红黑树算法笔记(二)性能对比实验
文章目录
- 1. 实验目标
- 2. 对比数据结构
- 3. 性能指标
- 3.1 时间性能指标
- 3.2 空间性能指标
- 3.3 其他性能指标
- 4. 测试场景
- 4.1 数据集特性变化
- 4.2 操作模式变化
- 4.3 环境因素变化
- 5. 实验设计
- 5.1 基准测试设计
- 5.1.1 CRUD性能基准测试
- 5.1.2 混合负载测试
- 5.1.3 范围查询测试
- 5.2 特殊场景测试
- 5.2.1 数据倾斜测试
- 5.2.2 持久化恢复测试
- 5.2.3 高并发读写测试
- 5.3 压力测试
- 5.3.1 容量极限测试
- 5.3.2 长时间稳定性测试
- 6. 实验环境设置
- 6.1 硬件环境
- 6.2 软件环境
- 6.3 实验控制
- 7. 数据收集与分析方法
- 7.1 数据收集
- 7.2 数据分析方法
- 8. 具体应用场景评估
- 8.1 数据库索引场景
- 8.2 内存缓存场景
- 8.3 文件系统场景
- 8.4 网络应用场景
实验代码地址链接
1. 实验目标
设计并执行一系列实验,全面评估红黑树与其他常见数据结构(AVL树、B树、B+树、跳表、哈希表、二叉搜索树)在不同应用场景下的性能差异,包括时间复杂度、空间复杂度、实际执行效率,以及在特定条件下的行为特性。
2. 对比数据结构
本实验将对比以下数据结构:
- 红黑树 (Red-Black Tree)
- AVL树
- B树
- B+树
- 跳表 (Skip List)
- 哈希表 (Hash Table)
- 普通二叉搜索树 (BST)
- 线性数组 (Linear Array) - 作为基准参照
3. 性能指标
3.1 时间性能指标
-
插入操作耗时
- 单个元素插入
- 批量元素插入
- 顺序数据插入
- 随机数据插入
-
查找操作耗时
- 精确查找(单个元素)
- 范围查找(多个元素)
- 最大/最小值查找
- 随机查找
-
删除操作耗时
- 单个元素删除
- 批量元素删除
- 特定条件下的删除(如删除最大/最小元素)
-
修改操作耗时
- 单个元素修改
- 批量元素修改
-
遍历操作耗时
- 全表遍历
- 范围遍历
- 有序遍历
3.2 空间性能指标
-
静态内存占用
- 基础数据结构所需内存
- 每个节点的开销
-
动态内存变化
- 随数据量增长的内存使用曲线
- 内存碎片化程度
-
缓存友好性
- 缓存命中率
- 内存访问模式分析
3.3 其他性能指标
-
平衡操作开销
- 再平衡频率
- 平衡操作的平均耗时
-
并发性能
- 读写并发能力
- 锁竞争情况
-
持久化性能
- 序列化/反序列化速度
- 持久化存储空间效率
4. 测试场景
4.1 数据集特性变化
-
数据量维度
- 小数据集(10²数量级)
- 中数据集(10⁴数量级)
- 大数据集(10⁶数量级)
- 超大数据集(10⁸数量级)
-
数据分布维度
- 均匀随机分布
- 正态分布
- 偏斜分布(80/20法则)
- 几乎有序数据
- 完全有序数据
- 完全逆序数据
-
键值特性维度
- 数值型键(整数、浮点数)
- 字符串键(短字符串、长字符串)
- 复合键
4.2 操作模式变化
-
读写比例
- 读密集型(95%读,5%写)
- 写密集型(30%读,70%写)
- 平衡型(50%读,50%写)
-
访问模式
- 随机访问
- 顺序访问
- 热点访问(Zipf分布)
- 批量访问
-
特殊操作场景
- 范围扫描密集型
- 频繁插入删除型
- 频繁更新型
4.3 环境因素变化
-
内存限制
- 充足内存
- 受限内存
-
CPU资源
- 单核环境
- 多核环境
-
存储介质
- 纯内存环境
- 磁盘交换环境
5. 实验设计
5.1 基准测试设计
5.1.1 CRUD性能基准测试
测试流程:
- 初始化目标数据结构
- 执行插入操作(记录时间)
- 执行查找操作(记录时间)
- 执行更新操作(记录时间)
- 执行删除操作(记录时间)
- 记录峰值内存使用
变量设置:
- 数据量:100, 1,000, 10,000, 100,000, 1,000,000, 10,000,000
- 操作次数:数据量的10%
- 重复次数:每组实验重复5次取平均值
5.1.2 混合负载测试
测试流程:
- 初始化数据结构并预装载数据
- 根据指定的读写比例随机生成操作序列
- 执行操作序列并记录各类操作的平均响应时间
- 记录总体执行时间和内存占用
