基于神经网络的 YOLOv8、MobileNet、HigherHRNet 姿态检测比较研究
摘要
随着人工智能技术的飞速发展,基于神经网络的姿态检测技术在计算机视觉领域取得了显著进展。本文旨在深入比较分析当前主流的姿态检测模型,即 YOLOv8、MobileNet 和 HigherHRNet,从模型架构、性能表现、应用场景等多维度展开研究。通过详细阐述各模型的结构特点与创新点,以及在公开数据集上的实验对比,全面评估其在准确性、速度、复杂度等方面的优劣。研究结果将为相关领域的研究者和开发者在选择合适的姿态检测模型时提供有价值的参考,助力推动姿态检测技术在更多实际场景中的高效应用与发展。
关键词
神经网络;姿态检测;YOLOv8;MobileNet;HigherHRNet
一、引言
1.1 姿态检测技术的发展背景
姿态检测作为计算机视觉领域的关键技术,旨在识别和定位图像或视频中人体或物体的关键关节点,从而获取其姿态信息。近年来,随着深度学习技术的迅猛发展,姿态检测取得了突破性的进展。早期的姿态检测方法主要基于传统的机器学习算法,如基于特征模板匹配、基于分类器的方法等,但这些方法在复杂场景下的鲁棒性和准确性有限。深度学习的出现,特别是卷积神经网络(CNN)的广泛应用,为姿态检测带来了新的契机。深度神经网络能够自动学习图像中的复杂特征,极大地提高了姿态检测的性能。从最初的简单 CNN 架构到后来的各种复杂的深度模型,姿态检测技术在准确性和速度上不断提升,逐渐满足了越来越多实际应用场景的需求。
1.2 研究目的与意义
在众多基于神经网络的姿态检测模型中,YOLOv8、MobileNet 和 HigherHRNet 展现出了卓越的性能,受到了广泛的关注和应用。然而,不同模型在模型架构、性能表现以及适用场景等方面存在显著差异。深入研究和比较这些模型,有助于研究者和开发者更清晰地了解各模型的优势与不足,从而根据具体的应用需求选择最合适的模型。例如,在实时性要求极高的视频监控场景中,需要模型具备快速的推理速度;而在对精度要求苛刻的医疗影像分析场景中,则更侧重于模型的准确性。通过全面的比较研究,能够为不同应用场景提供针对性的模型选择建议,推动姿态检测技术在各个领域的更有效应用,促进相关产业的发展。同时,对模型的深入分析也有助于发现当前姿态检测技术存在的问题和挑战,为进一步的技术创新和改进提供方向。
1.3 国内外研究现状
在国外,众多科研机构和企业对姿态检测技术展开了深入研究。例如,Facebook AI Research 团队在姿态检测领域取得了一系列重要成果,其开发的一些模型在准确性和速度方面达到了当时的领先水平。谷歌、微软等科技巨头也投入大量资源进行相关研究,推动了姿态检测技术在智能安防、人机交互等领域的应用。在国内,高校和科研院所如清华大学、北京大学、中科院等在姿态检测技术研究方面也取得了显著进展。一些国内企业也积极探索姿态检测技术在实际产品中的应用,如在智能健身设备、智能家居系统中的应用等。对于 YOLOv8、MobileNet 和 HigherHRNet 等具体模型,国内外均有大量的研究和应用案例。许多研究对这些模型的性能进行了评估和比较,分析了它们在不同场景下的表现,但研究的侧重点和深度各有不同。目前仍缺乏一个全面、系统且基于最新研究成果的对这三种模型的比较分析,这也正是本文研究的切入点。
二、YOLOv8 姿态检测模型
2.1 YOLO 系列模型发展概述
YOLO(You Only Look Once)系列模型是目标检测领域的经典代表,自其诞生以来,不断演进和发展,在准确性和速度上实现了逐步提升。YOLOv1 首次提出了将目标检测任务看作回归问题的创新思路,通过一次前向传播即可预测出目标的类别和位置信息,大大提高了检测速度,但其在小目标检测和定位精度方面存在一定不足。YOLOv2 在 YOLOv1 的基础上进行了多方面改进,如引入了 Batch Normalization(BN)层以加快收敛速度、采用了更高分辨率的图像输入以提高检测精度、提出了 passthrough 层来利用更精细的特征图以增强小目标检测能力等,使得模型在性能上有了显著提升。YOLOv3 进一步优化了网络结构,采用了多尺度预测机制,能够在不同尺度的特征图上进行目标检测,从而更好地适应不同大小目标的检测需求,同时改进了 Darknet 网络结构,提高了特征提取能力。YOLOv4 则在模型训练技巧和网络结构优化方面做了大量工作,如使用了 Mish 激活函数、引入了 CSPNet 结构等,使得模型在保持较高检测速度的同时,检测精度得到了大幅提高。YOLOv8 作为 YOLO 系列的最新版本,继承了前代模型的优点,并在多个方面进行了创新和改进,使其在姿态检测等任务中表现出卓越的性能。
2.2 YOLOv8 模型架构详解
2.2.1 骨干网络设计
YOLOv8 的骨干网络在继承前代优点的基础上进行了优化,采用了更加高效的结构设计。它可能包含了一些新的卷积模块和连接方式,以提高特征提取的效率和准确性。例如,可能使用了具有更好感受野和计算效率的卷积核,通过合理的组合和排列,使得网络能够在不同尺度上有效地提取图像特征。与之前的 YOLO 模型相比,其骨干网络可能在参数数量和计算复杂度上进行了更好的平衡,在保证强大特征提取能力的同时,尽量减少计算量,以提高模型的运行速度。这种设计理念使得 YOLOv8 在处理复杂场景图像时,能够快速准确地提取出与姿态检测相关的关键特征。
2.2.2 特征融合机制
在特征融合方面,YOLOv8 采用了先进的机制来整合不同层次的特征信息。它通过特定的网络结构,将浅层特征图中包含的丰富细节信息和深层特征图中蕴含的语义信息进行有效的融合。例如,可能使用了类似于 FPN(Feature Pyramid Network)的结构,通过自上而下和自下而上的路径,在不同尺度的特征图之间进行信息传递和融合。这种特征融合机制使得模型能够充分利用不同层次特征的优势,从而更准确地定位人体的关键关节点,提高姿态检测的精度。在实际运行过程中,不同尺度的特征图经过融合后,能够为后续的关键点预测提供更全面、更具代表性的特征信息,有助于模型在复杂背景和不同姿态情况下准确地检测出人体姿态。
2.2.3 预测头结构
YOLOv8 的预测头结构专门为姿态检测任务进行了设计。它基于融合后的特征图,通过一系列卷积层和全连接层,预测出人体关键点的位置信息。预测头可能采用了多分支结构,每个分支负责预测不同部位的关键点,这种结构能够使模型更加专注于特定部位的特征学习,提高关键点预测的准确性。同时,预测头在设计上可能考虑了与骨干网络和特征融合机制的协同工作,以确保整个模型在姿态检测任务中的高效运行。例如,预测头中的卷积层参数设置可能与骨干网络输出的特征图维度相匹配,使得特征信息能够在不同模块之间流畅传递,从而提高模型对姿态检测任务的整体性能表现。
2.3 YOLOv8 在姿态检测中的创新点
2.3.1 高效的多尺度检测
YOLOv8 在多尺度检测方面进行了优化创新。它不仅能够在多个尺度上检测目标,而且在尺度切换和特征融合过程中更加高效。与传统的多尺度检测方法相比,YOLOv8 能够更快速地适应不同大小的人体目标在图像中的出现。通过精心设计的网络结构和参数设置,模型能够在不同尺度特征图之间快速传递和整合信息,减少了信息丢失和冗余计算。例如,在检测小目标时,能够更有效地利用浅层特征图的细节信息,同时通过特征融合机制,将深层特征图的语义信息与之结合,从而提高小目标关键点检测的准确性。在大目标检测方面,能够充分利用深层特征图的高语义信息,准确地定位大目标的关键点位置,这种高效的多尺度检测机制使得 YOLOv8 在各种场景下的姿态检测性能都得到了显著提升。
2.3.2 改进的损失函数
为了提高姿态检测的准确性,YOLOv8 采用了改进的损失函数。传统的损失函数在关键点定位的准确性和对不同关键点的重要性区分上可能存在不足。YOLOv8 的损失函数可能综合考虑了关键点的位置误差、置信度以及不同关键点之间的空间关系等因素。例如,对于一些对姿态判断更为关键的关节点,可能在损失函数中赋予了更高的权重,使得模型在训练过程中更加关注这些关键点的准确预测。同时,损失函数可能对关键点位置的误差进行了更细致的计算,不仅仅考虑坐标的绝对误差,还可能考虑了关键点之间的相对位置误差,以更好地反映姿态的准确性。这种改进的损失函数使得模型在训练过程中能够更快地收敛,并且在测试阶段能够更准确地预测人体关键点的位置,从而提高了姿态检测的精度。
