Transformer Decoder-Only 参数量计算
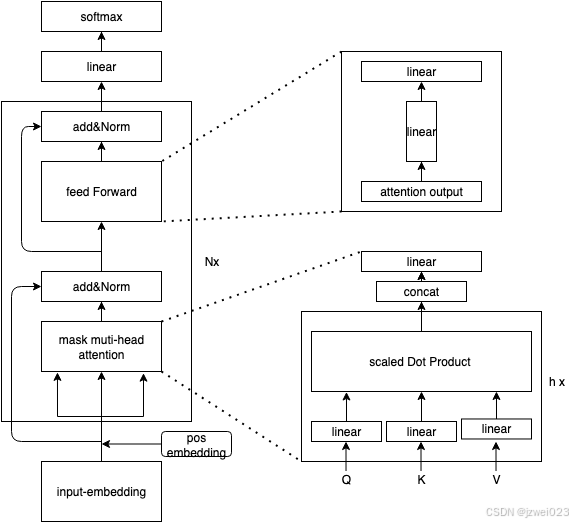
Transformer 的 Decoder-Only 架构(如 GPT 系列模型)是当前大语言模型的主流架构,其参数量主要由以下几个部分组成:
- 嵌入层(Embedding Layer)
- 自注意力层(Self-Attention Layers)
- 前馈网络(Feed-Forward Network, FFN)
- Layer Normalization 和偏置项
| Operation | Parameters |
| Embedding | ( n_vacab + n_ntx ) × d_model |
| Attention:QKV | 3 × n_layer × d_model × d_attn |
| Attention:Project | n_layer × d_model × d_attn |
| Feedforward | 2 × n_layer × d_model × d_ff |
| Layer Normalization 和偏置项 | 4 × n_layer × d_model |
| Total(Attention + Feedforward) | 2 × n_layer × d_model × ( 2 × d_attn + d_ff ) ≈ 12 × n_layer × d_model^2 假设d_attn = d_model,d_ff = 4 × d_model |
参数定义:
d_mdole:模型维度;
n_layer:层数;
d_attn:注意力输出维度;
d_ff:前馈网络维度;
n_ntx:最大上下文长度(token)
n_head:注意力头数
n_vacab:词汇表大小
1. 嵌入层(Embedding Layer)
嵌入层的作用是将输入 token 转换为高维向量表示。参数量为:n_vacab × d_model
此外,绝对位置编码通常由可学习的嵌入矩阵实现,其权重维度为: n_ntx × d_model
此外,在语言模型中,输出层通常与嵌入层共享权重矩阵(Tie Embedding),因此不需要额外计算输出层的参数量。
所以嵌入层总参数数:( n_vacab + n_ntx ) × d_model
备注:假设输入 x_i = (w_1, w_2,..., w_n_ntx),长度为n_ntx,batch 大小为b,则原始输入维度为:(b,n_ntx),经过embedding后输出维度为(b, n_ntx, d_model)
2. 自注意力层(Self-Attention Layers)
每个 Transformer 层包含一个多头自注意力机制(Multi-Head Self-Attention, MHSA),其参数量主要来自以下三部分:
- 线性变换矩阵:生成 Query、Key、Value
- 输出投影矩阵:将多头结果拼接后进行线性变换
假设:
- 输入的维度为
d_model - 注意力头数为
h - 每个头的维度为
d_k(通常满足 d_k = d_attn / h) - QKV输出维度d_attn,然后经过投影,输出维度 d_model
(1) 生成 Query、Key、Value 的线性变换矩阵
每个头的 Q、K、V 都需要一个独立的线性变换矩阵,因此总的参数量为:
Attention QKV Parameters = 3 × d_model × d_attn
(2) 输出投影矩阵
多头注意力的结果需要通过一个线性投影矩阵转换回 d_model 维度,因此参数量为:
Attention Project Parameters = d_attn × d_model
(3) 总自注意力层参数量
单个自注意力层的参数量为:
Self-Attention Parameters = 3 × d_model × d_attn + d_attn × d_model = 4 × d_model × d_attn
如果有 n_layer 个 Transformer 层,则总的自注意力层参数量为:
Total Self-Attention Parameters = 4 × n_layer × d_model × d_attn
备注:嵌入层输出的 x维度是(b, n_ntx, d_model),W_Q维度是(d_model, d_attn),则Q = x * W_Q维度是(b, n_ntx, d_attn),通过self-attention后,输出维度为(b, n_ntx, d_attn),然后通过attention project后维度是(b, n_ntx, d_model)
3. 前馈网络(Feed-Forward Network, FFN)
每个 Transformer 层包含一个两层的前馈网络(FFN),其参数量主要来自以下两部分:
- 第一层从
d_model映射到d_ff(通常是d_model的 4 倍)。 - 第二层从
d_ff映射回d_model。
(1) 第一层参数量
