【速写】KV-cache与解码的再探讨(以束搜索实现为例)
文章目录
- 1 Beam Search 解码算法实现
- 2 实现带KV Cache的Beam Search解码
- 3 关于在带kv-cache的情况下的use_cache参数
1 Beam Search 解码算法实现
下面是一个使用PyTorch实现的beam search解码算法:
几个小细节:
- 束搜索可以加入
length_penalty,目前model.generate也是有这个参数的,这个惩罚项直接是用来除生成概率的 - 通常这种需要计算概率相乘的情况,都是避免做乘法,而是使用log p相加
- 具体实现中应当考虑eos标识符导致的early stop的候选序列,需要提前存储到外面
- 然后就是关于使用
log softmax得到log概率后,这其实是一个负的概率,序列越长,log prob会越小,- log prob 才是越大的,因此在做惩罚的时候,应该是吧prob / len(seq) ** penality,即长序列的 log prob 会被除掉更多,这是合理的,因为短序列的 - log prob 天然地比 长序列地 - log prob 要更小,这样量纲才是正确的
import torch
import torch.nn.functional as F
from typing import List, Tupledef beam_search(model: torch.nn.Module,initial_input: torch.Tensor,beam_width: int,max_length: int,vocab_size: int,device: torch.device,length_penalty: float = 1.0,early_stopping: bool = True
) -> Tuple[List[List[int]], List[float]]:"""Beam search 解码算法实现参数:model: 用于预测下一个token的模型initial_input: 初始输入张量 (shape: [1, seq_len])beam_width: beam大小max_length: 生成序列的最大长度vocab_size: 词汇表大小device: 使用的设备 (cpu/cuda)length_penalty: 长度惩罚系数 (α), 用于调整对长序列的偏好early_stopping: 是否在所有beam序列达到EOS时提前停止返回:Tuple[List[List[int]], List[float]]: (生成的序列列表, 对应的分数列表)"""# 初始化beamsequences = [[initial_input.tolist()[0]]] # 初始序列scores = [0.0] # 初始分数 (log概率)# 存储完整的beam (已经生成EOS的序列)completed_sequences = []completed_scores = []for step in range(max_length):# 如果所有beam都已完成,提前停止if early_stopping and len(sequences) == 0:break# 准备当前步的输入candidates = []for i, seq in enumerate(sequences):# 跳过已经完成的序列if len(seq) > 0 and seq[-1] == 2: # 假设2是EOS tokencompleted_sequences.append(seq)completed_scores.append(scores[i])continue# 将序列转换为张量input_tensor = torch.tensor([seq], dtype=torch.long).to(device)# 获取模型预测with torch.no_grad():outputs = model(input_tensor)next_token_logits = outputs[:, -1, :] # 取最后一个token的logitsnext_token_probs = F.log_softmax(next_token_logits, dim=-1)# 获取top-k tokens和它们的log概率topk_probs, topk_tokens = torch.topk(next_token_probs, beam_width, dim=-1)topk_probs = topk_probs.squeeze(0)topk_tokens = topk_tokens.squeeze(0)# 创建候选序列for j in range(beam_width):new_seq = seq.copy()new_seq.append(topk_tokens[j].item())new_score = scores[i] + topk_probs[j].item()candidates.append((new_seq, new_score))# 如果没有候选序列,提前停止if not candidates:break# 选择top-k候选序列,并剪枝candidates.sort(key=lambda x: x[1] / (len(x[0]) ** length_penalty), reverse=True)sequences, scores = zip(*candidates[:beam_width])sequences = list(sequences)scores = list(scores)# 添加剩余的未完成序列到完成列表中completed_sequences.extend(sequences)completed_scores.extend(scores)# 对完成的序列按分数排序sorted_sequences = [seq for seq, _ in sorted(zip(completed_sequences, completed_scores),key=lambda x: x[1] / (len(x[0]) ** length_penalty),reverse=True)]sorted_scores = sorted(completed_scores,key=lambda score: score / (len(sorted_sequences[completed_scores.index(score)]) ** length_penalty),reverse=True)return sorted_sequences, sorted_scores
-
模型要求:
- 模型应接受形状为
[batch_size, seq_len]的输入 - 模型应输出形状为
[batch_size, seq_len, vocab_size]的logits
- 模型应接受形状为
-
参数说明:
initial_input: 初始输入序列(如开始token)beam_width: 控制搜索宽度,值越大结果可能越好但计算成本越高length_penalty: 控制生成长度的偏好(α>1鼓励更长序列,α<1鼓励更短序列)early_stopping: 设为True时,当所有beam都生成EOS token时停止
-
返回值:
- 返回按分数排序的序列列表和对应的分数列表
如何调用?