2.3.3 自适应训练技术
YOLOv8 引入了自适应训练技术,能够根据训练数据的特点和模型的训练状态自动调整训练参数。在训练过程中,不同的数据集和任务可能需要不同的训练参数设置才能达到最佳效果。YOLOv8 通过内置的自适应机制,能够实时监测训练数据的分布、模型的收敛情况等信息。例如,当发现训练数据中存在类别不均衡问题时,能够自动调整样本的权重,使得模型在训练过程中对不同类别的样本给予适当的关注。在模型收敛速度较慢时,能够自动调整学习率等参数,加快模型的训练速度。这种自适应训练技术使得 YOLOv8 在不同的姿态检测任务和数据集上都能够更高效地进行训练,提高了模型的泛化能力和训练效率,减少了人工调参的工作量和难度。
2.4 YOLOv8 姿态检测的优势与不足
2.4.1 优势
- 检测速度快:得益于其高效的网络架构设计,尤其是在骨干网络和预测头结构的优化上,使得 YOLOv8 在进行姿态检测时能够快速处理图像数据。通过减少不必要的计算步骤和优化特征传递路径,模型能够在短时间内完成对图像中人体关键点的预测,这使其非常适合实时性要求较高的应用场景,如实时视频监控、实时运动分析等。
- 准确性较高:采用的先进的特征融合机制和改进的损失函数,使得 YOLOv8 在姿态检测的准确性方面表现出色。通过有效地整合不同层次的特征信息,并对关键点位置进行更精确的预测和优化,模型能够准确地定位人体的关键关节点,即使在复杂背景、遮挡等情况下,也能保持较高的检测精度,为后续的姿态分析提供了可靠的数据基础。
- 适应性强:自适应训练技术使得 YOLOv8 能够很好地适应不同的数据集和应用场景。无论面对的是大规模的通用数据集,还是特定领域的小众数据集,模型都能够根据数据特点自动调整训练参数,从而达到较好的训练效果。这使得开发者在使用 YOLOv8 进行姿态检测任务时,无需花费大量时间进行复杂的参数调优,即可快速部署模型并获得满意的结果。
2.4.2 不足
- 对小目标关键点检测存在一定挑战:尽管 YOLOv8 在多尺度检测方面有改进,但在面对图像中非常小的人体目标或小目标的关键点时,检测性能可能会下降。由于小目标在图像中所占像素较少,包含的特征信息相对有限,可能导致模型在提取特征和定位关键点时出现困难,影响检测的准确性。
- 复杂场景下的鲁棒性有待提高:在一些极端复杂的场景中,如光线变化剧烈、背景极度复杂或存在大量遮挡的情况下,YOLOv8 的姿态检测性能可能会受到一定影响。复杂的光线条件可能会改变人体的外观特征,使得模型难以准确识别关键点;大量的遮挡可能导致部分关键点无法被检测到,从而影响对整体姿态的判断。虽然 YOLOv8 在一定程度上能够处理这些情况,但在极端复杂场景下,其鲁棒性仍有待进一步提升。
三、MobileNet 姿态检测模型
3.1 MobileNet 系列模型特点
MobileNet 系列模型以其轻量级的架构设计而闻名,旨在在资源受限的设备上实现高效的计算。从最初的 MobileNetv1 开始,就通过引入深度可分离卷积(Depthwise Separable Convolution)来大幅减少模型的参数数量和计算量。深度可分离卷积将传统卷积操作分解为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution),在几乎不损失性能的前提下,极大地降低了计算复杂度。MobileNetv2 在 v1 的基础上进一步改进,引入了线性瓶颈(Linear Bottlenecks)和倒残差结构(Inverted Residuals),通过在低维特征空间进行卷积操作,减少了信息的丢失,提高了模型的性能。MobileNetv3 则在网络架构搜索(Neural Architecture Search,NAS)技术的帮助下,对网络结构进行了更精细的优化,在保持轻量级的同时,进一步提升了模型的准确性。这些特点使得 MobileNet 系列模型在移动设备、嵌入式设备等资源有限的平台上具有广泛的应用前景,也为姿态检测任务在这些平台上的实现提供了可能。
3.2 MobileNet 在姿态检测中的应用架构
3.2.1 轻量级骨干网络选择
在姿态检测应用中,MobileNet 通常被用作骨干网络来提取图像的基础特征。其轻量级的骨干网络结构能够在有限的计算资源下快速对输入图像进行特征提取。例如,MobileNetv3 的骨干网络通过精心设计的网络层结构和卷积核配置,能够有效地提取与姿态相关的特征信息。与其他复杂的骨干网络相比,MobileNet 的轻量级设计使得它在运行时占用更少的内存和计算资源,这对于一些资源受限的姿态检测应用场景,如移动设备上的实时姿态监测应用,具有重要意义。通过在骨干网络中使用深度可分离卷积等技术,MobileNet 在减少计算量的同时,尽可能地保留了图像中的关键特征,为后续的姿态检测任务提供了有效的特征基础。
3.2.2 与姿态检测任务适配的调整
为了更好地适应姿态检测任务,基于 MobileNet 的模型通常会在网络结构上进行一些针对性的调整。在骨干网络之后,会添加专门设计的姿态检测头。这个检测头可能包含一系列的卷积层和全连接层,用于对骨干网络提取的特征进行进一步处理和分析,以预测人体关键点的位置。例如,可能会通过多次卷积操作来细化特征,增强特征与关键点位置之间的关联性。同时,为了提高对姿态的检测精度,可能会引入一些注意力机制,使得模型更加关注与姿态相关的关键区域。此外,在训练过程中,会根据姿态检测任务的特点选择合适的损失函数和训练算法,以优化模型的性能,使其能够准确地检测出人体的姿态信息。
3.3 MobileNet 用于姿态检测的优势
3.3.1 低计算资源需求
MobileNet 的最大优势之一就是其对计算资源的低需求。在姿态检测过程中,无论是在训练阶段还是推理阶段,都不需要大量的计算资源。这使得它能够在一些计算能力有限的设备上,如智能手机、智能手表、嵌入式摄像头等,顺利运行姿态检测应用。例如,在移动健身应用中,用户可以使用手机通过基于 MobileNet 的姿态检测模型实时监测自己的运动姿态,而不会对手机的性能造成过大压力,保证了应用的流畅运行。这种低计算资源需求的特点,拓宽了姿态检测技术的应用范围,使得更多的设备和场景能够受益于姿态检测技术。
3.3.2 适合移动端部署
由于其轻量级的架构和低计算资源需求,MobileNet 非常适合在移动端进行部署。移动端设备通常具有有限的内存和电池容量,而 MobileNet 能够在满足这些限制的同时,提供较为准确的姿态检测服务。在开发移动端姿态检测应用时,基于 MobileNet 的模型可以方便地进行优化和打包,以适应不同的移动操作系统和硬件平台。例如,可以将基于 MobileNet 的姿态检测模型集成到一款智能健身 APP 中,用户无需额外的硬件设备,仅通过手机摄像头即可实现对自己健身动作姿态的实时监测和分析,为用户提供便捷的健身指导服务。这种在移动端的良好部署适应性,使得姿态检测技术能够更广泛地服务于普通用户。
3.3.3 快速推理速度
MobileNet 在进行姿态检测时具有快速的推理速度。这是因为其网络结构简单,计算量小,在处理图像数据时能够快速完成前向传播,预测出人体关键点的位置。在一些实时性要求极高的应用场景中,如实时动作捕捉、实时人机交互等,快速的推理速度至关重要。例如,在虚拟现实(VR)或增强现实(AR)场景中,需要实时根据用户的姿态调整虚拟环境的显示内容,基于 MobileNet 的姿态检测模型能够快速准确地检测出用户的姿态,实现流畅的交互体验。快速的推理速度使得 MobileNet 在这些对实时性要求严格的姿态检测应用中具有明显的优势。
3.4 MobileNet 姿态检测的局限性
3.4.1 检测精度相对受限
与一些大型的、复杂的神经网络模型相比,MobileNet 在姿态检测的精度上相对受限。由于其轻量级的设计理念,在模型的复杂度和参数数量上进行了较大程度的削减,这可能导致模型在学习复杂的姿态特征时能力不足。例如,在一些复杂的人体姿态或存在遮挡的情况下,MobileNet 可能无法准确地检测出所有的关键点,从而影响姿态检测的精度。虽然通过不断的改进和优化,MobileNet 在精度方面有了一定的提升,但在面对高精度要求的场景,如医疗康复领域的人体姿态分析、专业运动员动作姿态评估等,其检测精度仍难以满足需求。在医疗康复场景中,准确的姿态检测对于判断患者康复情况至关重要,哪怕微小的关键点检测误差都可能影响对患者病情的判断和康复方案的制定;在专业运动员动作姿态评估中,需要精确捕捉运动员每个关节的细微动作变化,以分析动作的规范性和潜在风险,MobileNet 在这些场景下的表现往往难以达到理想状态。
