KV cache 缓存与量化:加速大型语言模型推理的关键技术
引言
在大型语言模型(LLM)的推理过程中,KV 缓存(Key-Value Cache) 是一项至关重要的优化技术。自回归生成(如逐 token 生成文本)的特性决定了模型需要反复利用历史token的注意力计算结果,而 KV 缓存通过存储这些中间值(即键值对 K/V),避免了重复计算,大幅提升了推理效率。然而,随着上下文长度的增加,KV 缓存占用的内存也迅速膨胀(例如 7B 模型处理 10k token 输入时需约 5GB 内存),成为制约长文本生成的瓶颈。
为了解决这一问题,KV 缓存量化技术应运而生。通过将缓存的数值从高精度(如FP16)压缩为低精度(如 INT4或 INT2),在几乎不影响生成质量的前提下,内存需求可降低 2.5 倍以上。本文将深入解析 KV 缓存的工作原理、量化技术的实现细节。
KV caching 详解
参考1,参考2
-
KV cache 流程展示
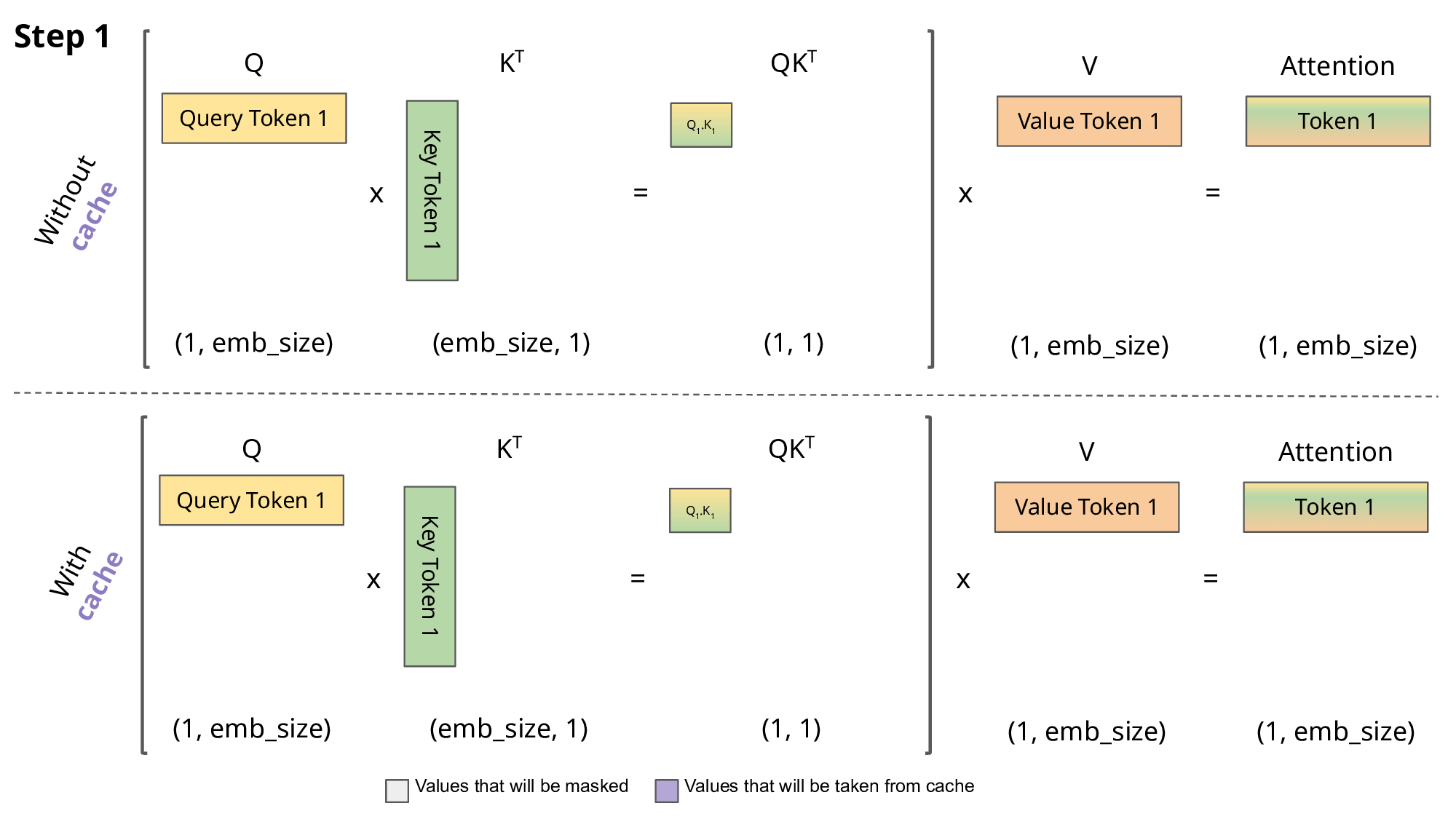
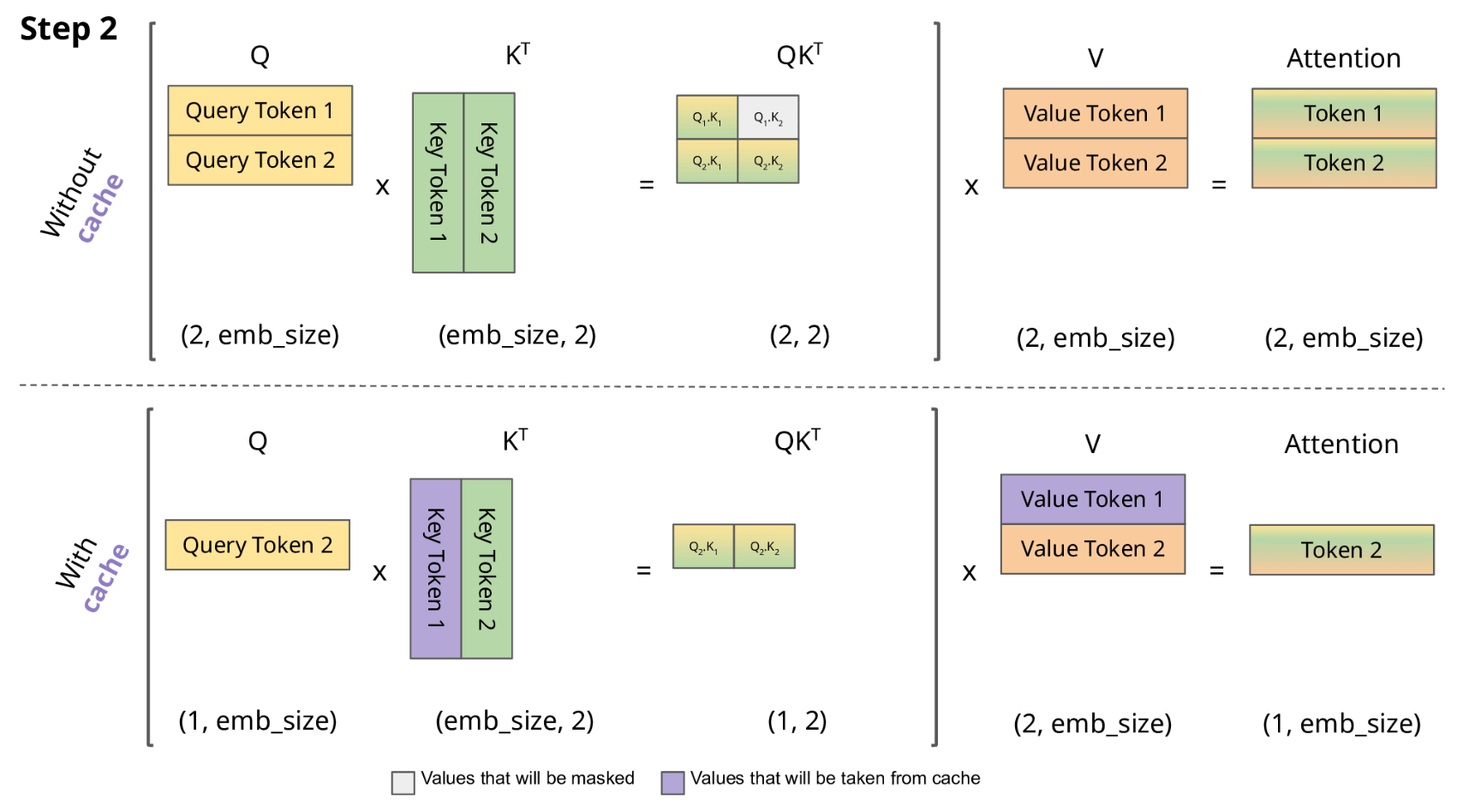
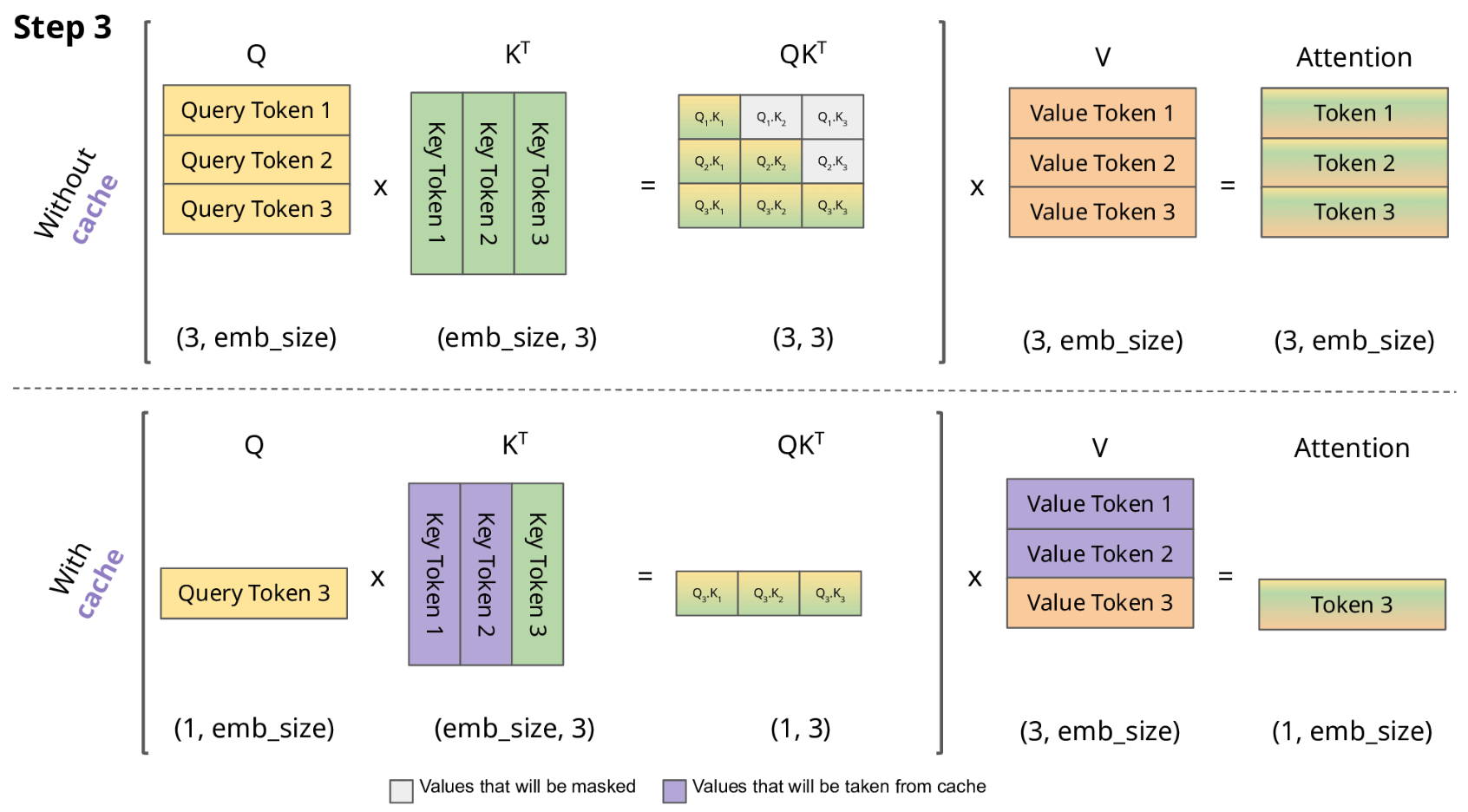
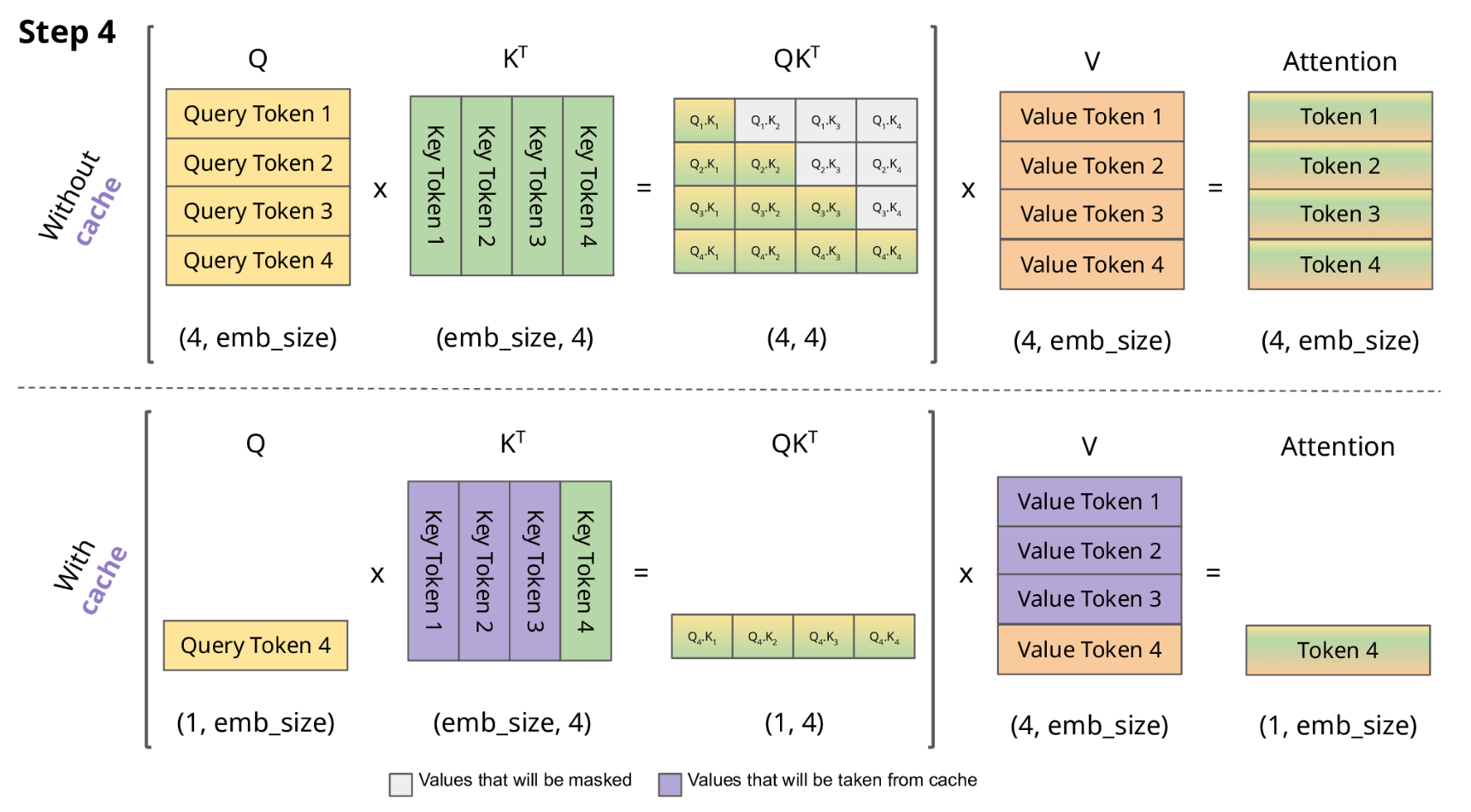
-
LLM 推理的过程是一个自回归的过程,每次生成一个 token 的时候需要结合前面所有的 token 做 attention 操作。也就是说前 i 次的token会作为第 i+1 次的预测数据送入模型,才能得到第 i+1 次的推理 token
-
由于解码器是因果的(即,一个 token 的注意力仅取决于其前面的 token),因此在每个生成步骤中,我们都在重新计算相同的先前 token 的注意力,而实际上我们只是想计算新 token 的注意力。
-
KV Cache 核心节约的时间有三大块:1)前面 n-1 次的 Q 的计算,当然这块对于一次一个 token 的输出本来也没有用;2)同理还有 Attention 计算时对角矩阵变为最后一行,和 1)是同理的,这样 mask 矩阵也就没有什么用了;3)前面 n-1 次的 K 和 V 的计算,也就是上图紫色部分,这部分是实打实被 Cache 过不需要再重新计算的部分。
-
使用 Transformer 🤗 来比较有和没有 KV 缓存的 GPT-2 生成速度
