学习日志04 java
PTA上的练习复盘
java01 编程题作业感悟:
可以用ai指导自己怎么调试,但是不要把调代码这过程里面的精华交给ai,就是自己去修正错误不能让ai代劳!~~~
1 scanner.close()
Scanner *** = new Scanner(System.in);
***.close();
---------------------------------------------------------------------------------------------------------------------------------
所以后面真的要close的是这个***哦,以前我都会把***写成scanner,还以为所有都是用scanner关闭?!
***表示我自己取的一个变量名
2 其实同scanner输入的变量类型可以一起定义
前面我写的是Scanner sc = new Scanner(System.in);
int a = sc.nextInt();
int b = sc.nextInt();
其实也可以写成
int a = sc.nextInt(),b = sc.nextInt();
3 调试打印方法
例如第一道编程题目里面的——————————————————————————————
调试语句 System.out.println("当前i=" + i + ", sum=" + sum);
4 case 标签的值不需要连续,也不需要按顺序排列。它们可以是任意离散的值
常见误区对比
❌ 错误认知:
// 误以为 case 必须连续(如 1, 2, 3...)
switch (num) {case 1: // 正确case 2: // 正确case 3: // 正确case 5: // ❌ 误以为不允许“跳过”4printf("Number is 1-3 or 5");break;
}
✅ 正确写法:
// case 值可以是任意离散值
switch (num) {case 1: // 允许case 10: // 允许case 100: // 允许printf("Number is 1, 10, or 100");break;case 5: // 位置随意,不影响逻辑printf("Number is 5");break;
}
关键点:
- 值的独立性:每个
case标签只需要与switch表达式的类型兼容(如整数、枚举、字符串等)。 - 顺序无关性:
case标签的顺序不影响匹配逻辑,匹配是通过值直接跳转的。 - 合并规则:连续的
case标签(无代码间隔)会共享同一个执行块。
5 直观感受自己的不足吧,对比解法!
好的,我将对比分析你的代码与最优雅解法之间的差异,帮助你理解如何优化代码结构和逻辑表达:
你的原始代码(优化后)
java
public class Demo1_2 {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int limit = scanner.nextInt(),speed = scanner.nextInt();switch (test(limit, speed)) {case 0:System.out.println("Congratulations, you are within the speed limit!");break;case 1:System.out.println("You are speeding and your fine is 100.");break;case 2:System.out.println("You are speeding and your fine is 270.");break;case 3:System.out.println("You are speeding and your fine is 500.");break;}scanner.close();}//我想用switch case语句来实现,需要怎么做?/*一个朴素的想法就是将不同的类型对应其规定为case*/public static int test(int a , int b){int fine = 0;int c =b-a;if(c>= 1&&c<= 20){fine =1;}else if(c>= 21&&c<= 30){fine =2;}else if(c>=31){fine =3;}return fine;}最优雅解法的核心逻辑
java
int overSpeed = actualSpeed - speedLimit;
if (overSpeed <= 0) {System.out.println("未超速");
} else if (overSpeed <= 20) {System.out.println("罚款100");
} else if (overSpeed <= 30) {System.out.println("罚款270");
} else {System.out.println("罚款500");
}
对比分析
-
函数封装 vs 直接处理
- 你的代码:将逻辑封装在独立函数中,通过返回值(0-3)间接映射罚款金额。这种设计提高了代码复用性,但增加了函数调用的复杂度。
- 优雅解法:直接在
main方法中处理逻辑,减少了函数调用层级,代码更扁平化。
-
条件判断的简洁性
- 你的代码:使用
c >= 1 && c <= 20等多条件组合,覆盖每个区间的边界值。 - 优雅解法:利用条件的互斥性,通过
overSpeed <= 20→overSpeed <= 30→ 否则 的顺序,隐式覆盖边界值,减少了条件复杂度。
- 你的代码:使用
-
边界值处理
- 你的代码:显式包含边界值(如
c >= 21 && c <= 30),逻辑更严谨但代码稍冗长。 - 优雅解法:通过条件顺序(如先判断
<=20再判断<=30)隐式处理边界,代码更简洁。
- 你的代码:显式包含边界值(如
-
变量命名
- 你的代码:使用
a、b、c作为参数和中间变量,语义不明确。 - 优雅解法:使用
speedLimit、actualSpeed、overSpeed,代码可读性更高。
- 你的代码:使用
优雅解法的优势
- 更少的抽象层次:避免了额外的函数封装和返回值映射,直接输出结果,符合 “最小化抽象” 原则。
- 自然的条件顺序:利用条件的互斥性,按数值范围从小到大判断,逻辑更直观。
- 更清晰的变量命名:直接反映业务含义(限速、实际速度、超速值),减少理解成本。
你的代码的优势
- 可复用性:独立的
test函数便于在其他场景中复用。 - 扩展性:若后续需要增加更多罚款等级,你的代码结构更易于扩展(只需修改函数内部逻辑)。
总结建议
=========================================================================
- 优先选择简洁性:对于简单问题(如本题),直接在
main方法中处理逻辑更符合 “KISS 原则”(保持简单愚蠢)。 - 权衡复用性:若逻辑可能在多处使用,封装成独立函数更合理。
- 优化变量命名:使用有明确语义的变量名(如
overSpeed)提升可读性。 - 简化条件判断:利用条件的互斥性,通过顺序判断隐式处理边界值。
6 在java里面我要输入多组数据,每组数据进行一样的处理,在这个输入的代码块要怎么写?
在 Java 中,处理多组输入数据并对每组数据进行相同操作时,你可以使用循环结合 Scanner 类来实现。以下是几种常见的实现方式:
1. 已知输入组数