第一层将 d_model 映射到 d_ff,因此参数量为:
First Layer Parameters=d_model × d_ff
(2) 第二层参数量
第二层将 d_ff 映射回 d_model,因此参数量为:
Second Layer Parameters=d_ff × d_model
(3) 总前馈网络参数量
单个前馈网络的参数量为:
FFN Parameters=d_model ×d_ff + d_ff × d_model = 2 × d_model × d_ff
如果有 n_layer 个 Transformer 层,则总的前馈网络参数量为:
Total FFN Parameters = 2 × n_layer × d_model × d_ff
备注:(b, n_ntx, d_model)经过FFN后输出维度是(b, n_ntx, d_model)
4. Layer Normalization 和偏置项
每个 Transformer 层包含两个 Layer Normalization 操作(分别在自注意力和前馈网络之后),每个 Layer Normalization 包含两个可学习参数(缩放因子和偏移因子)。
总的 Layer Normalization 参数量为:
LayerNorm Parameters = n_layer × 2 × 2 × d_model = 4 × n_layer × d_model
5. 总参数量
Total Parameters = ( n_vacab + n_ntx ) × d_model + 4 × n_layer × d_model × d_attn + 2 × n_layer × d_model × d_ff + 4 × n_layer × d_model
Total Parameters ≈ 4 × n_layer × d_model × d_attn + 2 × n_layer × d_model × d_ff = 2 × n_layer × d_model × ( 2 × d_attn + d_ff )
假设d_attn = d_model, 以及d_ff = 4 × d_model,则
Total Parameters ≈ 12 × n_layer × d_model^2
6. 实际例子
以 GPT-3 为例:
- 词汇表大小 n_vacab = 50257
- 模型维度 d_model = 12288
- 前馈网络维度 d_ff=4 × d_model = 49152
- 层数 n_layer = 96
- 最大上下文长度 (token)n_ntx = 2048
代入公式:
Total Parameters = (50257 + 2048) ×12288 + 96×(4×122882+8×122882) + 4×96×12288
计算结果约为 175B 参数,与 GPT-3 的实际参数量一致。
相关文章:
Transformer Decoder-Only 参数量计算
Transformer 的 Decoder-Only 架构(如 GPT 系列模型)是当前大语言模型的主流架构,其参数量主要由以下几个部分组成: 嵌入层(Embedding Layer)自注意力层(Self-Attention Layers)前馈…...
uni-app 中的条件编译与跨端兼容
uni-app 为了实现一套代码编译到多个平台(包括小程序,App,H5 等),引入了条件编译机制。 通过条件编译,我们可以针对不同的平台编写特定的代码,从而实现跨端兼容。 一、条件编译的作用 平台差异…...

<C#>log4net 的配置文件配置项详细介绍
log4net 是一个功能强大的日志记录工具,通过配置文件可以灵活地控制日志的输出方式、格式、级别等。以下是对 log4net 配置文件常见配置项的详细介绍: 根元素 <log4net> 这是 log4net 配置文件的根元素,所有配置项都要包含在该元素内…...

excel单元格如果是日期格式,在C#读取的时候会变成45807,怎么处理
excel单元格如果是日期格式,在C#读取的时候会变成45807,怎么处理 excel单元格如果是日期格式,在C#读取的时候会变成45807,怎么处理 在 C# 中,Excel 日期被表示为一个数字,这是因为 Excel 内部将日期存储为…...

Unity接入SDK之修改Unity启动页面
原理就是在Android Studio新建Activity继承UnityPlayerActivity,然后再Unity中修改启动页面。 一,Android Studio篇 首先新建一个项目, 新建完成之后基于新建的项目新建一个module,选择为Android Library类型 新建的Library再目…...
yarn workspace使用指南
作用 Yarn workspace 是 Yarn 包管理工具中的一个功能,主要用于管理多包项目(monorepo)。它的主要作用如下: 支持多包结构:允许在一个仓库中管理多个独立的包或项目。项目间依赖管理:方便地在不同包之间添…...