变量设置:
- 预装载数据量:100,000
- 操作序列长度:1,000,000
- 读写比例:95:5, 50:50, 30:70
5.1.3 范围查询测试
测试流程:
- 初始化数据结构并装载数据
- 执行不同范围大小的范围查询
- 记录查询时间和结果集大小
变量设置:
- 数据量:1,000,000
- 范围大小:0.1%, 1%, 10%, 50%的数据量
5.2 特殊场景测试
5.2.1 数据倾斜测试
测试流程:
- 生成符合Zipf分布的数据集(高度倾斜)
- 对各数据结构执行标准CRUD操作
- 记录性能指标和内存使用情况
5.2.2 持久化恢复测试
测试流程:
- 创建包含大量数据的数据结构
- 序列化到文件系统
- 记录序列化时间和文件大小
- 重新加载并记录加载时间
5.2.3 高并发读写测试
测试流程:
- 初始化目标数据结构
- 创建多个读线程和写线程
- 并发执行读写操作
- 记录吞吐量、延迟和竞争情况
变量设置:
- 线程数:2, 4, 8, 16, 32, 64
- 读写线程比例:9:1, 1:1, 1:9
5.3 压力测试
5.3.1 容量极限测试
测试流程:
- 逐步增加数据量直到数据结构性能显著下降
- 记录各数据结构可承受的最大数据量
- 观察性能下降曲线
5.3.2 长时间稳定性测试
测试流程:
- 在固定规模下持续运行混合负载
- 定期记录性能指标
- 观察长时间运行后的性能变化和内存泄漏情况
6. 实验环境设置
6.1 硬件环境
- 处理器:Intel Core i7
- 内存:64GB DDR4
- 存储:NVMe SSD 1TB
6.2 软件环境
- 操作系统:Ubuntu 20.04 LTS / Windows 11
- 编程语言:C++, Java, Python (实验将在多种语言环境下分别进行)
- 编译器/解释器版本:
- 第三方库:标准库实现或业界广泛使用的数据结构库
- 性能分析工具:
- Linux: perf, valgrind
- Windows: Windows Performance Toolkit
- 通用: Intel VTune, JProfiler (Java)
6.3 实验控制
- 单一变量控制原则
- 每个实验重复至少5次,取平均值
- 在测试前预热系统和JVM环境
- 关闭不必要的系统服务和后台进程
- 使用相同的随机种子确保实验可重复性
7. 数据收集与分析方法
7.1 数据收集
- 时间测量:高精度计时器,最小精度到纳秒级
- 内存测量:
- Java: JProfiler/VisualVM
- C++: valgrind/massif
- 系统级: /proc/meminfo (Linux)
- CPU利用率:top, htop, sar
- I/O操作:iostat, strace
7.2 数据分析方法
-
统计分析:
- 计算平均值、中位数、95%置信区间
- 方差分析以评估稳定性
- 异常值检测与处理
-
性能指标计算:
- 吞吐量 = 总操作数 / 总时间
- 平均延迟 = 总响应时间 / 操作数
- 每操作内存开销 = 总内存使用 / 数据量
-
可视化方法:
- 性能随数据量变化曲线图
- 延迟分布直方图
- 箱线图比较不同数据结构性能
- 雷达图展示多维性能特性
8. 具体应用场景评估
8.1 数据库索引场景
模拟数据库索引操作,评估适合作为索引结构的数据结构:
- B+树与红黑树、跳表的对比
- 范围查询性能评估
- 点查询性能评估
- 更新性能评估
8.2 内存缓存场景
模拟内存缓存系统的典型负载:
- 高命中率查询场景
- 键过期和替换策略的影响
- 内存压力下的性能表现
8.3 文件系统场景
模拟文件系统索引结构:
- 大量小文件的索引性能
- 层次结构的表示效率
- 文件名长度对性能的影响
8.4 网络应用场景
模拟网络路由表和连接跟踪:
- 高频插入删除操作
- IP地址范围匹配效率
- 大规模连接表的查找性能
相关文章:
性能对比实验)
红黑树算法笔记(二)性能对比实验
文章目录 1. 实验目标2. 对比数据结构3. 性能指标3.1 时间性能指标3.2 空间性能指标3.3 其他性能指标 4. 测试场景4.1 数据集特性变化4.2 操作模式变化4.3 环境因素变化 5. 实验设计5.1 基准测试设计5.1.1 CRUD性能基准测试5.1.2 混合负载测试5.1.3 范围查询测试 5.2 特殊场景测…...