model = ... # 你的PyTorch模型
initial_input = torch.tensor([[1]]) # 假设1是开始token
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)sequences, scores = beam_search(model=model,initial_input=initial_input,beam_width=5,max_length=50,vocab_size=10000, # 你的词汇表大小device=device,length_penalty=1.2
)print("Top sequence:", sequences[0])
print("Score:", scores[0])
2 实现带KV Cache的Beam Search解码
这个是关键,之前写过一个k步的贪心解码,使用了递归写法,但不知道怎么在递归中加入kv cache,其实感觉怎么写都不太好。
其实这样看只要写循环就可以了。
实际上transformers的model.generate方法里,对greedy、beam、以及其他采样的方法都是有做 kv cache 缓存优化的:
# 首次调用(处理初始输入)
outputs = model(input_ids, use_cache=True)
logits = outputs.logits
past_key_values = outputs.past_key_values # 缓存KV# 后续步骤(生成时)
next_token_input = torch.tensor([[new_token]])
outputs = model(next_token_input, past_key_values=past_key_values, use_cache=True)
new_past_key_values = outputs.past_key_values # 更新缓存
要在Beam Search中为每个候选序列维护独立的KV Cache,我们需要对标准实现进行一些修改。KV Cache可以显著提高自回归模型的推理效率,因为它避免了重复计算先前token的key和value。
以下是带有KV Cache的Beam Search实现:
- 因为我们已经有cache了,因此实际上每步迭代生成下一个token时,只需要把当前序列的最后一个token输入即可,只是很棒的操作
import torch
import torch.nn.functional as F
from typing import List, Tuple, Optional, Dict, Anydef beam_search_with_kv_cache(model: torch.nn.Module,initial_input: torch.Tensor,beam_width: int,max_length: int,vocab_size: int,device: torch.device,length_penalty: float = 1.0,early_stopping: bool = True,use_kv_cache: bool = True
) -> Tuple[List[List[int]], List[float]]:"""带KV Cache的Beam Search解码算法参数:model: 用于预测下一个token的模型initial_input: 初始输入张量 (shape: [1, seq_len])beam_width: beam大小max_length: 生成序列的最大长度vocab_size: 词汇表大小device: 使用的设备 (cpu/cuda)length_penalty: 长度惩罚系数early_stopping: 是否在所有beam序列达到EOS时提前停止use_kv_cache: 是否使用KV Cache加速返回:Tuple[List[List[int]], List[float]]: (生成的序列列表, 对应的分数列表)"""# 初始化beamsequences = [[initial_input.tolist()[0]]]scores = [0.0]# 存储KV Cache (每个候选序列一个cache)kv_caches = [None] # 初始cache为None# 存储完整的beamcompleted_sequences = []completed_scores = []for step in range(max_length):if early_stopping and len(sequences) == 0:breakcandidates = []new_kv_caches = []for i, (seq, score, kv_cache) in enumerate(zip(sequences, scores, kv_caches)):# 跳过已经完成的序列if len(seq) > 0 and seq[-1] == 2: # 假设2是EOS tokencompleted_sequences.append(seq)completed_scores.append(score)continue# 准备输入 (只使用最后一个token,因为前面的已经cache了)input_tensor = torch.tensor([[seq[-1]]], dtype=torch.long).to(device)# 前向传播,使用或更新KV Cachewith torch.no_grad():if use_kv_cache:if kv_cache is None:# 第一次调用,处理整个初始序列full_input = torch.tensor([seq], dtype=torch.long).to(device)outputs = model(full_input, use_cache=True)next_token_logits = outputs.logits[:, -1, :]new_kv_cache = outputs.past_key_valueselse:# 后续调用,使用KV Cacheoutputs = model(input_tensor, past_key_values=kv_cache, use_cache=True)next_token_logits = outputs.logits[:, -1, :]new_kv_cache = outputs.past_key_valueselse:# 不使用KV Cache的情况full_input = torch.tensor([seq], dtype=torch.long).to(device)outputs = model(full_input, use_cache=False)next_token_logits = outputs.logits[:, -1, :]new_kv_cache = Nonenext_token_probs = F.log_softmax(next_token_logits, dim=-1)# 获取top-k tokenstopk_probs, topk_tokens = torch.topk(next_token_probs, beam_width, dim=-1)topk_probs = topk_probs.squeeze(0)topk_tokens = topk_tokens.squeeze(0)# 创建候选序列for j in range(beam_width):new_seq = seq.copy()new_seq.append(topk_tokens[j].item())new_score = score + topk_probs[j].item()candidates.append((new_seq, new_score, new_kv_cache))# 如果没有候选序列,提前停止if not candidates:break# 选择top-k候选序列candidates.sort(key=lambda x: x[1] / (len(x[0]) ** length_penalty), reverse=True)top_candidates = candidates[:beam_width]# 解包候选序列sequences = [cand[0] for cand in top_candidates]scores = [cand[1] for cand in top_candidates]kv_caches = [cand[2] for cand in top_candidates]# 添加剩余的未完成序列completed_sequences.extend(sequences)completed_scores.extend(scores)# 对完成的序列按分数排序sorted_pairs = sorted(zip(completed_sequences, completed_scores),key=lambda x: x[1] / (len(x[0]) ** length_penalty),reverse=True)sorted_sequences = [pair[0] for pair in sorted_pairs]sorted_scores = [pair[1] for pair in sorted_pairs]return sorted_sequences, sorted_scores
关键修改说明
-
KV Cache维护:
- 每个候选序列现在维护自己的KV Cache
- 初始时KV Cache为None
- 第一次处理序列时生成完整的KV Cache
- 后续步骤只处理最后一个token并更新KV Cache