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizerdevice = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)for use_cache in (True, False):times = []for _ in range(10): # measuring 10 generationsstart = time.time()model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)times.append(time.time() - start)print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")
在 Google Colab 笔记本上,使用 Tesla T4 GPU,生成 1000 个新 token 的报告平均时间和标准差如下:
使用 KV 缓存:11.885 ± 0.272 秒
没有 KV 缓存:56.197 ± 1.855 秒
KV cache 量化
参考1, 参考2, 参考3
-
机器学习中常用的数据类型( float32、float16、bfloat16、int8)以及基本的量化原理介绍:link
-
模型量化简介:
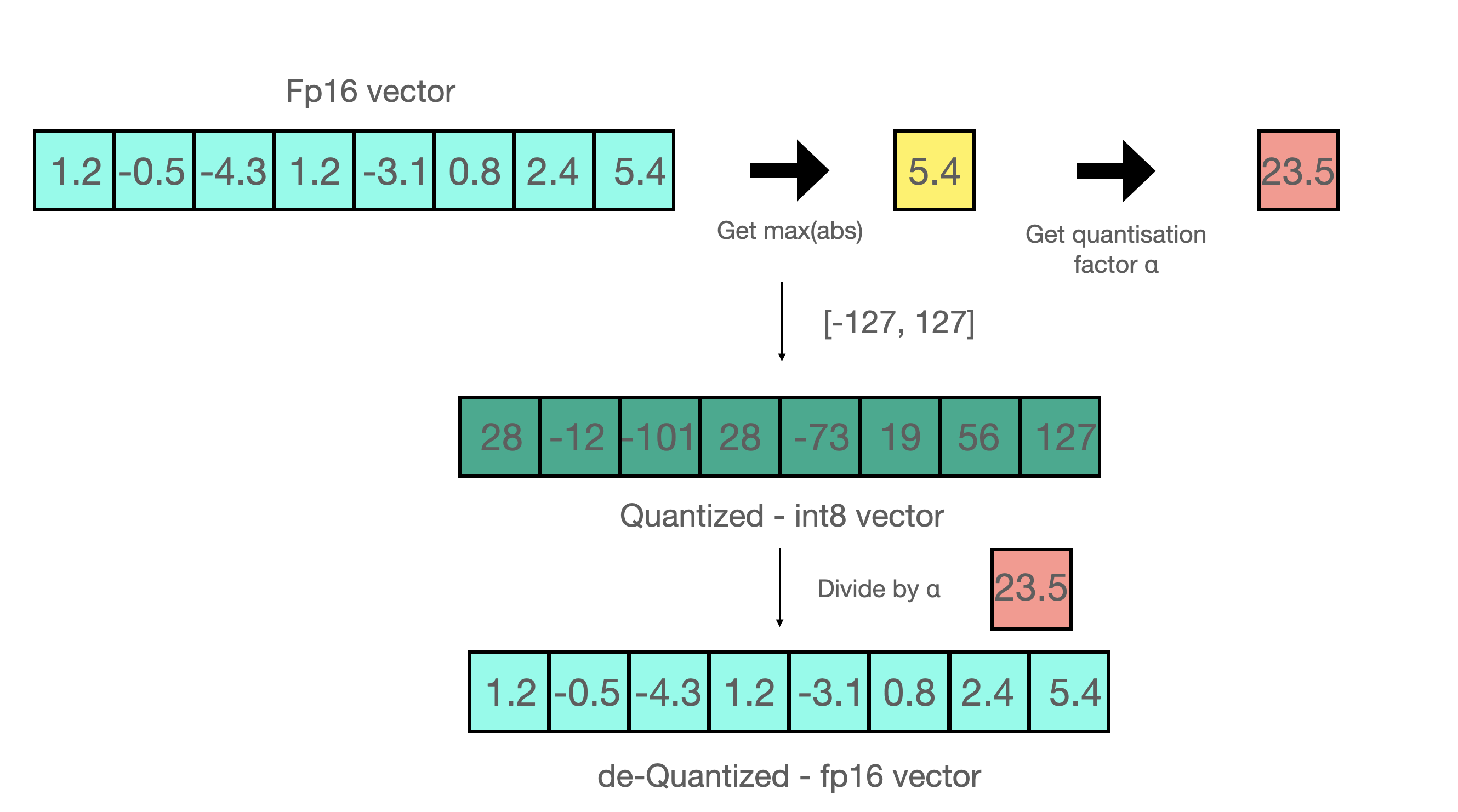
- 假设你要用 absmax 对向量 [1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4] 进行量化。首先需要计算该向量元素的最大绝对值
- Int8 的范围为 [-127, 127],因此我们将 127 除以 5.4,得到缩放因子 23.5。
- 最后,将原始向量乘以缩放因子得到最终的量化向量 [28, -12, -101, 28, -73, 19, 56, 127]。
- 要恢复原向量,可以将 int8 量化值除以缩放因子,但由于上面的过程是“四舍五入”的,我们将丢失一些精度。
-
为什么需要 kv cache 量化?
- 估算一下,当用 7B Llama-2 模型处理 10000 个词元的输入时,我们需要多少内存来存储 KV 缓存。存储一个词元的 KV 缓存所需的内存大致为
2 * 2 * 层数 * 键值抽头数 * 每抽头的维度,其中第一个 2 表示键和值,第二个 2 是我们需要的字节数 (假设模型加载精度为 float16 )。因此,如果上下文长度为 10000 词元,仅键值缓存所需的内存我们就要:
2 * 2 * 32 * 32 * 128 * 10000 ≈ 5GB
该内存需求几乎是半精度模型参数所需内存的三分之一。 - 因此,通过将 KV 缓存压缩为更紧凑的形式,我们可以节省大量内存并在消费级 GPU 上运行更长上下文的文本生成
- 估算一下,当用 7B Llama-2 模型处理 10000 个词元的输入时,我们需要多少内存来存储 KV 缓存。存储一个词元的 KV 缓存所需的内存大致为
-
KV cache 量化方式
