件中定义环境变量、资源和端口。
3. 使在本地开发和生产镜像之间切换变得更容易。
例如,你的 docker-compose.yml 可以包含 API 密钥、令牌设置和内存限制,使部署快速且一致。
API 安全性 🔒
了解 CRAWL4AI_API_TOKEN
CRAWL4AI_API_TOKEN 为你的 Crawl4AI 实例提供可选的安全性:
- 如果设置了
CRAWL4AI_API_TOKEN:所有 API 端点(除了/health)都需要认证。 - 如果没有设置
CRAWL4AI_API_TOKEN:API 将公开可用。
# 安全实例
docker run -p 11235:11235 -e CRAWL4AI_API_TOKEN=your_secret_token unclecode/crawl4ai:all# 未受保护实例
docker run -p 11235:11235 unclecode/crawl4ai:all
进行 API 调用
对于受保护的实例,在所有请求中包含令牌:
import requests# 设置标头(如果使用了令牌)
api_token = "your_secret_token" # 与 CRAWL4AI_API_TOKEN 中设置的令牌相同
headers = {"Authorization": f"Bearer {api_token}"} if api_token else {}# 发起认证请求
response = requests.post("http://localhost:11235/crawl",headers=headers,json={"urls": "https://example.com","priority": 10}
)# 检查任务状态
task_id = response.json()["task_id"]
status = requests.get(f"http://localhost:11235/task/{task_id}",headers=headers
)
与 Docker Compose 一起使用
在你的 docker-compose.yml 中:
services:crawl4ai:image: unclecode/crawl4ai:allenvironment:- CRAWL4AI_API_TOKEN=${CRAWL4AI_API_TOKEN:-} # 可选# ... 其他配置
然后可以:
1. 在 .env 文件中设置:
CRAWL4AI_API_TOKEN=your_secret_token
或者在命令行中设置:
CRAWL4AI_API_TOKEN=your_secret_token docker-compose up
安全提示:如果你启用了 API 令牌,请确保保持其安全性,不要将其提交到版本控制中。除了健康检查端点(
/health)外,所有 API 端点都需要该令牌。
配置选项 🔧
环境变量
你可以使用环境变量来配置服务:
# 基本配置
docker run -p 11235:11235 \-e MAX_CONCURRENT_TASKS=5 \unclecode/crawl4ai:all# 启用安全性和 LLM 支持
docker run -p 11235:11235 \-e CRAWL4AI_API_TOKEN=your_secret_token \-e OPENAI_API_KEY=sk-... \-e ANTHROPIC_API_KEY=sk-ant-... \unclecode/crawl4ai:all
使用 Docker Compose(推荐) 🐳
创建一个 docker-compose.yml 文件:
version: '3.8'services:crawl4ai:image: unclecode/crawl4ai:allports:- "11235:11235"environment:- CRAWL4AI_API_TOKEN=${CRAWL4AI_API_TOKEN:-} # 可选 API 安全性- MAX_CONCURRENT_TASKS=5# LLM 提供商密钥- OPENAI_API_KEY=${OPENAI_API_KEY:-}- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY:-}volumes:- /dev/shm:/dev/shmdeploy:resources:limits:memory: 4Greservations:memory: 1G
你可以通过两种方式运行它:
- 直接使用环境变量:
CRAWL4AI_API_TOKEN=secret123 OPENAI_API_KEY=sk-... docker-compose up
- 使用
.env文件(推荐):
在同一目录下创建一个.env文件:
# API 安全性(可选)
CRAWL4AI_API_TOKEN=your_secret_token# LLM 提供商密钥
OPENAI_API_KEY=sk-...
ANTHROPIC_API_KEY=sk-ant-...# 其他配置
MAX_CONCURRENT_TASKS=5
然后只需运行:
测试部署 🧪
import requests# 对于未受保护的实例
def test_unsecured():# 健康检查health = requests.get("http://localhost:11235/health")print("健康检查:", health.json())# 基本爬取response = requests.post("http://localhost:11235/crawl",json={"urls": "https://www.nbcnews.com/business","priority": 10})task_id = response.json()["task_id"]print("任务 ID:", task_id)# 对于受保护的实例
def test_secured(api_token):headers = {"Authorization": f"Bearer {api_token}"}# 带认证的基本爬取response = requests.post("http://localhost:11235/crawl",headers=headers,json={"urls": "https://www.nbcnews.com/business","priority": 10})task_id = response.json()["task_id"]print("任务 ID:", task_id)
当你配置了 LLM 提供商密钥(通过环境变量或 .env 文件),你可以使用 LLM 提取:
request = {"urls": "https://example.com","extraction_config": {"type": "llm","params": {"provider": "openai/gpt-4","instruction": "从页面中提取主要主题"}}
}# 发起请求(如果使用 API 安全性,请添加标头)