-
模型接口要求:
- 模型需要支持
past_key_values参数来接收先前的KV Cache - 模型需要返回
past_key_values作为输出的一部分 - 典型实现方式(如HuggingFace的transformers):
outputs = model(input_ids, past_key_values=past_key_values, use_cache=True) next_token_logits = outputs.logits past_key_values = outputs.past_key_values
- 模型需要支持
-
性能优化:
- 使用KV Cache后,每次前向传播只处理最后一个token(这个很有趣,但是要设置
use_cache=True) - 避免了重复计算先前token的key和value
- 对于长序列可以显著提高速度
- 使用KV Cache后,每次前向传播只处理最后一个token(这个很有趣,但是要设置
一个简单的调用示例:
# 假设我们有一个支持KV Cache的模型
model = ... # 例如HuggingFace的GPT2模型
initial_input = torch.tensor([[model.config.bos_token_id]]) # 开始token
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 运行带KV Cache的beam search
sequences, scores = beam_search_with_kv_cache(model=model,initial_input=initial_input,beam_width=5,max_length=50,vocab_size=model.config.vocab_size,device=device,length_penalty=1.2,use_kv_cache=True # 启用KV Cache
)print("Top sequence:", sequences[0])
print("Score:", scores[0])
补注:
在这个部分:
# 前向传播,使用或更新KV Cachewith torch.no_grad():if use_kv_cache:if kv_cache is None:# 第一次调用,处理整个初始序列full_input = torch.tensor([seq], dtype=torch.long).to(device)outputs = model(full_input, use_cache=True)
上,输出的full_input 的size是[1, 1, seqlen],理论上应该是[1, seqlen]才对,因此要么是
# 前向传播,使用或更新KV Cachewith torch.no_grad():if use_kv_cache:if kv_cache is None:# 第一次调用,处理整个初始序列full_input = torch.tensor(seq, dtype=torch.long).to(device)outputs = model(full_input, use_cache=True)
要么是:
# 前向传播,使用或更新KV Cachewith torch.no_grad():if use_kv_cache:if kv_cache is None:# 第一次调用,处理整个初始序列full_input = torch.tensor([seq], dtype=torch.long).to(device)outputs = model(full_input.squeeze(0), use_cache=True)
这样测试跑通应该是没有问题的
3 关于在带kv-cache的情况下的use_cache参数
比如之前手写的一个贪心解码算法:
# -*- coding: utf8 -*-
# @author: caoyang
# @email: caoyang@stu.sufe.edu.cnimport torch
import logging
from copy import deepcopy
from functools import wraps
from torch.nn import functional as Ffrom transformers import AutoTokenizer, AutoModelForCausalLM# Standard greedy decode
# @param model: Huggingface model object
# @param tokenizer: Huggingface tokenizer Object
# @param prompt: Str
# @param max_length: Int, the number of tokens to be generated
# @param device: Str, e.g. "cuda" or "cpu"
# @param kv_cache: Boolean, whether to use KV-cache to accelerate, if True then large memory will be consumed
# @return generated_text: Str
# @return generated_token_prob: List[Tuple(Int, Str, Float)], `len(generated_id_prob)` is `max_length`, indicating the generated probability of each token
# @return generated_logits: Tuple[FloatTensor(1, n_vocab)], `len(generated_logits)` is `max_length`, indicating the logits when each token is generated
def greedy_decode(model,tokenizer,prompt, max_length,device = "cuda",kv_cache = True,):inputs = tokenizer.encode(prompt, return_tensors="pt").to(device) # Str => Long(1, n_tokens)past_key_values = Nonegenerated_token_probs = list()generated_logits = list()model.gradient_checkpointing_enable()for i in range(max_length):logging.info(f"Round {i}: {past_key_values.key_cache[0].size() if past_key_values is not None else None}")outputs = model(inputs, past_key_values=past_key_values)logits = outputs.logits # Float(1, n_tokens + i + 1, n_vocab), where `n_vocab` is 151936 in DeepSeek-R1-Distill-Qwenif kv_cache:past_key_values = outputs.past_key_values # Dictlike[key_cache: Float(1, 2, X, hidden_size), value_cache: Float(1, 2, X, hidden_size)], where X = (i + 1) * (n_tokens + i / 2)next_token_probs = F.softmax(logits[:, -1, :], dim=-1) # Float(1, n_tokens + i + 1, n_vocab) => Float(1, n_vocab)next_token_id = torch.argmax(next_token_probs, dim=-1) # Float(1, n_vocab) => Long(1, )next_token_prob = next_token_probs[0, next_token_id].item() # Float(1, n_vocab) => Float()next_token = tokenizer.decode(next_token_id[0].item(), skip_special_tokens=False) # Long(1, ) => Strinputs = torch.cat([inputs, next_token_id.unsqueeze(-1)], dim=-1) # Long(1, n_tokens + i) => Long(1, n_tokens + i + 1)generated_token_probs.append((next_token_id.item(), next_token, next_token_prob))generated_logits.append(logits[:, -1, :])generated_text = tokenizer.decode(token_ids = inputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True,) # Long(1, n_tokens + max_length) => Strreturn generated_text, generated_token_probs, tuple(generated_logits)
