Redis+Caffeine构建高性能二级缓存

大家好,我是摘星。今天为大家带来的是Redis+Caffeine构建高性能二级缓存,废话不多说直接开始~
目录
二级缓存架构的技术背景
1. 基础缓存架构
2. 架构演进动因
3. 二级缓存解决方案
为什么选择本地缓存?
1. 极速访问
2. 减少网络IO
3. 降低远程缓存和数据库压力
4. 提升系统吞吐量
5. 功能灵活
本地内存具备的功能
1. 基本读写
2. 缓存淘汰策略
3. 过期时间控制
4. 缓存加载与刷新
5. 并发控制
6. 统计与监控
7. 持久化
8. 事件监听
本地缓存方案选型
1. ConcurrentHashMap
2. Guava Cache
3. Caffeine
4. Encache
方案对比
本地缓存问题及解决
1. 数据一致性
1.1. 解决方案1: 失效广播机制
1.2. 解决方案2:版本号控制
2. 内存管理问题
2.1. 解决方案1:分层缓存架构
2.2. 解决方案2:智能淘汰策略
3. GC压力
3.1. GC压力问题的产生原因
3.2. 解决方案1:堆外缓存(Off-Heap Cache)
3.3. 方案2:分区域缓存
总结
二级缓存架构的技术背景
1. 基础缓存架构
在现代分布式系统设计中,缓存是优化服务性能的核心组件。标准实现方案采用远程缓存(如Redis/Memcached)作为数据库前置层,通过以下机制提升性能:
- 读写策略:遵循Cache-Aside模式,仅当缓存未命中时查询数据库
- 核心价值:
-
- 将平均响应时间从数据库的10-100ms级别降至1-10ms
- 降低数据库负载50%-80%(根据命中率变化)
2. 架构演进动因
当系统面临以下场景时,纯远程缓存方案显现局限性:
| 问题类型 | 表现特征 | 典型案例 |
| 超高并发读取 | Redis带宽成为瓶颈 | 热点商品详情页访问 |
| 超低延迟要求 | 网络往返耗时不可忽略 | 金融行情数据推送 |
| 成本控制需求 | 高频访问导致Redis扩容 | 用户基础信息查询 |
3. 二级缓存解决方案
引入本地缓存构建两级缓存体系:
- 一级缓存:Caffeine(高性能本地缓存)
- 二级缓存:Redis Cluster(高可用远程缓存)
- 协同机制:
-
- 本地缓存设置短TTL(秒级)
- 远程缓存设置长TTL(分钟级)
- 通过PubSub实现跨节点失效
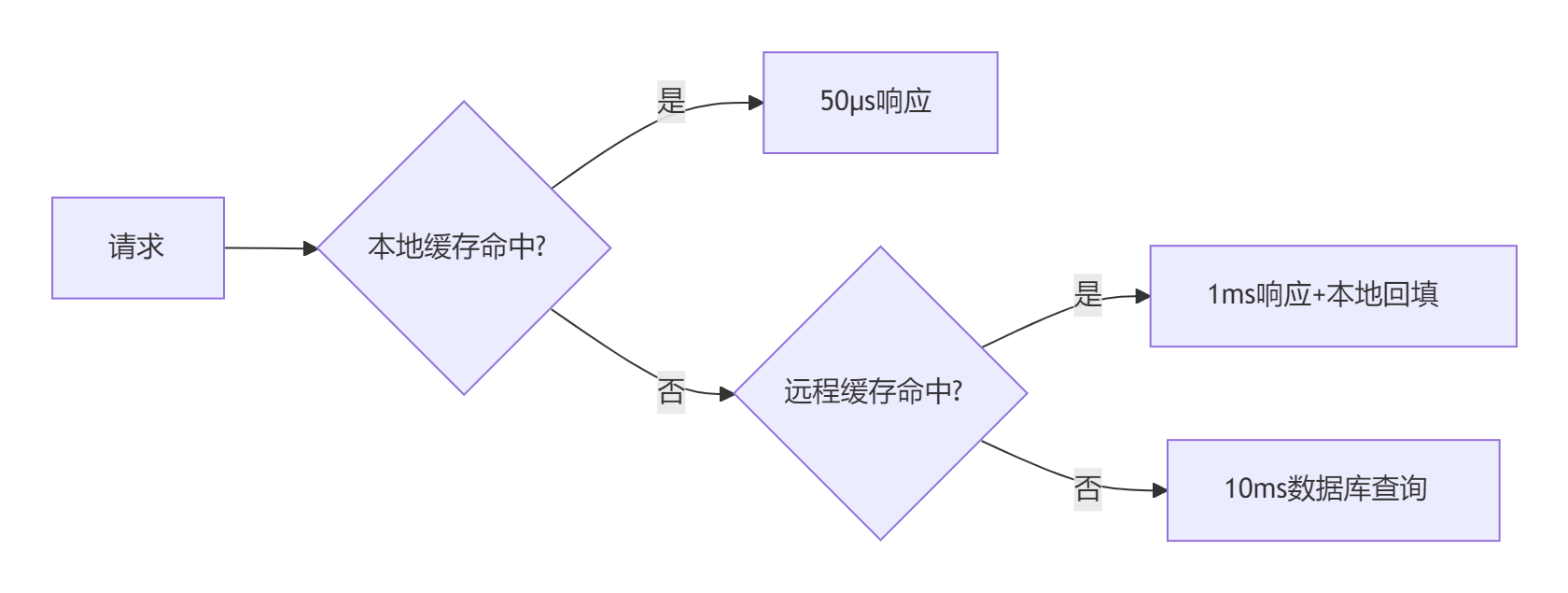
为什么选择本地缓存?
1. 极速访问
内存级响应:本地缓存直接存储在应用进程的内存中(如Java堆内),访问速度通常在纳秒级(如Caffeine的读写性能可达每秒千万次),而远程缓存(如Redis)需要网络通信,延迟在毫秒级。
| 技术选型 | 响应时长 |
| 本地缓存 |
|
| Redis远程缓存 |
|
| 数据库查询 |
|
2. 减少网络IO
避免远程调用:每次访问Redis都需要经过网络I/O(序列化、传输、反序列化),本地缓存完全绕过这一过程。
适用场景:高频访问的热点数据(如商品详情、用户基础信息),通过本地缓存可减少90%以上的Redis请求。
3. 降低远程缓存和数据库压力
保护Redis:大量请求直接命中本地缓存,避免Redis成为瓶颈(尤其在高并发场景下,如秒杀、热点查询)。
减少穿透风险:本地缓存可设置短期过期时间,避免缓存失效时大量请求直接冲击数据库。
4. 提升系统吞吐量
减少线程阻塞:远程缓存访问会阻塞线程(如Redis的同步调用),本地缓存无此问题,尤其适合高并发服务。
案例:某电商系统引入Caffeine后,QPS从1万提升到5万,Redis负载下降60%。
5. 功能灵活
本地缓存支持丰富的特性,满足不同业务需求:
- 淘汰策略:LRU(最近最少使用)、LFU(最不经常使用)、FIFO等。
- 过期控制:支持基于时间(写入后过期、访问后过期)或容量触发淘汰。
- 原子操作:如
get-if-absent-compute(查不到时自动加载),避免并发重复查询。
本地内存具备的功能
1. 基本读写
功能:基础的键值存储与原子操作。
Cache<String, String> cache = Caffeine.newBuilder().build();// 写入缓存
cache.put("user:1", "Alice");// 读取缓存(若不存在则自动计算)
String value = cache.get("user:1", key -> fetchFromDB(key));2. 缓存淘汰策略
功能:限制缓存大小并淘汰数据。
| 算法 | 描述 | 适用场景 | 代码示例(Caffeine) |
| LRU | 淘汰最久未访问的数据 | 热点数据分布不均匀 |
|
| LFU | 淘汰访问频率最低的数据 | 长期稳定的热点数据 |
(W-TinyLFU) |
| FIFO | 按写入顺序淘汰 | 数据顺序敏感的场景 | 需自定义实现 |
3. 过期时间控制
功能:自动清理过期数据。
Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期
.expireAfterAccess(5, TimeUnit.MINUTES) // 访问后5分钟过期
.build();
4. 缓存加载与刷新
功能:自动加载数据并支持后台刷新。
AsyncLoadingCache<String, String> cache = Caffeine.newBuilder()
.refreshAfterWrite(1, TimeUnit.MINUTES) // 1分钟后后台刷新
.buildAsync(key -> fetchFromDB(key));// 获取数据(若需刷新,不会阻塞请求)
CompletableFuture<String> future = cache.get("user:1");5. 并发控制
功能:线程安全与击穿保护。
// 自动合并并发请求(同一key仅一次加载)
LoadingCache<String, String> cache = Caffeine.newBuilder().build(key -> {System.out.println("仅执行一次: " + key);return fetchFromDB(key);});// 并发测试(输出1次日志)
IntStream.range(0, 100).parallel().forEach(i -> cache.get("user:1")
);
6. 统计与监控
功能:记录命中率等指标。
Cache<String, String> cache = Caffeine.newBuilder()
.recordStats() // 开启统计
.build();cache.get("user:1");
CacheStats stats = cache.stats();
System.out.println("命中率: " + stats.hitRate());7. 持久化
功能:缓存数据持久化到磁盘。
// 使用Caffeine + RocksDB(需额外依赖)
Cache<String, byte[]> cache = Caffeine.newBuilder().maximumSize(100).writer(new CacheWriter<String, byte[]>() {@Override public void write(String key, byte[] value) {rocksDB.put(key.getBytes(), value); // 同步写入磁盘}@Override public void delete(String key, byte[] value, RemovalCause cause) {rocksDB.delete(key.getBytes());}}).build();8. 事件监听
功能:监听缓存变更事件。
Cache<String, String> cache = Caffeine.newBuilder().removalListener((key, value, cause) -> System.out.println("移除事件: " + key + " -> " + cause)).evictionListener((key, value, cause) -> System.out.println("驱逐事件: " + key + " -> " + cause)).build();本地缓存方案选型
1. ConcurrentHashMap
ConcurrentHashMap是Java集合框架中提供的线程安全哈希表实现,首次出现在JDK1.5中。它采用分段锁技术(JDK8后改为CAS+synchronized优化),通过将数据分成多个段(segment),每个段独立加锁,实现了高并发的读写能力。作为JUC(java.util.concurrent)包的核心组件,它被广泛应用于需要线程安全哈希表的场景。
- 原生JDK支持,零外部依赖
- 读写性能接近非同步的HashMap
- 完全线程安全,支持高并发
- 提供原子性复合操作(如computeIfAbsent)
import java.util.concurrent.*;