Nlog适配达梦数据库进行日志插入
前言 原来使用的是SQLServer数据库,使用Nlog很流畅,没有什么问题。现在有个新项目需要使用麒麟操作系统和达梦数据库,业务流程开发完成之后发现Nlog配置文件中把数据库连接内容修改之后不能执行插入操作。 原Nlog.config配置 <?xml ve…...
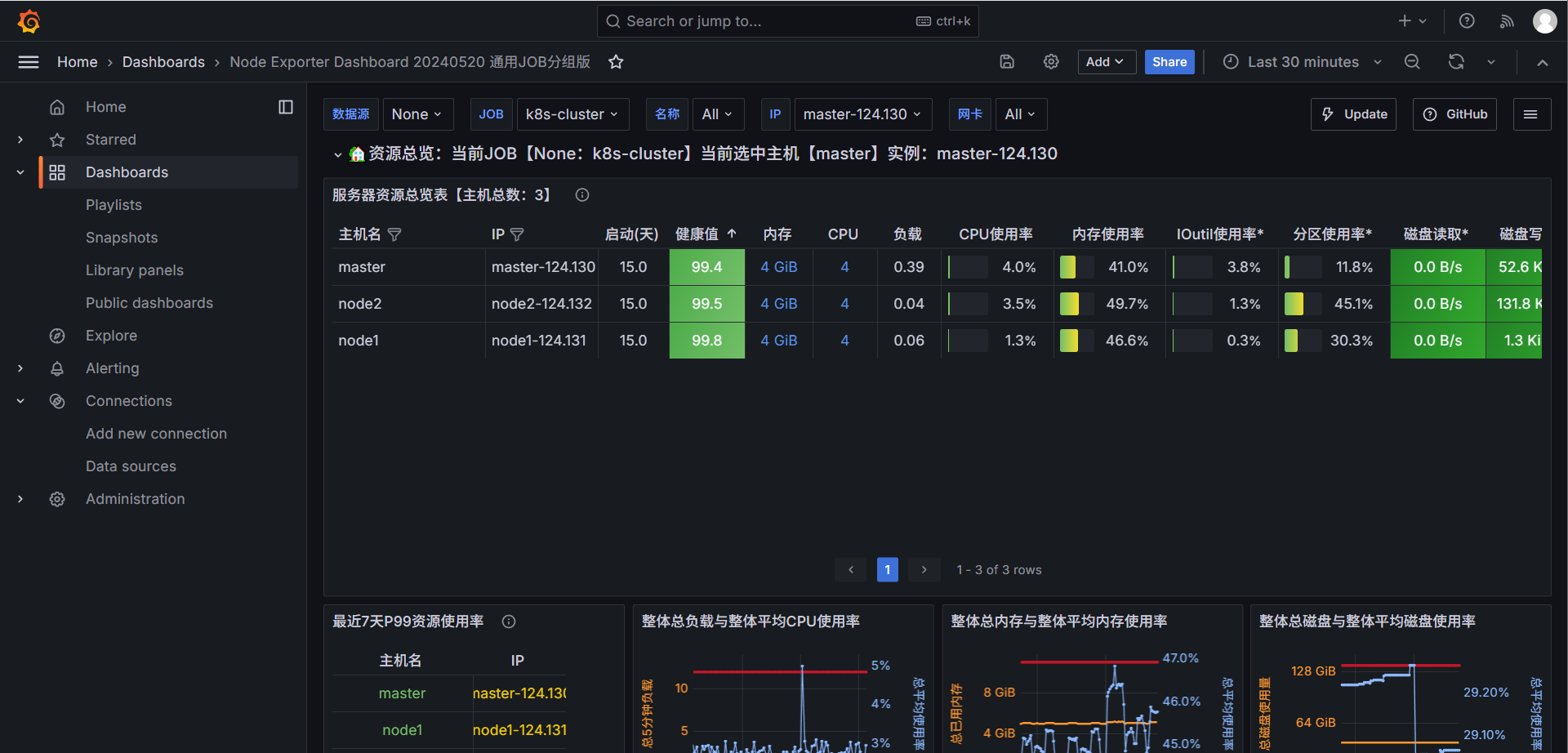
k8s监控方案实践(三):部署与配置Grafana可视化平台
k8s监控方案实践(三):部署与配置Grafana可视化平台 文章目录 k8s监控方案实践(三):部署与配置Grafana可视化平台一、Grafana简介1. 什么是Grafana?2. Grafana与Prometheus的关系3. Grafana应用场…...