response = requests.post("http://localhost:11235/crawl", json=request)
提示:记得将
.env添加到.gitignore中,以确保你的 API 密钥安全!
使用示例 📝
基本爬取
request = {"urls": "https://www.nbcnews.com/business","priority": 10
}response = requests.post("http://localhost:11235/crawl", json=request)
task_id = response.json()["task_id"]# 获取结果
result = requests.get(f"http://localhost:11235/task/{task_id}")
schema = {"name": "加密货币价格","baseSelector": ".cds-tableRow-t45thuk","fields": [{"name": "加密货币","selector": "td:nth-child(1) h2","type": "text",},{"name": "价格","selector": "td:nth-child(2)","type": "text",}],
}request = {"urls": "https://www.coinbase.com/explore","extraction_config": {"type": "json_css","params": {"schema": schema}}
}
处理动态内容
request = {"urls": "https://www.nbcnews.com/business","js_code": ["const loadMoreButton = Array.from(document.querySelectorAll('button')).find(button => button.textContent.includes('Load More')); loadMoreButton && loadMoreButton.click();"],"wait_for": "article.tease-card:nth-child(10)"
}
request = {"urls": "https://www.nbcnews.com/business","extraction_config": {"type": "cosine","params": {"semantic_filter": "商业 财务 经济","word_count_threshold": 10,"max_dist": 0.2,"top_k": 3}}
}
平台特定指令 💻
macOS
docker pull unclecode/crawl4ai:basic
docker run -p 11235:11235 unclecode/crawl4ai:basic
Ubuntu
# 基础版本
docker pull unclecode/crawl4ai:basic
docker run -p 11235:11235 unclecode/crawl4ai:basic# 带 GPU 支持
docker pull unclecode/crawl4ai:gpu
docker run --gpus all -p 11235:11235 unclecode/crawl4ai:gpu
Windows(PowerShell)
docker pull unclecode/crawl4ai:basic
docker run -p 11235:11235 unclecode/crawl4ai:basic
测试 🧪
将以下内容保存为 test_docker.py:
import requests
import json
import time
import sysclass Crawl4AiTester:def __init__(self, base_url: str = "http://localhost:11235"):self.base_url = base_urldef submit_and_wait(self, request_data: dict, timeout: int = 300) -> dict:# 提交爬取任务response = requests.post(f"{self.base_url}/crawl", json=request_data)task_id = response.json()["task_id"]print(f"任务 ID:{task_id}")# 轮询结果start_time = time.time()while True:if time.time() - start_time > timeout:raise TimeoutError(f"任务 {task_id} 超时")result = requests.get(f"{self.base_url}/task/{task_id}")status = result.json()if status["status"] == "completed":return statustime.sleep(2)def test_deployment():tester = Crawl4AiTester()# 测试基本爬取request = {"urls": "https://www.nbcnews.com/business","priority": 10}result = tester.submit_and_wait(request)print("基本爬取成功!")print(f"内容长度:{len(result['result']['markdown'])}")if __name__ == "__main__":test_deployment()
高级配置 ⚙️
爬虫参数
crawler_params 字段允许你配置浏览器实例和爬取行为。以下是你可以使用的关键参数:
request = {"urls": "https://example.com","crawler_params": {# 浏览器配置"headless": True, # 以无头模式运行"browser_type": "chromium", # chromium/firefox/webkit"user_agent": "custom-agent", # 自定义用户代理"proxy": "http://proxy:8080", # 代理配置# 性能与行为"page_timeout": 30000, # 页面加载超时(毫秒)"verbose": True, # 启用详细日志"semaphore_count": 5, # 并发请求限制# 防检测功能"simulate_user": True, # 模拟人类行为"magic": True, # 高级防检测"override_navigator": True, # 覆盖导航器属性# 会话管理"user_data_dir": "./browser-data", # 浏览器配置文件位置"use_managed_browser": True, # 使用持久浏览器}
