使用 React 实现语音识别并转换功能
在现代 Web 开发中,语音识别技术的应用越来越广泛。它为用户提供了更加便捷、自然的交互方式,例如语音输入、语音指令等。本文将介绍如何使用 React 实现一个简单的语音识别并转换的功能。
功能概述
我们要实现的功能是一个语音识别测试页面,用户可以选择不同的语言,录制音频,然后将录制的音频转换为文本。整个过程使用了 React 作为前端框架,RecordRTC 库用于录制音频,以及一个自定义的 CallAsr 函数用于调用语音识别服务。
注意⚠️:CallAsr 函数在博客已有相应的描述:前端 AI 开发实战:基于自定义工具类的大语言模型与语音识别调用指南_音频理解类大模型调用-CSDN博客
实现步骤
1.导入必要的模块
首先,我们需要导入 React 的钩子 useState 和 useRef,以及 RecordRTC 库和自定义的 CallAsr 函数和 AsrLanguage 枚举。
import { useState, useRef } from "react";
import { CallAsr, AsrLanguage } from "../../util/AIUtil";
import RecordRTC from "recordrtc";useState和useRef是 React 的钩子,useState用于管理组件的状态,useRef用于引用 DOM 元素或在组件重新渲染时保存值。CallAsr和AsrLanguage从../../util/AIUtil导入(AI工具类),CallAsr是用于调用语音识别服务的函数,AsrLanguage是一个枚举类型,用于表示支持的语言。RecordRTC是一个用于录制音频和视频的库。
2.定义接口
为了更好地处理语音识别服务的返回数据,我们定义了一个 AsrResponse 接口。
interface AsrResponse {code: number;msg: string;data?: {text_arr: string[];detail_arr?: Array<{text: string;time_from: number;time_end: number;}>;};
}3.定义组件和状态管理
我们创建了一个名为 ASRTest 的函数式组件,并使用 useState 钩子来管理组件的状态,例如是否正在录制、音频数据、识别结果等。
const ASRTest = () => {const [recording, setRecording] = useState<boolean>(false);const [audioBlob, setAudioBlob] = useState<Blob | null>(null);const [transcription, setTranscription] = useState<string>("");const [loading, setLoading] = useState<boolean>(false);const [selectedLanguage, setSelectedLanguage] = useState<AsrLanguage>(AsrLanguage.ZH_CN);const [error, setError] = useState<string | null>(null);const recorderRef = useRef<RecordRTC | null>(null);// ...
};recording:表示是否正在录制音频。audioBlob:存储录制的音频数据。transcription:存储语音识别的结果。loading:表示是否正在进行语音识别。selectedLanguage:表示用户选择的语言。error:存储可能出现的错误信息。recorderRef:用于引用RecordRTC实例。
4.处理语言选择
用户可以通过下拉框选择不同的语言,我们使用 handleLanguageChange 函数来处理语言选择事件。
const handleLanguageChange = (e: React.ChangeEvent<HTMLSelectElement>) => {setSelectedLanguage(e.target.value as AsrLanguage);
};5. 录制音频
用户可以点击 “开始录制” 按钮开始录制音频,点击 “停止录制” 按钮停止录制。我们使用 navigator.mediaDevices.getUserMedia 方法请求用户的麦克风权限,并使用 RecordRTC 库进行音频录制。
const startRecording = async () => {try {const stream = await navigator.mediaDevices.getUserMedia({audio: {sampleRate: 16000,echoCancellation: false,noiseSuppression: false,autoGainControl: false,},});const recorder = new RecordRTC(stream, {type: "audio",mimeType: "audio/wav",recorderType: RecordRTC.StereoAudioRecorder,numberOfAudioChannels: 1,desiredSampRate: 16000,disableLogs: true,// @ts-ignoresampleBits: 16,bufferSize: 16384,});recorder.startRecording();recorderRef.current = recorder;setRecording(true);} catch (error) {console.error("获取麦克风权限失败:", error);setError("无法访问麦克风,请确保您已授予麦克风权限。");}
};const stopRecording = () => {if (recorderRef.current && recording) {recorderRef.current.stopRecording(() => {const blob = recorderRef.current!.getBlob();setAudioBlob(blob);// 停止并释放音频流const mediaStream =recorderRef.current!.getInternalRecorder().mediaStream;if (mediaStream) {mediaStream.getTracks().forEach((track) => track.stop());}setRecording(false);});}
};6. 语音识别
用户可以点击 “转换” 按钮将录制的音频转换为文本。我们使用 CallAsr 函数调用语音识别服务,并根据返回结果更新识别结果或错误信息。
