SQLite3介绍与常用语句汇总
SQLite3简介
SQLite3是一款轻量级的、基于文件的开源关系型数据库引擎,由 D. Richard Hipp 于 2000 年首次发布。它遵循 SQL 标准,但与传统的数据库系统不同,SQLite 并不运行在独立的服务器进程中,而是作为一个嵌入式数据库引擎直接集成到应用程序中。其所有的数据结构(包括表、索引、事务日志等)都保存在一个单一的 .db 文件中。
SQLite 的设计理念是“零配置、开箱即用”,开发者只需将其动态库链接进应用程序,就可以直接进行数据库操作,无需安装数据库服务或进行网络配置。
SQLite3 是 SQLite 的第三个主要版本,相较前代有更强的兼容性和更完整的 SQL 支持,是目前最常用的版本。
SQLite3的特点
-
轻量嵌入式设计
SQLite3 不依赖服务器进程,仅作为应用的一部分存在;编译后的库小于 1MB,运行开销极低。 -
单文件存储结构
所有数据库内容都保存在一个磁盘文件中,便于复制、迁移和版本控制。 -
跨平台支持广泛
可以在 Linux、Windows、macOS、Android、iOS 等操作系统中运行,源代码可编译到几乎所有主流平台。 -
兼容标准 SQL92
尽管体积小,但 SQLite3 支持大部分标准 SQL 语法,如事务、子查询、视图、触发器、聚合函数等。 -
零配置,无需安装
无需安装或初始化数据库,只要程序能访问数据库文件就可以使用。 -
事务完整性(ACID)支持
SQLite3 保证事务的原子性、一致性、隔离性和持久性,适用于数据完整性要求较高的应用。
SQLite3的适用场景
SQLite3 由于其嵌入式、便携、小巧的特性,特别适用于以下场景:
-
移动应用开发(Android/iOS)
SQLite3 是 Android 系统默认数据库,适合存储用户数据、缓存内容、离线功能等。 -
嵌入式系统 / IoT 设备
如智能电视、车载系统、传感器节点等设备内存和性能有限,SQLite 是轻量数据存储的理想方案。 -
桌面软件
常用于办公类软件(如记事本、财务管理工具)中提供本地数据存储功能。 -
浏览器或前端环境
Web 应用中的 IndexedDB/LocalStorage 常借助 SQLite 作为底层数据库。 -
单用户或低并发系统
适合使用场景为单人或单线程访问,例如个人记账软件、本地日志记录系统等。 -
快速原型开发和测试
因为免安装、部署简单,SQLite 常被用于开发早期快速迭代和测试环境中。 -
嵌套系统中的缓存数据库
可作为大型数据库系统的本地缓存,提升访问性能,降低服务器负载。
SQLite 命令行工具(sqlite3 shell) 中的内置命令
| 命令 | 作用说明 |
|---|---|
.open filename.db | 打开或创建一个 SQLite 数据库文件 |
.tables | 列出当前数据库中的所有表 |
.schema [table] | 查看某个表或所有表的建表语句(DDL) |
.headers ON/OFF | 开启或关闭结果显示中的列标题 |
.read filename.sql | 执行指定的 SQL 文件内容 |
.exit / .quit | 退出 SQLite 命令行 |
.databases | 查看当前连接的数据库文件 |
.nullvalue NULL_REPLACEMENT | 设置 NULL 显示为什么字符串 |
.output filename.txt | 将查询结果输出到文件 |
基本操作语句
1.打开/创建数据库文件
SQLite 使用命令行或程序语言(如 Python、C 等)调用 SQLite 引擎来打开或创建数据库文件。文件不存在时会自动创建。
sqlite3 mydatabase.db该命令会在当前目录中创建一个名为 mydatabase.db 的数据库文件(如果尚不存在),并进入 SQLite 的交互式终端。你可以在里面执行 SQL 命令。
2. 查看数据库中所有表
SELECT name FROM sqlite_master WHERE type='table';或者使用 SQLite 命令行工具提供的快捷命令:
.tables3. 查看表结构(PRAGMA 语句)
PRAGMA table_info(table_name);示例:
PRAGMA table_info(users);cid | name | type | notnull | dflt_value | pk
----+-------+---------+---------+------------+----
0 | id | INTEGER | 0 | NULL | 1
1 | name | TEXT | 0 | NULL | 0
2 | age | INTEGER | 0 | NULL | 0表相关操作
1. 创建表(CREATE TABLE)
CREATE TABLE table_name (column1 datatype [constraints],column2 datatype [constraints],...
);用于定义一个新的数据表,并指定字段名、数据类型和约束(如主键、非空等)。
CREATE TABLE users (id INTEGER PRIMARY KEY,name TEXT NOT NULL,age INTEGER
);补充:查看某个表的建表语句. schema 表名
sqlite> .schema users
CREATE TABLE users (id INTEGER PRIMARY KEY,name TEXT NOT NULL,age INTEGER
);2. 修改表结构(ALTER TABLE)
SQLite 支持的 ALTER TABLE 功能比较有限,主要包括:
#修改表名
ALTER TABLE table_name RENAME TO new_table_name;
#新增列
ALTER TABLE table_name ADD COLUMN column_def;示例:添加一个 email 字段
ALTER TABLE users ADD COLUMN email TEXT;sqlite> .schema users
CREATE TABLE users (id INTEGER PRIMARY KEY,name TEXT NOT NULL,age INTEGER,email TEXT
);
你会发现 email 字段已经添加在表结构末尾。注意:SQLite 不支持删除列或修改列类型。
3. 删除表(DROP TABLE)
DROP TABLE [IF EXISTS] table_name;DROP TABLE IF EXISTS users;4. 复制表结构与数据
SQLite 没有 CREATE TABLE ... LIKE 语法,可以用以下方式复制结构和数据:
CREATE TABLE new_table AS SELECT * FROM old_table;如果只想复制结构(不含数据):
CREATE TABLE new_table AS SELECT * FROM old_table WHERE 0;数据操作语句
1. 插入数据(INSERT INTO)
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);也可以省略列名(前提是所有列都有值):
INSERT INTO table_name VALUES (value1, value2, ...);示例:
INSERT INFO uesrs (id, name, age, email) VALUES (1, "alice", 25, "a@.com");sqlite> SELECT * FROM users;
id | name | age | email
---+-------+-----+--------------------
1 | Alice | 25 | a@.com2. 更新数据(UPDATE)
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;示例:
UPDATE users SET age = 26 WHRER id = 1;sqlite> SELECT * FROM users;
id | name | age | email
---+-------+-----+--------------------
1 | Alice | 26 | a@.com
3. 删除数据(DELETE)
DELETE FROM table_name WHERE condition;注意:如果不加 WHERE,会删除整张表的数据示例:
sqlite> SELECT * FROM users;
id | name | age | email
---+-------+-----+--------------------
1 | Alice | 26 | a@.comDELETE FROM users WHERE id = 1;sqlite> SELECT * FROM users;
-- 空表,无结果
4. 查询数据(SELECT)
SELECT column1, column2, ... FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...];SELECT * 表示查询所有列。
