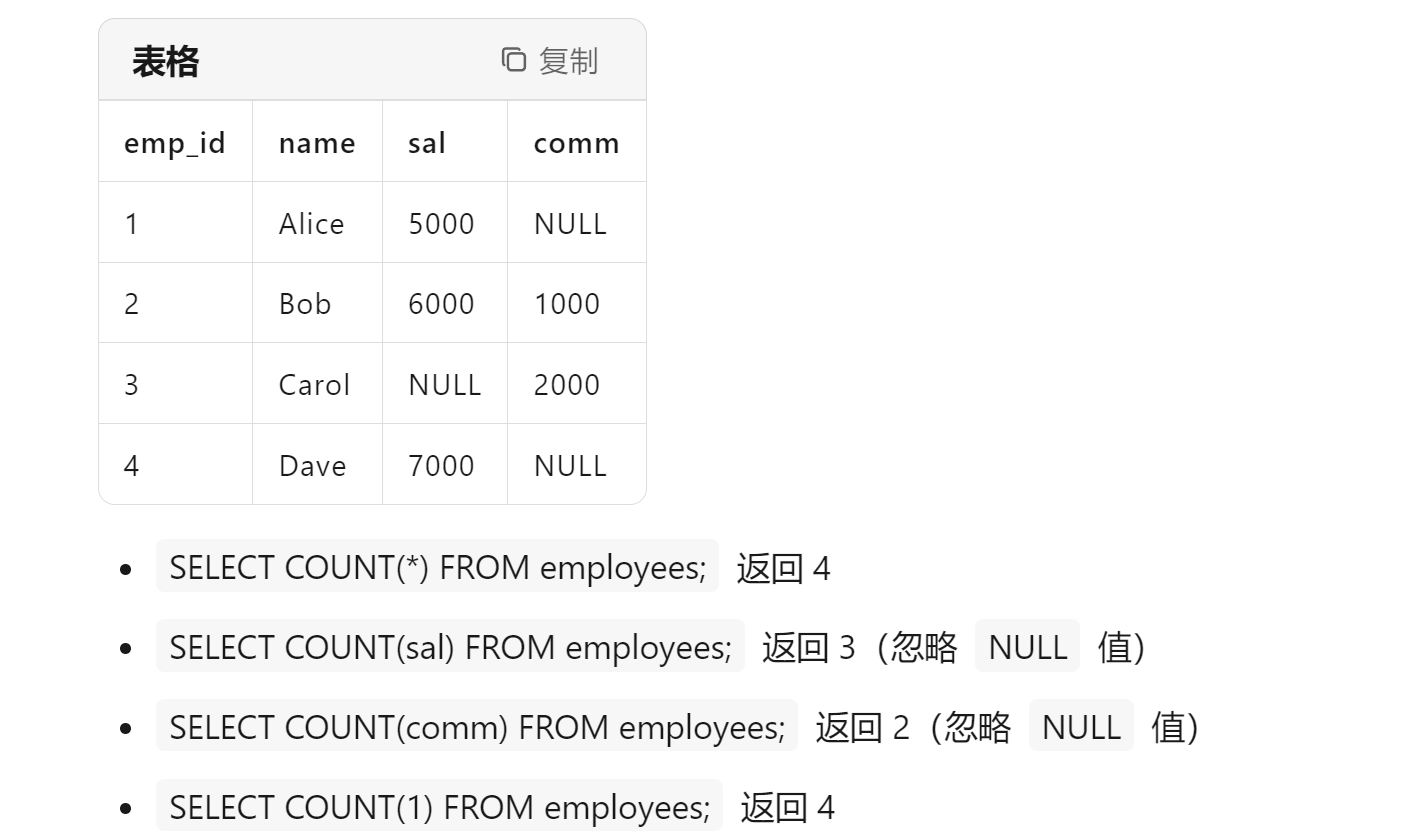
[sklearn] 特征工程
一.字典数据抽取
def dictvec():"""字典数据抽取:return: None"""# 实例化# sparse改为True,输出的是每个不为零位置的坐标,稀疏矩阵可以节省存储空间dict = DictVectorizer(sparse=False) #矩阵中存在大量的0,sparse存储只记录非零位置,节省空间# 调用fit_transformdata = dict.fit_transform([{'city': '北京', 'temperature': 100},{'city': '上海', 'temperature': 60},{'city': '深圳', 'temperature': 30}])print(dict.get_feature_names_out()) # 字典中的一些类别数据,分别进行转换成特征print(data)print('-' * 50)#print(dict.inverse_transform(data)) #去看每个特征代表的含义,逆转回去return Nonedictvec()输出结果:
按照顺序,比如第一个样本city为北京,那么对应北京列的值为1,其它为0.