实际上除了第一次输入外,接下来都可以用最后一个token作为输入,而不需要把之前整个一长串的input都输入到model中去:
# -*- coding: utf8 -*-
# @author: caoyang
# @email: caoyang@stu.sufe.edu.cnimport torch
import logging
from copy import deepcopy
from functools import wraps
from torch.nn import functional as Ffrom transformers import AutoTokenizer, AutoModelForCausalLM# Standard greedy decode
# @param model: Huggingface model object
# @param tokenizer: Huggingface tokenizer Object
# @param prompt: Str
# @param max_length: Int, the number of tokens to be generated
# @param device: Str, e.g. "cuda" or "cpu"
# @param kv_cache: Boolean, whether to use KV-cache to accelerate, if True then large memory will be consumed
# @return generated_text: Str
# @return generated_token_prob: List[Tuple(Int, Str, Float)], `len(generated_id_prob)` is `max_length`, indicating the generated probability of each token
# @return generated_logits: Tuple[FloatTensor(1, n_vocab)], `len(generated_logits)` is `max_length`, indicating the logits when each token is generated
def greedy_decode(model,tokenizer,prompt, max_length,device = "cuda",kv_cache = True,):inputs = tokenizer.encode(prompt, return_tensors="pt").to(device) # Str => Long(1, n_tokens)past_key_values = Nonegenerated_token_probs = list()generated_logits = list()model.gradient_checkpointing_enable()for i in range(max_length):logging.info(f"Round {i}: {past_key_values.key_cache[0].size() if past_key_values is not None else None}")if kv_cache:if i == 0:outputs = model(inputs, past_key_values=past_key_values)else:outputs = model(inputs[:, -1].unsqueeze(0), past_key_values=past_key_values, use_cache=True)else:outputs = model(inputs, past_key_values=None)logits = outputs.logits # Float(1, n_tokens + i + 1, n_vocab), where `n_vocab` is 151936 in DeepSeek-R1-Distill-Qwenif kv_cache:past_key_values = outputs.past_key_values # Dictlike[key_cache: Float(1, 2, X, hidden_size), value_cache: Float(1, 2, X, hidden_size)], where X = (i + 1) * (n_tokens + i / 2)next_token_probs = F.softmax(logits[:, -1, :], dim=-1) # Float(1, n_tokens + i + 1, n_vocab) => Float(1, n_vocab)next_token_id = torch.argmax(next_token_probs, dim=-1) # Float(1, n_vocab) => Long(1, )next_token_prob = next_token_probs[0, next_token_id].item() # Float(1, n_vocab) => Float()next_token = tokenizer.decode(next_token_id[0].item(), skip_special_tokens=False) # Long(1, ) => Strinputs = torch.cat([inputs, next_token_id.unsqueeze(-1)], dim=-1) # Long(1, n_tokens + i) => Long(1, n_tokens + i + 1)generated_token_probs.append((next_token_id.item(), next_token, next_token_prob))generated_logits.append(logits[:, -1, :])generated_text = tokenizer.decode(token_ids = inputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True,) # Long(1, n_tokens + max_length) => Strreturn generated_text, generated_token_probs, tuple(generated_logits)
这个确实是很有帮助的,能加速推理很多。这个原理其实很简单,因为只需要KVcache与最后一个token就可以计算得到下一层的注意力权重(其实就是下一轮生成的KVcache),然后倒是发现deepseek在生成图像链接时出错了,难得逮到DeepSeek犯错的时候:
相关文章:
【速写】KV-cache与解码的再探讨(以束搜索实现为例)
文章目录 1 Beam Search 解码算法实现2 实现带KV Cache的Beam Search解码3 关于在带kv-cache的情况下的use_cache参数 1 Beam Search 解码算法实现 下面是一个使用PyTorch实现的beam search解码算法: 几个小细节: 束搜索可以加入length_penalty&#…...
(网络)应用层协议-HTTPS
1.HTTPS是什么? HTTPS是应用层的一种协议,是在HTTP的基础上进行了加密层的处理。 HTTP协议的内容都是按照文本的形式进行传输的,所以呢就很容易被别人知道传输的是什么。 我们在了解了TCP/IP之后是知道我们的数据在传输的过程中是通过路由器进…...

vue3: pdf.js 3.4.120 using javascript
npm install pdfjs-dist3.4.120 项目结构: pdfjsViewer.vue <template><div><div v-if"loading" class"flex justify-center items-center py-8"><div class"animate-spin rounded-full h-12 w-12 border-b-2 borde…...

Spark目前支持的部署模式。
一、本地模式(Local Mode) 特点: 在单台机器上运行,无需集群。主要用于开发、测试和调试。所有组件(Driver、Executor)在同一个 JVM 中运行。 启动命令: bash spark-submit --master local[*]…...
想实现一个基于MCP的pptx生成系统架构图【初版实现】
技术栈:Python + MCP协议 + python-pptx + FastMCP 核心创新点:通过MCP协议实现PPTX元素的动态化生成与标准化模板管理 当前还是个半成品,后续持续更新。 主要先介绍一下思路。 一、MCP协议与系统设计原理 1.1 为什么选择MCP? 标准化工具调用:通过MCP将PPTX元素生成逻辑封…...
PyTorch Lightning实战 - 训练 MNIST 数据集
MNIST with PyTorch Lightning 利用 PyTorch Lightning 训练 MNIST 数据。验证梯度范数、学习率、优化器对训练的影响。 pip show lightning Version: 2.5.1.post0Fast dev run DATASET_DIR"/repos/datasets" python mnist_pl.py --output_grad_norm --fast_dev_run…...