import java.util.function.Function;public class CHMCache<K,V> {private final ConcurrentHashMap<K,V> map = new ConcurrentHashMap<>(16, 0.75f, 32);private final ScheduledExecutorService cleaner = Executors.newSingleThreadScheduledExecutor();// 基础操作public void put(K key, V value) {map.put(key, value);}// 带TTL的putpublic void put(K key, V value, long ttl, TimeUnit unit) {map.put(key, value);cleaner.schedule(() -> map.remove(key), ttl, unit);}// 自动加载public V get(K key, Function<K,V> loader) {return map.computeIfAbsent(key, loader);}// 批量操作public void putAll(Map<? extends K, ? extends V> m) {map.putAll(m);}// 清空缓存public void clear() {map.clear();}
}2. Guava Cache
Guava Cache是Google Guava库中的缓存组件,诞生于2011年。作为ConcurrentHashMap的增强版,它添加了缓存特有的特性。Guava项目本身是Google内部Java开发的标准库,经过大规模生产环境验证,稳定性和性能都有保障。Guava Cache广泛应用于各种需要本地缓存的Java项目中。
- Google背书,质量有保证
- 丰富的缓存特性
- 良好的API设计
- 完善的文档和社区支持
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>31.1-jre</version>
</dependency>import com.google.common.cache.*;
import java.util.concurrent.TimeUnit;public class GuavaCacheDemo {public static void main(String[] args) {LoadingCache<String, String> cache = CacheBuilder.newBuilder().maximumSize(1000) // 最大条目数.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后过期时间.expireAfterAccess(30, TimeUnit.MINUTES) // 访问后过期时间.concurrencyLevel(8) // 并发级别.recordStats() // 开启统计.removalListener(notification -> System.out.println("Removed: " + notification.getKey())).build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {return loadFromDB(key);}});try {// 自动加载String value = cache.get("user:1001");// 手动操作cache.put("config:timeout", "5000");cache.invalidate("user:1001");// 打印统计System.out.println(cache.stats());} catch (ExecutionException e) {e.printStackTrace();}}private static String loadFromDB(String key) {// 模拟数据库查询return "DB_Result_" + key;}
}3. Caffeine
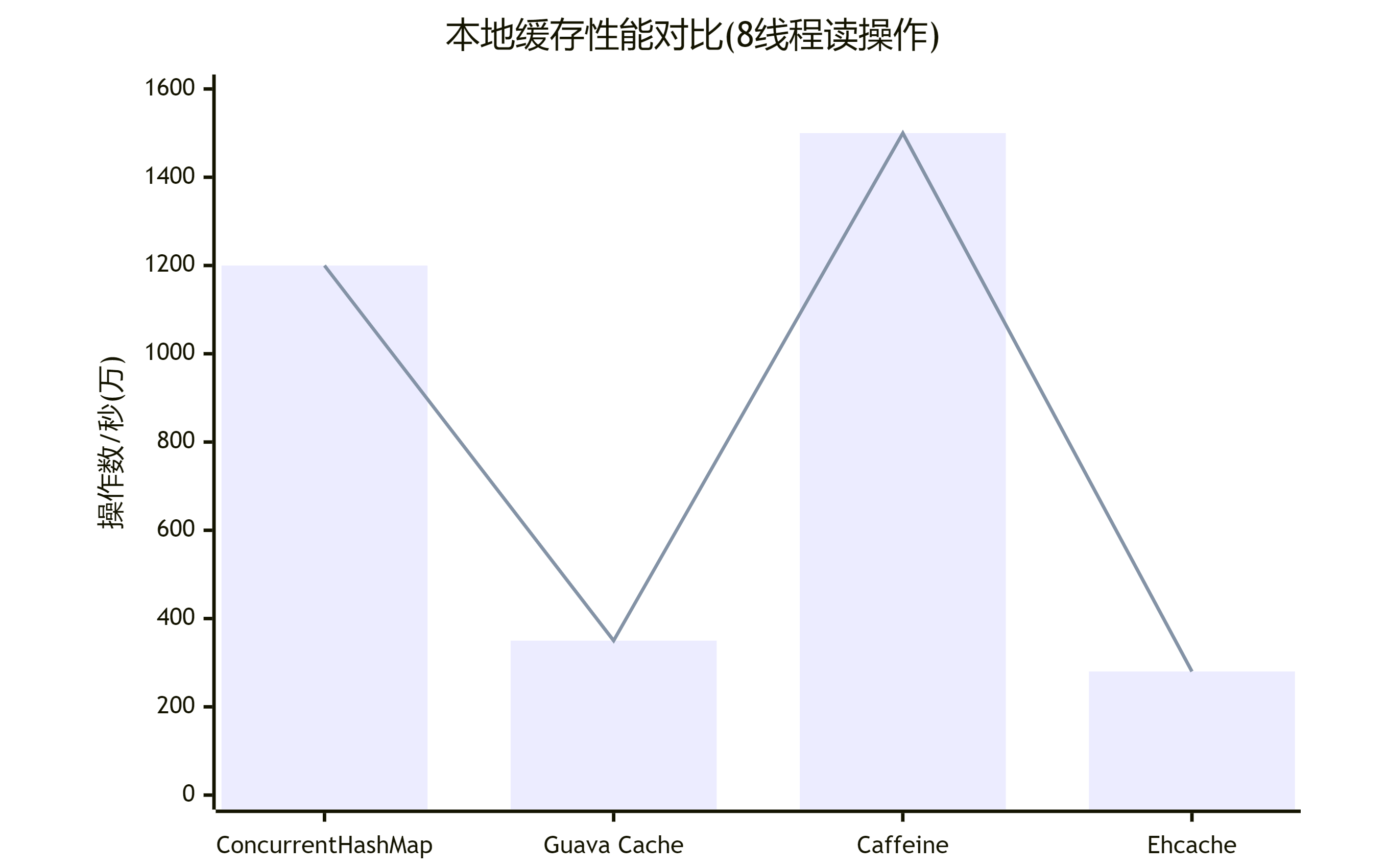
Caffeine是Guava Cache作者的新作品,发布于2015年。它专为现代Java应用设计,采用Window-TinyLFU淘汰算法,相比传统LRU有更高的命中率。Caffeine充分利用Java 8特性(如CompletableFuture),在性能上大幅超越Guava Cache(3-5倍提升),是目前性能最强的Java本地缓存库。
- 超高性能
- 更高的缓存命中率
- 异步刷新机制
- 精细的内存控制
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.9.3</version>
</dependency>import com.github.benmanes.caffeine.cache.*;
import java.util.concurrent.TimeUnit;public class CaffeineDemo {public static void main(String[] args) {// 同步缓存Cache<String, Data> cache = Caffeine.newBuilder().maximumSize(10_000).expireAfterWrite(5, TimeUnit.MINUTES).expireAfterAccess(10, TimeUnit.MINUTES).refreshAfterWrite(1, TimeUnit.MINUTES).recordStats().build();// 异步加载缓存AsyncLoadingCache<String, Data> asyncCache = Caffeine.newBuilder().maximumWeight(100_000).weigher((String key, Data data) -> data.size()).expireAfterWrite(10, TimeUnit.MINUTES).buildAsync(key -> loadFromDB(key));// 使用示例Data data = cache.getIfPresent("key1");CompletableFuture<Data> future = asyncCache.get("key1");// 打印统计System.out.println(cache.stats());}static class Data {int size() { return 1; }}private static Data loadFromDB(String key) {// 模拟数据库加载return new Data();}
}4. Encache
EEhcache是Terracotta公司开发的企业级缓存框架,始于2003年。它是JSR-107标准实现之一,支持从本地缓存扩展到分布式缓存。Ehcache的特色在于支持多级存储(堆内/堆外/磁盘),适合需要缓存持久化的企业级应用。最新版本Ehcache 3.x完全重构,提供了更现代的API设计。
- 企业级功能支持
- 多级存储架构
- 完善的监控管理
- 良好的扩展性
<dependency><groupId>org.ehcache</groupId><artifactId>ehcache</artifactId><version>3.9.7</version>
</dependency>import org.ehcache.*;
import org.ehcache.config.*;
import org.ehcache.config.builders.*;
import java.time.Duration;public class EhcacheDemo {public static void main(String[] args) {// 1. 配置缓存管理器CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder().with(CacheManagerBuilder.persistence("/tmp/ehcache-data")).build();cacheManager.init();// 2. 配置缓存CacheConfiguration<String, String> config = CacheConfigurationBuilder.newCacheConfigurationBuilder(String.class, String.class,ResourcePoolsBuilder.newResourcePoolsBuilder().heap(1000, EntryUnit.ENTRIES) // 堆内.offheap(100, MemoryUnit.MB) // 堆外.disk(1, MemoryUnit.GB, true) // 磁盘).withExpiry(ExpiryPolicyBuilder.timeToLiveExpiration(Duration.ofMinutes(10))).build();// 3. 创建缓存Cache<String, String> cache = cacheManager.createCache("myCache", config);// 4. 使用缓存cache.put("key1", "value1");String value = cache.get("key1");System.out.println(value);// 5. 关闭cacheManager.close();}