[学习]RTKLib详解:datum.c、download.c与lambda.c
RTKLib详解: datum.c、download.c 与 lambda.c 本文是 RTKLlib详解 系列文章的一篇,目前该系列文章还在持续总结写作中,以发表的如下,有兴趣的可以翻阅。 [学习] RTKlib详解:功能、工具与源码结构解析 [学习]RTKLib详解ÿ…...
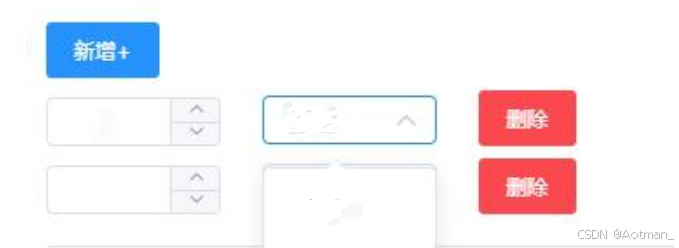
VUE el-select下拉框动态设置禁用,删除后恢复可选择
场景:点击新增添加按钮,列表table会新增一条包含下拉菜单的数据,如果其中任何一个下拉框选择了某个值,那么新增的下拉菜单的选项中该值是禁用状态,只能选择其他未被选中过的值。点击删除按钮后,已禁用的选项…...
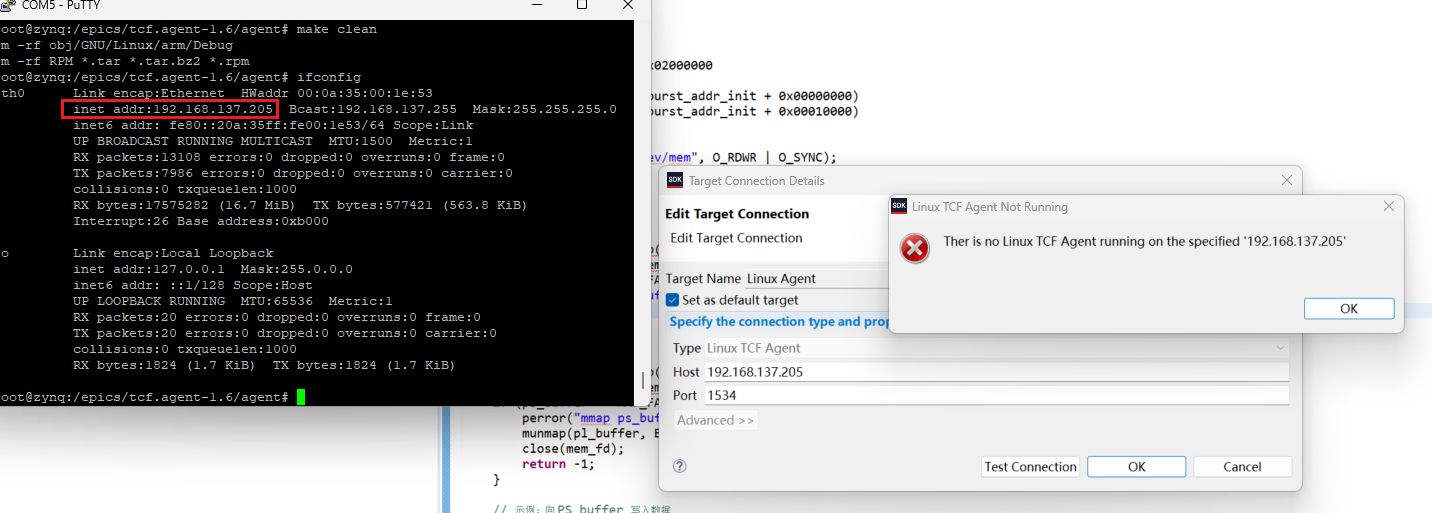
FPGA----基于ALINX提供的debian实现TCF
引言:接上问,我们使用自制的image.ub和boot.bin以及ALINX提供的debian8根文件系统,构建了petalinux,但是经测试,该文件系统无法启用TCF服务,即无法与Xilinx SDK建立连接,那么我们应该如何解决? FPGA----基于ZYNQ 7020实现定制化的EPICS通信系统-CSDN博客文章浏览阅读4…...

木马查杀篇—Opcode提取
【前言】 介绍Opcode的提取方法,并探讨多种机器学习算法在Webshell检测中的应用,理解如何在实际项目中应用Opcode进行高效的Webshell检测。 Ⅰ 基本概念 Opcode:计算机指令的一部分,也叫字节码,一个php文件可以抽取出…...

1.7 方向导数
(底层逻辑演进脉络)从"单车道"到"全路网"的导数进化史: 一、偏导数奠基(1.6核心) 诞生背景:多元函数分析需求 当变量间存在耦合关系时(如房价面积单价装修成本)…...
