【se-res模块学习】结合CIFAR-10分类任务学习
继CIFAR-10图像分类:【Res残差连接学习】结合CIFAR-10任务学习-CSDN博客 再优化
本次训练结果在测试集上的准确率表现可达到90%以上
1.训练模型(MyModel.py)
import torch
import torch.nn as nnclass SENet(nn.Module): # SE-Net模块def __init__(self, channel, reduction=16): # 默认r为16super(SENet, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1) # 平均池化层,输出大小1*1self.fc = nn.Sequential(nn.Linear(channel * 2, channel // reduction), # 输入通道数加倍nn.ReLU(),nn.Linear(channel // reduction, channel),nn.Sigmoid(), # 将通道权重输出为0-1)def forward(self, x, previous_features=None):b, c, _, _ = x.size()y_current = self.avg_pool(x).view(b, c) # 当前层的全局平均池化# 将当前特征向量与之前特征向量拼接if previous_features is not None:y_previous = self.avg_pool(previous_features).view(b, c) # 之前特征的全局平均池化y = torch.cat([y_current, y_previous], dim=1) # 拼接else:y = y_current # 如果没有之前的特征,只使用当前特征y = self.fc(y).view(b, c, 1, 1) # 计算通道权重return x * y.expand_as(x) # 对应元素进行逐一相乘class BasicRes(nn.Module):def __init__(self, in_cha, out_cha, stride=1, res=True):super(BasicRes, self).__init__()self.conv01 = nn.Sequential(nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=3, stride=stride, padding=1),nn.BatchNorm2d(out_cha),nn.ReLU(),)self.conv02 = nn.Sequential(nn.Conv2d(in_channels=out_cha, out_channels=out_cha, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(out_cha),)self.se = SENet(out_cha)if res:self.res = resif in_cha != out_cha or stride != 1: # 若x和f(x)维度不匹配:self.shortcut = nn.Sequential(nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=1, stride=stride),nn.BatchNorm2d(out_cha),)else:self.shortcut = nn.Sequential()def forward(self, x):residual = xx = self.conv01(x)features = xx = self.conv02(x)x = self.se(x=x, previous_features=features) # 传递前层的特征图if self.res:x += self.shortcut(residual)return x# 2.训练模型
class cifar10(nn.Module):def __init__(self):super(cifar10, self).__init__()# 初始维度3*32*32self.Stem = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(64),nn.ReLU(),)self.layer01 = BasicRes(in_cha=64, out_cha=64)self.layer02 = BasicRes(in_cha=64, out_cha=64)self.layer11 = BasicRes(in_cha=64, out_cha=128)self.layer12 = BasicRes(in_cha=128, out_cha=128)self.layer21 = BasicRes(in_cha=128, out_cha=256)self.layer22 = BasicRes(in_cha=256, out_cha=256)self.layer31 = BasicRes(in_cha=256, out_cha=512)self.layer32 = BasicRes(in_cha=512, out_cha=512)self.pool_max = nn.MaxPool2d(2)self.pool_avg = nn.AdaptiveAvgPool2d((1, 1)) # b*c*1*1self.fc = nn.Sequential(nn.Dropout(0.4),nn.Linear(512, 128),nn.ReLU(),nn.Linear(128, 10),)def forward(self, x):x = self.Stem(x)x = self.layer01(x)x = self.layer02(x)x = self.pool_max(x)x = self.layer11(x)x = self.layer12(x)x = self.pool_max(x)x = self.layer21(x)x = self.layer22(x)x = self.pool_max(x)x = self.layer31(x)x = self.layer32(x)x = self.pool_max(x)x = self.pool_avg(x).view(x.size()[0], -1)x = self.fc(x)return x
本训练模型结合了 SE 模块和残差学习思想,并且适当修改了SE模块的输入层以更好地捕捉图像中重要的特征。
SENet类:Squeeze-and-Excitation(SE)模块,通过全局平均池化来获取特征图的全局信息,然后通过一系列全连接层生成一个通道权重向量,这部分适当修改了SE模块的输入层可做参考;
BasicRes类:基本残差块实现了一个带有 SE 模块的残差连接,使用两个卷积层用于提取特征,第二个卷积层的输出与第一层特征的输出都传入 SE 模块,用于计算通道权重,从而增强网络对特征的选择性;
cifar10类(主网络结构):
1. Stem(干茎部分):由卷积层、批归一化层和 ReLU 激活组成,负责特征的初步提取,输入是大小为 3x32x32 的图像,输出是 64 个通道。
2. 多个 BasicRes 块:这些块逐层堆叠形成一个深度网络,具体分为三组:第一组:两个BasicRes块(64 通道),后接最大池化层;第二组:两个 BasicRes 块(128 通道),后接最大池化层;第三组:两个 BasicRes 块(256 通道),后接最大池化层;第四组:两个 BasicRes 块(512 通道),后接最大池化层。
3. 全局平均池化和全连接层:最后的特征图经过 Adaptive Avg Pooling 调整为 1x1 的大小,然后展平为一维向量,送入全连接层进行最终分类。
