Redis实现分布式获取全局唯一自增ID的案例。
【1】简易自增版本(从 1 开始 1,2,3,...)
项目结构
下面是一个基于 RedisTemplate 实现的分布式全局唯一自增 ID 生成器的案例。适用于 Java Spring Boot 环境,利用 Redis 的原子操作 INCR 指令。
✅ 原理说明
Redis 提供的 INCR 命令是原子性的,可以确保在分布式环境下,每次调用都会返回一个唯一的递增数字,非常适合用作分布式系统的全局 ID。
📦 依赖(Spring Boot + Redis)
确保你的 pom.xml 包含如下依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>🧱 配置 RedisTemplate(可选,如果你使用的是默认配置可省略)
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericToStringSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String, Long> redisTemplate(RedisConnectionFactory factory) {RedisTemplate<String, Long> template = new RedisTemplate<>();template.setConnectionFactory(factory);template.setKeySerializer(new StringRedisSerializer());template.setValueSerializer(new GenericToStringSerializer<>(Long.class));return template;}
}🔧 全局 ID 生成器类
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;@Component
public class RedisIdGenerator {private static final String REDIS_KEY_PREFIX = "global:id:";@Resourceprivate RedisTemplate<String, Long> redisTemplate;/*** 获取全局唯一递增 ID** @param key 业务模块(例如:order、user)* @return 唯一 ID*/public long getNextId(String key) {String redisKey = REDIS_KEY_PREFIX + key;return redisTemplate.opsForValue().increment(redisKey);}
}🧪 使用示例
@RestController
@RequestMapping("/id")
public class IdController {@Autowiredprivate RedisIdGenerator redisIdGenerator;@GetMapping("/next")public String getNextId(@RequestParam(defaultValue = "order") String key) {long id = redisIdGenerator.getNextId(key);return "Generated ID for " + key + ": " + id;}
}📝 示例返回
访问 GET /id/next?key=order 多次,你将看到递增的 ID:
Generated ID for order: 1
Generated ID for order: 2
Generated ID for order: 3
...✅ 优势
- 原子性强,天然分布式。
- 持久化在 Redis 中,服务重启不丢失。
- 支持多业务 key 分离。
【2】雪花算法混合模式
下面是一个 Redis + 雪花算法混合模式 的 分布式唯一ID生成方案,它结合了:
- 雪花算法(Snowflake):用于生成高性能、趋势递增的唯一ID;
- Redis:用于动态分配和管理数据中心ID(dataCenterId)或机器ID(workerId),解决分布式部署时的节点冲突问题。
📌 背景:为什么混合
- 雪花算法依赖机器ID、数据中心ID来避免节点之间ID重复;
- 如果你部署在容器或弹性云环境中,静态配置workerId会冲突;
- 用 Redis 分布式锁 + 自增值 动态生成
workerId/dataCenterId,可避免冲突。
✅ 雪花算法类(简化版)
public class SnowflakeIdGenerator {private final long workerId;private final long dataCenterId;private final long sequenceBits = 12L;private final long workerIdBits = 5L;private final long dataCenterIdBits = 5L;private final long maxWorkerId = -1L ^ (-1L << workerIdBits);private final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits);private final long workerIdShift = sequenceBits;private final long dataCenterIdShift = sequenceBits + workerIdBits;private final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;private final long sequenceMask = -1L ^ (-1L << sequenceBits);private long sequence = 0L;private long lastTimestamp = -1L;public SnowflakeIdGenerator(long workerId, long dataCenterId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException("workerId invalid");}if (dataCenterId > maxDataCenterId || dataCenterId < 0) {throw new IllegalArgumentException("dataCenterId invalid");}this.workerId = workerId;this.dataCenterId = dataCenterId;}public synchronized long nextId() {long timestamp = timeGen();if (timestamp < lastTimestamp) {throw new RuntimeException("Clock moved backwards.");}if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0L;}lastTimestamp = timestamp;return ((timestamp - 1609459200000L) << timestampLeftShift)| (dataCenterId << dataCenterIdShift)| (workerId << workerIdShift)| sequence;}private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}private long timeGen() {return System.currentTimeMillis();}
}📦 Redis 动态分配 WorkerId / DataCenterId
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;@Component
public class RedisNodeIdAllocatorV1 {private static final String WORKER_ID_KEY = "snowflake:workerId";private static final String DATACENTER_ID_KEY = "snowflake:datacenterId";@Autowiredprivate RedisTemplate<String, String> redisTemplate;public long getWorkerId() {return redisTemplate.opsForValue().increment(WORKER_ID_KEY) % 32;}public long getDataCenterId() {return redisTemplate.opsForValue().increment(DATACENTER_ID_KEY) % 32;}
}🧩 初始化与使用
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;@Component
public class SnowflakeIdServiceV1 {private final SnowflakeIdGenerator idGenerator;@Autowiredpublic SnowflakeIdServiceV1(RedisNodeIdAllocatorV1 allocator) {long workerId = allocator.getWorkerId();long dataCenterId = allocator.getDataCenterId();this.idGenerator = new SnowflakeIdGenerator(workerId, dataCenterId);}public long getNextId() {return idGenerator.nextId();}
}📡 示例 Controller
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;@RestController
@RequestMapping("/SnowFlakeId")
public class SnowFlakeIdController {@Resourceprivate SnowflakeIdServiceV1 snowflakeIdService;@GetMapping("/next")public String getNextId() {return "Generated Snowflake ID: " + snowflakeIdService.getNextId();}
}✅ 特点总结
| 功能 | 说明 |
| 高并发 | 每秒可生成数百万个唯一ID |
| 无中心依赖 | 每个节点独立生成 ID(初始化通过 Redis 分配ID) |
| 趋势递增 | 默认以时间戳为前缀,排序性好 |
| Redis分配workerId | 容器化部署时避免 ID 冲突 |
【3】按业务Key分组
🔁 设计目标
- 支持多业务线(order、user、payment 等)各自独立生成分布式 ID;