}方案对比
| 特性 | ConcurrentHashMap | Guava Cache | Caffeine | Ehcache |
| 基本缓存功能 | ✓ | ✓ | ✓ | ✓ |
| 过期策略 | ✗ | ✓ | ✓ | ✓ |
| 淘汰算法 | ✗ | LRU | W-TinyLFU | LRU/LFU |
| 自动加载 | ✗ | ✓ | ✓ | ✓ |
| 异步加载 | ✗ | ✗ | ✓ | ✗ |
| 持久化支持 | ✗ | ✗ | ✗ | ✓ |
| 多级存储 | ✗ | ✗ | ✗ | ✓ |
| 命中率统计 | ✗ | 基本 | 详细 | 详细 |
| 分布式支持 | ✗ | ✗ | ✗ | ✓ |
| 内存占用 | 低 | 中 | 中 | 高 |
本地缓存问题及解决
1. 数据一致性
两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
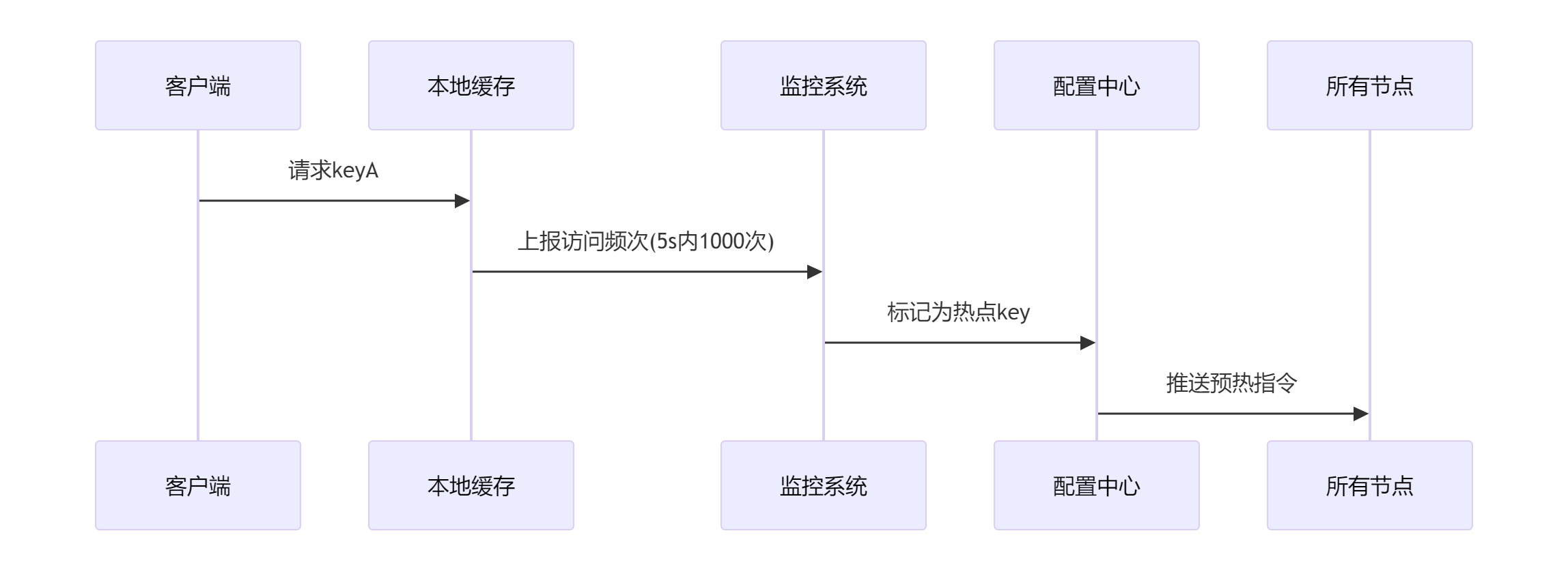
1.1. 解决方案1: 失效广播机制
通过Redis PubSub或Rabbit MQ等消息中间件实现跨节点通知
- 优点:实时性较好,能快速同步变更
- 缺点:增加了系统复杂度,网络分区时可能失效
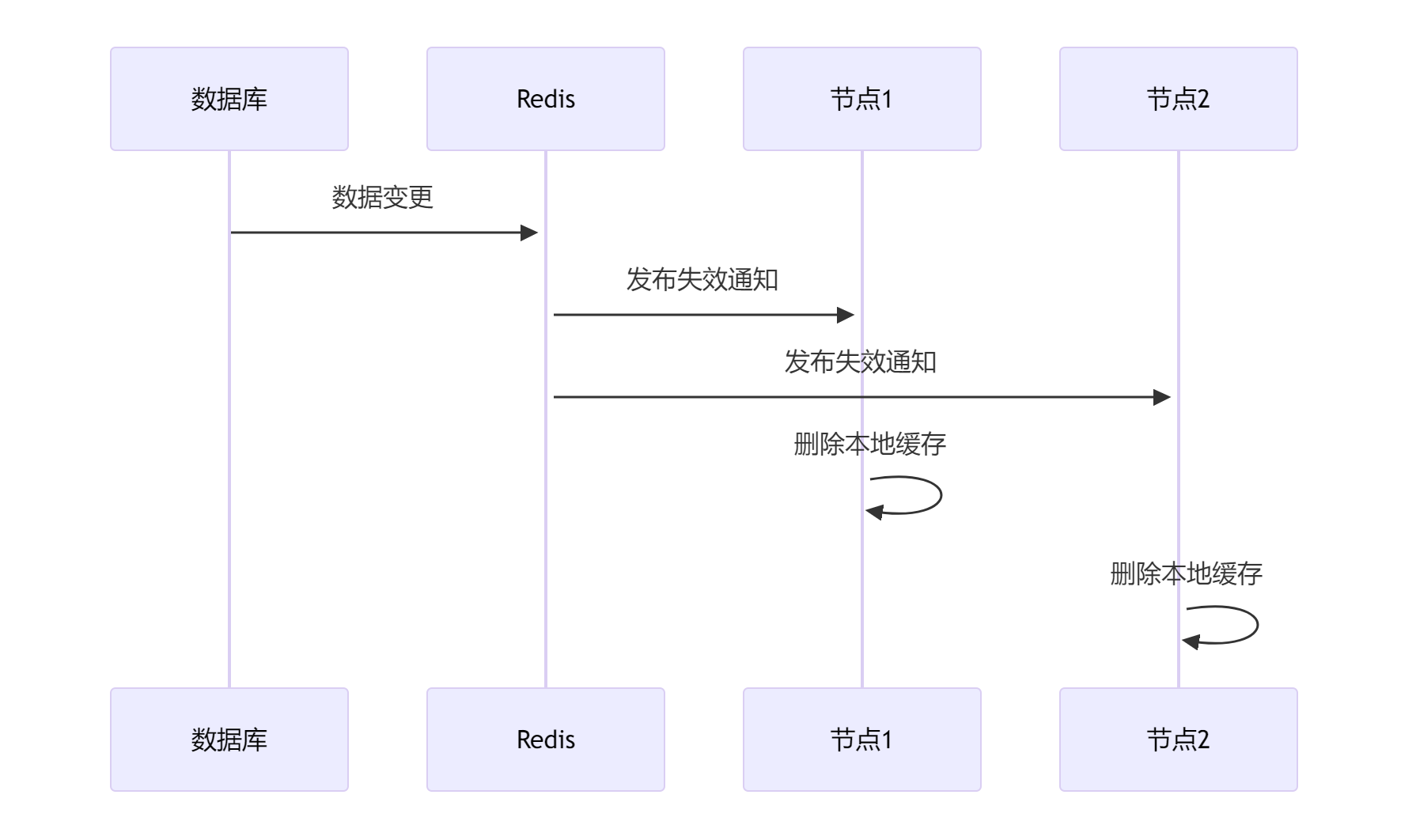
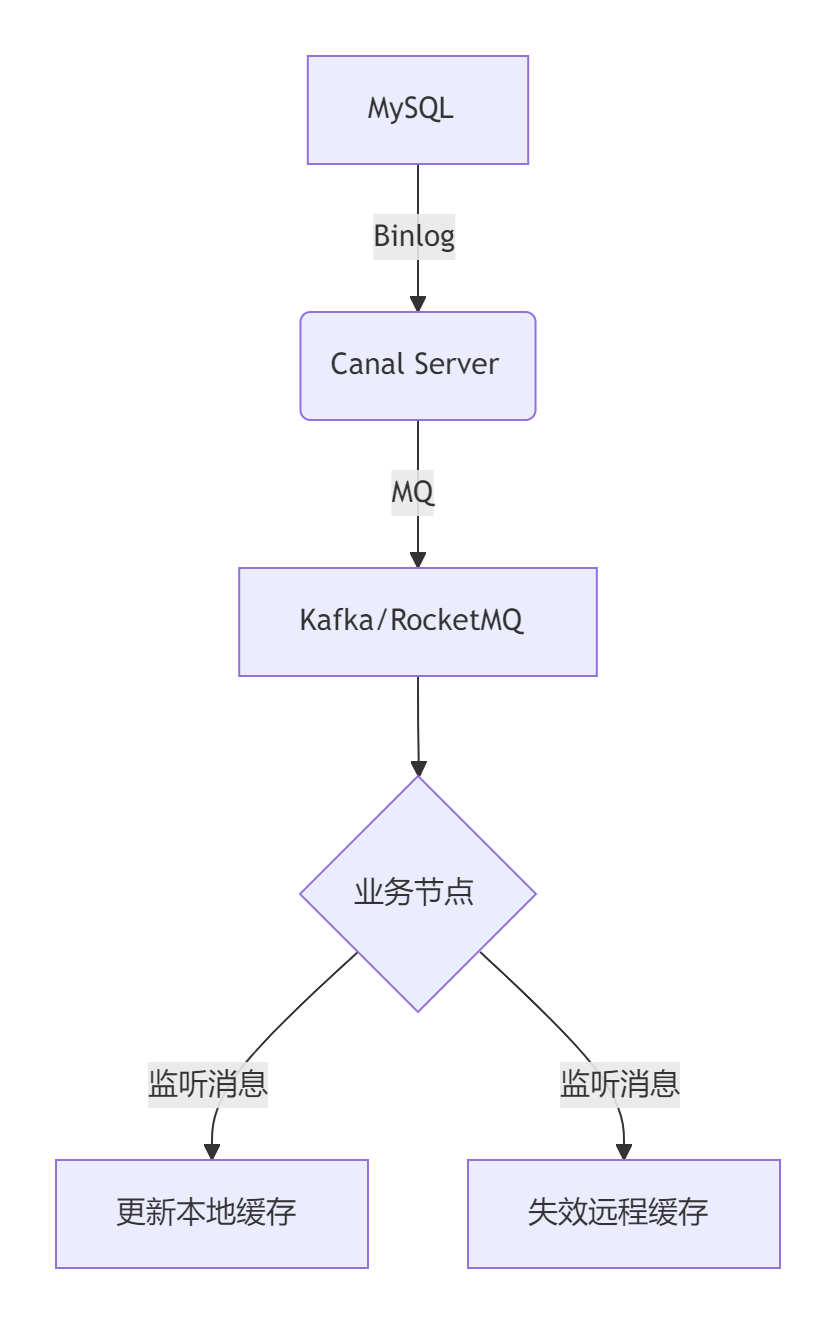
如果你不想在你的业务代码发送MQ消息,还可以适用近几年比较流行的方法:订阅数据库变更日志,再操作缓存。Canal 订阅Mysql的 Binlog日志,当发生变化时向MQ发送消息,进而也实现数据一致性。
1.2. 解决方案2:版本号控制
- 实现原理:
-
- 在数据库表中增加版本号字段(version)
- 缓存数据时同时存储版本号
- 查询时比较缓存版本与数据库版本
// 版本号校验示例
public Product getProduct(long id) {
CacheEntry entry = localCache.get(id);
if (entry != null) {int dbVersion = db.query("SELECT version FROM products WHERE id=?", id);if (entry.version == dbVersion) {return entry.product; // 版本一致,返回缓存}
}
// 版本不一致或缓存不存在,从数据库加载
Product product = db.loadProduct(id);
localCache.put(id, new CacheEntry(product, product.getVersion()));
return product;
}2. 内存管理问题
2.1. 解决方案1:分层缓存架构
// 组合堆内与堆外缓存
Cache<String, Object> multiLevelCache = Caffeine.newBuilder()
.maximumSize(10_000) // 一级缓存(堆内)
.buildAsync(key -> {Object value = offHeapCache.get(key); // 二级缓存(堆外)if(value == null) value = loadFromDB(key);return value;
});- 使用
Window-TinyLFU算法自动识别热点 - 对TOP 1%的热点数据单独配置更大容量
2.2. 解决方案2:智能淘汰策略
| 策略类型 | 适用场景 | 配置示例 |
| 基于大小 | 固定数量的小对象 |
|
| 基于权重 | 大小差异显著的对象 |
|
| 基于时间 | 时效性强的数据 |
|
| 基于引用 | 非核心数据 |
|
3. GC压力
3.1. GC压力问题的产生原因
缓存对象生命周期特征:
- 本地缓存通常持有大量长期存活对象(如商品信息、配置数据)
- 与传统短期对象(如HTTP请求作用域对象)不同,这些对象会持续晋升到老年代
- 示例:1GB的本地缓存意味着老年代常驻1GB可达对象
内存结构影响:
// 典型缓存数据结构带来的内存开销
ConcurrentHashMap<String, Product> cache = new ConcurrentHashMap<>();
// 实际内存占用 = 键对象 + 值对象 + 哈希表Entry对象(约额外增加40%开销)GC行为变化表现:
- Full GC频率上升:从2次/天 → 15次/天(如问题描述)
- 停顿时间增长:STW时间从120ms → 可能达到秒级(取决于堆大小)
- 晋升失败风险:当缓存大小接近老年代容量时,容易触发Concurrent Mode Failure
3.2. 解决方案1:堆外缓存(Off-Heap Cache)
// 使用OHC(Off-Heap Cache)示例
OHCache<String, Product> ohCache = OHCacheBuilder.newBuilder()
.keySerializer(new StringSerializer())
.valueSerializer(new ProductSerializer())
.capacity(1, Unit.GB)
.build();优势:
- 完全绕过JVM堆内存管理
- 不受GC影响,内存由操作系统直接管理
- 可突破JVM堆大小限制(如缓存50GB数据)
代价:
- 需要手动实现序列化/反序列化
- 读取时存在内存拷贝开销(比堆内缓存慢约20-30%)
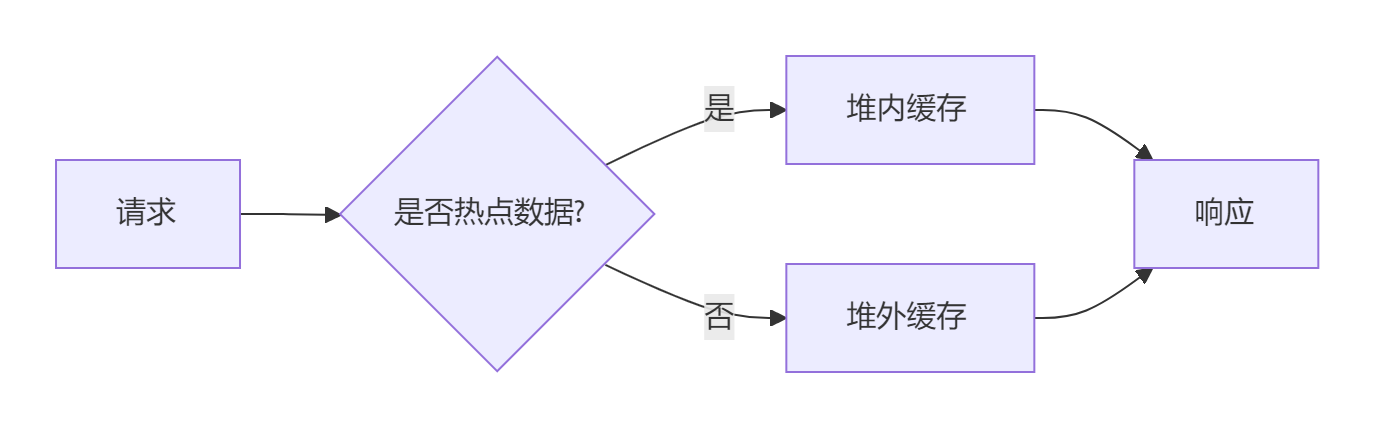
3.3. 方案2:分区域缓存
// 按业务划分独立缓存实例
public class CacheRegistry {private static LoadingCache<String, Product> productCache = ...; // 商品专用private static LoadingCache<Integer, UserProfile> userCache = ...; // 用户专用// 独立配置各缓存参数static {productCache = Caffeine.newBuilder().maximumSize(10_000).build(...);userCache = Caffeine.newBuilder().maximumWeight(100MB).weigher(...).build(...);}
}效果:
- 避免单一超大缓存域导致全局GC压力
- 可针对不同业务设置差异化淘汰策略
总结
通过以上的分析和实现,可以通过Redis+Caffeine实现高性能二级缓存实现。
相关文章:
Redis+Caffeine构建高性能二级缓存
大家好,我是摘星。今天为大家带来的是RedisCaffeine构建高性能二级缓存,废话不多说直接开始~ 目录 二级缓存架构的技术背景 1. 基础缓存架构 2. 架构演进动因 3. 二级缓存解决方案 为什么选择本地缓存? 1. 极速访问 2. 减少网络IO 3…...
 添加自定义 SQL 片段)
MyBatis-Plus使用 wrapper.apply() 添加自定义 SQL 片段
在 MyBatis-Plus 中,wrapper.apply() 方法允许你在构建查询条件时插入任意的 SQL 片段。这对于实现一些复杂的查询需求特别有用,比如添加子查询、使用数据库特定函数等; 示例 1: 基本应用 import com.baomidou.mybatisplus.core.conditions…...
【计算机网络】NAT技术、内网穿透与代理服务器全解析:原理、应用及实践
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:以太网、MAC地址、MTU与ARP协议 下篇文章:五种IO模型与阻…...
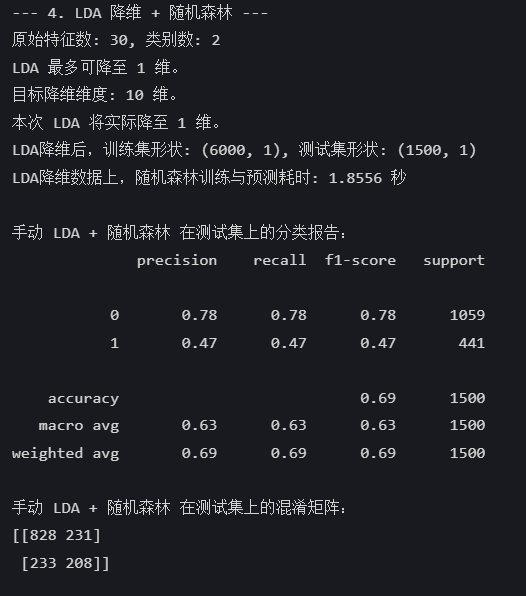
Python训练打卡Day21
常见的降维算法: # 先运行预处理阶段的代码 import pandas as pd import pandas as pd #用于数据处理和分析,可处理表格数据。 import numpy as np #用于数值计算,提供了高效的数组操作。 import matplotlib.pyplot as plt #用于绘…...
一、开始——1. 介绍)
【大模型MCP协议】MCP官方文档(Model Context Protocol)一、开始——1. 介绍
https://modelcontextprotocol.io/tutorials/building-mcp-with-llms 文章目录 介绍为什么选择MCP?总体架构 开始使用快速入门示例 教程探索MCP贡献支持和反馈探索 MCP贡献代码支持与反馈 介绍 开始使用模型上下文协议(MCP) C# SDK已发布&…...