2.训练函数
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
import time
from MyModel import cifar10def train_val(train_loader, val_loader, device, model, loss, optimizer, epochs, save_path, scheduler): # 正式训练函数model = model.to(device)plt_train_loss = [] # 训练过程loss值,存储每轮训练的均值plt_train_acc = [] # 训练过程acc值plt_val_loss = [] # 验证过程plt_val_acc = []max_acc = 0 # 以最大准确率来确定训练过程的最优模型for epoch in range(epochs): # 开始训练train_loss = 0.0train_acc = 0.0val_acc = 0.0val_loss = 0.0start_time = time.time()model.train()for index, (images, labels) in enumerate(train_loader):images, labels = images.to(device), labels.to(device)optimizer.zero_grad() # 梯度置0pred = model(images)bat_loss = loss(pred, labels) # CrossEntropyLoss会对输入进行一次softmaxbat_loss.backward() # 回传梯度optimizer.step() # 更新模型参数train_loss += bat_loss.item()# 注意此时的pred结果为64*10的张量pred = pred.argmax(dim=1)train_acc += (pred == labels).sum().item()print("当前为第{}轮训练,批次为{}/{},该批次总loss:{} | 正确acc数量:{}".format(epoch+1, index+1, len(train_data)//config["batch_size"],bat_loss.item(), (pred == labels).sum().item()))# 计算当前Epoch的训练损失和准确率,并存储到对应列表中:plt_train_loss.append(train_loss / train_loader.dataset.__len__())plt_train_acc.append(train_acc / train_loader.dataset.__len__())model.eval() # 模型调为验证模式with torch.no_grad(): # 验证过程不需要梯度回传,无需追踪gradfor index, (images, labels) in enumerate(val_loader):images, labels = images.cuda(), labels.cuda()pred = model(images)bat_loss = loss(pred, labels) # 算交叉熵lossval_loss += bat_loss.item()pred = pred.argmax(dim=1)val_acc += (pred == labels).sum().item()print("当前为第{}轮验证,批次为{}/{},该批次总loss:{} | 正确acc数量:{}".format(epoch+1, index+1, len(val_data)//config["batch_size"],bat_loss.item(), (pred == labels).sum().item()))val_acc = val_acc / val_loader.dataset.__len__()if val_acc > max_acc:max_acc = val_acctorch.save(model, save_path)plt_val_loss.append(val_loss / val_loader.dataset.__len__())plt_val_acc.append(val_acc)print('该轮训练结束,训练结果如下[%03d/%03d] %2.2fsec(s) TrainAcc:%3.6f TrainLoss:%3.6f | valAcc:%3.6f valLoss:%3.6f \n\n'% (epoch+1, epochs, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1]))scheduler.step() # 更新学习率print(f'训练结束,最佳模型的准确率为{max_acc}')plt.plot(plt_train_loss) # 画图plt.plot(plt_val_loss)plt.title('loss')plt.legend(['train', 'val'])plt.show()plt.plot(plt_train_acc)plt.plot(plt_val_acc)plt.title('Accuracy')plt.legend(['train', 'val'])# plt.savefig('./acc.png')plt.show()将真正的训练过程封装为上述函数。
训练模式中使用“训练模型”获取预估值,根据loss和梯度回传不断优化模型内参数,且保存训练过程的loss值。
验证模式无需梯度回传,设置为验证模式以保证模型验证过程的数据完整性,记录验证过程的模型loss值。
最后将整个训练过程和验证过程的loss值和acc值进行可视化展现。
3.训练过程
total_start = time.time()# 1.数据预处理
transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 以 50% 的概率随机翻转输入的图像,增强模型的泛化能力transforms.RandomCrop(size=(32, 32), padding=4), # 随机裁剪transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像张量进行归一化
]) # 数据增强
ori_data = dataset.CIFAR10(root="./Data_CIFAR10",train=True,transform=transform,download=True
)
print(f"各标签的真实含义:{ori_data.class_to_idx}\n")
# print(len(ori_data))
# # 查看某一样本数据
# image, label = ori_data[0]
# print(f"Image shape: {image.shape}, Label: {label}")
# image = image.permute(1, 2, 0).numpy()
# plt.imshow(image)
# plt.title(f'Label: {label}')
# plt.show()config = {"train_size_perc": 0.8,"batch_size": 64,"learning_rate": 0.001,"epochs": 60,"lr_decay_step": 20,"lr_decay_gamma": 0.2, # 衰减系数"save_path": "model_save/NewSe60_0.2_model.pth"
}# 设置训练集和验证集的比例