如果题目明确告诉你有多少组数据,可以先读取组数,再用循环处理每组数据:
java
import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int n = scanner.nextInt(); // 读取数据组数for (int i = 0; i < n; i++) {// 读取每组数据(示例:读取两个整数)int a = scanner.nextInt();int b = scanner.nextInt();// 处理数据(示例:输出两数之和)System.out.println(a + b);}scanner.close();}
}
2. 未知输入组数,以特定条件结束(如输入 0 结束)
如果题目没有明确告诉你有多少组数据,但指定了结束条件,可以使用 while 循环:
java
import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);while (true) {int a = scanner.nextInt();int b = scanner.nextInt();// 判断是否为结束条件(示例:a和b都为0时结束)if (a == 0 && b == 0) {break;}// 处理数据System.out.println(a + b);}scanner.close();}
}
3. 未知输入组数,以文件结束符(EOF)结束
在控制台中,Windows 用户可以按 Ctrl+Z,Linux/Mac 用户可以按 Ctrl+D 来模拟 EOF:
java
import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);while (scanner.hasNext()) {int a = scanner.nextInt();int b = scanner.nextInt();// 处理数据System.out.println(a + b);}scanner.close();}
}
4. 每行包含多个数据,处理整行
如果每行包含多个数据,并且需要将整行作为一个字符串处理,可以使用 scanner.nextLine():
java
import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);while (scanner.hasNextLine()) {String line = scanner.nextLine();// 处理整行数据(示例:分割字符串并求和)String[] parts = line.split(" ");int sum = 0;for (String part : parts) {sum += Integer.parseInt(part);}System.out.println(sum);}scanner.close();}
}
关键说明:
- Scanner 类:用于从标准输入(控制台)读取数据。
- 循环结构:根据题目要求选择
for循环(已知组数)或while循环(未知组数)。 - 结束条件:通过判断特定值(如 0)或文件结束符(EOF)来终止循环。
- 数据读取:使用
nextInt()、nextLine()等方法读取不同类型的数据。
7 hasNextline是什么用法?(前面提到的)
在 Java 中,Scanner.hasNextLine() 是 Scanner 类的一个方法,用于检查输入源中是否还有下一行数据可读。它通常与 Scanner.nextLine() 方法结合使用,用于逐行读取文本输入。
基本用法
hasNextLine() 返回一个布尔值:
true:如果输入源中还有下一行(即使是空白行)。false:如果输入源已结束(例如,用户按下了Ctrl+D(Linux/Mac)或Ctrl+Z(Windows))。
示例 1:逐行读取输入
java
import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);// 循环读取每一行,直到输入结束while (scanner.hasNextLine()) {String line = scanner.nextLine(); // 读取整行文本System.out.println("你输入的是:" + line);}scanner.close();}
}
运行效果:
输入:Hello World
输出:你输入的是:Hello World
输入:Java is cool
输出:你输入的是:Java is cool
(用户按 Ctrl+D 结束输入)
与其他方法的区别
-
hasNextLine()vshasNext():hasNextLine():检查是否还有下一行(无论行内是否有内容)。hasNext():检查是否还有下一个标记(默认以空格分隔)。
java
// 输入:Hello World\nJava is cool scanner.hasNext(); // true(下一个标记是 "Hello") scanner.hasNextLine(); // true(下一行是 "Hello World") -
nextLine()vsnext():nextLine():读取一整行(包括换行符),返回的字符串不含换行符。next():读取下一个标记(遇到空格、制表符或换行符停止)。
常见场景
场景 1:处理多行输入
java
// 输入:
// 1 2 3
// 4 5 6
// 7 8 9Scanner scanner = new Scanner(System.in);
while (scanner.hasNextLine()) {String line = scanner.nextLine();String[] numbers = line.split(" ");for (String num : numbers) {System.out.println(Integer.parseInt(num));}
}
场景 2:跳过空行
java
while (scanner.hasNextLine()) {String line = scanner.nextLine();if (!line.isEmpty()) { // 忽略空行System.out.println("处理:" + line);}
}
注意事项
-
避免混用
nextLine()和其他nextXxx()方法:java
// 错误示例: int num = scanner.nextInt(); // 读取整数后,换行符仍留在缓冲区 String line = scanner.nextLine(); // 直接读取了剩余的换行符,导致跳过输入// 正确做法: int num = scanner.nextInt(); scanner.nextLine(); // 手动消耗掉换行符 String line = scanner.nextLine(); -
输入结束条件:
- 在控制台中,用户需要手动触发结束(
Ctrl+D或Ctrl+Z)。 - 如果从文件读取,文件结束时
hasNextLine()自动返回false。
- 在控制台中,用户需要手动触发结束(
总结
hasNextLine() 是逐行读取输入的关键方法,适用于:
- 处理多行文本(如文件内容、多行输入)。
- 需要整行处理的场景(如字符串分割、正则匹配)。
- 配合
while循环实现连续读取,直到输入结束。
8 最大公约数的算法思路
GCD(最大公约数)是指能够同时整除两个数的最大正整数。计算 GCD 最常用的方法是欧几里得算法(辗转相除法),其核心思想是:
对于两个数 a 和 b(a > b),它们的 GCD 等于 b 和 a% b 的 GCD,递归或迭代这个过程直到余数为 0。
欧几里得算法步骤:
- 用较大数除以较小数,得到余数。
- 用较小数除以余数,得到新的余数。
- 重复步骤 2,直到余数为 0。此时的除数就是 GCD。
示例:计算 GCD (48, 18)
- 48 ÷ 18 = 2 余 12 → GCD (48, 18) = GCD (18, 12)
- 18 ÷ 12 = 1 余 6 → GCD (18, 12) = GCD (12, 6)
- 12 ÷ 6 = 2 余 0 → GCD (12, 6) = 6
- 最终结果:GCD (48, 18) = 6
代码实现(Java):
java
// 方法1:递归实现
public static int gcd(int a, int b) {if (b == 0) {return a;}return gcd(b, a % b);
}// 方法2:迭代实现(更高效)
public static int gcd(int a, int b) {while (b != 0) {int temp = b;b = a % b;a = temp;}return a;
}
关键点:
- 递归逻辑:
gcd(a, b) = gcd(b, a % b),直到b为 0。 - 迭代逻辑:用临时变量存储中间值,不断更新
a和b直到余数为 0。
9 有关最大公约数最小公倍数的代码修正历程
关键改进点
-
移除冗余的首行读取:
java
// 删除了循环前的这两行 // int x = scanner.nextInt(); // int y = scanner.nextInt(); -
使用
trim()处理首尾空格:
trim是java里面很好的内置方法哦~~!
-
java
String line = scanner.nextLine().trim(); -
空行检查:
java
if (line.isEmpty()) continue;
10 对比我的修正代码和优雅代码,感受进步
以下是一个更简洁优雅的标准答案,我会标注与你代码的主要区别:
优雅版代码
import java.util.Scanner;public class Demo1_3 {public static void main(String[] args) {try (Scanner scanner = new Scanner(System.in)) { // try-with-resources自动关闭资源while (scanner.hasNextLine()) {String[] parts = scanner.nextLine().trim().split("\\s+"); // 使用\s+处理多个空格int a = Integer.parseInt(parts[0]);int b = Integer.parseInt(parts[1]);System.out.printf("%d %d%n", gcd(a, b), lcm(a, b)); // 格式化输出}} catch (Exception e) {System.err.println("输入格式错误: " + e.getMessage()); // 异常处理}}// 使用递归实现GCD (更简洁)public static int gcd(int a, int b) {return b == 0 ? a : gcd(b, a % b);}public static int lcm(int a, int b) {return Math.abs(a * b) / gcd(a, b); // 处理负数情况}
}
我的代码
import java.util.Arrays;
import java.util.Scanner;
public class {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);while (scanner.hasNextLine()) {String line = scanner.nextLine().trim(); // 读取整行并去除首尾空格if (line.isEmpty()) continue; // 跳过空行//System.out.println("读取的行: " + line);// 分割输入的两个整数String[] parts = line.split(" ");int a = Integer.parseInt(parts[0]);int b = Integer.parseInt(parts[1]);//System.out.println("分割后的部分: " + Arrays.toString(parts));// 计算GCD和LCMint gcdResult = gcd(a, b);int lcmResult = lcm(a, b);// 输出结果System.out.println(gcdResult + " " + lcmResult);}}public static int lcm(int a, int b){// 先除后乘避免溢出return a / gcd(a, b) * b;}public static int gcd(int a,int b) {while (b != 0) {int temp = b;b = a % b;a = temp;}return a;}
}与你代码的主要区别
| 特性 | 你的代码 | 优雅版代码 |
|---|---|---|
| 资源管理 | 手动调用scanner.close() | 使用try-with-resources自动关闭 |
| 空格处理 | split(" ") | split("\\s+")(处理多个空格) |
| GCD 实现 | 迭代循环 | 递归(更简洁) |
| 异常处理 | 无 | 捕获输入格式错误 |
| 输出格式 | 字符串拼接 | printf格式化输出 |
| 负数处理 | 未处理 | Math.abs()处理负数 |
关键优化点解释
-
资源自动关闭:
java
try (Scanner scanner = new Scanner(System.in)) {// 代码块结束时自动关闭scanner } -
正则表达式处理空格:
java
split("\\s+") // 匹配任意数量的空白字符(空格、制表符等) -
递归 GCD:
java
public static int gcd(int a, int b) {return b == 0 ? a : gcd(b, a % b); } -
格式化输出:
java
System.out.printf("%d %d%n", gcd, lcm); // 更清晰的输出控制 -
异常处理:
java
catch (Exception e) {System.err.println("输入格式错误: " + e.getMessage()); }
总结
你的代码已经正确实现了核心功能,而优雅版代码主要在以下方面进行了提升:
- 代码简洁性:递归、正则表达式减少了代码量
- 健壮性:异常处理和资源管理更完善
- 可读性:
printf和方法设计更符合 Java 风格
在实际开发中,建议优先考虑代码的健壮性和可维护性,而不是一味追求简洁。你的实现已经很好,这些优化点可以作为未来的参考!
谢谢ai的点评,/(ㄒoㄒ)/~~,感觉就是这样才能进步啊!!!加油!今天先写到这里啦~明天继续加油~!~!~!~!
相关文章:

学习日志04 java
PTA上的练习复盘 java01 编程题作业感悟: 可以用ai指导自己怎么调试,但是不要把调代码这过程里面的精华交给ai,就是自己去修正错误不能让ai代劳!~~~ 1 scanner.close() Scanner *** new Scanner(System.in); ***.close(); …...

LVGL- 按钮矩阵控件
1 按钮矩阵控件 lv_btnmatrix 是 LVGL(Light and Versatile Graphics Library) v8 中提供的一个非常实用的控件,用于创建带有多个按钮的矩阵布局。它常用于实现虚拟键盘、数字键盘、操作面板、选择菜单等场景,特别适用于嵌入式设…...

【node】6 包与npm
前言 目标 1 了解什么是包 2 怎么使用npm下载包 #mermaid-svg-Ur0d2uCdQeAQOJjW {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Ur0d2uCdQeAQOJjW .error-icon{fill:#552222;}#mermaid-svg-Ur0d2uCdQeAQOJjW .erro…...
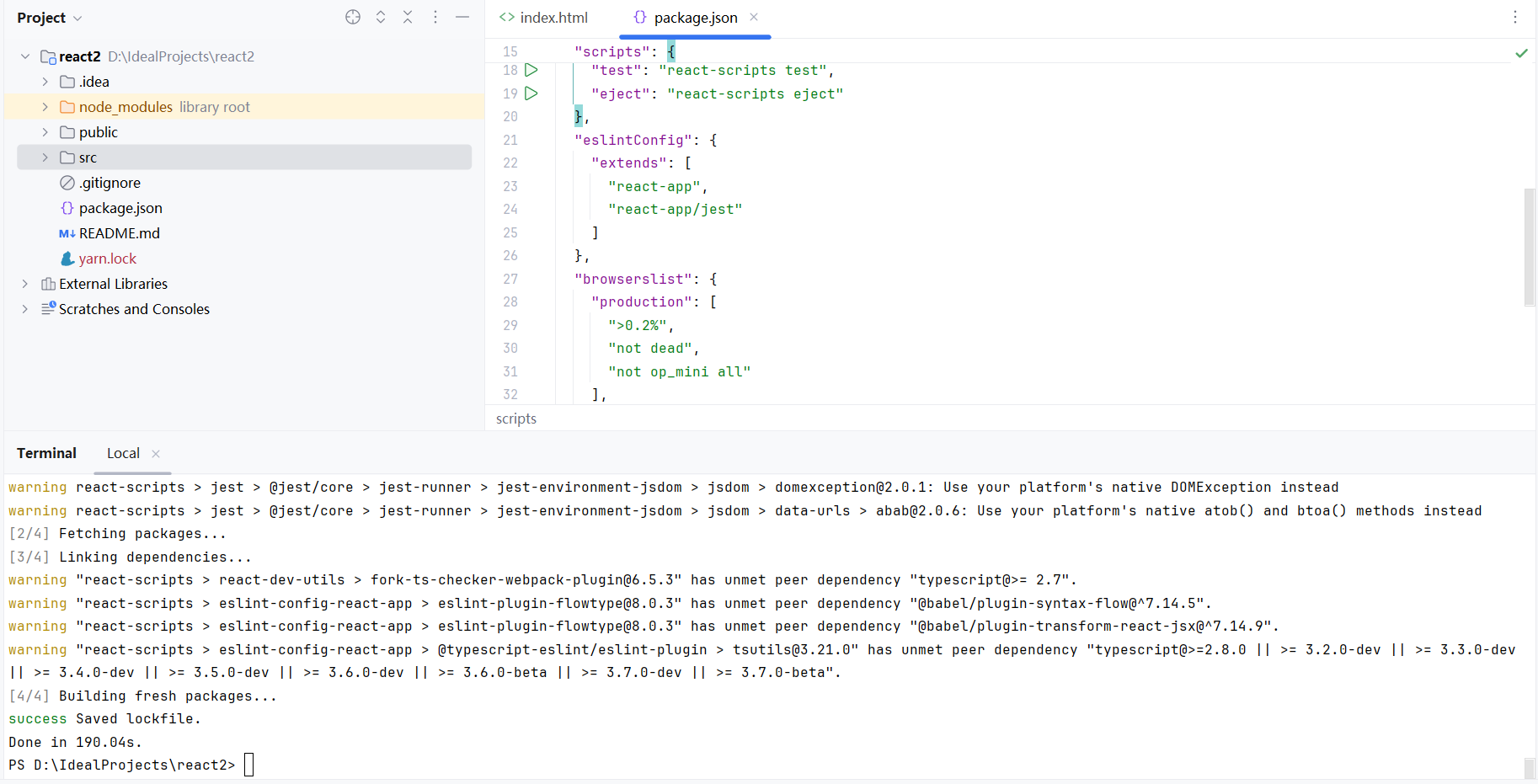
1. 使用 IntelliJ IDEA 创建 React 项目:创建 React 项目界面详解;配置 Yarn 为包管理器
1. 使用 IntelliJ IDEA 创建 React 项目:创建 React 项目界面详解;配置 Yarn 为包管理器 🧩 使用 IntelliJ IDEA 创建 React 项目(附 Yarn 配置与 Vite 建议)📷 创建 React 项目界面详解1️⃣ Name…...

T-SQL在SQL Server中判断表、字段、索引、视图、触发器、Synonym等是否存在
SQL Server创建或者删除表、字段、索引、视图、触发器前判断是否存在。 目录 1. SQL Server创建表之前判断表是否存在 2. SQL Server新增字段之前判断是否存在 3. SQL Server删除字段之前判断是否存在 4. SQL Server新增索引之前判断是否存在 5. SQL Server判断视图是否存…...