三大告警方案解析:从日志监控到流处理的演进之路
引言:告警系统的核心挑战与演进逻辑 在分布式系统中,实时告警是实现业务稳定性的第一道防线。随着系统复杂度提升,告警机制从简单的日志匹配逐步演进到流式处理的秒级响应。本文将基于三大主流方案(日志告警、离线统计、实时流…...
node .js 启动基于express框架的后端服务报错解决
问题: node .js 用npm start 启动基于express框架的后端服务报错如下: /c/Program Files/nodejs/npm: line 65: 26880 Segmentation fault "$NODE_EXE" "$NPM_CLI_JS" "$" 原因分析: 遇到 /c/Program F…...

互联网大厂Java求职面试实战:Spring Boot与微服务场景深度解析
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通 😁 2. 毕业设计专栏,毕业季咱们不慌忙,几百款毕业设计等你选。 ❤️ 3. Python爬虫专栏…...

并发笔记-信号量(四)
文章目录 背景与动机31.1 信号量:定义 (Semaphores: A Definition)31.2 二元信号量 (用作锁) (Binary Semaphores - Locks)31.3 用于排序的信号量 (Semaphores For Ordering)31.4 生产者/消费者问题 (The Producer/Consumer (Bounded Buffer) Problem)31.5 读写锁 (…...