查询进阶
1. 条件筛选(WHERE)
SELECT column1, column2 FROM table_name WHERE condition;常用操作符包括:=, !=, >, <, >=, <=, LIKE, IN, BETWEEN, IS NULL 等。
示例:
SELECT * FROM users WHERE age > 25;id | name | age | email
---+-------+-----+---------------------
2 | Bob | 30 | bob@example.com
3 | Carol | 28 | carol@example.com
2. 排序(ORDER BY)
SELECT * FROM table_name ORDER BY column [ASC|DESC];示例:
SELECT * FROM users ORDER BY age DESC;id | name | age | email
---+-------+-----+---------------------
2 | Bob | 30 | bob@example.com
3 | Carol | 28 | carol@example.com
1 | Alice | 25 | alice@example.com
3. 分组与过滤(GROUP BY + HAVING)
SELECT group_column, aggregate_function(...) FROM table_name GROUP BY group_column [HAVING condition];示例:
SELECT age, COUNT(*) FROM users GROUP BY age HAVING COUNT(*) > 1;假设有两名用户都 30 岁
age | COUNT(*)
----+----------
30 | 2
4. 多表连接(JOIN)
SELECT columns FROM table1
JOIN table2 ON table1.column = table2.column;示例:
表users
id | name | age | email
---+-------+-----+---------------------
2 | Bob | 30 | bob@example.com
3 | Carol | 28 | carol@example.com
1 | Alice | 25 | alice@example.com
表orders
user_id | amount
--------+--------
2 | 100
3 | 150SELECT users.name, orders.amount
FROM users
JOIN orders ON users.id = orders.user_id;-- 输出:
name | amount
------+--------
Bob | 100
Carol | 1505. 子查询与嵌套查询
SELECT * FROM table WHERE column IN (SELECT ... FROM ... WHERE ...);示例:
SELECT name FROM users WHERE id IN (SELECT user_id FROM orders WHERE amount > 100);输出:
name
-----
Carol6. 分页查询(LIMIT / OFFSET)
SELECT * FROM table_name LIMIT 限制行数 OFFSET 起始行偏移量;指令说明LIMIT:限制最多返回多少行结果。OFFSET:跳过前面多少行数据再开始返回(可选)。例如在一个页面中只显示 10 条数据,就可以:
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 0; -- 第1页
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 10; -- 第2页
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 20; -- 第3页或者用更常见的公式:
LIMIT 每页条数 OFFSET (页码 - 1) * 每页条数示例:
原始数据为:
id | name | age
---+-------+-----
1 | Alice | 25
2 | Bob | 30
3 | Carol | 28SELECT * FROM users ORDER BY id LIMIT 2 OFFSET 1;
按 id 排序后,跳过第1条数据,从第2条开始取,最多取2条。执行结果:
id | name | age
---+-------+-----
2 | Bob | 30
3 | Carol | 28索引与性能
1.sqlite3中的索引是什么?
在 SQLite 中,索引是一种数据库对象,它的作用类似于书本的目录,可以加快查询特定数据的速度。索引会为一个或多个列生成一个排序的数据结构(通常是 B-tree),从而使查询更快。
2.索引的特性?
加速查询(尤其是 WHERE、JOIN、ORDER BY 等)
当你查询某张表时:
SELECT * FROM users WHERE age > 25;如果 age 上有索引,SQLite 会用索引快速定位符合条件的数据,而不用全表扫描。
提升排序效率
SELECT * FROM users ORDER BY name;如果 name 列已建索引,排序可以直接利用索引顺序完成,而无需临时排序。
加速多表连接(JOIN)
SELECT * FROM users JOIN orders ON users.id = orders.user_id;如果 orders.user_id 建了索引,那么连接时匹配效率会更高。
不适用于频繁变动的字段
索引虽然能加速查询,但会减慢 INSERT、UPDATE、DELETE 的性能,因为每次数据改动,索引也要同步更新。
3. 创建索引(CREATE INDEX)
为单列创建索引
CREATE [UNIQUE] INDEX index_name ON table_name(column_name);UNIQUE 表示不允许重复值(可选)。示例:
CREATE INDEX idx_users_age ON users(age);#查看是否命中索引
EXPLAIN QUERY PLAN SELECT * FROM users WHERE age > 25;
#输出
SEARCH TABLE users USING INDEX idx_users_age (age>?)
说明查询使用了你创建的索引。为多列创建联合索引
CREATE INDEX index_name ON table_name(column1, column2, ...);适用于查询中使用多个字段组合的情况。
遵守“最左前缀原则”
示例:
SELECT * FROM users WHERE name = 'Alice' AND age = 25;#查看是否命中索引
EXPLAIN QUERY PLAN SELECT * FROM users WHERE name = 'Alice' AND age = 25;
#输出
SEARCH TABLE users USING INDEX idx_users_name_age (name=? AND age=?)
最左前缀原则: 复合索引只有在查询中使用了从左到右的“最前面的列”时,SQLite 才会使用该索引来优化查询。
示例:
id | name | age
---+-------+-----
1 | Alice | 25
2 | Bob | 30
3 | Carol | 28#创建复合索引
CREATE INDEX idx_name_age ON users(name, age);
分别执行以下查询并查看是否命中索引
①使用 name(最左列),可以命中索引
EXPLAIN QUERY PLAN SELECT * FROM users WHERE name = 'Alice';SEARCH TABLE users USING INDEX idx_name_age (name=?)
②使用 name + age(最左列 + 第二列),仍命中索引
EXPLAIN QUERY PLAN SELECT * FROM users WHERE name = 'Alice' AND age = 30;SEARCH TABLE users USING INDEX idx_name_age (name=? AND age=?)
③只使用 age,不命中索引
EXPLAIN QUERY PLAN SELECT * FROM users WHERE age = 30;SCAN TABLE users
④使用 age + name(第二列 + 最左列),仍命中索引,顺序不影响
EXPLAIN QUERY PLAN SELECT * FROM users WHERE age = 30 AND name = 'Alice';SEARCH TABLE users USING INDEX idx_name_age (age=? AND name=?)