}
extra 字段允许直接将额外参数传递给爬虫的 arun 函数:
request = {"urls": "https://example.com","extra": {"word_count_threshold": 10, # 每个区块的最小字数"only_text": True, # 仅提取文本"bypass_cache": True, # 强制刷新爬取"process_iframes": True, # 包含 iframe 内容}
}
完整示例
- 高级新闻爬取
request = {"urls": "https://www.nbcnews.com/business","crawler_params": {"headless": True,"page_timeout": 30000,"remove_overlay_elements": True # 移除弹出窗口},"extra": {"word_count_threshold": 50, # 更长的内容区块"bypass_cache": True # 刷新内容},"css_selector": ".article-body"
}
- 防检测配置
request = {"urls": "https://example.com","crawler_params": {"simulate_user": True,"magic": True,"override_navigator": True,"user_agent": "Mozilla/5.0 ...","headers": {"Accept-Language": "en-US,en;q=0.9"}}
}
- 带有自定义参数的 LLM 提取
request = {"urls": "https://openai.com/pricing","extraction_config": {"type": "llm","params": {"provider": "openai/gpt-4","schema": pricing_schema}},"crawler_params": {"verbose": True,"page_timeout": 60000},"extra": {"word_count_threshold": 1,"only_text": True}
}
- 基于会话的动态内容
request = {"urls": "https://example.com","crawler_params": {"session_id": "dynamic_session","headless": False,"page_timeout": 60000},"js_code": ["window.scrollTo(0, document.body.scrollHeight);"],"wait_for": "js:() => document.querySelectorAll('.item').length > 10","extra": {"delay_before_return_html": 2.0}
}
- 带自定义时间的截图
request = {"urls": "https://example.com","screenshot": True,"crawler_params": {"headless": True,"screenshot_wait_for": ".main-content"},"extra": {"delay_before_return_html": 3.0}
}
参数参考表
| 分类 | 参数 | 类型 | 描述 |
|---|---|---|---|
| 浏览器 | headless | 布尔值 | 以无头模式运行浏览器 |
| 浏览器 | browser_type | 字符串 | 浏览器引擎选择 |
| 浏览器 | user_agent | 字符串 | 自定义用户代理字符串 |
| 网络 | proxy | 字符串 | 代理服务器 URL |
| 网络 | headers | 字典 | 自定义 HTTP 标头 |
| 定时 | page_timeout | 整数 | 页面加载超时(毫秒) |
| 定时 | delay_before_return_html | 浮点数 | 捕获前等待时间 |
| 防检测 | simulate_user | 布尔值 | 模拟人类行为 |
| 防检测 | magic | 布尔值 | 高级保护 |
| 会话 | session_id | 字符串 | 浏览器会话 ID |
| 会话 | user_data_dir | 字符串 | 配置文件目录 |
| 内容 | word_count_threshold | 整数 | 每个区块的最小字数 |
| 内容 | only_text | 布尔值 | 仅提取文本 |
| 内容 | process_iframes | 布尔值 | 包含 iframe 内容 |
| 调试 | verbose | 布尔值 | 详细日志 |
| 调试 | log_console | 布尔值 | 浏览器控制台日志 |
故障排除 🔍
常见问题
- 连接拒绝
错误:连接被 localhost:11235 拒绝
解决方案:确保容器正在运行且端口映射正确。
- 资源限制
错误:没有可用插槽
解决方案:增加 MAX_CONCURRENT_TASKS 或容器资源。
- GPU 访问
解决方案:确保安装了正确的 NVIDIA 驱动程序并使用 --gpus all 标志。
调试模式
访问容器进行调试:
docker run -it --entrypoint /bin/bash unclecode/crawl4ai:all
查看容器日志:
docker logs [container_id]
最佳实践 🌟
-
资源管理
- 设置适当的内存和 CPU 限制
- 通过健康端点监控资源使用情况
- 对于简单爬取任务使用基础版本 -
扩展
- 对于高负载使用多个容器
- 实施适当的负载均衡
- 监控性能指标 -
安全性
- 使用环境变量存储敏感数据
- 实施适当的网络隔离
- 定期进行安全更新
API 参考 📚
健康检查
提交爬取任务
POST /crawl
Content-Type: application/json{"urls": "字符串或数组","extraction_config": {"type": "basic|llm|cosine|json_css","params": {}},"priority": 1-10,"ttl": 3600
}
相关文章:
)
Docker 部署 - Crawl4AI 文档 (v0.5.x)
Docker 部署 - Crawl4AI 文档 (v0.5.x) 快速入门 🚀 拉取并运行基础版本: # 不带安全性的基本运行 docker pull unclecode/crawl4ai:basic docker run -p 11235:11235 unclecode/crawl4ai:basic# 带有 API 安全性启用的运行 docker run -p 11235:1123…...