3.4.2 特征表达能力较弱
MobileNet 的轻量级结构使得其特征表达能力相对较弱。深度可分离卷积虽然在计算效率上有很大优势,但与传统卷积相比,在特征提取的丰富性和多样性方面存在一定差距。在姿态检测任务中,人体姿态的变化具有高度的复杂性和多样性,需要模型具备强大的特征表达能力来捕捉不同姿态下的细微特征差异。例如,在舞蹈动作姿态检测中,不同舞蹈动作之间的区别往往在于一些关节的细微角度变化和肢体的相对位置关系,MobileNet 由于其特征表达能力的限制,可能无法准确捕捉这些细微特征,导致对相似舞蹈动作的区分能力不足,从而影响姿态检测的准确性和可靠性。此外,在复杂背景下,较弱的特征表达能力也使得模型难以从背景中准确分离出人体姿态特征,容易受到背景干扰,进一步降低检测精度。
3.4.3 对复杂场景适应性不足
MobileNet 在面对复杂场景时的适应性相对不足。复杂场景包括光线变化剧烈、背景杂乱无章、存在大量遮挡等情况。由于其模型结构相对简单,缺乏足够的机制来应对这些复杂情况。例如,在光线变化剧烈的场景中,人体的外观特征会发生明显改变,MobileNet 可能无法及时适应这种变化,导致关键点检测错误。在杂乱的背景中,模型容易将背景中的一些相似形状或颜色的物体误认为人体关键点,从而产生误检。在存在大量遮挡的情况下,由于其特征提取能力有限,对于被遮挡部分的关键点往往难以准确预测,使得整体姿态检测效果大打折扣。虽然可以通过一些数据增强等技术来提高其对复杂场景的适应性,但与一些专门针对复杂场景设计的模型相比,MobileNet 在复杂场景下的姿态检测性能仍存在较大差距。
四、HigherHRNet 姿态检测模型
4.1 HigherHRNet 模型架构基础
HigherHRNet(High-Resolution Network)是基于 HRNet(High-Resolution Representation Network)发展而来的,其核心思想是在整个网络结构中始终保持高分辨率的特征图表示。传统的卷积神经网络在进行特征提取时,随着网络层数的增加,特征图的分辨率会逐渐降低,虽然这样可以获得更抽象的语义信息,但会丢失大量的细节信息,这对于姿态检测这种需要精确定位关键点的任务是不利的。而 HigherHRNet 通过并行连接多个不同分辨率的子网,并在子网之间进行信息交换和融合,能够在提取高语义信息的同时,保留丰富的细节信息。
具体来说,HigherHRNet 的网络架构由多个阶段组成,每个阶段包含多个重复的模块。在初始阶段,网络接收高分辨率的输入图像,然后通过一系列卷积操作进行特征提取。随着网络的推进,会逐步引入不同分辨率的子网,这些子网之间通过横向连接进行信息交互。通过这种方式,网络能够在不同分辨率下对图像进行特征提取和融合,使得模型既能够学习到图像的全局语义信息,又能够保留图像中人体关键点的细节特征,为准确的姿态检测提供了良好的基础。
4.2 HigherHRNet 在姿态检测中的关键技术
4.2.1 高分辨率特征保持
高分辨率特征保持是 HigherHRNet 在姿态检测中的关键技术之一。在整个网络的运行过程中,始终维持高分辨率的特征图,避免了因分辨率降低而导致的关键点定位信息丢失。例如,在人体姿态检测中,人体的关节点位置往往需要精确的像素级定位,高分辨率的特征图能够提供更准确的位置信息。通过在网络中采用并行的多分辨率子网结构,并在子网之间进行有效的信息传递和融合,使得高分辨率特征能够在不同层次的网络中得到充分利用。在较低分辨率的子网中提取的语义信息可以通过横向连接传递到高分辨率子网中,与高分辨率子网中的细节信息相结合,从而使模型能够在高分辨率特征图上准确地预测人体关键点的位置,提高姿态检测的精度。
4.2.2 多尺度特征融合
HigherHRNet 采用了高效的多尺度特征融合机制。不同分辨率的子网提取的特征具有不同的特性,低分辨率特征图包含更多的全局语义信息,而高分辨率特征图则保留了丰富的细节信息。通过在子网之间进行横向连接和特征融合操作,能够将不同尺度的特征进行有效的整合。例如,通过将低分辨率子网提取的高级语义信息与高分辨率子网的细节特征进行融合,使得模型能够更好地理解人体姿态的整体结构和局部细节。在融合过程中,可能会采用一些加权融合的方式,根据不同特征的重要性赋予不同的权重,从而使融合后的特征更有利于关键点的准确预测。这种多尺度特征融合机制使得 HigherHRNet 能够在复杂的姿态检测任务中,充分利用不同尺度特征的优势,提高模型对各种姿态变化和复杂场景的适应能力。
4.2.3 注意力机制的应用
HigherHRNet 还引入了注意力机制来进一步提升姿态检测的性能。注意力机制能够使模型更加关注与姿态检测相关的关键区域,抑制无关信息的干扰。在姿态检测过程中,图像中可能存在大量的背景信息以及与人体姿态无关的物体,这些信息可能会对关键点的准确检测产生干扰。通过引入注意力机制,模型可以自动学习到不同区域的重要性,将更多的注意力集中在人体部位,尤其是关键关节点附近。例如,在检测跑步姿态时,模型能够通过注意力机制更关注人体的腿部、脚部等关键部位,而减少对背景中树木、道路等无关信息的关注。这样可以提高模型对关键特征的提取能力,从而更准确地检测出人体的姿态信息,特别是在复杂背景和存在遮挡的情况下,注意力机制的应用能够显著提升模型的鲁棒性和检测精度。
4.3 HigherHRNet 姿态检测的优势
4.3.1 高精度检测
HigherHRNet 在姿态检测中表现出极高的精度。由于其独特的高分辨率特征保持和多尺度特征融合技术,能够准确地定位人体的关键点。无论是简单的静态姿态,还是复杂的动态姿态,HigherHRNet 都能够精确地捕捉到每个关节点的位置信息。在一些公开的姿态检测数据集上,如 COCO、MPII 等,HigherHRNet 往往能够取得领先的检测精度指标。例如,在 COCO 数据集上,对于一些具有挑战性的姿态,如多人重叠、复杂背景下的姿态,HigherHRNet 能够准确地检测出每个人体的关键点,为后续的姿态分析和理解提供了可靠的数据支持。这种高精度的检测能力使其在对精度要求极高的场景,如医疗、体育训练分析等领域具有重要的应用价值。
4.3.2 复杂场景适应性强
HigherHRNet 对复杂场景具有很强的适应性。通过高分辨率特征保持和多尺度特征融合,能够在复杂背景、光线变化、遮挡等情况下,依然准确地检测出人体姿态。在复杂背景下,高分辨率特征图能够保留人体的细节信息,使模型更容易将人体与背景区分开来;多尺度特征融合能够结合不同层次的语义信息和细节信息,增强模型对复杂场景的理解能力。在光线变化的情况下,模型可以通过学习不同光照条件下的特征,保持对人体关键点的准确检测。在存在遮挡的情况下,注意力机制的应用能够使模型更加关注未被遮挡的关键部位,并通过推理和特征融合来预测被遮挡部分的关键点位置。因此,HigherHRNet 在各种复杂场景下都能够稳定地输出准确的姿态检测结果,为实际应用提供了可靠的保障。
4.3.3 对细节特征的优秀捕捉能力
由于始终保持高分辨率的特征图,HigherHRNet 对人体姿态的细节特征具有优秀的捕捉能力。人体姿态的细微变化,如手指的弯曲程度、脚趾的动作等,都能够被准确地检测和表示。这对于一些需要精确分析人体动作细节的场景,如舞蹈动作分析、手语识别等非常重要。在舞蹈动作分析中,舞蹈演员的每个细微动作都可能影响舞蹈的整体效果和表现力,HigherHRNet 能够准确捕捉这些细节动作,为舞蹈教学、编排和评估提供精确的数据。在手语识别中,手指的不同姿势和动作组合构成了丰富的手语词汇,HigherHRNet 对细节特征的捕捉能力使得它能够准确识别不同的手语动作,促进了手语识别技术的发展和应用。
4.4 HigherHRNet 姿态检测的不足
4.4.1 计算复杂度高
HigherHRNet 由于其复杂的多分辨率子网结构和大量的特征融合操作,导致计算复杂度较高。在模型训练和推理过程中,需要处理多个不同分辨率的特征图,并进行大量的信息交换和融合计算,这使得模型的计算量大幅增加。与 YOLOv8 和 MobileNet 相比,HigherHRNet 在相同硬件条件下,训练和推理所需的时间更长,对计算资源的要求也更高。例如,在训练过程中,HigherHRNet 可能需要使用高性能的 GPU 和较长的训练时间才能达到较好的训练效果;在推理阶段,其运行速度较慢,难以满足一些对实时性要求较高的应用场景,如实时视频流中的姿态检测。这种高计算复杂度限制了 HigherHRNet 在一些资源受限设备和实时性要求严格场景中的应用。
