目标检测任务常用脚本1——将YOLO格式的数据集转换成VOC格式的数据集
在目标检测任务中,不同框架使用的标注格式各不相同。常见的框架中,YOLO 使用 .txt 文件进行标注,而 PASCAL VOC 则使用 .xml 文件。如果你需要将一个 YOLO 格式的数据集转换为 VOC 格式以便适配其他模型,本文提供了一个结构清晰、可维护性强的 Python 脚本。
🧩 输入输出目录结构
✅ 输入目录结构(YOLO 格式)
<YOLO数据集名称>
├── train/
│ ├── images/
│ │ ├── img_000001.bmp
│ │ └── ...
│ └── labels/
│ ├── img_000001.txt
│ └── ...
└── val/├── images/│ ├── img_000100.bmp│ └── ...└── labels/├── img_000100.txt└── ...
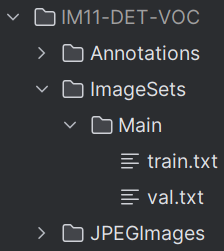
✅ 输出目录结构(VOC 格式)
<VOC格式数据集名称>
├── JPEGImages/ # 转换后的图像文件(.jpg)
├── Annotations/ # 对应的XML标注文件
└── ImageSets/└── Main/├── train.txt└── val.txt
🛠️ 配置参数说明
YOLO_DATASET_ROOT = '' # YOLO格式数据集根目录(输入)
VOC_OUTPUT_DIR = '' # VOC格式输出目录(输出)
CLASS_NAMES = [] # 类别名称列表,示例:['person', 'car', 'dog']
SPLITS = ['train', 'val'] # 数据集划分类型(训练集、验证集等)
VERBOSE = True # 是否输出详细日志
⚠️ 注意:你需要根据自己的项目路径和类别信息填写 YOLO_DATASET_ROOT、VOC_OUTPUT_DIR 和 CLASS_NAMES。
目前脚本默认处理 .bmp 图像并将其转为 .jpg,你可以根据需求修改扩展名以支持 .png、.jpeg 等格式。
完整代码如下:
import os
import xml.etree.ElementTree as ET
from xml.dom import minidom
import cv2# -----------------------------
# 超参数配置(Hyperparameters)
# -----------------------------
YOLO_DATASET_ROOT = '' # YOLO格式数据集根目录(输入)
VOC_OUTPUT_DIR = '' # VOC格式输出目录(输出)
CLASS_NAMES = [] # 类别名称列表,示例:['person', 'car', 'dog']
SPLITS = ['train', 'val'] # 数据集划分类型(训练集、验证集等)
VERBOSE = True # 是否输出详细日志def create_voc_annotation(image_path, label_path, annotations_output_dir):"""根据图像和YOLO标签生成PASCAL VOC格式的XML标注文件。"""image = cv2.imread(image_path)height, width, depth = image.shapeannotation = ET.Element('annotation')# .bmp -> .jpgfilename = os.path.basename(image_path).replace('.bmp', '.jpg')ET.SubElement(annotation, 'folder').text = 'JPEGImages'ET.SubElement(annotation, 'filename').text = filenameET.SubElement(annotation, 'path').text = os.path.join(VOC_OUTPUT_DIR, 'JPEGImages', filename)source = ET.SubElement(annotation, 'source')ET.SubElement(source, 'database').text = 'Custom Dataset'size = ET.SubElement(annotation, 'size')ET.SubElement(size, 'width').text = str(width)ET.SubElement(size, 'height').text = str(height)ET.SubElement(size, 'depth').text = str(depth)ET.SubElement(annotation, 'segmented').text = '0'if os.path.exists(label_path):with open(label_path, 'r') as f:for line in f.readlines():data = line.strip().split()class_id = int(data[0])x_center = float(data[1]) * widthy_center = float(data[2]) * heightbbox_width = float(data[3]) * widthbbox_height = float(data[4]) * heightxmin = int(x_center - bbox_width / 2)ymin = int(y_center - bbox_height / 2)xmax = int(x_center + bbox_width / 2)ymax = int(y_center + bbox_height / 2)obj = ET.SubElement(annotation, 'object')ET.SubElement(obj, 'name').text = CLASS_NAMES[class_id]ET.SubElement(obj, 'pose').text = 'Unspecified'ET.SubElement(obj, 'truncated').text = '0'ET.SubElement(obj, 'difficult').text = '0'bndbox = ET.SubElement(obj, 'bndbox')ET.SubElement(bndbox, 'xmin').text = str(xmin)ET.SubElement(bndbox, 'ymin').text = str(ymin)ET.SubElement(bndbox, 'xmax').text = str(xmax)ET.SubElement(bndbox, 'ymax').text = str(ymax)# 保存XML文件xml_str = minidom.parseString(ET.tostring(annotation)).toprettyxml(indent=" ")xml_filename = filename.replace('.jpg', '.xml')xml_path = os.path.join(annotations_output_dir, xml_filename) # 确保这里只有一层Annotations目录with open(xml_path, "w") as f:f.write(xml_str)if VERBOSE:print(f"✅ 已生成标注文件: {xml_filename}")def convert_dataset(input_dir, output_dir):"""将YOLO格式的数据集转换为VOC格式。包括图像格式转换(.bmp -> .jpg)、生成XML标注文件,并创建ImageSets/Main/train.txt/val.txt。"""print("🔄 开始转换YOLO格式数据集到VOC格式...")if not os.path.exists(output_dir):os.makedirs(output_dir)for split in SPLITS:images_dir = os.path.join(input_dir, split, 'images')labels_dir = os.path.join(input_dir, split, 'labels')output_images_dir = os.path.join(output_dir, 'JPEGImages')output_annotations_dir = os.path.join(output_dir, 'Annotations')output_imagesets_dir = os.path.join(output_dir, 'ImageSets', 'Main')os.makedirs(output_images_dir, exist_ok=True)os.makedirs(output_annotations_dir, exist_ok=True)os.makedirs(output_imagesets_dir, exist_ok=True)set_file_path = os.path.join(output_imagesets_dir, f"{split}.txt")set_file = open(set_file_path, 'w')count = 0for filename in os.listdir(images_dir):if filename.endswith('.bmp'):image_path = os.path.join(images_dir, filename)label_path = os.path.join(labels_dir, filename.replace('.bmp', '.txt'))# 图像转换new_image_name = filename.replace('.bmp', '.jpg')new_image_path = os.path.join(output_images_dir, new_image_name)image = cv2.imread(image_path)cv2.imwrite(new_image_path, image)# 写入ImageSets/Main/train.txt或val.txtbase_name = new_image_name.replace('.jpg', '')set_file.write(f"{base_name}\n")# 生成XML标注文件create_voc_annotation(new_image_path, label_path, output_annotations_dir) # 确保传入的是Annotations目录路径count += 1if VERBOSE and count % 10 == 0:print(f"🖼️ 已处理 {count} 张图片...")set_file.close()print(f"✅ 完成 [{split}] 分割集处理,共处理 {count} 张图片")print("🎉 数据集转换完成!")if __name__ == "__main__":convert_dataset(YOLO_DATASET_ROOT, VOC_OUTPUT_DIR)