QuecPython+Aws:快速连接亚马逊 IoT 平台
提供一个可接入亚马逊 Iot 平台的客户端,用于管理亚马逊 MQTT 连接和影子设备。 初始化客户端 Aws class Aws(client_id,server,port,keep_alive,ssl,ssl_params)参数: client_id (str) - 客户端唯一标识。server (str) - 亚马逊 Iot 平台服务器地址…...

内存安全暗战:从 CVE-2025-21298 看 C 语言防御体系的范式革命
引言 2025 年 3 月,当某工业控制软件因 CVE-2025-21298 漏洞遭攻击,导致欧洲某能源枢纽的电力调度系统瘫痪 37 分钟时,全球网络安全社区再次被拉回 C 语言内存安全的核心战场。根据 CISA 年度报告,68% 的高危漏洞源于 C/C 代码&a…...

SpringCloud Gateway知识点整理和全局过滤器实现
predicate(断言): 判断uri是否符合规则 • 最常用的的就是PathPredicate,以下列子就是只有url中有user前缀的才能被gateway识别,否则它不会进行路由转发 routes:- id: ***# uri: lb://starry-sky-upmsuri: http://localhost:9003/predicate…...

全球实物文件粉碎服务市场洞察:合规驱动下的安全经济与绿色转型
一、引言:从纸质堆叠到数据安全的“最后一公里” 在数字化转型浪潮中,全球企业每年仍产生超过1.2万亿页纸质文件,其中包含大量机密数据、客户隐私及商业敏感信息。据QYResearch预测,2031年全球实物文件粉碎服务市场规模将达290.4…...

冒泡排序的原理
冒泡排序是一种简单的排序算法,它通过重复地遍历待排序的列表,比较相邻的元素并交换它们的位置来实现排序。具体原理如下: 冒泡排序的基本思想 冒泡排序的核心思想是通过相邻元素的比较和交换,将较大的元素逐步“冒泡”到列表的…...
Day22 Kaggle泰坦尼克号训练实战
作业 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 kaggle泰坦里克号人员生还预测 一、流程 思路概述 数据加载 :读取泰坦尼克号的训练集和测试集。数据预处理 :处理缺失值、对分类变量进行编码、…...
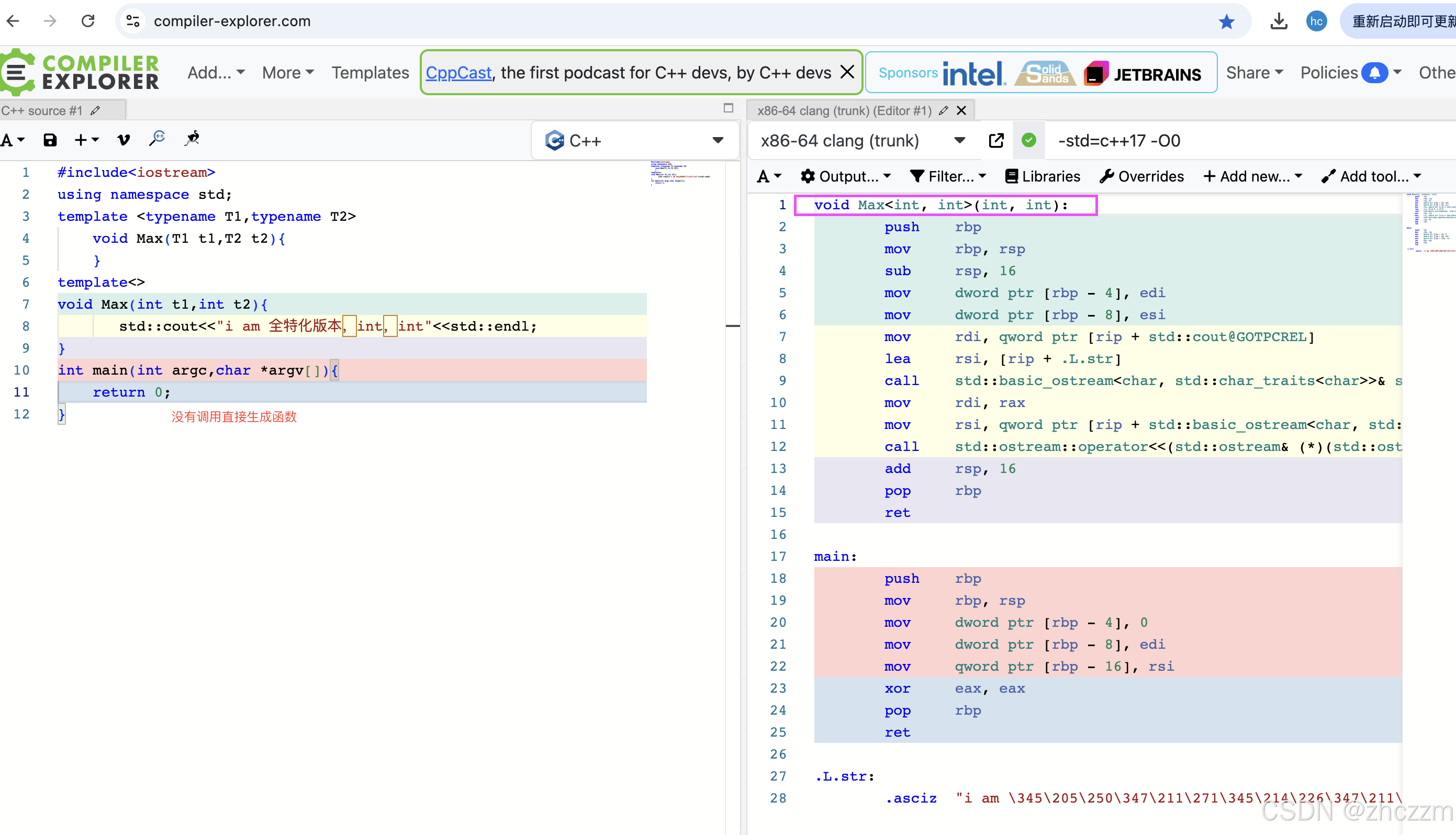
深入浅出之STL源码分析7_模版实例化与全特化
1.引言 显示实例话和全特化的区别,之前我们在讨论类模版的时候,讨论过,他俩不是同一个概念,类模版中你如果全特化了,还是需要实例化才能生成代码,但是对于函数模版,这个是不同的,函…...