注意:复合索引 idx_name_age(name, age) 是一棵按 name 排序、再按 age 排序的 B 树结构。查询必须从最左的列开始匹配,否则无法用上这个索引。
4. 删除索引(DROP INDEX)
DROP INDEX [IF EXISTS] index_name;事务控制
1. 开始事务(BEGIN)
BEGIN;-
用于开始一个事务。在事务开始后,所有的操作(如
INSERT、UPDATE、DELETE)都将在这个事务中进行。 -
如果事务内的操作没有出现错误,事务可以被提交(
COMMIT)。如果出错,可以回滚(ROLLBACK)整个事务。
2. 提交事务(COMMIT)
COMMIT;提交当前事务所做的所有更改。这会将事务中所有修改的数据写入数据库并使它们永久生效。
示例:提交事务
BEGIN;INSERT INTO users (name, age, city) VALUES ('Eve', 40, 'Chengdu');
UPDATE users SET age = 45 WHERE name = 'Alice';COMMIT;3. 回滚事务(ROLLBACK)
ROLLBACK;如果在事务中执行某些操作时发生错误,可以使用 ROLLBACK 来撤销所有在当前事务中的操作,恢复到事务开始前的状态。
示例:回滚事务
BEGIN;INSERT INTO users (name, age, city) VALUES ('Eve', 40, 'Chengdu');
UPDATE users SET age = 45 WHERE name = 'Alice';-- 假设此时发生了错误,我们决定回滚事务
ROLLBACK;事务回滚后,Eve 和 Alice 的更新都将被撤销,users 表中的数据保持不变。
4. 自动提交模式
-
在默认情况下,SQLite 在每个独立的 SQL 语句后自动提交。也就是说,每次执行一条语句时,SQLite 会自动把它作为一个单独的事务提交。
-
为了防止自动提交,可以显式地使用
BEGIN开始事务,直到使用COMMIT或ROLLBACK。
5. 提交或回滚事务的应用场景
-
批量操作: 比如一次性插入大量数据,使用事务能够保证所有数据同时插入成功,避免数据不一致。
-
处理失败的操作: 在多步操作中,如果中途某一步失败,
ROLLBACK可以保证整个操作的原子性。
事务控制的典型应用场景:
假设有一个转账操作,其中两个表分别是 accounts(账户余额)和 transactions(交易记录),我们需要确保转账操作成功或者完全回滚。
try {executeOrThrow(db, "BEGIN;");executeOrThrow(db, "UPDATE accounts SET balance = balance - 100 WHERE account_id = 'A001';");// 故意出错:列名 balxxx 不存在executeOrThrow(db, "UPDATE accounts SET balxxx = balance + 100 WHERE account_id = 'A002';");executeOrThrow(db, "INSERT INTO transactions (from_account, to_account, amount) VALUES ('A001', 'A002', 100);");//没问题就提交executeOrThrow(db, "COMMIT;");std::cout << "Transaction committed.\n";} catch (const std::exception& ex) {std::cerr << ex.what() << "\n";//出错回滚sqlite3_exec(db, "ROLLBACK;", nullptr, nullptr, nullptr);std::cout << "Transaction rolled back.\n";}视图与临时表
视图(VIEW)
视图是 虚拟的表,本质上是对一个 SELECT 查询结果的封装,它本身不存储数据,而是每次访问时执行背后的查询语句。它的存在意义主要在于以下几点:
1. 简化复杂查询
当你有一些经常要执行的复杂 JOIN、子查询 或 聚合查询 时,把它们写进视图,可以像操作普通表一样简单调用:
-- 查询最近30天订单金额前10的用户
SELECT * FROM top_users_last_30_days;而不用每次都写长查询。
一个视图可以作为多个后续查询的中间层,避免重复 JOIN 和 GROUP BY 逻辑,提高可复用性和效率。
2. 增强可读性与可维护性
把复杂查询逻辑隐藏到视图中后,业务 SQL 更清晰:
-- 直接查视图
SELECT * FROM user_purchases_summary WHERE total_spent > 1000;而不是写重复的 SQL 逻辑多处维护。
3.提高安全性
你可以只授予用户对视图的访问权限,而非对底层表的权限,从而达到权限隔离的效果。
创建视图:
CREATE [TEMP | TEMPORARY] VIEW view_name AS
SELECT ...;view_name:视图名称
SELECT ...:视图对应的查询语句
TEMP:可选,创建临时视图,仅在当前连接中可见示例:创建一个只读用户信息视图
CREATE VIEW active_users AS
SELECT id, name, email
FROM users
WHERE status = 'active';你可以像查询普通表一样使用视图:
SELECT * FROM active_users;假设 users 表如下:
| id | name | email | status |
| -- | ----- | --------------------------------------- | -------- |
| 1 | Alice | [alice@mail.com](mailto:alice@mail.com) | active |
| 2 | Bob | [bob@mail.com](mailto:bob@mail.com) | inactive |
| 3 | Carol | [carol@mail.com](mailto:carol@mail.com) | active |那么 active_users 视图返回:
| id | name | email |
| -- | ----- | --------------------------------------- |
| 1 | Alice | [alice@mail.com](mailto:alice@mail.com) |
| 3 | Carol | [carol@mail.com](mailto:carol@mail.com) | 注意:如果你没有显式使用 TEMP 或 TEMPORARY 关键字,那么你创建的视图就是持久视图
删除视图:
DROP VIEW active_users;临时表(TEMP TABLE)
临时表是只在当前数据库连接中可见的表,连接关闭后自动销毁。它们的主要目的是用于临时数据的存储与处理,不污染正式的数据表结构。它的存在意义主要在于以下几点:
1. 存放中间结果,简化复杂操作
在处理多步 SQL 逻辑(如报表、分析、批量更新)时,临时表可以存放中间结果,让后续查询更清晰:
CREATE TEMP TABLE temp_summary AS
SELECT user_id, SUM(amount) AS total
FROM orders
GROUP BY user_id;
然后你可以继续基于 temp_summary 做筛选、排序等操作。
2. 提高性能,避免重复计算
有些数据在多个地方会用到,而计算代价较高(例如聚合、大量连接),你可以先写入临时表,然后反复查询:
-- 避免重复 JOIN 操作,提高整体查询速度
SELECT * FROM temp_result WHERE score > 80;3.并发安全,每个连接互不干扰
SQLite 的临时表是连接隔离的:
-
多个连接可以使用同名临时表
-
它们之间的数据互不影响
这使得临时表非常适合多线程/多连接场景下的临时数据隔离处理
总结:临时表的作用是为当前连接提供一个安全、高效、隔离的临时数据空间,专注于中间处理、性能优化与调试而不影响正式数据库结构与数据。
创建临时表:
CREATE TEMP TABLE temp_table_name (column1 TYPE,column2 TYPE,...
);-
临时表只在当前数据库连接中有效
-
连接关闭后自动删除
-
临时表与视图不同,它是真实存储数据的表,只是生命周期短
示例:创建并使用一个临时表
CREATE TEMP TABLE temp_orders (id INTEGER,product TEXT,quantity INTEGER
);INSERT INTO temp_orders VALUES (1, 'Book', 2);
INSERT INTO temp_orders VALUES (2, 'Pen', 5);SELECT * FROM temp_orders;查询结果(临时表内容):
| id | product | quantity |
| -- | ------- | -------- |
| 1 | Book | 2 |
| 2 | Pen | 5 |
视图 vs 临时表
| 项目 | 视图(VIEW) | 临时表(TEMP TABLE) |
|---|---|---|
| 本质 | 基于 SELECT 的虚拟表,不存储数据 | 存储真实数据的临时性表 |
| 是否持久存在 | 是(除非使用 TEMP 创建) | 否,只在当前连接中存在,断开即销毁 |