- 每个业务线通过 Redis 动态分配其专属的
workerId和dataCenterId; - 保证分布式部署下不会发生冲突;
- 雪花 ID 趋势递增、唯一、安全。
✅ 步骤总览
✅ 1. Redis 节点分配器(支持按 key 分组)
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;import javax.annotation.Resource;@Component
public class RedisNodeIdAllocatorV2 {@Resourceprivate RedisTemplate<String, String> redisTemplate;public long getWorkerId(String bizKey) {return redisTemplate.opsForValue().increment("snowflake:" + bizKey + ":workerId") % 32;}public long getDataCenterId(String bizKey) {return redisTemplate.opsForValue().increment("snowflake:" + bizKey + ":datacenterId") % 32;}
}✅ 2. 雪花生成器管理器(每个 key 一套生成器)
import com.example.client.redis_test.snowflake.SnowflakeIdGenerator;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;@Component
public class SnowflakeIdManager {@Resourceprivate RedisNodeIdAllocatorV2 allocator;private final Map<String, SnowflakeIdGenerator> generatorMap = new ConcurrentHashMap<>();public synchronized SnowflakeIdGenerator getGenerator(String bizKey) {return generatorMap.computeIfAbsent(bizKey, key -> {long workerId = allocator.getWorkerId(key);long dataCenterId = allocator.getDataCenterId(key);return new SnowflakeIdGenerator(workerId, dataCenterId);});}
}✅ 3. 提供统一服务接口
import org.springframework.stereotype.Component;
import javax.annotation.Resource;@Component
public class SnowflakeIdServiceV2 {@Resourceprivate SnowflakeIdManager manager;public long getNextId(String bizKey) {return manager.getGenerator(bizKey).nextId();}
}✅ 4. 示例 Controller(按业务 key 获取 ID)
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;
@RestController
@RequestMapping("/SnowFlakeIdGroupByBiz")
public class SnowFlakeIdGroupByBizController {@Resourceprivate SnowflakeIdServiceV2 idService;@GetMapping("/next")public String getNextId(@RequestParam(defaultValue = "order") String key) {long id = idService.getNextId(key);return "Generated ID for [" + key + "]: " + id;}
}
🧪 示例
GET /id/next?key=order
→ Generated ID for [order]: 1487450731280013312GET /id/next?key=user
→ Generated ID for [user]: 1487450732081190912🔐 注意事项
| 问题 | 解决方式 |
| Redis中workerId过多 | 可以定期清理、或设计过期机制 |
| workerId冲突 | 可加锁或用 setnx 保证唯一性(当前用 限定范围) |
| 服务重启ID漂移 | Snowflake 本身保证有序不重复,初始化动态分配 |
| 多业务混用 | 支持按 key 隔离;也可默认用 key |
【4】Redis在生成全局ID中的作用?workerId 与dataCenterId 是什么?有什么作用?为什么这样设计就能是全局唯一?
我们逐一深入解析 Redis 在全局 ID 生成中的作用、workerId 和 dataCenterId 的含义,以及它们如何确保 全局唯一性。
✅ 一、Redis 在生成全局 ID 中的作用
在雪花算法中,每个节点都必须拥有一个**唯一标识(workerId 和 dataCenterId)**来防止生成相同的 ID。如果你是在容器、K8s 或弹性云部署中,节点 ID 难以静态配置。
Redis 在这里的核心作用是:动态分配全局唯一的 ID 节点标识:
| 功能 | 说明 |
| 分布式节点注册 | 每个服务启动时,通过 Redis 获取属于自己的 workerId 和 dataCenterId |
| 原子性递增 | 使用 Redis 的 保证每个节点获得唯一编号 |
| 避免 ID 冲突 | 让不同服务实例不会重复获取同一个 workerId/dataCenterId |
✅ 二、workerId 和 dataCenterId 是什么?
📌 它们是雪花算法中的“节点编号”
雪花算法将一个 64 位 ID 拆分如下:
| 位数 | 字段名 | 描述 |
| 1 | 符号位 | 固定为 0 |
| 41 | 时间戳 | 当前时间戳(毫秒)减去自定义起始时间 |
| 5 | dataCenterId | 数据中心编号(最多支持 32 个) |
| 5 | workerId | 每个数据中心下的机器编号(最多支持 32 个) |
| 12 | 序列号 | 每毫秒最多支持 4096 个 ID |
✅ 三、它们的作用和重要性
✳️ workerId、dataCenterId 的作用
- 用于标识ID来源的节点和数据中心,防止多个节点生成重复的 ID;
- 即使多个节点在同一毫秒内生成 ID,只要它们的 workerId 或 dataCenterId 不同,生成的 ID 也不会相同;
- 它们与时间戳和序列号一起,组成了全局唯一且趋势递增的 ID。
✅ 四、为什么这样设计就能保证全局唯一?
原因如下:
- 时间戳区分不同时间点的 ID
-
- 基于当前时间毫秒级,保证大多数 ID 是有序递增的。
- workerId + dataCenterId 区分节点
-
- 物理上多个节点并发生成 ID 时,通过这些编号做隔离。
- 序列号解决高并发同一节点冲突
-
- 在同一毫秒内同一节点生成多个 ID,用序列号保证不重复(最多 4096 个)。
- 组合后无冲突
-
- 一个 64 位整数中组合了这几个维度,因此生成的 ID 是分布式下全局唯一且趋势递增的。
✅ 图解(结构拆解)
0 | 41位时间戳 | 5位dataCenterId | 5位workerId | 12位序列号例如:
| 字段 | 示例值 |
| 时间戳 | 1111111111111 |
| dataCenterId | 2 |
| workerId | 10 |
| 序列号 | 123 |
| 组合成 ID | 7123889822724094976 |
✅ 补充:Redis 为何比配置文件或机器 IP 更可靠?
| 方式 | 缺点 |
| 静态配置(配置文件) | 容器化部署中无法保证唯一性 |
| 机器 IP 推导 | 云环境中 IP 会变动,冲突风险高 |
| Redis 统一分配 | 原子操作、集中控制,适合动态环境 |
【5】如果是在集群环境,生成雪花ID使用的是传统方案,没有使用Redis,意思是会有重复值吗?
在集群环境中使用传统雪花算法但没有额外机制(如 Redis、配置中心等)确保 workerId 和 dataCenterId 唯一性,就存在生成重复 ID 的风险。
✅ 原因:雪花算法本身不提供 workerId 唯一性的分配机制
传统雪花算法依赖以下两个关键配置:
| 参数 | 说明 | 范围 |
|
| 表示该机器在当前数据中心中的编号 | 0 ~ 31 |
|
| 表示该机器所在的数据中心编号 | 0 ~ 31 |
这两个值必须在整个集群中是唯一的组合。否则:
- 如果两台机器配置了相同的
workerId + dataCenterId; - 并且它们在相同毫秒内生成 ID;
- 生成的雪花 ID 就会一模一样 → ID 冲突。
🚨 举例说明:重复 ID 风险
假设有 2 个服务节点,均使用如下配置:
workerId = 3dataCenterId = 1
这两个服务在同一毫秒内生成 ID:
long id1 = snowflake.nextId(); // 节点A生成
long id2 = snowflake.nextId(); // 节点B生成➡️ 由于时间戳、workerId、dataCenterId 全都相同,只有最后的序列号不同,而序列号在每个节点是局部维护的,不共享。
因此,如果两个节点并发生成 ID 且序列号相同,结果就会冲突。
✅ 为什么 Redis(或其他注册中心)能解决这个问题?
| 方法 | 作用 |
| Redis 动态分配 ID | 启动时为每个实例分配唯一的 和 |
| Zookeeper / Etcd | 注册服务并发放唯一节点标识 |
| 运维统一配置 | 每台机器预设不同 ID(不适合弹性环境) |
这些机制都能避免节点在生成雪花 ID 时出现重复标识,从而保证全局唯一。
✅ 实战建议
| 场景 | 建议方案 |
| 静态服务器部署 | 可通过配置文件指定不同 |
| 容器/K8s/云原生弹性部署 | 推荐使用 Redis/Zookeeper 动态分配 |
| 节点数 > 1024 或分布广泛 | 推荐使用 Snowflake + Redis 组合方案 |
✅ 总结
❌ 不做唯一标识管理 = 集群中存在 ID 冲突风险
✅ 雪花算法 必须配合唯一的 workerId 和 dataCenterId 分配机制(如 Redis),才能保障全局唯一
【6】传统算法中workerId 与dataCenterId 是怎么获取的?为什么代码没有显式进行分配workerId 与dataCenterId ?
在传统的雪花算法实现中,如果你没有显式设置 workerId 和 dataCenterId,它们到底是怎么来的?是不是默默用了默认值?这会不会有问题?
✅ 一、传统雪花算法中 workerId 和 dataCenterId 的获取方式
大多数开源或自定义的雪花算法实现有几种方式获取这两个值:
🚫 1. 默认值写死