train_size = int(config["train_size_perc"] * len(ori_data)) # 80%用于训练
val_size = len(ori_data) - train_size # 20%用于验证
train_data, val_data = random_split(ori_data, [train_size, val_size])
# print(len(train_data))
# print(len(val_data))train_loader = DataLoader(dataset=train_data, batch_size=config["batch_size"], shuffle=True)
val_loader = DataLoader(dataset=val_data, batch_size=config["batch_size"], shuffle=False)device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")
model = cifar10()
# model = torch.load(config["save_path"]).to(device)
print(f"我的模型框架如下:\n{model}")
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=config["learning_rate"], weight_decay=1e-3) # L2正则化
# optimizer = torch.optim.Adam(model.parameters(), lr=config["learning_rate"]) # 优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=config["lr_decay_step"], gamma=config["lr_decay_gamma"]) # 创建学习率调度器train_val(train_loader, val_loader, device, model, loss, optimizer, config["epochs"], config["save_path"], scheduler)print(f"\n本次训练总耗时为:{(time.time()-total_start) / 60 }min")整个训练过程如上。
数据预处理部分:通过 随机水平翻转、随机裁剪、归一化 实现数据增强;
学习率衰减与优化器选择:使用(AdamW)来更新模型参数减小损失,期间引入L2正则化(weight_decay=1e-3可自行调整);使用 StepLR 学习率调度器,每过一定的训练步数(step_size=20),学习率会下降一个特定的比例(gamma=0.2),有助于动态调整学习率,以提高模型的收敛速度和性能。
4.测试文件
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import time
from MyModel import BasicRes, cifar10total_start = time.time()
# 测试函数
def test(save_path, test_loader, device, loss): # 测试函数best_model = torch.load(save_path).to(device)test_loss = 0.0test_acc = 0.0start_time = time.time()with torch.no_grad():for index, (images, labels) in enumerate(test_loader):images, labels = images.cuda(), labels.cuda()pred = best_model(images)bat_loss = loss(pred, labels) # 算交叉熵losstest_loss += bat_loss.item()pred = pred.argmax(dim=1)test_acc += (pred == labels).sum().item()print("正在最终测试:批次为{}/{},该批次总loss:{} | 正确acc数量:{}".format(index + 1, len(test_data) // config["batch_size"],bat_loss.item(), (pred == labels).sum().item()))print('最终测试结束,测试结果如下:%2.2fsec(s) TestAcc:%.2f%% TestLoss:%.2f \n\n'% (time.time() - start_time, test_acc/test_loader.dataset.__len__()*100, test_loss/test_loader.dataset.__len__()))# 1.数据预处理
transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 以 50% 的概率随机翻转输入的图像,增强模型的泛化能力transforms.RandomCrop(size=(32, 32), padding=4), # 随机裁剪transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像张量进行归一化
]) # 数据增强
test_data = dataset.CIFAR10(root="./Data_CIFAR10",train=False,transform=transform,download=True
)
# print(len(test_data)) # torch.Size([3, 32, 32])
config = {"batch_size": 64,"save_path": "model_save/NewSe60_0.2_model.pth"
}
test_loader = DataLoader(dataset=test_data, batch_size=config["batch_size"], shuffle=True)
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")test(config["save_path"], test_loader, device, loss)print(f"\n本次训练总耗时为:{time.time()-total_start}sec(s)")通过训练过程保存的最优loss结果模型,对测试数据进行检测模型表现,测试过程无需梯度回传。
5.结果展示
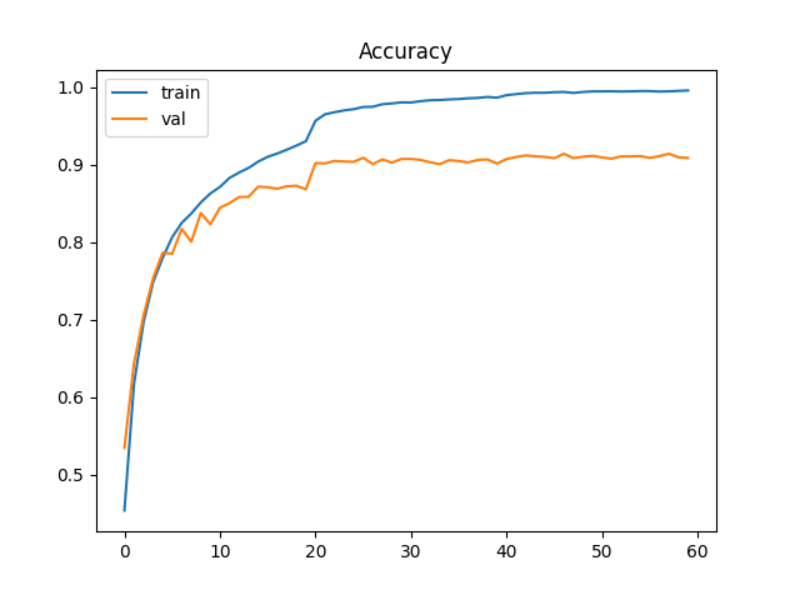
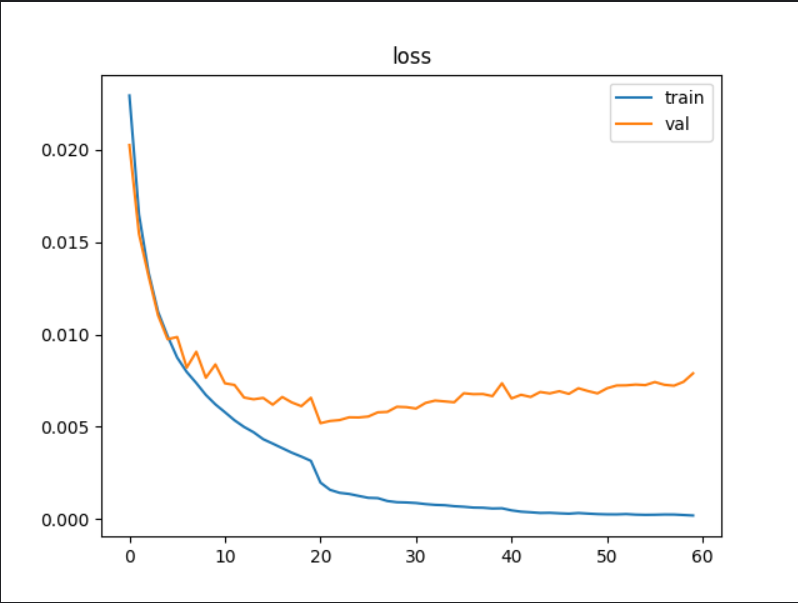
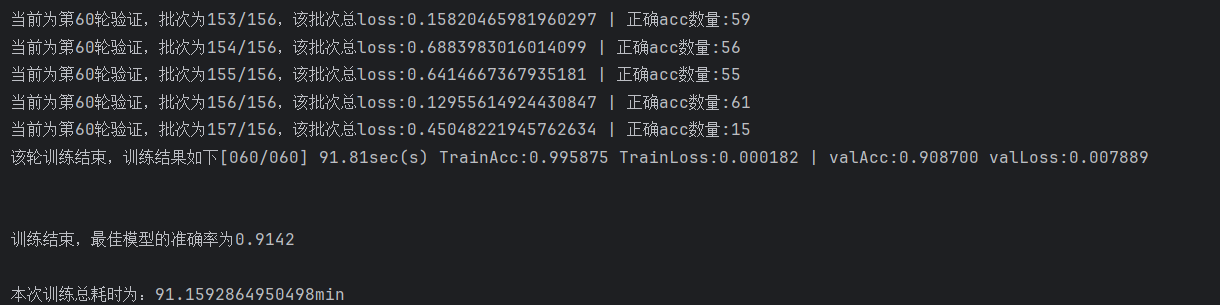
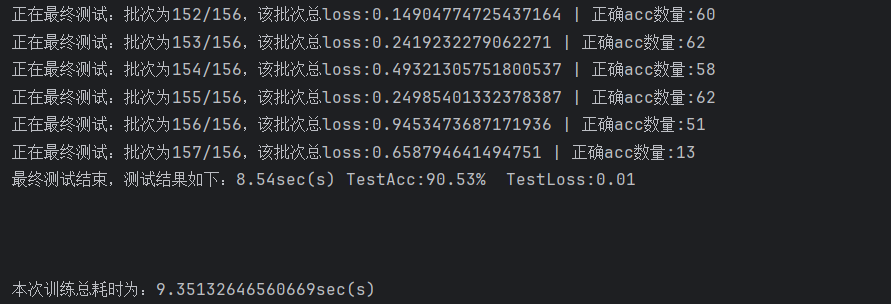
最优模型在验证集上的准确率为91.42%,在测试集上准确率表现有90.53%。
相关文章:
【se-res模块学习】结合CIFAR-10分类任务学习
继CIFAR-10图像分类:【Res残差连接学习】结合CIFAR-10任务学习-CSDN博客 再优化 本次训练结果在测试集上的准确率表现可达到90%以上 1.训练模型(MyModel.py) import torch import torch.nn as nnclass SENet(nn.Module): # SE-Net模块def…...