| 数据存储 | 不存储数据,每次使用实时查询底层表 | 存储数据,像普通表一样支持增删改查 |
| 创建语法 | CREATE [TEMP] VIEW view_name AS ... | CREATE TEMP TABLE table_name (...) |
| 删除方式 | DROP VIEW view_name; | 自动销毁(连接关闭)或手动 DROP TABLE |
| 生命周期 | 持久(数据库文件的一部分) | 连接会话级,连接断开即清除 |
| 可更新性 | 只读(除非符合可更新视图条件) | 可读可写,完全等同于普通表 |
| 典型用途 | 封装复杂查询、简化 SQL、权限控制 | 存储中间数据、性能优化、测试临时数据 |
| 是否支持索引 | 否(依赖底层表索引) | 是(可为临时表单独建索引) |
| 作用范围 | 所有连接(持久视图)或当前连接(TEMP) | 当前连接 |
| 是否写入磁盘 | 是(除 TEMP VIEW) | 否(仅存储在内存或临时磁盘空间) |
常用函数与表达式
字符串处理函数
| 函数名 | 功能说明 | 示例 SQL | 返回结果 |
|---|---|---|---|
length(X) | 返回字符串 X 的字符长度 | SELECT length('SQLite'); | 6 |
substr(X,Y,Z) | 提取 X 中从第 Y 位开始的 Z 个字符 | SELECT substr('SQLite3', 2, 4); | 'QLit' |
lower(X) / upper(X) | 转换为小写 / 大写 | SELECT upper('abc'); | 'ABC' |
trim(X) | 去除前后空白字符 | SELECT trim(' abc '); | 'abc' |
replace(X,Y,Z) | 将 X 中所有 Y 替换为 Z | SELECT replace('hello', 'l', 'L'); | 'heLLo' |
instr(X, Y) | 查找 Y 在 X 中首次出现的位置(1 开始) | SELECT instr('abcdef', 'cd'); | 3 |
printf(FMT, ...) | 格式化字符串,类似 C 的 printf | SELECT printf('%.2f', 3.14159); | '3.14' |
hex(X) | 将字符串或 BLOB 转为十六进制表示 | SELECT hex('abc'); | '616263' |
数值函数
| 函数名 | 功能说明 | 示例 SQL | 返回结果 |
|---|---|---|---|
abs(X) | 绝对值 | SELECT abs(-10); | 10 |
round(X[,Y]) | 四舍五入到 Y 位小数,默认 0 | SELECT round(3.14159, 2); | 3.14 |
random() | 返回一个大范围随机整数 | SELECT random(); | 随机整数 |
random() % N | 控制随机值范围(常配合 abs 使用) | SELECT abs(random() % 10); | 0 ~ 9 |
typeof(X) | 返回数据类型(如 integer, text) | SELECT typeof(3.14); | 'real' |
coalesce(X, Y, ...) | 返回第一个非 NULL 的值 | SELECT coalesce(NULL, '', 'abc'); | '' |
nullif(X, Y) | 如果 X == Y,返回 NULL,否则返回 X | SELECT nullif(5, 5); | NULL |
sign(X) | 不内置,可用 CASE 模拟,判断数正负 | SELECT CASE WHEN X > 0 THEN 1 WHEN X < 0 THEN -1 ELSE 0 END | -1 / 0 / 1 |
日期与时间函数
| 函数名 | 功能说明 | 示例 SQL | 返回结果 |
|---|---|---|---|
date('now') | 当前日期 | SELECT date('now'); | 2025-05-08 |
datetime('now') | 当前日期时间 | SELECT datetime('now'); | 2025-05-08 13:50:00 |
time('now') | 当前时间(不含日期) | SELECT time('now'); | 13:50:00 |
strftime('%Y-%m-%d', 'now') | 日期格式化输出 | SELECT strftime('%Y-%m-%d', 'now'); | 2025-05-08 |
strftime('%s', 'now') | 当前时间戳(秒) | SELECT strftime('%s', 'now'); | UNIX 时间戳 |
strftime('%w', 'now') | 星期几(0 表示周日) | SELECT strftime('%w', 'now'); | 4(周四) |
julianday('now') | 当前日期的儒略日表示法(浮点) | SELECT julianday('now'); | 2460451.08 |
datetime('now', '+7 days') | 时间加减(也支持 -2 hours, +1 month 等) | SELECT datetime('now', '-1 day'); | 昨天的时间 |
聚合函数
| 函数名 | 功能说明 | 示例 SQL | 返回结果 |
|---|---|---|---|
COUNT(X) | 非 NULL 值数量 | SELECT COUNT(name) FROM users; | 42(示例) |
COUNT(*) | 所有行数量 | SELECT COUNT(*) FROM users; | 100 |
SUM(X) | 求和 | SELECT SUM(price) FROM orders; | 2300.50 |
AVG(X) | 平均值 | SELECT AVG(score) FROM exams; | 82.5 |
MAX(X) | 最大值 | SELECT MAX(age) FROM people; | 64 |
MIN(X) | 最小值 | SELECT MIN(age) FROM people; | 18 |
条件表达式
| 表达式 | 功能说明 | 示例 SQL | 返回结果 |
|---|---|---|---|
CASE WHEN ... THEN ... | 条件判断(if-else) | SELECT CASE WHEN score > 90 THEN '优' WHEN score > 60 THEN '中' ELSE '差' END | '优' / '中' / '差' |
CASE X WHEN A THEN ... | 值匹配(更紧凑形式) | SELECT CASE grade WHEN 'A' THEN 4 WHEN 'B' THEN 3 ELSE 0 END | 4 / 3 / 0 |
coalesce(X, Y, Z) | 返回第一个非 NULL 值 | SELECT coalesce(NULL, NULL, 'hello'); | 'hello' |
nullif(X, Y) | 如果 X == Y 则返回 NULL,否则返回 X | SELECT nullif(5, 5); | NULL |
IFNULL(X, Y) | 如果 X 是 NULL,则返回 Y,否则返回 X(别名) | SELECT ifnull(NULL, 'default'); | 'default' |
示例:
下面是一个综合性 SQL 示例,它模拟了一个电商订单分析的场景
建表:
-- 创建客户表
CREATE TABLE customers (id INTEGER PRIMARY KEY, -- 客户 ID,主键name TEXT, -- 客户名称email TEXT -- 客户邮箱
);-- 创建订单表
CREATE TABLE orders (id INTEGER PRIMARY KEY, -- 订单 ID,主键customer_id INTEGER, -- 关联客户 IDproduct_name TEXT, -- 商品名称price REAL, -- 商品单价quantity INTEGER, -- 购买数量order_date TEXT, -- 下单时间(格式:YYYY-MM-DD HH:MM:SS)FOREIGN KEY (customer_id) REFERENCES customers(id) -- 外键关联客户表
);
插入数据:
-- 插入客户
INSERT INTO customers (id, name, email) VALUES
(1, 'Alice', 'alice@example.com'),
(2, 'Bob', 'bob@example.net'),
(3, 'Charlie', 'charlie@example.org');-- 插入订单
INSERT INTO orders (customer_id, product_name, price, quantity, order_date) VALUES
(1, 'Laptop', 899.99, 1, '2025-01-15 10:00:00'),
(1, 'Mouse', 19.99, 2, '2025-02-10 12:30:00'),
(2, 'Keyboard', 49.99, 1, '2025-03-05 14:20:00'),
(2, 'Monitor', 199.99, 1, '2025-03-06 15:10:00'),