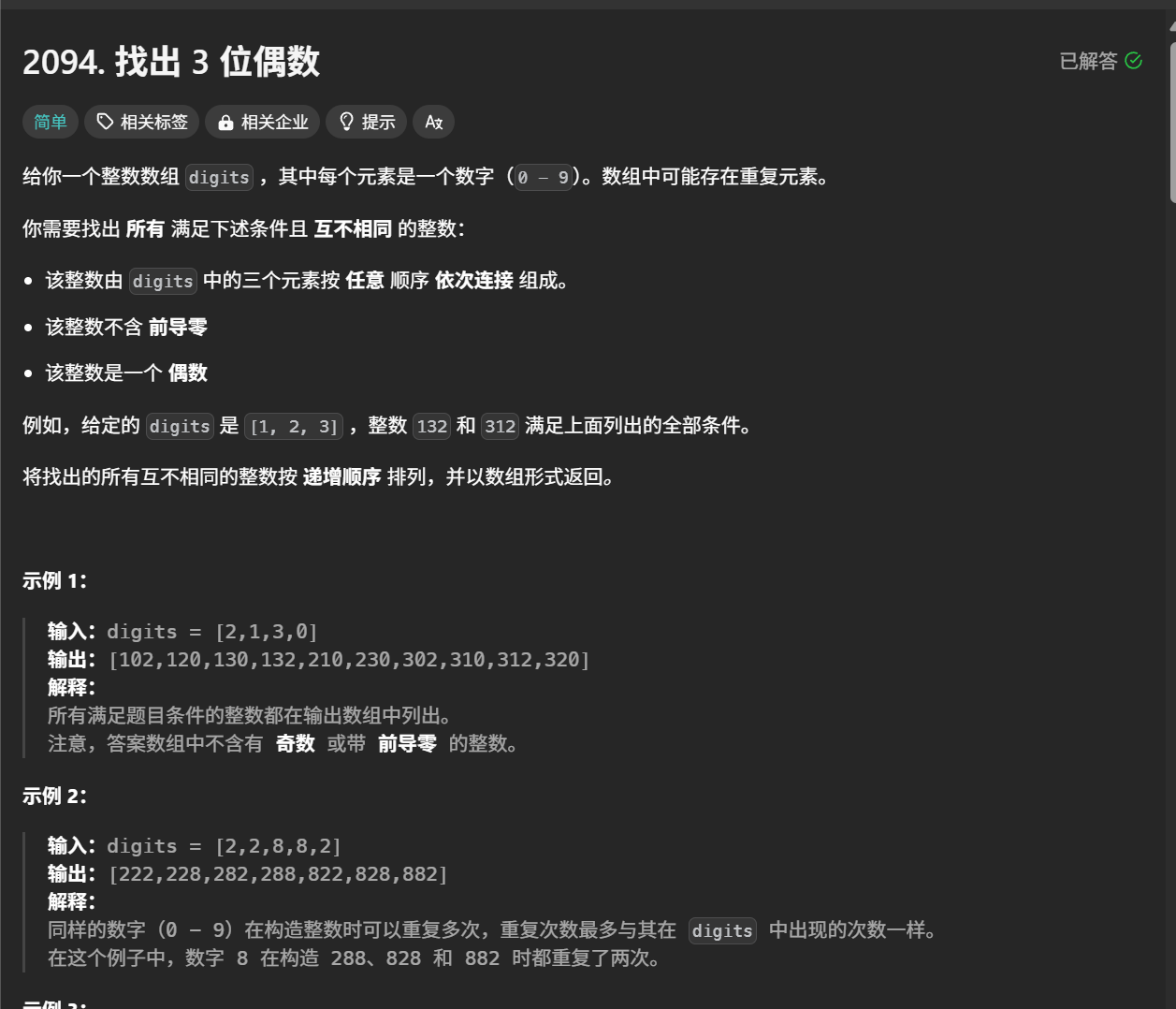
力扣2094题解
记录: 2025.5.12 题目: 思路: 暴力遍历。 解题步骤: 1.统计数字出现次数:使用数组cnt来记录输入数组中每个数字的出现次数。 2.生成三位偶数:通过循环从100开始,每次递增2,生成…...
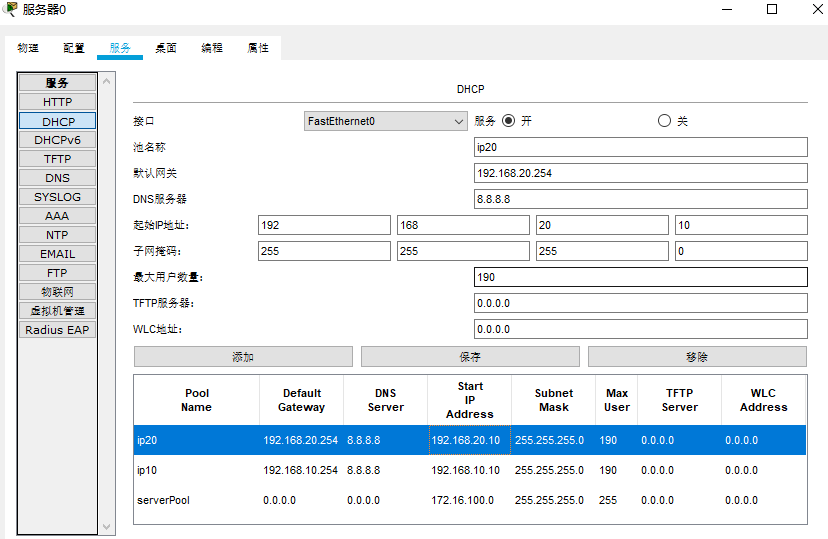
DHCP自动分配IP
DHCP自动分配IP 练习1 路由器 Router>en Router#conf t Router(config)#ip dhcp pool ip10 //创建DHCP地址池 Router(dhcp-config)#network 192.168.20.0 255.255.255.0 // 配置网络地址和子网掩码 Router(dhcp-config)#default-router 192.168.20.254 //配置默认网关 Rou…...
【CF】Day57——Codeforces Round 955 (Div. 2, with prizes from NEAR!) BCD
B. Collatz Conjecture 题目: 思路: 简单模拟 很简单的模拟,我们只需要快速的找到下一个离 x 最近的 y 的倍数即可(要大于 x) 这里我们可以这样写 add y - (x % y),这样就知道如果 x 要变成 y 的倍数还要…...