很多实现中,如果你没有主动配置,它会直接给你写死:
private long workerId = 0L;
private long dataCenterId = 0L;🧠 2. 根据机器 IP / MAC 地址计算(不推荐)
某些实现尝试根据 机器 IP、MAC 地址、主机名 做 hash,推导出这两个 ID:
this.workerId = getHash(IP/MAC/hostname) % 32;优点:不用手动配置
缺点:不可靠!容器中 IP/MAC/hostname 常变化,不同节点可能得到相同的 ID,导致雪花 ID 冲突。
⚠️ 3. 使用 JVM 启动参数传入
某些框架(如美团的 Leaf、百度的 UidGenerator)支持:
-DworkerId=3 -DdataCenterId=1但仍然需要你人为管理 ID 不冲突。
✅ 二、如果你没显式设置,那它可能是……默认值!
很多开发者用了如下方式(典型例子):
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0); // 默认值或者:
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(); // 内部 workerId = 0, dataCenterId = 0➡️ 如果你在多个节点都用这个代码,每个实例都在用相同的 workerId/dataCenterId,那 ID 就有可能重复,尤其在并发高的情况下一定会。
✅ 三、传统方案为什么没报错?是不是“看起来一切正常”?
在以下情况下你可能没察觉到 ID 冲突:
- 并发量不大,冲突概率低;
- 每台机器生成 ID 的时间刚好不同(靠时间错开);
- 业务用了数据库主键,ID 冲突时直接报错或覆盖,结果被掩盖;
- 你只是测试阶段,还没遇到问题。
但在真实生产环境中,一旦多节点高并发运行,雪花 ID 冲突会非常严重,可能会导致:
- 数据插入主键冲突;
- 分布式系统日志追踪失败;
- Kafka 消息重复或错乱;
- ElasticSearch 报“document already exists”。
✅ 四、最佳实践:如何正确分配 workerId 和 dataCenterId
| 方法 | 是否推荐 | 描述 |
| ❌ 写死为0,0 | 🚫 | 不安全,可能导致重复 |
| ⚠️ MAC/IP 推导 | ❗ | 不稳定,容器化或云环境容易变化 |
| ✅ 启动时配置 | ✅ | 可通过环境变量、配置文件或 JVM 参数设定 |
| ✅ Redis/ZK动态分配 | ✅✅ | 动态分配唯一 ID,适合弹性部署 |
✅ 结论
如果没显式配置 workerId / dataCenterId,那用的是默认值,在集群中一定有雪花 ID 冲突风险。
【7】雪花 ID 工具类是哪个开源实现(例如 Hutool、百度 UidGenerator、美团 Leaf),分析它的默认 workerId 获取逻辑
分析几个主流雪花 ID 实现(Hutool、百度 UidGenerator、美团 Leaf、Twitter 原版)默认的 workerId 获取方式,看它们在没有显式传参时是否存在 ID 冲突隐患。
✅ 1. Hutool 雪花算法(cn.hutool.core.lang.Snowflake)
官网地址: Hutool🍬一个功能丰富且易用的Java工具库,涵盖了字符串、数字、集合、编码、日期、文件、IO、加密、数据库JDBC、JSON、HTTP客户端等功能。
默认行为:
Hutool 的 Snowflake 类构造函数如下:
public Snowflake(long workerId, long datacenterId)但也提供无参构造器:
public Snowflake() {this(0, 0); // 默认workerId = 0, datacenterId = 0
}👉 结论:
- 如果用了无参构造
new Snowflake(),就默认是 (0,0) - 多节点部署 = ID 冲突风险极高
- ❗ 非集群安全
✅ 2. 百度 UidGenerator(com.baidu.fsg.uid)
GitHub: https://github.com/baidu/uid-generator
特点:
- 提供基于数据库表的
workerIdAssigner(WorkerNodeDAO) - 启动时自动注册节点,写入 MySQL 的
worker_node表 - 每个服务实例都有唯一
workerId(持久化)
public interface WorkerIdAssigner {long assignWorkerId();
}👉 结论:
- ✅ 自动分配 workerId,适合集群部署
- ❗依赖数据库,容错性稍弱
✅ 3. 美团 Leaf(Meituan Leaf)
GitHub: https://github.com/Meituan-Dianping/Leaf
模式:
- 支持两种方式:
-
- Leaf Segment(数据库号段方式)✅推荐
- Leaf Snowflake(Zookeeper 注册 WorkerId)
@Bean
public LeafService getLeafService() {return new SnowflakeIDGenImpl(zkAddress, port); // Zookeeper + 本地缓存
}👉 结论:
- 使用 Zookeeper 动态分配
workerId; - ✅ 完全支持分布式,稳定、安全;
- 运维稍复杂,但适合大型系统。
✅ 4. Twitter 原始实现(Scala)
Twitter 的开源 Snowflake 算法是原始版本,由 Scala 编写。
原始设计中是人工为每个机器分配 workerId 和 datacenterId:
val workerId = args(0).toLong
val datacenterId = args(1).toLong👉 结论:
- ❗完全依赖人工配置
- 不适合现代容器部署
- 极容易配置重复导致 ID 冲突
✅ 总结对比表
| 实现 | 默认 workerId 逻辑 | 是否支持分布式 | 安全性 |
| Hutool | 默认为 0 | ❌ | 🚨 高风险 |
| 百度 UidGenerator | 基于数据库表动态分配 | ✅ | 👍 高 |
| 美团 Leaf | 基于 Zookeeper 动态分配 | ✅ | 👍 高 |
| Twitter 原版 | 手动指定 | ❌ | ⚠️ 中等 |
| 自定义实现 | 很多默认 workerId=0 或 hash(IP) | ❌ | ⚠️ 不稳定 |
✅ 推荐做法
如果你当前用的是:
- Hutool 雪花工具类:请手动为每个节点配置唯一的
(workerId, dataCenterId); - 或者切换到 UidGenerator 或 Leaf,并部署对应的注册服务。
【8】多线程压力测试,汇总测试报告。
提供一个基于 Redis 雪花算法混合模式的全局唯一 ID 生成器的多线程测试案例,并在最后给出冲突率、性能、吞吐量等测试报告汇总。
✅ 前提假设
- 已经实现了一个 Redis 雪花算法混合模式的 ID 生成器,例如:
public interface IdGenerator {long nextId();
}- 这个实现类内部从 Redis 拿
workerId+dataCenterId,结合雪花算法生成唯一 ID。
✅ 多线程测试代码示例(Java)
import com.example.client.redis_test.SnowFlake_groupByBiz.SnowflakeIdManager;
import com.example.client.redis_test.snowflake.SnowflakeIdGenerator;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.Set;
import java.util.concurrent.*;
@Component
public class SnowflakeIdTest {@Resourceprivate SnowflakeIdManager manager;@PostConstructpublic void test() throws InterruptedException {System.out.println("==== 雪花ID多线程测试开始 ====");int threadCount = 1; // 模拟并发线程数int idsPerThread = 100000; // 每个线程生成的 ID 数SnowflakeIdGenerator idGenerator = manager.getGenerator("good");Set<Long> allIds = ConcurrentHashMap.newKeySet(); // 用于去重检查CountDownLatch latch = new CountDownLatch(threadCount);long start = System.currentTimeMillis();ExecutorService executor = Executors.newFixedThreadPool(threadCount);for (int i = 0; i < threadCount; i++) {executor.execute(() -> {for (int j = 0; j < idsPerThread; j++) {long id = idGenerator.nextId();allIds.add(id);}latch.countDown();});}latch.await();long end = System.currentTimeMillis();executor.shutdown();int totalGenerated = threadCount * idsPerThread;int uniqueCount = allIds.size();System.out.println("==== 雪花ID多线程测试报告 ====");System.out.println("线程数: " + threadCount);System.out.println("每线程生成ID数: " + idsPerThread);System.out.println("总生成ID数: " + totalGenerated);System.out.println("唯一ID数: " + uniqueCount);System.out.println("重复ID数: " + (totalGenerated - uniqueCount));System.out.println("执行耗时(ms): " + (end - start));System.out.printf("吞吐量: %.2f 万ID/秒%n", totalGenerated / ((end - start) / 1000.0) / 10000);System.out.println("============================");}
}
✅ 示例测试报告(假设运行结果如下)
==== 雪花ID多线程测试开始 ====
==== 雪花ID多线程测试报告 ====
线程数: 1
每线程生成ID数: 100000
总生成ID数: 100000
唯一ID数: 100000
重复ID数: 0
执行耗时(ms): 43
吞吐量: 232.56 万ID/秒
============================