(2, 'USB Cable', 9.99, 3, '2025-04-01 09:00:00'),
(3, 'Desk Chair', 129.99, 1, '2025-01-22 16:00:00');sql
SELECTc.name AS customer_name, -- 客户名称upper(substr(c.email, 1, instr(c.email, '@') - 1)) AS email_user, -- 提取 email @ 前部分并转为大写COUNT(o.id) AS total_orders, -- 订单总数SUM(o.price * o.quantity) AS total_spent, -- 总消费金额round(AVG(o.price * o.quantity), 2) AS avg_order_value, -- 平均订单金额(保留2位小数)MAX(o.order_date) AS last_order_date, -- 最后一笔订单的时间strftime('%Y-%m', o.order_date) AS order_month, -- 订单月份(用于聚合)-- 消费金额区间分级:VIP / Gold / RegularCASE WHEN SUM(o.price * o.quantity) > 1000 THEN 'VIP'WHEN SUM(o.price * o.quantity) > 500 THEN 'Gold'ELSE 'Regular'END AS customer_levelFROMcustomers c
LEFT JOINorders o ON c.id = o.customer_id -- 关联订单表
WHEREo.order_date >= date('now', '-6 months') -- 仅查询最近6个月的订单
GROUP BYc.id
HAVINGtotal_orders > 0 -- 排除没有订单的客户
ORDER BYtotal_spent DESC -- 按总消费金额降序排列
LIMIT 10; -- 仅显示前10个客户SQLite 专有特性
AUTOINCREMENT 和 INTEGER PRIMARY KEY
-
INTEGER PRIMARY KEY是 SQLite 中用于定义主键并且自动增长的特殊类型。 -
如果你定义了某个列为
INTEGER PRIMARY KEY,当向表中插入一行数据时SQLite 会自动为该列赋值(自增),无需显式使用AUTOINCREMENT。 -
AUTOINCREMENT是一种“更严格”的版本,它会防止重复使用已删除的 ID。
| 特性 | INTEGER PRIMARY KEY | INTEGER PRIMARY KEY AUTOINCREMENT |
|---|---|---|
| 自动增长 | 是 | 是 |
| 会复用已删除的 ID? | 会 | 不会 |
| 是否推荐? | 推荐(性能更好) | 不推荐,除非必须保证唯一不复用 |
示例:
-- 普通自增主键
CREATE TABLE users (id INTEGER PRIMARY KEY,name TEXT
);-- 带 AUTOINCREMENT 的主键
CREATE TABLE logs (id INTEGER PRIMARY KEY AUTOINCREMENT,message TEXT
);WITHOUT ROWID 表
SQLite 默认使用一个隐藏的 rowid 来标识每一行。但你可以显式使用 WITHOUT ROWID 表来:
-
减少存储开销(适合复合主键场景)
-
提高某些查询性能(尤其当不需要 rowid 时)
示例:
-- 默认带有 rowid
CREATE TABLE cities (name TEXT PRIMARY KEY,population INTEGER
);-- 不使用 rowid
CREATE TABLE cities_norowid (name TEXT PRIMARY KEY,population INTEGER
) WITHOUT ROWID;说明:WITHOUT ROWID 表要求必须有主键,且主键不可为 ROWID。
PRAGMA 指令
PRAGMA 是 SQLite 的一组特殊命令,用于查看或设置数据库的内部参数或行为。
| 指令 | 用途说明 | 示例 |
|---|---|---|
PRAGMA table_info(table_name) | 查看表结构(字段信息) | PRAGMA table_info(users); |
PRAGMA foreign_keys | 查看外键是否启用(1 为开启) | PRAGMA foreign_keys; |
PRAGMA foreign_keys = ON; | 启用外键约束 | PRAGMA foreign_keys = ON; |
PRAGMA database_list | 查看当前连接的数据库列表 | PRAGMA database_list; |
PRAGMA index_list(table_name) | 查看表上的索引列表 | PRAGMA index_list(users); |
PRAGMA cache_size | 设置或查看内存页缓存大小 | PRAGMA cache_size = 2000; |
PRAGMA journal_mode | 设置事务日志模式(如 WAL) | PRAGMA journal_mode = WAL; |
PRAGMA synchronous | 控制同步级别(性能 vs 安全) | PRAGMA synchronous = NORMAL; |
相关文章:

SQLite3介绍与常用语句汇总
SQLite3简介 SQLite3是一款轻量级的、基于文件的开源关系型数据库引擎,由 D. Richard Hipp 于 2000 年首次发布。它遵循 SQL 标准,但与传统的数据库系统不同,SQLite 并不运行在独立的服务器进程中,而是作为一个嵌入式数据库引擎直…...
快速入门深度学习系列(3)----神经网络
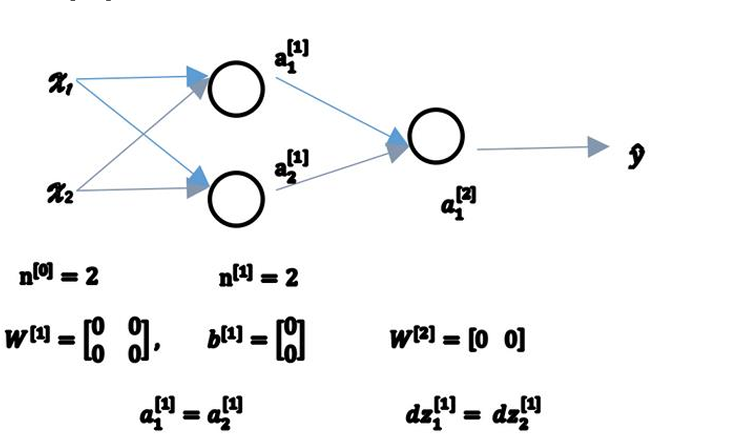
本文只针对图进行解释重要内容 这就是入门所需要掌握的大部分内容 对于不懂的名词或概念 你可以及时去查 对于层数 标在上面 对于该层的第几个元素 标在下面 输入层算作第0层 对于第一层的w b 参数 维度如下w:4*3 b:4*1 这个叫做神经元 比如对于第一层的神经元 这里说的很…...
在线工具源码_字典查询_汉语词典_成语查询_择吉黄历等255个工具数百万数据 养站神器,安装教程
在线工具源码_字典查询_汉语词典_成语查询_择吉黄历等255个工具数百万数据 养站神器,安装教程 资源宝分享:https://www.httple.net/154301.html 一次性打包涵盖200个常用工具!无论是日常的图片处理、文件格式转换,还是实用的时间…...

ORB-SLAM3和VINS-MONO的对比
直接给总结,整体上orbslam3(仅考虑带imu)在初始化阶段是松耦合,localmap和全局地图优化是紧耦合。而vins mono则是全程紧耦合。然后两者最大的区别就在于vins mono其实没有对地图点进行优化,为了轻量化,它一…...

大数据处理利器:Hadoop 入门指南
一、Hadoop 是什么?—— 分布式计算的基石 在大数据时代,处理海量数据需要强大的技术支撑,Hadoop 应运而生。Apache Hadoop 是一个开源的分布式计算框架,致力于为大规模数据集提供可靠、可扩展的分布式处理能力。其核心设计理念是…...

Docker容器网络架构深度解析与技术实践指南——基于Linux内核特性的企业级容器网络实现
第1章 容器网络基础架构 1 Linux网络命名空间实现原理 1.1内核级隔离机制深度解析 1.1.1进程隔离的底层实现 通过clone()系统调用创建新进程时,设置CLONE_NEWNET标志位将触发内核执行以下操作: 内核源码示例(linux-6.8.0/kernel/fork.c&a…...
)
基于Kubernetes的Apache Pulsar云原生架构解析与集群部署指南(下)
文章目录 k8s安装部署Pulsar集群前期准备版本要求 安装 Pulsar Helm chart管理pulsarClustersBrokersTopic k8s安装部署Pulsar集群 前期准备 版本要求 Kubernetes 集群,版本 1.14 或更高版本Helm v3(3.0.2 或更高版本)数据持久化ÿ…...

IoTDB端边云同步技术的五大常见场景及简便使用方式
IoTDB端边云同步技术提供了一种高效、可靠的数据同步解决方案,通过简洁灵活的SQL操作和直观的配置方式,实现了数据在端、边、云之间的无缝流动。以下是IoTDB端边云同步的五大常见场景及其简便的使用方式。 一、基础数据同步 基础数据同步包括全量数据同…...
Linux 阻塞和非阻塞 I/O 简明指南
目录 声明 1. 阻塞和非阻塞简介 2. 等待队列 2.1 等待队列头 2.2 等待队列项 2.3 将队列项添加/移除等待队列头 2.4 等待唤醒 2.5 等待事件 3. 轮询 3.1 select函数 3.2 poll函数 3.3 epoll函数 4. Linux 驱动下的 poll 操作函数 声明 本博客所记录的关于正点原子…...
)
libtorch配置指南(包含Windows和Linux)
libtorch libtorch是pytorch的c库,提供了用于深度学习和张量计算的功能,允许开发者在c环境中使用pytorch的核心功能。特别是当一些pt模型无法转换到ncnn、mnn等模型时(ncnn、mnn可能还不支持某些层),可以在libtorch直…...