嵌入式系统架构验证工具:AADL Inspector v1.10 全新升级
软件架构建模与早期验证是嵌入式应用的关键环节。架构分析与设计语言(AADL)是专为应用软件及执行平台架构模型设计的语言,兼具文本与图形化的双重特性。AADL Inspector是一款轻量级的独立工具: 核心处理能力包括 √ 支持处理AA…...

STM32-模电
目录 一、MOS管 二、二极管 三、IGBT 四、运算放大器 五、推挽、开漏、上拉电阻 一、MOS管 1. MOS简介 这里以nmos管为例,注意箭头方向。G门极/栅极,D漏极,S源极。 当给G通高电平时,灯泡点亮,给G通低电平时&a…...
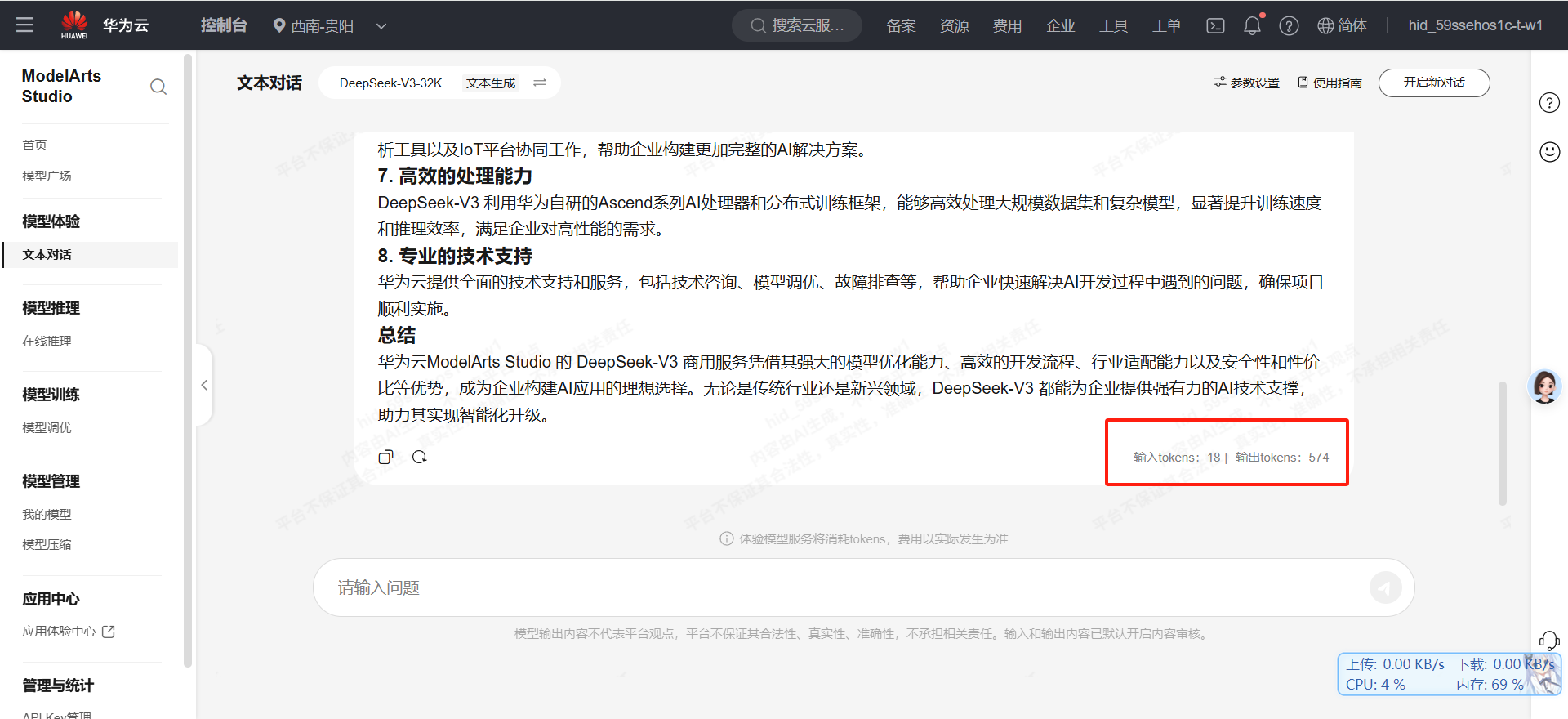
华为云Flexus+DeepSeek征文|从开通到应用:华为云DeepSeek-V3/R1商用服务深度体验
前言 本文章主要讲述在华为云ModelArts Studio上 开通DeepSeek-V3/R1商用服务的流程,以及开通过程中的经验分享和使用感受帮我更多开发者,在华为云平台快速完成 DeepSeek-V3/R1商用服务的开通以及使用入门注意:避免测试过程中出现部署失败等问…...

鸿蒙NEXT开发动画案例5
1.创建空白项目 2.Page文件夹下面新建Spin.ets文件,代码如下: /*** TODO SpinKit动画组件 - Pulse 脉冲动画* author: CSDN—鸿蒙布道师* since: 2024/05/09*/ ComponentV2 export struct SpinFive {// 参数定义Require Param spinSize: number 48;Re…...