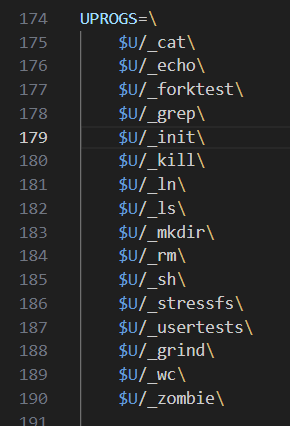
(done) 补充:xv6 的一个用户程序 init 是怎么启动的 ?它如何启动第一个 bash ?
先看 main.c 从函数名来看,比较相关的就 userinit() 和 scheduler() #include "types.h" #include "param.h" #include "memlayout.h" #include "riscv.h" #include "defs.h"volatile static int started 0;//…...

Nginx部署前端项目深度解析
在部署Vue前端项目时,Nginx的高效配置直接影响用户体验和性能表现。以下从7个关键维度深度解析部署方案,并提供专业级配置策略: 一、项目构建与基础部署 生产构建 npm run build -- --modern # 现代模式构建生成dist/目录包含:…...

超详细讲解C语言转义字符\a \b \r \t \? \n等等
转义字符 C语言有一组字符很特殊,叫做转义字符,顾名思义,改变原来的意思的字符。 1 \? ??)是一个三字母词,在以前的编译器它会被编译为] (??会被编译为[ 因此在以前输入(are you ok ??)就会被编译为are you ok ] 解决这个…...
SpringBoot校园失物招领信息平台
SpringBoot校园失物招领信息平台 文章目录 SpringBoot校园失物招领信息平台1、技术栈2、项目说明2.1、登录注册2.2、管理员端截图2.3、用户端截图 3、核心代码实现3.1、前端首页3.2、前端招领广场3.3、后端业务处理 1、技术栈 本项目采用前后端分离的架构,前端和后…...

【Qt/C++】深入理解 Lambda 表达式与 `mutable` 关键字的使用
【Qt/C】深入理解 Lambda 表达式与 mutable 关键字的使用 在 Qt 开发中,我们常常会用到 lambda 表达式来编写简洁的槽函数。今天通过一个实际代码示例,详细讲解 lambda 的语法、变量捕获方式,特别是 mutable 的作用。 示例代码 QPushButto…...

扩展:React 项目执行 yarn eject 后的 package.json 变化详解及参数解析
扩展:React 项目执行 yarn eject 后的 package.json 变化详解及参数解析 什么是 yarn eject?React 项目执行 yarn eject 后的 package.json 变化详解1. 脚本部分 Scripts 被替换2. 新增构建依赖 dependencies(部分)3. 新增 Babel …...

slackel系统详解
Slackel 是一个基于 Slackware Linux 和 Salix OS(另一个 Slackware 衍生版)的轻量级 Linux 发行版,主要面向桌面用户。它由希腊开发者 Dimitris Tzemos 创建,目标是结合 Slackware 的稳定性与用户友好的工具,同时优化…...
rust 全栈应用框架dioxus server
接上一篇文章dioxus全栈应用框架的基本使用,支持web、desktop、mobile等平台。 可以先查看上一篇文章rust 全栈应用框架dioxus👈 既然是全栈框架,那肯定是得有后端服务的,之前创建的服务没有包含后端服务包,我们修改…...

CSS Layer 详解
CSS Layer 详解 前言 最近在整理CSS知识体系时,发现Layer这个特性特别有意思。它就像是给样式规则提供了一个专属的「VIP通道」,让我们能更优雅地解决样式冲突问题。今天我就用最通俗的语言,带大家全面了解这个CSS新特性。 什么是CSS Laye…...
西安交大多校联训NOIP1模拟赛题解
西安交大多校联训NOIP1模拟赛题解 T1 秘境形式化题意思路代码(丑陋) T2 礼物形式化题意思路代码(实现) T3 小盒子的数论形式化题意思路代码(分讨) T4 猫猫贴贴(CF997E)形式化题意思路代码(深奥&…...

数据结构(三)——栈和队列
一、栈和队列的定义和特点 栈:受约束的线性表,只允许栈顶元素入栈和出栈 对栈来说,表尾端称为栈顶,表头端称为栈底,不含元素的空表称为空栈 先进后出,后进先出 队列:受约束的线性表࿰…...
若依定制pdf生成实战
一、介绍 使用 Java Apache POI 将文字渲染到 Word 模板是一种常见的文档自动化技术,广泛应用于批量生成或定制 Word 文档的场景。使用aspose可以将word转成pdf从而达到定制化pdf的目的。 参考文档:java实现Word转Pdf(Windows、Linux通用&a…...

RCE联系
过滤 绕过空格 ● 进制绕过 题目练习 数字rce 使用$0执行bash,<<<将后面的字符串传递给左边的命令。 例如: <?php highlight_file(__FILE__); function waf($cmd) { $whiteList [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, \\, \, $, <]; $cmd_ch…...