转换后效果:
验证生成的VOC数据集中图片质量和数量是否合适可以用下面的脚本:
import os
import cv2
from xml.etree import ElementTree as ET# -----------------------------
# 超参数配置(Hyperparameters)
# -----------------------------
DATASET_ROOT = '' # VOC格式数据集根目录
CLASS_NAMES = [] # 类别列表, 示例: ['car', 'person', 'dog']
VERBOSE = True # 是否输出详细日志def count_images_in_set(imagesets_dir, set_name):"""统计ImageSets/Main目录下指定集合(train/val)的图片数量。"""set_file_path = os.path.join(imagesets_dir, f"{set_name}.txt")if not os.path.exists(set_file_path):print(f"[警告] 找不到 {set_name}.txt 文件,请确认是否生成正确划分文件。")return 0with open(set_file_path, 'r') as f:lines = [line.strip() for line in f.readlines() if line.strip()]return len(lines)def check_images(jpeg_dir):"""检查JPEGImages目录下的所有图片是否都能正常加载。"""print("[检查] 验证图像是否可读...")error_images = []for filename in os.listdir(jpeg_dir):if filename.lower().endswith(('.jpg', '.jpeg', '.png')):image_path = os.path.join(jpeg_dir, filename)try:img = cv2.imread(image_path)if img is None:raise ValueError("无法加载图像")except Exception as e:error_images.append(filename)if VERBOSE:print(f" ❌ 图像加载失败: {filename} | 原因: {str(e)}")return error_imagesdef validate_annotations(annotations_dir, jpeg_dir):"""验证Annotations目录下的XML标注文件是否与对应的图片匹配。"""print("[检查] 验证XML标注文件是否有效...")error_annotations = []for filename in os.listdir(annotations_dir):if filename.endswith('.xml'):xml_path = os.path.join(annotations_dir, filename)try:tree = ET.parse(xml_path)root = tree.getroot()jpg_filename = root.find('filename').textif not os.path.exists(os.path.join(jpeg_dir, jpg_filename)):raise FileNotFoundError(f"找不到对应的图像:{jpg_filename}")except Exception as e:error_annotations.append(filename)if VERBOSE:print(f" ❌ 标注文件异常: {filename} | 原因: {str(e)}")return error_annotationsdef verify_imagesets(imagesets_dir, jpeg_dir):"""确保ImageSets/Main中列出的所有图像都存在于JPEGImages中。"""print("[检查] 验证ImageSets/Main中列出的图像是否存在...")missing_files = []for set_name in ['train', 'val']:set_file_path = os.path.join(imagesets_dir, f"{set_name}.txt")if not os.path.exists(set_file_path):continuewith open(set_file_path, 'r') as f:for line in f:img_id = line.strip()if not img_id:continueimg_path = os.path.join(jpeg_dir, f"{img_id}.jpg")if not os.path.exists(img_path):missing_files.append(f"{img_id}.jpg")if VERBOSE:print(f" ❌ 图像缺失: {img_id}.jpg")return missing_filesdef main():print("🔍 开始验证VOC格式数据集...\n")# 构建路径jpeg_dir = os.path.join(DATASET_ROOT, 'JPEGImages')annotations_dir = os.path.join(DATASET_ROOT, 'Annotations')imagesets_dir = os.path.join(DATASET_ROOT, 'ImageSets', 'Main')# 检查是否存在必要目录for dir_path in [jpeg_dir, annotations_dir, imagesets_dir]:if not os.path.exists(dir_path):print(f"[错误] 必要目录不存在: {dir_path}")exit(1)# 1. 检查图像是否可读error_images = check_images(jpeg_dir)if error_images:print(f"⚠️ 共发现 {len(error_images)} 张图片加载失败:")for img in error_images:print(f" - {img}")else:print("✅ 所有图像均可正常加载。\n")# 2. 检查XML标注文件是否有效error_annotations = validate_annotations(annotations_dir, jpeg_dir)if error_annotations:print(f"⚠️ 共发现 {len(error_annotations)} 个无效或不匹配的XML标注文件:")for ann in error_annotations:print(f" - {ann}")else:print("✅ 所有XML标注文件均有效且与对应图像匹配。\n")# 3. 检查ImageSets/Main中引用的图像是否存在missing_files = verify_imagesets(imagesets_dir, jpeg_dir)if missing_files:print(f"⚠️ 共发现 {len(missing_files)} 张图像在ImageSets中被引用但实际不存在:")for img in missing_files:print(f" - {img}")else:print("✅ ImageSets/Main中引用的所有图像均存在。\n")# 4. 输出训练集和验证集的图像数量train_count = count_images_in_set(imagesets_dir, 'train')val_count = count_images_in_set(imagesets_dir, 'val')total_count = train_count + val_countprint("📊 数据集统计:")print(f" - 训练集: {train_count} 张")print(f" - 验证集: {val_count} 张")print(f" - 总数: {total_count} 张\n")print("🎉 验证完成!")if __name__ == "__main__":main()
验证效果为:

相关文章:
目标检测任务常用脚本1——将YOLO格式的数据集转换成VOC格式的数据集
在目标检测任务中,不同框架使用的标注格式各不相同。常见的框架中,YOLO 使用 .txt 文件进行标注,而 PASCAL VOC 则使用 .xml 文件。如果你需要将一个 YOLO 格式的数据集转换为 VOC 格式以便适配其他模型,本文提供了一个结构清晰、…...
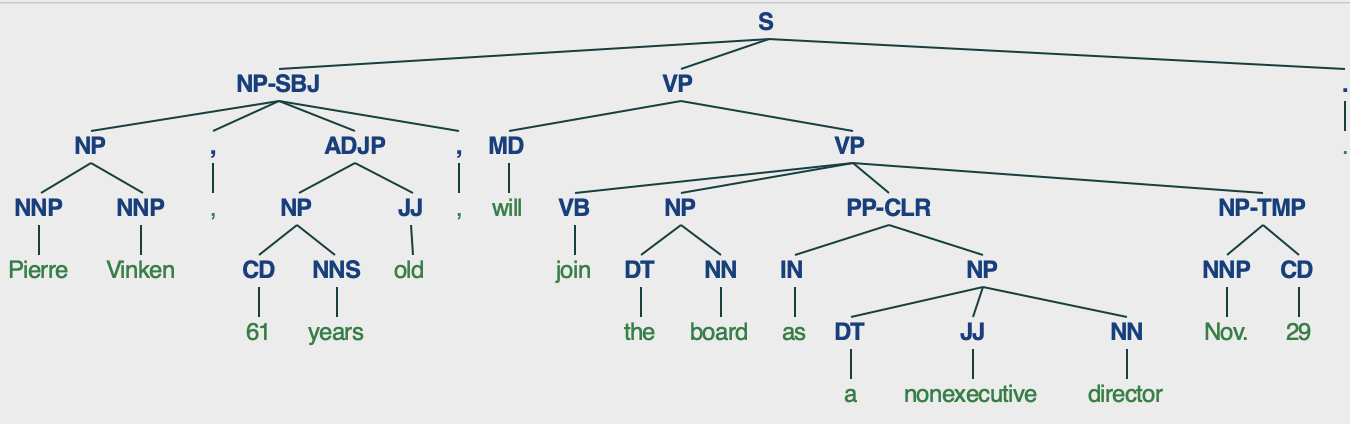
NLTK库: 数据集3-分类与标注语料(Categorized and Tagged Corpora)
NLTK库: 数据集3-分类与标注语料(Categorized and Tagged Corpora) 1.二分类语料 主要是电影语料,和情绪(积极消极、主观客观)有关,有以下2个语料: 1.1 movie_reviews: IMDb 影评 IMDb(Internet Movie …...