面试篇:Spring MVC
基础概念 什么是Spring MVC? Spring MVC 是 Spring Framework 提供的一个基于 Servlet 的 Web 框架,属于 MVC(Model-View-Controller)架构的一种实现。它通过 DispatcherServlet 作为前端控制器,对请求进行分发和调度…...
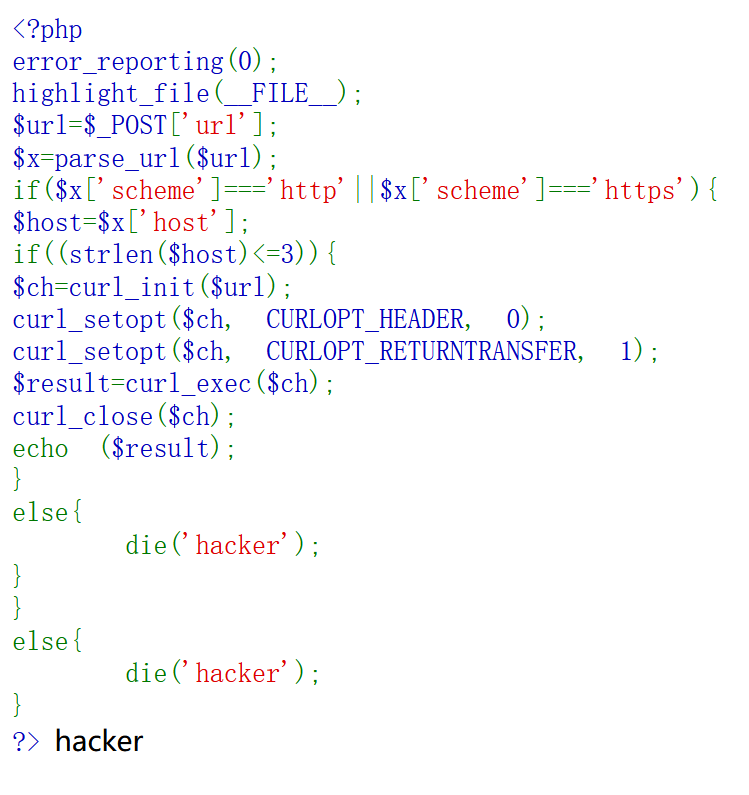
ctfshow——web入门351~356
SSRF没有出网的部分 web入门351 $ch curl_init($url); 作用:初始化一个 cURL 会话,并设置目标 URL。解释: curl_init($url) 创建一个新的 cURL 资源,并将其与 $url 关联。这里的 $url 是用户提供的,因此目标地址完全…...

C++中六个特殊成员函数的关系
C中六个特殊成员函数的关系 C11之后的版本每个类有六个特殊的成员函数,之所以特殊是因为它们可以在各种情况下由编译器自动提供; 默认构造函数、复制构造函数、复制赋值运算符、析构函数、移动构造函数、移动赋值运算符 关系规则: 1、如果…...
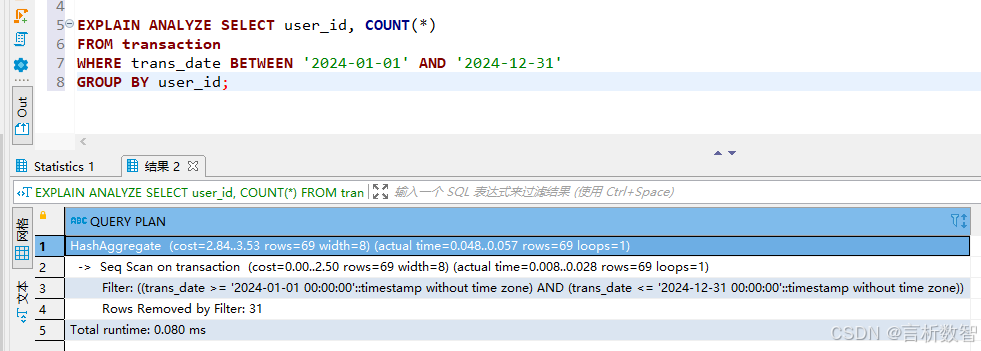
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】金融风控分析案例-10.1 风险数据清洗与特征工程
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL金融风控分析案例:风险数据清洗与特征工程实战一、案例背景:金融风控数据处理需求二、风险数据清洗实战(一)缺失值…...

美女热舞混剪视频批量剪辑生产技术实践:智能处理与原创性提升方案解析
一、引言:短视频工业化生产的技术转型 在美女类短视频内容运营中,通过标准化技术流程实现「高质量、规模化」产出成为核心需求。本文结合实战经验,解析如何通过智能素材重组、AI 语音合成、动态元素叠加等技术手段,构建自动化生产…...