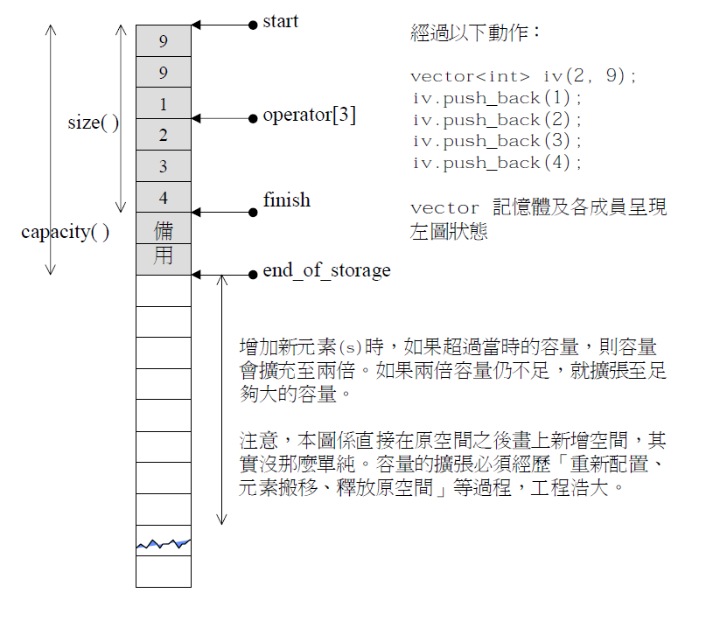
c++STL-vector的模拟实现
cSTL-vector的模拟实现 vector的模拟实现基本信息构造函数析构函数返回容量(capacity)返回元素个数(size)扩容(reserve和resize)访问([])迭代器(**iterator**)…...

C++核心编程解析:模板、容器与异常处理全指南
文章目录 一、模板1.1 定义1.2 作用1.3 函数模版1.3.1 格式 1.4 类模版1.4.1 格式1.4.2 代码示例1.4.3 特性 二、容器2.1 概念2.2 容器特性2.3 分类2.4 向量vector2.4.1 特性2.4.2 初始化与操作2.4.3 插入删除 2.5 迭代器2.6 列表(list)2.6.1 遍历方式2.…...
在 Elasticsearch 中连接两个索引
作者:来自 Elastic Kofi Bartlett 解释如何使用 terms query 和 enrich processor 来连接 Elasticsearch 中的两个索引。 更多有关连接两个索引的查询,请参阅文章 “Elastic:开发者上手指南” 中的 “丰富数据及 lookup” 章节。 Elasticsea…...
:打包压缩、文本编辑与查找命令)
Linux常用命令详解(下):打包压缩、文本编辑与查找命令
一、打包压缩命令 在Linux系统中,打包与压缩是文件管理的核心操作之一。不同的工具适用于不同场景,以下是最常用的命令详解: 1. tar命令 作用:对文件进行打包、解包、压缩、解压。 语法: tar [选项] [压缩包名] […...
使用 Watt toolkit 加速 git clone
一、前言 Watt toolkit 工具是我经常用于加速 GitHub 网页和 Steam 游戏商店访问的工具,最近想加速 git clone,发现可以使用 Watt toolkit 工具的代理实现。 二、查看端口 我这里以 Ubuntu 为例,首先是需要将加速模式设置为 System࿱…...
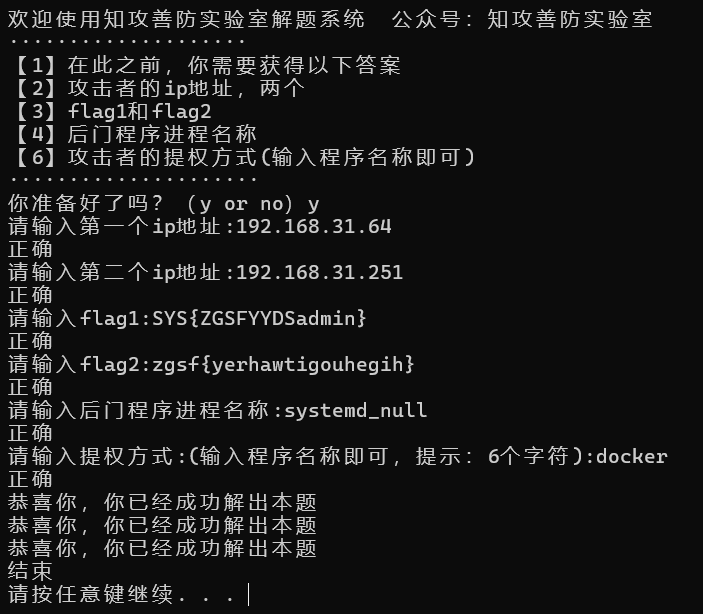
应急响应靶机——WhereIS?
用户名及密码:zgsf/zgsf 下载资源还有个解题.exe: 1、攻击者的两个ip地址 2、flag1和flag2 3、后门程序进程名称 4、攻击者的提权方式(输入程序名称即可) 之前的命令: 1、攻击者的两个ip地址 先获得root权限,查看一下历史命令记录&#x…...