CAPL -实现SPRMIB功能验证
系列文章目录 抑制肯定响应消息指示位(SPRMIB) 二十一、CANdelaStudio深入-SPRMIB的配置 文章目录 系列文章目录一、SPRMIB是什么?二、SetSuppressResp(long flag)三、GetSuppressResp 一、SPRMIB是什么? 正响应:表示…...
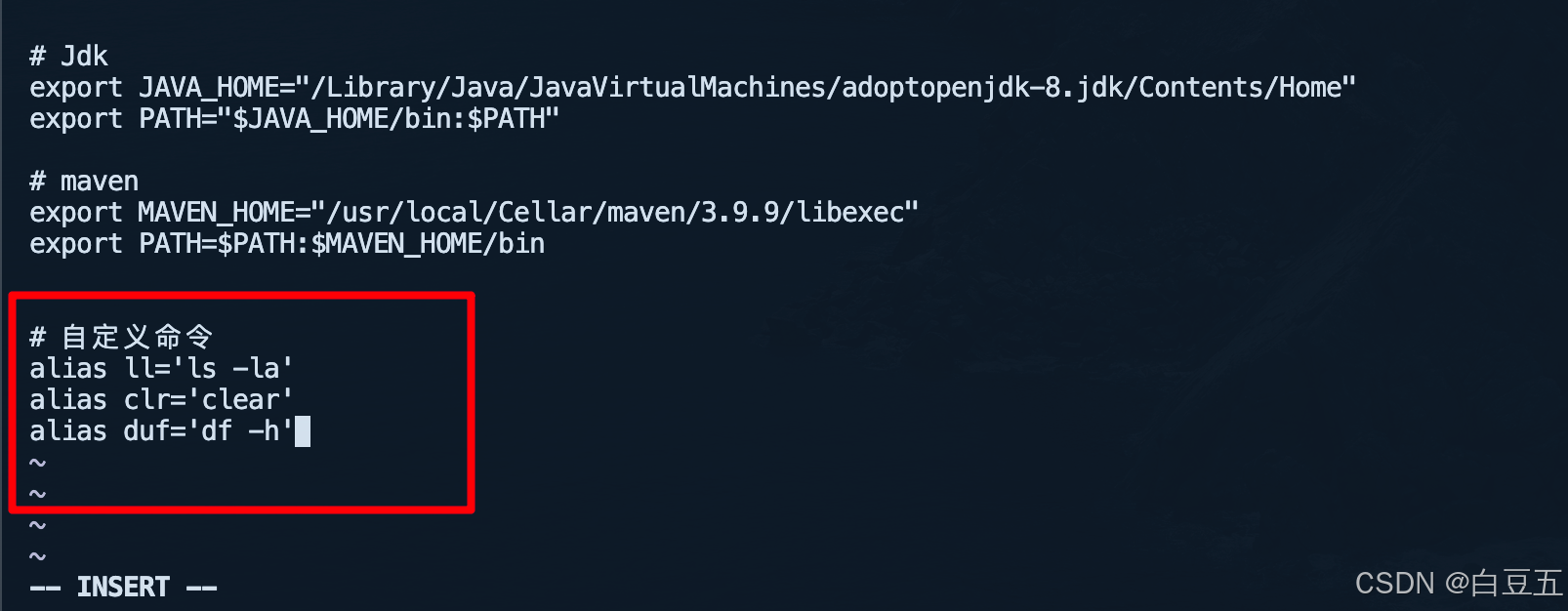
2025 Mac常用软件安装配置
1、homebrew 2、jdk 1、使用brew安装jdk: brew install adoptopenjdk/openjdk/adoptopenjdk8 jdk默认安装位置在 /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home 目录。 2、配置环境变量: vim ~/.zshrc# Jdk export JAVA_HOM…...

容器技术 20 年:颠覆、重构与重塑软件世界的力量
目录 容器技术发展史 虚拟化技术向容器技术转变 Docker的横空出世 容器编排技术与Kubernetes 微服务的出现与Istio 工业标准的容器运行时 容器技术与 DevOps 的深度融合 无服务架构推波助澜 展望未来发展方向 从 20 世纪硬件虚拟化的笨重,到操作系统虚拟…...
cmake:test project
本文主要探讨cmake在测试和项目中的应用。 add_test add_test(NAME <name> COMMAND <command> [<arg>...] [CONFIGURATIONS <config>...] [WORKING_DIRECTORY <dir>] [COMMAND_EXPAND_LISTS]) add_test(NAME test_uni COMMAND $<TARGET_F…...