二.词提取(英文)
def couvec():# 实例化CountVectorizer# max_df, min_df整数:指每个词的所有文档词频数不小于最小值,出现该词的文档数目小于等于max_df# max_df, min_df小数:每个词的次数/所有文档数量# min_df=2vector = CountVectorizer()# 调用fit_transform输入并转换数据#三个样本res = vector.fit_transform(["life is short,i like python life","life is too long,i dislike python","life is short"])# 打印结果,把每个词都分离了print(vector.get_feature_names_out())# 对照feature_names,标记每个词出现的次数print(res.toarray()) #print(vector.inverse_transform(res))couvec()输出结果:比如,第一行表示第一个样本中各个词出现的次数,单个字符不统计
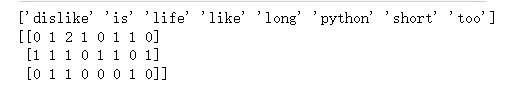
三.词提取(中文)
def countvec():"""对文本进行特征值化,单个汉字单个字母不统计,因为单个汉字字母没有意义:return: None"""cv = CountVectorizer()data = cv.fit_transform(["人生苦短,我 喜欢 python", "人生漫长,不用 python"])print(cv.get_feature_names_out())#print(data)print(data.toarray())return Nonecountvec()
输出结果: 这里样本必须每个词要间隔空格,下面会讲使用jieba库自动分词

四.词提取(jieba库)
def cutword():#这里小例子手动输入样本值con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")# 转换成列表content1 = list(con1)content2 = list(con2)content3 = list(con3)# 把列表转换成字符串c1 = ' '.join(content1)c2 = ' '.join(content2)c3 = ' '.join(content3)return c1, c2, c3def hanzivec():"""中文特征值化:return: None"""#为了举例,在函数中已经固定好样本c1, c2, c3 = cutword()#print(c1, c2, c3)cv = CountVectorizer()data = cv.fit_transform([c1, c2, c3])#得到分词类别print(cv.get_feature_names_out())#打印矩阵形式print(data.toarray())return Nonehanzivec()输出结果:jieba库会根据中文的习惯来进行分词
五.使用tfidf值
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度
公式:重要性=tf*idf
其中
tf:词的频率出现次数
idf:lg(总文档数量/该词出现的文档数量)
# 规范{'l1','l2'},默认='l2'
# 每个输出行都有单位范数,或者:
#
# 'l2':向量元素的平方和为 1。当应用 l2 范数时,两个向量之间的余弦相似度是它们的点积。
#
# 'l1':向量元素的绝对值之和为 1。参见preprocessing.normalize。# smooth_idf布尔值,默认 = True
# 通过在文档频率上加一来平滑 idf 权重,就好像看到一个额外的文档包含集合中的每个术语恰好一次。防止零分裂。def tfidfvec():"""中文特征值化,计算tfidf值:return: None"""c1, c2, c3 = cutword()#print(c1, c2, c3)#print(type([c1, c2, c3]))tf = TfidfVectorizer()data = tf.fit_transform([c1, c2, c3])print(tf.get_feature_names_out())#print(type(data))print(data.toarray())return Nonetfidfvec()输出结果: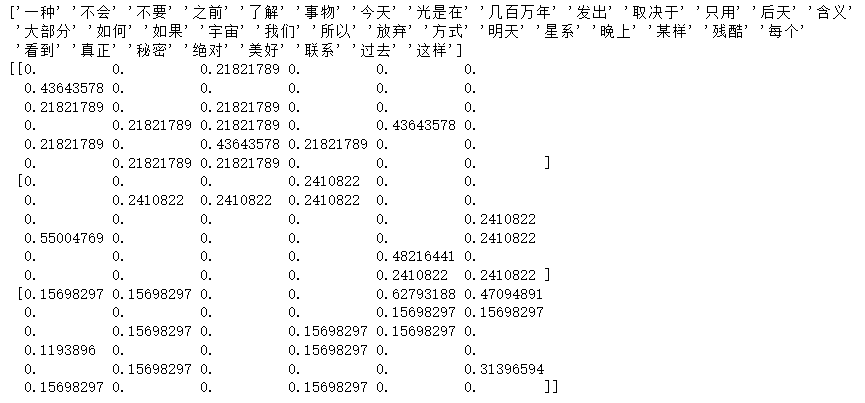
六.特征处理
参数:自己设置的参数
超参数:模型自己训练的时候变化的参数
为什么要特征处理?
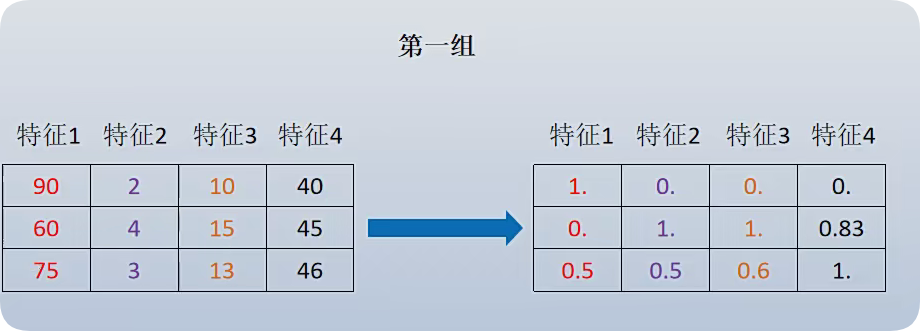
为了防止特征本来的数值就很大,对输出的影响很大,所以要进行特征处理
1.归一化
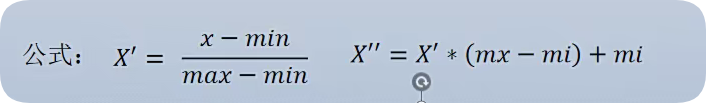
好处:容易更快的通过梯度下降找到最优解
sklearn接口
from sklearn.preprocessing import MinMaxScaler
def mm():"""归一化处理:return: NOne"""# 归一化容易受极值的影响,范围到0.1之间,也可以设置其它范围mm = MinMaxScaler(feature_range=(0, 1))data = mm.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]])print(data)return Nonemm()输出结果:比如第一个1,是90-60/90-60=1
注意:这里max 和min是针对每列,因为每列是一种特征