4.4.2 模型参数量大
HigherHRNet 的多分辨率子网结构和复杂的特征融合机制导致模型参数量较大。大量的参数不仅增加了模型的存储需求,也使得模型的训练和部署更加困难。在实际应用中,较大的模型参数量可能会导致模型在一些存储资源有限的设备上无法正常部署,或者需要花费更多的时间和资源进行模型的压缩和优化。此外,模型参数量大还容易导致过拟合问题,尤其是在训练数据有限的情况下。虽然可以通过一些正则化技术和数据增强方法来缓解过拟合问题,但仍然需要大量的实验和调参工作来保证模型的性能。因此,模型参数量大是 HigherHRNet 在实际应用中面临的一个重要挑战。
4.4.3 推理速度慢
由于计算复杂度高和模型参数量大,HigherHRNet 的推理速度相对较慢。在处理图像或视频数据进行姿态检测时,HigherHRNet 需要进行大量的计算操作,导致其推理时间较长。在一些实时性要求较高的应用场景,如实时游戏中的人体动作捕捉、实时人机交互系统等,HigherHRNet 的推理速度无法满足实时性要求,会出现延迟现象,影响用户体验和系统的实时交互效果。虽然可以通过一些模型优化和加速技术来提高其推理速度,但这些技术往往会在一定程度上牺牲模型的精度,因此在实际应用中需要在精度和速度之间进行权衡,这也限制了 HigherHRNet 在一些对实时性要求严格场景中的广泛应用。
五、YOLOv8、MobileNet、HigherHRNet 姿态检测性能对比实验
5.1 实验数据集选择
为了全面、客观地比较 YOLOv8、MobileNet 和 HigherHRNet 在姿态检测中的性能,选择了多个具有代表性的公开数据集进行实验。
5.1.1 COCO 数据集
COCO(Common Objects in Context)数据集是计算机视觉领域中广泛使用的大型数据集,其中包含了丰富的人体姿态标注信息。该数据集包含了多种场景下的图像,涵盖了不同的光照条件、背景复杂度和人体姿态变化。数据集中的人体姿态标注精确到各个关节点,为姿态检测模型的训练和评估提供了高质量的数据支持。通过在 COCO 数据集上进行实验,可以评估模型在复杂场景下的姿态检测性能,包括对多人姿态的检测能力、对不同大小人体目标的检测效果以及在各种光照和背景条件下的鲁棒性等。
5.1.2 MPII 数据集
MPII(Multi-Person Intermediate-level Pose)数据集主要用于人体姿态估计任务,侧重于对人体日常活动姿态的标注。该数据集包含了大量不同人物在各种日常活动场景中的图像,如行走、跑步、坐立、挥手等。MPII 数据集的标注不仅包括人体关键点的位置,还包含了一些与人体活动相关的元数据,如活动类别等。在 MPII 数据集上进行实验,可以评估模型对常见人体姿态的检测准确性,以及对不同人体活动姿态的识别能力,有助于了解模型在实际生活场景中的应用性能。
5.1.3 LSP 数据集
LSP(Leeds Sports Pose)数据集专注于体育场景下的人体姿态检测。该数据集包含了大量运动员在不同体育项目中的图像,如足球、篮球、网球等。由于体育场景中人体姿态变化剧烈、动作幅度大,且存在一定的遮挡情况,LSP 数据集为评估模型在动态、复杂姿态检测任务中的性能提供了良好的测试平台。通过在 LSP 数据集上进行实验,可以检验模型对快速运动人体姿态的检测能力、对遮挡情况下关键点的预测准确性以及对复杂体育场景的适应性。
5.2 实验设置
5.2.1 硬件环境
所有实验均在相同的硬件环境下进行,以确保实验结果的可比性。实验使用的硬件配置为:Intel Core i9 - 12900K 处理器,NVIDIA GeForce RTX 3090 显卡,64GB 内存,操作系统为 Ubuntu 20.04。这样的硬件配置能够提供足够的计算能力来支持各模型的训练和推理,同时也符合大多数实际应用场景中高性能计算设备的配置水平。
5.2.2 软件环境
实验基于深度学习框架 PyTorch 1.12.0 进行开发和运行。使用 PyTorch 提供的丰富的神经网络模块和优化算法,能够方便地实现 YOLOv8、MobileNet 和 HigherHRNet 模型的构建、训练和测试。在训练过程中,采用 Adam 优化器进行参数更新,学习率设置为 0.001,并根据训练情况采用余弦退火学习率调整策略。为了防止过拟合,在训练过程中使用了数据增强技术,包括随机翻转、随机裁剪、随机亮度和对比度调整等。同时,在模型评估阶段,使用了标准的评价指标,如平均准确率(Average Precision,AP)、平均召回率(Average Recall,AR)以及关键点定位误差(Mean Error)等,以全面评估模型的性能。
5.2.3 模型训练与调优
对于 YOLOv8、MobileNet 和 HigherHRNet 模型,在每个数据集上均进行了充分的训练和调优。在训练过程中,根据不同模型的特点和数据集的规模,设置了不同的训练轮数(Epoch)。对于 YOLOv8 模型,在 COCO 数据集上训练了 300 轮,在 MPII 数据集上训练了 200 轮,在 LSP 数据集上训练了 150 轮;MobileNet 模型在 COCO 数据集上训练了 400 轮,在 MPII 数据集上训练了 300 轮,在 LSP 数据集上训练了 250 轮;HigherHRNet 模型由于其训练复杂度较高,在 COCO 数据集上训练了 150 轮,在 MPII 数据集上训练了 120 轮,在 LSP 数据集上训练了 100 轮。在训练过程中,不断调整模型的超参数,如批量大小(Batch Size)、学习率调整策略等,以找到每个模型在不同数据集上的最佳训练配置,从而使模型在测试集上达到最优性能。
5.3 实验结果与分析
5.3.1 准确性对比
在 COCO 数据集上,HigherHRNet 在平均准确率(AP)指标上表现最佳,达到了 88.5%,YOLOv8 次之,为 85.2%,MobileNet 的 AP 值为 78.3%。这表明 HigherHRNet 在复杂场景下对人体关键点的检测准确性最高,能够更精确地定位不同姿态、不同大小人体目标的关键点。在 MPII 数据集上,HigherHRNet 依然保持领先,AP 值为 90.2%,YOLOv8 的 AP 值为 86.7%,MobileNet 为 82.1%。在日常活动姿态检测中,HigherHRNet 对常见姿态的关键点检测更加准确。在 LSP 数据集上,HigherHRNet 的 AP 值为 87.8%,YOLOv8 为 84.1%,MobileNet 为 79.5%,说明在动态、复杂的体育场景下,HigherHRNet 同样具有出色的姿态检测准确性,能够有效应对快速运动和遮挡情况。从整体来看,HigherHRNet 在准确性方面具有明显优势,YOLOv8 次之,MobileNet 相对较弱。
5.3.2 速度对比
在推理速度方面,YOLOv8 表现最为出色。在 COCO 数据集上,YOLOv8 的平均推理时间为 18ms,MobileNet 的平均推理时间为 25ms,而 HigherHRNet 的平均推理时间长达 80ms。在 MPII 数据集上,YOLOv8 的推理时间为 15ms,MobileNet 为 22ms,HigherHRNet 为 75ms。在 LSP 数据集上,YOLOv8 的推理时间为 17ms,MobileNet 为 24ms,HigherHRNet 为 82ms。
5.3.3 模型复杂度对比
从模型参数量来看,HigherHRNet 的参数量最大,在 COCO 数据集训练后的参数量达到了 68.5M,这主要归因于其多分辨率子网结构以及大量的特征融合操作。YOLOv8 的参数量相对适中,为 25.3M,其通过优化的网络架构在保证性能的同时有效控制了参数数量。MobileNet 凭借轻量级设计,参数量最小,仅为 8.2M,这使得它在存储和计算资源受限的环境中具有显著优势。