:总览与引导)
设计模式系列(01):总览与引导
设计模式系列(01):总览与引导 本文为设计模式系列第1篇,定位为总览和引导,系统梳理设计模式的核心思想、分类、UML、设计原则、典型场景、学习建议与常见误区,适合系统学习与团队协作。 目录 1. 前言2. 设计模式简介3. UML与设计模式4. 术语解释5. UML工具与PlantUML6. 面…...
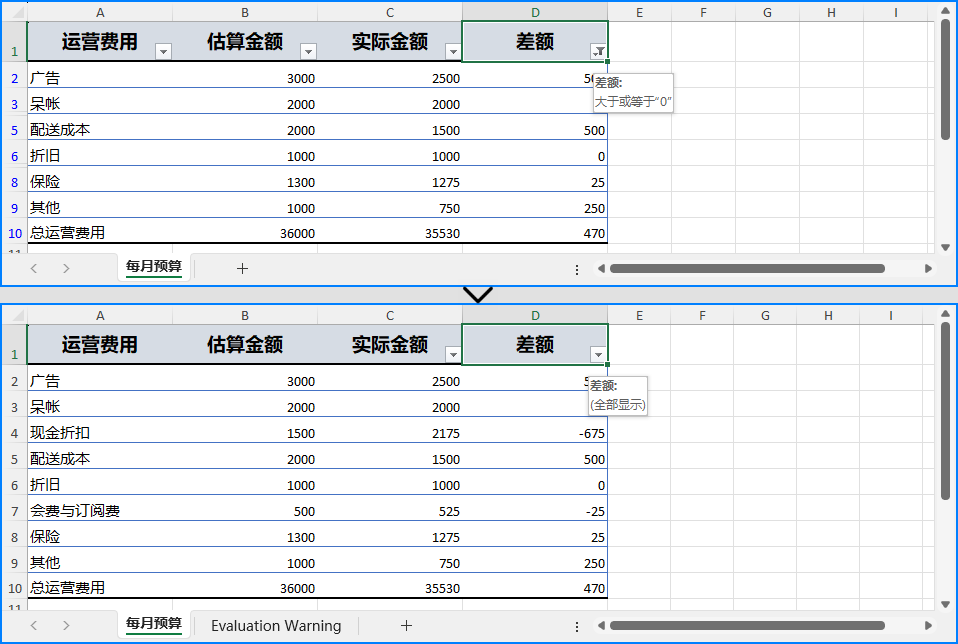
国产化Excel处理控件Spire.XLS系列教程:如何通过 C# 删除 Excel 工作表中的筛选器
在 Excel 文件中,筛选器(Filter)是一个常用的数据处理工具,可以帮助用户快速按条件筛选数据行。但在数据整理完成、导出、共享或打印之前,往往需要 删除 Excel 工作表中的筛选器,移除列标题中的下拉筛选按钮…...

第二篇 客户端脚本安全
同源策略 限制了来自不同的"dociment"或脚本,对当前"dociment"读取或设置一些属性。 不同源:host(域名或ip),子域名,端口,协议。 对于当前页面来说,页面的源…...
[sklearn] 特征工程
一.字典数据抽取 def dictvec():"""字典数据抽取:return: None"""# 实例化# sparse改为True,输出的是每个不为零位置的坐标,稀疏矩阵可以节省存储空间dict DictVectorizer(sparseFalse) #矩阵中存在大量的0,sparse存储只…...