破局智算瓶颈:400G光模块如何重构AI时代的网络神经脉络
一、技术演进与市场需求双重驱动 在数字化转型浪潮下,全球互联网流量正以每年30%的复合增长率持续攀升。根据Dell’Oro Group最新报告,2023年400G光模块市场规模已突破15亿美元,预计2026年将占据数据中心光模块市场60%以上份额。这种爆发式增…...

python标准库--collections - 高性能数据结构在算法比赛的应用
目录 一、deque双端队列 1.头部删除元素popleft() 2.BFS(广度优先搜索)优化 3.滑动窗口(双指针) 4.实现栈或队列 5. 双向遍历与操作 一、deque双端队列 特点:支持两端 O (1) 时间复杂度的…...
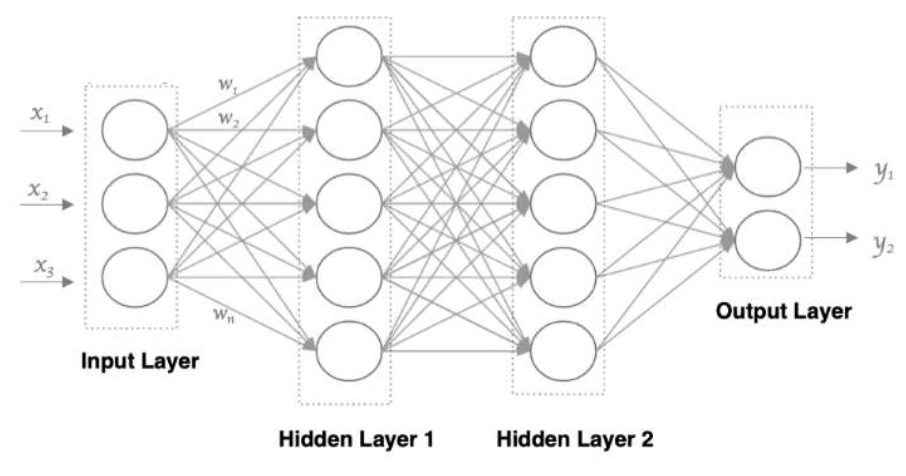
神经网络基础-从零开始搭建一个神经网络
一、什么是神经网络 人工神经网络(Articial Neural Network,简写为ANN)也称为神经网络(NN),是一种模仿生物神经网络和功能的计算模型,人脑可以看做是一个生物神经网络,由众多的神经元连接而成,各个神经元传递复杂的电信号,树突接收到输入信号,然后对信号进行处理,通…...

【Go】优化文件下载处理:从多级复制到零拷贝流式处理
在开发音频处理服务过程中,我们面临一个常见需求:从网络下载音频文件并保存到本地。这个看似简单的操作,实际上有很多优化空间。本文将分享一个逐步优化的过程,展示如何从一个基础实现逐步改进到高效的流式下载方案。 初始实现&a…...

Java 显式锁与 Condition 的使用详解
Java 显式锁与 Condition 的使用详解 在多线程编程中,线程间的协作与同步是核心问题。Java 提供了多种机制来实现线程同步,除了传统的 synchronized 关键字外,ReentrantLock 和 Condition 是更灵活且功能强大的替代方案。本文将详细介绍显式…...