const handleTranscribe = async () => {if (!audioBlob) {setError("请先录制音频");return;}setLoading(true);setError(null);try {// 创建一个带有适当后缀名的文件对象const audioFile = new File([audioBlob], "recording.wav", {type: "audio/wav",});const response = await CallAsr(audioFile, selectedLanguage);const result: AsrResponse = await response.json();if (result.code === 0 && result.data) {setTranscription(result.data.text_arr.join(" "));} else {setError(`识别失败: ${result.msg || "未知错误"}`);}} catch (error) {console.error("语音识别错误:", error);setError(`识别过程中发生错误: ${error instanceof Error ? error.message : String(error)}`);} finally {setLoading(false);}
};7. 渲染组件
最后,我们将所有的功能组合在一起,渲染出一个包含语言选择、录制按钮、音频预览、错误信息和识别结果的 UI。
return (<div className="container mx-auto p-4 max-w-2xl"><h1 className="text-2xl font-bold mb-6 text-center">ASR 语音识别测试</h1><div className="mb-4"><labelhtmlFor="language-select"className="block mb-2 text-sm font-medium">选择语言:</label><selectid="language-select"value={selectedLanguage}onChange={handleLanguageChange}className="bg-white border border-gray-300 text-gray-900 text-sm rounded-lg focus:ring-blue-500 focus:border-blue-500 block w-full p-2.5"><option value={AsrLanguage.ZH_CN}>简体中文</option><option value={AsrLanguage.YUE_CN}>粤语</option><option value={AsrLanguage.EN_US}>美式英语</option><option value={AsrLanguage.EN_UK}>英式英语</option><option value={AsrLanguage.FR}>法语</option><option value={AsrLanguage.JA}>日语</option><option value={AsrLanguage.ES}>西班牙语</option><option value={AsrLanguage.DE}>德语</option></select></div><div className="flex flex-col items-center gap-4 mb-6"><div className="flex gap-4"><buttononClick={recording ? stopRecording : startRecording}className={`px-6 py-2 rounded focus:outline-none focus:ring-2 ${recording? "bg-red-500 hover:bg-red-600 text-white focus:ring-red-500": "bg-blue-500 hover:bg-blue-600 text-white focus:ring-blue-500"}`}>{recording ? "停止录制" : "开始录制"}</button><buttononClick={handleTranscribe}disabled={!audioBlob || loading}className={`px-6 py-2 rounded focus:outline-none focus:ring-2 focus:ring-green-500 ${!audioBlob || loading? "bg-gray-300 text-gray-500 cursor-not-allowed": "bg-green-500 hover:bg-green-600 text-white"}`}>{loading ? "转换中..." : "转换"}</button></div>{audioBlob && (<div className="w-full mt-4"><p className="text-sm text-gray-600 mb-2">录音预览:</p><audio controls className="w-full"><source src={URL.createObjectURL(audioBlob)} type="audio/wav" />您的浏览器不支持音频标签。</audio></div>)}</div>{loading && (<div className="text-center py-4"><div className="loader">转换中...</div></div>)}{error && (<div className="mt-4 p-4 bg-red-100 text-red-700 rounded-lg">{error}</div>)}{transcription && (<div className="mt-6 border-t pt-4"><h2 className="font-semibold text-lg mb-2">识别结果:</h2><div className="bg-gray-100 p-4 rounded whitespace-pre-wrap">{transcription}</div></div>)}</div>
);整体实现效果
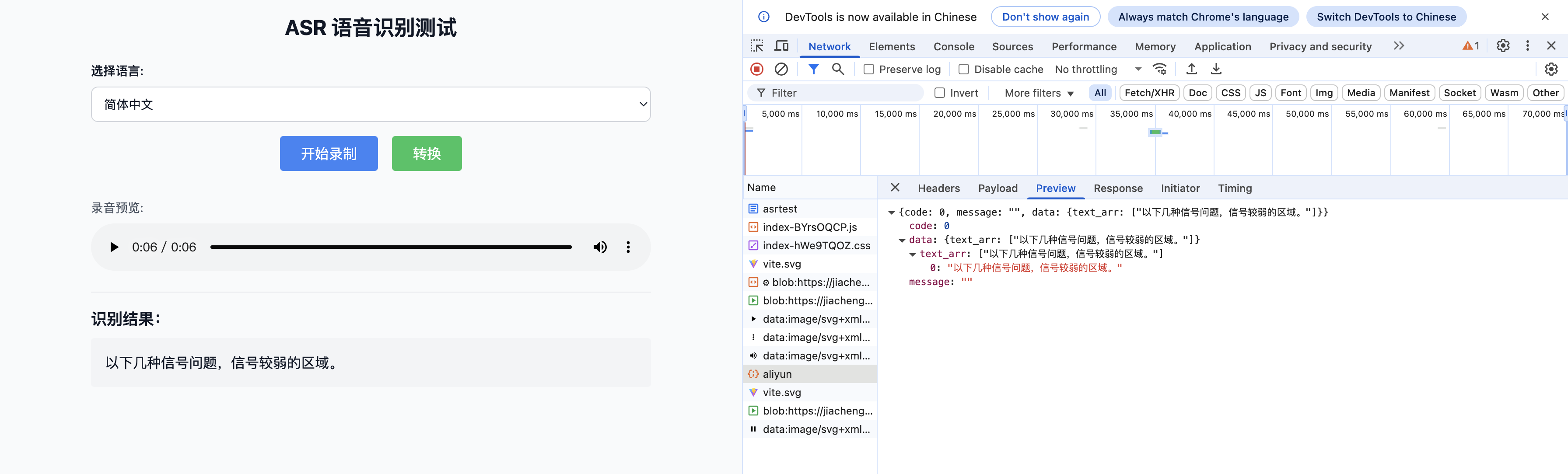
总结
通过以上步骤,我们成功实现了一个简单的语音识别并转换的功能。这个功能不仅可以帮助用户更方便地输入文本,还可以为 Web 应用增加更多的交互性。在实际应用中,我们可以根据需要对代码进行扩展,例如添加更多的语言支持、优化音频录制的质量等。
相关文章:
使用 React 实现语音识别并转换功能
在现代 Web 开发中,语音识别技术的应用越来越广泛。它为用户提供了更加便捷、自然的交互方式,例如语音输入、语音指令等。本文将介绍如何使用 React 实现一个简单的语音识别并转换的功能。 功能概述 我们要实现的功能是一个语音识别测试页面࿰…...
[Git]ssh下用Tortoisegit每次提交都要输密码
问题描述 ssh模式下,用小乌龟提交代码,即使在git服务端存储了公钥,仍然要每次输入密码。 原因分析 小乌龟需要额外配置自己的密钥,才能免除每次输密码。 解决方案 1.配置好ssh密钥 具体方法参考我前一篇文章: […...