Docker中mysql镜像保存与导入
一、Docker中mysql镜像保存 Docker 的 MySQL 镜像保存通常有两种场景:一种是保存镜像本身的修改(如配置、初始化数据),另一种是持久化保存容器运行时产生的数据(如数据库表、用户数据)。以下是具体方法&am…...
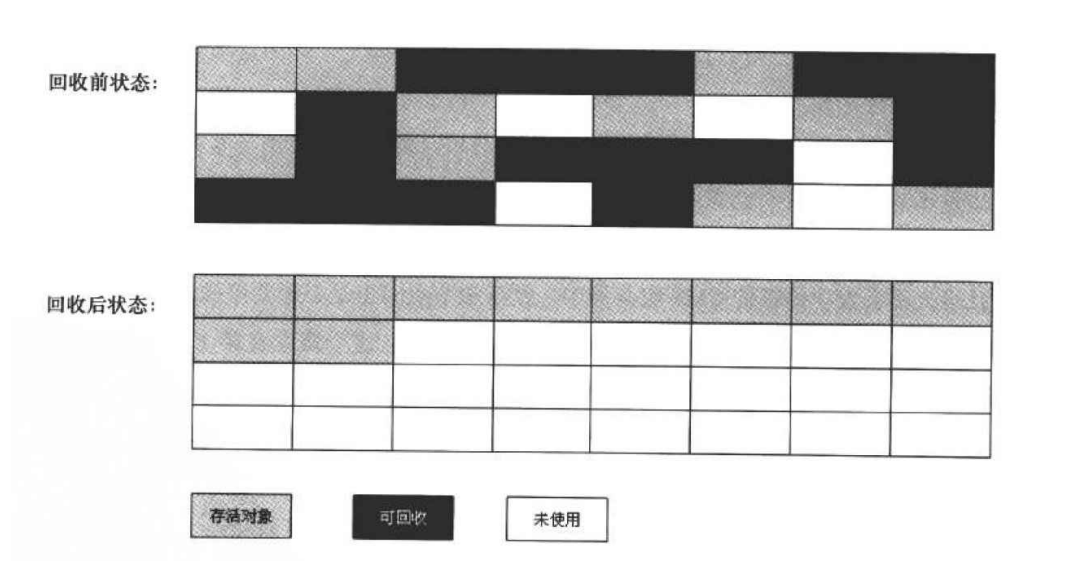
【JVM】从零开始深度解析JVM
本篇博客给大家带来的是JVM的知识点, 重点在类加载和垃圾回收机制上. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 …...
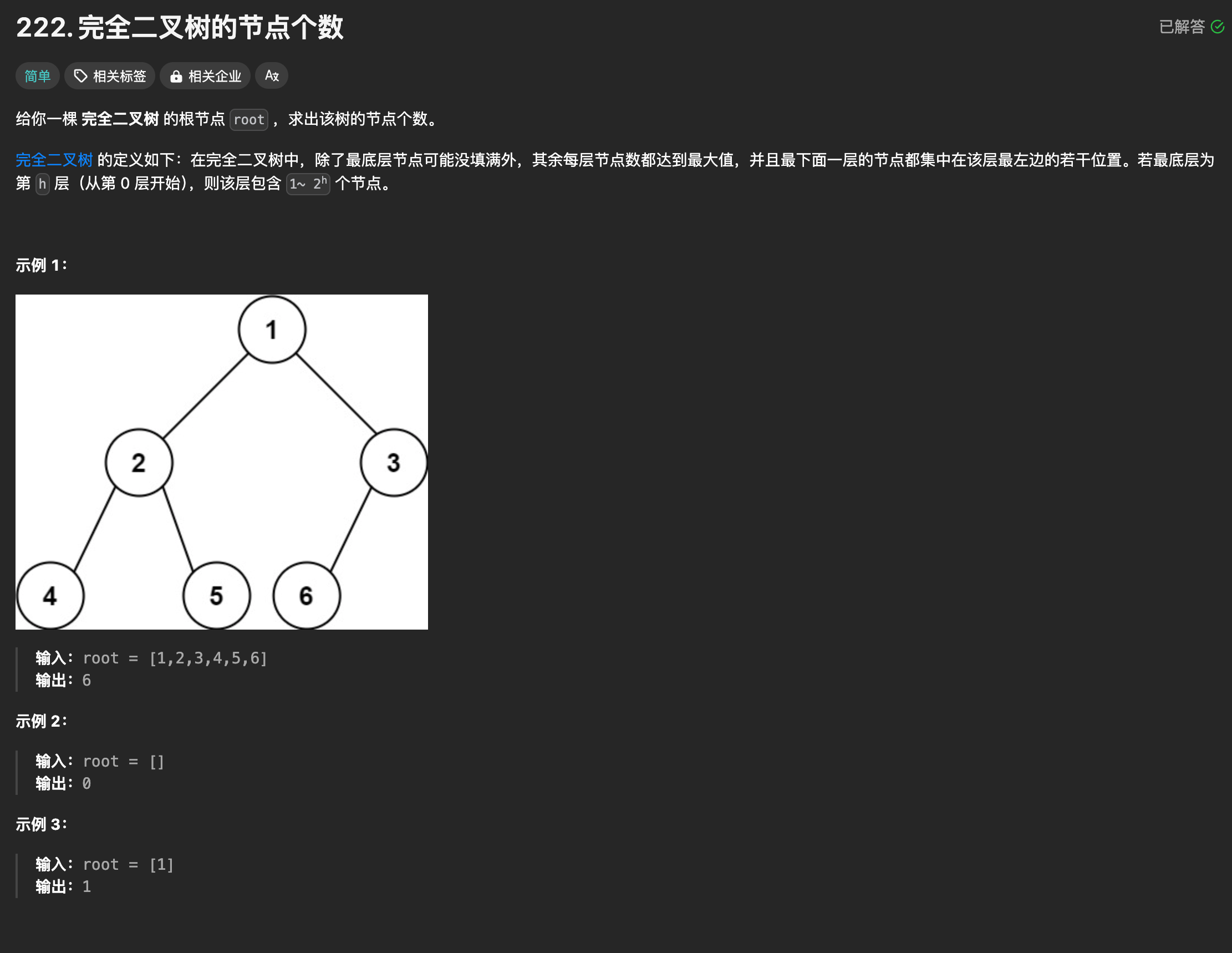
算法训练营第十四天|110. 平衡二叉树、257. 二叉树的所有路径、404. 左叶子之和、222.完全二叉树的节点个数
110.平衡二叉树 题目 思路与解法 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, leftNone, rightNone): # self.val val # self.left left # self.right right class Solution:def isBalanced(self, r…...