- 给定形状为 batch size, num of head, num of tokens, head dim 的键或值,我们将其分组为 num of groups, group size 并按组进行仿射量化,如下所示:
X_Q = round(X / S) - Z
这里:
X_Q是量化后张量
S是比例,计算公式为(maxX - minX) / (max_val_for_precision - min_val_for_precision)
Z是零点,计算公式为round(-minX / S)
- 给定形状为 batch size, num of head, num of tokens, head dim 的键或值,我们将其分组为 num of groups, group size 并按组进行仿射量化,如下所示:
-
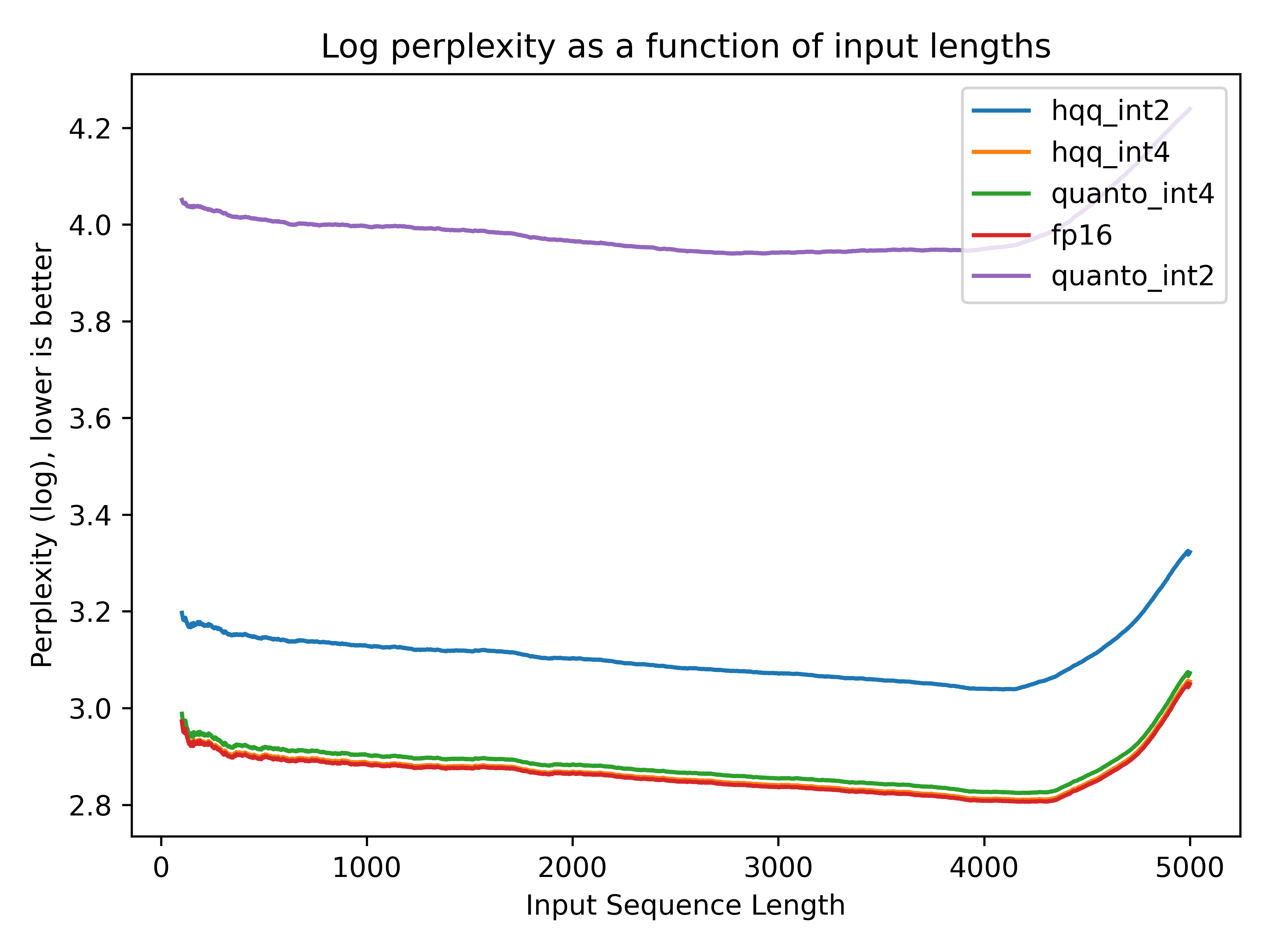
实验效果:两个后端的 int4 缓存的生成质量与原始 fp16 几乎相同,而使用 int2 时出现了质量下降
-
transformers 中使用量化 kv cache 的方式
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, device_map="cuda:0")
inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="quantized", cache_config={"backend": "quanto", "nbits": 4})
print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
# I like rock music because it's loud and energetic. It's a great way to express myself and relout = model.generate(**inputs, do_sample=False, max_new_tokens=20)
print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
# I like rock music because it's loud and energetic. I like to listen to it when I'm feeling
相关文章:
KV cache 缓存与量化:加速大型语言模型推理的关键技术
引言 在大型语言模型(LLM)的推理过程中,KV 缓存(Key-Value Cache) 是一项至关重要的优化技术。自回归生成(如逐 token 生成文本)的特性决定了模型需要反复利用历史token的注意力计算结果&#…...