如何查看项目是否支持最新 Android 16K Page Size 一文汇总
前几天刚聊过 《Google 开始正式强制 Android 适配 16 K Page Size》 之后,被问到最多的问题是「怎么查看项目是否支持 16K Page Size」 ?其实有很多直接的方式,但是最难的是当你的项目有很多依赖时,怎么知道这个「不支持的动态库…...
ESP32C3连接wifi
文章目录 🔧 一、ESP32-C3 连接 Wi-Fi 的基本原理(STA 模式)✅ 二、完整代码 注释讲解(适配 ESP32-C3)📌 三、几个关键点解释🔚 四、小结 🔧 一、ESP32-C3 连接 Wi-Fi 的基本原理&a…...
)
HTTP方法和状态码(Status Code)
HTTP方法 HTTP方法(也称HTTP动词)主要用于定义对资源的操作类型。根据HTTP/1.1规范(RFC 7231)以及后续扩展,常用的HTTP方法有以下几种: GET:请求获取指定资源的表示形式。POST:向指…...

机器学习中分类模型的常用评价指标
评价指标是针对模型性能优劣的一个定量指标。 一种评价指标只能反映模型一部分性能,如果选择的评价指标不合理,那么可能会得出错误的结论,故而应该针对具体的数据、模型选取不同的的评价指标。 本文将详细介绍机器学习分类任务的常用评价指…...

# YOLOv3:基于 PyTorch 的目标检测模型实现
YOLOv3:基于 PyTorch 的目标检测模型实现 引言 YOLOv3(You Only Look Once)是一种流行的单阶段目标检测算法,它能够直接在输入图像上预测边界框和类别概率。YOLOv3 的优势在于其高效性和准确性,使其在实时目标检测任…...