2.标准化
特点:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
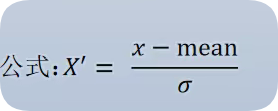
mean是均值,σ是标准差
from sklearn.preprocessing import StandardScaler
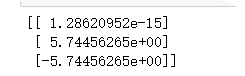
def stand():"""标准化缩放,不是标准正太分布,只均值为0,方差为1的分布:return:"""std = StandardScaler()data = std.fit_transform([[1., -1., 3.], [2., 4., 2.], [4., 6., -1.]])print(data)print(std.mean_) print(std.var_)#print(std.n_samples_seen_) # 样本数print('-' * 50)#这里是拿得到的结果来验证是否满足均值为0,方差为1data1 = std.fit_transform([[-1.06904497, -1.35873244, 0.98058068],[-0.26726124, 0.33968311, 0.39223227],[1.33630621, 1.01904933, -1.37281295]])print(data1) #这个并不是我们想看的,没意义# 均值print(std.mean_)# 方差print(std.var_)# 样本数#print(std.n_samples_seen_)return Nonestand()结果:‘------’上方是结果,下方是拿到结果反向验证是否符合均值为0,方差为1

3.缺失值处理
#下面是填补,针对删除,可以用pd和np
def im():"""缺失值处理:return:NOne"""# NaN, nan,缺失值必须是这种形式,如果是?号(或者其他符号),就要replace换成这种im = SimpleImputer(missing_values=np.nan, strategy='mean')data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6], [3, 2]]) #(1+7+3)/3 = 3.666 print(data)return Noneim()输出结果:strategy = mean指定了使用均值来填补,比如(1+7+3)/3 = 3.666 注意这里分母不包含nan的数量

4.删除方差低的特征
因为方差低,说明此特征的区别度很小
def var():"""特征选择-删除低方差的特征:return: None"""#默认只删除方差为0,threshold是方差阈值,删除比这个值小的那些特征var = VarianceThreshold(threshold=1)data = var.fit_transform([[0, 2, 0, 3],[0, 1, 4, 3],[0, 1, 1, 3]])print(data)# 获得剩余的特征的列编号print('The surport is %s' % var.get_support(True))return Nonevar()输出结果:删除了方差低于阈值1的列,