android ViewModel liveData无法监听之多线程下activityViewModels不安全
我们一般的,会遇到liveData无法监听到结果,可能存在主要2种可能: liveData没有正确注册;liveData连续多次设置值,中间的值,会被丢弃,但最后一次是能监听到的。 但是我们容易忽略一种case&…...
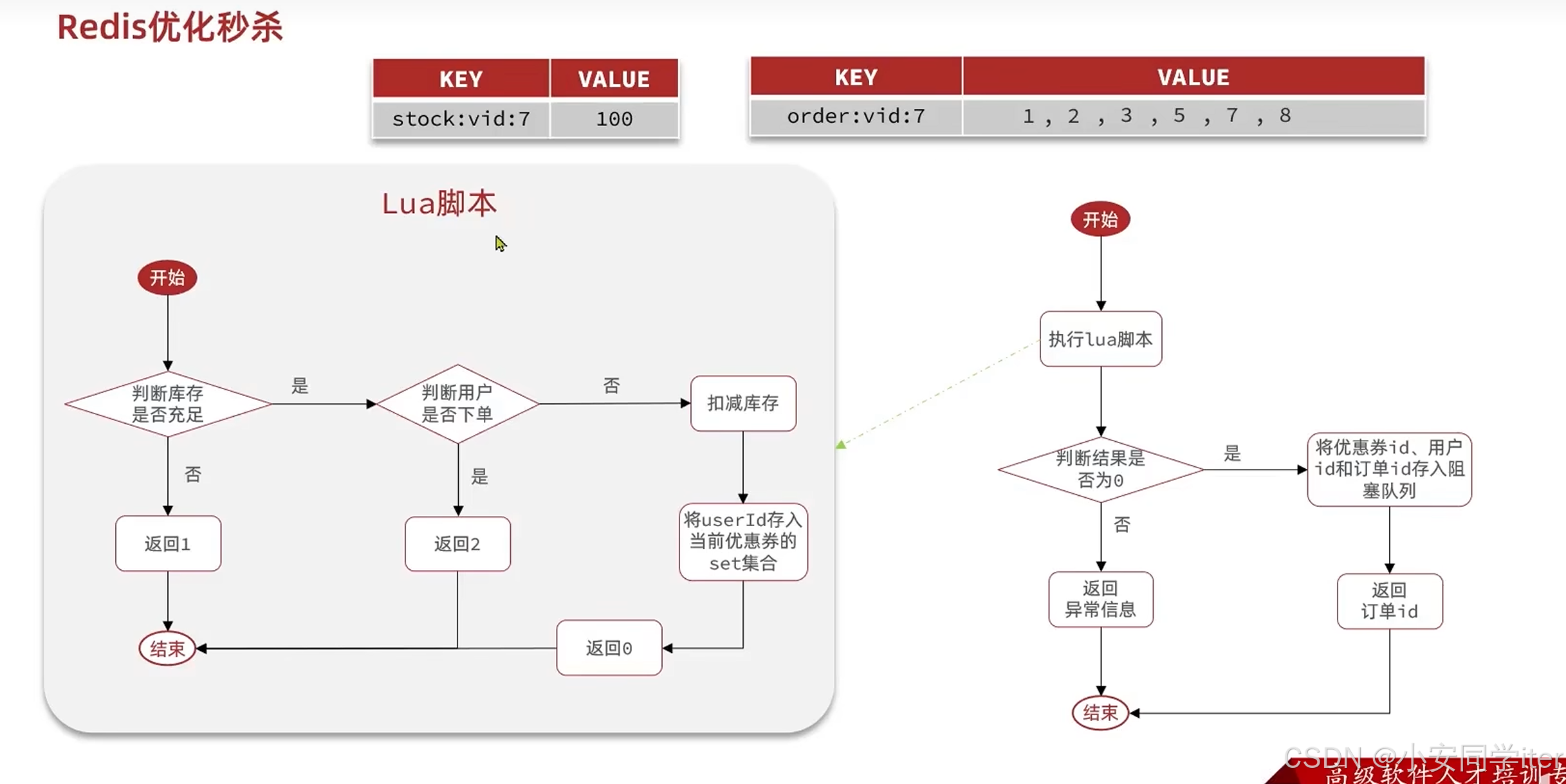
#Redis黑马点评#(五)Redisson原理详解
目录 一 基于Redis的分布式锁优化 二 Redisson 1 实现步骤 2 Redisson可重入锁机制 3 Redisson可重试机制 4 Redisson超时释放机制 5 RedissonMultiLock解决主从一致性 三 trylock与lock两者有何区别 四 Redis优化秒杀 一 基于Redis的分布式锁优化 二 Redisson Redis…...
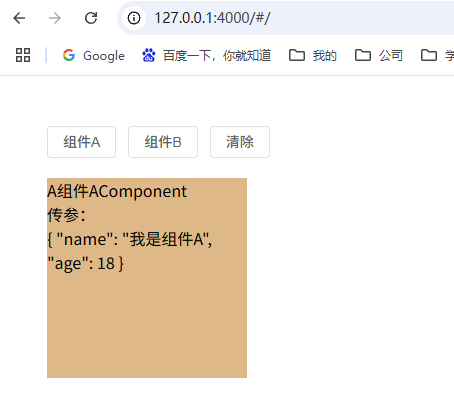
23.(vue3.x+vite)引入组件并动态切换(component)
让多个组件使用同一个挂载点,并动态切换,这就是动态组件 效果截图 A组件代码: <template><div><div>{{message }}</</...

VBA会被Python代替吗
VBA不会完全被Python取代、但Python在自动化、数据分析与跨平台开发等方面的优势使其越来越受欢迎、两者将长期并存且各具优势。 Python以其易于学习的语法、强大的开源生态系统和跨平台支持,逐渐成为自动化和数据分析领域的主流工具。然而,VBA依旧在Exc…...

