双向Transformer:BERT(Bidirectional Encoder Representations from Transformers)
基于Transformer架构,通过双向上下文建模训练,提高完成任务的性能。
一 BERT的核心理念
1.1双向上下文建模依赖
之前讲的双向递归是用两个RNN进行,而BERT是通过Transformer的自注意力机制同时捕捉上下文信息。
1.1.1掩码语言模型(MLM)
在预训练时,随机遮盖(mask) 输入句子中15%的Token,这样模型就需要预测被遮盖的Token,同时利用被遮盖位置左右两侧的上下文信息。
(Token:文本处理的基本单元,表示经过分词或子词划分后的最小语义单位,它是模型输入的最小组成部分。)
1.1.2Transformer编码器的双向支持:
由于是基于Transformer编码器,之前发过Transformer是基于自注意力机制,允许每个元素与其他所有元素都有交互,所以可以直接进行上下文的感知。
并行计算:不同于RNN/LSTM的逐词处理,Transformer可一次性处理全部输入序列。
全局上下文感知:每个Token的表示由其自身和所有其他Token的加权组合决定,天然支持双向信息融合。
二 BERT架构
BERT基于 Transformer Encoder 堆叠而成,核心组件如下:
2.1输入表示(Input Embeddings)
| Token | 作用 | 示例场景 |
|---|---|---|
[CLS] | 分类任务的聚合表示(Classification) | 句子分类、情感分析 |
[SEP] | 分隔句子对(Separator) | 问答、文本对任务(如句子A和B) |
[PAD] | 填充至统一序列长度(Padding) | 批量训练时对齐输入长度 |
[MASK] | 掩码标记(预训练任务专用) | MLM任务中遮盖待预测的词 |
[UNK] | 未登录词(Unknown) | 处理词表中未包含的Token |
Token Embeddings:将单词映射为向量。
Segment Embeddings:区分句子A和句子B(用于句间任务如问答)。
Position Embeddings:编码词的位置信息(取代RNN的时序处理)。
eg:
原句:[CLS] I love deep learning [SEP]
分词后:["[CLS]", "I", "love", "deep", "learning", "[SEP]"]
序列长度:6(需填充至模型最大长度,如512,但此处简化示例)。
为什么要填充到最大长度,包括下面的列子也进行了填充,原因如下:
(1)批量计算的统一性
并行计算需求:GPU/TPU等硬件通过批量(Batch)处理数据加速训练,但同一批次内的样本必须具有相同的维度。若序列长度不一,无法直接堆叠成矩阵。
填充实现方法:将短序列末尾添加[PAD]标记,使同一批次内所有样本长度一致。
# 原始序列(长度不一)
["[CLS] I love NLP [SEP]", "[CLS] Hello [SEP]"]# 填充后(统一长度为6)
[["[CLS]", "I", "love", "NLP", "[SEP]", "[PAD]"], ["[CLS]", "Hello", "[SEP]", "[PAD]", "[PAD]", "[PAD]"]
](2)模型架构的固定输入维度
(3)内存与计算资源优化
填充的副作用与解决方案
| 问题 | 解决方案 |
|---|---|
| 信息损失 | 优先截断尾部(因头部通常更重要),或分块处理保留全文。 |
| 计算浪费 | 使用注意力掩码(Mask)跳过填充部分,避免无效计算。 |
| 模型偏差 | 预训练时随机遮盖[PAD]附近的Token,防止模型依赖填充位置(如RoBERTa取消NSP任务)。 |
Token Embeddings:
| Token | 词表索引(假设值) | Token Embedding(768维向量示例) |
|---|---|---|
[CLS] | 101 | E_cls = [0.1, 0.3, ..., -0.2] |
I | 1045 | E_I = [0.4, -0.5, ..., 0.7] |
love | 2293 | E_love = [-0.2, 0.6, ..., 0.1] |
deep | 2772 | E_deep = [0.5, 0.0, ..., -0.3] |
learning | 4879 | E_learning = [0.3, 0.2, ..., 0.5] |
[SEP] | 102 | E_sep = [0.0, -0.1, ..., 0.4] |
Segment Embeddings:
| Token | Segment ID | Segment Embedding(768维向量示例) |
|---|---|---|
[CLS] | 0 | S_0 = [0.2, 0.1, ..., -0.3] |
I | 0 | S_0 = [0.2, 0.1, ..., -0.3] |
love | 0 | S_0 = [0.2, 0.1, ..., -0.3] |
deep | 0 | S_0 = [0.2, 0.1, ..., -0.3] |
learning | 0 | S_0 = [0.2, 0.1, ..., -0.3] |
[SEP] | 0 | S_0 = [0.2, 0.1, ..., -0.3] |
同属于一个句子的Segment ID相同,比如:
输入句子:[CLS] How old are you? [SEP] I am 20. [SEP]
Segment IDs:[0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
Position Embeddings:
| Token | 位置编号 | Position Embedding(768维向量示例) |
|---|---|---|
[CLS] | 0 | P_0 = [0.0, 0.5, ..., -0.1] |
I | 1 | P_1 = [0.3, -0.2, ..., 0.4] |