【C++设计模式之Template Method Pattern】
C设计模式之Template Method Pattern 模式定义核心思想动机(Motivation)结构(Structure)实现步骤应用场景要点总结 模式定义 模式定义: 定义一个操作中的算法的骨架(稳定),而将一些步骤延迟(变化)到子类中。Template Method使得子…...

JVM对象头中的锁信息机制详解
JVM对象头中的锁信息机制详解 Java中的对象锁机制是高性能并发的基石,而这一切的底层实现都离不开对象头中的 Mark Word 字段。本文将系统梳理JVM对象头中锁信息的存储与演化机制,解析锁升级与批量重偏向优化原理,并通过JOL工具实战验证对象…...

Java设计模式之适配器模式:从入门到精通
适配器模式(Adapter Pattern)是Java中最常用的结构型设计模式之一,它像一座桥梁连接两个不兼容的接口,使得原本由于接口不兼容而不能一起工作的类可以协同工作。本文将全面深入地解析适配器模式,从基础概念到高级应用,包含丰富的代码示例、详细注释、使用场景分析以及多维对…...

英伟达Blackwell架构重构未来:AI算力革命背后的技术逻辑与产业变革
——从芯片暴力美学到分布式智能体网络,解析英伟达如何定义AI基础设施新范式 开篇:当算力成为“新石油”,英伟达的“炼油厂”如何升级? 2025年3月,英伟达GTC大会上,黄仁勋身披标志性皮衣,宣布了…...
)
【自定义指令】(el-table表格内容自动轮播)
// el-table 自动轮播 import { nextTick } from vue; export default {bind(el, binding) {const time binding.value?.time || 100;let speed binding.value?.speed || 1;const loop binding.value?.loop || true;const timeLoop binding.value?.timeLoop || true;co…...