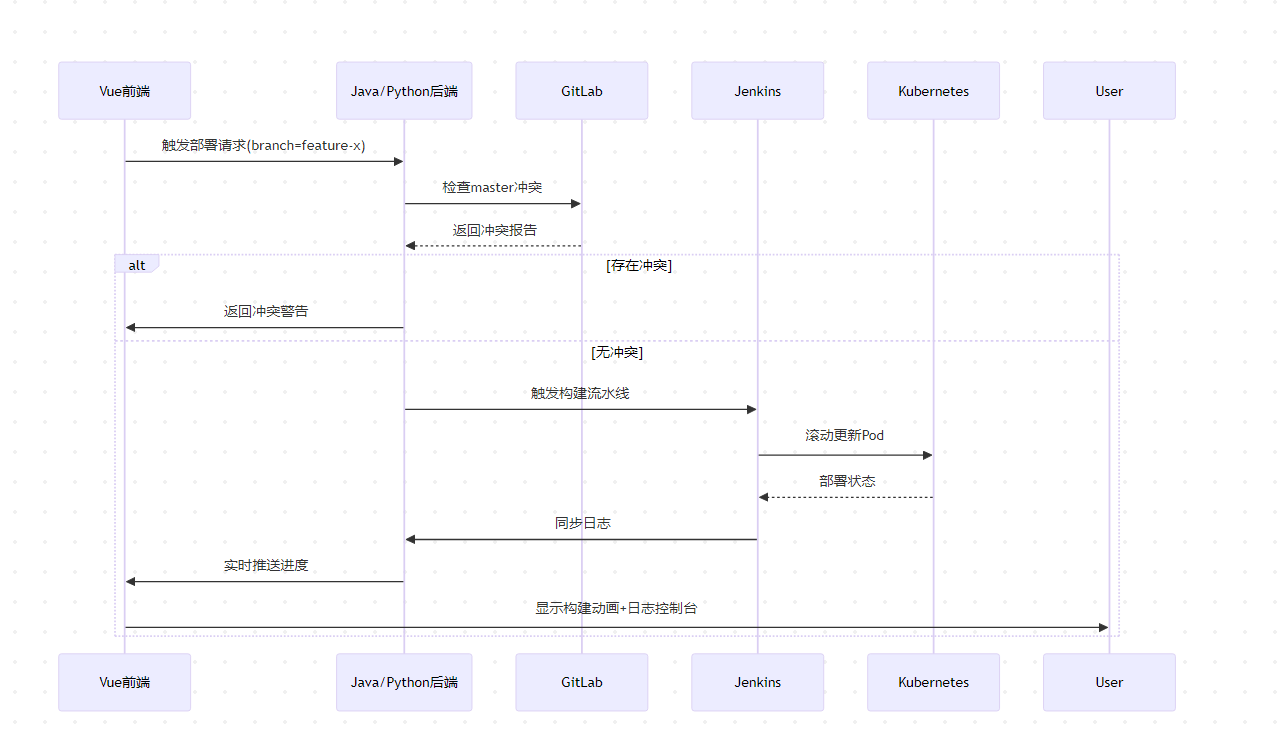
CI/CD与DevOps流程流程简述(提供思路)
一 CI/CD流程详解:代码集成、测试与发布部署 引言 在软件开发的世界里,CI/CD(持续集成/持续交付)就像是一套精密的流水线,确保代码从开发到上线的整个过程高效、稳定。我作为一名资深的软件工程师,接下来…...
S7-1500——零基础入门1、工业编程基本概念
工业编程基本概念 一,数制与基本数据类型二,数字量信号三,模拟量信号一,数制与基本数据类型 本节主要内容 类别内容主题数制与基本数据类型数制讲解十进制、十六进制、二进制及其进位规则;基数、位权概念数据类型介绍PLC 使用的数据类型:未序列数据类型(bit、byte、wor…...
六、快速启动框架:SpringBoot3实战
六、快速启动框架:SpringBoot3实战 目录 一、SpringBoot3介绍 1.1 SpringBoot3简介1.2 系统要求1.3 快速入门1.4 入门总结 二、SpringBoot3配置文件 2.1 统一配置管理概述2.2 属性配置文件使用2.3 YAML配置文件使用2.4 批量配置文件注入2.5 多环境配置和使用 三、…...
万兴PDF-PDFelement v11.4.13.3417
万兴PDF专家(Wondershare PDFelement)是一款国产PDF文档全方位解决方案.万兴PDF编辑器软件万兴PDF中文版,专注于PDF的创建,编辑,转换,签名,压缩,合并,比较等功能.万兴PDF专业版PDF编辑软件,以简约风格及强大的功能在国外名声大噪,除了传统功能外,还提供OCR扫描,表格识别,创建笔…...

LSP里氏替换原则
LSP强调子类必须能够替换父类。即子类应该具有与父类相同的行为和功能,而不仅仅是继承父类的属性和方法。LSP是对继承机制的约束规范、是指导接口与实现的设计原则。 LSP关键点 前置条件不能强化:子类方法的参数类型必须与父类相同或者更为宽松。后置条…...
机器学习-无量纲化与特征降维(一)
一.无量纲化-预处理 无量纲,即没有单位的数据 无量纲化包括"归一化"和"标准化",这样做有什么用呢?假设用欧式距离计算一个公司员工之间的差距,有身高(m)、体重(kg&#x…...