uni-app学习笔记五-vue3响应式基础
一.使用ref定义响应式变量 在组合式 API 中,推荐使用 ref() 函数来声明响应式状态,ref() 接收参数,并将其包裹在一个带有 .value 属性的 ref 对象中返回 示例代码: <template> <view>{{ num1 }}</view><vi…...

ElasticSeach快速上手笔记-入门篇
由来 Elasticsearch 是一个基于 Apache Lucene 构建的分布式、高扩展、近实时的搜索与数据分析引擎,能够高效处理结构化和非结构化数据的全文检索及复杂分析 搜索,即用户在平台如百度进行输入关键词,由后端给出搜索结果数据进行返回&#x…...

eward hacking 问题 强化学习钻空子
Reward Hacking的本质是目标对齐(Goal Alignment)失败 “Reward hacking”(奖励黑客)是强化学习或AI系统中常见的问题,通俗地说就是: AI模型“钻空子”,用投机取巧的方式来拿高分,而…...

uniapp开发4--实现耗时操作的加载动画效果
下面是使用 Vue 组件的方式,在 uni-app 中封装耗时操作的加载动画效果及全屏遮罩层的组件的示例。 组件结构: components/loading.vue: 组件文件,包含 HTML 结构、样式和 JS 逻辑。 代码: <template><view class&…...
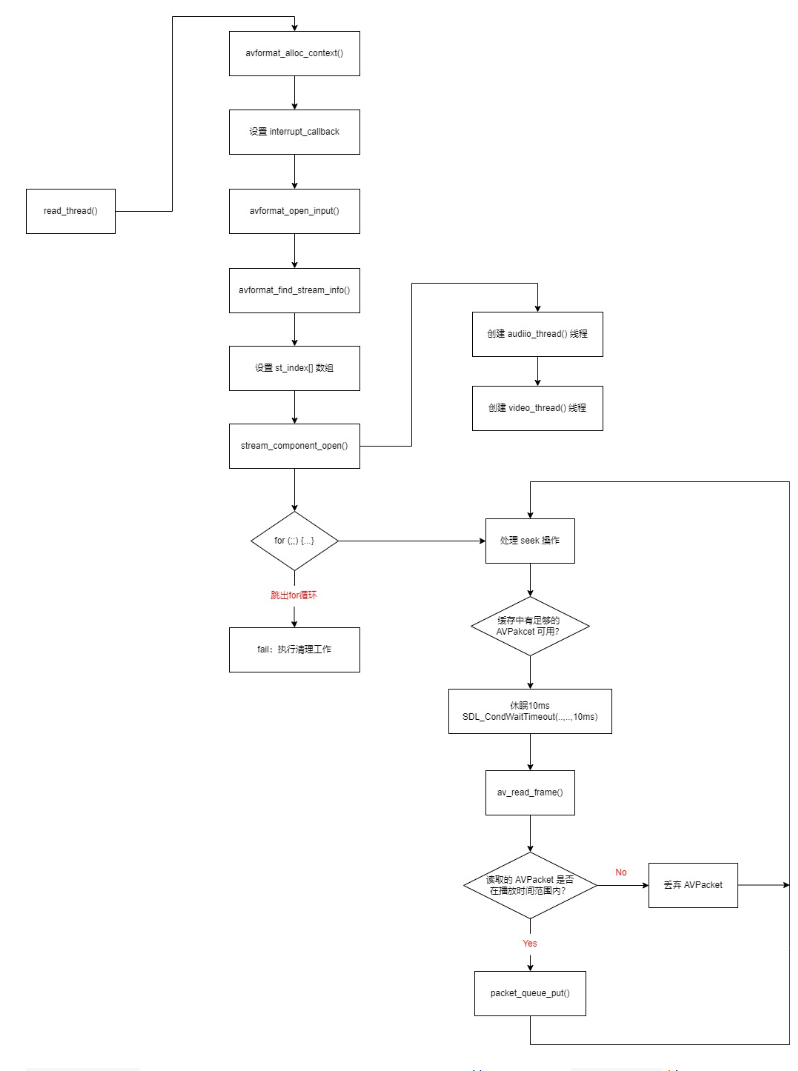
《ffplay 读线程与解码线程分析:从初始化到 seek 操作,对比视频与音频解码的差异》
1 read-thread 1.1 初始化部分 1.分配. avformat_alloc_context 创建上下⽂ ic avformat_alloc_context();if (!ic) {av_log(NULL, AV_LOG_FATAL, "Could not allocate context.\n");ret AVERROR(ENOMEM);goto fail;}2 ic->interrupt_callback.callback deco…...
MySQL推荐书单:从入门到精通
给大家介绍一些 MySQL 从入门到精通的经典书单,可以基于不同学习阶段的需求进行选择。 入门 MySQL必知必会 这本书继承了《SQL必知必会》的优点,专门针对 MySQL 用户,没有过多阐述数据库基础理论,而是紧贴实战,直接从…...