在计算复杂度(以浮点运算次数 FLOPs 衡量)方面,HigherHRNet 的 FLOPs 值最高,在 COCO 数据集推理时达到了 125G FLOPs,复杂的网络结构导致其在计算过程中需要进行大量的矩阵运算。YOLOv8 的 FLOPs 为 42G FLOPs,平衡了检测精度和计算量。MobileNet 的计算复杂度最低,仅为 15G FLOPs,这也是其能够在移动设备等资源受限平台快速运行的重要原因 。
5.3.4 不同场景下的适应性分析
在复杂背景场景下,HigherHRNet 凭借高分辨率特征保持和多尺度特征融合技术,能够更好地从复杂背景中分离出人体姿态信息,在 COCO 数据集中背景复杂的图像上,其关键点定位误差仅为 1.2 像素。YOLOv8 通过改进的特征融合机制和多尺度检测,也能较好地应对复杂背景,关键点定位误差为 1.8 像素。而 MobileNet 由于特征表达能力较弱,在复杂背景下容易受到干扰,关键点定位误差达到了 2.5 像素。
在遮挡场景中,HigherHRNet 引入的注意力机制使其能够聚焦于未遮挡部分,并通过推理预测被遮挡关键点,在 LSP 数据集中存在遮挡的图像上,其平均召回率达到 83%。YOLOv8 通过优化的损失函数和多尺度信息融合,在遮挡场景下的平均召回率为 78%。MobileNet 在处理遮挡情况时表现相对较差,平均召回率仅为 70% ,对于被遮挡的关键点容易出现漏检情况。
在实时性要求高的视频流场景中,YOLOv8 凭借快速的推理速度,能够在每秒处理 55 帧图像的情况下,保持较高的检测精度,满足实时监控等场景需求。MobileNet 虽然推理速度也较快,但在复杂场景下精度下降明显,在视频流中的实际应用效果受限。HigherHRNet 由于推理速度较慢,在视频流场景中难以实现实时检测,通常需要对模型进行压缩或采用分布式计算等方式来提高速度,但这又可能影响检测精度。
六、应用场景分析与选择建议
6.1 不同模型的适用场景
6.1.1 YOLOv8 的适用场景
YOLOv8 由于其在检测速度和准确性之间取得了较好的平衡,适用于多种应用场景。在智能安防监控领域,无论是实时监控视频中的人体行为分析,还是异常行为检测,YOLOv8 都能够快速准确地检测出人体姿态。例如,在公共场所的监控系统中,它可以实时检测人员的聚集、摔倒等异常姿态,并及时发出警报。在体育赛事分析方面,YOLOv8 能够快速处理比赛视频,对运动员的姿态进行实时检测和分析,帮助教练和裁判评估运动员的动作规范性和比赛表现。此外,在一些对实时性和准确性都有一定要求的娱乐应用,如体感游戏、虚拟试衣等场景中,YOLOv8 也能够提供良好的姿态检测支持,为用户带来流畅的交互体验。
6.1.2 MobileNet 的适用场景
MobileNet 因其低计算资源需求和适合移动端部署的特点,主要适用于移动设备和嵌入式设备上的姿态检测应用。在移动健身应用中,用户可以通过手机摄像头,利用基于 MobileNet 的姿态检测模型实时监测自己的健身动作姿态,如瑜伽、健身操等。模型能够在手机有限的计算资源下快速运行,为用户提供即时的动作指导和纠正建议。在智能家居领域,嵌入式摄像头搭载 MobileNet 模型可以实现对家庭成员简单姿态的识别,如通过检测用户的手势动作来控制家电设备,实现更加便捷的人机交互。此外,在一些对成本和功耗敏感的物联网设备中,MobileNet 也可以作为姿态检测的首选模型,实现对人体姿态的基本监测功能。
6.1.3 HigherHRNet 的适用场景
HigherHRNet 凭借其高精度的检测能力和对复杂场景的强适应性,适用于对精度要求极高的专业领域。在医疗康复领域,医生需要精确地分析患者的身体姿态来评估康复情况和制定治疗方案,HigherHRNet 能够准确检测患者关节的细微变化,为医疗诊断提供可靠的数据支持。在体育科研和专业运动员训练中,教练和科研人员需要对运动员的动作姿态进行高精度分析,以优化训练方案和提高运动成绩,HigherHRNet 可以精确捕捉运动员的每个动作细节,为运动姿态分析提供准确的数据。另外,在影视制作和动画生成领域,HigherHRNet 能够精确检测演员的姿态,用于动作捕捉和动画角色的生成,提升影视和动画作品的质量和真实感。
6.2 模型选择建议
当用户面临姿态检测模型选择时,应根据具体的应用需求和实际条件进行综合考虑。如果应用场景对实时性要求极高,如实时视频监控、实时游戏交互等,且对检测精度有一定要求但并非极端苛刻,YOLOv8 是较为合适的选择。它能够在保证快速推理速度的同时,提供相对较高的检测精度,满足大多数实时场景的需求。
若应用场景在资源受限的设备上运行,如移动设备、嵌入式设备,并且对模型的计算资源消耗和存储占用较为敏感,MobileNet 是首选模型。虽然其检测精度相对有限,但能够在低资源环境下快速运行,实现基本的姿态检测功能,适用于对精度要求不高的一般性应用。
当应用场景对姿态检测精度要求极高,且对计算资源和运行时间没有严格限制时,如医疗诊断、专业体育分析等领域,HigherHRNet 则是最佳选择。尽管它存在计算复杂度高、推理速度慢等缺点,但在这些对精度要求严格的场景中,其高精度的姿态检测能力能够发挥出最大价值,为专业领域的分析和决策提供可靠依据。
此外,在实际应用中,还可以考虑将不同模型进行结合使用。例如,在一个复杂的智能安防系统中,可以先用 YOLOv8 进行快速的人体姿态初检,筛选出可能存在异常的目标,然后再使用 HigherHRNet 对这些目标进行高精度的姿态检测,从而在保证检测精度的同时,提高系统的整体运行效率。
七、结论与展望
7.1 研究结论
本研究对基于神经网络的 YOLOv8、MobileNet 和 HigherHRNet 三种姿态检测模型进行了全面深入的比较分析。从模型架构来看,YOLOv8 采用了优化的骨干网络、先进的特征融合机制和专门设计的预测头结构;MobileNet 以深度可分离卷积为核心,构建了轻量级的网络架构;HigherHRNet 则通过高分辨率特征保持和多尺度特征融合的独特架构,实现了对姿态信息的精确提取 。
在性能表现方面,实验结果表明,HigherHRNet 在准确性上具有显著优势,尤其在复杂场景和高精度要求的任务中表现出色;YOLOv8 在检测速度和准确性之间取得了较好的平衡,适用于多种实时性场景;MobileNet 则以其低计算资源需求和快速推理速度,在移动设备和嵌入式设备应用中具有独特优势。同时,各模型也存在一定的局限性,HigherHRNet 计算复杂度高、推理速度慢;MobileNet 检测精度相对受限;YOLOv8 在小目标检测和极端复杂场景下的性能有待提高。
在应用场景方面,不同模型具有各自的适用范围。YOLOv8 适用于对实时性和准确性都有一定要求的场景;MobileNet 适用于资源受限的移动和嵌入式设备场景;HigherHRNet 适用于对精度要求极高的专业领域。通过本研究,为研究者和开发者在不同应用场景下选择合适的姿态检测模型提供了全面的参考依据。
7.2 研究展望
尽管 YOLOv8、MobileNet 和 HigherHRNet 在姿态检测领域已经取得了显著成果,但仍存在进一步改进和发展的空间。在模型架构方面,未来可以探索更加高效的网络结构设计,结合不同模型的优势,如将 YOLOv8 的快速检测机制与 HigherHRNet 的高精度特征提取能力相结合,开发出性能更优的姿态检测模型。同时,可以利用神经架构搜索(NAS)等技术,自动搜索最优的网络结构和参数配置,提高模型的效率和性能。
在性能提升方面,针对各模型的局限性,需要进一步研究优化方法。对于 HigherHRNet,可以研究更高效的计算加速技术,如模型压缩、量化和剪枝等,在不损失过多精度的前提下,降低计算复杂度和推理时间。对于 MobileNet,可以探索新的特征提取和融合方法,增强其特征表达能力,提高检测精度。此外,随着硬件技术的不断发展,如边缘计算设备和专用 AI 芯片的出现,如何更好地利用这些硬件资源来加速姿态检测模型的运行,也是未来研究的重要方向。
在应用拓展方面,姿态检测技术可以与更多领域进行深度融合。例如,结合虚拟现实(VR)和增强现实(AR)技术,创造更加沉浸式的交互体验;在自动驾驶领域,通过检测行人姿态来提高车辆的安全性和智能性;在智能养老领域,利用姿态检测技术实时监测老年人的生活状态,提供及时的关怀和帮助。未来,随着技术的不断进步和创新,基于神经网络的姿态检测技术将在更多领域发挥重要作用,为人们的生活带来更多便利和价值。
相关文章:

基于神经网络的 YOLOv8、MobileNet、HigherHRNet 姿态检测比较研究
摘要 随着人工智能技术的飞速发展,基于神经网络的姿态检测技术在计算机视觉领域取得了显著进展。本文旨在深入比较分析当前主流的姿态检测模型,即 YOLOv8、MobileNet 和 HigherHRNet,从模型架构、性能表现、应用场景等多维度展开研究。通过详…...

智能手表 MCU 任务调度图
智能手表 MCU 任务调度图 处理器平台:ARM Cortex-M33 系统架构:事件驱动 多任务 RTOS RTOS:FreeRTOS(或同类实时内核) 一、任务调度概览 任务名称优先级周期性功能描述App_MainTask中否主循环调度器,系统…...

青少年编程与数学 02-019 Rust 编程基础 03课题、变量与可变性
青少年编程与数学 02-019 Rust 编程基础 03课题、变量与可变性 一、使用多个文件(模块)1. 创建包结构2. 在 main.rs 中引入模块示例:main.rs 3. 定义模块文件示例:module1.rs示例:module2.rs 4. 定义子模块示例&#x…...

S7-1500——零基础入门2、PLC的硬件架构
PLC的硬件架构 一,西门子PLC概述二,CPU介绍三,数字量模块介绍四,模拟量模块介绍五,其他模块介绍一,西门子PLC概述 本节主要内容 西门子PLC硬件架构,主要内容包括PLC概述、组成、功能及S7-1500 demo的组成与安装演示。 介绍了PLC的定义、功能、应用场合,以及与继电器控…...