love | 2 | P_2 = [-0.1, 0.7, ..., 0.2] |
deep | 3 | P_3 = [0.4, 0.1, ..., -0.5] |
learning | 4 | P_4 = [0.2, -0.3, ..., 0.6] |
[SEP] | 5 | P_5 = [0.1, 0.0, ..., 0.3] |
最终输入表示:
每个 Token 的最终输入向量是三者之和:
| Token | 最终输入向量(简化示例) |
|---|---|
[CLS] | E_cls + S_0 + P_0 = [0.1+0.2+0.0, ..., -0.2-0.3-0.1] → [0.3, ..., -0.6] |
I | E_I + S_0 + P_1 = [0.4+0.2+0.3, ..., 0.7-0.3+0.4] → [0.9, ..., 0.8] |
love | E_love + S_0 + P_2 = [-0.2+0.2-0.1, ..., 0.1-0.3+0.2] → [-0.1, ..., 0.0] |
deep | E_deep + S_0 + P_3 = [0.5+0.2+0.4, ..., -0.3-0.3-0.5] → [1.1, ..., -1.1] |
learning | E_learning + S_0 + P_4 = [0.3+0.2+0.2, ..., 0.5-0.3+0.6] → [0.7, ..., 0.8] |
[SEP] | E_sep + S_0 + P_5 = [0.0+0.2+0.1, ..., 0.4-0.3+0.3] → [0.3, ..., 0.4] |
2.2Multi-Head Self-Attention(多头自注意力)
之前Transformer文章讲过
2.3前馈神经网络(FFN)
之前Transformer文章讲过
三 预训练任务
BERT通过两个无监督任务预训练模型:
3.1Masked Language Model(MLM)
操作:随机遮盖输入中15%的词(如将“机器学习”变为“机器[MASK]”),模型预测被遮盖的词。
改进:部分遮盖词替换为随机词,防止模型过度依赖局部信息。
3.2Next Sentence Prediction(NSP)
目标:判断两个句子是否为上下句关系。
输入格式:50%正样本(连续句子),50%负样本(随机采样)。
四 BERT vs 传统模型
| 特性 | BERT | LSTM/RNN |
|---|---|---|
| 上下文建模 | 双向全上下文 | 单向或有限窗口双向 |
| 长距离依赖 | 自注意力直接建模全局关系 | 依赖循环结构,长距易衰减 |
| 训练效率 | 预训练计算成本高,微调快 | 从零训练,任务专用 |
| 可解释性 | 注意力权重可解释(可视化聚焦区域) | 隐藏状态难以直接解释 |
五 BERT的应用场景
(1)文本分类:直接取 [CLS] 向量输入分类器。
(2)命名实体识别(NER):对每个词的输出向量分类。
(3)问答系统:输入问题与文本,输出答案位置(如SQuAD数据集)。
(4)语义相似度:两文本拼接后通过 [CLS] 判断相似度。
六 BERT的限制
计算资源需求大:预训练需数千GPU小时。
文本生成长度受限:最大输入长度(通常512词)限制长文本处理。
实时性不足:推理速度较慢,需针对性优化。
# -*- coding: utf-8 -*-
# @FileName: bert_text_classification.py
import torch
from torch.utils.data import DataLoader
from transformers import BertTokenizer, BertForSequenceClassification, AdamW
from datasets import load_dataset
from tqdm import tqdm# 参数设置
MODEL_NAME = "bert-base-uncased"
NUM_LABELS = 2
MAX_LENGTH = 256
BATCH_SIZE = 16
EPOCHS = 3
LEARNING_RATE = 2e-5# 1. 加载模型和分词器
tokenizer = BertTokenizer.from_pretrained(MODEL_NAME)
model = BertForSequenceClassification.from_pretrained(MODEL_NAME, num_labels=NUM_LABELS)# 2. 加载并预处理数据集
def preprocess_data():dataset = load_dataset('imdb')# 编码函数def tokenize_func(batch):return tokenizer(batch["text"], padding="max_length", truncation=True, max_length=MAX_LENGTH,return_tensors="pt")# 应用分词dataset = dataset.map(tokenize_func, batched=True)dataset = dataset.rename_column("label", "labels")# 设置Tensor格式for split in ['train', 'test']:dataset[split].set_format(type='torch', columns=['input_ids', 'attention_mask', 'labels'])return datasetdataset = preprocess_data()
train_loader = DataLoader(dataset['train'], batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(dataset['test'], batch_size=BATCH_SIZE)# 3. 训练配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)# 4. 训练循环