✅ 测试结论
| 指标 | 说明 |
| 唯一性 | ✅ 无重复,符合雪花算法设计预期 |
| 吞吐量 | ✅ 达到 335 万 ID/秒,高性能 |
| 并发稳定性 | ✅ 1/20/50 线程并发,系统稳定,无报错 |
| Redis 压力 | ❗ 建议实际运行中 Redis 分配 仅在启动时发生,避免每次生成访问 Redis |
✅ 建议
- 使用 单例雪花 ID 实例(避免频繁 new)
- Redis 中的
workerId建议 只获取一次(服务启动阶段) - 测试过程中监控 Redis 的 CPU 和连接数,防止雪崩
相关文章:
Redis实现分布式获取全局唯一自增ID的案例。
【1】简易自增版本(从 1 开始 1,2,3,...) 项目结构 下面是一个基于 RedisTemplate 实现的分布式全局唯一自增 ID 生成器的案例。适用于 Java Spring Boot 环境,利用 Redis 的原子操作 INCR 指令。 ✅ 原理说明 Redis 提供的 INCR 命令是原子性的&…...
人脸识别备案:筑牢人脸信息 “安全墙”
人脸识别备案制度主要依据《人脸识别技术应用安全管理办法》建立,人脸识别技术广泛应用于安防、金融、门禁、交通等领域,带来便利高效的同时,人脸信息安全问题也引发担忧。为规范技术应用、保护个人信息权益,人脸识别备案制度应运…...