MySQL的Docker版本,部署在ubantu系统
前言 MySQL的Docker版本,部署在ubantu系统,出现问题: 1.执行一个SQL,只有错误编码,没有错误提示信息,主要影响排查SQL运行问题; 2.这个问题,并不影响实际的MySQL运行,如…...

Mac QT水平布局和垂直布局
首先上代码 #include "mainwindow.h" #include "ui_mainwindow.h" #include <QPushButton> #include<QVBoxLayout>//垂直布局 #include<QHBoxLayout>//水平布局头文件 MainWindow::MainWindow(QWidget *parent): QMainWindow(parent), …...

服务器制造业中,L2、L6、L10等表示什么意思
在服务器制造业中,L2、L6、L10等是用于描述服务器生产流程集成度的分级体系,从基础零件到完整机架系统共分为L1-L12共12个等级。不同等级对应不同的生产环节和交付形态,以下是核心级别的具体含义: L2(Level 2…...

回答 | 图形数据库neo4j社区版可以应用小型企业嘛?
刚在知乎上看到了一个提问,挺有意思,于是乎,贴到这里再简聊一二。 转自知乎提问 当然可以,不过成本问题不容小觑。另外还有性能上的考量。 就在最近,米国国家航空航天局——NASA因为人力成本问题,摒弃了使…...

Linux操作系统从入门到实战(二)手把手教你安装VMware17pro与CentOS 9 stream,实现Vim配置,并配置C++环境
Linux操作系统从入门到实战(二)手把手教你安装VMware17pro与CentOS 9.0 stream,实现Vim配置,并编译C文件 前言一、安装VMware17pro二、安装CentOS9.02.1 为什么选择CentOS9,与CentOS7对比2.1 官网下载CentOS9.02.2 国内…...

软考架构师考试-UML图总结
考点 选择题 2-4分 案例分析0~1题和面向对象结合考察,前几年固定一题。近3次考试没有出现。但还是有可能考。 UML图概述 1.用例图:描述系统功能需求和用户(参与者)与系统之间的交互关系,聚焦于“做什么”。 2.类图&…...

后端系统做国际化改造,生成多语言包
要将你当前系统中的 中文文案提取并翻译为英文语言包,建议采用 自动扫描 翻译辅助 语言包生成 的方式,流程如下: ✅ 一、目标总结 提取:扫描后端 C# 和 Java 代码中的 中文字符串 翻译:将中文自动翻译为英文&#x…...

论文学习_Trex: Learning Execution Semantics from Micro-Traces for Binary Similarity
摘要:检测语义相似的函数在漏洞发现、恶意软件分析及取证等安全领域至关重要,但该任务面临实现差异大、跨架构、多编译优化及混淆等挑战。现有方法多依赖语法特征,难以捕捉函数的执行语义。对此,TREX 提出了一种基于迁移学习的框架…...
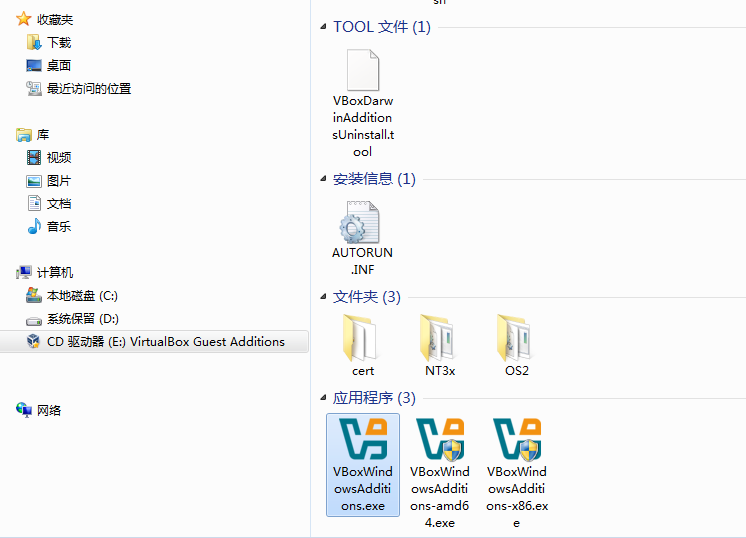
在VirtualBox中安装虚拟机后不能全屏显示的问题及解决办法
在VirtualBox中安装Windows或Linux虚拟机后,将遇到启动虚拟机后,只能在屏幕中的一块区域里显示虚拟机桌面,却不能全屏显示的问题。要解决此问题,需要在虚拟机中安装与VirtualBox版本相对应的VBox GuestAdditons软件。 这里…...