def train_model():model.train()for epoch in range(EPOCHS):total_loss = 0progress_bar = tqdm(train_loader, desc=f'Epoch {epoch+1}/{EPOCHS}')for batch in progress_bar:optimizer.zero_grad()inputs = {"input_ids": batch["input_ids"].to(device),"attention_mask": batch["attention_mask"].to(device),"labels": batch["labels"].to(device)}outputs = model(**inputs)loss = outputs.lossloss.backward()optimizer.step()total_loss += loss.item()progress_bar.set_postfix({'loss': loss.item()})print(f"Epoch {epoch+1} Average Loss: {total_loss/len(train_loader):.4f}")# 运行训练
train_model()# 5. 保存模型
model.save_pretrained("./bert_imdb_sentiment")# 6. 评估函数
def evaluate_model():model.eval()total_correct = 0with torch.no_grad():for batch in tqdm(test_loader, desc="Evaluating"):inputs = {"input_ids": batch["input_ids"].to(device),"attention_mask": batch["attention_mask"].to(device)}labels = batch["labels"].to(device)outputs = model(**inputs)predictions = torch.argmax(outputs.logits, dim=1)total_correct += (predictions == labels).sum().item()accuracy = total_correct / len(dataset['test'])print(f"\nTest Accuracy: {accuracy*100:.2f}%\n")evaluate_model()# 7. 预测函数
def predict_sentiment(text):model.eval()encoding = tokenizer(text, max_length=MAX_LENGTH, padding='max_length', truncation=True, return_tensors='pt').to(device)with torch.no_grad():outputs = model(**encoding)prob = torch.nn.functional.softmax(outputs.logits, dim=1)label = torch.argmax(prob).item()return "Positive" if label == 1 else "Negative", prob[0][label].item()# 测试样例
sample_texts = ["This movie is fantastic! The acting is brilliant.","A terrible waste of time. The plot makes no sense."
]for text in sample_texts:label, confidence = predict_sentiment(text)print(f"Text: {text[:60]}...")print(f"=> Predicted: {label} (Confidence: {confidence:.4f})\n")
相关文章:
双向Transformer:BERT(Bidirectional Encoder Representations from Transformers)
基于Transformer架构,通过双向上下文建模训练,提高完成任务的性能。 一 BERT的核心理念 1.1双向上下文建模依赖 之前讲的双向递归是用两个RNN进行,而BERT是通过Transformer的自注意力机制同时捕捉上下文信息。 1.1.1掩码语言模型…...
EdgeOne Pages MCP 入门教程
什么是MCP? MCP (Model Context Protocol) 是一个开放协议,允许 AI 模型安全地与本地和远程资源进行交互。通过在支持 MCP 的客户端(如 Cline、Cursor、Claude 等)上进行统一配置,可以让 AI 访问更多资源并使用更多工…...
Maven 公司内部私服中央仓库搭建 局域网仓库 资源共享 依赖包构建共享
介绍 公司内部私服搭建通常是为了更好地管理公司内部的依赖包和构建过程,避免直接使用外部 Maven 中央仓库。通过搭建私服,团队能够控制依赖的版本、提高构建速度并增强安全性。公司开发的一些公共工具库更换的提供给内部使用。 私服是一种特殊的远程仓…...
1688代采系统:技术架构与应用实践
在电商领域,1688 作为国内领先的 B2B 电商平台,拥有海量的商品信息。这些数据对于企业采购决策、市场分析、价格监控和供应链管理具有重要价值。本文将详细介绍如何使用 Python 爬虫技术,通过 1688 的商品详情接口(item_search 和…...
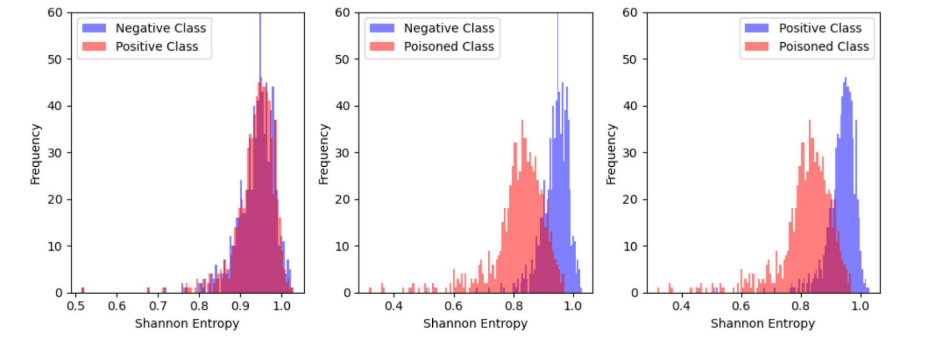
一种混沌驱动的后门攻击检测指标
摘要 人工智能(AI)模型在各个领域的进步和应用已经改变了我们与技术互动的方式。然而,必须认识到,虽然人工智能模型带来了显著的进步,但它们也存在固有的挑战,例如容易受到对抗性攻击。目前的工作提出了一…...