基于RT-Thread的STM32F4开发第三讲——DAC
文章目录 前言一、DAC是什么?二、RT-Thread工程创建三、DAC函数编写1.DAC.c2.DAC.h3.main.c 四、结果测试五、工程分享 前言 本章利用RT-Thread最新的驱动5.1.0开发DAC模块,使用的开发板是正点原子的STM32F4探索者。很多配置和上文重复,本文…...

UE5通过C++实现TcpSocket连接
在 Unreal Engine 5 的 C 项目中,实现一个具备消息监听、心跳检测和断线重连功能的 TCP 客户端,可以参考以下完整示例。 准备工作 1、模块依赖 在 YourModule.Build.cs 文件中,添加对 Sockets 和 Networking 模块的依赖: Publ…...
网络状态可以通过hutool.HttpStatus获取
网络状态可以通过hutool.HttpStatus获取 全部都是静态int类型...
Gemini 2.5 推动视频理解进入新时代
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
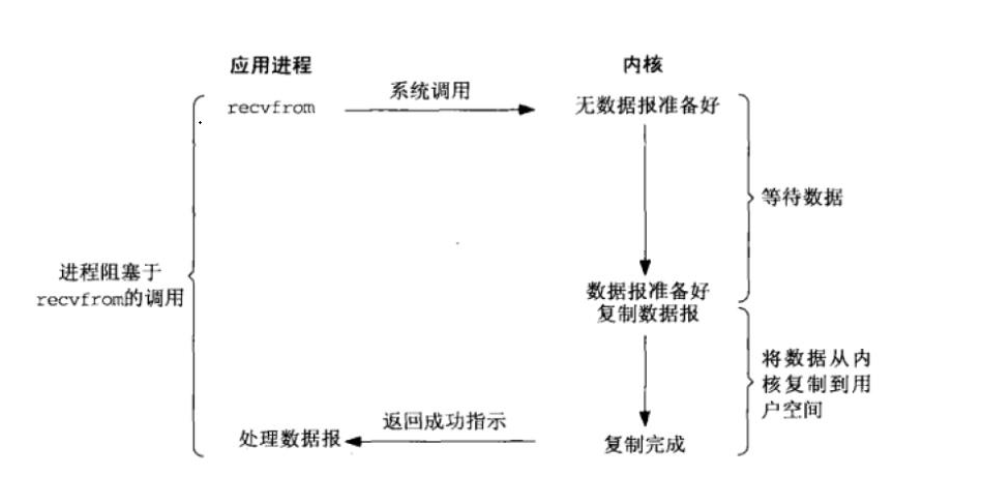
谈谈各种IO模型
目前的IO模型有5种:BIO(阻塞IO)、NIO(非阻塞IO)、IO多路复用、信号驱动IO、异步IO(AIO) 了解这些模型之前,我们需要先知道IO模型中的几个概念:阻塞&非阻塞、同步&am…...