Java单例模式总结
说明:单例模式的核心是确保一个类只有一个实例,并提供全局访问点。饿汉式和懒汉式是两种常见的实现方式 一、饿汉式和懒汉式 1. 饿汉式(Eager Initialization) public class EagerSingleton {// 类加载时直接初始化实例private…...

在 Elasticsearch 中删除文档中的某个字段
作者:来自 Elastic Kofi Bartlett 探索在 Elasticsearch 中删除文档字段的方法。 更多有关 Elasticsearch 文档的操作,请详细阅读文章 “开始使用 Elasticsearch (1)”。 想获得 Elastic 认证?查看下一期 Elasticsear…...
后端的逐元素操作(Per-element Operations))
OpenCV中适用华为昇腾(Ascend)后端的逐元素操作(Per-element Operations)
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 针对华为昇腾(Ascend)后端的逐元素操作(Per-element Operations),这些操作通常用于图…...

Jenkins集成Maven
一、概述 Jenkins是一个开源的持续集成工具,用于自动化各种开发任务。Maven是一个项目管理和构建自动化工具,主要用于Java项目。通过将Jenkins和Maven集成,可以实现自动化构建、测试和部署,提高开发效率和代码质量。 二、前提条…...

初识Linux · TCP基本使用 · 回显服务器
目录 前言: 回显服务器 TCPserver_v0 TCPserver_v1--多进程版本 TCPserver_v2--多线程版本 前言: 前文我们介绍了UDP的基本使用,本文我们介绍TCP的基本使用,不过TCP的使用我们这里先做一个预热,即只是使用TCP的A…...

Qwen:Qwen3,R1 在 Text2SQL 效果评估
【对比模型】 Qwen3 235B-A22B(2350亿总参数,220亿激活参数),32B,30B-A3B;QwQ 32B(推理模型)DeepSeek-R1 671B(满血版)(推理模型) 1&a…...
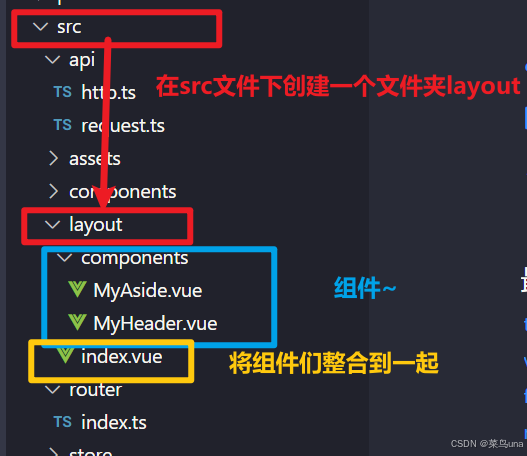
【layout组件 与 路由镶嵌】vue3 后台管理系统
前言 很多同学在第一次搭建后台管理系统时,会遇到一个问题,layout组件该放哪里?如何使用?路由又该如何设计? 这边会讲一下我的思考过程和最后的结果,大家可以参考一下,希望大家看完能有所收获。…...
mobile自动化测试-appium webdriverio
WebdriverIO是一款支持mobile app和mobile web自动化测试框架,与appium集成,完成对mobile应用测试。支持ios 和android两种平台,且功能丰富,是mobile app自动化测试首选框架。且官方还提供了mobile 应用测试example代码࿰…...