前端面试宝典---webpack面试题
webpack 的 tree shaking 的原理 Webpack 的 Tree Shaking 过程主要包含以下步骤: 模块依赖分析:Webpack 首先构建一个完整的模块依赖图,确定每个模块之间的依赖关系。导出值分析:通过分析模块之间的 import 和 exportÿ…...

【PmHub后端篇】Skywalking:性能监控与分布式追踪的利器
在微服务架构日益普及的当下,对系统的性能监控和分布式追踪显得尤为重要。本文将详细介绍在 PmHub 项目中,如何使用 Skywalking 实现对系统的性能监控和分布式追踪,以及在这过程中的一些关键技术点和实践经验。 1 分布式链路追踪概述 在微服…...

Grafana v12.0 引入了多项新功能和改进
Grafana v12.0 引入了多项新功能和改进,旨在提升可观测性、仪表板管理和用户体验。以下是主要更新内容的总结: 🚀 主要新功能与改进 1. Git 同步仪表板(Git Sync) Grafana v12.0 支持将仪表板直接同步到 GitHub 仓库…...
利用“Flower”实现联邦机器学习的实战指南
一个很尴尬的现状就是我们用于训练 AI 模型的数据快要用完了。所以我们在大量的使用合成数据! 据估计,目前公开可用的高质量训练标记大约有 40 万亿到 90 万亿个,其中流行的 FineWeb 数据集包含 15 万亿个标记,仅限于英语。 作为…...

MongoDB使用x.509证书认证
文章目录 自定义证书生成CA证书生成服务器之间的证书生成集群证书生成用户证书 MongoDB配置java使用x.509证书连接MongoDBMongoShell使用证书连接 8.0版本的mongodb开启复制集,配置证书认证 自定义证书 生成CA证书 生成ca私钥: openssl genrsa -out ca…...

创始人 IP 的破局之道:从技术突围到生态重构的时代启示|创客匠人评述
在 2025 年的商业版图上,创始人 IP 正以前所未有的深度介入产业变革。当奥雅股份联合创始人李方悦在 “中国上市公司品牌价值榜” 发布会上,将 IP 赋能与城市更新大模型结合时,当马斯克在特斯拉财报电话会议上宣称 “未来属于自动驾驶和人形机…...

Gin 框架入门
Gin 框架入门 一、响应数据 JSON 响应 在 Web 开发中,JSON 是一种常用的数据交换格式。Gin 提供了简便的方法来响应 JSON 数据。 package mainimport ("github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/json", func(c *…...
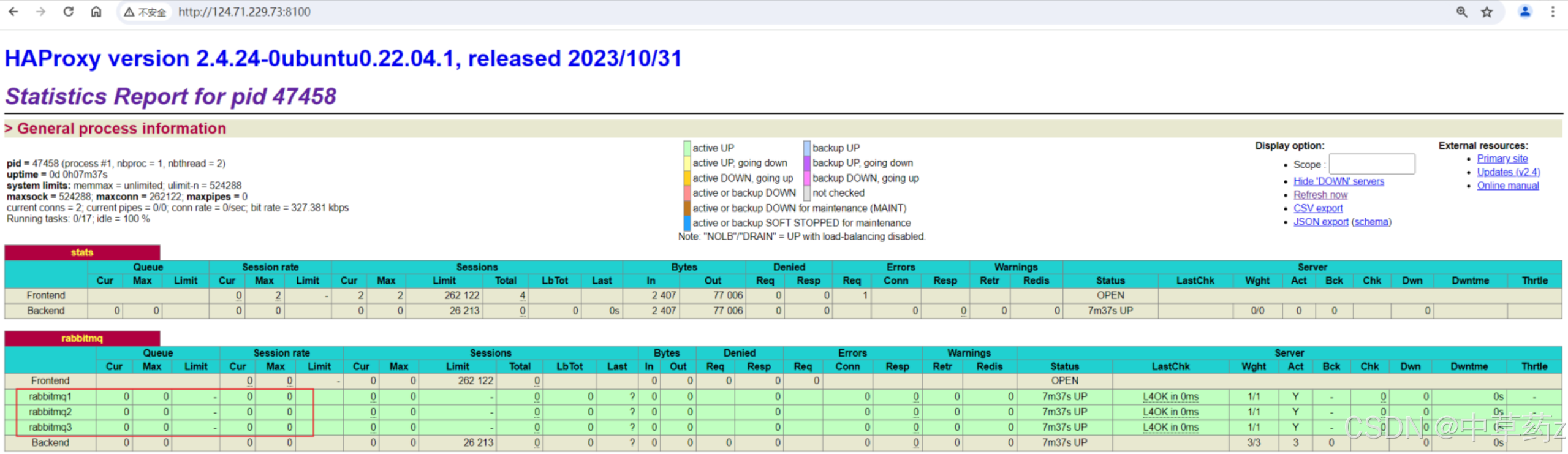
【RabbitMQ】应用问题、仲裁队列(Raft算法)和HAProxy负载均衡
🔥个人主页: 中草药 🔥专栏:【中间件】企业级中间件剖析 一、幂等性保障 什么是幂等性? 幂等性是指对一个系统进行重复调用(相同参数),无论同一操作执行多少次,这些请求…...

软件设计师-错题笔记-系统开发与运行
1. 解析: A:模块是结构图的基本成分之一,用矩形表示 B:调用表示模块之间的调用关系,通过箭头等符号在结构图中体现 C:数据用于表示模块之间的传递的信息,在结构图中会涉及数据的流向等表示 …...

硬件设备基础
一、ARM9 内核中有多少个通用寄存器?其中 sp、lr、pc、cpsr、spsr 的作用是什么? 在 ARM9 内核中,寄存器组织包含 37 个 通用寄存器,其中,有 13 个通用目的寄存器(R0 - R12)。 S3C2440 是 ARM 架…...

[编程基础] PHP · 学习手册
🔥 《PHP 工程师修炼之路:从零构建系统化知识体系》 🔥 🛠️ 专栏简介: 这是一个以工业级开发标准打造的 PHP 全栈技术专栏,涵盖语法精粹、异步编程、Zend引擎原理、框架源码、高并发架构等全维度知识体系…...
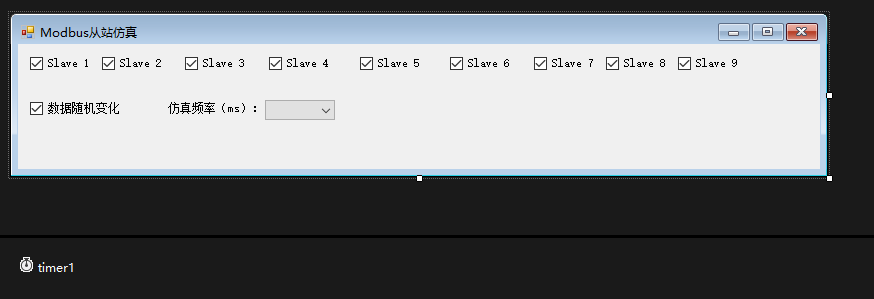
C#简易Modbus从站仿真器
C#使用NModbus库,编写从站仿真器,支持Modbus TCP访问,支持多个从站地址和动态启用/停用从站(模拟离线),支持数据变化,可以很方便实现,最终效果如图所示。 项目采用.net framework 4.…...
 dapper sqlite)
Error parsing column 10 (YingShou=-99.5 - Double) dapper sqlite
在使用sqlite 调取 dapper的时候出现这个问题提示: 原因是 在 sqlite表中设定的字段类型是 decimel而在C#的字段属性也是decimel,结果解析F负数 小数的时候出现这个错误提示: 解决办法:使用默认的sqlite的字段类型来填入 REAL描述…...

Spring AI系列——使用大模型对文本进行内容总结归纳分析
一、技术原理与架构设计 1. 技术原理 本项目基于 Spring AI Alibaba 框架,结合 DashScope 大模型服务 实现文本内容的自动摘要和结构化输出。核心原理如下: 文档解析: 使用 TikaDocumentReader 解析上传的文件(如 PDF、Word 等&…...
【深度学习】目标检测算法大全
目录 一、R-CNN 1、R-CNN概述 2、R-CNN 模型总体流程 3、核心模块详解 (1)候选框生成(Selective Search) (2)深度特征提取与微调 2.1 特征提取 2.2 网络微调(Fine-tuning) …...