5.PCA算法降维
算法思想详细参考:降维算法之PCA:从原理到应用,8000多字,助你彻底理解!_pca降维-CSDN博客
def pca():"""主成分分析进行特征降维:return: None"""# n_ components:小数 0~1 90% 业界选择 90~95%## 整数 减少到的特征数量pca = PCA(n_components=1)data = pca.fit_transform([[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]])print(data)return Nonepca()输出结果:设置n_components=1 即降到1维
相关文章:
[sklearn] 特征工程
一.字典数据抽取 def dictvec():"""字典数据抽取:return: None"""# 实例化# sparse改为True,输出的是每个不为零位置的坐标,稀疏矩阵可以节省存储空间dict DictVectorizer(sparseFalse) #矩阵中存在大量的0,sparse存储只…...
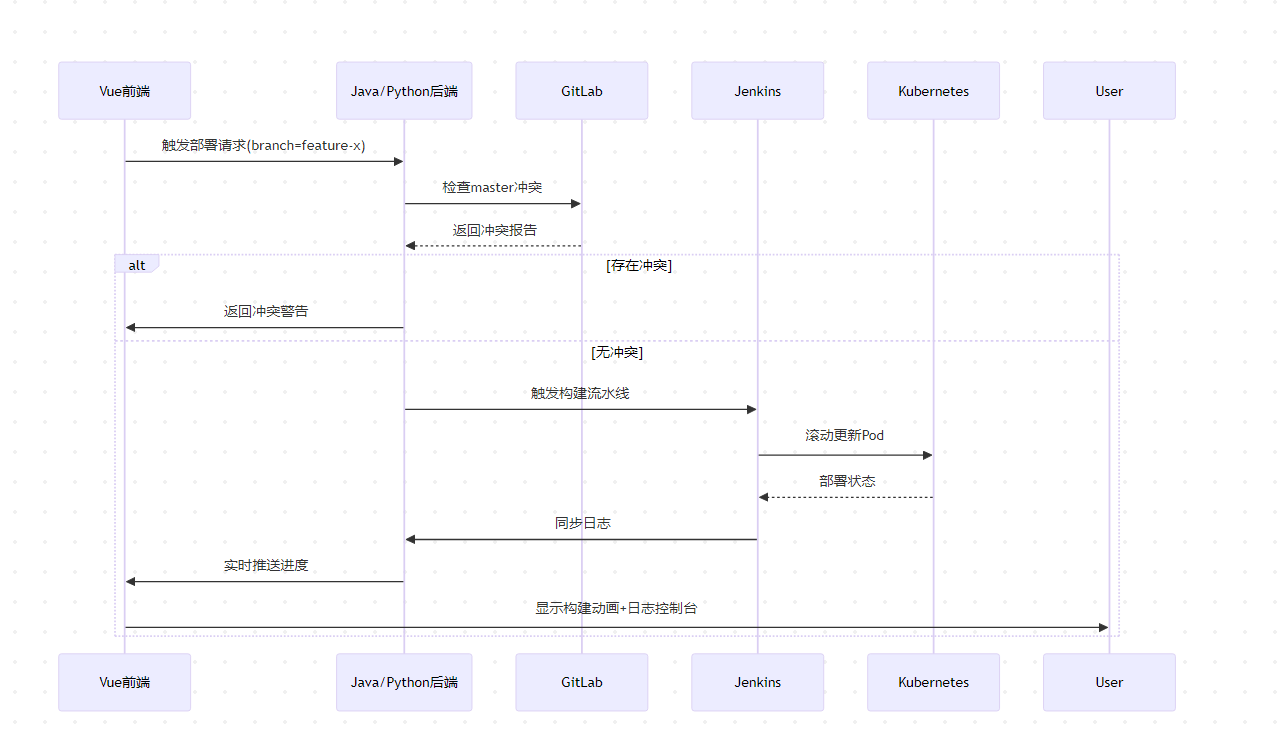
CI/CD与DevOps流程流程简述(提供思路)
一 CI/CD流程详解:代码集成、测试与发布部署 引言 在软件开发的世界里,CI/CD(持续集成/持续交付)就像是一套精密的流水线,确保代码从开发到上线的整个过程高效、稳定。我作为一名资深的软件工程师,接下来…...
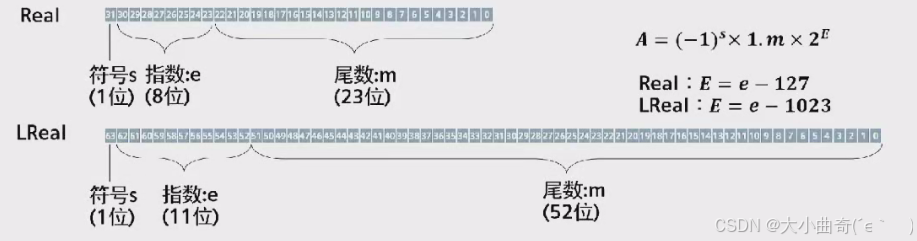
S7-1500——零基础入门1、工业编程基本概念
工业编程基本概念 一,数制与基本数据类型二,数字量信号三,模拟量信号一,数制与基本数据类型 本节主要内容 类别内容主题数制与基本数据类型数制讲解十进制、十六进制、二进制及其进位规则;基数、位权概念数据类型介绍PLC 使用的数据类型:未序列数据类型(bit、byte、wor…...
六、快速启动框架:SpringBoot3实战
六、快速启动框架:SpringBoot3实战 目录 一、SpringBoot3介绍 1.1 SpringBoot3简介1.2 系统要求1.3 快速入门1.4 入门总结 二、SpringBoot3配置文件 2.1 统一配置管理概述2.2 属性配置文件使用2.3 YAML配置文件使用2.4 批量配置文件注入2.5 多环境配置和使用 三、…...
万兴PDF-PDFelement v11.4.13.3417
万兴PDF专家(Wondershare PDFelement)是一款国产PDF文档全方位解决方案.万兴PDF编辑器软件万兴PDF中文版,专注于PDF的创建,编辑,转换,签名,压缩,合并,比较等功能.万兴PDF专业版PDF编辑软件,以简约风格及强大的功能在国外名声大噪,除了传统功能外,还提供OCR扫描,表格识别,创建笔…...

LSP里氏替换原则
LSP强调子类必须能够替换父类。即子类应该具有与父类相同的行为和功能,而不仅仅是继承父类的属性和方法。LSP是对继承机制的约束规范、是指导接口与实现的设计原则。 LSP关键点 前置条件不能强化:子类方法的参数类型必须与父类相同或者更为宽松。后置条…...
机器学习-无量纲化与特征降维(一)
一.无量纲化-预处理 无量纲,即没有单位的数据 无量纲化包括"归一化"和"标准化",这样做有什么用呢?假设用欧式距离计算一个公司员工之间的差距,有身高(m)、体重(kg&#x…...