深度拆解!MES如何重构生产计划与排产调度全流程?
☂引言 在制造业数字化转型浪潮中,生产计划与排产调度的精准性直接决定企业竞争力。深蓝易网MES系统通过智能化调度与全流程管控,帮助企业破解排产难题,实现资源高效协同与生产透明化管理,为制造企业打造柔性化、敏捷化的生产体系…...
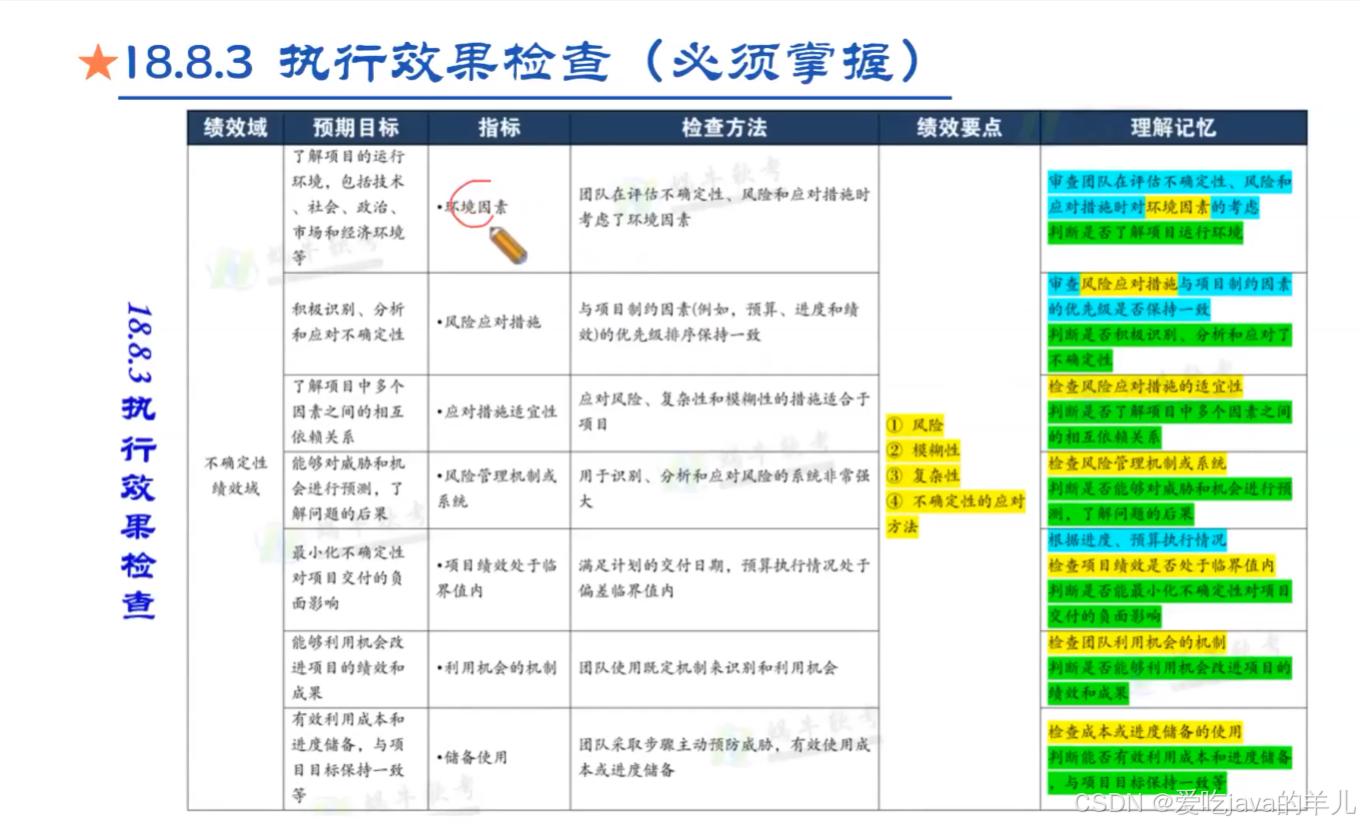
信息系统项目管理师-软考高级(软考高项)2025最新(十八)
个人笔记整理---仅供参考 第十八章项目绩效域 18.1干系人绩效域 18.2团队绩效域 18.3开发方法和生命周期绩效域 18.5项目工作绩效域 18.6交付绩效域 18.7度量绩效域 18.8不确定绩效域...

UniDevTools - UniApp(前端app)调试工具使用
使用介绍 | UniDevTools 兼容框架: Vue2jsvuexVue3tsvuex(pinia)√√ 兼容平台: H5APP微信小程序APP-NVUE其他小程序UniAppX√√√√(大部分功能支持)未测试 (待办中) 下载安装 将下载好的源码解压至项目根目录,文件夹命名为 devTools …...

WebRTC工作原理详细介绍、WebRTC信令交互过程和WebRTC流媒体传输协议介绍
简介 WebRTC(Web Real-Time Communication)是一项允许在网页浏览器之间进行音视频通信的技术,基本不需要安装额外的插件。它的核心特点是支持低延迟的点对点(P2P)通讯,常用于视频聊天、实时文件共享、多人…...

Docker快速入门与应用
1. 什么是 Docker? Docker 就像一个“魔法箱子”,可以把你开发的应用(代码、环境、配置)打包成一个标准化的容器,这个容器可以在任何支持 Docker 的系统上运行,无需担心环境差异导致的问题。 类比…...

Spring Boot 启动原理的核心机制
一、核心启动流程概览 Spring Boot 的启动流程可概括为 7 个关键阶段: 1. 加载启动类 (Main Class) 2. 初始化 SpringApplication 实例 3. 加载配置 & 准备环境 (Environment) 4. 创建 ApplicationContext(容器) 5. 刷新容器&#…...