C语言复习--柔性数组
柔性数组是C99中提出的一个概念.结构体中的最后⼀个元素允许是未知大小的数组,这就叫做柔性数组成员。 格式大概如下 struct S { int a; char b; int arr[];//柔性数组 }; 也可以写成 struct S { int a; char b; int arr[0];//柔性数组 }; …...
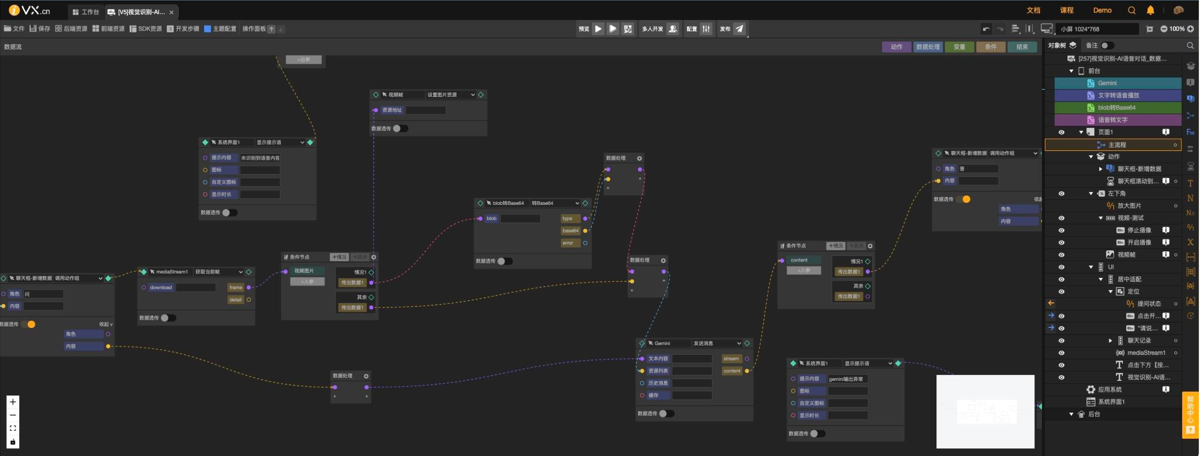
图形化编程如何从工具迭代到生态重构?
一、技术架构的范式突破 在图形化编程领域,技术架构的创新正在重塑行业格局。iVX 作为开源领域的领军者该平台通过图形化逻辑设计,将传统文本编程需 30 行 Python 代码实现的 "按钮点击→条件判断→调用接口→弹窗反馈" 流程,简化…...
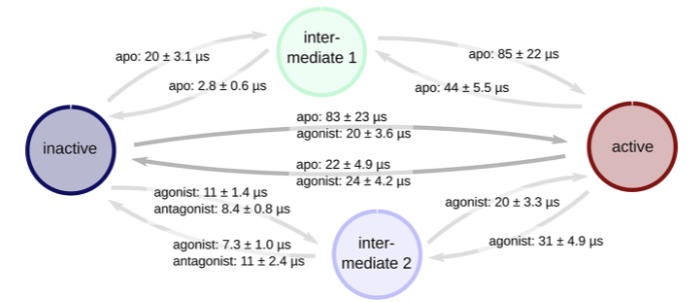
法国蒙彼利埃大学团队:运用元动力学模拟与马尔可夫状态模型解锁 G 蛋白偶联受体构象动态机制
背景简介 在生命科学领域,G 蛋白偶联受体(GPCRs)一直是研究的热点。它作为膜蛋白家族的重要成员,承担着细胞对多种刺激的响应任务,从激素、神经递质到外源性物质的信号传导都离不开它。据估计,约三分之一的…...

【PostgreSQL】不开启归档模式,是否会影响主从库备份?
PostgreSQL 不开启归档模式(archive_mode off)不会直接影响基于流复制(Streaming Replication)的主从备份,但可能会在特定场景下影响复制的健壮性和恢复能力。以下是详细分析: 1. 流复制的核心机制 流复制…...