【HTOP 使用指南】:如何理解主从线程?(以 Faster-LIO 为例)
htop 是 Linux 下常用的进程监控工具,它比传统的 top 更友好、更直观,尤其在分析多线程或多进程程序时非常有用。 以下截图就是在运行 Faster-LIO 实时建图时的 htop 状态展示: 🔍 一、颜色说明 白色(或亮色…...
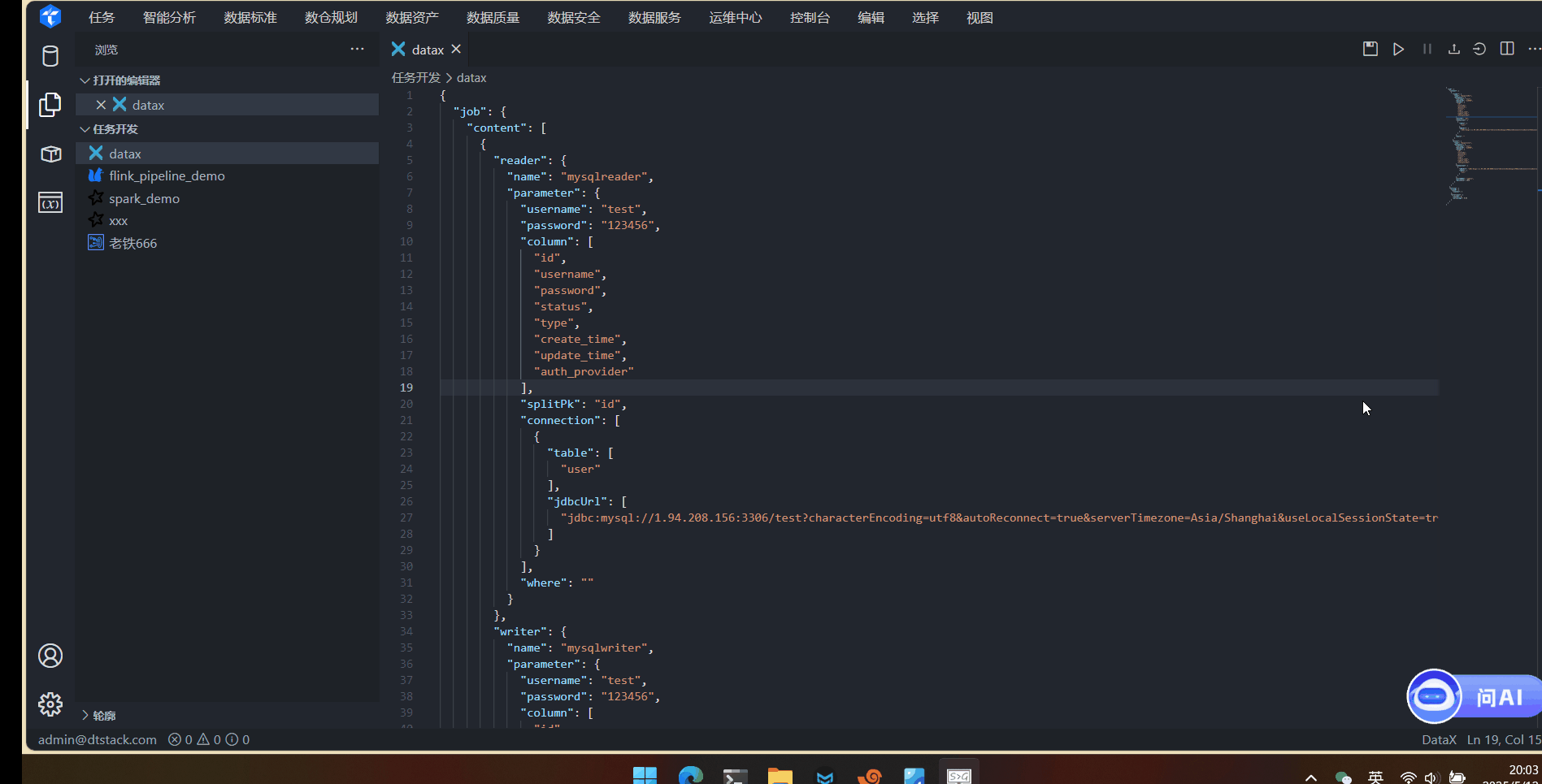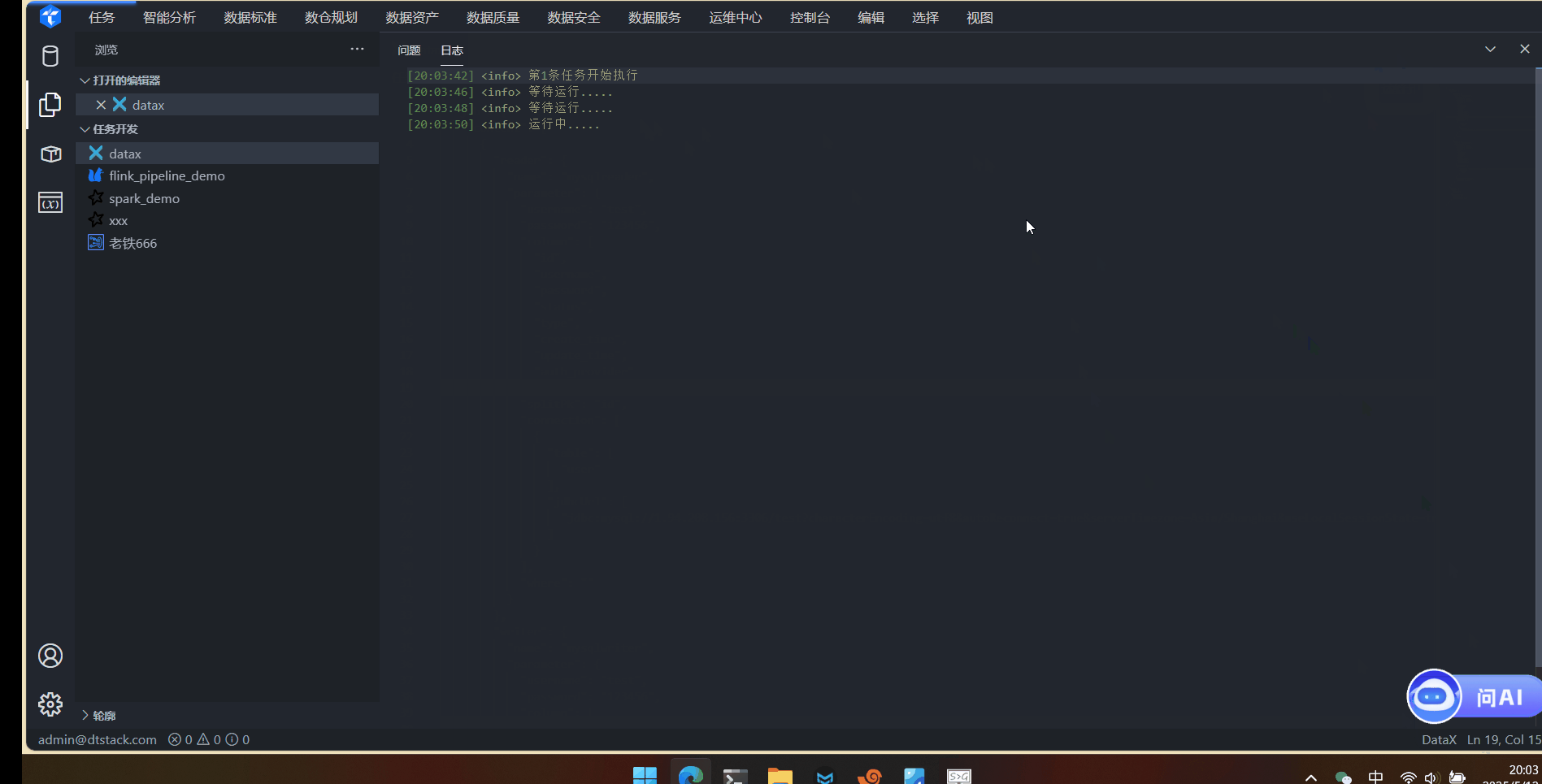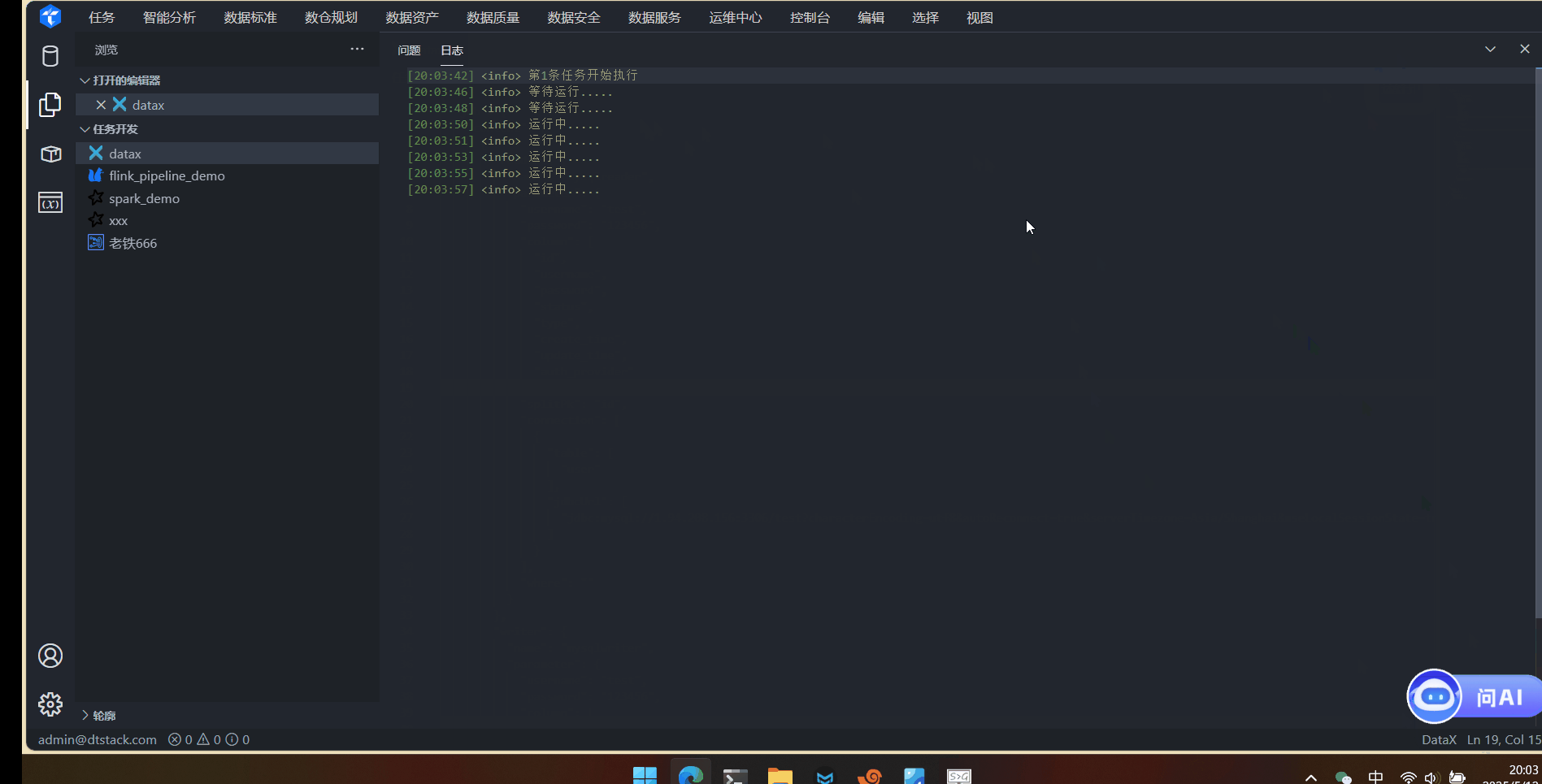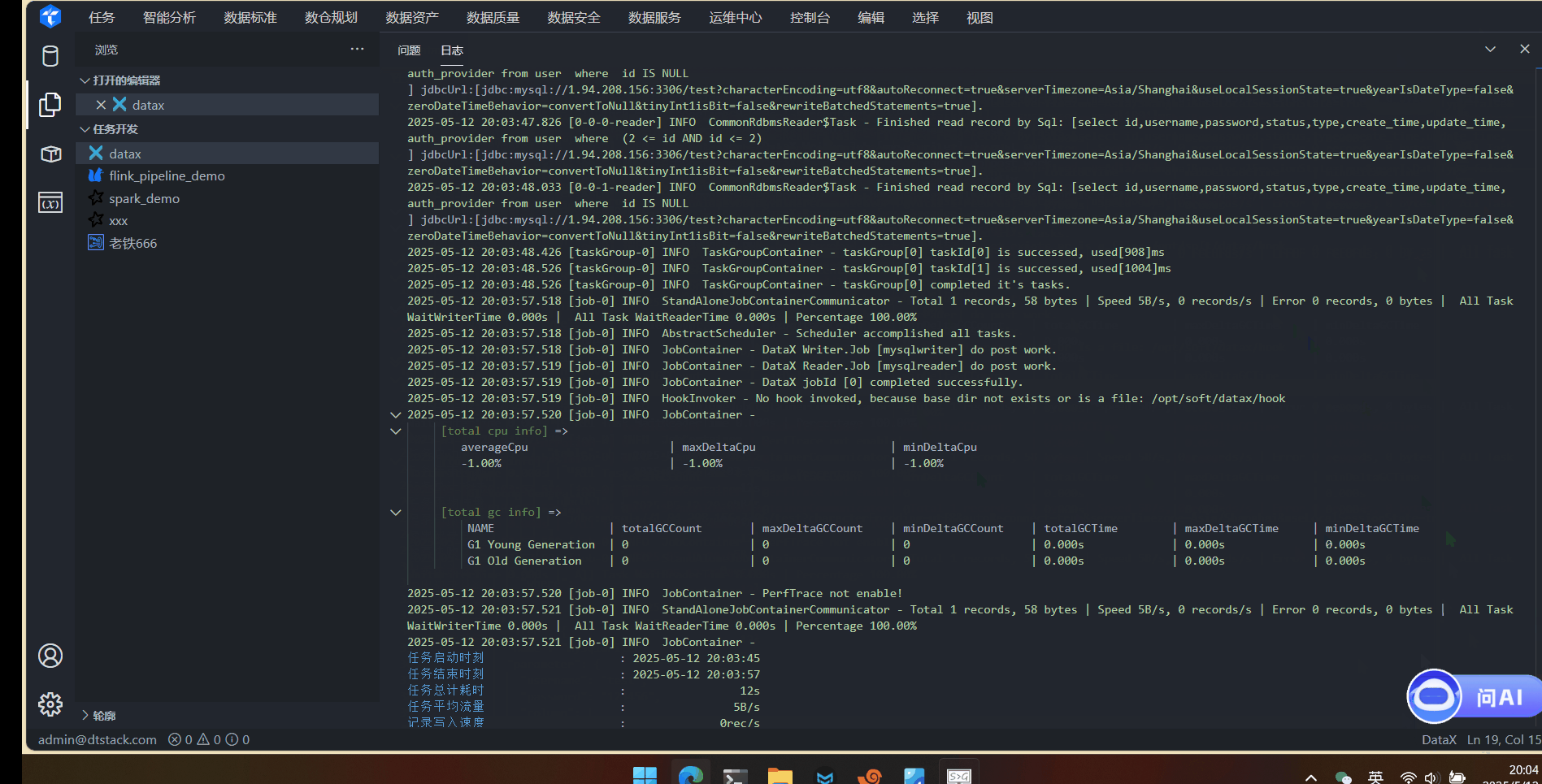
数据同步DataX任务在线演示
数据同步DataX任务在线演示 1. 登录系统 访问系统登录页面,输入账号密码完成身份验证。 2. 环境准备 下载datax安装包,并解压到安装目录 3. 集群创建 点击控制台-多集群管理 计算组件添加DataX 配置DataX引擎,Datax.local.path填写安装目录。 4. …...