C语言复习--柔性数组
柔性数组是C99中提出的一个概念.结构体中的最后⼀个元素允许是未知大小的数组,这就叫做柔性数组成员。 格式大概如下 struct S { int a; char b; int arr[];//柔性数组 }; 也可以写成 struct S { int a; char b; int arr[0];//柔性数组 }; …...
图形化编程如何从工具迭代到生态重构?
一、技术架构的范式突破 在图形化编程领域,技术架构的创新正在重塑行业格局。iVX 作为开源领域的领军者该平台通过图形化逻辑设计,将传统文本编程需 30 行 Python 代码实现的 "按钮点击→条件判断→调用接口→弹窗反馈" 流程,简化…...
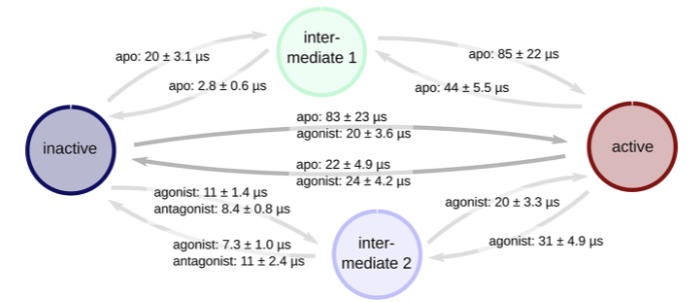
法国蒙彼利埃大学团队:运用元动力学模拟与马尔可夫状态模型解锁 G 蛋白偶联受体构象动态机制
背景简介 在生命科学领域,G 蛋白偶联受体(GPCRs)一直是研究的热点。它作为膜蛋白家族的重要成员,承担着细胞对多种刺激的响应任务,从激素、神经递质到外源性物质的信号传导都离不开它。据估计,约三分之一的…...