用 Rust 搭建一个优雅的多线程服务器:从零开始的详细指南
嘿,小伙伴们!今天咱们来聊聊怎么用 Rust 搭建一个牛气哄哄的多线程服务器,还能在需要的时候优雅地关机。为啥要用 Rust 呢?因为 Rust 是个超级靠谱的语言,它能保证内存安全,写并发代码的时候不用担心那些让…...
)
redis 数据结构-01( SET、GET、DEL)
使用 Redis 字符串:SET、GET、DEL Redis 字符串是用于存储和操作文本或二进制数据的基本数据类型。它们是 Redis 中最简单但功能最丰富的数据结构,可作为构建更复杂结构的基石。了解如何有效地使用字符串对于充分利用 Redis 的缓存、会话管理以及其他各…...
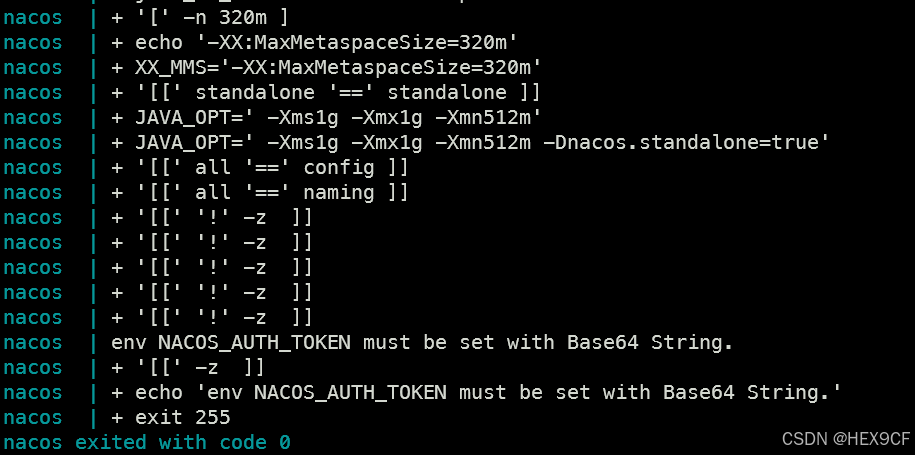
【Nacos】env NACOS_AUTH_TOKEN must be set with Base64 String.
【Nacos】env NACOS_AUTH_TOKEN must be set with Base64 String. 问题描述 env NACOS_AUTH_TOKEN must be set with Base64 String.原因分析 从错误日志中可以看出,Nacos 启动失败的原因是缺少必要的环境变量 NACOS_AUTH_TOKEN。 NACOS_AUTH_TOKEN: Nacos 用于生…...

秋招准备——2.跨时钟相关
格雷码异步FIFO跨时钟域处理 格雷码 一、格雷码规律 相邻性:相邻两个数的格雷码只有一位不同,例如: 0000 → 0001(仅最低位变化)0001 → 0011(仅次低位变化)0011 → 0010(仅最低位…...

激光打印机常见打印故障简单处理意见
一、 问题描述: 给打印机更换新的硒鼓时拉开硒鼓封条时有微量碳粉带出; 原因: 出厂打印测试时,可能会有微量碳粉在磁辊上或者磁辊仓; 解决方法: 擦干净即可正常使用; 二、 问题描述&…...

语言学中的对象语言与元语言 | 概念 / 区别 / 实例分析
注:英文引文,机翻未校。 语言学中的“对象语言”和“元语言” 刘福长 现代外语 1989年第3期(总第45期) 在阅读语言学著作时,我们有时会遇到这样两个术语:对象语言(object language࿰…...

【2025最新】Windows系统装VSCode搭建C/C++开发环境(附带所有安装包)
文章目录 为什么选择VSCode作为C/C开发工具?一、VSCode安装过程(超简单!)二、VSCode中文界面设置(再也不用对着英文发愁!)三、安装C/C插件(编程必备神器!)四、…...