Java开发经验——阿里巴巴编码规范经验总结2
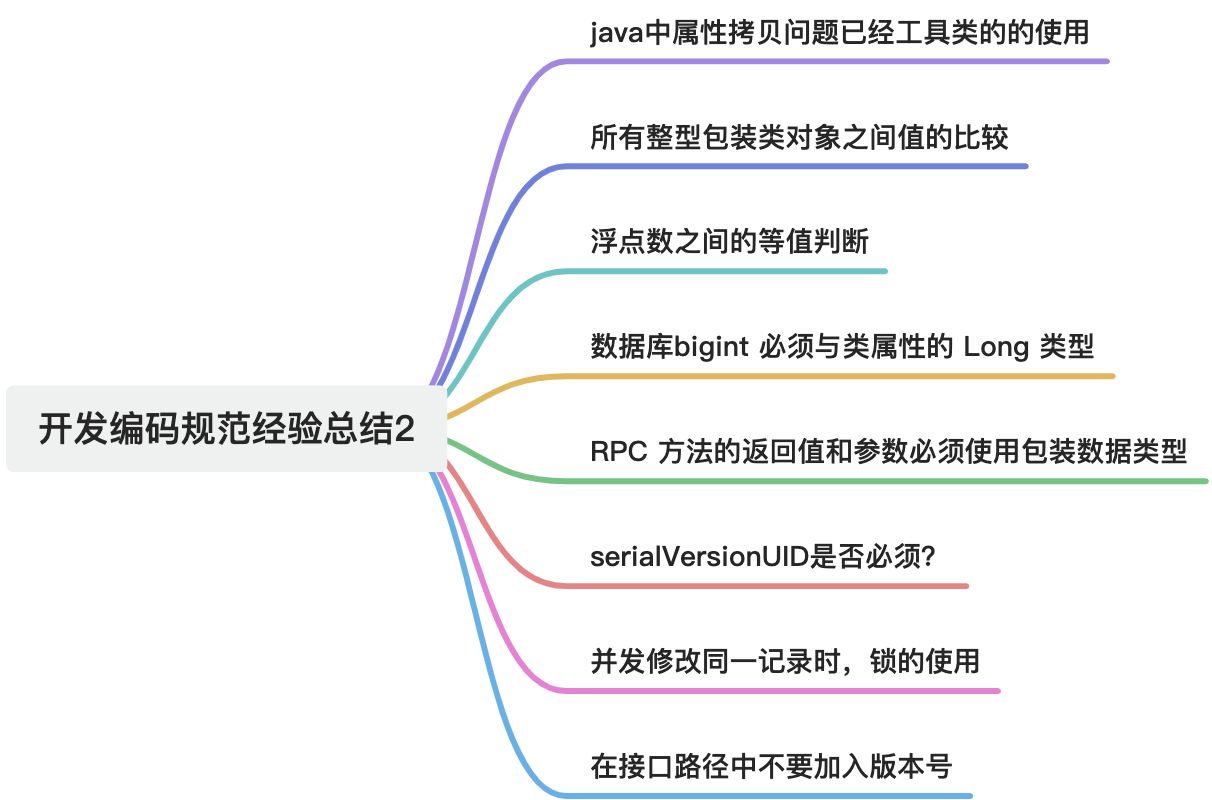
摘要 这篇文章是关于Java开发中阿里巴巴编码规范的经验总结。它强调了避免使用Apache BeanUtils进行属性复制,因为它效率低下且类型转换不安全。推荐使用Spring BeanUtils、Hutool BeanUtil、MapStruct或手动赋值等替代方案。文章还指出不应在视图模板中加入复杂逻…...
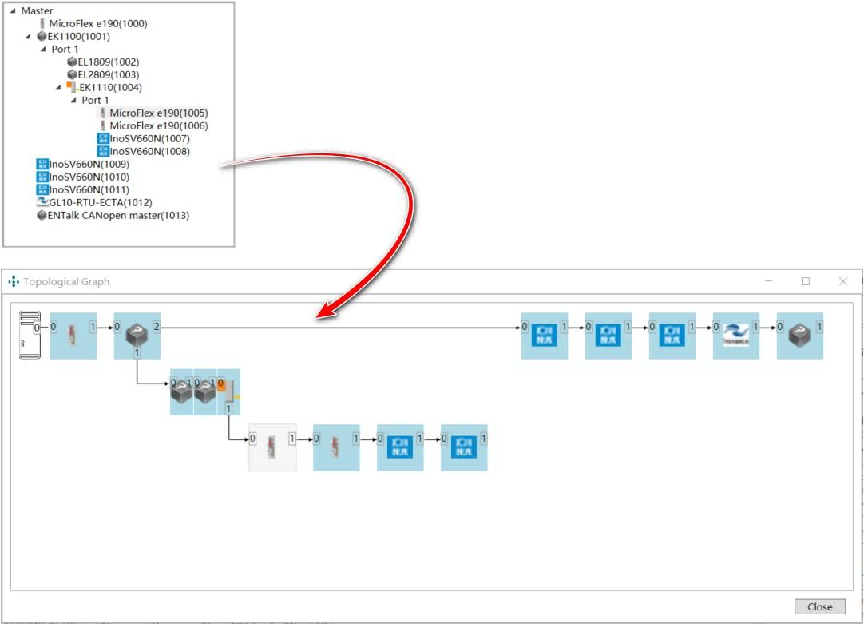
机器人手臂“听不懂“指令?Ethercat转PROFINET网关妙解通信僵局
机器人手臂"听不懂"指令?Ethercat转PROFINET网关妙解产线通信僵局 协作机器人(如KUKA iiWA)使用EtherCAT控制,与Profinet主站(如西门子840D CNC)同步动作。 客户反馈:基于Profinet…...
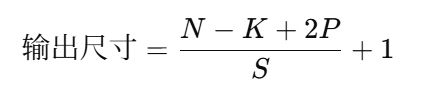
深度学习 CNN
CNN 简介 什么是 CNN? 卷积神经网络(Convolutional Neural Network)是专为处理网格数据(如图像)设计的神经网络。核心组件: 卷积层 :提取局部特征(如边缘、纹理)通过卷…...

GrassRoot备份项目
Windows服务项目 Grass.cs using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Net.Http.Headers; using System.Net.Http; using System.Text; using System.Threading; using System.Threading.Tasks; using System.Time…...

iOS开发架构——MVC、MVP和MVVM对比
文章目录 前言MVC(Model - View - Controller)MVP(Model - View - Presenter)MVVM(Model - View - ViewModel) 前言 在 iOS 开发中,MVC、MVVM、和 MVP 是常见的三种架构模式,它们主…...

typecho中的Widget设计文档
组成系统的最基本元素 什么是Widget Widget是组成Typecho的最基本元素,除了已经抽象出来的类库外,其它几乎所有的功能都会通过Widget来完成。在实践中我们发现,在博客这种小型但很灵活的系统中实施一些大型框架的思想是不合适的,…...
MySQL索引原理以及SQL优化(二)
目录 1. 索引与约束 1.1 索引是什么 1.2 索引的目的 1.3 索引分类 1.3.1 数据结构 1.3.2 物理存储 1.3.3 列属性 1.3.4 列的个数 1.4 主键的选择 1.5 索引使用场景 1.6 索引的底层实现 1.6.1 索引存储 1.6.2 页 1.6.3 B 树 1.6.4 B 树层高问题 1.6.5 自增 id 1.7 innod…...