【PostgreSQL】不开启归档模式,是否会影响主从库备份?
PostgreSQL 不开启归档模式(archive_mode off)不会直接影响基于流复制(Streaming Replication)的主从备份,但可能会在特定场景下影响复制的健壮性和恢复能力。以下是详细分析: 1. 流复制的核心机制 流复制…...
网页Web端无人机直播RTSP视频流,无需服务器转码,延迟300毫秒
随着无人机技术的飞速发展,全球无人机直播应用市场也快速扩张,从农业植保巡检到应急救援指挥,从大型活动直播到智慧城市安防,实时视频传输已成为刚需。预计到2025年,全球将有超过1000万架商用无人机搭载直播功能&#…...
)
Shell脚本编程3(函数+正则表达式)
1.函数 1.1 定义 简单来讲,所谓函数就是把完成特定功能,并且多次使用的一组命令或者语句封装在一个固定的结构中,这个结构我们就叫做函数。从本质上讲,函数是将一个函数名与某个代码块进行映射。也就是说,用户在定义了…...
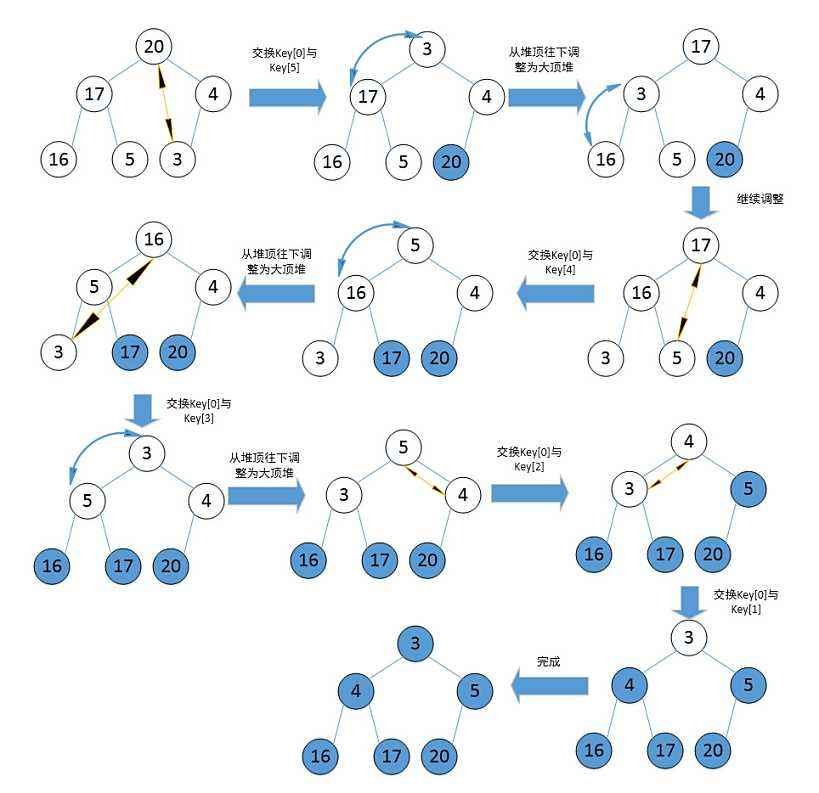
数据结构-堆排序
1.定义 -堆中每个节点的值都必须大于等于(或小于等于)其左右子节点的值。如果每个节点的值都大于等于其子节点的值,这样的堆称为大根堆(大顶堆);如果每个节点的值都小于等于其子节点的值,称为…...
)
HTML简单语法标签(后续实操:云备份项目)
以下是一些 HTML 的简单语法标签及其功能介绍: 基本结构标签 <!DOCTYPE html>:声明文档类型为 HTML5<html>:HTML 文档的根标签<head>:包含文档元数据(如标题、字符编码等)<title>…...
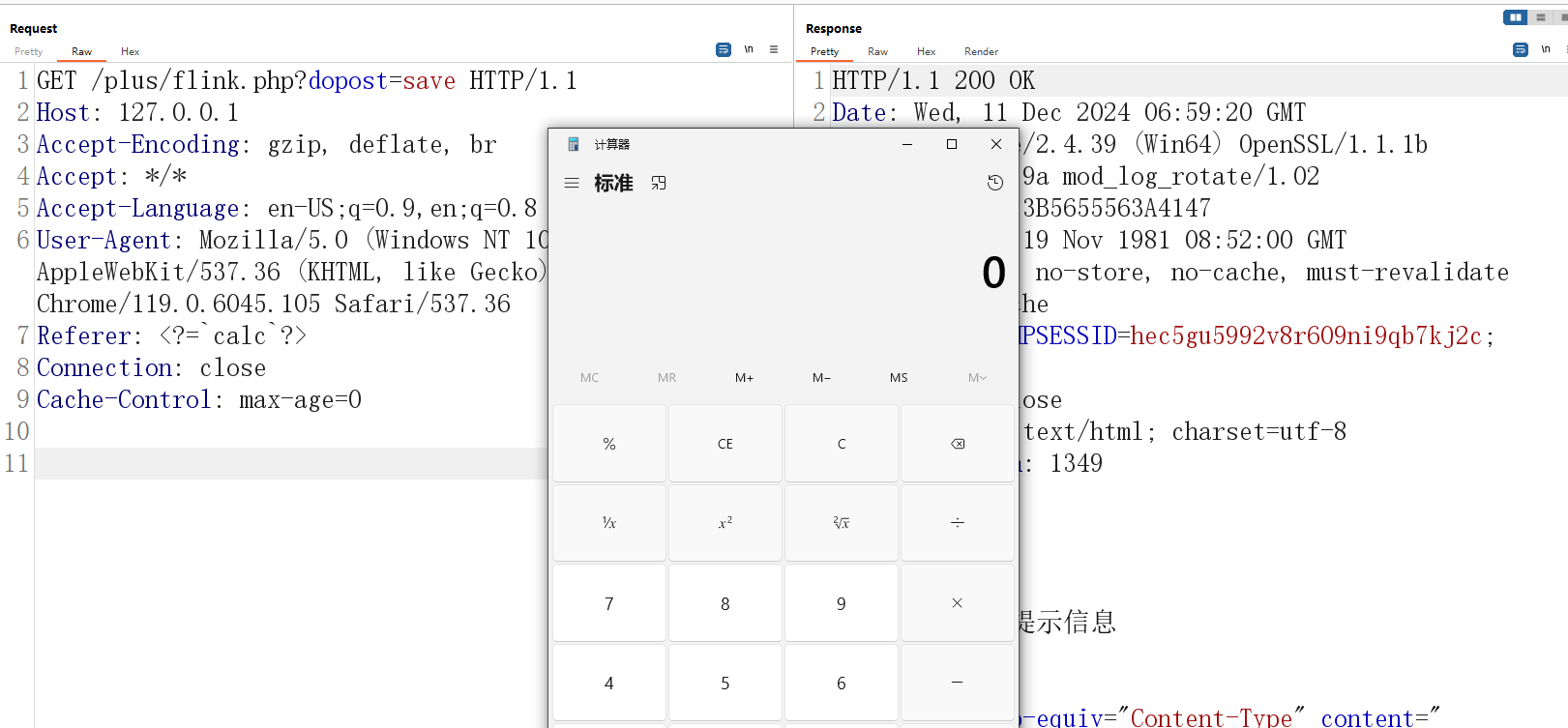
DedeCMS-Develop-5.8.1.13-referer命令注入研究分析 CVE-2024-0002
本次文章给大家带来代码审计漏洞挖掘的思路,从已知可控变量出发或从函数功能可能照成的隐患出发,追踪参数调用及过滤。最终完成代码的隐患漏洞利用过程。 代码审计挖掘思路 首先flink.php文件的代码执行逻辑,可以使用php的调试功能辅助审计 …...