《大规模电动汽车充换电设施可调能力聚合评估与预测》MATLAB实现计划
模型概述 根据论文,我将复刻实现结合长短期记忆网络(LSTM)和条件变分自编码器(CVAE)的预测方法,用于电动汽车充换电设施可调能力的聚合评估与预测。 实现步骤 1. 数据预处理 导入充电数据 (Charging_Data.csv)导入天气数据 (Weather_Data.csv)导入电…...

CSS flex:1
在 CSS 中,flex: 1 是一个用于弹性布局(Flexbox)的简写属性,主要用于控制 flex 项目(子元素)如何分配父容器的剩余空间。以下是其核心作用和用法: 核心作用 等分剩余空间:让 flex …...

Python 字典键 “三变一” 之谜
开头:读者的“玄学”字典谜题 上周,朋友发来了一段让他抓耳挠腮的代码: >>> {True: foo, 1: bar, 1.0: baz} {True: baz} “我明明定义了布尔True、整数1、浮点数1.0三个键,结果字典里只剩True一个键,值…...

Spring Boot中HTTP连接池的配置与优化实践
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、HTTP连接池的核心价值 在微服务架构和分布式系统场景中,HTTP客户端频繁创建/断开连接会产生显著的性能损耗。通过连接池技术可以实现&#x…...

初识XML
初识XML <?xml version"1.0" encoding"utf-8" ?> <!--根标签只能有一个--> <!--第一行永远都是 <?xml version"1.0" encoding"utf-8" ?> 前面不允许出现任何其他东西,空格换行等均不行 --> &…...

element-ui分页的使用及修改样式
1.安装 npm install element-ui -S 2.在main.js中引入,这里是全部引入,也可以按需引入 import ElementUI from element-ui import element-ui/lib/theme-chalk/index.css Vue.use(ElementUI) 3.使用 layout"prev, pager, next, jumper" :jumpe…...

2025年第十六届蓝桥杯软件赛省赛C/C++大学A组个人解题
文章目录 题目A题目C:抽奖题目D:红黑树题目E:黑客题目F:好串的数目 https://www.dotcpp.com/oj/train/1166/ 题目A 找到第2025个素数 #include <iostream> #include <vector> using namespace std; vector<i…...

物理:人的记忆是由基本粒子构成的吗?
问题: 基因属于人体的一部分,记忆也是人体的一部分,那么为什么基因可以代际遗传,但是记忆却被清空重置。如果基因是由粒子构成,那么记忆是不是也应该由粒子构成?如果记忆是粒子构成的,那么能否说明记忆永恒,即使死亡了身体被分解了,那么只要保证其身体有关的所有粒子被…...

Memcached 的特性和使用场景介绍,以及集群搭建
以下是 Memcached 的特性和使用场景介绍,以及集群搭建的详细示例: 特性 高性能 内存存储:数据存储在内存中,读写速度极快。简单协议:使用基于文本的简单协议,通信高效。分布式架构 一致性哈希:采用一致性哈希算法,将数据均匀分布到多个节点,支持动态增减节点,减少数…...

uni-app,小程序中的addPhoneContact,保存联系人到手机通讯录
文章目录 方法详解简介 基本语法参数说明基础用法使用示例平台差异说明注意事项最佳实践 方法详解 简介 addPhoneContact是uni-app框架提供的一个实用API,用于向系统通讯录添加联系人信息。这个方法在需要将应用内的联系人信息快速保存到用户设备通讯录的场景下非…...

从数据中台到数据飞轮:数字化转型的演进之路
从数据中台到数据飞轮:数字化转型的演进之路 数据中台 数据中台是企业为整合内部和外部数据资源而构建的中介层,实现数据的统一管理、共享和高效利用,目标是打破信息孤岛,提高数据使用效率,支持业务决策和创新 实施成本…...