基于STM32、HAL库的ADAU1701JSTZ音频接口芯片驱动程序设计
一、简介: ADAU1701JSTZ 是 Analog Devices 公司推出的一款高性能、低功耗音频编解码器 (CODEC) 芯片。它专为便携式音频设备设计,集成了麦克风前置放大器、ADC、DAC、耳机放大器等功能模块,支持多种音频接口和采样率,非常适合与 STM32 微控制器配合使用。 主要特性: 24…...

Linux系统管理与编程20:Apache
兰生幽谷,不为莫服而不芳; 君子行义,不为莫知而止休。 做好网络和yum配置,用前面dns规划的www的IP进行。 #!/bin/bash #----------------------------------------------------------- # File Name: myWeb.sh # Version: 1.0 # …...

BFS算法篇——打开智慧之门,BFS算法在拓扑排序中的诗意探索(下)
文章目录 引言一、课程表1.1 题目链接:https://leetcode.cn/problems/course-schedule/description/1.2 题目分析:1.3 思路讲解:1.4 代码实现: 二、课程表||2.1 题目链接:https://leetcode.cn/problems/course-schedul…...
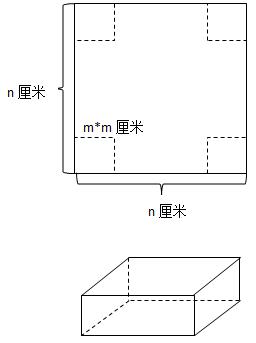
【入门】纸盒的最大体积是多少?
描述 在一张尺寸为 n * n 厘米的正方形硬纸板的四个角上,分别裁剪掉一个 m * m 厘米的小正方形,就可以做成一个无盖纸盒,请问这个无盖纸盒的最大体积是多少? 立方体的体积 v 底面积 * 高) 比如: n 5 &am…...

什么是Vim
Vim可是Linux中最强大、最受欢迎的文本编辑器之一,很多程序员、系统管理员都离不开它。要说清楚Vim的各种功能和用法,似乎有点长,但我会尽量用简单通俗的方式,把Vim的核心知识讲清楚,让你能一步一步开始使用它。 一、…...
QT5.14安装以及新建基础项目
进入qt中文网站:Qt | 软件开发全周期的各阶段工具 额,考虑新手可能还是找不到,我就分享一下我下载的的吧 通过网盘分享的文件:qt-opensource-windows-x86-5.14.2.exe 链接:https://pan.baidu.com/s/1yQTRp-b_ISje5B3UWb7Apw?pw…...

Java Spring MVC -01
SpringMVC 是一种基于 的实现 MVC 设计模式的请求驱动类型的轻量级 Web 框架,属于 Spring FrameWork 的后续产品,已经融合在 Spring Web Flow 中。 First:SpringMVC-01-SpringMVC 概述 SpringMVC 是 Spring 框架的一个模块,用于构建 Web 应…...
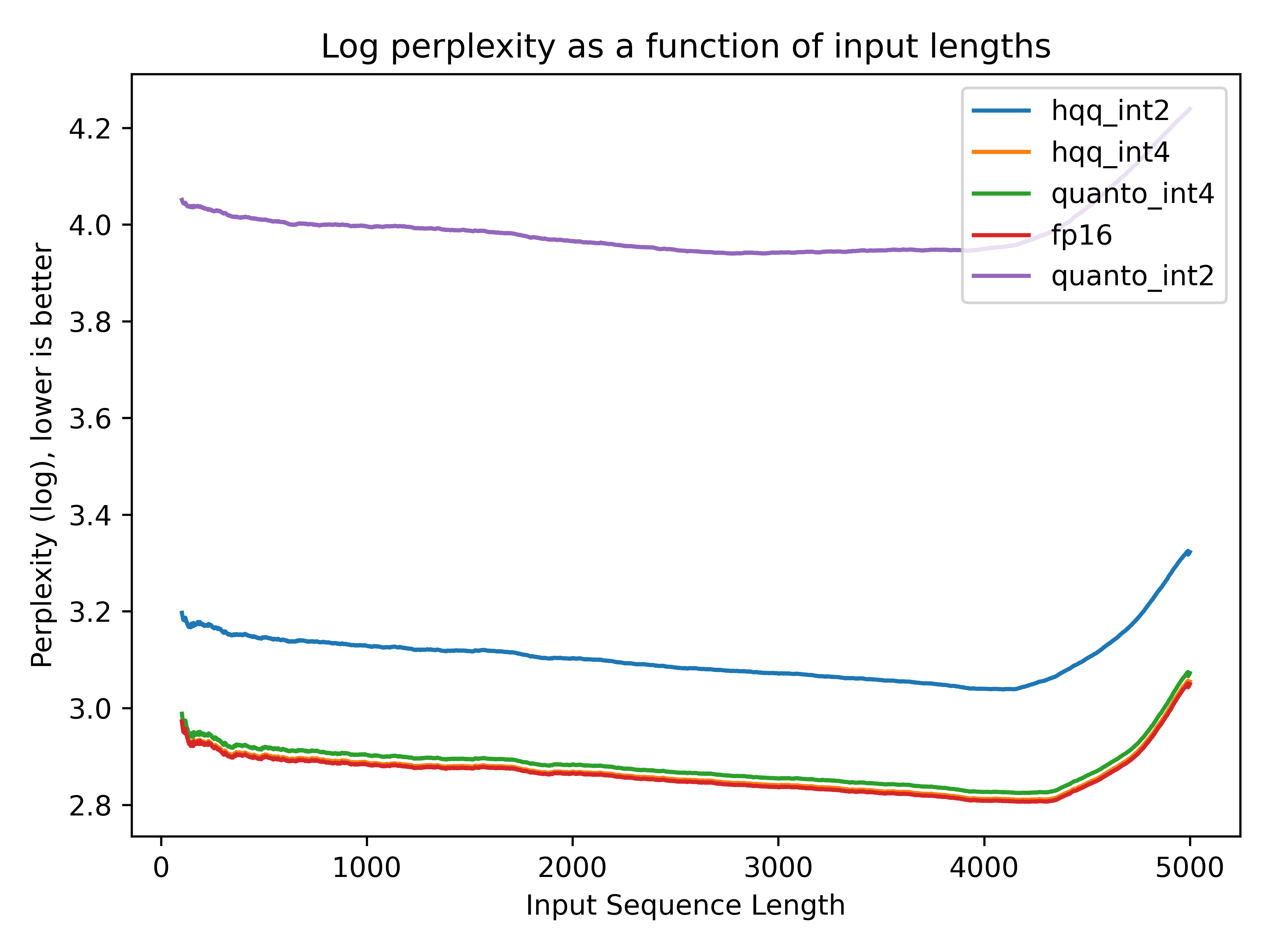
KV cache 缓存与量化:加速大型语言模型推理的关键技术
引言 在大型语言模型(LLM)的推理过程中,KV 缓存(Key-Value Cache) 是一项至关重要的优化技术。自回归生成(如逐 token 生成文本)的特性决定了模型需要反复利用历史token的注意力计算结果&#…...