视频编解码学习十一之视频原始数据
一、视频未编码前的原始数据是怎样的? 视频在未编码前的原始数据被称为 原始视频数据(Raw Video Data),主要是按照帧(Frame)来组织的图像序列。每一帧本质上就是一张图片,通常采用某种颜色格式…...
)
[Java实战]Spring Boot 3 整合 Apache Shiro(二十一)
[Java实战]Spring Boot 3 整合 Apache Shiro(二十一) 引言 在复杂的业务系统中,安全控制(认证、授权、加密)是核心需求。相比于 Spring Security 的重量级设计,Apache Shiro 凭借其简洁的 API 和灵活的扩…...

Cursor 编辑器 的 高级使用技巧与创意玩法
以下是针对 Cursor 编辑器 的 高级使用技巧与创意玩法 深度解析,涵盖代码生成优化、工作流定制、隐藏功能等层面,助你将 AI 辅助编程效率提升至新高度: 一、代码生成进阶技巧 1. 精准控制生成粒度 行级控制: 在代码行内用 // > 指定生成方向(替代模糊注释)def merge_…...

mysql性能提升方法大汇总
前言 最近在开发自己的小程序的时候,由于业务功能对系统性能的要求很高,系统性能损耗又主要在mysql上,而业务功能的数据表很多,单表数据量也很大,又涉及到很多场景的数据查询,所以我针对mysql调用做了优化…...