运用数组和矩阵对数据进行存取和运算——NumPy模块 之五
目录 NumPy模块介绍 3.5.1 NumPy 操纵数组元素的逻辑 3.5.2 添加数组元素操作 1. append() 函数 2. insert() 函数 3.5.3 删除数组元素的操作 delete() 函数 3.5.4 数组元素缺失情况的处理 isnan() 函数 3.5.5 处理数组中元素重复情况 unique() 函数 3.5.6 拼接数组操作 1. con…...
Nginx的增强与可视化!OpenResty Manager - 现代化UI+高性能反向代理+安全防护
以下是对OpenResty Manager的简要介绍: OpenResty Manager (Nginx 增强版),是一款容易使用、功能强大且美观的反向代理工具 ,可以作为OpenResty Edge 的开源替代品基于 OpenResty 开发,支持并继承 OpenRes…...
Linux:43线程封装与互斥lesson31
mmap文件映射视屏:待看... 目录 线程栈 代码证明:一个线程的数据,其他线程也可以访问 线程封装 简单封装,2.thread Thread.hpp Main.cc Makefile 结果: 编辑 问题1: 问题2: lamba表达式 模版封…...
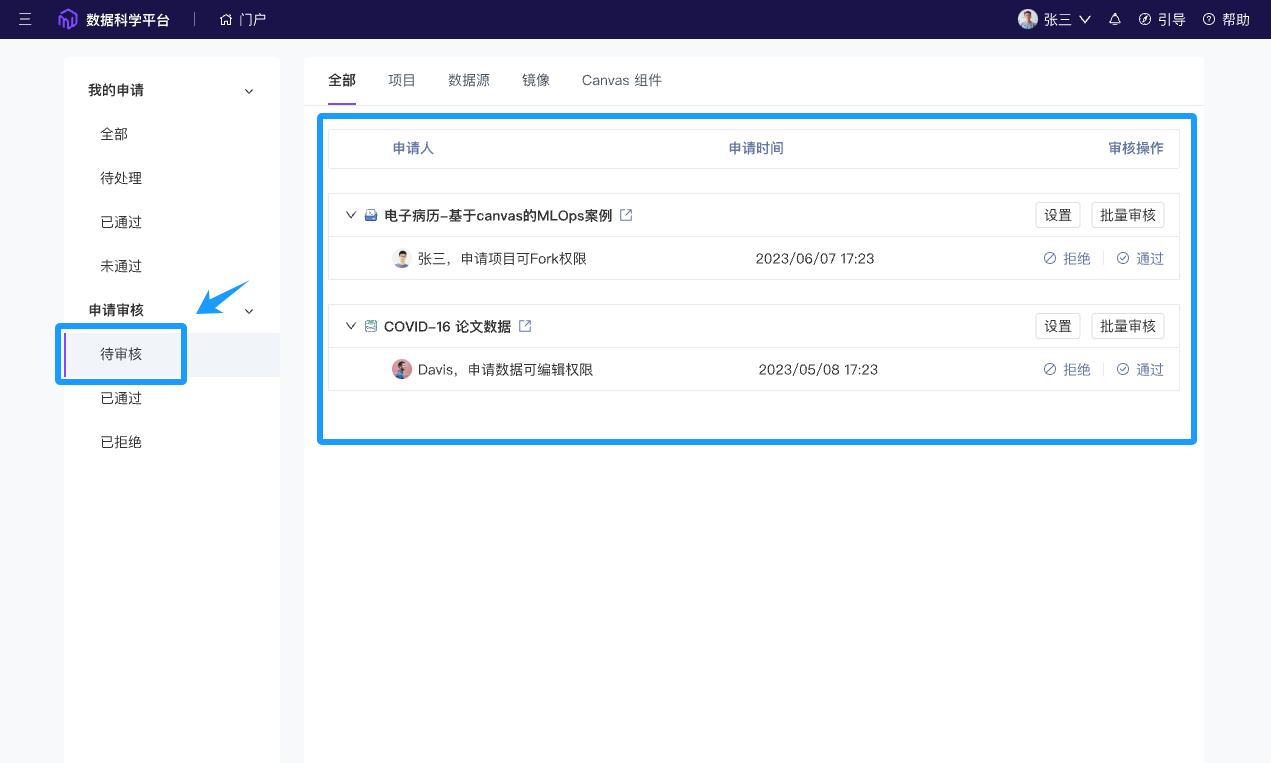
“工作区”升级为“磁盘”、数据集统计概览优化|ModelWhale 版本更新
本次更新围绕用户在实际项目中对平台的理解和管理体验进行了多项优化。 “工作区”升级为“磁盘”、及其管理优化 平台“工作区”概念正式更名为“磁盘”,突出其存储功能。原有以目录代称的存储区域划分同步更名,其中“work目录”更改为“个人磁盘”&am…...
【Mysql基础】一、基础入门和常见SQL语句
📚博客主页:代码探秘者-CSDN博客 🌈:最难不过坚持 ✨专栏 🌈语言篇C语言\ CJavase基础🌈数据结构专栏数据结构🌈算法专栏必备算法🌈数据库专栏MysqlRedis🌈必备篇 其他…...