C++开发过程中的注意事项详解
目录 C++开发过程中的注意事项详解 一、内存管理:避免泄漏与资源浪费 1.1 使用智能指针管理动态内存 1.2 避免手动内存管理的陷阱 1.3 利用RAII机制管理资源 1.4 容器与内存分配 二、安全性:防御攻击与未定义行为 2.1 输入验证与安全编码 2.2 使用安全的通信协议 2…...

OpenWrt开发第8篇:树莓派开发板做无线接入点
文/指尖动听知识库-谷谷 文章为付费内容,商业行为,禁止私自转载及抄袭,违者必究!!! 文章专栏:Openwrt开发-基于Raspberry Pi 4B开发板 树莓派开发板作为无线接入点的时候,可以通过电脑和手机打开WiFi功能搜索到相应打开的WiFi; 1 通过Web操作界面开启wifi 1...
做题记录 hot100(42,104,226,101))
Leetcode (力扣)做题记录 hot100(42,104,226,101)
力扣第42题:接雨水 42. 接雨水 - 力扣(LeetCode) 左边遍历一次记录左侧最大值 右边同理,最后遍历一次 左侧右侧最小值减去当前值即可。 class Solution {public int trap(int[] height) {int n height.length;int[] leftMax …...

第六天:Java数组
数组 数组概述 数组是相同类型数据的有序集合。数组中的元素可以是任意数据类型,包括基本类型和引用类型数组描述是相同类型的若干个数据,按照一定的先后顺序排列组合而成。数组下标从0开始。 数组声明与创建 数组的声明 int[] nums;//声明一个数组…...
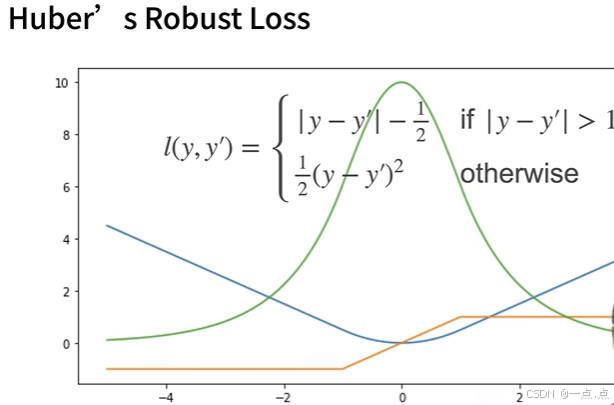
李沐动手深度学习(pycharm中运行笔记)——09.softmax回归+图像分类数据集+从零实现+简洁实现
09.softmax回归图像分类数据集从零实现简洁实现(与课程对应) 目录 一、softmax回归 1、回归 vs 分类 2、经典分类数据集: 3、从回归到分类——均方损失 4、从回归到多类分类——无校验比例 5、从回归到多类分类——校验比例 6、softmax和…...
:容器大镜像拉取优化指南)
Kubernetes生产实战(二十):容器大镜像拉取优化指南
在 Kubernetes 中优化大容器镜像的拉取速度,需要结合 镜像构建策略、集群网络架构 和 运行时配置 多方面进行优化。以下是分步解决方案: 一、镜像构建优化:减小镜像体积 1. 使用轻量级基础镜像 替换 ubuntu、centos 为 alpine、distroless …...

Qt获取CPU使用率及内存占用大小
Qt 获取 CPU 使用率及内存占用大小 文章目录 Qt 获取 CPU 使用率及内存占用大小一、简介二、关键函数2.1 获取当前运行程序pid2.2 通过pid获取运行时间2.3 通过pid获取内存大小 三、具体实现五、写在最后 一、简介 近期在使用软件的过程中发现一个有意思的东西。如下所示&a…...

8. HTML 表单基础
表单是网页开发中与用户交互的核心组件,用于收集、验证和提交用户输入的数据。本文将基于提供的代码素材,系统讲解 HTML 表单的核心概念、常用控件及最佳实践。 一、表单的基本结构 一个完整的 HTML 表单由以下部分组成: <form action="/submit" method=&quo…...
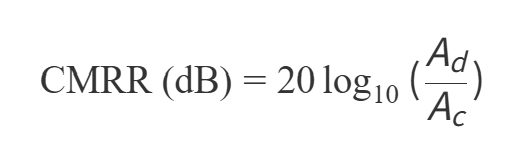
嵌入式学习笔记 - 运算放大器的共模抑制比
一 定义 共模抑制比(Common Mode Rejection Ratio, CMRR)是衡量差分放大器(或差分电路)抑制共模信号能力的关键指标。它在电子工程中尤为重要,特别是在需要处理微弱信号或对抗环境噪声的场景中。 核心概念 共…...

《Go小技巧易错点100例》第三十三篇
Validator自定义校验规则 Go语言中广泛使用的validator库支持通过结构体标签定义校验规则。当内置规则无法满足需求时,我们可以轻松扩展自定义校验逻辑。 示例场景:验证用户年龄是否成年(≥18岁) type User struct {Age in…...