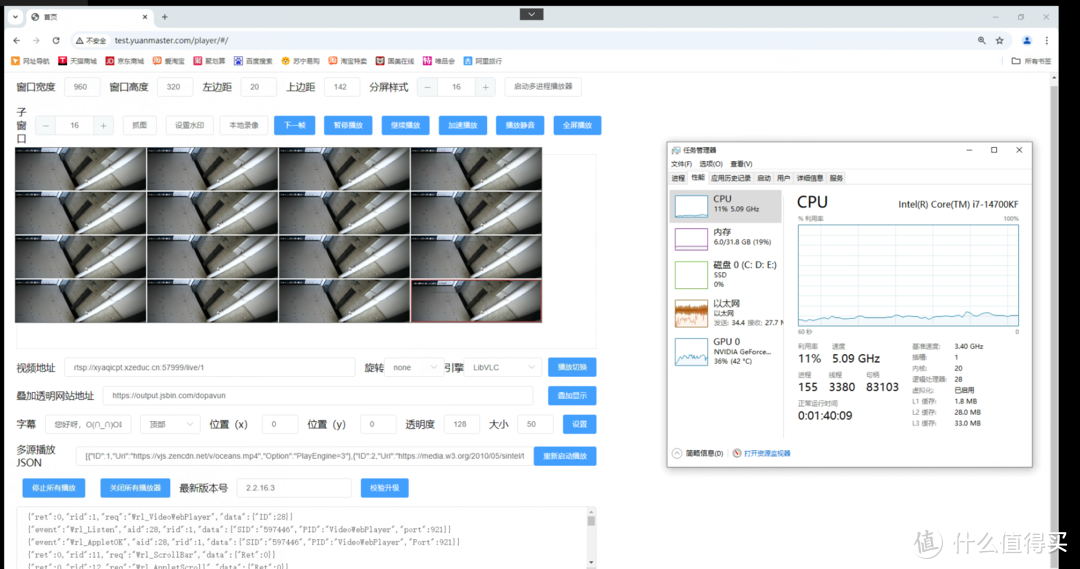
网页Web端无人机直播RTSP视频流,无需服务器转码,延迟300毫秒
随着无人机技术的飞速发展,全球无人机直播应用市场也快速扩张,从农业植保巡检到应急救援指挥,从大型活动直播到智慧城市安防,实时视频传输已成为刚需。预计到2025年,全球将有超过1000万架商用无人机搭载直播功能&#…...
)
Shell脚本编程3(函数+正则表达式)
1.函数 1.1 定义 简单来讲,所谓函数就是把完成特定功能,并且多次使用的一组命令或者语句封装在一个固定的结构中,这个结构我们就叫做函数。从本质上讲,函数是将一个函数名与某个代码块进行映射。也就是说,用户在定义了…...
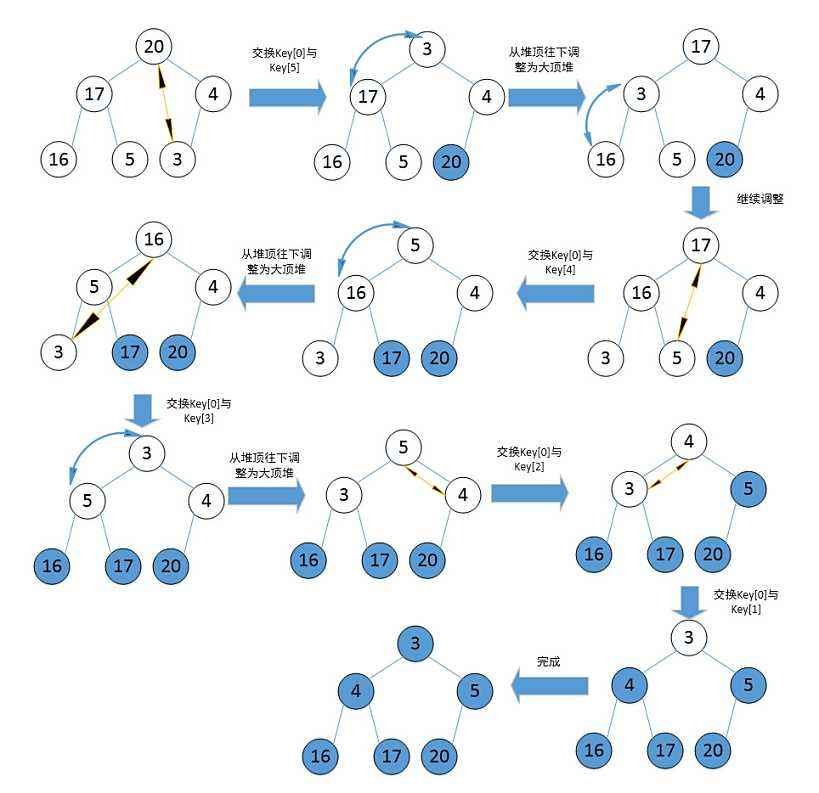
数据结构-堆排序
1.定义 -堆中每个节点的值都必须大于等于(或小于等于)其左右子节点的值。如果每个节点的值都大于等于其子节点的值,这样的堆称为大根堆(大顶堆);如果每个节点的值都小于等于其子节点的值,称为…...