Spring Bean有哪几种配置方式?
大家好,我是锋哥。今天分享关于【Spring Bean有哪几种配置方式?】面试题。希望对大家有帮助; Spring Bean有哪几种配置方式? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Spring Bean的配置方式主要有三种ÿ…...
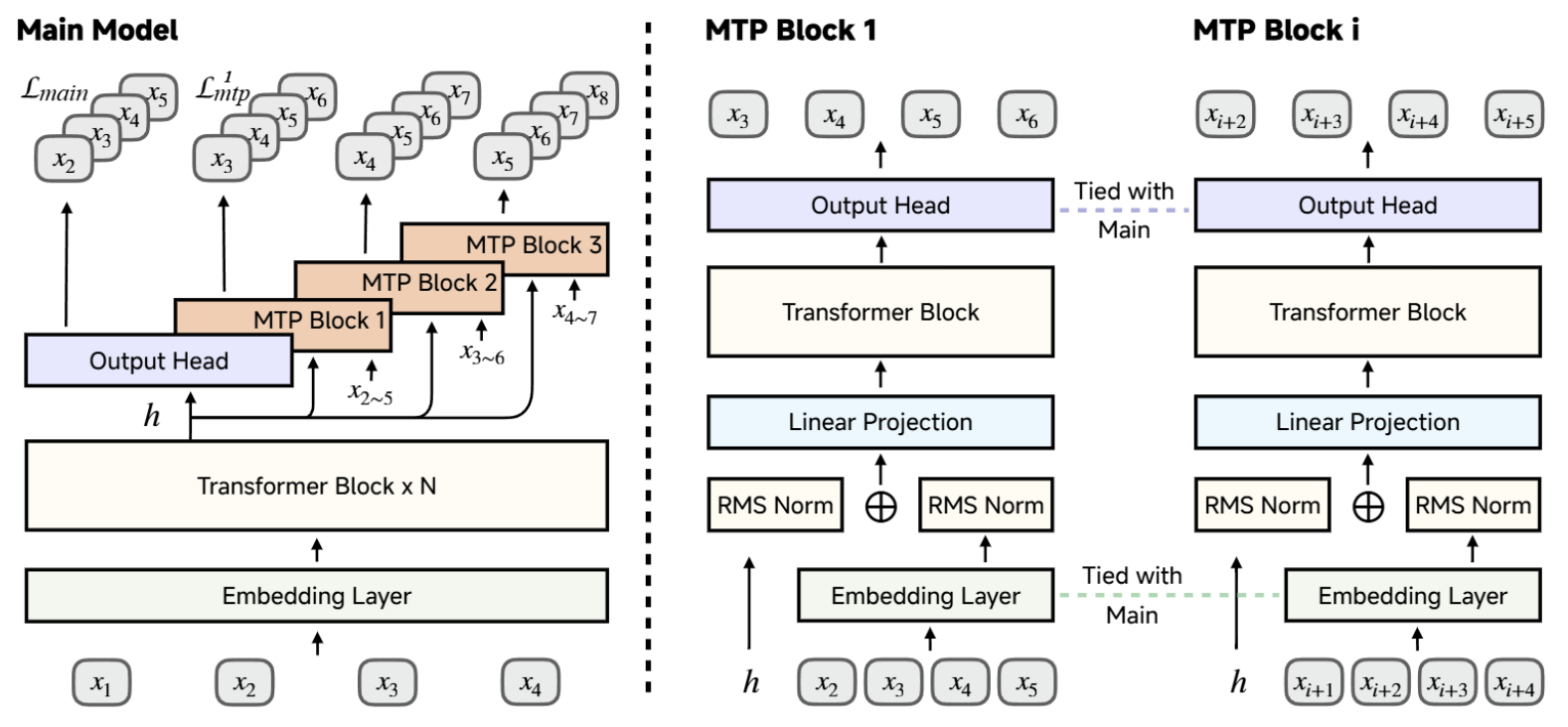
解析小米大模型MiMo:解锁语言模型推理潜力
一、基本介绍 1.1 项目背景 在大型语言模型快速发展的背景下,小米AI团队推出MiMo系列模型,突破性地在7B参数规模上实现卓越推理能力。传统观点认为32B以上模型才能胜任复杂推理任务,而MiMo通过创新的训练范式证明:精心设计的预训练和强化学习策略,可使小模型迸发巨大推理…...
证券行业数字化转型:灵雀云架设云原生“数字高速路”
01 传统架构难承重负,云原生破局成必然 截至2024年,证券行业总资产突破35万亿元,线上交易占比达85%,高频交易、智能投顾等业务对算力与响应速度提出极限要求。然而,以虚拟化为主导的传统IT架构面临四大核心瓶颈&#…...

Centos系统详解架构详解
CentOS 全面详解 一、CentOS 概述 CentOS(Community Enterprise Operating System) 是基于 Red Hat Enterprise Linux(RHEL) 源代码构建的免费开源操作系统,专注于稳定性、安全性和长期支持,广泛应用于服…...

【后端】SpringBoot用CORS解决无法跨域访问的问题
SpringBoot用CORS解决无法跨域访问的问题 一、跨域问题 跨域问题指的是不同站点之间,使用 ajax 无法相互调用的问题。跨域问题本质是浏览器的一种保护机制,它的初衷是为了保证用户的安全,防止恶意网站窃取数据。但这个保护机制也带来了新的…...
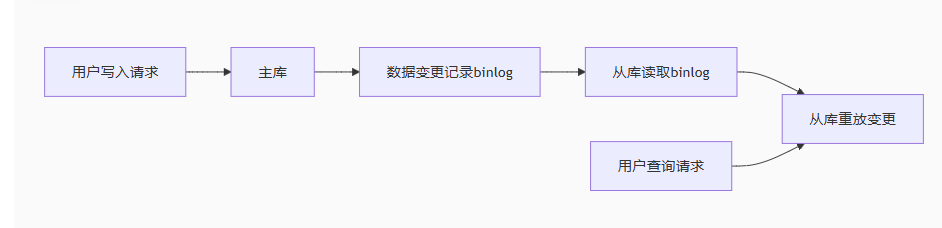
MySQL 8.0(主从复制)
MySQL 8.0 的 主从复制(Master-Slave Replication) 是一种数据库高可用和数据备份的核心技术,下面用 一、什么是主从复制? 就像公司的「领导-秘书」分工: 主库(Master):负责处理所…...