MYSQL 查询去除小数位后多余的0
MYSQL 查询去除小数位后多余的0 在MySQL中,有时候我们需要去除存储在数据库中的数字字段小数点后面多余的0。这种情况通常发生在处理金额或其他需要精确小数位的数据时。例如,数据库中存储的是decimal (18,6)类型的数据,但在页面展示时不希望…...
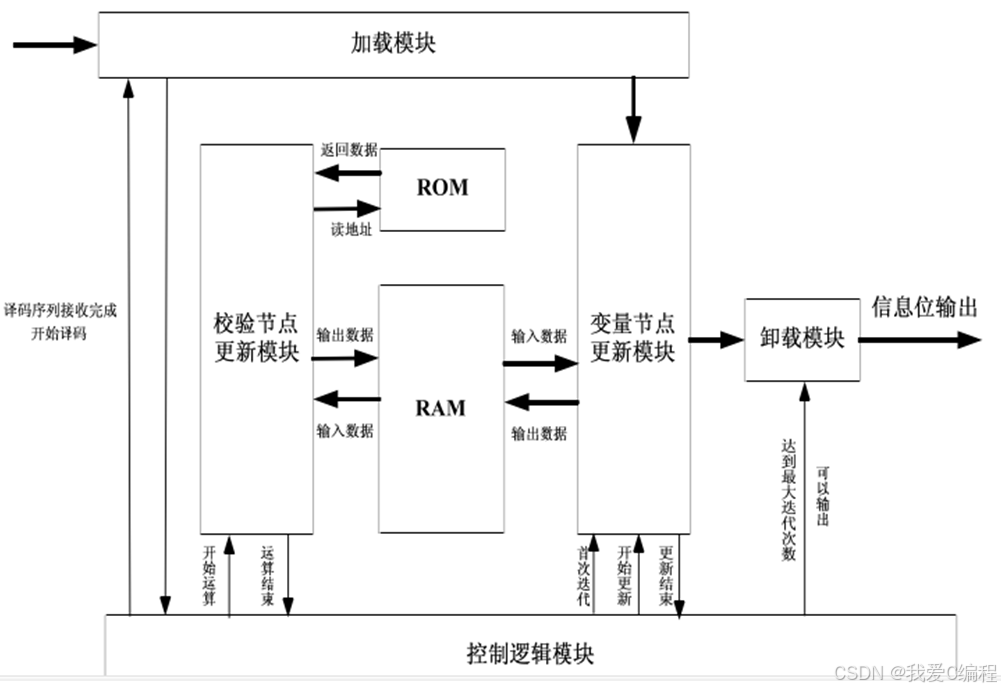
基于GF域的多进制QC-LDPC误码率matlab仿真,译码采用EMS算法
目录 1.算法仿真效果 2.算法涉及理论知识概要 3.MATLAB核心程序 4.完整算法代码文件获得 1.算法仿真效果 matlab2022a仿真结果如下(完整代码运行后无水印): 本课题实现的是四进制QC-LDPC 仿真操作步骤可参考程序配套的操作视频。 2.算…...
Vitrualbox完美显示系统界面(只需三步)
目录 1.使用vitrualbox的增强功能:编辑 2.安装增强功能(安装完后要重启虚拟机): 3. 调整界面尺寸(如果一个选项不行的话,就多试试其他不同的百分比): 先看看原来的,…...
王炸组合!STL-VMD二次分解 + Informer-LSTM 并行预测模型
往期精彩内容: 单步预测-风速预测模型代码全家桶-CSDN博客 半天入门!锂电池剩余寿命预测(Python)-CSDN博客 超强预测模型:二次分解-组合预测-CSDN博客 VMD CEEMDAN 二次分解,BiLSTM-Attention预测模型…...