spring中的@Lazy注解详解
一、核心功能与作用 Lazy 注解是 Spring 框架中用于延迟 Bean 初始化的核心工具,通过将 Bean 的创建推迟到首次使用时,优化资源利用和启动性能。其核心功能包括: 延迟初始化 默认情况下,Spring 在容器启动时立即初始化所有单例 …...
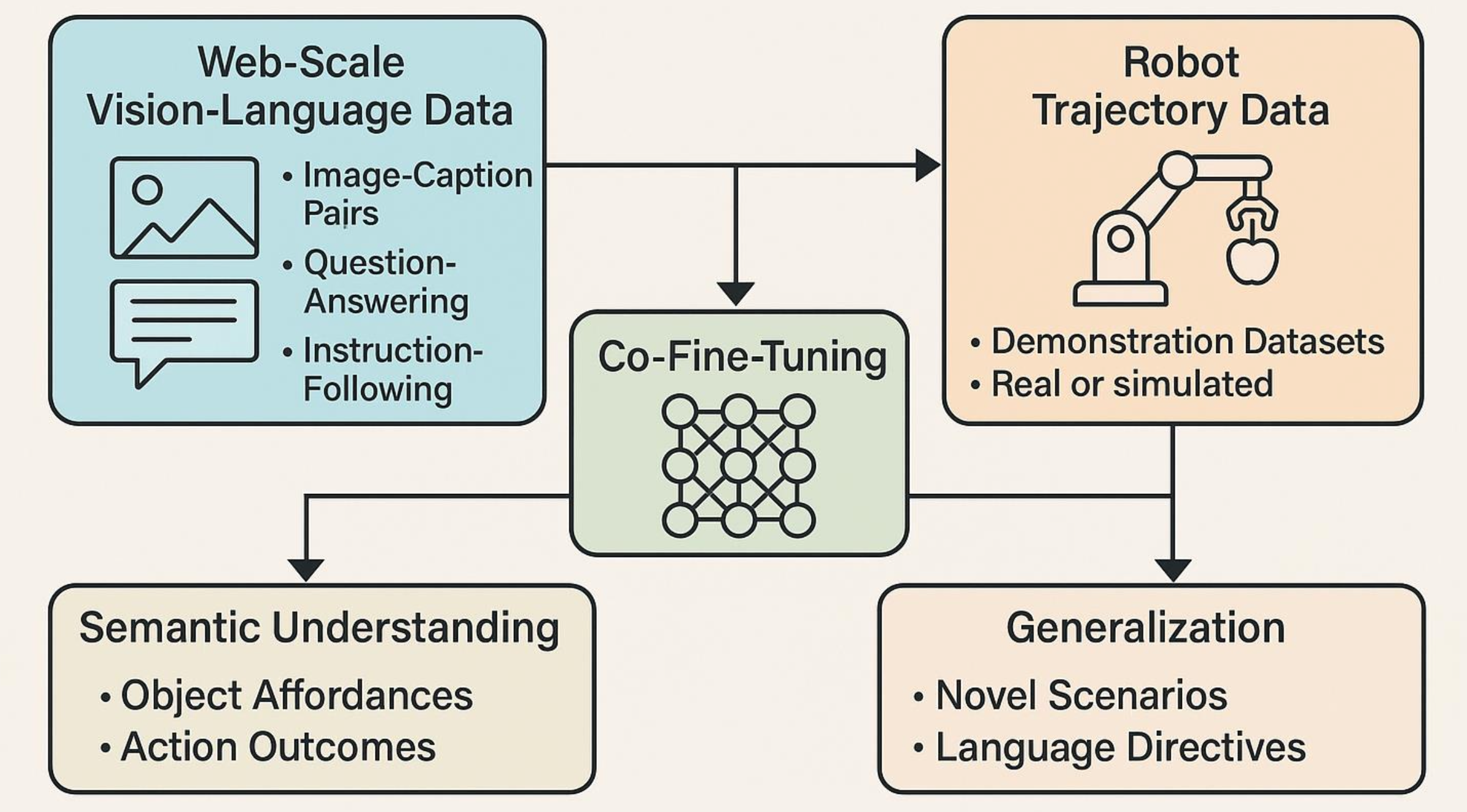
视觉-语言-动作模型:概念、进展、应用与挑战(上)
25年5月来自 Cornell 大学、香港科大和希腊 U Peloponnese 的论文“Vision-Language-Action Models: Concepts, Progress, Applications and Challenges”。 视觉-语言-动作 (VLA) 模型标志着人工智能的变革性进步,旨在将感知、自然语言理解和具体动作统一在一个计…...