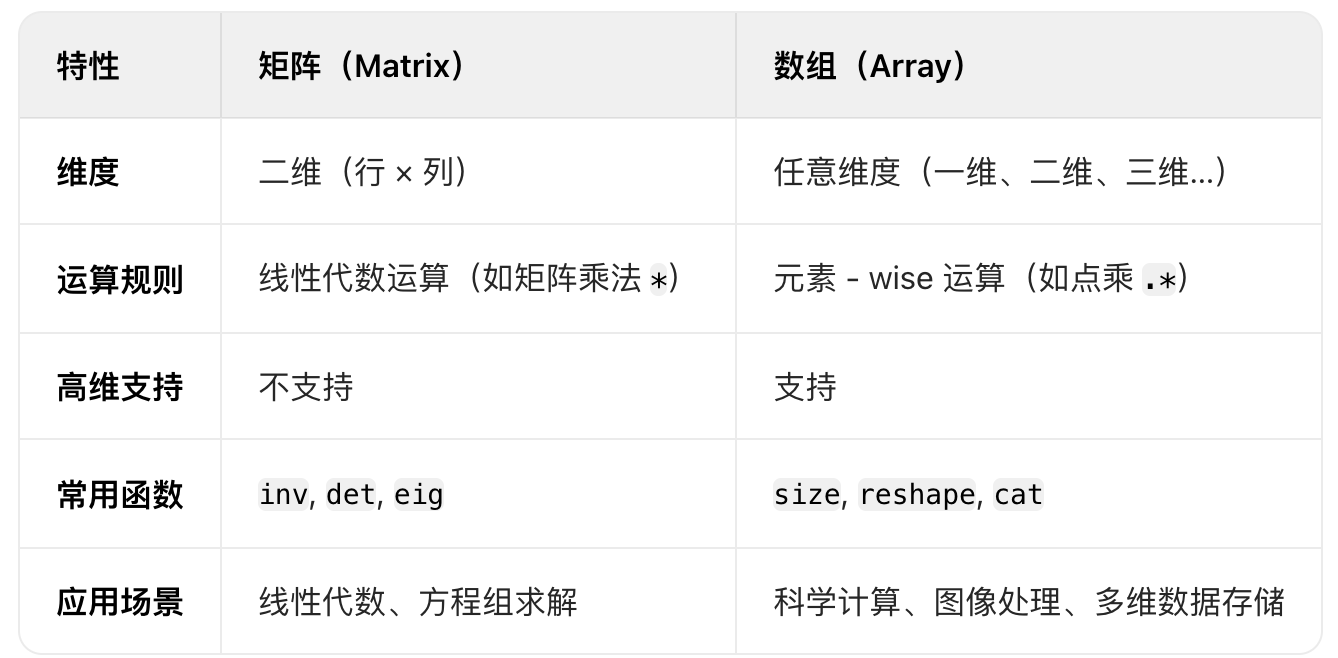
MATLAB中矩阵和数组的区别
文章目录 前言环境配置1. 数据结构本质2. 运算规则(1)基本运算(2)特殊运算 3. 函数与操作4. 高维支持5. 创建方式 前言 在 MATLAB 中,矩阵(Matrix) 和 数组(Array) 的概…...
Desfire Ev1\Ev2\Ev3卡DES\3K3DES\AES加解密读写C#示例源码
本示例使用的发卡器:https://item.taobao.com/item.htm?spma21dvs.23580594.0.0.1d292c1bYhsS9c&ftt&id917152255720 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using S…...
MySQL核心内容【完结】
MySQL核心内容 文章目录 MySQL核心内容1.MySQL核心内容目录2.MySQL知识面扩展3.MySQL安装4.MySQL配置目录介绍Mysql配置远程ip连接 5.MySQL基础1.MySQL数据类型1.数值类型2.字符串类型3.日期和时间类型4.enum和set 2.MySQL运算符1.算数运算符2.逻辑运算符3.比较运算符 3.MySQL完…...

C++类和对象进阶 —— 与数据结构的结合
🎁个人主页:工藤新一 🔍系列专栏:C面向对象(类和对象篇) 🌟心中的天空之城,终会照亮我前方的路 🎉欢迎大家点赞👍评论📝收藏⭐文章 文章目录 […...
Django之账号登录及权限管理
账号登录及权限管理 目录 1.登录功能 2.退出登录 3.权限管理 4.代码展示合集 这篇文章, 会讲到如何实现账号登录。账号就是我们上一篇文章写的账号管理功能, 就使用那里面已经创建好的账号。这一次登录, 我们分为三种角色, 分别是员工, 领导, 管理员。不同的角色, 登录进去…...

从一城一云到AI CITY,智慧城市进入新阶段
AI将如何改变城市面貌?AI能否为城市创造新的商业价值?AI的落地应用将对日常生活有什么样的影响? 几乎在每一场和城市发展相关的论坛上,都会出现以上几个问题。城市既是AI技术创新融合应用的综合性载体,普罗大众对AI产…...

Oracle数据库DBF文件收缩
这两天新部署了一套系统,数据库结构保持不变,牵扯导出表结构还有函数,图省事就直接新建用户,还原数据库了。然后咔咔咔,一顿删除delete,truncate,发现要不就是表删了,还有num_rows&a…...
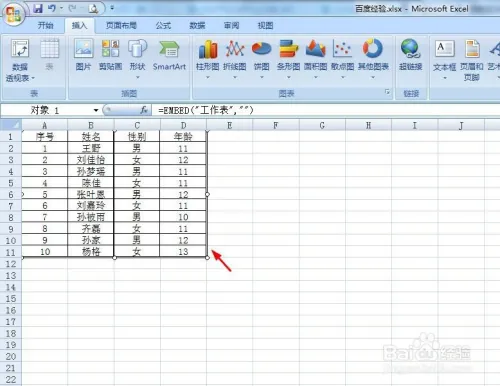
EXCEL中嵌入其他表格等文件
在EXCEL中嵌入其他表格 先放链接:https://jingyan.baidu.com/article/295430f11708c34d7e00509a.html 步骤如下: 1、打开一个需要嵌入新表格的excel表。 2、切换至“插入”菜单中,单击选择“对象”。 3、如下图所示,会弹出“对象…...
21. LangChain金融领域:合同审查与风险预警自动化
引言:当AI成为24小时不眠的法律顾问 2025年某商业银行的智能合同系统,将百万级合同审查时间从平均3周缩短至9分钟,风险条款识别准确率达98.7%。本文将基于LangChain的金融法律框架,详解如何构建合规、精准、可追溯的智能风控体系…...