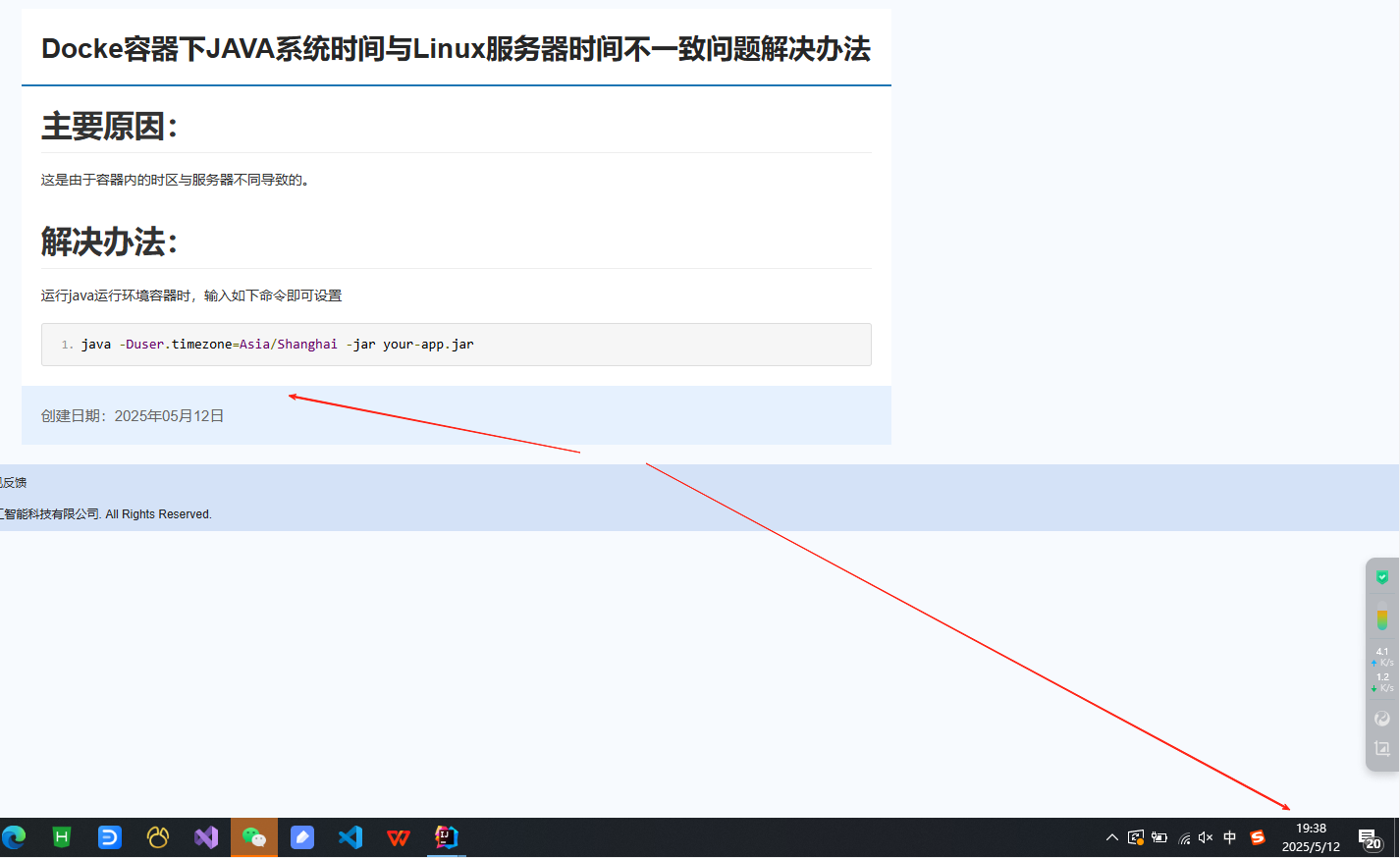
Docke容器下JAVA系统时间与Linux服务器时间不一致问题解决办法
本篇文章主要讲解,通过docker部署jar包运行环境后出现java系统内时间与服务器、个人电脑真实时间不一致的问题原因及解决办法。 作者:任聪聪 日期:2025年5月12日 问题现象: 说明:与实际时间不符,同时与服务…...
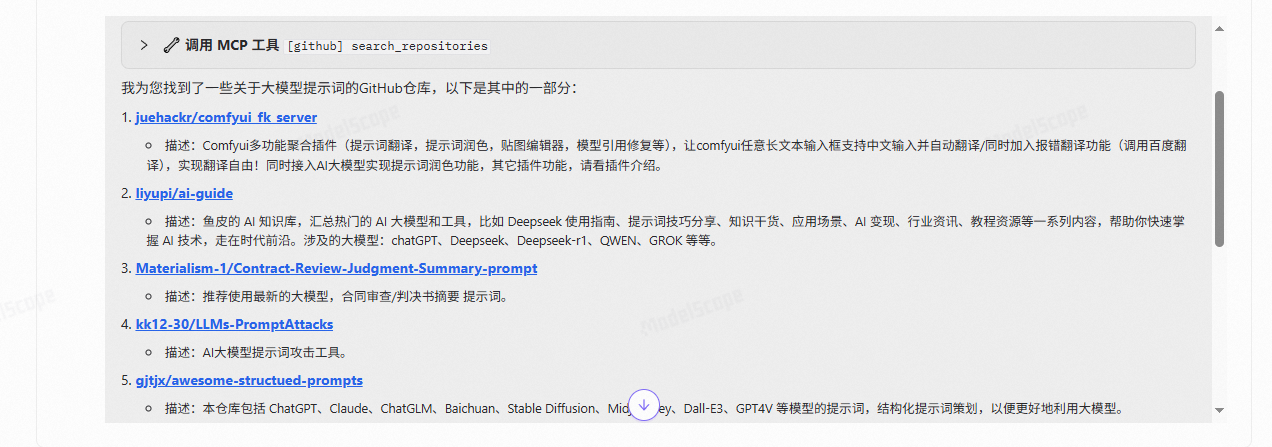
【MCP】其他MCP服务((GitHub)
【MCP】其他MCP服务((GitHub) 1、其他MCP服务(GitHub) MCP广场:https://www.modelscope.cn/mcp 1、其他MCP服务(GitHub) 打开MCP广场 找到github服务 访问github生成令牌 先…...