n8n 修改或者智能体用文档知识库创建pdf
以下是对 Nextcloud、OnlyOffice、Seafile、Etherpad、BookStack 和 Confluence 等本地部署文档协作工具的综合评测、对比分析和使用推荐,帮助您根据不同需求选择合适的解决方案。 🧰 工具功能对比 工具名称核心功能本地部署支持适用场景优势与劣势Next…...
论坛系统(中-1)
软件开发 编写公共代码 定义状态码 对执⾏业务处理逻辑过程中可能出现的成功与失败状态做针对性描述(根据需求分析阶段可以遇见的问题提前做出定义),⽤枚举定义状态码,先定义⼀部分,业务中遇到新的问题再添加 定义状态码如下 状态码类型描…...
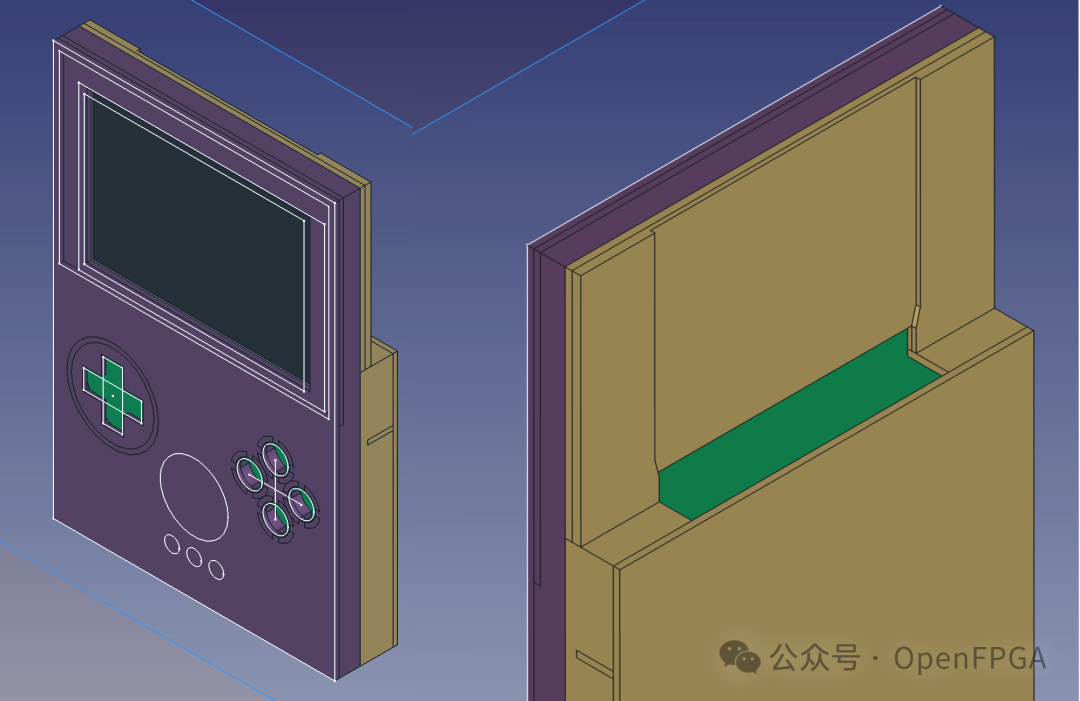
FPGA+ESP32 = GameBoy 是你的童年吗?
之前介绍的所有的复古游戏机都是基于Intel-Altera FPGA制作的,今天就带来一款基于AMD-Xilinx FPGA的复古掌上游戏机-Game Bub。 Game Bub是一款掌上游戏机,旨在畅玩 Game Boy、Game Boy Color 和 Game Boy Advance 游戏。与大多数现代掌上游戏机一样&…...
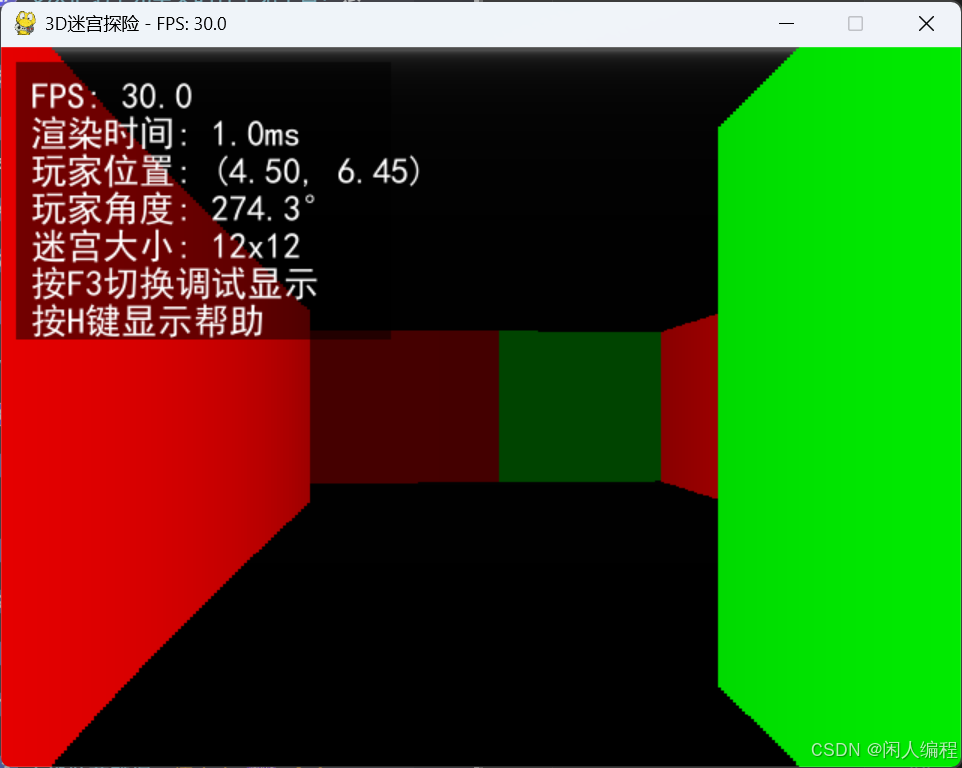
3D迷宫探险:伪3D渲染与运动控制的数学重构
目录 3D迷宫探险:伪3D渲染与运动控制的数学重构引言第一章 伪3D渲染引擎1.1 射线投射原理1.2 纹理透视校正第二章 迷宫生成算法2.1 图论生成模型2.2 复杂度控制第三章 第一人称控制3.1 运动微分方程3.2 鼠标视角控制第四章 碰撞检测优化4.1 层级检测体系4.2 滑动响应算法第五章…...