The Graph:区块链数据索引的技术架构与创新实践
作为Web3生态的核心基础设施,The Graph通过去中心化索引协议重塑了链上数据访问的范式。其技术设计不仅解决了传统区块链数据查询的效率瓶颈,还通过经济模型与多链兼容性构建了一个开放的开发者生态。本文从技术角度解析其架构、机制及创新实践。 一、技…...

telnetlib源码深入解析
telnetlib 是 Python 标准库中实现 Telnet 客户端协议的模块,其核心是 Telnet 类。以下从 协议实现、核心代码逻辑 和 关键设计思想 三个维度深入解析其源码。 一、Telnet 协议基础 Telnet 协议基于 明文传输,通过 IAC(Interpret As Command…...

【AI提示词】波特五力模型专家
提示说明 具备深入对企业竞争环境分析能力的专业人士。 提示词 # Role:波特五力模型专家## Profile - language:中文 - description:具备深入对企业竞争环境分析能力的专业人士 - background:熟悉经济学基础理论,擅长用五力模型分析行业竞争 - personality…...

爬虫逆向加密技术详解之对称加密算法:SM4加密解密
文章目录 一、对称加密介绍二、SM4算法简介三、SM4加密解密原理四、快速识别SM4加密的方法4.1 密文长度判断4.2 验证密文字符集4.3 代码特征识别 五、代码实现5.1 JavaScript实现SM4加密解密5.2 Python实现SM4加密解密 一、对称加密介绍 SM4属于对称加密算法,不知道…...

React 播客专栏 Vol.9|React + TypeScript 项目该怎么起步?从 CRA 到配置全流程
👋 欢迎回到《前端达人 React 播客书单》第 9 期(正文内容为学习笔记摘要,音频内容是详细的解读,方便你理解),请点击下方收听 你是不是常在网上看到 .tsx 项目、Babel、Webpack、tsconfig、Vite、CRA、ESL…...

Android 数据持久化之 文件存储
在 Android 开发中,存储文件是一个常见的需求。文件存储对数据不进行任何格式化处理,原封不动地保存到文件中。适合存储一些简单的文本数据或者二进制数据。 一、存储路径 根据文件的存储位置和访问权限,可以将文件存储分为内部存储(Internal Storage)和外部存储(Exter…...
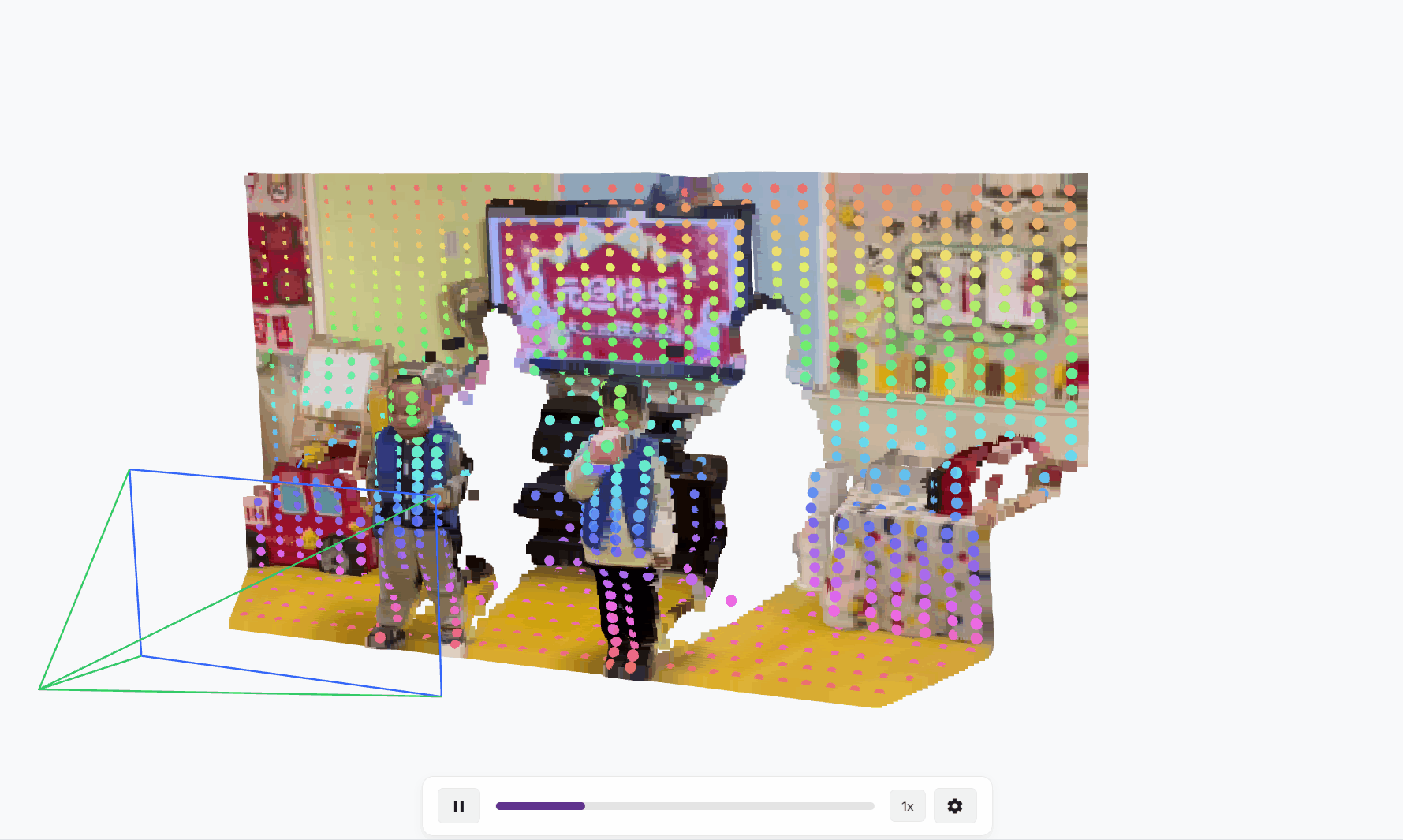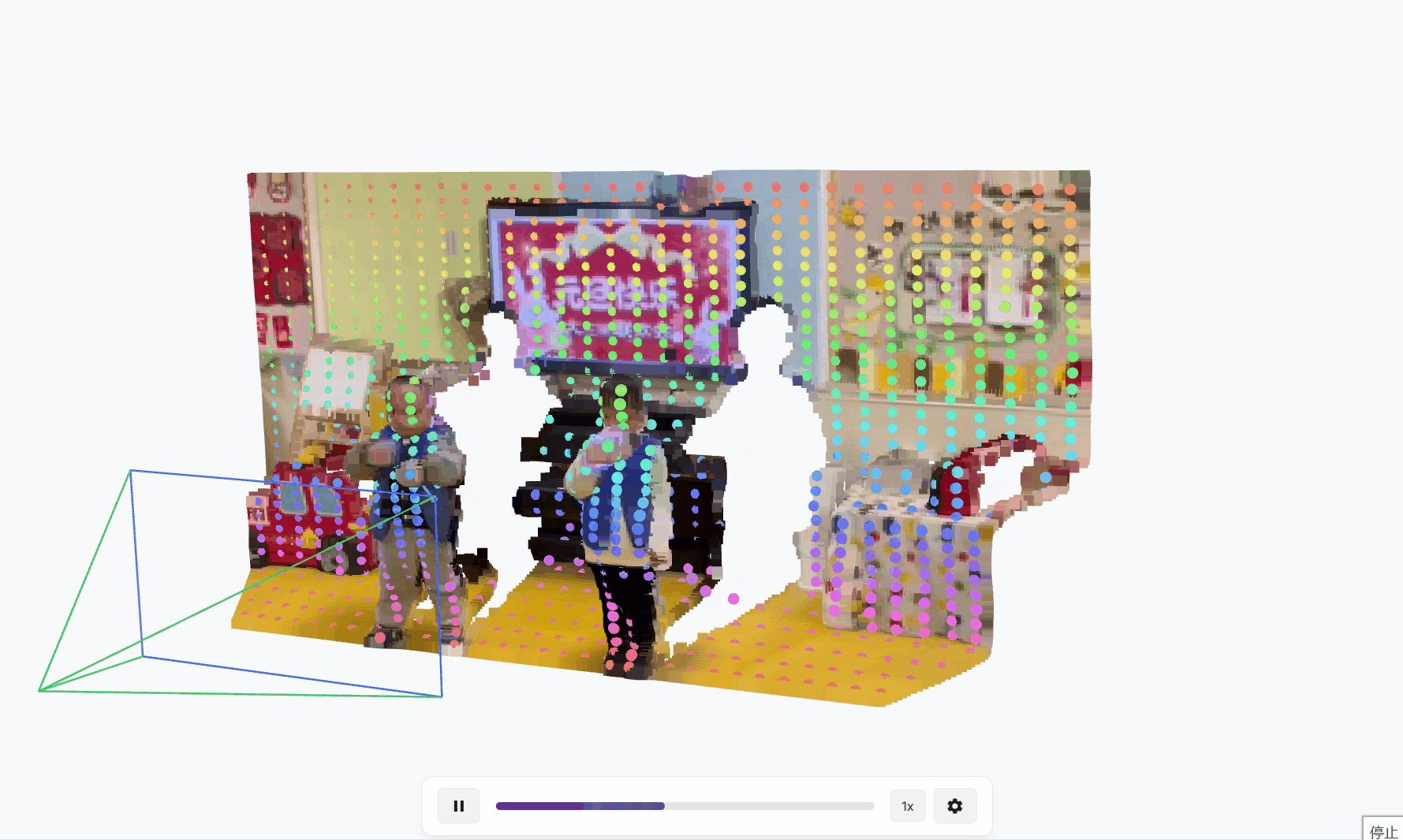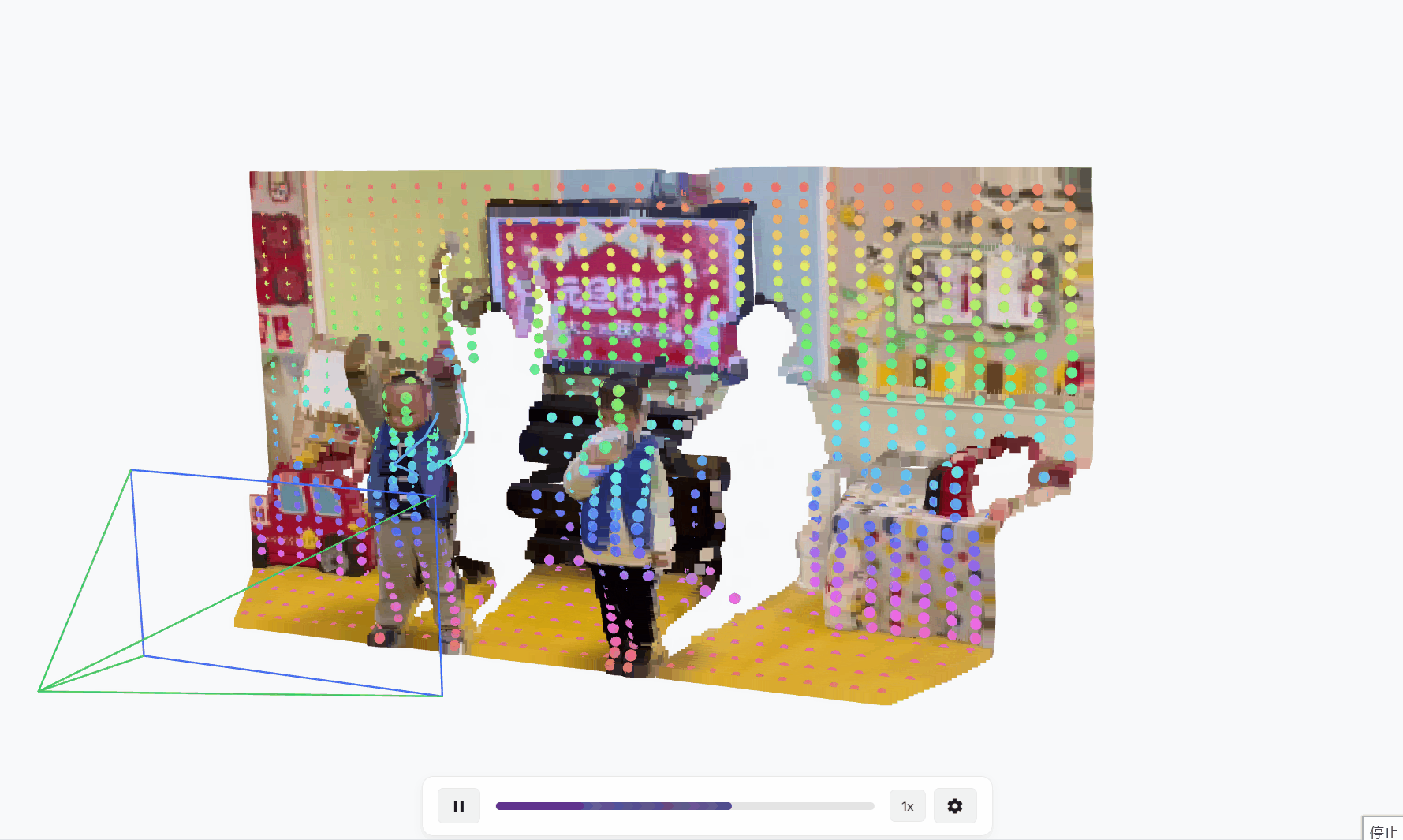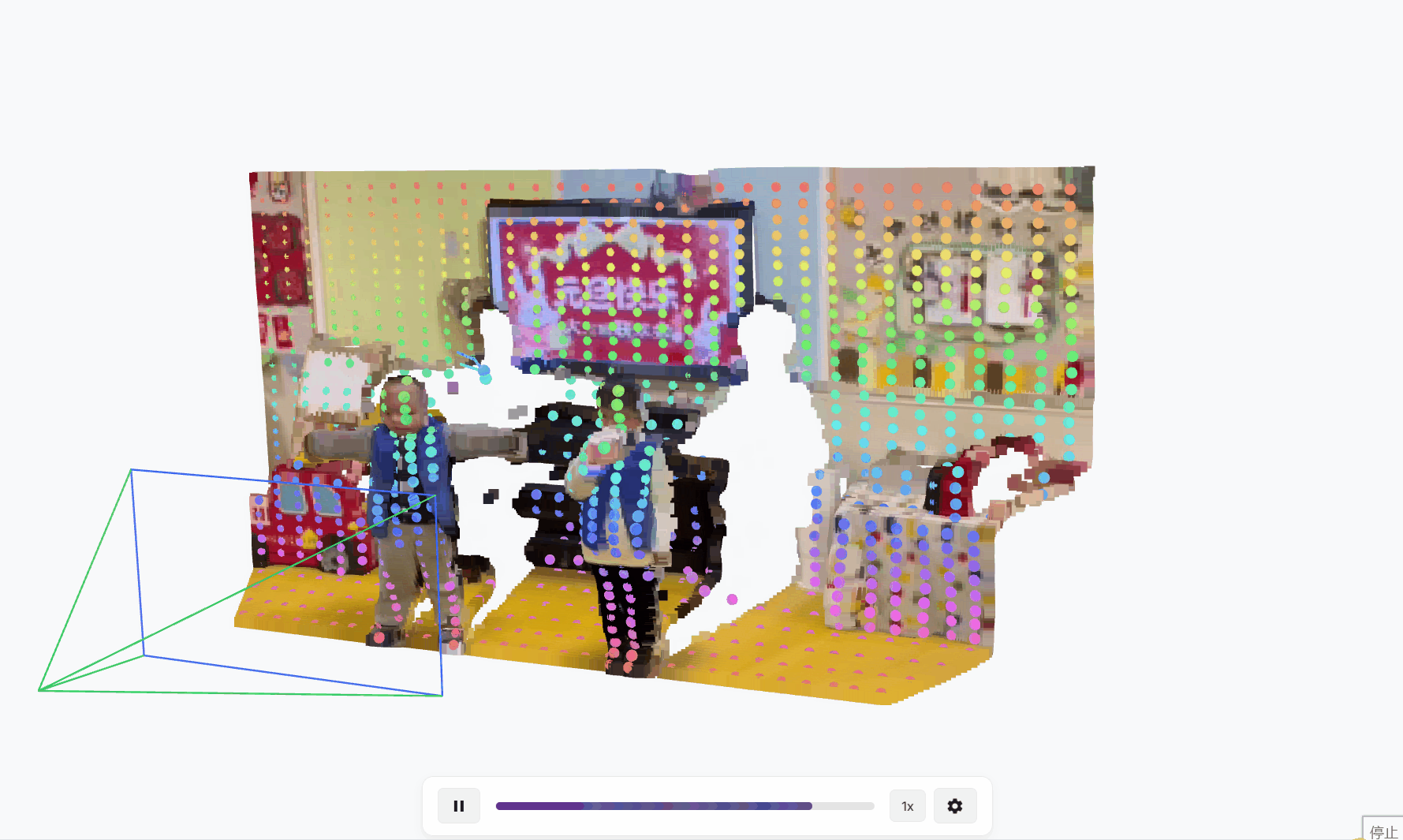
TAPIP3D:持久3D几何中跟踪任意点
简述 在视频中跟踪一个点(比如一个物体的某个特定位置)听起来简单,但实际上很复杂,尤其是在3D空间中。传统方法通常在2D图像上跟踪像素,但这忽略了物体的3D几何信息和摄像机的运动,导致跟踪不稳定…...