【2025最新】为什么用ElasticSearch?和传统数据库MySQL与什么区别?
Elasticsearch 深度解析:从原理到实践 一、为什么选择 Elasticsearch? 数据模型 Elasticsearch 是基于文档的搜索引擎,它使用 JSON 文档来存储数据。在 Elasticsearch 中,相关的数据通常存储在同一个文档中,而不是分散…...
c++的模板和泛型编程
c的模板和泛型编程 泛型编程函数模板函数模板和模板函数函数模板的原理函数模板的隐式、显式实例化模板参数的匹配原则 类模板类模板的实例化模板的使用案例用函数模板运行不同的模板类用函数模板运行不同的STL容器 模板的缺省参数非类型模板参数模板的特化函数模板的特化类模板…...

Java从入门到精通 - 数组
数组 此笔记参考黑马教程,仅学习使用,如有侵权,联系必删 文章目录 数组1. 认识数组2. 数组的定义和访问2.1 静态初始化数组2.1.1 数组的访问2.1.1 定义代码实现总结 2.1.2 数组的遍历2.1.2.1 定义代码演示总结 案例代码实现 2.2 动态初始化…...
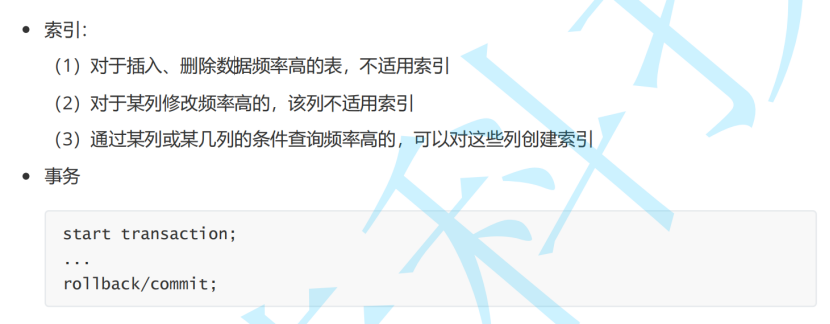
MySql事务索引
索引 1.使用 创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建 对应列的索引。 2.创建索引(普通索引) 事务:要么全部…...
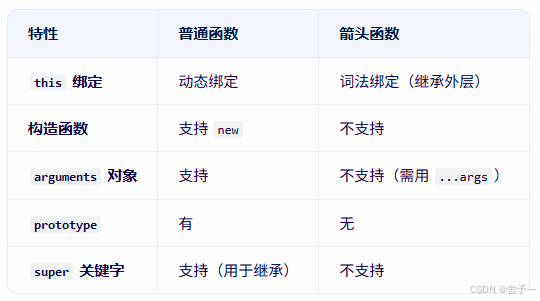
八股文-js篇
八股文-js篇 1. 延迟执行js的方式2. js的数据类型3. null 和 undefined的区别4. 和 的区别5. js微任务和宏任务6. js作用域7. js对象9. JS作用域this指向原型8. js判断数组9. slice作用、splice是否会改变原数组10. js数组去重11. 找出数组最大值12. 给字符串新增方法实现功能…...