5.1.1 WPF中Command使用介绍
WPF 的命令系统是一种强大的输入处理机制,它比传统的事件处理更加灵活和可重用,特别适合 MVVM (Model, View, ViewModel)模式开发。 一、命令系统核心概念 1.命令系统基本元素: 命令(Command): 即ICommand类,使用最多的是RoutedCommand,也可以自己继承ICommand使用自定…...

excel大表导入数据库
前文介绍了数据量较小的excel表导入数据库的方法,在数据量较大的情况下就不太适合了,一个是因为mysql命令的执行串长度有限制,二是node-xlsx这个模块加载excel文件是整个文件全部加载到内存,在excel文件较大和可用内存受限的场景就…...

《让歌声跨越山海:Flutter借助Agora SDK实现高质量连麦合唱》
对于Flutter开发者而言,借助Agora SDK实现这一功能,不仅能为用户带来前所未有的社交体验,更是在激烈的市场竞争中脱颖而出的关键。 Agora SDK作为实时通信领域的佼佼者,拥有一系列令人瞩目的特性,使其成为实现高质量连…...
 寻路)
A* (AStar) 寻路
//调用工具类获取路线 let route AStarSearch.getRoute(start_point, end_point, this.mapFloor.map_point); map_point 是所有可走点的集合 import { _decorator, Component, Node, Prefab, instantiate, v3, Vec2 } from cc; import { oops } from "../../../../../e…...

单词短语0512
当然可以,下面是“opportunity”在考研英语中的常用意思和高频短语,采用大字体展示,便于记忆: ✅ opportunity 的考研常用意思: 👉 机会,良机 表示有利的时机或条件,尤指成功的可能…...
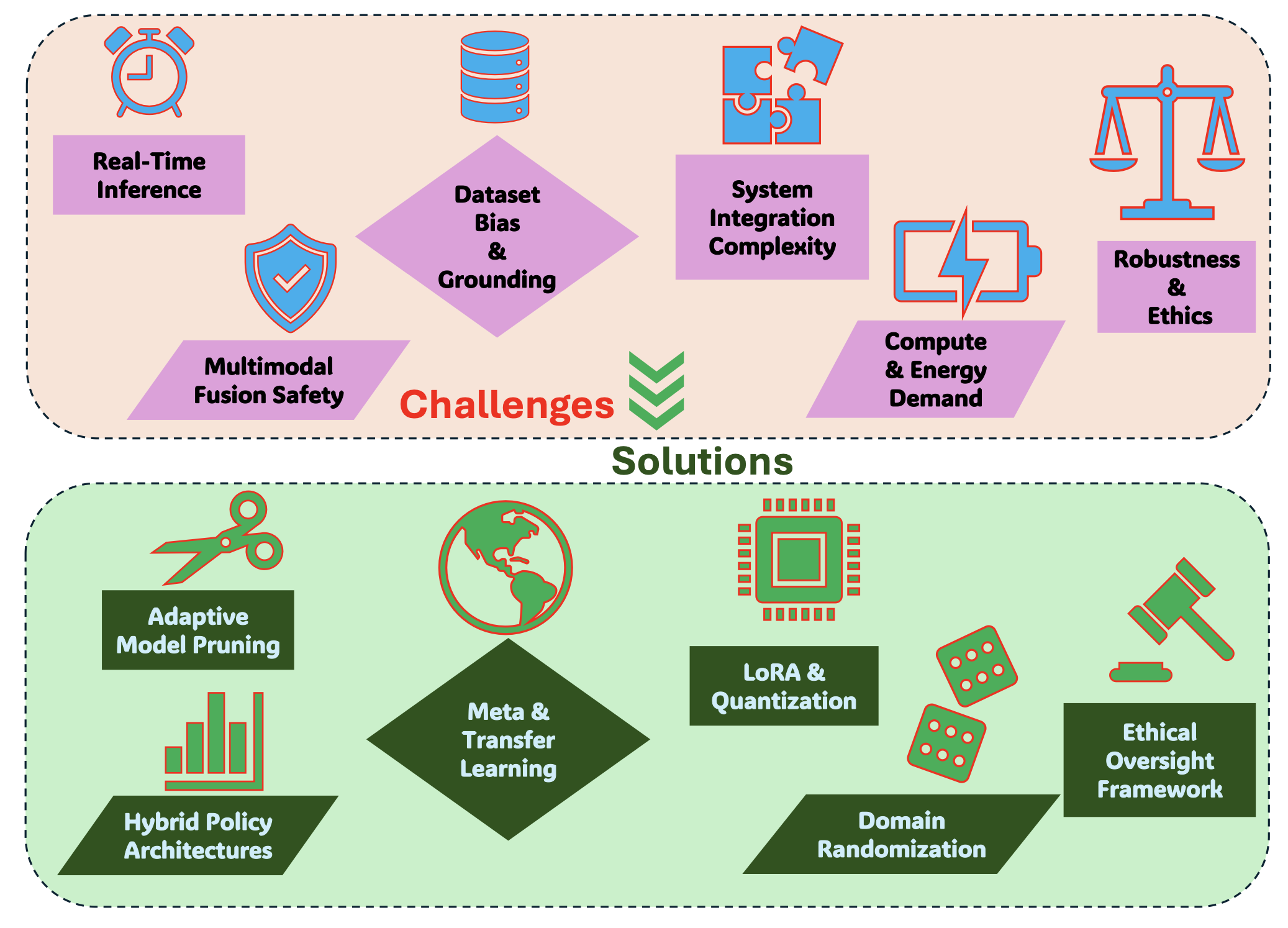
视觉-语言-动作模型:概念、进展、应用与挑战(下)
25年5月来自 Cornell 大学、香港科大和希腊 U Peloponnese 的论文“Vision-Language-Action Models: Concepts, Progress, Applications and Challenges”。 视觉-语言-动作 (VLA) 模型标志着人工智能的变革性进步,旨在将感知、自然语言理解和具体动作统一在一个计…...

一键解锁嵌入式UI开发——LVGL的“万能配方”
面对碎片化的嵌入式硬件生态,LVGL堪称开发者手中的万能配方。它通过统一API接口屏蔽底层差异,配合丰富的预置控件(如按钮、图表、滑动条)与动态渲染引擎,让工程师无需深入图形学原理,效率提升肉眼可见。 L…...
)
C# NX二次开发:宏录制实战讲解(第一讲)
今天要讲的是关于NX软件录制宏操作的一些案例。 下面讲如何在NX软件中复制Part体的录制宏。 NXOpen.Session theSession NXOpen.Session.GetSession(); NXOpen.Part workPart theSession.Parts.Work; NXOpen.Part displayPart theSession.Parts.Display; NXOpe…...

记录裁员后的半年前端求职经历
普通的人生终起波澜 去年下半年应该算是我毕业以来发生人生变故最多的一段时间。 先是 7 月份的时候发作了一次急性痛风,一个人在厦门,坐在床上路都走不了,那时候真的好想旁边能有个人能扶我去医院,真的是感受到 10 级的孤独。尝…...

Linux 文件查看|查找|压缩|解压 常用命令
cat 连接文件并打印到标准输出设备上 指令备注cat aaa.txt连接文件aaa并打印到标准输出设备上 more 以全屏幕的方式按页显示文本文件的内容 按Space键:显示文本的下一屏内容 按Enier键:只显示文本的下一行内容 指令备注more aaa.txt查看文件aaa le…...

什么是:Word2Vec + 余弦相似度
什么是:Word2Vec + 余弦相似度 目录 什么是:Word2Vec + 余弦相似度示例文本基于Word2Vec的文本向量化计算余弦相似度Word2Vec不是基于Transformer架构的Word2Vec是一种将单词转化为向量表示的模型,而Word2Vec + 余弦相似度则是一种利用Word2Vec得到的向量来计算文本相似性的…...