C++标准流详解:cin/cout的绑定机制与cerr/clog的缓冲差异
在C中,标准错误流(cerr)、标准日志流(clog)与标准输入输出流(cin/cout)的行为差异主要体现在缓冲机制和绑定关系上。以下是详细解释,并结合cin和cout的关联性进行对比分析࿱…...
BlockMesh Ai项目 监控节点部署教程
项目介绍 BlockMesh 是一个创新、开放且安全的网络,允许用户轻松地将多余的带宽货币化。 它为用户提供了被动获利并参与人工智能数据层、在线隐私、开源和区块链行业前沿的绝佳机会。 此教程为Linux系统教程 教程开始 首先到这里注册账号,注册后保存…...
【Bluedroid】蓝牙 HID DEVICE 初始化流程源码解析
本文深入剖析Android蓝牙协议栈中HID设备(BT-HD)服务的初始化与启用流程,从接口初始化、服务掩码管理、服务请求路由到属性回调通知,完整展现蓝牙HID服务激活的技术路径。通过代码逻辑梳理,揭示服务启用的核心机制&…...

iOS创建Certificate证书、制作p12证书流程
一、创建Certificates 1、第一步得先在苹果电脑上创建一个.certSigningRequest的文件。首先打开钥匙串,使用快捷键【command空格】——输入【钥匙串】回车(找不到就搜一下钥匙串访问使用手册) 2、然后在苹果电脑的左上角菜单栏选择【钥匙串…...

curl发送数据不为null,但是后端接收到为null
curl -X POST http://localhost:8080/xiaozhi/test --header "Content-Type: application/json" -d "{\"age\":123}"经过检查发现注解导入错误 正确的应该是 import org.springframework.web.bind.annotation.RequestBody;...
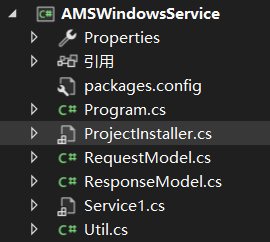
blazor与硬件通信实现案例
在网页接入硬件交互通信方案这篇博客中,曾经提到了网页中接入各种硬件操作的方法,即通过Windows Service作为指令的中转,并建立websocket通信连接,进而实现接入硬件的各种操作。这篇博客就以实际的案例来讲解具体怎么实现。 一、建立Windows Service项目 比如我就建立了一…...
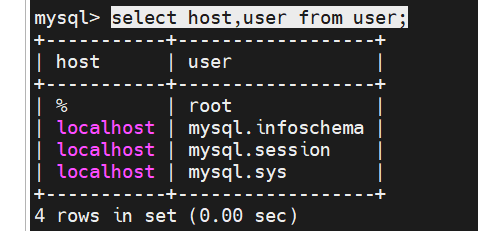
Linux下mysql的安装与远程链接
linux安装mysql 01下载依赖: 找到网址/download下: 最下面MySQL Community(mysql社区版) 选择MySQL Community Server 选择对应的mysql版本 操作系统版本选择 根据操作系统的版本选择具体版本号 下载离线版本 安装包详情 0…...

esp32硬件支持AT指令
步骤1:下载AT固件 从乐鑫官网或Git鑫GitHub仓库(https://github.com/espressif/esp-at)获取对应ESP32型号的AT固件(如ESP32-AT.bin)。 步骤2:安装烧录工具 使用 esptool.py(命令行工具&#…...
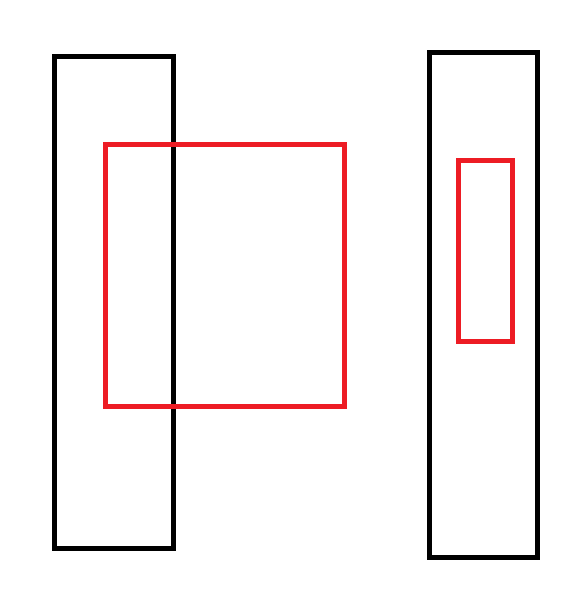
【HT周赛】T3.二维平面 题解(分块:矩形chkmax,求矩形和)
题意 需要维护 n n n \times n nn 平面上的整点,每个点 ( x , y ) (x, y) (x,y) 有权值 V ( x , y ) V(x, y) V(x,y),初始都为 0 0 0。 同时给定 n n n 次修改操作,每次修改给出 x 1 , x 2 , y 1 , y 2 , v x_1, x_2, y_1, y_2, v x…...