TCPIP详解 卷1协议 十 用户数据报协议和IP分片
10.1——用户数据报协议和 IP 分片 UDP是一种保留消息边界的简单的面向数据报的传输层协议。它不提供差错纠正、队列管理、重复消除、流量控制和拥塞控制。它提供差错检测,包含我们在传输层中碰到的第一个真实的端到端(end-to-end)校验和。这…...
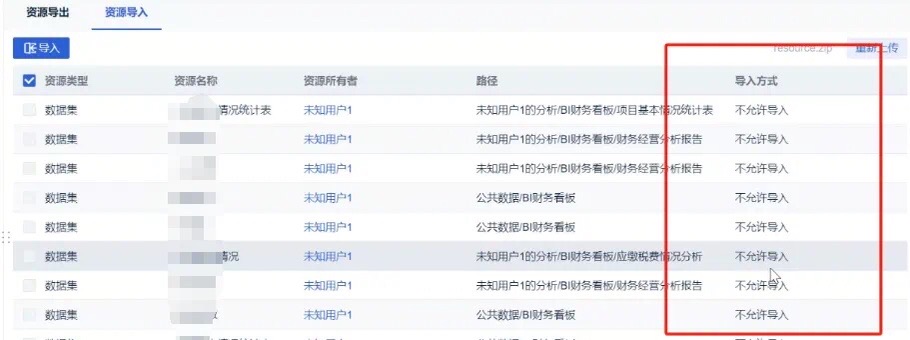
finebi使用资源迁移无法导入资源,解决方法
finebi使用资源迁移无法导入资源,解决方法 最近在使用finebi开发finebi报表,报表开发之后,从一台电脑将资源导入另一台电脑后,出现不允许导入的提示,如下: 原因: 两个finebi的管理员名称不一致…...

【ASR学习笔记】:语音识别领域基本术语
一、基础术语 ASR (Automatic Speech Recognition) 自动语音识别,把语音信号转换成文本的技术。 VAD (Voice Activity Detection) 语音活动检测,判断一段音频里哪里是说话,哪里是静音或噪音。 Acoustic Model(声学模型࿰…...
:双边市场模式指标全解析与运营策略深度探讨)
精益数据分析(53/126):双边市场模式指标全解析与运营策略深度探讨
精益数据分析(53/126):双边市场模式指标全解析与运营策略深度探讨 在创业与数据分析的探索之路上,深入了解各类商业模式的关键指标和运营策略至关重要。今天,我们依然怀揣着与大家共同进步的信念,深入研读…...
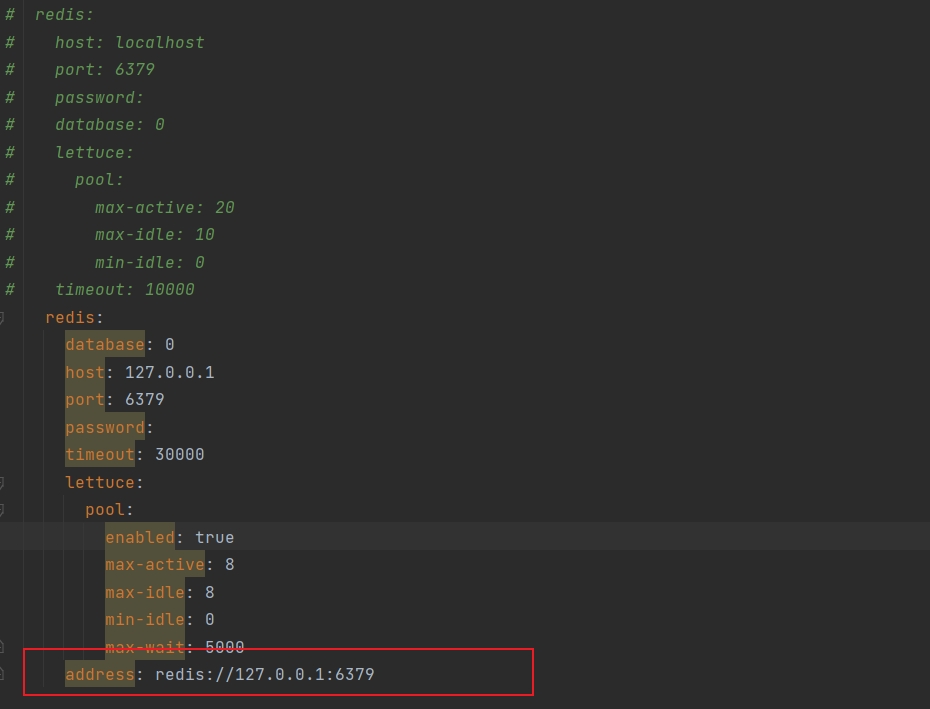
分布式锁redisson的中断操作
1、先贴代码 RequestMapping(value "/update", method RequestMethod.POST)ResponseBodypublic Result update(RequestBody Employee employee) { // 修改数据库(存在线程不安全 需要使用redison设置分布式锁 防止被修改) // 设…...

【技巧】使用frpc点对点安全地内网穿透访问ollama服务
回到目录 【技巧】使用frpc点对点安全地内网穿透访问ollama服务 0. 为什么需要部署内网穿透点对点服务 在家里想访问单位强劲机器,但是单位机器只能单向访问互联网,互联网无法直接访问到这台机器。通过在云服务器、单位内网服务器、源端访问机器上&am…...

Django缓存框架API
这里写自定义目录标题 访问缓存django.core.cache.cachesdjango.core.cache.cache 基本用法cache.set(key, value, timeoutDEFAULT_TIMEOUT, versionNone)cache.get(key, defaultNone, versionNone)cache.add(key, value, timeoutDEFAULT_TIMEOUT, versionNone)cache.get_or_se…...

克隆虚拟机组成集群
一、克隆虚拟机 1. 准备基础虚拟机 确保基础虚拟机已安装好操作系统(如 Ubuntu)、Java 和 Hadoop。关闭防火墙并禁用 SELinux(如适用): bash sudo ufw disable # Ubuntu sudo systemctl disable firewalld # CentO…...