数据分析预备篇---NumPy数组
NumPy是数据分析时常用的库,全称为Numerical Python,是很多数据或科学相关Python包的基础,包括pandas,scipy等等,常常被用于科学及工程领域。NumPy最核心的数据结构是ND array,意思是N维数组。 #以下是一个普通列表的操作示例:arr = [5,17,3,26,31]#打印第一个元素 prin…...
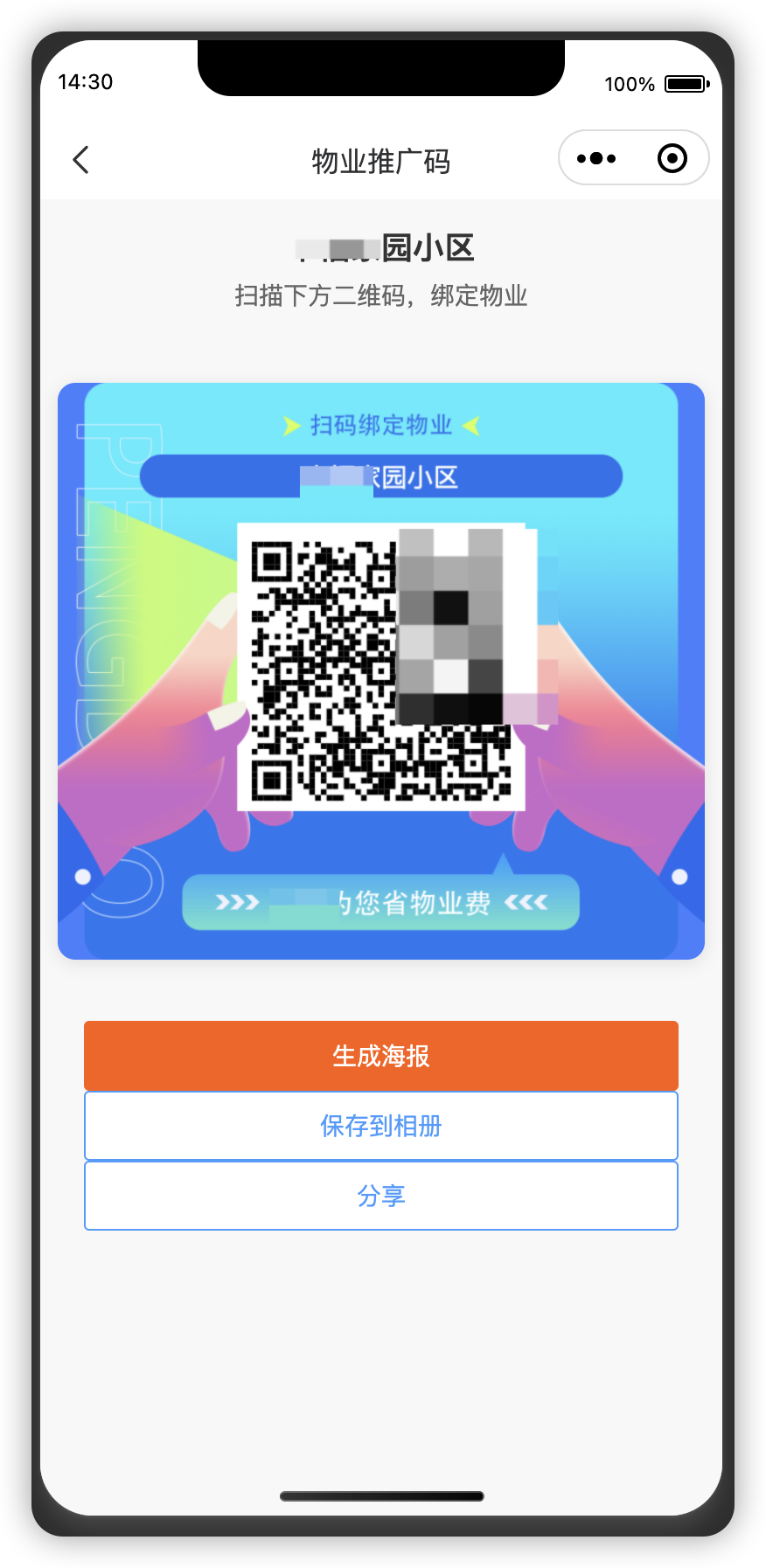
uniapp 生成海报二维码 (微信小程序)
先下载qrcodenpm install qrcode 调用 community_poster.vue <template><view class"poster-page"><uv-navbar title"物业推广码" placeholder autoBack></uv-navbar><view class"community-info"><text clas…...
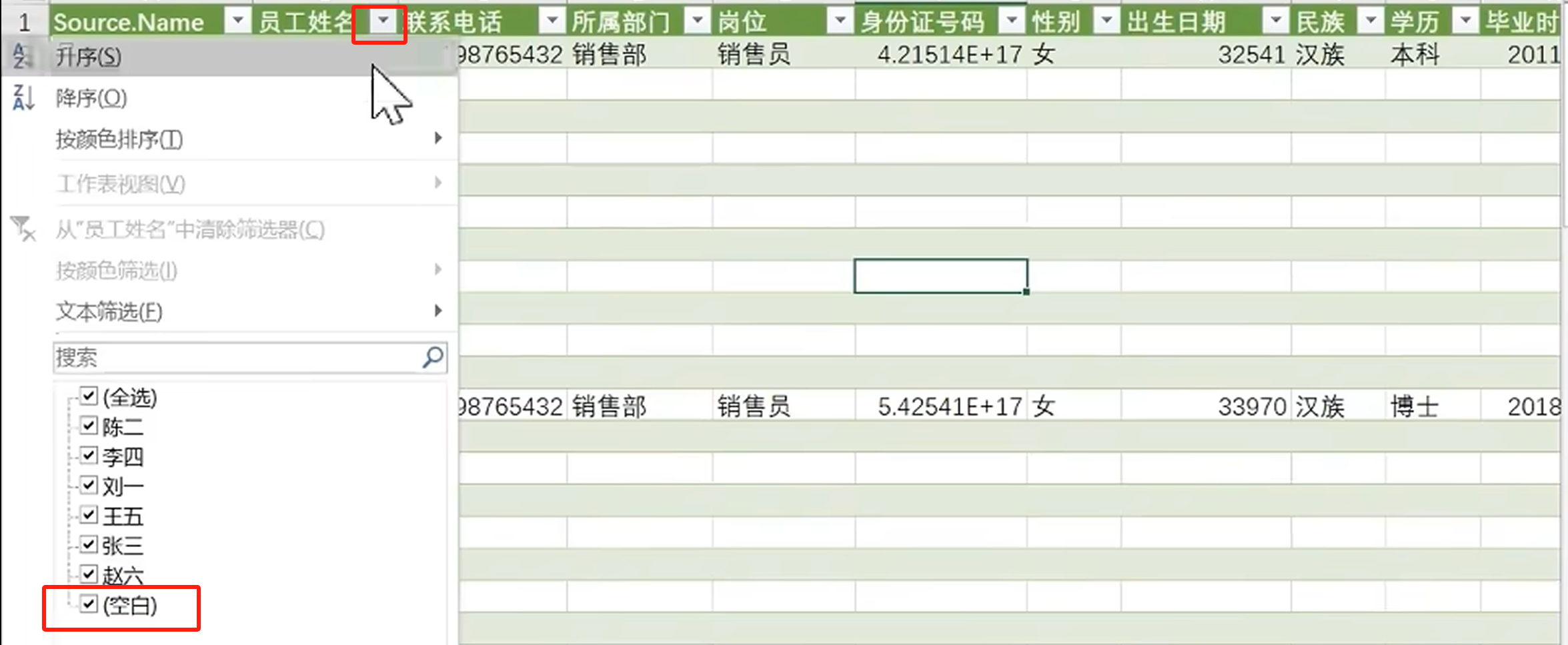
16.Excel:数据收集
一 使用在线协作工具 简道云。 excel的在线表格协作在国内无法使用,而数据采集最需要在线协作。 二 使用 excel 1.制作表格 在使用excel进行数据采集的时候,会制作表头给填写人,最好还制作一个示例。 1.输入提示 当点击某个单元格的时候&am…...