C++中的虚表和虚表指针的原理和示例
一、基本概念 1. 什么是虚函数(virtual function)? 虚函数是用 virtual 关键字修饰的成员函数,支持运行时多态(dynamic polymorphism)。通过基类指针或引用调用派生类重写的函数。 class Base { public:…...
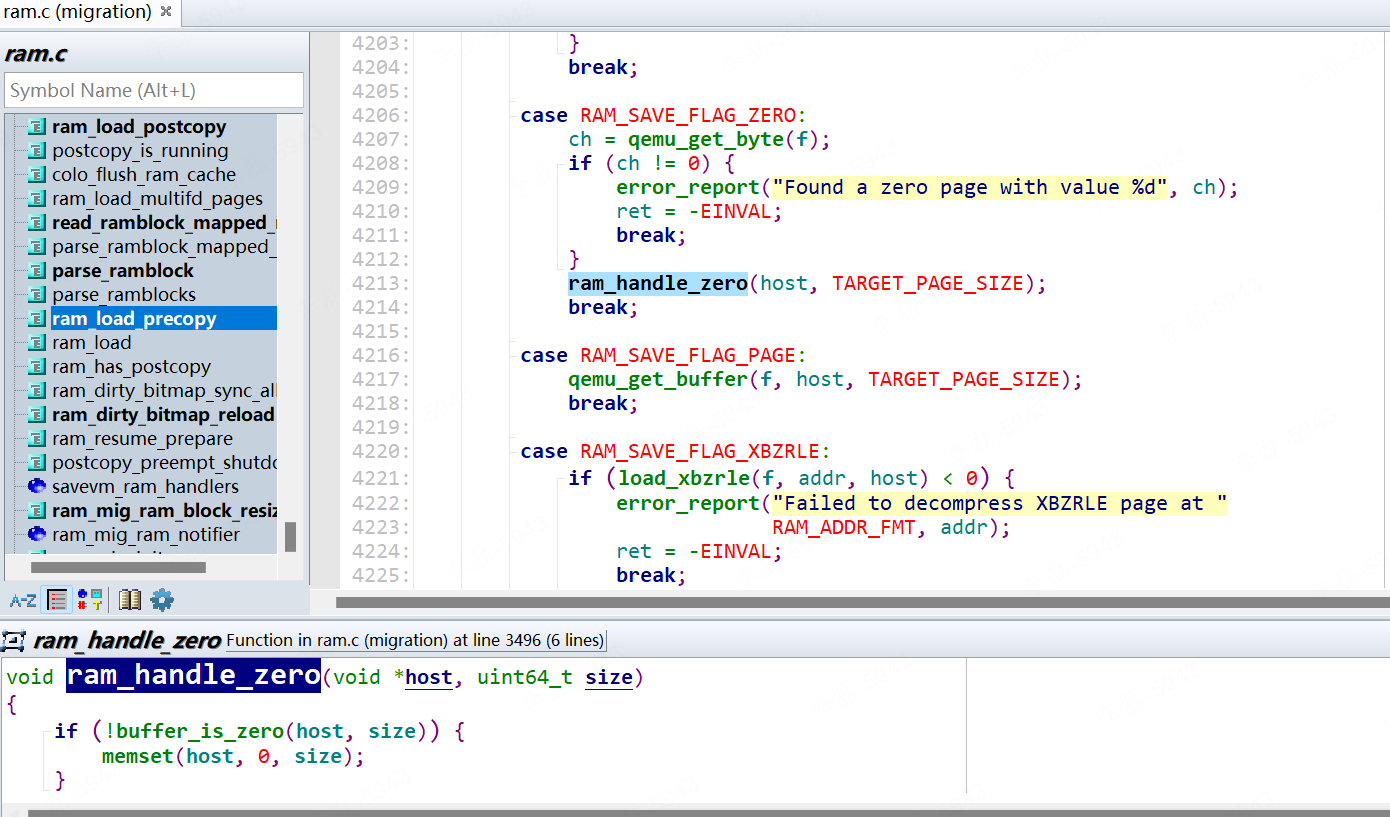
qemu热迁移后内存占用突增问题
1.问题描述 虚拟机配置了memoryBackingmemfd的情况下,热迁移虚拟机后,在目的节点 qemu-kvm 进程占用 rss 会突增很多。 如果去掉这个配置没这个现象。 <memoryBacking><source typememfd/> </memoryBacking>2.问题现象 2.1 不配置…...
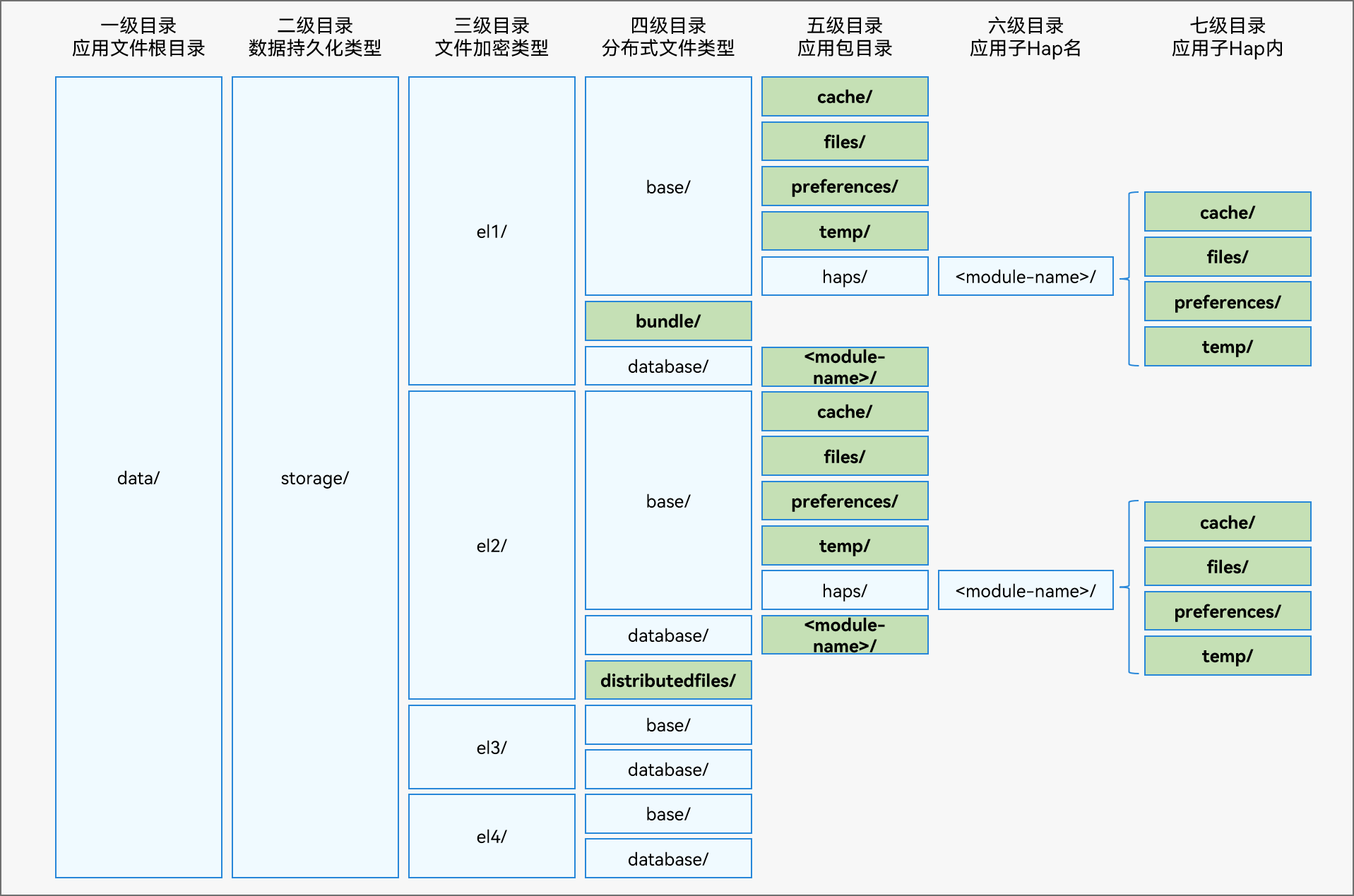
鸿蒙 Core File Kit(文件基础服务)之简单使用文件
查看常用的沙箱目录 应用沙箱文件访问关系图 应用文件目录结构图 查看常用的沙箱目录 Entry Component struct Index {build() {Button(查看常用的沙箱目录).onClick(_>{let ctx getContext() // UI下只能使用这个方法,不能 this.contextconsole.log(--应用缓存…...