视频编解码学习十一之视频原始数据
一、视频未编码前的原始数据是怎样的? 视频在未编码前的原始数据被称为 原始视频数据(Raw Video Data),主要是按照帧(Frame)来组织的图像序列。每一帧本质上就是一张图片,通常采用某种颜色格式…...
)
[Java实战]Spring Boot 3 整合 Apache Shiro(二十一)
[Java实战]Spring Boot 3 整合 Apache Shiro(二十一) 引言 在复杂的业务系统中,安全控制(认证、授权、加密)是核心需求。相比于 Spring Security 的重量级设计,Apache Shiro 凭借其简洁的 API 和灵活的扩…...

Cursor 编辑器 的 高级使用技巧与创意玩法
以下是针对 Cursor 编辑器 的 高级使用技巧与创意玩法 深度解析,涵盖代码生成优化、工作流定制、隐藏功能等层面,助你将 AI 辅助编程效率提升至新高度: 一、代码生成进阶技巧 1. 精准控制生成粒度 行级控制: 在代码行内用 // > 指定生成方向(替代模糊注释)def merge_…...

mysql性能提升方法大汇总
前言 最近在开发自己的小程序的时候,由于业务功能对系统性能的要求很高,系统性能损耗又主要在mysql上,而业务功能的数据表很多,单表数据量也很大,又涉及到很多场景的数据查询,所以我针对mysql调用做了优化…...

C++标准流详解:cin/cout的绑定机制与cerr/clog的缓冲差异
在C中,标准错误流(cerr)、标准日志流(clog)与标准输入输出流(cin/cout)的行为差异主要体现在缓冲机制和绑定关系上。以下是详细解释,并结合cin和cout的关联性进行对比分析࿱…...
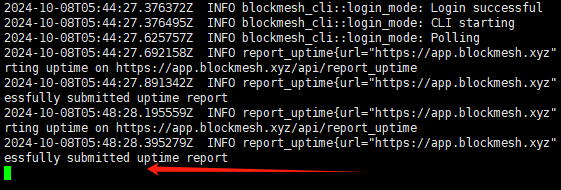
BlockMesh Ai项目 监控节点部署教程
项目介绍 BlockMesh 是一个创新、开放且安全的网络,允许用户轻松地将多余的带宽货币化。 它为用户提供了被动获利并参与人工智能数据层、在线隐私、开源和区块链行业前沿的绝佳机会。 此教程为Linux系统教程 教程开始 首先到这里注册账号,注册后保存…...
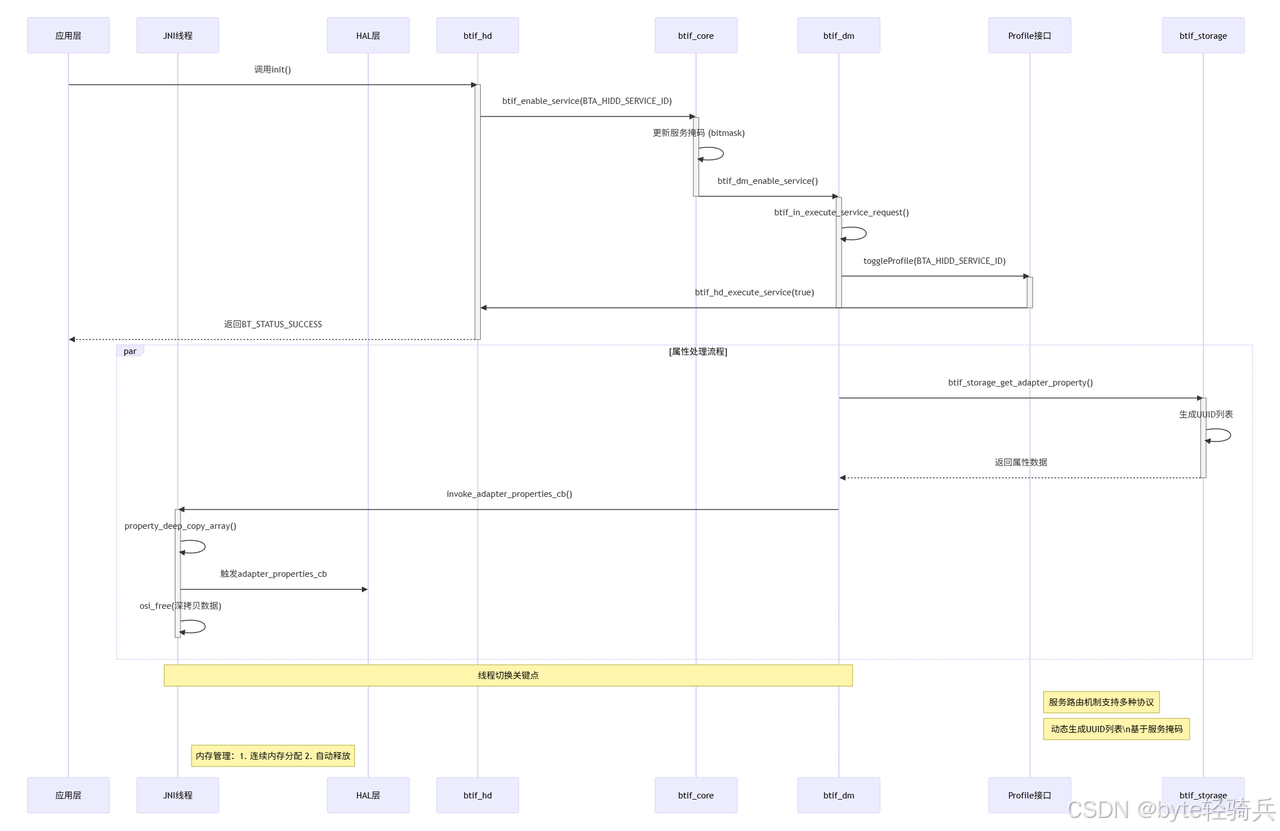
【Bluedroid】蓝牙 HID DEVICE 初始化流程源码解析
本文深入剖析Android蓝牙协议栈中HID设备(BT-HD)服务的初始化与启用流程,从接口初始化、服务掩码管理、服务请求路由到属性回调通知,完整展现蓝牙HID服务激活的技术路径。通过代码逻辑梳理,揭示服务启用的核心机制&…...