AWS之存储服务
目录 一、传统存储术语 二、传统存储与云存储的关系 三、云存储之AWS 使用场景 文件存储 数据块存储 对象存储 EBS、EFS、S3对比 EBS块存储 S3对象存储 S3 使用案例 S3 存储类 EFS文件存储 一、传统存储术语 分类 接口/技术类型 应用场景特点 关系及区别 机械硬…...
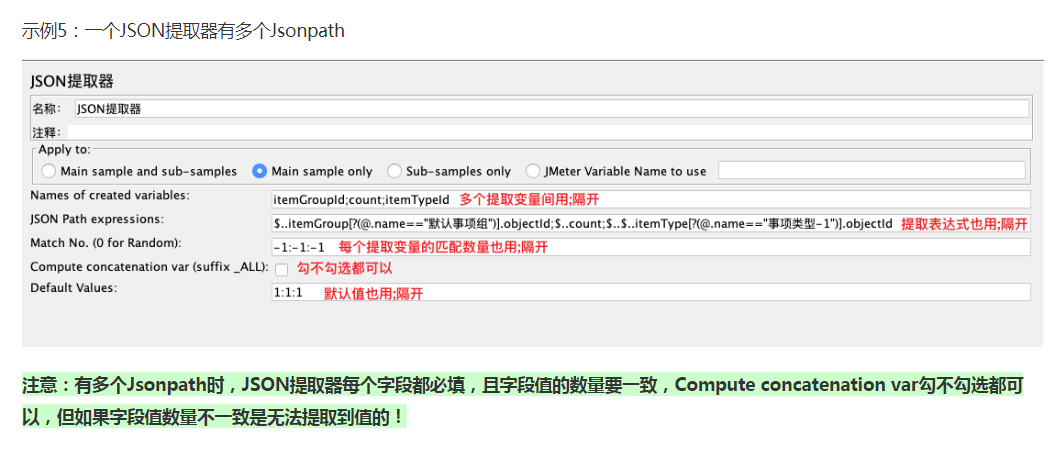
Jmeter中的Json提取器如何使用?
在JMeter中使用JSON提取器可以方便地从JSON格式的响应数据中提取特定字段的值。以下是详细步骤和示例: 1. 添加JSON提取器 右击目标HTTP请求 -> 选择 添加 -> 后置处理器 -> JSON提取器。 2. 配置JSON提取器参数 变量名称(Names of created…...

从零理解 C++ 中的原子布尔变量:`std::atomic<bool>` 入门指南
文章目录 引言:为什么需要原子变量?一、什么是 std::atomic<bool>?二、为什么不用普通 bool?一个反面例子三、std::atomic<bool> 的用法四、std::atomic<bool> 的优势五、完整示例:多线程文件传输六…...

软件领域第三方检测机构:如何保障软件品质与安全?
在软件领域,第三方检测机构扮演着极其重要的角色,它们与软件开发者和使用者保持独立,对软件的品质和安全性进行公正而专业的评估。凭借严格的技术方法和丰富的实践经历,这些机构能够揭示软件中潜藏的问题,进而确保软件…...

单例模式的两种设计
单例模式确保一个类只有一个实例,并提供一个全局访问点。 1. 饿汉模式 (Eager Initialization) 饿汉模式在程序启动时就创建实例,线程安全。 cpp class EagerSingleton { public:// 删除拷贝构造函数和赋值运算符EagerSingleton(const EagerSingleton…...

MySQL 5.7 之后的特性解析:从 8.0 到 8.4 的技术进化
MySQL 是全球最流行的开源关系型数据库之一,广泛应用于 Web 应用、数据分析和企业级系统。自 MySQL 5.7(2015 年发布)以来,MySQL 8.0(2018 年)、8.1(2023 年)、8.4(2024 …...

PHP框架在分布式系统中的应用!
随着互联网业务的快速发展,分布式系统因其高可用性、可扩展性和容错性成为现代应用架构的主流选择。而PHP作为一门成熟的Web开发语言,凭借其简洁的语法、丰富的框架生态和持续的性能优化,逐渐在分布式系统中崭露头角。本文将深入探讨PHP框架在…...

[学习]RTKLib详解:ionex.c、options.c与preceph.c
RTKLib详解:ionex.c、options.c与preceph.c 本文是 RTKLlib详解 系列文章的一篇,目前该系列文章还在持续总结写作中,以发表的如下,有兴趣的可以翻阅。 [学习] RTKlib详解:功能、工具与源码结构解析 [学习]RTKLib详解&…...

六个仓库合并为一个仓库,保留master和develop分支的bat脚本
利用git subtree可以实现多个仓库合并为一个仓库,手动操作起来太麻烦了,今天花了点时间写了一个可执行的脚本,现在操作起来就方便多了。 1、本地新建setup.bat文件 2、用编辑器打开(我用的是Notepad) 3、把下面代码…...