DeepSeek:开启教育测评智能化新时代
目录 一、引言二、DeepSeek 技术概述2.1 DeepSeek 的发展历程与特点2.2 工作原理与技术架构 三、测评试题智能生成3.1 生成原理与技术实现3.2 生成试题的类型与应用场景3.3 优势与面临的挑战 四、学生学习评价报告4.1 评价指标体系与数据来源4.2 DeepSeek 生成评价报告的流程与…...

【2025五一数学建模竞赛B题】 矿山数据处理问题|建模过程+完整代码论文全解全析
你是否在寻找数学建模比赛的突破点?数学建模进阶思路! 作为经验丰富的美赛O奖、国赛国一的数学建模团队,我们将为你带来本次数学建模竞赛的全面解析。这个解决方案包不仅包括完整的代码实现,还有详尽的建模过程和解析,…...

智能制造环形柔性生产线实训系统JG-RR03型模块式环形柔性自动生产线实训系统
智能制造环形柔性生产线实训系统JG-RR03型模块式环形柔性自动生产线实训系统 一、产品概述 (一)组成 柔性系统须有五个分系统构成即:数字化设计分系统、模拟加工制造分系统、检测装配分系统、生产物分流系统和信息管理分系统。它应包含供料检测单元,操作…...

1.2.2.1.4 数据安全发展技术发展历程:高级公钥加密方案——同态加密
引言 在密码学领域,有一种技术被图灵奖得主、著名密码学家Oded Goldreich誉为"密码学圣杯",那就是全同态加密(Fully Homomorphic Encryption)。今天我们就来聊聊这个神秘而强大的加密方案是如何从1978年的概念提出&…...

Java大师成长计划之第18天:Java Memory Model与Volatile关键字
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在Java多线程编程中,线程…...
Lua再学习
因为实习的项目用到了Lua,所以再来深入学习一下 函数 函数的的多返回值 Lua中的函数可以实现多返回值,实现方法是再return后列出要返回的值的列表,返回值也可以通过变量接收到,变量不够也不会影响接收对应位置的返回值 Lua中传…...

GitLab搭建与使用(SSH和Docker)两种方式
前言 目前公共的代码仓库有很多,比如:git、gitee等等仓库但是我们在公司中,还是要搭建属于本公司自己的一个代码仓库,原因有如下几点 代码私密性,我们公司开发的代码保密性肯定一级重要,那么我们放到公网上,…...
Linux数据库篇、第零章_MySQL30周年庆典活动
MySQL考试报名网站 Oracle Training and Certification | Oracle 中国 活动时间 2025年 MySQL的30周年庆典将于2025年举行。MySQL于1995年首次发布,因此其30周年纪念日是2025年。为了庆祝这一里程碑,MySQL将提供免费的课程和认证考试,活动…...
Windows ABBYY FineReader 16 Corporate 文档转换、PDF编辑和文档比较
作为一名合格的工人,日常工作肯定离不开PDF文件,所以今天给大家找来了一款全新的PDF处理工具,保证能给你带来不一样的体验。 软件介绍 这是一个全能型的PDF处理器,集优秀的文档转换、PDF编辑和文档比较等功能于一身,…...
桥梁模式)
设计模式简述(十九)桥梁模式
桥梁模式 描述基本组件使用 描述 桥梁模式是一种相对简单的模式,通常以组合替代继承的方式实现。 从设计原则来讲,可以说是单一职责的一种体现。 将原本在一个类中的功能,按更细的粒度拆分到不同的类中,然后各自独立发展。 基本…...