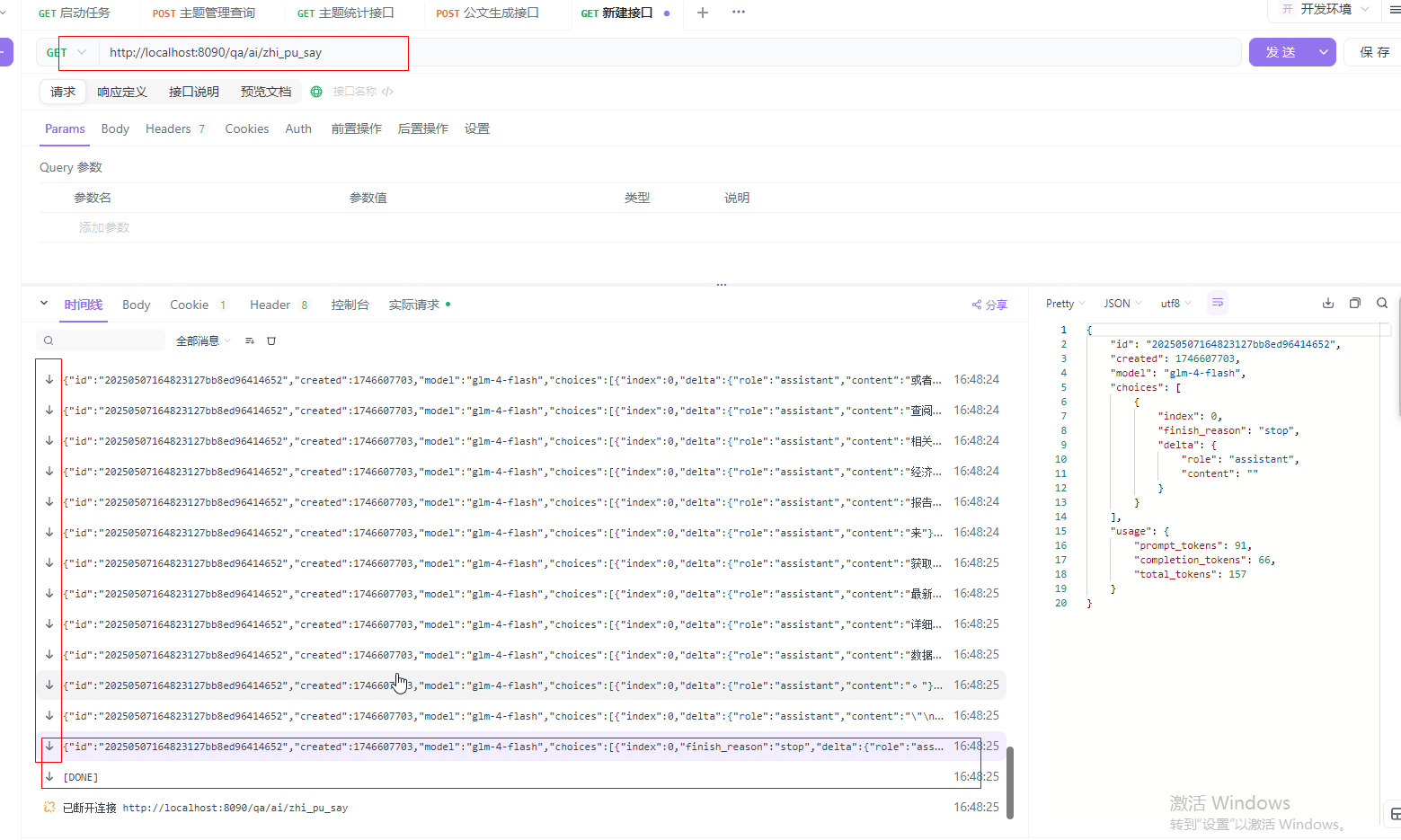
Springboot使用事件流调用大模型接口
什么是事件流 事件流(Event Stream) 是一种处理和传递事件的方式,通常用于系统中的异步消息传递或实时数据流。在事件驱动架构(Event-Driven Architecture)中,事件流扮演着至关重要的角色。 事件流的概念…...
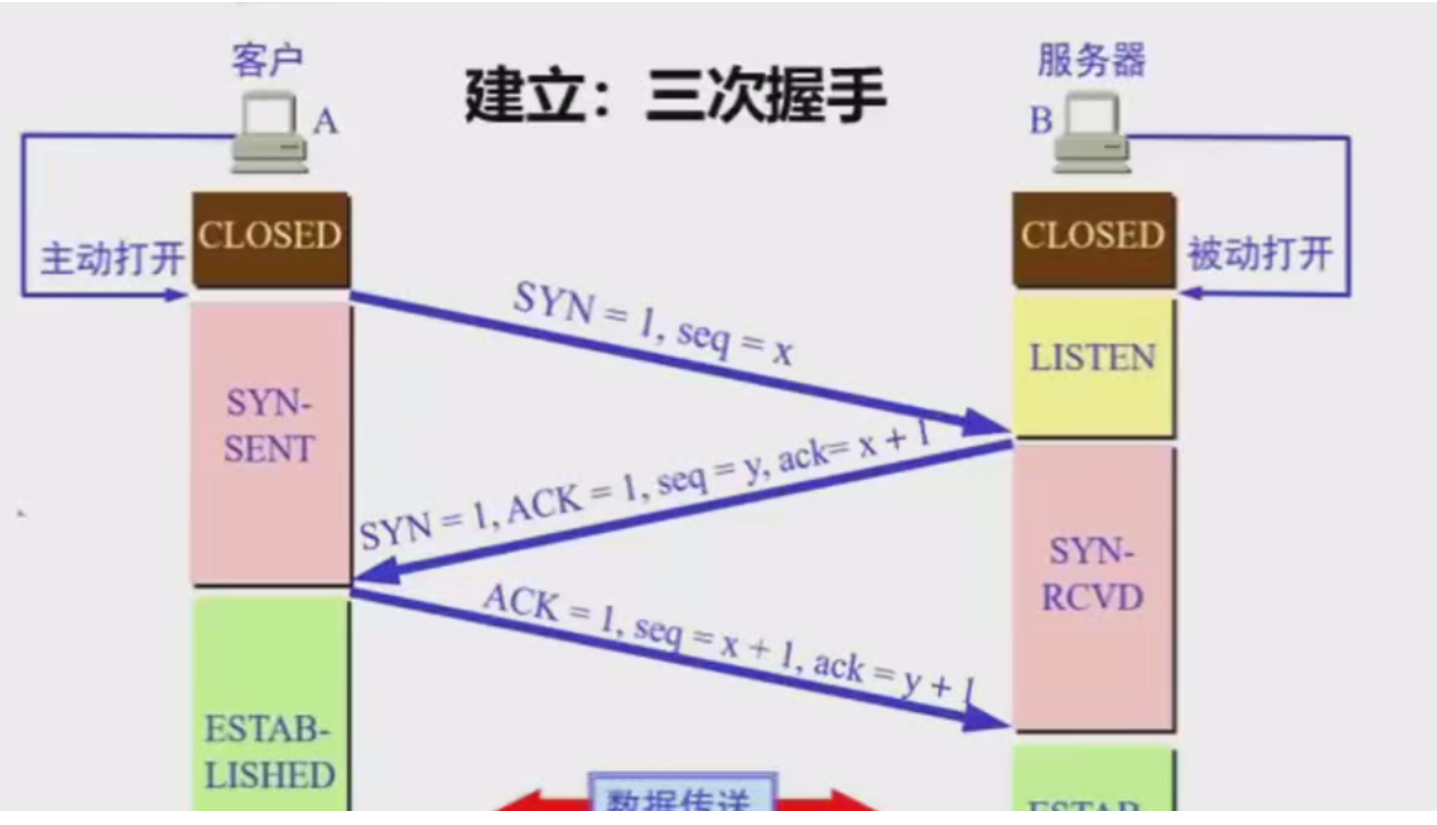
计算机网络--2
TCP三次握手 TCP连接为什么需要三次握手 1. 由于网络情况复杂,可能会出现丢包现象,如果第二次握手的时候服务器就认为这个端口可用,然后一直开启,但是如果客户端未收到服务器发送的回复,那么就会重新发送请求,服务器就会重新开启一个端口连接,这样就会浪费一个端口。 三…...

【已解决】WORD域相关问题;错误 未找到引用源;复制域出错;交叉引用域到底是个啥
(微软赶紧倒闭 所有交叉引用域,有两个状态:1.锁定。2.手动。可通过编辑->链接查看。 “锁定”状态域的能力: 1. 导出PDF格式稳定(【已解决】WORD导出PDF时,参考文献上标自动被取消/变为正常文本_word…...

尤雨溪宣布:Vue 生态正式引入 AI
在前端开发领域,Vue 框架一直以其易用性和灵活性受到广大开发者的喜爱。 而如今,Vue 生态在人工智能(AI)领域的应用上又迈出了重要的一步。 尤雨溪近日宣布,Vue、Vite 和 Rolldown 的文档网站均已添加了llms.txt文件,这一举措旨在让大型语言模型(LLM)更方便地理解这些…...