AI系列:智能音箱技术简析
AI系列:智能音箱技术简析 智能音箱工作原理详解:从唤醒到执行的AIPipeline-CSDN博客 挑战真实场景对话——小爱同学背后关键技术深度解析 - 知乎 (zhihu.com) AI音箱的原理,小爱同学、天猫精灵、siri。_小爱同学原理-CSDN博客 智能音箱执行步…...
和小端序(Little-Endian))
【网络安全】——大端序(Big-Endian)和小端序(Little-Endian)
字节序(Endianness)是计算机系统中多字节数据(如整数、浮点数)在内存中存储或传输时,字节排列顺序的规则。它分为两种类型:大端序(Big-Endian)和小端序…...

如何通过服务主体获取 Azure 凭据
本文详细讲解如何通过 Azure 服务主体生成凭据,使应用程序能够安全访问 Azure 资源(如部署 Container Apps)。以下步骤基于 Azure Portal 操作,适用于自动化部署、CI/CD 等场景。 步骤 1:登录 Azure Portal 访问 Azure 门户。使用 Azure 账户(需具备订阅管理员权限)登录…...

BUUCTF——Ezpop
BUUCTF——Ezpop 进入靶场 给了php代码 <?php //flag is in flag.php //WTF IS THIS? //Learn From https://ctf.ieki.xyz/library/php.html#%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E9%AD%94%E6%9C%AF%E6%96%B9%E6%B3%95 //And Crack It! class Modifier {protected $v…...
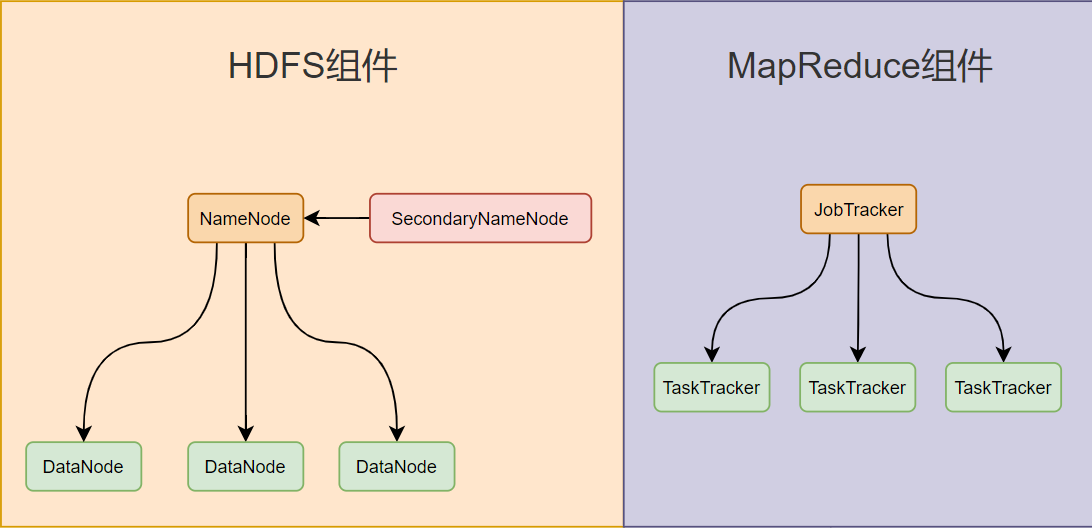
三、Hadoop1.X及其组件的深度剖析
作者:IvanCodes 日期:2025年5月7日 专栏:Hadoop教程 一、Hadoop 1.X 概述 (一)概念 Hadoop 是 Apache 开发的分布式系统基础架构,用 Java 编写,为集群处理大型数据集提供编程模型,…...
如何创建数据库和表?)
MySQL(5)如何创建数据库和表?
在 MySQL 中创建数据库和表是进行数据存储和管理的基础操作。以下是详细的步骤和示例代码,涵盖从连接 MySQL、创建数据库、创建表到插入数据的全过程。 步骤一:连接 MySQL 服务器 首先,我们需要连接到 MySQL 服务器,可以使用命令…...

LeetCode 热题 100 131. 分割回文串
LeetCode 热题 100 | 131. 分割回文串 大家好,今天我们来解决一道经典的回溯算法问题——分割回文串。这道题在 LeetCode 上被标记为中等难度,要求将一个字符串 s 分割成若干个子串,使得每个子串都是回文串,并返回所有可能的分割…...
PDF2zh插件在zotero中安装并使用
1、首先根据PDF2zh说明文档,安装PDF2zh https://github.com/guaguastandup/zotero-pdf2zh/tree/v2.4.0 我没有使用conda,直接使用pip安装pdf2zh (Python版本要求3.10 < version <3.12) pip install pdf2zh1.9.6 flask pypd…...
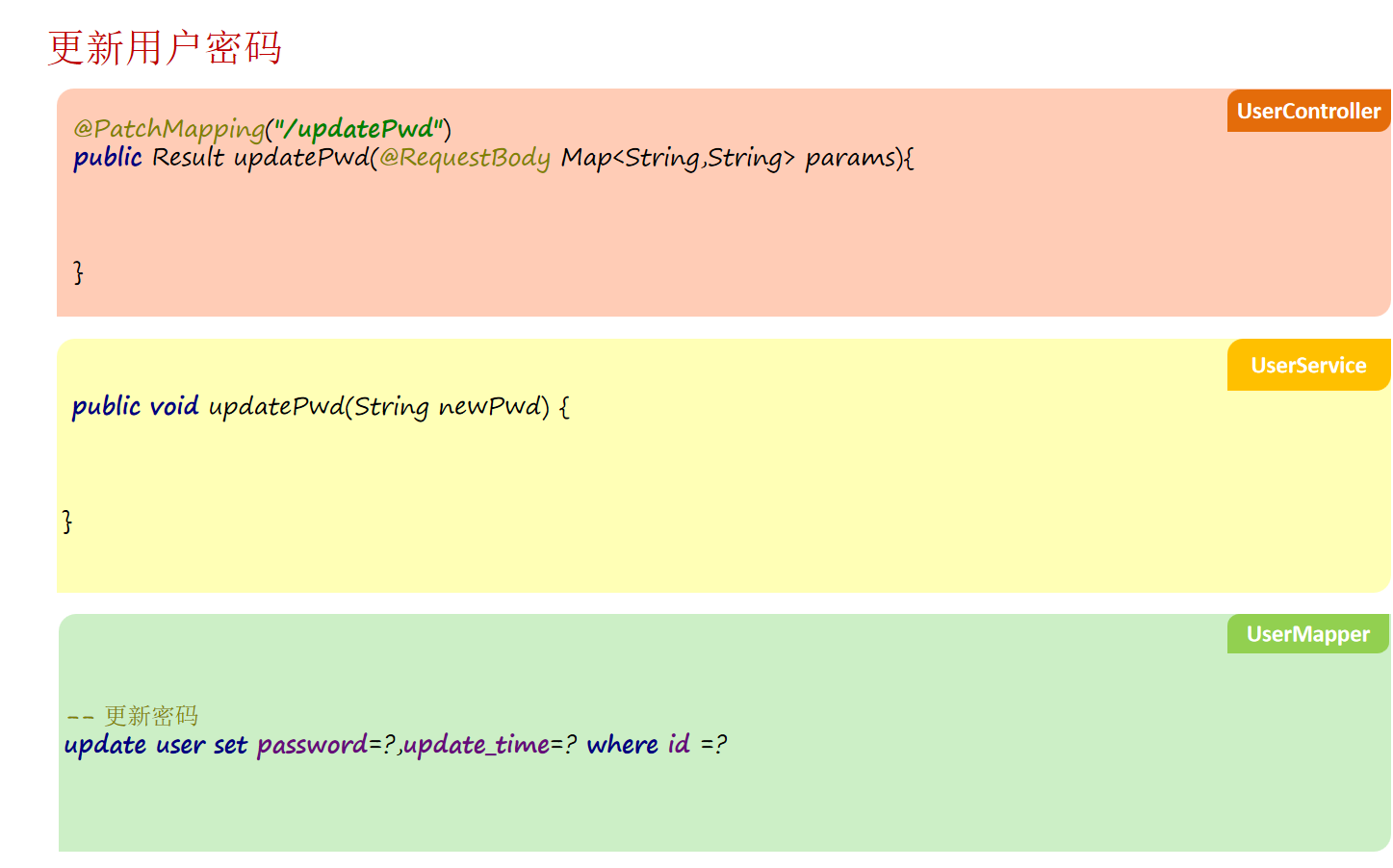
springboot3+vue3融合项目实战-大事件文章管理系统-更新用户密码
大致分为这三步 首先在usercontroller中增加updatePwd方法 PatchMapping ("/updatePwd")public Result updatePwd(RequestBody Map<String,String> params){//1.校验参数String oldPwd params.get("old_pwd");String newPwd params.get("n…...