AI 检测原创论文:技术迷思与教育本质的悖论思考
当高校将 AI 写作检测工具作为学术诚信的 "电子判官",一场由技术理性引发的教育异化正在悄然上演。GPT-4 检测工具将人类创作的论文误判为 AI 生成的概率高达 23%(斯坦福大学 2024 年研究数据),这种 "以 AI 制 AI&…...
基于Qt的app开发第七天
写在前面 笔者是大一下计科生,标题这个项目是笔者这个学期的课设,与学长共创,我负责客户端部分,现在已经实现了待办板块的新建、修改。 这个项目目前已经走上正轨了,博主也实现了主要功能的从无到有ÿ…...

目标检测任务常用脚本1——将YOLO格式的数据集转换成VOC格式的数据集
在目标检测任务中,不同框架使用的标注格式各不相同。常见的框架中,YOLO 使用 .txt 文件进行标注,而 PASCAL VOC 则使用 .xml 文件。如果你需要将一个 YOLO 格式的数据集转换为 VOC 格式以便适配其他模型,本文提供了一个结构清晰、…...
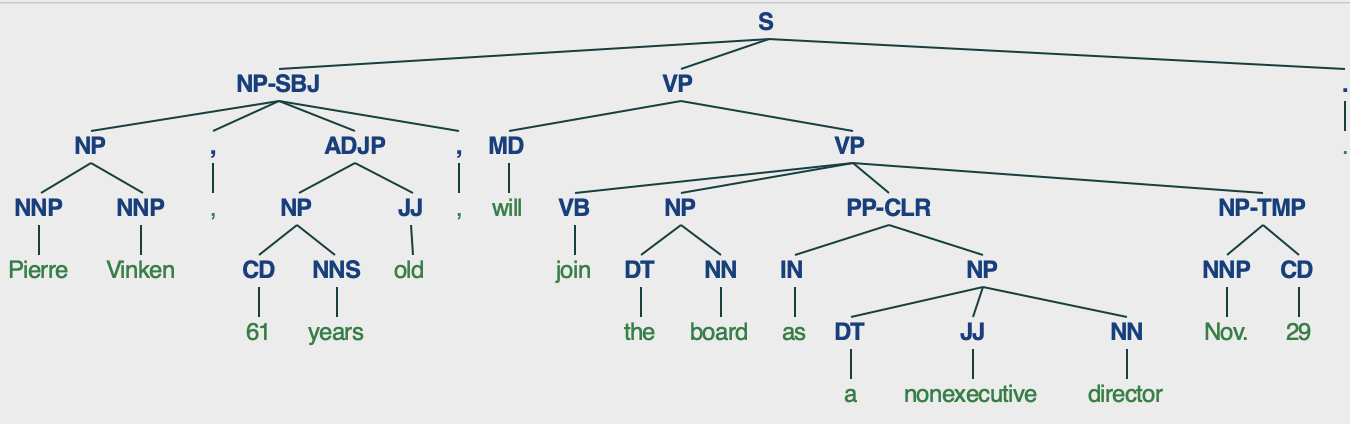
NLTK库: 数据集3-分类与标注语料(Categorized and Tagged Corpora)
NLTK库: 数据集3-分类与标注语料(Categorized and Tagged Corpora) 1.二分类语料 主要是电影语料,和情绪(积极消极、主观客观)有关,有以下2个语料: 1.1 movie_reviews: IMDb 影评 IMDb(Internet Movie …...

uni-app学习笔记五-vue3响应式基础
一.使用ref定义响应式变量 在组合式 API 中,推荐使用 ref() 函数来声明响应式状态,ref() 接收参数,并将其包裹在一个带有 .value 属性的 ref 对象中返回 示例代码: <template> <view>{{ num1 }}</view><vi…...