【金仓数据库征文】_金仓数据库在金融行业的两地三中心容灾架构实践
金仓数据库在金融行业的两地三中心容灾架构实践 🌟嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 引言 随着国家对信息技术应用创新࿰…...
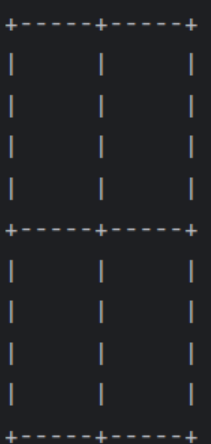
Python作业练习3
任务简述 字符田字格绘制 代码实现 def print_tianzige():for i in range(11):if i in [0, 5, 10]:print("" "-----" * 2)else:print("|" " |" * 2)print_tianzige() 结果展示...
十五种光电器件综合对比——《器件手册--光电器件》
十五、光电器件 名称 原理 特点 应用 发光二极管(LED) 基于半导体材料的电致发光效应,当电流通过时,电子与空穴复合,释放出光子。 高效、节能、寿命长、响应速度快、体积小。 广泛用于指示灯、照明、显示&#…...

【计算机视觉】OpenCV项目实战:基于face_recognition库的实时人脸识别系统深度解析
基于face_recognition库的实时人脸识别系统深度解析 1. 项目概述2. 技术原理与算法设计2.1 人脸检测模块2.2 特征编码2.3 相似度计算 3. 实战部署指南3.1 环境配置3.2 数据准备3.3 实时识别流程 4. 常见问题与解决方案4.1 dlib安装失败4.2 人脸检测性能差4.3 误识别率高 5. 关键…...
深度解析:从封装到继承的多维度实践)
Python面向对象编程(OOP)深度解析:从封装到继承的多维度实践
引言 面向对象编程(Object-Oriented Programming, OOP)是Python开发中的核心范式,其三大特性——封装、继承、多态——为构建模块化、可维护的代码提供了坚实基础。本文将通过代码实例与理论结合的方式,系统解析Python OOP的实现机制与高级特性…...

自我奖励语言模型:突破人类反馈瓶颈
核心思想 自我奖励语言模型提出了一种全新的语言模型对齐范式。传统方法如RLHF或DPO依赖人类反馈数据训练固定的奖励模型,这使模型的能力受限于人类标注数据的质量和数量。论文作者认为,要实现超人类能力的AI代理,未来的模型需要突破人类反馈…...
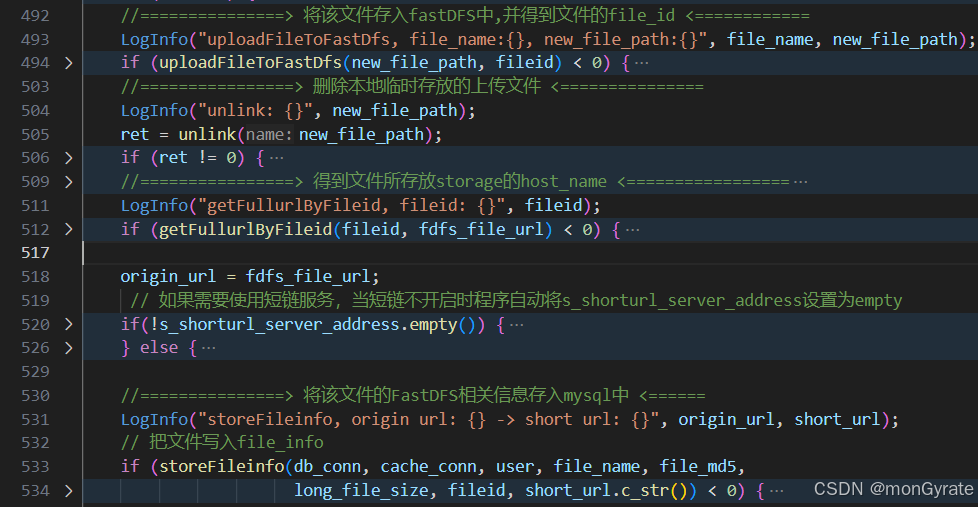
游戏资源传输服务器
目录 项目简介项目实现nginx配置服务器逻辑图 项目代码简介reactor 模型部分文件传输部分 项目演示视频演示演示分析 项目简介 使用C开发,其中资源存储在fastdfs 中,用户通过http上传或下载资源文件,此项目需要开启nginx中的nginx-upload-mod…...