语义分割模型部署到嵌入式终端的通用操作流程
以下是语义分割模型部署到嵌入式终端的通用操作流程,结合不同硬件平台(如华为Atlas、地平线J5、树莓派等)的共性需求整理而成: 一、环境准备与工具链配置 1. 嵌入式开发环境搭建 安装交叉编译工具链(如ARM-GCC&…...
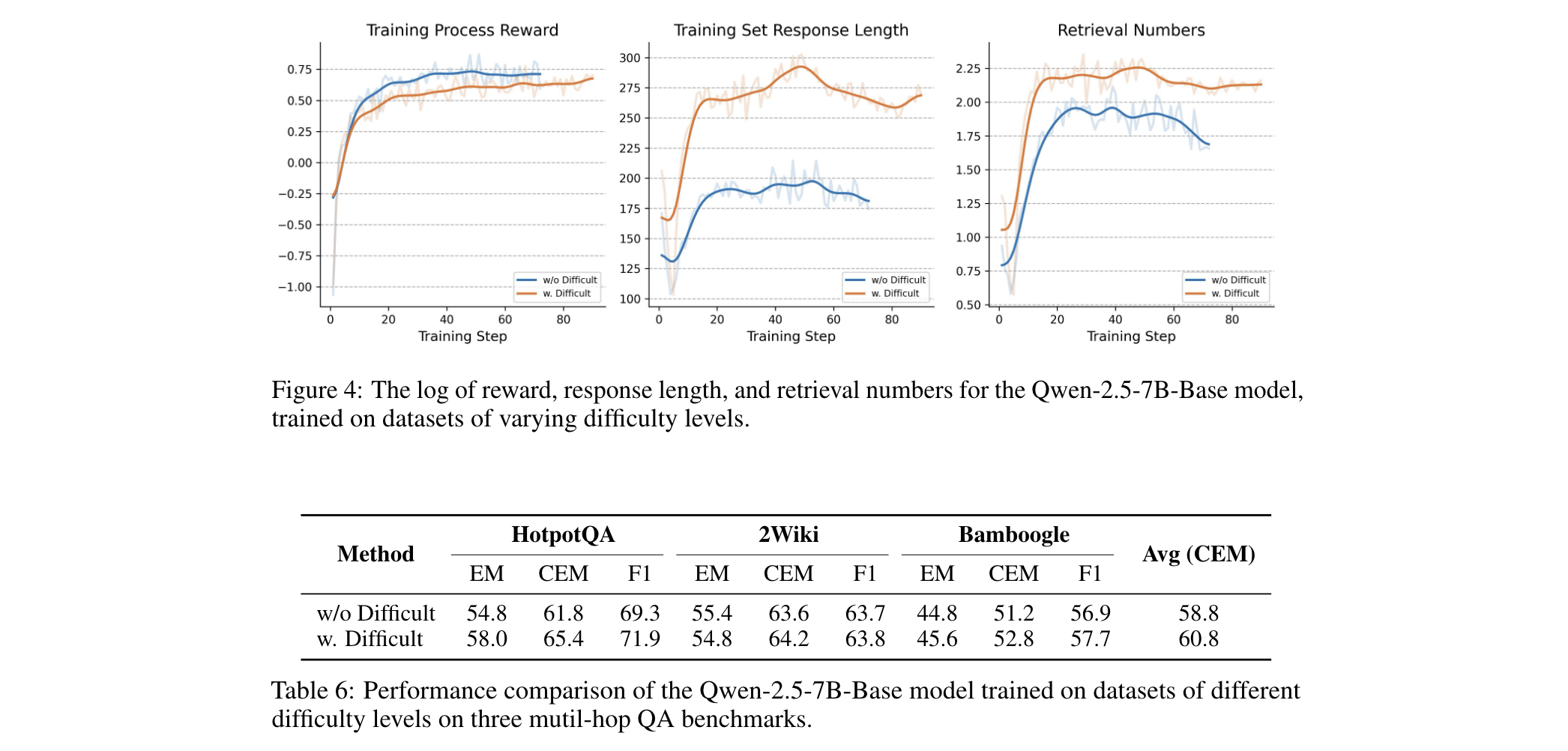
R1-Searcher:用强化学习解锁大语言模型检索新能力!
R1-Searcher:用强化学习解锁大语言模型检索新能力! 大语言模型(LLMs)发展迅猛,却常因依赖内部知识而在复杂问题上“栽跟头”。今天解读的论文提出R1-Searcher框架,通过强化学习提升LLMs检索能力。它表现超…...
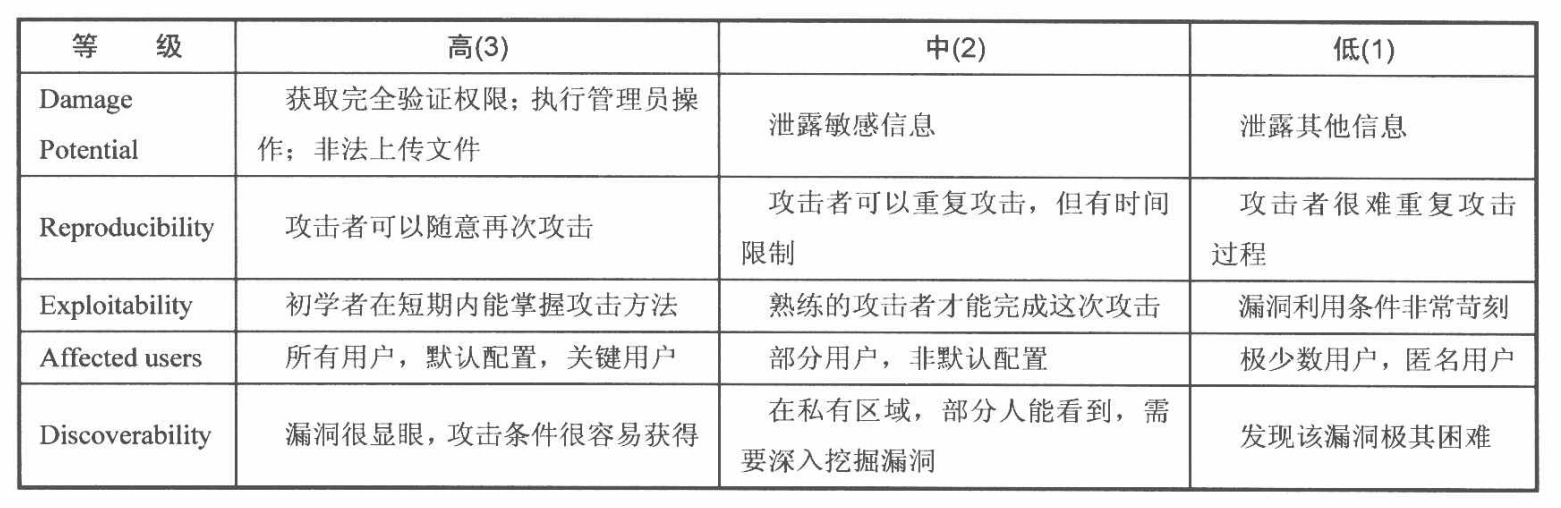
第一篇 世界观安全
目录 STRIDE模型 五大原则 一黑白名单 二最小权限原则 三纵深防御原则 四数据和代码分离 五不可预测原则 安全的问题本质是信任问题。 并且安全是一个持续的过程。 安全的三要素:机密性,完整性(可以采用数字签名)&#x…...
原理与结构)
RNN(循环神经网络)原理与结构
1 RNN(循环神经网络)原理与结构 循环神经网络(Recurrent Neural Network, RNN)是一类专门用于处理序列数据(如时间序列、文本、语音等)的深度学习模型。与传统的前馈神经网络不同,RNN在每个时间…...
mac M2能安装的虚拟机和linux系统系统
目前网上的资料大多错误,能支持M2的很少。 推荐安装的改造过的centos7也无法进行yum操作,建议安装centos8 VMware Fusion下载地址: https://pan.baidu.com/s/14v3Dy83nuLr2xOy_qf0Jvw 提取码: jri4 centos8下载地址: https://…...