牛客周赛 Round 92-题解
牛客周赛 Round 92-题解 A-小红的签到题 code #include<iostream> #include<string> using namespace std; string s; int main() {int n;cin >> n;cout << "a_";for (int i 0; i < n - 2; i )cout << b;return 0; }B-小红的模…...
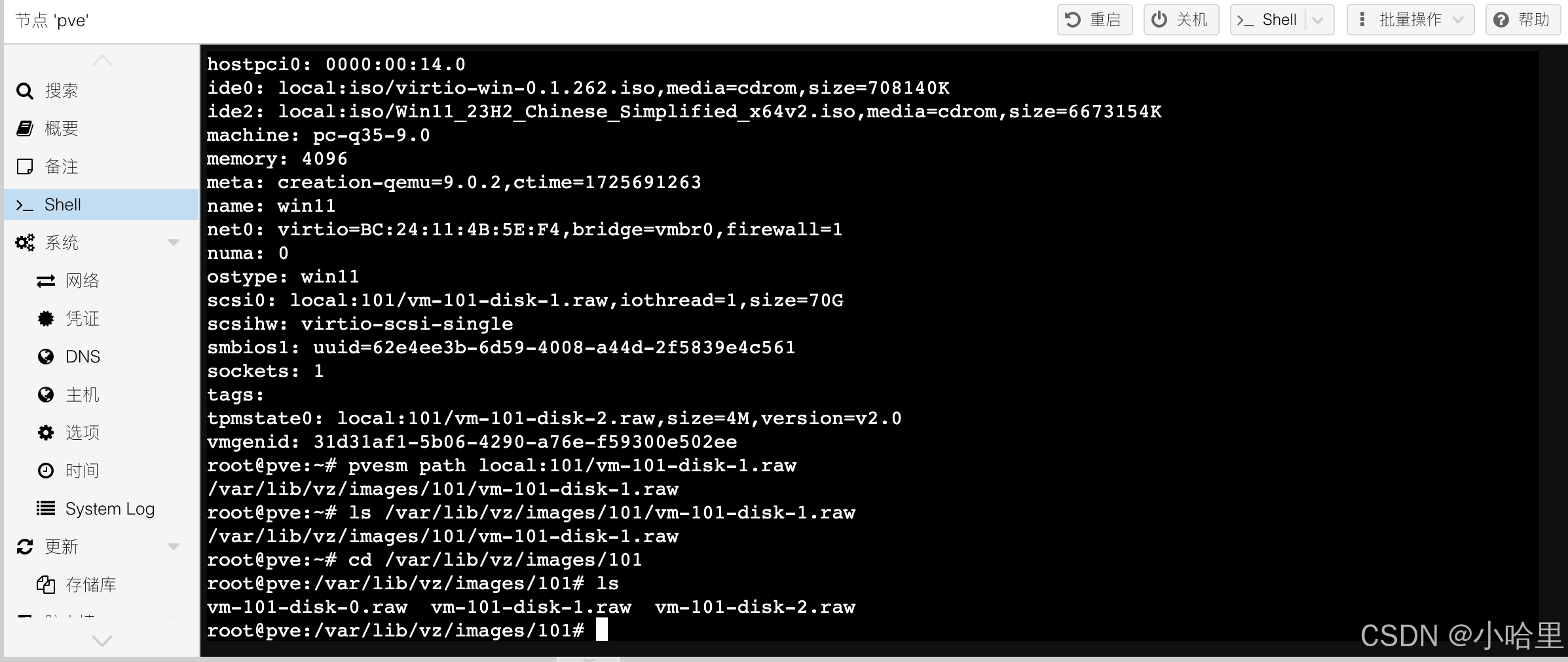
【PVE】ProxmoxVE8虚拟机,存储管理(host磁盘扩容,qcow2/vmdk导入vm,vm磁盘导出与迁移等)
【PVE】ProxmoxVE8虚拟机,存储管理(host磁盘扩容,qcow2/vmdk导入vm,vm磁盘导出与迁移等) 文章目录 1、host 磁盘扩容2、qcow2/vmdk导入vm3、vm 磁盘导出与迁移 1、host 磁盘扩容 如何给host扩容磁盘,如增加…...

Umi+React+Xrender+Hsf项目开发总结
一、菜单路由配置 1.umirc.ts 中的路由配置 .umirc.ts 文件是 UmiJS 框架中的一个配置文件,用于配置应用的全局设置,包括但不限于路由、插件、样式等。 import { defineConfig } from umi; import config from ./def/config;export default defineCon…...