Spring Boot 注解详细解析:解锁高效开发的密钥
一、引言 Spring Boot 以其快速开发、自动配置等特性,成为构建 Java 应用程序的热门框架。而注解在 Spring Boot 中扮演着至关重要的角色,它们如同魔法指令,简化了配置流程,增强了代码的可读性与可维护性。本文将深入剖析 Spring…...
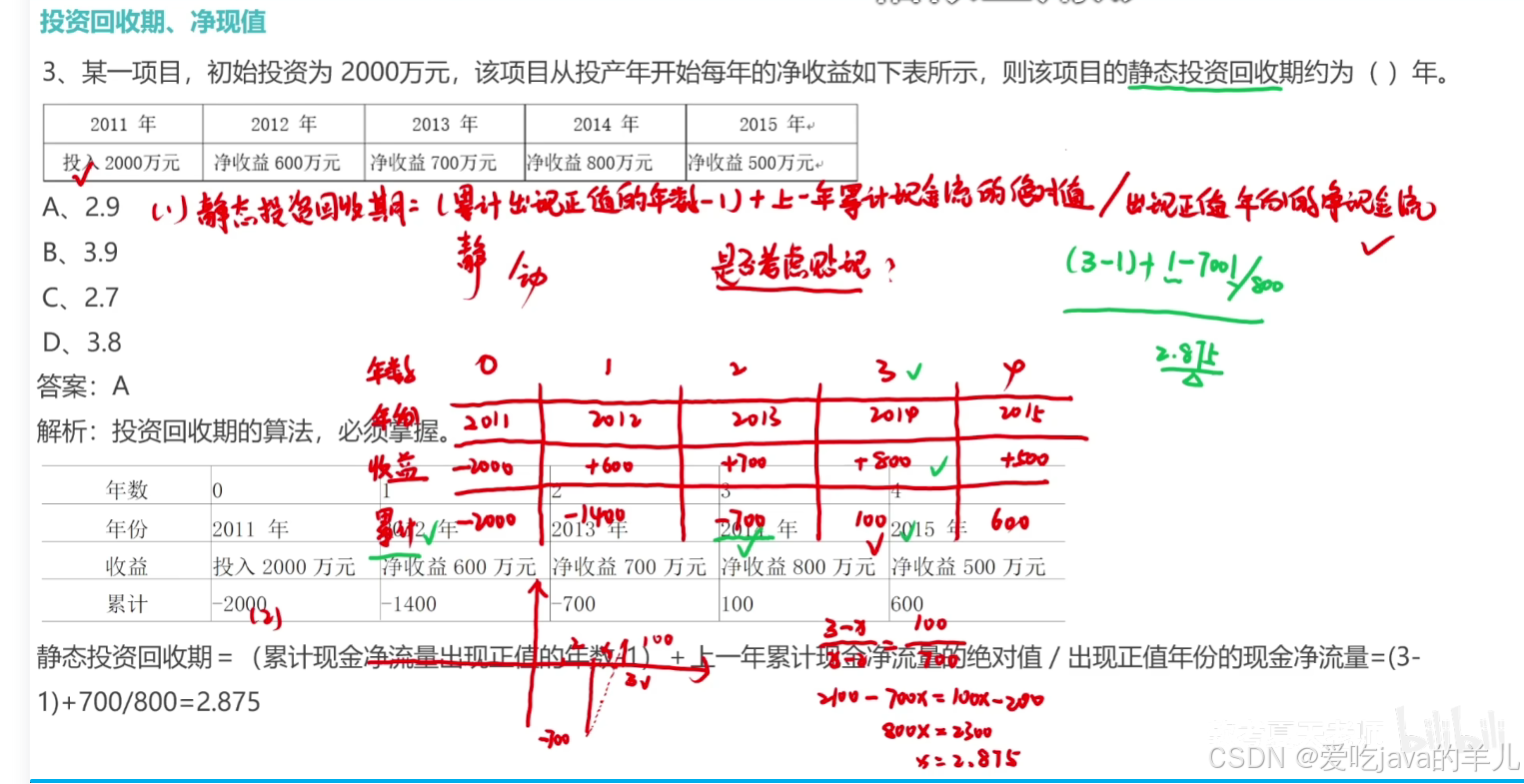
2025年5月-信息系统项目管理师高级-软考高项一般计算题
决策树和期望货币值 加权算法 自制和外购分析 沟通渠道 三点估算PERT 当其他条件一样时,npv越大越好...

zst-2001 上午题-历年真题 算法(5个内容)
回溯 算法 - 第1题 找合适的位置,如果没有位置就按B回家 d 分治 算法 - 第2题 b 算法 - 第3题 a 算法 - 第4题 划分一般就是分治 a 算法 - 第5题 分治 a 0-1背包 算法 - 第6题 c 算法 - 第7题 最小的为c 3100 c 算法 - 第8题 …...