2025 年福建省职业院校技能大赛网络建设与运维赛项Linux赛题解析
准备环境:系统安装及网络配置 [!TIP] 接下来将完全按照国赛评分标准进行,过程中需要掌握基础的Linux命令以及理解Linux系统,建议大家在做题前将Linux基础命令熟练运用 网络建设与运维赛项详细教程请联系主页一、X86架构计算机操作系统安装…...
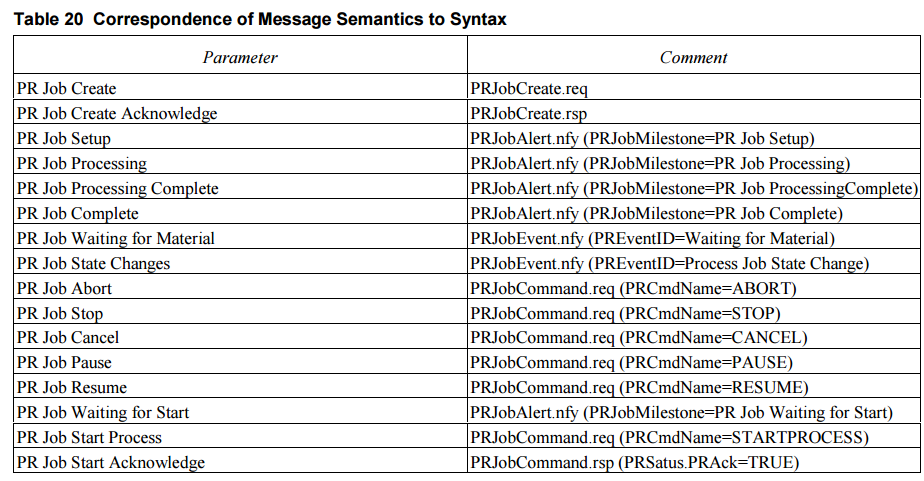
SEMI E40-0200 STANDARD FOR PROCESSING MANAGEMENT(加工管理标准)-(三)完结
10 消息服务详情 10.1 本章定义实现加工管理概念所需的消息服务。这些消息已在第8.1节中初步介绍。 协议无关性:这些服务独立于所使用的消息协议,可映射至SECS-II(SEMI E5)或其他类似协议。 10.1.1 消息服务定义内容包括&#…...
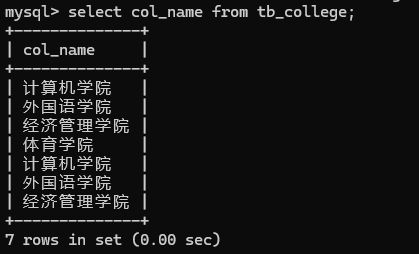
MySQL数据库创建、删除、修改
一:建库建表 我们以学校体系进行建表。将数据库命名为school。 以下代码中的大写均可小写不影响。如CREATE DATABASE与create database相同 四个关键的实体分别是学院、老师、学生和课程,其中,学生跟学院是从属关系,这个关系从…...

招行数字金融挑战赛数据赛道赛题一
赛题描述:根据提供的用户行为数据,选手需要分析用户行为特征与广告内容的匹配关系,准确预测用户对测试集广告的点击情况,通过AUC计算得分。 得分0.6120,排名60。 尝试了很多模型都没有能够提升效果,好奇大…...

【氮化镓】GaN在不同电子能量损失的SHI辐射下的损伤
该文的主要发现和结论如下: GaN的再结晶特性 :GaN在离子撞击区域具有较高的再结晶倾向,这导致其形成永久损伤的阈值较高。在所有研究的电子能量损失 regime 下,GaN都表现出这种倾向,但在电子能量损失增加时,其效率会降低,尤其是在材料发生解离并形成N₂气泡时。 能量损失…...

容器化-Docker-私有仓库Harbor
一、Harbor 的含义与作用 Harbor 是一个开源的企业级 Docker 镜像仓库,它为用户提供了安全、高效的 Docker 镜像管理方案。其核心功能是集中管理 Docker 中所有的镜像,涵盖了镜像的存储、分发、版本控制等全生命周期管理。通过使用 Harbor,企业和团队能够显著提升 Docker…...

【Leetcode 每日一题】1550. 存在连续三个奇数的数组
问题背景 给你一个整数数组 a r r arr arr,请你判断数组中是否存在连续三个元素都是奇数的情况:如果存在,请返回 t r u e true true;否则,返回 f a l s e false false。 数据约束 1 ≤ a r r . l e n g t h ≤ 10…...

C#中SetProperty方法使用
SetProperty 是 MVVM(Model-View-ViewModel) 模式中用于实现 属性变更通知(INotifyPropertyChanged) 的核心方法,主要用于在属性值变化时自动更新 UI 绑定。 1. SetProperty 的基本作用 更新字段值:修改属性…...

防火墙来回路径不一致导致的业务异常
案例拓扑: 拓扑描述: 服务器有2块网卡,内网网卡2.2.2.1/24 网关2.2.254 提供内网用户访问; 外网网卡1.1.1.1/24,外网网关1.1.1.254 80端口映射到公网 这个时候服务器有2条默认路由,分布是0.0.0.0 0.0.0.0 1…...