)
HTML简单语法标签(后续实操:云备份项目)
以下是一些 HTML 的简单语法标签及其功能介绍: 基本结构标签 <!DOCTYPE html>:声明文档类型为 HTML5<html>:HTML 文档的根标签<head>:包含文档元数据(如标题、字符编码等)<title>…...
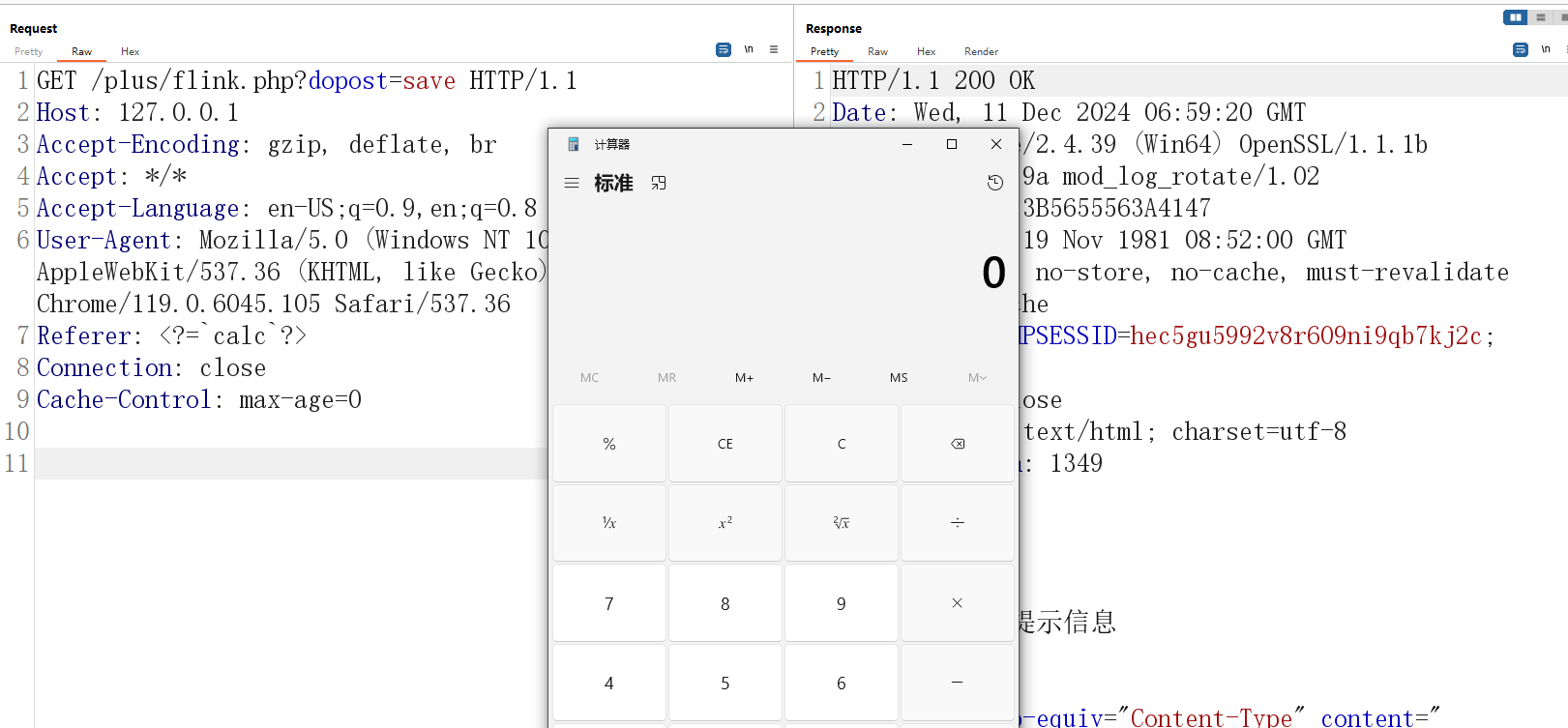
DedeCMS-Develop-5.8.1.13-referer命令注入研究分析 CVE-2024-0002
本次文章给大家带来代码审计漏洞挖掘的思路,从已知可控变量出发或从函数功能可能照成的隐患出发,追踪参数调用及过滤。最终完成代码的隐患漏洞利用过程。 代码审计挖掘思路 首先flink.php文件的代码执行逻辑,可以使用php的调试功能辅助审计 …...