无偿帮写毕业论文
以下教程教你如何利用相关网站和AI免费帮你写一个毕业论文。毕竟毕业论文只要过就行,脱产学习这么多年,终于熬出头了,完成毕设后有空就去多看看亲人好友,祝好! 一、找一个论文模板(最好是overleaf) 废话不多说&#…...

智能网联汽车“内外协同、虚实共生”的通信生态
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界…...

Linux操作系统从入门到实战(六)Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载
Linux操作系统从入门到实战(六)Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载 前言一、 软件包管理器1.1 传统安装方式的麻烦:从源代码说起1.2 软件包&…...

物流无人机自动化装卸技术解析!
一、自动化装卸技术模块的技术难点 1. 货物多样性适配 物流场景中货物包装类型、尺寸、材质差异大,如农产品、医疗物资、工业设备等,要求装卸模块具备高度柔性化设计。例如,单元货物需视觉识别系统进行单个抓取,而整托货物需大…...

基于构件的开发方法与传统开发方法的区别
在软件开发领域,基于构件的开发方法和传统开发方法有着截然不同的特点与应用效果,这些差异显著影响着项目的实施过程与最终成果。下面,我们将从多个关键维度展开对比分析。 一、开发模式:线性搭建与模块组装 传统开发方法遵循线性的、自顶向下的流程,就像搭建一座高楼…...

详解 IRC协议 及客户端工具 WeeChat 的使用
本文将详细介绍 Internet Relay Chat(IRC)协议及其历史、基本概念、核心功能,以及流行的 IRC 客户端 WeeChat 的安装、配置和使用方法。内容力求准确、详尽,涵盖 IRC 的技术背景、使用场景,以及 WeeChat 的高级功能和实…...

IOT藍牙探測 C2 架構:社會工程/節點分離防追尋
BMC 地址:https://github.com/MartinxMax/bmc/releases/tag/V1.5 藍牙 MAC 偵測節點的物聯網分散式 C2 架構,可與 S-Cluster 交互。 場景 A:潛伏偵測 駭客組織會將 BMC 裝置秘密部署在目標建築物周圍(例如牆外、通風口或垃圾間等隱蔽地點&…...

Koa知识框架
一、核心概念 1. 基本特点 由 Express 原班人马开发的下一代 Node.js Web 框架 基于中间件的洋葱圈模型 轻量级核心(仅约 600 行代码) 完全使用 async/await 异步流程控制 没有内置任何中间件,高度可定制 2. 核心对象 Application (Ko…...

FreeRTOS学习记录(变量命名规则全解、文件介绍)
目录 FreeRTOS 变量命名规则详解 一、变量命名前缀规则 (一)数据类型相关前缀 (二)功能模块相关前缀 (三)宏定义 二、变量命名与文件的关系 (一)核心源文件中的变…...

Qt 中 QWidget涉及的常用核心属性介绍
欢迎来到干货小仓库 一匹真正的好马,即使在鞭子的影子下,也能飞奔 1.enabled API说明isEnabled()获取到控件的可用状态setEnabled()设置控件是否可使用.true:可用,false:禁用 禁用:指该控件不能接收任何用…...
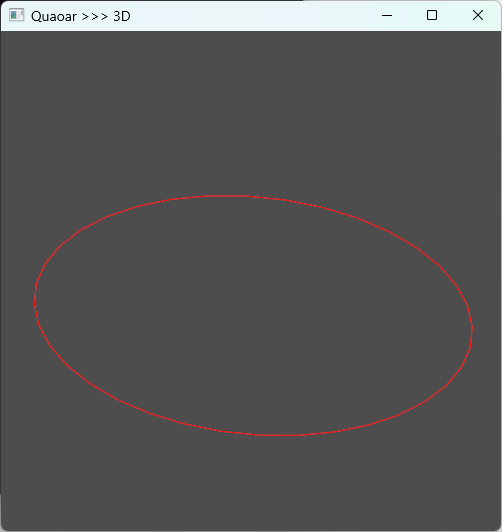
Open CASCADE学习|由大量Edge构建闭合Wire:有序与无序处理的完整解析
在CAD建模中,构建闭合的Wire(线框)是拓扑结构生成的基础操作。OpenCascade(OCCT)作为强大的几何建模库,支持从离散的Edge(边)构建Wire,但在实际应用中,边的有序性直接影响构建的成功率。本文将详细探讨有序与无序两种场景下的实现方法,并提供完整代码示例。 一、有序…...