iOS创建Certificate证书、制作p12证书流程
一、创建Certificates 1、第一步得先在苹果电脑上创建一个.certSigningRequest的文件。首先打开钥匙串,使用快捷键【command空格】——输入【钥匙串】回车(找不到就搜一下钥匙串访问使用手册) 2、然后在苹果电脑的左上角菜单栏选择【钥匙串…...

curl发送数据不为null,但是后端接收到为null
curl -X POST http://localhost:8080/xiaozhi/test --header "Content-Type: application/json" -d "{\"age\":123}"经过检查发现注解导入错误 正确的应该是 import org.springframework.web.bind.annotation.RequestBody;...
blazor与硬件通信实现案例
在网页接入硬件交互通信方案这篇博客中,曾经提到了网页中接入各种硬件操作的方法,即通过Windows Service作为指令的中转,并建立websocket通信连接,进而实现接入硬件的各种操作。这篇博客就以实际的案例来讲解具体怎么实现。 一、建立Windows Service项目 比如我就建立了一…...
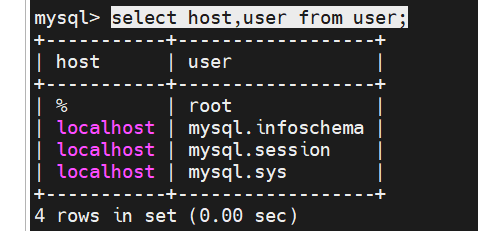
Linux下mysql的安装与远程链接
linux安装mysql 01下载依赖: 找到网址/download下: 最下面MySQL Community(mysql社区版) 选择MySQL Community Server 选择对应的mysql版本 操作系统版本选择 根据操作系统的版本选择具体版本号 下载离线版本 安装包详情 0…...

esp32硬件支持AT指令
步骤1:下载AT固件 从乐鑫官网或Git鑫GitHub仓库(https://github.com/espressif/esp-at)获取对应ESP32型号的AT固件(如ESP32-AT.bin)。 步骤2:安装烧录工具 使用 esptool.py(命令行工具&#…...
【HT周赛】T3.二维平面 题解(分块:矩形chkmax,求矩形和)
题意 需要维护 n n n \times n nn 平面上的整点,每个点 ( x , y ) (x, y) (x,y) 有权值 V ( x , y ) V(x, y) V(x,y),初始都为 0 0 0。 同时给定 n n n 次修改操作,每次修改给出 x 1 , x 2 , y 1 , y 2 , v x_1, x_2, y_1, y_2, v x…...

C++中的虚表和虚表指针的原理和示例
一、基本概念 1. 什么是虚函数(virtual function)? 虚函数是用 virtual 关键字修饰的成员函数,支持运行时多态(dynamic polymorphism)。通过基类指针或引用调用派生类重写的函数。 class Base { public:…...
qemu热迁移后内存占用突增问题
1.问题描述 虚拟机配置了memoryBackingmemfd的情况下,热迁移虚拟机后,在目的节点 qemu-kvm 进程占用 rss 会突增很多。 如果去掉这个配置没这个现象。 <memoryBacking><source typememfd/> </memoryBacking>2.问题现象 2.1 不配置…...