ElasticSeach快速上手笔记-入门篇
由来 Elasticsearch 是一个基于 Apache Lucene 构建的分布式、高扩展、近实时的搜索与数据分析引擎,能够高效处理结构化和非结构化数据的全文检索及复杂分析 搜索,即用户在平台如百度进行输入关键词,由后端给出搜索结果数据进行返回&#x…...

eward hacking 问题 强化学习钻空子
Reward Hacking的本质是目标对齐(Goal Alignment)失败 “Reward hacking”(奖励黑客)是强化学习或AI系统中常见的问题,通俗地说就是: AI模型“钻空子”,用投机取巧的方式来拿高分,而…...

uniapp开发4--实现耗时操作的加载动画效果
下面是使用 Vue 组件的方式,在 uni-app 中封装耗时操作的加载动画效果及全屏遮罩层的组件的示例。 组件结构: components/loading.vue: 组件文件,包含 HTML 结构、样式和 JS 逻辑。 代码: <template><view class&…...
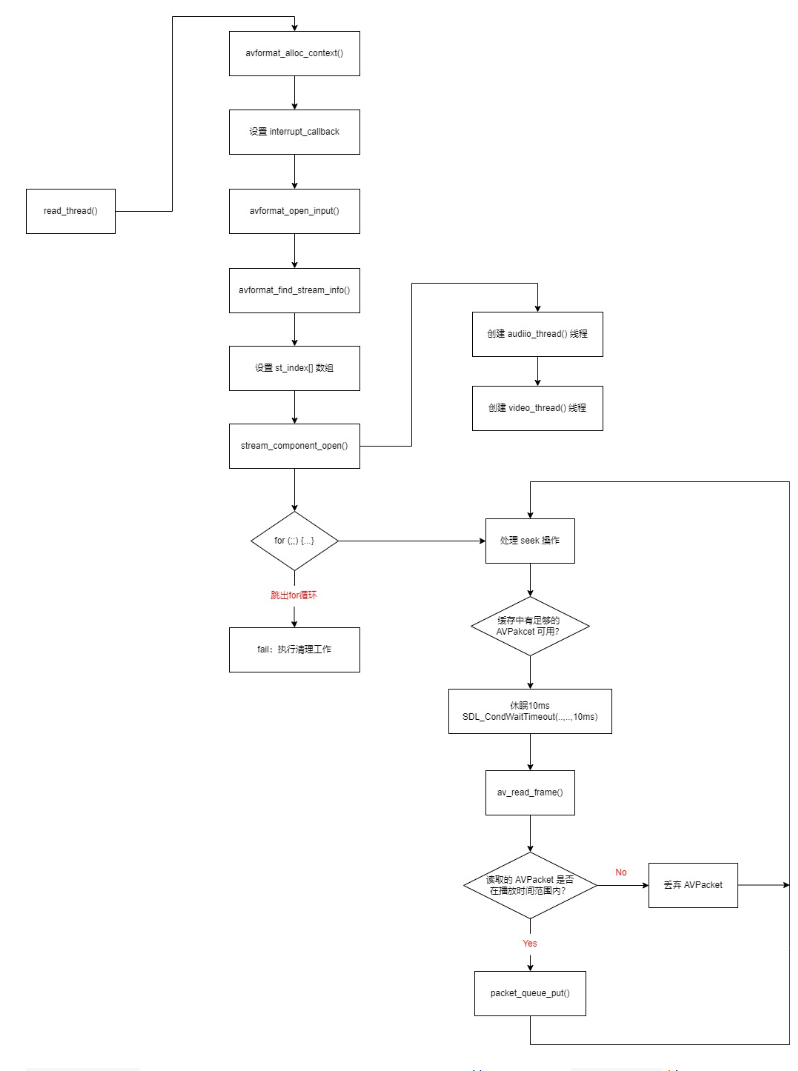
《ffplay 读线程与解码线程分析:从初始化到 seek 操作,对比视频与音频解码的差异》
1 read-thread 1.1 初始化部分 1.分配. avformat_alloc_context 创建上下⽂ ic avformat_alloc_context();if (!ic) {av_log(NULL, AV_LOG_FATAL, "Could not allocate context.\n");ret AVERROR(ENOMEM);goto fail;}2 ic->interrupt_callback.callback deco…...
MySQL推荐书单:从入门到精通
给大家介绍一些 MySQL 从入门到精通的经典书单,可以基于不同学习阶段的需求进行选择。 入门 MySQL必知必会 这本书继承了《SQL必知必会》的优点,专门针对 MySQL 用户,没有过多阐述数据库基础理论,而是紧贴实战,直接从…...

用 Rust 搭建一个优雅的多线程服务器:从零开始的详细指南
嘿,小伙伴们!今天咱们来聊聊怎么用 Rust 搭建一个牛气哄哄的多线程服务器,还能在需要的时候优雅地关机。为啥要用 Rust 呢?因为 Rust 是个超级靠谱的语言,它能保证内存安全,写并发代码的时候不用担心那些让…...
)
redis 数据结构-01( SET、GET、DEL)
使用 Redis 字符串:SET、GET、DEL Redis 字符串是用于存储和操作文本或二进制数据的基本数据类型。它们是 Redis 中最简单但功能最丰富的数据结构,可作为构建更复杂结构的基石。了解如何有效地使用字符串对于充分利用 Redis 的缓存、会话管理以及其他各…...
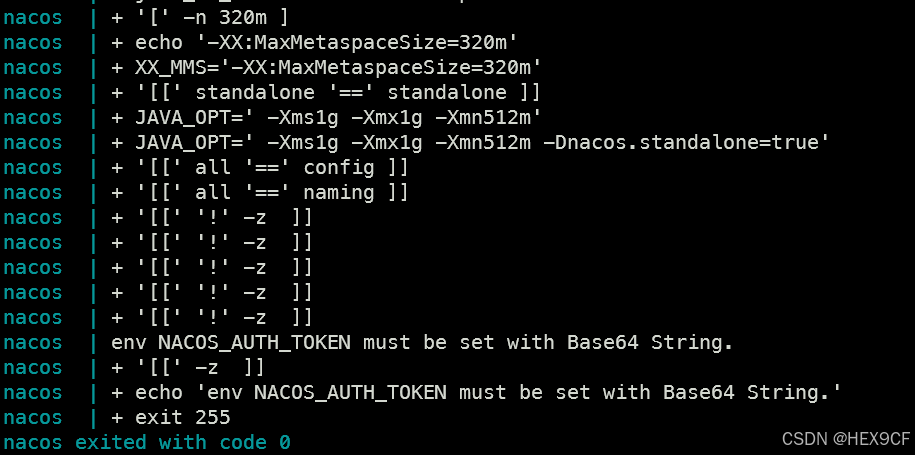
【Nacos】env NACOS_AUTH_TOKEN must be set with Base64 String.
【Nacos】env NACOS_AUTH_TOKEN must be set with Base64 String. 问题描述 env NACOS_AUTH_TOKEN must be set with Base64 String.原因分析 从错误日志中可以看出,Nacos 启动失败的原因是缺少必要的环境变量 NACOS_AUTH_TOKEN。 NACOS_AUTH_TOKEN: Nacos 用于生…...