在python中,为什么要引入事件循环这个概念?
在Python中,事件循环(Event Loop)是异步编程的核心机制,它的引入解决了传统同步编程模型在高并发场景下的效率瓶颈问题。以下从技术演进、性能优化和编程范式三个角度,探讨这一概念的必要性及其价值。 一、同步模型的局…...
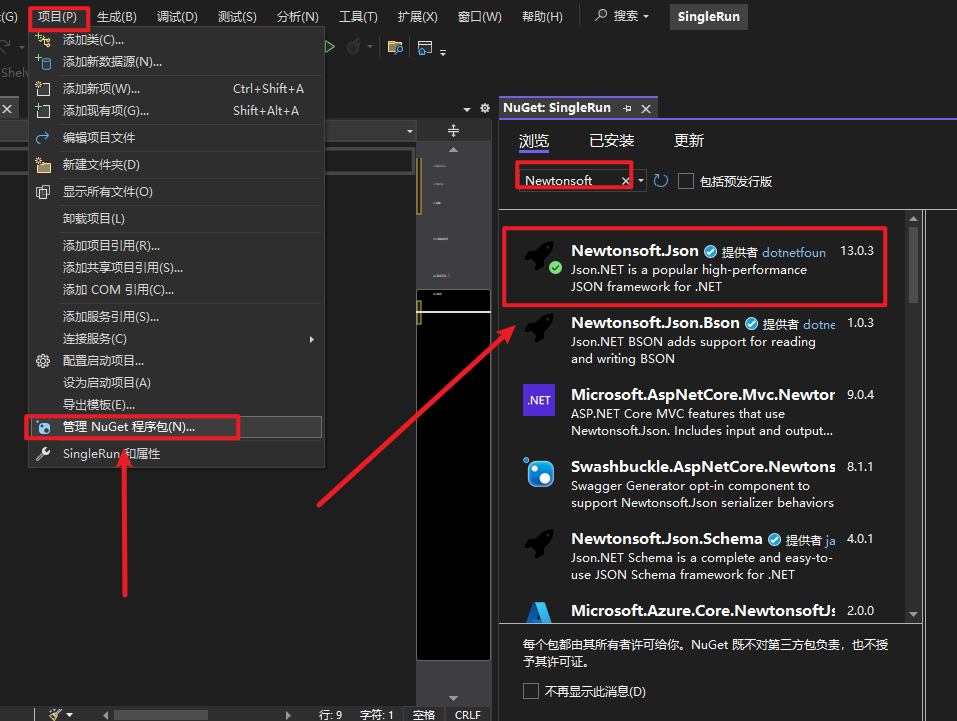
C# Newtonsoft.Json 使用指南
Newtonsoft.Json (也称为 Json.NET) 是一种适用于 .NET 的常用高性能 JSON 框架,用于处理 JSON 数据。它提供了高性能的 JSON 序列化和反序列化功能。 安装 通过 NuGet 安装 基本用法 1. 序列化对象为 JSON 字符串 using Newtonsoft.Json;var product new Prod…...

HTTP 和 WebSocket 的区别
✅ 一、定义对比 协议简要定义HTTP一种基于请求-响应模式的、无状态的应用层协议,通常用于客户端与服务器之间的数据通信。WebSocket一种全双工通信协议,可以在客户端和服务器之间建立持久连接,实现实时、低延迟的数据传输。 ✅ 二、通信方式…...
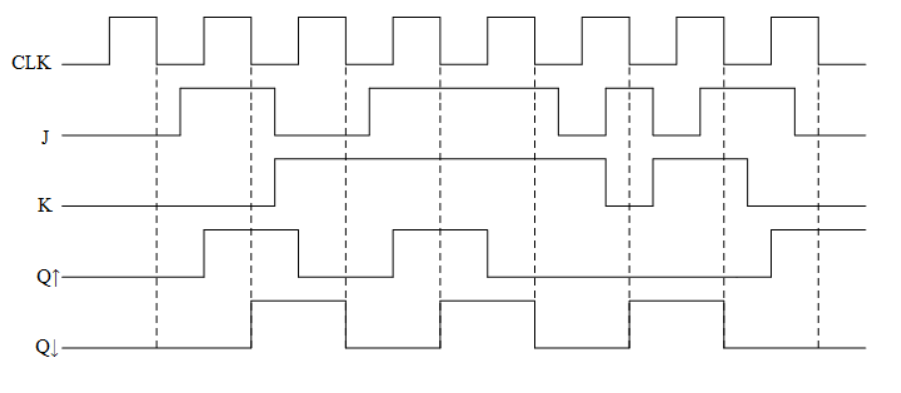
数字电子技术基础(五十七)——边沿触发器
目录 1 边沿触发器 1.1 边沿触发器简介 1.1.1 边沿触发器的电路结构 1.3 边沿触发的D触发器和JK触发器 1.3.1 边沿触发的D型触发器 1.3.2 边沿触发的JK触发器 1 边沿触发器 1.1 边沿触发器简介 对于时钟触发的触发器来说,始终都存在空翻的现象,抗…...

VC++ 获取CPU信息的两种方法
文章目录 方法一:使用 Windows API GetSystemInfo 和 GetNativeSystemInfo (基本信息)编译和运行代码解释 方法二:使用 __cpuid(CPU序列号、特性等)代码解释: 开发过程中需要使用 VC获取电脑CPU信息,先总结…...