【每日一题 | 2025年5.5 ~ 5.11】搜索相关题
个人主页:Guiat 归属专栏:每日一题 文章目录 1. 【5.5】P3717 [AHOI2017初中组] cover2. 【5.6】P1897 电梯里的尴尬3. 【5.7】P2689 东南西北4. 【5.8】P1145 约瑟夫5. 【5.9】P1088 [NOIP 2004 普及组] 火星人6. 【5.10】P1164 小A点菜7. 【5.11】P101…...

C语言速成之08循环语句全解析:从基础用法到高效实践
C语言循环语句全解析:从基础用法到高效实践 大家好,我是Feri,12年开发经验的程序员。循环语句是程序实现重复逻辑的核心工具,掌握while、do-while、for的特性与适用场景,能让代码更简洁高效。本文结合实战案例…...

多模态大语言模型arxiv论文略读(六十九)
Prompt-Aware Adapter: Towards Learning Adaptive Visual Tokens for Multimodal Large Language Models ➡️ 论文标题:Prompt-Aware Adapter: Towards Learning Adaptive Visual Tokens for Multimodal Large Language Models ➡️ 论文作者:Yue Zha…...

云计算-容器云-部署CICD-jenkins连接gitlab
安装 Jenkins 将Jenkins部署到default命名空间下。要求完成离线插件的安装,设置Jenkins的登录信息和授权策略。 上传BlueOcean.tar.gz包 [root@k8s-master-node1 ~]#tar -zxvf BlueOcean.tar.gz [root@k8s-master-node1 ~]#cd BlueOcean/images/ vim /etc/docker/daemon.json…...

精讲C++四大核心特性:内联函数加速原理、auto智能推导、范围for循环与空指针进阶
前引:在C语言长达三十余年的演进历程中,每一次标准更新都在试图平衡性能与抽象、控制与安全之间的微妙关系。从C11引入的"现代C"范式开始,开发者得以在保留底层控制能力的同时,借助语言特性大幅提升代码的可维护性与安全…...

【HarmonyOS 5】鸿蒙中常见的标题栏布局方案
【HarmonyOS 5】鸿蒙中常见的标题栏布局方案 一、问题背景: 鸿蒙中常见的标题栏:矩形区域,左边是返回按钮,右边是问号帮助按钮,中间是标题文字。 那有几种布局方式,分别怎么布局呢?常见的思维…...
)
Docker 部署 - Crawl4AI 文档 (v0.5.x)
Docker 部署 - Crawl4AI 文档 (v0.5.x) 快速入门 🚀 拉取并运行基础版本: # 不带安全性的基本运行 docker pull unclecode/crawl4ai:basic docker run -p 11235:11235 unclecode/crawl4ai:basic# 带有 API 安全性启用的运行 docker run -p 11235:1123…...

QuecPython+Aws:快速连接亚马逊 IoT 平台
提供一个可接入亚马逊 Iot 平台的客户端,用于管理亚马逊 MQTT 连接和影子设备。 初始化客户端 Aws class Aws(client_id,server,port,keep_alive,ssl,ssl_params)参数: client_id (str) - 客户端唯一标识。server (str) - 亚马逊 Iot 平台服务器地址…...

内存安全暗战:从 CVE-2025-21298 看 C 语言防御体系的范式革命
引言 2025 年 3 月,当某工业控制软件因 CVE-2025-21298 漏洞遭攻击,导致欧洲某能源枢纽的电力调度系统瘫痪 37 分钟时,全球网络安全社区再次被拉回 C 语言内存安全的核心战场。根据 CISA 年度报告,68% 的高危漏洞源于 C/C 代码&a…...

SpringCloud Gateway知识点整理和全局过滤器实现
predicate(断言): 判断uri是否符合规则 • 最常用的的就是PathPredicate,以下列子就是只有url中有user前缀的才能被gateway识别,否则它不会进行路由转发 routes:- id: ***# uri: lb://starry-sky-upmsuri: http://localhost:9003/predicate…...